-
Notifications
You must be signed in to change notification settings - Fork 18
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
docs: Improve clarity for radix sort
- Loading branch information
Showing
4 changed files
with
60 additions
and
43 deletions.
There are no files selected for viewing
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -1,68 +1,78 @@ | ||
| # Radix Sort | ||
|
|
||
| ## Background | ||
|
|
||
| Radix Sort is a non-comparison based, stable sorting algorithm that conventionally uses counting sort as a subroutine. | ||
|
|
||
| Radix Sort performs counting sort several times on the numbers. It sorts starting with the least-significant segment | ||
| to the most-significant segment. | ||
| to the most-significant segment. What a 'segment' refers to is explained below. | ||
|
|
||
| ### Segments | ||
| The definition of a 'segment' is user defined and defers from implementation to implementation. | ||
| It is most commonly defined as a bit chunk. | ||
| ### Idea | ||
| The definition of a 'segment' is user-defined and could vary depending on implementation. | ||
|
|
||
| For example, if we aim to sort integers, we can sort each element | ||
| from the least to most significant digit, with the digits being our 'segments'. | ||
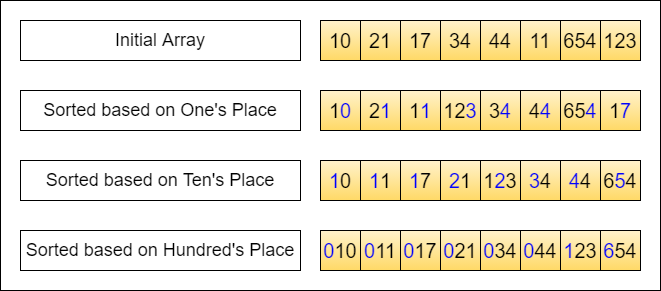
| Let's consider sorting an array of integers. We interpret the integers in base-10 as shown below. | ||
| Here, we treat each digit as a 'segment' and sort (counting sort as a sub-routine here) the elements | ||
| from the least significant digit (right) to most significant digit (left). In other words, the sub-routine sort is just | ||
| focusing on 1 digit at a time. | ||
|
|
||
| Within our implementation, we take the binary representation of the elements and | ||
| partition it into 8-bit segments. An integer is represented in 32 bits, | ||
| this gives us 4 total segments to sort through. | ||
| <div align="center"> | ||
| <img src="../../../../../../docs/assets/images/RadixSort.png" width="65%"> | ||
| <br> | ||
| Credits: Level Up Coding | ||
| </div> | ||
|
|
||
| Note that the number of segments is flexible and can range up to the number of digits in the binary representation. | ||
| (In this case, sub-routine sort is done on every digit from right to left) | ||
| The astute would note that a **stable version of counting sort** has to be used here, otherwise the relative ordering | ||
| based on previous segments might get disrupted when sorting with subsequent segments. | ||
|
|
||
|  | ||
| ### Segment Size | ||
| Naturally, the choice of using just 1 digit in base-10 for segmenting is an arbitrary one. The concept of Radix Sort | ||
| remains the same regardless of the segment size, allowing for flexibility in its implementation. | ||
|
|
||
| We place each element into a queue based on the number of possible segments that could be generated. | ||
| Suppose the values of our segments are in base-10, (limited to a value within range *[0, 9]*), | ||
| we get 10 queues. We can also see that radix sort is stable since | ||
| they are enqueued in a manner where the first observed element remains at the head of the queue | ||
| In practice, numbers are often interpreted in their binary representation, with the 'segment' commonly defined as a | ||
| bit chunk of a specified size (usually 8 bits/1 byte, though this number could vary for optimization). | ||
|
|
||
| *Source: Level Up Coding* | ||
| For our implementation, we utilize the binary representation of elements, partitioning them into 8-bit segments. | ||
| Given that an integer is typically represented in 32 bits, this results in four segments per integer. | ||
| By applying the sorting subroutine to each segment across all integers, we can efficiently sort the array. | ||
| This method requires sorting the array four times in total, once for each 8-bit segment, | ||
|
|
||
| ### Implementation Invariant | ||
| At the end of the *ith* iteration, the elements are sorted based on their numeric value up till the *ith* segment. | ||
|
|
||
| At the start of the *i-th* segment we are sorting on, the array has already been sorted on the | ||
| previous *(i - 1)-th* segments. | ||
|
|
||
| ### Common Misconceptions | ||
|
|
||
| While Radix Sort is non-comparison based, | ||
| the that total ordering of elements is still required. | ||
| This total ordering is needed because once we assigned a element to a order based on a segment, | ||
| the order *cannot* change unless deemed by a segment with a higher significance. | ||
| Hence, a stable sort is required to maintain the order as | ||
| the sorting is done with respect to each of the segments. | ||
| ### Common Misconception | ||
| While Radix Sort is a non-comparison-based algorithm, | ||
| it still necessitates a form of total ordering among the elements to be effective. | ||
| Although it does not involve direct comparisons between elements, Radix Sort achieves ordering by processing elements | ||
| based on individual segments or digits. This process depends on Counting Sort, which organizes elements into a | ||
| frequency map according to a **predefined, ascending order** of those segments. | ||
|
|
||
| ## Complexity Analysis | ||
| Let b-bit words be broken into r-bit pieces. Let n be the number of elements to sort. | ||
| Let b-bit words be broken into r-bit pieces. Let n be the number of elements. | ||
|
|
||
| *b/r* represents the number of segments and hence the number of counting sort passes. Note that each pass | ||
| of counting sort takes *(2^r + n)* (O(k+n) where k is the range which is 2^r here). | ||
| of counting sort takes *(2^r + n)* (or more commonly, O(k+n) where k is the range which is 2^r here). | ||
|
|
||
| **Time**: *O((b/r) * (2^r + n))* | ||
|
|
||
| **Space**: *O(n + 2^r)* | ||
| **Space**: *O(2^r + n)* <br> | ||
| Note that our implementation has some slight space optimization - creating another array at the start so that we can | ||
| repeatedly recycle the use of original and the copy (saves space!), | ||
| to write and update the results after each iteration of the sub-routine function. | ||
|
|
||
| ### Choosing r | ||
| Previously we said the number of segments is flexible. Indeed, it is but for more optimised performance, r needs to be | ||
| Previously we said the number of segments is flexible. Indeed, it is, but for more optimised performance, r needs to be | ||
| carefully chosen. The optimal choice of r is slightly smaller than logn which can be justified with differentiation. | ||
|
|
||
| Briefly, r=lgn --> Time complexity can be simplified to (b/lgn)(2n). <br> | ||
| For numbers in the range of 0 - n^m, b = mlgn and so the expression can be further simplified to *O(mn)*. | ||
| Briefly, r=logn --> Time complexity can be simplified to (b/lgn)(2n). <br> | ||
| For numbers in the range of 0 - n^m, b = number of bits = log(n^m) = mlogn <br> | ||
| and so the expression can be further simplified to *O(mn)*. | ||
|
|
||
| ## Notes | ||
| - Radix sort's time complexity is dependent on the maximum number of digits in each element, | ||
| hence it is ideal to use it on integers with a large range and with little digits. | ||
| - This could mean that Radix Sort might end up performing worst on small sets of data | ||
| if any one given element has a in-proportionate amount of digits. | ||
| - Radix Sort doesn't compare elements against each other, which can make it faster than comparative sorting algorithms | ||
| like QuickSort or MergeSort for large datasets with a small range of key values | ||
| - Useful for large sets of numeric data, especially if stability is important | ||
| - Also works well for data that can be divided into segments of equal size, with the ordering between elements known | ||
|
|
||
| - Radix sort's efficiency is closely tied to the number of digits in the largest element. So, its performance | ||
| might not be optimal on small datasets that include elements with a significantly higher number of digits compared to | ||
| others. This scenario could introduce more sorting passes than desired, diminishing the algorithm's overall efficiency. | ||
| - Avoid for datasets with sparse data |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters