In this project I have explored Red Wine Quality dataset and further tried to predict wine quality from the data.
With the increase in social consumption, the red wine industry has recently grown exponentially. Today, industry participants are using product quality certification to promote their products. This is a time-consuming process that requires evaluation by human experts, making this process very expensive.
With the human evaluation being a rather abstract concept this dataset aims to classify the quality of wine purely on the basis of its chemical composition.

The dataset populated with chemical components of the wine samples has over 1600 rows with columns describing various aspects such as:
- Fixed Acidity
- Volatile Acidity
- Citric Acid
- Residual Sugar
- Chlorides
- Free Sulfer Dioxide
- Total Sulfer Dioxide
- Density
- pH
- Sulphates
- ALcohol
The initial training of model is performed using 3 models which on further analysis will be further optimized for best results. The models that are used are:
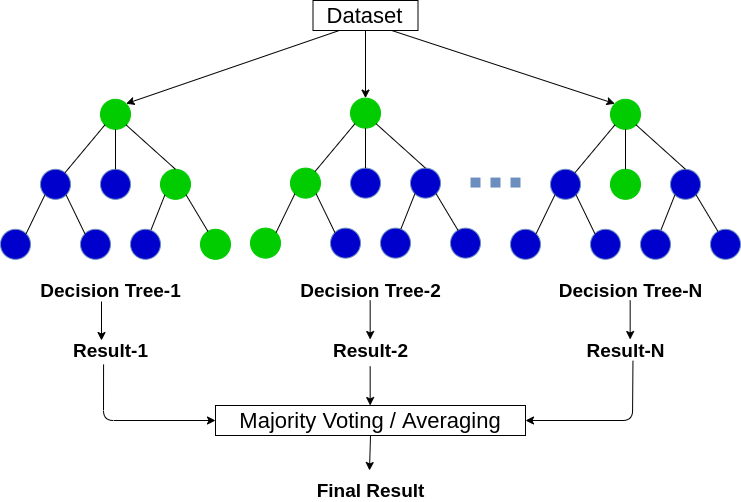
- Random Forest Classifier:
Random forest classifier creates a set of decision trees from randomly selected subset of training set. It then aggregates the votes from different decision trees to decide the final class of the test object.
- Stochastic Gradient Descent Classifier:
Stochastic Gradient Descent (SGD) is a simple yet efficient optimization algorithm used to find the values of parameters/coefficients of functions that minimize a cost function. In other words, it is used for discriminative learning of linear classifiers under convex loss functions such as SVM and Logistic regression.
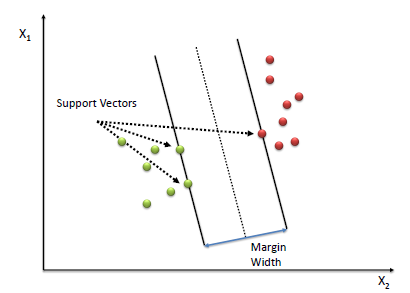
- Support Vector Classifier: A support vector machine (SVM) is a supervised machine learning model that uses classification algorithms for two-group classification problems. After giving an SVM model sets of labeled training data for each category, they're able to categorize new text.

Having the results from the basic training we use optimization techniques to get the best result that can be achieved.
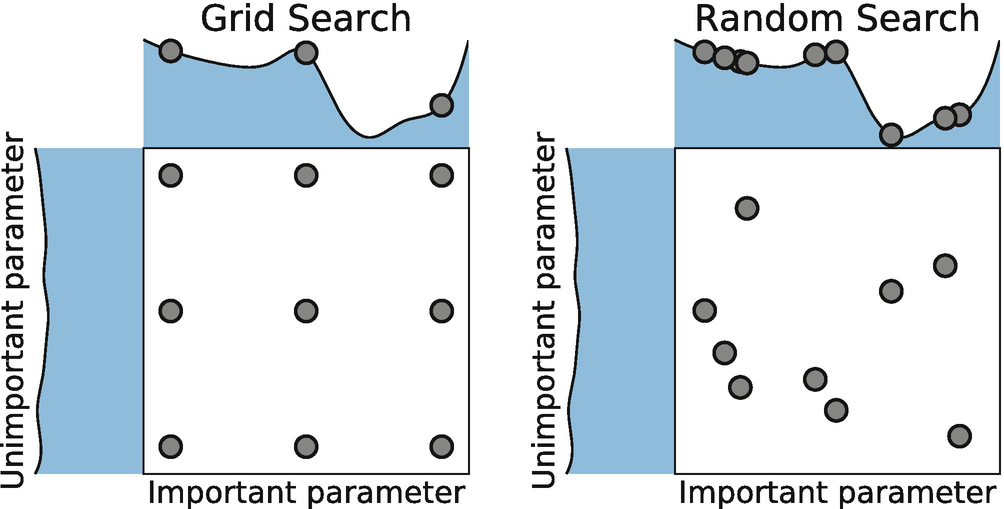
- Grid Search:
Grid search is a process that searches exhaustively through a manually specified subset of the hyperparameter space of the targeted algorithm.
- Cross Validation:
We will be sing Cross Validation for Random Forest results.
Cross-validation is a resampling procedure used to evaluate machine learning models on a limited data sample. The procedure has a single parameter called k that refers to the number of groups that a given data sample is to be split into. As such, the procedure is often called k-fold cross-validation.

Setting up the python requirements using requirements.txt
pip install -r requirements.txt
A lot of my code was inspired by this notebook.