Project 4
All the images and jmx files can be found here - https://github.com/airavata-courses/scrapbook/tree/jmeter/assets/jmeter_tests
Through load, fault tolerance and spike testing, we could qualitatively define our system limits and behavior towards a large number of users. Below are a few pointers that sum up our testing.
We had to make a few tweaks to our architecture and then redeploy. Previously, we were using free tier of 2 cloud services namely,
- redis cloud
- mongo atlas
to handle our persistent storage. These cloud services have various restrictions that hindered our system's capabilities. For example, the throughput and error rates for logging in was about 10req/s and 90% respectively due to the fact that redis cloud rate limits requests. Redis cloud only allows 30 requests per second which is why the cloud would throw an error, bringing down the login.
We solved this by spinning up a VM on Jetstream for Redis as well as MongoDB. So essentially, our full application is not on Jetstream apart from the ones that use the Google API. This significantly improved the throughput and reduced the error rate. This is our updated architecture diagram:

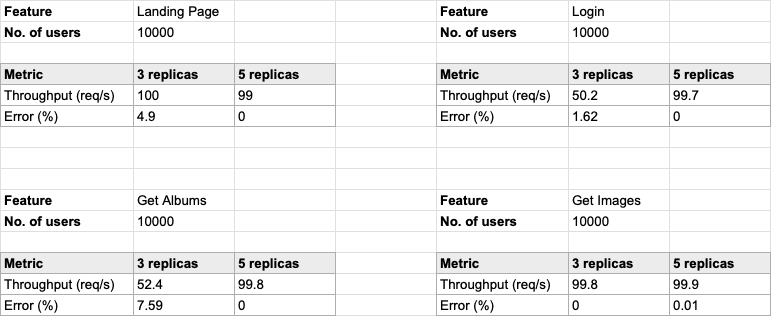
Through the load tests, we observed the performance (throughput) was much better when testing with services with 5 replicas than that with 3. Having that said, for all the tested functions we had an average of 50+ requests per second for 3 and 5 replicas. Below are a few graphs that compare the stress test for 3 and 5 replicas by comparing the throughput and error rates.
Through the testing, we feel that our system is fairly fault tolerant. We manually killed instances on our Kubernetes cluster to test out how our system reacts to failed pods. The errors spike for a brief moment (a few second) spiked but Kubernetes was able pull up new instances immediately.
