LSTM FCN models, from the paper LSTM Fully Convolutional Networks for Time Series Classification, augment the fast classification performance of Temporal Convolutional layers with the precise classification of Long Short Term Memory Recurrent Neural Networks.
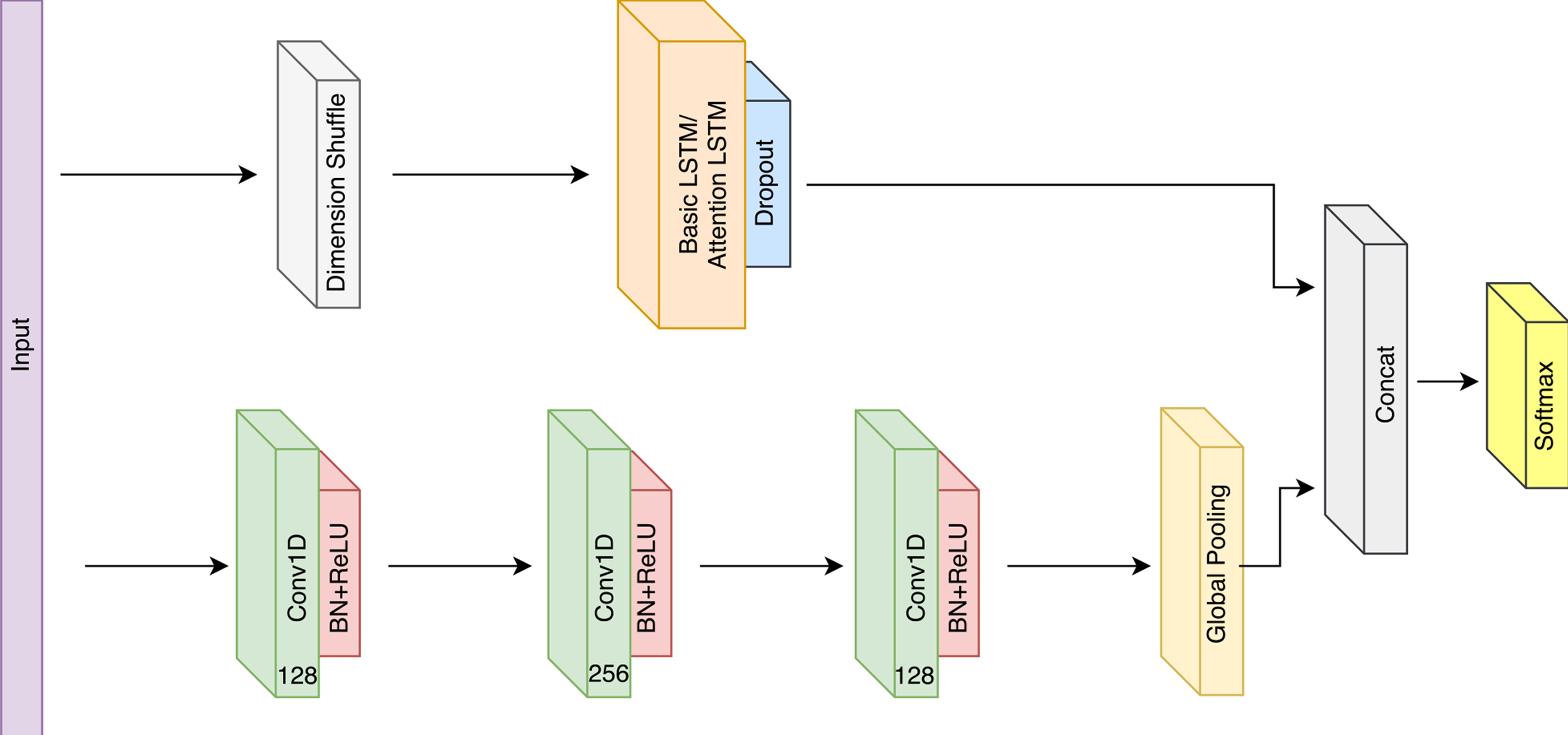
General LSTM-FCNs are high performance models for univariate datasets. However, on multivariate datasets, we find that their performance is not optimal if applied directly. Therefore, we introduce Multivariate LSTM-FCN (MLSTM-FCN) for such datasets.
Paper: Multivariate LSTM-FCNs for Time Series Classification
Repository: MLSTM-FCN
Download the repository and apply pip install -r requirements.txt to install the required libraries.
Keras with the Tensorflow backend has been used for the development of the models, and there is currently no support for Theano or CNTK backends. The weights have not been tested with those backends.
The data can be obtained as a zip file from here - http://www.cs.ucr.edu/~eamonn/time_series_data/
Extract that into some folder and it will give 85 different folders. Copy paste the util script extract_all_datasets.py to this folder and run it to get a single folder _data with all 85 datasets extracted. Cut-paste these files into the Data directory.
Note : The input to the Input layer of all models will be pre-shuffled to be in the shape (Batchsize, 1, Number of timesteps), and the input will be shuffled again before being applied to the CNNs (to obtain the correct shape (Batchsize, Number of timesteps, 1)). This is in contrast to the paper where the input is of the shape (Batchsize, Number of timesteps, 1) and the shuffle operation is applied before the LSTM to obtain the input shape (Batchsize, 1, Number of timesteps). These operations are equivalent.
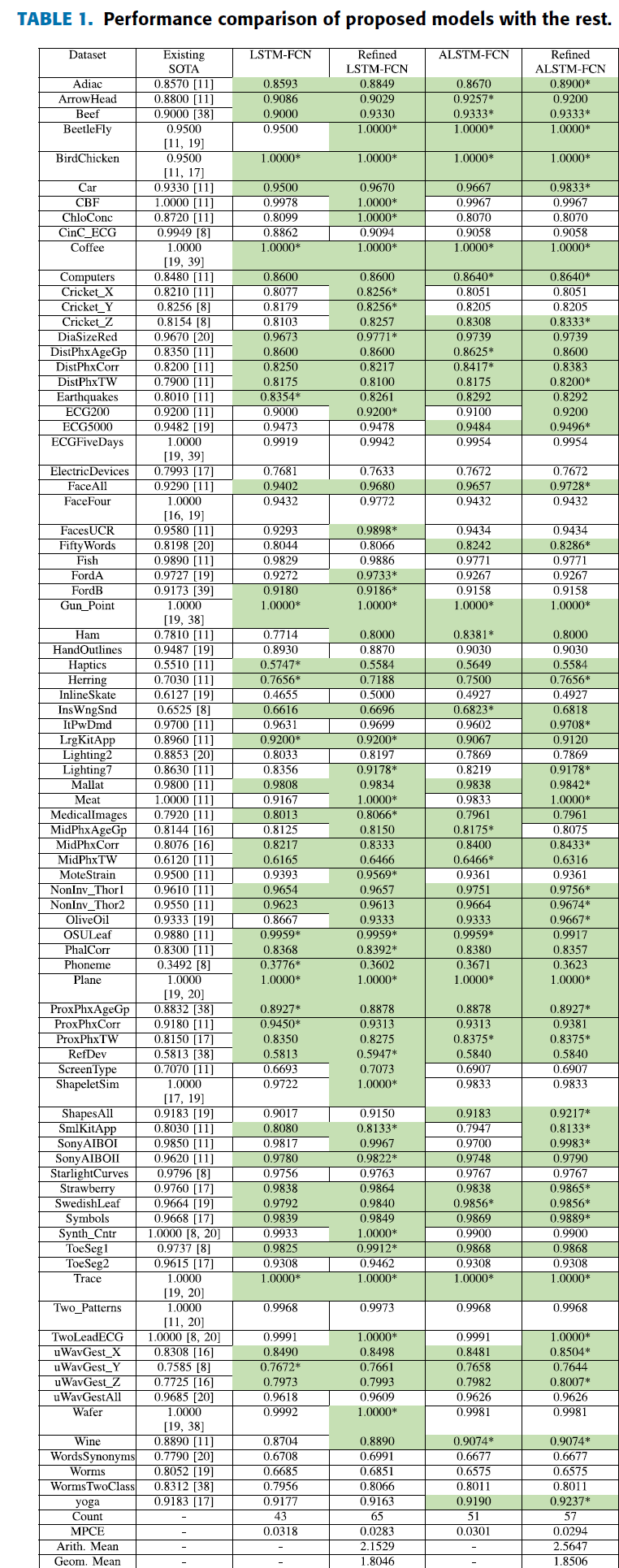
All 85 UCR datasets can be evaluated with the provided code and weight files. Refer to the weights directory for clarification.
There is 1 script file for each UCR dataset, and 4 major sections in the code. For each of these code files, please keep the line below uncommented.
- To use the LSTM FCN model :
model = generate_model() - To use the ALSTM FCN model :
model = generate_model_2()
To train the a model, uncomment the line below and execute the script. Note that '???????' will already be provided, so there is no need to replace it. It refers to the prefix of the saved weight file. Also, if weights are already provided, this operation will overwrite those weights.
train_model(model, DATASET_INDEX, dataset_prefix='???????', epochs=2000, batch_size=128)
To evaluate the performance of the model, simply execute the script with the below line uncommented.
evaluate_model(model, DATASET_INDEX, dataset_prefix='???????', batch_size=128)
To visualize the context vector of the Attention LSTM module, please ensure that the model being generated is the Attention LSTM FCN model by setting model = generate_model_2(). Then, uncomment the lines below and execute the script.
This will generate a sample from each class of that dataset and plot the train test sequence, along with the context sequence of each.
visualize_context_vector(model, DATASET_INDEX, dataset_prefix='???????', visualize_sequence=True,
visualize_classwise=True, limit=1)
To generate the context over all samples in the dataset, modify limit=None. Setting visualize_classwise=False is also recommended to speed up the computation. Note that for the larger datasets, generation of the image may take exorbitant amounts of time, and the output may not be pleasant. We suggest visualizing classwise with 1 sample per class instead, as shown above.
visualize_context_vector(model, DATASET_INDEX, dataset_prefix='???????', visualize_sequence=True,
visualize_classwise=False, limit=None)
To visualize the class activation map of the final convolution layer, uncomment the below line and execute the script. The class of the input signal being visualized can be changed by changing the class_id from (0 to NumberOfClasses-1).
visualize_cam(model, DATASET_INDEX, dataset_prefix='???????', class_id=0)
@misc{Karim_Majumdar2017,
Author = {Fazle Karim and Somshubra Majumdar and Houshang Darabi and Shun Chen},
Title = {LSTM Fully Convolutional Networks for Time Series Classification},
Year = {2017},
Eprint = {arXiv:1709.05206},
}