用两个栈实现一个队列。队列的声明如下,请实现它的两个函数 appendTail 和 deleteHead ,分别完成在队列尾部插入整数和在队列头部删除整数的功能。(若队列中没有元素,deleteHead 操作返回 -1 )
示例1
输入:
["CQueue","appendTail","deleteHead","deleteHead"]
[[],[3],[],[]]
输出:[null,null,3,-1]
示例2:
输入:
["CQueue","deleteHead","appendTail","appendTail","deleteHead","deleteHead"]
[[],[],[5],[2],[],[]]
输出:[null,-1,null,null,5,2]
思路
用两个栈,一个栈用来进行数据的进栈操作,另一个栈是用来出战,注意的是,当第二个栈空的时候才把第一个栈的数据转移到第二个栈中。
例程
class CQueue {
public:
CQueue() {
}
void appendTail(int value) {
s1.push(value);
}
int deleteHead() {
if (s2.empty()) {
while (!s1.empty()) {
int tmp = s1.top();
s1.pop();
s2.push(tmp);
}
}
if (s2.empty()) {
return -1;
}
int tmp = s2.top();
s2.pop();
return tmp;
}
stack<int> s1;
stack<int> s2;
};
/**
* Your CQueue object will be instantiated and called as such:
* CQueue* obj = new CQueue();
* obj->appendTail(value);
* int param_2 = obj->deleteHead();
*/写一个函数,输入 n ,求斐波那契(Fibonacci)数列的第 n 项(即 F(N))。斐波那契数列的定义如下:
F(0) = 0, F(1) = 1
F(N) = F(N - 1) + F(N - 2), 其中 N > 1.
斐波那契数列由 0 和 1 开始,之后的斐波那契数就是由之前的两数相加而得出。
答案需要取模 1e9+7(1000000007),如计算初始结果为:1000000008,请返回 1。
示例1:
输入:n = 2
输出:1
示例2:
输入:n = 5
输出:5
思路
可以用递归,但是递归会增加很多运算,简单的方法是从第一个数往后算。
例程
class Solution {
public:
int fib(int n) {
if (n == 0) {
return 0;
}
vector<int>f(n + 1, 0);
f[1] = 1;
for (int i = 2; i <= n; i++) {
f[i] = f[i - 1] + f[i - 2];
f[i] = f[i] % 1000000007;
}
return f[n];
}
};找出数组中重复的数字。
在一个长度为 n 的数组 nums 里的所有数字都在 0~n-1 的范围内。数组中某些数字是重复的,但不知道有几个数字重复了,也不知道每个数字重复了几次。请找出数组中任意一个重复的数字。
示例:
输入:
[2, 3, 1, 0, 2, 5, 3]
输出:2 或 3
例程
class Solution {
public:
int findRepeatNumber(vector<int>& nums) {
int flag_zero = 0;
for (int i = 0; i < nums.size(); i++) {
int tmp = abs(nums[i]);
if (tmp == 0 && flag_zero)
return tmp;
else if (tmp == 0 && !flag_zero)
flag_zero = 1;
if (nums[tmp] < 0)
return tmp;
else
nums[tmp] = -nums[tmp];
}
return -1;
}
};class Solution(object):
def findRepeatNumber(self, nums):
"""
:type nums: List[int]
:rtype: int
"""
flag = 0
n=len(nums)
for index in xrange(n):
num =abs(nums[index])
if num == 0 and flag==0:
flag=1
elif num==0 and flag ==1:
return 0
elif nums[num] <0:
return num
else:
nums[num] = -nums[num]在一个 n * m 的二维数组中,每一行都按照从左到右递增的顺序排序,每一列都按照从上到下递增的顺序排序。请完成一个高效的函数,输入这样的一个二维数组和一个整数,判断数组中是否含有该整数。
示例:
现有矩阵 matrix 如下:
[
[1, 4, 7, 11, 15],
[2, 5, 8, 12, 19],
[3, 6, 9, 16, 22],
[10, 13, 14, 17, 24],
[18, 21, 23, 26, 30]
]
给定 target = 5,返回 true。
给定 target = 20,返回 false。
例程:
class Solution {
public:
bool findNumberIn2DArray(vector<vector<int>>& matrix, int target) {
if (matrix.empty() || matrix[0].empty())
return false;
int n = matrix.size();
int m = matrix[0].size();
int i = 0, j = m - 1;
while (i < n && j >= 0) {
if (matrix[i][j] == target) {
return true;
}
else if (matrix[i][j] > target) {
j--;
}
else {
i++;
}
}
return false;
}
};一只青蛙一次可以跳上1级台阶,也可以跳上2级台阶。求该青蛙跳上一个 n 级的台阶总共有多少种跳法。
答案需要取模 1e9+7(1000000007),如计算初始结果为:1000000008,请返回 1。
示例1:
输入:n = 2
输出:2
示例2:
输入:n = 7
输出:21
示例3:
输入:n = 0
输出:1
思路
其实这道题是斐波那契数列,下面的解法是空间压缩法,空间复杂度是常数c
例程
class Solution {
public:
int numWays(int n) {
vector<int>result{ 1,1 };
if (n <= 1) {
return result[n];
}
int one = 1, two = 1, ans = 0;
for (int i = 2; i <= n; i++) {
ans = one + two;
ans %= 1000000007;
one = two;
two = ans;
}
return ans;
}
};把一个数组最开始的若干个元素搬到数组的末尾,我们称之为数组的旋转。输入一个递增排序的数组的一个旋转,输出旋转数组的最小元素。例如,数组 [3,4,5,1,2] 为 [1,2,3,4,5] 的一个旋转,该数组的最小值为1。
示例1:
输入:[3,4,5,1,2]
输出:1
示例2:
输入:[2,2,2,0,1]
输出:0
例程
class Solution {
public:
int minArray(vector<int>& numbers) {
if (numbers.empty())
return -1;
int n = numbers.size();
int l = 0, r = n - 1, mid = l;
while (numbers[l] >= numbers[r]) {
if (r - l <= 1) {
mid = r;
break;
}
mid = (l + r) / 2;
if (numbers[mid] == numbers[l] && numbers[mid] == numbers[r]) {
return orderFindMin(numbers, l, r);
}
if (numbers[mid] >= numbers[l])
l = mid;
else if(numbers[mid] <= numbers[r])
r = mid;
}
return numbers[mid];
}
int orderFindMin(vector<int>& numbers, int l, int r) {
int ans = numbers[l];
for (int i = l + 1; i <= r; i++) {
if (ans > numbers[i])
ans = numbers[i];
}
return ans;
}
};给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。
例如,在下面的 3×4 的矩阵中包含单词 "ABCCED"(单词中的字母已标出)。

示例1:
输入:board = [["A","B","C","E"],["S","F","C","S"],["A","D","E","E"]], word = "ABCCED"
输出:true
示例2:
输入:board = [["a","b"],["c","d"]], word = "abcd"
输出:false
思路
回溯法
例程
class Solution {
public:
bool exist(vector<vector<char>>& board, string word) {
int n = board.size(), m = board[0].size();
vector<vector<bool>>visited(n, vector<bool>(m, false));
bool find = false;
for (int i = 0; i < n; i++) {
if (find)
break;
for (int j = 0; j < m; j++) {
if (find)
break;
backtracking(board, word, visited, 0, i, j, find);
}
}
return find;
}
void backtracking(vector<vector<char>>& board, string word, vector<vector<bool>>& visited,
int pose, int x, int y, bool& find) {
int n = board.size(), m = board[0].size();
if (x < 0 || x >= n || y < 0 || y >= m) {
return;
}
if (find || visited[x][y])
return;
if (board[x][y] != word[pose])
return;
if (pose == word.length() - 1) {
find = true;
return;
}
visited[x][y] = true;
backtracking(board, word, visited, pose + 1, x + 1, y, find);
backtracking(board, word, visited, pose + 1, x, y + 1, find);
backtracking(board, word, visited, pose + 1, x - 1, y, find);
backtracking(board, word, visited, pose + 1, x, y - 1, find);
visited[x][y] = false;
}
};请实现一个函数,把字符串 s 中的每个空格替换成"%20"。
示例:
输入:s = "We are happy."
输出:"We%20are%20happy."
例程
class Solution {
public:
string replaceSpace(string s) {
int oriLenght = s.length();
int spaceNum = 0;
for (int i = 0; i < oriLenght; i++) {
if (s[i] == ' ')
spaceNum++;
}
int newLenght = oriLenght + spaceNum * 2;
string ans(newLenght, ' ');
newLenght--;
while (oriLenght) {
if (s[oriLenght - 1] == ' ') {
ans[newLenght--] = '0';
ans[newLenght--] = '2';
ans[newLenght--] = '%';
}
else {
ans[newLenght--] = s[oriLenght-1];
}
oriLenght--;
}
return ans;
}
};地上有一个m行n列的方格,从坐标 [0,0] 到坐标 [m-1,n-1] 。一个机器人从坐标 [0, 0] 的格子开始移动,它每次可以向左、右、上、下移动一格(不能移动到方格外),也不能进入行坐标和列坐标的数位之和大于k的格子。例如,当k为18时,机器人能够进入方格 [35, 37] ,因为3+5+3+7=18。但它不能进入方格 [35, 38],因为3+5+3+8=19。请问该机器人能够到达多少个格子?
示例1:
输入:m = 2, n = 3, k = 1
输出:3
示例2:
输入:m = 3, n = 1, k = 0
输出:1
思路
广度优先搜索或者深度优先搜索
例程
class Solution {
public:
int movingCount(int m, int n, int k) {
vector<vector<bool>> visited(m, vector<bool>(n, false));
int count = 0;
count += dfs(visited, 0, 0, m, n, k);
return count;
}
int dfs(vector<vector<bool>>& visited, int x, int y, int m, int n, int k) {
if (x < 0 || x >= m || y < 0 || y >= n) {
return 0;
}
if (visited[x][y])
return 0;
if (!checkVisited(x, y, k)) {
return 0;
}
visited[x][y] = true;
int count = 1;
count += dfs(visited, x + 1, y, m, n, k);
count += dfs(visited, x, y + 1, m, n, k);
count += dfs(visited, x - 1, y, m, n, k);
count += dfs(visited, x, y - 1, m, n, k);
return count;
}
bool checkVisited(int x, int y, int k) {
int num = 0;
while (x) {
num += x % 10;
x = x / 10;
}
while (y) {
num += y % 10;
y = y / 10;
}
if (num > k)
return false;
return true;
}
};输入一个链表的头节点,从尾到头反过来返回每个节点的值(用数组返回)。
示例1:
输入:head = [1,3,2]
输出:[2,3,1]
例程
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
vector<int> reversePrint(ListNode* head) {
vector<int>ans;
helper(ans, head);
return ans;
}
void helper(vector<int>& ans, ListNode* head) {
if (head) {
helper(ans, head->next);
ans.push_back(head->val);
}
}
};输入某二叉树的前序遍历和中序遍历的结果,请构建该二叉树并返回其根节点。
假设输入的前序遍历和中序遍历的结果中都不含重复的数字。
示例1:

Input: preorder = [3,9,20,15,7], inorder = [9,3,15,20,7]
Output: [3,9,20,null,null,15,7]
例程:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {
if (preorder.empty() || inorder.empty())
return nullptr;
unordered_map<int, int>inorderMap;
for (int i = 0; i < inorder.size(); i++) {
inorderMap[inorder[i]] = i;
}
TreeNode* root = buildTreeHelper(preorder, inorderMap, 0, preorder.size() - 1, 0);
return root;
}
TreeNode* buildTreeHelper(vector<int>& preorder, unordered_map<int, int>&inorderMap, int s1, int e1, int s2) {
if (s1 > e1)
return nullptr;
TreeNode* root = new TreeNode(preorder[s1]);
int pose = inorderMap[preorder[s1]];
int leftLength = pose - s2;
int leftStart = s1 + 1;
int leftEnd = s1 + leftLength;
int rightStart = s1 + leftLength + 1;
int rightEnd = e1;
root->left = buildTreeHelper(preorder, inorderMap, leftStart, leftEnd, s2);
root->right = buildTreeHelper(preorder, inorderMap, rightStart, rightEnd, s2 + leftLength + 1);
return root;
}
};给你一根长度为 n 的绳子,请把绳子剪成整数长度的 m 段(m、n都是整数,n>1并且m>1),每段绳子的长度记为 k[0],k[1]...k[m-1] 。请问 k[0]k[1]...*k[m-1] 可能的最大乘积是多少?例如,当绳子的长度是8时,我们把它剪成长度分别为2、3、3的三段,此时得到的最大乘积是18。
示例1:
输入: 2
输出: 1
解释: 2 = 1 + 1, 1 × 1 = 1
示例2:
输入: 10
输出: 36
解释: 10 = 3 + 3 + 4, 3 × 3 × 4 = 36
例程
class Solution {
public:
int cuttingRope(int n) {
vector<int> dp(n + 1, 1);
for (int i = 2; i <= n; i++) {
for (int j = 1; j < i; j++) {
dp[i] = max(dp[i], max(dp[i - j], i-j) * j);
}
}
return dp[n];
}
};给你一根长度为 n 的绳子,请把绳子剪成整数长度的 m 段(m、n都是整数,n>1并且m>1),每段绳子的长度记为 k[0],k[1]...k[m - 1] 。请问 k[0]k[1]...*k[m - 1] 可能的最大乘积是多少?例如,当绳子的长度是8时,我们把它剪成长度分别为2、3、3的三段,此时得到的最大乘积是18。
答案需要取模 1e9+7(1000000007),如计算初始结果为:1000000008,请返回 1。
示例1:
输入: 2
输出: 1
解释: 2 = 1 + 1, 1 × 1 = 1
示例2:
输入: 10
输出: 36
解释: 10 = 3 + 3 + 4, 3 × 3 × 4 = 36
例程
class Solution {
public:
int cuttingRope(int n) {
if (n < 4)
return n - 1;
long ans = 1;
while (n > 4) {
ans = ans * 3 % 1000000007;
n -= 3;
}
return int(ans * n % 1000000007);
}
};输入两个递增排序的链表,合并这两个链表并使新链表中的节点仍然是递增排序的。
示例1
输入:1->2->4, 1->3->4
输出:1->1->2->3->4->4
例程
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2) {
ListNode* head = new ListNode(0), * cur = head;
while (l1 && l2) {
if (l1->val > l2->val) {
cur->next = l2;
l2 = l2->next;
cur = cur->next;
}
else {
cur->next = l1;
l1 = l1->next;
cur = cur->next;
}
}
if (l1) {
cur->next = l1;
}
if (l2) {
cur->next = l2;
}
return head->next;
}
};输入两棵二叉树A和B,判断B是不是A的子结构。(约定空树不是任意一个树的子结构)
B是A的子结构, 即 A中有出现和B相同的结构和节点值。
例如: 给定的树 A:
3
/ \
4 5
/ \
1 2
给定的树 B:
4
/
1
返回 true,因为 B 与 A 的一个子树拥有相同的结构和节点值。
示例1:
输入:A = [1,2,3], B = [3,1]
输出:false
示例2:
输入:A = [3,4,5,1,2], B = [4,1]
输出:true
例程
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
bool isSubStructure(TreeNode* A, TreeNode* B) {
if (!B)
return false;
bool ans = true;
help1(A, B, ans);
return ans;
}
void help1(TreeNode* A, TreeNode* B, bool& ans) {
if (!ans)
return;
help2(A, B, ans);
if (!ans && A && A->left) {
ans = true;
help1(A->left, B, ans);
}
if (!ans && A && A->right) {
ans = true;
help1(A->right, B, ans);
}
}
void help2(TreeNode* A, TreeNode* B, bool& ans) {
if (!ans)
return;
if (!A && B) {
ans = false;
return;
}
if (!B)
return;
if (A->val != B->val) {
ans = false;
return;
}
help2(A->left, B->left, ans);
help2(A->right, B->right, ans);
}
};请完成一个函数,输入一个二叉树,该函数输出它的镜像。
例如输入:
4
/ \
2 7
/ \ / \
1 3 6 9
镜像输出:
4
/ \
7 2
/ \ / \
9 6 3 1
示例1:
输入:root = [4,2,7,1,3,6,9]
输出:[4,7,2,9,6,3,1]
例程
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
TreeNode* mirrorTree(TreeNode* root) {
if (!root)
return root;
TreeNode* tmp = root->left;
root->left = root->right;
root->right = tmp;
mirrorTree(root->left);
mirrorTree(root->right);
return root;
}
};请实现一个函数,用来判断一棵二叉树是不是对称的。如果一棵二叉树和它的镜像一样,那么它是对称的。
例如,二叉树 [1,2,2,3,4,4,3] 是对称的。
1
/ \
2 2
/ \ / \
3 4 4 3
但是下面这个 [1,2,2,null,3,null,3] 则不是镜像对称的:
1
/ \
2 2
\ \
3 3
示例1:
输入:root = [1,2,2,3,4,4,3]
输出:true
示例2:
输入:root = [1,2,2,null,3,null,3]
输出:false
例程
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
bool isSymmetric(TreeNode* root) {
if (!root)
return true;
bool ans = true;
isSymmetricHelper(root->left, root->right, ans);
return ans;
}
void isSymmetricHelper(TreeNode* left, TreeNode* right, bool& ans) {
if (!ans)
return;
if (!left && right) {
ans = false;
return;
}
if (left && !right) {
ans = false;
return;
}
if (!left && !right) {
return;
}
if (left->val != right->val) {
ans = false;
return;
}
isSymmetricHelper(left->left, right->right, ans);
isSymmetricHelper(left->right, right->left, ans);
}
};请实现一个函数用来判断字符串是否表示数值(包括整数和小数)。
数值(按顺序)可以分成以下几个部分:
1、若干空格 2、一个 小数 或者 整数 3、(可选)一个 'e' 或 'E' ,后面跟着一个 整数 4、若干空格 小数(按顺序)可以分成以下几个部分:
1、(可选)一个符号字符('+' 或 '-') 2、下述格式之一: 1、至少一位数字,后面跟着一个点 '.' 2、至少一位数字,后面跟着一个点 '.' ,后面再跟着至少一位数字 3、一个点 '.' ,后面跟着至少一位数字 整数(按顺序)可以分成以下几个部分:
1、(可选)一个符号字符('+' 或 '-') 2、至少一位数字 部分数值列举如下:
["+100", "5e2", "-123", "3.1416", "-1E-16", "0123"]
部分非数值列举如下:
["12e", "1a3.14", "1.2.3", "+-5", "12e+5.4"]
示例1:
输入:s = "0"
输出:true
示例2:
输入:s = "e"
输出:false
示例3:
输入:s = "."
输出:false
示例4:
输入:s = " .1 "
输出:true
例程
class Solution {
public:
bool isNumber(string s) {
int n = 0;
// 跨过前面的若干空格
while (s[n] == ' ') n++;
// 跨过正负号(其实小数和整数里第一部分可能存在正负号是干扰条件,判断了直接跨过就行!)
if (s[n] == '+' || s[n] == '-') n++;
// 判断是否紧跟着小数或者整数
// integerAOrDecimal是自定义的函数,可以判断后面是否存在小数或者整数,如果是则会返回
// 小数或者整数结束的下一个索引位置,如果不是则返回-1。返回-1那么这个字符串就不是数值,
// 直接返回false
n = integerAOrDecimal(s, n);
if (n == -1) return false;
// 可选是不是存在e\E
if (s[n] == 'e' || s[n] == 'E') {
// 跨过e\E
n++;
// 跨过正负号
if (s[n] == '+' || s[n] == '-') n++;
int n_orig = n;
// 自定义的函数integer用来判断是不是紧跟着整数,返回紧跟着的整数结束的后一位索引,
// 不存在不会返回-1,只会返回原来的索引n。所以需要判断是否存在,不存在返回fasle
n = integer(s, n);
if (n_orig == n) return false;
}
// 判断结尾空格,存在不是空格的就返回false
while (s[n] != '\0') {
if (s[n] != ' ') return false;
n++;
}
// 都没问题就返回true
return true;
}
int integer(string& s, int n) {
// 判断当前字符是不是0-9,是则判断下一个,不是则返回当前索引
while (s[n] != '\0') {
if (s[n] < '0' || s[n] > '9') break;
n++;
}
// n指向第一个不为0-9的索引
return n;
}
int integerAOrDecimal(string& s, int n) {
// 记录下初始索引
int n_orig1 = n;
// 调用自定义的函数integer判断整数
n = integer(s, n);
int n_vary1 = n;
// 判断是否是整数。接下来的位置不是'.'就是整数的情况
if (s[n] != '.') {
// 如果integer(s, n)的返回结果n_vary1和输入的索引n_orig1相同,则代表不存在整数,
// 那么根据定义需要返回-1,若不相同则代表存在,返回输出值n_vary1
return n_vary1 == n_orig1 ? -1 : n_vary1;
}
// 判断是否是小数
// 跨过小数点
n++;
// 记录跨过小数点后的初始位置
int n_orig2 = n;
n = integer(s, n);
int n_vary2 = n;
// 这时候需要剔除一种不是小数的情况,那就是NULL.NULL
if (n_orig1 == n_vary1 && n_orig2 == n_vary2) return -1;
return n_vary2;
}
};输入一个整数数组,实现一个函数来调整该数组中数字的顺序,使得所有奇数位于数组的前半部分,所有偶数位于数组的后半部分。
示例:
输入:nums = [1,2,3,4]
输出:[1,3,2,4]
注:[3,1,2,4] 也是正确的答案之一。
例程
class Solution {
public:
vector<int> exchange(vector<int>& nums) {
if (nums.size() <= 1)
return nums;
int pose1 = 0, pose2 = nums.size() - 1;
for (int i = pose1; i <= pose2;) {
if (nums[i] % 2) {
pose1++;
i++;
}
else {
int tmp = nums[pose2];
nums[pose2] = nums[i];
nums[i] = tmp;
pose2--;
}
}
return nums;
}
};编写一个函数,输入是一个无符号整数(以二进制串的形式),返回其二进制表达式中数字位数为 '1' 的个数(也被称为 汉明重量).)。
提示:
1、请注意,在某些语言(如 Java)中,没有无符号整数类型。在这种情况下,输入和输出都将被指定为有符号整数类型,并且不应影响您的实现,因为无论整数是有符号的还是无符号的,其内部的二进制表示形式都是相同的。 2、在 Java 中,编译器使用 二进制补码 记法来表示有符号整数。因此,在上面的 示例 3 中,输入表示有符号整数 -3。
示例1:
输入:n = 11 (控制台输入 00000000000000000000000000001011)
输出:3
解释:输入的二进制串 00000000000000000000000000001011 中,共有三位为 '1'。
示例2:
输入:n = 128 (控制台输入 00000000000000000000000010000000)
输出:1
解释:输入的二进制串 00000000000000000000000010000000 中,共有一位为 '1'。
例程
class Solution {
public:
int hammingWeight(uint32_t n) {
int ans = 0;
while (n) {
ans++;
n=(n-1)&n;
}
return ans;
}
};输入一个矩阵,按照从外向里以顺时针的顺序依次打印出每一个数字。
示例1
输入:matrix = [[1,2,3],[4,5,6],[7,8,9]]
输出:[1,2,3,6,9,8,7,4,5]
示例2:
输入:matrix = [[1,2,3,4],[5,6,7,8],[9,10,11,12]]
输出:[1,2,3,4,8,12,11,10,9,5,6,7]
例程
class Solution {
public:
vector<int> spiralOrder(vector<vector<int>>& matrix) {
vector<int> ans;
if (matrix.empty() || matrix[0].empty())
return ans;
int left = 0, right = matrix[0].size() - 1;
int top = 0, b = matrix.size() - 1;
while (1) {
for (int i = left; i <= right; i++) {
ans.push_back(matrix[top][i]);
}
if (++top > b)
break;
for (int i = top; i <= b; i++) {
ans.push_back(matrix[i][right]);
}
if (--right < left)
break;
for (int i = right; i >= left; i--) {
ans.push_back(matrix[b][i]);
}
if (--b < top)
break;
for (int i = b; i >= top; i--) {
ans.push_back(matrix[i][left]);
}
if (++left > right)
break;
}
return ans;
}
};输入一个链表,输出该链表中倒数第k个节点。为了符合大多数人的习惯,本题从1开始计数,即链表的尾节点是倒数第1个节点。
例如,一个链表有 6 个节点,从头节点开始,它们的值依次是 1、2、3、4、5、6。这个链表的倒数第 3 个节点是值为 4 的节点。
示例
给定一个链表: 1->2->3->4->5, 和 k = 2.
返回链表 4->5.
例程
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* getKthFromEnd(ListNode* head, int k) {
int nodeNum = 0;
ListNode* cur = head;
while (cur) {
nodeNum++;
cur = cur->next;
}
if (nodeNum < k)
return nullptr;
int target = nodeNum - k;
cur = head;
while (target) {
cur = cur->next;
target--;
}
return cur;
}
};实现 pow(x, n) ,即计算 x 的 n 次幂函数(即,xn)。不得使用库函数,同时不需要考虑大数问题。、
示例1:
输入:x = 2.00000, n = 10
输出:1024.00000
示例2:
输入:x = 2.10000, n = 3
输出:9.26100
示例3:
输入:x = 2.00000, n = -2
输出:0.25000
解释:2-2 = 1/22 = 1/4 = 0.25
例程
class Solution {
public:
double myPow(double x, int n) {
long b = n;
if (b == 0) {
if (x == 0.0) {
return -1.0;
}
return 1.0;
}
if (x == 1.0)
return x;
if (b < 0) {
x = 1 / x;
b = -b;
}
double ans = 1.0;
while (b)
{
if (b & 1) {
ans *= x;
b--;
}
if (b) {
b = b >> 1;
x = x * x;
}
}
return ans;
}
};输入数字 n,按顺序打印出从 1 到最大的 n 位十进制数。比如输入 3,则打印出 1、2、3 一直到最大的 3 位数 999。
示例1:
输入: n = 1
输出: [1,2,3,4,5,6,7,8,9]
例程
class Solution {
public:
vector<int> printNumbers(int n) {
int maxInt = 0;
vector<int> ans;
while (n) {
maxInt = maxInt * 10 + 9;
n--;
}
for (int i = 1; i <= maxInt; i++) {
ans.push_back(i);
}
return ans;
}
};请实现一个函数用来匹配包含'. '和''的正则表达式。模式中的字符'.'表示任意一个字符,而''表示它前面的字符可以出现任意次(含0次)。在本题中,匹配是指字符串的所有字符匹配整个模式。例如,字符串"aaa"与模式"a.a"和"abaca"匹配,但与"aa.a"和"ab*a"均不匹配。
示例1:
输入:
s = "aa"
p = "a"
输出: false
解释: "a" 无法匹配 "aa" 整个字符串。
示例2:
输入:
s = "aa"
p = "a*"
输出: true
解释: 因为 '*' 代表可以匹配零个或多个前面的那一个元素, 在这里前面的元素就是 'a'。因此,字符串 "aa" 可被视为 'a' 重复了一次。
示例3:
输入:
s = "ab"
p = ".*"
输出: true
解释: ".*" 表示可匹配零个或多个('*')任意字符('.')。
示例4:
输入:
s = "aab"
p = "c*a*b"
输出: true
解释: 因为 '*' 表示零个或多个,这里 'c' 为 0 个, 'a' 被重复一次。因此可以匹配字符串 "aab"。
例程
class Solution {
public:
bool isMatch(string s, string p) {
int n = s.size(), m = p.size();
int dp[n + 5][m + 5];
memset(dp, 0, sizeof(dp));
dp[0][0] = 1;
for(int i = 0; i <= n; i++) {
for(int j = 1; j <= m; j++) {
if(p[j - 1] != '*') {
if(i >= 1 && (s[i - 1] == p[j - 1] || p[j - 1] == '.')) dp[i][j] = dp[i - 1][j - 1];
}
else {
if(j >= 2) dp[i][j] |= dp[i][j - 2];
if(i >= 1 && j >= 2 && (s[i - 1] == p[j - 2] || p[j - 2] == '.')) dp[i][j] |= dp[i - 1][j];
}
}
}
return dp[n][m];
}
};定义一个函数,输入一个链表的头节点,反转该链表并输出反转后链表的头节点。
示例:
输入: 1->2->3->4->5->NULL
输出: 5->4->3->2->1->NULL
例程
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* reverseList(ListNode* head) {
ListNode* prev = nullptr, * cur = head, *next = nullptr;
while (cur) {
next = cur->next;
cur->next = prev;
prev = cur;
cur = next;
}
return prev;
}
};给定单向链表的头指针和一个要删除的节点的值,定义一个函数删除该节点。
返回删除后的链表的头节点。
示例1:
输入: head = [4,5,1,9], val = 5
输出: [4,1,9]
解释: 给定你链表中值为 5 的第二个节点,那么在调用了你的函数之后,该链表应变为 4 -> 1 -> 9.
示例2:
输入: head = [4,5,1,9], val = 1
输出: [4,5,9]
解释: 给定你链表中值为 1 的第三个节点,那么在调用了你的函数之后,该链表应变为 4 -> 5 -> 9.
例程
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode* deleteNode(ListNode* head, int val) {
if (!head)
return nullptr;
if (head->val == val) {
return deleteNode(head->next, val);
}
head->next = deleteNode(head->next, val);
return head;
}
};请实现 copyRandomList 函数,复制一个复杂链表。在复杂链表中,每个节点除了有一个 next 指针指向下一个节点,还有一个 random 指针指向链表中的任意节点或者 null。
示例1:

输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]]
输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]
示例2:

输入:head = [[1,1],[2,1]]
输出:[[1,1],[2,1]]
例程:
/*
// Definition for a Node.
class Node {
public:
int val;
Node* next;
Node* random;
Node(int _val) {
val = _val;
next = NULL;
random = NULL;
}
};
*/
class Solution {
public:
Node* copyRandomList(Node* head) {
if (!head)
return nullptr;
unordered_map<Node*, Node*> hash;
Node* newHead = new Node(0), * newCur = newHead, * cur = head;
while (cur) {
newCur->next = new Node(cur->val);
newCur = newCur->next;
hash[cur] = newCur;
cur = cur->next;
}
cur = head;
while (cur) {
hash[cur]->random = hash[cur->random];
cur = cur->next;
}
return newHead->next;
}
};输入整数数组 arr ,找出其中最小的 k 个数。例如,输入4、5、1、6、2、7、3、8这8个数字,则最小的4个数字是1、2、3、4。
示例1:
输入:arr = [3,2,1], k = 2
输出:[1,2] 或者 [2,1]
示例2:
输入:arr = [0,1,2,1], k = 1
输出:[0]
例程:
class Solution {
public:
vector<int> getLeastNumbers(vector<int>& arr, int k) {
int n = arr.size();
if (n <= k)
return arr;
sort(arr.begin(), arr.end());
vector<int>ans;
for (int i = 0; i < k; i++) {
ans.push_back(arr[i]);
}
return ans;
}
};定义栈的数据结构,请在该类型中实现一个能够得到栈的最小元素的 min 函数在该栈中,调用 min、push 及 pop 的时间复杂度都是 O(1)。
示例:
MinStack minStack = new MinStack();
minStack.push(-2);
minStack.push(0);
minStack.push(-3);
minStack.min(); --> 返回 -3.
minStack.pop();
minStack.top(); --> 返回 0.
minStack.min(); --> 返回 -2.
例程
class MinStack {
public:
/** initialize your data structure here. */
MinStack() {
}
void push(int x) {
data.push(x);
if (min_s.empty() || min_s.top() > x) {
min_s.push(x);
}
else {
min_s.push(min_s.top());
}
}
void pop() {
if (data.size() <= 0 || min_s.size() <= 0) {
return;
}
data.pop();
min_s.pop();
}
int top() {
if (data.size() <= 0 || min_s.size() <= 0) {
return -1;
}
return data.top();
}
int min() {
if (data.size() <= 0 || min_s.size() <= 0) {
return -1;
}
return min_s.top();
}
stack<int> data;
stack<int> min_s;
};
/**
* Your MinStack object will be instantiated and called as such:
* MinStack* obj = new MinStack();
* obj->push(x);
* obj->pop();
* int param_3 = obj->top();
* int param_4 = obj->min();
*/如何得到一个数据流中的中位数?如果从数据流中读出奇数个数值,那么中位数就是所有数值排序之后位于中间的数值。如果从数据流中读出偶数个数值,那么中位数就是所有数值排序之后中间两个数的平均值。
例如,
[2,3,4] 的中位数是 3
[2,3] 的中位数是 (2 + 3) / 2 = 2.5
设计一个支持以下两种操作的数据结构:
1、void addNum(int num) - 从数据流中添加一个整数到数据结构中。 2、double findMedian() - 返回目前所有元素的中位数。
示例1:
输入:
["MedianFinder","addNum","addNum","findMedian","addNum","findMedian"]
[[],[1],[2],[],[3],[]]
输出:[null,null,null,1.50000,null,2.00000]
示例2:
输入:
["MedianFinder","addNum","findMedian","addNum","findMedian"]
[[],[2],[],[3],[]]
输出:[null,null,2.00000,null,2.50000]
例程
class MedianFinder {
private:
priority_queue<int, vector<int>, less<int>> bigHeap;
priority_queue<int, vector<int>, greater<int>> smallHeap;
public:
/** initialize your data structure here. */
MedianFinder() {
}
void addNum(int num) {
if (bigHeap.size() == smallHeap.size()) {
smallHeap.push(num);
int value = smallHeap.top();
smallHeap.pop();
bigHeap.push(value);
}
else {
bigHeap.push(num);
int value = bigHeap.top();
bigHeap.pop();
smallHeap.push(value);
}
}
double findMedian() {
if (bigHeap.size() == smallHeap.size()) {
return (double)(bigHeap.top() + smallHeap.top()) / 2;
}
else
return (double)bigHeap.top();
}
};
/**
* Your MedianFinder object will be instantiated and called as such:
* MedianFinder* obj = new MedianFinder();
* obj->addNum(num);
* double param_2 = obj->findMedian();
*/输入一个整型数组,数组中的一个或连续多个整数组成一个子数组。求所有子数组的和的最大值。
要求时间复杂度为O(n)。
示例1:
输入: nums = [-2,1,-3,4,-1,2,1,-5,4]
输出: 6
解释: 连续子数组 [4,-1,2,1] 的和最大,为 6。
例程
class Solution {
public:
int maxSubArray(vector<int>& nums) {
int n = nums.size();
if (n <= 0)
return 0;
vector<int>dp(n + 1, nums[0]);
int ans = nums[0];
for (int i = 2; i <= n; i++) {
dp[i] = max(nums[i - 1], dp[i - 1] + nums[i - 1]);
if (dp[i] > ans)
ans = dp[i];
}
return ans;
}
};输入一棵二叉搜索树,将该二叉搜索树转换成一个排序的循环双向链表。要求不能创建任何新的节点,只能调整树中节点指针的指向。
为了让您更好地理解问题,以下面的二叉搜索树为例:
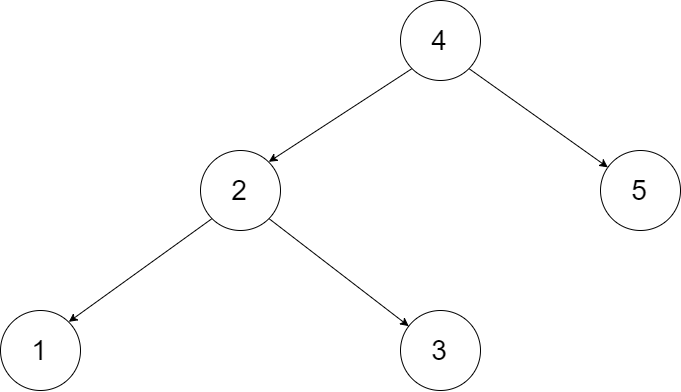
我们希望将这个二叉搜索树转化为双向循环链表。链表中的每个节点都有一个前驱和后继指针。对于双向循环链表,第一个节点的前驱是最后一个节点,最后一个节点的后继是第一个节点。
下图展示了上面的二叉搜索树转化成的链表。“head” 表示指向链表中有最小元素的节点。
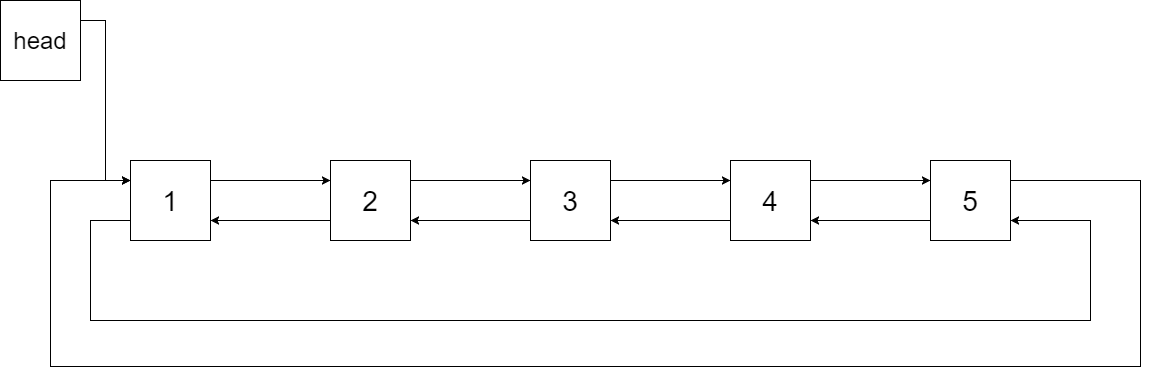
特别地,我们希望可以就地完成转换操作。当转化完成以后,树中节点的左指针需要指向前驱,树中节点的右指针需要指向后继。还需要返回链表中的第一个节点的指针。
例程:
/*
// Definition for a Node.
class Node {
public:
int val;
Node* left;
Node* right;
Node() {}
Node(int _val) {
val = _val;
left = NULL;
right = NULL;
}
Node(int _val, Node* _left, Node* _right) {
val = _val;
left = _left;
right = _right;
}
};
*/
class Solution {
public:
Node* treeToDoublyList(Node* root) {
if (!root)
return nullptr;
dfs(root);
head->left = prev;
prev->right = head;
return head;
}
private:
Node* prev, * head;
void dfs(Node* cur) {
if (!cur)
return;
dfs(cur->left);
if (prev) {
prev->right = cur;
}
else {
head = cur;
}
cur->left = prev;
prev = cur;
dfs(cur->right);
}
};输入两个整数序列,第一个序列表示栈的压入顺序,请判断第二个序列是否为该栈的弹出顺序。假设压入栈的所有数字均不相等。例如,序列 {1,2,3,4,5} 是某栈的压栈序列,序列 {4,5,3,2,1} 是该压栈序列对应的一个弹出序列,但 {4,3,5,1,2} 就不可能是该压栈序列的弹出序列。
示例1:
输入:pushed = [1,2,3,4,5], popped = [4,5,3,2,1]
输出:true
解释:我们可以按以下顺序执行:
push(1), push(2), push(3), push(4), pop() -> 4,
push(5), pop() -> 5, pop() -> 3, pop() -> 2, pop() -> 1
示例2:
输入:pushed = [1,2,3,4,5], popped = [4,3,5,1,2]
输出:false
解释:1 不能在 2 之前弹出。
例程
class Solution {
public:
bool validateStackSequences(vector<int>& pushed, vector<int>& popped) {
if (pushed.size() != popped.size())
return false;
if (pushed.empty())
return true;
stack<int>s;
s.push(pushed[0]);
int index1 = 1, index2 = 0;
int n = pushed.size();
while (index1 < n && index2 < n) {
if (s.empty() || s.top() != popped[index2]) {
s.push(pushed[index1]);
index1++;
}
else {
s.pop();
index2++;
}
}
if (index1 < n)
return false;
while (index2 < n) {
if (s.empty())
return false;
if (s.top() != popped[index2])
return false;
index2++;
s.pop();
}
return s.empty();
}
};请实现两个函数,分别用来序列化和反序列化二叉树。
你需要设计一个算法来实现二叉树的序列化与反序列化。这里不限定你的序列 / 反序列化算法执行逻辑,你只需要保证一个二叉树可以被序列化为一个字符串并且将这个字符串反序列化为原始的树结构。
示例
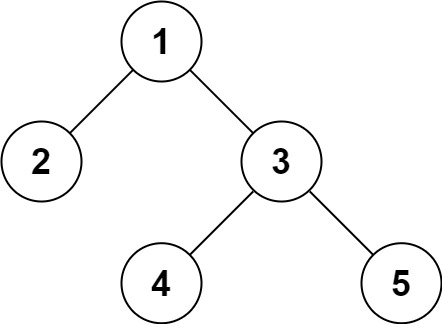
输入:root = [1,2,3,null,null,4,5]
输出:[1,2,3,null,null,4,5]
例程
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Codec {
public:
// Encodes a tree to a single string.
string serialize(TreeNode* root) {
if (root == nullptr) return "null";
return to_string(root->val) + ' ' + serialize(root->left) + ' ' + serialize(root->right);
}
TreeNode* dfs_deserialize(istringstream& iss) {
string val; iss >> val;
if (val == "null") return nullptr;
return new TreeNode(stoi(val), dfs_deserialize(iss), dfs_deserialize(iss));
}
// Decodes your encoded data to tree.
TreeNode* deserialize(string data) {
istringstream iss(data);
return dfs_deserialize(iss);
}
};
// Your Codec object will be instantiated and called as such:
// Codec codec;
// codec.deserialize(codec.serialize(root));输入一个字符串,打印出该字符串中字符的所有排列。
你可以以任意顺序返回这个字符串数组,但里面不能有重复元素。
示例
输入:s = "abc"
输出:["abc","acb","bac","bca","cab","cba"]
例程
class Solution {
public:
vector<string> permutation(string s) {
vector<string> result;
string tmp = s;
unordered_map<string, bool>m;
permutationHelper(result, tmp, 0, m);
return result;
}
void permutationHelper(vector<string>& result, string tmp, int pose, unordered_map<string, bool>&m) {
if (pose >= tmp.length()-1) {
if (m.find(tmp) == m.end()) {
result.push_back(tmp);
m[tmp] = true;
}
return;
}
int n = tmp.length();
for (int i = pose; i < n; i++) {
swap(tmp[i], tmp[pose]);
permutationHelper(result,tmp, pose + 1,m);
swap(tmp[i], tmp[pose]);
}
}
};输入一个整数 n ,求1~n这n个整数的十进制表示中1出现的次数。
例如,输入12,1~12这些整数中包含1 的数字有1、10、11和12,1一共出现了5次。
示例1:
输入:n = 12
输出:5
示例2:
输入:n = 13
输出:6
例程:
class Solution {
public:
int countDigitOne(int n) {
if (n <= 0)
return 0;
string num = to_string(n);
return NumerOf1(num);
}
int NumerOf1(string& num) {
if (num.length() == 0)
return 0;
int first = num[0] - '0';
int length = num.length();
if (first < 0 || first>9) {
return 0;
}
if (length == 1 && first > 0)
return 1;
int numFiristDigit = 0;
if (first > 1) {
numFiristDigit = powerBase10(length - 1);
}
else if (first == 1) {
numFiristDigit = atoi(num.substr(1,length-1).c_str()) + 1;
}
int numOtherDights = first * (length - 1) * powerBase10(length - 2);
string left = num.substr(1, length - 1);
int numRecursive = NumerOf1(left);
return numFiristDigit + numOtherDights + numRecursive;
}
int powerBase10(int n) {
int ans = 1;
for (int i = 0; i < n; i++) {
ans *= 10;
}
return ans;
}
};数组中有一个数字出现的次数超过数组长度的一半,请找出这个数字。
你可以假设数组是非空的,并且给定的数组总是存在多数元素。
示例1:
输入: [1, 2, 3, 2, 2, 2, 5, 4, 2]
输出: 2
例程
class Solution {
public:
int majorityElement(vector<int>& nums) {
int tmp = nums[0], count = 1;
int n = nums.size();
for (int i = 1; i < n; i++) {
if (nums[i] == tmp) {
count++;
}
else {
count--;
}
if (!count) {
tmp = nums[i];
count = 1;
}
}
return tmp;
}
};从上到下打印出二叉树的每个节点,同一层的节点按照从左到右的顺序打印。
例如:
给定二叉树: [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回:
[3,9,20,15,7]
例程:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
vector<int> levelOrder(TreeNode* root) {
vector<int>result;
if (!root)
return result;
queue<TreeNode*> q;
q.push(root);
while (!q.empty()) {
TreeNode* tmp = q.front();
q.pop();
result.push_back(tmp->val);
if (tmp->left)
q.push(tmp->left);
if (tmp->right)
q.push(tmp->right);
}
return result;
}
};从上到下按层打印二叉树,同一层的节点按从左到右的顺序打印,每一层打印到一行。
例如:
给定二叉树: [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回其层次遍历结果:
[
[3],
[9,20],
[15,7]
]
例程:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root) {
vector<vector<int>>result;
if (!root)
return result;
queue<TreeNode*> q;
q.push(root);
while (!q.empty())
{
int count = q.size();
vector<int> level;
for (int i = 0; i < count; i++) {
TreeNode* tmp = q.front();
level.push_back(tmp->val);
q.pop();
if (tmp->left)
q.push(tmp->left);
if (tmp->right)
q.push(tmp->right);
}
result.push_back(level);
}
return result;
}
};数字以0123456789101112131415…的格式序列化到一个字符序列中。在这个序列中,第5位(从下标0开始计数)是5,第13位是1,第19位是4,等等。
请写一个函数,求任意第n位对应的数字。
示例1:
输入:n = 3
输出:3
示例2:
输入:n = 11
输出:0
例程:
class Solution {
public:
int findNthDigit(int n) {
// digit :表示 digit 位数
// max : 表示 dight 位数的最大下标
// lastMax : 表示 dight - 1 位数的最大下标
long max = 9, lastMax = 0;
int digit = 1;
// 找到这个数是几位数,也就是更新 digit 的过程
while (n > max) {
digit++;
lastMax = max;
max += digit * 9 * pow(10, digit - 1);
}
// 根据这个数的位数,就可以求出索引为n是哪个数的第几位
long num = (n - lastMax) / digit + (int)pow(10, digit - 1);
long nth = (n - lastMax) % digit;
// 特殊情况 余数为0时,更新 nth 为这个数的最后一位
if (nth == 0) {
num--;
nth = digit;
}
// 将求出的数 num 转化为 字符串,返回第 nth 位
return to_string(num)[nth-1]-'0';
}
};请实现一个函数按照之字形顺序打印二叉树,即第一行按照从左到右的顺序打印,第二层按照从右到左的顺序打印,第三行再按照从左到右的顺序打印,其他行以此类推。
例如:
给定二叉树: [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回其层次遍历结果:
[
[3],
[20,9],
[15,7]
]
例程:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
vector<vector<int>> levelOrder(TreeNode* root) {
vector<vector<int>>result;
if (!root)
return result;
deque<TreeNode*> q;
q.push_back(root);
int layer = 0;
while (!q.empty())
{
int count = q.size();
vector<int> level;
for (int i = 0; i < count; i++) {
if (layer & 1) {
TreeNode* tmp = q.back();
level.push_back(tmp->val);
q.pop_back();
if (tmp->right)
q.push_front(tmp->right);
if (tmp->left)
q.push_front(tmp->left);
}
else {
TreeNode* tmp = q.front();
level.push_back(tmp->val);
q.pop_front();
if (tmp->left)
q.push_back(tmp->left);
if (tmp->right)
q.push_back(tmp->right);
}
}
layer++;
result.push_back(level);
}
return result;
}
};输入一个整数数组,判断该数组是不是某二叉搜索树的后序遍历结果。如果是则返回 true,否则返回 false。假设输入的数组的任意两个数字都互不相同。
参考以下这颗二叉搜索树:
5
/ \
2 6
/ \
1 3
示例1:
输入: [1,6,3,2,5]
输出: false
示例2:
输入: [1,3,2,6,5]
输出: true
例程:
class Solution {
public:
bool verifyPostorder(vector<int>& postorder) {
bool result = true;
int left = 0;
int right = postorder.size() - 1;
verifyHelper(postorder, left, right, result);
return result;
}
void verifyHelper(vector<int>& postorder, int left, int right, bool& result) {
if (left >= right) {
return;
}
if (!result)
return;
int root = postorder[right];
int leftStart = left;
int leftEnd = right - 1;
int rightStart = -1;
int rightEnd = right - 1;
for (int i = left; i < right; i++) {
if (postorder[i] > root) {
leftEnd = i - 1;
rightStart = i;
break;
}
}
if (rightStart != -1) {
for (int i = rightStart; i < right; i++) {
if (postorder[i] < root) {
result = false;
return;
}
}
verifyHelper(postorder, rightStart, rightEnd, result);
}
verifyHelper(postorder, leftStart, leftEnd, result);
}
};在字符串 s 中找出第一个只出现一次的字符。如果没有,返回一个单空格。 s 只包含小写字母。
示例1:
输入:s = "abaccdeff"
输出:'b'
示例2:
输入:s = ""
输出:' '
例程
class Solution {
public:
char firstUniqChar(string s) {
unordered_map<char, bool> m;
vector<char> c;
for (char& ch : s) {
if (m.find(ch) == m.end())
c.push_back(ch);
m[ch] = m.find(ch) == m.end();
}
for (int i = 0; i < c.size(); i++) {
if (m[c[i]])
return c[i];
}
return ' ';
}
};给你二叉树的根节点 root 和一个整数目标和 targetSum ,找出所有 从根节点到叶子节点路径总和等于给定目标和的路径。
叶子节点 是指没有子节点的节点。
示例1:
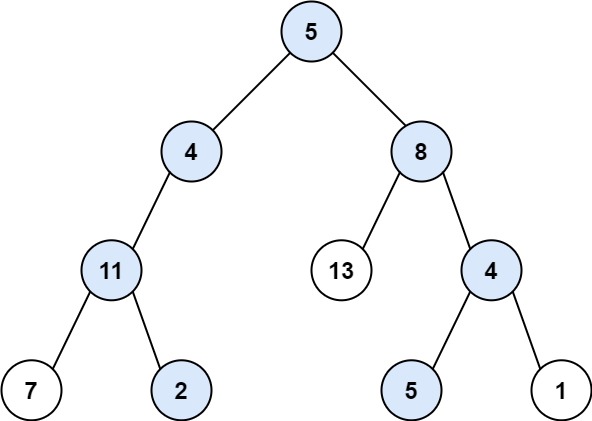
输入:root = [5,4,8,11,null,13,4,7,2,null,null,5,1], targetSum = 22
输出:[[5,4,11,2],[5,8,4,5]]
示例2:
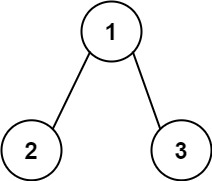
输入:root = [1,2,3], targetSum = 5
输出:[]
示例3:
输入:root = [1,2], targetSum = 0
输出:[]
例程:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left), right(right) {}
* };
*/
class Solution {
public:
vector<vector<int>> pathSum(TreeNode* root, int target) {
vector<int>tmp;
vector<vector<int>>result;
pathSumHelper(root, target, result, tmp);
return result;
}
void pathSumHelper(TreeNode* root, int target, vector<vector<int>>& result, vector<int>tmp) {
if (!root) {
return;
}
tmp.push_back(root->val);
if (root->val == target&&!root->left&&!root->right) {
result.push_back(tmp);
}
pathSumHelper(root->left, target - root->val, result, tmp);
pathSumHelper(root->right, target - root->val, result, tmp);
}
};在数组中的两个数字,如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对。输入一个数组,求出这个数组中的逆序对的总数。
示例:
输入: [7,5,6,4]
输出: 5
例程:
class Solution {
public:
int reversePairs(vector<int>& nums) {
if (nums.empty())
return 0;
vector<int>copy;
for (int& num : nums) {
copy.push_back(num);
}
int count = reversePairsHelper(nums, copy, 0, nums.size() - 1);
return count;
}
int reversePairsHelper(vector<int>& nums, vector<int>& copy, int start, int end) {
if (start == end) {
return 0;
}
int length = (end - start + 1) / 2;
int left = reversePairsHelper(copy, nums, start, start + length - 1);
int right = reversePairsHelper(copy, nums, start + length, end);
int i = start + length - 1;
int j = end;
int count = 0;
int index = end;
while (i >= start && j >= start + length) {
if (nums[i] > nums[j]) {
copy[index--] = nums[i--];
count += j - start - length + 1;
}
else {
copy[index--] = nums[j--];
}
}
for (; i >= start; i--)
copy[index--] = nums[i];
for (; j >= start + length; j--)
copy[index--] = nums[j];
return left + right + count;
}
};输入一棵二叉树的根节点,求该树的深度。从根节点到叶节点依次经过的节点(含根、叶节点)形成树的一条路径,最长路径的长度为树的深度。
例如:
给定二叉树 [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
返回它的最大深度 3 。
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
int maxDepth(TreeNode* root) {
return root == nullptr ? 0 : 1 + max(maxDepth(root->left), maxDepth(root->right));
}
};一个整型数组 nums 里除两个数字之外,其他数字都出现了两次。请写程序找出这两个只出现一次的数字。要求时间复杂度是O(n),空间复杂度是O(1)。
示例1:
输入:nums = [4,1,4,6]
输出:[1,6] 或 [6,1]
示例2:
输入:nums = [1,2,10,4,1,4,3,3]
输出:[2,10] 或 [10,2]
例程:
class Solution {
public:
vector<int> singleNumbers(vector<int>& nums) {
int x = 0, y = 0, dight = 1, diff = 0;
int n = nums.size();
for (int&num: nums) {
diff ^= num;
}
while (!(diff & 1)) {
diff = diff >> 1;
dight = dight << 1;
}
for (int& num : nums) {
if (num & dight) {
x ^= num;
}
else {
y ^= num;
}
}
return { x,y };
}
};在一个数组 nums 中除一个数字只出现一次之外,其他数字都出现了三次。请找出那个只出现一次的数字。
示例1:
输入:nums = [3,4,3,3]
输出:4
示例2:
输入:nums = [9,1,7,9,7,9,7]
输出:1
例程:
class Solution {
public:
int singleNumber(vector<int>& nums) {
unordered_map<int, int>count;
for (int& num : nums) {
if (count.find(num) != count.end()) {
count[num]++;
}
else {
count[num] = 1;
}
}
for (auto& item : count) {
if (item.second == 1) {
return item.first;
}
}
return -1;
}
};输入一个递增排序的数组和一个数字s,在数组中查找两个数,使得它们的和正好是s。如果有多对数字的和等于s,则输出任意一对即可。
示例1:
输入:nums = [2,7,11,15], target = 9
输出:[2,7] 或者 [7,2]
示例2:
输入:nums = [10,26,30,31,47,60], target = 40
输出:[10,30] 或者 [30,10]
例程:
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
int l = 0, r = nums.size() - 1;
while (l<r)
{
int sum = nums[l] + nums[r];
if (sum > target) {
r--;
}
else if (sum < target) {
l++;
}
else {
return { nums[l], nums[r] };
}
}
return { -1,-1 };
}
};输入一个非负整数数组,把数组里所有数字拼接起来排成一个数,打印能拼接出的所有数字中最小的一个。
示例1:
输入: [10,2]
输出: "102"
示例2:
输入: [3,30,34,5,9]
输出: "3033459"
例程:
class Solution {
public:
string minNumber(vector<int>& nums) {
sort(nums.begin(),nums.end(),[](const int& a,const int& b){
string a1,b1;
a1=to_string(a); //将整型转变成字符串类型进行比较
b1=to_string(b);
return a1+b1<b1+a1;
});
string s;
for(auto i:nums)
s+=to_string(i);
return s;
}
};输入一个正整数 target ,输出所有和为 target 的连续正整数序列(至少含有两个数)。
序列内的数字由小到大排列,不同序列按照首个数字从小到大排列。
示例1:
输入:target = 9
输出:[[2,3,4],[4,5]]
示例2:
输入:target = 15
输出:[[1,2,3,4,5],[4,5,6],[7,8]]
例程:
class Solution {
public:
vector<vector<int>> findContinuousSequence(int target) {
int end = 0;
if (target & 1) {
end = target / 2 + 1;
}
else {
end = target / 2;
}
vector<vector<int>>result;
vector<int>tmp;
for (int i = 1; i < end; i++) {
tmp.push_back(i);
int tmpTarget = target - i;
for (int j = i + 1; j <= end; j++) {
tmp.push_back(j);
if (tmpTarget == j) {
result.push_back(tmp);
break;
}
else if(tmpTarget < j){
break;
}
tmpTarget -= j;
}
tmp.clear();
}
return result;
}
};给定一个数字,我们按照如下规则把它翻译为字符串:0 翻译成 “a” ,1 翻译成 “b”,……,11 翻译成 “l”,……,25 翻译成 “z”。一个数字可能有多个翻译。请编程实现一个函数,用来计算一个数字有多少种不同的翻译方法。
示例:
输入: 12258
输出: 5
解释: 12258有5种不同的翻译,分别是"bccfi", "bwfi", "bczi", "mcfi"和"mzi"
例程:
class Solution {
public:
int translateNum(int num) {
string s = to_string(num);
int n = s.length();
if (n == 0)
return 0;
vector<int>dp(n + 1, 1);
char pre = s[0];
for (int i = 2; i <= n; i++) {
char cur = s[i - 1];
if ((pre - '0' == 2 && cur - '0' < 6) || (pre - '0' == 1)) {
dp[i] = dp[i - 1] + dp[i - 2];
}
else {
dp[i] = dp[i - 1];
}
pre = cur;
}
return dp[n];
}
};输入两个链表,找出它们的第一个公共节点。
如下面的两个链表:

在节点 c1 开始相交。
示例1:
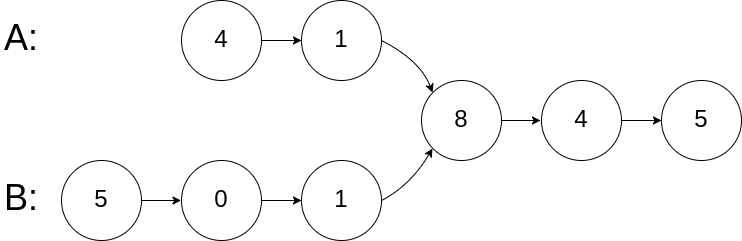
输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,0,1,8,4,5], skipA = 2, skipB = 3
输出:Reference of the node with value = 8
输入解释:相交节点的值为 8 (注意,如果两个列表相交则不能为 0)。从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,0,1,8,4,5]。在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
示例2:
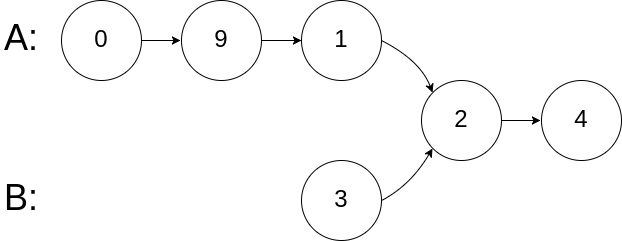
输入:intersectVal = 2, listA = [0,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1
输出:Reference of the node with value = 2
输入解释:相交节点的值为 2 (注意,如果两个列表相交则不能为 0)。从各自的表头开始算起,链表 A 为 [0,9,1,2,4],链表 B 为 [3,2,4]。在 A 中,相交节点前有 3 个节点;在 B 中,相交节点前有 1 个节点。
例程:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* ListNode *next;
* ListNode(int x) : val(x), next(NULL) {}
* };
*/
class Solution {
public:
ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {
ListNode* A = headA, * B = headB;
int lengthA = 0, lengthB = 0;
while (A) {
lengthA++;
A = A->next;
}
while (B) {
lengthB++;
B = B->next;
}
A = headA, B = headB;
if (lengthA > lengthB) {
swap(lengthA, lengthB);
swap(A, B);
}
while (lengthB > lengthA) {
lengthB--;
B = B->next;
}
while (A && B) {
if (A == B)
return A;
A = A->next;
B = B->next;
}
return nullptr;
}
};在一个 m*n 的棋盘的每一格都放有一个礼物,每个礼物都有一定的价值(价值大于 0)。你可以从棋盘的左上角开始拿格子里的礼物,并每次向右或者向下移动一格、直到到达棋盘的右下角。给定一个棋盘及其上面的礼物的价值,请计算你最多能拿到多少价值的礼物?
示例1:
输入:
[
[1,3,1],
[1,5,1],
[4,2,1]
]
输出: 12
解释: 路径 1→3→5→2→1 可以拿到最多价值的礼物
例程:
class Solution {
public:
int maxValue(vector<vector<int>>& grid) {
if (grid.empty() || grid[0].empty())
return 0;
int n = grid.size(), m = grid[0].size();
vector<vector<int>> board(n, vector<int>(m, 0));
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
if (i == 0 && j == 0) {
board[i][j] = grid[i][j];
}
else if (i == 0) {
board[i][j] = grid[i][j] + board[i][j - 1];
}
else if (j == 0) {
board[i][j] = grid[i][j] + board[i - 1][j];
}
else {
board[i][j] = grid[i][j] + max(board[i - 1][j], board[i][j - 1]);
}
}
}
return board[n - 1][m - 1];
}
};输入一个英文句子,翻转句子中单词的顺序,但单词内字符的顺序不变。为简单起见,标点符号和普通字母一样处理。例如输入字符串"I am a student. ",则输出"student. a am I"。
示例1:
输入: "the sky is blue"
输出: "blue is sky the"
示例2:
输入: " hello world! "
输出: "world! hello"
解释: 输入字符串可以在前面或者后面包含多余的空格,但是反转后的字符不能包括。
例程:
class Solution {
public:
string reverseWords(string s) {
vector<string>v;
int n = s.length();
for (int i = 0; i < n; i++) {
if (s[i] == ' ')
continue;
for (int j = i; j < n; j++) {
if (s[j] == ' ') {
v.push_back(s.substr(i, j - i));
i = j;
break;
}
else if (j == n - 1) {
v.push_back(s.substr(i, j - i + 1));
i = j;
break;
}
}
}
int m = v.size();
string ans = "";
for (int i = m - 1; i >= 0; i--) {
ans = ans + " " + v[i];
}
return ans.length()? ans.substr(1):"";
}
};统计一个数字在排序数组中出现的次数。
示例1:
输入: nums = [5,7,7,8,8,10], target = 8
输出: 2
示例2:
输入: nums = [5,7,7,8,8,10], target = 6
输出: 0
例程:
class Solution {
public:
int search(vector<int>& nums, int target) {
int result = 0;
int n = nums.size();
for (int i = 0; i < n; i++) {
if (nums[i] == target) {
result++;
}
}
return result;
}
};字符串的左旋转操作是把字符串前面的若干个字符转移到字符串的尾部。请定义一个函数实现字符串左旋转操作的功能。比如,输入字符串"abcdefg"和数字2,该函数将返回左旋转两位得到的结果"cdefgab"。
示例1:
输入: s = "abcdefg", k = 2
输出: "cdefgab"
示例2:
输入: s = "lrloseumgh", k = 6
输出: "umghlrlose"
例程:
class Solution {
public:
string reverseLeftWords(string s, int n) {
int k = s.length();
if (k == 0 || k < n)
return s;
return s.substr(n) + s.substr(0, n);
}
};一个长度为n-1的递增排序数组中的所有数字都是唯一的,并且每个数字都在范围0~n-1之内。在范围0~n-1内的n个数字中有且只有一个数字不在该数组中,请找出这个数字。
示例1
输入: [0,1,3]
输出: 2
示例2:
输入: [0,1,2,3,4,5,6,7,9]
输出: 8
例程:
class Solution {
public:
int missingNumber(vector<int>& nums) {
int n = nums.size();
int flagZore = 0;
int over = 0;
for (int i = 0; i < n; i++) {
int tmp = abs(nums[i]);
if (tmp == n) {
over = 1;
continue;
}
if (nums[tmp] > 0) {
nums[tmp] = -nums[tmp];
}
else if (nums[tmp] == 0) {
flagZore = 1;
}
}
for (int i = 0; i < n; i++) {
int tmp = nums[i];
if (tmp == 0 && !flagZore) {
return i;
}
else if(tmp > 0) {
return i;
}
}
return over ? -1 : n;
}
};请从字符串中找出一个最长的不包含重复字符的子字符串,计算该最长子字符串的长度。
示例1:
输入: "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
示例2:
输入: "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
示例3:
输入: "pwwkew"
输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。
例程:
class Solution {
public:
int lengthOfLongestSubstring(string s) {
int l = 0, r = 1, n = s.length();
if (n <= 1)
return n;
unordered_map<char, int> hash;
hash[s[l]]++;
int maxLength = 1;
while (l < n && r < n) {
if (hash.find(s[r]) == hash.end() || !hash[s[r]]) {
hash[s[r]] = 1;
r++;
maxLength = max(maxLength, r - l);
}
else {
hash[s[l]]--;
l++;
}
}
return maxLength;
}
};给定一棵二叉搜索树,请找出其中第k大的节点。
示例1:
输入: root = [3,1,4,null,2], k = 1
3
/ \
1 4
\
2
输出: 4
示例2:
输入: root = [5,3,6,2,4,null,null,1], k = 3
5
/ \
3 6
/ \
2 4
/
1
输出: 4
例程:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
int kthLargest(TreeNode* root, int k) {
TreeNode* result = nullptr;
int num = 0;
kthLargestHelper(root, k, num, result);
if (result)
return result->val;
return 0;
}
void kthLargestHelper(TreeNode* root, int k, int& num, TreeNode*& result) {
if (!root)
return;
if (result)
return;
kthLargestHelper(root->right, k, num, result);
num++;
if (num == k) {
result = root;
return;
}
kthLargestHelper(root->left, k, num, result);
}
};我们把只包含质因子 2、3 和 5 的数称作丑数(Ugly Number)。求按从小到大的顺序的第 n 个丑数。
示例:
输入: n = 10
输出: 12
解释: 1, 2, 3, 4, 5, 6, 8, 9, 10, 12 是前 10 个丑数。
例程:
class Solution {
public:
int nthUglyNumber(int n) {
vector<int>dp(n + 1, 1);
int x2 = 1;
int x3 = 1;
int x5 = 1;
for (int i = 2; i <= n; i++) {
int tmp2 = dp[x2] * 2;
int tmp3 = dp[x3] * 3;
int tmp5 = dp[x5] * 5;
dp[i] = min(min(tmp2, tmp3), tmp5);
if (dp[i] == tmp2)
x2++;
if (dp[i] == tmp3)
x3++;
if (dp[i] == tmp5)
x5++;
}
return dp[n];
}
};写一个函数,求两个整数之和,要求在函数体内不得使用 “+”、“-”、“*”、“/” 四则运算符号。
示例1:
输入: a = 1, b = 1
输出: 2
例程:
class Solution {
public:
int add(int a, int b) {
return b == 0 ? a : add(a^b, (unsigned int)(a&b) << 1);
}
};给定一个数组 nums 和滑动窗口的大小 k,请找出所有滑动窗口里的最大值。
示例:
输入: nums = [1,3,-1,-3,5,3,6,7], 和 k = 3
输出: [3,3,5,5,6,7]
解释:
滑动窗口的位置 最大值
--------------- -----
[1 3 -1] -3 5 3 6 7 3
1 [3 -1 -3] 5 3 6 7 3
1 3 [-1 -3 5] 3 6 7 5
1 3 -1 [-3 5 3] 6 7 5
1 3 -1 -3 [5 3 6] 7 6
1 3 -1 -3 5 [3 6 7] 7
例程:
class Solution {
public:
vector<int> maxSlidingWindow(vector<int>& nums, int k) {
int n = nums.size();
if (n <= 0)
return vector<int>();
deque<int>win;
vector<int>result;
for (int i = 0; i < k; i++) {
if (i >= n) {
result.push_back(nums[win.front()]);
return result;
}
while (!win.empty() && nums[win.back()] < nums[i]) {
win.pop_back();
}
win.push_back(i);
}
result.push_back(nums[win.front()]);
for (int i = k; i < n; i++) {
while (!win.empty() && nums[win.back()] < nums[i]) {
win.pop_back();
}
win.push_back(i);
while (win.front() <= i - k) {
win.pop_front();
}
result.push_back(nums[win.front()]);
}
return result;
}
};请定义一个队列并实现函数 max_value 得到队列里的最大值,要求函数max_value、push_back 和 pop_front 的均摊时间复杂度都是O(1)。
若队列为空,pop_front 和 max_value 需要返回 -1
示例1:
输入:
["MaxQueue","push_back","push_back","max_value","pop_front","max_value"]
[[],[1],[2],[],[],[]]
输出: [null,null,null,2,1,2]
示例2:
输入:
["MaxQueue","pop_front","max_value"]
[[],[],[]]
输出: [null,-1,-1]
例程:
class MaxQueue {
public:
MaxQueue() {
}
int max_value() {
if (data.empty() || maxData.empty())
return -1;
return maxData.front();
}
void push_back(int value) {
while (!maxData.empty() && maxData.back() < value) {
maxData.pop_back();
}
maxData.push_back(value);
data.push(value);
}
int pop_front() {
if (data.empty())
return -1;
int result = data.front();
if(result==maxData.front())
maxData.pop_front();
data.pop();
return result;
}
private:
queue<int>data;
deque<int>maxData;
};
/**
* Your MaxQueue object will be instantiated and called as such:
* MaxQueue* obj = new MaxQueue();
* int param_1 = obj->max_value();
* obj->push_back(value);
* int param_3 = obj->pop_front();
*/给定一个数组 A[0,1,…,n-1],请构建一个数组 B[0,1,…,n-1],其中 B[i] 的值是数组 A 中除了下标 i 以外的元素的积, 即 B[i]=A[0]×A[1]×…×A[i-1]×A[i+1]×…×A[n-1]。不能使用除法。
示例:
输入: [1,2,3,4,5]
输出: [120,60,40,30,24]
例程:
class Solution {
public:
vector<int> constructArr(vector<int>& a) {
int n = a.size();
vector<int> b(n, 1);
for (int i = 1; i < n; i++) {
b[i] = b[i - 1] * a[i - 1];
}
int tmp = 1;
for (int i = n - 2; i >= 0; i--) {
tmp *= a[i + 1];
b[i] *= tmp;
}
return b;
}
};把n个骰子扔在地上,所有骰子朝上一面的点数之和为s。输入n,打印出s的所有可能的值出现的概率。
你需要用一个浮点数数组返回答案,其中第 i 个元素代表这 n 个骰子所能掷出的点数集合中第 i 小的那个的概率。
示例1:
输入: 1
输出: [0.16667,0.16667,0.16667,0.16667,0.16667,0.16667]
示例2:
输入: 2
输出: [0.02778,0.05556,0.08333,0.11111,0.13889,0.16667,0.13889,0.11111,0.08333,0.05556,0.02778]
例程:
class Solution {
public:
vector<double> dicesProbability(int n) {
vector<double>dp(6, 1.0 / 6);
for (int i = 2; i <= n; i++) {
vector<double>tmp(5 * i + 1, 0.0);
for (int j = 1; j <= 5 * i + 1; j++) {
for (int k = 0; k < 6; k++) {
if (j > k && j - k <= dp.size()) {
tmp[j - 1] += dp[j - k-1] / 6;
}
}
}
dp = tmp;
}
return dp;
}
void dicesProbilityHelper(vector<double>& result, int num, int n, int sum, double probility) {
if (num == n) {
result[sum] += probility;
return;
}
for (int i = 1; i <= 6; i++) {
sum += i;
//probility *= 1.0 / 6;
dicesProbilityHelper(result, num + 1, n, sum, probility/6);
sum -= i;
}
}
};写一个函数 StrToInt,实现把字符串转换成整数这个功能。不能使用 atoi 或者其他类似的库函数。
首先,该函数会根据需要丢弃无用的开头空格字符,直到寻找到第一个非空格的字符为止。
当我们寻找到的第一个非空字符为正或者负号时,则将该符号与之后面尽可能多的连续数字组合起来,作为该整数的正负号;假如第一个非空字符是数字,则直接将其与之后连续的数字字符组合起来,形成整数。
该字符串除了有效的整数部分之后也可能会存在多余的字符,这些字符可以被忽略,它们对于函数不应该造成影响。
注意:假如该字符串中的第一个非空格字符不是一个有效整数字符、字符串为空或字符串仅包含空白字符时,则你的函数不需要进行转换。
在任何情况下,若函数不能进行有效的转换时,请返回 0。
说明:
假设我们的环境只能存储 32 位大小的有符号整数,那么其数值范围为 [−231, 231 − 1]。如果数值超过这个范围,请返回 INT_MAX (231 − 1) 或 INT_MIN (−231) 。
示例1:
输入: "42"
输出: 42
示例2:
输入: " -42"
输出: -42
解释: 第一个非空白字符为 '-', 它是一个负号。
我们尽可能将负号与后面所有连续出现的数字组合起来,最后得到 -42 。
示例3:
输入: "4193 with words"
输出: 4193
解释: 转换截止于数字 '3' ,因为它的下一个字符不为数字。
示例4:
输入: "words and 987"
输出: 0
解释: 第一个非空字符是 'w', 但它不是数字或正、负号。
因此无法执行有效的转换。
示例5:
输入: "-91283472332"
输出: -2147483648
解释: 数字 "-91283472332" 超过 32 位有符号整数范围。
因此返回 INT_MIN (−231) 。
例程:
class Solution {
public:
int strToInt(string str) {
int i = 0;
int flag = 0;
for (; i < str.length(); i++) {
if (str[i] >= '0' && str[i] <= '9') {
break;
}
else if(str[i]=='-') {
flag = 1;
i++;
break;
}
else if (str[i] == '+') {
i++;
break;
}
else if(str[i]!=' ') {
return 0;
}
}
if (i == str.length())
return 0;
int ans = 0;
if (flag) {
while (i < str.length()) {
if (ans > 0) {
ans = -ans;
}
if (str[i] >= '0' && str[i] <= '9') {
if ((long)ans * 10 <= INT_MIN) {
return INT_MIN;
}
else {
ans *= 10;
if ((long)ans - str[i] + '0' <= INT_MIN) {
return INT_MIN;
}
else {
ans = ans - (str[i] - '0');
}
}
}
else {
break;
}
i++;
}
}
else {
while (i < str.length()) {
if (str[i] >= '0' && str[i] <= '9') {
if ((long)ans * 10 >= INT_MAX) {
return INT_MAX;
}
else {
ans *= 10;
if ((long)ans + str[i] - '0' >= INT_MAX) {
return INT_MAX;
}
else {
ans = ans + (str[i] - '0');
}
}
}
else {
break;
}
i++;
}
}
return ans;
}
};从若干副扑克牌中随机抽 5 张牌,判断是不是一个顺子,即这5张牌是不是连续的。2~10为数字本身,A为1,J为11,Q为12,K为13,而大、小王为 0 ,可以看成任意数字。A 不能视为 14。
示例1:
输入: [1,2,3,4,5]
输出: True
示例2:
输入: [0,0,1,2,5]
输出: True
例程:
class Solution {
public:
bool isStraight(vector<int>& nums) {
if (nums.size() != 5)
return false;
sort(nums.begin(), nums.end());
int numOfZore = nums[0] == 0 ? 1 : 0;
int prev = nums[0];
for (int i = 1; i < nums.size(); i++) {
if (nums[i] == 0)
numOfZore++;
else if (prev != 0) {
if (nums[i] - prev != 1) {
if (numOfZore) {
i--;
prev++;
numOfZore--;
}
else
return false;
}
else {
prev = nums[i];
}
}
else {
prev = nums[i];
}
}
return true;
}
};输入一棵二叉树的根节点,判断该树是不是平衡二叉树。如果某二叉树中任意节点的左右子树的深度相差不超过1,那么它就是一棵平衡二叉树。
示例1:
给定二叉树 [3,9,20,null,null,15,7]
3
/ \
9 20
/ \
15 7
返回 true 。
示例2:
给定二叉树 [1,2,2,3,3,null,null,4,4]
1
/ \
2 2
/ \
3 3
/ \
4 4
返回 false 。
例程:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
bool isBalanced(TreeNode* root) {
int depth = isBalancedHelper(root);
if (depth == -1)
return false;
return true;
}
int isBalancedHelper(TreeNode* root) {
if (!root)
return 0;
int left = isBalancedHelper(root->left);
int right = isBalancedHelper(root->right);
if (left == -1 || right == -1)
return -1;
if (abs(left - right) > 1)
return -1;
return 1 + max(left, right);
}
};0,1,···,n-1这n个数字排成一个圆圈,从数字0开始,每次从这个圆圈里删除第m个数字(删除后从下一个数字开始计数)。求出这个圆圈里剩下的最后一个数字。
例如,0、1、2、3、4这5个数字组成一个圆圈,从数字0开始每次删除第3个数字,则删除的前4个数字依次是2、0、4、1,因此最后剩下的数字是3。
示例1:
输入: n = 5, m = 3
输出: 3
示例2:
输入: n = 10, m = 17
输出: 2
例程:
class Solution {
public:
int lastRemaining(int n, int m) {
int ans = 0;
for (int i = 2; i <= n; i++) {
ans = (ans + m) % i;
}
return ans;
}
};假设把某股票的价格按照时间先后顺序存储在数组中,请问买卖该股票一次可能获得的最大利润是多少?
示例1:
输入: [7,1,5,3,6,4]
输出: 5
解释: 在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。
注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格。
示例2:
输入: [7,6,4,3,1]
输出: 0
解释: 在这种情况下, 没有交易完成, 所以最大利润为 0。
例程:
class Solution {
public:
int maxProfit(vector<int>& prices) {
int buy = INT_MIN;
int sell = 0;
int n = prices.size();
for (int i = 0; i < n; i++) {
buy = max(buy, -prices[i]);
sell = max(sell, buy + prices[i]);
}
return sell;
}
};求 1+2+...+n ,要求不能使用乘除法、for、while、if、else、switch、case等关键字及条件判断语句(A?B:C)。
示例1:
输入: n = 3
输出: 6
示例2:
输入: n = 9
输出: 45
例程:
class Solution {
public:
int sumNums(int n) {
int ans = 0, A = n, B = n + 1;
(B & 1) && (ans += A);
A <<= 1;
B >>= 1;
(B & 1) && (ans += A);
A <<= 1;
B >>= 1;
(B & 1) && (ans += A);
A <<= 1;
B >>= 1;
(B & 1) && (ans += A);
A <<= 1;
B >>= 1;
(B & 1) && (ans += A);
A <<= 1;
B >>= 1;
(B & 1) && (ans += A);
A <<= 1;
B >>= 1;
(B & 1) && (ans += A);
A <<= 1;
B >>= 1;
(B & 1) && (ans += A);
A <<= 1;
B >>= 1;
(B & 1) && (ans += A);
A <<= 1;
B >>= 1;
(B & 1) && (ans += A);
A <<= 1;
B >>= 1;
(B & 1) && (ans += A);
A <<= 1;
B >>= 1;
(B & 1) && (ans += A);
A <<= 1;
B >>= 1;
(B & 1) && (ans += A);
A <<= 1;
B >>= 1;
(B & 1) && (ans += A);
A <<= 1;
B >>= 1;
return ans >> 1;
}
};给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
例如,给定如下二叉搜索树: root = [6,2,8,0,4,7,9,null,null,3,5]
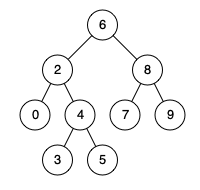
示例1:
输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 8
输出: 6
解释: 节点 2 和节点 8 的最近公共祖先是 6。
示例2:
输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 4
输出: 2
解释: 节点 2 和节点 4 的最近公共祖先是 2, 因为根据定义最近公共祖先节点可以为节点本身。
例程:
/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode(int x) : val(x), left(NULL), right(NULL) {}
* };
*/
class Solution {
public:
TreeNode* lowestCommonAncestor(TreeNode* root, TreeNode* p, TreeNode* q) {
if (root == NULL)
return NULL;
if (root == p || root == q)
return root;
TreeNode* left = lowestCommonAncestor(root->left, p, q);
TreeNode* right = lowestCommonAncestor(root->right, p, q);
if (left == NULL)
return right;
if (right == NULL)
return left;
if (left && right)
return root;
return NULL;
}
};