Home
ha-store, or High-Availability store, is wrapper to abstract common optimization and security patterns for data fetching.
It's goals are to
- Decouple performance, security and degradation fallback concerns from the rest of the application logic.
- Provide an extensible interface to control traffic influx matching a classically distributed pattern.
- Reduce the infrastructure-related costs of orchestration-type applications with smart caching.
Facebook's dataloader is a close competitor, but it lacks a few key features.
dataloader's documentation suggests implementing a new instance on each request, only coalescing data queries within the scope of that request- with a batching frequency that runs on Node's event-loop (nextTick). This approach fits their caching strategy, since they do not have caching, they are forced to make their entire stores short-lived so that they do not cause memory concerns.
ha-store, on the other end prefers global, permanent stores. This means that data query coalescing is application-wide, with the batching tick rate customizable- to allow users to really optimize roundtrips.
The xfetch Rust crate is what comes closest in terms of philosophy and features. They also link to scientific papers explaining the benefits of Optimal Probabilistic Cache Stampede Prevention.
The following diagrams represent an application which connects to a data-source. Each pattern explains how HA-store improves the requests from that application to the data-source.
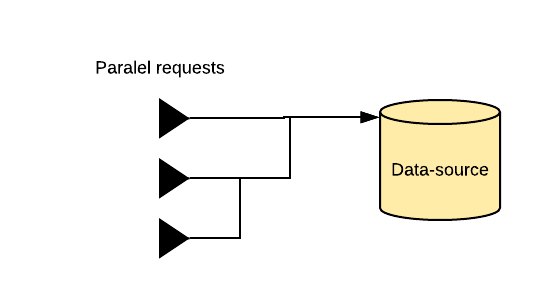
Coalescing is an optimization strategy that consists in detecting duplicated requests and picking up transit handles. In the case of ha-store, this consists in detecting if a data-source request is sent for a given entity, and in such cases, returns the Promise handle of the original request instead of creating a new one.
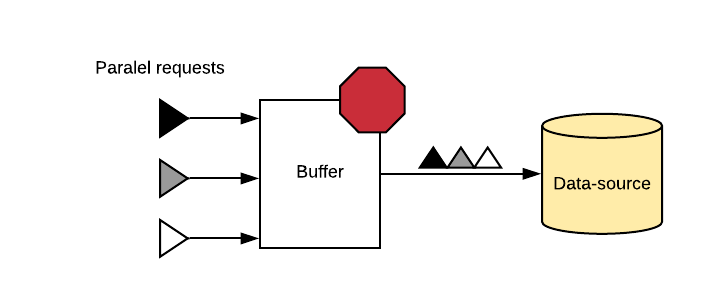
Batching is a blocking protocol. It involves adding a buffer of a given duration for incoming requests. This buffer allows the application to better understand an bundle requests. HA-store implements this with a tick value, that controls the amount of time between batches to a specific data-source. Another option, max controls the maximum allowed number of distinct records in a batch.
Entity caching via Redis or memcache is a common solution to speed up applications that communicate to data-sources. Unfortunately, only a subset of the data is considered "hot" and queried often, the rest occupies space and, in the event that the information is not in the cache, a call is still required to the data-source. Not to mention the extra infrastructure concerns like cost, maintenance, etc. Caching in HA-store uses the common TLRU pattern which works great for data distributed in a classic zipfian distribution (See Zeta distribution).
In order to leverage Caching to its fullest, the first step is understanding the distribution of traffic on your application.
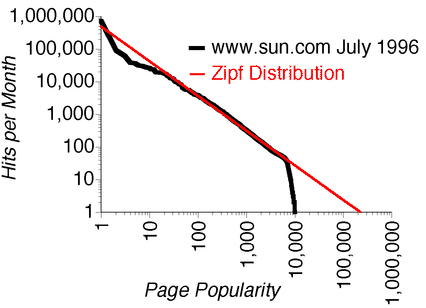
https://www.nngroup.com/articles/zipf-curves-and-website-popularity/
For example, if you are running a blog, you would want to know which articles are being requested and at which frequency. This z-distribution, also referred to as Zipf's distribution, should tell you what percentage of traffic you can optimize with caching based on the x-axis.
For example, in this schema, caching the 3 first entries covers 50% of traffic.
Caching for even distribution datasets is not recommended as it is likely that you will either get a negligible hit rate or saturate your store with too many records and thus run out of memory.
Includes all of the ha-store features (retry, circuit-breaker, batching, coalescing, caching) in this very classical Express+Mongo application: Gist
For live testing: Runkit