- Implemented a data pipeline which monitors, scrapes and dedupes latest news (MongoDB, Redis, RabbitMQ);
- Designed data monitors for obtaining latest news from famous websites and recommend to web server.
- Successfully fetch useful data from original news websites by building news scrapers.
- Build dedupers which filter same news by using NLP (TF-IDF) to analyze similarities of articles scraped from news websites.
- Use Tensorflow for machine learning which can shows news according to users interests. Build a single-page web.
- Build up App Component with Marerialize Styling
- Build up NewsPanel Component
- Build up NewsCard Component
- Refactor those Components into Web Server file
- Express application generator - NodeJS Server
- Configure APP.js
- Server Side Routing
- RESTful API: Send Backend data from Server(Mock Data)
- NewsPanel Requests to Backend for Loading More JSON data
- Access Control Allow Origin
- Handle Scrolling
- Debounce
- SOA Desgin Pattern
- RPC Backend Service
- JSONRPClib Libraries
- Testing by Postman
- NodeJS Server as a RPCclient - jayson
- CloudAMQP
- CloudAMQP & Pika
- CloudAMQP with Python(doc)
- Heart Beat
- Backend API send Request to CloudAMQPClient API for Asking News in Queue
- Refactor: Operations
- [CloudAMQP_Client]
- [Mongodb_Client]
- [News_api_Client]
- [News_recommendation_service_Client]
Monitor -> Q(scrape) -> Fetcher -> Q(dedupe)
- News Monitor w/ Redis, RabbitMQ, News API
- Send News to Redis (hashlib)
- Send to RabbitMQ
- Create a Took to clean the Queue
- Web Scrapers(has been replaced)
- News Fetcher
- Newspaper 3k replaces XPath in News Fetcher
- Newspaper3k(doc)
- Test Monitor and Fetcher
- Check if user owns a token or redirect to login page
- FrontEnd Auth - token base
- Base Component with Login and SignUp
- Send Http Request to Backend to handle login logic
- LoginPage(deal with logic)
- SignUpPage
- isUserAuthenticated()
- React Router in Client
-
Hash and Salt the password since we couldn't directly save into Database
-
Valide the Email Input to aviod Rainbow attack
-
Deat With DB connection and Passpord Campare
-
Check Token the user own to authoritize user to load more news

- Base : Whole React App (Navbar + App)
- App : Image(title) + NewsPanel
- NewsPanel : Concludes many NewsCard such as News Lists (While user scorlling, backend send new NewsCard continously)
- NewsCard : Single News adding into NewsPanel with News image, News title, News contents, News description, News Tage and Links to News.(Would record the clicked by users in future)
- Deal with webpack and give a whole framework
- Install CRA (Global) : Local Developing Tool
sudo npm install -g create-react-app
- Create a new React App
create-react-app top-news
- Test Connection
cd top-news
npm start
- public : images
- src : Each Component has its own folder
App / App.js
- There is only one div tag in render function
- import React , './App.css', CSS file and logo
- Use "className" instead of "class" : Since in ES6, we use class for define a App class
import React from 'react';
import './App.css';
import logo from './logo.png';
class App extends React.Component {
render() {
return(
<div>
<img className = 'logo' src = {logo} alt = 'logo'/>
<div className = 'container'>
{/* TODO */}
</div>
</div>
);
}
}
export default App;- Why use "default App"?
- If not, while you want to import App from other file, you need to type :
import { App } from './App.js';- But if you have default, you could get rid of {}
- CSS setup
.App {
text-align: center;
}
.logo {
display: block;
margin-left: auto;
margin-right: auto;
padding-top: 30px;
width: 20%;
}- install in Client sie
npm install materialize-css --save
- Import
import 'materialize-css/dist/css/materialize.min.css';- Build a index.js for starting the client side
touch src/index.js
- index.js
import React from 'react';
import ReactDOM from 'react-dom';
import App from './App/App';
ReactDOM.render(
<App />,
document.getElementById('root')
);- Where is root?
- public -> index.html
<div id="root"></div>- Create NewsPanel folder and NewsPanel.js
mkdir src/NewsPanel
code src/NewsPanel/NewsPanel.js
import React from 'react';
import './NewsPanel.css';- Since we Need to save the News content, we need an internal variable (need constructor)
class NewsPanel extends React.Component {
constructor() {
super();
this.state = { news: null };
}- state = {news: null} -> lists of JSON
- Render conditions : there is a news and then create a NewsCard or show the loading message
render() {
if (this.state.news) {
return (
<div>
{this.renderNews()}
</div>
);
} else {
return (
<div>
Loading ...
</div>
);- local function, renderNews() : Render out the News and dynamactiy deal with the NewCards.
- Clickable - Use A tag in HTML
- Key - in React, if you would like to use a list, need to give a 'key' since the Virtual DOM need to know which items were changed in lists and just change that item insteads of renewing all items.
- "list-group-item" needs to be put into "list-group" and show the {news_list} in list group
- Get All News from state news -> Make all news in list -> Make all news become a NewsCard -> Put NewsCards into list-group
renderNews() {
const news_list = this.state.news.map(news => {
return (
<a className = 'list-group-item' key = {news.digest} href = '#'>
<NewsCard news = {news} />
</a>
);
});
return (
<div className = 'container-fluid'>
<div className = "list-group">
{news_list}
</div>
</div>
);
}- local function, loadMoreNews() : Get News from backend - init load. (Now we gave a mock data)
loadMoreNews() {
this.setState({
news : [
{....data
}]
});
}- After render() was ran, it will execute componentDidMount() -> Load News in state
componentDidMount () {
this.loadMoreNews();
}- Import NewsCard
import NewsCard from '../NewsCard/NewsCard';- Export NewPanel
export default NewsPanel;- By default for future using
touch src/NewsPanel/NewsPanel.css
- App.js
import NewsPanel from '../NewsPanel/NewsPanel';
<div className = 'container'>
<NewsPanel />
</div>- Create NewsCard Component Folder
mkdir src/NewsCard
touch src/NewsCard/NewsCard.js
src/NewsCard/NewsCard.css
- class NewsCard (For HTML contents)
class NewsCard extends React.Component {
render() {
return(
HTML....- news-container
- row
- col s4 fill
- image
- col s8
- news-intro-col
- news-intro-panel
- news-description
- news-chip
- onClick -> redirectToUrl()
redirectToUrl(url, event) {
event.preventDefault();
window.open(url, '_blank');
}- Get the data from props.news from NewsPanel.js
<h4>
{this.props.news.title}
</h4>- NewsCard could get the data from NewsPanel since it was passed from :
<a className = 'list-group-item' key = {news.digest} href = '#'>
<NewsCard news = {news} />
</a> - Dont get chips if there is no source (this.props.news.source != null &&)
{this.props.news.source != null && <div className='chip light-blue news-chip'>{this.props.news.source}</div>}- CSS file
.news-intro-col {
display: inline-flex;
color: black;
height: 100%;
}
CSS....- Create a web_server file and move top-news which was renamed "client" into it
mkdir web_server
mv top-news/ ./web_server/client
-
Deploy to AWS, there is no different likes server and client.
-
Create React App provide "Development Server" for developing, but we wont use this to serve Users
-
Development: Node Server + Development Server
-
Publishment: Node Server + build (built by React App)
- Install Globally
sudo npm install express-generator -g
- Create a Server in web_server
express server // Usage: express [options] [dir]
- Install dependencies
cd server
npm install
npm start
(defualtly installed lots of requirements)
- Delete :
- bodyParser: POST Request
- cookieParser: Authentication
- logger: Login
- users: Login
- Change views engine
- Put the default folder to /client/build
app.set('views', path.join(__dirname, '../client/build'));- Express Static : Find the image **** Find Bug!!!!! -> missing: '/static'
app.use('/static',
express.static(path.join(__dirname, '../client/build/static')));- Client Webpack: Build a build folder for server to use
- static - css
- static - js
- Error Handler
app.use(function(req, res, next) {
res.status(404);
});r
- package.json : change start
"scripts": {
"start": "nodemon ./bin/www"
},- Since init run the '/', redirect to the routes/ index.js
app.use('/', index);
- index.js : send index.html from build to server side
- Get home page!
var express = require('express');
var router = express.Router();
var path = require('path';)
router.get('/', function(req, res, next) {
res.sendFile("index.html",
{ root: path.join(__dirname, '../../client/build')});
});
module.exports = router;- bin -> www : Place for init the App.
- In routes/news.js
touch server/routes/news.js
- Give a mock data here and send as a JSON file
var express = require('express');
var router = express.Router();
router.get('/', function(req, res, next) {
news = [
.....DATA
];
res.json(news);
]
});
module.exports = router;- In app.js require the news Route
var news = require('./routes/news');
app.use('/news', news);- NewsPanel.js -> loadMoreNews() with backEnd
- Cache: False -> if true, it might show the old news from cache
- news_url -> window.location.hostname
- 'http://' + window.location.hostname + ':3000' + '/news'
- method: GET
const news_url = 'http://' + window.location.hostname + ':3000' + '/news';
const request = new Request(news_url, {method:'GET', cache:false});- Fetch + .then : Http Request & Promise
- res.json -> Ansynchrons : so we need another ".then" 調用JSON
- After we got JSON, deal with the news data
- If there is no news on web, directly give the new one, but if not, "concat" to the old ones
fetch(request)
.then(res => res.json())
.then(news => {
this.setState({
news: this.state.news ? this.state.news.concat(news) : news,
});
});-
Since we couldn't cross localhost:3000 and localhost:3001 ! Run in the different PORT.
-
Temporarily access to run in different PORT
- (BUT NEED TO BE REMOVED WHEN FINAL PUBLISH)
- app.js
app.all('*', function(req, res, next) {
res.header("Access-Control-Allow-Origin", "*");
res.header("Access-Control-Allow-Headers", "X-Requested-With");
next();
});Failed to load http://localhost:3000/news: No 'Access-Control-Allow-Origin' header is present on the requested resource. Origin 'http://localhost:3001' is therefore not allowed access.
- Keep using loadMoreNews by combining Scroll EventListener
- | | -
document. | | |
body. | | ScrollY
offestHeight | | |
| |__________| _
| | | -
| | | window.innerHeight
- |__________| _
- window.innerHeight + scrollY >= document.body.offsetHeight - 50 means when touch the boundry of bottom -> load more News
- Couldn't use "this.loadMoreNews()" until you change handleScroll to arrow function
window.addEventListener('scroll', () => this.handleScroll);- handleScroll()
handleScroll() {
const scrollY = window.scrollY
|| window.pageYOffset
|| document.documentElement.scrollYTop;
if((window.innerHeight) + scrollY) >= (document.body.offsetHeight - 50);
}- DONT FORGET THE () -> THIS.HANDLESCROLL()
componentDidMount() {
this.loadMoreNews();
window.addEventListener('scroll', () => this.handleScroll());
}- Install Lodash inclient
npm install lodash --save
- Solve the Scroll frequent problems (Scroll Events happened too much)
- Send several requests to backend too frequently
import _ from 'lodash';
componentDidMount() {
this.loadMoreNews();
this.loadMoreNews = _.debounce(this.loadMoreNews, 1000);
window.addEventListener('scroll', () => this.handleScroll());
}- All service interfaces should be designed for both internal and external users
Benefit:
Isolation - language / technology / tools /
decoupleing / independency / deployment / maintenance
Ownership - minimal gray area and gap
Scalability - easy to scale up and modify
=======
Con:
Complexity - sometimes unnecessary
Latency - network communication eats time
Test effort - all services require E2E tests
DevOp : On-call!!!
- Often built as a three tier architecture:
[Desktop User]
|
[Presentation Tier] : Client interatcion via a web browser
|
[Logic Tier] : provide the appliction's
| functionality via detailed processing
|Storage Tier|: handle persisting and retrieving application data
- Ohter types of users
- Attachments
- Bulk operations
- Data pipelines
- Notifications
- Monitoring
- Testing
Mobile Destop UI
User User Test
\ | /
Chrome
Extension - Presentation - Prober
Tier
File File
Upload \ | / Download
Logic
Notifica- - Tier - Command
tions Line Tool
/ | \
CSV Storage CSV
Upload Tier Download
/ \
Data Data
Provider Consumer
- Fort-end Service handles all external interactions
- Back-end implements one protocol to talk to front-end
- All clients see same business abstraction
- Consistent business logic enforcement
- Easy internal refactoring

|| Client || || Node Server || || Backend Server || || Redis || || MongoDB || || ML Server ||
| | | Check if in Redis | | |
|---------------> | |<------------------>| | |
| fetch more news |---------------->| (If not) get news from DB | |
|(userID/ pageNum)| getNewsSunmmaire|<------------------------------->| |
| | sForUser | Get Recommended news from ML server |
|<----------------|(userID /pageNum)|<---------------------------------------------->|
| Sliced News | |Store combined news | | |
| |<----------------| in Redis | | |
| | Sliced News |------------------->| | |
| | | | | |
|| Client || || Node Server || || Backend Server || || Redis || || MongoDB || || ML Server ||
- Open a file backend_server and a service.py
mkdir backend_server
touch backend_server/service.py
-
Build a Client or Server to send or receive RPC Request
-
Not have a good support to Python 3.5, so we need a jsonrpclib-pelix to help development JSONRPClib JSONRPClib-pelix
-
install library
pip3 install jsonrpclib
pip3 install jsonrpclib-pelix
- Server Host define
- Server Port define
- (Reason why we define is that in the future if we want to change that we could only change in the first line)
- Give a function - add
- Register host and port and your fnuctions
from jsonrpclib.SimpleJSONRPCServer import SimpleJSONRPCServer
SERVER_HOST = 'localhost';
SERVER_PORT = 4040;
def add(a, b):
print("Add is called with %d and %d " %(a, b))
return a + b
RPC_SERVER = SimpleJSONRPCServer((SERVER_HOST, SERVER_PORT))
RPC_SERVER.register_function(add, 'add')
print("Starting RPC server")
RPC_SERVER.serve_forever()- Send a REQUEST:
- jsonpc version
- id : to identify
- method : add
- params : give a & b
POST Request:
{
"jsonrpc" : "2.0",
"id" : 1,
"method" : "add",
"params" : [1,2]
}
Result:
{
"result": 3,
"id": 1,
"jsonrpc": "2.0"
}
Add is called with 13 and 2
127.0.0.1 - - [13/Jan/2018 14:48:25] "POST / HTTP/1.1" 200 -
- Open a new folder in web_server/server/
mkdir web_server/server/rpc_client
- Change news.js server not to hard code the data here but get News from our backend server
var express = require('express');
var router = express.Router();
/* GET News List. */
router.get('/', function(req, res, next) {
news = backend_server.getNews();
res.json(news);
});
module.exports = router;- install jayson in server
npm install jayson --save
- Open a rpc_client.js with a helper method to let news.js could "getNoews()" from our backend server
var jayson = require('jayson');
// create a client
var client = jayson.client.http({
hostname: 'localhost',
port: 4040
});
function add(a, b, callback) {
client.request('add', [a, b], function(err, response) {
if(err) throw err;
console.log(response.result);
callback(response.result);
});
}
module.exports = {
add : add
}- open a rpc_client_test.js
touch rpc_client/rpc_client_test.js
- Import rpc_Client
var client = require('./rpc_client');
// invoke 'add'
client.add(1, 2, function(res){
console.assert(res == 3);
});- How to test?
- Open the backend server
- Execute the rpc_client_test.js
node rpc_client_test.js
- Install mongoDB (Since we need to train the data so store in the local side)
sudo apt-get install -y mongodb-org
-
MongoCli MongoCli
-
Run Mongod
./mongod
- Run Mongo shell
./mongo
- show DB
show dbs
- Switch DB
use top-news
- See Collections / Tables
show collections
show tables
- (Query Documents)[https://docs.mongodb.com/manual/tutorial/query-documents/]
db.news.find
db.news.fundOne()
db.news.count()
- Export db
./mongoexport --db top-news --collection news --out demo_news_1.json
- Import db
mongoimport --db top-news --collection news --file demo_news_1.json
- Install pymongo
pip3 install pymongo
- Set up all dependencies List(likes in NPM we used package.json)
https://api.mongodb.com/python/current/pip3 install -r requirements.txt
- open a file utils in backend_server
mkdir utils
touch utils/mongodb_client.py
- Making a Connection with MongoClient and Getting a Database
from pymongo import MongoClient
MONGO_DB_HOST = "localhost"
MONGO_DB_PORT = 27017
DB_NAME = "test"
client = MongoClient(MONGO_DB_HOST, MONGO_DB_PORT)
def get_db(db = DB_NAME):
db = client[db]
return db- Connect to MongoClient to CURD
- Open Test File
touch utils/mongodb_client_test.py
- Set Only when user call test_basic()
- db = client.get_db('test')!!!!! used "_"
import mongodb_client as client
def test_basic():
db = client.get_db('test')
db.test.drop()
assert db.test.count() == 0
db.test.insert({'test' : 1})
assert db.test.count() == 1
db.test.drop()
assert db.test.count() == 0
print('test_basic passed!')
if __name__ == "__main__":
test_basic()RabbitMQ is a message broker: it accepts and forwards messages. You can think about it as a post office: when you put the mail that you want posting in a post box, you can be sure that Mr. Postman will eventually deliver the mail to your recipient. In this analogy, RabbitMQ is a post box, a post office and a postman.
The major difference between RabbitMQ and the post office is that it doesn't deal with paper, instead it accepts, stores and forwards binary blobs of data ‒ messages.
-
AMQP URL is the address to receive and send the messages
-
Pika to manupulate AMQP pika
[RabbitMQ Pika]
- Install Pika by adding in requirements.txt
pika
- Make a file for CloudAMQP client
touch backend_server/utils/cloudAMQP_client.py
- String -> JSON -> Serialization
- Name of Queue based on instance thus we need to create a class
- Parameters of URL
- Set a socket timeout
- Connection by Pika(blocking Connection)
- Open a Channel for receiving message
- Declare the channel as queue name
class CloudAMQPClient:
def __init__(self, cloud_amqp_url, queue_name):
self.cloud_amqp_url = cloud_amqp_url
self.queue_name = queue_name
self.params = pika.URLParameters(cloud_amqp_url)
self.params.socket_timeout = 3
self.connection = pika.BlockingConnection(self.params)
self.channel = self.connection.channel()
self.channel.queue_declare(queue = queue_name)- Decode
return json.loads(body.decode('utf-8'))def sendMessage(self, message):
self.channel.basic_publish(exchange='',
routing_key = self.queue_name,
body = json.dumps(message))
print("[X] Sent message to %s:%s" %(self.queue_name, message))Get a single message from the AMQP broker. Returns a sequence with the method frame, message properties, and body.
Returns:
a three-tuple; (None, None, None) if the queue was empty; otherwise (method, properties, body); NOTE: body may be None
- Geive a Delivery tag when everytime broker receive a message and return back from String to JSON
# Get a message
def getMessage(self):
method_frame, header_frame, body = self.channel.basic_get(self.queue_name)
if method_frame:
print("[x] Received message from %s:%s" % (self.queue_name, body))
self.channel.basic_ack(method_frame.delivery_tag)
return json.loads(body)
else:
print("No message returned.")
return None- BlockingConnection.sleep is a safer way to sleep than time.sleep().
- This will repond to server's heartbeat.
def sleep(self, seconds):
self.connection.sleep(seconds)- Open a test file
touch utils/couldAMQP_client_test.py
- Import CloudAMQPClient class from client, try test_basic() method with params
from cloudAMQP_client import CloudAMQPClient
CloudAMQP_URL = "amqp://xggyaoov:[email protected]/xggyaoov"
TEST_QUEUE_NAME = "test"
def test_basic():
client = CloudAMQPClient(CloudAMQP_URL,TEST_QUEUE_NAME )
sentMsg = {"test":"test"}
client.sendMessage(sentMsg)
reveivedMsg = client.getMessage()
assert sendMsg == reveivedMsg
print("test_basic passed!")
if __name__ == "__main__":
test_basic()- Test for get one news on service.py
- import json and package dumps to transfer from BSON to JSON
- Register server in this RPC Server
This module provides two helper methods dumps and loads that wrap the native json methods and provide explicit BSON conversion to and from JSON. JSONOptions provides a way to control how JSON is emitted and parsed, with the default being the legacy PyMongo format. json_util can also generate Canonical or Relaxed Extended JSON when CANONICAL_JSON_OPTIONS or RELAXED_JSON_OPTIONS is provided, respectively.
import json
from bson.json_util import dumps
def get_one_news():
print("get_one_news is called.")
news = mongodb_client.get_db()['news'].find_one()
return json.loads(dumps(news))
RPC_SERVER.register_function(get_one_news, 'get_one_news')
- Import 'utils' (Python file import) to import mongodb_client - use os and sys
import os
import sys
# import utils packages
sys.path.append(os.path.join(os.path.dirname(__file__), 'utils'))
import mongodb_client- Install PyLint
pip3 install pylint
- Analyze Outcomes
C: 1, 0: Missing module docstring (missing-docstring)
E: 10, 0: Unable to import 'mongodb_client' (import-error)
C: 10, 0: Import "import mongodb_client" should be placed at the top of the module (wrong-import-position)
C: 16, 0: Invalid argument name "a" (invalid-name)
C: 16, 0: Invalid argument name "b" (invalid-name)
C: 16, 0: Missing function docstring (missing-docstring)
C: 20, 0: Missing function docstring (missing-docstring)
- missing-docstring : Add docstring -> """XXX"""
- import-error: In our case, we need to write an exception to surpass the error
- wrong-import-position: Need to put on the top
- invalid-name : couldn't use argument named a -> num1
- bad-whitespace: 1, 2
- Get One News need to be put other files to let service become a simple surface just receive the API request
- open a file "operations.py"
import os
import sys
import json
from bson.json_util import dumps
# import utils packages
sys.path.append(os.path.join(os.path.dirname(__file__), 'utils'))
import mongodb_client
NEWS_TABLE_NAME = "news"
def getOneNews():
db = mongodb_client.get_db()
news = db[NEWS_TABLE_NAME].find_one()
return json.loads(dumps(news))- Import operations in service.pu
import operationsmkdir common
mv backend_server/utils/* common/
mv backend_server/requirements.txt ./
rmdir backend_server/utils
- Chagne the path from service.py and operations.py from utils to common
sys.path.append(os.path.join(os.path.dirname(__file__), '..', 'common'))- News API
- New Monitor(Thread) : Through News API to get the latest News URL, run every 10 sec
- Redis(Save collection News) : To solve the duplicated problems, if it has been collected, we'll ignore that News.
- RabbitMQ : Receive the accepted News URL from News Monitor and Send it to Web Scrapers
- Web Scrapers : Receive News URL and scrape the contenct(XPath) from the website
- RabbitMQ : Receive the New Contents from Web Scrapers
- NewS Deduper : Receive the scraped News from RabbitMQ and Filter the same contents News by using NLP - TLITF
-
- News Monitor
-
- News Fetcher - XPath
-
- News Deduper
-
- News Fetcher - third party package (Replace XPtah)
https://newsapi.org/v2/top-headlines?country=us&category=business&apiKey=715e9632a2a94ea1a4546e3f314a76a5
- source :
- apiKey :
status": "ok",
"totalResults": 20,
-"articles": [ ...
touch common/news_api_client.py
- Install requests and add in requirements.txt
pip3 install requests
- getNewsFromSource()
- private buildUrl
- DEFAULT_SOURCES / SORT_BY_TOP
- Response is a String and we need to transfer it into a JSON and decode into utf-8
import requests
from json import loads
DEFAULT_SOURCES = [CNN]
CNN = 'cnn'
SORT_BY_TOP = 'top'
NEWS_API_KEY = '715e9632a2a94ea1a4546e3f314a76a5'
NEWS_API_ENDPOINT = "https://newsapi.org/v1/"
ARTICLES_API = "article"
def _buildUrl(endPoint = NEWS_API_ENDPOINT, apiName = ARTICLES_API):
return endPoint + apiName
def getNewsFromSource(sources = DEFAULT_SOURCES, sortBy = SORT_BY_TOP):
articles = []
for source in sources:
payload = {'apiKey' : NEWS_API_KEY,
'source' : source,
'sourBy' : sortBy}
response = requests.get(_buildUrl(), params = payload)
res_json = loads(response.content.decode('utf-8'))- To see if the response is vaild
- status -> ok, source and res_json not None
- Populate news source into articles : Add Soucre into the result
.....'publishedAt': '2018-01-14T10:36:26Z', 'source': 'cnn'}]
# Extract news from response
if (res_json is not None and
res_json['status'] == 'ok' and
res_json['source'] is not None):
# populate news source in each articles.
for news in res_json['articles']:
news['source'] = res_json['source']
articles.extend(res_json['articles'])
return articles- test_basic()
- use getNewsFromSource, makes sure the ammount of news > 0 and tries another sources
import news_api_client as client
def test_basic():
news = client.getNewsFromSource()
print(news)
assert len(news) > 0
news = client.getNewsFromSource(sources=['cnn'], sortBy='top')
assert len(news) > 0
print('test_basic passed!')
if __name__ == "__main__":
test_basic()- Connect with Redis
- Connect with RebbitMQ
- Connect with News API Client
- Install Redis
pip3 install redis
-
News Monitor
-
number_of_news to record the number of news
-
Record: title / description / text / url / author / source / publishedAt:date / urlToImage / class / digest
-
What digest to be used? To see if there is a dupilcate in Redis by transfering Digest into a Hashlib which could save the space in Redis
-
Others, we could use it in React Frontend
-
Add back digest to News JSON
"""News Monitor"""
import hashlib
import redis
import os
import sys
sys.path.append(os.path.join(os.path.dirname(__file__), '..', 'common'))
import news_api_client
NEWS_SOURCES = "cnn"
while True:
news_list = news_api_client.getNewsFromSource(NEWS_SOURCES)
number_of_news = 0
for news in news_list:
news_diget = hashlib.md5(news['title'].encode('utf-8')).hexdigest()- Connect Redis and use it to find if there is in Redis or not
REDIS_HOST = 'localhost'
REDIS_PORT = 6379
redis_client = redis.StrictRedis(REDIS_HOST, REDIS_PORT)
if redis_client.get(news_digest) is None:
number_of_news += 1- Deal with the publishAt problems. Since some news didn't get the publishAt data but we need that to sort the News. Thus, we use the datetime we got that news to represent the publishAt time
"publishedAt": "2018-01-14T20:17:50Z"
import datetime
for news in news_list:
news_diget = hashlib.md5(news['title'].encode('utf-8')).hexdigest()
# Connect with Redis and check if it's in Redis
if redis_client.get(news_digest) is None:
number_of_news += 1
# Deal with publishAt problems
if news['publishedAt'] is None:
news['publishedAt'] = datetime.datetime.utcnow().strftime("%Y-%m-%dT%H:%M:%SZ")
# Save into Redis
redis_client.set(news_digest, "True")
redis_client.expire(news_digest, NEWS_TIME_OUT_IN_SECONDS)- init and import CloudAMQP Client
- Need to apply anotehr QUEUE different from TEST URL
from cloudAMQP_client import CloudAMQPClient
SCRAPE_NEWS_TASK_QUEUE_URL =
SCRAPE_NEWS_TASK_QUEUE_NAME = "top-news-scrape-news-task-queue"
SLEEP_TIME_IN_SECOND = 10
cloudAMQP_client = CloudAMQPClient(SCRAPE_NEWS_TASK_QUEUE_URL, SCRAPE_NEWS_TASK_QUEUE_NAME)
# Send Tasks to cloudAMQP
cloudAMQP_client.sendMessage(news)
print("Fetched %d news." % number_of_news)
cloudAMQP_client.sleep(SLEEP_TIME_IN_SECOND)pika.exceptions.ProbableAuthenticationError: (403, 'ACCESS_REFUSED - Login was refused using authentication mechanism PLAIN. For details see the broker logfile.')
import os
import sys
# import common package in parent directory
sys.path.append(os.path.join(os.path.dirname(__file__), '..', 'common'))
from cloudAMQP_client import CloudAMQPClient
SCRAPE_NEWS_TASK_QUEUE_URL = "amqp://cbzkwlek:[email protected]/cbzkwlek"
SCRAPE_NEWS_TASK_QUEUE_NAME = "top-news-SCRAPE_NEWS_TASK_QUEUE"
# DEDUPE_NEWS_TASK_QUEUE_URL = #TODO: use your own config.
# DEDUPE_NEWS_TASK_QUEUE_NAME = #TODO: use your own config.
def clearQueue(queue_url, queue_name):
scrape_news_queue_client = CloudAMQPClient(queue_url, queue_name)
num_of_messages = 0
while True:
if scrape_news_queue_client is not None:
msg = scrape_news_queue_client.getMessage()
if msg is None:
print("Cleared %d messages." % num_of_messages)
return
num_of_messages += 1
if __name__ == "__main__":
clearQueue(SCRAPE_NEWS_TASK_QUEUE_URL, SCRAPE_NEWS_TASK_QUEUE_NAME)
# clearQueue(DEDUPE_NEWS_TASK_QUEUE_URL, DEDUPE_NEWS_TASK_QUEUE_NAME)- XPath Helper
"""//p[contains(@class, 'zn-body__paragraph')]//text() | //div[contains(@class, 'zn-body__paragraph')]//text()"""- Open a scrapers folder and cnn news scraper file
- Imitate the behaviors of browsers
- session & header
- Imitate a real User Agent as a Header
def extract_news(news_url):
session_requests = requests.session()
response = session_requests.get(news_url, headers=_get_headers())
news = {}- Get the Header by looping the Mock User Agent File
def _get_headers():
ua = random.choice(USER_AGENTS)
headers = {
"Connection" : "close",
"User-Agent" : ua
}
return headers- Import html from lxml
- Used XPATH method by separating it into tree and news from the tree
- Join the LIST of news together to become a whole STRING
from lxml import html
try:
tree = html.fromstring(response.content)
news = tree.xpath(GET_CNN_NEWS_XPATH)
news = ''.join(news)
except Exception:
return {}
return news- Grab the Agent info form file and randomly select one of them
# Load user agents
USER_AGENTS_FILE = os.path.join(os.path.dirname(__file__), 'user_agents.txt')
USER_AGENTS = []
with open(USER_AGENTS_FILE, 'rb') as uaf:
for ua in uaf.readlines():
if ua:
USER_AGENTS.append(ua.strip()[1:-1])
random.shuffle(USER_AGENTS)- Take a News Url from Queue(news monitor) and use scraper to get the contents and send it into the next Queue
- While loop likes Moniter, get a message from scrape_news_queue_client and use handle message
while True:
if scrape_news_queue_client is not None:
msg = scrape_news_queue_client.getMessage()
if msg is not None:
# Parse and process the task
try:
handle_message(msg)
except Exception as e:
print(e)
pass
scrape_news_queue_client.sleep(SLEEP_TIME_IN_SECONDS)- handleMessage()
def handle_message(msg):
if msg is None or not isinstance(msg, dict):
print('message is broken')
return
task = msg
text = None- Check if the source is from cnn, and extractNews by task['url'] from news scraper and Rewrite the text into task
if task['source'] == 'cnn':
print('scraping CNN news')
text = cnn_news_scraper.extractNews(task['url'])
else
print('News source [%s] is not supported. ' % task['source'])
task['text'] = text- Send out the task to dedupe Queue
dedupe_news_queue_client.sendMessage(task)- Import os,sys and the CloudAMQP CLIENT
import os
import sys
# import common package in parent directory
sys.path.append(os.path.join(os.path.dirname(__file__), '..', 'common'))
from cloudAMQP_client import CloudAMQPClient
DEDUPE_NEWS_TASK_QUEUE_URL =
DEDUPE_NEWS_TASK_QUEUE_NAME = "top-new-DEDUPE_NEWS_TASK_QUEUE_NAME"
SCRAPE_NEWS_TASK_QUEUE_URL = "
SCRAPE_NEWS_TASK_QUEUE_NAME = "top-news-SCRAPE_NEWS_TASK_QUEUE"
SLEEP_TIME_IN_SECONDS = 5
dedupe_news_queue_client = CloudAMQPClient(DEDUPE_NEWS_TASK_QUEUE_URL, DEDUPE_NEWS_TASK_QUEUE_NAME)
scrape_news_queue_client = CloudAMQPClient(SCRAPE_NEWS_TASK_QUEUE_URL, SCRAPE_NEWS_TASK_QUEUE_NAME)- Clear Redis
redis-cli flushall
- Queue_helper (if needed)
python3 queue_helper.py
- Get News URL From News Api (Faster)
python3 news_monitor.py
- Get News URL and Scrape on website
python3 news_fetcher.py
- With the dependencies:
- numpy
- scipy
- python-dateutil : Judge the News published date to compare
pip3 install sklearn
pip3 install numpy
pip3 install scipy
pip3 install python-dateutil
from sklearn.feature_extraction.text import TfidfVectorizer
doc1 = "I like apples. I like oranges too"
doc2 = "I love apples. I hate doctors"
doc3 = "An apple a day keeps the doctor away"
doc4 = "Never compare an apple to an orang"
documents = [doc1, doc2, doc3, doc4]
tfidf = TfidfVectorizer().fit_transform(documents)
pairwise_sim = tfidf * tfidf.T
print(pairwise_sim.A)- Outcomes :
[[ 1. 0.12693309 0. 0. ]
[ 0.12693309 1. 0. 0. ]
[ 0. 0. 1. 0.27993128]
[ 0. 0. 0.27993128 1. ]]
- Get the news from Queue and Analyze if the TFIDF value greater than 0.8 and dont add in the DB
- Go through cloudAMQP to get message
while True:
if cloudAMQP_client is not None:
msg = cloudAMQP_client.getMessage()
if msg is not None:
# Paese and process the task
try:
handle_message(msg)
except Exception as e:
print(e)
pass
cloudAMQP_client.sleep(SLEEP_TIME_IN_SECONDS)- Handle the message and get all recent news based on publishedAt attribute
def handle_message(meg):
if msg is None or not isinstance(msg, dict) :
return
task = msg
text = task['text']
if text is None:
return- Parser the String to datetime util to compare
- give a begin time and end time(+1days)
publised_at = parser.parse(task['publishedAt'])
published_at_day_begin = datetime.datetime(published_at.year, published_at.month, published_at.day, 0, 0, 0, 0)
published_at_day_end = published_at_day_begin + datetime.timedelta(days=1)- Connect with MongoDB
- Get the same day news by their begin and end time (greater and less than)
# import common package in parent directory
sys.path.append(os.path.join(os.path.dirname(__file__), '..', 'common'))
db = mongodb_client.get_db()
same_day_news_list = list(db[NEWS_TABLE_NAME].find({'publishedAt': {'$gte': published_at_day_begin, '$lt': published_at_day_end}}))- Used TFIDF to count if the News should be put together
- Only sage the text
if same_day_news_list is not None and len(same_day_news_list) > 0:
documents = [news['text'] for news in same_day_news_list]
documents.insert(0, text)- TFIDF : we only need to see the row, if the one of the value in row is > SAME_NEWS_SIMILARITY_THRESHOLD = 0.9 , ignore the news
# Calculate similarity matrix
tfidf = TfidfVectorizer().fit_transform(documents)
pairwise_sim = tfidf * tfidf.T
print(pairwise_sim)
rows, _ = pairwise_sim.shape
for row in range(1, rows):
if pairwise_sim[row, 0] > SAME_NEWS_SIMILARITY_THRESHOLD:
# Duplicated news. Ignore.
print("Duplicated news. Ignore.")
return- Save other News
- CHange the publishedAt type to the MongoDB friendly datetime Schema
- Used digest to be the Key's Id
task['publishedAt'] = parser.parse(task['publishedAt'])
db[NEWS_TABLE_NAME].replace_one({'digest': task['digest']}, task, upsert=True)- Used this library insteads of our scraper
- Since if we would like to get the news from different sources, we need to analyze each pages and get the structure of XPath
pip3 install newspaper3k
from newspaper import Article
article = Article(task['url'])
article.download()
article.parse()
task['text'] = article.textNEWS_SOURCES = [
'bbc-news',
'bbc-sport',
'bloomberg',
'cnn',
'entertainment-weekly',
'espn',
'ign',
'techcrunch',
'the-new-york-times',
'the-wall-street-journal',
'the-washington-post'
]- Separate Logic and UI
-
JavaScript Destruction (ES6) Destructuring assignment
-
直接把 Object 展開
const LoginForm = ({
onSubmit,
onChange,
errors,
user,
}) => (
html codes
);- onSubmit : function
- onChange : function
- errors : value - deal with the show of error message
- user : value
Login title
Error message
Text Field (Account)
Error message
Text Field (Password)
Error Meessage
Submit button
Sign up
- Error Message : if ther is a errors.summary, then show the
{errors.summary && <div className="row"><p className="error-message">{errors.summary}</p></div>}- Submit button
<input type="submit" className="waves-effect waves-light btn indigo lighten-1" value='Log in'/>- Check parameters: When Using LoginForm, we need four params (onSubmit, onChange, errors, user), if not we will return an error
LoginForm.propTypes = {
onSubmit: PropTypes.func.isRequired,
onChange: PropTypes.func.isRequired,
errors: PropTypes.object.isRequired,
user: PropTypes.object.isRequired
}- render -> onSubmit / onChange / errors / user
render() {
return (
<LoginForm
onSubmit = {(e) => this.processForm(e)}
onChange = {(e) => this.changeUser(e)}
errors = {this.state.errors}
user = {this.state.user}
/>- Constructor : errors, user(email, password)
constructor(props) {
super(prop);
this.state = {
errors: {},
user: {
email: '',
password: ''
}
};
}- processForm : get the states of user email and password
processForm(event) {
event.preventDefault();
const email = this.state.user.email;
const password = this.state.user.password;
console.log('email: ' + email);
console.log('password: ' + package);
// TODO: post login data
}- changeUser : if user input email or password ,give a new value to
changeUser(event) {
const field = event.target.name;
const user = this.state.user;
user[field] = event.target.value;
this.setState({user});
}import React from 'react';
import ReactDOM from 'react-dom';
import App from './App/App';
import LoginPage from './Login/LoginPage';
ReactDOM.render(
<LoginPage />,
document.getElementById('root')
);-
Then we will face the Problem between jQuery and React (Since our materical need a jQuery to give the styling)
-
In public / index.html, add in Head to import jQuery CDN
<script src="https://code.jquery.com/jquery-2.1.1.min.js"></script>- App.js import materizlize js
import 'materialize-css/dist/css/materialize.min.css';
import 'materialize-css/dist/js/materialize.min.js';-Add a password comfirm
<div className="row">
<div className="input-field col s12">
<input id="confirm_password" type="password" name="confirm_password" className="validate" onChange={onChange}/>
<label htmlFor="confirm_password">Conform Password</label>
</div>
</div>- Add a password comfirm
this.state = {
errors: {},
user: {
email: '',
password: '',
confirm_password: ''
}
};
if (password !== confirm_password) {
return;
}
- 只能判斷 localStorage 是否有 token,但實際判斷用戶身份,還是握在Server端
- SignUp Page: 直接Post Request給後端
- Login Page: 直接 Post Request 給後端
- Base: React Router 若 User 沒有登入 redirect 到 Login
- 處理 SignUp 的 Request,檢查input,將密碼 salt + Hash 之後,將用戶email & password 存入 DB (validator + bcrypt + passport)
- 處理 Login的 Request,比對密碼 (passport) ( passport + mongoose 處理所有 DataBase間的連接,與密碼比對)
- loadMoreNews() 被調用時,會透過 auth_checker 檢查存在前端的 token 是否正確 (jwt)
router| app.post('auth/login')
Normal| validateSignupForm()
Normal| passport.authenticate()
Passport|'local-login' strategy
Token| sign and return token
router|app.post('auth/signup')
Normal|validateLoginForm()
Normal|passport.authenticate()
Passport|'local-signup' strategy
XXXX| loadMoreNews (with token)
Token| authChecker
Token| verify token
router| app.get('news')
Normal|return news
- 登入成功後給個token,存在cache中
- client/src/Auth
- Auth.js 見一個類,控制讀寫LocalStorage內的Token,HashMap操作
- Show user email and use email as account
- isUserAuthenticated 用來判斷有無token字段,token是否正確由後端處理
static authenticateUser(token, email) {
localStorage.setItem('token', token);
localStorage.setItem('email', email);
}
static isUserAuthenticated() {
return localStorage.getItem('token') !== null;
}
static deauthenticateUser() {
localStorage.removeItem('token');
localStorage.removeItem('email');
}
static getToken() {
return localStorage.getItem('token');
}
static getEmail() {
return localStorage.getItem('email');
}只能從Salt推到Hash
Signup: f(password, salt) = hash(password + salt)
- For each user, we generate a random a salt and add it to user's password. Server-side generated password.
Login: hash([provided password] + [stored salt]) == [stored hash] - Then the user is authenticated.
- 用戶沒登入:顯示LoginPage
(<div>
<li><Link to="/login">Log in</Link></li>
<li><Link to="/signup">Sign up</Link></li>
</div>)- 用戶已登入:顯示App UI
(<div>
<li>{Auth.getEmail()}</li>
<li><Link to="/logout">Log out</Link></li>
</div>)- navbar :
- 判斷 Aith
{Auth.isUserAuthenticated() ? A : B- 把權限上交給React Router
{children}- 超連結 for React Router </Link to ="">
<li><Link to="/login">Log in</Link></li>npm install -s react-router@"<4.0.0"
- 用戶在根目錄時:顯示新聞,判斷是否註冊,使用isUserAuthenticated(),callback -> App / LoginPage
{
path: '/',
getComponent: (location, callback) => {
if (Auth.isUserAuthenticated()) {
callback(null, App);
} else {
callback(null, LoginPage);
}
}
},- Login / SingUp
{
path: "/login",
component: LoginPage
},
{
path: "/signup",
component: SignUpPage
},- Logout : deauthenticateUser()
{
path: '/logout',
onEnter: (nextState, replace) => {
Auth.deauthenticateUser();
// change the current URL to /
replace('/')
}import ReactDom from 'react-dom';
import React from 'react';
import { browserHistory, Router } from 'react-router';
import routes from './routes';
ReactDom.render(
<Router history={browserHistory} routes={routes} />,
document.getElementById('root')
);- npm cors : 只需要Import後,直接使用,但僅限於開發環境才允許跨域
npm cors
- Server上將有個新的Api處理註冊與登入
- LoginPage / SignUpPage
const url = 'http://' + window.location.hostname + ':3000' + '/auth/signup';
const url = 'http://' + window.location.hostname + ':3000' + '/auth/login';- 發送POST請求,必須是一個String化的JSON
const url = 'http://' + window.location.hostname + ':3000' + '/auth/login';
const request = new Request(
url,
{
method: 'Post',
headers: {
'Accept': 'application/json',
'Content-Type': 'application/json',
},
body: JSON.stringify({
email: this.state.user.email,
password: this.state.user.password
})
}
);- Fetch,先確認收到的res是正確的 ==200
fetch(request).then(response => {
if (response.status === 200) {
this.setState({
errors: {}
});
response.json().then(json => {
console.log(json);
Auth.authenticateUser(json.token, email);
this.context.router.replace('/');
});- React Router
this.context.router.replace('/');- 錯誤時:
else {
console.log('Login failed.');
response.json().then(json => {
const errors = json.errors? json.errors : {};
errors.summmary = json.message;
this.setState({errors});
});
}
});- To make react-router work.
LoginPage.contextTypes = {
router: PropTypes.object.isRequired
};{
"mongoDbUri": "mongodb://test:[email protected]:58579/cs503",
"jwtSecret": "a secret phrase!!"
}npm install -s mongoose
使用Schema做Mapping,存取兩個字段 email 和 password。
- UserSchema 加入 comparePassword(),驗證用戶提交的密碼是否和儲存的密碼相等,用bcrypt.compare來比較。
UserSchema.methods.comparePassword = function comparePassword(password, callback) {
bcrypt.compare(password, this.password, callback);
};- 可能遇到的狀況,如果用戶名和password沒有更改,無法繼續,接著生成一個Salt(genSalt),如果有saltError直接return,如果沒問題,使用salt和用戶的password做hash,如果有hashError再return,最後將user password賦值 hash(最重要一步)。
UserSchema.pre('save', function saveHook(next) {
const user = this;
// proceed furhter only if the password is modified or the user is new.
if (!user.isModified('password')) return next();
return bcrypt.genSalt((saltError, salt) => {
if (saltError) { return next(saltError); }
return bcrypt.hash(user.password, salt, (hashError, hash) => {
if (hashError) { return next(hashError); }
// replace a password string with hashed value.
user.password = hash;
return next();
});
});
});- 讓UserSchema初始化並連接到MongoDB中。
var config = require('./config/config.json');
require('./models/main.js').connect(config.mongoDbUri);npm install -s passport
npm install -s passport-local
npm install -s jsonwebtoken
-
導出PassportLocalStrategy,裡面有usernameField / passwordField ,其他並不重要,按照document上操作。
-
利用email找出User,利用User.findOne -> mongoose中定義的UserSchema,如果連接不上MongoDB,會提出error
-
如果!user,找不到用戶,返回一個錯誤訊息,切記不要返回任何User信息。
const error = new Error('Incorrect email or password');- 比對 userPassword -> user.comparePassWord 剛才在user.js裡面寫好的method
// check if a hashed user's password is equal to a value saved in the database
return user.comparePassword(userData.password, (passwordErr, isMatch) => {
if (passwordErr) { return done(passwordErr); }
if (!isMatch) {
const error = new Error('Incorrect email or password');
error.name = 'IncorrectCredentialsError';
return done(error);
}- MongoDB自動生成一個id,並把token配給該userid,會返回 name: user.email ,但其實前端並不依賴後端返回該內容
const payload = {
sub: user._id
};
// create a token string
const token = jwt.sign(payload, config.jwtSecret);
const data = {
name: user.email
};- 一樣使用PassportLocalStrategy,只要去MongoDB查找是否有相同的User,或是可以嘗試添加一個email,如果加入失敗了會返回error,代表用戶存在,如果成功加入就正常返回。
- 在 Auth 的API後才會真正使用,現在先綁定
var passport = require('passport');
app.use(passport.initialize());
var localSignUpStrategy = require('./passport/signup_passport');
var localLoginStrategy = require('./passport/login_passport');
passport.use('local-signup', localSignUpStrategy);
passport.use('local-login', localLoginStrategy);- auth_checker
- 接了req之後,生成res,讓下一個人使用(express框架)。
- jwt.verify 用來解開 token,讓userid = decoded.sub,按照這個id去MongoDB中findById,如果確認有這位用戶,就正常到next()
- 為什麼是middleware?驗證完了,才與許用戶去看新聞,所以得在user調用news之前。
const authChecker = require('./middleware/auth_checker');
app.use('/', index);
app.use('/auth', auth);
app.use('/news', authChecker);
app.use('/news', news);- 把用戶POST的String,轉化成JSON
npm install --save body-parser
var bodyParser = require('body-parser');
app.use(bodyParser.json());- 用來驗證用戶的輸入,有些惡意攻擊,必須在使用之前先做個validate,除了英語也支持很多語言。
npm install --s validator
- validateSignupForm 檢查用戶輸入是否為String,內部的error要轉化成外部的Error Message
function validateSignupForm(payload) {
console.log(payload);
const errors = {};
let isFormValid = true;
let message = '';
if (!payload || typeof payload.email !== 'string' || !validator.isEmail(payload.email)) {
isFormValid = false;
errors.email = 'Please provide a correct email address.';
}
if (!payload || typeof payload.password !== 'string' || payload.password.length < 8) {
isFormValid = false;
errors.password = 'Password must have at least 8 characters.';
}
if (!isFormValid) {
message = 'Check the form for errors.';
}
return {
success: isFormValid,
message,
errors
};
}var auth = require('./routes/auth');
app.use('/auth', auth);- Pagination
- Preference Model
- Click Log Processor
- process of dividing a document into discrete pages
- User doesn't need all data
- User cannot handle too much data
- System cannot handle too much data
- User cannnot wait too long(or browser freeze)
- No change on backend: backend sends all data to client
- Pro: easy as no backend assistance
- Cons: client would be slow due to I/O and memory consumption
- 第一次就把所有新聞傳給用戶,針對Client端的數據做Slice呈現
- Server sneds paginated data to client
- Pros: much better user experience
- Cons: Extra work and storage on backend; Need coordination between client and server
- Client每次
- new Function
- api used _ , in opeartion funcion used camelCase
def get_news_summaries_for_user(user_id, page_num):
print("get_news_summaries_for_user is called with %s and %s" %(user_id, page_num))
return operations.getNewsSummaries(user_id, page_num)- used pickle : make JSON(dic) becomes the String that could be read by Redis
REDIS_HOST = "localhost"
REDIS_PORT = 6379
redis_client = redis.StrictRedis(REDIS_HOST, REDIS_PORT, db=0)- Need a reide to store News (with begin index)
- NEWS_LIST_BATCH_SIZE = 10 means the number of news sent everytime when client requests
- If the News isn't in the redis, go searching in MongoDB and give a new limit by sort News depends on 'publishedAt;
- pickle.dump to transfer digest (As a key to search in MongoDB)
page_num = int(page_num)
begin_index = (page_num - 1) * NEWS_LIST_BATCH_SIZE
end_index = page_num * NEWS_LIST_BATCH_SIZE
sliced_news = [] if redis_client.get(user_id) is not None:
total_new_digests = pickle.loads(redis_client.get(user_id))
sliced_news_digests = total_new_digests[begin_index:end_index]
db = mongodb_client.get_db()
sliced_news = list(db[NEWS_TABLE_NAME].find({'digest' : {'$in': sliced_news_digests}})) else:
db = mongodb_client.get_db()
total_news = list(db[NEWS_TABLE_NAME].find().sort([('publishedAt', -1)]).limit(NEWS_LIMIT))
total_news_digest = [x['digest'] for x in total_news]
redis_client.set(user_id, pickle.dumps(total_news_digest))
redis_client.expire(user_id, USER_NEWS_TIME_OUT_IN_SECONDS)
sliced_news = total_news[begin_index:end_index]- Test if it could request the News
def test_getNewsSummariesForUser_basic():
news = operations.getNewsSummariesForUser('test', 1)
assert len(news) > 0
print('test_getNewsSummariesForUser_basic passed')- Test the pagination : If page 1 and 2 could be requested and If there is the same digest of News appeared in two pages(fail)
def test_getNewsSummariesForUser_pagination():
news_page_1 = operations.getNewsSummariesForUser('test', 1)
news_page_2 = operations.getNewsSummariesForUser('test', 2)
assert len(news_page_1) > 0
assert len(news_page_2) > 0
digests_page_1_set = set(news['digest'] for news in news_page_1)
digests_page_2_set = set(news['digest'] for news in news_page_2)
assert len(digests_page_1_set.intersection(digests_page_2_set)) == 0
print('test_getNewsSummariesForUser_pagination passed')- Call the backend server by API (getNewsSummariesForUser)
function getNewsSummariesForUser(user_id, page_num, callback) {
client.request('getNewsSummariesForUser', [user_id, page_num], function(err, response){
if(err) throw err;
console.log(response.result);
callback(response.result);
});
}
module.exports = {
add : add,
getNewsSummariesForUser: getNewsSummariesForUser
}- Test getNewsSummariesForUser
// invoke "getNewsSummariesForUser"
client.getNewsSummariesForUser('test_user', 1, function(response) {
console.assert(response != null);
});- To get data by calling API
// "localhost:3000/news/userId/[email protected]/pageNum/2"
router.get('/userId/:userId/pageNum/:pageNum', function(req, res, next) {
console.log('Fetching news...');
user_id = req.params['userId'];
page_num = req.params['pageNum'];
rpc_client.getNewsSummariesForUser(user_id, page_num, function(response) {
res.json(response);
});
});- Save the pageNum start from 1
- Status of loadedAll -> if true, we wont send request to server
this.state = { news:null, pageNum:1, loadedAll:false};
// if (!news || news.length == 0) {
// this.setState({loadedAll:true});
// }- loadMoreNews()
- Check the state first
- Auth.getEmail() to get userID
- Auth.getToken()
- this.state.pageNum to get pageNum
- Change the State while loading new pageNum
loadMoreNews() {
if (this.state.loadedAll == true) {
return;
}
const news_url = 'http://' + window.location.hostname + ':3000' +
'/news/userId/' + Auth.getEmail() + '/pageNum/' + this.state.pageNum;
const request = new Request(
encodeURI(news_url),
{
method:'GET',
headers: {
'Authorization': 'bearer ' + Auth.getToken(),
}
});
fetch(request)
.then(res => res.json())
.then(news => {
if (!news || news.length == 0) {
this.setState({loadedAll:true});
}
this.setState({
news: this.state.news ? this.state.news.concat(news) : news,
pageNum: this.state.pageNum + 1,
});
});
}- We need a model to represent user's news preference.
- Possible Dimensions:
Topic - Political, Sport..
Source - CNN, BBS ...
Time - newest...
- Topic Based
- Based on user's click
- More weight on more recent activities
- Topic is associated with predict click probability
- All topics start with same probability.
- If selected : p = (1 - a) * p + a
- If not selected : p = (1 - a) * p
- a is the time decay weight: larger -> more weight on recent (picked a = 0.2)
| Topic | Probability |
|---|---|
| Sport | 0.33 |
| Entertainment | 0.33 |
| World | 0.33 |
If User Clicks a news whoses topic is "Sport"
- For Sport, we apply (1- 0.2) * 0.33 + 0.2
- Others, we apply (1 - 0.2) * 0.33
| Topic | Probability |
|---|---|
| Sport | 0.464 |
| Entertainment | 0.264 |
| World | 0.264 |
- Then, we could depend how to show those lists to our user
- Log then analyzing later / Real Time event
- Understand user's behavior
- Improve UI experience
- A/B Test
- Pre-load / Pre-fetch
- Future product
- Click log processing is not necessarily a synchronized step. (發進RabbitMQ中,不需要是一個blocking的操作,本身只需要紀錄行為不需要返回值,非緊急需要處理的事情先放入Queue中)
- Don't let backend service directly Load In a MongoDB to process Recommendation, we build up another Recommendation Service. (對於Backend Server來說,不需要知道DB內是如何存取Model的或是用哪種模型得到結果的,只要得到一個Topic List和preference)
- 如果讓Backend Server直接聯繫DB,DB中Model的調整與修改就會影響到Backend Server,增加多於修改的工作,所以用一個Recommendation Service來傳遞DB內的資料和結果
- Recommendation Service Client & Recommendation Service
Client
| logNewsClickForUser(news_id, user_id)
Web
Server
| logNewsClickForUser(news_id, user_id)
Backend
Server -------------------------- Recommendation
| getPreferenceForUser Service Client
Click |
Logger Send CLick Log mes: |
Queue {news_id, user_id} |
| |
ClickLogProcessor |
in DB ----------- DB ------ Recommdndation
: Service
( Handle click Log event:
Update preference model )
- POST a event to backend
- Authorization : Need to have a token, not everyone could send event to backend
- Fetch : Send out the request
redirectToUrl(url, event) {
event.preventDefault();
this.sendClickLog();
sendClickLog() {
const url = 'http://' + window.location.hostname + ':3000' +
'/news/userId/' + Auth.getEmail() + '/newsId/' + this.props.news.digest;
const request = new Request(
encodeURI(url),
{
method: 'POST',
headers: { 'Authorization': 'bearer ' + Auth.getToken()},
});
fetch(request);
}- Make a new Function
- no need a callback
- Export the function
function logNewsClickForUser(user_id, news_id) {
client.request('logNewsClickForUser', [user_id, news_id], function(err, response){
if(err) throw err;
console.log(response.result);
});
}
module.exports = {
add : add,
getNewsSummariesForUser: getNewsSummariesForUser,
logNewsClickForUser : logNewsClickForUser
}- Need to wait until we finish RPC server(python) Backend server
client.logNewsClickForUser('test_user', 'test_news');- news.js
- post request
router.post('/userId/:userId/newsId/:newsId', function(req, res, next) {
console.log('Logging news click...');
user_id = req.params['userId'];
newsId = req.params['newsId'];
rpc_client.logNewsClickForUser(user_id, newsId);
res.status(200);
});- service.py
def log_news_click_for_user(user_id, news_id):
print("log_news_click_for_user is called with %s and %s" %(user_id, news_id))
return operations.logNewsClickForUser(user_id, news_id)- operations.py
- Strinlization
- Give another queue to save the Reference data
LOG_CLICKS_TASK_QUEUE_URL = #TODO: use your own config.
LOG_CLICKS_TASK_QUEUE_NAME = "tap-news-log-clicks-task-queue"def logNewsClickForUser(user_id, news_id):
# Send log task to machine learning service for prediction
message = {'userId': user_id, 'newsId': news_id, 'timestamp': str(datetime.utcnow())}
cloudAMQP_client.sendMessage(message);mkdir recommendation_service
code click_log_processor.py
- Take a message from Queue each time
def run():
while True:
if cloudAMQP_client is not None:
msg = cloudAMQP_client.getMessage()
if msg is not None:
# Parse and process the task
try:
handle_message(msg)
except Exception as e:
print(e)
pass
# Remove this if this becomes a bottleneck.
cloudAMQP_client.sleep(SLEEP_TIME_IN_SECONDS)- Update user's preference into User preference Model Table
PREFERENCE_MODEL_TABLE_NAME = "user_preference_model"
db = mongodb_client.get_db()
model = db[PREFERENCE_MODEL_TABLE_NAME].find_one({'userId': userId})- Init: Create a new Table with same perference rate
if model is None:
print('Creating preference model for new user: %s' % userId)
new_model = {'userId' : userId}
preference = {}
for i in news_classes.classes:
preference[i] = float(INITIAL_P)
new_model['preference'] = preference
model = new_model
print('Updating preference model for new user: %s' % userId)- If user's preference table has already been created, just update the modle
- Class was made by TensorFlow
news = db[NEWS_TABLE_NAME].find_one({'digest': newsId})
if (news is None
or 'class' not in news
or news['class'] not in news_classes.classes):
print('Skipping processing...')
return
click_class = news['class'] # Update the clicked one.
old_p = model['preference'][click_class]
model['preference'][click_class] = float((1 - ALPHA) * old_p + ALPHA)
# Update not clicked classes.
for i, prob in model['preference'].items():
if not i == click_class:
model['preference'][i] = float((1 - ALPHA) * model['preference'][i])
print(model)
db[PREFERENCE_MODEL_TABLE_NAME].replace_one({'userId': userId}, model, upsert=True)NUM_OF_CLASSES = 8
=================
for i in news_classes.classes:
- The length of Lists need to be the same as Classes number
classes = [
"World",
"US",
"Business",
"Technology",
"Entertainment",
"Sports",
"Health",
"Crime",
]- Create a message
- Drop userId and make sure the DB is clean
import click_log_processor
import os
import sys
from datetime import datetime
# import common package in parent directory
sys.path.append(os.path.join(os.path.dirname(__file__), '..', 'common'))
import mongodb_client
PREFERENCE_MODEL_TABLE_NAME = "user_preference_model"
NEWS_TABLE_NAME = "news"
NUM_OF_CLASSES = 8
# Start MongoDB before running following tests.
def test_basic():
db = mongodb_client.get_db()
db[PREFERENCE_MODEL_TABLE_NAME].delete_many({"userId": "test_user"})
msg = {"userId": "test_user",
"newsId": "test_news",
"timestamp": str(datetime.utcnow())}
click_log_processor.handle_message(msg)
model = db[PREFERENCE_MODEL_TABLE_NAME].find_one({'userId':'test_user'})
assert model is not None
assert len(model['preference']) == NUM_OF_CLASSES
print('test_basic passed!')
if __name__ == "__main__":
test_basic()- 這部分需要再研究
import operator
import os
import sys
from jsonrpclib.SimpleJSONRPCServer import SimpleJSONRPCServer
# import common package in parent directory
sys.path.append(os.path.join(os.path.dirname(__file__), '..', 'common'))
import mongodb_client
PREFERENCE_MODEL_TABLE_NAME = "user_preference_model"
SERVER_HOST = 'localhost'
SERVER_PORT = 5050
# Ref: https://www.python.org/dev/peps/pep-0485/#proposed-implementation
# Ref: http://stackoverflow.com/questions/5595425/what-is-the-best-way-to-compare-floats-for-almost-equality-in-python
def isclose(a, b, rel_tol=1e-09, abs_tol=0.0):
return abs(a-b) <= max(rel_tol * max(abs(a), abs(b)), abs_tol)
def getPreferenceForUser(user_id):
""" Get user's preference in an ordered class list """
db = mongodb_client.get_db()
model = db[PREFERENCE_MODEL_TABLE_NAME].find_one({'userId':user_id})
if model is None:
return []
sorted_tuples = sorted(list(model['preference'].items()), key=operator.itemgetter(1), reverse=True)
sorted_list = [x[0] for x in sorted_tuples]
sorted_value_list = [x[1] for x in sorted_tuples]
# If the first preference is same as the last one, the preference makes
# no sense.
if isclose(float(sorted_value_list[0]), float(sorted_value_list[-1])):
return []
return sorted_list
# Threading HTTP Server
RPC_SERVER = SimpleJSONRPCServer((SERVER_HOST, SERVER_PORT))
RPC_SERVER.register_function(getPreferenceForUser, 'getPreferenceForUser')
print("Starting HTTP server on %s:%d" % (SERVER_HOST, SERVER_PORT))
RPC_SERVER.serve_forever()- Let backend server (operations.py) to use the method
import jsonrpclib
URL = "http://localhost:5050/"
client = jsonrpclib.ServerProxy(URL)
def getPreferenceForUser(userId):
preference = client.getPreferenceForUser(userId)
print("Preference list: %s" % str(preference))
return preferenceimport news_recommendation_service_client- Get Preference for the user
# Get preference for the user
preference = news_recommendation_service_client.getPreferenceForUser(user_id)
topPreference = None
if preference is not None and len(preference) > 0:
topPreference = preference[0]
for news in sliced_news:
# Remove text field to save bandwidth.
del news['text']
if news['class'] == topPreference:
news['reason'] = 'Recommend'
if news['publishedAt'].date() == datetime.today().date():
news['time'] = 'today'
return json.loads(dumps(sliced_news))- Jupyter : On Docker
- Build a CNN Model
- Trainer
- Server
- Integration with News Pipeline
- We will use 500 news with labeled topic to train our model. The format of the data is
[#class_number],[news_title],[news_description],[news_source]
- An Example:
3,Trump: Netanyahu should 'hold back' on settlements,"President Donald Trump told Israeli Prime Minister Benjamin Netanyahu Wednesday that the US is going to push for a peace deal with the Palestinians and asked Israel ""to hold back"" on settlement construction.",cnn
- 1: "World",
- 2: "US",
- 3: "Business",
- 4: "Technology",
- 5: "Entertainment",
- 6: "Sports",
- 7: "Health",
- 8: "Crime"
import pandas as pd
DATA_SET_FILE = './labeled_news.csv'
df = pd.read_csv(DATA_SET_FILE, header=None)
print(df[3])Let's first take a look at our data from a statistics perspective.
We can use pandas to do a quick (data analysis)[http://machinelearningmastery.com/quick-and-dirty-data-analysis-with-pandas/]
- In order to see the distribution of data.
- We need to get to know more about our data by quick analysising it using pandas.
import pandas as pd
DATA_SET_FILE = './labeled_news.csv'
df = pd.read_csv(DATA_SET_FILE, header=None)
print("class description")
print(df[0].describe())
print("""
=====================
""")
print("source description")
print(df[3].describe())class description
count 545.000000
source description
count 545
unique 13
top cnn
freq 132
Name: 3, dtype: object
df[3].value_counts().plot(kind="bar")- Tensorflow provides a easy-to-use tool to do embedding.
- One example:
Sentence 1: "I like apple"
Sentence 2: "I like banana"
Sentence 3: "I eat apple"
- We scan all 3 sentences then we found there are 5 unique words:
['I', 'like', 'eat', 'apple', 'banana']
Now we can use number to represent each of them:
[0, 1, 2, 3, 4]
So, the three sentences can be encoded into:
Sentence 1: [0, 1, 3]
Sentence 2: [0, 1, 4]
Sentence 3: [0, 2, 3]
- Tensorflow provides a easy-to-use tool to do embedding.
import numpy as np
import tensorflow as tf
MAX_DOCUMENT_LENGTH = 5
vocab_processor = tf.contrib.learn.preprocessing.VocabularyProcessor(MAX_DOCUMENT_LENGTH)
# fit and transform
sentences = [
"I like apple",
"I like banana",
"I eat apple"
]
embedded_sentences = np.array(list(vocab_processor.fit_transform(sentences)))
print(embedded_sentences)
print('Total unique words: %d' % len(vocab_processor.vocabulary_))
print("")
# just fit: unseen words will be interpreted as 0
new_sentences = [
"This is a brand new sentence which we never seen before and is very long",
"I hate doing homework!",
"I like banana",
"I eat apple"
]
new_embedded_sentences = np.array(list(vocab_processor.transform(new_sentences)))
print(new_embedded_sentences)- Result : Total unique words: 6
[[1 2 3 0 0]
[1 2 4 0 0]
[1 5 3 0 0]]
Total unique words: 6
[[0 0 0 0 0]
[1 0 0 0 0]
[1 2 4 0 0]
[1 5 3 0 0]]
We have converted the string into an integer vector. But that is not good enough. We need to convert a word into one-hot vector:
Assume we only have 10 unique words.
0 -> [1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
1 -> [0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
2 -> [0, 0, 1, 0, 0, 0, 0, 0, 0, 0]
3 -> [0, 0, 0, 1, 0, 0, 0, 0, 0, 0]
4 -> [0, 0, 0, 0, 1, 0, 0, 0, 0, 0]
5 -> [0, 0, 0, 0, 0, 1, 0, 0, 0, 0]
6 -> [0, 0, 0, 0, 0, 0, 1, 0, 0, 0]
7 -> [0, 0, 0, 0, 0, 0, 0, 1, 0, 0]
8 -> [0, 0, 0, 0, 0, 0, 0, 0, 1, 0]
9 -> [0, 0, 0, 0, 0, 0, 0, 0, 0, 1]
Thus, one setence is converted into a matrix:
Assume there are only 5 unique words:
"I like apple"
->
[1 2 3 0 0]
->
[
[0, 1, 0, 0, 0], => I
[0, 0, 1, 0, 0], => like
[0, 0, 0, 1, 0], => apple
[1, 0, 0, 0, 0], => padding
[1, 0, 0, 0, 0] => padding
]
Tensorflow provides tf.contrib.layers.embed_sequence which can help use with one-hot embedding.
In real world, we don't use native [0, 1] way to label a word, but use a real number.
import tensorflow as tf
vocab_size = 6
embed_dim = 3
sentences = [
[1, 2, 3, 0, 0]
]
embedded_setences = tf.contrib.layers.embed_sequence(sentences, vocab_size, embed_dim)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
result = sess.run(embedded_setences)
print(result)We cannot dive deep into what is convolution here.
But here is a great article about CNNs for NLP: http://www.wildml.com/2015/11/understanding-convolutional-neural-networks-for-nlp/

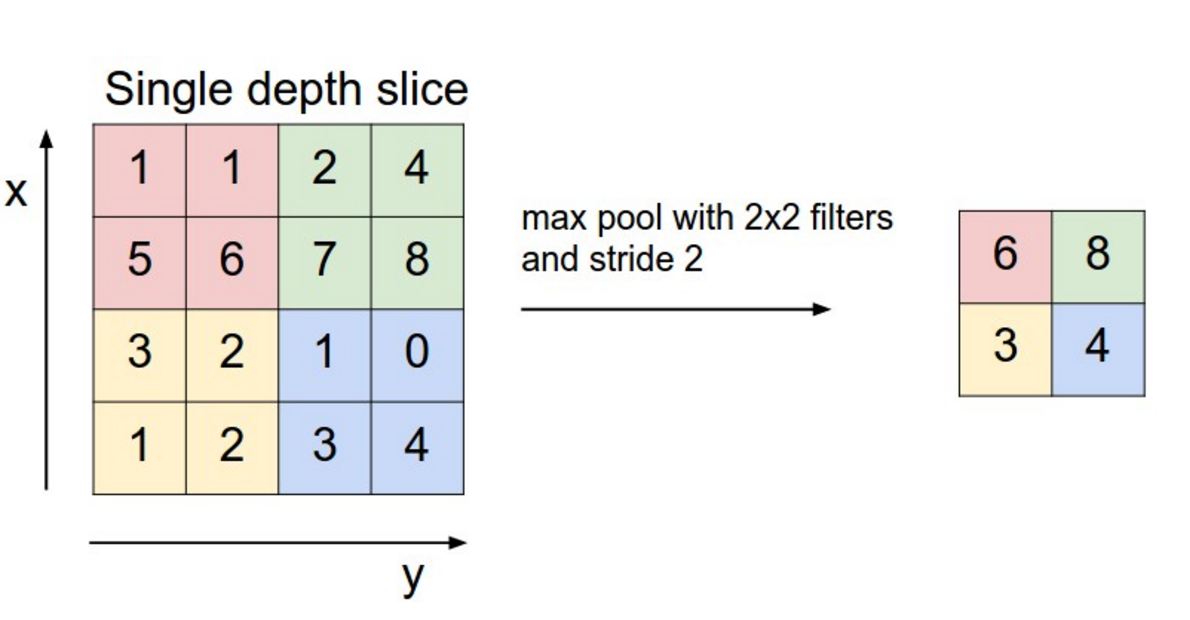
# -*- coding: utf-8 -*-
import numpy as np
import os
import pandas as pd
import pickle
import shutil
import tensorflow as tf
from sklearn import metrics
learn = tf.contrib.learn
DATA_SET_FILE = './labeled_news.csv'
MAX_DOCUMENT_LENGTH = 500
N_CLASSES = 8
EMBEDDING_SIZE = 100
N_FILTERS = 10
WINDOW_SIZE = 10
FILTER_SHAPE1 = [WINDOW_SIZE, EMBEDDING_SIZE]
FILTER_SHAPE2 = [WINDOW_SIZE, N_FILTERS]
POOLING_WINDOW = 4
POOLING_STRIDE = 2
LEARNING_RATE = 0.01
STEPS = 200
def generate_cnn_model(n_classes, n_words):
"""2 layer CNN to predict from sequence of words to a class."""
def cnn_model(features, target):
# Convert indexes of words into embeddings.
# This creates embeddings matrix of [n_words, EMBEDDING_SIZE] and then
# maps word indexes of the sequence into [batch_size, sequence_length,
# EMBEDDING_SIZE].
target = tf.one_hot(target, n_classes, 1, 0)
word_vectors = tf.contrib.layers.embed_sequence(
features, vocab_size=n_words, embed_dim=EMBEDDING_SIZE, scope='words')
word_vectors = tf.expand_dims(word_vectors, 3)
with tf.variable_scope('CNN_layer1'):
# Apply Convolution filtering on input sequence.
conv1 = tf.contrib.layers.convolution2d(
word_vectors, N_FILTERS, FILTER_SHAPE1, padding='VALID')
# Add a RELU for non linearity.
conv1 = tf.nn.relu(conv1)
# Max pooling across output of Convolution+Relu.
pool1 = tf.nn.max_pool(
conv1,
ksize=[1, POOLING_WINDOW, 1, 1],
strides=[1, POOLING_STRIDE, 1, 1],
padding='SAME')
# Transpose matrix so that n_filters from convolution becomes width.
pool1 = tf.transpose(pool1, [0, 1, 3, 2])
with tf.variable_scope('CNN_layer2'):
# Second level of convolution filtering.
conv2 = tf.contrib.layers.convolution2d(
pool1, N_FILTERS, FILTER_SHAPE2, padding='VALID')
# Max across each filter to get useful features for classification.
pool2 = tf.squeeze(tf.reduce_max(conv2, 1), squeeze_dims=[1])
# Apply regular WX + B and classification.
logits = tf.contrib.layers.fully_connected(pool2, n_classes, activation_fn=None)
loss = tf.contrib.losses.softmax_cross_entropy(logits, target)
train_op = tf.contrib.layers.optimize_loss(
loss,
tf.contrib.framework.get_global_step(),
optimizer='Adam',
learning_rate=LEARNING_RATE)
return ({
'class': tf.argmax(logits, 1),
'prob': tf.nn.softmax(logits)
}, loss, train_op)
return cnn_model
def main(unused_argv):
# Prepare training and testing data
df = pd.read_csv(DATA_SET_FILE, header=None)
# Random shuffle
df.sample(frac=1)
train_df = df[0:450]
test_df = df.drop(train_df.index)
# x - news title, y - class
x_train = train_df[1]
y_train = train_df[0]
x_test = test_df[1]
y_test = test_df[0]
# Process vocabulary
vocab_processor = learn.preprocessing.VocabularyProcessor(MAX_DOCUMENT_LENGTH)
x_train = np.array(list(vocab_processor.fit_transform(x_train)))
x_test = np.array(list(vocab_processor.transform(x_test)))
n_words = len(vocab_processor.vocabulary_)
print('Total words: %d' % n_words)
# Build model
classifier = learn.Estimator(
model_fn=generate_cnn_model(N_CLASSES, n_words))
# Train and predict
classifier.fit(x_train, y_train, steps=STEPS)
# Evaluate model
y_predicted = [
p['class'] for p in classifier.predict(x_test, as_iterable=True)
]
print(y_predicted)
score = metrics.accuracy_score(y_test, y_predicted)
print('Accuracy: {0:f}'.format(score))
if __name__ == '__main__':
tf.app.run(main=main)cp -r week7/ week8
mkdir