{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
由于MHA(mha4mysql-manager)工具2018年已经停止维护更新,且不支持Gtid复制模式,在原版基础上增补功能难度较大,固考虑将其重构。
参考了原版MHA的故障切换思路,改进的地方如下:
1)无需打通ssh公私钥互信认证,只需在app1.cnf配置文件里提供用户名和密码(root权限)即可,这一步的作用是漂移VIP,工具会直接进入远程主机上执行ip addr add VIP
2)目前主流版本MySQL 5.7和8.0的复制模式是基于Gtid,因事务号是唯一的,更改同步复制源不需要知道binlog文件名和position位置点,固简化了在客户端部署agent做数据补齐。
3)无需安装,就两个文件,一个是(环境配置检查)可执行文件masterha_check_repl_mysql,一个是(故障自动转移autofailover和在线平滑切换online switch)可执行文件masterha_manager_mysql
4 ) 基于主从复制(Gtid复制模式)才可以运行,masterha_check_repl_mysql工具会检测,如果是基于binlog和position(位置点复制模式)不能运行。可开启半同步复制确保切换以后数据完整性(至少有一个从库确认已接收到所有事件)。
5 ) masterha_manager_mysql守护进程主控文件,集成了 (masterha_master_switch + master_ip_failover + masterha_secondary_check + shutdown_script + weixin_alarm)捆绑在一起
6)AutoFailover自动故障切换(转移)VIP后,会发送微信公众号报警通知
7)支持远控卡重启服务器(避免脑裂问题)。例如删除VIP失败,主机已经hang住,只能通过远程管理卡去重启机器。在这里你可以调用远控卡命令,比如DELL服务器的ipmitool命令 https://www.cnblogs.com/EricDing/p/8995263.html
8)增补对MariaDB Gtid的支持
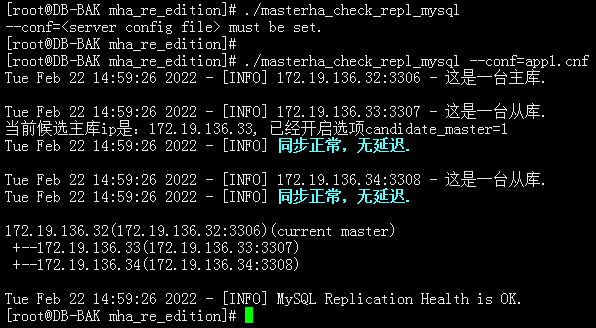
(注:指定不同的配置文件,可以支持监控多套MySQL主从复制架构)

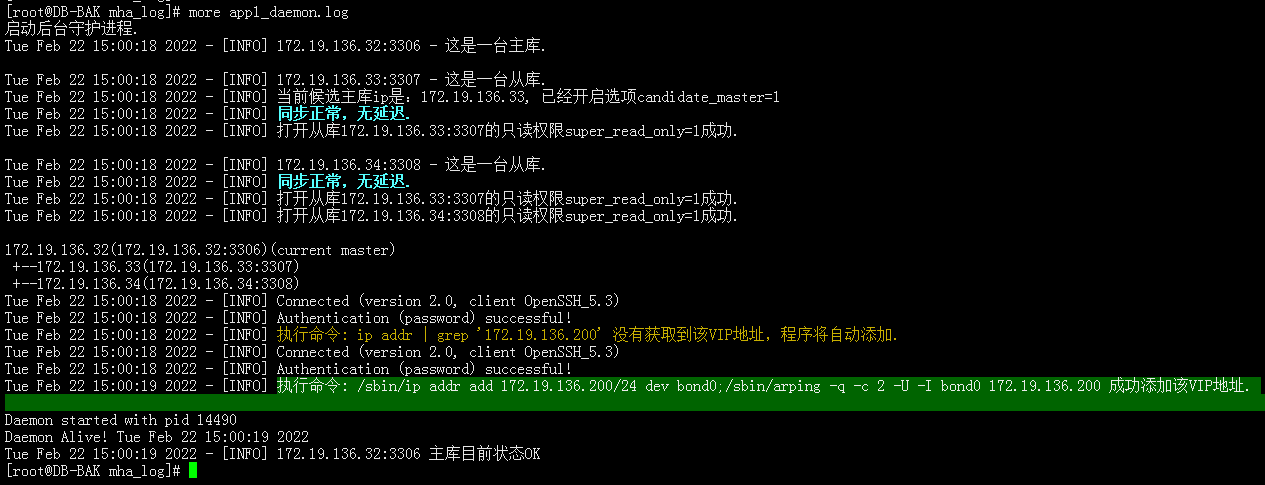
1)MHA Re-Edition管理机每隔app1.cnf配置文件参数connect_interval=1(秒),去连接主库,当试图连接3次失败后,尝试去其他从库上去连接并执行select 1探测,这里需要你在app1.cnf配置文件里设置masterha_secondary_check = slave1,slave2
设置完后,slave1和slave2去连接,如果有一台从库可以连接到主库,不认定主库down掉,不进行故障转移操作,会在log日志中输出warning警告信息,提示网络有问题,请排查。
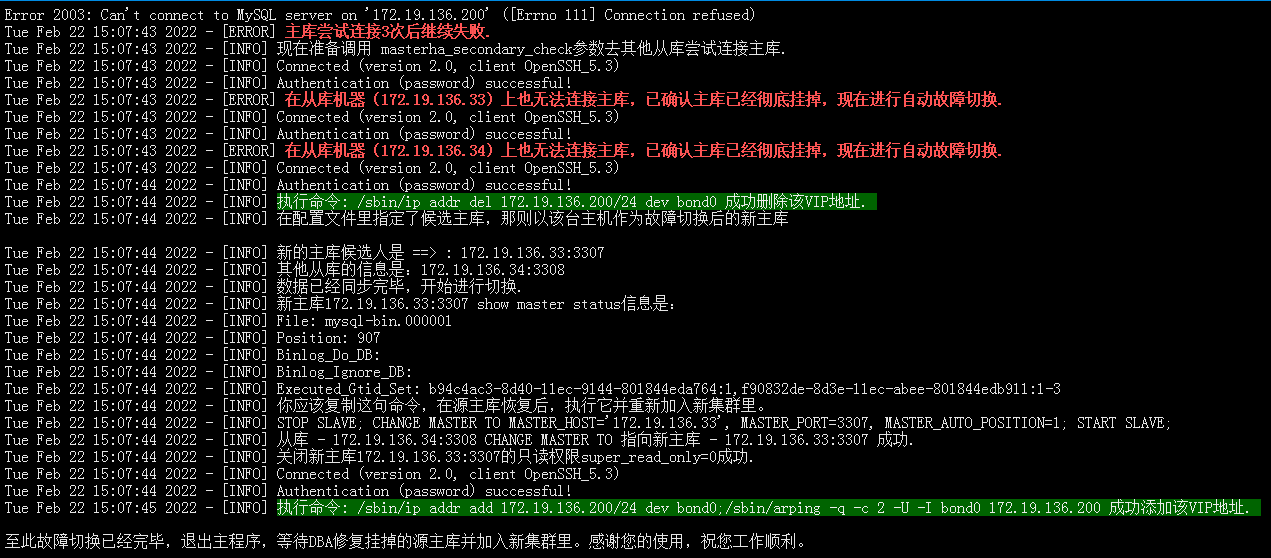
如果MHA Re-Edition管理机和其他slave从库都无法访问连接,则认定主库挂掉,开始进行故障切换。
2)如果你在app1.cnf配置文件里设置candidate_master = 1,指定了候选主库,则默认提升该新主库。
如果你没有在app1.cnf配置文件里设置candidate_master = 1,则根据从库执行的Gtid事件最新的将其提升为主库。
3)当从库出现延迟时,在app1.cnf配置文件里,超过参数running_updates_limit = 60 单位(秒)内,且未同步完数据,则强制开启VIP故障切换转移,并在log日志中输出warning警告信息。否则会一直等待60秒内执行完从库的Gtid事件。
4)其他从库会change master to改变同步源为候选主库,并在log日志中输出show master status新主库的状态信息。
5)关闭候选主库的set global super_read_only = 0只读权限
6)候选主库不执行reset slave all清空同步信息,这一步操作交给用户处理。
7)漂移VIP至新的主库。至此故障转移流程跑完。
1)首先检测当前存活主机master(172.19.136.32:3306)、slave1(172.19.136.33:3307)和slave2(172.19.136.34:3308)
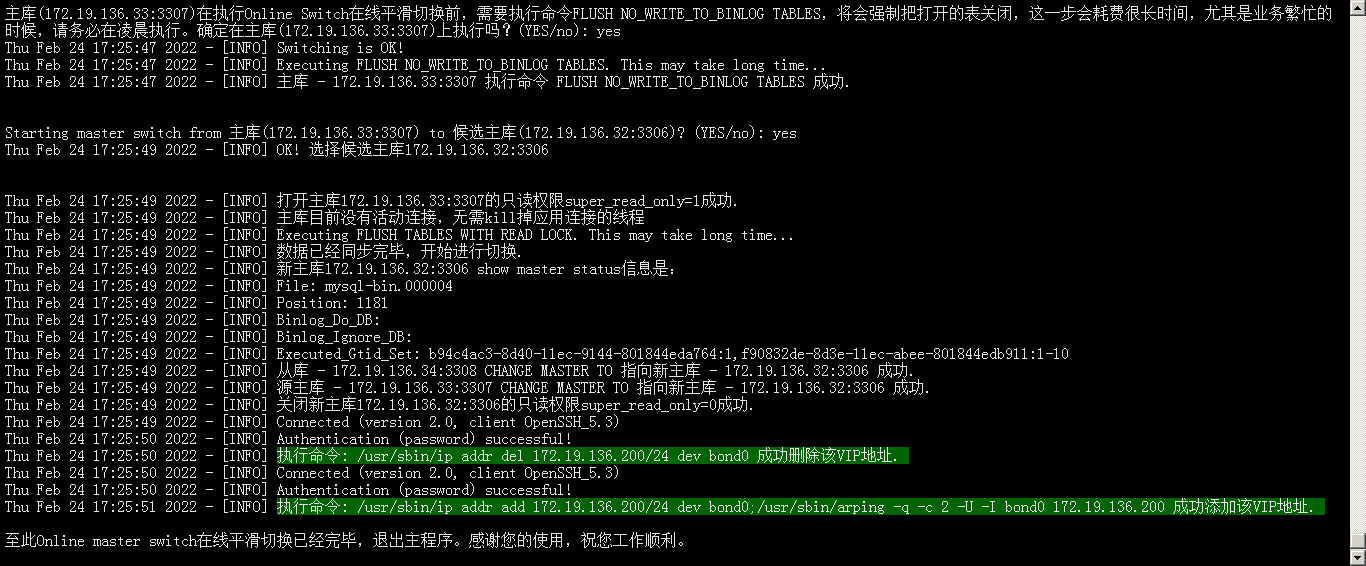
2)输入YES后,在原master上执行FLUSH NO_WRITE_TO_BINLOG TABLES操作,将会强制把打开的表关闭,这一步会耗费很长时间,尤其是业务繁忙的时候,请务必在凌晨执行。
3)之后会询问是否要把master(172.19.136.32:3306) 切换到(172.19.136.33:3307)?输入yes
(如果在app1.cnf配置文件里设置candidate_master = 1,指定了候选主库,则默认提升该新主库。
如果没有在app1.cnf配置文件里设置candidate_master = 1,则根据从库执行的Gtid事件最新的将其提升为主库。)
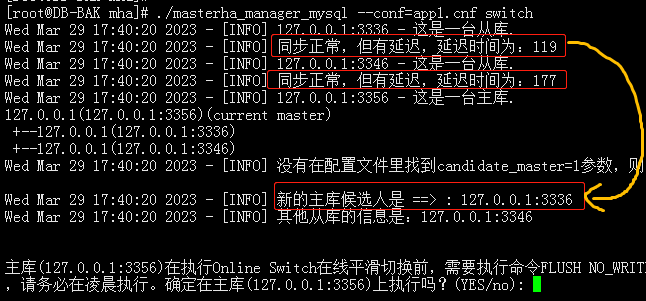
4)将原master上的虚拟VIP摘除。
5)设置原master为只读模式set global read_only=1
6)原master上KILL掉所有应用连接的线程。
7)原master上执行FLUSH TABLES WITH READ LOCK全局读锁。
8)在候选master上执行 select SELECT WAIT_FOR_EXECUTED_GTID_SET(master_gtid_executed, timeout),等待执行完Gtid事件。当候选主库出现延迟时,在app1.cnf配置文件里,超过参数running_updates_limit = 60 单位(秒)内,且未同步完数据,则强制开启VIP切换转移,并在log日志中输出warning警告信息。否则会一直等待60秒内执行完从库的Gtid事件。
9)新提升的master为读写模式set global read_only=0
10)在slave2上,执行CHANGE MASTER TO new_master
11)在原master上解除锁表UNLOCK TABLES
12)在原master上,执行CHANGE MASTER TO new_master
13)新提升的master上,执行stop slave; 不执行reset slave all清空同步信息,这一步操作交给用户处理。
- 将VIP切换到新提升的master上
15)整个切换流程结束。
shell> cd /usr/lib/systemd/system
shell> touch hh_phone.service
[Unit]
Description=MHA hh_phone Process Restart Script
After=network.target
[Service]
User=root
TimeoutStartSec=10s
Type=simple
PIDFile=/tmp/daemon_hh_phone.cnf.pid
KillMode=process
WorkingDirectory=/data/MHA-Re-Edition-main
ExecStart=/data/MHA-Re-Edition-main/masterha_manager_mysql --conf=/etc/mha/hh_phone.cnf start
Restart=on-abnormal
RestartSec=5s
LimitNOFILE=5555
StartLimitInterval=60s
StartLimitBurst=3
[Install]
WantedBy=multi-user.target
shell> systemctl start hh_phone.service
shell> systemctl status hh_phone.service
shell> systemctl enable hh_phone.service