This is fork was made to have this package available on meteor 1.10.2, remove the coffescrip dependency and use the npm version of later.js. It will be maintained by me as I need it for my project. I'm happy to take a look at your contribution if you send me a PR.
job-collection is a powerful and easy to use job manager designed and built for Meteor.js.
It solves the following problems (and more):
- Schedule jobs to run (and repeat) in the future, persisting across server restarts
- Create repeating jobs with complex schedules using Later.js. See demo here
- Move work out of Meteor's single threaded event-loop
- Enable work on computationally expensive jobs to run anywhere, on any number of machines
- Track jobs and their progress, and automatically retry failed jobs
- Easily build an admin UI to manage all of the above using Meteor's reactivity and UI goodness
A live demo of job-collection is at https://jcplayground.meteorapp.com.
Source code for this demo app is at meteor-job-collection-playground
Source code for a plain node.js worker for the demo app is at meteor-job-collection-playground-worker
- Added
errorCallbackoption toprocessJobs(). This gives workers a way to log network and other errors and do something other than write them toconsole.error(the default and previous behavior). - Progress information is now preserved in the job document on 'done' or 'fail', previously it was set to hard coded values.
A complete list of changes can be found in the HISTORY file.
- Quick example
- Design
- Installation
- Use
- JobCollection API
- Job API
- JobQueue API
- Job document data models
- DDP Method reference
- Zombie jobs
The code snippets below show a Meteor server that creates a JobCollection, Meteor client code that
subscribes to it and creates a new job, and a pure node.js program that can run anywhere and work
on such jobs.
///////////////////
// Server
if (Meteor.isServer) {
var myJobs = new JobCollection('myJobQueue');
myJobs.allow({
// Grant full permission to any authenticated user
admin: function (userId, method, params) {
return (userId ? true : false);
}
});
Meteor.startup(function () {
// Normal Meteor publish call, the server always
// controls what each client can see
Meteor.publish('allJobs', function () {
return myJobs.find({});
});
// Start the myJobs queue running
return myJobs.startJobServer();
});
}Alright, the server is set-up and running, now let's add some client code to create/manage a job.
///////////////////
// Client
if (Meteor.isClient) {
var myJobs = new JobCollection('myJobQueue');
Meteor.startup(function () {
Meteor.subscribe('allJobs');
// Because of the server settings, the code below will
// only work if the client is authenticated.
// On the server, all of it would run unconditionally.
// Create a job:
var job = new Job(myJobs, 'sendEmail', // type of job
// Job data that you define, including anything the job
// needs to complete. May contain links to files, etc...
{
address: '[email protected]',
subject: 'Critical rainbow hair shortage',
message: 'LOL; JK, KThxBye.'
}
);
// Set some properties of the job and then submit it
job.priority('normal')
.retry({ retries: 5,
wait: 15*60*1000 }) // 15 minutes between attempts
.delay(60*60*1000) // Wait an hour before first try
.save(); // Commit it to the server
// Now that it's saved, this job will appear as a document
// in the myJobs Collection, and will reactively update as
// its status changes, etc.
// Any job document from myJobs can be turned into a Job object
job = new Job(myJobs, myJobs.findOne({}));
// Or a job can be fetched from the server by _id
myJobs.getJob(_id, function (err, job) {
// If successful, job is a Job object corresponding to _id
// With a job object, you can remotely control the
// job's status (subject to server allow/deny rules)
// Here are some examples:
job.pause();
job.cancel();
job.remove();
// etc...
});
});
}Q: Okay, that's cool, but where does the actual work get done?
A: Anywhere you want!
job-collection is extremely flexible in where the work can get done; from workers that only run on a single Meteor server to hundreds of node.js workers running on a cluster or in the cloud. Work can also be done on other Meteor servers (different from the one hosting the Job collection), or in some cases it can be done within properly authenticated Meteor clients!
Below is a pure node.js program that can obtain jobs from the server above and "get 'em done". Powerfully, this can be run anywhere that has node.js and can connect to the server. The secret sauce here is the meteor-job npm package, which is fully interoperable with job-collection.
NOTE! Worker code very similar to what is shown below (without all of the DDP setup) can also run
on the Meteor server or even in a Meteor client. Everything before the call to Job.processJobs()
is just code to connect and authenticate a pure node.js script with a Meteor server.
///////////////////
// node.js Worker
var DDP = require('ddp');
var DDPlogin = require('ddp-login');
var Job = require('meteor-job');
// `Job` here has essentially the same API as JobCollection on Meteor.
// In fact, job-collection is built on top of the 'meteor-job' npm package!
// Setup the DDP connection
var ddp = new DDP({
host: "meteor.mydomain.com",
port: 3000,
use_ejson: true
});
// Connect Job with this DDP session
Job.setDDP(ddp);
// Open the DDP connection
ddp.connect(function (err) {
if (err) throw err;
// Call below will prompt for email/password if an
// authToken isn't available in the process environment
DDPlogin(ddp, function (err, token) {
if (err) throw err;
// We're in!
// Create a worker to get sendMail jobs from 'myJobQueue'
// This will keep running indefinitely, obtaining new work
// from the server whenever it is available.
// Note: If this worker was running within the Meteor environment,
// Then only the call below is necessary to setup a worker!
// However in that case processJobs is a method on the JobCollection
// object, and not Job.
var workers = Job.processJobs('myJobQueue', 'sendEmail',
function (job, cb) {
// This will only be called if a
// 'sendEmail' job is obtained
var email = job.data; // Only one email per job
sendEmail(email.address, email.subject, email.message,
function(err) {
if (err) {
job.log("Sending failed with error" + err,
{level: 'warning'});
job.fail("" + err);
} else {
job.done();
}
// Be sure to invoke the callback
// when work on this job has finished
cb();
}
);
}
);
});
});The design of job-collection is heavily influenced by Kue and to a lesser extent by the [Maui Cluster Scheduler] (https://en.wikipedia.org/wiki/Maui_Cluster_Scheduler). However, unlike Kue's use of Redis Pub/Sub and an HTTP API, job-collection uses MongoDB, Meteor, and Meteor's DDP protocol to provide persistence, reactivity, and secure remote access.
As the name implies, a JobCollection looks and acts like a Meteor Collection because under the
hood it actually is one. However, other than .find() and .findOne(), most accesses to a
JobCollection happen via the easy to use API on Job objects. Most Job API calls are
transformed internally to Meteor Method calls. This is
cool because the underlying Job class is implemented as pure Javascript that can run in both the
Meteor server and client environments, and most significantly as pure node.js code running
independently from Meteor (as shown in the example code above).
To add to your project, run:
meteor add simonsimcity:job-collection
The package exposes a global object JobCollection on both client and server.
To run tests (using Meteor meteortesting:mocha) run from within the packages/job-collection subdirectory:
meteor test-packages ./ --driver-package meteortesting:mocha
Or run the meteor-app this repository contains:
npm run test
# Logical OR was added because some tests currently fail.
npm run coverage || npm run coverage:html
In case you ran the last line in your shell, you can find the coverage report in the .coverage/lcov-report folder.
A basic sample application that implements a basic image gallery with upload/download support and automatic generation of thumbnail images is available. It also implements a basic job manager UI that allows control of both individual jobs and changes to the entire collection at once. It is available here: https://github.com/vsivsi/meteor-file-job-sample-app
job-collections are backed by Meteor Collections and may be
used in similar ways. .find() and .findOne() work as you would expect and are fully reactive on
the client just as with a normal collection.
Other than the find methods mentioned above, interactions with a job collection occur using the
JobCollection, Job and JobQueue APIs documented below. The Job document model used in a job
collection is fully specified, maintained and enforced by the APIs.
Meteor clients are automatically denied permission to directly insert, update or remove jobs
from a job collection. To accomplish these types of tasks, a client must use the provided APIs,
subject to permissions set by specific allow/deny rules on the job collection. Servers retain access
to the standard insert, update or remove methods, but should avoid using them unless
absolutely necessary, favoring the job collection APIs to perform various tasks.
It is also possible (and highly useful!) to write your own clients outside of Meteor as vanilla
node.js programs using the meteor-job npm package,
which is actually used by job-collection internally, and implements essentially identical
functionality via the same interfaces.
Securing a job collection is done using mechanisms that will be familiar to anyone who has used the
Meteor publish and subscribe mechanism and
Meteor Collection allow/deny rules.
For a client to have access to perform find() operations on a job collection, the server must
publish the collection and the client must subscribe to it. This works identically to normal Meteor
collections.
Compared to vanilla Meteor collections, job-collections have a different set of remote methods with
specific security implications. Where the allow/deny methods on a Meteor collection take functions
to grant permission for insert, update and remove, job-collection has more functionality to
secure and configure.
There are currently over a dozen Meteor methods defined by each job-collection. In many cases it
will be most convenient to write allow/deny rules to one of the four predefined permission groups:
admin, manager, creator and worker. These defined roles separate security concerns and
permit you to efficiently add allow/deny rules for groups of functions that various client
functionalities are likely to need. Where these roles do not meet the requirements of a specific
project, each remote method can also be individually secured with custom allow/deny rules.
The performance of job-collection will be almost entirely dependent on the speed of the MongoDB server it is hosted on. By default job-collection creates these indexes in the underlying database:
jc._ensureIndex({ type : 1, status : 1 });
jc._ensureIndex({ priority : 1, retryUntil : 1, after : 1 });If you anticipate having large job collections (ie. with over 1000 jobs at a time) and you will be doing custom queries on the database, you will want to create appropriate additional indexes to ensure that your application performs well.
Unless you do something to prevent it, completed and canceled jobs will accumulate in your database. In some scenarios this may be desirable, but if it's not, there are a few options to clean out old jobs from the database:
- Add a job cleaning job. This will take care of the most common use cases. It will allow you customize the logic to fit your specific needs. There's an example of a cleaning job in the "playground" sample app.
- Use events to remove jobs once they complete or are removed.
The server can easily log all activity (both successes and failures) on a job collection by passing
any valid node.js writable Stream to jc.setLogStream(writeStream). If you're just getting started try process.stdout to log to your console.
Looking for more control over the output? Define a listener on the jc.events call event to implement custom logging.
Creating a new JobCollection is similar to creating a new Meteor Collection. You simply specify a
name (which defaults to "queue"). On the server there are some additional methods you will
probably want to invoke on the returned object to configure it further.
options:
noCollectionSuffix-- Iftrue,'.jobs'won't be appended to the collection name. Default:false- In addition, JobCollection supports the same options as Meteor [Mongo.Collection] (http://docs.meteor.com/#/full/mongo_collection)
For security and simplicity the traditional client allow/deny rules for Meteor collections are
preset to deny all direct client insert, update and remove type operations on a
JobCollection. This effectively channels all remote activity through the JobCollection DDP
methods, which may be secured using allow/deny rules specific to JobCollection. See the
documentation for jc.allow() and jc.deny() for more information.
// the "new" is required
jc = new JobCollection('defaultJobCollection');You can log everything that happens to a job collection on the server by providing any valid
writable stream. You may only call this once, unless you first call jc.shutdown(), which will
automatically close the existing logStream.
// Log everything to stdout
jc.setLogStream(process.stdout);jc.logConsole = false // Default. Do not log method calls to the client consolejc.promote() may be called at any time to change the polling rate. job-collection must poll for
this operation because it is time that is changing, not the contents of the database, so there are
no database updates to listen for.
jc.promote(15*1000); // Default: 15 secondsNote: if you are running multiple Meteor instances that share access to a single job collection, you
can set the time each instance waits to promote to N * milliseconds, where N is the number of
Meteor instances. The instances will each take turns promoting jobs at 1/Nth of the desired rate.
By default no remote operations are allowed, and in this configuration job-collection exists only as a server-side service; with the creation, management and execution of all jobs dependent on server-side Meteor code.
The opposite extreme is to allow any remote client to perform any action. Obviously this is totally insecure, but is perhaps valuable for early development stages on a local firewalled network.
// Allow any remote client (Meteor client or
// node.js application) to perform any action
jc.allow({
// The "admin" below represents
// the grouping of all remote methods
admin: function (userId, method, params) {
return true;
}
});If this seems a little reckless (and it should), then here is how you can grant admin rights specifically to an single authenticated Meteor userId:
// Allow only the authenticated "admin user" to perform any action
jc.allow({
// Assume "adminUserId" contains the Meteor
// userId string of an admin super-user.
// The array below is assumed to be an array of userIds
admin: [ adminUserId ]
});
// The array notation in the above code is a shortcut for:
var adminUsers = [ adminUserId ];
jc.allow({
// Assume "adminUserId" contains the Meteor
// userId string of an admin super-user.
admin: function (userId, method, params) {
return (adminUsers.indexOf(userId) !== -1);
}
});In addition to the all-encompassing admin method group, there are three others:
manager-- Managers can remotely manage the job collection (e.g. cancelling jobs).creator-- Creators can remotely make new jobs to run.worker-- Workers can get Jobs to work on and can update their status as work proceeds.
All remote methods affecting the job collection fall into at least one of the four groups, and for each client-capable API method below, the group(s) it belongs to will be noted.
In addition to the above groups, it is possible to write allow/deny rules specific to each
job-collection DDP method. This is a more advanced feature and the intent is that the four
permission groups described above should be adequate for many applications. The DDP methods are
generally lower-level than the methods available on Job and they do not necessarily have a
one-to-one relationship. Here's an example of how to grant permission to create new "email" jobs to
a single userId:
// Assumes emailCreator contains a Meteor userId
jc.allow({
jobSave: function (userId, method, params) {
// params[0] is the new job doc
if ((userId === emailCreator) &&
(params[0].type === 'email')) {
return true;
}
return false;
}
});This call has the same semantic relationship with allow() as it does in Meteor collections. If any
deny rule is true, then permission for a remote method call will be denied, regardless of the status
of any other allow/deny rules. This is powerful and far reaching. For example, the following code
will turn off all remote access to a job collection (regardless of any other rules that may be in
force):
jc.deny({
// The "admin" below represents the
// grouping of all remote methods
admin: function (userId, method, params) {
return true;
}
});See the allow method above for more details.
options: No options currently defined
callback(error, result) -- Result is true if successful.
jc.startJobServer(); // Callback is optionaloptions:
timeout: In ms, how long until the server forcibly fails all still running jobs. Default:60*1000(1 minute)
callback(error, result) -- Result is true if successful.
jc.shutdownJobServer(
{
timeout: 60000
}
); // Callback is optionalSee documentation below for Job object API
Returns undefined if no such job exists.
id: -- The id of the job to get.
options:
getLog-- Iftrue, get the current log of the job. Default isfalseto save bandwidth since logs can be large.
callback(error, result) -- Optional only on Meteor Server with Fibers. result is a job object or
undefined
if (Meteor.isServer) {
// Note, the server could also use the callback pattern in the
// else clause below, but because of Fibers, it doesn't have to.
job = jc.getJob( // Job will be undefined or contain a Job object
id, // job id of type Match.Where(validId)
{
getLog: false // Default, don't include the log information
}
);
// Job may be undefined
} else {
jc.getJob(
id, // job id of type Match.Where(validId)
{
getLog: true // include the log information
},
function (err, job) {
if (job) {
// Here's your job
}
}
);
}getWork differs from getJob in that the status of the returned job(s) is now "running" in the
job collection, and it is the responsibility of the caller to eventually call job.done() or
job.fail() on each job. While running, a job will never be assigned to another worker. If
unreliable workers are an issue, it is straightforward to write a recurring server job that
identifies stale running jobs (whose workers have presumably died) and "autofail" them so that they
may be retried by another worker.
getWork implements a "pull" model, where each call will return an array of zero or more jobs
depending on availability of work and the value of maxJobs. See jc.processJobs() below for
a "push"-like model for automatically obtaining jobs to work on.
options:
maxJobs-- Maximum number of jobs to get. Default:1workTimeout-- When requesting work, tells the server to automatically fail the requested job(s) if more thanworkTimeoutmilliseconds elapses between updates (job.progress(),job.log()) from the worker, before processing on the job is completed. This is optional, and allows the server to automatically fail running jobs that may never finish because a worker went down or lost connectivity. Default:undefined
callback(error, result) -- Optional only on Meteor Server with Fibers. Result will be an array or
single value depending on options.maxJobs.
if (Meteor.isServer) {
// Note, the server could also use the callback pattern in the
// else clause below, but because of Fibers, it doesn't have to.
job = jc.getWork( // Job will be undefined or contain a Job object
'jobType', // type of job to request
{
maxJobs: 1 // Default, only get one job, returned as a single object
}
);
} else {
jc.getWork(
[ 'jobType1', 'jobType2' ] // can request multiple types in array
{
maxJobs: 5 // If maxJobs > 1, result is an array of jobs
},
function (err, jobs) {
// jobs contains between 0 and maxJobs jobs, depending
// on availability, job type is available as
if (job[0].type === 'jobType1') {
// Work on jobType1...
} else if (job[0].type === 'jobType2') {
// Work on jobType2...
} else {
// Sadness
}
}
);
}Asynchronously calls the worker function whenever jobs become available. See documentation below for
the JobQueue object API for methods on the returned jq object.
options:
concurrency-- Maximum number of async calls toworkerthat can be outstanding at a time. Default:1payload-- Maximum number of job objects to provide to each worker, Default:1Ifpayload > 1the first parameter toworkerwill be an array of job objects rather than a single job object.pollInterval-- How often to ask the remote job Collection for more work, in ms. Any falsy value for this parameter will completely disable polling (seeq.trigger()for an alternative way to drive the queue), and any truthy, non-numeric value will yield the default poll interval. Default:5000(5 seconds)prefetch-- How many extra jobs to request beyond the capacity of all workers (concurrency * payload) to compensate for latency getting more work.workTimeout-- When requesting work, tells the server to automatically fail the requested job(s) if more thanworkTimeoutmilliseconds elapses between updates (job.progress(),job.log()) from the worker, before processing on the job is completed. This is optional, and allows the server to automatically fail running jobs that may never finish because a worker went down or lost connectivity. Default:undefinedcallbackStrict-- Whentruethrows an error if a worker function calls its callback more than once. Even when false, a message will be written to stderr when multiple callbacks are invoked. Default:falseerrorCallback-- An optional function (ec(err)) that is called anytime an error occurs within the running JobQueue object. If not provided a default function is provided that writes errors toconsole.error.
worker(result, callback)
result-- either a single job object or an array of job objects depending onoptions.payload.callback-- must be eventually called exactly once whenjob.done()orjob.fail()has been called on all jobs in result.
queue = jc.processJobs(
// Type of job to request
// Can also be an array of job types
'jobType',
{
concurrency: 4,
payload: 1,
pollInterval: 5000,
prefetch: 1
},
function (job, callback) {
// Only called when there is a valid job
job.done();
callback();
}
);
// The job queue has methods...
queue.pause();
queue.resume();
queue.shutdown();This is much more efficient than calling jc.getJob() in a loop because it gets Jobs from the
server in batches.
It is valid to call jc.readyJobs() without ids (or with an empty array), in which case all 'waiting' jobs that are ready to run (any waiting period has passed) and have no dependencies will have their status changed to 'ready'. This call uses the force and time options just the same as job.ready(). This is much more efficient than calling job.ready() in a loop because it readies jobs in batches on the server.
This is much more efficient than calling job.pause() in a loop because it pauses jobs in batches
on the server.
This is much more efficient than calling job.resume() in a loop because it resumes jobs in batches
on the server.
This is much more efficient than calling job.cancel() in a loop because it cancels jobs in batches
on the server.
This is much more efficient than calling job.restart() in a loop because it restarts jobs in
batches on the server.
This is much more efficient than calling job.remove() in a loop because it removes jobs in
batches on the server.
jc.events is a node.js Event Emitter interface that can be used for custom logging, statistics generation, or any other server management.
The server emits two primary events in response to job-collection DDP method calls:
'call'-- success'error'-- error thrown
There are also individual events emitted for each DDP method, such as 'jobDone', regardless of success or error.
Event handlers are called with a message object using this schema:
{
error: // An error object, or null if no error
method: // The DDP method name
connection: // The Meteor connection object for the call, or undefined on server
userId: userId // The Meteor userID for the connection, null if unauthenticated, undefined on server
params: params, // Array of parameters passed to the DDP method
returnVal: ret // Return value from the DDP method, undefined if error != null
}A simple example to console.log successfully completed jobs:
jc.events.on('call', function (msg) {
if (msg.method === 'jobDone') {
console.log("Job" + msg.params[0] + "finished!");
}
});
// The above is equivalent to:
jc.events.on('jobDone', function (msg) {
if (!msg.error) {
console.log("Job" + msg.params[0] + "finished!");
}
});job = new Job(jc, 'jobType', { work: "to", be: "done" })
.retry({ retries: jc.forever }) // Default for .retry()
.repeat({ repeats: jc.forever }); // Default for .repeat()Constant value used to indicate a future Date that will never arrive
job = new Job(jc, 'jobQueue', 'jobType', { work: "to", be: "done" })
.retry({ until: Job.foreverDate }) // Default for .retry()
.repeat({ until: Job.foreverDate }); // Default for .repeat()This is the mapping between the valid string priorities accepted by job.priority() and the numeric
priority values it also uses.
jc.jobPriorities = { "low": 10, "normal": 0, "medium": -5,
"high": -10, "critical": -15 };These are the seven possible states that a job can be in, illustrated below along with the relationships between the main five states (disregarding "paused" and "cancelled"):
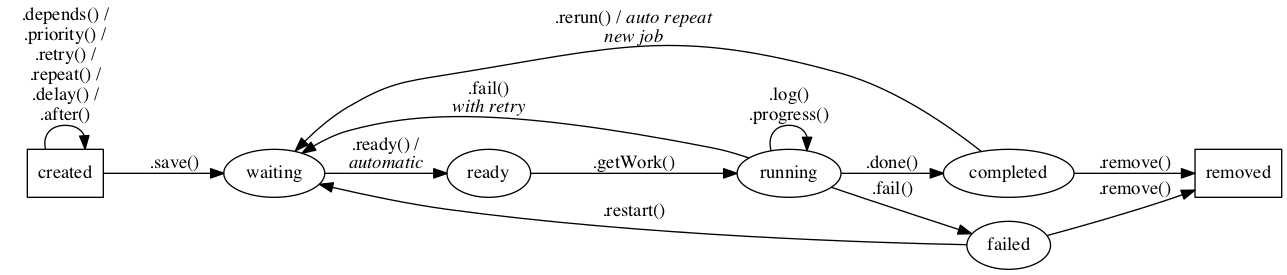
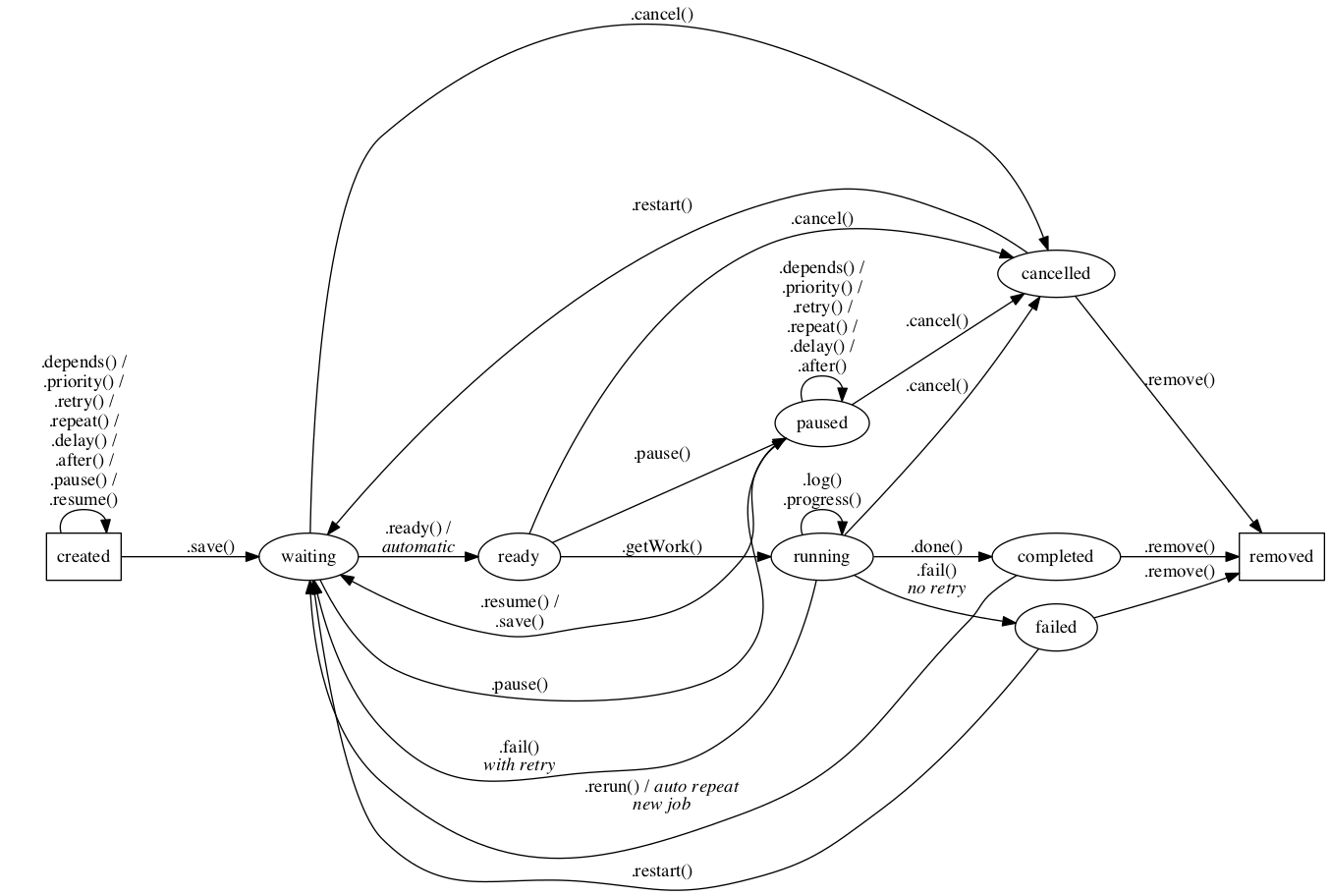
A somewhat more complicated-looking diagram showing the relationship between all seven states can be
seen here. If
this looks crazy, don't despair; the relationships added by .pause() and .cancel() are pretty
straightforward when viewed on their own. See jc.jobStatusCancellable and jc.jobStatusPausable
below for more info.
{kind=link}
jc.jobStatuses = [ 'waiting', 'paused', 'ready', 'running',
'failed', 'cancelled', 'completed' ];jc.jobRetryBackoffMethods = [ 'constant', 'exponential' ];If these look familiar, it's because they correspond to some of the Bootstrap [context] (http://getbootstrap.com/css/#helper-classes) and alert classes.
jc.jobLogLevels = [ 'info', 'success', 'warning', 'danger' ];To be cancellable, a job must currently be in one of these states. Below is a state diagram of the relationships of the "cancelled" state:
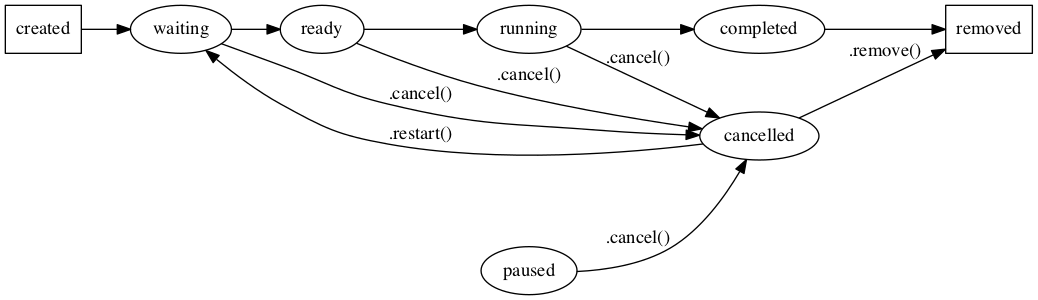
jc.jobStatusCancellable = [ 'running', 'ready', 'waiting', 'paused' ];These are the only states that may be paused. Below is a state diagram of the relationships of the "paused" state:
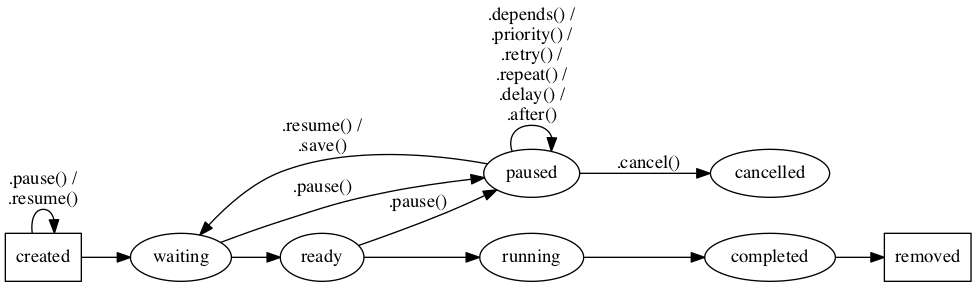 .
.
jc.jobStatusPausable = [ 'ready', 'waiting' ];Only jobs in one of these states may be removed. To remove any other job, simply cancel it first.
jc.jobStatusRemovable = [ 'cancelled', 'completed', 'failed' ];Only jobs in one of these terminal states may be restarted. Successfully completed jobs may be re-run using a different command (job.rerun()).
jc.jobStatusRestartable = [ 'cancelled', 'failed' ];These are all of valid job-collection DDP method names. These are also the names of the coinciding method-specific allow/deny rules. For more information about the DDP method API see the documentation on that topic near the end of this README.
jc.ddpMethods = [ 'startJobServer', 'shutdownJobServer', 'jobRemove',
'jobPause', 'jobResume', 'jobReady', 'jobCancel',
'jobRestart', 'jobSave', 'jobRerun', 'getWork', 'getJob',
'jobLog','jobProgress', 'jobDone', 'jobFail' ];These are the currently defined allow/deny method permission groups.
jc.ddpPermissionLevels = [ 'admin', 'manager', 'creator', 'worker' ];This is the mapping between job-collection DDP methods and permission groups.
jc.ddpMethodPermissions = {
'startJobServer': ['startJobServer', 'admin'],
'shutdownJobServer': ['shutdownJobServer', 'admin'],
'jobRemove': ['jobRemove', 'admin', 'manager'],
'jobPause': ['jobPause', 'admin', 'manager'],
'jobResume': ['jobResume', 'admin', 'manager'],
'jobReady': ['jobReady', 'admin', 'manager'],
'jobCancel': ['jobCancel', 'admin', 'manager'],
'jobRestart': ['jobRestart', 'admin', 'manager'],
'jobSave': ['jobSave', 'admin', 'creator'],
'jobRerun': ['jobRerun', 'admin', 'creator'],
'getWork': ['getWork', 'admin', 'worker'],
'getJob': ['getJob', 'admin', 'worker'],
'jobLog': [ 'jobLog', 'admin', 'worker'],
'jobProgress': ['jobProgress', 'admin', 'worker'],
'jobDone': ['jobDone', 'admin', 'worker'],
'jobFail': ['jobFail', 'admin', 'worker']
};Object that can be used with the Meteor check package to validate job documents
if (! Match.test(job.doc, jc.jobDocPattern)) {
// Something is wrong with this job's document!
}See job.repeat() for more information and a usage example.
Data should be reasonably small, if worker requires a lot of data (e.g. video, image or sound files), they should be included by reference (e.g. with a URL pointing to the data, and another to where the result should be saved).
job = new Job( // new is optional
jc, // JobCollection to use
'jobType', // type of the job
{ /* ... */ } // Data for the worker, any valid EJSON object
);Creates a new Job object. This is used in cases where a valid Job document is obtained from
another source, such as a database lookup.
job = new Job( // new is optional
jc, // JobCollection to use
{ /* ... */ } // any valid Job document
);New Job objects are also created using the following JobCollection API calls:
jc.getJob()-- Look-up aJobobject from the job collection by Idjc.getJobs()-- Look-up multipleJobobjects from a job collection using an array of Idsjc.getWork()-- Get aJobto work on. This changes the job status fromwaitingtorunningjc.processJobs()-- Call a worker callback function with aJobto work on when work is available
The methods below may be performed on Job objects regardless of their source. All Job methods
may be run on the client or server.
This job will not run until these jobs have successfully completed. Defaults to an empty array (no
dependencies). Returns job, so it is chainable. Calling job.depends() with a falsy value will clear any existing
dependencies for this job.
// job1 and job2 are Job objects,
// and must successfully complete before job will run
job.depends([job1, job2]);
// Clear any dependencies previously added on this job
job.depends();Added antecendent jobs must have already had .save() run on them, so they will have the _id attribute that
is used to form the dependency.
// Create a job:
var sendJob = new Job(myJobs, 'sendEmail', {
address: '[email protected]',
subject: 'Critical rainbow hair shortage',
message: 'LOL; JK, KThxBye.'
});
// Save it
sendJob.save();
// Assuming synchronous style with Fibers...
// archiveJob will not run until sendJob has
// successfully completed.
var archiveJob = new Job(myJobs, 'archiveEmail', {
emailRef: sendJob.data
}).depends([sendJob]).save();Note! Using depends() does not automatically pass any data from an antecedent job1 to a dependent job2. This is typically handled by including a reference in the data object for job2 that can be used by its worker to look up any results from job1 that may be required.
Can be integer numeric or one of Job.jobPriorities. Defaults to 'normal' priority, which is
priority 0. Returns job, so it is chainable.
job.priority('high'); // Maps to -10
job.priority(-10); // Same as aboveReturns job, so it is chainable.
options:
retries-- Number of times to retry a failing job. Default:Job.foreveruntil-- Keep retrying until thisDate, or until the number of retries is exhausted, whichever comes first. Default:Job.foreverDate. Note that if you specify a value foruntilon a repeating job, it will only apply to the first run of the job. Any repeated runs of the job will use the repeat'suntilvalue for all retries.wait-- Initial value for how long to wait between attempts, in ms. Default:300000(5 minutes)backoff-- Method to use in determining how to calculate wait value for each retry:'constant': Always delay retrying bywaitms. Default value.'exponential': Delay by twice as long for each subsequent retry, e.g.wait,2*wait,4*wait...
[options] may also be a non-negative integer, which is interpreted as { retries: [options] }
Note that the above stated defaults are those when .retry() is explicitly called. When a new job
is created, the default number of retries is 0.
job.retry({
retries: 5, // Retry 5 times,
wait: 20000, // waiting 20 seconds between attempts
backoff: 'constant' // wait constant amount of time between each retry
});Each time it is re-run, a new job is created in the job collection. This is equivalent to running
job.rerun(). Only 'completed' jobs are repeated. Failing jobs that exhaust their retries will
not repeat. By default, if an infinitely repeating job is added to the job Collection, any existing
repeating jobs of the same type will also continue to repeat. See option.cancelRepeats for
job.save() for more info on how to override this behavior. Returns job, so it is chainable.
options:
repeats-- Number of times to rerun the job. Default:Job.foreveruntil-- Keep repeating until thisDate, or until the number of repeats is exhausted, whichever comes first. Default:Job.foreverDatewait-- How long to wait between re-runs, in ms. Default:300000(5 minutes).schedule-- Repeat using a valid later.js schedule. The first run of this job will occur at the first valid scheduled time unless.after()or.delay()have been called, in which case it will run at the first scheduled time thereafter. For convenience on both client and serverjc.lateris initialized with a later.js object.
Note: the schedule and wait options above are mutually exclusive.
[options] may also be a non-negative integer, which is interpreted as { repeats: [options] }
Note that the above stated defaults are those when .repeat() is explicitly called. When a new job
is created, the default number of repeats is 0.
job.repeat({
repeats: 5, // Rerun this job 5 times,
wait: 20000 // wait 20 seconds between each re-run.
});
// Using later.js
job.repeat({
schedule: jc.later.parse.text('every 5 mins') // Rerun this job every 5 minutes
});Counts from when it is initially saved to the job Collection.
Returns job, so it is chainable.
job.delay(0); // Do not wait. This is the default.time is a date object. It is not guaranteed to run "at" this time because there may be no workers
available when it is reached. Returns job, so it is chainable.
// Run the job anytime after right now
// This is the default.
job.after(new Date());May be called before a new job is saved. message must be a string.
options:
level: One ofJobs.jobLogLevels:'info','success','warning', or'danger'. Default is'info'.data: An arbitrary object that will be written to thedatafield in the log entry.echo: Echo this log entry to the console.'danger'and'warning'level messages are echoed usingconsole.error()andconsole.warn()respectively. Others are echoed usingconsole.log(). If echo istrueall messages will be echoed. Ifechois one of theJob.jobLogLevelslevels, only messages of that level or higher will be echoed.
callback(error, result) -- Result is true if logging was successful. When running as
Meteor.isServer with fibers, for a saved object the callback may be omitted and the return value
is the result. If called on an unsaved object, the result is job and can be chained.
job.log(
"This is a message",
{
level: 'warning'
echo: true // Default is false
},
function (err, result) {
if (result) {
// The log method worked!
}
}
);
var verbosityLevel = 'warning';
job.log("Don't echo this",
{ level: 'info',
echo: verbosityLevel } );May be called before a new job is saved. completed must be a number >= 0 and total must be a
number > 0 with total >= completed.
options:
echo: Echo this progress update to the console usingconsole.log().
callback(error, result) -- Result is true if progress update was successful. When running as
Meteor.isServer with fibers, for a saved object the callback may be omitted and the return value
is the result. If called on an unsaved object, the result is job and can be chained.
job.progress(
50,
100, // Half done!
{
echo: true // Default is false
},
function (err, result) {
if (result) {
// The progress method worked!
}
}
);Only valid if this is a new job, or if the job is currently paused in the job Collection. If the job
is already saved and paused, then most properties of the job may change (but not all, e.g. the
jobType may not be changed.)
options:
cancelRepeats: If true and this job is an infinitely repeating job, will cancel any existing jobs of the same job type. This is useful for background maintenance jobs that may get added on each server restart (potentially with new parameters). Default isfalse.
callback(error, result) -- Result is the job _id value if save was successful. When running as
Meteor.isServer with fibers, the callback may be omitted and the return value is the result.
job.save(
{
// Cancel any jobs of the same type,
// but only if this job repeats forever.
// Default: false.
cancelRepeats: true
}
);Note that if you subscribe to the job Collection, the job documents will stay in sync with the server automatically via Meteor reactivity.
options:
getLog-- If true, also refresh the jobs log data (which may be large). Default:falsegetFailures-- If true, also refresh the jobs failure results (which may be large). Default:false
callback(error, result) -- Result is true if refresh was successful. When running as
Meteor.isServer with fibers, the callback may be omitted and the return value is the result, so in
this case this method is chainable.
job.refresh(function (err, result) {
if (result) {
// Refreshed
}
});result is any EJSON object. If this job is configured to repeat, a new job will automatically be
cloned to rerun in the future. Result will be saved as an object. If passed result is not an
object, it will be wrapped in one.
options:
-
repeatId-- If true, changes the return value of successful call fromtrueto be the_idof a newly scheduled job if this is a repeating job. Default:false -
delayDeps-- Integer. If defined, this sets the number of milliseconds before dependent jobs will run. It is equivalent to settingjob.delay(delayDeps)on each dependent job, with a check to ensure that such jobs will not run sooner than they would have otherwise. Default: undefined.
callback(error, result) -- Result is true if completion was successful. When running as
Meteor.isServer with fibers, the callback may be omitted and the return value is the result.
job.done(someResult, { repeatId: true }, function (err, newId) {
if (newId && newId !== true) {
// Next repeat job scheduled with _id = newId
}
});
// Pass a non-object result
job.done("Done!");
// This will be saved as:
// { "value": "Done!" }The job's next state depends on how its job.retry() settings are configured. It will either become
'failed' or go to 'waiting' for the next retry. error is any EJSON object and will be saved as
an object. If passed error is not an object, it will be wrapped in one. If the job becomes 'failed',
all dependent jobs will be cancelled.
options:
fatal-- If true, no additional retries will be attempted and this job will go to a'failed'state. Default:false
callback(error, result) -- Result is true if failure was successful (heh). When running as
Meteor.isServer with fibers, the callback may be omitted and the return value is the result.
job.fail(
{
reason: 'This job has failed again!',
code: 44
}
{
fatal: false // Default case
},
function (err, result) {
if (result) {
// Status updated
}
}
});
// Pass a non-object error
job.fail("Error!");
// This will be saved as:
// { "value": "Error!" }Only 'ready' and 'waiting' jobs may be paused. This specifically does nothing to affect running
jobs. To stop a running job, you must use job.cancel().
options: -- None currently.
callback(error, result) -- Result is true if pausing was successful. When running as
Meteor.isServer with fibers, the callback may be omitted and the return value is the result.
job.pause(function (err, result) {
if (result) {
// Status updated
}
});options: -- None currently.
callback(error, result) -- Result is true if resuming was successful. When running as
Meteor.isServer with fibers, the callback may be omitted and the return value is the result.
job.resume(function (err, result) {
if (result) {
// Status updated
}
});Any job that is 'waiting' may be readied. Jobs with unsatisfied dependencies will not be changed to 'ready' unless the force option is used.
options:
time-- ADateobject. If the job was set to run before the specified time, it will be set to'ready'now. Default: the current timeforce-- Force all dependencies to be satisfied. Default:false
callback(error, result) -- Result is true if state was changed to ready. When running on Meteor Server or with Fibers, the callback may be omitted, and then errors will throw and the return value is the result.
job.ready(
{
time: new Date(), // Job.foreverDate would make this unconditional
force: false
},
function (err, result) {
if (result) {
// Status updated
}
}
);Any job that isn't 'completed', 'failed' or already 'cancelled' may be cancelled. Cancelled
jobs retain any remaining retries and/or repeats if they are later restarted.
options:
antecedents-- Also cancel all cancellable jobs that this job depends on. Default:falsedependents-- Also cancel all cancellable jobs that depend on this job. Default:true
callback(error, result) -- Result is true if cancellation was successful. When running as
Meteor.isServer with fibers, the callback may be omitted and the return value is the result.
job.cancel(
{
antecedents: false,
dependents: true // Also cancel all jobs that will
// never run without this one.
},
function (err, result) {
if (result) {
// Status updated
}
}
);A restarted job will retain any repeat count state it had when it failed or was cancelled.
options:
retries-- Number of additional retries to attempt before failing withjob.retry(). These retries add to any remaining retries already on the job (such as if it was cancelled). Can be any non-negative Integer. Default:1.until-- Keep retrying until thisDate, or until the number of retries is exhausted, whichever comes first. Default: Prior value ofuntil. Note that if you specify a value foruntilwhen restarting a repeating job, it will only apply to the first run of the job. Any repeated runs of the job will use the repeatuntilvalue for retries.antecedents-- Also restart all'cancelled'or'failed'jobs that this job depends on. Default:truedependents-- Also restart all'cancelled'or'failed'jobs that depend on this job. Default:false
callback(error, result) -- Result is true if restart was successful. When running as
Meteor.isServer with fibers, the callback may be omitted and the return value is the result.
job.restart(
{
antecedents: true, // Also restart all jobs that must
// complete before this job can run.
dependents: false,
retries: 0 // Only try one more time. This is the default.
},
function (err, result) {
if (result) {
// Status updated
}
}
);options:
repeats-- Number of times to repeat the job, as withjob.repeat().until-- Keep repeating until thisDate, or until the number of repeats is exhausted, whichever comes first. Default: prior value ofuntilwait-- Time to wait between reruns. Default is the existingjob.repeat({ wait: ms })setting for the job.
callback(error, result) -- Result is true if rerun was successful. When running as
Meteor.isServer with fibers, the callback may be omitted and the return value is the result.
job.rerun(
{
repeats: 0, // Only repeat this once
// This is the default
wait: 60000 // Wait a minute between repeats
// Default is previous setting
},
function (err, result) {
if (result) {
// Status updated
}
}
);The job must be 'completed', 'failed', or 'cancelled' to be removed.
options: -- None currently.
callback(error, result) -- Result is true if removal was successful. When running as
Meteor.isServer with fibers, the callback may be omitted and the return value is the result.
job.remove(function (err, result) {
if (result) {
// Job removed from server.
}
});Always a string. Useful for when getWork or processJobs are configured to accept multiple job
types. This may not be changed after a job is created.
Always an object. This may not be changed after a job is created.
Always an object, as stored in the underlying JobCollection. This may not be changed after a job is created.
JobQueue is similar in spirit to the async.js queue and cargo
except that it gets its work from the job collection via calls to jc.getWork()
New jobQueues are created by calling the following job-collection method (documented above):
q = jc.processJobs()
All JobQueue methods may be run on the server or client
This means that no more work will be requested from the job collection, and no new workers will be
called with jobs that already exist in this local queue. Jobs that are already running locally will
run to completion. Note that a JobQueue may be created in the paused state by running q.pause()
immediately on the returned new jobQueue.
q.pause()q.resume()This method manually causes the same action that expiration of the pollInterval does internally
within JobQueue. This is useful for creating responsive JobQueues that are triggered by a Meteor
observe based mechanism, rather than time based polling.
// Simple observe based queue
q = jc.processJobs(
// Type of job to request
// Can also be an array of job types
'jobType',
{
pollInterval: 1000000000, // Don't poll
},
function (job, callback) {
// Only called when there is a valid job
job.done();
callback();
}
);
jc.find({ type: 'jobType', status: 'ready' })
.observe({
added: function () { q.trigger(); }
});Non-Meteor node.js worker scripts cannot use the jc.find(...).observe(...) portion of the above example. Please see the documentation for the meteor-job npm package for an alternative approach that works outside of the Meteor environment.
options:
level-- May be 'hard' or 'soft'. Any other value will lead to a "normal" shutdown.quiet-- true or false. False by default, which leads to a "Shutting down..." message onprocess.stderr.
callback() -- Invoked once the requested shutdown conditions have been achieved.
Shutdown levels:
'soft'-- Allow all local jobs in the queue to start and run to a finish, but do not request any more work. Normal program exit should be possible.'normal'-- Allow all running jobs to finish, but do not request any more work and fail any jobs that are in the local queue but haven't started to run. Normal program exit should be possible.'hard'-- Fail all local jobs, running or not. Return as soon as the server has been updated. Note: after a hard shutdown, there may still be outstanding work in the event loop. To exit immediately may requireprocess.exit()depending on how often asynchronous workers invoke'job.progress()'and whether they die when it fails.
q.shutdown({ quiet: true, level: 'soft' }, function () {
// shutdown complete
});The definitions below use a slight shorthand of the Meteor Match pattern syntax to describe the valid structure of a job document. As a user of job-collection this is mostly for your information because jobs are automatically built and maintained by the package.
Note: If you would like to add private server-side data to a job document, you may add whatever
you would like in a subdocument called _private. Such data will not be accepted via or returned
from any of the jobCollection method calls. IMPORTANT CAVEAT!: If you use this feature, you
must be careful to exclude _private from any query cursors returned from within a publish
function, or you will leak this data to potentially untrusted clients.
validId = (
Match.test(v, Match.OneOf(String, Meteor.Collection.ObjectID))
);
validStatus = (
Match.test(v, String) &&
(v in ['waiting', 'paused', 'ready', 'running',
'failed', 'cancelled', 'completed'])
);
validLogLevel = (
Match.test(v, String) &&
(v in ['info', 'success', 'warning', 'danger'])
);
validRetryBackoff = (
Match.test(v, String) &&
(v in ['constant', 'exponential'])
);
validLog = [{
time: Date,
runId: Match.OneOf(
Match.Where(validId),
null
),
level: Match.Where(validLogLevel),
message: String,
data: Match.Optional(Object)
}];
validProgress = {
completed: Match.Where(validNumGTEZero),
total: Match.Where(validNumGTEZero),
percent: Match.Where(validNumGTEZero)
};
validLaterJSObj = {
schedules: [ Object ]
exceptions: Match.Optional([ Object ])
};
validJobDoc = {
_id: Match.Optional(
Match.OneOf(
Match.Where(validId),
null
)
),
runId: Match.OneOf(
Match.Where(validId),
null
),
type: String,
status: Match.Where(validStatus),
data: Object,
result: Match.Optional(Object),
failures: Match.Optional([ Object ]),
priority: Match.Integer,
depends: [ Match.Where(validId) ],
resolved: [ Match.Where(validId) ],
after: Date,
updated: Date,
workTimeout: Match.Optional Match.Where(validIntGTEOne)
expiresAfter: Match.Optional Date
log: Match.Optional(validLog()),
progress: validProgress(),
retries: Match.Where(validIntGTEZero),
retried: Match.Where(validIntGTEZero),
repeatRetries: Match.Optional Match.Where(validIntGTEZero),
retryUntil: Date,
retryWait: Match.Where(validIntGTEZero),
retryBackoff: Match.Where(validRetryBackoff),
repeats: Match.Where(validIntGTEZero),
repeated: Match.Where(validIntGTEZero),
repeatUntil: Date,
repeatWait: Match.OneOf(Match.Where(validIntGTEZero), Match.Where(_validLaterJSObj))
created: Date
};These are the underlying Meteor methods that are actually invoked when a method like .save() or
.getWork() is called. In most cases you will not need to program to this interface because the
JobCollection and Job APIs do this work for you. One exception to this general rule is if you
need finer control over allow/deny rules than is provided by the predefined admin, manager,
creator, and worker access categories.
Each job-collection you create on a server causes a number of Meteor methods to be defined. The method names are prefaced with the name of the job collection (e.g. "myJobs_getWork") so that multiple job-collections on a server will not interfere with one another. Below you will find the Method API reference.
-
options-- No options currently usedMatch.Optional({})
Returns: Boolean - Success or failure
-
options-- Supports the following options:timeout-- Time in ms until all outstanding jobs will be marked as failed.
Match.Optional({ timeout: Match.Optional(Match.Where(validIntGTEOne)) })
Returns: Boolean - Success or failure
-
ids-- an Id or array of Ids to get from serverids: Match.OneOf(Match.Where(validId), [ Match.Where(validId) ]) -
options-- Supports the following options:getLog-- If true include the job log data in the returned job data. Default is false.
Match.Optional({ getLog: Match.Optional(Boolean) })
Returns: validJobDoc() or [ validJobDoc() ] depending on if ids is a single value or an array.
-
type-- a string job type or an array of such typestype: Match.OneOf(String, [ String ]) -
options-- Supports the following options:maxJobs-- The maximum number of jobs to return, Default:1
Match.Optional({ maxJobs: Match.Optional(Match.Where(validIntGTEOne)) })workTimeout-- Number milliseconds until a running job may be automatically failed if not updated.
Match.Optional({ workTimeout: Match.Optional(Match.Where(validIntGTEOne)) })
Returns: validJobDoc() or [ validJobDoc() ] depending on if maxJobs > 1.
-
ids-- an Id or array of Ids to remove from serverids: Match.OneOf(Match.Where(validId), [ Match.Where(validId) ]) -
options-- No options currently usedMatch.Optional({})
Returns: Boolean - Success or failure
-
ids-- an Id or array of Ids to pause on serverids: Match.OneOf(Match.Where(validId), [ Match.Where(validId) ]) -
options-- No options currently usedMatch.Optional({})
Returns: Boolean - Success or failure
-
ids-- an Id or array of Ids to resume on serverids: Match.OneOf(Match.Where(validId), [ Match.Where(validId) ]) -
options-- No options currently usedMatch.Optional({})
Returns: Boolean - Success or failure
Readies a waiting job in the job collection. Jobs with dependencies will not be readied unless the force option is used.
-
ids-- an Id or array of Ids to make ready on server. May be an empty Array, in which case all waiting jobs that are ready to run (given the options below) will be set to'ready'.ids: Match.OneOf(Match.Where(validId), [ Match.Where(validId) ]) -
options-- Supports the following options:time-- ADateobject. If the job was set to run before the specified time, it will be set to'ready'now. Default: the current timeforce-- If true, all dependencies will be removed. Default:false
Match.Optional({ time: Match.Optional(Date), force: Match.Optional(Boolean) })
Returns: Boolean - Success or failure
Cancels a job in the job collection. Cancelled jobs will not run and will stop running if already running.
-
ids-- an Id or array of Ids to cancel on serverids: Match.OneOf(Match.Where(validId), [ Match.Where(validId) ]) -
options-- Supports the following options:antecedents-- If true, all jobs that this one depends upon will also be cancelled. Default:falsedependents-- If true, all jobs that depend on this one will also be be cancelled. Default:true
Match.Optional({ antecedents: Match.Optional(Boolean), dependents: Match.Optional(Boolean) })
Returns: Boolean - Success or failure
-
ids-- an Id or array of Ids to restart from serverids: Match.OneOf(Match.Where(validId), [ Match.Where(validId) ]) -
options-- Supports the following options:retries-- Number of additional times to retry running this job. Default: 1until-- Retry until this time, or until the retries count is exhausted, whicever comes first. Default: prior value.antecedents-- If true, all jobs that this one depends upon will also be restarted. Default:truedependents-- If true, all jobs that depend on this one will also be be restarted. Default:false
Match.Optional({ retries: Match.Optional(Match.Where validIntGTEZero), until: Match.Optional(Date), antecedents: Match.Optional(Boolean), dependents: Match.Optional(Boolean) })
Returns: Boolean - Success or failure
-
doc-- Job document of job to save to the server job-collectionvalidJobDoc() -
options-- Supports the following options:cancelRepeats-- If true and this job is an infinitely repeating job, will cancel any existing jobs of the same job type. Default is false.
Match.Optional({ cancelRepeats: Match.Optional(Boolean) })
Returns: Match.Where(validId) of the added job.
-
id-- The id of the job to rerunMatch.Where(validId) -
options-- Supports the following options:wait-- Amount of time to wait until the new job runs in ms. Default: 0repeats-- Number of times to repeat the new job. Default: 0until-- Repeat until this time, or until the repeats count is exhausted, whicever comes first. Default: prior value.
Match.Optional({ repeats: Match.Optional(Match.Where validIntGTEZero), until: Match.Optional(Date), wait: Match.Optional(Match.Where validIntGTEZero) })
Returns: Match.Where(validId) of the added job.
-
id-- The id of the job to updateMatch.Where(validId) -
runId-- The runId of this workerMatch.Where(validId) -
completed-- The estimated amount of effort completedMatch.Where(validNumGTEZero) -
total-- The estimated total effortMatch.Where(validNumGTZero) -
options-- No options currently usedMatch.Optional({})
Returns: Boolean - Success or failure or null if job-collection is shutting down
-
id-- The id of the job to updateMatch.Where(validId) -
runId-- The runId of this workerMatch.Where(validId) -
message-- The text of the message to add to the logString -
options-- Supports the following options:level-- The information level of this log entry. Must be a valid log level. Default:'info'data-- An arbitrary object to store in the log entry
Match.Optional({ level: Match.Optional(Match.Where(validLogLevel)) data: Match.Optional Object })
Returns: Boolean - Success or failure
-
id-- The id of the job to updateMatch.Where(validId) -
runId-- The runId of this workerMatch.Where(validId) -
result-- A result object to store with the completed job.Object -
options-- No options currently usedrepeatId-- If true, a successful return value for a repeating job will be the_idof the new job. Default:false.
Match.Optional({ repeatId: Match.Optional(Boolean) })delayDeps-- Integer. If defined, this sets the number of milliseconds before dependent jobs will run. It is equivalent to settingjob.delay(delayDeps)on each dependent job, with a check to ensure that such jobs will not run sooner than they would have otherwise. Default: undefined.
Match.Optional({ delayDeps: Match.Optional(Match.Where validIntGTEZero) })
Returns: Boolean - Success or failure unless repeatId option is true, when it may return the _id value of a created repeating job.
-
id-- The id of the job to updateMatch.Where(validId) -
runId-- The runId of this workerMatch.Where(validId) -
err-- An error object to store with the failed job.Object -
options-- Supports the following options:fatal-- If true, cancels any remaining repeat runs this job was scheduled to have. Default:false.
options: Match.Optional({ fatal: Match.Optional(Boolean) })
Returns: Boolean - Success or failure
Zombie jobs are those, whose worker stopped without any notification. When a job is started by a worker, it receives the status 'running'. If the worker now stops without notifying the database, the job is actually a zombie job, because it looks like someone is working on it but it isn't. Now - what can we do to prevent these zombie jobs? Well, there are two techniques who will help you here.
1. Mark every still running job as failed if the process of the worker needs to stop.
This is the best case, because it prevents the raise of zombie jobs - but there are certain cases where this doesn't work. You can f.e. use this if the process is stopped by a SIGTERM signal, but it won't work for a SIGKILL signal. If you have jobs running on the same process meteor runs, you can add the following code to your project to make use of this:
const cleanup = Meteor.bindEnvironment(() => {
// Copied from the ddp-method shutdownJobServer, but without setInterval().
const cursor = StripesJobs.find({ status: 'running' }, { transform: null });
const failedJobs = cursor.count();
if (failedJobs !== 0) {
console.warn(`Failing ${failedJobs} jobs on queue stop.`);
}
cursor.forEach(d => StripesJobs._DDPMethod_jobFail(d._id, d.runId, { message: 'Running at Job Server shutdown.' }));
if (StripesJobs.logStream) {
// Shutting down closes the logStream!
StripesJobs.logStream.end();
StripesJobs.logStream = null;
}
});
// When this app is terminated by process.exit(), which now includes SIGINT, SIGTERM and SIGHUP.
process.on('exit', () => cleanup());
function exitHandler() {
process.exit();
}
// catches ctrl+c event
process.on('SIGINT', exitHandler);
// catches a SIGTERM, sent by a posix-os
process.on('SIGTERM', exitHandler);
// catches closing the parent-process (f.e. console window)
process.on('SIGHUP', exitHandler);An example for a remote job-queue can be found here: https://github.com/vsivsi/meteor-job-collection-playground-worker/blob/master/work.coffee#L120
This will also work on Windows but - as on POSIX-systems - there are limitations.
2. Assume that every job that didn't responded for the last X seconds is a zombie.
Because the first approach can't cover all cases, there's also a second approach, which doesn't prevent the rise of zombies, but shoots them once they are discovered. You have to be careful so you do not also hit a normal job.
Every worker-queue (started by jc.processJobs()) has a second, optional parameter which accepts a property called workTimeout. If a queue discoveres, that there are jobs in the database, set to 'running' but their last update (done by f.e. job.process() or job.log()) was more than X milliseconds ago, it marks this job as 'failed'. According to this definition, a job has to report something within workTimeout milliseconds. Just make sure, that this time cannot be hit under normal conditions, and you're fine.