diff --git a/docs/PRETRAINED.md b/docs/PRETRAINED.md
index 2f899863e..670d71dcd 100644
--- a/docs/PRETRAINED.md
+++ b/docs/PRETRAINED.md
@@ -24,7 +24,7 @@ We replicate OpenAI's results on ViT-B/32, reaching a top-1 ImageNet-1k zero-sho
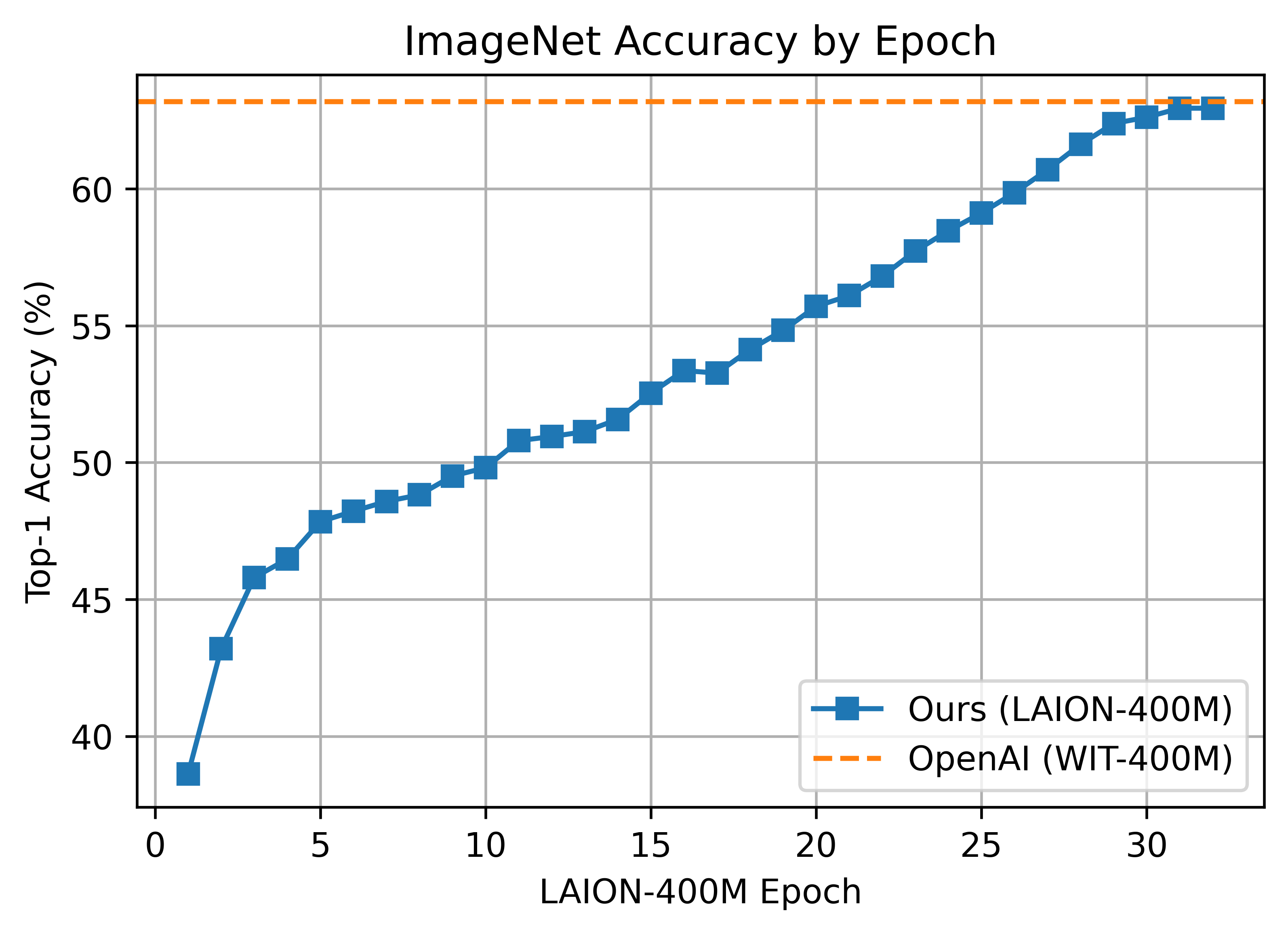 -__Zero-shot comparison (courtesy of Andreas Fürst)__
+**Zero-shot comparison (courtesy of Andreas Fürst)**
-__Zero-shot comparison (courtesy of Andreas Fürst)__
+**Zero-shot comparison (courtesy of Andreas Fürst)**
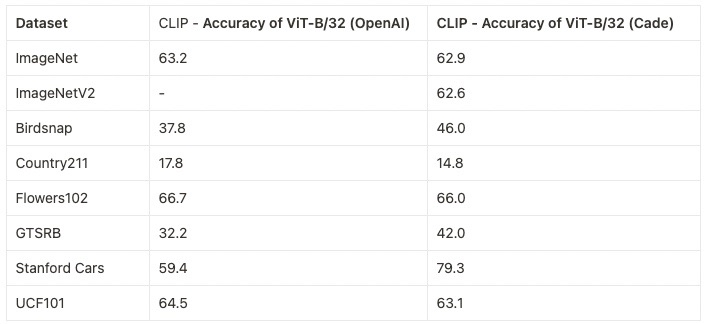 ViT-B/32 was trained with 128 A100 (40 GB) GPUs for ~36 hours, 4600 GPU-hours. The per-GPU batch size was 256 for a global batch size of 32768. 256 is much lower than it could have been (~320-384) due to being sized initially before moving to 'local' contrastive loss.
@@ -44,9 +44,10 @@ ViT-B/16 was trained with 176 A100 (40 GB) GPUS for ~61 hours, 10700 GPU-hours.
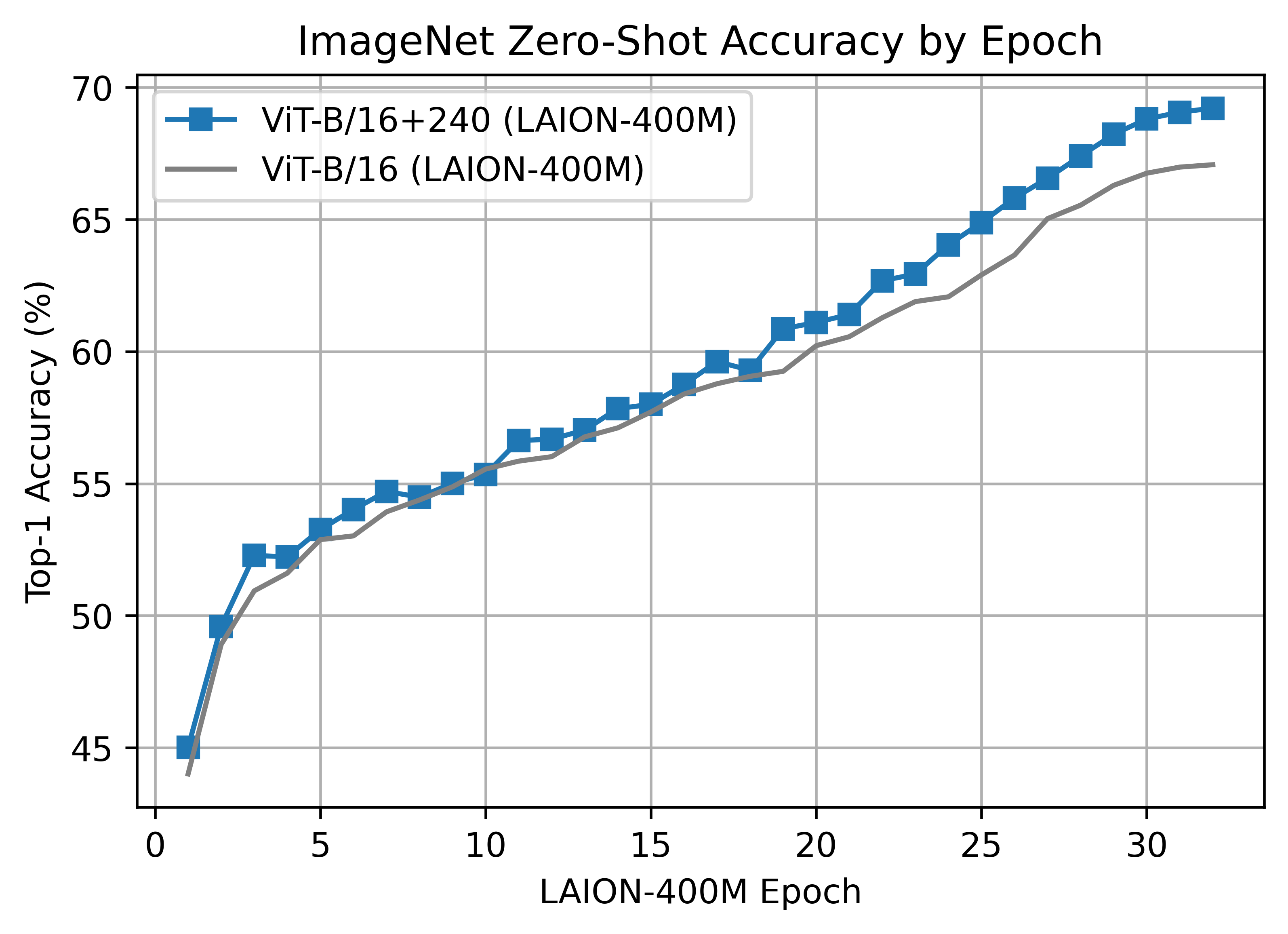
The B/16+ 240x240 LAION400M training reached a top-1 ImageNet-1k zero-shot validation score of 69.21.
This model is the same depth as the B/16, but increases the
- * vision width from 768 -> 896
- * text width from 512 -> 640
- * the resolution 224x224 -> 240x240 (196 -> 225 tokens)
+
+- vision width from 768 -> 896
+- text width from 512 -> 640
+- the resolution 224x224 -> 240x240 (196 -> 225 tokens)
ViT-B/32 was trained with 128 A100 (40 GB) GPUs for ~36 hours, 4600 GPU-hours. The per-GPU batch size was 256 for a global batch size of 32768. 256 is much lower than it could have been (~320-384) due to being sized initially before moving to 'local' contrastive loss.
@@ -44,9 +44,10 @@ ViT-B/16 was trained with 176 A100 (40 GB) GPUS for ~61 hours, 10700 GPU-hours.
The B/16+ 240x240 LAION400M training reached a top-1 ImageNet-1k zero-shot validation score of 69.21.
This model is the same depth as the B/16, but increases the
- * vision width from 768 -> 896
- * text width from 512 -> 640
- * the resolution 224x224 -> 240x240 (196 -> 225 tokens)
+
+- vision width from 768 -> 896
+- text width from 512 -> 640
+- the resolution 224x224 -> 240x240 (196 -> 225 tokens)
 @@ -67,6 +68,7 @@ ViT-L/14 was trained with 400 A100 (40 GB) GPUS for ~127 hours, 50800 GPU-hours.
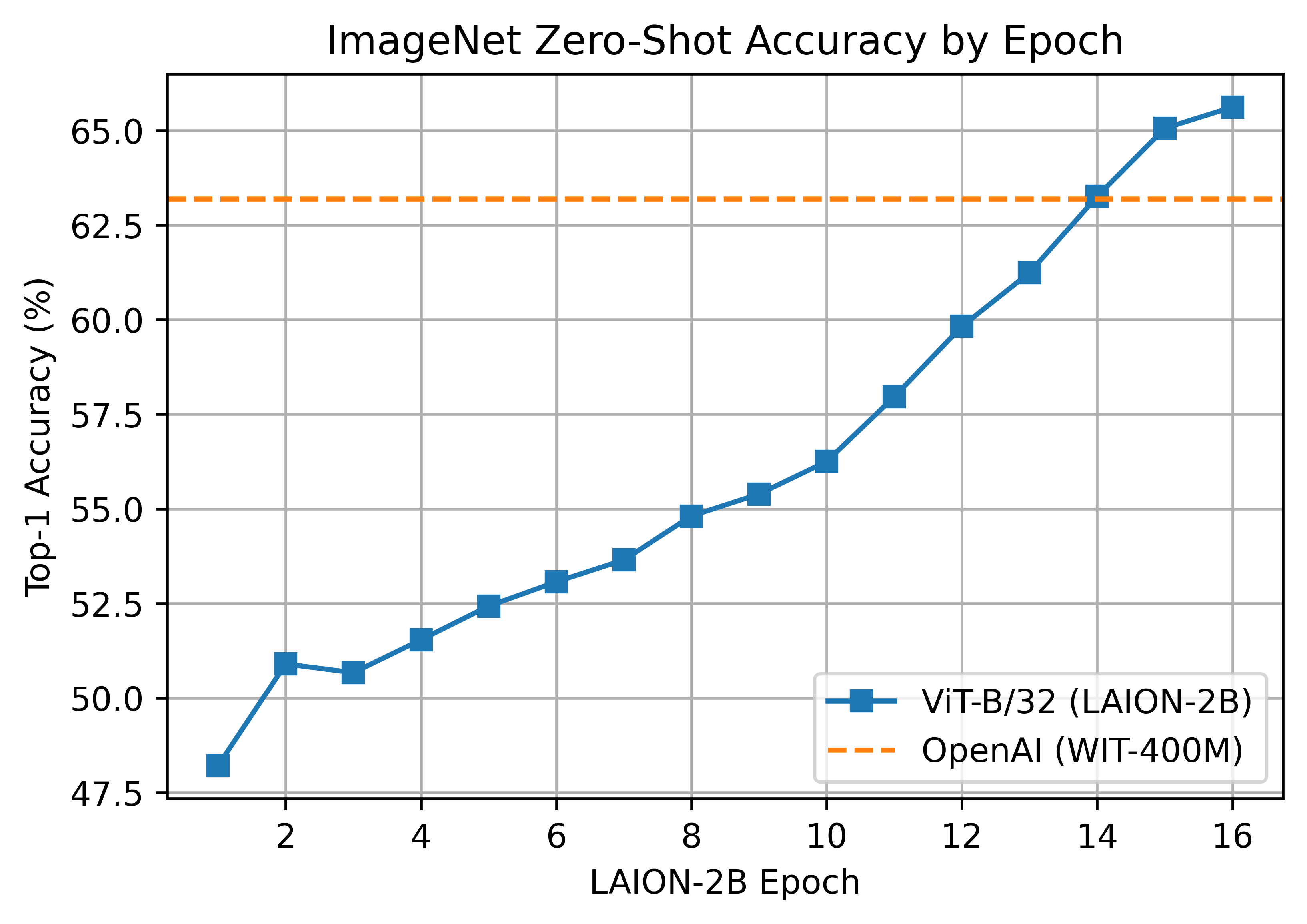
A ~2B sample subset of LAION-5B with english captions (https://huggingface.co/datasets/laion/laion2B-en)
#### ViT-B/32 224x224
+
A ViT-B/32 trained on LAION-2B, reaching a top-1 ImageNet-1k zero-shot accuracy of 65.62%.
@@ -67,6 +68,7 @@ ViT-L/14 was trained with 400 A100 (40 GB) GPUS for ~127 hours, 50800 GPU-hours.
A ~2B sample subset of LAION-5B with english captions (https://huggingface.co/datasets/laion/laion2B-en)
#### ViT-B/32 224x224
+
A ViT-B/32 trained on LAION-2B, reaching a top-1 ImageNet-1k zero-shot accuracy of 65.62%.
 @@ -91,7 +93,6 @@ A ViT-g/14 with a 76.6% top-1 ImageNet-1k zero-shot was trained on JUWELS Booste
This model was trained with a shorted schedule than other LAION-2B models with 12B samples seen instead of 32+B. It matches LAION-400M training in samples seen. Many zero-shot results are lower as a result, but despite this it performs very well in some OOD zero-shot and retrieval tasks.
-
#### ViT-B/32 roberta base
A ViT-B/32 with roberta base encoder with a 61.7% top-1 ImageNet-1k zero-shot was trained on stability. See model details here https://huggingface.co/laion/CLIP-ViT-B-32-roberta-base-laion2B-s12B-b32k
@@ -113,22 +114,20 @@ See full english [metrics](https://huggingface.co/laion/CLIP-ViT-H-14-frozen-xlm
On zero shot classification on imagenet with translated prompts this model reaches:
-* 56% in italian (vs 21% for https://github.com/clip-italian/clip-italian)
-* 53% in japanese (vs 54.6% for https://github.com/rinnakk/japanese-clip)
-* 55.7% in chinese (to be compared with https://github.com/OFA-Sys/Chinese-CLIP)
-
+- 56% in italian (vs 21% for https://github.com/clip-italian/clip-italian)
+- 53% in japanese (vs 54.6% for https://github.com/rinnakk/japanese-clip)
+- 55.7% in chinese (to be compared with https://github.com/OFA-Sys/Chinese-CLIP)
#### YFCC-15M
Below are checkpoints of models trained on YFCC-15M, along with their zero-shot top-1 accuracies on ImageNet and ImageNetV2. These models were trained using 8 GPUs and the same hyperparameters described in the "Sample running code" section, with the exception of `lr=5e-4` and `epochs=32`.
-* [ResNet-50](https://github.com/mlfoundations/open_clip/releases/download/v0.2-weights/rn50-quickgelu-yfcc15m-455df137.pt) (32.7% / 27.9%)
-* [ResNet-101](https://github.com/mlfoundations/open_clip/releases/download/v0.2-weights/rn101-quickgelu-yfcc15m-3e04b30e.pt) (34.8% / 30.0%)
+- [ResNet-50](https://github.com/mlfoundations/open_clip/releases/download/v0.2-weights/rn50-quickgelu-yfcc15m-455df137.pt) (32.7% / 27.9%)
+- [ResNet-101](https://github.com/mlfoundations/open_clip/releases/download/v0.2-weights/rn101-quickgelu-yfcc15m-3e04b30e.pt) (34.8% / 30.0%)
#### CC12M - https://github.com/google-research-datasets/conceptual-12m
-* [ResNet-50](https://github.com/mlfoundations/open_clip/releases/download/v0.2-weights/rn50-quickgelu-cc12m-f000538c.pt) (36.45%)
-
+- [ResNet-50](https://github.com/mlfoundations/open_clip/releases/download/v0.2-weights/rn50-quickgelu-cc12m-f000538c.pt) (36.45%)
### CommonPool and DataComp models
@@ -138,14 +137,13 @@ The best performing models are specified below for the xlarge scale, see our pap
Additional models and more information can be found at [/docs/datacomp_models.md](/docs/datacomp_models.md).
+- `datacomp_xl_s13b_b90k`: A ViT-L/14 trained on DataComp-1B for 12.8B steps and batch size 90k. Achieves 79.2% zero-shot accuracy on ImageNet. Available at https://huggingface.co/laion/CLIP-ViT-L-14-DataComp.XL-s13B-b90K.
-* `datacomp_xl_s13b_b90k`: A ViT-L/14 trained on DataComp-1B for 12.8B steps and batch size 90k. Achieves 79.2% zero-shot accuracy on ImageNet. Available at https://huggingface.co/laion/CLIP-ViT-L-14-DataComp.XL-s13B-b90K.
-
-* `commonpool_xl_clip_s13b_b90k`: A ViT-L/14 trained on CommonPool-XL filtered using CLIP scores, for 12.8B steps and batch size 90k. Achieves 76.4% zero-shot accuracy on ImageNet. Available at https://huggingface.co/laion/CLIP-ViT-L-14-CommonPool.XL.clip-s13B-b90K.
+- `commonpool_xl_clip_s13b_b90k`: A ViT-L/14 trained on CommonPool-XL filtered using CLIP scores, for 12.8B steps and batch size 90k. Achieves 76.4% zero-shot accuracy on ImageNet. Available at https://huggingface.co/laion/CLIP-ViT-L-14-CommonPool.XL.clip-s13B-b90K.
-* `commonpool_xl_laion_s13b_b90k`: A ViT-L/14 trained on CommonPool-XL filtered using the LAION-2B filtering scheme, for 12.8B steps and batch size 90k. Achieves 75.5% zero-shot accuracy on ImageNet. Available at https://huggingface.co/laion/CLIP-ViT-L-14-CommonPool.XL.laion-s13B-b90K.
+- `commonpool_xl_laion_s13b_b90k`: A ViT-L/14 trained on CommonPool-XL filtered using the LAION-2B filtering scheme, for 12.8B steps and batch size 90k. Achieves 75.5% zero-shot accuracy on ImageNet. Available at https://huggingface.co/laion/CLIP-ViT-L-14-CommonPool.XL.laion-s13B-b90K.
-* `commonpool_xl_s13b_b90k`: A ViT-L/14 trained on CommonPool-XL without any filtering, for 12.8B steps and batch size 90k. Achieves 72.3% zero-shot accuracy on ImageNet. Available at https://huggingface.co/laion/CLIP-ViT-L-14-CommonPool.XL-s13B-b90K.
+- `commonpool_xl_s13b_b90k`: A ViT-L/14 trained on CommonPool-XL without any filtering, for 12.8B steps and batch size 90k. Achieves 72.3% zero-shot accuracy on ImageNet. Available at https://huggingface.co/laion/CLIP-ViT-L-14-CommonPool.XL-s13B-b90K.
If you use models trained on DataComp-1B or CommonPool variations, please consider citing the following:
@@ -158,15 +156,13 @@ If you use models trained on DataComp-1B or CommonPool variations, please consid
}
```
-
### MetaCLIP
MetaCLIP models are described in the paper [Demystifying CLIP Data](https://arxiv.org/abs/2309.16671).
These models were developed by Hu Xu, Saining Xie, Xiaoqing Ellen Tan, Po-Yao Huang, Russell Howes, Vasu Sharma, Shang-Wen Li, Gargi Ghosh, Luke Zettlemoyer and Christoph Feichtenhofer from Meta, New York University and the University of Washington.
Models are licensed under CC-BY-NC.
-More details are available at https://github.com/facebookresearch/MetaCLIP.
-
+More details are available at https://github.com/facebookresearch/MetaCLIP.
If you use MetaCLIP models, please cite the following:
@@ -179,7 +175,6 @@ If you use MetaCLIP models, please cite the following:
}
```
-
### EVA-CLIP
EVA-CLIP models are described in the paper [EVA-CLIP: Improved Training Techniques for CLIP at Scale](https://arxiv.org/abs/2303.15389).
@@ -188,7 +183,6 @@ These models were developed by Quan Sun, Yuxin Fang, Ledell Wu, Xinlong Wang and
Models are licensed under the MIT License.
More details are available at https://github.com/baaivision/EVA/tree/master/EVA-CLIP.
-
If you use EVA models, please cite the following:
```bibtex
@@ -200,15 +194,21 @@ If you use EVA models, please cite the following:
}
```
+### NLLB-CLIP
+
+NLLB-CLIP models are described in the paper [NLLB-CLIP - train performant multilingual image retrieval model on a budget](https://arxiv.org/abs/2309.01859) by Alexander Visheratin.
+
+The model was trained following the [LiT](https://arxiv.org/abs/2111.07991) methodology: the image tower was frozen, the text tower was initialized from the [NLLB](https://arxiv.org/abs/2207.04672) encoder and unfrozen.
-### NLLB
+The model was trained on the [LAION-COCO-NLLB](https://huggingface.co/datasets/visheratin/laion-coco-nllb) dataset.
-NLLB models are described in the paper [NLLB-CLIP -- train performant multilingual image retrieval model on a budget
-](https://arxiv.org/abs/2309.01859) by Alexander Visheratin.
+The first version of the model (`nllb-clip`) described in the paper was trained using the OpenAI CLIP image encoder.
+
+The second version of the model (`nllb-clip-siglip`) was trained using the [SigLIP](https://arxiv.org/abs/2303.15343) image encoder.
Models are licensed under CC-BY-NC.
-If you use NLLB models, please cite the following:
+If you use NLLB-CLIP models, please cite the following:
```bibtex
@article{visheratin2023nllb,
@@ -219,7 +219,6 @@ If you use NLLB models, please cite the following:
}
```
-
### CLIPA
CLIPA models are described in the following papers by Xianhang Li, Zeyu Wang, Cihang Xie from UC Santa Cruz:
@@ -230,12 +229,11 @@ CLIPA models are described in the following papers by Xianhang Li, Zeyu Wang, Ci
Models are licensed under Apache 2.0.
More details are available at https://github.com/UCSC-VLAA/CLIPA and [here](clipa.md).
-
If you use CLIPA models, please cite the following:
```bibtex
@inproceedings{li2023clipa,
- title={An Inverse Scaling Law for CLIP Training},
+ title={An Inverse Scaling Law for CLIP Training},
author={Xianhang Li and Zeyu Wang and Cihang Xie},
booktitle={NeurIPS},
year={2023},
@@ -244,7 +242,7 @@ If you use CLIPA models, please cite the following:
```bibtex
@article{li2023clipav2,
- title={CLIPA-v2: Scaling CLIP Training with 81.1% Zero-shot ImageNet Accuracy within a $10,000 Budget; An Extra $4,000 Unlocks 81.8% Accuracy},
+ title={CLIPA-v2: Scaling CLIP Training with 81.1% Zero-shot ImageNet Accuracy within a $10,000 Budget; An Extra $4,000 Unlocks 81.8% Accuracy},
author={Xianhang Li and Zeyu Wang and Cihang Xie},
journal={arXiv preprint arXiv:2306.15658},
year={2023},
@@ -259,7 +257,6 @@ These models were developed by Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov
Models are licensed under the Apache 2 license.
More details are available at hhttps://github.com/google-research/big_vision.
-
If you use SigLIP models, please cite the following:
```bibtex
@@ -91,7 +93,6 @@ A ViT-g/14 with a 76.6% top-1 ImageNet-1k zero-shot was trained on JUWELS Booste
This model was trained with a shorted schedule than other LAION-2B models with 12B samples seen instead of 32+B. It matches LAION-400M training in samples seen. Many zero-shot results are lower as a result, but despite this it performs very well in some OOD zero-shot and retrieval tasks.
-
#### ViT-B/32 roberta base
A ViT-B/32 with roberta base encoder with a 61.7% top-1 ImageNet-1k zero-shot was trained on stability. See model details here https://huggingface.co/laion/CLIP-ViT-B-32-roberta-base-laion2B-s12B-b32k
@@ -113,22 +114,20 @@ See full english [metrics](https://huggingface.co/laion/CLIP-ViT-H-14-frozen-xlm
On zero shot classification on imagenet with translated prompts this model reaches:
-* 56% in italian (vs 21% for https://github.com/clip-italian/clip-italian)
-* 53% in japanese (vs 54.6% for https://github.com/rinnakk/japanese-clip)
-* 55.7% in chinese (to be compared with https://github.com/OFA-Sys/Chinese-CLIP)
-
+- 56% in italian (vs 21% for https://github.com/clip-italian/clip-italian)
+- 53% in japanese (vs 54.6% for https://github.com/rinnakk/japanese-clip)
+- 55.7% in chinese (to be compared with https://github.com/OFA-Sys/Chinese-CLIP)
#### YFCC-15M
Below are checkpoints of models trained on YFCC-15M, along with their zero-shot top-1 accuracies on ImageNet and ImageNetV2. These models were trained using 8 GPUs and the same hyperparameters described in the "Sample running code" section, with the exception of `lr=5e-4` and `epochs=32`.
-* [ResNet-50](https://github.com/mlfoundations/open_clip/releases/download/v0.2-weights/rn50-quickgelu-yfcc15m-455df137.pt) (32.7% / 27.9%)
-* [ResNet-101](https://github.com/mlfoundations/open_clip/releases/download/v0.2-weights/rn101-quickgelu-yfcc15m-3e04b30e.pt) (34.8% / 30.0%)
+- [ResNet-50](https://github.com/mlfoundations/open_clip/releases/download/v0.2-weights/rn50-quickgelu-yfcc15m-455df137.pt) (32.7% / 27.9%)
+- [ResNet-101](https://github.com/mlfoundations/open_clip/releases/download/v0.2-weights/rn101-quickgelu-yfcc15m-3e04b30e.pt) (34.8% / 30.0%)
#### CC12M - https://github.com/google-research-datasets/conceptual-12m
-* [ResNet-50](https://github.com/mlfoundations/open_clip/releases/download/v0.2-weights/rn50-quickgelu-cc12m-f000538c.pt) (36.45%)
-
+- [ResNet-50](https://github.com/mlfoundations/open_clip/releases/download/v0.2-weights/rn50-quickgelu-cc12m-f000538c.pt) (36.45%)
### CommonPool and DataComp models
@@ -138,14 +137,13 @@ The best performing models are specified below for the xlarge scale, see our pap
Additional models and more information can be found at [/docs/datacomp_models.md](/docs/datacomp_models.md).
+- `datacomp_xl_s13b_b90k`: A ViT-L/14 trained on DataComp-1B for 12.8B steps and batch size 90k. Achieves 79.2% zero-shot accuracy on ImageNet. Available at https://huggingface.co/laion/CLIP-ViT-L-14-DataComp.XL-s13B-b90K.
-* `datacomp_xl_s13b_b90k`: A ViT-L/14 trained on DataComp-1B for 12.8B steps and batch size 90k. Achieves 79.2% zero-shot accuracy on ImageNet. Available at https://huggingface.co/laion/CLIP-ViT-L-14-DataComp.XL-s13B-b90K.
-
-* `commonpool_xl_clip_s13b_b90k`: A ViT-L/14 trained on CommonPool-XL filtered using CLIP scores, for 12.8B steps and batch size 90k. Achieves 76.4% zero-shot accuracy on ImageNet. Available at https://huggingface.co/laion/CLIP-ViT-L-14-CommonPool.XL.clip-s13B-b90K.
+- `commonpool_xl_clip_s13b_b90k`: A ViT-L/14 trained on CommonPool-XL filtered using CLIP scores, for 12.8B steps and batch size 90k. Achieves 76.4% zero-shot accuracy on ImageNet. Available at https://huggingface.co/laion/CLIP-ViT-L-14-CommonPool.XL.clip-s13B-b90K.
-* `commonpool_xl_laion_s13b_b90k`: A ViT-L/14 trained on CommonPool-XL filtered using the LAION-2B filtering scheme, for 12.8B steps and batch size 90k. Achieves 75.5% zero-shot accuracy on ImageNet. Available at https://huggingface.co/laion/CLIP-ViT-L-14-CommonPool.XL.laion-s13B-b90K.
+- `commonpool_xl_laion_s13b_b90k`: A ViT-L/14 trained on CommonPool-XL filtered using the LAION-2B filtering scheme, for 12.8B steps and batch size 90k. Achieves 75.5% zero-shot accuracy on ImageNet. Available at https://huggingface.co/laion/CLIP-ViT-L-14-CommonPool.XL.laion-s13B-b90K.
-* `commonpool_xl_s13b_b90k`: A ViT-L/14 trained on CommonPool-XL without any filtering, for 12.8B steps and batch size 90k. Achieves 72.3% zero-shot accuracy on ImageNet. Available at https://huggingface.co/laion/CLIP-ViT-L-14-CommonPool.XL-s13B-b90K.
+- `commonpool_xl_s13b_b90k`: A ViT-L/14 trained on CommonPool-XL without any filtering, for 12.8B steps and batch size 90k. Achieves 72.3% zero-shot accuracy on ImageNet. Available at https://huggingface.co/laion/CLIP-ViT-L-14-CommonPool.XL-s13B-b90K.
If you use models trained on DataComp-1B or CommonPool variations, please consider citing the following:
@@ -158,15 +156,13 @@ If you use models trained on DataComp-1B or CommonPool variations, please consid
}
```
-
### MetaCLIP
MetaCLIP models are described in the paper [Demystifying CLIP Data](https://arxiv.org/abs/2309.16671).
These models were developed by Hu Xu, Saining Xie, Xiaoqing Ellen Tan, Po-Yao Huang, Russell Howes, Vasu Sharma, Shang-Wen Li, Gargi Ghosh, Luke Zettlemoyer and Christoph Feichtenhofer from Meta, New York University and the University of Washington.
Models are licensed under CC-BY-NC.
-More details are available at https://github.com/facebookresearch/MetaCLIP.
-
+More details are available at https://github.com/facebookresearch/MetaCLIP.
If you use MetaCLIP models, please cite the following:
@@ -179,7 +175,6 @@ If you use MetaCLIP models, please cite the following:
}
```
-
### EVA-CLIP
EVA-CLIP models are described in the paper [EVA-CLIP: Improved Training Techniques for CLIP at Scale](https://arxiv.org/abs/2303.15389).
@@ -188,7 +183,6 @@ These models were developed by Quan Sun, Yuxin Fang, Ledell Wu, Xinlong Wang and
Models are licensed under the MIT License.
More details are available at https://github.com/baaivision/EVA/tree/master/EVA-CLIP.
-
If you use EVA models, please cite the following:
```bibtex
@@ -200,15 +194,21 @@ If you use EVA models, please cite the following:
}
```
+### NLLB-CLIP
+
+NLLB-CLIP models are described in the paper [NLLB-CLIP - train performant multilingual image retrieval model on a budget](https://arxiv.org/abs/2309.01859) by Alexander Visheratin.
+
+The model was trained following the [LiT](https://arxiv.org/abs/2111.07991) methodology: the image tower was frozen, the text tower was initialized from the [NLLB](https://arxiv.org/abs/2207.04672) encoder and unfrozen.
-### NLLB
+The model was trained on the [LAION-COCO-NLLB](https://huggingface.co/datasets/visheratin/laion-coco-nllb) dataset.
-NLLB models are described in the paper [NLLB-CLIP -- train performant multilingual image retrieval model on a budget
-](https://arxiv.org/abs/2309.01859) by Alexander Visheratin.
+The first version of the model (`nllb-clip`) described in the paper was trained using the OpenAI CLIP image encoder.
+
+The second version of the model (`nllb-clip-siglip`) was trained using the [SigLIP](https://arxiv.org/abs/2303.15343) image encoder.
Models are licensed under CC-BY-NC.
-If you use NLLB models, please cite the following:
+If you use NLLB-CLIP models, please cite the following:
```bibtex
@article{visheratin2023nllb,
@@ -219,7 +219,6 @@ If you use NLLB models, please cite the following:
}
```
-
### CLIPA
CLIPA models are described in the following papers by Xianhang Li, Zeyu Wang, Cihang Xie from UC Santa Cruz:
@@ -230,12 +229,11 @@ CLIPA models are described in the following papers by Xianhang Li, Zeyu Wang, Ci
Models are licensed under Apache 2.0.
More details are available at https://github.com/UCSC-VLAA/CLIPA and [here](clipa.md).
-
If you use CLIPA models, please cite the following:
```bibtex
@inproceedings{li2023clipa,
- title={An Inverse Scaling Law for CLIP Training},
+ title={An Inverse Scaling Law for CLIP Training},
author={Xianhang Li and Zeyu Wang and Cihang Xie},
booktitle={NeurIPS},
year={2023},
@@ -244,7 +242,7 @@ If you use CLIPA models, please cite the following:
```bibtex
@article{li2023clipav2,
- title={CLIPA-v2: Scaling CLIP Training with 81.1% Zero-shot ImageNet Accuracy within a $10,000 Budget; An Extra $4,000 Unlocks 81.8% Accuracy},
+ title={CLIPA-v2: Scaling CLIP Training with 81.1% Zero-shot ImageNet Accuracy within a $10,000 Budget; An Extra $4,000 Unlocks 81.8% Accuracy},
author={Xianhang Li and Zeyu Wang and Cihang Xie},
journal={arXiv preprint arXiv:2306.15658},
year={2023},
@@ -259,7 +257,6 @@ These models were developed by Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov
Models are licensed under the Apache 2 license.
More details are available at hhttps://github.com/google-research/big_vision.
-
If you use SigLIP models, please cite the following:
```bibtex