Elaboration
Figure Domain-1 gives an overview of VRPipe's core domain model.
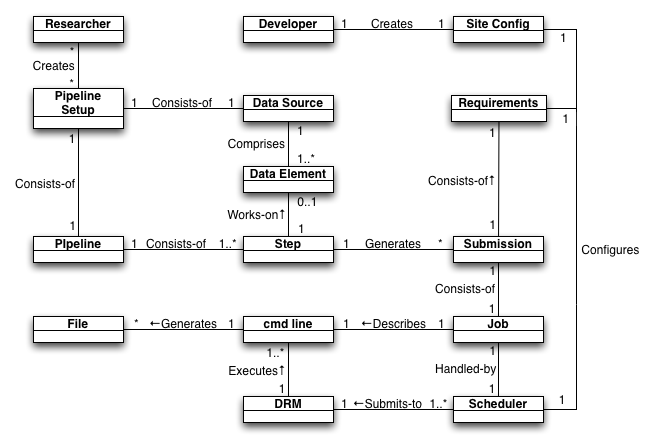 Figure Domain-1. VRPipe partial domain model
Figure Domain-1. VRPipe partial domain model
Some of the key considerations of a pipeline system are its efficiency and fault tolerance. To judge these, a more detailed look at how jobs (executable steps of a pipeline) are run in VRPipe and competing systems may be instructive.
EnsEMBL eHive is a competing pipeline system.
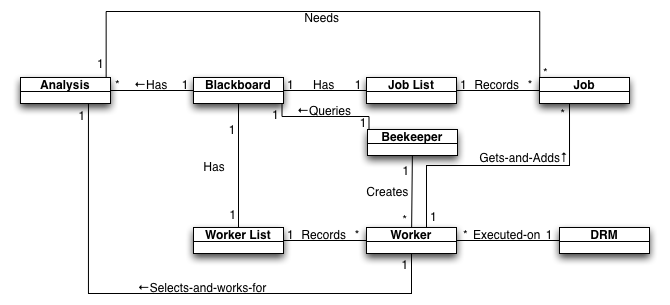 Figure JobExecution-eHive. eHive execution model
Figure JobExecution-eHive. eHive execution model
A user executes the Beekeeper Perl script for a particular pre-configured pipeline. This Beekeeper runs in a loop on the command line, periodically creating Workers and then sleeping until the next loop. It queries the Blackboard, a MySQL database, for Analyses (steps of a single pipeline) that have not completed. According to various configuration it will create enough Workers to satisfy the demand for jobs generated by the analyses. In actual terms, the Beekeeper submits a job to the DRM, resulting in a compute node eventually running a Worker Perl script. A Worker will itself query the blackboard to select an Analysis that still needs jobs run for itself. It then retrieves a Job of that Analysis from the blackboard, runs the associated code to generate some kind of result, which may result in it creating a new Job which gets stored back in the Blackboard. This Worker will continue to retrieve subsequent Jobs until there are no more Jobs to run for that Analysis, or an hour time-limit has passed.
- All state-tracking and communication is via a centralised database.
- There is no direct correspondence between what is executed on the DRM and what steps comprise the pipeline. This allows many small steps in the pipeline, yet good efficiency in terms of DRM scheduling due to 1 Worker potentially running many of these small steps.
- A single Perl script is used to query and spawn Workers for a single pipeline.
- It doesn't matter much if a particular Worker dies or fails; the Beekeeper will soon spawn another to replace it, assuming the Beekeeper is alive. Beekeeper can reap failed Jobs and new Workers can try those Jobs again.
- Different pipelines are not aware of each other and may compete inefficiently in the DRM.
- Users must carefully manage their own pipelines by running a Beekeeper for each one. There is no centralised system to ensure that all pipelines are running as expected.
run-pipeline was VertrebrateResequencing's original pipeline system, used to process the 1000 Genomes project data amongst others.
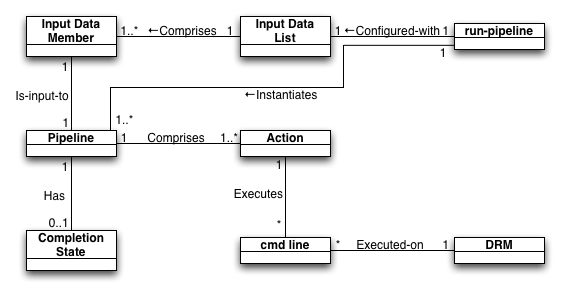 Figure JobExecution-runpipeline. run-pipeline execution model
Figure JobExecution-runpipeline. run-pipeline execution model
A user runs the run-pipeline Perl script for one or more pipelines, supplying their configuration at the same time. run-pipeline loops through each pipeline configuration. For each of them the input data is determined. For each Member of the input data, the Perl Pipeline module corresponding to the current pipeline is loaded and an ordered list of Actions is retrieved. Each of those is tested in turn until an incomplete Action is found. The code of that Action will be triggered, which may result in one or more system command lines ('cmd line') being executed. Some of those commands may resolve to job submissions to the DRM, requesting that it run a 'real' command line on the compute cluster.
- A single Perl script runs through a linear series of nested loops. At any time the script may wait for time-consuming operations to complete before continuing with remaining loops (Actions for other Data Members in the same pipeline, or different pipelines), resulting in possible long delays in starting jobs of the last pipeline (or last Data Member of the first pipeline), wasting time when all those jobs could have been running in parallel if they had started nearer to the same time.
- Not all command lines are necessarily executed via the DRM, possibly resulting in inappropriate use of system resources.
- Those command lines that are submitted to the DRM are independent; similar jobs will not be grouped for efficiency.
- State-tracking is primarily on-disc. Some Pipelines currently have an ad-hoc system of storing their completion state in a database, but this is not a generalised system. Action completion state is almost exclusively stored on disc, which is grossly inefficient for "high-performance" file systems such as Lustre.
- A single run-pipeline process can centrally manage all pipelines, so you only have to worry about keeping one process up and running to have confidence all your pipelines are being processed.
VRPipe is the proposed new system.
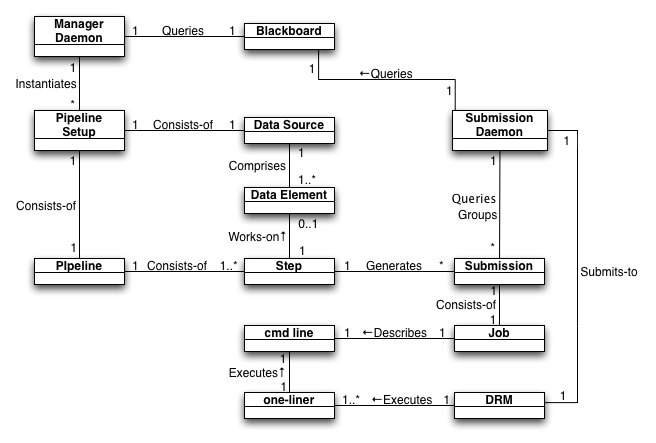 Figure JobExecution-VRPipe. VRPipe execution model
Figure JobExecution-VRPipe. VRPipe execution model
A Manager Daemon runs on the system and periodically queries the Blackboard (database) for Pipeline Setups (previously created externally by users) that are not currently being processed. For each of those a new process is spawned to consider the state of that Pipeline Setup. For each Data Element of that Pipeline Setup, the next un-started Action of that Pipeline is triggered, which may create new Submissions on the Blackboard. Actions that have already started but not yet completed have their Submissions queried to see if all are complete yet; if so the Action is marked as completed.
Independently a Submission Daemon runs on the system and periodically queries the Blackboard for incomplete Submissions (regardless of which Pipeline they are for). It handles failed ones appropriately, groups together similar ones (those sharing the same Requirements) and submits those to the DRM. What the DRM will end up executing on a given compute node is a small Perl one-liner that forks to do 2 things: send a periodic "heart-beat" to the Blackboard so that the Submission Daemon can know the health of each Job irrespective of the health of the DRM; execute the cmd line described by the Job the Submission was for. If the cmd line completes successfully the one-liner records success of the Job on the Blackboard. The Submission Daemon will then later interpret success of the Job as success of the Submission and record that on the Blackboard as well.
- Multiple pipelines have their needs considered simultaneously.
- Central management of all pipelines without any user action.
- Different pipelines can have their Submissions grouped together for efficient use of the DRM and system resources.
- All state-tracking and communication is via a centralised database.
- Minimised querying of the DRM.
- Different processes handle Pipeline maintenance (new Submission creation) and execution of pipeline steps (submitting Submissions to the DRM), allowing these to run in parallel and minimise wasted times.