- Dec, 2024: We have released the dataset, trained model
$\text{RankMistral}_{100}$ (download) and codes.
This repository contains the code for our paper Sliding Windows Are Not the End: Exploring Full Ranking with Long-Context Large Language Models.

Large Language Models (LLMs) have shown exciting performance in listwise passage ranking. Due to the limited input length, existing methods often adopt the sliding window strategy. Such a strategy, though effective, is inefficient as it involves repetitive and serialized processing, which usually re-evaluates relevant passages multiple times. As a result, it incurs redundant API costs, which are proportional to the number of inference tokens. The development of long-context LLMs enables the full ranking of all passages within a single inference, avoiding redundant API costs. In this paper, we conduct a comprehensive study of long-context LLMs for ranking tasks in terms of efficiency and effectiveness. Surprisingly, our experiments reveal that full ranking with long-context LLMs can deliver superior performance in the supervised fine-tuning setting with a huge efficiency improvement. Furthermore, we identify two limitations of fine-tuning the full ranking model based on existing methods: (1) sliding window strategy fails to produce a full ranking list as a training label, and (2) the language modeling loss cannot emphasize top-ranked passage IDs in the label. To alleviate these issues, we propose a complete listwise label construction approach and a novel importance-aware learning objective for full ranking. Experiments show the superior performance of our method over baselines.
conda create -n fullrank python=3.9
conda activate fullrank
In our project, we utilize JDK version 11.0.8 (other versions may also be compatible).
bash env.shFor the evaluation of effectiveness, please run the following script:
bash run_rank_llm.shThe evaluation script uses vllm for acceleration. Please place the open-source long-context LLM to be evaluated in llm/, and place our trained_models/.
Note: If you want to call the OpenAI API, remember to create a file named .env.local in the root directory of the project and set a variable OPEN_AI_API_KEY={YOUR_KEY}.
For the evaluation of efficiency, please run the following script:
bash test_latency.shNote that we choose not to use vllm technique for a fair comparison. The following image shows the latency across different LLMs:

The training data is constructed by multi-pass sliding window and the model is optimized with importance-aware loss. Here is the overall framework:
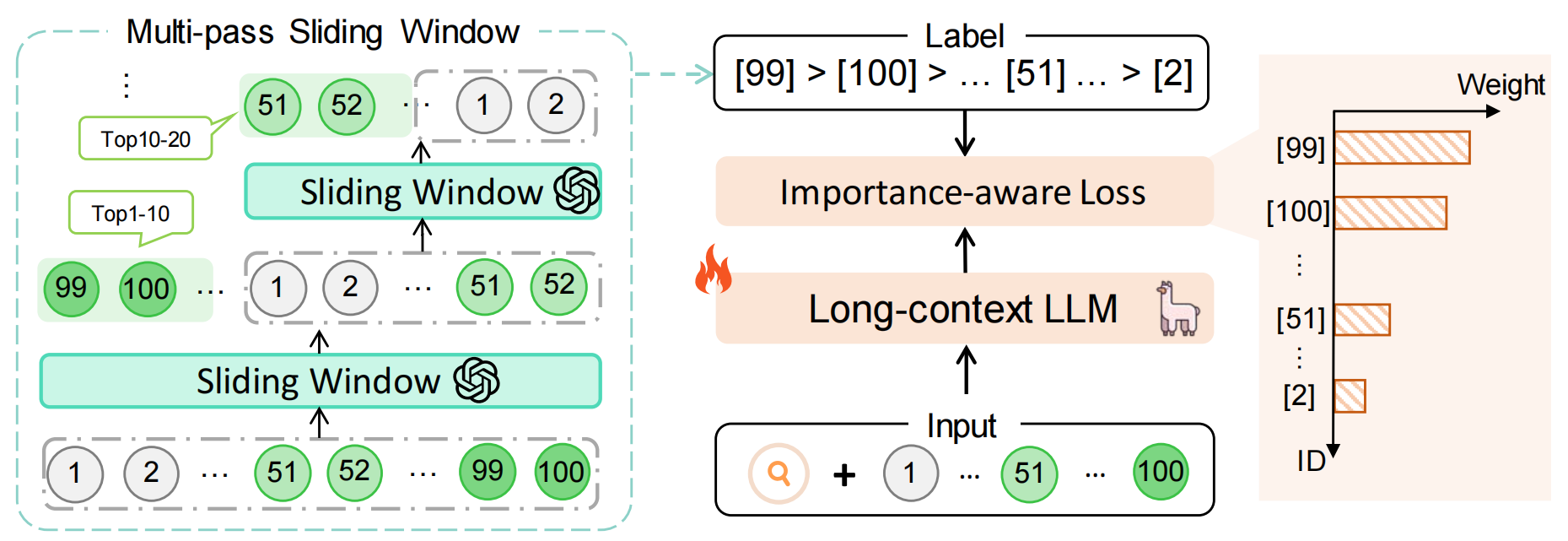
The training data is placed in training_data/, which can also be downloaded from here. The data is generated by performing multi-pass sliding windows based on GPT-4o-2024-08-06. Below defines a piece of training data:
{
"qid": "689440",
"initial_list": ["4600588", "722358", "6582134", "2071892", "7466269", "2071888", "6093666", "562673", "562665", "1758980", "562679", "7757482", "1758979", "393724", "159972", "3916807", "687135", "1758973", "1758974", "8133472", "8133471", "625649", "3825484", "5600557", "7174178", "3018593", "2071889", "458944", "4015452", "7687108", "1472705", "458945", "5876966", "7397074", "2275276", "6551342", "7218862", "6881961", "1028265", "302030", "323769", "4704236", "6363015", "6881962", "6881963", "1472707", "6881964", "1116098", "7718211", "562670", "2071893", "3018587", "323765", "392148", "7544711", "7055748", "4015454", "49880", "3431733", "6451002", "7239242", "1250186", "7710675", "908920", "2509285", "1127726", "6289406", "6722658", "4413752", "1224378", "1774822", "3396051", "6881965", "6138380", "6138381", "2699391", "4217197", "1372040", "1886768", "6294509", "6707614", "431934", "4542554", "6138382", "2076787", "3284239", "3449908", "625646", "625648", "973146", "7031192", "2215635", "4413747", "5427959", "2857247", "6592283", "6629150", "729281", "7761482", "2476063"],
"final_list": ["2071889", "2476063", "2071888", "3449908", "6582134", "1886768", "2076787", "625646", "625648", "1472705", "458944", "49880", "625649", "2275276", "6881962", "6451002", "7544711", "6138380", "722358", "2071892", "6138382", "6138381", "2071893", "3396051", "458945", "3284239", "7466269", "562673", "562665", "1758980", "6592283", "4413752", "4413747", "6881964", "6551342", "6881965", "1472707", "7174178", "6881961", "3431733", "2509285", "6881963", "6289406", "4217197", "5427959", "4542554", "1250186", "7239242", "4600588", "6093666", "7031192", "431934", "687135", "159972", "973146", "1127726", "392148", "6363015", "6707614", "1224378", "4704236", "7710675", "7055748", "7718211", "2699391", "1028265", "6294509", "302030", "908920", "1116098", "323769", "323765", "1774822", "1372040", "7757482", "562679", "1758979", "393724", "8133472", "1758973", "1758974", "5876966", "6722658", "7687108", "7397074", "562670", "8133471", "3018593", "7218862", "4015452", "4015454", "5600557", "3825484", "3018587", "6629150", "2215635", "7761482", "3916807", "2857247", "729281"]
}Field Explanations:
qid: This represents the query identifier.initial_list: This is the list of passage IDs retrieved using the BM25 algorithm.final_list: This is the reordered list of passage IDs after processing by the teacher reranker.
Run the following code to fine-tune a full ranking model:
cd training
bash run_train.shFor training with standard language modeling loss, set the parameter weighted_loss=False.
If you have any questions or suggestions related to this project, feel free to open an issue or pull request. You also can email Wenhan Liu ([email protected]).
If you find this repository useful, please consider giving a star ⭐ and citation
@article{liu2024sliding,
title={Sliding Windows Are Not the End: Exploring Full Ranking with Long-Context Large Language Models},
author={Liu, Wenhan and Ma, Xinyu and Zhu, Yutao and Zhao, Ziliang and Wang, Shuaiqiang and Yin, Dawei and Dou, Zhicheng},
journal={arXiv preprint arXiv:2412.14574},
year={2024}
}
We also acknowledge the opens-source repo RankLLM, which is instrumental for this work.