This repository contains the code for the paper: "DROPO: Sim-to-Real Transfer with Offline Domain Randomization".
Abstract: In recent years, domain randomization has gained a lot of traction as a method for sim-to-real transfer of reinforcement learning policies; however, coming up with optimal randomization ranges can be difficult. In this paper, we introduce DROPO, a novel method for estimating domain randomization ranges for a safe sim-to-real transfer. Unlike prior work, DROPO only requires a precollected offline dataset of trajectories, and does not converge to point estimates. We demonstrate that DROPO is capable of recovering dynamic parameter distributions in simulation and finding a distribution capable of compensating for an unmodelled phenomenon. We also evaluate the method on two zero-shot sim-to-real transfer scenarios, showing a successful domain transfer and improved performance over prior methods.
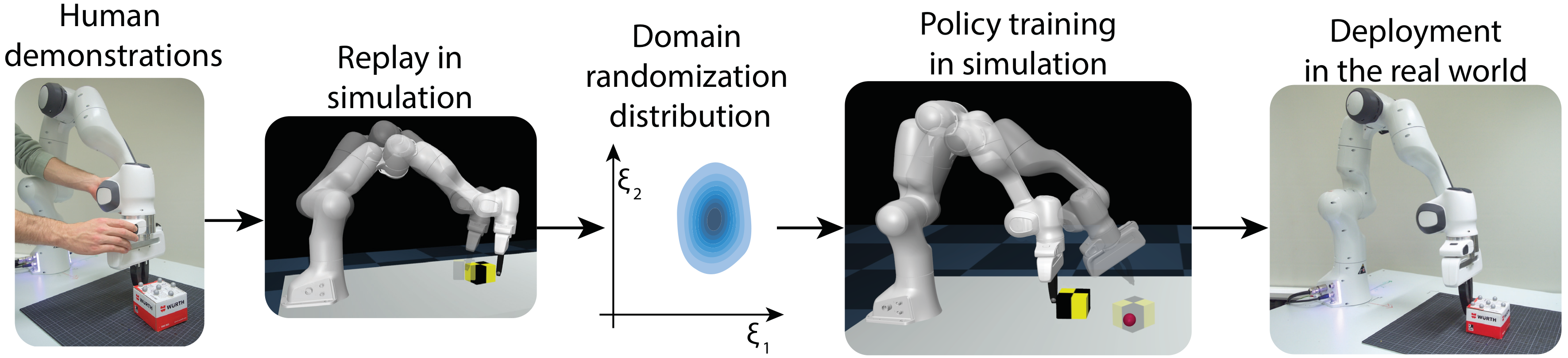
Dropo currently only supports gym environments registered with the old APIs gym<=0.25. Refer to the compatibility guidelines for running newly registered gym environments with this implementation.
Install DROPO:
cd dropo
pip install -r requirements.txt
pip install .
Test this implementation on the OpenAI gym Hopper environment with test_dropo.py (see below).
Prior to running the code, an offline dataset of trajectories from the target (real) environment needs to be collected. This dataset can be generated either by rolling out any previously trained policy, or by kinesthetic guidance of the robot.
The dataset object must be formatted as follows:
n : int
state space dimensionality
a : int
action space dimensionality
t : int
number of state transitions
dataset : dict,
object containing offline-collected trajectories
dataset['observations'] : ndarray
2D array (t, n) containing the current state information for each timestep
dataset['next_observations'] : ndarray
2D array (t, n) containing the next-state information for each timestep
dataset['actions'] : ndarray
2D array (t, a) containing the action commanded to the agent at the current timestep
dataset['terminals'] : ndarray
1D array (t,) of booleans indicating whether or not the current state transition is terminal (ends the episode)
Augment the simulated environment with the following methods to allow Domain Randomization and its optimization:
-
env.set_task(*new_task)# Set new dynamics parameters -
env.get_task()# Get current dynamics parameters -
mjstate = env.get_sim_state()# Get current internal mujoco state -
env.get_initial_mjstate(state)andenv.get_full_mjstate(state)# Get the internal mujoco state from given state -
env.set_sim_state(mjstate)# Set the simulator to a specific mujoco state -
env.set_task_search_bounds()# Set the search bound for the mean of the dynamics parameters -
(optional)
env.get_task_lower_bound(i)# Get lower bound for i-th dynamics parameter -
(optional)
env.get_task_upper_bound(i)# Get upper bound for i-th dynamics parameter
Sample file to launch DROPO on custom gym-registered environments (gym<=0.25). To parallelize DROPO execution, use the dedicated --now dropo parameter instead of vectorized gym environments.
You can test DROPO out-of-the-box on the OpenAI gym Hopper environment with test_dropo.py --env RandomHopper-v0 (requires random-envs package and mujoco installed on your system). A corresponding offline dataset of 20 trajectories has already been collected by a semi-converged policy and made available in datasets/ dir.
E.g.:
-
Quick test (10 sparse transitions and 1000 obj. function evaluations only):
python test_dropo.py --env RandomHopper-v0 --sparse-mode -n 10 -l 1 --budget 1000 -av --epsilon 1e-5 --seed 100 --dataset datasets/hopper10000 --normalize --logstdevs
-
Advanced test (2 trajectories are considered, with 5000 obj. function evaluations, and 10 parallel workers):
python test_dropo.py --env RandomHopper-v0 -n 2 -l 1 --budget 5000 -av --epsilon 1e-5 --seed 100 --dataset datasets/hopper10000 --normalize --logstdevs --now 10
-
Advanced test on the unmodeled Hopper variant:
python test_dropo.py --env RandomHopperUnmodeled-v0 -n 2 -l 1 --budget 5000 -av --epsilon 1e-3 --seed 100 --dataset datasets/hopper10000 --normalize --logstdevs --now 10
test_dropo.py will return the optimized domain randomization distribution, suitable for training a reinforcement learning policy on the same simulated environment.
If you use this repository, please consider citing
@article{tiboni2023dropo,
title = {DROPO: Sim-to-real transfer with offline domain randomization},
journal = {Robotics and Autonomous Systems},
pages = {104432},
year = {2023},
issn = {0921-8890},
doi = {https://doi.org/10.1016/j.robot.2023.104432},
url = {https://www.sciencedirect.com/science/article/pii/S0921889023000714},
author = {Gabriele Tiboni and Karol Arndt and Ville Kyrki},
keywords = {Robot learning, Transfer learning, Reinforcement learning, Domain randomization}
}