| created_at | updated_at | slug |
|---|---|---|
2019-10-27 05:28:48 -0700 |
2021-02-16 15:24:32 -0800 |
kubernetes-deployment-introduction |
前面介绍了各种Kubernetes资源以及使用方法,但在实际使用中,发布和升级总是避免不了的话题。使用一个容器级别的工具,每次发布时候敲一大段命令肯定是不行的,K8S提供声明式的发布升级方式,只需替换镜像即可触发,且提供滚动升级、回滚、暂停等操作。
应用发布后,有两种升级方法可选
-
停用所有现有pod,然后创建新的pod 这种方式会使服务停用一段时间,但不会造成两个版本同时运行的情况。 实际操作上,先修改RC的模板,然后删除现有pod,这样RC会使用新的模板创建pod。
-
先创建新的pod,待新的pod准备就绪后,再删除旧的pod 这种方式虽然是无缝切换,但这会造成同时有两个版本的应用在运行。 实际操作上,有两种方式
-
蓝绿部署 如下图所示,新建一个RC,待所有pod就绪后再通过Service的选择器设置将流量转到新的pod上。
-
滚动升级 实现这种方式的最笨办法就是对旧的RC缩容,新的RC扩容,直到完全到新的RC掌控。
-

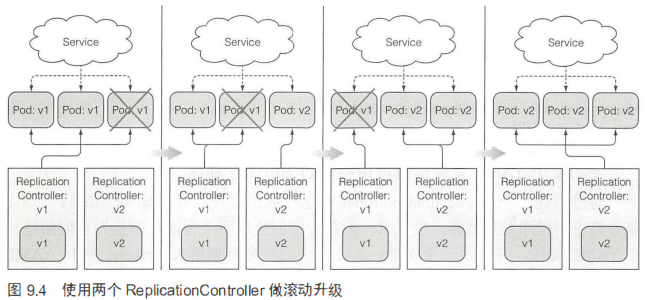
上述滚动升级的自动执行方式如下所示。kubia-v1是原先版本的RC,kubia-v2是需要创建的新的RC(不需要给定义文件),--image指定了新的镜像。这样k8s会自动一步一步地执行上述滚动升级的操作。
kubectl rolling-update kubia-v1 kubia-v2 --image=luksa/kubia:v2k8s是如何做到的呢?如下图,在创建kubia-v2这个RC时,k8s将原有pod增加了一个deployment标签,其值为3ddd开头。新RC创建的pod标签也增加了deployment=757d...标签。这样就能区分那个pod是新的,哪个pod是旧的。
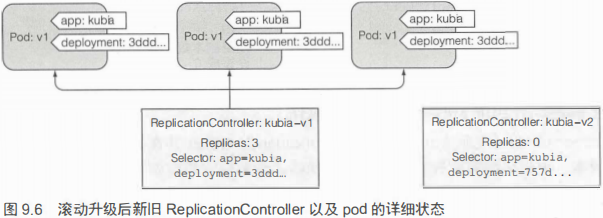
然后再对kubia-v1执行缩容,对kubia-v2执行扩容,直到完全切换到kubia-v2
不过很遗憾的是,这种升级方式已过时。因为rolling-update的每一步缩容扩容都是kubectl客户端在请求,如果网络出现问题,将会造成升级到一半卡主的情况。并且手动增删pod和修改正在运行的pod的标签等属性是不符合k8s的策略的。
正是由于rolling-update的过时,催生了Deployment。它是一种k8s资源,用于以声明的方式升级应用,而不是通过操作底层的RC。通过这种方式用户只需要定义单个Deployment需要达到的状态,中间操作都将由k8s处理。
Deployment的创建和RS创建很相似。它并不能直接管理pod,而是创建ReplicaSet来替它管理。
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: kubia
spec:
replicas: 3
progressDeadlineSeconds: 600 # 可选,允许最长升级时间,默认十分钟
miniReadySeconds: 10 # 可选,设置pod就绪后至少10秒才创建新的pod
strategy: # 可选,升级策略,默认为滚动升级
type: rollingUpdate
rollingUpdate:
masSurage: 1 # 这两个参数后面会讲
maxUnavailable: 0
template:
matadata:
name: kubia
labels:
app: kubia
spec:
containers:
- image: zou8944/kubia:v1
name: nicai# 创建Deployment, record很重要,会记录每次修改,用于回滚和升级log记录
kubectl create -f <上面的yaml> --record
# 创建Deployment后可使用如下命令查看状态
kubectl get deployment
kubectl describe deployment
kubectl rollout status deployment kubia从创建步骤和基本原理分析上,Deployment和rolling-update貌似没什么不同,这里展现其杀手锏。执行如下命令,仅是修改了Deployment资源中的镜像,k8s的控制处理器就会执行升级操作,其所有过程都是在服务端完成的,客户端仅仅请求了修改一个字段,这样会非常可靠。当然,整个滚动升级过程和rolling-update是非常类似的,只不过指定点移动到了服务端。
# 手动触发滚动升级
kubectl set image deployment kubia nicai=zou8944/kubia:v2主要注意的是,这里的升级也有两种策略
- Recreate: 先删除旧的pod,再创建新的pod
- RollingUpdate: 逐渐删除旧的pod,同时创建新的pod,默认并推荐使用这种方式。
还要注意的是,执行滚动升级后,Deployment会创建新的RS,同时原有的RS会保留,次数不要删除原有RS,它是用于回滚操作的,如果删除了就无法回滚到对应版本了。如下图所示
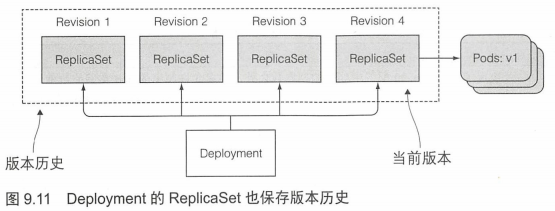
如果只想发布一个pod用于观察情况,可以在升级启动后暂停,观察OK后再继续升级。需要注意的是,这并不是金丝雀发布的正确打开方式。
# 触发升级
kubectl set image deployment kubia nicai=zou8944/kubia:v3
# 暂停升级
kubectl rollout pause deployment kubia
# 如果发现不妙,取消本次升级
kubectl rollout undo deployment kubia
# 恢复升级
kubectl rollout resume deployment kubia# 回滚到上一个版本
kubectl rollout undo deployment kubia
# 回滚到特定的版本
kubectl rollout undo deployment kubia --to-revision=1
# 查看回滚历史
kubectl rollout history deployment kubia有三个关键的参数,maxSurge、maxUnavailable、minReadySeconds.
-
maxSurge: Deployment期望的副本数之外,最多允许超出pod实例的数量,默认25%
-
maxUnavailable: 滚动升级期间,允许多少个pod实例处于不可用状态
-
minReadySeconds: 指定新创建的pod至少成功运行多久,才能将其视为可用。成功运行的起点为就绪探针发挥成功。如果就绪探针失败,会停止升级操作。

也可为Deployment配置deadline,默认情况下,如果升级过程超过十分钟,将会被视为失败。
尽管上面已经有过描述,但这里还是想加强一下,因此单独列出一个三级标题。取消失败的升级和回滚一样
kubectl rollout undo deployment kubia