Standard Imperative Language
TODO: review and revise these ideas.
"Standard Imperative Language" (SIL) is the concept of a medium-level language built out of Loyc trees in a standarized way. "Standard Imperative Language" would be something close to C++ and C#, and it would serve as an intermediate representation between two different programming languages. It would also serve as the starting point for writing back-ends.
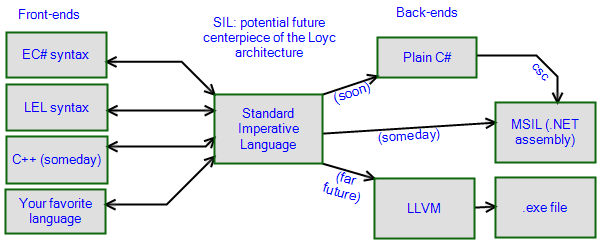
I believe SIL will actually have to be a whole family of similar languages rather than one language; you can think of SIL as a parameterized template: SIL<feature1, feature2, ...>. Each optional feature is a concept that exists in some languages but not others; a good example is closures. Some languages have anonymous inner functions (closures) while others do not. When converting between two languages that both support closures, the SIL can include closures. But when converting from a language that has closures to one that doesn't, the process takes three steps:
- Convert source language to
SIL<+closures> - Convert
SIL<+closures>toSIL<-closures> - Convert
SIL<-closures>to target language
The target language, by the way, could be a higher-level language, like EC# or C++, or a lower-level language, like CIL a.k.a. MSIL.
Of course, it is not necessary to go in the reverse direction--to create closures in the target language when the source language does not have them--but perhaps heuristics could be designed and built to detect cases where a function "should" be an anonymous function and convert it.
But if there are lots of variations on SIL, in what way is it "standard"? Well, it would include a set of conventions. For instance, every programming language may have its own set of loops, but SIL would define a few standard loops and give them standard names. Modularity is handled in different ways in different languages; SIL would attempt to define a common model for namespaces and accessibility (public, private, protected...). Different programming languages may have different names for 32-bit integers; SIL would give this integer a standard name. So SIL will provide a common ground that simplifies conversion between any arbitrary pair of programming languages.
SIL will not be an truly "neutral" language. Like all programming languages, it will be biased in certain ways, and its design will involve tradeoffs.
SIL will be an imperative language, but supporting a functional style. It will be multi-paradigm, supporting OO and non-OO styles, and perhaps supporting both the .NET and C++/D styles of generic programming (simultaneously). It should be possible to convert languages with unique execution models or semantics, such as Haskell and Prolog, to SIL, but the reverse conversion may be impossible or impractical. There may be multiple conversion modes; for example, consider Haskell. Haskell is a fundamentally lazy language, while most languages are fundamentally greedy (including SIL). While it may be possible to compile Haskell to SIL while preserving lazy evaluation, I assume that the resultant code may be ugly and/or hard to follow. Therefore, there could be a second conversion mode that does not model Haskell semantics as closely, but produces output that is easier to understand and/or better-looking.
The most explicit bias is that SIL will be designed for imperative code, and its low-level constructs will be based on a typical computer's capabilities. So programs in SIL will not generally be "goal-oriented" or pure functional descriptions, they will be a series of "statements", but those statements can use a functional style and have arbitrary complexity. I believe that an imperative model makes the most sense as a default "lingua franca" (programming interlanguage) because a computers actually operate in an imperative manner, and because most popular languages are imperative.
SIL will be like C, in supporting low-level code well (ideally it will be better than C, defining intrinsics like "rotate right" that C does not.) I will give an example of this bias by comparison with [http://nemerle.org Nemerle]. In Nemerle, the "if" statement is not a core construct; it is a macro. The "if" macro translates into Nemerle's pattern-matching construct:
// "if" macro call:
if (c) foo();
else bar();
// expands to:
match (c)
{
| true => foo()
| _ => bar()
}
In Nemerle, the functional construct match() is considered more "fundamental" than "if". In SIL, however, I envision that "if" will be considered more fundamental: pattern matching will reduce to "if" statements, not the other way around. And then, for the sake of future back-ends like LLVM, "if" statements could optionally be reduced to some kind of conditional branching construct (goto). Such an "extreme" reduction would only be performed, however, if it is needed by the target language.
Another obvious bias is that SIL (and the whole of Loyc) will be designed primarily to support statically typed languages, rather than dynamic ones. Frankly, I think static typing is "the future", and I tend to consider dynamically-typed languages a special case of statically-typed languages, in which all variables have the same type, likely to be called #dynamic in SIL (that's not to say that dynamic languages have only one type; no, many types exist, but there is only one type of variable.)
Hopefully this doesn't mean SIL won't be useful for dynamically-typed languages; but apart from Javascript (whose importance is a "force of nature"), I don't want to focus my energy on dynamic languages because I value high runtime performance and compilers that catch bugs before I run the program. I realize that dynamic languages may have features that static languages usually don't have, like attaching arbitrary attributes to an object at runtime, but I think that those kinds of features could be integrated into a statically-typed language as well.
Note: I recently learned about Julia which is an insightful re-imagining of what a dynamic language should be. Although fairly dynamic, it is designed specifically for high performance (albeit with high memory usage) and also offers some degree of static typing. I look forward to using Julia some time soon, and I look forward to learning about how well its new paradigm works in practice.
I'm planning to use EC# as a starting point for the semantics of SIL. This means that SIL will use the rules of EC# when there is no reason not to use those rules (it should be noted that some limitations remain in EC# that were inherited from C#, and I'll try to avoid all flaws that I am aware of). This will be another source of bias, but I hope it will also be a source of strength. Many programmers are already familiar with C- or Java, and since EC# is just C# with design tweaks and extra features, people that know C- or Java should easily grasp SIL. By anchoring SIL's "defaults" to one language, newcomers can have some idea what to expect from it. This should promote participation, avoid confusion, and accelerate development. Please note that the semantics of EC# itself are not entirely defined yet, and I am open to your ideas.
I am not planning a particularly interesting type system for SIL, not yet anyway. I myself lack background in type theory (I don't suppose there are any online courses I could take?) and I have the impression that little has been settled about what "should" be in type system. I recognize that type systems are extremely important, and I have my eye on new approaches like that of [http://www.rust-lang.org/ Rust] and [http://ceylon-lang.org/ Celyon], but for now I'm stalling; I'll deal with the issue later. Hopefully, smart people will join the community who will provide insight into typing issues and suggest typing ideas that are useful in a multi-language infrastructure.
For now, I'm going to take the .NET type system as-is. As long as Loyc runs on .NET, we are quite limited in how we can improve it anyway.
Although I haven't formally studied typing, I do have some strong opinions on it. For example, I think .NET was in error to treat void as if it is not a real type, and I think it's a mistake that an empty structure still consumes 1 byte of storage (which, in real life, is almost always padded out to 4 or 8 bytes). Loyc will therefore define its own "void" type and we'll have to work out when to use the .NET void type (which, not being a "real" type, has drawbacks) and when to use the Loyc void type (which, not being supported by the .NET runtime, will have unnecessary overhead.)
I also want to support an "alias" concept that I think will be an important tool in language conversion. Aliases allow a single type to have multiple "interfaces", essentially making types "skinnable". For example, List<T> could have an alias that makes it look and act like a C++ STL container (vector<T>).
I also believe that unit checking (actually unit inference) will be an important feature someday. Unit inference will allow you to indicate that one integer is measured in "bytes" and another is measured in "DWORDs", and then the compiler can detect if you mix the values incorrectly. Unit inference will not be supported in the near future, but it's a great feature that I always keep at the back of my mind.
I have come to think of typing as two almost orthogonal things. The first "kind" of typing is the kind we are most used to, which I call "physical" typing. For example, a "string" and a "double" value are physically very different from each other; they are not just used for different purposes, but also they have different sizes and different internal structure.
The second "kind" of typing is more nebulous; I'm struggling to find a name for it, but for now let's call it "unphysical" typing. It is related to the usage, meaning, or properties of a variable or a value. "aliases" and "units" are both examples of this kind of typing, and I can imagine more ways of typing in the "unphysical" category. For example, there are some languages where an integer can have an explicit range, such as "0 to 100", or even "must be odd, greater than 1". This is quite different from the usual manner of integer typing, as it separates the idea of "which number could this variable contain?" from "how many bits is this integer?" Another example would be a hypothetical type system in which we could mark a list as "sorted" while independently choosing the data structure (array, List<T>, AList<T>, etc), and then the language would prevent us from doing anything that would disturb the sort order.
While a piece of data can only have a single physical structure and therefore only one physical type, "unphysical" typing could support several different "type systems" simultaneously.
For example, suppose we define an integer count of type ByteCount. ByteCount could be defined physically as a 32-bit integer, but perhaps it could also have other notions of type:
-
ByteCountmust be measured in "bytes" -
ByteCountmust be non-negative -
ByteCountcould have conversion methods defined on it likeToKB()andToMB().
Someday I would like to tackle ideas like these and integrate them into Loyc, but I'm not sure that I'm the right man for the job.
People may want different kinds of code conversion in different circumstances. While the SIL concept will be geared toward faithfully preserving semantics where possible, "surface" conversions that do not preserve semantics may also be useful, and will not involve SIL so much. For instance, given C++ code with templates:
template<class T>
T Add(T a, T b) { return a + b; }
Generally the only way to convert it to C# faithfully will be to expand all of the instantiated templates. But a "surface syntax" converter would simply output this as
public static T Add<T>(T a, T b) { return a + b; }
And this is not semantically valid C#. This kind of conversion would serve as a useful starting point for a manual code conversion project. A surface syntax converter will be the easiest kind to write, and we can build them before SIL is ready to use. It will preserve the structure of the source language, and this may be better suited to a manual code conversion project.
At the other end of the spectrum, sometimes users will want code conversion that is guaranteed to preserve semantics; they will want a fully automatic conversions that ensures their code will behave exactly the same in each target language. This would allow them to write a library of code in many languages simultaneously, but only need to test the code in a single language. In general, that's impossible; some things just don't translate, or don't translate perfectly. But if developers are willing to be limited to a certain subset of a programming language, it is possible to write code in that language and get perfect conversion to several other languages (the Ć Language tries to provide this.)
By default, SIL will attempt to stand in the middle--providing accurate translation where possible, and approximate translation if not.