Vision
This document describes the high-level goals and constraints, the business case, and provides an executive summary.
We envision a new "pipeline" system, "VRPipe", for the managed and automated execution of sequences of arbitrary software against massive datasets across large compute clusters. The system would have the flexibility to support varying dataset types, software collections, clusters, types of user (both within and external to the Sanger Institute), and be both robust and efficient.
Existing pipeline systems are not designed with the particular constraints imposed by massive datasets and "high-performance" file-systems in mind, resulting, for instance, in a lack of deeply integrated file integrity checking and other paranoia-based features. None have both command line and web front-ends, allowing both automated systems and casual users easy access to configure, start and monitor pipelines. Only one claims to easily integrate with many third-party systems, but it does so in a way that presents significant compatibility problems. None are able to consider all running pipelines and make the most efficient use of resources at the global level. Ease of use and ease of extension to meet our own specific needs make existing pipeline systems unsatisfactory, creating a need for a new system that rectifies all of these issues.
Current pipeline systems suffer from a range of problems, including but not limited to one or more of: inflexibility in pipeline construction and automation; poor fault handling; non-portability; inflexibility in input data specification and handling; limitations on or lack of status reporting; lack of system for reproducing pipelines. These problems lead to an inability to reliably initiate a pipeline and see it through to completion in a timely manner, affecting investigators, project groups and entire scientific communities.
This system is primarily aimed at the bioinformatic community, specifically those working with large datasets such as next-generation sequencing. Its outstanding features include its comprehensive built-in fault handling and recovery systems, its efficient use of compute resources, the flexibility it affords in defining new pipelines, and its portability and ease of use by any bioinformatition.
- Good web-based front-end, makes it easy for end-users to build their own pipelines from collections of pre-made tools. Given a saved pipeline it is also easy to alter parameters. These features make it easy to setup and alter pipelines. This core strength of Galaxy would be duplicated in VRPipe.
- Normally runs tools on local machine, but can take advantage of compute clusters. None-the-less, suffers potential performance and scaling issues thanks to a single python process handling all job management.
- Virtual machine setup that can be used on Amazon Cloud. Has a 1TB data storage limit for user uploads; no way of manually adding more data. Max of 20 nodes?
- Error handling and status reporting limited.
- Written in Python, not designed for programmatic extension at all levels.
- Potentially highly scalable system of workers (though not necessarily resulting in the most efficient usage of compute resources). This core strength of not being limited by a single process would be duplicated in VRPipe.
- Command-line only.
- Error handling and status reporting limited.
- Written in modular Perl with potential for programmatic extension at all levels, though limited API documentation.
Team Leaders/Principle Investigators and External Collaborators need to know when analyses (pipelines) have started or finished, have good estimates on completion time whilst they are still running, and be assured that once finished the results are complete and correct (their integrity has not been compromised).
Team Leaders and System Administrators may also need to know the pattern and quantity of compute resources used for a given analysis (pipeline) to guide future purchasing decisions or prioritise certain pipelines over others when existing resources are limited.
Scientific Research Publications may require complete details of an analysis (the specifics of each step of a pipeline), so this must be easily recallable after a pipeline has finished.
Researchers need a very easy way of carrying out an analysis on their dataset by choosing or creating a pipeline and running it. They need to be notified of non-recoverable errors and should have an option of monitoring progress, but otherwise wish to continue working on other things and not worry about the pipeline whilst it runs. They need to be notified when the pipeline has completed. They need to be able to remind themselves of what exactly the pipeline did, and what result files it generated.
Developers need to be able to extend the system in various ways, primarily by adding new pipeline components. They need to be able to do this without affecting other existing pipelines, and they need to be able to extensively test all new code added within the pipeline framework but without having to run a full-scale analysis on the compute farm.
Managers want to be able to define ongoing analysis projects and automate the start up and completion of their pipelines so that analyses occur without any human action at all.
Past extensive experience running pipelines for the 1000 Genomes Project and the Mouse Genomes Project has led to identification of the following key goals and problems:
Priority: High
Problems & Concerns:
- Reduced efficiency as data quantity increases.
- Increased likelihood of subtle/silent data corruption with massive files.
- Lack of up-to-date and accurate information about the state of pipelines and lack of estimates of time to completion.
- Pipelines hitting a non-recoverable error and wasting days if no user is notified of or otherwise notices the problem.
- No knowledge of where results are stored, or exactly how they were generated.
Current Solutions: Existing pipeline systems provide core functionality, and particular systems may address some of the above problems and concerns, but no single system addresses all of them.
TBA
The users (and external systems) need a system to fulfill these goals:
- Researcher: monitor status of their pipeline(s), start & stop their pipeline(s), define custom pipelines, reuse existing or recommended pipelines, discover exactly what a pipeline will or did do, force a pipeline to restart, resolve errors that can't be recovered automatically, alter pipeline parameters for certain subsets of the input data after the pipeline has started
- Developer: test pipelines locally (on a single CPU), extend and implement new pipelines
- Manager: monitor status of all pipelines, start & stop all pipelines, change priority of certain pipelines
VRPipe will usually be run on the login node(s) of large computing clusters (farms). It expects each compute node to have access to a centralised file system. It will provide services to users, and collaborate with other systems, as indicated in Figure Vision-1.
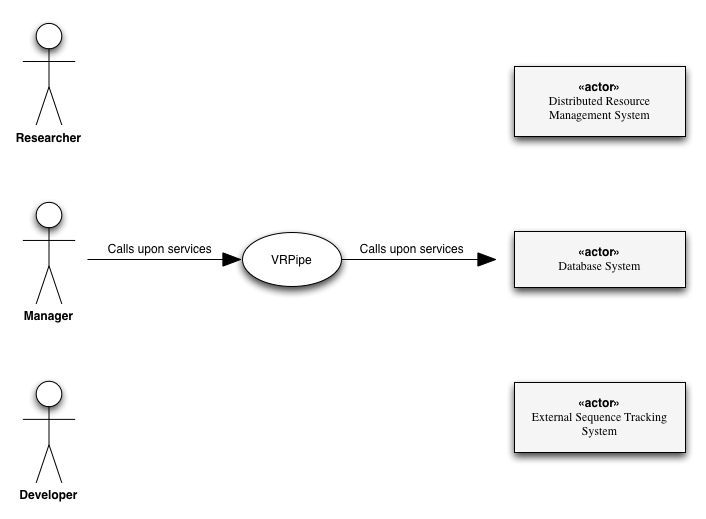 Figure Vision-1. VRPipe context diagram
Figure Vision-1. VRPipe context diagram
- The system will provide the core functionality expected of a pipeline system, including the running of a chain of software tools on a definable dataset on a computing cluster and tracking those jobs. Benefit: automated analysis of large datasets with many tools.
- Automatic detection of failures, intelligently retrying failed actions a number of times in a number of different ways, before notifying users of non-recoverable errors. Benefit: analyses more likely to proceed without consuming researcher time, and less likely to exceed time-to-completion estimates due to time wasted in failure states.
- Highly configurable pipelines, allowing even the introduction of custom steps at configuration time requiring no programming knowledge, with reporting of pipeline steps. Benefit: flexibility in defining brand new analyses quickly, and being able to report exactly what an analysis consisted of in research publications.
- Integrated file management, tracking and assigning files to appropriate file systems whilst avoiding unnecessary file system access. Benefit: efficient use of resources, lowering costs and increasing speed of running analyses.
- Global view of tasks that must be executed by all pipelines, with optimal grouping and submission of these tasks to the compute cluster. Benefit: efficient use of resources, lowering costs and increasing speed of running analyses.
- fine-grained pipeline setup
- run pipeline
- fine-grained pipeline status monitoring
- pipeline administration (restart, kill, pause, re-prioritise)
- storage of analysis results in database
- internal job tracking, coping with third-party distributed resource management system failures
- internal file tracking, coping with third-party file-system issues
- easily extendible and reusable code
- database and resource management system independence
- intelligent automatic error recovery
- secure password storage
Including design constraints, usability, reliability, performance, supportability, documentation and so forth: see the Supplementary Specification and the Use Cases.