Presenters: Jeremiah Jordan from Morningstar, Inc.
PyCon 2012 presentation page: https://us.pycon.org/2012/schedule/presentation/122/
Slides: http://goo.gl/8Byd8
Video running time: 31:00
- You were too lazy to get out of your seat.
- Someone said "NoSQL".
- You want to learn about using Cassandra from Python.
- What is Cassandra
- Starting up a local dev/unit test instance
- Using Cassandra from Python
- Indexing/Schema design
- Setting up and maintaining a production cluster
points to
http://www.slideshare.net/jeremiahdjordan/pycon-2012-apache-cassandra
"Cassandra is a highly scalable, eventually consistent, distributed, structured key-value store. Cassandra brings together the distributed systems technologies from Dynamo and the data model from Google's BigTable. Like Dynamo, Cassandra is eventually consistent. Like BigTable, Cassandra provides a ColumnFamily-based data model richer than typical key/value systems."
From the Cassandra Wiki: http://wiki.apache.org/cassandra/
- Column based key value store (multi level dictionary)
- Combination of Dynamo (Amazon) and BigTable (Google)
- Schema-optional
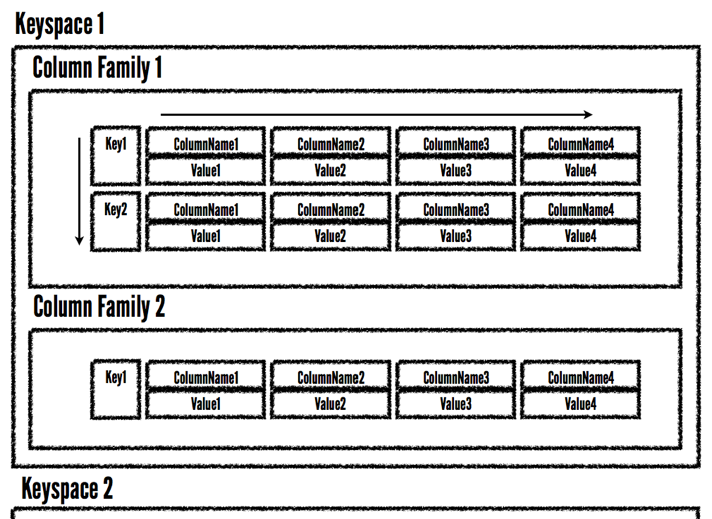
- A keyspace is kind of like a schema in a relational database.
- A column family is kind of like a table in a relational database.
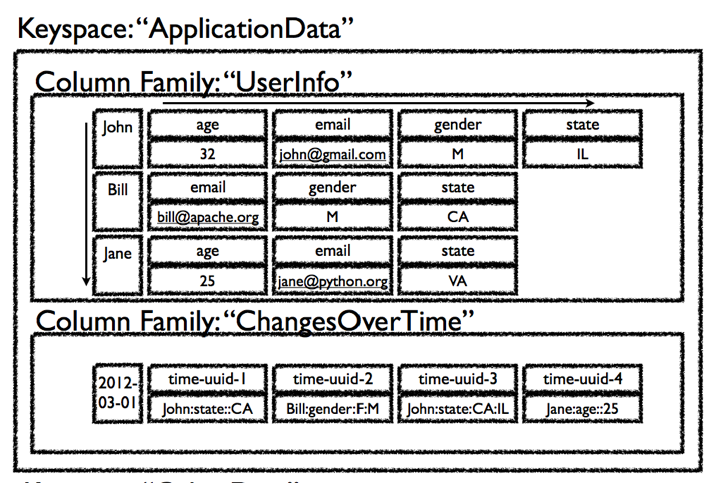
- Keys are in a random order; the recommended way of using Cassandra; allows distributing things evenly over your cluster
- With ordered keys, you have to be careful not to create hotspots in your cluster
- Column names are sorted in alphabetic order
- You can optionally type values
- Every value has a timestamp associated with it; used for conflict resolution -- make sure that clocks are in sync.
Column Family
| Columns
↓ |
{"UserInfo": ↓
{"John": {"age": 32,
↑ "email": "[email protected]",
| "gender": "M",
| "state": "IL"}}}
| ↑
Key |
Values{"UserInfo":
{"John":
OrderedDict(
[("age", 32),
("email", "[email protected]"),
("gender", "M"),
("state", "IL")])}}From the Apache Cassandra project:
or DataStax hosts some Debian and RedHat packages:
http://www.datastax.com/docs/1.0/install
Edit :file:`conf/cassandra.yaml`:
- Change data/commit log locations
- defaults: :file:`/var/cassandra/data` and :file:`/var/cassandra/commitlog`
Edit :file:`conf/log4j-server.properties`:
- Change the log location/levels
- default: :file:`/var/log/cassandra/system.log`
Edit :file:`conf/cassandra-env.sh` (:file:`bin/cassandra.bat` on Windows)
- Update JVM memory usage
- default: 1/2 your RAM
$ ./cassandra -f # -f means launch in foregroundMake templates out of :file:`cassandra.yaml` and :file:`log4j-server.properties`
Update :file:`cassandra` script to generate the actual files
(run them through :program:`sed` or something).
$ ./cassandra-cli
connect localhost/9160;
create keyspace ApplicationData
with placement_strategy =
'org.apache.cassandra.locator.SimpleStrategy'
and strategy_options =
[{replication_factor:1}];use ApplicationData;
create column family UserInfo
and comparator = 'AsciiType';
create column family ChangesOverTime
and comparator = 'TimeUUIDType';http://wiki.apache.org/cassandra/ClientOptions
Thrift - See the "interface" directory (Do not use!!!)
Pycassa - pip install pycassa -- the one we'll talk about today
Telephus (twisted) - pip install telephus
DB-API 2.0 (CQL) - pip install cassandra-dbapi2

import pycassa
from pycassa.pool import ConnectionPool
from pycassa.columnfamily import ColumnFamily
pool = ConnectionPool('ApplicationData',
['localhost:9160'])
col_fam = ColumnFamily(pool, 'UserInfo')
col_fam.insert('John', {'email': '[email protected]'})http://pycassa.github.com/pycassa/
http://github.com/twissandra/twissandra/ -- An example application; Twitter clone using Django and Pycassa
""" Keyspace
|
↓ """
pool = ConnectionPool('ApplicationData',
['localhost:9160'])
""" ↑
|
Server list """Cassandra scales very linearly. Netflix has some nice papers online about it.
""" Connection Pool
|
↓ """
col_fam = ColumnFamily(pool, 'UserInfo')
""" ↑
|
Column Family """col_fam.insert('John', {'email': '[email protected]'})readData = col_fam.get('John',
columns=['email'])col_fam.remove('John',
columns=['email'])col_fam.batch_insert(
{'John': {'email': '[email protected]',
'state': 'IL',
'gender': 'M'},
'Jane': {'email': '[email protected]',
'state': 'CA'
'gender': 'M'}})b = col_fam.batch(queue_size=10)
b.insert('John',
{'email': '[email protected]',
'state': 'IL',
'gender': 'M'})
b.insert('Jane',
{'email': '[email protected]',
'state': 'CA'})
b.remove('John', ['gender'])
b.remove('Jane')
b.send()from pycassa.batch import Mutator
import uuid
b = Mutator(pool)
b.insert(col_fam,
'John', {'gender': 'M'})
b.insert(index_fam,
'2012-03-09',
{uuid.uuid1().bytes:
'John:gender:F:M'})readData = col_fam.multiget(['John', 'Jane', 'Bill'])d = col_fam.get('Jane',
column_start='email',
column_finish='state')
d = col_fam.get('Bill',
column_reversed = True,
column_count=2)
startTime = pycassa.util.convert_time_to_uuid(time.time() - 600)
d = index_fam.get('2012-03-31',
column_start=startTime,
column_count=30)from pycassa.types import *
col_fam.column_validators['age'] = IntegerType()
col_fam.column_validators['height'] = FloatType()
col_fam.insert('John', {'age': 32, 'height': 6.1})from pycassa.types import *
class User(object):
key = Utf8Type()
email = AsciiType()
age = IntegerType()
height = FloatType()
joined = DateType()
# `(18:48) <https://www.youtube.com/watch?v=188mXjwdkak&feature=autoplay&list=PLBC82890EA0228306&lf=plpp_video&playnext=1#t=18m48s>`_
from pycassa.columnfamilymap import ColumnFamilyMap
cfmap = ColumnFamilyMap(User, pool, 'UserInfo')from datetime import datetime
user = User()
user.key = 'John'
user.email = '[email protected]'
user.age = 32
user.height = 6.1
user.joined = datetime.now()
cfmap.insert(user)user = cfmap.get('John')
users = cfmap.multiget(['John', 'Jane'])
cfmap.remove(user)col_fam.read_consistency_level = ConsistencyLevel.QUORUM
col_fam.write_consistency_level = ConsistencyLevel.ONE
col_fam.get('John',
read_consistency_level=ConsistencyLevel.ONE)
col_fam.get('John',
include_timestamp=True)A quorum is n / 2 nodes.
Native secondary indexes
Roll your own with wide rows
Intro to indexing
Blog post and presentation going through some options
- http://www.anuff.com/2011/02/indexing-in-cassandra.html
- http://www.slideshare.net/edanuff/indexing-in-cassandra
Another blog post describing different patterns for indexing
Easy to add, just update the schema
Can use filtering queries
Not recommended for high cardinality values (i.e.: timestamps, birth dates, keywords, etc.)
Makes writes slower to indexed columns
update column family UserInfo
with column_metadata = [
{column_name: state,
validation_class: UTF8Type,
index_type: KEYS};from pycassa.index import *
state_expr = create_index_expression('state', 'IL')
age_expr = create_index_expression('age', 20, GT)
clause = create_index_clause([state_expr, age_expr], count=20)
for key, userInfo in col_fam.get_indexed_slices(clause):
# Do stuffRemoving changed values yourself
Know the new value doesn't exist, no read before write
Index can be denormalized query, not just an index
Can use things like composite columns and other tricks