![]()
AiNiee 是一款专注于Ai翻译的工具,可以用来一键自动翻译RPG SLG游戏,Epub TXT小说,Srt Lrc字幕等等
- 多格式支持: json/xlsx导出文件、Epub/TXT 小说、Srt/Lrc 字幕等。
- 多平台接入: 支持国内外主流AI接口平台,可方便快速使用OpenAI、Google、Anthropic、Deepseek、智谱等平台的接口。
- 多语言翻译: 支持多种语言的互相翻译,例如中文、英文、日文、韩文、俄语等。
- 灵活配置: 自定义请求格式、平台、模型、翻译行数、线程数等。
- 高效翻译: 拥有多文件批量翻译、多线程翻译、多key轮询、混合平台翻译等功能。
- 翻译优化: 思维链翻译、动态Few-Shot、提示书编写、上文自携带、文本自适应处理、回复检查等。

-
📖文本提取工具工具名 介绍 Mtool 上手简单,推荐新人使用 Translator++ 上手中等,功能强大,推荐大佬使用 SExtractor 上手复杂,功能强大,推荐大佬使用 -
🤖AI调用平台支持平台 模型 白嫖情况 模型价格 限制情况 OpenAI平台 ChatGPT系列 现无免费额度 贵 用途广泛 GooGle平台 Gemini系列 免费账号可白嫖,速度缓慢 贵 安全限制 Cohere平台 Command系列 免费账号可白嫖,速度一般 一般 用途广泛 Anthropic平台 Claude系列 免费账号绑卡可白嫖少量额度,速度缓慢 贵 用途广泛 月之暗面平台 Moonshot系列 注册送少量免费额度 一般 用途广泛 零一万物平台 Yi系列 注册送少量免费额度 一般 安全限制 智谱平台 GLM系列 注册送少量免费额度 一般 安全限制 Deepseek平台 Deepseek系列 注册送少量免费额度,速度极快 便宜 用途广泛 Dashscope平台 千问系列 注册送大量免费额度 便宜 安全限制 Volcengine平台 豆包系列 注册送大量免费额度,速度极快 便宜 安全限制 SakuraLLM Sakura系列 本地模型,需显卡 点击查看一键包 免费 用途广泛 -
📺视频教程视频链接 说明 Mtool教程 初次使用推荐观看 T++教程 初次使用推荐观看 -
📡 下载地址: AiNiee下载地址 -
🟪 魔法工具:强烈建议您选择优质稳定的代理工具,不然接口会报错Connection eror或者一直没有回复
-
OpenAI官方配置示例:

账号类型: 新注册的5刀余额账号为免费账号,有各种限制,单号速度不快;付费账号是有过付费记录,且达到一些条件才会升级模型选择: 请自行了解模型之间的区别后再进行更改。API KEY: 填入由OpenAi账号生成的api_key -
代理平台配置示例:

请求地址: 填入国内代理平台提供的请求地址,示例:https://api.XXXXX.com,不要在后面单带一个/自动补全: 会在上面输入的请求地址自动补全“v1”请求格式: 根据中转能够支持的请求格式进行选择,一般是openai格式模型选择: 可下拉选择,也可以自行填入模型名字API KEY: 填入国内代理平台给你生成的API KEY
每次发送文本上限: 限制每次发送文本的容量大小,以tokens为单位每分钟请求数: RPM (requests per minute)每分钟向openai发送的翻译任务数量每分钟tokens数: TPM (tokens per minute)每分钟向openai发送的tokens总数(类似字符总数) -
SakuraLLM配置:
模型部署与应用设置请参考 SakuraLLMServer - 一键获取免费且高质量的日语翻译能力
-
配置示例:
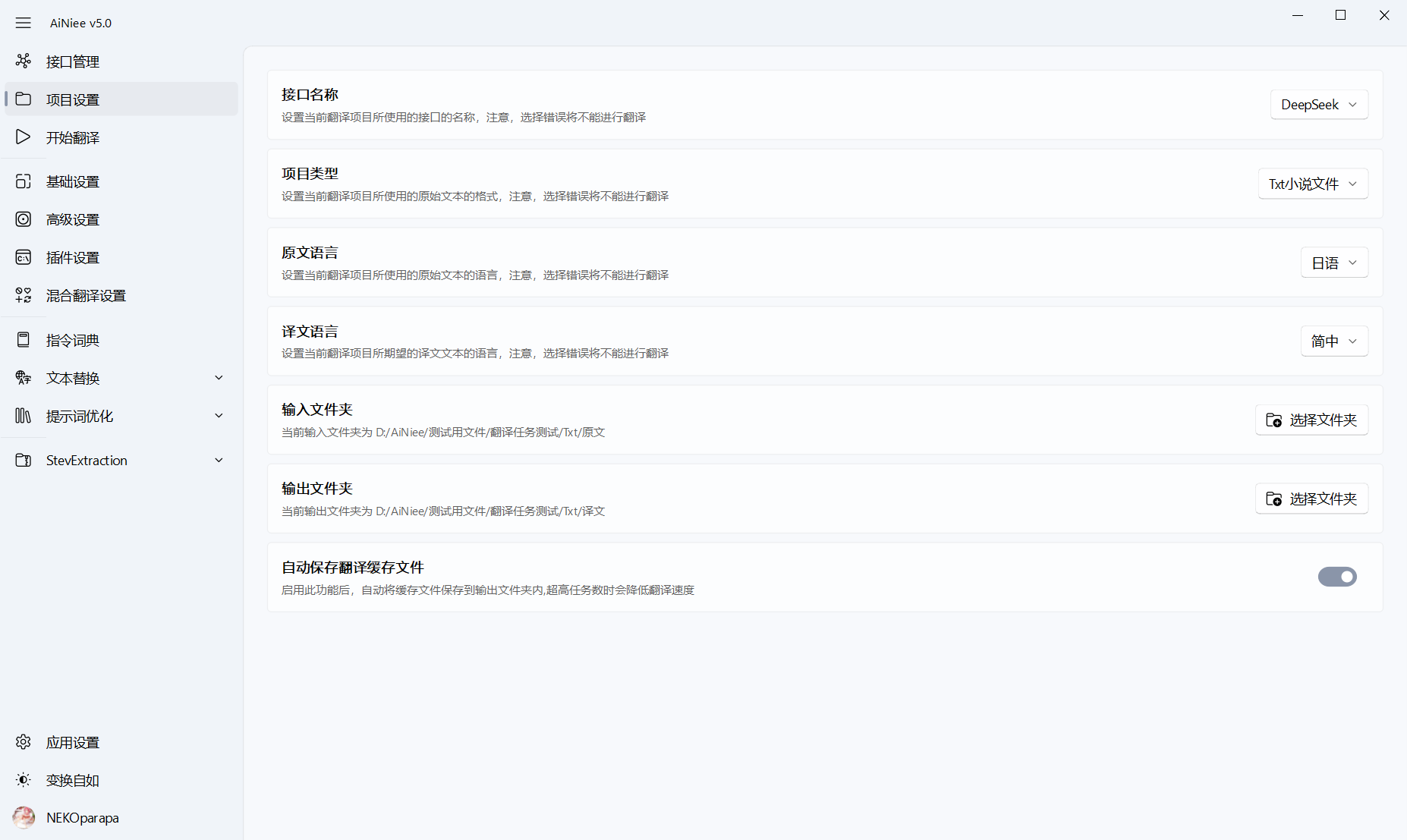
项目类型: 需要翻译的原文文件接口名称: 翻译文本时希望使用的平台原文语言: 根据你需要翻译游戏的语言选择相应的源语言译文语言: 你希望翻译成的语言输入文件夹: 选择你需要翻译的原文文件,把原文尽量放在一个干净的文件夹内,文件夹内没有其他文件,因为会读取该文件夹内所有相关的文件,包括子文件输出文件夹: 选择翻译后文件的存储文件夹,请不要和输入文件夹一个路径自动备份缓存文件: 会自动备份缓存文件到输出文件夹,高并发情况下会影响速度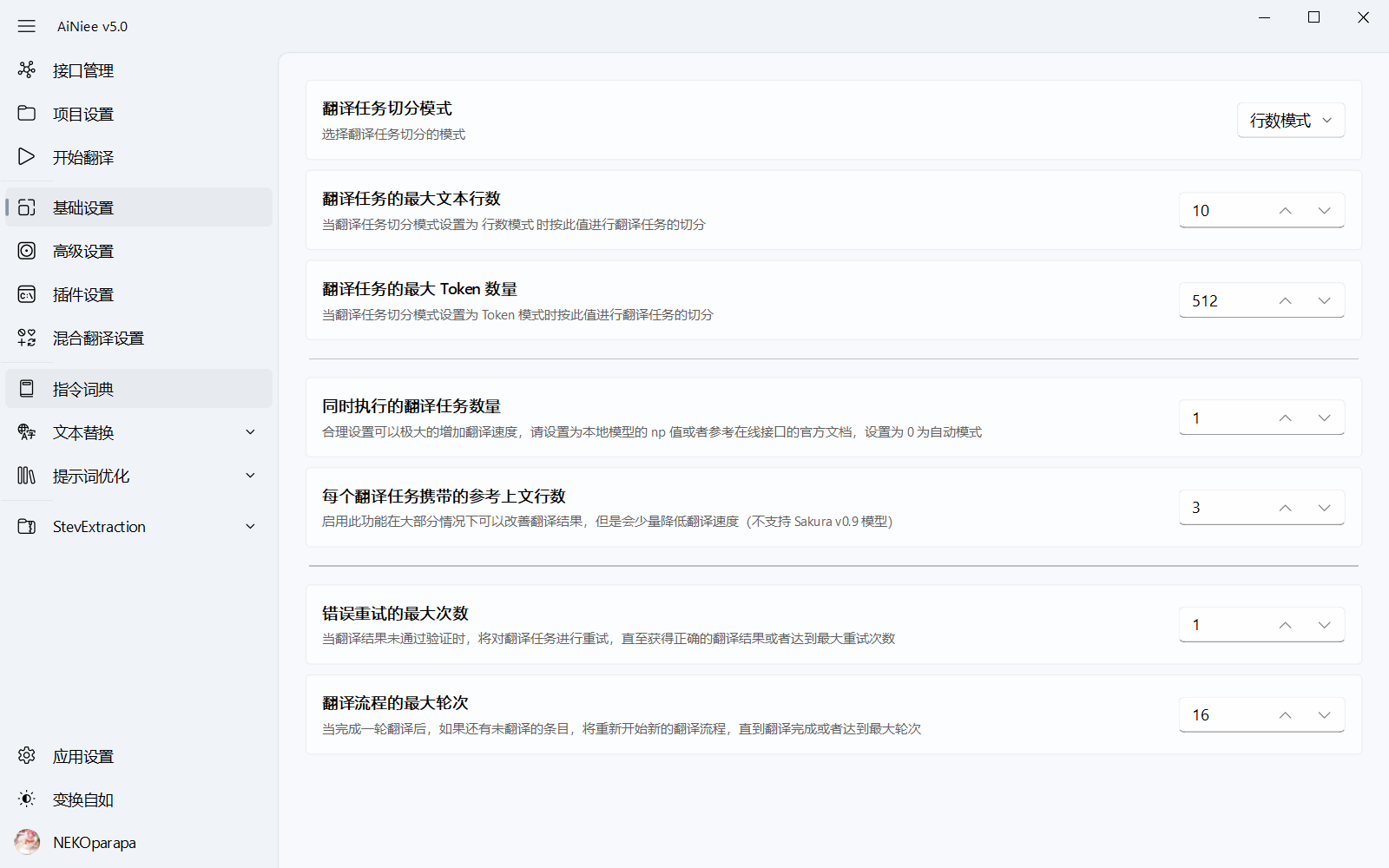
行数切分模式: 每次请求翻译的文本行数。行数设置越大,整体的翻译效果会更好,上下文更加流畅,但每次请求回复速度会越慢,回复的内容越容易出错,请根据模型类型来进行设置。tokens数切分模式: 每次请求翻译的文本tokens数,整体效果和行数模式差不多,只不过这个可以更加精确控制发送的大小,从而提高效率翻译任务并发数: 请根据翻译平台的速率进行设置,线程数越大,越容易吃满速率限制,翻译速度越快。多出的线程数不会影响翻译,但会增加电脑性能消耗携带上文行数: 弱小的模型不建议携带上文,且不建议携带过多行数错误重翻最大次数限制: 就是一段文本,出现错误回复时,最多允许重复翻译的次数翻译流程最大轮次限制: 有些在上一轮始终无法成功翻译的文本会进行拆分,并进入下一轮次翻译,如此循环翻译。所以是限制循环拆分的最大轮次数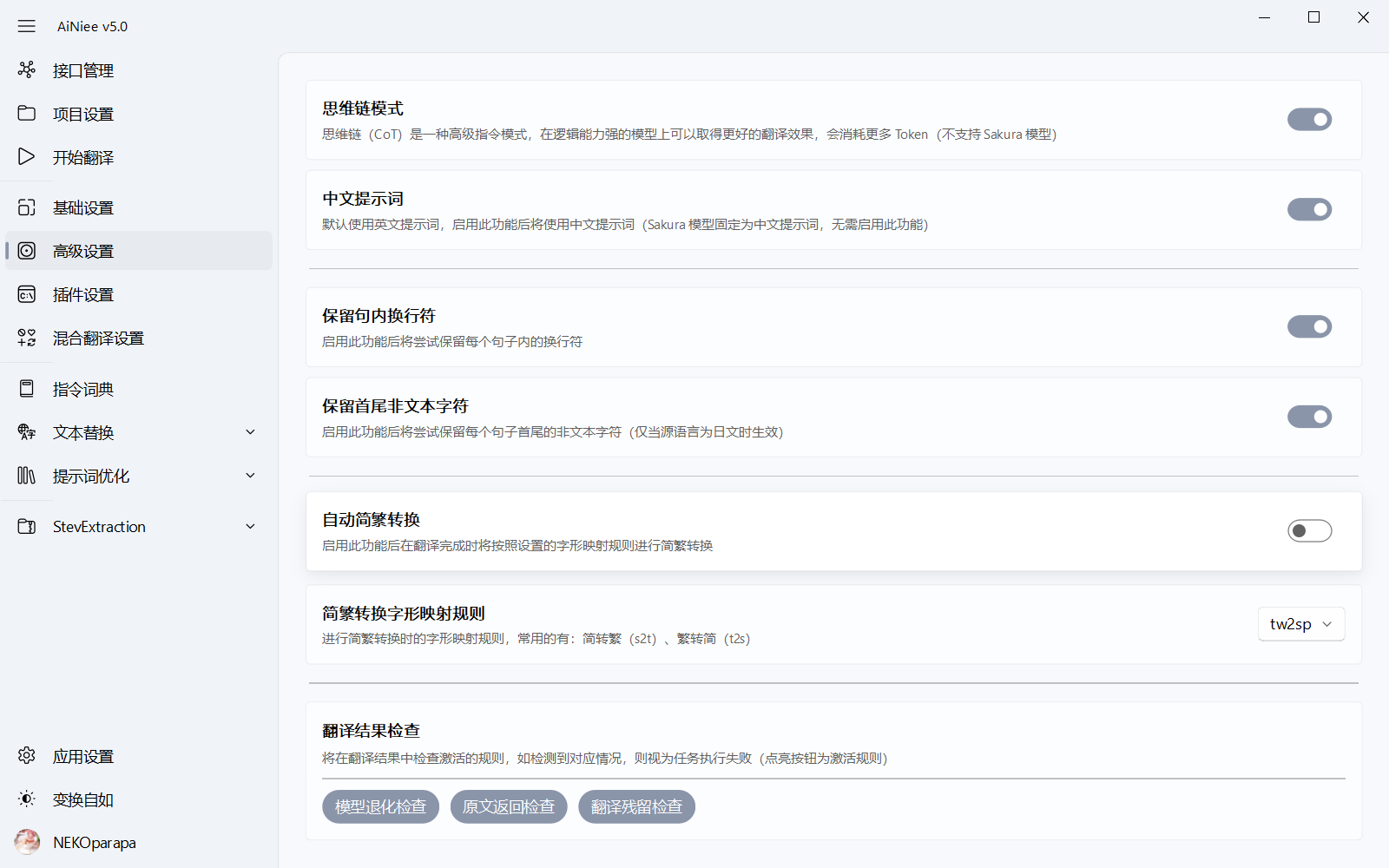
使用思维链翻译: 会与提示书功能进行联动,让AI主动思考已经提供的上文,角色,背景等等信息,当然消耗会翻倍,并且建议在高性能模型下使用。使用中文提示词: 会更改发送的prompt结构为全中文结构,部分大模型会在中文提示词下表现更优。保留句内换行符: 在翻译前将换行符替换成特殊字符,再进行翻译,AI仍会吞符号,不是百分百保留。保留首尾非文本字符: 主要用于T++导出的文本,该工具导出的文本带很多代码文本,可以截取处理了首尾的占位代码等,翻译了,再复原回来中文字形转换: 可以将翻译后的中文字体进行简体,繁体,香港体等待进行转换。配置文件说明,请参考 https://github.com/BYVoid/OpenCC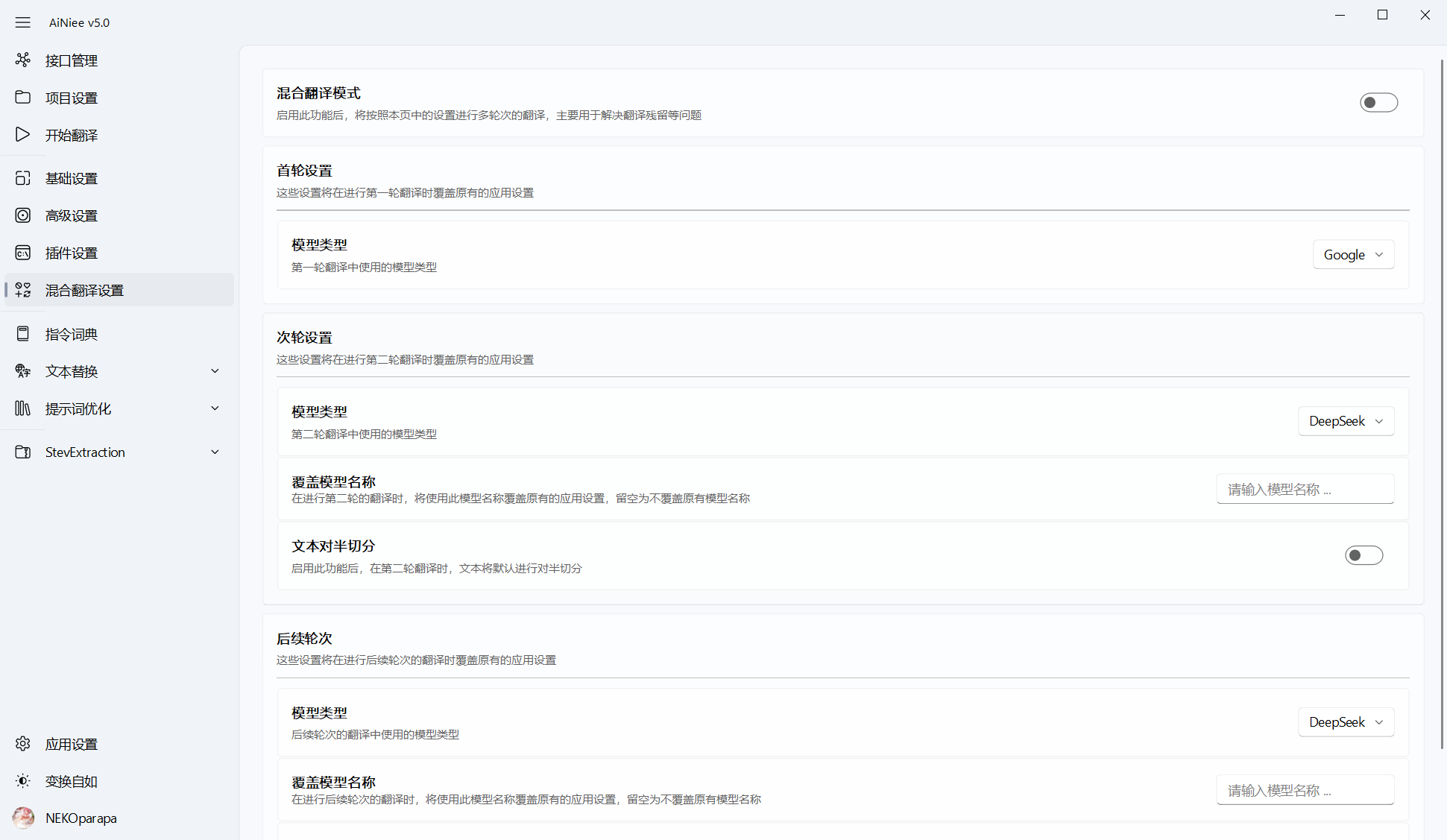
首轮翻译平台: 文本会首先以当初设置的翻译行数进行翻译, 如果翻译时出现错误回复次数达到限制,则进入下轮次再次翻译次轮翻译平台: 将之前没能成功翻译的文本拆分翻译,会重新自动计算翻译行数,并更换翻译平台,如果不设置,则沿用上轮设置的翻译平台末轮翻译平台: 后续的所有轮次都使用该次指定的翻译平台,如果不设置,则沿用上轮设置的翻译平台更换轮次时不拆分: 更换翻译轮次时不会对文本进行拆分,继续按设置行数翻译
-
1.使用Mtool打开游戏,并在翻译功能界面,选择导出游戏原文文件,会在游戏根目录生成:ManualTransFile.json
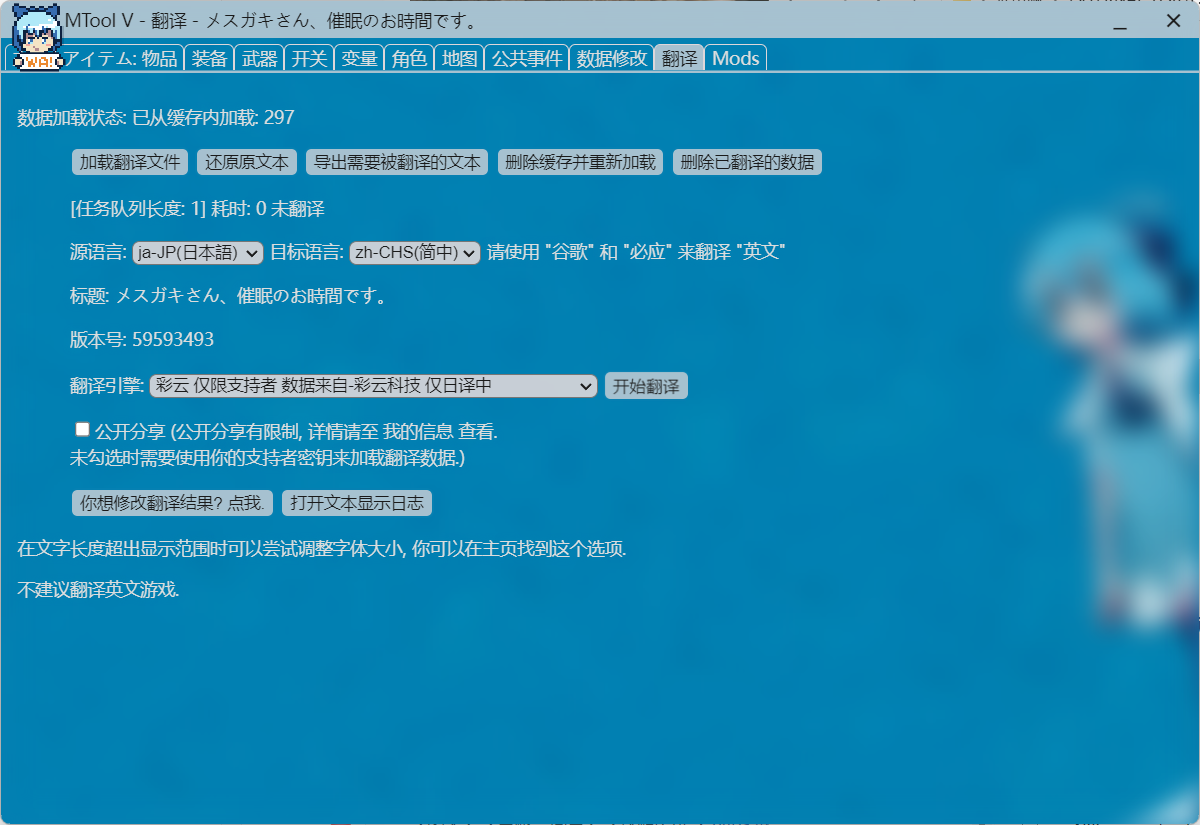 |
|
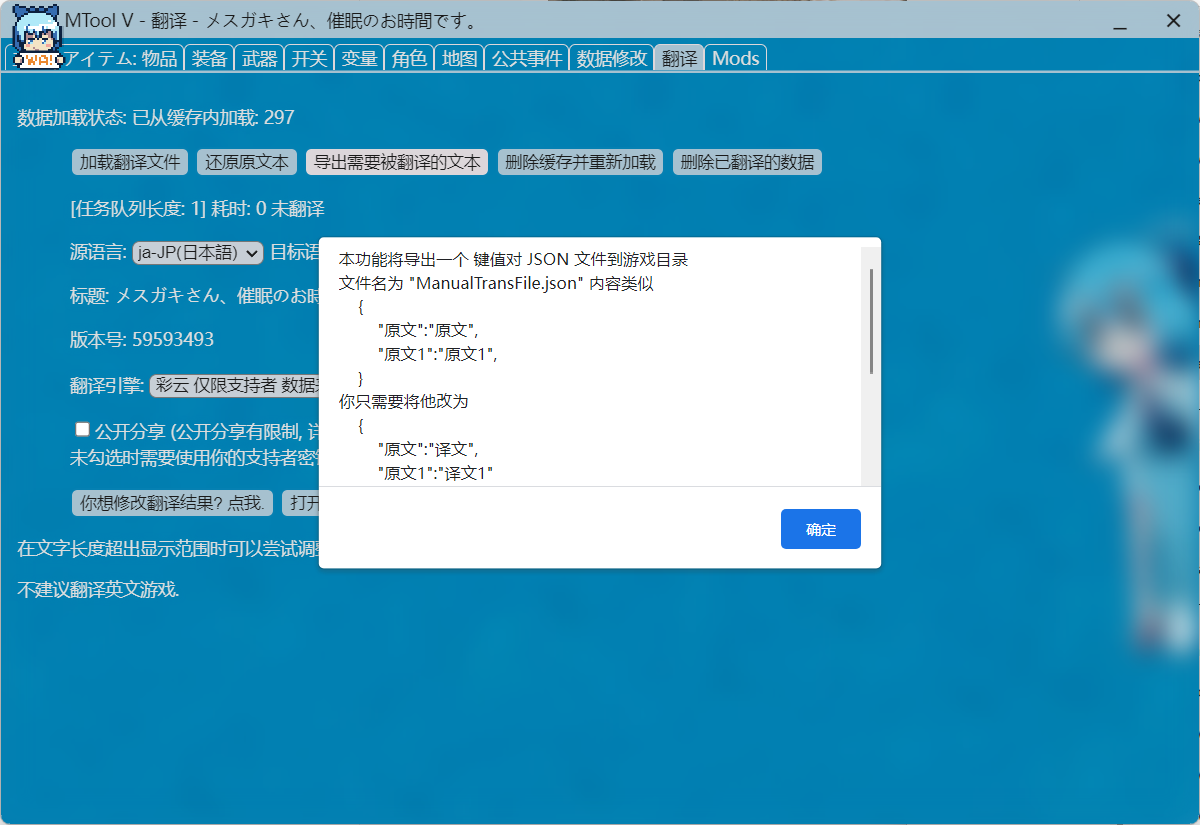
-
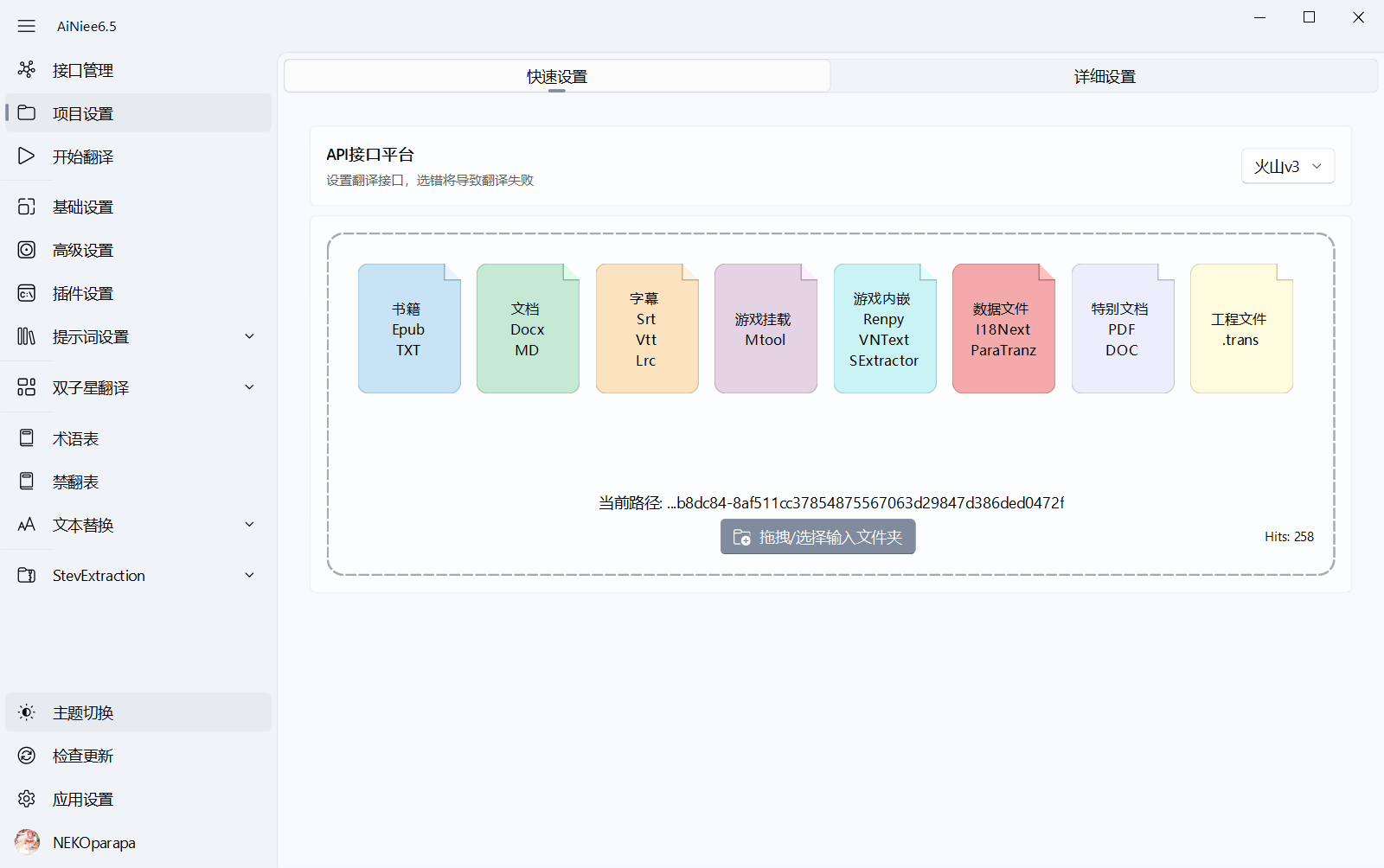
2.在
翻译设置界面的翻译项目选择🔵Mtool导出文件,并配置翻译设置配置示例:
-
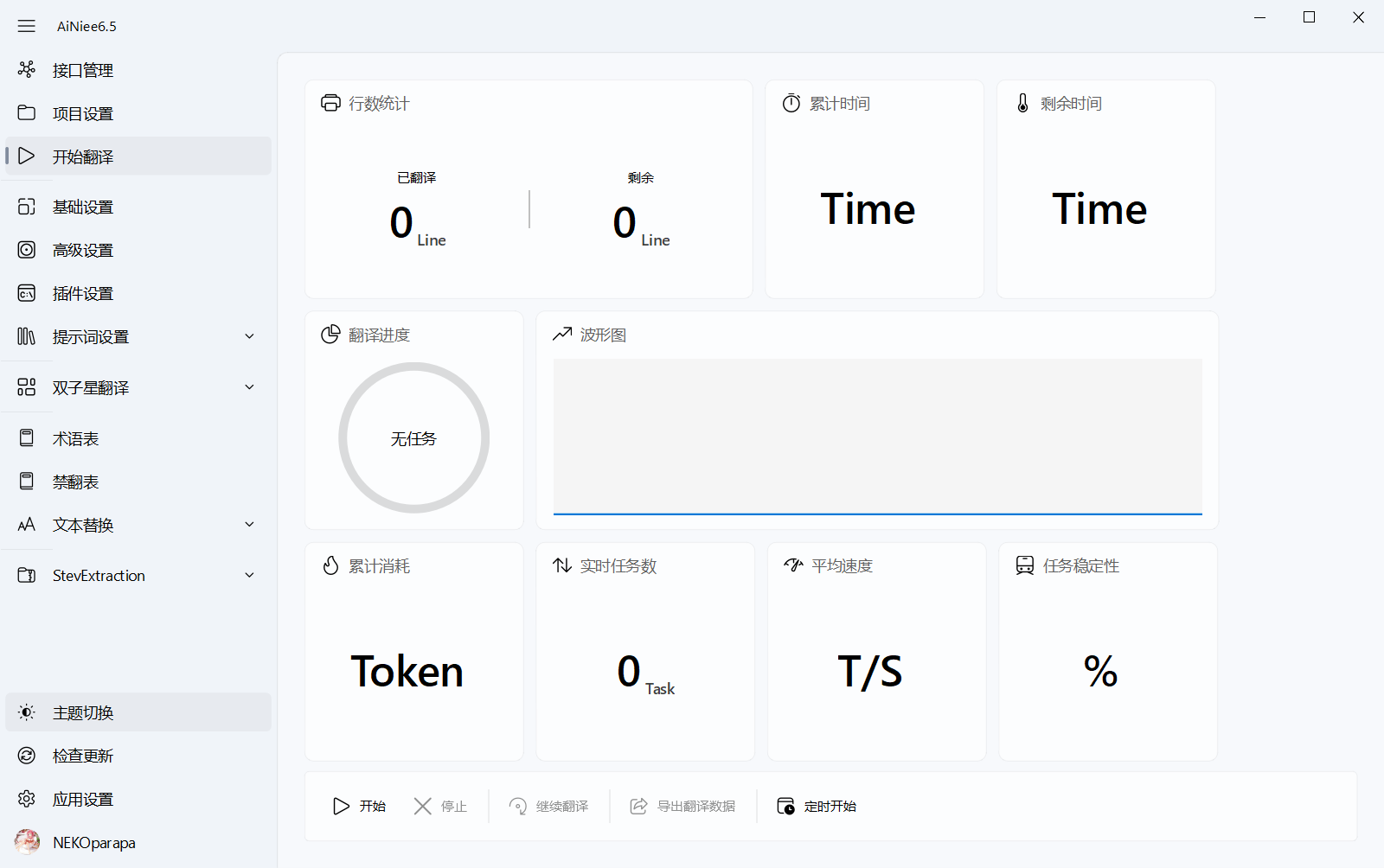
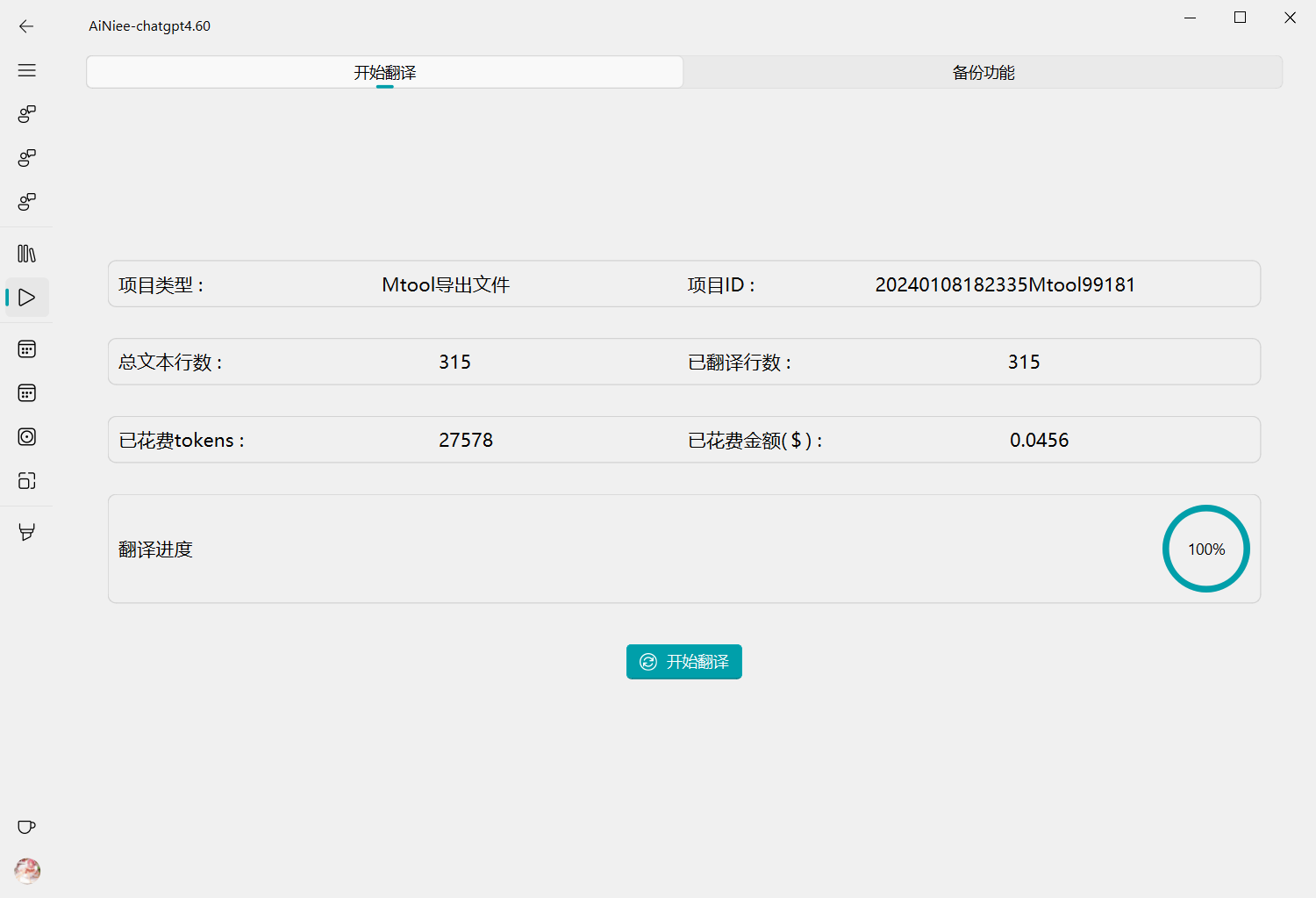
3.🖱️到开始翻译页面,点击开始翻译按钮,看控制台输出日志或者进度条。之后等待翻译进度到百分百,自动生成翻译好的文件在输出文件夹中
正在进行翻译
已经完成翻译
-
4.回到
🔵Mtool工具,依然在翻译功能界面,选择加载翻译文件,选择翻译后的文件即可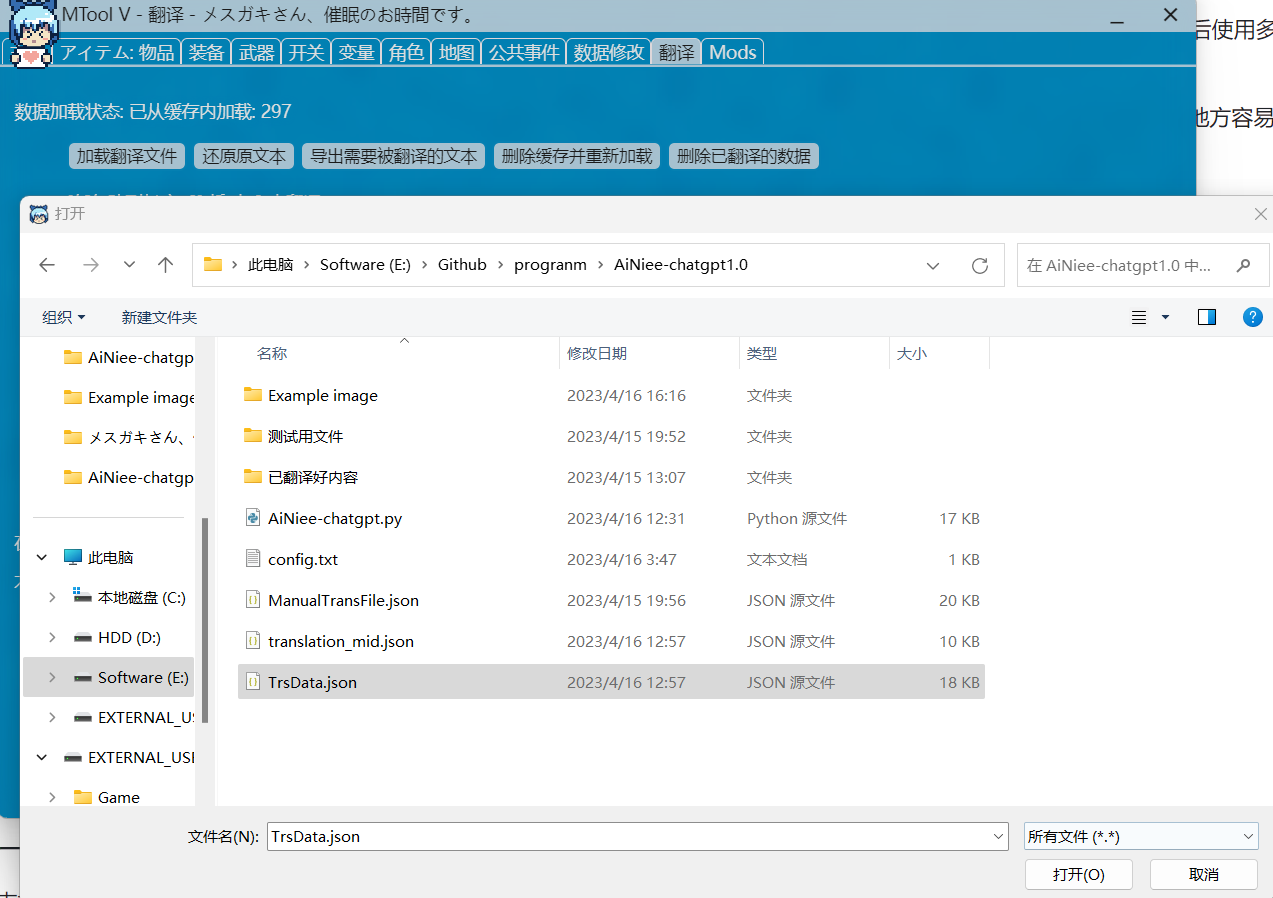
-
1.🖱️打开
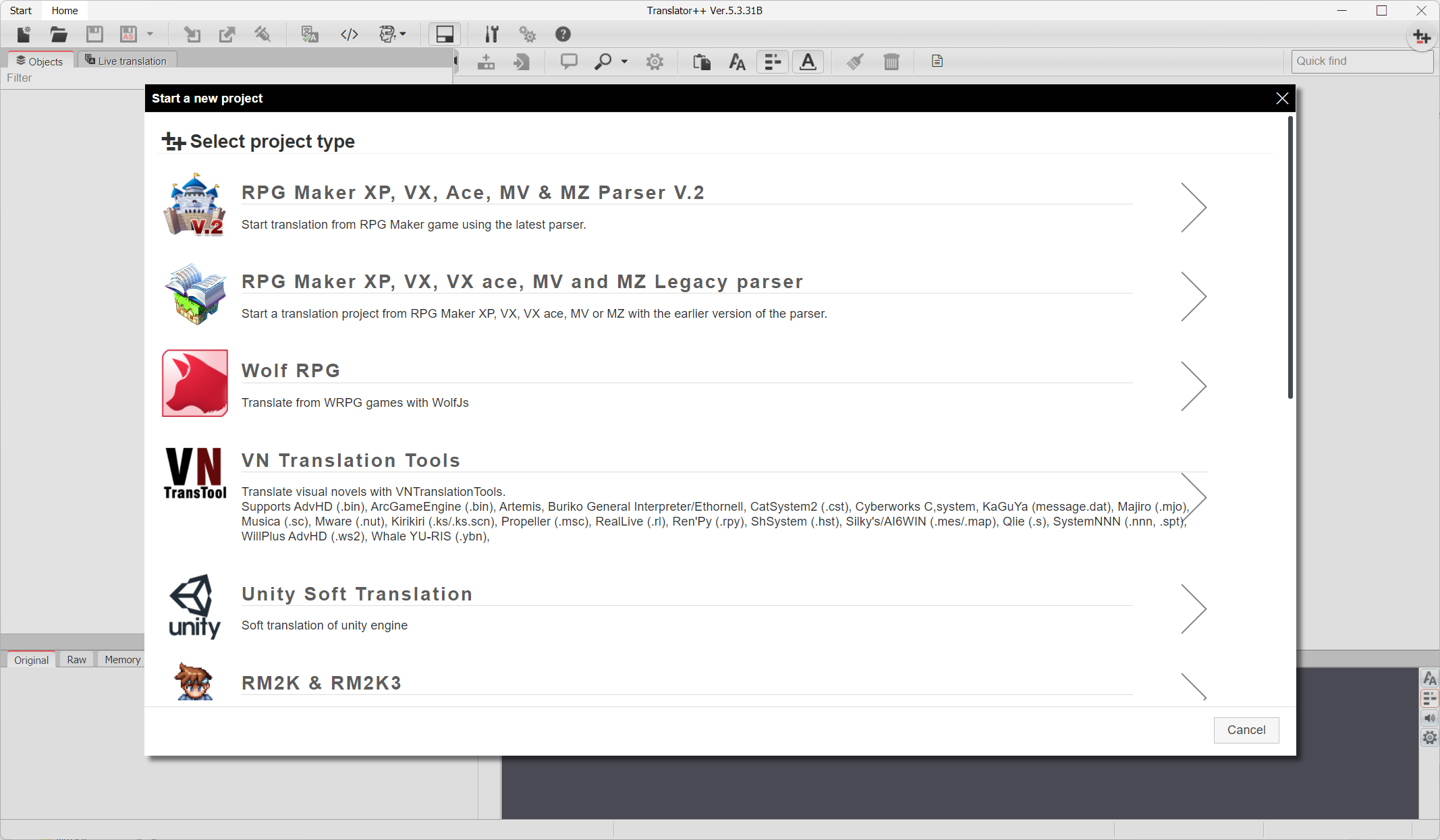
🔴Translator++,选择“start a new project”,根据你的游戏图标来选择对应的游戏引擎 |
| 
-
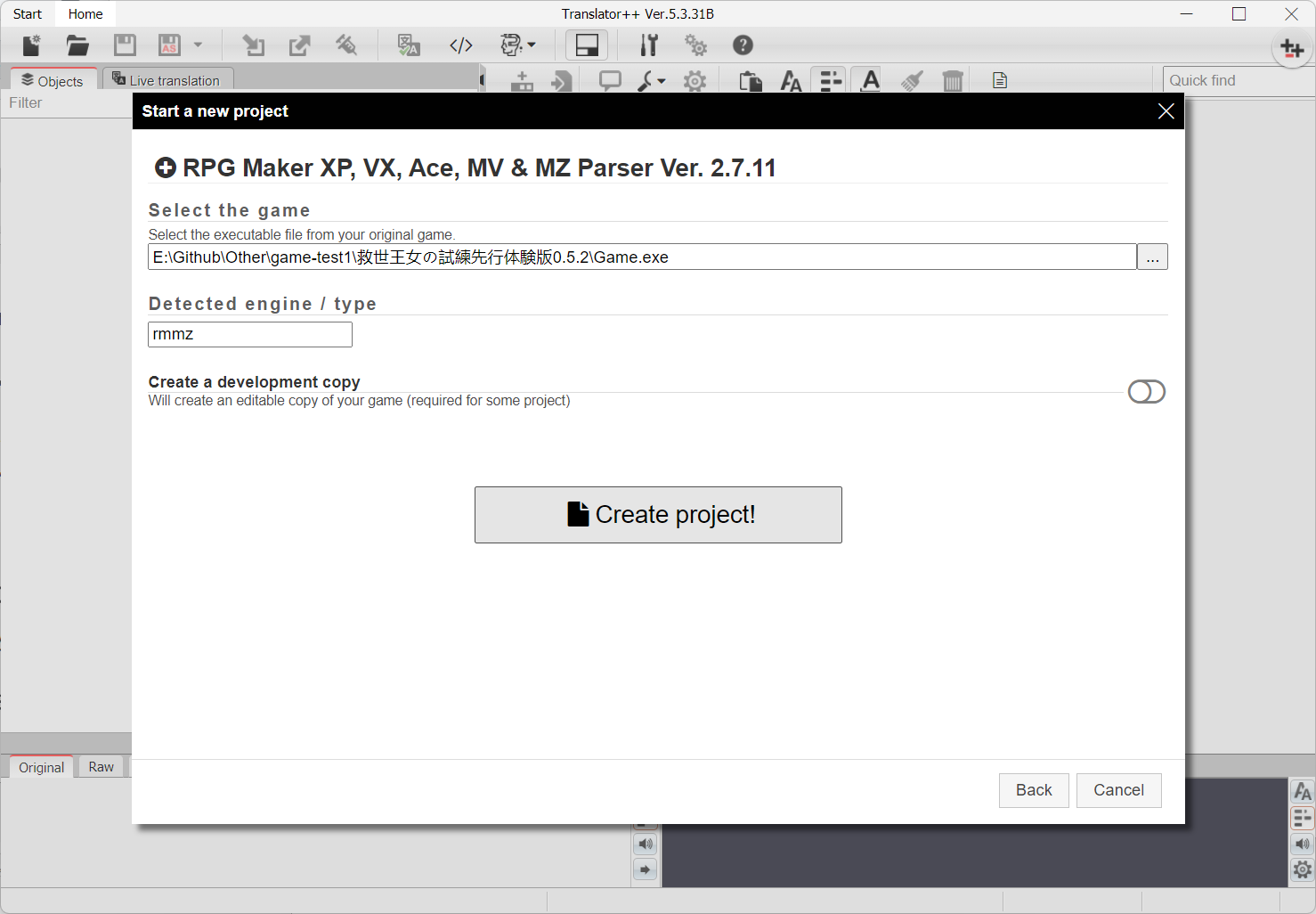
2.选择你的游戏文件,创建新工程,软件会自动解包和导入游戏数据
 |
| 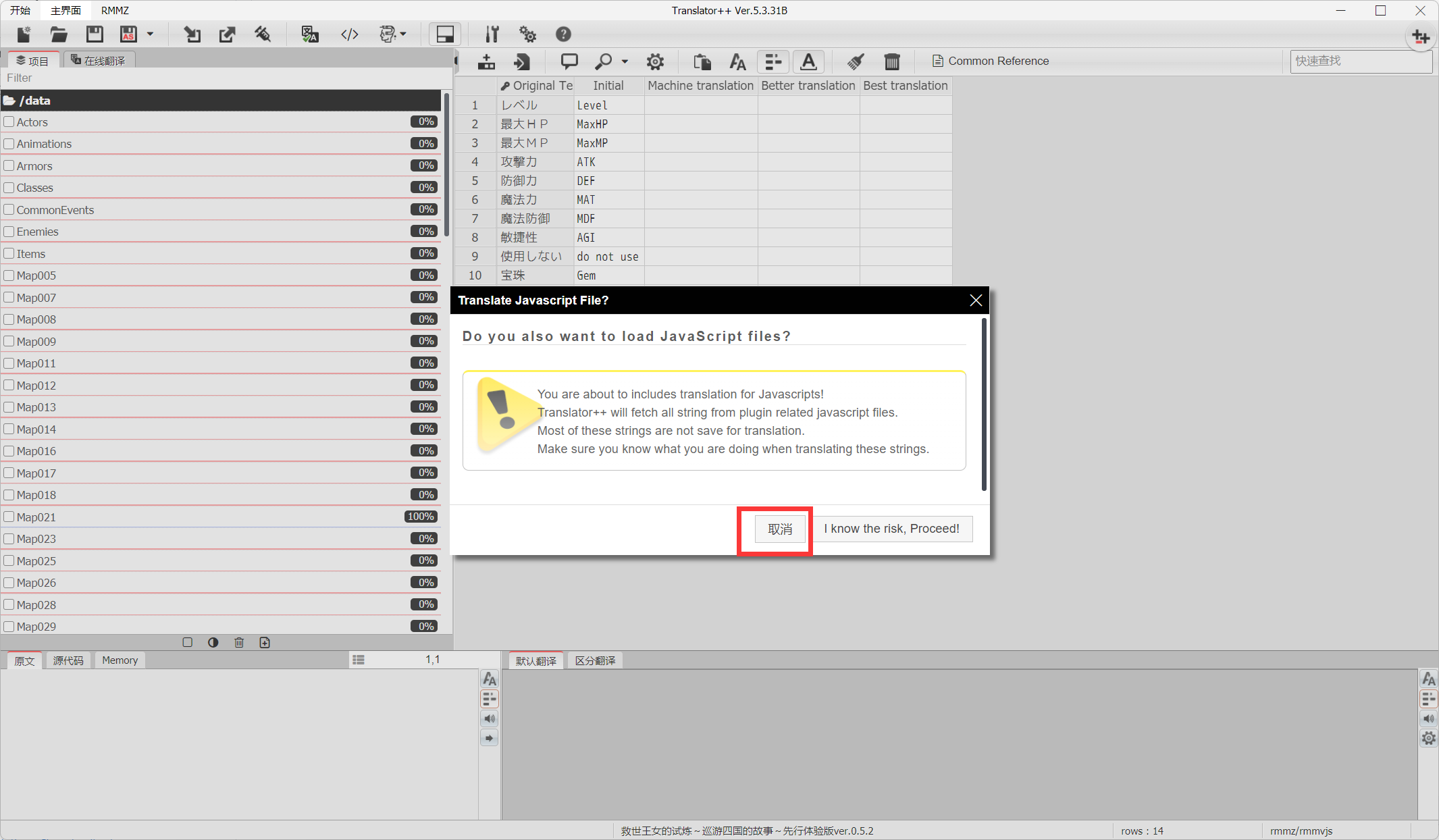
当弹出提示框,问你:Do you also want to load JavaScript files时,选择Cancel,加载脚本里的文本修改容易出错
-
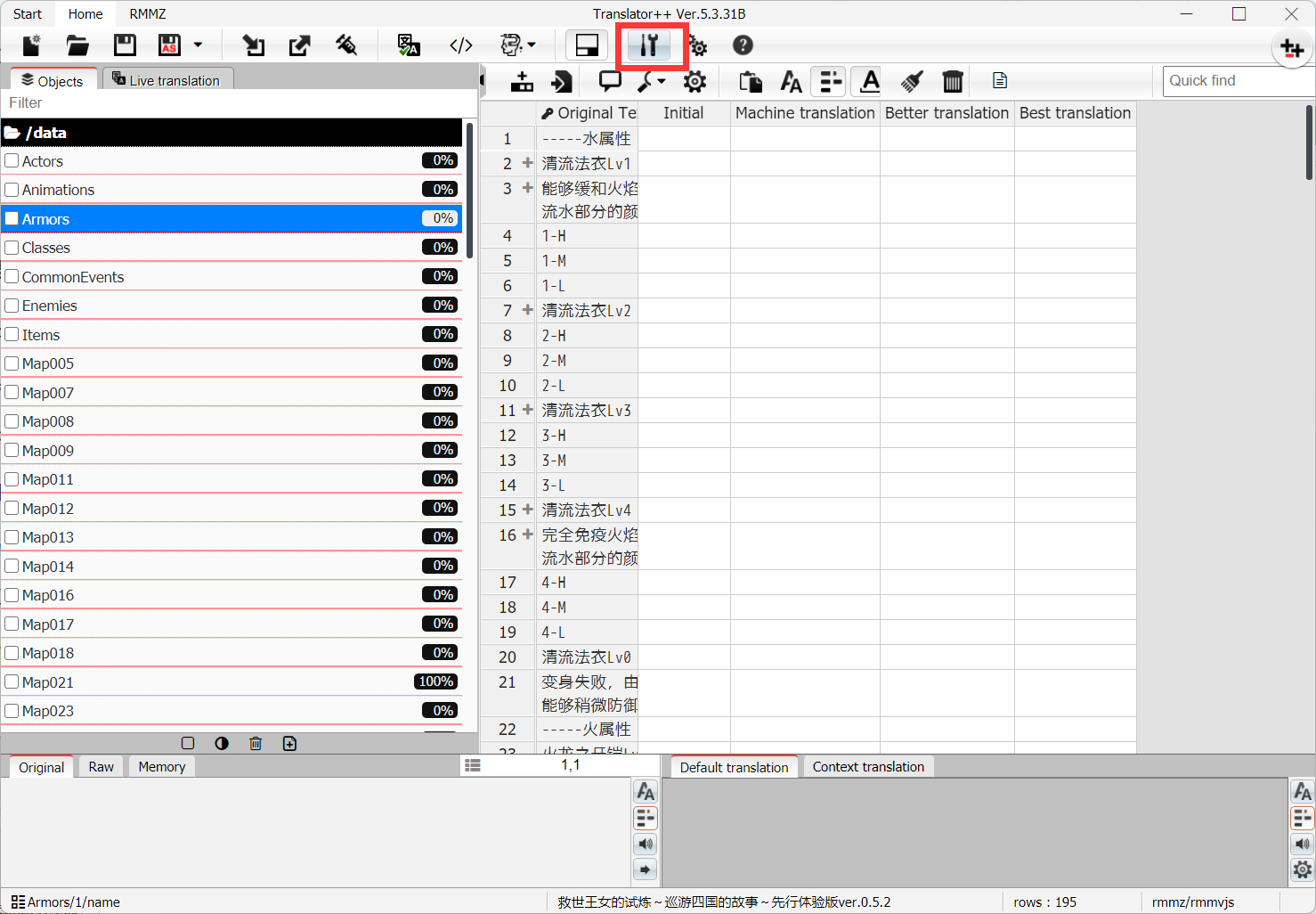
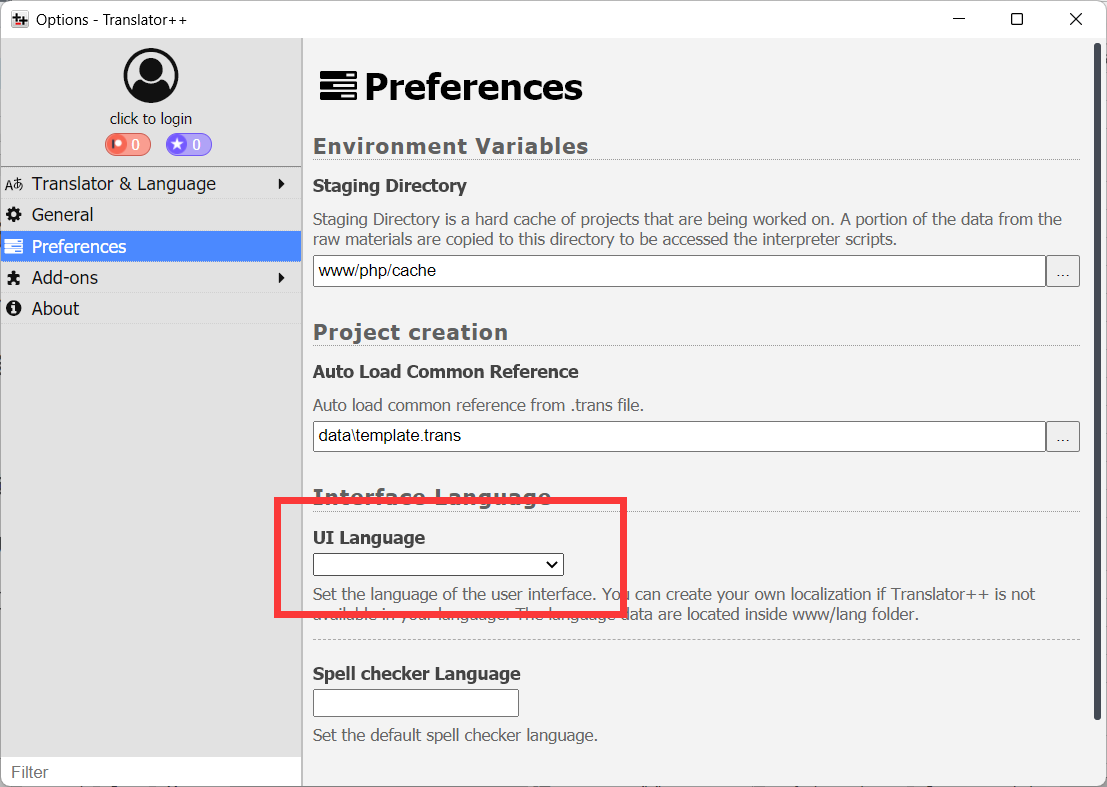
3.🖱️点"Options"按钮,选择"Preferences",选择"UI Language",选择简体中文,方便之后操作
 |
| 
-
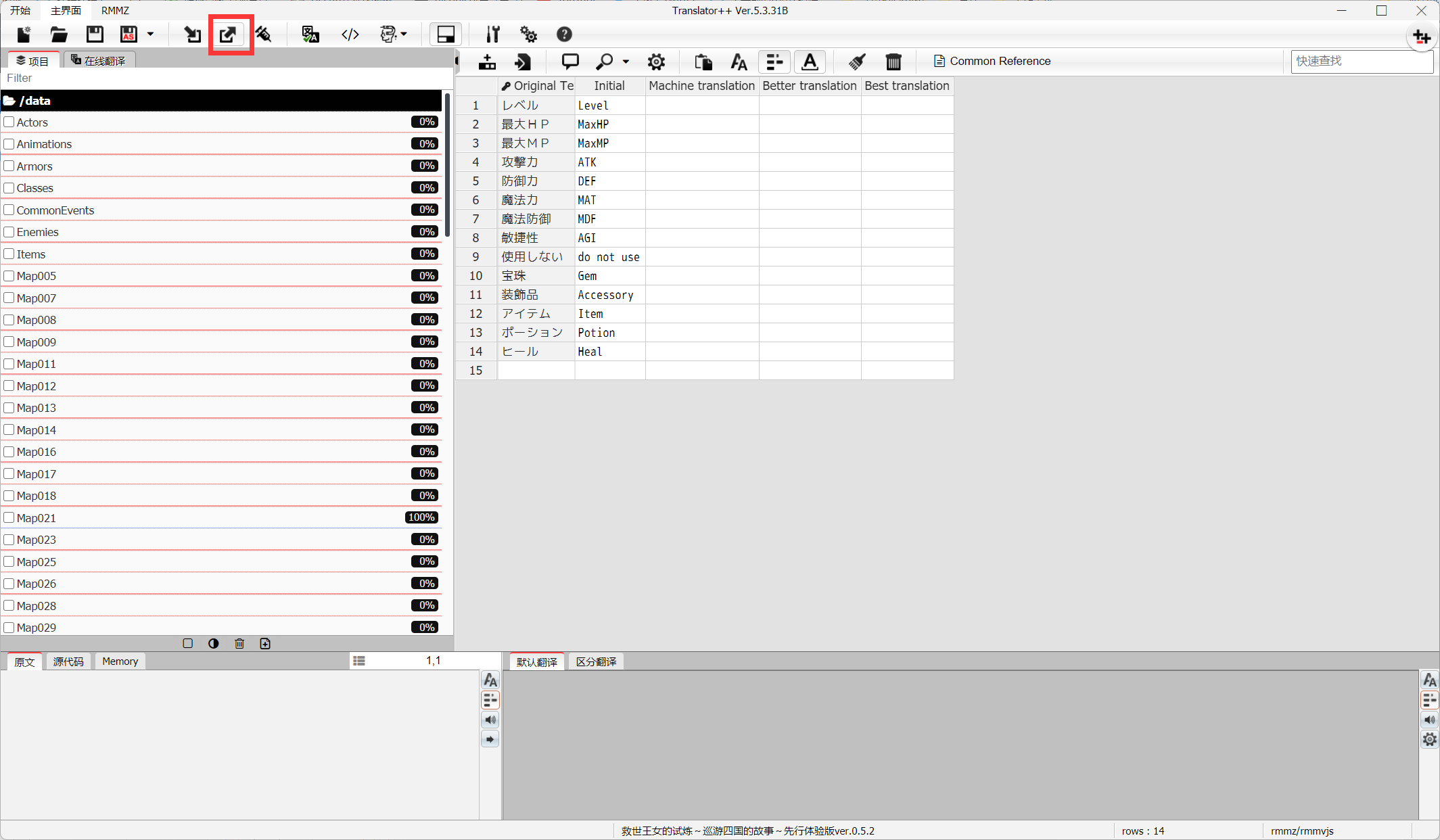
4.点左上角的导出工程,选择导出格式为XML格式到你指定的文件夹,生成data文件夹
 |
| 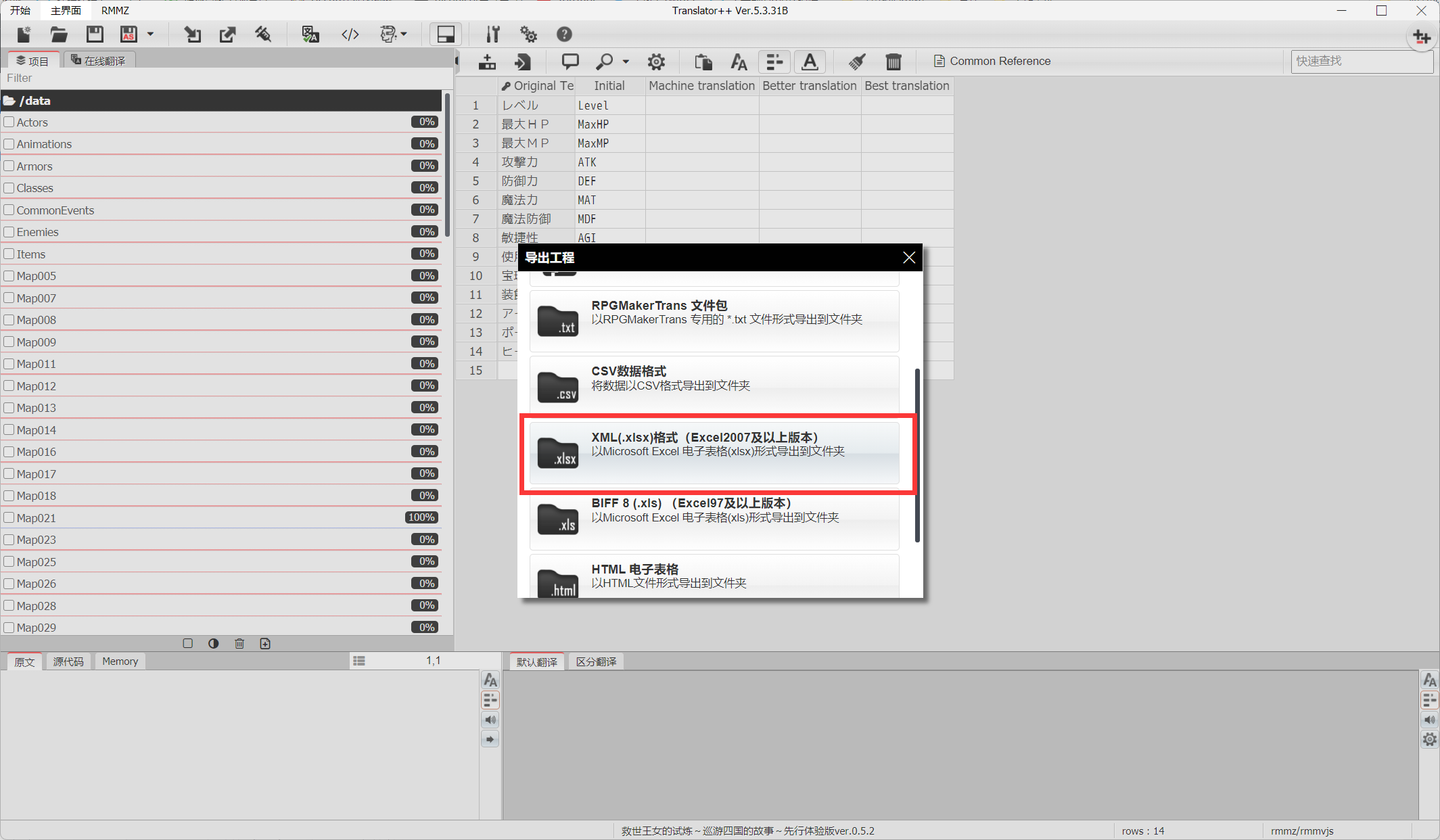
当弹出提示框,问如何处理标记列,就点击红色和选择Do not process row with selected tag,或者不设置直接导出,因为这工具暂时存在bug,无法过滤标记内容
-
5.在
翻译设置界面的翻译项目选择🔴T++导出文件,配置翻译设置配置示例
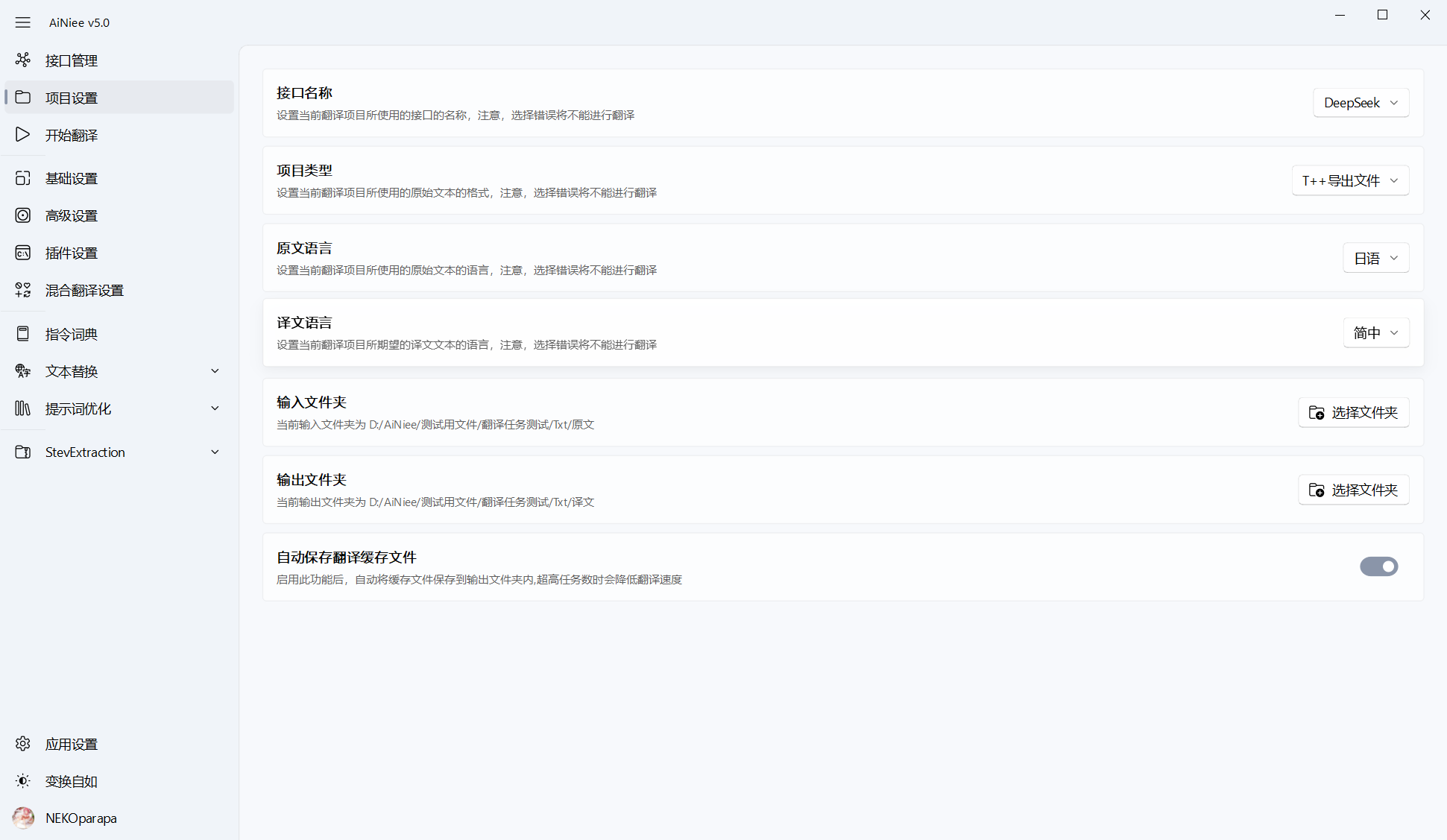
项目文件夹: 选择之前🔴Translator++导出的项目文件夹data
输出文件夹: 选择翻译后项目文件夹的存储文件夹 -
6.🖱️到开始翻译页面,点开始翻译按钮,等待翻译进度到百分百,生成翻译好的data文件夹在输出文件夹中
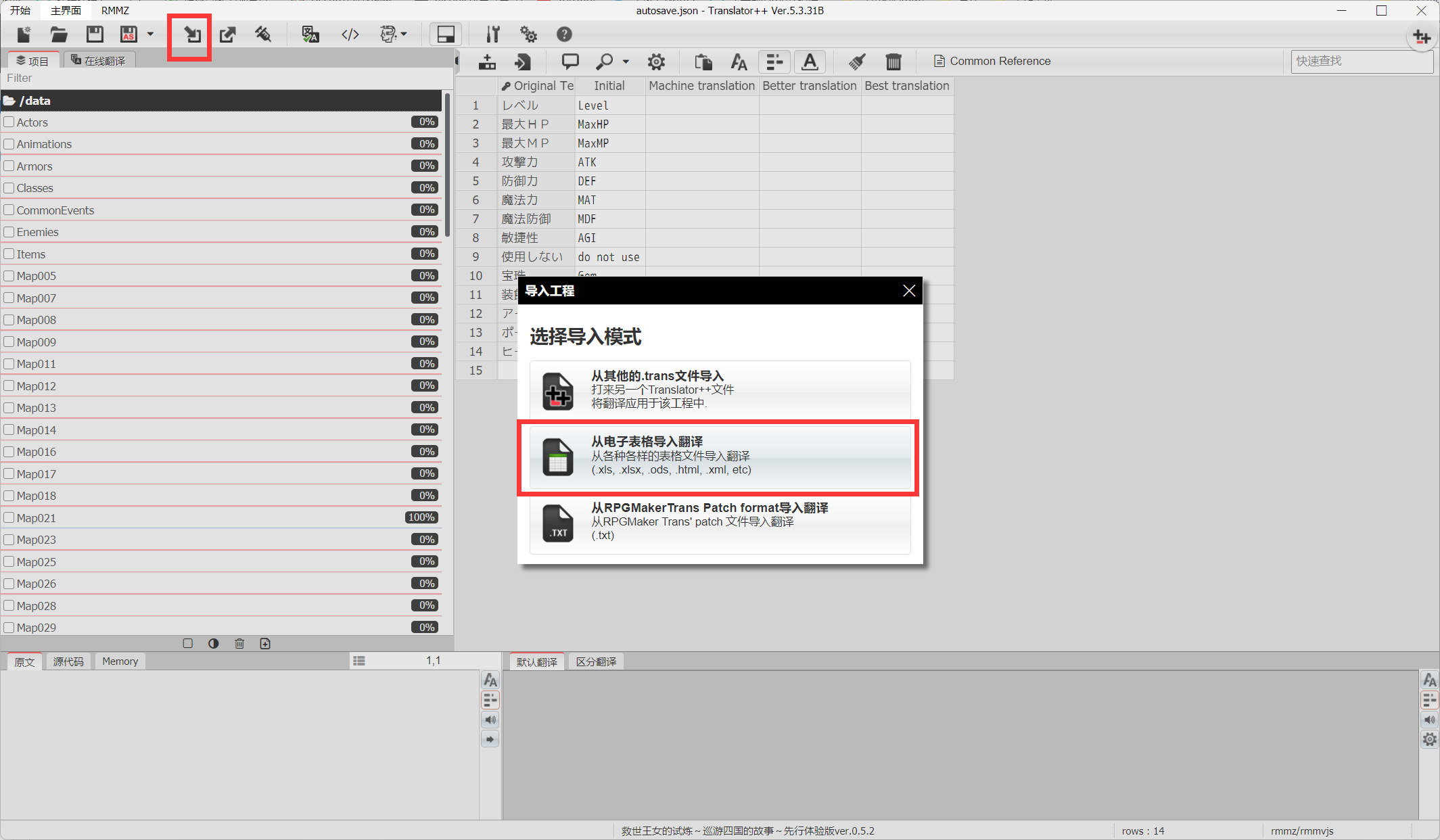
1.回到
🔴Translator+++,点击导入工程,选择从电子表格导入翻译,点击“Import Folder”,选择输出文件夹里的data文件夹,点击导入
 |
|
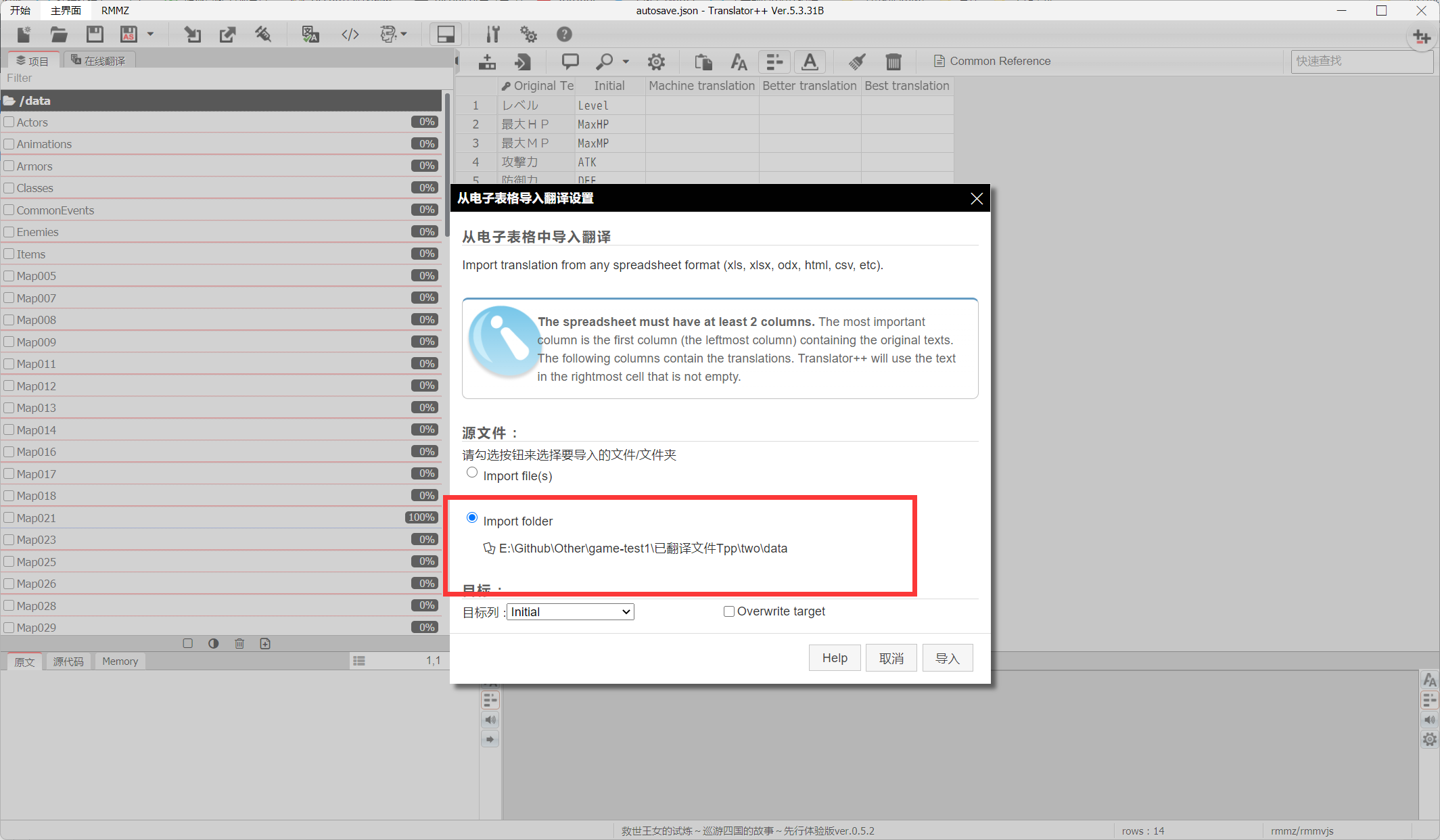
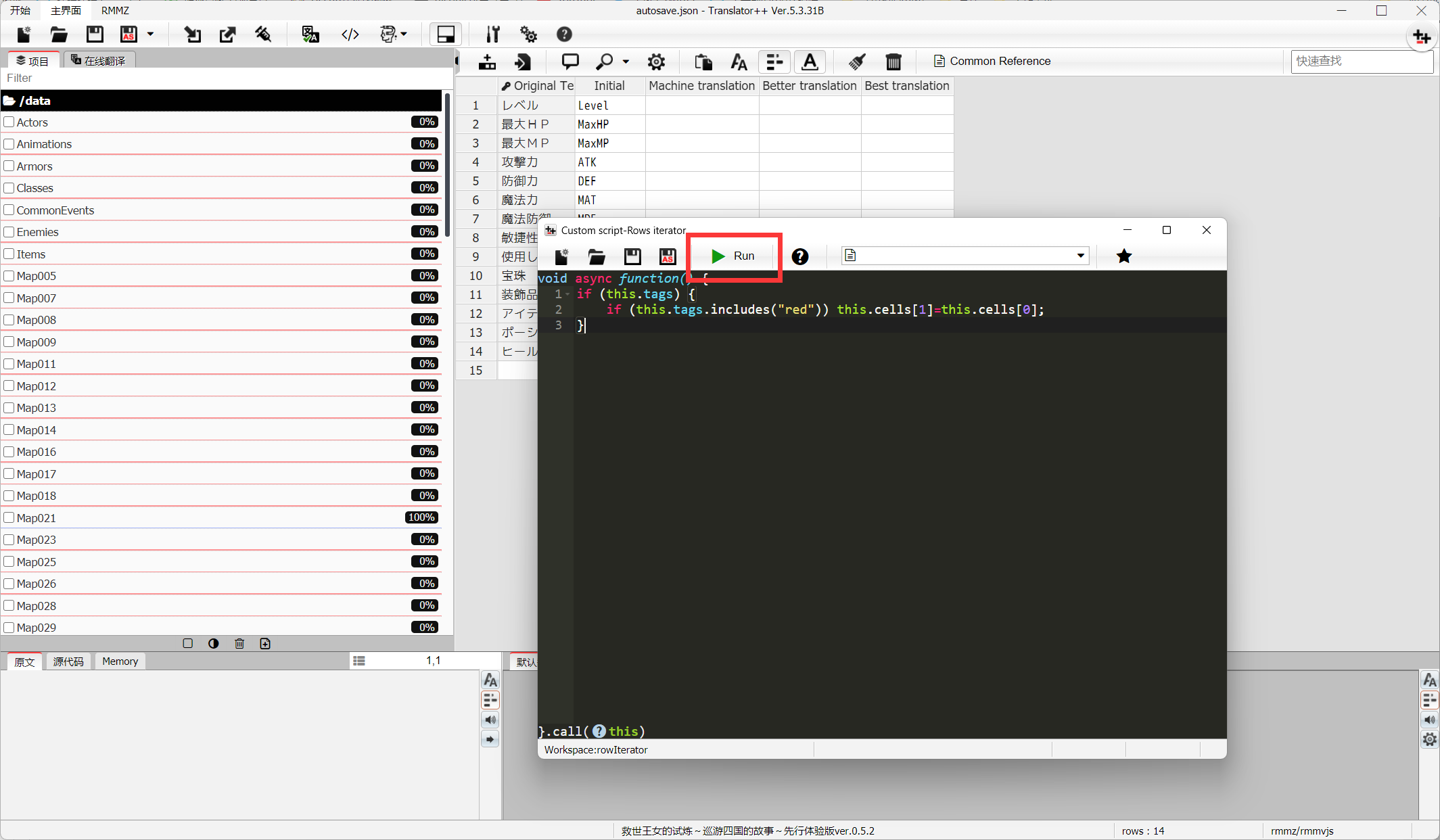
2.🖱️右键左侧区域,移到"全部选择",选择"Create Automation",选择"对每行",复制粘贴下面的代码运行
-
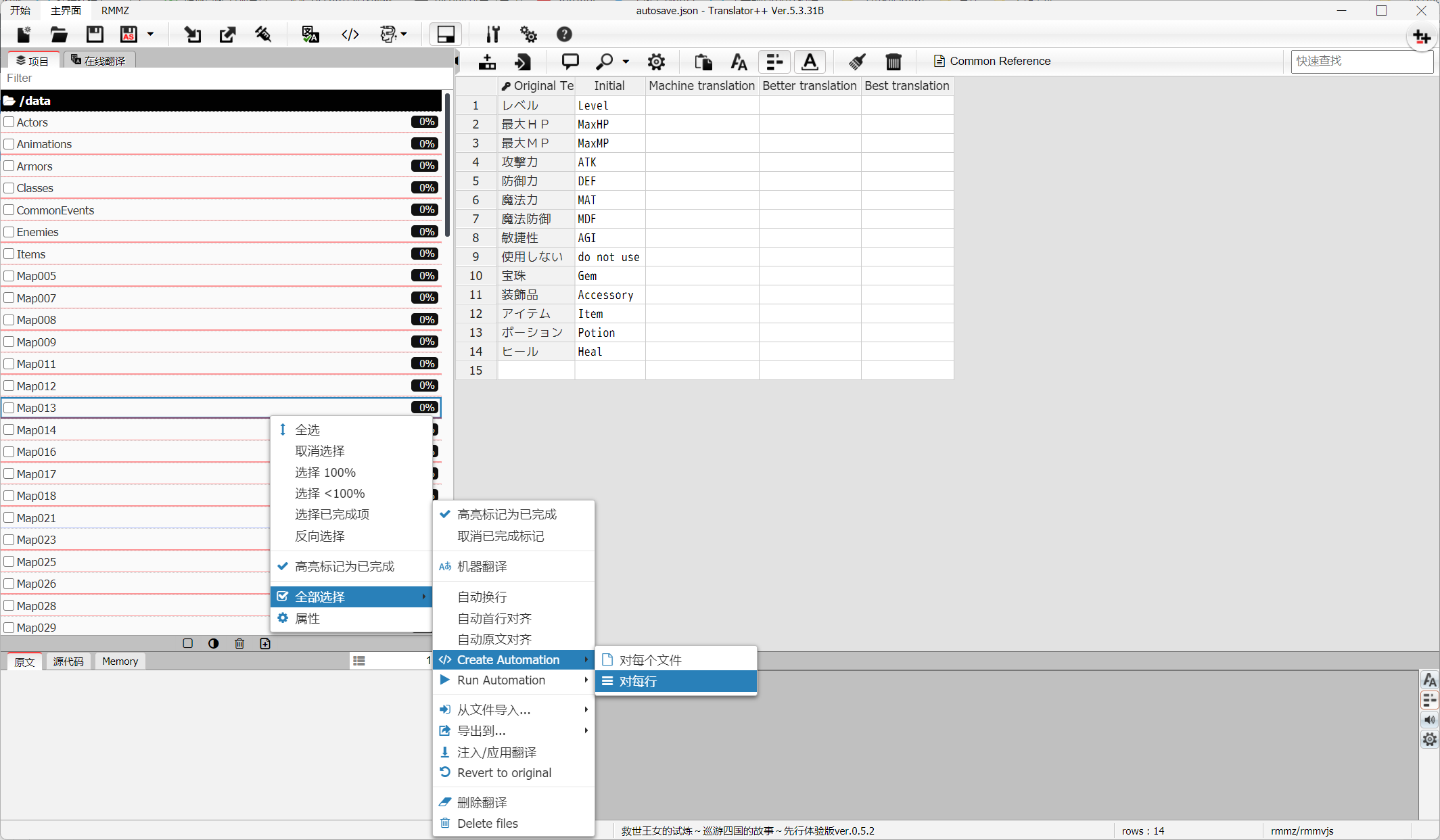
7.对红色标签内容进行修改,这些内容不能翻译,以免游戏脚本出现错误。
if (this.tags) { if (this.tags.includes("red")) this.cells[1]=this.cells[0]; }
 |
| 
3.查看左边文件有哪个没有到达百分百的,寻找到空行并自行翻译
-
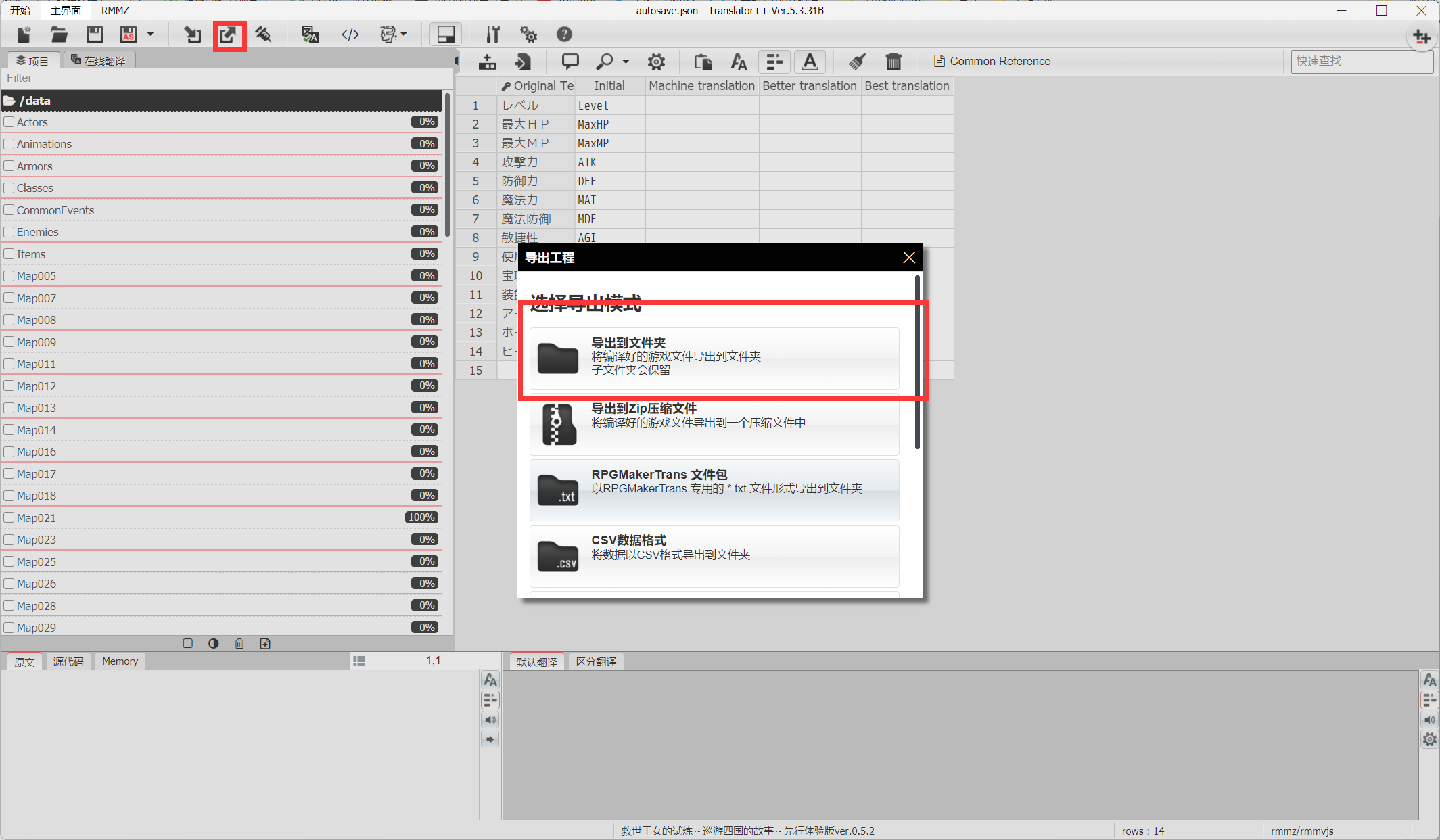
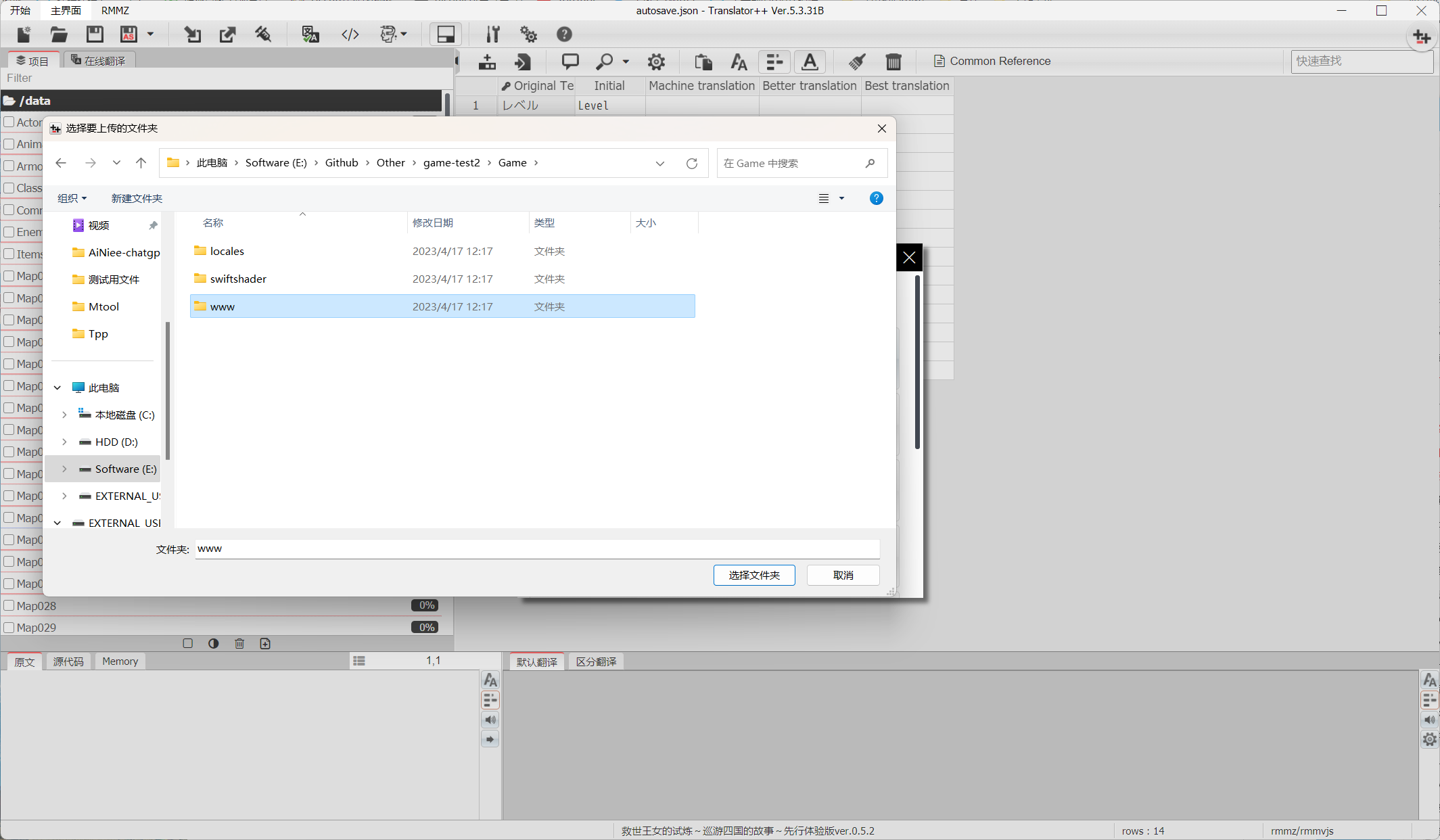
8.最后选择导出工程,选择导出到文件夹,指定你的游戏目录里的data文件夹的上一级文件夹,原文件会被替换,请注意备份原游戏
 |
| 
-
0.工具详情功能及介绍:工具原作者页面
-
1.在提取页面进行提取,目前只能适应于RPG Maker MVMZ游戏,能提取到游戏的原文和人物名字
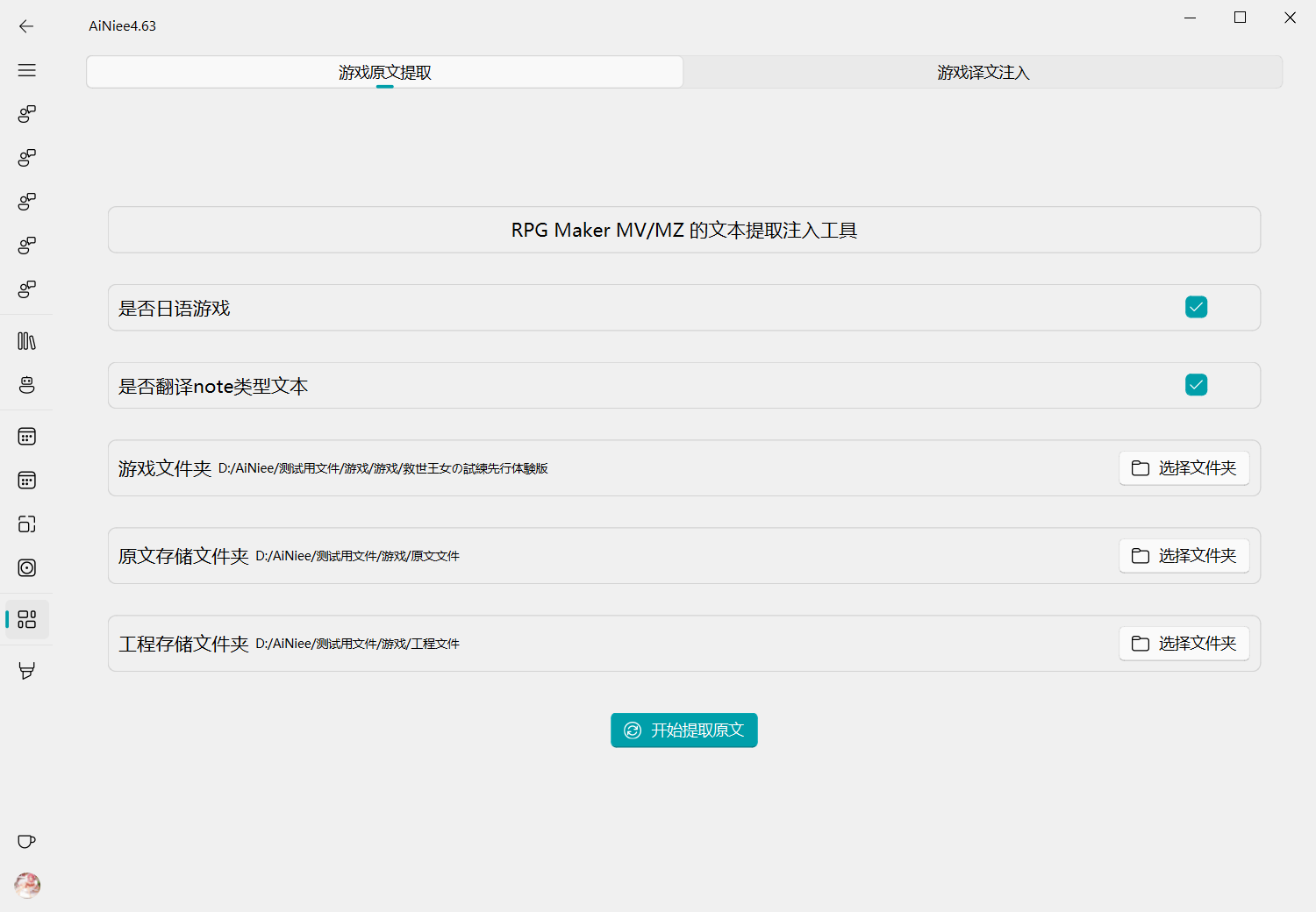
是否日语游戏: 根据游戏进行选择是否翻译note类型文本: # 在翻译ACT游戏时,尝试关闭该选项,否则大概率无法攻击或攻击没有效果游戏文件夹: 游戏根目录原文存储文件夹: 提取到的游戏原文存储的地方工程存储文件夹: 关于这个游戏的工程数据存储的地方,后面注入还会用到 -
2.在
翻译设置界面的翻译项目选择🔵T++导出文件,并配置翻译设置 -
3.注入回原文
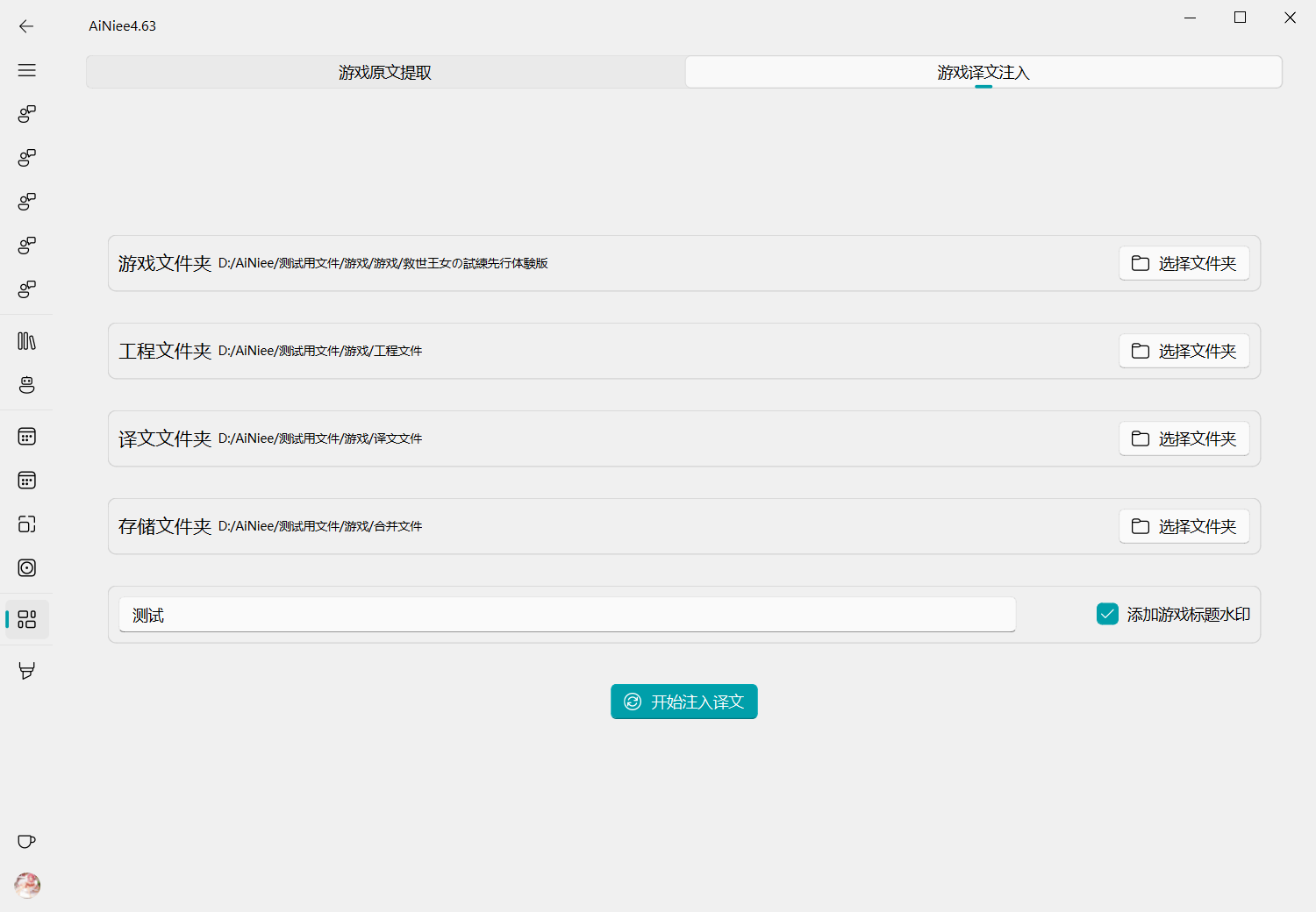
游戏文件夹: 游戏根目录译文文件夹: 之前经过翻译的原文文件工程文件夹: 之前这个游戏的工程数据存储的地方存储文件夹: 注入译文后存储的地方
-
0.工具详情:官方网站 这是一个专用于业余翻译工作的站点,与 Ainiee 的对接主要用于预先对文本进行机翻,之后可以进行校对。
-
1.在项目的
文件管理界面,对需要进行翻译的原文,执行下载原始数据,将下载下来的数据复制到翻译设置中的输入文件夹目录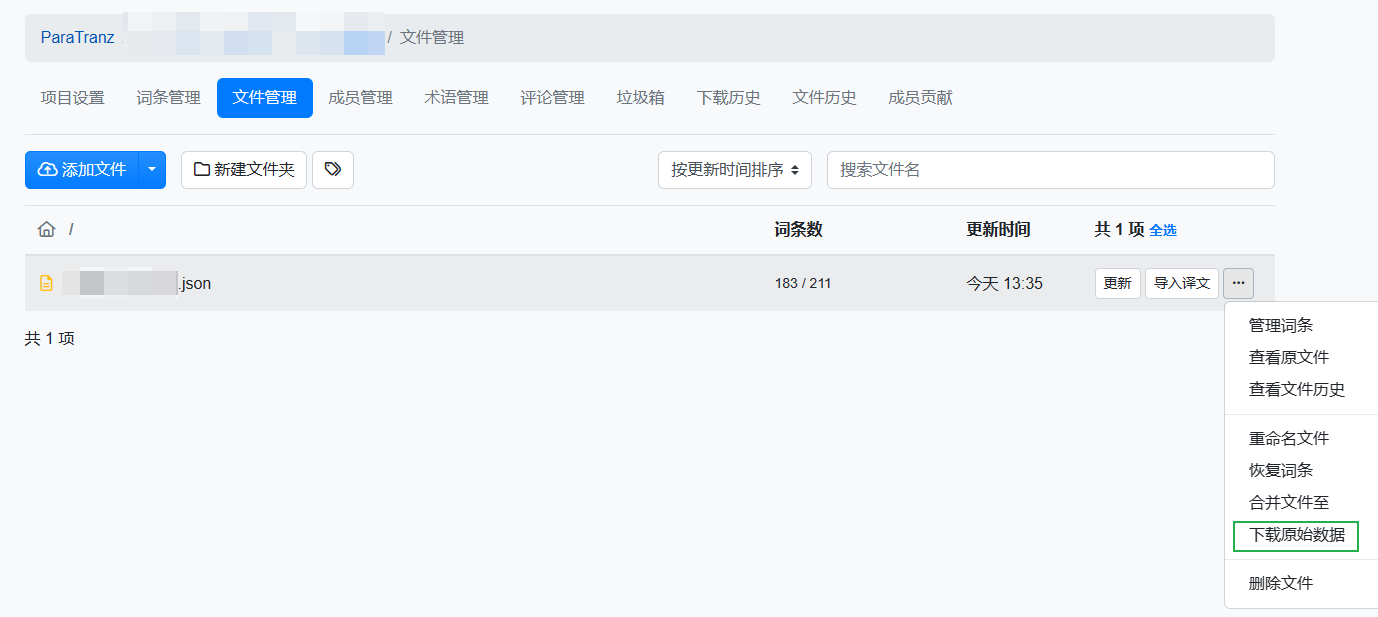
-
2.在
翻译设置界面的翻译项目选择🔵Paratranz导出文件,并配置翻译设置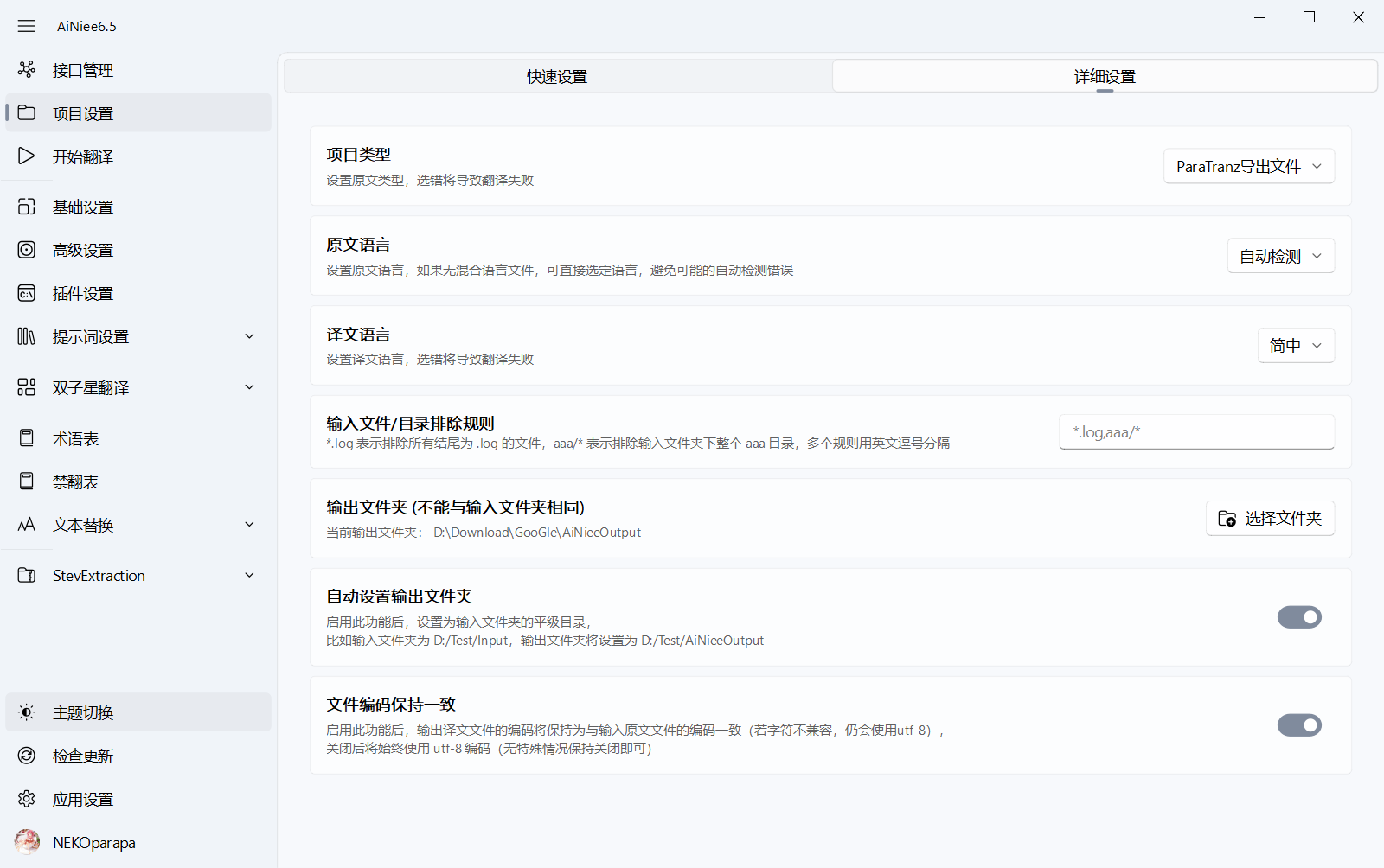
-
3.🖱️到开始翻译页面,点击开始翻译按钮,看控制台输出日志或者进度条。之后等待翻译进度到百分百,自动生成翻译好的文件在输出文件夹中
-
4.回到
Paratranz工具,依然在文件管理界面,选择导入译文,选择翻译后的 json 文件进行导入即可
-
多key轮询如果想使用多个key来分担消耗压力,根据key数量进行加速翻译,请使用同类型账号的key,而且输入时在每个key中间加上英文逗号,不要换行。例如:key1,key2,key3
-
批量文件翻译把所有相同类型的文件放在输入文件夹即可,也支持多文件夹结构
-
配置迁移配置信息都会存储在resource的config.json中,下载新版本可以把它复制到新版本的resource中。
-
自定义请求格式与模型在代理平台页面中,选择相应的请求格式,并在模型选择的下拉框中直接输入模型名字,可以自定义组合发送格式与模型。如果想在官方接口调用新模型,需要自行编辑Resource/platform文件夹里的模型信息文件。
-
翻译暂停继续暂停时请耐心等待提示全部任务暂停完成,暂停后可更换设置,继续后会以新的设置继续翻译
-
自动备份缓存文件到输出文件夹当翻译遇到问题时,可以之后更改翻译项目为缓存文件,并在输入文件夹选择该缓存文件所在的文件夹进行继续翻译。当继续翻译Epub小说文件时,还需要把原来的文件和缓存文件放在同一个文件夹里面。开启该功能会因硬盘的写入速度而影响软件的翻译速度,开启超多线程时,可以关闭此功能。
-
导出当前任务的已翻译文件会将已经翻译好的内容和未翻译的内容导出。mtool项目与Paratranz项目会分为两个文件,会带有不同的后缀。T++项目会仍然是同一个文件里,已翻译文本的右边会有内容,未翻译的没有。其他项目都会混合在一个文件里输出。
-
指令词典用来统一名词的翻译,让AI翻译的人名,物品名词,怪物名词,特殊名词能够翻译成你想要的样子。备注信息可写可不写
-
提示书用来提高翻译的准确度和流畅性,写好各种内容,配合高性能模型,能够提升翻译的质量
-
AI实时调教用来改变AI的参数设定,控制AI生成内容时的随机性,重复性,通常用来解决模型退化,语气词重复的问题
-
【如何反馈自己在使用中遇到的问题】————————将CMD窗口(黑黑的那个框框)的内容完整截图下来,里面有程序运行日志,还有软件界面设置截图,然后将问题描述清晰带上截图到群里或者issue提问。当进一步排除问题,需要到原文本或者翻译后文本时,请压缩并上传。
-
【翻译“卡住”了】————————如果运行日志中,无错误提醒,请耐心等待
-
【mtool导入翻译文本后,显示一句原文一句译文,或者全部原文】————————更新mtool到最新版,或者找mtool作者反馈该问题
-
【翻译后文本导入到T++不完全,部分未能百分百导入全部译文】————————在非RPGMVZ游戏中,出现该问题比较多,使用最新赞助版T++可以缓解,还可以自己手动打开表格,自己复制粘贴进去
该款AI翻译工具仅供个人合法用途,任何使用该工具进行直接或者间接非法盈利活动的行为,均不属于授权范围,也不受到任何支持和认可。
交♂交流群: QQ交流群(主要):821624890,备用TG群:https://t.me/+JVHbDSGo8SI2Njhl ,