Event sourcing and Command Query Responsibility Segregation (CQRS) are frequently mentioned together. Although neither one necessarily implies the other, you will see that they do complement each other. This chapter introduces the key concepts that underlie event sourcing, with some pointers to the potential relationship with the CQRS pattern. This chapter is an introduction; the chapter "A CQRS/ES Deep Dive" explores event sourcing and its relationship with CQRS in more depth.
Before going any further, we should have a basic definition of events that captures their essential characteristics:
- Events happen in the past. For example, "the speaker was booked," "the seat was reserved," "the cash was dispensed." Notice how we describe these events using the past tense.
- Events are immutable. Because events happen in the past, they cannot be changed or undone. Subsequent events may alter or negate the effects of earlier events. For example, "the reservation was cancelled."
- Events are one-way messages. Events have a single source (publisher) that fires the event. One or more recipients (subscribers) may receive events.
- Typically, events include parameters that provide additional information about the event. For example, "Seat E23 was booked by Alice."
- In the context of event sourcing, events should describe business intent. For example, "Seat E23 was booked by Alice" describes in business terms what has happened and is more descriptive in business terms than, "In the bookings table, the row with key E23 had the name field updated with the value Alice."
We will also assume that the events being discussed in this chapter are associated with aggregates; see the chapter "CQRS in Context" for a descriptions of the DDD terms: aggregates, aggregate roots, and entities. The features of aggregates that are relevant to events and event sourcing are:
- Aggregates define consistency boundaries for groups of related entities; therefore, you can use an event raised by an aggregate to notify interested parties that a transaction (consistent set of updates) has taken place on that group of entities.
- Every aggregate has a unique ID; therefore, you can use that ID to record which aggregate in the system was the source of a particular event.
For the remainder of this chapter, we will use the term aggregate to refer to a cluster of associated objects that are treated as a unit for the purposes of data changes. This does mean that event sourcing is directly related to the DDD approach; we are simply using the terminology from DDD to try to maintain some consistency in our terminology.
Event sourcing is a way of storing your application's state by storing the history that determines the current state of your application. For example, a conference management system needs to track the number of completed bookings for a conference so it can check whether there are still seats available when someone tries to make a new booking. The system could store the total number of bookings for a conference in two ways:
- It could store the total number of bookings for a particular conference and adjust this number whenever someone makes or cancels a booking. You can think of the number of bookings as being an integer value stored in a specific column of a table that has a row for each conference in the system.
- It could store all the booking and cancellation events for each conference and then calculate the current number of bookings by replaying the events associated with the conference for which you wanted to check the current total number of bookings.

Using an ORM mapping layer
Figure 1 illustrates the first approach to storing the total number of reservations. The following list of steps corresponds to the numbers in the diagram:
- A command is issued, from the UI or from a saga, to reserve seats for two attendees on a conference with an ID of 157. The command is handled by the command handler for the SeatsAvailability aggregate type.
- If necessary, the ORM layer populates an aggregate instance with data. The ORM retrieves the data by issuing a query against the table (or tables) in the data store. This includes the existing number of reservations for the conference.
- The command handler invokes the business method on the aggregate instance to make the reservations.
- The SeatsAvailability aggregate performs its domain logic. In this example, this includes calculating the new number of reservations for the conference.
- The ORM persists the information in the aggregate instance to the data store. The ORM layer constructs the necessary update (or updates) that must be executed.
This diagram provides a deliberately simplified view of the process. In practice, the mapping performed by the ORM will be significantly more complex. You will also need to consider exactly when the load and save operations must happen to balance the demands of consistency, reliability, scalability, and performance.

Using event sourcing
Figure 2 illustrates the second approach, using event sourcing in place of an ORM layer and an RDMS.
Note: You might decide to implement the event store using an RDBMS, but it will have a much simpler schema than in the first approach. You can also use a custom event store.
The following list of steps corresponds to the numbers in the diagram. Note that steps one, two, and four are the same.
- A command is issued, from the UI or from a saga, to reserve seats for two attendees on a conference with an ID of 157. The command is handled by the command handler for the SeatsAvailability aggregate type.
- An aggregate instance is populated by querying for all of the events that belong to SeatsAvailability aggregate 157.
- The command handler invokes the business method on the aggregate instance to make the reservations.
- The SeatsAvailability aggregate performs its domain logic. In this example, this includes calculating the new number of reservations for the conference. The aggregate creates an event to record the effects of the command.
- The system appends the event that records making two new reservations to the list of events associated with the aggregate in the event store.
This second approach is simpler because it dispenses with the ORM layer, and replaces a complex relational schema in the data store with a much simpler one. The data store only needs to support querying for events by aggregate ID and appending new events. You will still need to consider performance and scalability optimizations for reading from and writing to the store, but the impact of these optimizations on reliability and consistency should be much easier to understand.
Note: Some optimizations to consider are using snapshots so you don't need to query the full list of events to obtain the current state of the aggregate, and maintaining cached copies of aggregates in memory.
You must also ensure that you have a mechanism that enables an aggregate to rebuild its state by querying for its list of historical events.
What you have also gained with the second approach is a complete history, or audit trail, of the bookings and cancellations for a conference.
In some domains, such as accounting, event sourcing is the natural, well-established approach: accounting systems store individual transactions from which it always possible to reconstruct the current state of the system. Event sourcing can bring a number of benefits to other domains.
So far, the only justification we have offered for event sourcing is the fact that it stores a complete history of the events associated with the aggregates in your domain. This is a vital feature in some domains such as accounting where you need a complete audit trail of the financial transactions, and where events must be immutable. Once a transaction has happened, you cannot delete or change it, although you can create a new corrective or reversing transaction if necessary.
The following list describes some of the additional benefits that you can derive from using event sourcing. The significance of the individual benefits will vary depending on the domain you are working in.
- Performance. Because events are immutable, you can use an append-only when you save them. Events are also simple, stand-alone objects. Both these factors can lead to better performance and scalability for the system than approaches that use complex relational storage models.
- Simplification. Events are simple objects that describe what has happened in the system. By simply saving events, you are avoiding the complications associated with saving complex domain objects to a relational store: the object-relational impedance mismatch.
- Audit Trail. Events are immutable and store the full history of the state of the system. As such, they can provide a detailed audit trail of what has taken place within the system.
- Integration with other sub-systems. Events provide a useful way of communicating with other sub-systems. Your event store can publish events to notify other interested sub-systems of changes to the application's state. Again, the event store provides a complete record of all the events that it published to other systems.
- Deriving additional business value from event history. By storing events, you have the ability to determine what the state of the system was at any previous point in time by querying the events associated with a domain object up to that point in time. This enables you to answer historical questions from the business about the system. In addition, you cannot predict what questions the business might want to ask about the information stored in a system. If you store your events, you are not discarding information that may prove to be valuable in the future.
- Production troubleshooting. You can use the event store to troubleshoot problems in a production system by taking a copy of the production event store and replaying it in a test environment. If you know the time that an issue occurred in the production system then you can easily replay the event stream up to that point to observe exactly what was happening.
- Fixing errors. You might discover a coding error that results in the system calculating an incorrect value. Rather than fixing the coding error and performing a risky manual adjustment on a stored item of data, you can fix the coding error and replay the event stream so that the system calculates the value correctly based on the new version of the code.
The chapter "A CQRS/ES Deep Dive" discusses these benefits in more detail. There are also many illustrations of these benefits in these chapters in the section "A CQRS Journey."
From experience, ORMs lead you down the path of a structural model while ES leads you down the path of a behavioral model. Sometimes one just makes more sense than the other. For example, in my own domain (not model) I get to integrate with other parties that send a lot of really non-interesting information that I need to send out again later on when something interesting happens on my end. It's inherently structural. Putting those things into events would be a waste of time, effort, space. Contrast this with another part of the domain that benefits a lot from knowing what happened, why it happened, when it did or didn't happen, where time and historical data are important to make the next business decision. Putting that into a structural model is asking for a world of pain. It depends, get over it, choose wisely, and above all: make your own mistakes.
- Yves Reynhout (CQRS Advisors Mail List)
The previous section described some of the benefits that you might obtain if you decide to use event sourcing in your system. However, there may be some concerns that you will need to address if you decide to use event sourcing in your system:
- Performance. Although event sourcing typically improves the performance of updates, you may need to consider the time it takes to load domain object state by querying the event store for all of the events that relate to the state of an aggregate. Using snapshots may enable you limit the amount of data that you need to load: you can go back to the latest snapshot and replay the events from that point forward. See the chapter "A CQRS/ES Deep Dive" for more information about snapshots.
- Versioning. You may find it necessary to change the definition of a particular event type or aggregate at some point in the future. You must consider how your system will be able to handle multiple versions of an event type and aggregates.
- Querying. Although it is easy to load the current state of an object by replaying its event stream (or its state at some point in the past), it is difficult or expensive to run a query such as: find all my orders where the total value is greater than $250. However, you should remember that such queries will typically be executed on the read-side where you can ensure that you build data projections that are specifically designed to answer such questions.
The chapter "Introducing Command Query Responsibility Segregation" suggested that events can form the basis of the push synchronization of the applications state from the data store on the write-side to the data store on the read-side. Remember that typically the read-side data-store contains denormalized data that is optimized for the queries that are run against your data, for example to display information in your application's UI.
ES is a great pattern to use to implement the link between the thing that writes and the thing that reads. It's by no means the only possible way to create that link, but it's a reasonable one and there's plenty of prior art with various forms of logs and log shipping. The major tipping point for whether the link is "ES" seem to be whether the log is ephemeral or a permanent source of truth. The CQRS pattern itself merely mandates a split between the write and the read thing, so ES is strictly complementary.
- Clemens Vasters (CQRS Advisors Mail List)
Event Sourcing is about the state of the domain model being persisted as a stream of events rather than as a single snapshot, not about how the command and query sides are kept in sync (usually with a publish/subscribe message-based approach).
- Udi Dahan (CQRS Advisors Mail List)
You can use the events that you persist in your event store to propagate all the updates made on the write-side to the read-side. The read-side can use the information contained in the events to maintain whatever de-normalized data you require on the read-side to support your queries.
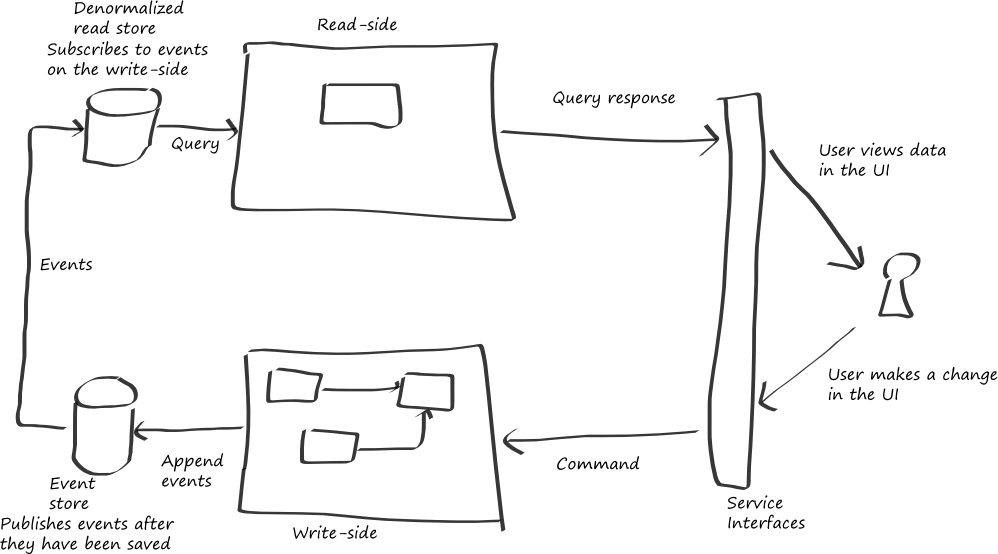
CQRS and Event Sourcing
Notice how the write-side publishes events after it persists them to the event store. This avoids the need to use a two-phase commit, which would be the case if the aggregate were responsible for saving the event to the even store and publishing the event to the read-side.
Normally, these events will enable you to keep the data on the read-side up to date in close to real-time; there will be some delay due to the transport mechanism, and the chapter "A CQRS/ES Deep Dive" discusses the possible consequences of this delay.
You can also rebuild the data on the read-side from scratch at any time by replaying the events from your event-store on the write-side. You might need to do this if the read-side data store got out of synchronization for some reason, or because you needed to modify the structure of the read-side data store to support a new query.
You need to be careful replaying the events from the event store to rebuild the read-side data store if other bounded contexts also subscribe to the same events. It might be easy to empty the read-side data store before replaying the events, it might not be so easy to ensure the consistency of another bounded context if it sees a duplicate stream of events.
Remember that the CQRS pattern does not mandate you to use different stores on the read-side and the write-side. You could decide to use a single relational store with a schema in third normal form and a set of denormalized views over that schema. However, replaying events is a very convenient mechanism for re-synchronizing the read-side data store with the write-side data store.
You can use event sourcing without also applying the CQRS pattern. The ability to rebuild the application state, to mine the event history for new business data, and to simplify the data storage part of the application are all valuable in some scenarios.