- 数据结构篇
- 二叉树
- maximum-depth-of-binary-tree二叉树的最大深度
- balanced-binary-tree平衡二叉树
- binary-tree-maximum-path-sum二叉树中的最大路径和
- lowest-common-ancestor-of-a-binary-tree二叉树的最近公共祖先
- binary-tree-level-order-traversal二叉树的层序遍历
- binary-tree-level-order-traversal-ii二叉树的层次遍历 II
- binary-tree-zigzag-level-order-traversal 二叉树的锯齿形层次遍历
- validate-binary-search-tree 验证二叉搜索树
- insert-into-a-binary-search-tree二叉搜索树中的插入操作
- 链表
- remove-duplicates-from-sorted-list 删除排序链表中的重复元素
- remove-duplicates-from-sorted-list-ii删除排序链表中的重复元素 II
- reverse-linked-list反转链表
- reverse-linked-list-ii反转链表 II
- merge-two-sorted-list合并两个有序链表
- partition-list分隔链表
- sort-list 排序链表
- reorder-list 重排链表
- linked-list-cycle环形链表
- linked-list-cycle-ii 环形链表 II
- palindrome-linked-list 回文链表
- copy-list-with-random-pointer复制带随机指针的链表
- 栈和队列
- 二进制
- 二叉树
- 基础算法篇
- 二分搜索
- 动态规划
- 背景
- 使用场景
- 四点要素
- 常见四种类型
- 1、矩阵类型(10\x)
- minimum-path-sum最小路径和
- unique-paths不同路径
- unique-paths-ii不同路径 II
- 2、序列类型(40\x)
- climbing-stairs爬楼梯
- jump-game跳跃游戏
- jump-game-ii跳跃游戏 II
- palindrome-partitioning-ii分割回文串 II
- longest-increasing-subsequence最长上升子序列
- word-break单词拆分
- 小结
- 3. Two Sequences DP(40\x)
- longest-common-subsequence最长公共子序列
- edit-distance编辑距离
- 4.零钱和背包(10\x)
- coin-change零钱兑换
- 算法思维
maximum-depth-of-binary-tree二叉树的最大深度
给定一个二叉树,找出其最大深度。
思路:分治法
int maxDepth(struct TreeNode* root){
//返回条件处理
if(root == NULL)return 0;
//divide: 左右子树分别计算
int l = maxDepth(root->left);
int r = maxDepth(root->right);
//conquer: 合并左右子树结果
return (l > r ? l : r) + 1;
}balanced-binary-tree平衡二叉树
给定一个二叉树,判断它是否是高度平衡的二叉树。
思路:分治法,左边平衡&&右边平衡&&左右两边高度<=1。
不平衡的情况有3种:左树不平衡、右树不平衡、左树和右树差的绝对值大于1
int Depth(struct TreeNode *root) {//求左右深度
if(root == NULL) return 0;
int l = Depth(root->left), r = Depth(root->right);
return (l > r ? l : r) + 1;
}
bool isBalanced(struct TreeNode* root){
if(root == NULL) return true;
int l = Depth(root->left);
int r = Depth(root->right);
if(abs(l - r) > 1) return false;
return isBalanced(root->left) && isBalanced(root->right);//左右是否平衡
}binary-tree-maximum-path-sum二叉树中的最大路径和
给定一个非空二叉树,返回其最大路径和。
思路:分治法,对于任意一个点,如果最大和路径包含该节点,那么有两种可能:
- 其左右子树所构成的路径值较大的加上该节点的值后向父节点回溯构成最大路径
- 左右子树都在最大路径中,加上该节点的值就构成最终的最大路径
class Solution {
public:
int result;
int dfs(TreeNode *root) {
if(root == NULL) return 0;
int l = max(dfs(root->left), 0);//如果子树路径和为赋值应当置为0表示最大路径不包含子树
int r = max(dfs(root->right), 0);
result = max(root->val + l + r, result);//判断在该节点包含左右子树和是否大于当前最大路径和
return root->val + max(0, max(l, r));
}
int maxPathSum(struct TreeNode* root){
if(root == NULL) return 0;
result = root->val;
dfs(root);
return result;
}
};lowest-common-ancestor-of-a-binary-tree二叉树的最近公共祖先
lowest-common-ancestor-of-a-binary-tree
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
思路:分治法,有左子树的公共祖先或者有右子树的公共祖先,就返回子树的祖先,否则返回根节点
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if(root == NULL) return NULL;
if(root == p || root == q) {//回溯的关键代表左边和右边的公共祖先
return root;
}
root->left = lowestCommonAncestor(root->left, p, q);//公共祖先在左边
root->right = lowestCommonAncestor(root->right, p, q);//公共祖先在左边
if(root->left && root->right) {//左右都有公共祖先那公共祖先是root
return root;
}
if(root->left == NULL) {//左边的公共祖先为NULL,那么公共祖先是右边的
return root->right;
}
if(root->right == NULL) {//右边的公共祖先为NULL,那么公共祖先是左边的
return root->left;
}
return NULL;
}
};binary-tree-level-order-traversal二叉树的层序遍历
binary-tree-level-order-traversal
给你一个二叉树,请你返回其按 层序遍历 得到的节点值。 (即逐层地,从左到右访问所有节点)
**BFS**广搜
class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root) {
vector <vector <int>> ret;//二维的数组
if (!root) return ret;
queue <TreeNode*> q;
q.push(root);
while (!q.empty()) {
int currentLevelSize = q.size();//记录每层的
ret.push_back(vector <int> ());
for (int i = 1; i <= currentLevelSize; ++i) {
auto node = q.front(); q.pop();
ret.back().push_back(node->val);
if (node->left) q.push(node->left);
if (node->right) q.push(node->right);
}
}
return ret;
}
};binary-tree-level-order-traversal-ii二叉树的层次遍历 II
binary-tree-level-order-traversal-ii
给定一个二叉树,返回其节点值自底向上的层次遍历。 (即按从叶子节点所在层到根节点所在的层,逐层从左向右遍历)
思路:在上一题的层次遍历基础上,翻转一下结果即可
class Solution {
public:
vector<vector<int>> levelOrderBottom(TreeNode* root) {
vector<vector<int>>ret;
if(!root) return ret;
queue<TreeNode *>q;
q.push(root);
while(!q.empty()) {
int temp = q.size();
ret.push_back(vector<int>());
for(int i = 1; i <= temp; i++) {
auto node = q.front();
q.pop();
ret.back().push_back(node->val);
if(node->left) q.push(node->left);
if(node->right)q.push(node->right);
}
}
reverse(ret.begin(), ret.end());//结果反转一下就行
return ret;
}
};binary-tree-zigzag-level-order-traversal 二叉树的锯齿形层次遍历
binary-tree-zigzag-level-order-traversal
给定一个二叉树,返回其节点值的锯齿形层次遍历。Z 字形遍历
对结果进行处理,偶数行翻转就行了
class Solution {
public:
vector<vector<int>> zigzagLevelOrder(TreeNode* root) {
vector<vector<int>>ret;
if(!root) return ret;
queue<TreeNode *>q;
q.push(root);
int flag = 1;
while(!q.empty()) {
int temp = q.size();
vector<int>out;
for(int i = 1; i <= temp; i++) {
auto node = q.front();
q.pop();
out.push_back(node->val);
if(node->left) q.push(node->left);
if(node->right)q.push(node->right);
}
if(flag % 2 == 0) {
reverse(out.begin(), out.end());
}
flag++;
ret.push_back(out);
}
return ret;
}
};validate-binary-search-tree 验证二叉搜索树
给定一个二叉树,判断其是否是一个有效的二叉搜索树。
- 思路 1:中序遍历,检查结果列表是否已经有序
- 思路 2:分治法,判断左 MAX < 根 < 右 MIN
class Solution {
public:
bool isValidBST(TreeNode* root) {
stack<TreeNode*> stack;
long long inorder = (long long)INT_MIN - 1;
while (!stack.empty() || root != nullptr) {
while (root != nullptr) {
stack.push(root);
root = root -> left;
}
root = stack.top();
stack.pop();
// 如果中序遍历得到的节点的值小于等于前一个 inorder,说明不是二叉搜索树
if (root -> val <= inorder) return false;
inorder = root -> val;
root = root -> right;
}
return true;
}
};
class Solution {
public:
bool helper(TreeNode* root, long long lower, long long upper) {
if (root == nullptr) return true;
if (root -> val <= lower || root -> val >= upper) return false;
return helper(root -> left, lower, root -> val) && helper(root -> right, root -> val, upper);//最小值 < left, right < 最大值
}
bool isValidBST(TreeNode* root) {
return helper(root, LONG_MIN, LONG_MAX);//LONG_MIN在LONG中最小值
}
};insert-into-a-binary-search-tree二叉搜索树中的插入操作
insert-into-a-binary-search-tree
给定二叉搜索树(BST)的根节点和要插入树中的值,将值插入二叉搜索树。 返回插入后二叉搜索树的根节点。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
TreeNode* insertIntoBST(TreeNode* root, int val) {
if(root == NULL) {
return new TreeNode(val);
}
if(root->val < val) {
root->right = insertIntoBST(root->right, val);
}
if(root->val > val) {
root->left = insertIntoBST(root->left, val);
}
return root;
}
};remove-duplicates-from-sorted-list 删除排序链表中的重复元素
remove-duplicates-from-sorted-list
给定一个排序链表,删除所有重复的元素,使得每个元素只出现一次。
struct ListNode* deleteDuplicates(struct ListNode* head){
struct ListNode *p = head, *q;
while(p && p->next) {
if(p->val != p->next->val) {//不相同就一直往后走
p = p->next;
} else {//相同时删除后面结点
q = p->next;
p->next = q->next;
free(q);
}
}
return head;
}remove-duplicates-from-sorted-list-ii删除排序链表中的重复元素 II
remove-duplicates-from-sorted-list-ii
给定一个排序链表,删除所有含有重复数字的节点,只保留原始链表中 没有重复出现的数字。
有可能把头删掉
struct ListNode* deleteDuplicates(struct ListNode* head){
struct ListNode dummy;//虚拟头结点
dummy.next = head;
struct ListNode *p = &dummy;
while(p->next && p->next->next) {
if(p->next->val == p->next->next->val) {
struct ListNode *q = p->next;
while(q && q->next && q->val == q->next->val) {
q = q->next;
}
p->next = q->next;
} else {
p = p->next;
}
}
return dummy.next;
}reverse-linked-list反转链表
反转一个单链表。
struct ListNode* reverseList(struct ListNode* head){
if(head == NULL) return NULL;
struct ListNode ret, *p, *q;
ret.next = NULL;
p = head;
while(p) {
q = p->next;
p->next = ret.next;
ret.next = p;
p = q;
}
return ret.next;
}reverse-linked-list-ii反转链表 II
反转从位置 m 到 n 的链表。请使用一趟扫描完成反转。
struct ListNode* reverseBetween(struct ListNode* head, int m, int n){
if(head== NULL) return NULL;
struct ListNode ret;
ret.next = head;
struct ListNode *p;
p = &ret;
for(int i = 1; i < m; i++){//先找到要翻转的起点前一个位置
p = p->next;
}
head = p->next;//因为不要返回head,所以这里可以直接利用head
for(int i = m; i < n; i++) {
struct ListNode *q = head->next;
head->next = q->next;
q->next = p->next;
p->next = q;
}
return ret.next;
}
merge-two-sorted-list合并两个有序链表
将两个升序链表合并为一个新的升序链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
思路:使用ret连接各个元素.
struct ListNode* mergeTwoLists(struct ListNode* l1, struct ListNode* l2){
struct ListNode ret, *p = &ret;
ret.next = NULL;
while(l1 || l2) {//都为空的时候跳出
if(l2 == NULL || (l1 && l1->val <= l2->val)) {//l2为空,或者l1不为空且l1->val <= l2->val
p->next = l1;
l1= l1->next;
} else {//l1为空连接l2,或者l2不为空且l1->val > l2->val;
p->next = l2;
l2 = l2->next;
}
p = p->next;//p往后走一个
p->next = NULL;//末未处理
}
return ret.next;
}partition-list分隔链表
给定一个链表和一个特定值 x,对链表进行分隔,使得所有小于 x 的节点都在大于或等于 x 的节点之前。
思路:将大于 x 的节点,放到另外一个链表,最后连接这两个链表
struct ListNode* partition(struct ListNode* head, int x){
if(head == NULL) return head;
struct ListNode headLess, headGreater;
struct ListNode *curLess, *curGreater;
headLess.next = headGreater.next = NULL;
curLess = &headLess;
curGreater = &headGreater;
while(head) {
if(head->val < x) {
curLess->next = head;
curLess = curLess->next;
} else {
curGreater->next = head;
curGreater = curGreater->next;
}
head = head->next;
}
curGreater->next = NULL;
curLess->next = headGreater.next;
return headLess.next;
}sort-list 排序链表
在 O(n log n) 时间复杂度和常数级空间复杂度下,对链表进行排序。
思路:归并排序,找中点和合并操作
class Solution {
public:
ListNode* sortList(ListNode* head) {
ListNode dummyHead(0);
dummyHead.next = head;
auto p = head;
int length = 0;
while (p) {
++length;
p = p->next;
}
for (int size = 1; size < length; size <<= 1) {
auto cur = dummyHead.next;
auto tail = &dummyHead;
while (cur) {
auto left = cur;
auto right = cut(left, size);
cur = cut(right, size);
tail->next = merge(left, right);
while (tail->next) {
tail = tail->next;
}
}
}
return dummyHead.next;
}
ListNode* cut(ListNode* head, int n) {
auto p = head;
while (--n && p) {
p = p->next;
}
if (!p) return nullptr;
auto next = p->next;
p->next = nullptr;
return next;
}
ListNode* merge(ListNode* l1, ListNode* l2) {
ListNode dummyHead(0);
auto p = &dummyHead;
while (l1 && l2) {
if (l1->val < l2->val) {
p->next = l1;
p = l1;
l1 = l1->next;
} else {
p->next = l2;
p = l2;
l2 = l2->next;
}
}
p->next = l1 ? l1 : l2;
return dummyHead.next;
}
};reorder-list 重排链表
给定一个单链表 L:L→L→…→L__n→L 将其重新排列后变为: L→L__n→L→L__n→L→L__n→…
双指针,l++, r--
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
void reorderList(ListNode* head) {
if(head == NULL) return;
vector<ListNode *>vec;
ListNode *p = head;
while(p) {
vec.push_back(p);
p = p ->next;
}
int l = 0, r = vec.size() - 1;
while(l < r) {
vec[l]->next = vec[r];
vec[r--]->next = vec[++l];//核心
}
vec[l]->next = nullptr;
}
};linked-list-cycle环形链表
给定一个链表,判断链表中是否有环。
思路:快慢指针,快慢指针相同则有环
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
bool hasCycle(ListNode *head) {
if(head == NULL) return false;
ListNode *p = head, *q = head;
do{
p = p->next;
q = q->next;
if(p == NULL || p->next == NULL) {
return false;
}
p = p->next;
}while(p != q);
return true;
}
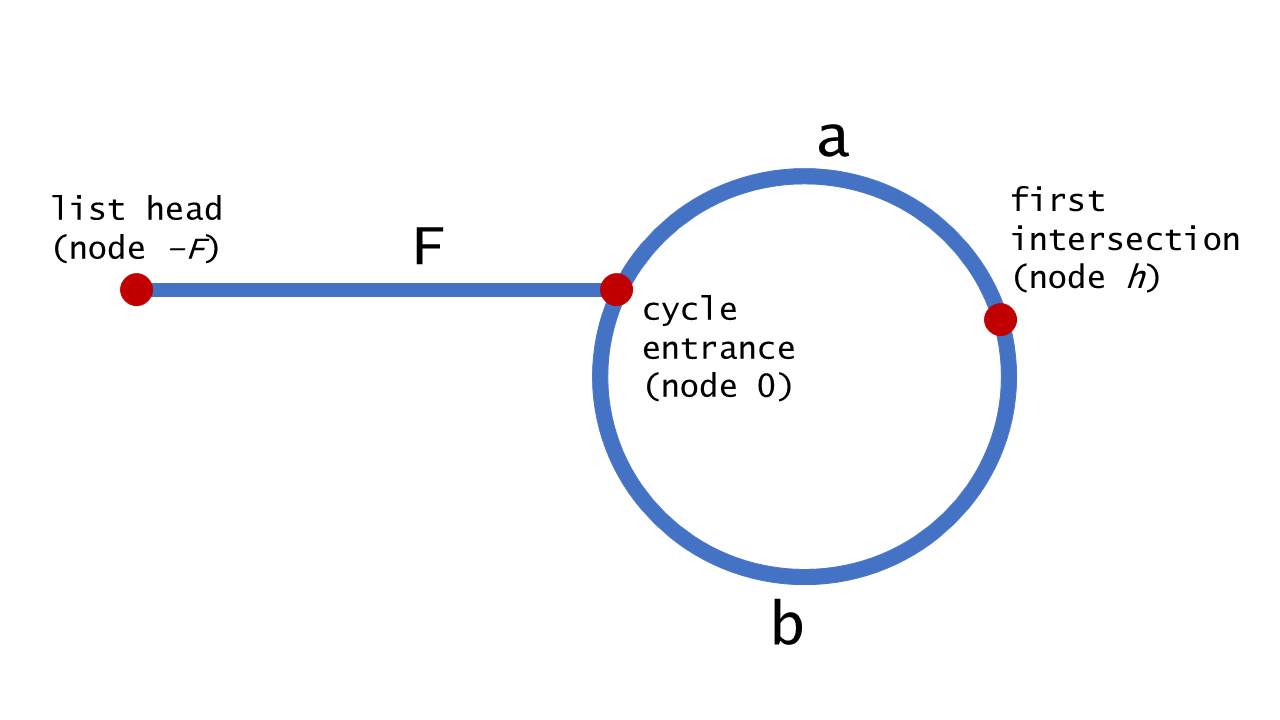
};linked-list-cycle-ii 环形链表 II
给定一个链表,返回链表开始入环的第一个节点。 如果链表无环,则返回
null。
思路:快慢指针,快慢相遇之后,慢指针回到头,快慢指针步调一致一起移动,相遇点即为入环点
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *detectCycle(ListNode *head) {
if(head == NULL) return NULL;
ListNode *p = head, *q = head;
do {
p = p->next;
q = q->next;
if(p == NULL || p->next == NULL) return NULL;
p = p->next;
}while(p != q);
p = head;
while(p != q) {
p = p->next;
q = q->next;
}
return p;
}
}palindrome-linked-list 回文链表
请判断一个链表是否为回文链表。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
bool isPalindrome(ListNode* head) {
stack<ListNode *>stk;
ListNode *q = head;
while(q) {
stk.push(q);
q = q->next;
}
q = head;
while(!stk.empty()) {
ListNode *temp = stk.top();
stk.pop();
if(temp->val != q->val) return false;
q = q->next;
}
return true;
}
};copy-list-with-random-pointer复制带随机指针的链表
给定一个链表,每个节点包含一个额外增加的随机指针,该指针可以指向链表中的任何节点或空节点。 要求返回这个链表的 深拷贝。
思路:1、hash 表存储指针,2、复制节点跟在原节点后面
/*
// Definition for a Node.
class Node {
public:
int val;
Node* next;
Node* random;
Node(int _val) {
val = _val;
next = NULL;
random = NULL;
}
};
*/
class Solution {
public:
Node* copyRandomList(Node* head) {
if(head == NULL) return head;
Node *cur = head;
// 复制节点,紧挨到到后面
// 1->2->3 ==> 1->1'->2->2'->3->3'
while(cur) {
Node *clone = new Node(cur->val, cur->next, nullptr);
Node *temp = cur->next;
cur->next = clone;
cur = temp;
}
//处理random指针
cur = head;
while(cur) {
if(cur->random) {
cur->next->random = cur->random->next;
}
cur = cur->next->next;
}
// 分离两个链表
cur = head;
Node *ret = head->next;
while(cur->next) {
Node *temp = cur->next;
cur->next = cur->next->next;
cur = temp;
}
// 原始链表头:head 1->2->3
// 克隆的链表头:cloneHead 1'->2'->3'
return ret;
}
};min-stack 最小栈
设计一个支持 push,pop,top 操作,并能在常数时间内检索到最小元素的栈。
思路:用两个栈实现,一个最小栈始终保证最小值在顶部,一个栈保存原,一个栈保存最小栈顶
class MinStack {
public:
/** initialize your data structure here. */
stack<int>stk1, stk2;
MinStack() {
}
void push(int x) {
stk1.push(x);
if(stk2.empty() || x <= stk2.top()) {
stk2.push(x);
}
}
void pop() {
if(stk2.top() == stk1.top()) {
stk2.pop();
}
stk1.pop();
}
int top() {
return stk1.top();
}
int getMin() {
return stk2.top();
}
};
/**
* Your MinStack object will be instantiated and called as such:
* MinStack* obj = new MinStack();
* obj->push(x);
* obj->pop();
* int param_3 = obj->top();
* int param_4 = obj->getMin();
*/evaluate-reverse-polish-notation逆波兰表达式求值
波兰表达式计算 > 输入:
["2", "1", "+", "3", "*"]> 输出: 9解释:
((2 + 1) * 3) = 9
思路:通过栈保存原来的元素,遇到表达式弹出运算,再推入结果,重复这个过程
class Solution {
public:
int evalRPN(vector<string>& tokens) {
stack<int>t;
for(int i = 0; i < tokens.size(); i++) {
if(tokens[i]=="+" || tokens[i] == "-"|| tokens[i] == "*"|| tokens[i] == "/"){
if(t.size() < 2) {
return -1;
}
int b = t.top();
t.pop();
int a = t.top();
t.pop();
int ret = 0;
if(tokens[i] == "+")ret = a + b;
if(tokens[i] == "-")ret = a - b;
if(tokens[i] == "*")ret = a * b;
if(tokens[i] == "/")ret = a / b;
t.push(ret);
} else {
int w = atoi(tokens[i].c_str());
t.push(w);
}
}
return t.top();
}
};decode-string字符串解码
给定一个经过编码的字符串,返回它解码后的字符串。 s = "3[a]2[bc]", 返回 "aaabcbc". s = "3[a2[c]]", 返回 "accaccacc". s = "2[abc]3[cd]ef", 返回 "abcabccdcdcdef".
思路:通过栈辅助进行操作
class Solution {
public:
string decodeString(string s) {
stack<int>numstk;
stack<string>strstk;
string cur = "";
string result = "";
int n = s.size();
int num = 0;
for(int i = 0; i < n; i++) {
if(s[i] >= '0' && s[i] <= '9') {
num = num * 10 + s[i] - '0';
} else if(s[i] == '['){
numstk.push(num);
strstk.push(cur);
num = 0;
cur.clear();
} else if((s[i] >= 'a' && s[i] <= 'z') || (s[i] >= 'A' && s[i] <= 'Z')) cur += s[i];
else if(s[i] == ']') {
int k = numstk.top();
numstk.pop();
for(int j = 0; j < k; j++) {
strstk.top() += cur;
}
cur = strstk.top();
strstk.pop();
}
}
result = result + cur;
return result;
}
};binary-tree-inorder-traversal二叉树的中序遍历
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<int> ret;
void inorder(TreeNode *root) {
if(root == NULL) return;
if(root->left) inorder(root->left);
ret.push_back(root->val);
if(root->right) inorder(root->right);
}
vector<int> inorderTraversal(TreeNode* root) {
if(root == NULL) return ret;
inorder(root);
return ret;
}
};clone-graph克隆图
给你无向连通图中一个节点的引用,请你返回该图的深拷贝(克隆)。
/*
// Definition for a Node.
class Node {
public:
int val;
vector<Node*> neighbors;
Node() {
val = 0;
neighbors = vector<Node*>();
}
Node(int _val) {
val = _val;
neighbors = vector<Node*>();
}
Node(int _val, vector<Node*> _neighbors) {
val = _val;
neighbors = _neighbors;
}
};
*/
class Solution {
public:
Node* visit[101] = {nullptr};
Node* cloneGraph(Node* node) {
if(node == NULL) return node;
int n = node->neighbors.size();
Node *root = new Node(node->val, vector<Node *>());
visit[node->val] = root;
for(int i = 0; i < n; i++) {
if(!visit[node->neighbors[i]->val]) {
root->neighbors.push_back(cloneGraph(node->neighbors[i]));
} else {
root->neighbors.push_back(visit[node->neighbors[i]->val]);
}
}
return root;
}
};number-of-islands岛屿数量
给定一个由 '1'(陆地)和 '0'(水)组成的的二维网格,计算岛屿的数量。一个岛被水包围,并且它是通过水平方向或垂直方向上相邻的陆地连接而成的。你可以假设网格的四个边均被水包围。
class Solution {
public:
char a[310][310];
int check[310][310];
int dir[4][2] = {1, 0, 0, 1, -1, 0, 0, -1};
void dfs(int x, int y) {
for(int i = 0; i < 4; i++) {
int dx = x + dir[i][0];
int dy = y + dir[i][1];
if(a[dx][dy] == '1') {
a[dx][dy] = '0';
dfs(dx, dy);
}
}
return;
}
int numIslands(vector<vector<char>>& grid) {
int n = grid.size();
int m = grid[0].size();
for(int i = 0; i < n; i++) {
for(int j = 0; j < m; j++) {
a[i + 1][j + 1] = grid[i][j];
}
}
int sum = 0;
for(int i = 1; i <= n; i++) {
for(int j = 1; j <= m; j++) {
if(a[i][j] == '1') {
sum++;
a[i][j] = '0';
dfs(i, j);
}
}
}
return sum;
}
};largest-rectangle-in-histogram柱状图中最大的矩形
给定 n 个非负整数,用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度为 1 。 求在该柱状图中,能够勾勒出来的矩形的最大面积。
基本思想:单调栈,单调递增栈的作用就是为了以栈顶元素为中心,向两边延伸找到小于栈顶元素的左右边界。时间复杂度O(n)空间复杂度O(n)。
- 当前heights[i]元素大于栈顶,则元素入栈,否则开始计算以栈顶元素为矩形的高往两侧延伸
- 直到遇到左右两侧第一个比这个矩形条的高度更小的矩形条,此时以栈顶元素为矩形的宽度就是该矩形最大宽度
- 寻找右边界,很明显,就是当前heights[i]元素右边界为i,如果heights[i]大于等于栈顶元素就入栈了
- 寻找左边界,显然就是栈顶下一个元素,如果栈顶没有下一个元素,说明栈顶元素是整个前i个元素最小的了,左边界就是-1
- 只要当前heights[i]元素小于栈顶元素或者i已经到底了,就计算以栈顶元素为矩形的高情况下矩形最大面积,确定左右边界
class Solution {
public:
int largestRectangleArea(vector<int>& heights) {
heights.push_back(0);
int sum = 0;
int n = heights.size();
stack<int>stk;
for(int i = 0; i < n; i++) {
while(!stk.empty() && heights[stk.top()] > heights[i]) {
int h = heights[stk.top()];
stk.pop();
sum = max(sum, h * (stk.empty() ? i : i - stk.top() - 1));
}
stk.push(i);
}
return sum;
}
};implement-queue-using-stacks用栈实现队列
class MyQueue {
public:
stack<int>stk1;
stack<int>stk2;
/** Initialize your data structure here. */
MyQueue() {
}
/** Push element x to the back of queue. */
void push(int x) {
stk1.push(x);
}
/** Removes the element from in front of queue and returns that element. */
int pop() {
while(!stk1.empty()) {
stk2.push(stk1.top());
stk1.pop();
}
int w = stk2.top();
stk2.pop();
while(!stk2.empty()) {
stk1.push(stk2.top());
stk2.pop();
}
return w;
}
/** Get the front element. */
int peek() {
while(!stk1.empty()) {
stk2.push(stk1.top());
stk1.pop();
}
int w = stk2.top();
while(!stk2.empty()) {
stk1.push(stk2.top());
stk2.pop();
}
return w;
}
/** Returns whether the queue is empty. */
bool empty() {
return stk1.size() == 0;
}
};
/**
* Your MyQueue object will be instantiated and called as such:
* MyQueue* obj = new MyQueue();
* obj->push(x);
* int param_2 = obj->pop();
* int param_3 = obj->peek();
* bool param_4 = obj->empty();
*/01-mtrix01 矩阵
给定一个由 0 和 1 组成的矩阵,找出每个元素到最近的 0 的距离。 两个相邻元素间的距离为 1
BFS
struct node{
int x, y, z;
};
class Solution {
public:
int dir[4][2] = {1, 0, 0, 1, -1, 0, 0, -1};
vector<vector<int>> updateMatrix(vector<vector<int>>& matrix) {
queue<node>q;
int n = matrix.size();
int m = matrix[0].size();
vector<vector<int>> vis(n, vector<int>(m, 0));
vector<vector<int>> ret(n, vector<int>(m, 0));
for(int i = 0; i < n; i++) {
for(int j = 0; j < m; j ++) {
if(matrix[i][j] == 0) q.push({i, j, 0}), vis[i][j] = 1;
}
}
while(!q.empty()) {
node temp = q.front();
q.pop();
vis[temp.x][temp.y] = 1;
for(int i = 0; i < 4; i++) {
int dx = temp.x + dir[i][0];
int dy = temp.y + dir[i][1];
if(dx < 0 || dy < 0 || dx >= n || dy >= m || vis[dx][dy]) continue;
q.push(node{dx, dy, temp.z + 1});
ret[dx][dy] = temp.z + 1;
vis[dx][dy] = 1;
}
}
return ret;
}
};常见的二进制操作
-
基本操作
a = 0 ^ a = a ^ 0
0 = a ^ a
得知 a = a ^ b ^ b
-
交换两个数
a = a ^ b
b = a ^ b
a = a^ b
-
移除最后一个1
a = n & (n - 1)
-
获取最后一个1
diff = (n & (n - 1)) ^ n
或 diff = (diff & -diff)
single-number只出现一次的数字
给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。
class Solution {
public:
int singleNumber(vector<int>& nums) {
// 10 ^ 10 == 00
// 两个数异或就变成0
int size = nums.size();
for(int i = 1; i < size; i++) {
nums[0] ^= nums[i];
}
return nums[0];
}
};single-number-ii只出现一次的数字 II
给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现了三次。找出那个只出现了一次的元素。
- 解释下:假设有一个数为x,那么则有如下规律:
- 0 ^ x = x,
- x ^ x = 0;
- x & ~x = 0,
- x & ~0 =x;
-那么就是很好解释上面的代码了。一开始a = 0, b = 0;
- x第一次出现后,a = (a ^ x) & ~b的结果为 a = x, b = (b ^ x) & ~a的结果为此时因为a = x了,所以b = 0。
- x第二次出现:a = (a ^ x) & ~b, a = (x ^ x) & ~0, a = 0; b = (b ^ x) & ~a 化简, b = (0 ^ x) & ~0 ,b = x;
- x第三次出现:a = (a ^ x) & ~b, a = (0 ^ x) & ~x ,a = 0; b = (b ^ x) & ~a 化简, b = (x ^ x) & ~0 , b = 0;所以出现三次同一个数,a和b最终都变回了0.
- 只出现一次的数,按照上面x第一次出现的规律可知a = x, b = 0;因此最后返回a.
class Solution {
public:
int singleNumber(vector<int>& nums) {
int a = 0, b = 0;
for(auto num : nums) {
a = (a ^ num) & ~b;
b = (b ^ num) & ~a;
}
return a;
}
};single-number-iii只出现一次的数字 III
给定一个整数数组
nums,其中恰好有两个元素只出现一次,其余所有元素均出现两次。 找出只出现一次的那两个元素。
class Solution {
public:
vector<int> singleNumber(vector<int>& nums) {
int diff = 0;
for(int i = 0; i < nums.size(); i++) {
diff ^= nums[i];
}
vector<int>ret;
ret.push_back(0);
ret.push_back(0);
diff = (diff&(diff - 1)) ^ diff;//最后一个1的位置// diff = (diff & -diff);
for(int i = 0; i < nums.size(); i++) {
if(diff & nums[i]) {//根据0的位置不同
ret[0] ^= nums[i];
} else {
ret[1] ^= nums[i];
}
}
return ret;
}
};number-of-1-bits位1的个数
编写一个函数,输入是一个无符号整数,返回其二进制表达式中数字位数为 ‘1’ 的个数(也被称为汉明重量)。
n & (n - 1)去除最一位1
class Solution {
public:
int hammingWeight(uint32_t n) {
int sum = 0;
while(n) {
n = n & (n - 1);
sum ++;
n >>= 1;
}
return sum;
}
};counting-bits比特位计数
给定一个非负整数 num。对于 0 ≤ i ≤ num 范围中的每个数字 i ,计算其二进制数中的 1 的数目并将它们作为数组返回。
class Solution {
public:
vector<int> countBits(int num) {
vector<int>ret(num + 1, 0);
for(int i = 1; i <= num; i++) {
ret[i] = ret[i & (i - 1)] + 1;//因为每个数之间差为1,所以可以用前面的树树计算后面的
}
return ret;
}
};reverse-bits颠倒二进制位
颠倒给定的 32 位无符号整数的二进制位。
class Solution {
public:
uint32_t reverseBits(uint32_t n) {
uint32_t w = 0;
int t = 31;
while(n) {
w += (n & 1) << t;//把最后一位取出来送给w
n >>= 1;//然后右一位
t --;
}
return w;
}
};bitwise-and-of-numbers-range数字范围按位与
给定范围 [m, n],其中 0 <= m <= n <= 2147483647,返回此范围内所有数字的按位与(包含 m, n 两端点)。
class Solution {
public:
int rangeBitwiseAnd(int m, int n) {
// m 5 1 0 1
// 6 1 1 0
// n 7 1 1 1
// 把可能包含0的全部右移变成
// m 5 1 0 0
// 6 1 0 0
// n 7 1 0 0
// 所以最后结果就是m<<count
int count = 0;
while(m != n) {
m >>= 1;
n >>= 1;
count ++;
}
return m<<count;
}
};
binary-search二分查找
给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。
class Solution {
public:
int search(vector<int>& nums, int target) {
int l = 0, r = nums.size() - 1;
while(l <= r) {
int mid = (l + r) >> 1;
if(nums[mid] > target) r = mid - 1;
else if(nums[mid] < target) l = mid + 1;
else return mid;
}
return -1;
}
};search-insert-position搜索插入位置
给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。
class Solution {
public:
int searchInsert(vector<int>& nums, int target) {
int l = 0, r = nums.size() - 1;
while(l <= r) {
int mid = (l + r) >> 1;
if(nums[mid] == target) {
return mid;
} else if(nums[mid] > target){
r = mid - 1;
} else {
l = mid + 1;
}
}
return l;
}
};search-a-2d-matrix搜索二维矩阵
编写一个高效的算法来判断 m x n 矩阵中,是否存在一个目标值。该矩阵具有如下特性:
- 每行中的整数从左到右按升序排列。
- 每行的第一个整数大于前一行的最后一个整数。
class Solution {
public:
bool searchMatrix(vector<vector<int>>& matrix, int target) {
if(matrix.size() == 0) return false;
int n = matrix.size();
int m = matrix[0].size();
int l = n - 1;
int r = 0;
while(l >= 0 && l < n && r >= 0 && r < m) {
if(matrix[l][r] > target) {
l --;
} else if(matrix[l][r] < target) {
r ++;
} else if(matrix[l][r] == target){
return true;
}
}
return false;
}
};first-bad-version第一个错误的版本
假设你有 n 个版本 [1, 2, ..., n],你想找出导致之后所有版本出错的第一个错误的版本。 你可以通过调用 bool isBadVersion(version) 接口来判断版本号 version 是否在单元测试中出错。实现一个函数来查找第一个错误的版本。你应该尽量减少对调用 API 的次数。
// The API isBadVersion is defined for you.
// bool isBadVersion(int version);
class Solution {
public:
int firstBadVersion(int n) {
long long l = 1, r = n;
while(l < r) {
long long mid = (l + r) >> 1;
if(isBadVersion(mid)) {
r = mid;
} else {
l = mid + 1;
}
}
return l;
}
};find-minimum-in-rotated-sorted-array寻找旋转排序数组中的最小值
假设按照升序排序的数组在预先未知的某个点上进行了旋转( 例如,数组 [0,1,2,4,5,6,7] 可能变为 [4,5,6,7,0,1,2] )。 请找出其中最小的元素。
class Solution {
public:
int findMin(vector<int>& nums) {
if(nums.size() == 0) return -1;
int l = 0, r = nums.size() - 1;
while(l + 1 < r) {
int mid = (l + r) >> 1;
if(nums[mid] <= nums[r]) {
r = mid;
} else {
l = mid;
}
}
if(nums[l] > nums[r]) {
return nums[r];
}
return nums[l];
}
};find-minimum-in-rotated-sorted-array-ii寻找旋转排序数组中的最小值 II
假设按照升序排序的数组在预先未知的某个点上进行了旋转 ( 例如,数组 [0,1,2,4,5,6,7] 可能变为 [4,5,6,7,0,1,2] )。 请找出其中最小的元素。(包含重复元素)
class Solution {
public:
int findMin(vector<int>& nums) {
if(nums.size() == 0) return -1;
int l = 0, r = nums.size() - 1;
while(l + 1 < r) {
while(l < r && nums[r] == nums[r - 1]) {//去除重复元素
r --;
}
while(l < r && nums[l] == nums[l + 1]) {//去除重复元素
l ++;
}
int mid = (l + r) >> 1;
if(nums[mid] <= nums[r]) {
r = mid;
} else {
l = mid;
}
}
if(nums[l] > nums[r]) {
return nums[r];
}
return nums[l];
}
};search-in-rotated-sorted-array搜索旋转排序数组
假设按照升序排序的数组在预先未知的某个点上进行了旋转。 ( 例如,数组 [0,1,2,4,5,6,7] 可能变为 [4,5,6,7,0,1,2] )。 搜索一个给定的目标值,如果数组中存在这个目标值,则返回它的索引,否则返回 -1 。 你可以假设数组中不存在重复的元素。
class Solution {
public:
int search(vector<int>& nums, int target) {
int l = 0, r = nums.size() - 1;
while(l + 1 < r) {
int mid = (l + r) >> 1;
if(nums[mid] == target) return mid;
if(nums[l] < nums[mid]) {
if(nums[l] <= target && target <= nums[mid]) {
r = mid;
} else {
l = mid;
}
} else if(nums[r] > nums[mid]){
if(nums[r] >= target && target >= nums[mid]) {
l = mid;
} else {
r = mid;
}
}
}
if(nums[l] == target) {
return l;
} else if(nums[r] == target) {
return r;
}
return -1;
}
};search-in-rotated-sorted-array-ii搜索旋转排序数组 II
假设按照升序排序的数组在预先未知的某个点上进行了旋转。 ( 例如,数组 [0,0,1,2,2,5,6] 可能变为 [2,5,6,0,0,1,2] )。 编写一个函数来判断给定的目标值是否存在于数组中。若存在返回 true,否则返回 false。(包含重复元素)
class Solution {
public:
bool search(vector<int>& nums, int target) {
if(nums.size() == 0) return false;
int l = 0, r = nums.size() - 1;
while(l + 1 < r) {
int mid = (l + r) >> 1;
while(l < r && nums[r] == nums[r - 1]) {//去重
r --;
}
while(l < r && nums[l] == nums[l + 1]) {
l ++;
}
if(nums[mid] == target) return true;
if(nums[mid] > nums[l]) {
if(nums[l] <= target && target <= nums[mid]) {
r = mid;
} else {
l = mid;
}
} else if(nums[r] > nums[mid]){
if(nums[r] >= target && target >= nums[mid]) {
l = mid;
} else {
r = mid;
}
}
}
if(nums[l] == target || nums[r] == target) {
return true;
}
return false;
}
};先从一道题目开始~
如题 triangle
给定一个三角形,找出自顶向下的最小路径和。每一步只能移动到下一行中相邻的结点上。
例如,给定三角形:
[
[2],
[3,4],
[6,5,7],
[4,1,8,3]
]自顶向下的最小路径和为 11(即,2 + 3 + 5 + 1 = 11)。
使用 DFS(遍历 或者 分治法)
遍历

分治法

优化 DFS,缓存已经被计算的值(称为:记忆化搜索 本质上:动态规划)

动态规划就是把大问题变成小问题,并解决了小问题重复计算的方法称为动态规划
动态规划和 DFS 区别
- 二叉树 子问题是没有交集,所以大部分二叉树都用递归或者分治法,即 DFS,就可以解决
- 像 triangle 这种是有重复走的情况,子问题是有交集,所以可以用动态规划来解决
动态规划,自底向上
class Solution {
public:
int minimumTotal(vector<vector<int>>& triangle) {
int n = triangle.size();
for(int i = n - 2; i >= 0; i--) {
for(int j = 0; j <= i; j++) {
triangle[i][j] = min(triangle[i + 1][j], triangle[i + 1][j + 1]) + triangle[i][j];
}
}
return triangle[0][0];
}
};满足两个条件
- 满足以下条件之一
- 求最大/最小值(Maximum/Minimum )
- 求是否可行(Yes/No )
- 求可行个数(Count(*) )
- 满足不能排序或者交换(Can not sort / swap )
- 状态 State
- 灵感,创造力,存储小规模问题的结果
- 方程 Function
- 状态之间的联系,怎么通过小的状态,来算大的状态
- 初始化 Intialization
- 最极限的小状态是什么, 起点
- 答案 Answer
- 最大的那个状态是什么,终点
- Matrix DP (10%)
- Sequence (40%)
- Two Sequences DP (40%)
- Backpack (10%)
注意点
- 贪心算法大多题目靠背答案,所以如果能用动态规划就尽量用动规,不用贪心算法
minimum-path-sum最小路径和
给定一个包含非负整数的 m x n 网格,请找出一条从左上角到右下角的路径,使得路径上的数字总和为最小。
class Solution {
public:
int minPathSum(vector<vector<int>>& grid) {
int n = grid.size();
int m = grid[0].size();
vector<vector<int>>f(n, vector<int>(m, 0));
for(int i = 0; i < n; i++) {
for(int j = 0; j < m; j++) {
if(i == 0 && j != 0) {
f[i][j] += f[i][j - 1] +grid[i][j];
} else if(j == 0 && i != 0) {
f[i][j] += f[i - 1][j] + grid[i][j];
} else if(i == 0 && j == 0) f[i][j] = grid[i][j];
else f[i][j] += min(f[i - 1][j], f[i][j - 1]) + grid[i][j];
}
}
return f[n - 1][m - 1];
}
};unique-paths不同路径
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为“Start” )。 机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为“Finish”)。 问总共有多少条不同的路径?
class Solution {
public:
int uniquePaths(int m, int n) {
vector<vector<int>>f(n, vector<int>(m, 1));
for(int i = 1; i < n; i++) {
for(int j = 1; j < m; j++) {
f[i][j] = f[i - 1][j] + f[i][j - 1];
}
}
return f[n - 1][m - 1];
}
};unique-paths-ii不同路径 II
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为“Start” )。 机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为“Finish”)。 问总共有多少条不同的路径? 现在考虑网格中有障碍物。那么从左上角到右下角将会有多少条不同的路径?
class Solution {
public:
int uniquePathsWithObstacles(vector<vector<int>>& obstacleGrid) {
if(obstacleGrid[0][0] == 1) return 0;
int n = obstacleGrid.size();
int m = obstacleGrid[0].size();
vector<vector<int>>f(n, vector<int>(m, 1));
for(int i = 1; i < n; i++) {
if(obstacleGrid[i][0] == 1 || f[i - 1][0] == 0) {
f[i][0] = 0;
}
}
for(int j = 1; j < m; j++) {
if(obstacleGrid[0][j] == 1 || f[0][j - 1] == 0) {
f[0][j] = 0;
}
}
for(int i = 1; i < n; i++) {
for(int j = 1; j < m; j++) {
if(obstacleGrid[i][j] == 1) {
f[i][j] = 0;
} else {
f[i][j] = f[i - 1][j] + f[i][j - 1];
}
}
}
return f[n - 1][m - 1];
}
};climbing-stairs爬楼梯
假设你正在爬楼梯。需要 n 阶你才能到达楼顶。
class Solution {
public:
int climbStairs(int n) {
if(n == 1 || n == 0) return n;
vector<int>f(n + 1, 0);
f[1] = 1;
f[2] = 2;
for(int i = 3; i <= n; i++) {
f[i] = f[i - 1] + f[i - 2];
}
return f[n];
}
};jump-game跳跃游戏
给定一个非负整数数组,你最初位于数组的第一个位置。 数组中的每个元素代表你在该位置可以跳跃的最大长度。 判断你是否能够到达最后一个位置。
class Solution {
public:
bool canJump(vector<int>& nums) {
int w = 0;
for(int i = 0; i < nums.size(); i++) {
if(i > w) return false;
w = max(w, i + nums[i]);
}
return true;
}
};jump-game-ii跳跃游戏 II
给定一个非负整数数组,你最初位于数组的第一个位置。 数组中的每个元素代表你在该位置可以跳跃的最大长度。 你的目标是使用最少的跳跃次数到达数组的最后一个位置。
class Solution {
public:
int jump(vector<int>& nums) {
int n = nums.size();
int end = 0;
int mmax = 0;
int res = 0;
for(int i = 0; i < n - 1; i ++) {
mmax = max(mmax, i + nums[i]);
if(end == i) {//更新点
end = mmax;
res ++;
}
}
return res;
}
};palindrome-partitioning-ii分割回文串 II
给定一个字符串 s,将 s 分割成一些子串,使每个子串都是回文串。 返回符合要求的最少分割次数。
class Solution {
public:
int minCut(string s) {
/*
dp[i] 记录的是到字符这个地方所切割的次数
*/
if(s.empty()) return 0;
int n = s.size();
vector<vector<bool> >P(n, vector<bool>(n, false));
vector<int>dp(n, 0);
for(int i = 0; i < n; i++) {
dp[i] = i;
for(int j = 0; j <= i; j++) {
if(s[i] == s[j] && (i - j < 2 || P[j + 1][i - 1])) {
// acba不行,P[j + 1][i- 1]记录最里层是否为回文串abbccba, s[i]=s[j],p[j + 1][- 1]=true此处的true是里层的s[i] = s[j]
P[j][i] = true;//标记为回文
dp[i] = j==0? 0 : min(dp[i], dp[j - 1] + 1);//前面切割的次数+1是本次切割的次数,然后记录一个最小的到此处
}
}
}
return dp[n - 1];
}
};longest-increasing-subsequence最长上升子序列
给定一个无序的整数数组,找到其中最长上升子序列的长度。
class Solution {
public:
int lengthOfLIS(vector<int>& nums) {
int n = nums.size();
if(n == 0) return 0;
vector<int>f(n, 1);
for(int i = 1; i < n; i++) {
for(int j = 0; j < i; j++) {
if(nums[i] > nums[j])f[i] = max(f[i], f[j] + 1);
}
}
int mmax = 0;
for(int i = 0; i < n; i++) {
mmax = max(mmax, f[i]);
}
return mmax;
}
};word-break单词拆分
给定一个非空字符串 s 和一个包含非空单词列表的字典 wordDict,判定 s 是否可以被空格拆分为一个或多个在字典中出现的单词。
未优化:
class Solution {
public:
bool wordBreak(string s, vector<string>& wordDict) {
vector<bool>dp(s.size() + 1, false);
unordered_set<string> m(wordDict.begin(), wordDict.end());
dp[0] = true;
for(int i = 1; i <= s.size(); i++) {
for(int j = 0; j < i; j++) {
if(dp[j] && m.find(s.substr(j, i - j)) != m.end()) {
dp[i] = true;
break;
}
}
}
return dp[s.size()];
}
};优化:
class Solution {
public:
bool wordBreak(string s, vector<string>& wordDict) {
vector<bool>dp(s.size() + 1, false);
unordered_set<string> m(wordDict.begin(), wordDict.end());
dp[0] = true;
int mmax = 0;
for(int i = 0; i < wordDict.size(); i++) {
mmax = max(mmax, (int)wordDict[i].size());
}
for(int i = 1; i <= s.size(); i++) {
for(int j = max(i - mmax, 0); j < i; j++) {//没必要每次都从0开始,i - mmax前都没用
if(dp[j] && m.find(s.substr(j, i - j)) != m.end()) {
dp[i] = true;
break;
}
}
}
return dp[s.size()];
}
};
常见处理方式是给 0 位置占位,这样处理问题时一视同仁,初始化则在原来基础上 length+1,返回结果 f[n]
- 状态可以为前 i 个
- 初始化 length+1
- 取值 index=i-1
- 返回值:
f[n]或者f[m][n]
longest-common-subsequence最长公共子序列
给定两个字符串 text1 和 text2,返回这两个字符串的最长公共子序列。 一个字符串的 子序列 是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删除任何字符)后组成的新字符串。 例如,"ace" 是 "abcde" 的子序列,但 "aec" 不是 "abcde" 的子序列。两个字符串的「公共子序列」是这两个字符串所共同拥有的子序列。
class Solution {
public:
int longestCommonSubsequence(string text1, string text2) {
// dp[i][j] a前i个和b前j个字符最长公共子序列
// dp[m+1][n+1]
// ' a d c e
// ' 0 0 0 0 0
// a 0 1 1 1 1
// c 0 1 1 2 1
//
int n = text1.size();
int m = text2.size();
vector<vector<int> >f(n + 1, vector<int>(m + 1, 0));
for(int i = 1; i <= n; i++) {
for(int j = 1; j <= m; j++) {
if(text1[i - 1] == text2[j - 1]) {
f[i][j] = f[i - 1][j - 1] + 1;
} else {
f[i][j] = max(f[i][j - 1], f[i - 1][j]);
}
}
}
return f[n][m];
}
};-
从 1 开始遍历到最大长度
-
索引需要减一
edit-distance编辑距离
给你两个单词 word1 和 word2,请你计算出将 word1 转换成 word2 所使用的最少操作数 你可以对一个单词进行如下三种操作: 插入一个字符 删除一个字符 替换一个字符

class Solution {
public:
int minDistance(string word1, string word2) {
int n = word1.size();
int m = word2.size();
vector<vector<int> >dp(n + 1, vector<int>(m + 1, 0));
for(int i = 1; i <= n; i++) {
dp[i][0] = i;
}
for(int j = 1; j <= m; j++) {
dp[0][j] = j;
}
for(int i = 1; i <= n; i++) {
for(int j = 1; j <= m; j++) {
if(word1[i - 1] == word2[j - 1]) {
dp[i][j] = dp[i - 1][j - 1];
} else {
dp[i][j] = min(min(dp[i - 1][j], dp[i][j - 1]), dp[i - 1][j - 1]) + 1;
}
}
}
return dp[n][m];
}
};思路:和上题很类似,相等则不需要操作,否则取删除、插入、替换最小操作次数的值+1
coin-change零钱兑换
给定不同面额的硬币 coins 和一个总金额 amount。编写一个函数来计算可以凑成总金额所需的最少的硬币个数。如果没有任何一种硬币组合能组成总金额,返回 -1。
思路:和其他 DP 不太一样,i 表示钱或者容量
class Solution {
public:
int coinChange(vector<int>& coins, int amount) {
vector<int>dp(amount + 1, 0);
int n = coins.size();
dp[0] = 0;
for(int i = 1; i <= amount; i++) {
dp[i] = 0x3f3f3f3f;
for(int j = 0; j < n; j++) {
if(coins[j] <= i) {
dp[i] = min(dp[i], dp[i - coins[j]] + 1);
}
}
}
return dp[amount] == 0x3f3f3f3f ? -1 : dp[amount];
}
};注意
dp[i-a[j]] 决策 a[j]是否参与
编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组
char[]的形式给出。
class Solution {
public:
void reverseString(vector<char>& s) {
/*for (int i = 0, j = s.size() - 1; i < j; i++, j--) {
swap(s[i], s[j]);
}*/
reverse(s.begin(), s.end());
return ;
}
};给定一个链表,两两交换其中相邻的节点,并返回交换后的链表。 你不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode() : val(0), next(nullptr) {}
* ListNode(int x) : val(x), next(nullptr) {}
* ListNode(int x, ListNode *next) : val(x), next(next) {}
* };
*/
class Solution {
public:
ListNode* swapPairs(ListNode* head) {
if(head == NULL || head->next == NULL) return head;
ListNode *p, *q, ret;
p = &ret;
q = head;
while(q && q->next) {
p->next = q->next;
q->next = p->next->next;
p->next->next = q;
p = q;
q = q->next;
}
return ret.next;
}
};给定一个整数 n,生成所有由 1 ... n 为节点所组成的二叉搜索树。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<TreeNode*> generate(int start, int end) {
if(start > end) {
return {nullptr};
}
vector<TreeNode *> res;
for(int i = start; i <= end; i++) {
//递归生成左右子树
vector<TreeNode *>leftTrees = generate(start, i - 1);
vector<TreeNode *>rightTrees = generate(i + 1, end);
//合并左右子树返回
for(int j = 0; j < leftTrees.size(); j++) {
for(int k = 0; k < rightTrees.size(); k++) {
TreeNode *node = new TreeNode(i);
node->left = leftTrees[j];
node->right = rightTrees[k];
res.push_back(node);
}
}
}
return res;
}
vector<TreeNode*> generateTrees(int n) {
vector<TreeNode*>res;
if(n == 0) return res;
return generate(1, n);
}
};斐波那契数,通常用 F(n) 表示,形成的序列称为斐波那契数列。该数列由 0 和 1 开始,后面的每一项数字都是前面两项数字的和。也就是: F(0) = 0, F(1) = 1 F(N) = F(N - 1) + F(N - 2), 其中 N > 1. 给定 N,计算 F(N)。
class Solution {
public:
int f[150000];
int fib(int N) {
if(N < 2) return N;
if(f[N] != 0) return f[N];
int ret = fib(N - 1) + fib(N - 2);
f[N] = ret;
return ret;
}
};给定两个字符串 s1 和 s2,写一个函数来判断 s2 是否包含 s1 的排列。
class Solution {
public:
bool checkInclusion(string s1, string s2) {
//排除异常的边界情况,也限定了模式串的长度
if(s1.size() > s2.size()) return false;
//匹配采用的窗口大小为模式串大小
int windowSize = s1.size();
//模式串的字典:可以看作一种频率分布
vector<int>hashmap1(26, 0);
//动态更新的匹配窗口字典
//构建字典
vector<int>hashmap2(26, 0);
for(int i = 0; i < windowSize; i++) {
hashmap1[s1[i] - 'a']++;
hashmap2[s2[i] - 'a']++;
}
//对于每一轮滑动窗口查询,如果两个字典相等(频率分布一致),则命中
for(int i = windowSize; i < s2.size(); i++) {
//两个字典相等(频率分布一致)则命中
if(hashmap1 == hashmap2) return true;
//否则,向右滑动窗口,滑动窗口对于hash表的操作对应频率的增减
hashmap2[s2[i - windowSize] - 'a'] --;
hashmap2[s2[i] - 'a']++;
}
//整个算法采用左闭右开区间,因此最后还有一个窗口没有判断
return hashmap2 == hashmap1;
}
};给定一个字符串 s 和一个非空字符串 p,找到 s 中所有是 p 的字母异位词的子串,返回这些子串的起始索引。
class Solution {
public:
vector<int> findAnagrams(string s, string p) {
vector<int>res;
if(s.size() == 0) return res;
if(s.size() < p.size()) return res;
vector<int>hashmap1(26, 0);
int n = p.size();
vector<int>hashmap2(26, 0);
for(int i = 0; i < n; i++) {
hashmap1[p[i] - 'a']++;
hashmap2[s[i] - 'a']++;
}
for(int i = n; i < s.size(); i++) {
if(hashmap2 == hashmap1) res.push_back(i - n);
hashmap2[s[i - n] - 'a']--;
hashmap2[s[i] - 'a']++;
}
if(hashmap2 == hashmap1) {
res.push_back(s.size() - n);
}
return res;
}
};给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。 示例 1:
输入: "abcabcbb" 输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
// 滑动窗口核心点:1、右指针右移 2、根据题意收缩窗口 3、左指针右移更新窗口 4、根据题意计算结果
class Solution {
public:
int lengthOfLongestSubstring(string s) {
int ind[256] = {0};
int temp = 0;
int ans = 0;
for(int i = 0; s[i]; i++) {
temp += 1;
temp = min(temp, i + 1 - ind[s[i]]);//取最小值避开了中间存在重复值
ind[s[i]] = i + 1;
ans = max(ans, temp);
}
return ans;
}
};- 和双指针题目类似,更像双指针的升级版,滑动窗口核心点是维护一个窗口集,根据窗口集来进行处理
- 核心步骤
- right 右移
- 收缩
- left 右移
- 求结果
- 每个节点中的值必须大于(或等于)存储在其左侧子树中的任何值。
- 每个节点中的值必须小于(或等于)存储在其右子树中的任何值。
验证二叉搜索树
思路:中序遍历判断是否为递增
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
int pre = -(0x3f3f3f3f);
bool isValidBST(TreeNode* root) {
if(root != NULL) {
if(!isValidBST(root->left)) return false;
if(root->val <= pre) return false;
pre = root->val;
if(!isValidBST(root->right)) return false;
}
return true;
}
};给定二叉搜索树(BST)的根节点和要插入树中的值,将值插入二叉搜索树。 返回插入后二叉搜索树的根节点。 保证原始二叉搜索树中不存在新值。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
TreeNode* insertIntoBST(TreeNode* root, int val) {
if(root == NULL) return new TreeNode(val);
if(root->val < val) {
root->right = insertIntoBST(root->right, val);
}
if(root->val > val) {
root->left = insertIntoBST(root->left, val);
}
return root;
}
};给定一个二叉搜索树的根节点 root 和一个值 key,删除二叉搜索树中的 key 对应的节点,并保证二叉搜索树的性质不变。返回二叉搜索树(有可能被更新)的根节点的引用。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
TreeNode* deleteNode(TreeNode* root, int key) {
// 删除节点分为三种情况:
// 1、只有左节点 替换为右
// 2、只有右节点 替换为左
// 3、有左右子节点 左子节点连接到右边最左节点即可
if(root == NULL) return root;
if(root->val < key) {
root->right = deleteNode(root->right, key);
} else if(root->val > key) {
root->left = deleteNode(root->left, key);
} else {
if(root->left == NULL) {
return root->right;
} else if(root->right == NULL) {
return root->left;
} else {
TreeNode *cur = root->right;
// 一直向左找到最后一个左节点即可
while(cur->left != NULL) {
cur = cur->left;
}
cur->left = root->left;
return root->right;
}
}
return root;
}
};
给定一个二叉树,判断它是否是高度平衡的二叉树。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
int depth(TreeNode *root) {//查找子树深度
if(root == NULL) return 0;
int l = depth(root->left), r = depth(root->right);
return (l > r ? l : r) + 1;
}
bool isBalanced(TreeNode* root) {
if(root == NULL) return true;
int l = depth(root->left), r = depth(root->right);//左边深度,右边深度
if(abs(l - r) > 1) return false;
return isBalanced(root->left) && isBalanced(root->right);//左右是否都合法
}
};给定一组不含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集)。
class Solution {
public:
vector<vector<int>> subsets(vector<int>& nums) {//二进制法
vector<vector<int>>res;
int n = nums.size();
vector<int>w;
for(int i = 0; i < pow(2, n); i++) {
for(int j = 0; j < n; j++) {
if((i >> j) & 1) {
w.push_back(nums[j]);
}
}
res.push_back(w);
w.clear();
}
return res;
}
};给定一个可能包含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集)。说明:解集不能包含重复的子集。
class Solution {
public:
vector<vector<int>> subsetsWithDup(vector<int>& nums) {
set<vector<int>>res;
int n = nums.size();
vector<int>w;
for(int i = 0; i < pow(2, n); i++) {
for(int j = 0; j < n; j++) {
if((i >> j) & 1) {
w.push_back(nums[j]);
}
}
sort(w.begin(), w.end());
res.insert(w);
w.clear();
}
vector<vector<int>>ret;
for(auto i : res) {
ret.push_back(i);
}
return ret;
}
};给定一个 没有重复 数字的序列,返回其所有可能的全排列。
思路:需要记录已经选择过的元素,满足条件的结果才进行返回
class Solution {
public:
vector<vector<int>>ret;
void dfs(vector<int>& now, vector<int>& nums, vector<int>&check) {
if(now.size() == nums.size()) {
ret.push_back(now);
return;
}
for(int i = 0; i < nums.size(); i++) {
if(!check[i]) {
check[i] = true;
now.push_back(nums[i]);
dfs(now, nums, check);
check[i] = false;
now.pop_back();
}
}
}
vector<vector<int>> permute(vector<int>& nums) {
vector<int>a;
vector<int>check(nums.size() + 1, false);
dfs(a, nums, check);
return ret;
}
};给定一个可包含重复数字的序列,返回所有不重复的全排列。
class Solution {
public:
set<vector<int>>ret;
void dfs(vector<int>& now, vector<int>& nums, vector<int>&check) {
if(now.size() == nums.size()) {
ret.insert(now);
return;
}
for(int i = 0; i < nums.size(); i++) {
if(!check[i]) {
check[i] = true;
now.push_back(nums[i]);
dfs(now, nums, check);
check[i] = false;
now.pop_back();
}
}
}
vector<vector<int>> permuteUnique(vector<int>& nums) {
vector<int>a;
vector<int>check(nums.size() + 1, false);
dfs(a, nums, check);
vector<vector<int>>res;
for(auto i : ret) {
res.push_back(i);
}
return res;
}
};class Solution {
public:
vector<vector<int>> combinationSum(vector<int>& candidates, int target) {
vector<vector<int>> res;
vector<int>track;
sort(candidates.begin(), candidates.end());
dfs(res, track, candidates, target, 0, 0);
return res;
}
void dfs(vector<vector<int>> &res, vector<int>&track, vector<int>&candidates, int target, int lastnum, int sum) {
if(sum == target) {
res.push_back(track);
return;
}
for(int i = lastnum; i < candidates.size(); i++) {
if(sum + candidates[i] > target) break;
track.push_back(candidates[i]);
dfs(res, track, candidates, target, i, sum + candidates[i]);
track.pop_back();
}
}
};
class Solution {
public:
string s[10] = {"", "", "abc", "def", "ghi", "jkl", "mno", "pqrs", "tuv", "wxyz"};
vector<string>res;
string cur;
vector<string> letterCombinations(string digits) {
if(!digits.size()) return res;
DFS(digits);
return res;
}
void DFS(string digits) {
if(!digits.size()) {
res.push_back(cur);
} else {
char num = digits[0];
string letter = s[num - '0'];
for(int i = 0; i < letter.size(); i++) {
cur.push_back(letter[i]);
DFS(digits.substr(1));
cur.pop_back();
}
}
}
};class Solution {
public:
vector<vector<int>>res;
vector<int>temp;
bool isPalindome(string s) {
int i = 0, j = s.size() - 1;
while(i < j) {
if(s[i] != s[j]) {
return false;
}
i++;
j--;
}
return true;
}
void recursion(string s, int a, int b) {
if(a > b) {
res.push_back(temp);
return;
}
for(int i = 1; i <= b - a + 1; i++) {
if(isPalindome(s.substr(a, i))) {
temp.push_back(s.substr(a, i));
recursion(s, a + i, b);
temp.pop_back();
}
}
}
vector<vector<string>> partition(string s) {
recursion(s, 0, s.size() - 1);
return res;
}
};class Solution {
public:
vector<string>res;
vector<string> restoreIpAddresses(string s) {
if(s.size() > 12 || s.size() < 4) return {};
dfs(s, "", 0, 0);
return res;
}
void dfs(string &s, string cur, int depth, int start) {
if(depth == 4) {
if(cur.size() - 3 == s.size()) {//3是加了3个"."
res.push_back(cur);
}
return;
}
int num = 0;
string str = "";
for(int i = 1; i <= 3; i++) {
num = num * 10 + (s[start + i - 1] - '0');
if(num > 255 || (i > 1 && num < 10)){break;}//排除大于255和前导0
str += s[start + i - 1];
dfs(s, cur + str + (depth==3 ? "":"."), depth + 1, start + i);
}
}
};