Getting the results of a Hive query into ArcGIS
There are extra steps if you are using a VM : See Issue 22 for further details
This tutorial will take a Hive query and export it to ArcGIS. The opposite direction, moving a feature to HDFS here.
If you have already generated a JSON table using a query, skip to step 5.
-
Start the hive command line and add the functions and jar files [similar to the sample example for steps 1-4]:
add jar gis-tools-for-hadoop/samples/lib/esri-geometry-api.jar gis-tools-for-hadoop/samples/lib/spatial-sdk-hadoop.jar; create temporary function ST_Point as 'com.esri.hadoop.hive.ST_Point'; create temporary function ST_Contains as 'com.esri.hadoop.hive.ST_Contains'; create temporary function ST_Bin as 'com.esri.hadoop.hive.ST_Bin'; create temporary function ST_BinEnvelope as 'com.esri.hadoop.hive.ST_BinEnvelope';
-
Generate your earthquake table and remove the first row of null values:
CREATE TABLE IF NOT EXISTS earthquakes (earthquake_date STRING, latitude DOUBLE, longitude DOUBLE, magnitude DOUBLE) ROW FORMAT DELIMITED FIELDS TERMINATED BY ','; LOAD DATA LOCAL INPATH './earthquakes.csv' OVERWRITE INTO TABLE earthquakes;
CREATE TABLE earthquakes_new(earthquake_date STRING, latitude DOUBLE, longitude DOUBLE, magnitude DOUBLE); INSERT OVERWRITE TABLE earthquakes_new SELECT earthquake_date, latitude, longitude, magnitude FROM earthquakes WHERE latitude is not null;
-
Generate a new empty table
agg_sampto save your query into.DROP TABLE agg_samp; CREATE TABLE agg_samp(area binary, count double) ROW FORMAT SERDE 'com.esri.hadoop.hive.serde.EsriJsonSerDe' STORED AS INPUTFORMAT 'com.esri.json.hadoop.EnclosedEsriJsonInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat';
-
Generate your Query to bin your data using bins of 0.5 degrees, save this into your new table
agg_sampFROM (SELECT ST_Bin(0.5, ST_Point(longitude, latitude)) bin_id, * FROM earthquakes_new) bins INSERT OVERWRITE TABLE agg_samp SELECT ST_BinEnvelope(0.5, bin_id) shape, count(*) count GROUP BY bin_id;
-
If you have not already done so, download the Geoprocessing Toolbox and follow the given Instructions.
-
You will now use tools from the geoprocessing toolbox to move your table to a feature class. We recommend building a model using model builder and drag two tools from your toolbox into the model:
Copy from HDFSandJSON to Features. -
Double click on the
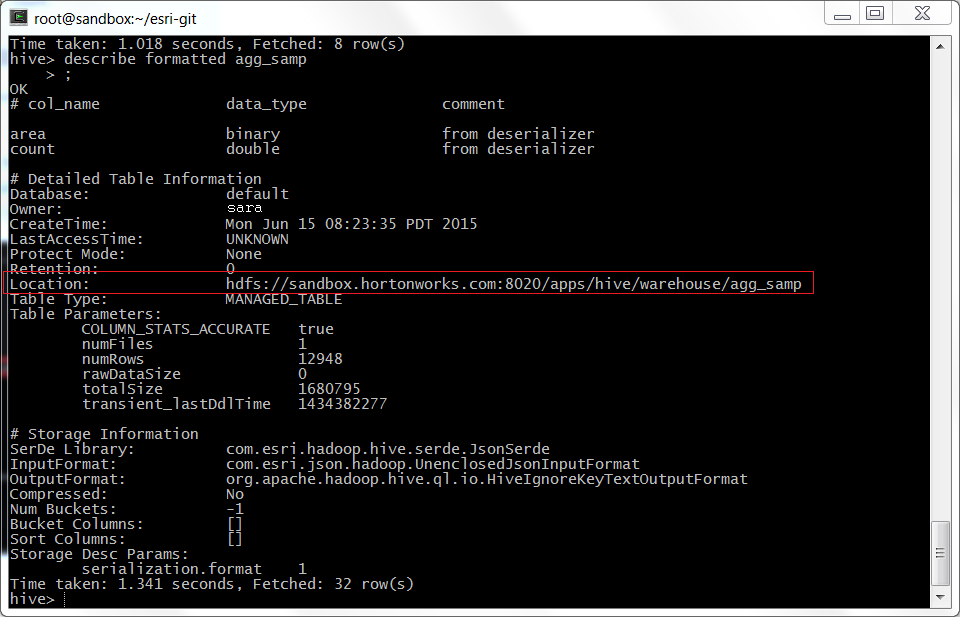
Copy from HDFStool.In hive type:
describe formatted table_name, wheretable_nameis the table you generated in Step 4 (i.e.describe formatted agg_samp).

||Standalone Cluster|Using a VM| |---------|----------|----------|--------| |HDFS server hostname (Box 1): | This is your name node found above|'localhost', but make note of the name node as well| |HDFS TCP port number ( Box 2):| Use the default unless you know another value|Use the default unless you know another value| |HDFS username (Box 3):| In the terminal type: whoami [exit hive first]|root| |HDFS remote file (Box 4):| Use everything after and including the single slash (above)|Use everything after and including the single slash (above)| |Output Local File (Box 5):| Save it to a file, add .json on the end|Save it to a file, add .json on the end|
VM Steps: You need to add your VM as localhost. Follow these steps and add the line 127.0.0.1 sandbox.hortonworks.com to the file and save.  If you aren't using Hortonworks - this is the namenode you found for box 1 above.
If you aren't using Hortonworks - this is the namenode you found for box 1 above.

-
Double click on
JSON to Featurestool
||| |---------|----------|----------| |Input JSON (Box 1): | This is the same file you output from Copy from HDFS| |Output feature Class (Box 2): | This is the output, saved in a file geodatabase | |JSON type (optional) (Box 3): | Choose UNENCLOSED_JSON|
-
Run the model, and add the new feature class to your map.

-
Your final result should look something like this (after updating the symbology) :
