- 执行训练脚本,开始训练语音识别模型, 每训练一轮和每2000个batch都会保存一次模型,模型保存在
PaddlePaddle-DeepSpeech/models/param/目录下,默认会使用数据增强训练,如何不想使用数据增强,只需要将参数augment_conf_path设置为None即可。关于数据增强,请查看数据增强部分。如果没有关闭测试,在每一轮训练结果之后,都会执行一次测试计算模型在测试集的准确率。执行训练时,如果是Linux下,通过CUDA_VISIBLE_DEVICES可以指定多卡训练。
CUDA_VISIBLE_DEVICES=0,1 python train.py训练输出结果如下:
----------- Configuration Arguments -----------
augment_conf_path: ./conf/augmentation.json
batch_size: 32
learning_rate: 0.0001
max_duration: 20.0
mean_std_path: ./dataset/mean_std.npz
min_duration: 0.0
num_conv_layers: 2
num_epoch: 50
num_rnn_layers: 3
output_model_dir: ./models/param
pretrained_model: None
resume_model: None
rnn_layer_size: 1024
shuffle_method: batch_shuffle_clipped
test_manifest: ./dataset/manifest.test
test_off: False
train_manifest: ./dataset/manifest.train
use_gpu: True
vocab_path: ./dataset/zh_vocab.txt
------------------------------------------------
dataset/manifest.noise不存在,已经忽略噪声增强操作!
[2021-08-31 22:40:36.473431] 训练数据数量:102394
W0831 22:40:36.624647 4879 device_context.cc:404] Please NOTE: device: 0, GPU Compute Capability: 7.5, Driver API Version: 11.0, Runtime API Version: 10.2
W0831 22:40:36.626874 4879 device_context.cc:422] device: 0, cuDNN Version: 7.6.
W0831 22:40:37.996898 4879 parallel_executor.cc:601] Cannot enable P2P access from 0 to 1
W0831 22:40:37.996917 4879 parallel_executor.cc:601] Cannot enable P2P access from 1 to 0
W0831 22:40:39.725975 4879 fuse_all_reduce_op_pass.cc:76] Find all_reduce operators: 44. To make the speed faster, some all_reduce ops are fused during training, after fusion, the number of all_reduce ops is 23.
Train [2021-08-31 22:40:41.633553] epoch: [1/50], batch: [0/1599], learning rate: 0.00020000, train loss: 2053.378662, eta: 3 days, 8:51:04
Train [2021-08-31 22:41:43.713666] epoch: [1/50], batch: [100/1599], learning rate: 0.00020000, train loss: 86.532333, eta: 12:59:38
Train [2021-08-31 22:42:40.098206] epoch: [1/50], batch: [200/1599], learning rate: 0.00020000, train loss: 87.101303, eta: 12:07:12
Train [2021-08-31 22:43:33.444587] epoch: [1/50], batch: [300/1599], learning rate: 0.00020000, train loss: 84.560562, eta: 11:42:34
Train [2021-08-31 22:44:24.759048] epoch: [1/50], batch: [400/1599], learning rate: 0.00020000, train loss: 81.681633, eta: 11:18:40
Train [2021-08-31 22:45:14.196539] epoch: [1/50], batch: [500/1599], learning rate: 0.00020000, train loss: 72.275848, eta: 10:27:17
Train [2021-08-31 22:46:02.194968] epoch: [1/50], batch: [600/1599], learning rate: 0.00020000, train loss: 76.041451, eta: 9:51:43
- 在训练过程中,程序会使用VisualDL记录训练结果,可以通过以下的命令启动VisualDL。
visualdl --logdir=log --host=0.0.0.0- 然后再浏览器上访问
http://localhost:8040可以查看结果显示,如下。
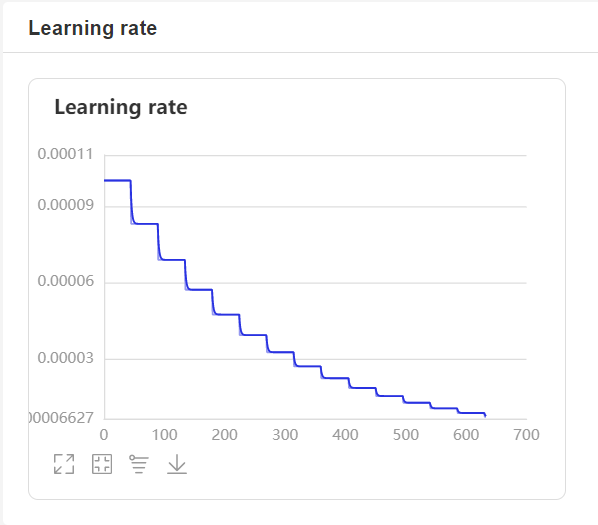
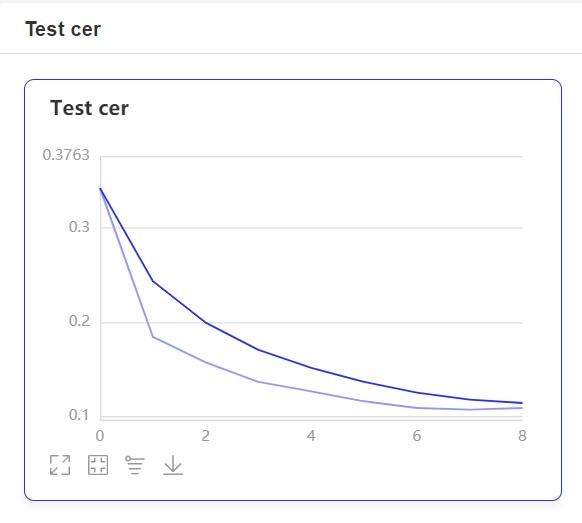
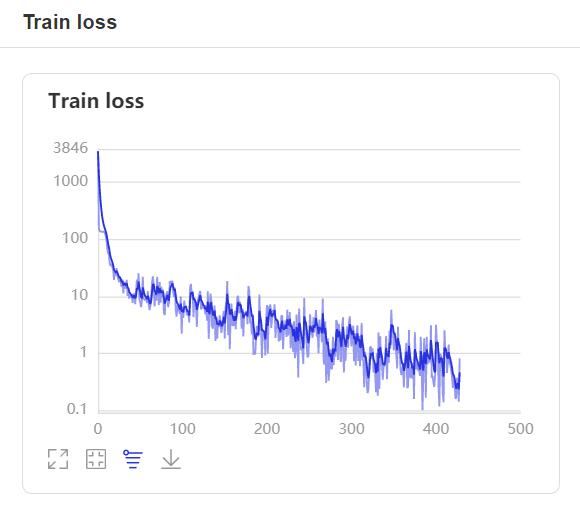
如果在训练的时候中断了,可以通过参数resume_model指定模型,然后在这基础上恢复训练,在启动训练之后会加载该模型,并以当前epoch继续训练。
CUDA_VISIBLE_DEVICES=0,1 python train.py --resume_model=models/param/23.pdparams如果读者已经训练或者下载了模型,想使用自己的数据集微调模型,除了使用resume_model参数指定模型外,还需要修改训练的num_epoch,因为该模型已经是最大num_epoch保存的模型,如果不修改参数的话,可能直接就停止训练了,可以设置为60,模型就会在原来的模型在训练10个epoch。数据集需要加上原来的数据合并一起训练。
CUDA_VISIBLE_DEVICES=0,1 python train.py --resume_model=models/param/50.pdparams --num_epoch=60