There are several articles on ‘internet’ including large companies, showing their microservices using REST, this guide has how to show some good practices and standards so that you have a microservice architecture that is the best possible, totally decoupled and scalable.
- What not to do
- HTTP Vs Broker
- Definition of microservices
- Publish-subscriber Pattern
- Choosing Message Broker
- Comparisons Between Message Broker
- What is the API Gateway pattern?
- What's BFF ?
- Service registry Pattern
- Deploy
I'm pretty sure that when you were sold the vision of microservices you weren't also sold the idea wasting time and CPU resources parsing an object, to text, only to collect it on the other side as text and back to an object. But if you're using REST for communication between micro-services, that's most likely what you're doing. It's slow. Sure in human time a few milliseconds aren't that bad, but when you do this several times for each interaction an end user makes, and do it thousands or millions of times a day, it really builds up and takes a toll. It's slow because it wasn't designed to be used thousands or millions of times a day, it was designed to be used once during a single API call at the edge of your system and to an external system that is not in your control.
Mahmoud Swehli
The biggest controversy revolves around REST communication, being the most used because it is simpler and does not require a deep technical knowledge about communication.
However, this practice brings big problems with the increase in the flow of the application.
Let's see which ones.
Microservice architecture has become the de facto choice for modern application development. As the name suggests, Microservice architecture is an approach to building a server application as a set of small services. With the wide adoption of trending architecture, there are lots of challenges to deal with small service as it doesn’t suggest common standards and patterns. The implementation depends on team maturity and business requirements. Architecture becomes more mature and independent as the team faces the problems over time.
Rajesh Khadka
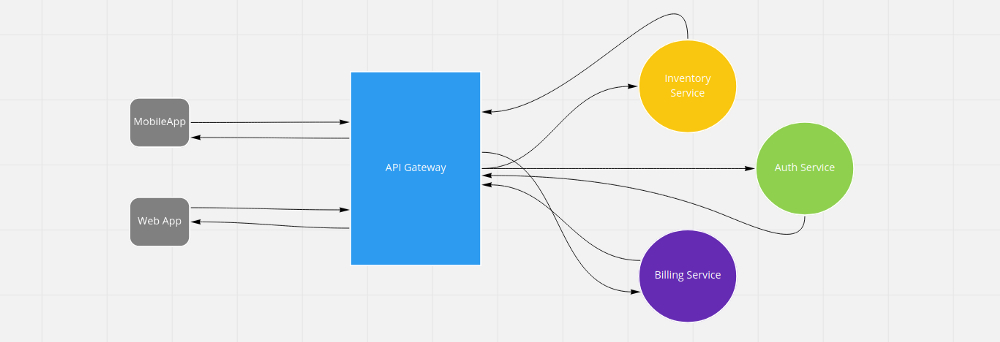
The microservice's architecture, aims to have several services communicating with the client using the API Gateway design pattern, the most used today for this approach.
When using HTTP this is making a synchronous request which is blocking the client until the response is returned, this in the short term, does not make much difference, but in the long term with the increase in requests the response will become increasingly slower.
Due to the popularity of RESTful services today, I see many companies falling into the trap of using REST as an “all-in-one” tool. Certainly, some of this popularity is due to the power REST provides based on its own merits. Developers are also used to designing applications with synchronous request/reply since APIs and Databases have trained developers to invoke a method and expect an immediate response.
In fact, Martin Thomson once said, “Synchronous communication is the crystal meth of distributed software” because it feels good at the time but in the long run is bad for you. This over reliance on the use of REST and synchronous patterns have negative consequences that apply primarily to the communication between microservice within the enterprise and that in some cases are at odds with the principles of proper microservice architecture:
When invoking a REST service, your service is blocked waiting for a response. This hurts application performance because this thread could be processing other requests. Think of it this way: What if a bartender took a drink order, made the cocktail and waited patiently for the patron to finish the drink before moving on to the next customer? That customer would have a great experience, but all of the other customers would be thirsty and quite unhappy. The bar could add additional bartenders, but would need one for each customer. Obviously, it would be expensive for the bar, and impossible to scale up and down as patrons came and went. In many ways, these same challenges occur when threads are blocked in applications waiting for RESTful services to respond. Threads are expensive and difficult to manage, much like bartenders!
When having a monolithic app, you use a load balancer for balance charge in pods. But you can't load the balance for each feature.

For scaling a monolithic application, you can update the replication number

But our app is slow in some features , that way every application is slow. To resolve it, we'll alter to small services.

Now we can scale for each feature

It is essential to keep in your mind that each microservice must have only one functionality, to meet the following requirements
- easy maintenance
- simple code
- vertical and horizontal scalability
- small and objective codes
When any events occur in the services it may need to communicate with other services to complete the job. Publisher and subscriber model is an asynchronous pattern which reduces the coupling in the distributed system.
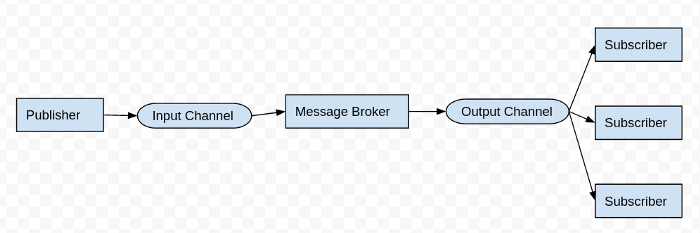
The publisher doesn’t need the subscriber to be up and available. It sends a message to the message queue. Nor does the publisher need to know about the subscriber application that needs to receive the message. Once the message is published in the specific topic the message gets broadcast in the channel to notify the subscribers. Subscribers consume the message in the queue.
The subscriber subscribes to a particular topic to get notified once the message is published in the respective topic. There may be many subscribers as client request grow
Channel used by the publisher to send message to the subscriber.
Channel used by the subscriber to consume the message.
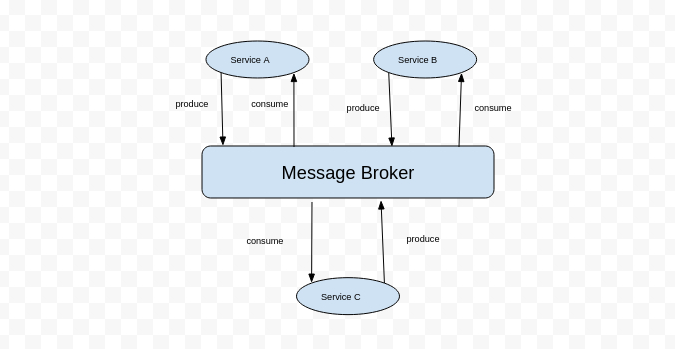
Message from the publisher is copied from the input channel to the output channel of interested subscribers, this mechanism is handled by the message broker. All these events occur asynchronously. There are many message broker and third-party services to facilitate the publish/subscribe protocol.
Among them, RabbitMQ, Amazon SQS, Redis, Apache Kafka, Amazon SQS, Google Cloud Pub/Sub are used widely.
CoteJs is a small library that allows us to communicate using TCP between various microservices in a very simple and fast way.
const cote = require('cote')
const UserService = new cote.Responder({name:'UserService'})
UserService.on('user.create',async (req,cb) =>{
})
UserService.on('user.update',async (req,cb) =>{
})
UserService.on('user.delete',async (req,cb) =>{
})
UserService.on('user.list',async (req,cb) =>{
})Choosing a message broker as per business requirements is the crucial portion of service communication. There are various parameters for choosing the right message broker.
Broker Scale: The number of messages sent per second in the system
Data Persistency: The ability to recover messages
Consumer capability: The broker capability to deal with one to one and one to many
It provides the flexibility to send messages up-to 50k per second. Message brokers can be configurable to both transient and persistent. The subscriber can be both one or many as per need. It follows the Advanced message queuing protocols. RabbitMQ is best suited for complex routing.
General programming languages are supported.
Kafka is an open-source stream-processing software platform developed by LinkedIn. It has high-throughput, low latency for handling real-time data feeds. It provides the data persistency as well and supports one to many subscribers only. It is best to fit to play with large amounts of data.
Using Nats as a transport, you will have a great speed in the delivery of messages, in addition to having the "replay" after sending a message from your producer your consumer can return the return, something that is not possible using Kafka as transport
you can use a TCP-based carrier in a very simple way. An example of this implementation is CoteJS, a library for microservices that uses TCP with 0 of considerably quick configuration and easy to use.
Redis is an in-memory data structure project implementing a distributed, in-memory key-value database with optional durability. It can send up to a million messages per second. It is best suited for the use case of short message retention and where persistence doesn’t matter. It supports one to many subscribers and provides extremely fast service.
It is similar to the Facade pattern from object-oriented design.
It provides the abstraction of the internal communication of microservices as it is tailored to each client.
It might have other responsibilities such as authentication, monitoring, load balancing, caching, request shaping, and static response handling.
It also communicates with microservices using a broker
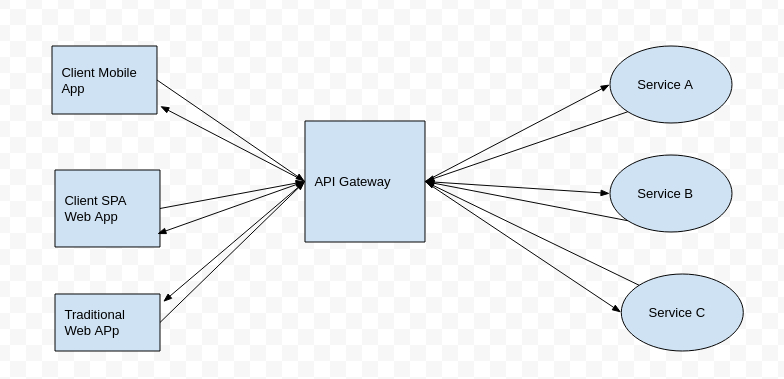
When splitting the API Gateway tier into multiple API Gateways, if your application has multiple client apps, that can be a primary pivot when identifying the multiple API Gateways types, so that you can have a different facade for the needs of each client app.
Using the broker concept, we have Polka - a very simple and fast library that can be used to create our gateway.
const polka = require('polka')
const route = polka()
const broker = require('../util/broker')
route
.get('/',(req,res) =>{
broker('user.list', res)
})
.post('/',(req,res) =>{
broker('user.create',res,req.body)
})
.put('/',(req,res) =>{
broker('user.update',res,req.body)
})
.delete('/:id',(req,res) =>{
broker('user.delete',res,req.params)
})BBF (Back For Front) is the microservice responsible for processing information, before it is consumed by the frontend or mobile
It allows us to have a better treatment of data by removing some business rules from our microservice, thus leaving it more decoupled from the application and facilitating its re-usability.
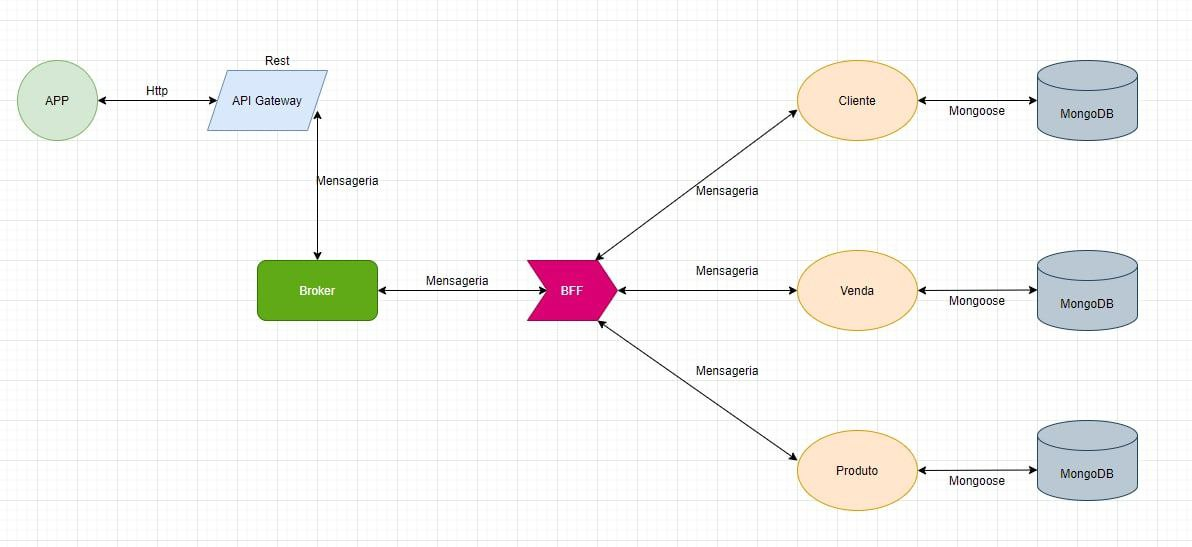
We can also use multiple BFFs, each of them for a specific microservice, so we have total isolation from the business rule of each microservice.
The disadvantage of this approach is that we will have 2 locations to provide maintenance, the BFF and the microservice itself.
** no pain no gain **
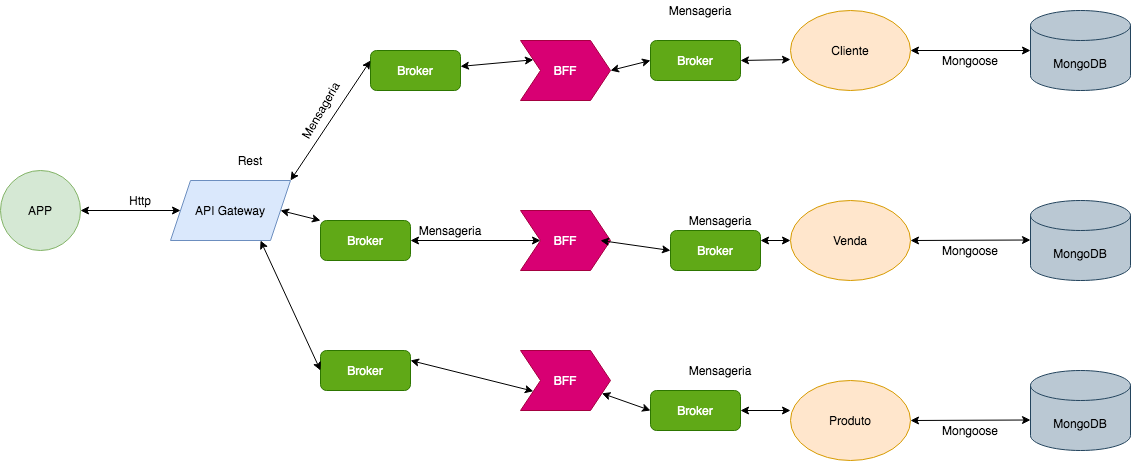
And we have the last approach which is to use the Api Gateway itself as a BFF, let's analyze this choice more closely
Api Gateway is a pattern, where you have all the microservices entries in one place, including the authentication treatment using the idea of middleware
BFF is also a pattern, where data processing is decoupled, so we have simpler microservices
It is also worth remembering that if we use BFF as our API Gateway, we will have to deal with each, response of each microservice, this in the short term does not have as much impact, but in the long term, maintenance can be difficult.
Service Registry is collective information of services along with related details including, the location of service and number of instances.
Since service registry is the database of services available, it must be highly available. There are two stages of interaction with Service Registry-
-
Registration — whenever a new service or service instance scales in/out, it needs to register/de-register itself with Service Registry.
-
Discovery — whenever client needs to interact with service, client would lookup for service details or discover service on Service Registry.
In this method, the microservice registers itself when it has just gone up, so we have information such as port, name, and endpoint.
An implementation that can be done in this model would be using Eureka
const Eureka = require('eureka-js-client').Eureka;
// example configuration
const client = new Eureka({
// application instance information
instance: {
app: 'jqservice',
hostName: 'localhost',
ipAddr: '127.0.0.1',
port: 8080,
vipAddress: 'jq.test.something.com',
dataCenterInfo: {
name: 'MyOwn',
},
},
eureka: {
// eureka server host / port
host: '192.168.99.100',
port: 32768,
},
});Discovery is very different, we have a client that monitors our microservices, and he will give us information about their status
There are several registration services, we will address here a very simple one to implement the Consul
{
"service": {
"name": "api-gateway",
"tags": [
"api-gateway"
],
"port": 3000,
"check": {
"args": [
"curl",
"localhost"
],
"interval": "10s"
}
}
}That way too, we will know the health of each microservice, using the Consul's own API, or using its UI.
When using Microservices, you need to be aware that all services have a separate job, so you have to make a container for each service. This allows you to, scale one service at a time.
When you use a service separately, you may use different servers. Example: to have a service on AWS and another service on Heruko and API gateway on GCP. Remember that all communications are done through messaging.
communication-over-microservices