The code of a runtime is stored in its own state, and when performing a runtime upgrade, this code is replaced. The new runtime can contain runtime migrations that adapt the state to the state layout as defined by the runtime code. This runtime migration is executed when building the first block with the new runtime code. Anything that interacts with the runtime state uses the state layout as defined by the runtime code. So, when trying to load something from the state in the block that applied the runtime upgrade, it will use the new state layout but will decode the data from the non-migrated state. In the worst case, the data is incorrectly decoded, which may lead to crashes or halting of the chain.
+This RFC proposes to store the new runtime code under a different storage key when applying a runtime upgrade. This way, all the off-chain logic can still load the old runtime code under the default storage key and decode the state correctly. The block producer is then required to use this new runtime code to build the next block. While building the next block, the runtime is executing the migrations and moves the new runtime code to the default runtime code location. So, the runtime code found under the default location is always the correct one to decode the state from which the runtime code was loaded.
+While the issue of having undecodable state only exists for the one block in which the runtime upgrade was applied, it still impacts anything that reads state data, like block explorers, UIs, nodes, etc. For block explorers, the issue mainly results in indexing invalid data and UIs may show invalid data to the user. For nodes, reading incorrect data may lead to a performance degradation of the network. There are also ways to prevent certain decoding issues from happening, but it requires that developers are aware of this issue and also requires introducing extra code, which could introduce further bugs down the line.
+So, this RFC tries to solve these issues by fixing the underlying problem of having temporary undecodable state.
+Because the first block built with the new runtime code will move the runtime code from :pending_code to :code, the runtime code will need to be loaded. This means the runtime code will appear in the proof of validity of a parachain for the first block built with the new runtime code. Generally this is not a problem as the runtime code is also loaded by the parachain when setting the new runtime code.
+There is still the possibility of having state that is not migrated even when following the proposal as presented by this RFC. The issue is that if the amount of data to be migrated is too big, not all of it can be migrated in one block, because either it takes more time than there is assigned for a block or parachains for example have a fixed budget for their proof of validity. To solve this issue there already exist multi-block migrations that can chunk the migration across multiple blocks. Consensus-critical data needs to be migrated in the first block to ensure that block production etc., can continue. For the other data being migrated by multi-block migrations the migrations could for example expose to the outside which keys are being migrated and should not be indexed until the migration is finished.
+Testing should be straightforward and most of the existing testing should already be good enough. Extending with some checks that :pending_code is moved to :code.
+The performance should not be impacted besides requiring loading the runtime code in the first block being built with the new runtime code.
+It only alters the way blocks are produced and imported after applying a runtime upgrade. This means that only nodes need to be adapted to the changes of this RFC.
+The change will require that the nodes are upgraded before the runtime starts using this feature. Otherwise they will fail to import the block build by :pending_code.
+For Polkadot/Kusama this means that also the parachain nodes need to be running with a relay chain node version that supports this new feature. Otherwise the parachains will stop producing/finalizing nodes as they can not sync the relay chain any more.
+Given that these mistakes are likely, it is necessary to provide a solution to either prevent them or enable access to a pure account on a target chain.
-Runtime Users, Runtime Devs, wallets, cross-chain dApps.
-One possible solution is to allow a proxy to create or replicate a pure proxy relationship for the same pure account on a target chain. For example, Alice, as the proxy of the pure1 pure account on parachain A, should be able to set a proxy for the same pure1 account on parachain B.
The replication process will be facilitated by XCM, with the first claim made using the DescendOrigin instruction. The replication call on parachain A would require a signed origin by the pure account and construct an XCM program for parachain B, where it first descends the origin, resulting in the ParachainA/AccountId32(pure1) origin location on the receiving side.
@@ -903,7 +969,7 @@
- The receiving chain has to trust the sending chain's claim that the account controlling the pure account has commanded the replication.
@@ -912,21 +978,21 @@
We could eliminate the first disadvantage by allowing only the spawner of the pure proxy to recreate the pure proxies, if they sign the transaction on a remote chain and supply the witness/preimage. Since the preimage of a pure account includes the account ID of the spawner, we can verify that the account signing the transaction is indeed the spawner of the given pure account. However, this approach would grant exclusive rights to the spawner over the pure account, which is not a property of pure proxies at present. This is why it's not an option for us.
As an alternative to requiring clients to provide a witness data, we could label pure accounts on the source chain and trust it on the receiving chain. However, this would require the receiving chain to place greater trust in the source chain. If the source chain is compromised, any type of account on the trusting chain could also be compromised.
A conceptually different solution would be to not implement replication of pure proxies and instead inform users that ownership of a pure proxy on one chain does not imply ownership of the same account on another chain. This solution seems complex, as it would require UIs and clients to adapt to this understanding. Moreover, mistakes would likely remain unavoidable.
-
+
Each chain expressly authorizes another chain to replicate its pure proxies, accepting the inherent risk of that chain potentially being compromised. This authorization allows a malicious actor from the compromised chain to take control of any pure proxy account on the chain that granted the authorization. However, this is limited to pure proxies that originated from the compromised chain if they have a chain-specific seed within the preimage.
There is a security issue, not introduced by the proposed solution but worth mentioning. The same spawner can create the pure accounts on different chains controlled by the different accounts. This is possible because the current preimage version of the proxy pallet does not include any non-reproducible, chain-specific data, and elements like block numbers and extrinsic indexes can be reproduced with some effort. This issue could be addressed by adding a chain-specific seed into the preimages of pure accounts.
-
-
+
+
The replication is facilitated by XCM, which adds some additional load to the communication channel. However, since the number of replications is not expected to be large, the impact is minimal.
-
+
The proposed solution does not alter any existing interfaces. It does require clients to obtain the witness data which should not be an issue with support of an indexer.
-
+
None.
-
+
None.
-
+
None.
-
+
- Pure Proxy documentation - https://wiki.polkadot.network/docs/learn-proxies-pure
@@ -961,20 +1027,20 @@
+
This RFC proposes compressing the state response message during the state syncing process to reduce the amount of data transferred.
-
+
State syncing can require downloading several gigabytes of data, particularly for blockchains with large state sizes, such as Astar, which
has a state size exceeding 5 GiB (https://github.com/AstarNetwork/Astar/issues/1110). This presents a significant
challenge for nodes with slower network connections. Additionally, the current state sync implementation lacks a persistence feature (https://github.com/paritytech/polkadot-sdk/issues/4),
meaning any network disruption forces the node to re-download the entire state, making the process even more difficult.
-
+
This RFC benefits all projects utilizing the Substrate framework, specifically in improving the efficiency of state syncing.
- Node Operators.
- Substrate Users.
-
+
The largest portion of the state response message consists of either CompactProof or Vec<KeyValueStateEntry>, depending on whether a proof is requested (source):
CompactProof: When proof is requested, compression yields a lower ratio but remains beneficial, as shown in warp sync tests in the Performance section below.
-
+
None identified.
-
+
The code changes required for this RFC are straightforward: compress the state response on the sender side and decompress it on the receiver side. Existing sync tests should ensure functionality remains intact.
-
-
+
+
This RFC optimizes network bandwidth usage during state syncing, particularly for blockchains with gigabyte-sized states, while introducing negligible CPU overhead for compression and decompression. For example, compressing the state response during a recent Polkadot warp sync (around height #22076653) reduces the data transferred from 530,310,121 bytes to 352,583,455 bytes — a 33% reduction, saving approximately 169 MiB of data.
Performance data is based on this patch, with logs available here.
-
+
None.
-
+
No compatibility issues identified.
-
+
None.
-
+
None.
-
+
None.
(source)
Table of Contents
@@ -1031,11 +1097,11 @@ | Authors | Pablo Dorado, Daniel Olano |
-
+
In an attempt to mitigate risks derived from unwanted behaviours around long decision periods on
referenda, this proposal describes how to finalize and decide a result of a poll via a
mechanism similar to candle auctions.
-
+
Referenda protocol provide permissionless and efficient mechanisms to enable governance actors to
decide the future of the blockchains around Polkadot network. However, they pose a series of risks
derived from the game theory perspective around these mechanisms. One of them being where an actor
@@ -1051,7 +1117,7 @@
be determined right after the confirm period finishes, thus decreasing the chances of actors to
alter the results of a poll on confirming state, and instead incentivizing them to cast their votes
earlier, on deciding state.
-
+
- Governance actors: Tokenholders and Collectives that vote on polls that have this mechanism
enabled should be aware this change affects the outcome of failing a poll on its confirm period.
@@ -1060,7 +1126,7 @@ Tooling and UI developers: Applications that interact with referenda must update to reflect
the new Finalizing state.
-
+
Currently, the process of a referendum/poll is defined as an sequence between an ongoing state
(where accounts can vote), comprised by a with a preparation period, a decision period, and a
confirm period. If the poll is passing before the decision period ends, it's possible to push
@@ -1142,43 +1208,43 @@
-
+
This approach doesn't include a mechanism to determine whether a change of the poll status in the
confirming period is due to a legitimate change of mind of the voters, or an exploitation of its
aforementioned vulnerabilities (like a sniping attack), instead treating all of them as potential
attacks.
This is an issue that can be addressed by additional mechanisms, and heuristics that can help
determine the probability of a change of poll status to happen as a result of a legitimate behaviour.
-
+
The implementation of this RFC will be tested on testnets (Paseo and Westend) first. Furthermore, it
should be enabled in a canary network (like Kusama) to ensure the behaviours it is trying to address
is indeed avoided.
An audit will be required to ensure the implementation doesn't introduce unwanted side effects.
There are no privacy related concerns.
-
-
+
+
The added steps imply pessimization, necessary to meet the expected changes. An implementation MUST
exit from the Finalization period as early as possible to minimize this impact.
-
+
This proposal does not alter the already exposed interfaces or developers or end users. However, they
must be aware of the changes in the additional overhead the new period might incur (these depend on the
implemented VRF).
-
+
This proposal does not break compatibility with existing interfaces, older versions, but it alters the
previous implementation of the referendum processing algorithm.
An acceptable upgrade strategy that can be applied is defining a point in time (block number, poll index)
from which to start applying the new mechanism, thus, not affecting the already ongoing referenda.
-
+
-
+
- How to determine in a statistically meaningful way that a change in the poll status corresponds to an
organic behaviour, and not an unwanted, malicious behaviour?
-
+
A proposed implementation of this change can be seen on this Pull Request.
(source)
Table of Contents
@@ -1211,12 +1277,12 @@
+
The protocol change introduces flexibility in the governance structure by enabling the referenda
track list to be modified dynamically at runtime. This is achieved by replacing static slices in
TracksInfo with iterators, facilitating storage-based track management. As a result, governance
tracks can be modified or added based on real-time decisions and without requiring runtime upgrades.
-
+
Polkadot's governance system is designed to be adaptive and decentralized, but modifying the
referenda tracks (which determine decision-making paths for proposals) has historically required
runtime upgrades. This poses an operational challenge, delaying governance changes until an upgrade
@@ -1224,12 +1290,12 @@
dynamically, reflecting real-time changes in governance needs without the latency and risks
associated with runtime upgrades. This reduces governance bottlenecks and allows for quicker
adaptation to emergent scenarios.
-
+
- Network stakeholders: the change means reduced coordination effort for track adjustments.
- Governance participants: this enables more responsive decision-making pathways.
-
+
The protocol modification replaces the current static slice method used for storing referenda tracks
with an iterator-based approach that allows tracks to be managed dynamically using chain storage.
Governance participants can define and modify referenda tracks as needed, which are then accessed
@@ -1241,12 +1307,12 @@
-
+
The most significant drawback is the increased complexity for developers managing track configurations
via storage-based iterators, which require careful handling to avoid misuse or inefficiencies.
Additionally, this flexibility could introduce risks if track configurations are modified improperly
during runtime, potentially leading to governance instabilities.
-
+
To ensure security, the change must be tested in testnet environments first (Paseo, Westend),
particularly in scenarios where multiple track changes happen concurrently. Potential
vulnerabilities in governance adjustments must be addressed to prevent abuse.
@@ -1254,27 +1320,27 @@
-
+
+
The proposal optimizes governance track management by avoiding the overhead of runtime upgrades,
reducing downtime, and eliminating the need for full consensus on upgrades. However, there is a
slight performance cost related to runtime access to storage-based iterators, though this is
mitigated by the overall system efficiency gains.
-
+
Developers and governance actors benefit from simplified governance processes but must account for
the technical complexity of managing iterator-based track configurations.
Tools may need to be developed to help streamline track adjustments in runtime.
-
+
The change is backward compatible with existing governance operations, and does not require developers
to adjust how they interact with referenda tracks.
A migration is required to convert existing statically-defined tracks to dynamic storage-based
configurations without disruption.
-
+
This dynamic governance track approach builds on previous work around Polkadot's on-chain governance
and leverages standard iterator patterns in Rust programming to improve runtime flexibility.
Comparable solutions in other governance networks were examined, but this proposal uniquely tailors
them to Polkadot’s decentralized, runtime-upgradable architecture.
-
+
- How to handle governance transitions for currently ongoing referenda when changing configuration
parameters of an existing track? Ideally, most tracks should not have to go through this change,
@@ -1282,7 +1348,7 @@
-
+
There are already two proposed solutions for both the implementation and
- This Pull Request proposes changing
pallet-referenda's TracksInfo to make tracks
@@ -1327,11 +1393,11 @@
+
XCM programs generated by the InitiateAssetTransfer instruction shall have the option to carry over the original origin all the way to the final destination. They shall do so by internally making use of AliasOrigin or ClearOrigin depending on given parameters.
This allows asset transfers to retain their original origin even across multiple hops.
Ecosystem chains would have to change their trusted aliasing rules to effectively make use of this feature.
-
+
Currently, all XCM asset transfer instructions ultimately clear the origin in the remote XCM message by use of the ClearOrigin instruction. This is done for security considerations to ensure that subsequent (user-controlled) instructions cannot command the authority of the sending chain.
The problem with this approach is that it limits what can be achieved on remote chains through XCM. Most XCM operations require having an origin, and following any asset transfer the origin is lost, meaning not much can be done other than depositing the transferred assets to some local account or transferring them onward to another chain.
For example, we cannot transfer some funds for buying execution, then do a Transact (all in the same XCM message).
@@ -1339,9 +1405,9 @@
Transact XCM programs today require a two step process:
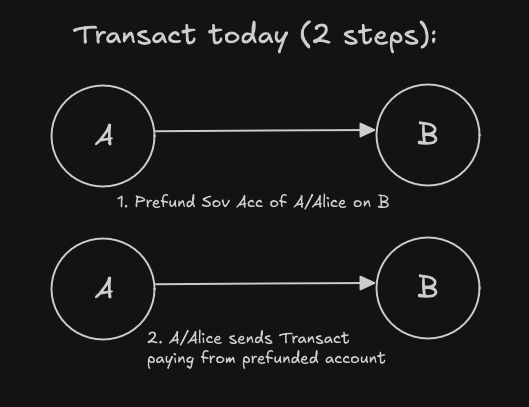
And we want to be able to do it using a single XCM program.
-
+
Runtime Users, Runtime Devs, wallets, cross-chain dApps.
-
+
In the case of XCM programs going from source-chain directly to dest-chain without an intermediary hop, we can enable scenarios such as above by using the AliasOrigin instruction instead of the ClearOrigin instruction.
Instead of clearing the source-chain origin, the destination chain shall attempt to alias source-chain to "original origin" on the source chain.
Most common such origin aliasing would be X1(Parachain(source-chain)) -> X2(Parachain(source-chain), AccountId32(origin-account)) for the case of a single hop transfer where the initiator is a (signed/pure/proxy) account origin-account on source-chain.
@@ -1391,35 +1457,35 @@
 -
+
-
+
In terms of ergonomics and user experience, this support for combining an asset transfer with a subsequent action (like Transact) is a net positive.
In terms of performance, and privacy, this is neutral with no changes.
In terms of security, the feature by itself is also neutral because it allows preserve_origin: false usage for operating with no extra trust assumptions. When wanting to support preserving origin, chains need to configure secure origin aliasing filters. The one suggested in this RFC should be the right choice for the majority of chains, but each chain will ultimately choose depending on their business model and logic (e.g. chain does not plan to integrate with Asset Hub). It is up to the individual chains to configure accordingly.
-
+
Barriers should now allow AliasOrigin, DescendOrigin or ClearOrigin.
Normally, XCM program builders should audit their programs and eliminate assumptions of "no origin" on remote side of this instruction. In this case, the InitiateAssetsTransfer has not been released yet, it will be part of XCMv5, and we can make this change part of the same XCMv5 so that there isn't even the possibility of someone in the wild having built XCM programs using this instruction on those wrong assumptions.
The working assumption going forward is that the origin on the remote side can either be cleared or it can be the local origin's reanchored location. This assumption is in line with the current behavior of remote XCM programs sent over using pallet_xcm::send.
The existing DepositReserveAsset, InitiateReserveWithdraw and InitiateTeleport cross chain asset transfer instructions will not attempt to do origin aliasing and will always clear origin same as before for compatibility reasons.
-
-
+
+
No impact.
-
+
Improves ergonomics by allowing the local origin to operate on the remote chain even when the XCM program includes an asset transfer.
-
+
At the executor-level this change is backwards and forwards compatible. Both types of programs can be executed on new and old versions of XCM with no changes in behavior.
New version of the InitiateAssetsTransfer instruction acts same as before when used with preserve_origin: false.
For using the new capabilities, the XCM builder has to verify that the involved chains have the required origin-aliasing filters configured and use some new version of Barriers aware of AliasOrigin as an allowed alternative to ClearOrigin.
For compatibility reasons, this RFC proposes this mechanism be added as an enhancement to the yet unreleased InitiateAssetsTransfer instruction, thus eliminating possibilities of XCM logic breakages in the wild.
Following the same logic, the existing DepositReserveAsset, InitiateReserveWithdraw and InitiateTeleport cross chain asset transfer instructions will not attempt to do origin aliasing and will always clear the origin same as before for compatibility reasons.
Any one of DepositReserveAsset, InitiateReserveWithdraw and InitiateTeleport instructions can be replaced with a InitiateAssetsTransfer instruction with or without origin aliasing, thus providing a clean and clear upgrade path for opting-in this new feature.
-
+
-
+
None
-
+
(source)
Table of Contents
@@ -1450,7 +1516,7 @@ | Authors | Leemo / ChaosDAO |
-
+
This RFC proposes to change the duration of the Confirmation Period for the Big Tipper and Small Tipper tracks in Polkadot OpenGov:
-
+
Currently, these are the durations of treasury tracks in Polkadot OpenGov. Confirmation periods for the Spender tracks were adjusted based on RFC20 and its related conversation.
| Track Description | Confirmation Period Duration |
|---|
| Treasurer | 7 Days |
@@ -1474,12 +1540,12 @@
You can see that there is a general trend on the Spender track that when the privilege level (the amount the track can spend) the confirmation period approximately doubles.
I believe that the Big Tipper and Small Tipper track's confirmation periods should be adjusted to match this trend.
In the current state it is possible to somewhat positively snipe these tracks, and whilst the power/privilege level of these tracks is very low (they cannot spend a large amount of funds), I believe we should increase the confirmation periods to something higher. This is backed up by the recent sentiment in the greater community regarding referendums submitted on these tracks. The parameters of Polkadot OpenGov can be adjusted based on the general sentiment of token holders when necessary.
-
+
The primary stakeholders of this RFC are:
– DOT token holders – as this affects the protocol's treasury
– Entities wishing to submit a referendum on these tracks – as this affects the referendum's timeline
– Projects with governance app integrations – see Performance, Ergonomics and Compatibility section below
-
+
This RFC proposes to change the duration of the confirmation period for both the Big Tipper and Small Tipper tracks. To achieve this the confirm_period parameter for those tracks should be changed.
You can see the lines of code that need to be adjusted here:
This RFC proposes to change the confirm_period for the Big Tipper track to DAYS (i.e. 1 Day) and the confirm_period for the Small Tipper track to 12 * HOURS (i.e. 12 Hours).
-
+
The drawback of changing these confirmation periods is that the lifecycle of referenda submitted on those tracks would be ultimately longer, and it would add a greater potential to negatively "snipe" referenda on those tracks by knocking the referendum out of its confirmation period once the decision period has ended. This can be a good or a bad thing depending on your outlook of positive vs negative sniping.
-
+
This referendum will enhance the security of the protocol as it relates to its treasury. The confirmation period is one of the last lines of defense for the Polkadot token holder DAO to react to a potentially bad referendum and vote NAY in order for its confirmation period to be aborted.
-
-
+
+
This is a simple change (code wise) that should not affect the performance of the Polkadot protocol, outside of increasing the duration of the confirmation periods for these 2 tracks.
As per the implementation of changes described in RFC-20, it was identified that governance UIs automatically update to meet the new parameters:
@@ -1505,11 +1571,11 @@
+
N/A
-
+
Some token holders may want these confirmation periods to remain as they are currently and for them not to increase. If this is something that the Polkadot Technical Fellowship considers to be an issue to implement into a runtime upgrade then I can create a Wish For Change to obtain token holder approval.
-
+
The parameters of Polkadot OpenGov will likely continue to change over time, there are additional discussions in the community regarding adjusting the min_support for some tracks so that it does not trend towards 0%, similar to the current state of the Whitelisted Caller track. This is outside of the scope of this RFC and requires a lot more discussion.
(source)
Table of Contents
@@ -1551,9 +1617,9 @@
This proposes a periodic, sale-based method for assigning Polkadot Coretime, the analogue of "block space" within the Polkadot Network. The method takes into account the need for long-term capital expenditure planning for teams building on Polkadot, yet also provides a means to allow Polkadot to capture long-term value in the resource which it sells. It supports the possibility of building rich and dynamic secondary markets to optimize resource allocation and largely avoids the need for parameterization.
-
+
The Polkadot Ubiquitous Computer, or just Polkadot UC, represents the public service provided by the Polkadot Network. It is a trust-free, WebAssembly-based, multicore, internet-native omnipresent virtual machine which is highly resilient to interference and corruption.
The present system of allocating the limited resources of the Polkadot Ubiquitous Computer is through a process known as parachain slot auctions. This is a parachain-centric paradigm whereby a single core is long-term allocated to a single parachain which itself implies a Substrate/Cumulus-based chain secured and connected via the Relay-chain. Slot auctions are on-chain candle auctions which proceed for several days and result in the core being assigned to the parachain for six months at a time up to 24 months in advance. Practically speaking, we only see two year periods being bid upon and leased.
@@ -1574,7 +1640,7 @@ The solution SHOULD avoid creating additional dependencies on functionality which the Relay-chain need not strictly provide for the delivery of the Polkadot UC.
Furthermore, the design SHOULD be implementable and deployable in a timely fashion; three months from the acceptance of this RFC should not be unreasonable.
-
+
Primary stakeholder sets are:
- Protocol researchers and developers, largely represented by the Polkadot Fellowship and Parity Technologies' Engineering division.
@@ -1583,7 +1649,7 @@
Socialization:
The essensials of this proposal were presented at Polkadot Decoded 2023 Copenhagen on the Main Stage. A small amount of socialization at the Parachain Summit preceeded it and some substantial discussion followed it. Parity Ecosystem team is currently soliciting views from ecosystem teams who would be key stakeholders.
-
+
Upon implementation of this proposal, the parachain-centric slot auctions and associated crowdloans cease. Instead, Coretime on the Polkadot UC is sold by the Polkadot System in two separate formats: Bulk Coretime and Instantaneous Coretime.
When a Polkadot Core is utilized, we say it is dedicated to a Task rather than a "parachain". The Task to which a Core is dedicated may change at every Relay-chain block and while one predominant type of Task is to secure a Cumulus-based blockchain (i.e. a parachain), other types of Tasks are envisioned.
@@ -2015,16 +2081,16 @@
- Governance upgrade proposal(s).
- Monitoring of the upgrade process.
-
+
No specific considerations.
Parachains already deployed into the Polkadot UC must have a clear plan of action to migrate to an agile Coretime market.
While this proposal does not introduce documentable features per se, adequate documentation must be provided to potential purchasers of Polkadot Coretime. This SHOULD include any alterations to the Polkadot-SDK software collection.
-
+
Regular testing through unit tests, integration tests, manual testnet tests, zombie-net tests and fuzzing SHOULD be conducted.
A regular security review SHOULD be conducted prior to deployment through a review by the Web3 Foundation economic research group.
Any final implementation MUST pass a professional external security audit.
The proposal introduces no new privacy concerns.
-
+
RFC-3 proposes a means of implementing the high-level allocations within the Relay-chain.
RFC-5 proposes the API for interacting with Relay-chain.
Additional work should specify the interface for the instantaneous market revenue so that the Coretime-chain can ensure Bulk Coretime placed in the instantaneous market is properly compensated.
@@ -2040,7 +2106,7 @@
+
Robert Habermeier initially wrote on the subject of Polkadot blockspace-centric in the article Polkadot Blockspace over Blockchains. While not going into details, the article served as an early reframing piece for moving beyond one-slot-per-chain models and building out secondary market infrastructure for resource allocation.
(source)
Table of Contents
@@ -2073,10 +2139,10 @@
+
In the Agile Coretime model of the Polkadot Ubiquitous Computer, as proposed in RFC-1 and RFC-3, it is necessary for the allocating parachain (envisioned to be one or more pallets on a specialised Brokerage System Chain) to communicate the core assignments to the Relay-chain, which is responsible for ensuring those assignments are properly enacted.
This is a proposal for the interface which will exist around the Relay-chain in order to communicate this information and instructions.
-
+
The background motivation for this interface is splitting out coretime allocation functions and secondary markets from the Relay-chain onto System parachains. A well-understood and general interface is necessary for ensuring the Relay-chain receives coretime allocation instructions from one or more System chains without introducing dependencies on the implementation details of either side.
@@ -2088,7 +2154,7 @@ The interface MUST allow for the allocating chain to instruct changes to the number of cores which it is able to allocate.
- The interface MUST allow for the allocating chain to be notified of changes to the number of cores which are able to be allocated by the allocating chain.
-
+
Primary stakeholder sets are:
- Developers of the Relay-chain core-management logic.
@@ -2096,7 +2162,7 @@
Socialization:
This content of this RFC was discussed in the Polkdot Fellows channel.
-
+
The interface has two sections: The messages which the Relay-chain is able to receive from the allocating parachain (the UMP message types), and messages which the Relay-chain is able to send to the allocating parachain (the DMP message types). These messages are expected to be able to be implemented in a well-known pallet and called with the XCM Transact instruction.
Future work may include these messages being introduced into the XCM standard.
@@ -2171,17 +2237,17 @@
-
+
- Infrastructure providers (people who run validator/collator nodes)
- Polkadot Treasury
-
+
This protocol builds on the existing
Collator Selection pallet
and its notion of Invulnerables. Invulnerables are collators (identified by their AccountIds) who
@@ -2310,27 +2376,27 @@
- of which 15 are Invulnerable, and
- five are elected by bond.
-
+
The primary drawback is a reliance on governance for continued treasury funding of infrastructure
costs for Invulnerable collators.
-
+
The vast majority of cases can be covered by unit testing. Integration test should ensure that the
Collator Selection UpdateOrigin, which has permission to modify the Invulnerables and desired
number of Candidates, can handle updates over XCM from the system's governance location.
-
+
This proposal has very little impact on most users of Polkadot, and should improve the performance
of system chains by reducing the number of missed blocks.
-
+
As chains have strict PoV size limits, care must be taken in the PoV impact of the session manager.
Appropriate benchmarking and tests should ensure that conservative limits are placed on the number
of Invulnerables and Candidates.
-
+
The primary group affected is Candidate collators, who, after implementation of this RFC, will need
to compete in a bond-based election rather than a race to claim a Candidate spot.
-
+
This RFC is compatible with the existing implementation and can be handled via upgrades and
migration.
-
+
- GitHub: Collator Selection Roadmap
@@ -2345,9 +2411,9 @@ None at this time.
-
+
There may exist in the future system chains for which this model of collator selection is not
appropriate. These chains should be evaluated on a case-by-case basis.
(source)
@@ -2386,10 +2452,10 @@ | Authors | Pierre Krieger |
-
+
The full nodes of the Polkadot peer-to-peer network maintain a distributed hash table (DHT), which is currently used for full nodes discovery and validators discovery purposes.
This RFC proposes to extend this DHT to be used to discover full nodes of the parachains of Polkadot.
-
+
The maintenance of bootnodes has long been an annoyance for everyone.
When a bootnode is newly-deployed or removed, every chain specification must be updated in order to take the update into account. This has lead to various non-optimal solutions, such as pulling chain specifications from GitHub repositories.
When it comes to RPC nodes, UX developers often have trouble finding up-to-date addresses of parachain RPC nodes. With the ongoing migration from RPC nodes to light clients, similar problems would happen with chain specifications as well.
@@ -2398,9 +2464,9 @@ Because the list of bootnodes in chain specifications is so annoying to modify, the consequence is that the number of bootnodes is rather low (typically between 2 and 15). In order to better resist downtimes and DoS attacks, a better solution would be to use every node of a certain chain as potential bootnode, rather than special-casing some specific nodes.
While this RFC doesn't solve these problems for relay chains, it aims at solving it for parachains by storing the list of all the full nodes of a parachain on the relay chain DHT.
Assuming that this RFC is implemented, and that light clients are used, deploying a parachain wouldn't require more work than registering it onto the relay chain and starting the collators. There wouldn't be any need for special infrastructure nodes anymore.
-
+
This RFC has been opened on my own initiative because I think that this is a good technical solution to a usability problem that many people are encountering and that they don't realize can be solved.
-
+
The content of this RFC only applies for parachains and parachain nodes that are "Substrate-compatible". It is in no way mandatory for parachains to comply to this RFC.
Note that "Substrate-compatible" is very loosely defined as "implements the same mechanisms and networking protocols as Substrate". The author of this RFC believes that "Substrate-compatible" should be very precisely specified, but there is controversy on this topic.
While a lot of this RFC concerns the implementation of parachain nodes, it makes use of the resources of the Polkadot chain, and as such it is important to describe them in the Polkadot specification.
@@ -2437,10 +2503,10 @@
+
The peer_id and addrs fields are in theory not strictly needed, as the PeerId and addresses could be always equal to the PeerId and addresses of the node being registered as the provider and serving the response. However, the Cumulus implementation currently uses two different networking stacks, one of the parachain and one for the relay chain, using two separate PeerIds and addresses, and as such the PeerId and addresses of the other networking stack must be indicated. Asking them to use only one networking stack wouldn't feasible in a realistic time frame.
The values of the genesis_hash and fork_id fields cannot be verified by the requester and are expected to be unused at the moment. Instead, a client that desires connecting to a parachain is expected to obtain the genesis hash and fork ID of the parachain from the parachain chain specification. These fields are included in the networking protocol nonetheless in case an acceptable solution is found in the future, and in order to allow use cases such as discovering parachains in a not-strictly-trusted way.
-
+
Because not all nodes want to be used as bootnodes, implementers are encouraged to provide a way to disable this mechanism. However, it is very much encouraged to leave this mechanism on by default for all parachain nodes.
This mechanism doesn't add or remove any security by itself, as it relies on existing mechanisms.
However, if the principle of chain specification bootnodes is entirely replaced with the mechanism described in this RFC (which is the objective), then it becomes important whether the mechanism in this RFC can be abused in order to make a parachain unreachable.
@@ -2449,22 +2515,22 @@
-
+
+
The DHT mechanism generally has a low overhead, especially given that publishing providers is done only every 24 hours.
Doing a Kademlia iterative query then sending a provider record shouldn't take more than around 50 kiB in total of bandwidth for the parachain bootnode.
Assuming 1000 parachain full nodes, the 20 Polkadot full nodes corresponding to a specific parachain will each receive a sudden spike of a few megabytes of networking traffic when the key rotates. Again, this is relatively negligible. If this becomes a problem, one can add a random delay before a parachain full node registers itself to be the provider of the key corresponding to BabeApi_next_epoch.
Maybe the biggest uncertainty is the traffic that the 20 Polkadot full nodes will receive from light clients that desire knowing the bootnodes of a parachain. Light clients are generally encouraged to cache the peers that they use between restarts, so they should only query these 20 Polkadot full nodes at their first initialization.
If this every becomes a problem, this value of 20 is an arbitrary constant that can be increased for more redundancy.
-
+
Irrelevant.
-
+
Irrelevant.
-
+
None.
-
+
While it fundamentally doesn't change much to this RFC, using BabeApi_currentEpoch and BabeApi_nextEpoch might be inappropriate. I'm not familiar enough with good practices within the runtime to have an opinion here. Should it be an entirely new pallet?
-
+
It is possible that in the future a client could connect to a parachain without having to rely on a trusted parachain specification.
(source)
Table of Contents
@@ -2485,13 +2551,13 @@
+
The Polkadot UC will generate revenue from the sale of available Coretime. The question then arises: how should we handle these revenues? Broadly, there are two reasonable paths – burning the revenue and thereby removing it from total issuance or divert it to the Treasury. This Request for Comment (RFC) presents arguments favoring burning as the preferred mechanism for handling revenues from Coretime sales.
-
+
How to handle the revenue accrued from Coretime sales is an important economic question that influences the value of DOT and should be properly discussed before deciding for either of the options. Now is the best time to start this discussion.
-
+
Polkadot DOT token holders.
-
+
This RFC discusses potential benefits of burning the revenue accrued from Coretime sales instead of diverting them to Treasury. Here are the following arguments for it.
It's in the interest of the Polkadot community to have a consistent and predictable Treasury income, because volatility in the inflow can be damaging, especially in situations when it is insufficient. As such, this RFC operates under the presumption of a steady and sustainable Treasury income flow, which is crucial for the Polkadot community's stability. The assurance of a predictable Treasury income, as outlined in a prior discussion here, or through other equally effective measures, serves as a baseline assumption for this argument.
Consequently, we need not concern ourselves with this particular issue here. This naturally begs the question - why should we introduce additional volatility to the Treasury by aligning it with the variable Coretime sales? It's worth noting that Coretime revenues often exhibit an inverse relationship with periods when Treasury spending should ideally be ramped up. During periods of low Coretime utilization (indicated by lower revenue), Treasury should spend more on projects and endeavours to increase the demand for Coretime. This pattern underscores that Coretime sales, by their very nature, are an inconsistent and unpredictable source of funding for the Treasury. Given the importance of maintaining a steady and predictable inflow, it's unnecessary to rely on another volatile mechanism. Some might argue that we could have both: a steady inflow (from inflation) and some added bonus from Coretime sales, but burning the revenue would offer further benefits as described below.
@@ -2534,13 +2600,13 @@ | Authors | Joe Petrowski |
-
+
Since the introduction of the Collectives parachain, many groups have expressed interest in forming
new -- or migrating existing groups into -- on-chain collectives. While adding a new collective is
relatively simple from a technical standpoint, the Fellowship will need to merge new pallets into
the Collectives parachain for each new collective. This RFC proposes a means for the network to
ratify a new collective, thus instructing the Fellowship to instate it in the runtime.
-
+
Many groups have expressed interest in representing collectives on-chain. Some of these include:
- Parachain technical fellowship (new)
@@ -2556,12 +2622,12 @@
-
+
- Polkadot stakeholders who would like to organize on-chain.
- Technical Fellowship, in its role of maintaining system runtimes.
-
+
The group that wishes to operate an on-chain collective should publish the following information:
- Charter, including the collective's mandate and how it benefits Polkadot. This would be similar
@@ -2595,22 +2661,22 @@
-
+
Please suggest a better name for BlockExecutiveMode. We already tried: RuntimeExecutiveMode,
ExtrinsicInclusionMode. The names of the modes Normal and Minimal were also called
AllExtrinsics and OnlyInherents, so if you have naming preferences; please post them.
=> renamed to ExtrinsicInclusionMode
Is post_inherents more consistent instead of last_inherent? Then we should change it.
=> renamed to last_inherent
-
+
The long-term future here is to move the block building logic into the runtime. Currently there is a tight dance between the block author and the runtime; the author has to call into different runtime functions in quick succession and exact order. Any misstep causes the block to be invalid.
This can be unified and simplified by moving both parts into the runtime.
(source)
@@ -2752,14 +2818,14 @@ | Authors | Bryan Chen |
-
+
This RFC proposes a set of changes to the parachain lock mechanism. The goal is to allow a parachain manager to self-service the parachain without root track governance action.
This is achieved by remove existing lock conditions and only lock a parachain when:
- A parachain manager explicitly lock the parachain
- OR a parachain block is produced successfully
-
+
The manager of a parachain has permission to manage the parachain when the parachain is unlocked. Parachains are by default locked when onboarded to a slot. This requires the parachain wasm/genesis must be valid, otherwise a root track governance action on relaychain is required to update the parachain.
The current reliance on root track governance actions for managing parachains can be time-consuming and burdensome. This RFC aims to address this technical difficulty by allowing parachain managers to take self-service actions, rather than relying on general public voting.
The key scenarios this RFC seeks to improve are:
@@ -2778,12 +2844,12 @@ A parachain SHOULD be locked when it successfully produced the first block.
- A parachain manager MUST be able to perform lease swap without having a running parachain.
-
+
- Parachain teams
- Parachain users
-
+
A parachain can either be locked or unlocked. With parachain locked, the parachain manager does not have any privileges. With parachain unlocked, the parachain manager can perform following actions with the paras_registrar pallet:
@@ -2823,31 +2889,31 @@
- Parachain never produced a block. Including from expired leases.
- Parachain manager never explicitly lock the parachain.
-
+
Parachain locks are designed in such way to ensure the decentralization of parachains. If parachains are not locked when it should be, it could introduce centralization risk for new parachains.
For example, one possible scenario is that a collective may decide to launch a parachain fully decentralized. However, if the parachain is unable to produce block, the parachain manager will be able to replace the wasm and genesis without the consent of the collective.
It is considered this risk is tolerable as it requires the wasm/genesis to be invalid at first place. It is not yet practically possible to develop a parachain without any centralized risk currently.
Another case is that a parachain team may decide to use crowdloan to help secure a slot lease. Previously, creating a crowdloan will lock a parachain. This means crowdloan participants will know exactly the genesis of the parachain for the crowdloan they are participating. However, this actually providers little assurance to crowdloan participants. For example, if the genesis block is determined before a crowdloan is started, it is not possible to have onchain mechanism to enforce reward distributions for crowdloan participants. They always have to rely on the parachain team to fulfill the promise after the parachain is alive.
Existing operational parachains will not be impacted.
-
+
The implementation of this RFC will be tested on testnets (Rococo and Westend) first.
An audit maybe required to ensure the implementation does not introduce unwanted side effects.
There is no privacy related concerns.
-
+
This RFC should not introduce any performance impact.
-
+
This RFC should improve the developer experiences for new and existing parachain teams
-
+
This RFC is fully compatibility with existing interfaces.
-
+
- Parachain Slot Extension Story: https://github.com/paritytech/polkadot/issues/4758
- Allow parachain to renew lease without actually run another parachain: https://github.com/paritytech/polkadot/issues/6685
- Always treat parachain that never produced block for a significant amount of time as unlocked: https://github.com/paritytech/polkadot/issues/7539
-
+
None at this stage.
-
+
This RFC is only intended to be a short term solution. Slots will be removed in future and lock mechanism is likely going to be replaced with a more generalized parachain manage & recovery system in future. Therefore long term impacts of this RFC are not considered.
-
+
The Relay Chain contains most of the core logic for the Polkadot network. While this was necessary
prior to the launch of parachains and development of XCM, most of this logic can exist in
parachains. This is a proposal to migrate several subsystems into system parachains.
-
+
Polkadot's scaling approach allows many distinct state machines (known generally as parachains) to
operate with common guarantees about the validity and security of their state transitions. Polkadot
provides these common guarantees by executing the state transitions on a strict subset (a backing
@@ -3848,13 +3914,13 @@
By minimising state transition logic on the Relay Chain by migrating it into "system chains" -- a
set of parachains that, with the Relay Chain, make up the Polkadot protocol -- the Polkadot
Ubiquitous Computer can maximise its primary offering: secure blockspace.
-
+
- Parachains that interact with affected logic on the Relay Chain;
- Core protocol and XCM format developers;
- Tooling, block explorer, and UI developers.
-
+
The following pallets and subsystems are good candidates to migrate from the Relay Chain:
- Identity
@@ -4000,36 +4066,36 @@
Staking is the subsystem most constrained by PoV limits. Ensuring that elections, payouts, session
changes, offences/slashes, etc. work in a parachain on Kusama -- with its larger validator set --
will give confidence to the chain's robustness on Polkadot.
-
+
These subsystems will have reduced resources in cores than on the Relay Chain. Staking in particular
may require some optimizations to deal with constraints.
-
+
Standard audit/review requirements apply. More powerful multi-chain integration test tools would be
useful in developement.
-
+
Describe the impact of the proposal on the exposed functionality of Polkadot.
-
+
This is an optimization. The removal of public/user transactions on the Relay Chain ensures that its
primary resources are allocated to system performance.
-
+
This proposal alters very little for coretime users (e.g. parachain developers). Application
developers will need to interact with multiple chains, making ergonomic light client tools
particularly important for application development.
For existing parachains that interact with these subsystems, they will need to configure their
runtimes to recognize the new locations in the network.
-
+
Implementing this proposal will require some changes to pallet APIs and/or a pub-sub protocol.
Application developers will need to interact with multiple chains in the network.
-
+
-
+
There remain some implementation questions, like how to use balances for both Staking and
Governance. See, for example, Moving Staking off the Relay
Chain.
-
+
Ideally the Relay Chain becomes transactionless, such that not even balances are represented there.
With Staking and Governance off the Relay Chain, this is not an unreasonable next step.
With Identity on Polkadot, Kusama may opt to drop its People Chain.
@@ -4064,13 +4130,13 @@
+
At the moment, we have system_version field on RuntimeVersion that derives which state version is used for the
Storage.
We have a use case where we want extrinsics root is derived using StateVersion::V1. Without defining a new field
under RuntimeVersion,
we would like to propose adding system_version that can be used to derive both storage and extrinsic state version.
-
+
Since the extrinsic state version is always StateVersion::V0, deriving extrinsic root requires full extrinsic data.
This would be problematic when we need to verify the extrinsics root if the extrinsic sizes are bigger. This problem is
further explored in https://github.com/polkadot-fellows/RFCs/issues/19
@@ -4082,11 +4148,11 @@ StateVersion::V1, then we do not need to pass the full extrinsic data but
rather at maximum, 32 byte of extrinsic data.
-
+
- Technical Fellowship, in its role of maintaining system runtimes.
-
+
In order to use project specific StateVersion for extrinsic roots, we proposed
an implementation that introduced
parameter to frame_system::Config but that unfortunately did not feel correct.
@@ -4112,26 +4178,26 @@
system_version: 1,
};
}
-
+
There should be no drawbacks as it would replace state_version with same behavior but documentation should be updated
so that chains know which system_version to use.
-
+
AFAIK, should not have any impact on the security or privacy.
-
+
These changes should be compatible for existing chains if they use state_version value for system_verision.
-
+
I do not believe there is any performance hit with this change.
-
+
This does not break any exposed Apis.
-
+
This change should not break any compatibility.
-
+
We proposed introducing a similar change by introducing a
parameter to frame_system::Config but did not feel that
is the correct way of introducing this change.
-
+
I do not have any specific questions about this change at the moment.
-
+
IMO, this change is pretty self-contained and there won't be any future work necessary.
(source)
Table of Contents
@@ -4160,9 +4226,9 @@
+
This RFC proposes a new host function for parachains, storage_proof_size. It shall provide the size of the currently recorded storage proof to the runtime. Runtime authors can use the proof size to improve block utilization by retroactively reclaiming unused storage weight.
-
+
The number of extrinsics that are included in a parachain block is limited by two constraints: execution time and proof size. FRAME weights cover both concepts, and block-builders use them to decide how many extrinsics to include in a block. However, these weights are calculated ahead of time by benchmarking on a machine with reference hardware. The execution-time properties of the state-trie and its storage items are unknown at benchmarking time. Therefore, we make some assumptions about the state-trie:
- Trie Depth: We assume a trie depth to account for intermediary nodes.
@@ -4171,12 +4237,12 @@ These pessimistic assumptions lead to an overestimation of storage weight, negatively impacting block utilization on parachains.
In addition, the current model does not account for multiple accesses to the same storage items. While these repetitive accesses will not increase storage-proof size, the runtime-side weight monitoring will account for them multiple times. Since the proof size is completely opaque to the runtime, we can not implement retroactive storage weight correction.
A solution must provide a way for the runtime to track the exact storage-proof size consumed on a per-extrinsic basis.
-
+
- Parachain Teams: They MUST include this host function in their runtime and node.
- Light-client Implementors: They SHOULD include this host function in their runtime and node.
-
+
This RFC proposes a new host function that exposes the storage-proof size to the runtime. As a result, runtimes can implement storage weight reclaiming mechanisms that improve block utilization.
This RFC proposes the following host function signature:
The host function MUST return an unsigned 64-bit integer value representing the current proof size. In block-execution and block-import contexts, this function MUST return the current size of the proof. To achieve this, parachain node implementors need to enable proof recording for block imports. In other contexts, this function MUST return 18446744073709551615 (u64::MAX), which represents disabled proof recording.
-Parachain nodes need to enable proof recording during block import to correctly implement the proposed host function. Benchmarking conducted with balance transfers has shown a performance reduction of around 0.6% when proof recording is enabled.
-The host function proposed in this RFC allows parachain runtime developers to keep track of the proof size. Typical usage patterns would be to keep track of the overall proof size or the difference between subsequent calls to the host function.
-Parachain teams will need to include this host function to upgrade.
-This RFC might be difficult to implement in Substrate due to the internal code design. It is not clear to the author of this RFC how difficult it would be.
The API of these new functions was heavily inspired by API used by the C programming language.
-The changes in this RFC would need to be benchmarked. This involves implementing the RFC and measuring the speed difference.
It is expected that most host functions are faster or equal speed to their deprecated counterparts, with the following exceptions:
