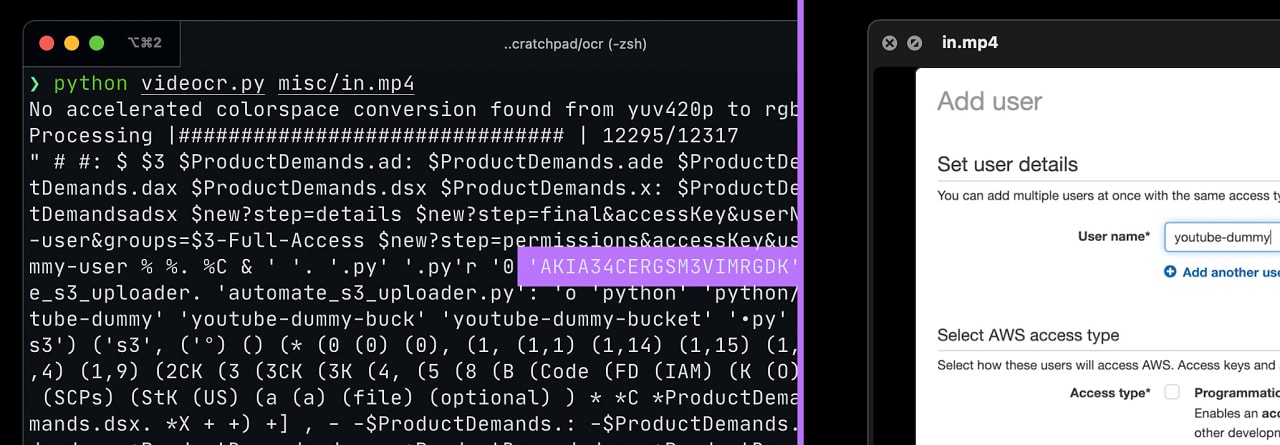
videocr.py uses macOS's native OCR to extract text from videos. This can then be perused or grep-ed for credentials, usernames, AWS access keys, or other personal data you may not want to be in a video you plan to share.
python videocr.py in.mp4
Other than the Python packages in requirements.txt, you'll need:
- FFmpeg
- Python 3.10 or higher
- macOS Monterey or higher
This is only a rough proof of concept for now. I intend to have it automatically alert on specific, common token types, to tell you where in the video they appear, and to let you specify your own usernames and password fragments to search for.
If you wish to take this code and turn it into something more generally useful, be my guest, but if you reuse specific code from the project, then include the necessary copyright attribution as per LICENSE. Thank you.
There is another project called videocr which extracts hard-coded subtitles from videos. It's also written in Python but works cross-platform by using Tesseract (which I also tried, but it's just too slow). I may rename this project due to this, but as it's currently a prototype and the other videocr hasn't been updated in nearly three years, I'll let it sit for now.
A huge debt goes to those who work on the amazing FFmpeg project for starters.
Also thanks to Rhet Turnbull whose code I found to learn about ways to call macOS's OCR routines from Python.