Click the banner to activate $200 free personal cloud credits on DigitalOcean (deploy anything).

- Automated web scraping tool for capturing full-page screenshots.
- Utilizes Puppeteer with a stealth plugin to avoid detection by anti-bot mechanisms.
- Designed for efficiency with customizable timeout settings.
- Run
npm ito install dependencies (Puppetteer libraries, seepackage.jsonfor details). - Copy
.env.templateand rename this new file.env. Then add yourOPENAI_API_KEYand save the file. Runsource .envproperly mount this into the environment. - Set up browser confguration to allow for websites that require login authentication (LinkedIn, Instagram, etc). Make sure you log in ahead of time, that way your browser agent can access content without problems. For paywalled sites, it is your choice but hey:
https://removepaywall.com/<URL>. This is a GitHub project, not a moral essay, so decide for yourself and move on. I will say, however, that sites such as NYT, CNN, FOX, Guardian, etc., shouldn't be misrepresenting themselves as "news" when they're making you pay for truth. But I (and you probably if you're the type of person reading a GitHub project description) see nothing valuable in sites like those anyways that is worth scraping. For the best browser, install Chrome Canary (log into the website of choice before continuing this next step). Then reference it insnapshot.jsas follows:
MacOS (using Chrome Canary)
executablePath: '/Applications/Google\ Chrome\ Canary.app/Contents/MacOS/Google\ Chrome\ Canary',
userDataDir: '/Users/<USERNAME>/Library/Application\ Support/Google/Chrome\ Canary/Default',
Windows (using Chrome)
executablePath: 'C:/Program Files/Google/Chrome/Application/chrome.exe',
userDataDir: 'C:/Users/<USERNAME>/AppData/Local/Google/Chrome/User Data',
Linux (using Chrome)
executablePath: '/usr/bin/google-chrome',
userDataDir: '/home/<USERNAME>/.config/google-chrome',
Reference:
-
executablePathis the full pathname of your desktop Chrome app -
userDataDiris the specific directory where Puppeteer stores user-specific data like cookies and local storage. Useful for maintaining independent browser sessions with separate user data. Ensures clean slate for each session without previous user data. Also enables concurrent automation of multiple browser sessions. Tldr; it maximizes user control and flexibility. -
Can use Chrome or Chrome Canary, substitute throughout as needed.
-
Replace
<USERNAME>with your system username. -Tip: Depending on what terminal you are running from, there may be escape characters messing things up, so try replacing/with\\ -
Run
node snapshot.js "<URL>". Insert any URL in place of<URL>.
Ex:
node snapshot.js "https://en.wikipedia.org/wiki/Devious_lick"
Wait for few seconds (adjust const timeout = 6000; if too slow), and snapshot.jpg will magically appear in root directory of project:
This next part is better than a lot of OCR software for common tasks- in my opinion.
Set up Python environment and install packages:
python3 -m venv myenv
source myenv/bin/activate
pip install -r requirements.txt
Edit the following lines in gpt4v_scraper.py, replacing with your own website URL and then a system prompt (command to the GPT-4V API) about what to scrape for. See my example:
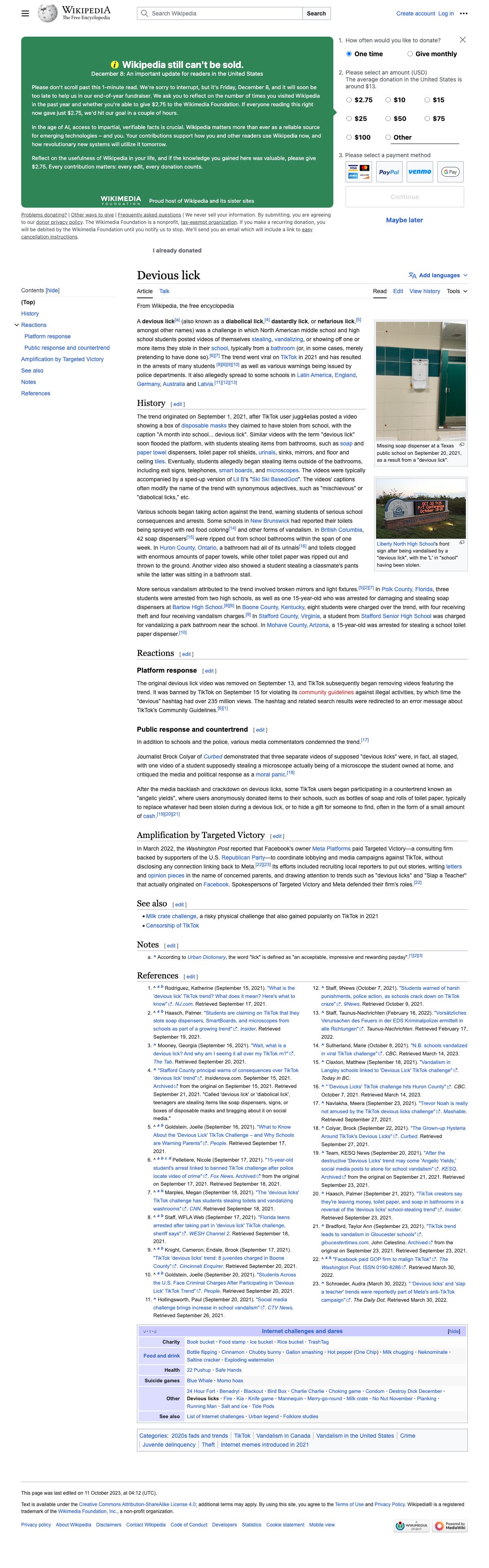
# Running the function w/ a example website + prompt
result = web_capture_and_extract("https://vd7.io/experience", "Extract this dude's Experience info")
print(result)
You should see two things happen:
snapshot.jpgwill be the screenshot of the scraped site- the console will display the text in the
snapshot.jpgwith additional context and answers to your prompt input
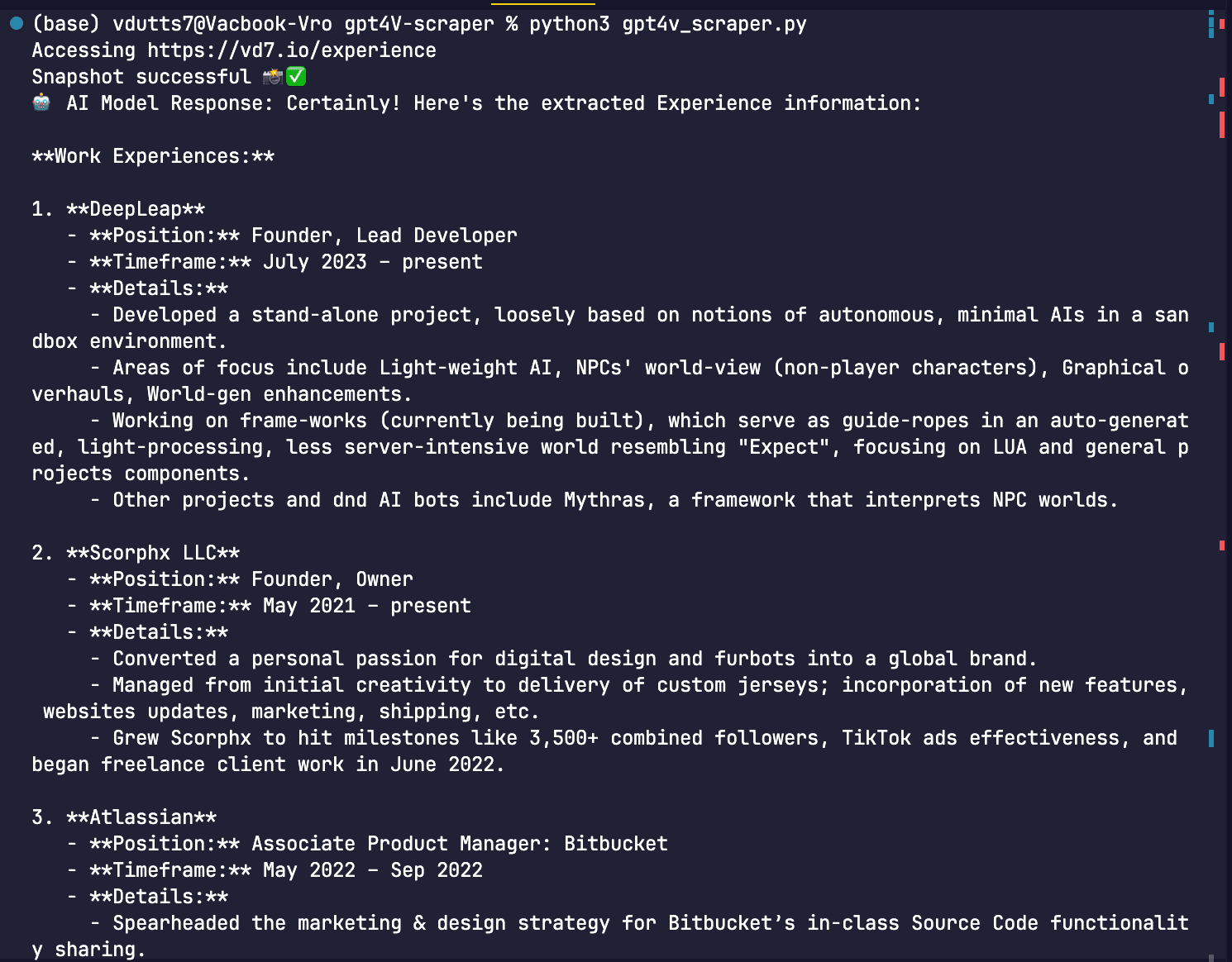
Chat with GPT-4V Web Agent in realtime to guide it across Bing search.
Run node web_agent.js :
🔥 GPT-4V Web Agent: Sup, ask me something!
You:
For example:
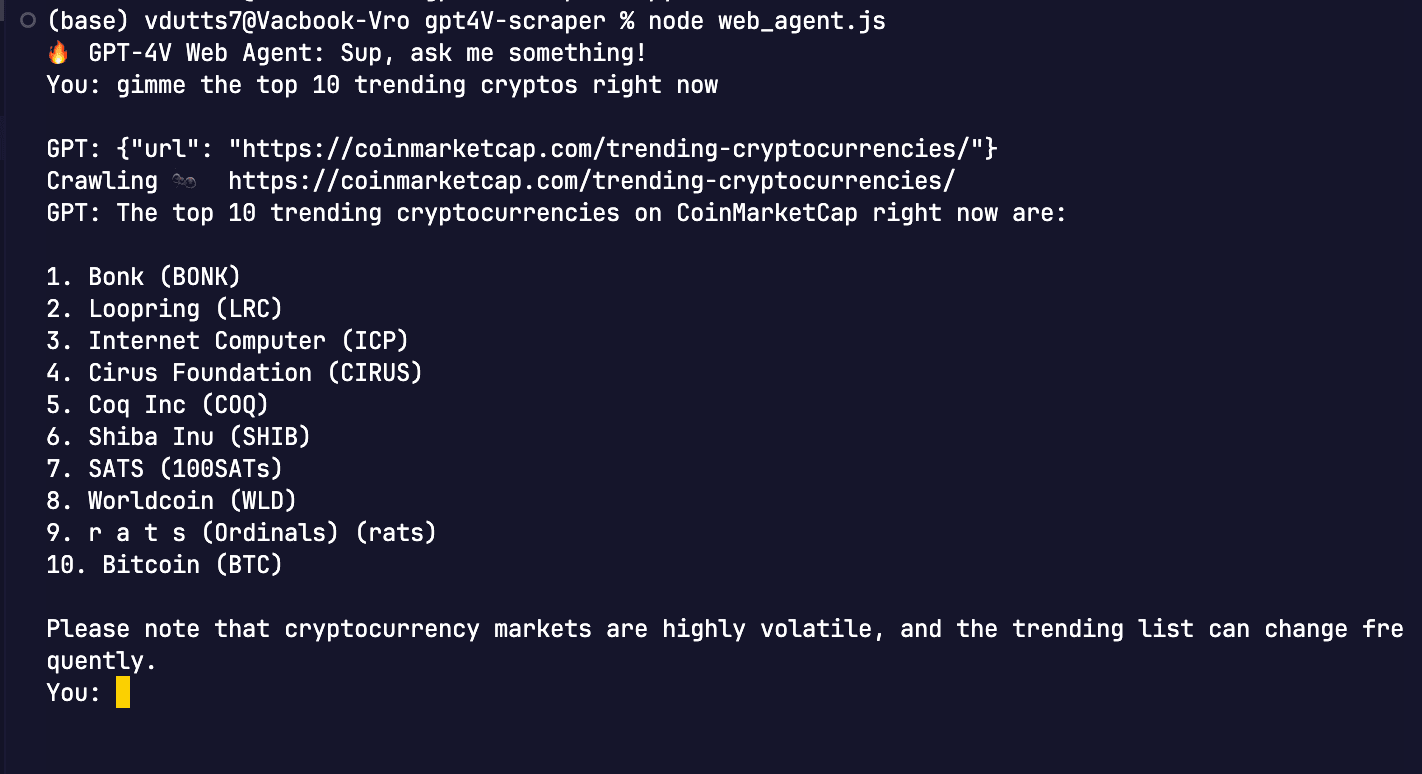
which matches the trending cryptos list on CoinMarketCap:
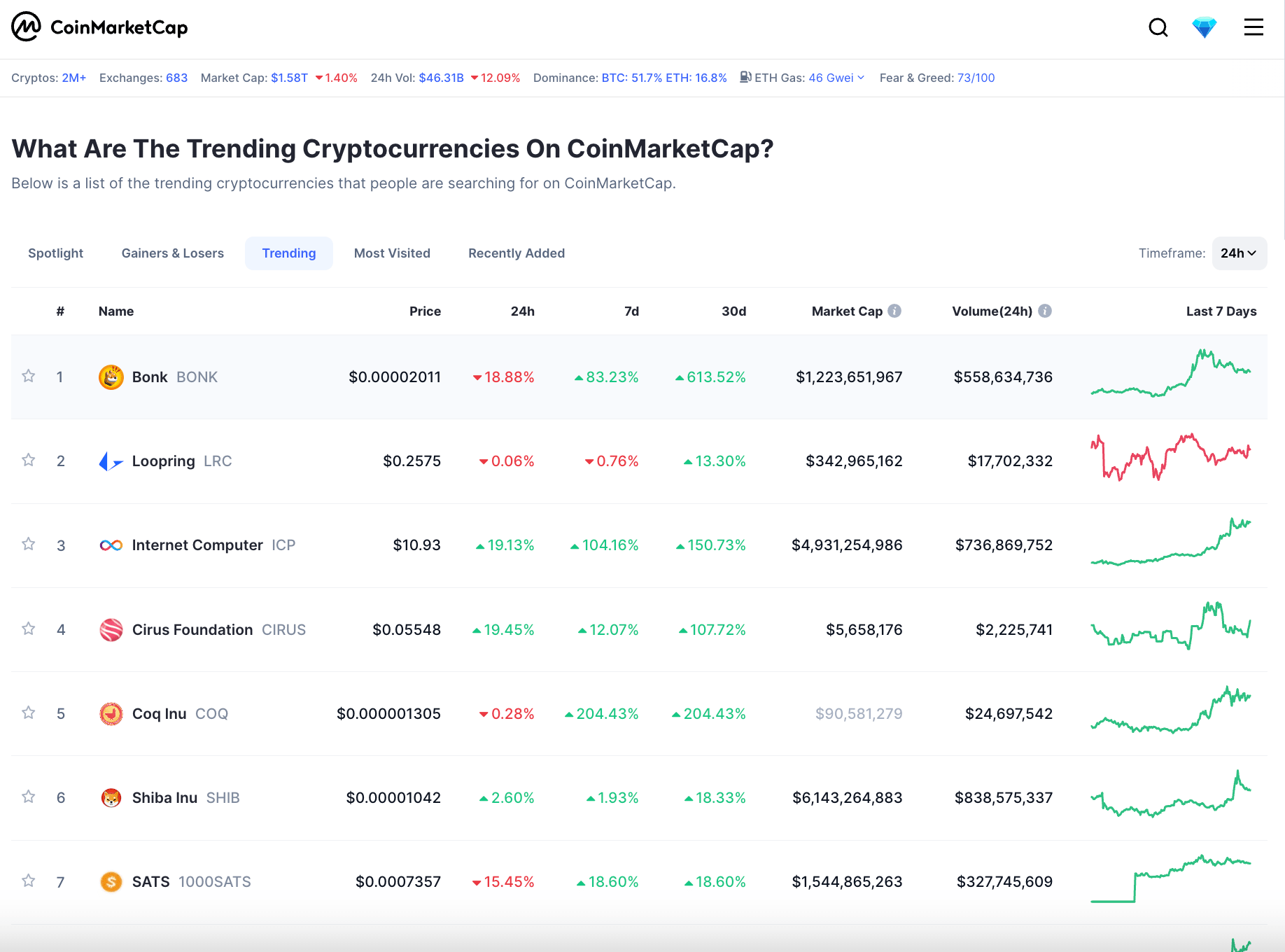
Here's the extended convo 😂 :
(base) vdutts7@Vacbook-Vro gpt4V-scraper % node web_agent.js
🔥 GPT-4V Web Agent: Sup, ask me something!
You: gimme the top 10 trending cryptos right now
GPT: {"url": "https://coinmarketcap.com/trending-cryptocurrencies/"}
Crawling 🐜 https://coinmarketcap.com/trending-cryptocurrencies/
GPT: The top 10 trending cryptocurrencies on CoinMarketCap right now are:
1. Bonk (BONK)
2. Loopring (LRC)
3. Internet Computer (ICP)
4. Cirus Foundation (CIRUS)
5. Coq Inc (COQ)
6. Shiba Inu (SHIB)
7. SATS (100SATs)
8. Worldcoin (WLD)
9. r a t s (Ordinals) (rats)
10. Bitcoin (BTC)
Please note that cryptocurrency markets are highly volatile, and the trending list can change frequently.
You: which ones looks smexy
GPT: It's important to clarify that the term "smexy," which is often a colloquial or slang term for "smart and sexy," doesn't really apply to cryptocurrencies. Cryptocurrencies are digital or virtual currencies and don't possess physical attributes that can be defined as attractive or not in the way that term suggests.
However, if you're asking about which cryptocurrencies on the list are potentially interesting or have seen significant attention, people often consider a few factors such as market performance, innovation, and the presence of a strong community or technological potential behind the cryptocurrency.
If we look at the trend data provided and the percentage changes in price over the past 7 days from the snapshot:
1. Bonk (BONK) has seen a remarkable 613.52% increase over 7 days.
2. Cirus Foundation (CIRUS) has grown by 107.72% over the same time frame.
3. Worldcoin (WLD) has appreciated by 105.97% over the last 7 days.
These significant increases might signal market excitement around these tokens, suggesting that some traders may find these trends to be metaphorically "smexy."
However, this should not be considered investment advice. Cryptocurrency investments can be highly speculative and carry a high level of risk. It's important to conduct thorough research or consult a financial advisor before making investment decisions.
You: