Love plaintext? This script downloads an URL, parses it with readability and returns the plaintext (as markdown). It supports RSS feeds (will convert every article in the feed) and saves every article.
My usecase is twofold. One is to convert RSS feeds to a Gopher site, the second is to get full text in my RSS reader.
The script contains a few workarounds for so-called cookiewalls. It also pauses between RSS feed articles to not do excessive requests.
The readability part is handled by Python, no external services are used.
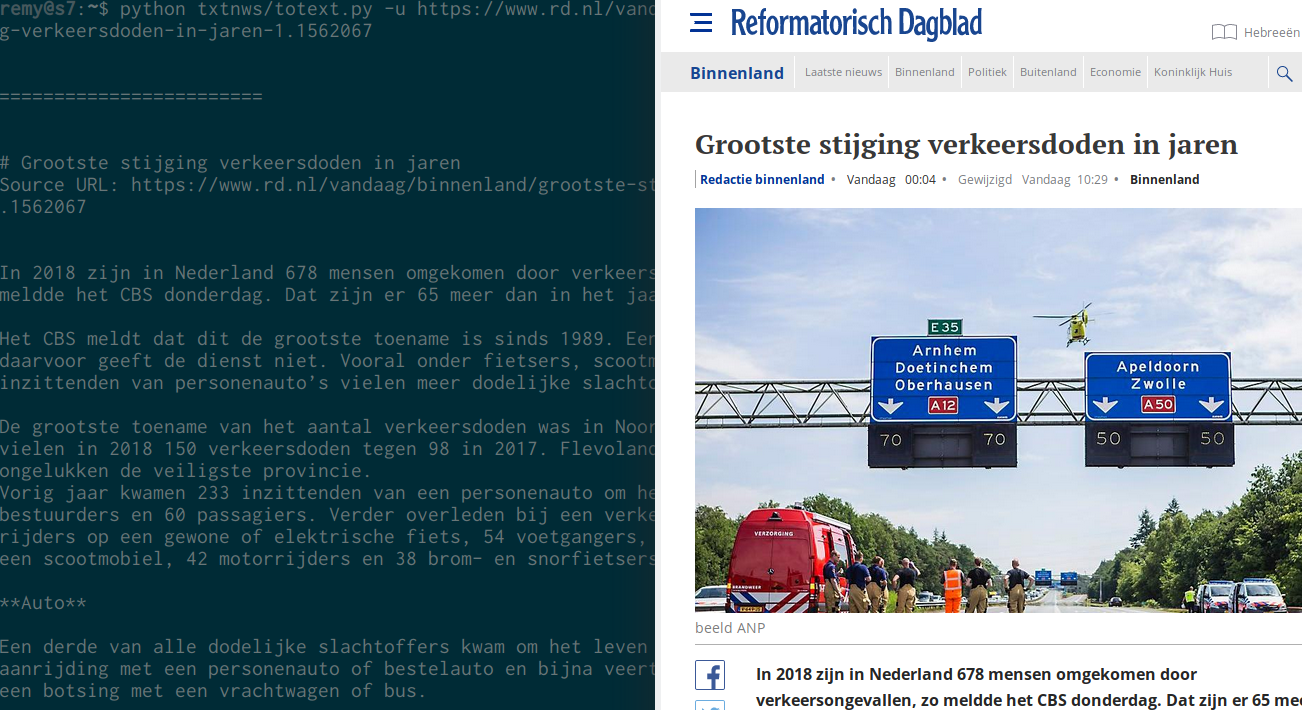
Here's an example of a news article. On the left, the text-only parsed version, on the right, the webpage:
First install the required libraries.
On Ubuntu:
apt-get install python python-pip #python2
pip install html2text requests readability-lxml feedparser lxml
Other distro's, use the pip command above.
Clone the repository:
git clone https://github.com/RaymiiOrg/to-text.py
usage: totext.py [-h] -u URL [-s SLEEP] [-r] [-n]
Convert HTML page to text using readability and html2text.
arguments:
-h, --help show this help message and exit
-u URL, --url URL URL to convert (Required)
-s SLEEP, --sleep SLEEP
Sleep X seconds between URLs (only in rss)
-r, --rss URL is RSS feed. Parse every item in feed
-n, --noprint Dont print converted contents
-o, --original Dont parse content with readability
If you want to run the script via a cronjob, use the -n option to not have output.
If an article doesnt look good (for example you get comments instead of content),
use the --original option to just convert the page to text instead of using
readability. You will get extra markup and stuff.
If the parsing failed, the article will contain the text: parsing failed.
python totext.py --rss --url https://raymii.org/s/feed.xml
python totext.py --url https://www.rd.nl/vandaag/binnenland/grootste-stijging-verkeersdoden-in-jaren-1.1562067
Every file converted will also be saved to the folder saved/$hostname. The
filenames are sorted by date.
GNU GPLv2.
vim /usr/lib/python2.7/dist-packages/pygopherd/handlers/UMN.py
class UMNDirHandler(DirHandler):
"""This module strives to be bug-compatible with UMN gopherd."""
def prepare(self):
"""Override parent to do a few more things and override sort order."""
# Initialize.
self.linkentries = []
# Let the parent do the directory walking for us. Will call
# prep_initfiles_canaddfile and prep_entriesappend.
if DirHandler.prepare(self):
# Returns 1 if it didn't load from the cache.
# Merge and sort.
self.MergeLinkFiles()
- self.fileentries.sort(self.entrycmp)
+ self.fileentries.sort(self.entrycmp, reverse=True)