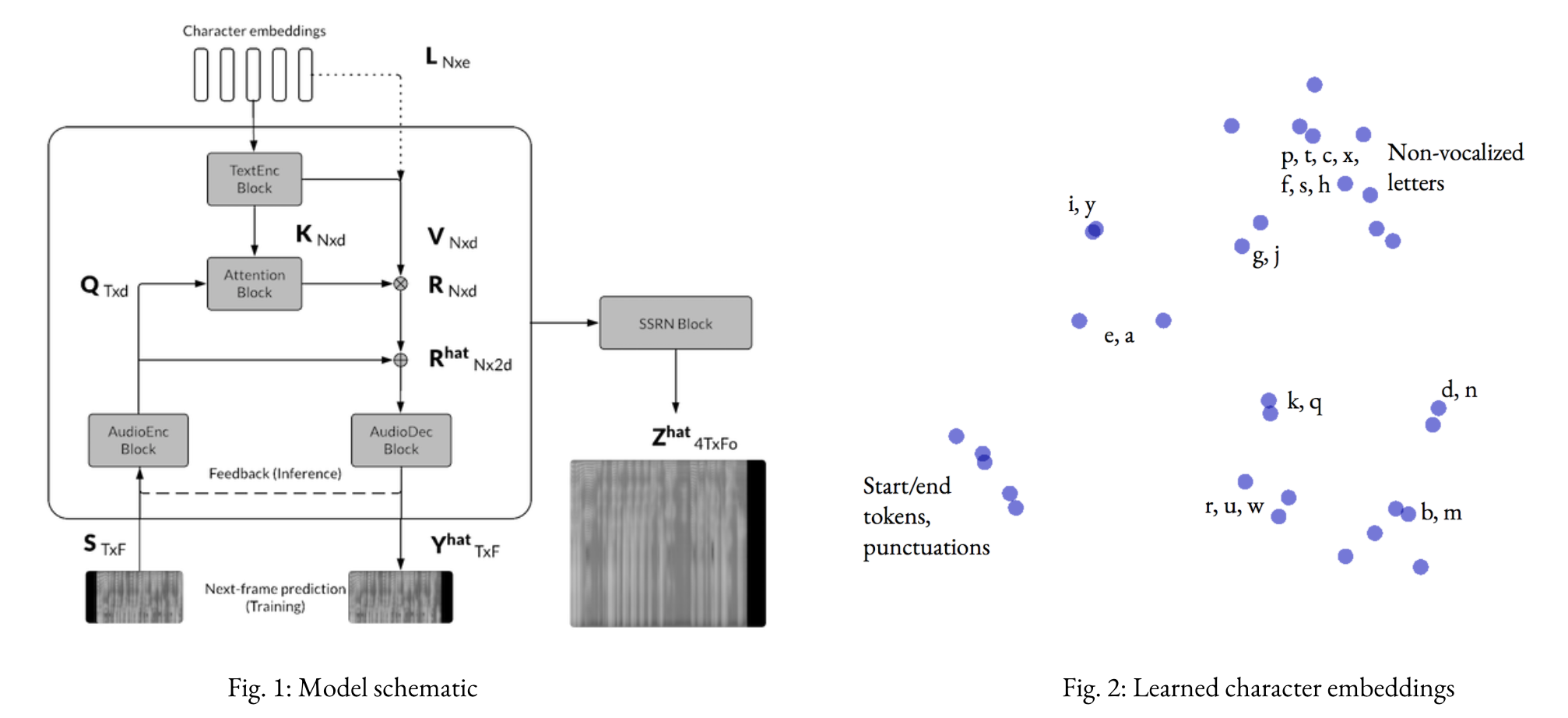
Implementation of a convolutional seq2seq-based text-to-speech model based on Tachibana et. al. (2017). Given a sequence of characters, the model predicts a sequence of spectrogram frames in two stages (Text2Mel and SSRN).
As discussed in the report, we can get fairly decent audio quality with Text2Mel trained for 60k steps, SSRN for 100k steps. This corresponds to about (6+12) hours of training on a single Tesla K80 GPU on the LJ Speech Dataset.
Pretrained Model: [download]
Samples: [base-model-M4] [unsupervised-decoder-M1]
For more details see:
Poster Paper
- runs (contains checkpoints and params.json file for each different run. params.json specifies various hyperameters: see params-examples folder)
- run1/params.json ...
- src (implementation code package)
- sentences (contains test sentences in .txt files)
train.py
evaluate.py
synthesize.py
../data (directory containing data in format below)
- FOLDER
- train.csv, val.csv (files containing [wav_file_name|transcript|normalized_trascript] as in LJ-Speech dataset)
- wavs (folder containing corresponding .wav audio files)
Run each file with python <script_file>.py -h to see usage details.
python train.py <PATH_PARAMS.JSON> <MODE>
python evaluate.py <PATH_PARAMS.JSON> <MODE>
python synthesize.py <TEXT2MEL_PARAMS> <SSRN_PARAMS> <SENTENCES.txt> (<N_ITER> <SAMPLE_DIR>)
- Evaluation: Runs model predictions across the entire training and validation sets for different saved model checkpoints and saves the final results.
- Demo: Interactively type input sentences and listen to the generated output audio.
- Training on different languages with smaller amount of data available Dataset of Indian languages
- Exploring use of semi-supervised methods to accelerate training, using a pre-trained 'audio-language model' as initialization
(From src/init.py) Utility Code has been referenced from the following sources, all other code is the author's own:
- src/data_load.py, dsp_utils.py (with modifications)
https://www.github.com/kyubyong/dc_tts, (Author: kyubyong park, @Kyubyong) https://github.com/r9y9/deepvoice3_pytorch/blob/master/audio.py (Author: @r9y9) - src/spsi.py (referenced)
https://github.com/lonce/SPSI_Python (Author: @lonce) - src/utils.py (referenced)
https://github.com/cs230-stanford/cs230-code-examples https://www.github.com/kyubyong/dc_tts https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/layers/common_attention.py