| layout | title | permalink | comments |
|---|---|---|---|
page |
Visualisierungen |
/visualisierungen |
true |
Visualisierung von Wahldaten
Der folgende Text soll eine kurze und einfache Einführung in das Thema Visualisierung von Wahldaten geben. Dazu wird das Wahlergebnis der Bundespräsidentenwahl 2016/erster Wahlgang verwendet. Zunächst geht es um die Quelle und die Aufbereitung der Daten, anschließend wird Schritt für Schritt eine Grafik zum Gesamtergebnis erstellt.
Die Idee einer Visualisierung ist, etwas grafisch so darzustellen, dass es auch grafisch verstanden werden kann (sprich ohne die genauen Daten) - im Idealfall sogar besser/zugänglicher.
Das heißt nicht, dass man auf Zahlen verzichten muss, diese können oftmals die nötige Präzision liefern, die visuell nicht wahrnehmbar ist - wenn man aber die Zahlen benötigt, um die Grafik überhaupt zu verstehen, kann man sich aber auch überlegen, ob eine Tabelle nicht sinnvoller wäre (was keine Schande ist - oft ist auch das ein Ergebnis einer versuchten Visualisierung).
Etwas visuell darzustellen heißt auch viel Experimentieren und Herumprobieren. Ungewohnte Darstellungsformen können Bekanntes neu und aufschlussreich zeigen, aber auch überfordern. Wie so oft gilt: Meistens ist weniger mehr, und (scheinbare) Einfachheit besser als zu komplexe und verworrene Grafiken. Aber: Viele Punkte sind schlicht Geschmacksache.
Was einem immer klar sein sollte: Im Zweifel schlägt der optische Eindruck/das Bild jeden Erklärungstext, den man der Grafik beifügt.
Im Grunde lassen sich viele Daten unter einem politischen Blickwinkel betrachten, die größte Hürde ist oftmals die Verfügbarkeit (und die Idee). Die in diesem Sinn wahrscheinlich am "leichtesten" zu visualisierenden politischen Daten in Österreich sind Wahlergebnisse: Sie sind für die Bundes- und Länderebene überwiegend in bearbeitbarer Form verfügbar, die Datensätze sind komplett und vergleichsweise überschaubar.
Gut wäre es, sich ein ungefähres Ziel zu überlegen: Will ich eine Sache konkret darstellen? Oder will ich einfach ausprobieren, wie die Daten (in unterschiedlicher Form) aussehen? Je nachdem kann man sich anders an eine Grafik machen.
Daten zu Wahlergebnissen auf Bundesebene findet man in Österreich beim Innenministerium. Dort sind alle Ergebnisse zu den Wahlen seit 1945 - Nationalrat, Bundespräsidentschaft, EU-Parlament - gesammelt, allerdings gibt es erst ab den 2000er Jahren Datensätze, die auch direkt weiterverarbeitet werden können (üblicherweise Excel-Dateien).
Die Ergebnisdatei zum ersten Wahlgang gibt es hier - und diese schaut so aus:
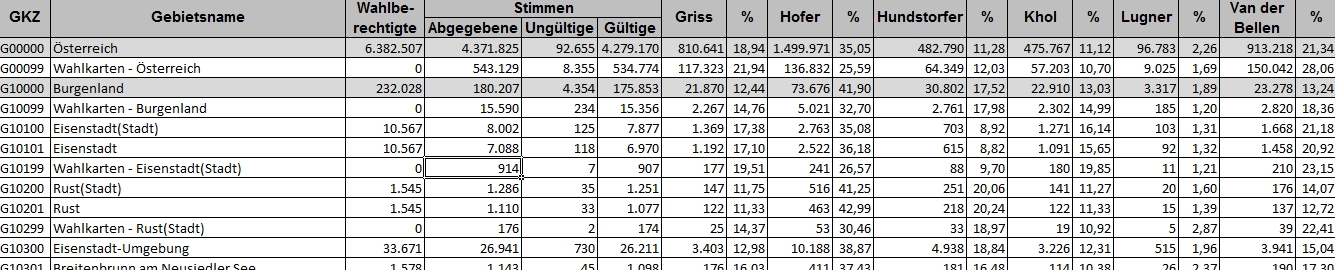
hier ein Teil zu den Nutzungsrechten?
Die Spalten sind soweit selbsterklärend, für viele Darstellungen hilfreich ist die "GKZ" oder Gemeindekennziffer: Die erste Stelle steht für das Bundesland, die ersten drei Stellen für den Bezirk und die gesamte Zahl für eine Gemeinde (das vorangestellte "G" kann man ignorieren).
Neben der Zahl der Wahlberechtigten finden sich die abgegebenen, ungültigen und gültigen Stimmen in absoluten Zahlen. Hier ist es wichtig zu wissen, welche Basis jeweils für die Ergebnisberechnung verwendet wird: Die Wahlbeteiligung berechnet sich aus der Zahl der abgegebenen Stimmen (abgegebene Stimmen / Wahlberechtigte), die Stimmenanteile der KandidatInnen aus den gültigen abgegebenen Stimmen (Stimmenanteil KandidatIn / gültige Stimmen).
In der Spalte "Gebietsname" stehen neben den Gemeinde-, Bezirks- und Bundeslandergebnissen auch weitere Zeilen speziell zu Wahlkarten - das heißt, man muss sich die gewünschten Zeilen heraussuchen und kann nicht automatisch die gesamte Datei verwenden.
Die Auswahl der relevanten Daten ist meistens der erste Schritt auf dem Weg zu einer grafischen Darstellung. Uns interessiert in erster Linie einmal das Gesamtergebnis der KandidatInnen. Das heißt, wir arbeiten mit der ersten Zeile - dem Österreich-Ergebnis - weiter. Um die Datenquelle übersichtlicher zu gestalten könnten wir alle Spalten bis auf die Prozentwerte der kandidierenden Personen löschen. Allerdings werden diese in der BMI-Datei durch eine Formel erst im Excel selbst berechnet, daher müssen wir sie behalten, oder aber die Daten als Werte neu einfügen.
Oft ist es besser, in der Quelldatei mit den absoluten Zahlen zu arbeiten, und etwaige Prozent-Werte erst im Zuge der Visualisierung zu berechnen - das macht das Arbeiten flexibler, da man später weitere Berechnungen anstellen kann, ohne wieder rückrechnen zu müssen.
Was gegen ein Löschen der Spalten spricht ist, dass wir damit Informationen verlieren. Diese sind vielleicht momentan noch nicht wichtig, aber können später interessant werden, wenn wir durch unsere Visualisierung auf etwas gestoßen sind, das wir überprüfen wollen. Ein nachträgliches Einfügen gelöschter Daten ist meistens mühsam und fehleranfällig.
Je nachdem, mit welchem Programm die Visualisierung umgesetzt wird, kann es nötig sein, die Daten dort neu zu importieren. Ein gängiges Format dafür sind CSV-Dateien, das sind Text-Dateien, in denen jede Spalte mit einem eindeutigen Trennzeichen - normalerweise einem "," - getrennt wird. Dieses Trennzeichen kann aber auch etwas anderes sein, das deutschsprachige Excel verwendet etwa einen ";".
Diese Kleinigkeit hat große Auswirkungen, sobald ein anderes Programm automatisch mit einem "," rechnet. In dem Fall kann es die Spalten nicht finden. Zusätzlich würden dann ",", die als Komma-Zeichen verwendet werden, als ein Trennzeichen interpretiert, so kommt es zu neuen und falschen Spaltenzuordnungen. Daher ist es wichtig, auf diese Formatierung zu achten und sie zu vereinheitlichen.
Ein weiterer Punkt ist das so genannte Encoding einer Datei: Das bestimmt den Zeichensatz, der verwendet wird, kurz gesagt die Buchstaben. In deutschsprachigen Programmen ist es ganz klar, dass es Umlaute gibt, im englischen Sprachraum gibt es diese Zeichen nicht. Um die zahlreichen Umlaute in den österreichischen Gemeindenamen nicht zu verlieren, sollte man als Encoding immer UTF-8 verwenden.
Das BMI (nicht nur) nutzt in den Namen von Bezirken - speziell Wien - teilweise Beistriche, was beim Export als CSV problematisch sein kann, daher sollte man diese Beistriche vorab löschen.
Letzter Punkt ist die Formatierung: Englischsprachige Tools verwenden andere Trennzeichen in Zahlen als deutschsprachige Programme: Die Zahl 100.000,99 (100tausend Komma 99) versteht ein englischsprachiges Programm als 100,0 (plus Formatfehler). Umgekehrt würde sie englischsprachig so aussehen : 100,000.99.
Exkurs: Vom (deutschen) Excel zum (englischen) CSV Es kann mitunter umständlich sein, aus einer Excel-Datei ein CSV zu machen, das dann problemlos weiterverwendet werden kann. Ein möglicher Weg ist:
- zuerst im Excel einstellen, dass keine Tausender-Trennzeichen verwendet werden
- die Excel-Datei dann mit "Speichern als" als "Unicode Text" speichern
- anschließend diese Datei mit einem Texteditor (zb Notepad++ öffnen
- mittels Suchen/Ersetzen alle "," durch "." ersetzen (ersetzt alle Komma-Zeichen)
- die Datei verwendet wahrscheinlich das Tabulator-Zeichen als Trennzeichen zwischen Spalten - am besten markiert man den leeren Platz zwischen zwei Einträgen und kopiert diesen
- mittels Suchen/Ersetzen alle " " durch "," ersetzen (ersetzt alle Tabulator-Zeichen)
- jetzt kann man die Dateiendung noch auf ".csv" ändern
Wir bleiben vorerst einfach beim Österreich-Ergebnis und probieren eine erste Darstellung der Stimmanteile, also der Prozentwerte der KandidatInnen:
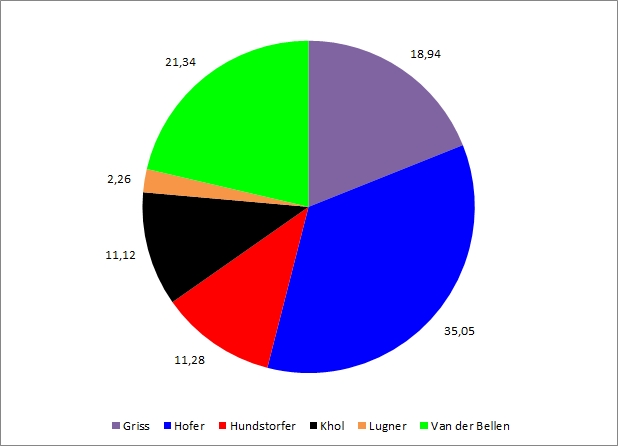
Obwohl die Grafik alles enthält, was sie laut Ziel enthalten soll (KandidatInnen und deren Ergebnis), ist sie ausbaufähig. Man erkennt zwar, dass Hofer den größten Teil des Kuchens hat, der Unterschied zwischen Griss und Van der Bellen verschwimmt aber bereits. Wie viel Prozent Hofer erhalten hat, ist ohne die Zahlenangabe ein Ratespiel.
Kurz gesagt, Kreisdiagramme sind optisch schwer zu verarbeiten, ihre Aussagen manchmal unklar. Sie können gut funktionieren, wenn man nur zwei Teile vergleicht (z.B. bei einer Stichwahl), es gibt aber oftmals bessere Diagrammtypen - etwa ein Säulendiagramm:
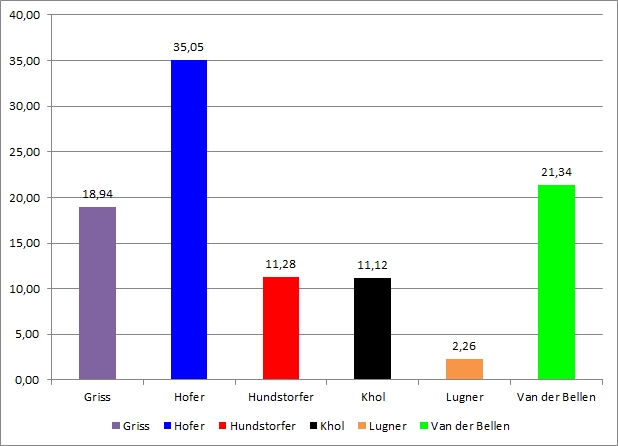
Das mag zugegeben hin und wieder schon etwas fad sein, aber die Aussage ist deutlich klarer: Auch ohne die konkreten Werte lassen sich die Stimmenanteile der KandidatInnen erkennen. Die Verhältnisse zwischen den Balken sind ebenfalls recht gut vergleichbar, die Van der Bellen-Säule ist erkennbar rund doppelt so groß wie die Hundstorfer/Khol-Säulen (wer Lust hat möge testweise diesen optischen Vergleich beim Kreis-Diagramm probieren).
Die Darstellung hat aber noch Luft nach oben: Zunächst lässt sie sich dadurch verbessern, indem man die Werte nach der Größe sortiert:
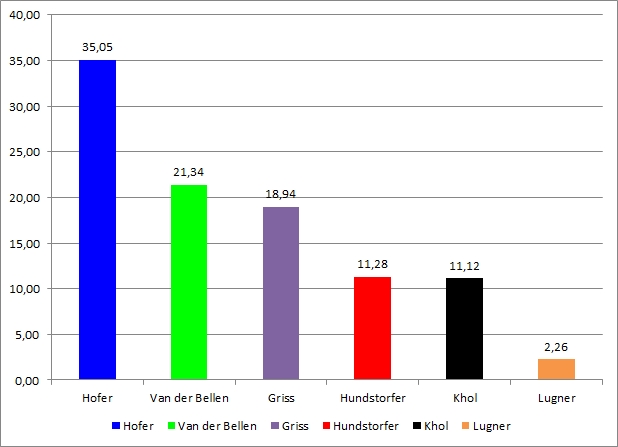
Es macht oft Sinn, Daten zu sortieren, bevor man sie visualisiert, da dadurch erst Muster klar erkennbar werden. Man nimmt so auch dem Betrachter viel Arbeit ab und hilft beim "Lesen" und Verstehen der Daten.
Die Sortierung muss dabei auch nicht automatisch dem größten Wert folgen, es kann Sinn machen, Daten nach ganz anderen Kriterien zu sortieren. Im konkreten Fall freilich - siehe die Zielsetzung - ist die absteigende Reihung passend und verbessert die Aussage der Grafik. Die Reihenfolge ist auf einen Blick erkennbar, auch das relativ knappe Ergebnis zwischen Platz 2 und 3 gut vergleichbar.
Nachdem die grundlegende Form einmal stimmt, können wir den visuellen Eindruck noch ausbauen. Das beginnt bei den Farben: Diese sind zwar hier gut unterscheidbar, aber grell und wenig ansehnlich. Matte und gedeckte Farben sind in diesem Fall eine bessere Wahl.
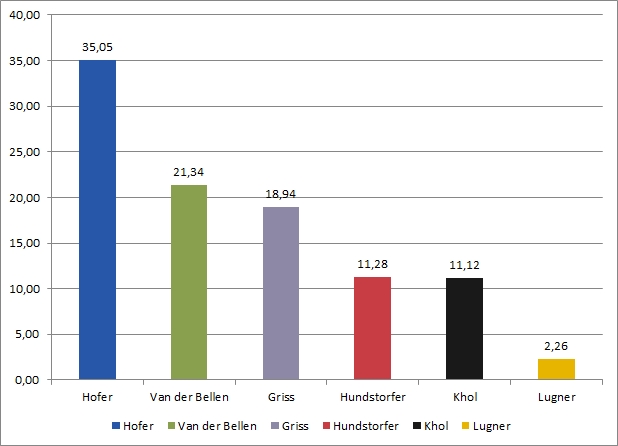
Es macht Sinn, dass die Säulen hier unterschiedliche Farben haben, die Mehrheit der KandidatInnen kann einer Partei (und damit deren Farbe) zugerechnet werden. Allerdings ist es kein Muss, besonders bunt zu arbeiten, man sollte sich stets überlegen, ob die Farben auch tatsächlich einen Mehrwert bringen. Drücken sie etwa einen qualitativen Unterschied aus (zwischen verschiedenen Personen, Parteien usw.)? Unterschiedliche Dinge? Falls nein kann Einfärbigkeit auch eine gute Wahl sein. Farbpaletten finden sich im Internet viele, z.B. Color Brewer oder Color Picker.
Ein immer schwieriger Punkt ist die Skalierung, also die Frage, in welches Verhältnis die Werte gesetzt werden. Beim Beispiel geht es um die y-Achse. Deren Maximum liegt hier bei der nächsten runden Zahl über dem Maximalwert. Das ist an sich ok, die Größenverhältnisse passen. Eine solche Darstellung betont allerdings das Ergebnis des Erstplatzierten deutlich stärker als beispielsweise eine Skala, die von 0 bis 100 (Prozent) reicht:
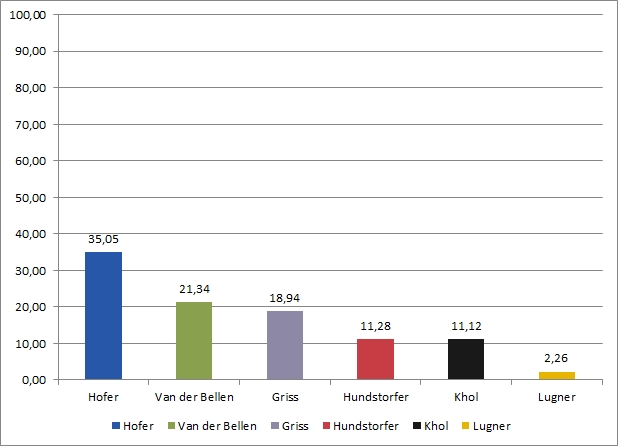
Auch hier ist Hofers Platz 1 unangefochten, optisch wirkt die Grafik aber anders als das vorherige Beispiel. Es gibt keinen "richtigen" Maximalwert, man sollte aber stets überlegen, was mit der jeweiligen Skalierung ausgedrückt wird: Bleiben wir bei 45 Prozent, dann steht der "überlegene" Sieg Hofers im Vordergrund. Nimmt man 100 Prozent, dann kann man auch optisch zeigen, wie weit alle KandidatInnen von den notwendigen 50 Prozent entfernt sind.
Am anderen Ende der Skala sollte normalerweise eine 0 stehen. Es kann gute/spezielle Gründe geben, eine y-Achse nicht bei 0 zu beginnen, aber im Zweifel sorgt der Nullpunkt dafür, dass es zu keinen (ungewollten/gewollten) Verzerrungen der Daten kommt. For the sake of the argument:
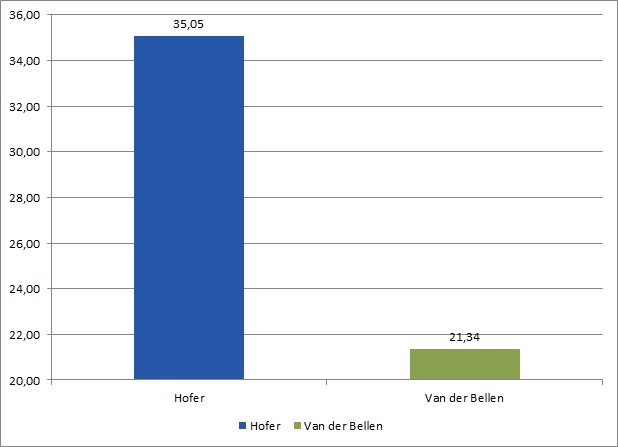
Bei anderen Chart-Typen können andere Überlegungen der Skalierung Vorrang haben: Bei Liniendiagrammen/Zeitreihen von Umfragen etwa kann eine sehr breite Skala (0-100 Prozent) eine Stabilität suggerieren, die nicht gegeben ist, umgekehrt kann eine enge Skala sprunghafte Veränderungen zeigen, die allein von den Daten nicht abgesichert sind.
In unserem Beispiel könnten wir etwa 70 Prozent als Maximalwert wählen, also das Doppelte des Sieger-Werts. Damit entschärft man eine zu stark zugeschnittene Skala, gleichzeitig reduzieren wir den leeren Platz. Bei der Gelegenheit noch ein paar weitere Anpassungen: Die Legende können wir löschen, da die Namen der KandidatInnen bei den Balken stehen und diese auch noch eingefärbt sind. Auch entfernen wir jede Menge Linien im Hintergrund und machen die Achsenlinien heller, um sie weniger dominant wirken zu lassen:
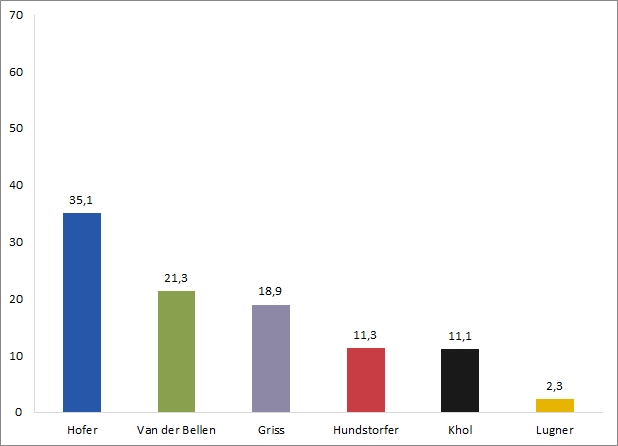
Quasi schon im Endspurt kann man nochmals zum Ziel kommen: Es geht um die Darstellung der Ergebnisse im ersten Wahlgang der Bundespräsidentenwahl. In diesem Wahlgang gibt es eine klare "Daten"-Grenze, die inhaltlich relevant ist - wer über 50 Prozent kommt, hat gewonnen und ist PräsidentIn. Um das optisch zu unterstreichen, kann man diese Grenze hervorheben, was der Visualisierung eine zusätzliche optische Information mitgibt. Da das Gitternetz im Hintergrund doch abgeht, können wir es wieder ergänzen. Die Linien können zur Orientierung durchaus Sinn machen, wir rücken sie farblich aber stärker in den Hintergrund. Das Endprodukt:
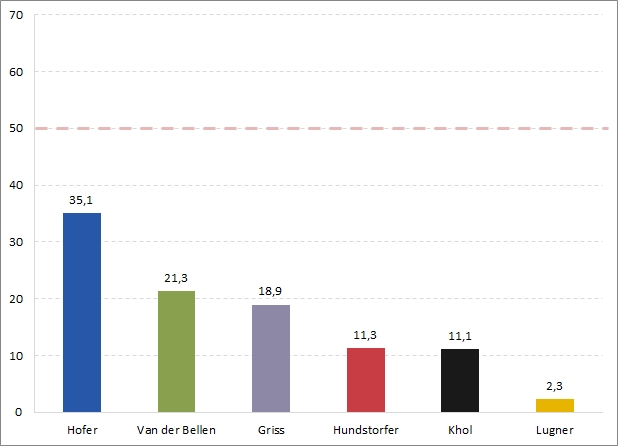
Soweit ein einfaches Beispiel mit einigen Überlegungen. Über viele Punkte kann man diskutieren, vieles lässt sich anders machen. Vor allem sollte man nicht hier stoppen, die Daten geben mehr her. Zum Beispiel: Wie haben die KandidatInnen in unterschiedlichen Bundesländern abgeschnitten?
Dazu können wir zunächst wieder einfach die Ergebnisse als Säulen darstellen, gruppiert je KandidatIn. Die Darstellung ist auf den ersten Blick recht überladen, ein paar Aussagen lassen sich aber dennoch bereits in dieser Form treffen:
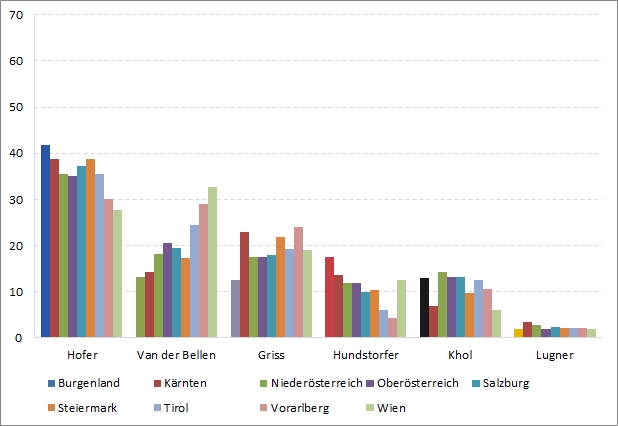
So hat z.B. Norbert Hofer offenbar nicht in allen Bundesländern die Mehrheit erreicht, in Wien lag Alexander Van der Bellen vorne und in Vorarlberg war es knapp. Irmgard Griss kam ebenfalls in zwei Bundesländern auf Platz 2. Die unterschiedlichen Farben der Säulen sind notwendig, um diese unterscheiden zu können, die Zuordnung ist allerdings etwas mühsam.
Wir können daher einen anderen Grafik-Typ ausprobieren, die gestapelten Balken (stacked bar chart). Die Ergebnisse werden wieder nach dem Höchstwert sortiert:
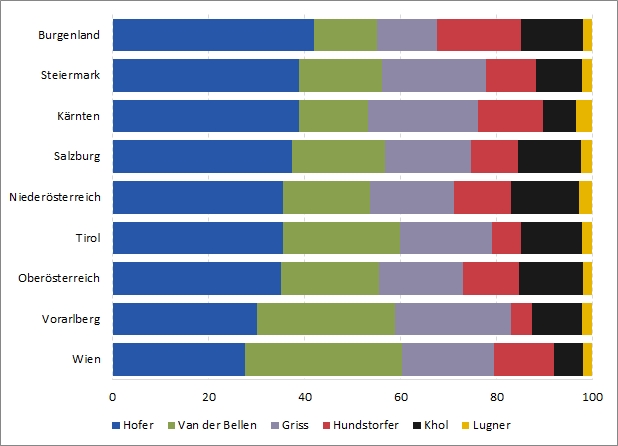
Die Ergebnisse des Erstplatzierten sind gut vergleichbar, dahinter wird es aber schwieriger, zumindest ungefähr lassen sich starke/schwache Ergebnisse aber erkennen. Ein Nachteil ist, dass der Vergleich zwischen den KandidatInnen innerhalb eines Bundeslandes schwierig ist, vor allem bei knappen Ergebnissen. Das Beispiel zeigt gut, dass es nicht den einen besten Typ einer Visualisierung gibt, sondern diese unterschiedliche Stärken und Schwächen haben.
Eine andere Variante für die Bundesländer wäre noch, nicht alle Daten in eine Grafik zu packen, sondern mehrere, kleine Diagramme zu erstellen. Solche "small multiples" eignen sich vor allem für Vergleiche zwischen Untergruppen:
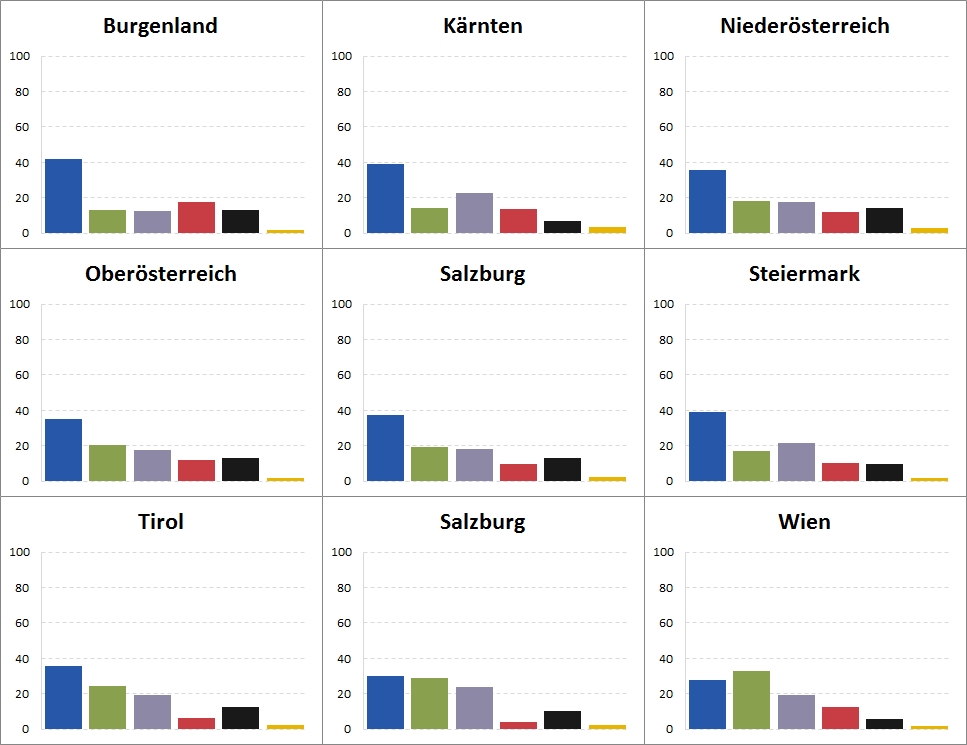
- Bund: Bundesministerium für Inneres (Nationalrats-, Europa- und Bundespräsidentenwahlen)
In den Bundesländern finden sich vor allem die Landtagswahl-Ergebnisse, teilweise aber auch Gemeinderatswahl-Resultate:
- Wahlrecht: Stimmenanteile berechnen sich immer nur auf die gültigen Stimmen; Wahlkarten werden bundesweit nur auf Bezirksebene gezählt, Gemeindeergebnisse sind immer ohne Wahlkarten (bei "Gemeinden" wie Linz oder Graz können Bezirk und Gemeinde identisch sein).
- Daher enthalten die Excel-Dateien des BMI auch viele zusätzliche Ergebniszeilen neben den Gemeinden, die man je nach Bedarf filtern muss (Bezirke gesamt, nur Wahlkarten Bezirk, Wahlkreis, Bundesland gesamt usw.)
- Österreich hat auf der einen Seite sehr viele sehr kleine Gemeinden, und auf der anderen Seite Wien (und Graz) - eine lineare Skalierung ist daher meistens nicht zielführend, wenn man mit absoluten Zahlen arbeitet, da Wien alles überragt (eine Alternative ist es, Größenkategorien zu bilden).
Unterschiedliche Typen von Grafiken eignen sich besser oder schlechter für verschiedene Zwecke. Auch das sollte man bei der Wahl der Visualisierung überlegen:
{kind=link}
tbc...