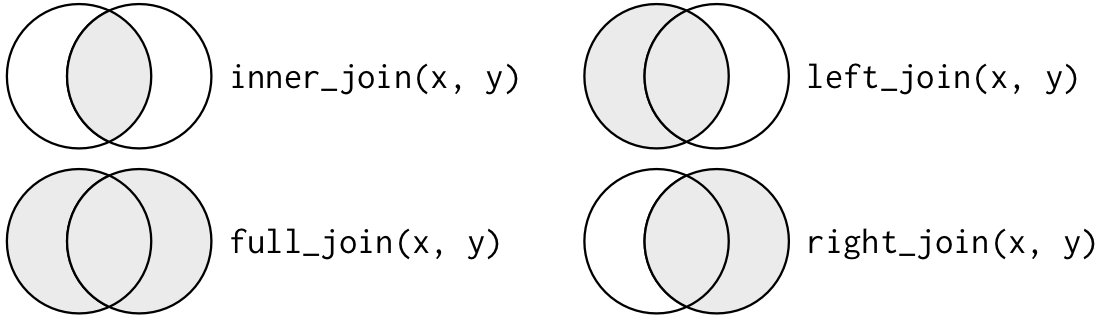diff --git a/search.json b/search.json
index e55f2f8..23e5610 100644
--- a/search.json
+++ b/search.json
@@ -1,4 +1,11 @@
[
+ {
+ "objectID": "projects.html",
+ "href": "projects.html",
+ "title": "Projects",
+ "section": "",
+ "text": "Project 0 (optional)\n\n\n\n\n\n\n\nproject 0\n\n\nprojects\n\n\n\n\nInformation for Project 0 (entirely optional, but hopefully useful and fun!)\n\n\n\n\n\n\nLeonardo Collado Torres\n\n\n\n\n\n\n \n\n\n\n\nProject 1\n\n\n\n\n\n\n\nproject 1\n\n\nprojects\n\n\n\n\nFinding great chocolate bars!\n\n\n\n\n\n\nLeonardo Collado Torres\n\n\n\n\n\n\n \n\n\n\n\nProject 2\n\n\n\n\n\n\n\nproject 2\n\n\nprojects\n\n\n\n\nExploring temperature and rainfall in Australia\n\n\n\n\n\n\nLeonardo Collado Torres\n\n\n\n\n\n\n \n\n\n\n\nProject 3\n\n\n\n\n\n\n\nproject 3\n\n\nprojects\n\n\n\n\nExploring album sales and sentiment of lyrics from Beyoncé and Taylor Swift\n\n\n\n\n\n\nLeonardo Collado Torres\n\n\n\n\n\n\nNo matching items"
+ },
{
"objectID": "lectures.html",
"href": "lectures.html",
@@ -7,718 +14,578 @@
"text": "01 - Welcome!\n\n\n\n\n\n\n\ncourse-admin\n\n\nmodule 1\n\n\nweek 1\n\n\n\n\nOverview course information for BSPH Biostatistics 140.776 in Fall 2023\n\n\n\n\n\n\nLeonardo Collado Torres\n\n\n\n\n\n\n \n\n\n\n\n02 - Introduction to R and RStudio!\n\n\n\n\n\n\n\nmodule 1\n\n\nweek 1\n\n\nR\n\n\nprogramming\n\n\nRStudio\n\n\n\n\nLet’s dig into the R programming language and the RStudio integrated developer environment\n\n\n\n\n\n\nLeonardo Collado Torres\n\n\n\n\n\n\n \n\n\n\n\n03 - Introduction to git/GitHub\n\n\n\n\n\n\n\nmodule 1\n\n\nweek 1\n\n\nprogramming\n\n\nversion control\n\n\ngit\n\n\nGitHub\n\n\n\n\nVersion control is a game changer; or how I learned to love git/GitHub\n\n\n\n\n\n\nLeonardo Collado Torres\n\n\n\n\n\n\n \n\n\n\n\n04 - Reproducible Research\n\n\n\n\n\n\n\nmodule 1\n\n\nweek 1\n\n\nR\n\n\nreproducibility\n\n\n\n\nIntroduction to reproducible research covering some basic concepts and ideas that are related to reproducible reporting\n\n\n\n\n\n\nLeonardo Collado Torres\n\n\n\n\n\n\n \n\n\n\n\n05 - Literate Statistical Programming\n\n\n\n\n\n\n\nmodule 1\n\n\nweek 1\n\n\nR Markdown\n\n\nprogramming\n\n\n\n\nIntroduction to literate statistical programming tools including R Markdown\n\n\n\n\n\n\nLeonardo Collado Torres\n\n\n\n\n\n\n \n\n\n\n\n06 - Reference management\n\n\n\n\n\n\n\nmodule 1\n\n\nweek 1\n\n\nR Markdown\n\n\nprogramming\n\n\n\n\nHow to use citations and incorporate references from a bibliography in R Markdown.\n\n\n\n\n\n\nLeonardo Collado Torres\n\n\n\n\n\n\n \n\n\n\n\n07 - Reading and Writing data\n\n\n\n\n\n\n\nmodule 2\n\n\nweek 2\n\n\nR\n\n\nprogramming\n\n\nreadr\n\n\nhere\n\n\ntidyverse\n\n\n\n\nHow to get data in and out of R using relative paths\n\n\n\n\n\n\nLeonardo Collado Torres\n\n\n\n\n\n\n \n\n\n\n\n08 - Managing data frames with the Tidyverse\n\n\n\n\n\n\n\nmodule 2\n\n\nweek 2\n\n\nR\n\n\nprogramming\n\n\ndplyr\n\n\nhere\n\n\ntibble\n\n\ntidyverse\n\n\n\n\nAn introduction to data frames in R and the managing them with the dplyr R package\n\n\n\n\n\n\nLeonardo Collado Torres\n\n\n\n\n\n\n \n\n\n\n\n09 - Tidy data and the Tidyverse\n\n\n\n\n\n\n\nmodule 2\n\n\nweek 2\n\n\nR\n\n\nprogramming\n\n\ntidyr\n\n\nhere\n\n\ntidyverse\n\n\n\n\nIntroduction to tidy data and how to convert between wide and long data with the tidyr R package\n\n\n\n\n\n\nLeonardo Collado Torres\n\n\n\n\n\n\n \n\n\n\n\n10 - Joining data in R\n\n\n\n\n\n\n\nmodule 2\n\n\nweek 2\n\n\nR\n\n\nprogramming\n\n\ndplyr\n\n\nhere\n\n\ntidyverse\n\n\n\n\nIntroduction to relational data and join functions in the dplyr R package\n\n\n\n\n\n\nLeonardo Collado Torres\n\n\n\n\n\n\n \n\n\n\n\n11 - Plotting Systems\n\n\n\n\n\n\n\nmodule 3\n\n\nweek 3\n\n\nR\n\n\nprogramming\n\n\nggplot2\n\n\ndata viz\n\n\n\n\nOverview of three plotting systems in R\n\n\n\n\n\n\nLeonardo Collado Torres\n\n\n\n\n\n\n \n\n\n\n\n12 - The ggplot2 plotting system: qplot()\n\n\n\n\n\n\n\nmodule 3\n\n\nweek 3\n\n\nR\n\n\nprogramming\n\n\nggplot2\n\n\ndata viz\n\n\n\n\nAn overview of the ggplot2 plotting system in R with qplot()\n\n\n\n\n\n\nLeonardo Collado Torres\n\n\n\n\n\n\n \n\n\n\n\n13 - The ggplot2 plotting system: ggplot()\n\n\n\n\n\n\n\nmodule 3\n\n\nweek 3\n\n\nR\n\n\nprogramming\n\n\nggplot2\n\n\ndata viz\n\n\n\n\nAn overview of the ggplot2 plotting system in R with ggplot()\n\n\n\n\n\n\nLeonardo Collado Torres\n\n\n\n\n\n\n \n\n\n\n\n14 - R Nuts and Bolts\n\n\n\n\n\n\n\nmodule 4\n\n\nweek 4\n\n\nR\n\n\nprogramming\n\n\n\n\nIntroduction to data types and objects in R\n\n\n\n\n\n\nLeonardo Collado Torres\n\n\n\n\n\n\n \n\n\n\n\n15 - Control Structures\n\n\n\n\n\n\n\nmodule 4\n\n\nweek 4\n\n\nR\n\n\nprogramming\n\n\n\n\nIntroduction to control the flow of execution of a series of R expressions\n\n\n\n\n\n\nLeonardo Collado Torres\n\n\n\n\n\n\n \n\n\n\n\n16 - Functions\n\n\n\n\n\n\n\nmodule 4\n\n\nweek 4\n\n\nR\n\n\nprogramming\n\n\nfunctions\n\n\n\n\nIntroduction to writing functions in R\n\n\n\n\n\n\nLeonardo Collado Torres\n\n\n\n\n\n\n \n\n\n\n\n17 - Vectorization and loop functionals\n\n\n\n\n\n\n\nmodule 4\n\n\nweek 5\n\n\nR\n\n\nprogramming\n\n\nfunctions\n\n\n\n\nIntroduction to vectorization and loop functionals\n\n\n\n\n\n\nLeonardo Collado Torres\n\n\n\n\n\n\n \n\n\n\n\n18 - Debugging R Code\n\n\n\n\n\n\n\nmodule 4\n\n\nweek 5\n\n\nprogramming\n\n\ndebugging\n\n\n\n\nHelp! What’s wrong with my code???\n\n\n\n\n\n\nLeonardo Collado Torres\n\n\n\n\n\n\n \n\n\n\n\n19 - Error Handling and Generation\n\n\n\n\n\n\n\nmodule 4\n\n\nweek 5\n\n\nprogramming\n\n\ndebugging\n\n\n\n\nImplement exception handling routines in R functions\n\n\n\n\n\n\nLeonardo Collado Torres\n\n\n\n\n\n\n \n\n\n\n\n20 - Working with dates and times\n\n\n\n\n\n\n\nmodule 5\n\n\nweek 6\n\n\ntidyverse\n\n\nR\n\n\nprogramming\n\n\ndates and times\n\n\n\n\nIntroduction to lubridate for dates and times in R\n\n\n\n\n\n\nLeonardo Collado Torres\n\n\n\n\n\n\n \n\n\n\n\n21 - Regular expressions\n\n\n\n\n\n\n\nmodule 5\n\n\nweek 6\n\n\ntidyverse\n\n\nR\n\n\nprogramming\n\n\nstrings and regex\n\n\n\n\nIntroduction to working with character strings and regular expressions in R\n\n\n\n\n\n\nLeonardo Collado Torres\n\n\n\n\n\n\n \n\n\n\n\n22 - Factors\n\n\n\n\n\n\n\nmodule 5\n\n\nweek 7\n\n\ntidyverse\n\n\nfactors\n\n\ncategorial variables\n\n\n\n\nAn introduction to working categorial variables using factors in R\n\n\n\n\n\n\nLeonardo Collado Torres\n\n\n\n\n\n\n \n\n\n\n\n23 - Tidytext and sentiment analysis\n\n\n\n\n\n\n\nmodule 5\n\n\nweek 7\n\n\ntidyverse\n\n\ntidytext\n\n\nsentiment analysis\n\n\n\n\nIntroduction to tidytext and sentiment analysis\n\n\n\n\n\n\nLeonardo Collado Torres\n\n\n\n\n\n\n \n\n\n\n\n24 - Best practices for data analyses\n\n\n\n\n\n\n\nmodule 6\n\n\nweek 8\n\n\nbest practices\n\n\n\n\nA noncomprehensive set of best practices for building data analyses\n\n\n\n\n\n\nLeonardo Collado Torres\n\n\n\n\n\n\n \n\n\n\n\n25 - Python for R Users\n\n\n\n\n\n\n\nweek 8\n\n\nmodule 6\n\n\npython\n\n\nR\n\n\nprogramming\n\n\n\n\nIntroduction to using Python in R and the reticulate package\n\n\n\n\n\n\nLeonardo Collado Torres\n\n\n\n\n\n\nNo matching items"
},
{
- "objectID": "posts/11-plotting-systems/index.html",
- "href": "posts/11-plotting-systems/index.html",
- "title": "11 - Plotting Systems",
+ "objectID": "resources.html",
+ "href": "resources.html",
+ "title": "Resources",
+ "section": "",
+ "text": "Learning R\n\nR 101 LIBD rstats club blog post: https://research.libd.org/rstatsclub/2018/12/24/r_101/\nIntroductory videos from the LIBD rstats club such as this one:\n\n\n\n\n\n\nBig Book of R: https://www.bigbookofr.com\nList of resources to learn R (but also Python, SQL, Javascript): https://github.com/delabj/datacamp_alternatives/blob/master/index.md\nlearnr4free. Resources (books, videos, interactive websites, papers) to learn R. Some of the resources are beginner-friendly and start with the installation process: https://www.learnr4free.com/en\nData Science with R by Danielle Navarro: https://robust-tools.djnavarro.net"
+ },
+ {
+ "objectID": "posts/13-ggplot2-plotting-system-part-2/index.html",
+ "href": "posts/13-ggplot2-plotting-system-part-2/index.html",
+ "title": "13 - The ggplot2 plotting system: ggplot()",
"section": "",
"text": "This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history."
},
{
- "objectID": "posts/11-plotting-systems/index.html#the-base-plotting-system",
- "href": "posts/11-plotting-systems/index.html#the-base-plotting-system",
- "title": "11 - Plotting Systems",
- "section": "The Base Plotting System",
- "text": "The Base Plotting System\nThe base plotting system is the original plotting system for R. The basic model is sometimes referred to as the “artist’s palette” model.\nThe idea is you start with blank canvas and build up from there.\nIn more R-specific terms, you typically start with plot() function (or similar plot creating function) to initiate a plot and then annotate the plot with various annotation functions (text, lines, points, axis)\nThe base plotting system is often the most convenient plotting system to use because it mirrors how we sometimes think of building plots and analyzing data.\nIf we do not have a completely well-formed idea of how we want to look at some data, often we will start by “throwing some data on the page” and then slowly add more information to it as our thought process evolves.\n\n\n\n\n\n\nExample\n\n\n\nWe might look at a simple scatterplot and then decide to add a linear regression line or a smoother to it to highlight the trends.\n\ndata(airquality)\nwith(airquality, {\n plot(Temp, Ozone)\n lines(loess.smooth(Temp, Ozone))\n})\n\n\n\n\nScatterplot with loess curve\n\n\n\n\n\n\nIn the code above:\n\nThe plot() function creates the initial plot and draws the points (circles) on the canvas.\nThe lines function is used to annotate or add to the plot (in this case it adds a loess smoother to the scatterplot).\n\nNext, we use the plot() function to draw the points on the scatterplot and then use the main argument to add a main title to the plot.\n\ndata(airquality)\nwith(airquality, {\n plot(Temp, Ozone, main = \"my plot\")\n lines(loess.smooth(Temp, Ozone))\n})\n\n\n\n\nScatterplot with loess curve\n\n\n\n\n\n\n\n\n\n\nNote\n\n\n\nOne downside with constructing base plots is that you cannot go backwards once the plot has started.\nIt is possible that you could start down the road of constructing a plot and realize later (when it is too late) that you do not have enough room to add a y-axis label or something like that\n\n\nIf you have specific plot in mind, there is then a need to plan in advance to make sure, for example, that you have set your margins to be the right size to fit all of the annotations that you may want to include.\nWhile the base plotting system is nice in that it gives you the flexibility to specify these kinds of details to painstaking accuracy, sometimes it would be nice if the system could just figure it out for you.\n\n\n\n\n\n\nNote\n\n\n\nAnother downside of the base plotting system is that it is difficult to describe or translate a plot to others because there is no clear graphical language or grammar that can be used to communicate what you have done.\nThe only real way to describe what you have done in a base plot is to just list the series of commands/functions that you have executed, which is not a particularly compact way of communicating things.\nThis is one problem that the ggplot2 package attempts to address.\n\n\n\n\n\n\n\n\nExample\n\n\n\nAnother typical base plot is constructed with the following code.\n\ndata(cars)\n\n## Create the plot / draw canvas\nwith(cars, plot(speed, dist))\n\n## Add annotation\ntitle(\"Speed vs. Stopping distance\")\n\n\n\n\nBase plot with title\n\n\n\n\n\n\nWe will go into more detail on what these functions do in later lessons."
+ "objectID": "posts/13-ggplot2-plotting-system-part-2/index.html#basic-components-of-a-ggplot2-plot",
+ "href": "posts/13-ggplot2-plotting-system-part-2/index.html#basic-components-of-a-ggplot2-plot",
+ "title": "13 - The ggplot2 plotting system: ggplot()",
+ "section": "Basic components of a ggplot2 plot",
+ "text": "Basic components of a ggplot2 plot\n\n\n\n\n\n\nKey components\n\n\n\nA ggplot2 plot consists of a number of key components.\n\nA data frame: stores all of the data that will be displayed on the plot\naesthetic mappings: describe how data are mapped to color, size, shape, location\ngeoms: geometric objects like points, lines, shapes\nfacets: describes how conditional/panel plots should be constructed\nstats: statistical transformations like binning, quantiles, smoothing\nscales: what scale an aesthetic map uses (example: left-handed = red, right-handed = blue)\ncoordinate system: describes the system in which the locations of the geoms will be drawn\n\n\n\nIt is essential to organize your data into a data frame before you start with ggplot2 (and all the appropriate metadata so that your data frame is self-describing and your plots will be self-documenting).\nWhen building plots in ggplot2 (rather than using qplot()), the “artist’s palette” model may be the closest analogy.\nEssentially, you start with some raw data, and then you gradually add bits and pieces to it to create a plot.\n\n\n\n\n\n\nNote\n\n\n\nPlots are built up in layers, with the typically ordering being\n\nPlot the data\nOverlay a summary\nAdd metadata and annotation\n\n\n\nFor quick exploratory plots you may not get past step 1."
},
{
- "objectID": "posts/11-plotting-systems/index.html#the-lattice-system",
- "href": "posts/11-plotting-systems/index.html#the-lattice-system",
- "title": "11 - Plotting Systems",
- "section": "The Lattice System",
- "text": "The Lattice System\nThe lattice plotting system is implemented in the lattice R package which comes with every installation of R (although it is not loaded by default).\nTo use the lattice plotting functions, you must first load the lattice package with the library function.\n\nlibrary(lattice)\n\nWith the lattice system, plots are created with a single function call, such as xyplot() or bwplot().\nThere is no real distinction between functions that create or initiate plots and functions that annotate plots because it all happens at once.\nLattice plots tend to be most useful for conditioning types of plots, i.e. looking at how y changes with x across levels of z.\n\ne.g. these types of plots are useful for looking at multi-dimensional data and often allow you to squeeze a lot of information into a single window or page.\n\nAnother aspect of lattice that makes it different from base plotting is that things like margins and spacing are set automatically.\nThis is possible because entire plot is specified at once via a single function call, so all of the available information needed to figure out the spacing and margins is already there.\n\n\n\n\n\n\nExample\n\n\n\nHere is a lattice plot that looks at the relationship between life expectancy and income and how that relationship varies by region in the United States.\n\nstate <- data.frame(state.x77, region = state.region)\nxyplot(Life.Exp ~ Income | region, data = state, layout = c(4, 1))\n\n\n\n\nLattice plot\n\n\n\n\n\n\nYou can see that the entire plot was generated by the call to xyplot() and all of the data for the plot were stored in the state data frame.\nThe plot itself contains four panels—one for each region—and within each panel is a scatterplot of life expectancy and income.\nThe notion of panels comes up a lot with lattice plots because you typically have many panels in a lattice plot (each panel typically represents a condition, like “region”).\n\n\n\n\n\n\nNote\n\n\n\nDownsides with the lattice system\n\nIt can sometimes be very awkward to specify an entire plot in a single function call (you end up with functions with many many arguments).\nAnnotation in panels in plots is not especially intuitive and can be difficult to explain. In particular, the use of custom panel functions and subscripts can be difficult to wield and requires intense preparation.\nOnce a plot is created, you cannot “add” to the plot (but of course you can just make it again with modifications)."
+ "objectID": "posts/13-ggplot2-plotting-system-part-2/index.html#example-bmi-pm2.5-asthma",
+ "href": "posts/13-ggplot2-plotting-system-part-2/index.html#example-bmi-pm2.5-asthma",
+ "title": "13 - The ggplot2 plotting system: ggplot()",
+ "section": "Example: BMI, PM2.5, Asthma",
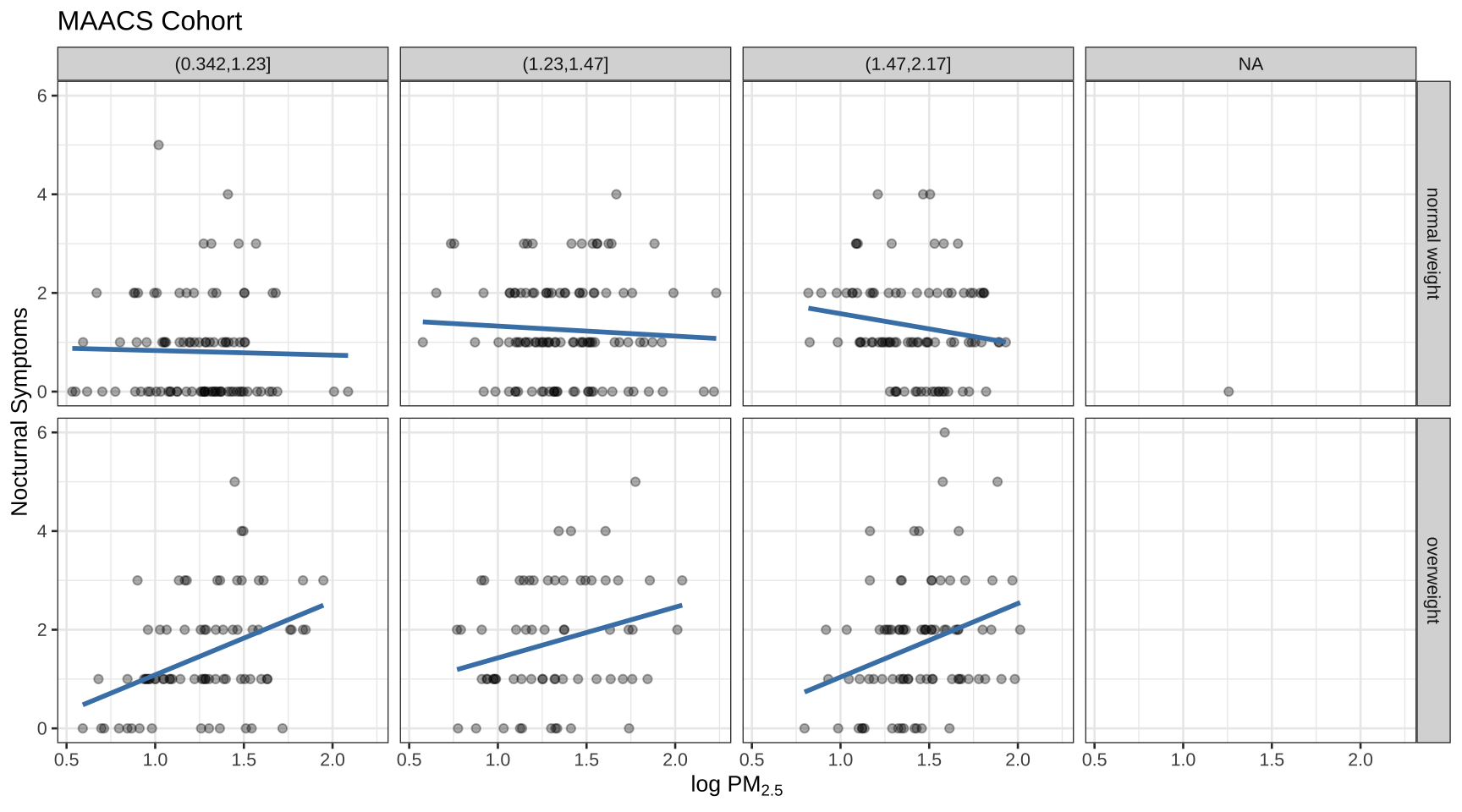
+ "text": "Example: BMI, PM2.5, Asthma\nTo demonstrate the various pieces of ggplot2 we will use a running example from the Mouse Allergen and Asthma Cohort Study (MAACS). Here, the question we are interested in is\n\n“Are overweight individuals, as measured by body mass index (BMI), more susceptible than normal weight individuals to the harmful effects of PM2.5 on asthma symptoms?”\n\nThere is a suggestion that overweight individuals may be more susceptible to the negative effects of inhaling PM2.5.\nThis would suggest that increases in PM2.5 exposure in the home of an overweight child would be more deleterious to his/her asthma symptoms than they would be in the home of a normal weight child.\nWe want to see if we can see that difference in the data from MAACS.\n\n\n\n\n\n\nNote\n\n\n\nBecause the individual-level data for this study are protected by various U.S. privacy laws, we cannot make those data available.\nFor the purposes of this lesson, we have simulated data that share many of the same features of the original data, but do not contain any of the actual measurements or values contained in the original dataset.\n\n\n\n\n\n\n\n\nExample\n\n\n\nWe can look at the data quickly by reading it in as a tibble with read_csv() in the tidyverse package.\n\nlibrary(\"tidyverse\")\nlibrary(\"here\")\nmaacs <- read_csv(here(\"data\", \"bmi_pm25_no2_sim.csv\"),\n col_types = \"nnci\"\n)\nmaacs\n\n# A tibble: 517 × 4\n logpm25 logno2_new bmicat NocturnalSympt\n <dbl> <dbl> <chr> <int>\n 1 1.25 1.18 normal weight 1\n 2 1.12 1.55 overweight 0\n 3 1.93 1.43 normal weight 0\n 4 1.37 1.77 overweight 2\n 5 0.775 0.765 normal weight 0\n 6 1.49 1.11 normal weight 0\n 7 2.16 1.43 normal weight 0\n 8 1.65 1.40 normal weight 0\n 9 1.55 1.81 normal weight 0\n10 2.04 1.35 overweight 3\n# ℹ 507 more rows\n\n\n\n\nThe outcome we will look at here (NocturnalSymp) is the number of days in the past 2 weeks where the child experienced asthma symptoms (e.g. coughing, wheezing) while sleeping.\nThe other key variables are:\n\nlogpm25: average level of PM2.5 over the course of 7 days (micrograms per cubic meter) on the log scale\nlogno2_new: exhaled nitric oxide on the log scale\nbmicat: categorical variable with BMI status"
},
{
- "objectID": "posts/11-plotting-systems/index.html#the-ggplot2-system",
- "href": "posts/11-plotting-systems/index.html#the-ggplot2-system",
- "title": "11 - Plotting Systems",
- "section": "The ggplot2 System",
- "text": "The ggplot2 System\nThe ggplot2 plotting system attempts to split the difference between base and lattice in a number of ways.\n\n\n\n\n\n\nNote\n\n\n\nTaking cues from lattice, the ggplot2 system automatically deals with spacings, text, titles but also allows you to annotate by “adding” to a plot.\n\n\nThe ggplot2 system is implemented in the ggplot2 package (part of the tidyverse package), which is available from CRAN (it does not come with R).\nYou can install it from CRAN via\n\ninstall.packages(\"ggplot2\")\n\nand then load it into R via the library() function.\n\nlibrary(ggplot2)\n\nSuperficially, the ggplot2 functions are similar to lattice, but the system is generally easier and more intuitive to use.\nThe defaults used in ggplot2 make many choices for you, but you can still customize plots to your heart’s desire.\n\n\n\n\n\n\nExample\n\n\n\nA typical plot with the ggplot2 package looks as follows.\n\nlibrary(tidyverse)\ndata(mpg)\nmpg %>%\n ggplot(aes(displ, hwy)) +\n geom_point()\n\n\n\n\nggplot2 plot\n\n\n\n\n\n\nThere are additional functions in ggplot2 that allow you to make arbitrarily sophisticated plots.\nWe will discuss more about this in the next lecture."
+ "objectID": "posts/13-ggplot2-plotting-system-part-2/index.html#first-plot-with-point-layer",
+ "href": "posts/13-ggplot2-plotting-system-part-2/index.html#first-plot-with-point-layer",
+ "title": "13 - The ggplot2 plotting system: ggplot()",
+ "section": "First plot with point layer",
+ "text": "First plot with point layer\nTo make a scatter plot, we need add at least one geom, such as points.\nHere, we add the geom_point() function to create a traditional scatter plot.\n\ng <- maacs %>%\n ggplot(aes(logpm25, NocturnalSympt))\ng + geom_point()\n\n\n\n\nScatterplot of PM2.5 and days with nocturnal symptoms\n\n\n\n\nHow does ggplot know what points to plot? In this case, it can grab them from the data frame maacs that served as the input into the ggplot() function."
},
{
- "objectID": "posts/05-literate-programming/index.html",
- "href": "posts/05-literate-programming/index.html",
- "title": "05 - Literate Statistical Programming",
- "section": "",
- "text": "This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history."
+ "objectID": "posts/13-ggplot2-plotting-system-part-2/index.html#adding-more-layers",
+ "href": "posts/13-ggplot2-plotting-system-part-2/index.html#adding-more-layers",
+ "title": "13 - The ggplot2 plotting system: ggplot()",
+ "section": "Adding more layers",
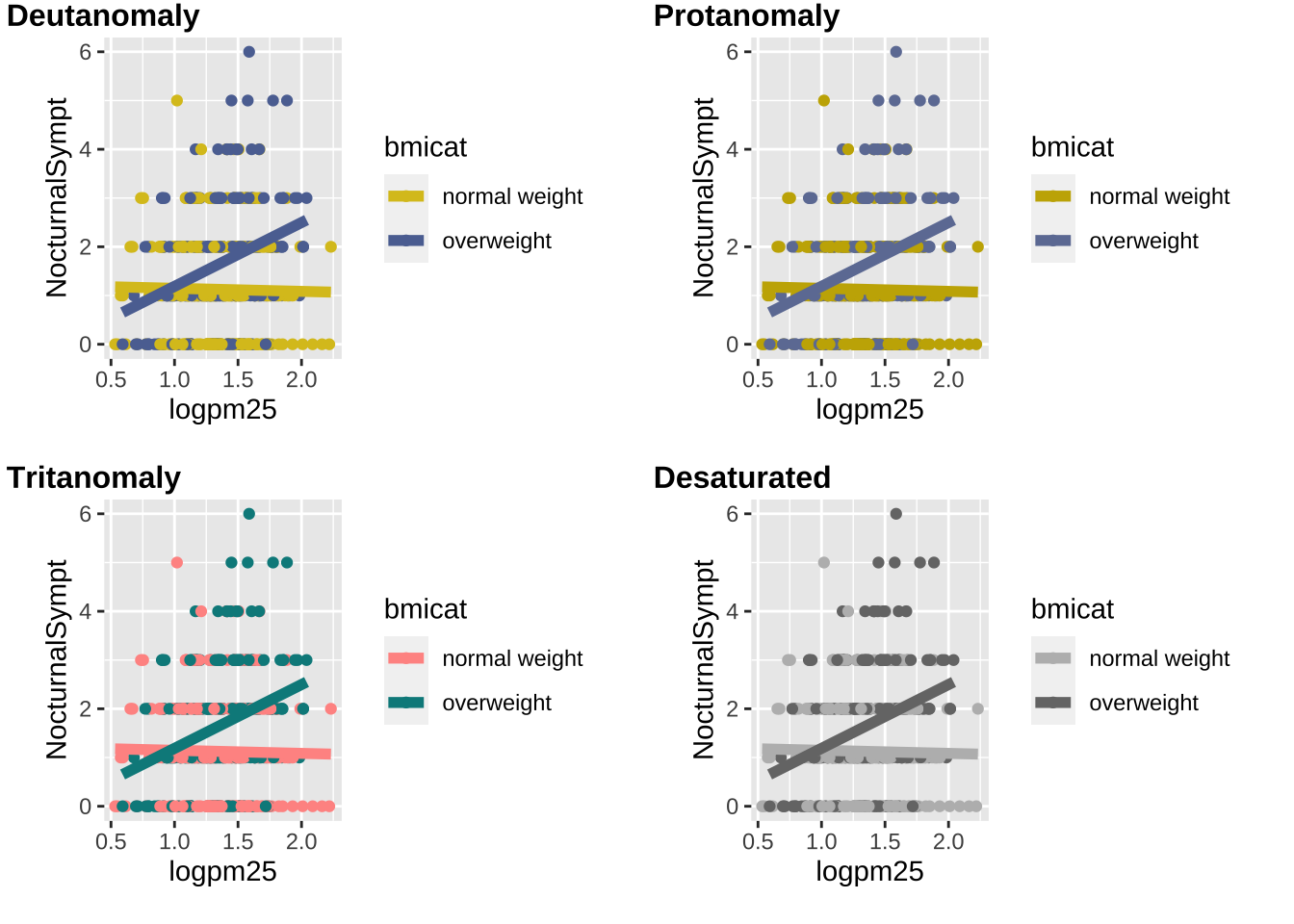
+ "text": "Adding more layers\n\nsmooth\nBecause the data appear rather noisy, it might be better if we added a smoother on top of the points to see if there is a trend in the data with PM2.5.\n\ng +\n geom_point() +\n geom_smooth()\n\n\n\n\nScatterplot with smoother\n\n\n\n\nThe default smoother is a loess smoother, which is flexible and nonparametric but might be too flexible for our purposes. Perhaps we’d prefer a simple linear regression line to highlight any first order trends. We can do this by specifying method = \"lm\" to geom_smooth().\n\ng +\n geom_point() +\n geom_smooth(method = \"lm\")\n\n\n\n\nScatterplot with linear regression line\n\n\n\n\nHere, we can see there appears to be a slight increasing trend, suggesting that higher levels of PM2.5 are associated with increased days with nocturnal symptoms.\n\n\n\n\n\n\nQuestion\n\n\n\nLet’s use the ggplot() function with our palmerpenguins dataset example and make a scatter plot with flipper_length_mm on the x-axis, bill_length_mm on the y-axis, colored by species, and a smoother by adding a linear regression.\n\n# try it yourself\n\nlibrary(\"palmerpenguins\")\npenguins\n\n# A tibble: 344 × 8\n species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g\n <fct> <fct> <dbl> <dbl> <int> <int>\n 1 Adelie Torgersen 39.1 18.7 181 3750\n 2 Adelie Torgersen 39.5 17.4 186 3800\n 3 Adelie Torgersen 40.3 18 195 3250\n 4 Adelie Torgersen NA NA NA NA\n 5 Adelie Torgersen 36.7 19.3 193 3450\n 6 Adelie Torgersen 39.3 20.6 190 3650\n 7 Adelie Torgersen 38.9 17.8 181 3625\n 8 Adelie Torgersen 39.2 19.6 195 4675\n 9 Adelie Torgersen 34.1 18.1 193 3475\n10 Adelie Torgersen 42 20.2 190 4250\n# ℹ 334 more rows\n# ℹ 2 more variables: sex <fct>, year <int>\n\n\n\n\n\n\nfacets\nBecause our primary question involves comparing overweight individuals to normal weight individuals, we can stratify the scatter plot of PM2.5 and nocturnal symptoms by the BMI category (bmicat) variable, which indicates whether an individual is overweight or not.\nTo visualize this we can add a facet_grid(), which takes a formula argument.\n\n\n\n\n\n\nExample\n\n\n\nWe want one row and two columns, one column for each weight category. So we specify bmicat on the right hand side of the forumla passed to facet_grid().\n\ng +\n geom_point() +\n geom_smooth(method = \"lm\") +\n facet_grid(. ~ bmicat)\n\n\n\n\nScatterplot of PM2.5 and nocturnal symptoms by BMI category\n\n\n\n\n\n\nNow it seems clear that the relationship between PM2.5 and nocturnal symptoms is relatively flat among normal weight individuals, while the relationship is increasing among overweight individuals.\nThis plot suggests that overweight individuals may be more susceptible to the effects of PM2.5."
},
{
- "objectID": "posts/05-literate-programming/index.html#footnotes",
- "href": "posts/05-literate-programming/index.html#footnotes",
- "title": "05 - Literate Statistical Programming",
- "section": "Footnotes",
- "text": "Footnotes\n\n\nThis will become a hover-able footnote↩︎"
+ "objectID": "posts/13-ggplot2-plotting-system-part-2/index.html#customizing-the-smooth",
+ "href": "posts/13-ggplot2-plotting-system-part-2/index.html#customizing-the-smooth",
+ "title": "13 - The ggplot2 plotting system: ggplot()",
+ "section": "Customizing the smooth",
+ "text": "Customizing the smooth\nWe can also customize aspects of the geoms.\nFor example, we can customize the smoother that we overlay on the points with geom_smooth().\nHere we change the line type and increase the size from the default. We also remove the shaded standard error from the line.\n\ng +\n geom_point(aes(color = bmicat),\n size = 2,\n alpha = 1 / 2\n ) +\n geom_smooth(\n linewidth = 4,\n linetype = 3,\n method = \"lm\",\n se = FALSE\n )\n\n\n\n\nCustomizing a smoother"
},
{
- "objectID": "posts/07-reading-and-writing-data/index.html",
- "href": "posts/07-reading-and-writing-data/index.html",
- "title": "07 - Reading and Writing data",
- "section": "",
- "text": "This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history.\n[Source]"
+ "objectID": "posts/13-ggplot2-plotting-system-part-2/index.html#changing-the-theme",
+ "href": "posts/13-ggplot2-plotting-system-part-2/index.html#changing-the-theme",
+ "title": "13 - The ggplot2 plotting system: ggplot()",
+ "section": "Changing the theme",
+ "text": "Changing the theme\nThe default theme for ggplot2 uses the gray background with white grid lines.\nIf you don’t find this suitable, you can use the black and white theme by using the theme_bw() function.\nThe theme_bw() function also allows you to set the typeface for the plot, in case you don’t want the default Helvetica. Here we change the typeface to Times.\n\n\n\n\n\n\nNote\n\n\n\nFor things that only make sense globally, use theme(), i.e. theme(legend.position = \"none\"). Two standard appearance themes are included\n\ntheme_gray(): The default theme (gray background)\ntheme_bw(): More stark/plain\n\n\n\n\ng +\n geom_point(aes(color = bmicat)) +\n theme_bw(base_family = \"Times\")\n\n\n\n\nModifying the theme for a plot\n\n\n\n\n\n\n\n\n\n\nQuestion\n\n\n\nLet’s take our palmerpenguins scatterplot from above and change out the theme to use theme_dark().\n\n# try it yourself\n\nlibrary(\"palmerpenguins\")\npenguins\n\n# A tibble: 344 × 8\n species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g\n <fct> <fct> <dbl> <dbl> <int> <int>\n 1 Adelie Torgersen 39.1 18.7 181 3750\n 2 Adelie Torgersen 39.5 17.4 186 3800\n 3 Adelie Torgersen 40.3 18 195 3250\n 4 Adelie Torgersen NA NA NA NA\n 5 Adelie Torgersen 36.7 19.3 193 3450\n 6 Adelie Torgersen 39.3 20.6 190 3650\n 7 Adelie Torgersen 38.9 17.8 181 3625\n 8 Adelie Torgersen 39.2 19.6 195 4675\n 9 Adelie Torgersen 34.1 18.1 193 3475\n10 Adelie Torgersen 42 20.2 190 4250\n# ℹ 334 more rows\n# ℹ 2 more variables: sex <fct>, year <int>"
},
{
- "objectID": "posts/07-reading-and-writing-data/index.html#txt-or-csv",
- "href": "posts/07-reading-and-writing-data/index.html#txt-or-csv",
- "title": "07 - Reading and Writing data",
- "section": "txt or csv",
- "text": "txt or csv\nThere are a few primary functions reading data from base R.\n\nread.table(), read.csv(): for reading tabular data\nreadLines(): for reading lines of a text file\n\nThere are analogous functions for writing data to files\n\nwrite.table(): for writing tabular data to text files (i.e. CSV) or connections\nwriteLines(): for writing character data line-by-line to a file or connection\n\nLet’s try reading some data into R with the read.csv() function.\n\ndf <- read.csv(here(\"data\", \"team_standings.csv\"))\ndf\n\n Standing Team\n1 1 Spain\n2 2 Netherlands\n3 3 Germany\n4 4 Uruguay\n5 5 Argentina\n6 6 Brazil\n7 7 Ghana\n8 8 Paraguay\n9 9 Japan\n10 10 Chile\n11 11 Portugal\n12 12 USA\n13 13 England\n14 14 Mexico\n15 15 South Korea\n16 16 Slovakia\n17 17 Ivory Coast\n18 18 Slovenia\n19 19 Switzerland\n20 20 South Africa\n21 21 Australia\n22 22 New Zealand\n23 23 Serbia\n24 24 Denmark\n25 25 Greece\n26 26 Italy\n27 27 Nigeria\n28 28 Algeria\n29 29 France\n30 30 Honduras\n31 31 Cameroon\n32 32 North Korea\n\n\nWe can use the $ symbol to pick out a specific column:\n\ndf$Team\n\n [1] \"Spain\" \"Netherlands\" \"Germany\" \"Uruguay\" \"Argentina\" \n [6] \"Brazil\" \"Ghana\" \"Paraguay\" \"Japan\" \"Chile\" \n[11] \"Portugal\" \"USA\" \"England\" \"Mexico\" \"South Korea\" \n[16] \"Slovakia\" \"Ivory Coast\" \"Slovenia\" \"Switzerland\" \"South Africa\"\n[21] \"Australia\" \"New Zealand\" \"Serbia\" \"Denmark\" \"Greece\" \n[26] \"Italy\" \"Nigeria\" \"Algeria\" \"France\" \"Honduras\" \n[31] \"Cameroon\" \"North Korea\" \n\n\nWe can also ask for the full paths for specific files\n\nhere(\"data\", \"team_standings.csv\")\n\n[1] \"/Users/leocollado/Dropbox/Code/jhustatcomputing2023/data/team_standings.csv\"\n\n\n\n\n\n\n\n\nQuestions\n\n\n\n\nWhat happens when you use readLines() function with the team_standings.csv data?\nHow would you only read in the first 5 lines?"
+ "objectID": "posts/13-ggplot2-plotting-system-part-2/index.html#modifying-labels",
+ "href": "posts/13-ggplot2-plotting-system-part-2/index.html#modifying-labels",
+ "title": "13 - The ggplot2 plotting system: ggplot()",
+ "section": "Modifying labels",
+ "text": "Modifying labels\n\n\n\n\n\n\nNote\n\n\n\nThere are a variety of annotations you can add to a plot, including different kinds of labels.\n\nxlab() for x-axis labels\nylab() for y-axis labels\nggtitle() for specifying plot titles\n\nlabs() function is generic and can be used to modify multiple types of labels at once\n\n\nHere is an example of modifying the title and the x and y labels to make the plot a bit more informative.\n\ng +\n geom_point(aes(color = bmicat)) +\n labs(title = \"MAACS Cohort\") +\n labs(\n x = expression(\"log \" * PM[2.5]),\n y = \"Nocturnal Symptoms\"\n )\n\n\n\n\nModifying plot labels"
},
{
- "objectID": "posts/07-reading-and-writing-data/index.html#r-code",
- "href": "posts/07-reading-and-writing-data/index.html#r-code",
- "title": "07 - Reading and Writing data",
- "section": "R code",
- "text": "R code\nSometimes, someone will give you a file that ends in a .R.\nThis is what’s called an R script file. It may contain code someone has written (maybe even you!), for example, a function that you can use with your data. In this case, you want the function available for you to use.\nTo use the function, you have to first, read in the function from R script file into R.\nYou can check to see if the function already is loaded in R by looking at the Environment tab.\nThe function you want to use is\n\nsource(): for reading in R code files\n\nFor example, it might be something like this:\n\nsource(here::here(\"functions.R\"))"
+ "objectID": "posts/13-ggplot2-plotting-system-part-2/index.html#a-quick-aside-about-axis-limits",
+ "href": "posts/13-ggplot2-plotting-system-part-2/index.html#a-quick-aside-about-axis-limits",
+ "title": "13 - The ggplot2 plotting system: ggplot()",
+ "section": "A quick aside about axis limits",
+ "text": "A quick aside about axis limits\nOne quick quirk about ggplot2 that caught me up when I first started using the package can be displayed in the following example.\nIf you make a lot of time series plots, you often want to restrict the range of the y-axis while still plotting all the data.\nIn the base graphics system you can do that as follows.\n\ntestdat <- data.frame(\n x = 1:100,\n y = rnorm(100)\n)\ntestdat[50, 2] <- 100 ## Outlier!\nplot(testdat$x,\n testdat$y,\n type = \"l\",\n ylim = c(-3, 3)\n)\n\n\n\n\nTime series plot with base graphics\n\n\n\n\nHere, we have restricted the y-axis range to be between -3 and 3, even though there is a clear outlier in the data.\n\n\n\n\n\n\nExample\n\n\n\nWith ggplot2 the default settings will give you this.\n\ng <- ggplot(testdat, aes(x = x, y = y))\ng + geom_line()\n\n\n\n\nTime series plot with default settings\n\n\n\n\nOne might think that modifying the ylim() attribute would give you the same thing as the base plot, but it doesn’t (?????)\n\ng +\n geom_line() +\n ylim(-3, 3)\n\n\n\n\nTime series plot with modified ylim\n\n\n\n\n\n\nEffectively, what this does is subset the data so that only observations between -3 and 3 are included, then plot the data.\nTo plot the data without subsetting it first and still get the restricted range, you have to do the following.\n\ng +\n geom_line() +\n coord_cartesian(ylim = c(-3, 3))\n\n\n\n\nTime series plot with restricted y-axis range\n\n\n\n\nAnd now you know!"
},
{
- "objectID": "posts/07-reading-and-writing-data/index.html#r-objects",
- "href": "posts/07-reading-and-writing-data/index.html#r-objects",
- "title": "07 - Reading and Writing data",
- "section": "R objects",
- "text": "R objects\nAlternatively, you might be interested in reading and writing R objects.\nWriting data in e.g. .txt, .csv or Excel file formats is good if you want to open these files with other analysis software, such as Excel. However, these formats do not preserve data structures, such as column data types (numeric, character or factor). In order to do that, the data should be written out in a R data format.\nThere are several types R data file formats to be aware of:\n\n.RData: Stores multiple R objects\n.Rda: This is short for .RData and is equivalent.\n.Rds: Stores a single R object\n\n\n\n\n\n\n\nQuestion\n\n\n\nWhy is saving data in as a R object useful?\nSaving data into R data formats can typically reduce considerably the size of large files by compression.\n\n\nNext, we will learn how to read and save\n\nA single R object\nMultiple R objects\nYour entire work space in a specified file\n\n\nReading in data from files\n\nload(): for reading in single or multiple R objects (opposite of save()) with a .Rda or .RData file format (objects must be same name)\nreadRDS(): for reading in a single object with a .Rds file format (can rename objects)\nunserialize(): for reading single R objects in binary form\n\n\n\nWriting data to files\n\nsave(): for saving an arbitrary number of R objects in binary format (possibly compressed) to a file.\nsaveRDS(): for saving a single object\nserialize(): for converting an R object into a binary format for outputting to a connection (or file).\nsave.image(): short for ‘save my current workspace’; while this sounds nice, it’s not terribly useful for reproducibility (hence not suggested); it’s also what happens when you try to quit R and it asks if you want to save your work space.\n\n\n\n\n\n\nSave data into R data file formats: RDS and RDATA\n\n\n\n\n[Source]\n\n\nExample\nLet’s try an example. Let’s save a vector of length 5 into the two file formats.\n\nx <- 1:5\nsave(x, file = here(\"data\", \"x.Rda\"))\nsaveRDS(x, file = here(\"data\", \"x.Rds\"))\nlist.files(path = here(\"data\"))\n\n [1] \"2016-07-19.csv.bz2\" \"b_lyrics.RDS\" \n [3] \"bmi_pm25_no2_sim.csv\" \"chicago.rds\" \n [5] \"chocolate.RDS\" \"flights.csv\" \n [7] \"maacs_sim.csv\" \"sales.RDS\" \n [9] \"storms_2004.csv.gz\" \"team_standings.csv\" \n[11] \"ts_lyrics.RDS\" \"tuesdata_rainfall.RDS\" \n[13] \"tuesdata_temperature.RDS\" \"x.Rda\" \n[15] \"x.Rds\" \n\n\nHere we assign the imported data to an object using readRDS()\n\nnew_x1 <- readRDS(here(\"data\", \"x.Rds\"))\nnew_x1\n\n[1] 1 2 3 4 5\n\n\nHere we assign the imported data to an object using load()\n\nnew_x2 <- load(here(\"data\", \"x.Rda\"))\nnew_x2\n\n[1] \"x\"\n\n\n\n\n\n\n\n\nNote\n\n\n\nload() simply returns the name of the objects loaded. Not the values.\n\n\nLet’s clean up our space.\n\nfile.remove(here(\"data\", \"x.Rda\"))\n\n[1] TRUE\n\nfile.remove(here(\"data\", \"x.Rds\"))\n\n[1] TRUE\n\nrm(x)\n\n\n\n\n\n\n\nQuestion\n\n\n\nWhat do you think this code will do?\nHint: change eval=TRUE to see result\n\nx <- 1:5\ny <- x^2\nsave(x, y, file = here(\"data\", \"x.Rda\"))\nnew_x2 <- load(here(\"data\", \"x.Rda\"))\n\nWhen you are done:\n\nfile.remove(here(\"data\", \"x.Rda\"))"
+ "objectID": "posts/10-joining-data-in-r/index.html",
+ "href": "posts/10-joining-data-in-r/index.html",
+ "title": "10 - Joining data in R",
+ "section": "",
+ "text": "This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history."
},
{
- "objectID": "posts/07-reading-and-writing-data/index.html#other-data-types",
- "href": "posts/07-reading-and-writing-data/index.html#other-data-types",
- "title": "07 - Reading and Writing data",
- "section": "Other data types",
- "text": "Other data types\nNow, there are of course, many R packages that have been developed to read in all kinds of other datasets, and you may need to resort to one of these packages if you are working in a specific area.\nFor example, check out\n\nDBI for relational databases\nhaven for SPSS, Stata, and SAS data\nhttr for web APIs\nreadxl for .xls and .xlsx sheets\ngooglesheets4 for Google Sheets\ngoogledrive for Google Drive files\nrvest for web scraping\njsonlite for JSON\nxml2 for XML."
+ "objectID": "posts/10-joining-data-in-r/index.html#keys",
+ "href": "posts/10-joining-data-in-r/index.html#keys",
+ "title": "10 - Joining data in R",
+ "section": "Keys",
+ "text": "Keys\nThe variables used to connect each pair of tables are called keys. A key is a variable (or set of variables) that uniquely identifies an observation. In simple cases, a single variable is sufficient to identify an observation.\n\n\n\n\n\n\nNote\n\n\n\nThere are two types of keys:\n\nA primary key uniquely identifies an observation in its own table.\nA foreign key uniquely identifies an observation in another table.\n\n\n\nLet’s consider an example to help us understand the difference between a primary key and foreign key."
},
{
- "objectID": "posts/07-reading-and-writing-data/index.html#reading-data-files-with-read.table",
- "href": "posts/07-reading-and-writing-data/index.html#reading-data-files-with-read.table",
- "title": "07 - Reading and Writing data",
- "section": "Reading data files with read.table()",
- "text": "Reading data files with read.table()\n\n\nFor details on reading data with read.table(), click here.\n\nThe read.table() function is one of the most commonly used functions for reading data. The help file for read.table() is worth reading in its entirety if only because the function gets used a lot (run ?read.table in R).\nI know, I know, everyone always says to read the help file, but this one is actually worth reading.\nThe read.table() function has a few important arguments:\n\nfile, the name of a file, or a connection\nheader, logical indicating if the file has a header line\nsep, a string indicating how the columns are separated\ncolClasses, a character vector indicating the class of each column in the dataset\nnrows, the number of rows in the dataset. By default read.table() reads an entire file.\ncomment.char, a character string indicating the comment character. This defaults to \"#\". If there are no commented lines in your file, it’s worth setting this to be the empty string \"\".\nskip, the number of lines to skip from the beginning\nstringsAsFactors, should character variables be coded as factors? This defaults to FALSE. However, back in the “old days”, it defaulted to TRUE. The reason for this was because, if you had data that were stored as strings, it was because those strings represented levels of a categorical variable. Now, we have lots of data that is text data and they do not always represent categorical variables. So you may want to set this to be FALSE in those cases. If you always want this to be FALSE, you can set a global option via options(stringsAsFactors = FALSE).\n\nI’ve never seen so much heat generated on discussion forums about an R function argument than the stringsAsFactors argument. Seriously.\nFor small to moderately sized datasets, you can usually call read.table() without specifying any other arguments\n\ndata <- read.table(\"foo.txt\")\n\n\n\n\n\n\n\nNote\n\n\n\nfoo.txt is not a real dataset here. It is only used as an example for how to use read.table()\n\n\nIn this case, R will automatically:\n\nskip lines that begin with a #\nfigure out how many rows there are (and how much memory needs to be allocated)\nfigure what type of variable is in each column of the table.\n\nTelling R all these things directly makes R run faster and more efficiently.\n\n\n\n\n\n\nNote\n\n\n\nThe read.csv() function is identical to read.table() except that some of the defaults are set differently (like the sep argument)."
+ "objectID": "posts/10-joining-data-in-r/index.html#example-of-keys",
+ "href": "posts/10-joining-data-in-r/index.html#example-of-keys",
+ "title": "10 - Joining data in R",
+ "section": "Example of keys",
+ "text": "Example of keys\nImagine you are conduct a study and collecting data on subjects and a health outcome.\nOften, subjects will make multiple visits (a so-called longitudinal study) and so we will record the outcome for each visit. Similarly, we may record other information about them, such as the kind of housing they live in.\n\nThe first table\nThis code creates a simple table with some made up data about some hypothetical subjects’ outcomes.\n\nlibrary(tidyverse)\n\noutcomes <- tibble(\n id = rep(c(\"a\", \"b\", \"c\"), each = 3),\n visit = rep(0:2, 3),\n outcome = rnorm(3 * 3, 3)\n)\n\nprint(outcomes)\n\n# A tibble: 9 × 3\n id visit outcome\n <chr> <int> <dbl>\n1 a 0 3.07\n2 a 1 3.25\n3 a 2 3.93\n4 b 0 2.18\n5 b 1 2.91\n6 b 2 2.83\n7 c 0 1.49\n8 c 1 2.56\n9 c 2 1.46\n\n\nNote that subjects are labeled by a unique identifer in the id column.\n\n\nA second table\nHere is some code to create a second table (we will be joining the first and second tables shortly). This table contains some data about the hypothetical subjects’ housing situation by recording the type of house they live in.\n\nsubjects <- tibble(\n id = c(\"a\", \"b\", \"c\"),\n house = c(\"detached\", \"rowhouse\", \"rowhouse\")\n)\n\nprint(subjects)\n\n# A tibble: 3 × 2\n id house \n <chr> <chr> \n1 a detached\n2 b rowhouse\n3 c rowhouse\n\n\n\n\n\n\n\n\nQuestion\n\n\n\nWhat is the primary key and foreign key?\n\nThe outcomes$id is a primary key because it uniquely identifies each subject in the outcomes table.\nThe subjects$id is a foreign key because it appears in the subjects table where it matches each subject to a unique id."
},
{
- "objectID": "posts/07-reading-and-writing-data/index.html#reading-in-larger-datasets-with-read.table",
- "href": "posts/07-reading-and-writing-data/index.html#reading-in-larger-datasets-with-read.table",
- "title": "07 - Reading and Writing data",
- "section": "Reading in larger datasets with read.table()",
- "text": "Reading in larger datasets with read.table()\n\n\nFor details on reading larger datasets with read.table(), click here.\n\nWith much larger datasets, there are a few things that you can do that will make your life easier and will prevent R from choking.\n\nRead the help page for read.table(), which contains many hints\nMake a rough calculation of the memory required to store your dataset (see the next section for an example of how to do this). If the dataset is larger than the amount of RAM on your computer, you can probably stop right here.\nSet comment.char = \"\" if there are no commented lines in your file.\nUse the colClasses argument. Specifying this option instead of using the default can make read.table() run MUCH faster, often twice as fast. In order to use this option, you have to know the class of each column in your data frame. If all of the columns are “numeric”, for example, then you can just set colClasses = \"numeric\". A quick an dirty way to figure out the classes of each column is the following:\n\n\ninitial <- read.table(\"datatable.txt\", nrows = 100)\nclasses <- sapply(initial, class)\ntabAll <- read.table(\"datatable.txt\", colClasses = classes)\n\nNote: datatable.txt is not a real dataset here. It is only used as an example for how to use read.table().\n\nSet nrows. This does not make R run faster but it helps with memory usage. A mild overestimate is okay. You can use the Unix tool wc to calculate the number of lines in a file.\n\nIn general, when using R with larger datasets, it’s also useful to know a few things about your system.\n\nHow much memory is available on your system?\nWhat other applications are in use? Can you close any of them?\nAre there other users logged into the same system?\nWhat operating system ar you using? Some operating systems can limit the amount of memory a single process can access"
+ "objectID": "posts/10-joining-data-in-r/index.html#left-join",
+ "href": "posts/10-joining-data-in-r/index.html#left-join",
+ "title": "10 - Joining data in R",
+ "section": "Left Join",
+ "text": "Left Join\nRecall the outcomes and subjects datasets above.\n\noutcomes\n\n# A tibble: 9 × 3\n id visit outcome\n <chr> <int> <dbl>\n1 a 0 3.07\n2 a 1 3.25\n3 a 2 3.93\n4 b 0 2.18\n5 b 1 2.91\n6 b 2 2.83\n7 c 0 1.49\n8 c 1 2.56\n9 c 2 1.46\n\nsubjects\n\n# A tibble: 3 × 2\n id house \n <chr> <chr> \n1 a detached\n2 b rowhouse\n3 c rowhouse\n\n\nSuppose we want to create a table that combines the information about houses (subjects) with the information about the outcomes (outcomes).\nWe can use the left_join() function to merge the outcomes and subjects tables and produce the output above.\n\nleft_join(x = outcomes, y = subjects, by = \"id\")\n\n# A tibble: 9 × 4\n id visit outcome house \n <chr> <int> <dbl> <chr> \n1 a 0 3.07 detached\n2 a 1 3.25 detached\n3 a 2 3.93 detached\n4 b 0 2.18 rowhouse\n5 b 1 2.91 rowhouse\n6 b 2 2.83 rowhouse\n7 c 0 1.49 rowhouse\n8 c 1 2.56 rowhouse\n9 c 2 1.46 rowhouse\n\n\n\n\n\n\n\n\nNote\n\n\n\nThe by argument indicates the column (or columns) that the two tables have in common.\n\n\n\nLeft Join with Incomplete Data\nIn the previous examples, the subjects table didn’t have a visit column. But suppose it did? Maybe people move around during the study. We could image a table like this one.\n\nsubjects <- tibble(\n id = c(\"a\", \"b\", \"c\"),\n visit = c(0, 1, 0),\n house = c(\"detached\", \"rowhouse\", \"rowhouse\"),\n)\n\nprint(subjects)\n\n# A tibble: 3 × 3\n id visit house \n <chr> <dbl> <chr> \n1 a 0 detached\n2 b 1 rowhouse\n3 c 0 rowhouse\n\n\nWhen we left joint the tables now we get:\n\nleft_join(outcomes, subjects, by = c(\"id\", \"visit\"))\n\n# A tibble: 9 × 4\n id visit outcome house \n <chr> <dbl> <dbl> <chr> \n1 a 0 3.07 detached\n2 a 1 3.25 <NA> \n3 a 2 3.93 <NA> \n4 b 0 2.18 <NA> \n5 b 1 2.91 rowhouse\n6 b 2 2.83 <NA> \n7 c 0 1.49 rowhouse\n8 c 1 2.56 <NA> \n9 c 2 1.46 <NA> \n\n\n\n\n\n\n\n\nNote\n\n\n\nTwo things to point out here:\n\nIf we do not have information about a subject’s housing in a given visit, the left_join() function automatically inserts an NA value to indicate that it is missing.\nWe can “join” on multiple variable (e.g. here we joined on the id and the visit columns).\n\n\n\nWe may even have a situation where we are missing housing data for a subject completely. The following table has no information about subject a.\n\nsubjects <- tibble(\n id = c(\"b\", \"c\"),\n visit = c(1, 0),\n house = c(\"rowhouse\", \"rowhouse\"),\n)\n\nsubjects\n\n# A tibble: 2 × 3\n id visit house \n <chr> <dbl> <chr> \n1 b 1 rowhouse\n2 c 0 rowhouse\n\n\nBut we can still join the tables together and the house values for subject a will all be NA.\n\nleft_join(x = outcomes, y = subjects, by = c(\"id\", \"visit\"))\n\n# A tibble: 9 × 4\n id visit outcome house \n <chr> <dbl> <dbl> <chr> \n1 a 0 3.07 <NA> \n2 a 1 3.25 <NA> \n3 a 2 3.93 <NA> \n4 b 0 2.18 <NA> \n5 b 1 2.91 rowhouse\n6 b 2 2.83 <NA> \n7 c 0 1.49 rowhouse\n8 c 1 2.56 <NA> \n9 c 2 1.46 <NA> \n\n\n\n\n\n\n\n\nImportant\n\n\n\nThe bottom line for left_join() is that it always retains the values in the “left” argument (in this case the outcomes table).\n\nIf there are no corresponding values in the “right” argument, NA values will be filled in."
},
{
- "objectID": "posts/07-reading-and-writing-data/index.html#advantages",
- "href": "posts/07-reading-and-writing-data/index.html#advantages",
- "title": "07 - Reading and Writing data",
- "section": "Advantages",
- "text": "Advantages\nThe advantage of the read_csv() function is perhaps better understood from an historical perspective.\n\nR’s built in read.csv() function similarly reads CSV files, but the read_csv() function in readr builds on that by removing some of the quirks and “gotchas” of read.csv() as well as dramatically optimizing the speed with which it can read data into R.\nThe read_csv() function also adds some nice user-oriented features like a progress meter and a compact method for specifying column types."
+ "objectID": "posts/10-joining-data-in-r/index.html#inner-join",
+ "href": "posts/10-joining-data-in-r/index.html#inner-join",
+ "title": "10 - Joining data in R",
+ "section": "Inner Join",
+ "text": "Inner Join\nThe inner_join() function only retains the rows of both tables that have corresponding values. Here we can see the difference.\n\ninner_join(x = outcomes, y = subjects, by = c(\"id\", \"visit\"))\n\n# A tibble: 2 × 4\n id visit outcome house \n <chr> <dbl> <dbl> <chr> \n1 b 1 2.91 rowhouse\n2 c 0 1.49 rowhouse"
},
{
- "objectID": "posts/07-reading-and-writing-data/index.html#example-1",
- "href": "posts/07-reading-and-writing-data/index.html#example-1",
- "title": "07 - Reading and Writing data",
- "section": "Example",
- "text": "Example\nA typical call to read_csv() will look as follows.\n\nlibrary(readr)\nteams <- read_csv(here(\"data\", \"team_standings.csv\"))\n\nRows: 32 Columns: 2\n── Column specification ────────────────────────────────────────────────────────\nDelimiter: \",\"\nchr (1): Team\ndbl (1): Standing\n\nℹ Use `spec()` to retrieve the full column specification for this data.\nℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.\n\nteams\n\n# A tibble: 32 × 2\n Standing Team \n <dbl> <chr> \n 1 1 Spain \n 2 2 Netherlands\n 3 3 Germany \n 4 4 Uruguay \n 5 5 Argentina \n 6 6 Brazil \n 7 7 Ghana \n 8 8 Paraguay \n 9 9 Japan \n10 10 Chile \n# ℹ 22 more rows\n\n\nBy default, read_csv() will open a CSV file and read it in line-by-line. Similar to read.table(), you can tell the function to skip lines or which lines are comments:\n\nread_csv(\"The first line of metadata\n The second line of metadata\n x,y,z\n 1,2,3\",\n skip = 2\n)\n\nRows: 1 Columns: 3\n── Column specification ────────────────────────────────────────────────────────\nDelimiter: \",\"\ndbl (3): x, y, z\n\nℹ Use `spec()` to retrieve the full column specification for this data.\nℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.\n\n\n# A tibble: 1 × 3\n x y z\n <dbl> <dbl> <dbl>\n1 1 2 3\n\n\nAlternatively, you can use the comment argument:\n\nread_csv(\"# A comment I want to skip\n x,y,z\n 1,2,3\",\n comment = \"#\"\n)\n\nRows: 1 Columns: 3\n── Column specification ────────────────────────────────────────────────────────\nDelimiter: \",\"\ndbl (3): x, y, z\n\nℹ Use `spec()` to retrieve the full column specification for this data.\nℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.\n\n\n# A tibble: 1 × 3\n x y z\n <dbl> <dbl> <dbl>\n1 1 2 3\n\n\nIt will also (by default), read in the first few rows of the table in order to figure out the type of each column (i.e. integer, character, etc.). From the read_csv() help page:\n\nIf ‘NULL’, all column types will be imputed from the first 1000 rows on the input. This is convenient (and fast), but not robust. If the imputation fails, you’ll need to supply the correct types yourself.\n\nYou can specify the type of each column with the col_types argument.\n\n\n\n\n\n\nNote\n\n\n\nIn general, it is a good idea to specify the column types explicitly.\nThis rules out any possible guessing errors on the part of read_csv().\nAlso, specifying the column types explicitly provides a useful safety check in case anything about the dataset should change without you knowing about it.\n\n\nHere is an example of how to specify the column types explicitly:\n\nteams <- read_csv(here(\"data\", \"team_standings.csv\"),\n col_types = \"cc\"\n)\n\nNote that the col_types argument accepts a compact representation. Here \"cc\" indicates that the first column is character and the second column is character (there are only two columns). Using the col_types argument is useful because often it is not easy to automatically figure out the type of a column by looking at a few rows (especially if a column has many missing values).\n\n\n\n\n\n\nNote\n\n\n\nThe read_csv() function will also read compressed files automatically.\nThere is no need to decompress the file first or use the gzfile connection function.\n\n\nThe following call reads a gzip-compressed CSV file containing download logs from the RStudio CRAN mirror.\n\nlogs <- read_csv(here(\"data\", \"2016-07-19.csv.bz2\"),\n n_max = 10\n)\n\nRows: 10 Columns: 10\n── Column specification ────────────────────────────────────────────────────────\nDelimiter: \",\"\nchr (6): r_version, r_arch, r_os, package, version, country\ndbl (2): size, ip_id\ndate (1): date\ntime (1): time\n\nℹ Use `spec()` to retrieve the full column specification for this data.\nℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.\n\n\nNote that the warnings indicate that read_csv() may have had some difficulty identifying the type of each column. This can be solved by using the col_types argument.\n\nlogs <- read_csv(here(\"data\", \"2016-07-19.csv.bz2\"),\n col_types = \"ccicccccci\",\n n_max = 10\n)\nlogs\n\n# A tibble: 10 × 10\n date time size r_version r_arch r_os package version country ip_id\n <chr> <chr> <int> <chr> <chr> <chr> <chr> <chr> <chr> <int>\n 1 2016-07-19 22:00… 1.89e6 3.3.0 x86_64 ming… data.t… 1.9.6 US 1\n 2 2016-07-19 22:00… 4.54e4 3.3.1 x86_64 ming… assert… 0.1 US 2\n 3 2016-07-19 22:00… 1.43e7 3.3.1 x86_64 ming… stringi 1.1.1 DE 3\n 4 2016-07-19 22:00… 1.89e6 3.3.1 x86_64 ming… data.t… 1.9.6 US 4\n 5 2016-07-19 22:00… 3.90e5 3.3.1 x86_64 ming… foreach 1.4.3 US 4\n 6 2016-07-19 22:00… 4.88e4 3.3.1 x86_64 linu… tree 1.0-37 CO 5\n 7 2016-07-19 22:00… 5.25e2 3.3.1 x86_64 darw… surviv… 2.39-5 US 6\n 8 2016-07-19 22:00… 3.23e6 3.3.1 x86_64 ming… Rcpp 0.12.5 US 2\n 9 2016-07-19 22:00… 5.56e5 3.3.1 x86_64 ming… tibble 1.1 US 2\n10 2016-07-19 22:00… 1.52e5 3.3.1 x86_64 ming… magrit… 1.5 US 2\n\n\nYou can specify the column type in a more detailed fashion by using the various col_*() functions.\nFor example, in the log data above, the first column is actually a date, so it might make more sense to read it in as a Date object.\nIf we wanted to just read in that first column, we could do\n\nlogdates <- read_csv(here(\"data\", \"2016-07-19.csv.bz2\"),\n col_types = cols_only(date = col_date()),\n n_max = 10\n)\nlogdates\n\n# A tibble: 10 × 1\n date \n <date> \n 1 2016-07-19\n 2 2016-07-19\n 3 2016-07-19\n 4 2016-07-19\n 5 2016-07-19\n 6 2016-07-19\n 7 2016-07-19\n 8 2016-07-19\n 9 2016-07-19\n10 2016-07-19\n\n\nNow the date column is stored as a Date object which can be used for relevant date-related computations (for example, see the lubridate package).\n\n\n\n\n\n\nNote\n\n\n\nThe read_csv() function has a progress option that defaults to TRUE.\nThis options provides a nice progress meter while the CSV file is being read.\nHowever, if you are using read_csv() in a function, or perhaps embedding it in a loop, it is probably best to set progress = FALSE."
+ "objectID": "posts/10-joining-data-in-r/index.html#right-join",
+ "href": "posts/10-joining-data-in-r/index.html#right-join",
+ "title": "10 - Joining data in R",
+ "section": "Right Join",
+ "text": "Right Join\nThe right_join() function is like the left_join() function except that it gives priority to the “right” hand argument.\n\nright_join(x = outcomes, y = subjects, by = c(\"id\", \"visit\"))\n\n# A tibble: 2 × 4\n id visit outcome house \n <chr> <dbl> <dbl> <chr> \n1 b 1 2.91 rowhouse\n2 c 0 1.49 rowhouse"
},
{
- "objectID": "posts/24-best-practices-data-analyses/index.html",
- "href": "posts/24-best-practices-data-analyses/index.html",
- "title": "24 - Best practices for data analyses",
+ "objectID": "posts/20-working-with-dates-and-times/index.html",
+ "href": "posts/20-working-with-dates-and-times/index.html",
+ "title": "20 - Working with dates and times",
"section": "",
"text": "This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history."
},
{
- "objectID": "posts/24-best-practices-data-analyses/index.html#defining-ethics",
- "href": "posts/24-best-practices-data-analyses/index.html#defining-ethics",
- "title": "24 - Best practices for data analyses",
- "section": "Defining ethics",
- "text": "Defining ethics\nWe start with a grounding in the definition of Ethics:\nEthics, also called moral philosophy, has three main branches:\n\nApplied ethics “is a branch of ethics devoted to the treatment of moral problems, practices, and policies in personal life, professions, technology, and government.”\nEthical theory “is concerned with the articulation and the justification of the fundamental principles that govern the issues of how we should live and what we morally ought to do. Its most general concerns are providing an account of moral evaluation and, possibly, articulating a decision procedure to guide moral action.”\nMetaethics “is the attempt to understand the metaphysical, epistemological, semantic, and psychological, presuppositions and commitments of moral thought, talk, and practice.”\n\nWhile, unfortunately, there are myriad examples of ethical data science problems (see, for example, blog posts bookclub and data feminism), here I aim to connect some of the broader data science ethics issues with the existing philosophical literature.\nNote, I am only scratching the surface and a deeper dive might involve education in related philosophical fields (epistemology, metaphysics, or philosophy of science), philosophical methodologies, and ethical schools of thought, but you can peruse all of these through, for example, a course or readings introducing the discipline of philosophy.\nBelow we provide some thoughts on how to approach a data science problem using a philosophical lens."
+ "objectID": "posts/20-working-with-dates-and-times/index.html#the-lubridate-package",
+ "href": "posts/20-working-with-dates-and-times/index.html#the-lubridate-package",
+ "title": "20 - Working with dates and times",
+ "section": "The lubridate package",
+ "text": "The lubridate package\nHere, we will focus on the lubridate R package, which makes it easier to work with dates and times in R.\n\n\n\n\n\n\nPro-tip\n\n\n\nCheck out the lubridate cheat sheet at https://lubridate.tidyverse.org\n\n\nA few things to note about it:\n\nIt largely replaces the default date/time functions in base R\nIt contains methods for date/time arithmetic\nIt handles time zones, leap year, leap seconds, etc.\n\n [Source: Artwork by Allison Horst]\nlubridate is installed when you install tidyverse, but it is not loaded when you load tidyverse. Alternatively, you can install it separately.\n\ninstall.packages(\"lubridate\")\n\n\nlibrary(tidyverse)\nlibrary(lubridate)"
},
{
- "objectID": "posts/24-best-practices-data-analyses/index.html#case-study",
- "href": "posts/24-best-practices-data-analyses/index.html#case-study",
- "title": "24 - Best practices for data analyses",
- "section": "Case Study",
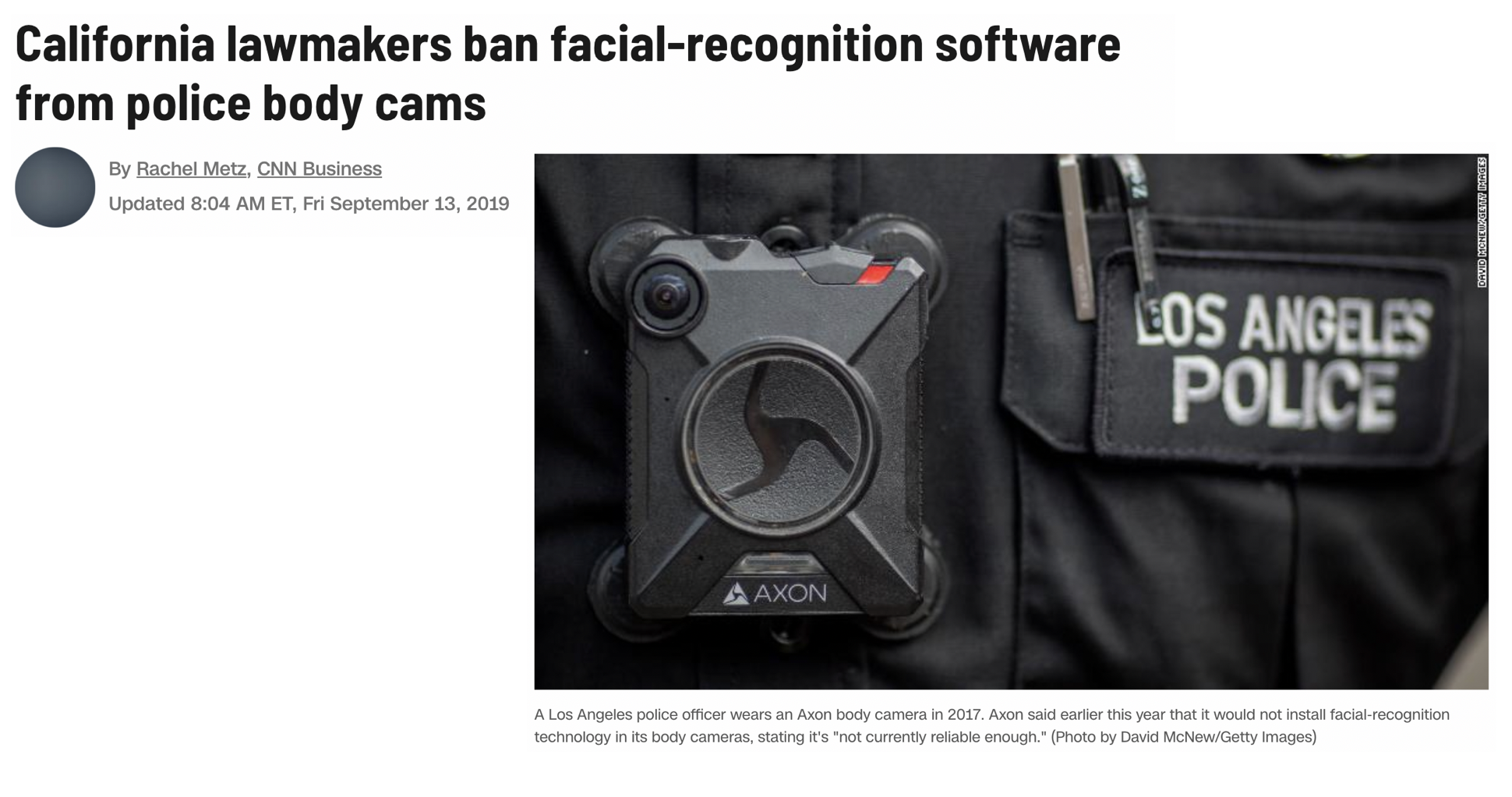
- "text": "Case Study\nWe begin by considering a case study around ethical data analyses.\nMany ethics case studies provided in a classroom setting describe algorithms built on data which are meant to predict outcomes.\n\n\n\n\n\n\nNote\n\n\n\nLarge scale algorithmic decision making presents particular ethical predicaments because of both the scale of impact and the “black-box” sense of how the algorithm is generating predictions.\n\n\nConsider the well-known issue of using facial recognition software in policing.\nThere are many questions surrounding the policing issue:\n\nWhat are the action options with respect to the outcome of the algorithm?\nWhat are the good and bad aspects of each action and how are these to be weighed against each other?\n\n\n[Source: CNN]\n\n\n\n\n\n\nImportant questions\n\n\n\nThe two main ethical concerns surrounding facial recognition software break down into\n\nHow the algorithms were developed?\nHow the algorithm is used?\n\n\n\nWhen thinking about the questions below, reflect on the good aspects and the bad aspects and how one might weight the good versus the bad.\n\nCreating the algorithm\n\nWhat data should be used to train the algorithm?\n\nIf the accuracy rates of the algorithm differ based on the demographics of the subgroups within the data, is more data and testing required?\n\nWho and what criteria should be used to tune the algorithm?\n\nWho should be involved in decisions on the tuning parameters of the algorithm?\nWhich optimization criteria should be used (e.g., accuracy? false positive rate? false negative rate?)\n\nIssues of access:\n\nWho should own or have control of the facial image data?\n\nDo individuals have a right to keep their facial image private from being in databases?\nDo individuals have a right to be notified that their facial image is in the data base? For example, if I ring someone’s doorbell and my face is captured in a database, do I need to be told? [While traditional human subjects and IRB requirements necessitate consent to be included in any research project, in most cases it is legal to photograph a person without their consent.]\n\nShould the data be accessible to researchers working to make the field more equitable? What if allowing accessibility thereby makes the data accessible to bad actors?\n\n\n\n\nUsing the algorithm\n\nIssues of personal impact:\n\nThe software might make it easier to accurately associate an individual with a crime, but it might also make it easier to mistakenly associate an individual with a crime. How should the pro vs con be weighed against each other?\nDo individuals have a right to know, correct, or delete personal information included in a database?\n\nIssues of societal impact:\n\nIs it permissible to use a facial recognition software which has been trained primarily on Caucasian faces, given that this results in false positive and false negative rates that are not equally dispersed across racial lines?\nWhile the software might make it easier to protect against criminal activity, it also makes it easier to undermine specific communities when their members are mistakenly identified with criminal activity. How should the pro vs con of different communities be weighed against each other?\n\nIssues of money:\n\nIs it permissible for a software company to profit from an algorithm while having no financial responsibility for its misuse or negative impacts?\nWho should pay the court fees and missed work hours of those who were mistakenly accused of crimes?\n\n\nTo settle the questions above, we need to study various ethical theories, and it turns out that the different theories may lead us to different conclusions. As non-philosophers, we recognize that the suggested readings and ideas may come across as overwhelming. If you are overwhelmed, we suggest that you choose one ethical theory, think carefully about how it informs decision making, and help your students to connect the ethical framework to a data science case study."
+ "objectID": "posts/20-working-with-dates-and-times/index.html#from-a-string",
+ "href": "posts/20-working-with-dates-and-times/index.html#from-a-string",
+ "title": "20 - Working with dates and times",
+ "section": "1. From a string",
+ "text": "1. From a string\nDates are of the Date class.\n\nx <- today()\nclass(x)\n\n[1] \"Date\"\n\n\nDates can be coerced from a character strings using some helper functions from lubridate. They automatically work out the format once you specify the order of the component.\nTo use the helper functions, identify the order in which year, month, and day appear in your dates, then arrange “y”, “m”, and “d” in the same order.\nThat gives you the name of the lubridate function that will parse your date. For example:\n\nymd(\"1970-01-01\")\n\n[1] \"1970-01-01\"\n\nymd(\"2017-01-31\")\n\n[1] \"2017-01-31\"\n\nmdy(\"January 31st, 2017\")\n\n[1] \"2017-01-31\"\n\ndmy(\"31-Jan-2017\")\n\n[1] \"2017-01-31\"\n\n\n\n\n\n\n\n\nPro-tip\n\n\n\n\nWhen reading in data with read_csv(), you may need to read in as character first and then convert to date/time\nDate objects have their own special print() methods that will always format as “YYYY-MM-DD”\nThese functions also take unquoted numbers.\n\n\nymd(20170131)\n\n[1] \"2017-01-31\"\n\n\n\n\n\nAlternate Formulations\nDifferent locales have different ways of formatting dates\n\nymd(\"2016-09-13\") ## International standard\n\n[1] \"2016-09-13\"\n\nymd(\"2016/09/13\") ## Just figure it out\n\n[1] \"2016-09-13\"\n\nmdy(\"09-13-2016\") ## Mostly U.S.\n\n[1] \"2016-09-13\"\n\ndmy(\"13-09-2016\") ## Europe\n\n[1] \"2016-09-13\"\n\n\nAll of the above are valid and lead to the exact same object.\nEven if the individual dates are formatted differently, ymd() can usually figure it out.\n\nx <- c(\n \"2016-04-05\",\n \"2016/05/06\",\n \"2016,10,4\"\n)\nymd(x)\n\n[1] \"2016-04-05\" \"2016-05-06\" \"2016-10-04\"\n\n\nCool right?"
},
{
- "objectID": "posts/24-best-practices-data-analyses/index.html#final-thoughts",
- "href": "posts/24-best-practices-data-analyses/index.html#final-thoughts",
- "title": "24 - Best practices for data analyses",
- "section": "Final thoughts",
- "text": "Final thoughts\nThis is a challenging topic, but as you analyze data, ask yourself the following broad questions to help you with ethical considerations around the data analysis.\n\n\n\n\n\n\nQuestions to ask yourself when analyzing data?\n\n\n\n\nWhy are we producing this knowledge?\nFor whom are we producing this knowledge?\nWhat communities do they serve?\nWhich stakeholders need to be involved in making decisions in and around the data analysis?"
+ "objectID": "posts/20-working-with-dates-and-times/index.html#from-individual-date-time-components",
+ "href": "posts/20-working-with-dates-and-times/index.html#from-individual-date-time-components",
+ "title": "20 - Working with dates and times",
+ "section": "2. From individual date-time components",
+ "text": "2. From individual date-time components\nSometimes the date components will come across multiple columns in a dataset.\n\nlibrary(nycflights13)\n\nflights %>%\n select(year, month, day)\n\n# A tibble: 336,776 × 3\n year month day\n <int> <int> <int>\n 1 2013 1 1\n 2 2013 1 1\n 3 2013 1 1\n 4 2013 1 1\n 5 2013 1 1\n 6 2013 1 1\n 7 2013 1 1\n 8 2013 1 1\n 9 2013 1 1\n10 2013 1 1\n# ℹ 336,766 more rows\n\n\nTo create a date/time from this sort of input, use\n\nmake_date(year,month,day) for dates, or\nmake_datetime(year,month,day,hour,min,sec,tz) for date-times\n\nWe combine these functions inside of mutate to add a new column to our dataset:\n\nflights %>%\n select(year, month, day) %>%\n mutate(departure = make_date(year, month, day))\n\n# A tibble: 336,776 × 4\n year month day departure \n <int> <int> <int> <date> \n 1 2013 1 1 2013-01-01\n 2 2013 1 1 2013-01-01\n 3 2013 1 1 2013-01-01\n 4 2013 1 1 2013-01-01\n 5 2013 1 1 2013-01-01\n 6 2013 1 1 2013-01-01\n 7 2013 1 1 2013-01-01\n 8 2013 1 1 2013-01-01\n 9 2013 1 1 2013-01-01\n10 2013 1 1 2013-01-01\n# ℹ 336,766 more rows\n\n\n\n\n\n\n\n\nQuestions\n\n\n\nThe flights also contains a hour and minute column.\n\nflights %>%\n select(year, month, day, hour, minute)\n\n# A tibble: 336,776 × 5\n year month day hour minute\n <int> <int> <int> <dbl> <dbl>\n 1 2013 1 1 5 15\n 2 2013 1 1 5 29\n 3 2013 1 1 5 40\n 4 2013 1 1 5 45\n 5 2013 1 1 6 0\n 6 2013 1 1 5 58\n 7 2013 1 1 6 0\n 8 2013 1 1 6 0\n 9 2013 1 1 6 0\n10 2013 1 1 6 0\n# ℹ 336,766 more rows\n\n\nLet’s use make_datetime() to create a date-time column called departure:\n\n# try it yourself"
},
{
- "objectID": "posts/24-best-practices-data-analyses/index.html#fair-principles",
- "href": "posts/24-best-practices-data-analyses/index.html#fair-principles",
- "title": "24 - Best practices for data analyses",
- "section": "FAIR principles",
- "text": "FAIR principles\nSharing data proves more useful when others can easily find and access, interpret, and reuse the data. To maximize the benefit of sharing your data, follow the findable, accessible, interoperable, and reusable (FAIR) guiding principles of data sharing, which optimize reuse of generated data.\n\n\n\n\n\n\nFAIR data sharing principles\n\n\n\n\nFindable. The first step in (re)using data is to find them. Metadata and data should be easy to find for both humans and computers. Machine-readable metadata are essential for automatic discovery of datasets and services, so this is an essential component of the FAIRification process.\nAccessible. Once the user finds the required data, she/he needs to know how can they be accessed, possibly including authentication and authorization.\nInteroperable. The data usually need to be integrated with other data. In addition, the data need to interoperate with applications or workflows for analysis, storage, and processing.\nReusable. The ultimate goal of FAIR is to optimize the reuse of data. To achieve this, metadata and data should be well-described so that they can be replicated and/or combined in different settings."
+ "objectID": "posts/20-working-with-dates-and-times/index.html#from-other-types",
+ "href": "posts/20-working-with-dates-and-times/index.html#from-other-types",
+ "title": "20 - Working with dates and times",
+ "section": "3. From other types",
+ "text": "3. From other types\nYou may want to switch between a date-time and a date.\nThat is the job of as_datetime() and as_date():\n\ntoday()\n\n[1] \"2023-08-17\"\n\nas_datetime(today())\n\n[1] \"2023-08-17 UTC\"\n\nnow()\n\n[1] \"2023-08-17 21:47:52 EDT\"\n\nas_date(now())\n\n[1] \"2023-08-17\""
},
{
- "objectID": "posts/24-best-practices-data-analyses/index.html#why-share",
- "href": "posts/24-best-practices-data-analyses/index.html#why-share",
- "title": "24 - Best practices for data analyses",
- "section": "Why share?",
- "text": "Why share?\n\nBenefits of sharing data to science and society. Sharing data allows for transparency in scientific studies and allows one to fully understand what occurred in an analysis and reproduce the results. Without complete data, metadata, and information about resources used to generate the data, reproducing a study proves impossible.\nBenefits of sharing data to individual researchers. Sharing data increases the impact of a researcher’s work and reputation for sound science. Awards for those with an excellent record of data sharing or data reuse can exemplify this reputation.\n\n\nAddressing common concerns about data sharing\nDespite the clear benefits of sharing data, some researchers still have concerns about doing so.\n\nNovelty. Some worry that sharing data may decrease the novelty of their work and their chance to publish in prominent journals. You can address this concern by sharing your data only after publication. You can also choose to preprint your manuscript when you decide to share your data. Furthermore, you only need to share the data and metadata required to reproduce your published study.\nTime spent on sharing data. Some have concerns about the time it takes to organize and share data publicly. Many add ‘data available upon request’ to manuscripts instead of depositing the data in a public repository in hopes of getting the work out sooner. It does take time to organize data in preparation for sharing, but sharing data publicly may save you time. Sharing data in a public repository that guarantees archival persistence means that you will not have to worry about storing and backing up the data yourself.\nHuman subject data. Sharing of data on human subjects requires special ethical, legal, and privacy considerations. Existing recommendations largely aim to balance the privacy of human participants with the benefits of data sharing by de-identifying human participants and obtaining consent for sharing. Sharing human data poses a variety of challenges for analysis, transparency, reproducibility, interoperability, and access.\n\n\n\n\n\n\n\nHuman data\n\n\n\nSometimes you cannot publicly post all human data, even after de-identification. We suggest three strategies for making these data maximally accessible.\n\nDeposit raw data files in a controlled-access repository. Controlled-access repositories allow only qualified researchers who apply to access the data.\nEven if you cannot make individual-level raw data available, you can make as much processed data available as possible. This may take the form of summary statistics such as means and standard deviations, rather than individual-level data.\nYou may want to generate simulated data distinct from the original data but statistically similar to it. Simulated data would allow others to reproduce your analysis without disclosing the original data or requiring the security controls needed for controlled access."
+ "objectID": "posts/20-working-with-dates-and-times/index.html#from-a-string-1",
+ "href": "posts/20-working-with-dates-and-times/index.html#from-a-string-1",
+ "title": "20 - Working with dates and times",
+ "section": "From a string",
+ "text": "From a string\nymd() and friends create dates.\nTo create a date-time from a character string, add an underscore and one or more of “h”, “m”, and “s” to the name of the parsing function:\nTimes can be coerced from a character string with ymd_hms()\n\nymd_hms(\"2017-01-31 20:11:59\")\n\n[1] \"2017-01-31 20:11:59 UTC\"\n\nmdy_hm(\"01/31/2017 08:01\")\n\n[1] \"2017-01-31 08:01:00 UTC\"\n\n\nYou can also force the creation of a date-time from a date by supplying a timezone:\n\nymd_hms(\"2016-09-13 14:00:00\")\n\n[1] \"2016-09-13 14:00:00 UTC\"\n\nymd_hms(\"2016-09-13 14:00:00\", tz = \"America/New_York\")\n\n[1] \"2016-09-13 14:00:00 EDT\"\n\nymd_hms(\"2016-09-13 14:00:00\", tz = \"\")\n\n[1] \"2016-09-13 14:00:00 EDT\""
},
{
- "objectID": "posts/24-best-practices-data-analyses/index.html#what-data-to-share",
- "href": "posts/24-best-practices-data-analyses/index.html#what-data-to-share",
- "title": "24 - Best practices for data analyses",
- "section": "What data to share?",
- "text": "What data to share?\nDepending on the data type, you might be able to share the data itself, or a summarized version of it. Boradly thought, you want to share the following:\n\nThe data itself, or a summarized version, or a simulated data similar to the original.\nAny metadata to describe the primary data and the resources used to generate it. Most disciplines have specific metadata standards to follow (e.g. microarrays).\nData dictionary. These have crucial role in organizing your data, especially explaining the variables and their representation. Data dictionaries should provide short names for each variable, a longer text label for the variable, a definition for each variable, data type (such as floating-point number, integer, or string), measurement units, and expected minimum and maximum values. Data dictionaries can make explicit what future users would otherwise have to guess about the representation of data.\nSource code. Ideally, readers should have all materials needed to completely reproduce the study described in a publication, not just data. These materials include source code, preprocessing, and analysis scripts. Guidelines for organization of computational project can help you arrange your data and scripts in a way that will make it easier for you and other to access and reuse them.\nLicensing. Clear licensing information attached to your data avoids any questions of whether others may reuse it. Many data resources turn out not to be as reusable as the providers intended, due to lack of clarity in licensing or restrictive licensing choices.\n\n\n\n\n\n\n\nHow should you document your data?\n\n\n\nDocument your data in three ways:\n\nWith your manuscript.\nWith description fields in the metadata collected by repositories\nWith README files. README files provide abbreviated information about a collection of files (e.g. explain organization, file locations, observations and variables present in each file, details on the experimental design, etc)."
+ "objectID": "posts/20-working-with-dates-and-times/index.html#posixct-or-the-posixlt-class",
+ "href": "posts/20-working-with-dates-and-times/index.html#posixct-or-the-posixlt-class",
+ "title": "20 - Working with dates and times",
+ "section": "POSIXct or the POSIXlt class",
+ "text": "POSIXct or the POSIXlt class\nLet’s get into some hairy details about date-times. Date-times are represented using the POSIXct or the POSIXlt class in R. What are these things?\n\nPOSIXct\nPOSIXct is just a very large integer under the hood. It is a useful class when you want to store times in something like a data frame.\nTechnically, the POSIXct class represents the number of seconds since 1 January 1970. (In case you were wondering, “POSIXct” stands for “Portable Operating System Interface”, calendar time.)\n\nx <- ymd_hm(\"1970-01-01 01:00\")\nclass(x)\n\n[1] \"POSIXct\" \"POSIXt\" \n\nunclass(x)\n\n[1] 3600\nattr(,\"tzone\")\n[1] \"UTC\"\n\ntypeof(x)\n\n[1] \"double\"\n\nattributes(x)\n\n$class\n[1] \"POSIXct\" \"POSIXt\" \n\n$tzone\n[1] \"UTC\"\n\n\n\n\nPOSIXlt\nPOSIXlt is a list underneath and it stores a bunch of other useful information like the day of the week, day of the year, month, day of the month\n\ny <- as.POSIXlt(x)\ny\n\n[1] \"1970-01-01 01:00:00 UTC\"\n\ntypeof(y)\n\n[1] \"list\"\n\nattributes(y)\n\n$names\n [1] \"sec\" \"min\" \"hour\" \"mday\" \"mon\" \"year\" \"wday\" \"yday\" \n [9] \"isdst\" \"zone\" \"gmtoff\"\n\n$class\n[1] \"POSIXlt\" \"POSIXt\" \n\n$tzone\n[1] \"UTC\"\n\n$balanced\n[1] TRUE\n\n\n\n\n\n\n\n\nPro-tip\n\n\n\nPOSIXlts are rare inside the tidyverse. They do crop up in base R, because they are needed to extract specific components of a date, like the year or month.\nSince lubridate provides helpers for you to do this instead, you do not really need them imho.\nPOSIXct’s are always easier to work with, so if you find you have a POSIXlt, you should always convert it to a regular data time lubridate::as_datetime()."
},
{
- "objectID": "posts/24-best-practices-data-analyses/index.html#motiviation",
- "href": "posts/24-best-practices-data-analyses/index.html#motiviation",
- "title": "24 - Best practices for data analyses",
- "section": "Motiviation",
- "text": "Motiviation\n\n\n\n\n\n\nQuote from a hero of mine\n\n\n\n“The greatest value of a picture is when it forces us to notice what we never expected to see.” -John W. Tukey\n\n\n\n\n\n\n\n\n\n\n\nMistakes, biases, systematic errors and unexpected variability are commonly found in data regardless of applications. Failure to discover these problems often leads to flawed analyses and false discoveries.\nAs an example, consider that measurement devices sometimes fail and not all summarization procedures, such as the mean() function in R, are designed to detect these. Yet, these functions will still give you an answer.\nFurthermore, it may be hard or impossible to notice an error was made just from the reported summaries.\nData visualization is a powerful approach to detecting these problems. We refer to this particular task as exploratory data analysis (EDA), coined by John Tukey.\nOn a more positive note, data visualization can also lead to discoveries which would otherwise be missed if we simply subject the data to a battery of statistical summaries or procedures.\nWhen analyzing data, we often make use of exploratory plots to motivate the analyses we choose.\nIn this section, we will discuss some types of plots to avoid, better ways to visualize data, some principles to create good plots, and ways to use ggplot2 to create expository (intended to explain or describe something) graphs.\n\n\n\n\n\n\nExample\n\n\n\nThe following figure is from Lippmann et al. 2006:\n\n\n\nNickel concentration and PM10 health effects (Blue points represent average county-level concentrations from 2000–2005 for 72 U.S. counties representing 69 communities).\n\n\nThe following figure is from Dominici et al. 2007, in response to the work by Lippmann et al. above.\n\n\n\nNickel concentration and PM10 health effects (with and without New York).\n\n\nElevated levels of Ni and V PM2.5 chemical components in New York are likely attributed to oil-fired power plants and emissions from ships burning oil, as noted by Lippmann et al. (2006).\n\n\n\nGenerating data visualizations\nIn order to determine the effectiveness or quality of a visualization, we need to first understand three things:\n\n\n\n\n\n\nQuestions to ask yourself when building data visualizations\n\n\n\n\nWhat is the question we are trying to answer?\nWhy are we building this visualization?\nFor whom are we producing this data visualization for? Who is the intended audience to consume this visualization?\n\n\n\nNo plot (or any statistical tool, really) can be judged without knowing the answers to those questions. No plot or graphic exists in a vacuum. There is always context and other surrounding factors that play a role in determining a plot’s effectiveness.\nConversely, high-quality, well-made visualizations usually allow one to properly deduce what question is being asked and who the audience is meant to be. A good visualization tells a complete story in a single frame.\n\n\n\n\n\n\nBroad steps for creating data visualizations\n\n\n\nThe act of visualizing data typically proceeds in two broad steps:\n\nGiven the question and the audience, what type of plot should I make?\nGiven the plot I intend to make, how can I optimize it for clarity and effectiveness?"
+ "objectID": "posts/20-working-with-dates-and-times/index.html#arithmetic",
+ "href": "posts/20-working-with-dates-and-times/index.html#arithmetic",
+ "title": "20 - Working with dates and times",
+ "section": "Arithmetic",
+ "text": "Arithmetic\nYou can add and subtract dates and times.\n\nx <- ymd(\"2012-01-01\", tz = \"\") ## Midnight\ny <- dmy_hms(\"9 Jan 2011 11:34:21\", tz = \"\")\nx - y ## this works\n\nTime difference of 356.5178 days\n\n\nYou can do comparisons too (i.e. >, <, and ==)\n\nx < y ## this works\n\n[1] FALSE\n\nx > y ## this works\n\n[1] TRUE\n\nx == y ## this works\n\n[1] FALSE\n\nx + y ## what??? why does this not work?\n\nError in `+.POSIXt`(x, y): binary '+' is not defined for \"POSIXt\" objects\n\n\n\n\n\n\n\n\nNote\n\n\n\nThe class of x is POSIXct.\n\nclass(x)\n\n[1] \"POSIXct\" \"POSIXt\" \n\n\nPOSIXct objects are a measure of seconds from an origin, usually the UNIX epoch (1st Jan 1970).\nJust add the requisite number of seconds to the object:\n\nx + 3 * 60 * 60 # add 3 hours\n\n[1] \"2012-01-01 03:00:00 EST\"\n\n\n\n\nSame goes for days. For example, you can just keep the date portion using date():\n\ny <- date(y)\ny\n\n[1] \"2011-01-09\"\n\n\nAnd then add a number to the date (in this case 1 day)\n\ny + 1\n\n[1] \"2011-01-10\"\n\n\nCool eh?"
},
{
- "objectID": "posts/24-best-practices-data-analyses/index.html#data-viz-principles",
- "href": "posts/24-best-practices-data-analyses/index.html#data-viz-principles",
- "title": "24 - Best practices for data analyses",
- "section": "Data viz principles",
- "text": "Data viz principles\n\nDeveloping plots\nInitially, one must decide what information should be presented. The following principles for developing analytic graphics come from Edward Tufte’s book Beautiful Evidence.\n\nShow comparisons\nShow causality, mechanism, explanation\nShow multivariate data\nIntegrate multiple modes of evidence\nDescribe and document the evidence\nContent is king - good plots start with good questions\n\n\n\nOptimizing plots\n\nMaximize the data/ink ratio – if “ink” can be removed without reducing the information being communicated, then it should be removed.\nMaximize the range of perceptual conditions – your audience’s perceptual abilities may not be fully known, so it’s best to allow for a wide range, to the extent possible (or knowable).\nShow variation in the data, not variation in the design.\n\nWhat’s sub-optimal about this plot?\n\nd <- airquality %>%\n mutate(Summer = ifelse(Month %in% c(7, 8, 9), 2, 3))\nwith(d, {\n plot(Temp, Ozone, col = unclass(Summer), pch = 19, frame.plot = FALSE)\n legend(\"topleft\",\n col = 2:3, pch = 19, bty = \"n\",\n legend = c(\"Summer\", \"Non-Summer\")\n )\n})\n\n\n\n\nWhat’s sub-optimal about this plot?\n\nairquality %>%\n mutate(Summer = ifelse(Month %in% c(7, 8, 9),\n \"Summer\", \"Non-Summer\"\n )) %>%\n ggplot(aes(Temp, Ozone)) +\n geom_point(aes(color = Summer), size = 2) +\n theme_minimal()\n\n\n\n\nSome of these principles are taken from Edward Tufte’s Visual Display of Quantitative Information:"
+ "objectID": "posts/20-working-with-dates-and-times/index.html#leaps-and-bounds",
+ "href": "posts/20-working-with-dates-and-times/index.html#leaps-and-bounds",
+ "title": "20 - Working with dates and times",
+ "section": "Leaps and Bounds",
+ "text": "Leaps and Bounds\nEven keeps track of leap years, leap seconds, daylight savings, and time zones.\nLeap years\n\nx <- ymd(\"2012-03-01\")\ny <- ymd(\"2012-02-28\")\nx - y\n\nTime difference of 2 days\n\n\nNot a leap year\n\nx <- ymd(\"2013-03-01\")\ny <- ymd(\"2013-02-28\")\nx - y\n\nTime difference of 1 days\n\n\nBUT beware of time zones!\n\nx <- ymd_hms(\"2012-10-25 01:00:00\", tz = \"\")\ny <- ymd_hms(\"2012-10-25 05:00:00\", tz = \"GMT\")\ny - x\n\nTime difference of 0 secs\n\n\nThere are also things called leap seconds.\n\n.leap.seconds\n\n [1] \"1972-07-01 GMT\" \"1973-01-01 GMT\" \"1974-01-01 GMT\" \"1975-01-01 GMT\"\n [5] \"1976-01-01 GMT\" \"1977-01-01 GMT\" \"1978-01-01 GMT\" \"1979-01-01 GMT\"\n [9] \"1980-01-01 GMT\" \"1981-07-01 GMT\" \"1982-07-01 GMT\" \"1983-07-01 GMT\"\n[13] \"1985-07-01 GMT\" \"1988-01-01 GMT\" \"1990-01-01 GMT\" \"1991-01-01 GMT\"\n[17] \"1992-07-01 GMT\" \"1993-07-01 GMT\" \"1994-07-01 GMT\" \"1996-01-01 GMT\"\n[21] \"1997-07-01 GMT\" \"1999-01-01 GMT\" \"2006-01-01 GMT\" \"2009-01-01 GMT\"\n[25] \"2012-07-01 GMT\" \"2015-07-01 GMT\" \"2017-01-01 GMT\""
},
{
- "objectID": "posts/24-best-practices-data-analyses/index.html#plots-to-avoid",
- "href": "posts/24-best-practices-data-analyses/index.html#plots-to-avoid",
- "title": "24 - Best practices for data analyses",
- "section": "Plots to Avoid",
- "text": "Plots to Avoid\nThis section is based on a talk by Karl W. Broman titled “How to Display Data Badly,” in which he described how the default plots offered by Microsoft Excel “obscure your data and annoy your readers” (here is a link to a collection of Karl Broman’s talks).\n\n\n\n\n\n\nFYI\n\n\n\nKarl’s lecture was inspired by the 1984 paper by H. Wainer: How to display data badly. American Statistician 38(2): 137–147.\nDr. Wainer was the first to elucidate the principles of the bad display of data.\nHowever, according to Karl Broman, “The now widespread use of Microsoft Excel has resulted in remarkable advances in the field.”\nHere we show examples of “bad plots” and how to improve them in R.\n\n\n\n\n\n\n\n\nSome general principles of bad plots\n\n\n\n\nDisplay as little information as possible.\nObscure what you do show (with chart junk).\nUse pseudo-3D and color gratuitously.\nMake a pie chart (preferably in color and 3D).\nUse a poorly chosen scale.\nIgnore significant figures."
+ "objectID": "posts/20-working-with-dates-and-times/index.html#date-elements",
+ "href": "posts/20-working-with-dates-and-times/index.html#date-elements",
+ "title": "20 - Working with dates and times",
+ "section": "Date Elements",
+ "text": "Date Elements\n\nx <- ymd_hms(c(\n \"2012-10-25 01:13:46\",\n \"2015-04-23 15:11:23\"\n), tz = \"\")\nyear(x)\n\n[1] 2012 2015\n\nmonth(x)\n\n[1] 10 4\n\nday(x)\n\n[1] 25 23\n\nweekdays(x)\n\n[1] \"Thursday\" \"Thursday\""
},
{
- "objectID": "posts/24-best-practices-data-analyses/index.html#examples",
- "href": "posts/24-best-practices-data-analyses/index.html#examples",
- "title": "24 - Best practices for data analyses",
- "section": "Examples",
- "text": "Examples\nHere are some examples of bad plots and suggestions on how to improve\n\nPie charts\nLet’s say we are interested in the most commonly used browsers. Wikipedia has a table with the “usage share of web browsers” or the proportion of visitors to a group of web sites that use a particular web browser from July 2017.\n\nbrowsers <- c(\n Chrome = 60, Safari = 14, UCBrowser = 7,\n Firefox = 5, Opera = 3, IE = 3, Noinfo = 8\n)\nbrowsers.df <- gather(\n data.frame(t(browsers)),\n \"browser\", \"proportion\"\n)\n\nLet’s say we want to report the results of the usage. The standard way of displaying these is with a pie chart:\n\npie(browsers, main = \"Browser Usage (July 2022)\")\n\n\n\n\nIf we look at the help file for pie():\n\n?pie\n\nIt states:\n\n“Pie charts are a very bad way of displaying information. The eye is good at judging linear measures and bad at judging relative areas. A bar chart or dot chart is a preferable way of displaying this type of data.”\n\nTo see this, look at the figure above and try to determine the percentages just from looking at the plot. Unless the percentages are close to 25%, 50% or 75%, this is not so easy. Simply showing the numbers is not only clear, but also saves on printing costs.\n\nInstead of pie charts, try bar plots\nIf you do want to plot them, then a barplot is appropriate. Here we use the geom_bar() function in ggplot2. Note, there are also horizontal lines at every multiple of 10, which helps the eye quickly make comparisons across:\n\np <- browsers.df %>%\n ggplot(aes(\n x = reorder(browser, -proportion),\n y = proportion\n )) +\n geom_bar(stat = \"identity\")\np\n\n\n\n\nNotice that we can now pretty easily determine the percentages by following a horizontal line to the x-axis.\n\n\nPolish your plots\nWhile this figure is already a big improvement over a pie chart, we can do even better. When you create figures, you want your figures to be self-sufficient, meaning someone looking at the plot can understand everything about it.\nSome possible critiques are:\n\nmake the axes bigger\nmake the labels bigger\nmake the labels be full names (e.g. “Browser” and “Proportion of users”, ideally with units when appropriate)\nadd a title\n\nLet’s explore how to do these things to make an even better figure.\nTo start, go to the help file for theme()\n\n?ggplot2::theme\n\nWe see there are arguments with text that control all the text sizes in the plot. If you scroll down, you see the text argument in the theme command requires class element_text. Let’s try it out.\nTo change the x-axis and y-axis labels to be full names, use xlab() and ylab()\n\np <- p + xlab(\"Browser\") +\n ylab(\"Proportion of Users\")\np\n\n\n\n\nMaybe a title\n\np + ggtitle(\"Browser Usage (July 2022)\")\n\n\n\n\nNext, we can also use the theme() function in ggplot2 to control the justifications and sizes of the axes, labels and titles.\nTo center the title\n\np + ggtitle(\"Browser Usage (July 2022)\") +\n theme(plot.title = element_text(hjust = 0.5))\n\n\n\n\nTo create bigger text/labels/titles:\n\np <- p + ggtitle(\"Browser Usage (July 2022)\") +\n theme(\n plot.title = element_text(hjust = 0.5),\n text = element_text(size = 15)\n )\np\n\n\n\n\n\n\n“I don’t like that theme”\n\np + theme_bw()\n\n\n\n\n\np + theme_dark()\n\n\n\n\n\np + theme_classic() # axis lines!\n\n\n\n\n\np + ggthemes::theme_base()\n\n\n\n\n\n\n\n3D barplots\nPlease, avoid a 3D version because it obfuscates the plot, making it more difficult to find the percentages by eye.\n\n\n\nDonut plots\nEven worse than pie charts are donut plots.\n\nThe reason is that by removing the center, we remove one of the visual cues for determining the different areas: the angles. There is no reason to ever use a donut plot to display data.\n\n\n\n\n\n\nQuestion\n\n\n\nWhy are pie/donut charts so common?\nhttps://blog.usejournal.com/why-humans-love-pie-charts-9cd346000bdc\n\n\n\n\nBarplots as data summaries\nWhile barplots are useful for showing percentages, they are incorrectly used to display data from two groups being compared. Specifically, barplots are created with height equal to the group means; an antenna is added at the top to represent standard errors. This plot is simply showing two numbers per group and the plot adds nothing:\n\n\nInstead of bar plots for summaries, try box plots\nIf the number of points is small enough, we might as well add them to the plot. When the number of points is too large for us to see them, just showing a boxplot is preferable.\nLet’s recreate these barplots as boxplots and overlay the points. We will simulate similar data to demonstrate one way to improve the graphic above.\n\nset.seed(1000)\ndat <- data.frame(\n \"Treatment\" = rnorm(10, 30, sd = 4),\n \"Control\" = rnorm(10, 36, sd = 4)\n)\ngather(dat, \"type\", \"response\") %>%\n ggplot(aes(type, response)) +\n geom_boxplot() +\n geom_point(position = \"jitter\") +\n ggtitle(\"Response to drug treatment\")\n\n\n\n\nNotice how much more we see here: the center, spread, range, and the points themselves. In the barplot, we only see the mean and the standard error (SE), and the SE has more to do with sample size than with the spread of the data.\nThis problem is magnified when our data has outliers or very large tails. For example, in the plot below, there appears to be very large and consistent differences between the two groups:\n\nHowever, a quick look at the data demonstrates that this difference is mostly driven by just two points.\n\nset.seed(1000)\ndat <- data.frame(\n \"Treatment\" = rgamma(10, 10, 1),\n \"Control\" = rgamma(10, 1, .01)\n)\ngather(dat, \"type\", \"response\") %>%\n ggplot(aes(type, response)) +\n geom_boxplot() +\n geom_point(position = \"jitter\")\n\n\n\n\n\n\nUse log scale if data includes outliers\nA version showing the data in the log-scale is much more informative.\n\ngather(dat, \"type\", \"response\") %>%\n ggplot(aes(type, response)) +\n geom_boxplot() +\n geom_point(position = \"jitter\") +\n scale_y_log10()\n\n\n\n\n\n\n\nBarplots for paired data\nA common task in data analysis is the comparison of two groups. When the dataset is small and data are paired, such as the outcomes before and after a treatment, two-color barplots are unfortunately often used to display the results.\n\n\nInstead of paired bar plots, try scatter plots\nThere are better ways of showing these data to illustrate that there is an increase after treatment. One is to simply make a scatter plot, which shows that most points are above the identity line. Another alternative is to plot the differences against the before values.\n\nset.seed(1000)\nbefore <- runif(6, 5, 8)\nafter <- rnorm(6, before * 1.15, 2)\nli <- range(c(before, after))\nymx <- max(abs(after - before))\n\npar(mfrow = c(1, 2))\nplot(before, after,\n xlab = \"Before\", ylab = \"After\",\n ylim = li, xlim = li\n)\nabline(0, 1, lty = 2, col = 1)\n\nplot(before, after - before,\n xlab = \"Before\", ylim = c(-ymx, ymx),\n ylab = \"Change (After - Before)\", lwd = 2\n)\nabline(h = 0, lty = 2, col = 1)\n\n\n\n\n\n\nor line plots\nLine plots are not a bad choice, although they can be harder to follow than the previous two. Boxplots show you the increase, but lose the paired information.\n\nz <- rep(c(0, 1), rep(6, 2))\npar(mfrow = c(1, 2))\nplot(z, c(before, after),\n xaxt = \"n\", ylab = \"Response\",\n xlab = \"\", xlim = c(-0.5, 1.5)\n)\naxis(side = 1, at = c(0, 1), c(\"Before\", \"After\"))\nsegments(rep(0, 6), before, rep(1, 6), after, col = 1)\n\nboxplot(before, after, names = c(\"Before\", \"After\"), ylab = \"Response\")\n\n\n\n\n\n\n\nGratuitous 3D\nThe figure below shows three curves. Pseudo 3D is used, but it is not clear why. Maybe to separate the three curves? Notice how difficult it is to determine the values of the curves at any given point:\n\nThis plot can be made better by simply using color to distinguish the three lines:\n\nx <- read_csv(\"https://github.com/kbroman/Talk_Graphs/raw/master/R/fig8dat.csv\") %>%\n as_tibble(.name_repair = make.names)\n\np <- x %>%\n gather(\"drug\", \"proportion\", -log.dose) %>%\n ggplot(aes(\n x = log.dose, y = proportion,\n color = drug\n )) +\n geom_line()\np\n\n\n\n\nThis plot demonstrates that using color is more than enough to distinguish the three lines.\nWe can make this plot better using the functions we learned above\n\np + ggtitle(\"Survival proportion\") +\n theme(\n plot.title = element_text(hjust = 0.5),\n text = element_text(size = 15)\n )\n\n\n\n\n\nLegends\nWe can also move the legend inside the plot\n\np + ggtitle(\"Survival proportion\") +\n theme(\n plot.title = element_text(hjust = 0.5),\n text = element_text(size = 15),\n legend.position = c(0.2, 0.3)\n )\n\n\n\n\nWe can also make the legend transparent\n\ntransparent_legend <- theme(\n legend.background = element_rect(fill = \"transparent\"),\n legend.key = element_rect(\n fill = \"transparent\",\n color = \"transparent\"\n )\n)\n\np + ggtitle(\"Survival proportion\") +\n theme(\n plot.title = element_text(hjust = 0.5),\n text = element_text(size = 15),\n legend.position = c(0.2, 0.3)\n ) +\n transparent_legend\n\n\n\n\n\n\n\nToo many significant digits\nBy default, statistical software like R returns many significant digits. This does not mean we should report them. Cutting and pasting directly from R is a bad idea since you might end up showing a table, such as the one below, comparing the heights of basketball players:\n\nheights <- cbind(\n rnorm(8, 73, 3), rnorm(8, 73, 3), rnorm(8, 80, 3),\n rnorm(8, 78, 3), rnorm(8, 78, 3)\n)\ncolnames(heights) <- c(\"SG\", \"PG\", \"C\", \"PF\", \"SF\")\nrownames(heights) <- paste(\"team\", 1:8)\nheights\n\n SG PG C PF SF\nteam 1 68.88065 73.07480 81.80948 76.60455 82.23521\nteam 2 70.05272 66.86024 74.64847 72.70140 78.55640\nteam 3 71.33653 73.63946 81.00483 78.56787 77.86893\nteam 4 73.36414 81.01021 81.68293 76.90146 77.35226\nteam 5 72.63738 69.31895 83.66281 81.17280 82.39133\nteam 6 68.99188 75.50274 79.36564 75.77514 78.68900\nteam 7 73.51017 74.59772 82.09829 73.95492 78.32287\nteam 8 73.46524 71.05953 77.88069 76.44808 73.86569\n\n\nWe are reporting precision up to 0.00001 inches. Do you know of a tape measure with that much precision? This can be easily remedied:\n\nround(heights, 1)\n\n SG PG C PF SF\nteam 1 68.9 73.1 81.8 76.6 82.2\nteam 2 70.1 66.9 74.6 72.7 78.6\nteam 3 71.3 73.6 81.0 78.6 77.9\nteam 4 73.4 81.0 81.7 76.9 77.4\nteam 5 72.6 69.3 83.7 81.2 82.4\nteam 6 69.0 75.5 79.4 75.8 78.7\nteam 7 73.5 74.6 82.1 74.0 78.3\nteam 8 73.5 71.1 77.9 76.4 73.9\n\n\n\n\nMinimal figure captions\nRecall the plot we had before:\n\ntransparent_legend <- theme(\n legend.background = element_rect(fill = \"transparent\"),\n legend.key = element_rect(\n fill = \"transparent\",\n color = \"transparent\"\n )\n)\n\np + ggtitle(\"Survival proportion\") +\n theme(\n plot.title = element_text(hjust = 0.5),\n text = element_text(size = 15),\n legend.position = c(0.2, 0.3)\n ) +\n xlab(\"dose (mg)\") +\n transparent_legend\n\n\n\n\nWhat type of caption would be good here?\nWhen creating figure captions, think about the following:\n\nBe specific\n\n\nA plot of the proportion of patients who survived after three drug treatments.\n\n\nLabel the caption\n\n\nFigure 1. A plot of the proportion of patients who survived after three drug treatments.\n\n\nTell a story\n\n\nFigure 1. Drug treatment survival. A plot of the proportion of patients who survived after three drug treatments.\n\n\nInclude units\n\n\nFigure 1. Drug treatment survival. A plot of the proportion of patients who survived after three drug treatments (milligram).\n\n\nExplain aesthetics\n\n\nFigure 1. Drug treatment survival. A plot of the proportion of patients who survived after three drug treatments (milligram). Three colors represent three drug treatments. Drug A results in largest survival proportion for the larger drug doses."
+ "objectID": "posts/20-working-with-dates-and-times/index.html#time-elements",
+ "href": "posts/20-working-with-dates-and-times/index.html#time-elements",
+ "title": "20 - Working with dates and times",
+ "section": "Time Elements",
+ "text": "Time Elements\n\nx <- ymd_hms(c(\n \"2012-10-25 01:13:46\",\n \"2015-04-23 15:11:23\"\n), tz = \"\")\nminute(x)\n\n[1] 13 11\n\nsecond(x)\n\n[1] 46 23\n\nhour(x)\n\n[1] 1 15\n\nweek(x)\n\n[1] 43 17"
},
{
- "objectID": "posts/24-best-practices-data-analyses/index.html#final-thoughts-data-viz",
- "href": "posts/24-best-practices-data-analyses/index.html#final-thoughts-data-viz",
- "title": "24 - Best practices for data analyses",
- "section": "Final thoughts data viz",
- "text": "Final thoughts data viz\nIn general, you should follow these principles:\n\nCreate expository graphs to tell a story (figure and caption should be self-sufficient; it’s the first thing people look at)\n\nBe accurate and clear\nLet the data speak\nMake axes, labels and titles big\nMake labels full names (ideally with units when appropriate)\nAdd informative legends; use space effectively\n\nShow as much information as possible, taking care not to obscure the message\nScience not sales: avoid unnecessary frills (especially gratuitous 3D)\nIn tables, every digit should be meaningful\n\n\nSome further reading\n\nN Cross (2011). Design Thinking: Understanding How Designers Think and Work. Bloomsbury Publishing.\nJ Tukey (1977). Exploratory Data Analysis.\nER Tufte (1983) The visual display of quantitative information. Graphics Press.\nER Tufte (1990) Envisioning information. Graphics Press.\nER Tufte (1997) Visual explanations. Graphics Press.\nER Tufte (2006) Beautiful Evidence. Graphics Press.\nWS Cleveland (1993) Visualizing data. Hobart Press.\nWS Cleveland (1994) The elements of graphing data. CRC Press.\nA Gelman, C Pasarica, R Dodhia (2002) Let’s practice what we preach: Turning tables into graphs. The American Statistician 56:121-130.\nNB Robbins (2004) Creating more effective graphs. Wiley.\nNature Methods columns"
+ "objectID": "posts/20-working-with-dates-and-times/index.html#reading-in-the-data",
+ "href": "posts/20-working-with-dates-and-times/index.html#reading-in-the-data",
+ "title": "20 - Working with dates and times",
+ "section": "Reading in the Data",
+ "text": "Reading in the Data\n\nlibrary(here)\nlibrary(readr)\nstorm <- read_csv(here(\"data\", \"storms_2004.csv.gz\"), progress = FALSE)\nstorm\n\n# A tibble: 52,409 × 51\n BEGIN_YEARMONTH BEGIN_DAY BEGIN_TIME END_YEARMONTH END_DAY END_TIME\n <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>\n 1 200412 29 1800 200412 30 1200\n 2 200412 29 1800 200412 30 1200\n 3 200412 8 1800 200412 8 1800\n 4 200412 19 1500 200412 19 1700\n 5 200412 14 600 200412 14 800\n 6 200412 21 400 200412 21 800\n 7 200412 21 400 200412 21 800\n 8 200412 26 1500 200412 27 800\n 9 200412 26 1500 200412 27 800\n10 200412 11 800 200412 11 1300\n# ℹ 52,399 more rows\n# ℹ 45 more variables: EPISODE_ID <dbl>, EVENT_ID <dbl>, STATE <chr>,\n# STATE_FIPS <dbl>, YEAR <dbl>, MONTH_NAME <chr>, EVENT_TYPE <chr>,\n# CZ_TYPE <chr>, CZ_FIPS <dbl>, CZ_NAME <chr>, WFO <chr>,\n# BEGIN_DATE_TIME <chr>, CZ_TIMEZONE <chr>, END_DATE_TIME <chr>,\n# INJURIES_DIRECT <dbl>, INJURIES_INDIRECT <dbl>, DEATHS_DIRECT <dbl>,\n# DEATHS_INDIRECT <dbl>, DAMAGE_PROPERTY <chr>, DAMAGE_CROPS <chr>, …\n\n\n\nnames(storm)\n\n [1] \"BEGIN_YEARMONTH\" \"BEGIN_DAY\" \"BEGIN_TIME\" \n [4] \"END_YEARMONTH\" \"END_DAY\" \"END_TIME\" \n [7] \"EPISODE_ID\" \"EVENT_ID\" \"STATE\" \n[10] \"STATE_FIPS\" \"YEAR\" \"MONTH_NAME\" \n[13] \"EVENT_TYPE\" \"CZ_TYPE\" \"CZ_FIPS\" \n[16] \"CZ_NAME\" \"WFO\" \"BEGIN_DATE_TIME\" \n[19] \"CZ_TIMEZONE\" \"END_DATE_TIME\" \"INJURIES_DIRECT\" \n[22] \"INJURIES_INDIRECT\" \"DEATHS_DIRECT\" \"DEATHS_INDIRECT\" \n[25] \"DAMAGE_PROPERTY\" \"DAMAGE_CROPS\" \"SOURCE\" \n[28] \"MAGNITUDE\" \"MAGNITUDE_TYPE\" \"FLOOD_CAUSE\" \n[31] \"CATEGORY\" \"TOR_F_SCALE\" \"TOR_LENGTH\" \n[34] \"TOR_WIDTH\" \"TOR_OTHER_WFO\" \"TOR_OTHER_CZ_STATE\"\n[37] \"TOR_OTHER_CZ_FIPS\" \"TOR_OTHER_CZ_NAME\" \"BEGIN_RANGE\" \n[40] \"BEGIN_AZIMUTH\" \"BEGIN_LOCATION\" \"END_RANGE\" \n[43] \"END_AZIMUTH\" \"END_LOCATION\" \"BEGIN_LAT\" \n[46] \"BEGIN_LON\" \"END_LAT\" \"END_LON\" \n[49] \"EPISODE_NARRATIVE\" \"EVENT_NARRATIVE\" \"DATA_SOURCE\" \n\n\n\n\n\n\n\n\nQuestions\n\n\n\nLet’s take a look at the BEGIN_DATE_TIME, EVENT_TYPE, and DEATHS_DIRECT variables from the storm dataset.\nTasks:\n\nCreate a subset of the storm dataset with only the four columns above.\nCreate a new column called begin that contains the BEGIN_DATE_TIME that has been converted to a date/time R object.\nRename the EVENT_TYPE column as type.\nRename the DEATHS_DIRECT column as deaths.\n\n\nlibrary(dplyr)\n\n# try it yourself\n\n\n\nNext, we do some wrangling to create a storm_sub data frame (code chunk set to echo=FALSE for the purposes of the lecture, but code is in the R Markdown).\n\nstorm_sub\n\n# A tibble: 52,409 × 3\n begin type deaths\n <dttm> <chr> <dbl>\n 1 2004-12-29 18:00:00 Heavy Snow 0\n 2 2004-12-29 18:00:00 Heavy Snow 0\n 3 2004-12-08 18:00:00 Winter Storm 0\n 4 2004-12-19 15:00:00 High Wind 0\n 5 2004-12-14 06:00:00 Winter Weather 0\n 6 2004-12-21 04:00:00 Winter Storm 0\n 7 2004-12-21 04:00:00 Winter Storm 0\n 8 2004-12-26 15:00:00 Winter Storm 0\n 9 2004-12-26 15:00:00 Winter Storm 0\n10 2004-12-11 08:00:00 Storm Surge/Tide 0\n# ℹ 52,399 more rows"
},
{
- "objectID": "posts/16-functions/index.html",
- "href": "posts/16-functions/index.html",
- "title": "16 - Functions",
+ "objectID": "posts/20-working-with-dates-and-times/index.html#histograms-of-datestimes",
+ "href": "posts/20-working-with-dates-and-times/index.html#histograms-of-datestimes",
+ "title": "20 - Working with dates and times",
+ "section": "Histograms of Dates/Times",
+ "text": "Histograms of Dates/Times\nWe can make a histogram of the dates/times to get a sense of when storm events occur.\n\nlibrary(ggplot2)\nstorm_sub %>%\n ggplot(aes(x = begin)) +\n geom_histogram(bins = 20) +\n theme_bw()\n\n\n\n\nWe can group by event type too.\n\nlibrary(ggplot2)\nstorm_sub %>%\n ggplot(aes(x = begin)) +\n facet_wrap(~type) +\n geom_histogram(bins = 20) +\n theme_bw() +\n theme(axis.text.x.bottom = element_text(angle = 90))"
+ },
+ {
+ "objectID": "posts/20-working-with-dates-and-times/index.html#scatterplots-of-datestimes",
+ "href": "posts/20-working-with-dates-and-times/index.html#scatterplots-of-datestimes",
+ "title": "20 - Working with dates and times",
+ "section": "Scatterplots of Dates/Times",
+ "text": "Scatterplots of Dates/Times\n\nstorm_sub %>%\n ggplot(aes(x = begin, y = deaths)) +\n geom_point()\n\n\n\n\nIf we focus on a single month, the x-axis adapts.\n\nstorm_sub %>%\n filter(month(begin) == 6) %>%\n ggplot(aes(begin, deaths)) +\n geom_point()\n\n\n\n\nSimilarly, we can focus on a single day.\n\nstorm_sub %>%\n filter(month(begin) == 6, day(begin) == 16) %>%\n ggplot(aes(begin, deaths)) +\n geom_point()"
+ },
+ {
+ "objectID": "posts/11-plotting-systems/index.html",
+ "href": "posts/11-plotting-systems/index.html",
+ "title": "11 - Plotting Systems",
"section": "",
"text": "This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history."
},
{
- "objectID": "posts/16-functions/index.html#functions-in-r",
- "href": "posts/16-functions/index.html#functions-in-r",
- "title": "16 - Functions",
- "section": "Functions in R",
- "text": "Functions in R\nFunctions in R are “first class objects”, which means that they can be treated much like any other R object.\n\n\n\n\n\n\nImportant facts about R functions\n\n\n\n\nFunctions can be passed as arguments to other functions.\n\nThis is very handy for the various apply functions, like lapply() and sapply().\n\nFunctions can be nested, so that you can define a function inside of another function.\n\n\n\nIf you are familiar with common language like C, these features might appear a bit strange. However, they are really important in R and can be useful for data analysis."
+ "objectID": "posts/11-plotting-systems/index.html#the-base-plotting-system",
+ "href": "posts/11-plotting-systems/index.html#the-base-plotting-system",
+ "title": "11 - Plotting Systems",
+ "section": "The Base Plotting System",
+ "text": "The Base Plotting System\nThe base plotting system is the original plotting system for R. The basic model is sometimes referred to as the “artist’s palette” model.\nThe idea is you start with blank canvas and build up from there.\nIn more R-specific terms, you typically start with plot() function (or similar plot creating function) to initiate a plot and then annotate the plot with various annotation functions (text, lines, points, axis)\nThe base plotting system is often the most convenient plotting system to use because it mirrors how we sometimes think of building plots and analyzing data.\nIf we do not have a completely well-formed idea of how we want to look at some data, often we will start by “throwing some data on the page” and then slowly add more information to it as our thought process evolves.\n\n\n\n\n\n\nExample\n\n\n\nWe might look at a simple scatterplot and then decide to add a linear regression line or a smoother to it to highlight the trends.\n\ndata(airquality)\nwith(airquality, {\n plot(Temp, Ozone)\n lines(loess.smooth(Temp, Ozone))\n})\n\n\n\n\nScatterplot with loess curve\n\n\n\n\n\n\nIn the code above:\n\nThe plot() function creates the initial plot and draws the points (circles) on the canvas.\nThe lines function is used to annotate or add to the plot (in this case it adds a loess smoother to the scatterplot).\n\nNext, we use the plot() function to draw the points on the scatterplot and then use the main argument to add a main title to the plot.\n\ndata(airquality)\nwith(airquality, {\n plot(Temp, Ozone, main = \"my plot\")\n lines(loess.smooth(Temp, Ozone))\n})\n\n\n\n\nScatterplot with loess curve\n\n\n\n\n\n\n\n\n\n\nNote\n\n\n\nOne downside with constructing base plots is that you cannot go backwards once the plot has started.\nIt is possible that you could start down the road of constructing a plot and realize later (when it is too late) that you do not have enough room to add a y-axis label or something like that\n\n\nIf you have specific plot in mind, there is then a need to plan in advance to make sure, for example, that you have set your margins to be the right size to fit all of the annotations that you may want to include.\nWhile the base plotting system is nice in that it gives you the flexibility to specify these kinds of details to painstaking accuracy, sometimes it would be nice if the system could just figure it out for you.\n\n\n\n\n\n\nNote\n\n\n\nAnother downside of the base plotting system is that it is difficult to describe or translate a plot to others because there is no clear graphical language or grammar that can be used to communicate what you have done.\nThe only real way to describe what you have done in a base plot is to just list the series of commands/functions that you have executed, which is not a particularly compact way of communicating things.\nThis is one problem that the ggplot2 package attempts to address.\n\n\n\n\n\n\n\n\nExample\n\n\n\nAnother typical base plot is constructed with the following code.\n\ndata(cars)\n\n## Create the plot / draw canvas\nwith(cars, plot(speed, dist))\n\n## Add annotation\ntitle(\"Speed vs. Stopping distance\")\n\n\n\n\nBase plot with title\n\n\n\n\n\n\nWe will go into more detail on what these functions do in later lessons."
},
{
- "objectID": "posts/16-functions/index.html#your-first-function",
- "href": "posts/16-functions/index.html#your-first-function",
- "title": "16 - Functions",
- "section": "Your First Function",
- "text": "Your First Function\nFunctions are defined using the function() directive and are stored as R objects just like anything else.\n\n\n\n\n\n\nImportant\n\n\n\nIn particular, functions are R objects of class function.\nHere’s a simple function that takes no arguments and does nothing.\n\nf <- function() {\n ## This is an empty function\n}\n## Functions have their own class\nclass(f)\n\n[1] \"function\"\n\n## Execute this function\nf()\n\nNULL\n\n\n\n\nNot very interesting, but it is a start!\nThe next thing we can do is create a function that actually has a non-trivial function body.\n\nf <- function() {\n # this is the function body\n hello <- \"Hello, world!\\n\"\n cat(hello)\n}\nf()\n\nHello, world!\n\n\n\n\n\n\n\n\nPro-tip\n\n\n\ncat() is useful and preferable to print() in several settings. One reason is that it doesn’t output new lines (i.e. \\n).\n\nhello <- \"Hello, world!\\n\"\n\nprint(hello)\n\n[1] \"Hello, world!\\n\"\n\ncat(hello)\n\nHello, world!\n\n\n\n\nThe last aspect of a basic function is the function arguments.\nThese are the options that you can specify to the user that the user may explicitly set.\nFor this basic function, we can add an argument that determines how many times “Hello, world!” is printed to the console.\n\nf <- function(num) {\n for (i in seq_len(num)) {\n hello <- \"Hello, world!\\n\"\n cat(hello)\n }\n}\nf(3)\n\nHello, world!\nHello, world!\nHello, world!\n\n\nObviously, we could have just cut-and-pasted the cat(\"Hello, world!\\n\") code three times to achieve the same effect, but then we wouldn’t be programming, would we?\nAlso, it would be un-neighborly of you to give your code to someone else and force them to cut-and-paste the code however many times the need to see “Hello, world!”.\n\n\n\n\n\n\nPro-tip\n\n\n\nIf you find yourself doing a lot of cutting and pasting, that’s usually a good sign that you might need to write a function.\n\n\nFinally, the function above doesn’t return anything.\nIt just prints “Hello, world!” to the console num number of times and then exits.\nBut often it is useful if a function returns something that perhaps can be fed into another section of code.\nThis next function returns the total number of characters printed to the console.\n\nf <- function(num) {\n hello <- \"Hello, world!\\n\"\n for (i in seq_len(num)) {\n cat(hello)\n }\n chars <- nchar(hello) * num\n chars\n}\nmeaningoflife <- f(3)\n\nHello, world!\nHello, world!\nHello, world!\n\nprint(meaningoflife)\n\n[1] 42\n\n\nIn the above function, we did not have to indicate anything special in order for the function to return the number of characters.\nIn R, the return value of a function is always the very last expression that is evaluated.\nBecause the chars variable is the last expression that is evaluated in this function, that becomes the return value of the function.\n\n\n\n\n\n\nNote\n\n\n\nThere is a return() function that can be used to return an explicitly value from a function, but it is rarely used in R (we will discuss it a bit later in this lesson).\n\n\nFinally, in the above function, the user must specify the value of the argument num. If it is not specified by the user, R will throw an error.\n\nf()\n\nError in f(): argument \"num\" is missing, with no default\n\n\nWe can modify this behavior by setting a default value for the argument num.\nAny function argument can have a default value, if you wish to specify it.\nSometimes, argument values are rarely modified (except in special cases) and it makes sense to set a default value for that argument. This relieves the user from having to specify the value of that argument every single time the function is called.\nHere, for example, we could set the default value for num to be 1, so that if the function is called without the num argument being explicitly specified, then it will print “Hello, world!” to the console once.\n\nf <- function(num = 1) {\n hello <- \"Hello, world!\\n\"\n for (i in seq_len(num)) {\n cat(hello)\n }\n chars <- nchar(hello) * num\n chars\n}\n\n\nf() ## Use default value for 'num'\n\nHello, world!\n\n\n[1] 14\n\nf(2) ## Use user-specified value\n\nHello, world!\nHello, world!\n\n\n[1] 28\n\n\nRemember that the function still returns the number of characters printed to the console.\n\n\n\n\n\n\nPro-tip\n\n\n\nThe formals() function returns a list of all the formal arguments of a function\n\nformals(f)\n\n$num\n[1] 1"
+ "objectID": "posts/11-plotting-systems/index.html#the-lattice-system",
+ "href": "posts/11-plotting-systems/index.html#the-lattice-system",
+ "title": "11 - Plotting Systems",
+ "section": "The Lattice System",
+ "text": "The Lattice System\nThe lattice plotting system is implemented in the lattice R package which comes with every installation of R (although it is not loaded by default).\nTo use the lattice plotting functions, you must first load the lattice package with the library function.\n\nlibrary(lattice)\n\nWith the lattice system, plots are created with a single function call, such as xyplot() or bwplot().\nThere is no real distinction between functions that create or initiate plots and functions that annotate plots because it all happens at once.\nLattice plots tend to be most useful for conditioning types of plots, i.e. looking at how y changes with x across levels of z.\n\ne.g. these types of plots are useful for looking at multi-dimensional data and often allow you to squeeze a lot of information into a single window or page.\n\nAnother aspect of lattice that makes it different from base plotting is that things like margins and spacing are set automatically.\nThis is possible because entire plot is specified at once via a single function call, so all of the available information needed to figure out the spacing and margins is already there.\n\n\n\n\n\n\nExample\n\n\n\nHere is a lattice plot that looks at the relationship between life expectancy and income and how that relationship varies by region in the United States.\n\nstate <- data.frame(state.x77, region = state.region)\nxyplot(Life.Exp ~ Income | region, data = state, layout = c(4, 1))\n\n\n\n\nLattice plot\n\n\n\n\n\n\nYou can see that the entire plot was generated by the call to xyplot() and all of the data for the plot were stored in the state data frame.\nThe plot itself contains four panels—one for each region—and within each panel is a scatterplot of life expectancy and income.\nThe notion of panels comes up a lot with lattice plots because you typically have many panels in a lattice plot (each panel typically represents a condition, like “region”).\n\n\n\n\n\n\nNote\n\n\n\nDownsides with the lattice system\n\nIt can sometimes be very awkward to specify an entire plot in a single function call (you end up with functions with many many arguments).\nAnnotation in panels in plots is not especially intuitive and can be difficult to explain. In particular, the use of custom panel functions and subscripts can be difficult to wield and requires intense preparation.\nOnce a plot is created, you cannot “add” to the plot (but of course you can just make it again with modifications)."
},
{
- "objectID": "posts/16-functions/index.html#summary",
- "href": "posts/16-functions/index.html#summary",
- "title": "16 - Functions",
- "section": "Summary",
- "text": "Summary\nWe have written a function that\n\nhas one formal argument named num with a default value of 1. The formal arguments are the arguments included in the function definition.\nprints the message “Hello, world!” to the console a number of times indicated by the argument num\nreturns the number of characters printed to the console"
+ "objectID": "posts/11-plotting-systems/index.html#the-ggplot2-system",
+ "href": "posts/11-plotting-systems/index.html#the-ggplot2-system",
+ "title": "11 - Plotting Systems",
+ "section": "The ggplot2 System",
+ "text": "The ggplot2 System\nThe ggplot2 plotting system attempts to split the difference between base and lattice in a number of ways.\n\n\n\n\n\n\nNote\n\n\n\nTaking cues from lattice, the ggplot2 system automatically deals with spacings, text, titles but also allows you to annotate by “adding” to a plot.\n\n\nThe ggplot2 system is implemented in the ggplot2 package (part of the tidyverse package), which is available from CRAN (it does not come with R).\nYou can install it from CRAN via\n\ninstall.packages(\"ggplot2\")\n\nand then load it into R via the library() function.\n\nlibrary(ggplot2)\n\nSuperficially, the ggplot2 functions are similar to lattice, but the system is generally easier and more intuitive to use.\nThe defaults used in ggplot2 make many choices for you, but you can still customize plots to your heart’s desire.\n\n\n\n\n\n\nExample\n\n\n\nA typical plot with the ggplot2 package looks as follows.\n\nlibrary(tidyverse)\ndata(mpg)\nmpg %>%\n ggplot(aes(displ, hwy)) +\n geom_point()\n\n\n\n\nggplot2 plot\n\n\n\n\n\n\nThere are additional functions in ggplot2 that allow you to make arbitrarily sophisticated plots.\nWe will discuss more about this in the next lecture."
},
{
- "objectID": "posts/16-functions/index.html#named-arguments",
- "href": "posts/16-functions/index.html#named-arguments",
- "title": "16 - Functions",
- "section": "Named arguments",
- "text": "Named arguments\nAbove, we have learned that functions have named arguments, which can optionally have default values.\nBecause all function arguments have names, they can be specified using their name.\n\nf(num = 2)\n\nHello, world!\nHello, world!\n\n\n[1] 28\n\n\nSpecifying an argument by its name is sometimes useful if a function has many arguments and it may not always be clear which argument is being specified.\nHere, our function only has one argument so there’s no confusion."
+ "objectID": "posts/01-welcome/index.html",
+ "href": "posts/01-welcome/index.html",
+ "title": "01 - Welcome!",
+ "section": "",
+ "text": "This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history.\nWelcome! I am very excited to have you in our one-term (i.e. half a semester) course on Statistical Computing course number (140.776) offered by the Department of Biostatistics at the Johns Hopkins Bloomberg School of Public Health. This will be my first time as the lead instructor of a JHBSPH course! 🙌🏽\nThis course is designed for ScM and PhD students at Johns Hopkins Bloomberg School of Public Health. I am pretty flexible about permitting outside students, but I want everyone to be aware of the goals and assumptions so no one feels like they are surprised by how the class works.\nThis class is not designed to teach the theoretical aspects of statistical or computational methods, but rather the goal is to help with the practical issues related to setting up a statistical computing environment for data analyses, developing high-quality R packages, conducting reproducible data analyses, best practices for data visualization and writing code, and creating websites for personal or project use."
},
{
- "objectID": "posts/16-functions/index.html#argument-matching",
- "href": "posts/16-functions/index.html#argument-matching",
- "title": "16 - Functions",
- "section": "Argument matching",
- "text": "Argument matching\nCalling an R function with multiple arguments can be done in a variety of ways.\nThis may be confusing at first, but it’s really handy when doing interactive work at the command line. R functions arguments can be matched positionally or by name.\n\nPositional matching just means that R assigns the first value to the first argument, the second value to second argument, etc.\n\nSo, in the following call to rnorm()\n\nstr(rnorm)\n\nfunction (n, mean = 0, sd = 1) \n\nmydata <- rnorm(100, 2, 1) ## Generate some data\n\n100 is assigned to the n argument, 2 is assigned to the mean argument, and 1 is assigned to the sd argument, all by positional matching.\nThe following calls to the sd() function (which computes the empirical standard deviation of a vector of numbers) are all equivalent.\n\n\n\n\n\n\nNote\n\n\n\nsd(x, na.rm = FALSE) has two arguments:\n\nx indicates the vector of numbers\nna.rm is a logical indicating whether missing values should be removed or not (default is FALSE)\n\n\n## Positional match first argument, default for 'na.rm'\nsd(mydata)\n\n[1] 1.014286\n\n## Specify 'x' argument by name, default for 'na.rm'\nsd(x = mydata)\n\n[1] 1.014286\n\n## Specify both arguments by name\nsd(x = mydata, na.rm = FALSE)\n\n[1] 1.014286\n\n\n\n\nWhen specifying the function arguments by name, it doesn’t matter in what order you specify them.\nIn the example below, we specify the na.rm argument first, followed by x, even though x is the first argument defined in the function definition.\n\n## Specify both arguments by name\nsd(na.rm = FALSE, x = mydata)\n\n[1] 1.014286\n\n\nYou can mix positional matching with matching by name.\nWhen an argument is matched by name, it is “taken out” of the argument list and the remaining unnamed arguments are matched in the order that they are listed in the function definition.\n\nsd(na.rm = FALSE, mydata)\n\n[1] 1.014286\n\n\nHere, the mydata object is assigned to the x argument, because it’s the only argument not yet specified.\n\n\n\n\n\n\nPro-tip\n\n\n\nThe args() function displays the argument names and corresponding default values of a function\n\nargs(f)\n\nfunction (num = 1) \nNULL\n\n\n\n\nBelow is the argument list for the lm() function, which fits linear models to a dataset.\n\nargs(lm)\n\nfunction (formula, data, subset, weights, na.action, method = \"qr\", \n model = TRUE, x = FALSE, y = FALSE, qr = TRUE, singular.ok = TRUE, \n contrasts = NULL, offset, ...) \nNULL\n\n\nThe following two calls are equivalent.\nlm(data = mydata, y ~ x, model = FALSE, 1:100)\nlm(y ~ x, mydata, 1:100, model = FALSE)\n\n\n\n\n\n\nPro-tip\n\n\n\nEven though it’s legal, I don’t recommend messing around with the order of the arguments too much, since it can lead to some confusion.\n\n\nMost of the time, named arguments are helpful:\n\nOn the command line when you have a long argument list and you want to use the defaults for everything except for an argument near the end of the list\nIf you can remember the name of the argument and not its position on the argument list\n\nFor example, plotting functions often have a lot of options to allow for customization, but this makes it difficult to remember exactly the position of every argument on the argument list.\nFunction arguments can also be partially matched, which is useful for interactive work.\n\n\n\n\n\n\nPro-tip\n\n\n\nThe order of operations when given an argument is\n\nCheck for exact match for a named argument\nCheck for a partial match\nCheck for a positional match\n\n\n\nPartial matching should be avoided when writing longer code or programs, because it may lead to confusion if someone is reading the code. However, partial matching is very useful when calling functions interactively that have very long argument names."
+ "objectID": "posts/01-welcome/index.html#disability-support-service",
+ "href": "posts/01-welcome/index.html#disability-support-service",
+ "title": "01 - Welcome!",
+ "section": "Disability Support Service",
+ "text": "Disability Support Service\nStudents requiring accommodations for disabilities should register with Student Disability Service (SDS). It is the responsibility of the student to register for accommodations with SDS. Accommodations take effect upon approval and apply to the remainder of the time for which a student is registered and enrolled at the Bloomberg School of Public Health. Once you are f a student in your class has approved accommodations you will receive formal notification and the student will be encouraged to reach out. If you have questions about requesting accommodations, please contact BSPH.dss@jhu.edu."
},
{
- "objectID": "posts/16-functions/index.html#lazy-evaluation",
- "href": "posts/16-functions/index.html#lazy-evaluation",
- "title": "16 - Functions",
- "section": "Lazy Evaluation",
- "text": "Lazy Evaluation\nArguments to functions are evaluated lazily, so they are evaluated only as needed in the body of the function.\nIn this example, the function f() has two arguments: a and b.\n\nf <- function(a, b) {\n a^2\n}\nf(2)\n\n[1] 4\n\n\nThis function never actually uses the argument b, so calling f(2) will not produce an error because the 2 gets positionally matched to a.\nThis behavior can be good or bad. It’s common to write a function that doesn’t use an argument and not notice it simply because R never throws an error.\nThis example also shows lazy evaluation at work, but does eventually result in an error.\n\nf <- function(a, b) {\n print(a)\n print(b)\n}\nf(45)\n\n[1] 45\n\n\nError in f(45): argument \"b\" is missing, with no default\n\n\nNotice that “45” got printed first before the error was triggered! This is because b did not have to be evaluated until after print(a).\nOnce the function tried to evaluate print(b) the function had to throw an error."
+ "objectID": "posts/01-welcome/index.html#previous-versions-of-the-class",
+ "href": "posts/01-welcome/index.html#previous-versions-of-the-class",
+ "title": "01 - Welcome!",
+ "section": "Previous versions of the class",
+ "text": "Previous versions of the class\n\nhttps://www.stephaniehicks.com/jhustatcomputing2022\nhttps://www.stephaniehicks.com/jhustatcomputing2021\nhttps://rdpeng.github.io/Biostat776"
},
{
- "objectID": "posts/16-functions/index.html#the-...-argument",
- "href": "posts/16-functions/index.html#the-...-argument",
- "title": "16 - Functions",
- "section": "The ... Argument",
- "text": "The ... Argument\nThere is a special argument in R known as the ... argument, which indicates a variable number of arguments that are usually passed on to other functions.\nThe ... argument is often used when extending another function and you do not want to copy the entire argument list of the original function\nFor example, a custom plotting function may want to make use of the default plot() function along with its entire argument list. The function below changes the default for the type argument to the value type = \"l\" (the original default was type = \"p\").\nmyplot <- function(x, y, type = \"l\", ...) {\n plot(x, y, type = type, ...) ## Pass '...' to 'plot' function\n}\nGeneric functions use ... so that extra arguments can be passed to methods.\n\nmean\n\nfunction (x, ...) \nUseMethod(\"mean\")\n<bytecode: 0x1075ea1e8>\n<environment: namespace:base>\n\n\nThe ... argument is necessary when the number of arguments passed to the function cannot be known in advance. This is clear in functions like paste() and cat().\n\npaste(\"one\", \"two\", \"three\")\n\n[1] \"one two three\"\n\npaste(\"one\", \"two\", \"three\", \"four\", \"five\", sep = \"_\")\n\n[1] \"one_two_three_four_five\"\n\n\n\nargs(paste)\n\nfunction (..., sep = \" \", collapse = NULL, recycle0 = FALSE) \nNULL\n\n\nBecause paste() prints out text to the console by combining multiple character vectors together, it is impossible for this function to know in advance how many character vectors will be passed to the function by the user.\nSo the first argument in the function is ...."
+ "objectID": "posts/01-welcome/index.html#typos-and-corrections",
+ "href": "posts/01-welcome/index.html#typos-and-corrections",
+ "title": "01 - Welcome!",
+ "section": "Typos and corrections",
+ "text": "Typos and corrections\nFeel free to submit typos/errors/etc via the GitHub repository associated with the class: https://github.com/lcolladotor/jhustatcomputing2023/issues. You will have the thanks of your grateful instructor!"
},
{
- "objectID": "posts/16-functions/index.html#arguments-coming-after-the-...-argument",
- "href": "posts/16-functions/index.html#arguments-coming-after-the-...-argument",
- "title": "16 - Functions",
- "section": "Arguments Coming After the ... Argument",
- "text": "Arguments Coming After the ... Argument\nOne catch with ... is that any arguments that appear after ... on the argument list must be named explicitly and cannot be partially matched or matched positionally.\nTake a look at the arguments to the paste() function.\n\nargs(paste)\n\nfunction (..., sep = \" \", collapse = NULL, recycle0 = FALSE) \nNULL\n\n\nWith the paste() function, the arguments sep and collapse must be named explicitly and in full if the default values are not going to be used.\nHere, I specify that I want “a” and “b” to be pasted together and separated by a colon.\n\npaste(\"a\", \"b\", sep = \":\")\n\n[1] \"a:b\"\n\n\nIf I don’t specify the sep argument in full and attempt to rely on partial matching, I don’t get the expected result.\n\npaste(\"a\", \"b\", se = \":\")\n\n[1] \"a b :\""
+ "objectID": "posts/03-introduction-to-gitgithub/index.html",
+ "href": "posts/03-introduction-to-gitgithub/index.html",
+ "title": "03 - Introduction to git/GitHub",
+ "section": "",
+ "text": "This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history.\n\n\nPre-lecture materials\n\nRead ahead\n\n\n\n\n\n\nRead ahead\n\n\n\nBefore class, you can prepare by reading the following materials:\n\nHappy Git with R from Jenny Bryan\nChapter on git and GitHub in dsbook from Rafael Irizarry\n\n\n\n\n\nAcknowledgements\nMaterial for this lecture was borrowed and adopted from\n\nhttps://andreashandel.github.io/MADAcourse\n\n\n\n\nLearning objectives\n\n\n\n\n\n\nLearning objectives\n\n\n\nAt the end of this lesson you will:\n\nKnow what Git and GitHub are.\nKnow why one might want to use them.\nHave created and set up a GitHub account.\n\n\n\n\n\nIntroduction to git/GitHub\nThis document gives a brief explanation of GitHub and how we will use it for this course.\n\ngit\nGit is what is called a version control system for file management. The main idea is that as you (and your collaborators) work on a project, the software tracks, and records any changes made by anyone.\n\nSimilar to the “track changes” features in Microsoft Word, but more rigorous, powerful, and scaled up to multiple files\nGreat for solo or collaborative work\n\n\n\nGitHub\nGitHub is a hosting service on internet for git-aware folders and projects\n\nSimilar to the DropBox or Google, but more structured, powerful, and programmatic\nGreat for solo or collaborative work!\nTechnically GitHub is distinct from Git. However, GitHub is in some sense the interface and Git the underlying engine (a bit like RStudio and R).\n\nSince we will only be using Git through GitHub, I tend to not distinguish between the two. In the following, I refer to all of it as just GitHub. Note that other interfaces to Git exist, e.g., Bitbucket, but GitHub is the most widely used one.\n\n\nWhy use git/GitHub?\nYou want to use GitHub to avoid this:\n\n\n\n\n\nHow not to use GitHub [image from PhD Comics]\n\n\n\n\n[Source: PhD Comics]\nGitHub gives you a clean way to track your projects. It is also very well suited to collaborative work. Historically, version control was used for software development. However, it has become broader and is now used for many types of projects, including data science projects.\nTo learn a bit more about Git/GitHub and why you might want to use it, read this article by Jenny Bryan.\nNote her explanation of what’s special with the README.md file on GitHub.\n\n\nWhat to (not) do\nGitHub is ideal if you have a project with a fair number of files, most of those files are text files (such as code, \\(LaTeX\\), (R)markdown, etc.) and different people work on different parts of the project.\nGitHub is less useful if you have a lot of non-text files (e.g. Word or Powerpoint) and different team members might want to edit the same document at the same time. In that instance, a solution like Google Docs, Word+Dropbox, Word+Onedrive, etc. might be better.\n\n\nHow to use Git/GitHub\nGit and GitHub is fundamentally based on commands you type into the command line. Lots of online resources show you how to use the command line. This is the most powerful, and the way I almost always interact with git/GitHub. However, many folks find this the most confusing way to use git/GitHub. Alternatively, there are graphical interfaces.\n\nGitHub itself provides a grapical interface with basic functionality.\nRStudio also has Git/GitHub integration. Of course this only works for R project GitHub integration.\nThere are also third party GitHub clients with many advanced features, most of which you won’t need initially, but might eventually.\n\nNote: As student, you can (and should) upgrade to the Pro version of GitHub for free (i.e. access to unlimited private repositories is one benefit), see the GitHub student developer pack on how to do this.\nWe will mostly be using Git commands through the RStudio Git panel. This panel will show up by default if RStudio recognizes that you have installed Git already.\n\n\n\nGetting Started\nOne of my favorite resources for getting started with git/GitHub is the Happy Git with R from Jenny Bryan:\n\nhttps://happygitwithr.com\n\n\n\n\n\n\nA screenshot of the Happy Git with R online book from Jenny Bryan\n\n\n\n\nIt truly is one of the best resources out there for getting started with git/GitHub, especially with the integration to RStudio. Therefore, at this point, I will encourage all of you to go read through the online book.\nSome of you may only need to skim it, others will need to spend some time reading through it. Either way, I will bet that you won’t regret the time investment.\nAlternatively, check the git to know git: an 8 minute introduction blog post by Amy Peterson.\n\n\nUsing git/GitHub in our course\nIn this course, you will use git/GitHub in the following ways:\n\nProject 0 (optional) - You will create a website introducing yourself to folks in the course and deploy it on GitHub.\nProjects 1-3 - You can practice using git locally (on your compute environment) to track your changes over time and, if you wish (but highly suggested), you can practice pushing your project solutions to a private GitHub repository on your GitHub account (i.e. git add, git commit, git push, git pull, etc) .\n\nLearning these skills will be useful down the road if you ever work collaboratively on a project (i.e. writing code as a group). In this scenario, you will use the skills you have been practicing in your projects to work together as a team in a single GitHub repository.\n\n\n“Help me help you”: reprex::reprex()\nInstall the reprex R package.\n\ninstall.packages(\"reprex\")\n\n\nWe’ll learn more about reproducible code soon. But in the meantime, you will definitely want to learn about reprex: Prepare Reproducible Example Code via the Clipboard.\nAs a quick exercise:\n\nInstall reprex\nLog in to your GitHub account and access https://github.com/lcolladotor/jhustatcomputing2023/issues/2\nCopy paste the following R code stop(\"This R error is weird\").\nType reprex::reprex() in your R console.\nPaste the output into https://github.com/lcolladotor/jhustatcomputing2023/issues/2 and click on the “comment” green button.\n\nHere is an actual example where I used reprex to ask a question: https://github.com/Bioconductor/BiocFileCache/issues/48.\nFor more details on reprex, check this video:\n\n\n\n\nPost-lecture materials\n\nFinal Questions\nHere are some post-lecture questions to help you think about the material discussed.\n\n\n\n\n\n\nQuestions\n\n\n\n\nWhat is version control?\nWhat is the difference between git and GitHub?\nWhat are other version controls software/tools that are available besides git?\n\n\n\n\n\nAdditional Resources\n\n\n\n\n\n\nTip\n\n\n\n\ngit and GitHub in the dsbook by Rafael Irizarry\n\n\n\n\n\n\nR session information\n\noptions(width = 120)\nsessioninfo::session_info()\n\n─ Session info ───────────────────────────────────────────────────────────────────────────────────────────────────────\n setting value\n version R version 4.3.1 (2023-06-16)\n os macOS Ventura 13.5\n system aarch64, darwin20\n ui X11\n language (EN)\n collate en_US.UTF-8\n ctype en_US.UTF-8\n tz America/Mexico_City\n date 2023-08-29\n pandoc 3.1.5 @ /opt/homebrew/bin/ (via rmarkdown)\n\n─ Packages ───────────────────────────────────────────────────────────────────────────────────────────────────────────\n package * version date (UTC) lib source\n cli 3.6.1 2023-03-23 [1] CRAN (R 4.3.0)\n colorout 1.2-2 2023-05-06 [1] Github (jalvesaq/colorout@79931fd)\n digest 0.6.33 2023-07-07 [1] CRAN (R 4.3.0)\n evaluate 0.21 2023-05-05 [1] CRAN (R 4.3.0)\n fastmap 1.1.1 2023-02-24 [1] CRAN (R 4.3.0)\n htmltools 0.5.6 2023-08-10 [1] CRAN (R 4.3.0)\n htmlwidgets 1.6.2 2023-03-17 [1] CRAN (R 4.3.0)\n jsonlite 1.8.7 2023-06-29 [1] CRAN (R 4.3.0)\n knitr 1.43 2023-05-25 [1] CRAN (R 4.3.0)\n rlang 1.1.1 2023-04-28 [1] CRAN (R 4.3.0)\n rmarkdown 2.24 2023-08-14 [1] CRAN (R 4.3.1)\n rstudioapi 0.15.0 2023-07-07 [1] CRAN (R 4.3.0)\n sessioninfo 1.2.2 2021-12-06 [1] CRAN (R 4.3.0)\n xfun 0.40 2023-08-09 [1] CRAN (R 4.3.0)\n yaml 2.3.7 2023-01-23 [1] CRAN (R 4.3.0)\n\n [1] /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/library\n\n──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────"
},
{
- "objectID": "posts/16-functions/index.html#the-name-of-a-function-is-important",
- "href": "posts/16-functions/index.html#the-name-of-a-function-is-important",
- "title": "16 - Functions",
- "section": "The name of a function is important",
- "text": "The name of a function is important\nIn an ideal world, you want the name of your function to be short but clearly describe what the function does. This is not always easy, but here are some tips.\nThe function names should be verbs, and arguments should be nouns.\nThere are some exceptions:\n\nnouns are ok if the function computes a very well known noun (i.e. mean() is better than compute_mean()).\nA good sign that a noun might be a better choice is if you are using a very broad verb like “get”, “compute”, “calculate”, or “determine”. Use your best judgement and do not be afraid to rename a function if you figure out a better name later.\n\n\n# Too short\nf()\n\n# Not a verb, or descriptive\nmy_awesome_function()\n\n# Long, but clear\nimpute_missing()\ncollapse_years()"
+ "objectID": "posts/02-introduction-to-r-and-rstudio/index.html",
+ "href": "posts/02-introduction-to-r-and-rstudio/index.html",
+ "title": "02 - Introduction to R and RStudio!",
+ "section": "",
+ "text": "This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history.\n\nThere are only two kinds of languages: the ones people complain about and the ones nobody uses. —Bjarne Stroustrup\n\n\nPre-lecture materials\n\nRead ahead\n\n\n\n\n\n\nRead ahead\n\n\n\nBefore class, you can prepare by reading the following materials:\n\nAn overview and history of R from Roger Peng\nInstalling R and RStudio from Rafael Irizarry\nGetting Started in R and RStudio from Rafael Irizarry\n\n\n\n\n\nAcknowledgements\nMaterial for this lecture was borrowed and adopted from\n\nhttps://rdpeng.github.io/Biostat776/lecture-introduction-and-overview.html\nhttps://rafalab.github.io/dsbook\nhttps://rmd4sci.njtierney.com\nhttps://andreashandel.github.io/MADAcourse\n\n\n\n\nLearning objectives\n\n\n\n\n\n\nLearning objectives\n\n\n\nAt the end of this lesson you will:\n\nLearn about (some of) the history of R.\nIdentify some of the strengths and weaknesses of R.\nInstall R and Rstudio on your computer.\nKnow how to install and load R packages.\n\n\n\n\n\nOverview and history of R\nBelow is a very quick introduction to R, to get you set up and running. We’ll go deeper into R and coding later.\n\ntl;dr (R in a nutshell)\nLike every programming language, R has its advantages and disadvantages. If you search the internet, you will quickly discover lots of folks with opinions about R. Some of the features that are useful to know are:\n\nR is open-source, freely accessible, and cross-platform (multiple OS).\nR is a “high-level” programming language, relatively easy to learn.\n\nWhile “Low-level” programming languages (e.g. Fortran, C, etc) often have more efficient code, they can also be harder to learn because it is designed to be close to a machine language.\nIn contrast, high-level languages deal more with variables, objects, functions, loops, and other abstract CS concepts with a focus on usability over optimal program efficiency.\n\nR is great for statistics, data analysis, websites, web apps, data visualizations, and so much more!\nR integrates easily with document preparation systems like \\(\\LaTeX\\), but R files can also be used to create .docx, .pdf, .html, .ppt files with integrated R code output and graphics.\nThe R Community is very dynamic, helpful and welcoming.\n\nCheck out the #rstats or #rtistry on Twitter, TidyTuesday podcast and community activity in the R4DS Online Learning Community, and r/rstats subreddit.\nIf you are looking for more local resources, check out R-Ladies Baltimore.\n\nThrough R packages, it is easy to get lots of state-of-the-art algorithms.\nDocumentation and help files for R are generally good.\n\nWhile we use R in this course, it is not the only option to analyze data. Maybe the most similar to R, and widely used, is Python, which is also free. There is also commercial software that can be used to analyze data (e.g., Matlab, Mathematica, Tableau, SAS, SPSS). Other more general programming languages are suitable for certain types of analyses as well (e.g., C, Fortran, Perl, Java, Julia).\nDepending on your future needs or jobs, you might have to learn one or several of those additional languages. The good news is that even though those languages are all different, they all share general ways of thinking and structuring code. So once you understand a specific concept (e.g., variables, loops, branching statements or functions), it applies to all those languages. Thus, learning a new programming language is much easier once you already know one. And R is a good one to get started with.\nWith the skills gained in this course, hopefully you will find R a fun and useful programming language for your future projects.\n\n\n\nArtwork by Allison Horst on learning R\n\n\n[Source: Artwork by Allison Horst]\n\n\nBasic Features of R\nToday R runs on almost any standard computing platform and operating system. Its open source nature means that anyone is free to adapt the software to whatever platform they choose. Indeed, R has been reported to be running on modern tablets, phones, PDAs, and game consoles.\nOne nice feature that R shares with many popular open source projects is frequent releases. These days there is a major annual release, typically at the end of April, where major new features are incorporated and released to the public. Throughout the year, smaller-scale bugfix releases will be made as needed. The frequent releases and regular release cycle indicates active development of the software and ensures that bugs will be addressed in a timely manner. Of course, while the core developers control the primary source tree for R, many people around the world make contributions in the form of new feature, bug fixes, or both.\nAnother key advantage that R has over many other statistical packages (even today) is its sophisticated graphics capabilities. R’s ability to create “publication quality” graphics has existed since the very beginning and has generally been better than competing packages. Today, with many more visualization packages available than before, that trend continues. R’s base graphics system allows for very fine control over essentially every aspect of a plot or graph. Other newer graphics systems, like lattice (not as used nowadays) and ggplot2 (very widely used now) allow for complex and sophisticated visualizations of high-dimensional data.\nR has maintained the original S philosophy (see box below), which is that it provides a language that is both useful for interactive work, but contains a powerful programming language for developing new tools. This allows the user, who takes existing tools and applies them to data, to slowly but surely become a developer who is creating new tools.\n\n\n\n\n\n\nTip\n\n\n\nFor a great discussion on an overview and history of R and the S programming language, read through this chapter from Roger D. Peng.\n\n\nFinally, one of the joys of using R has nothing to do with the language itself, but rather with the active and vibrant user community. In many ways, a language is successful inasmuch as it creates a platform with which many people can create new things. R is that platform and thousands of people around the world have come together to make contributions to R, to develop packages, and help each other use R for all kinds of applications. The R-help and R-devel mailing lists have been highly active for over a decade now and there is considerable activity on web sites like GitHub, Posit (RStudio) Community, Bioconductor Support, Stack Overflow, Twitter #rstats, #rtistry, and Reddit.\n\n\nFree Software\nA major advantage that R has over many other statistical packages and is that it’s free in the sense of free software (it’s also free in the sense of free beer). The copyright for the primary source code for R is held by the R Foundation and is published under the GNU General Public License version 2.0.\nAccording to the Free Software Foundation, with free software, you are granted the following four freedoms\n\nThe freedom to run the program, for any purpose (freedom 0).\nThe freedom to study how the program works, and adapt it to your needs (freedom 1). Access to the source code is a precondition for this.\nThe freedom to redistribute copies so you can help your neighbor (freedom 2).\nThe freedom to improve the program, and release your improvements to the public, so that the whole community benefits (freedom 3). Access to the source code is a precondition for this.\n\n\n\n\n\n\n\nTip\n\n\n\nYou can visit the Free Software Foundation’s web site to learn a lot more about free software. The Free Software Foundation was founded by Richard Stallman in 1985 and Stallman’s personal web site is an interesting read if you happen to have some spare time.\n\n\n\n\nDesign of the R System\nThe primary R system is available from the Comprehensive R Archive Network, also known as CRAN. CRAN also hosts many add-on packages that can be used to extend the functionality of R.\nThe R system is divided into 2 conceptual parts:\n\nThe “base” R system that you download from CRAN:\n\n\nLinux\nWindows\nMac\n\n\nEverything else.\n\nR functionality is divided into a number of packages.\n\nThe “base” R system contains, among other things, the base package which is required to run R and contains the most fundamental functions.\nThe other packages contained in the “base” system include utils, stats, datasets, graphics, grDevices, grid, methods, tools, parallel, compiler, splines, tcltk, stats4.\nThere are also “Recommended” packages: boot, class, cluster, codetools, foreign, KernSmooth, lattice, mgcv, nlme, rpart, survival, MASS, spatial, nnet, Matrix.\n\nWhen you download a fresh installation of R from CRAN, you get all of the above, which represents a substantial amount of functionality. However, there are many other packages available:\n\nThere are over 10,000 packages on CRAN that have been developed by users and programmers around the world.\nThere are also over 2,000 packages associated with the Bioconductor project.\nPeople often make packages available on GitHub (very common) and their personal websites (not so common nowadays); there is no reliable way to keep track of how many packages are available in this fashion.\n\n\n\n\nSlide from 2012 by Roger D. Peng\n\n\n\n\n\n\n\n\nQuestions\n\n\n\n\nHow many R packages are on CRAN today?\nHow many R packages are on Bioconductor today?\nHow many R packages are on GitHub today?\n\n\n\nWant to learn more about Bioconductor? Check this video:\n\n\n\n\nLimitations of R\nNo programming language or statistical analysis system is perfect. R certainly has a number of drawbacks. For starters, R is essentially based on almost 50 year old technology, going back to the original S system developed at Bell Labs. There was originally little built in support for dynamic or 3-D graphics (but things have improved greatly since the “old days”).\nAnother commonly cited limitation of R is that objects must generally be stored in physical memory (though this is increasingly not true anymore). This is in part due to the scoping rules of the language, but R generally is more of a memory hog than other statistical packages. However, there have been a number of advancements to deal with this, both in the R core and also in a number of packages developed by contributors. Also, computing power and capacity has continued to grow over time and amount of physical memory that can be installed on even a consumer-level laptop is substantial. While we will likely never have enough physical memory on a computer to handle the increasingly large datasets that are being generated, the situation has gotten quite a bit easier over time.\nAt a higher level one “limitation” of R is that its functionality is based on consumer demand and (voluntary) user contributions. If no one feels like implementing your favorite method, then it’s your job to implement it (or you need to pay someone to do it). The capabilities of the R system generally reflect the interests of the R user community. As the community has ballooned in size over the past 10 years, the capabilities have similarly increased. When I first started using R, there was very little in the way of functionality for the physical sciences (physics, astronomy, etc.). However, now some of those communities have adopted R and we are seeing more code being written for those kinds of applications.\n\n\n\nUsing R and RStudio\n\nIf R is the engine and bare bones of your car, then RStudio is like the rest of the car. The engine is super critical part of your car. But in order to make things properly functional, you need to have a steering wheel, comfy seats, a radio, rear and side view mirrors, storage, and seatbelts. — Nicholas Tierney\n\n[Source]\nThe RStudio layout has the following features:\n\nOn the upper left, something called a Rmarkdown script\nOn the lower left, the R console\nOn the lower right, the view for files, plots, packages, help, and viewer.\nOn the upper right, the environment / history pane\n\n\n\n\nA screenshot of the RStudio integrated developer environment (IDE) – aka the working environment\n\n\nThe R console is the bit where you can run your code. This is where the R code in your Rmarkdown document gets sent to run (we’ll learn about these files later).\nThe file/plot/pkg viewer is a handy browser for your current files, like Finder, or File Explorer, plots are where your plots appear, you can view packages, see the help files. And the environment / history pane contains the list of things you have created, and the past commands that you have run.\n\nInstalling R and RStudio\n\nIf you have not already, install R first. If you already have R installed, make sure it is a fairly recent version, version 4.3.1 or newer. If yours is older that version 4.2.0, I suggest you update (install a new R version).\nOnce you have R installed, install the free version of RStudio Desktop. Again, make sure it’s a recent version.\n\n\n\n\n\n\n\nTip\n\n\n\nInstalling R and RStudio should be fairly straightforward. However, a great set of detailed instructions is in Rafael Irizarry’s dsbook\n\nhttps://rafalab.github.io/dsbook/installing-r-rstudio.html\n\n\n\nIf things don’t work, ask for help in the Courseplus discussion board.\nI have both a macOS and a winOS computer, and have used Linux (Ubuntu) in the past too, but I might be more limited in how much I can help you on Linux.\n\n\nRStudio default options\nTo first get set up, I highly recommend changing the following setting\nTools > Global Options (or Cmd + , on macOS)\nUnder the General tab:\n\nFor workspace\n\nUncheck restore .RData into workspace at startup\nSave workspace to .RData on exit : “Never”\n\nFor History\n\nUncheck “Always save history (even when not saving .RData)\nUncheck “Remove duplicate entries in history”\n\n\nThis means that you won’t save the objects and other things that you create in your R session and reload them. This is important for two reasons\n\nReproducibility: you don’t want to have objects from last week cluttering your session\nPrivacy: you don’t want to save private data or other things to your session. You only want to read these in.\n\nYour “history” is the commands that you have entered into R.\nAdditionally, not saving your history means that you won’t be relying on things that you typed in the last session, which is a good habit to get into!\n\n\nInstalling and loading R packages\nAs we discussed, most of the functionality and features in R come in the form of add-on packages. There are tens of thousands of packages available, some big, some small, some well documented, some not. We will be using many different packages in this course. Of course, you are free to install and use any package you come across for any of the assignments.\nThe “official” place for packages is the CRAN website. If you are interested in packages on a specific topic, the CRAN task views provide curated descriptions of packages sorted by topic.\nTo install an R package from CRAN, one can simply call the install.packages() function and pass the name of the package as an argument. For example, to install the ggplot2 package from CRAN: open RStudio,go to the R prompt (the > symbol) in the lower-left corner and type\n\ninstall.packages(\"ggplot2\")\n\n## Below is an example for installing more than one package at a time:\n\n## Install R packages for project 0\ninstall.packages(\n c(\"postcards\", \"usethis\", \"gitcreds\")\n)\n\nand the appropriate version of the package will be installed.\nOften, a package needs other packages to work (called dependencies), and they are installed automatically. It usually does not matter if you use a single or double quotation mark around the name of the package.\n\n\n\n\n\n\nQuestions\n\n\n\n\nAs you installed the ggplot2 package, what other packages were installed?\nWhat happens if you tried to install GGplot2?\n\n\n\nIt could be that you already have all packages required by ggplot2 installed. In that case, you will not see any other packages installed. To see which of the packages above ggplot2 needs (and thus installs if it is not present), type into the R console:\n\ntools::package_dependencies(\"ggplot2\")\n\nIn RStudio, you can also install (and update/remove) packages by clicking on the ‘Packages’ tab in the bottom right window.\nIt is very common these days for packages to be developed on GitHub. It is possible to install packages from GitHub directly. Those usually contain the latest version of the package, with features that might not be available yet on the CRAN website. Sometimes, in early development stages, a package is only on GitHub until the developer(s) feel it is good enough for CRAN submission. So installing from GitHub gives you the latest. The downside is that packages under development can often be buggy and not working right. To install packages from GitHub, you need to install the remotes package and then use the following function\n\nremotes::install_github()\n\nWe will not do that now, but it is quite likely that at one point later in this course we will.\nYou only need to install a package once, unless you upgrade/re-install R. Once installed, you still need to load the package before you can use it. That has to happen every time you start a new R session. You do that using the library() command. For instance to load the ggplot2 package, type\n\nlibrary(\"ggplot2\")\n\nYou may or may not see a short message on the screen. Some packages show messages when you load them, and others do not.\nThis was a quick overview of R packages. We will use a lot of them, so you will get used to them rather quickly.\n\n\nGetting started in RStudio\nWhile one can use R and do pretty much every task, including all the ones we cover in this class, without using RStudio, RStudio is very useful, has lots of features that make your R coding life easier and has become pretty much the default integrated development environment (IDE) for R. Since RStudio has lots of features, it takes time to learn them. A good resource to learn more about RStudio are the R Studio Essentials collection of videos.\n\n\n\n\n\n\nTip\n\n\n\nFor more information on setting up and getting started with R, RStudio, and R packages, read the Getting Started chapter in the dsbook:\n\nhttps://rafalab.github.io/dsbook/getting-started.html\n\nThis chapter gives some tips, shortcuts, and ideas that might be of interest even to those of you who already have R and/or RStudio experience.\n\n\n\n\n\nPost-lecture materials\n\nFinal Questions\nHere are some post-lecture questions to help you think about the material discussed.\n\n\n\n\n\n\nQuestions\n\n\n\n\nIf a software company asks you, as a requirement for using their software, to sign a license that restricts you from using their software to commit illegal activities, is this consistent with the “Four Freedoms” of Free Software?\nWhat is an R package and what is it used for?\nWhat function in R can be used to install packages from CRAN?\nWhat is a limitation of the current R system?\n\n\n\n\n\nAdditional Resources\n\n\n\n\n\n\nTip\n\n\n\n\nR for Data Science (2e) by Wickham & Grolemund (2017, 2e is from July 18th 2023). Covers most of the basics of using R for data analysis.\nAdvanced R by Wickham (2014). Covers a number of areas including object-oriented, programming, functional programming, profiling and other advanced topics.\nRStudio IDE cheatsheet\n\n\n\n\n\n\nR session information\n\noptions(width = 120)\nsessioninfo::session_info()\n\n─ Session info ───────────────────────────────────────────────────────────────────────────────────────────────────────\n setting value\n version R version 4.3.1 (2023-06-16)\n os macOS Ventura 13.5\n system aarch64, darwin20\n ui X11\n language (EN)\n collate en_US.UTF-8\n ctype en_US.UTF-8\n tz America/Mexico_City\n date 2023-08-28\n pandoc 3.1.5 @ /opt/homebrew/bin/ (via rmarkdown)\n\n─ Packages ───────────────────────────────────────────────────────────────────────────────────────────────────────────\n package * version date (UTC) lib source\n cli 3.6.1 2023-03-23 [1] CRAN (R 4.3.0)\n colorout 1.2-2 2023-05-06 [1] Github (jalvesaq/colorout@79931fd)\n digest 0.6.33 2023-07-07 [1] CRAN (R 4.3.0)\n evaluate 0.21 2023-05-05 [1] CRAN (R 4.3.0)\n fastmap 1.1.1 2023-02-24 [1] CRAN (R 4.3.0)\n htmltools 0.5.6 2023-08-10 [1] CRAN (R 4.3.0)\n htmlwidgets 1.6.2 2023-03-17 [1] CRAN (R 4.3.0)\n jsonlite 1.8.7 2023-06-29 [1] CRAN (R 4.3.0)\n knitr 1.43 2023-05-25 [1] CRAN (R 4.3.0)\n rlang 1.1.1 2023-04-28 [1] CRAN (R 4.3.0)\n rmarkdown 2.24 2023-08-14 [1] CRAN (R 4.3.1)\n rstudioapi 0.15.0 2023-07-07 [1] CRAN (R 4.3.0)\n sessioninfo 1.2.2 2021-12-06 [1] CRAN (R 4.3.0)\n xfun 0.40 2023-08-09 [1] CRAN (R 4.3.0)\n yaml 2.3.7 2023-01-23 [1] CRAN (R 4.3.0)\n\n [1] /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/library\n\n──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────"
},
{
- "objectID": "posts/16-functions/index.html#snake_case-vs-camelcase",
- "href": "posts/16-functions/index.html#snake_case-vs-camelcase",
- "title": "16 - Functions",
- "section": "snake_case vs camelCase",
- "text": "snake_case vs camelCase\nIf your function name is composed of multiple words, use “snake_case”, where each lowercase word is separated by an underscore.\n“camelCase” is a popular alternative. It does not really matter which one you pick, the important thing is to be consistent: pick one or the other and stick with it.\nR itself is not very consistent, but there is nothing you can do about that. Make sure you do not fall into the same trap by making your code as consistent as possible.\n\n# Never do this!\ncol_mins <- function(x, y) {}\nrowMaxes <- function(x, y) {}"
+ "objectID": "posts/06-reference-management/index.html",
+ "href": "posts/06-reference-management/index.html",
+ "title": "06 - Reference management",
+ "section": "",
+ "text": "This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history.\n\n\nPre-lecture materials\n\nRead ahead\n\n\n\n\n\n\nRead ahead\n\n\n\nBefore class, you can prepare by reading the following materials:\n\nAuthoring in R Markdown from RStudio\nCitations from Reproducible Research in R from the Monash Data Fluency initiative\nBibliography from R Markdown Cookbook\n\n\n\n\n\nAcknowledgements\nMaterial for this lecture was borrowed and adopted from\n\nhttps://andreashandel.github.io/MADAcourse\nhttps://rmarkdown.rstudio.com/authoring_bibliographies_and_citations.html\nhttps://bookdown.org/yihui/rmarkdown-cookbook/bibliography.html\nhttps://monashdatafluency.github.io/r-rep-res/citations.html\n\n\n\n\nLearning objectives\n\n\n\n\n\n\nLearning objectives\n\n\n\nAt the end of this lesson you will:\n\nKnow what types of bibliography file formats can be used in a R Markdown file\nLearn how to add citations to a R Markdown file\nKnow how to change the citation style (e.g. APA, Chicago, etc)\n\n\n\n\n\nIntroduction\nFor almost any data analysis, especially if it is meant for publication in the academic literature, you will have to cite other people’s work and include the references (bibliographies or citations) in your work. In this class, you are likely to need to include references and cite other people’s work like in a regular research paper.\nR provides nice function citation() that helps us generating citation blob for R packages that we have used. Let’s try generating citation text for rmarkdown package by using the following command\n\ncitation(\"rmarkdown\")\n\nTo cite package 'rmarkdown' in publications use:\n\n Allaire J, Xie Y, Dervieux C, McPherson J, Luraschi J, Ushey K,\n Atkins A, Wickham H, Cheng J, Chang W, Iannone R (2023). _rmarkdown:\n Dynamic Documents for R_. R package version 2.24,\n <https://github.com/rstudio/rmarkdown>.\n\n Xie Y, Allaire J, Grolemund G (2018). _R Markdown: The Definitive\n Guide_. Chapman and Hall/CRC, Boca Raton, Florida. ISBN\n 9781138359338, <https://bookdown.org/yihui/rmarkdown>.\n\n Xie Y, Dervieux C, Riederer E (2020). _R Markdown Cookbook_. Chapman\n and Hall/CRC, Boca Raton, Florida. ISBN 9780367563837,\n <https://bookdown.org/yihui/rmarkdown-cookbook>.\n\nTo see these entries in BibTeX format, use 'print(<citation>,\nbibtex=TRUE)', 'toBibtex(.)', or set\n'options(citation.bibtex.max=999)'.\n\n\nI assume you are familiar with how citing references works, and hopefully, you are already using a reference manager. If not, let me know in the discussion boards.\nTo have something that plays well with R Markdown, you need file format that stores all the references. Click here to learn more other possible file formats available to you to use within a R Markdown file:\n\nhttps://rmarkdown.rstudio.com/authoring_bibliographies_and_citations.html\n\n\nCitation management software\nAs you can see, there are ton of file formats including .medline (MEDLINE), .bib (BibTeX), .ris (RIS), .enl (EndNote).\nI will not discuss underlying citational management software itself, but I will talk briefly how you might create one of these file formats.\nIf you recall the output from citation(\"rmarkdown\") above, we might consider manually copying and pasting the output into a citation management software, but instead we can use write_bib() function from knitr package to create a bibliography file ending in .bib.\nLet’s run the following code in order to generate a my-refs.bib file\n\nknitr::write_bib(\"rmarkdown\", file = \"my-refs.bib\")\n\nNow we can see we have the file saved locally.\n\nlist.files()\n\n[1] \"index.qmd\" \"index.rmarkdown\" \"my-refs.bib\" \n\n\nIf you open up the my-refs.bib file, you will see\n@Manual{R-rmarkdown,\n title = {rmarkdown: Dynamic Documents for R},\n author = {JJ Allaire and Yihui Xie and Jonathan McPherson and Javier Luraschi and Kevin Ushey and Aron Atkins and Hadley Wickham and Joe Cheng and Winston Chang and Richard Iannone},\n year = {2021},\n note = {R package version 2.8},\n url = {https://CRAN.R-project.org/package=rmarkdown},\n}\n\n@Book{rmarkdown2018,\n title = {R Markdown: The Definitive Guide},\n author = {Yihui Xie and J.J. Allaire and Garrett Grolemund},\n publisher = {Chapman and Hall/CRC},\n address = {Boca Raton, Florida},\n year = {2018},\n note = {ISBN 9781138359338},\n url = {https://bookdown.org/yihui/rmarkdown},\n}\n\n@Book{rmarkdown2020,\n title = {R Markdown Cookbook},\n author = {Yihui Xie and Christophe Dervieux and Emily Riederer},\n publisher = {Chapman and Hall/CRC},\n address = {Boca Raton, Florida},\n year = {2020},\n note = {ISBN 9780367563837},\n url = {https://bookdown.org/yihui/rmarkdown-cookbook},\n}\n\nNote there are three keys that we will use later on:\n\nR-rmarkdown\nrmarkdown2018\nrmarkdown2020\n\n\n\n\nLinking .bib file with .rmd (and .qmd) files\nIn order to use references within a R Markdown file, you will need to specify the name and a location of a bibliography file using the bibliography metadata field in a YAML metadata section. For example:\n---\ntitle: \"My top ten favorite R packages\"\noutput: html_document\nbibliography: my-refs.bib\n---\nYou can include multiple reference files using the following syntax, alternatively you can concatenate two bib files into one.\n---\nbibliography: [\"my-refs1.bib\", \"my-refs2.bib\"]\n---\n\n\nInline citation\nNow we can start using those bib keys that we have learned just before, using the following syntax\n\n[@key] for single citation\n[@key1; @key2] multiple citation can be separated by semi-colon\n[-@key] in order to suppress author name, and just display the year\n[see @key1 p 12; also this ref @key2] is also a valid syntax\n\nLet’s start by citing the rmarkdown package using the following code and press Knit button:\n\nI have been using the amazing Rmarkdown package (Allaire et al. 2023)! I should also go and read (Xie, Allaire, and Grolemund 2018; and Xie, Dervieux, and Riederer 2020) books.\n\nPretty cool, eh??\n\n\nCitation styles\nBy default, Pandoc will use a Chicago author-date format for citations and references.\nTo use another style, you will need to specify a CSL (Citation Style Language) file in the csl metadata field, e.g.,\n---\ntitle: \"My top ten favorite R packages\"\noutput: html_document\nbibliography: my-refs.bib\ncsl: biomed-central.csl\n---\n\nTo find your required formats, we recommend using the Zotero Style Repository, which makes it easy to search for and download your desired style.\n\nCSL files can be tweaked to meet custom formatting requirements. For example, we can change the number of authors required before “et al.” is used to abbreviate them. This can be simplified through the use of visual editors such as the one available at https://editor.citationstyles.org.\n\n\nOther cool features\n\nAdd an item to a bibliography without using it\nBy default, the bibliography will only display items that are directly referenced in the document. If you want to include items in the bibliography without actually citing them in the body text, you can define a dummy nocite metadata field and put the citations there.\n---\nnocite: |\n @item1, @item2\n---\n\n\nAdd all items to the bibliography\nIf we do not wish to explicitly state all of the items within the bibliography but would still like to show them in our references, we can use the following syntax:\n---\nnocite: '@*'\n---\nThis will force all items to be displayed in the bibliography.\n\nYou can also have an appendix appear after bibliography. For more on this, see:\n\nhttps://bookdown.org/yihui/rmarkdown-cookbook/bibliography.html\n\n\n\n\n\n\nOther useful tips\nWe have learned that inside your file that contains all your references (e.g. my-refs.bib), typically each reference gets a key, which is a shorthand that is generated by the reference manager or you can create yourself.\nFor instance, I use a format of lower-case first author last name followed by 4 digit year for each reference followed by a keyword (e.g name of a software package). Alternatively, you can omit the keyword. But note that if I cite a paper by the same first author that was published in the same year, then a lower case letter is added to the end. For instance, for a paper that I wrote as 1st author in 2010, my bibtex key might be hicks2022 or hicks2022a. You can decide what scheme to use, just pick one and use it forever.\nIn your R Markdown document, you can then cite the reference by adding the key, such as ...in the paper by Hicks et al. [@hicks2022]....\n\n\nSciWheel\nI use SciWheel for managing citations and writing papers on Google Docs as documented at https://lcolladotor.github.io/bioc_team_ds/writing-papers.html. I mention it here because you can import \\(BibTeX\\) files (.bib) on SciWheel, which can make your life easier if you want to import R package citations that way.\n\n\nPost-lecture materials\n\nPractice\nHere are some post-lecture tasks to practice some of the material discussed.\n\n\n\n\n\n\nQuestions\n\n\n\nTry out the following:\n\nWhat do you notice that’s different when you run citation(\"tidyverse\") (compared to citation(\"rmarkdown\"))?\nInstall the following packages:\n\n\ninstall.packages(c(\"bibtex\", \"RefManageR\"))\n\nWhat do they do? How might they be helpful to you in terms of reference management?\n\nInstead of using a .bib file, try using a different bibliography file format in an R Markdown document.\nPractice using a different CSL file to change the citation style.\n\n\n\n\n\n\nR session information\n\noptions(width = 120)\nsessioninfo::session_info()\n\n─ Session info ───────────────────────────────────────────────────────────────────────────────────────────────────────\n setting value\n version R version 4.3.1 (2023-06-16)\n os macOS Ventura 13.5\n system aarch64, darwin20\n ui X11\n language (EN)\n collate en_US.UTF-8\n ctype en_US.UTF-8\n tz America/Mexico_City\n date 2023-08-29\n pandoc 3.1.5 @ /opt/homebrew/bin/ (via rmarkdown)\n\n─ Packages ───────────────────────────────────────────────────────────────────────────────────────────────────────────\n package * version date (UTC) lib source\n cli 3.6.1 2023-03-23 [1] CRAN (R 4.3.0)\n colorout 1.2-2 2023-05-06 [1] Github (jalvesaq/colorout@79931fd)\n digest 0.6.33 2023-07-07 [1] CRAN (R 4.3.0)\n evaluate 0.21 2023-05-05 [1] CRAN (R 4.3.0)\n fastmap 1.1.1 2023-02-24 [1] CRAN (R 4.3.0)\n htmltools 0.5.6 2023-08-10 [1] CRAN (R 4.3.0)\n htmlwidgets 1.6.2 2023-03-17 [1] CRAN (R 4.3.0)\n jsonlite 1.8.7 2023-06-29 [1] CRAN (R 4.3.0)\n knitr 1.43 2023-05-25 [1] CRAN (R 4.3.0)\n rlang 1.1.1 2023-04-28 [1] CRAN (R 4.3.0)\n rmarkdown 2.24 2023-08-14 [1] CRAN (R 4.3.1)\n rstudioapi 0.15.0 2023-07-07 [1] CRAN (R 4.3.0)\n sessioninfo 1.2.2 2021-12-06 [1] CRAN (R 4.3.0)\n xfun 0.40 2023-08-09 [1] CRAN (R 4.3.0)\n yaml 2.3.7 2023-01-23 [1] CRAN (R 4.3.0)\n\n [1] /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/library\n\n──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────\n\n\n\n\n\n\n\nReferences\n\nAllaire, JJ, Yihui Xie, Christophe Dervieux, Jonathan McPherson, Javier Luraschi, Kevin Ushey, Aron Atkins, et al. 2023. Rmarkdown: Dynamic Documents for r. https://CRAN.R-project.org/package=rmarkdown.\n\n\nXie, Yihui, J. J. Allaire, and Garrett Grolemund. 2018. R Markdown: The Definitive Guide. Boca Raton, Florida: Chapman; Hall/CRC. https://bookdown.org/yihui/rmarkdown.\n\n\nXie, Yihui, Christophe Dervieux, and Emily Riederer. 2020. R Markdown Cookbook. Boca Raton, Florida: Chapman; Hall/CRC. https://bookdown.org/yihui/rmarkdown-cookbook."
},
{
- "objectID": "posts/16-functions/index.html#use-a-common-prefix",
- "href": "posts/16-functions/index.html#use-a-common-prefix",
- "title": "16 - Functions",
- "section": "Use a common prefix",
- "text": "Use a common prefix\nIf you have a family of functions that do similar things, make sure they have consistent names and arguments.\nIt’s a good idea to indicate that they are connected. That is better than a common suffix because autocomplete allows you to type the prefix and see all the members of the family.\n\n# Good\ninput_select()\ninput_checkbox()\ninput_text()\n\n# Not so good\nselect_input()\ncheckbox_input()\ntext_input()"
+ "objectID": "posts/09-tidy-data-and-the-tidyverse/index.html",
+ "href": "posts/09-tidy-data-and-the-tidyverse/index.html",
+ "title": "09 - Tidy data and the Tidyverse",
+ "section": "",
+ "text": "This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history.\n\n\n“Happy families are all alike; every unhappy family is unhappy in its own way.” —- Leo Tolstoy\n\n\n“Tidy datasets are all alike, but every messy dataset is messy in its own way.” —- Hadley Wickham\n\n\nPre-lecture materials\n\nRead ahead\n\n\n\n\n\n\nRead ahead\n\n\n\nBefore class, you can prepare by reading the following materials:\n\nTidy Data paper published in the Journal of Statistical Software\nhttps://r4ds.had.co.nz/tidy-data\ntidyr cheat sheet from RStudio\n\n\n\n\n\nAcknowledgements\nMaterial for this lecture was borrowed and adopted from\n\nhttps://rdpeng.github.io/Biostat776/lecture-tidy-data-and-the-tidyverse\nhttps://r4ds.had.co.nz/tidy-data\n\n\n\n\nLearning objectives\n\n\n\n\n\n\nLearning objectives\n\n\n\nAt the end of this lesson you will:\n\nDefine tidy data\nBe able to transform non-tidy data into tidy data\nBe able to transform wide data into long data\nBe able to separate character columns into multiple columns\nBe able to unite multiple character columns into one column\n\n\n\n\n\nTidy data\nAs we learned in the last lesson, one unifying concept of the tidyverse is the notion of tidy data.\nAs defined by Hadley Wickham in his 2014 paper published in the Journal of Statistical Software, a tidy dataset has the following properties:\n\nEach variable forms a column.\nEach observation forms a row.\nEach type of observational unit forms a table.\n\n\n\n\nArtwork by Allison Horst on tidy data\n\n\n[Source: Artwork by Allison Horst]\nThe purpose of defining tidy data is to highlight the fact that most data do not start out life as tidy.\nIn fact, much of the work of data analysis may involve simply making the data tidy (at least this has been our experience).\n\nOnce a dataset is tidy, it can be used as input into a variety of other functions that may transform, model, or visualize the data.\n\n\n\n\n\n\n\nExample\n\n\n\nAs a quick example, consider the following data illustrating religion and income survey data with the number of respondents with income range in column name.\nThis is in a classic table format:\n\nlibrary(tidyr)\nrelig_income\n\n# A tibble: 18 × 11\n religion `<$10k` `$10-20k` `$20-30k` `$30-40k` `$40-50k` `$50-75k` `$75-100k`\n <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>\n 1 Agnostic 27 34 60 81 76 137 122\n 2 Atheist 12 27 37 52 35 70 73\n 3 Buddhist 27 21 30 34 33 58 62\n 4 Catholic 418 617 732 670 638 1116 949\n 5 Don’t k… 15 14 15 11 10 35 21\n 6 Evangel… 575 869 1064 982 881 1486 949\n 7 Hindu 1 9 7 9 11 34 47\n 8 Histori… 228 244 236 238 197 223 131\n 9 Jehovah… 20 27 24 24 21 30 15\n10 Jewish 19 19 25 25 30 95 69\n11 Mainlin… 289 495 619 655 651 1107 939\n12 Mormon 29 40 48 51 56 112 85\n13 Muslim 6 7 9 10 9 23 16\n14 Orthodox 13 17 23 32 32 47 38\n15 Other C… 9 7 11 13 13 14 18\n16 Other F… 20 33 40 46 49 63 46\n17 Other W… 5 2 3 4 2 7 3\n18 Unaffil… 217 299 374 365 341 528 407\n# ℹ 3 more variables: `$100-150k` <dbl>, `>150k` <dbl>,\n# `Don't know/refused` <dbl>\n\n\n\n\nWhile this format is canonical and is useful for quickly observing the relationship between multiple variables, it is not tidy.\nThis format violates the tidy form because there are variables in the columns.\n\nIn this case the variables are religion, income bracket, and the number of respondents, which is the third variable, is presented inside the table.\n\nConverting this data to tidy format would give us\n\nlibrary(tidyverse)\n\nrelig_income %>%\n pivot_longer(-religion, names_to = \"income\", values_to = \"respondents\") %>%\n mutate(religion = factor(religion), income = factor(income))\n\n# A tibble: 180 × 3\n religion income respondents\n <fct> <fct> <dbl>\n 1 Agnostic <$10k 27\n 2 Agnostic $10-20k 34\n 3 Agnostic $20-30k 60\n 4 Agnostic $30-40k 81\n 5 Agnostic $40-50k 76\n 6 Agnostic $50-75k 137\n 7 Agnostic $75-100k 122\n 8 Agnostic $100-150k 109\n 9 Agnostic >150k 84\n10 Agnostic Don't know/refused 96\n# ℹ 170 more rows\n\n\nSome of these functions you have seen before, others might be new to you. Let’s talk about each one in the context of the tidyverse R packages.\n\n\nThe “Tidyverse”\nThere are a number of R packages that take advantage of the tidy data form and can be used to do interesting things with data. Many (but not all) of these packages are written by Hadley Wickham and the collection of packages is often referred to as the “tidyverse” because of their dependence on and presumption of tidy data.\n\n\n\n\n\n\nNote\n\n\n\nA subset of the “Tidyverse” packages include:\n\nggplot2: a plotting system based on the grammar of graphics\nmagrittr: defines the %>% operator for chaining functions together in a series of operations on data\ndplyr: a suite of (fast) functions for working with data frames\ntidyr: easily tidy data with pivot_wider() and pivot_longer() functions (also separate() and unite())\n\nA complete list can be found here (https://www.tidyverse.org/packages).\n\n\nWe will be using these packages quite a bit.\nThe “tidyverse” package can be used to install all of the packages in the tidyverse at once.\nFor example, instead of starting an R script with this:\n\nlibrary(dplyr)\nlibrary(tidyr)\nlibrary(readr)\nlibrary(ggplot2)\n\nYou can start with this:\n\nlibrary(tidyverse)\n\nIn the example above, let’s talk about what we did using the pivot_longer() function.\nWe will also talk about pivot_wider().\n\npivot_longer()\nThe tidyr package includes functions to transfer a data frame between long and wide.\n\nWide format data tends to have different attributes or variables describing an observation placed in separate columns.\nLong format data tends to have different attributes encoded as levels of a single variable, followed by another column that contains tha values of the observation at those different levels.\n\n\n\n\n\n\n\nExample\n\n\n\nIn the section above, we showed an example that used pivot_longer() to convert data into a tidy format.\nThe key problem with the tidyness of the data is that the income variables are not in their own columns, but rather are embedded in the structure of the columns.\nTo fix this, you can use the pivot_longer() function to gather values spread across several columns into a single column, here with the column names gathered into an income column.\nNote: when gathering, exclude any columns that you do not want “gathered” (religion in this case) by including the column names with a the minus sign in the pivot_longer() function.\nFor example:\n\n# Gather everything EXCEPT religion to tidy data\nrelig_income %>%\n pivot_longer(-religion, names_to = \"income\", values_to = \"respondents\")\n\n# A tibble: 180 × 3\n religion income respondents\n <chr> <chr> <dbl>\n 1 Agnostic <$10k 27\n 2 Agnostic $10-20k 34\n 3 Agnostic $20-30k 60\n 4 Agnostic $30-40k 81\n 5 Agnostic $40-50k 76\n 6 Agnostic $50-75k 137\n 7 Agnostic $75-100k 122\n 8 Agnostic $100-150k 109\n 9 Agnostic >150k 84\n10 Agnostic Don't know/refused 96\n# ℹ 170 more rows\n\n\n\n\nEven if your data is in a tidy format, pivot_longer() is occasionally useful for pulling data together to take advantage of faceting, or plotting separate plots based on a grouping variable. We will talk more about that in a future lecture.\n\n\npivot_wider()\nThe pivot_wider() function is less commonly needed to tidy data. It can, however, be useful for creating summary tables.\n\n\n\n\n\n\nExample\n\n\n\nYou use the summarize() function in dplyr to summarize the total number of respondents per income category.\n\nrelig_income %>%\n pivot_longer(-religion, names_to = \"income\", values_to = \"respondents\") %>%\n mutate(religion = factor(religion), income = factor(income)) %>%\n group_by(income) %>%\n summarize(total_respondents = sum(respondents)) %>%\n pivot_wider(\n names_from = \"income\",\n values_from = \"total_respondents\"\n ) %>%\n knitr::kable()\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n<$10k\n>150k\n$10-20k\n$100-150k\n$20-30k\n$30-40k\n$40-50k\n$50-75k\n$75-100k\nDon’t know/refused\n\n\n\n\n1930\n2608\n2781\n3197\n3357\n3302\n3085\n5185\n3990\n6121\n\n\n\n\n\n\n\nNotice in this example how pivot_wider() has been used at the very end of the code sequence to convert the summarized data into a shape that offers a better tabular presentation for a report.\n\n\n\n\n\n\nNote\n\n\n\nIn the pivot_wider() call, you first specify the name of the column to use for the new column names (income in this example) and then specify the column to use for the cell values (total_respondents here).\n\n\n\n\n\n\n\n\nExample of pivot_longer()\n\n\n\nLet’s try another dataset. This data contain an excerpt of the Gapminder data on life expectancy, GDP per capita, and population by country.\n\nlibrary(gapminder)\ngapminder\n\n# A tibble: 1,704 × 6\n country continent year lifeExp pop gdpPercap\n <fct> <fct> <int> <dbl> <int> <dbl>\n 1 Afghanistan Asia 1952 28.8 8425333 779.\n 2 Afghanistan Asia 1957 30.3 9240934 821.\n 3 Afghanistan Asia 1962 32.0 10267083 853.\n 4 Afghanistan Asia 1967 34.0 11537966 836.\n 5 Afghanistan Asia 1972 36.1 13079460 740.\n 6 Afghanistan Asia 1977 38.4 14880372 786.\n 7 Afghanistan Asia 1982 39.9 12881816 978.\n 8 Afghanistan Asia 1987 40.8 13867957 852.\n 9 Afghanistan Asia 1992 41.7 16317921 649.\n10 Afghanistan Asia 1997 41.8 22227415 635.\n# ℹ 1,694 more rows\n\n\nIf we wanted to make lifeExp, pop and gdpPercap (all measurements that we observe) go from a wide table into a long table, what would we do?\n\n# try it yourself\n\n\n\n\n\n\n\n\n\nExample\n\n\n\nOne more! Try using pivot_longer() to convert the the following data that contains made-up revenues for three companies by quarter for years 2006 to 2009.\nAfterward, use group_by() and summarize() to calculate the average revenue for each company across all years and all quarters.\nBonus: Calculate a mean revenue for each company AND each year (averaged across all 4 quarters).\n\ndf <- tibble(\n \"company\" = rep(1:3, each = 4),\n \"year\" = rep(2006:2009, 3),\n \"Q1\" = sample(x = 0:100, size = 12),\n \"Q2\" = sample(x = 0:100, size = 12),\n \"Q3\" = sample(x = 0:100, size = 12),\n \"Q4\" = sample(x = 0:100, size = 12),\n)\ndf\n\n# A tibble: 12 × 6\n company year Q1 Q2 Q3 Q4\n <int> <int> <int> <int> <int> <int>\n 1 1 2006 99 6 54 47\n 2 1 2007 28 79 90 9\n 3 1 2008 7 72 69 24\n 4 1 2009 16 56 6 100\n 5 2 2006 42 58 75 25\n 6 2 2007 64 1 100 6\n 7 2 2008 43 88 37 77\n 8 2 2009 95 74 17 44\n 9 3 2006 34 47 77 38\n10 3 2007 73 31 31 54\n11 3 2008 4 49 93 0\n12 3 2009 57 4 45 96\n\n\n\n# try it yourself\n\n\n\n\n\nseparate() and unite()\nThe same tidyr package also contains two useful functions:\n\nunite(): combine contents of two or more columns into a single column\nseparate(): separate contents of a column into two or more columns\n\nFirst, we combine the first three columns into one new column using unite().\n\ngapminder %>%\n unite(\n col = \"country_continent_year\",\n country:year,\n sep = \"_\"\n )\n\n# A tibble: 1,704 × 4\n country_continent_year lifeExp pop gdpPercap\n <chr> <dbl> <int> <dbl>\n 1 Afghanistan_Asia_1952 28.8 8425333 779.\n 2 Afghanistan_Asia_1957 30.3 9240934 821.\n 3 Afghanistan_Asia_1962 32.0 10267083 853.\n 4 Afghanistan_Asia_1967 34.0 11537966 836.\n 5 Afghanistan_Asia_1972 36.1 13079460 740.\n 6 Afghanistan_Asia_1977 38.4 14880372 786.\n 7 Afghanistan_Asia_1982 39.9 12881816 978.\n 8 Afghanistan_Asia_1987 40.8 13867957 852.\n 9 Afghanistan_Asia_1992 41.7 16317921 649.\n10 Afghanistan_Asia_1997 41.8 22227415 635.\n# ℹ 1,694 more rows\n\n\nNext, we show how to separate the columns into three separate columns using separate() using the col, into and sep arguments.\n\ngapminder %>%\n unite(\n col = \"country_continent_year\",\n country:year,\n sep = \"_\"\n ) %>%\n separate(\n col = \"country_continent_year\",\n into = c(\"country\", \"continent\", \"year\"),\n sep = \"_\"\n )\n\n# A tibble: 1,704 × 6\n country continent year lifeExp pop gdpPercap\n <chr> <chr> <chr> <dbl> <int> <dbl>\n 1 Afghanistan Asia 1952 28.8 8425333 779.\n 2 Afghanistan Asia 1957 30.3 9240934 821.\n 3 Afghanistan Asia 1962 32.0 10267083 853.\n 4 Afghanistan Asia 1967 34.0 11537966 836.\n 5 Afghanistan Asia 1972 36.1 13079460 740.\n 6 Afghanistan Asia 1977 38.4 14880372 786.\n 7 Afghanistan Asia 1982 39.9 12881816 978.\n 8 Afghanistan Asia 1987 40.8 13867957 852.\n 9 Afghanistan Asia 1992 41.7 16317921 649.\n10 Afghanistan Asia 1997 41.8 22227415 635.\n# ℹ 1,694 more rows\n\n\n\n\n\nPost-lecture materials\n\nFinal Questions\nHere are some post-lecture questions to help you think about the material discussed.\n\n\n\n\n\n\nQuestions\n\n\n\n\nUsing prose, describe how the variables and observations are organised in a tidy dataset versus an non-tidy dataset.\nWhat do the extra and fill arguments do in separate()? Experiment with the various options for the following two toy datasets.\n\n\ntibble(x = c(\"a,b,c\", \"d,e,f,g\", \"h,i,j\")) %>%\n separate(x, c(\"one\", \"two\", \"three\"))\n\ntibble(x = c(\"a,b,c\", \"d,e\", \"f,g,i\")) %>%\n separate(x, c(\"one\", \"two\", \"three\"))\n\n\nBoth unite() and separate() have a remove argument. What does it do? Why would you set it to FALSE?\nCompare and contrast separate() and extract(). Why are there three variations of separation (by position, by separator, and with groups), but only one unite()?\n\n\n\n\n\nAdditional Resources\n\n\n\n\n\n\nTip\n\n\n\n\nTidy Data paper published in the Journal of Statistical Software\nhttps://r4ds.had.co.nz/tidy-data.html\ntidyr cheat sheet from RStudio\n\n\n\n\n\n\nR session information\n\noptions(width = 120)\nsessioninfo::session_info()\n\n─ Session info ───────────────────────────────────────────────────────────────────────────────────────────────────────\n setting value\n version R version 4.3.1 (2023-06-16)\n os macOS Ventura 13.5\n system aarch64, darwin20\n ui X11\n language (EN)\n collate en_US.UTF-8\n ctype en_US.UTF-8\n tz America/New_York\n date 2023-08-17\n pandoc 3.1.5 @ /opt/homebrew/bin/ (via rmarkdown)\n\n─ Packages ───────────────────────────────────────────────────────────────────────────────────────────────────────────\n package * version date (UTC) lib source\n cli 3.6.1 2023-03-23 [1] CRAN (R 4.3.0)\n colorout 1.2-2 2023-05-06 [1] Github (jalvesaq/colorout@79931fd)\n colorspace 2.1-0 2023-01-23 [1] CRAN (R 4.3.0)\n digest 0.6.33 2023-07-07 [1] CRAN (R 4.3.0)\n dplyr * 1.1.2 2023-04-20 [1] CRAN (R 4.3.0)\n evaluate 0.21 2023-05-05 [1] CRAN (R 4.3.0)\n fansi 1.0.4 2023-01-22 [1] CRAN (R 4.3.0)\n fastmap 1.1.1 2023-02-24 [1] CRAN (R 4.3.0)\n forcats * 1.0.0 2023-01-29 [1] CRAN (R 4.3.0)\n gapminder * 1.0.0 2023-03-10 [1] CRAN (R 4.3.0)\n generics 0.1.3 2022-07-05 [1] CRAN (R 4.3.0)\n ggplot2 * 3.4.3 2023-08-14 [1] CRAN (R 4.3.1)\n glue 1.6.2 2022-02-24 [1] CRAN (R 4.3.0)\n gtable 0.3.3 2023-03-21 [1] CRAN (R 4.3.0)\n hms 1.1.3 2023-03-21 [1] CRAN (R 4.3.0)\n htmltools 0.5.6 2023-08-10 [1] CRAN (R 4.3.0)\n htmlwidgets 1.6.2 2023-03-17 [1] CRAN (R 4.3.0)\n jsonlite 1.8.7 2023-06-29 [1] CRAN (R 4.3.0)\n knitr 1.43 2023-05-25 [1] CRAN (R 4.3.0)\n lifecycle 1.0.3 2022-10-07 [1] CRAN (R 4.3.0)\n lubridate * 1.9.2 2023-02-10 [1] CRAN (R 4.3.0)\n magrittr 2.0.3 2022-03-30 [1] CRAN (R 4.3.0)\n munsell 0.5.0 2018-06-12 [1] CRAN (R 4.3.0)\n pillar 1.9.0 2023-03-22 [1] CRAN (R 4.3.0)\n pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.3.0)\n purrr * 1.0.2 2023-08-10 [1] CRAN (R 4.3.0)\n R6 2.5.1 2021-08-19 [1] CRAN (R 4.3.0)\n readr * 2.1.4 2023-02-10 [1] CRAN (R 4.3.0)\n rlang 1.1.1 2023-04-28 [1] CRAN (R 4.3.0)\n rmarkdown 2.24 2023-08-14 [1] CRAN (R 4.3.1)\n rstudioapi 0.15.0 2023-07-07 [1] CRAN (R 4.3.0)\n scales 1.2.1 2022-08-20 [1] CRAN (R 4.3.0)\n sessioninfo 1.2.2 2021-12-06 [1] CRAN (R 4.3.0)\n stringi 1.7.12 2023-01-11 [1] CRAN (R 4.3.0)\n stringr * 1.5.0 2022-12-02 [1] CRAN (R 4.3.0)\n tibble * 3.2.1 2023-03-20 [1] CRAN (R 4.3.0)\n tidyr * 1.3.0 2023-01-24 [1] CRAN (R 4.3.0)\n tidyselect 1.2.0 2022-10-10 [1] CRAN (R 4.3.0)\n tidyverse * 2.0.0 2023-02-22 [1] CRAN (R 4.3.0)\n timechange 0.2.0 2023-01-11 [1] CRAN (R 4.3.0)\n tzdb 0.4.0 2023-05-12 [1] CRAN (R 4.3.0)\n utf8 1.2.3 2023-01-31 [1] CRAN (R 4.3.0)\n vctrs 0.6.3 2023-06-14 [1] CRAN (R 4.3.0)\n withr 2.5.0 2022-03-03 [1] CRAN (R 4.3.0)\n xfun 0.40 2023-08-09 [1] CRAN (R 4.3.0)\n yaml 2.3.7 2023-01-23 [1] CRAN (R 4.3.0)\n\n [1] /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/library\n\n──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────"
},
{
- "objectID": "posts/16-functions/index.html#avoid-overriding-exisiting-functions",
- "href": "posts/16-functions/index.html#avoid-overriding-exisiting-functions",
- "title": "16 - Functions",
- "section": "Avoid overriding exisiting functions",
- "text": "Avoid overriding exisiting functions\nWhere possible, avoid overriding existing functions and variables.\nIt is impossible to do in general because so many good names are already taken by other packages, but avoiding the most common names from base R will avoid confusion.\n\n# Don't do this!\nT <- FALSE\nc <- 10\nmean <- function(x) sum(x)"
+ "objectID": "posts/04-reproducible-research/index.html",
+ "href": "posts/04-reproducible-research/index.html",
+ "title": "04 - Reproducible Research",
+ "section": "",
+ "text": "This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history.\n[Link to Claerbout and Karrenbach (1992) article]"
},
{
- "objectID": "posts/16-functions/index.html#use-comments",
- "href": "posts/16-functions/index.html#use-comments",
- "title": "16 - Functions",
- "section": "Use comments",
- "text": "Use comments\nUse comments are lines starting with #. They can explain the “why” of your code.\nYou generally should avoid comments that explain the “what” or the “how”. If you can’t understand what the code does from reading it, you should think about how to rewrite it to be more clear.\n\nDo you need to add some intermediate variables with useful names?\nDo you need to break out a subcomponent of a large function so you can name it?\n\nHowever, your code can never capture the reasoning behind your decisions:\n\nWhy did you choose this approach instead of an alternative?\nWhat else did you try that didn’t work?\n\nIt’s a great idea to capture that sort of thinking in a comment."
+ "objectID": "posts/04-reproducible-research/index.html#here",
+ "href": "posts/04-reproducible-research/index.html#here",
+ "title": "04 - Reproducible Research",
+ "section": "here",
+ "text": "here\nhere makes it easy to write code that you can share by avoiding full file paths and making it easier to use relative file paths. The file paths are made relative to your project home, which is automatically detected based on a few files. These can be:\n\nThe directory where you have a .git directory. That is, the beginning of your git repository.\nThe directory where you have an RStudio project file (*.Rproj). For RStudio projects with a git repository, this is typically the same directory.\nThe directory where you have a .here file (very uncommon scenario).\n\n\n## This is my relative directory\nhere::here()\n\n[1] \"/Users/leocollado/Dropbox/Code/jhustatcomputing2023\"\n\n## I can now easily share code to access files from this project\n## such as access to the flight.csv file saved under the data\n## directory.\nhere::here(\"data\", \"flights.csv\")\n\n[1] \"/Users/leocollado/Dropbox/Code/jhustatcomputing2023/data/flights.csv\"\n\n## This would not be easily shareable as you don't have\n## \"/Users/leocollado/Dropbox/Code\" on your computer\nfull_path <- \"/Users/leocollado/Dropbox/Code/jhustatcomputing2023/data/flights.csv\""
},
{
- "objectID": "posts/12-ggplot2-plotting-system-part-1/index.html",
- "href": "posts/12-ggplot2-plotting-system-part-1/index.html",
- "title": "12 - The ggplot2 plotting system: qplot()",
+ "objectID": "posts/04-reproducible-research/index.html#sessioninfo",
+ "href": "posts/04-reproducible-research/index.html#sessioninfo",
+ "title": "04 - Reproducible Research",
+ "section": "sessioninfo",
+ "text": "sessioninfo\nThis R package is excellent for sharing all details about the R packages you are using for a particular script. I typically include these lines at the end of my scripts as you can see at https://github.com/LieberInstitute/template_project/blob/3987e7f307611b2bcf657d1aa6930e76c4cc2b9a/code/01_read_data_to_r/01_read_data_to_r.R#L32-L39:\n\n## Reproducibility information\nprint(\"Reproducibility information:\")\nSys.time()\nproc.time()\noptions(width = 120)\nsessioninfo::session_info()\n\nNote that I made a GitHub permalink (permanent link) above, which is another way we can communicate precisely with others. It’s very useful to include GitHub permalinks when asking questions about code you or others have made public on GitHub. See https://docs.github.com/en/get-started/writing-on-github/working-with-advanced-formatting/creating-a-permanent-link-to-a-code-snippet for more details about how to create GitHub permalinks.\nHere is the actual output of those commands:\n\n## Reproducibility information\nprint(\"Reproducibility information:\")\n\n[1] \"Reproducibility information:\"\n\nSys.time()\n\n[1] \"2023-08-29 09:18:40 CST\"\n\nproc.time()\n\n user system elapsed \n 0.574 0.086 0.696 \n\noptions(width = 120)\nsessioninfo::session_info()\n\n─ Session info ───────────────────────────────────────────────────────────────────────────────────────────────────────\n setting value\n version R version 4.3.1 (2023-06-16)\n os macOS Ventura 13.5\n system aarch64, darwin20\n ui X11\n language (EN)\n collate en_US.UTF-8\n ctype en_US.UTF-8\n tz America/Mexico_City\n date 2023-08-29\n pandoc 3.1.5 @ /opt/homebrew/bin/ (via rmarkdown)\n\n─ Packages ───────────────────────────────────────────────────────────────────────────────────────────────────────────\n package * version date (UTC) lib source\n cli 3.6.1 2023-03-23 [1] CRAN (R 4.3.0)\n colorout 1.2-2 2023-05-06 [1] Github (jalvesaq/colorout@79931fd)\n colorspace 2.1-0 2023-01-23 [1] CRAN (R 4.3.0)\n digest 0.6.33 2023-07-07 [1] CRAN (R 4.3.0)\n dplyr 1.1.2 2023-04-20 [1] CRAN (R 4.3.0)\n emojifont 0.5.5 2021-04-20 [1] CRAN (R 4.3.0)\n evaluate 0.21 2023-05-05 [1] CRAN (R 4.3.0)\n fansi 1.0.4 2023-01-22 [1] CRAN (R 4.3.0)\n fastmap 1.1.1 2023-02-24 [1] CRAN (R 4.3.0)\n generics 0.1.3 2022-07-05 [1] CRAN (R 4.3.0)\n ggplot2 3.4.3 2023-08-14 [1] CRAN (R 4.3.0)\n glue 1.6.2 2022-02-24 [1] CRAN (R 4.3.0)\n gtable 0.3.3 2023-03-21 [1] CRAN (R 4.3.0)\n here * 1.0.1 2020-12-13 [1] CRAN (R 4.3.0)\n htmltools 0.5.6 2023-08-10 [1] CRAN (R 4.3.0)\n htmlwidgets 1.6.2 2023-03-17 [1] CRAN (R 4.3.0)\n jsonlite 1.8.7 2023-06-29 [1] CRAN (R 4.3.0)\n knitr 1.43 2023-05-25 [1] CRAN (R 4.3.0)\n lifecycle 1.0.3 2022-10-07 [1] CRAN (R 4.3.0)\n magrittr 2.0.3 2022-03-30 [1] CRAN (R 4.3.0)\n munsell 0.5.0 2018-06-12 [1] CRAN (R 4.3.0)\n pillar 1.9.0 2023-03-22 [1] CRAN (R 4.3.0)\n pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.3.0)\n proto 1.0.0 2016-10-29 [1] CRAN (R 4.3.0)\n R6 2.5.1 2021-08-19 [1] CRAN (R 4.3.0)\n rlang 1.1.1 2023-04-28 [1] CRAN (R 4.3.0)\n rmarkdown 2.24 2023-08-14 [1] CRAN (R 4.3.1)\n rprojroot 2.0.3 2022-04-02 [1] CRAN (R 4.3.0)\n rstudioapi 0.15.0 2023-07-07 [1] CRAN (R 4.3.0)\n scales 1.2.1 2022-08-20 [1] CRAN (R 4.3.0)\n sessioninfo 1.2.2 2021-12-06 [1] CRAN (R 4.3.0)\n showtext 0.9-6 2023-05-03 [1] CRAN (R 4.3.0)\n showtextdb 3.0 2020-06-04 [1] CRAN (R 4.3.0)\n sysfonts 0.8.8 2022-03-13 [1] CRAN (R 4.3.0)\n tibble 3.2.1 2023-03-20 [1] CRAN (R 4.3.0)\n tidyselect 1.2.0 2022-10-10 [1] CRAN (R 4.3.0)\n utf8 1.2.3 2023-01-31 [1] CRAN (R 4.3.0)\n vctrs 0.6.3 2023-06-14 [1] CRAN (R 4.3.0)\n xfun 0.40 2023-08-09 [1] CRAN (R 4.3.0)\n yaml 2.3.7 2023-01-23 [1] CRAN (R 4.3.0)\n\n [1] /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/library\n\n──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────\n\n\nsessioninfo::session_info() has a first section that includes information about my R installation and other computer environment variables (like my operating system). The second section includes information about the R packages that I used, their version numbers, and where I installed them from.\n\nlibrary(\"colorout\") ## Load a package I installed from GitHub\nsessioninfo::session_info()\n\n─ Session info ───────────────────────────────────────────────────────────────────────────────────────────────────────\n setting value\n version R version 4.3.1 (2023-06-16)\n os macOS Ventura 13.5\n system aarch64, darwin20\n ui X11\n language (EN)\n collate en_US.UTF-8\n ctype en_US.UTF-8\n tz America/Mexico_City\n date 2023-08-29\n pandoc 3.1.5 @ /opt/homebrew/bin/ (via rmarkdown)\n\n─ Packages ───────────────────────────────────────────────────────────────────────────────────────────────────────────\n package * version date (UTC) lib source\n cli 3.6.1 2023-03-23 [1] CRAN (R 4.3.0)\n colorout * 1.2-2 2023-05-06 [1] Github (jalvesaq/colorout@79931fd)\n colorspace 2.1-0 2023-01-23 [1] CRAN (R 4.3.0)\n digest 0.6.33 2023-07-07 [1] CRAN (R 4.3.0)\n dplyr 1.1.2 2023-04-20 [1] CRAN (R 4.3.0)\n emojifont 0.5.5 2021-04-20 [1] CRAN (R 4.3.0)\n evaluate 0.21 2023-05-05 [1] CRAN (R 4.3.0)\n fansi 1.0.4 2023-01-22 [1] CRAN (R 4.3.0)\n fastmap 1.1.1 2023-02-24 [1] CRAN (R 4.3.0)\n generics 0.1.3 2022-07-05 [1] CRAN (R 4.3.0)\n ggplot2 3.4.3 2023-08-14 [1] CRAN (R 4.3.0)\n glue 1.6.2 2022-02-24 [1] CRAN (R 4.3.0)\n gtable 0.3.3 2023-03-21 [1] CRAN (R 4.3.0)\n here * 1.0.1 2020-12-13 [1] CRAN (R 4.3.0)\n htmltools 0.5.6 2023-08-10 [1] CRAN (R 4.3.0)\n htmlwidgets 1.6.2 2023-03-17 [1] CRAN (R 4.3.0)\n jsonlite 1.8.7 2023-06-29 [1] CRAN (R 4.3.0)\n knitr 1.43 2023-05-25 [1] CRAN (R 4.3.0)\n lifecycle 1.0.3 2022-10-07 [1] CRAN (R 4.3.0)\n magrittr 2.0.3 2022-03-30 [1] CRAN (R 4.3.0)\n munsell 0.5.0 2018-06-12 [1] CRAN (R 4.3.0)\n pillar 1.9.0 2023-03-22 [1] CRAN (R 4.3.0)\n pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.3.0)\n proto 1.0.0 2016-10-29 [1] CRAN (R 4.3.0)\n R6 2.5.1 2021-08-19 [1] CRAN (R 4.3.0)\n rlang 1.1.1 2023-04-28 [1] CRAN (R 4.3.0)\n rmarkdown 2.24 2023-08-14 [1] CRAN (R 4.3.1)\n rprojroot 2.0.3 2022-04-02 [1] CRAN (R 4.3.0)\n rstudioapi 0.15.0 2023-07-07 [1] CRAN (R 4.3.0)\n scales 1.2.1 2022-08-20 [1] CRAN (R 4.3.0)\n sessioninfo 1.2.2 2021-12-06 [1] CRAN (R 4.3.0)\n showtext 0.9-6 2023-05-03 [1] CRAN (R 4.3.0)\n showtextdb 3.0 2020-06-04 [1] CRAN (R 4.3.0)\n sysfonts 0.8.8 2022-03-13 [1] CRAN (R 4.3.0)\n tibble 3.2.1 2023-03-20 [1] CRAN (R 4.3.0)\n tidyselect 1.2.0 2022-10-10 [1] CRAN (R 4.3.0)\n utf8 1.2.3 2023-01-31 [1] CRAN (R 4.3.0)\n vctrs 0.6.3 2023-06-14 [1] CRAN (R 4.3.0)\n xfun 0.40 2023-08-09 [1] CRAN (R 4.3.0)\n yaml 2.3.7 2023-01-23 [1] CRAN (R 4.3.0)\n\n [1] /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/library\n\n──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────\n\n\nFor packages that we installed from GitHub, it includes the specific git commit ID for the version we installed. This is super precise information that is very useful to have.\nCheck https://github.com/LieberInstitute/template_project/blob/main/code/01_read_data_to_r/01_read_data_to_r.R for a full script example part of https://github.com/LieberInstitute/template_project.\nCheck https://github.com/Bioconductor/BiocFileCache/issues/48 for an example on how the output from sessioninfo::session_info() provided useful hints that allowed me and others to resolve a problem.\nIn this video I talked about both here and sessioninfo as well as R and RStudio:\n\n\nhere and sessioninfo are so useful that people have made a Python versions of these R packages."
+ },
+ {
+ "objectID": "posts/17-loop-functions/index.html",
+ "href": "posts/17-loop-functions/index.html",
+ "title": "17 - Vectorization and loop functionals",
"section": "",
"text": "This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history."
},
{
- "objectID": "posts/12-ggplot2-plotting-system-part-1/index.html#the-basics-qplot",
- "href": "posts/12-ggplot2-plotting-system-part-1/index.html#the-basics-qplot",
- "title": "12 - The ggplot2 plotting system: qplot()",
- "section": "The Basics: qplot()",
- "text": "The Basics: qplot()\nThe qplot() function in ggplot2 is meant to get you going quickly.\nIt works much like the plot() function in base graphics system. It looks for variables to plot within a data frame, similar to lattice, or in the parent environment.\nIn general, it is good to get used to putting your data in a data frame and then passing it to qplot().\n\n\n\n\n\n\nPro tip\n\n\n\nThe qplot() function is somewhat discouraged in ggplot2 now and new users are encouraged to use the more general ggplot() function (more details in the next lesson).\nHowever, the qplot() function is still useful and may be easier to use if transitioning from the base plotting system or a different statistical package.\n\n\nPlots are made up of\n\naesthetics (e.g. size, shape, color)\ngeoms (e.g. points, lines)\n\nFactors play an important role for indicating subsets of the data (if they are to have different properties) so they should be labeled properly.\nThe qplot() hides much of what goes on underneath, which is okay for most operations, ggplot() is the core function and is very flexible for doing things qplot() cannot do."
+ "objectID": "posts/17-loop-functions/index.html#vector-arithmetics",
+ "href": "posts/17-loop-functions/index.html#vector-arithmetics",
+ "title": "17 - Vectorization and loop functionals",
+ "section": "Vector arithmetics",
+ "text": "Vector arithmetics\n\nRescaling a vector\nIn R, arithmetic operations on vectors occur element-wise. For a quick example, suppose we have height in inches:\n\ninches <- c(69, 62, 66, 70, 70, 73, 67, 73, 67, 70)\n\nand want to convert to centimeters.\nNotice what happens when we multiply inches by 2.54:\n\ninches * 2.54\n\n [1] 175.26 157.48 167.64 177.80 177.80 185.42 170.18 185.42 170.18 177.80\n\n\nIn the line above, we multiplied each element by 2.54.\nSimilarly, if for each entry we want to compute how many inches taller or shorter than 69 inches (the average height for males), we can subtract it from every entry like this:\n\ninches - 69\n\n [1] 0 -7 -3 1 1 4 -2 4 -2 1\n\n\n\n\nTwo vectors\nIf we have two vectors of the same length, and we sum them in R, they will be added entry by entry as follows:\n\nx <- 1:10\ny <- 1:10\nx + y\n\n [1] 2 4 6 8 10 12 14 16 18 20\n\n\nThe same holds for other mathematical operations, such as -, * and /.\n\nx <- 1:10\nsqrt(x)\n\n [1] 1.000000 1.414214 1.732051 2.000000 2.236068 2.449490 2.645751 2.828427\n [9] 3.000000 3.162278\n\n\n\ny <- 1:10\nx * y\n\n [1] 1 4 9 16 25 36 49 64 81 100"
},
{
- "objectID": "posts/12-ggplot2-plotting-system-part-1/index.html#before-you-start-label-your-data",
- "href": "posts/12-ggplot2-plotting-system-part-1/index.html#before-you-start-label-your-data",
- "title": "12 - The ggplot2 plotting system: qplot()",
- "section": "Before you start: label your data",
- "text": "Before you start: label your data\nOne thing that is always true, but is particularly useful when using ggplot2, is that you should always use informative and descriptive labels on your data.\nMore generally, your data should have appropriate metadata so that you can quickly look at a dataset and know\n\nwhat are variables?\nwhat do the values of each variable mean?\n\n\n\n\n\n\n\nPro tip\n\n\n\n\nEach column of a data frame should have a meaningful (but concise) variable name that accurately reflects the data stored in that column\nNon-numeric or categorical variables should be coded as factor variables and have meaningful labels for each level of the factor.\n\nMight be common to code a binary variable as a “0” or a “1”, but the problem is that from quickly looking at the data, it’s impossible to know whether which level of that variable is represented by a “0” or a “1”.\nMuch better to simply label each observation as what they are.\nIf a variable represents temperature categories, it might be better to use “cold”, “mild”, and “hot” rather than “1”, “2”, and “3”.\n\n\n\n\nWhile it is sometimes a pain to make sure all of your data are properly labeled, this investment in time can pay dividends down the road when you’re trying to figure out what you were plotting.\nIn other words, including the proper metadata can make your exploratory plots essentially self-documenting."
+ "objectID": "posts/17-loop-functions/index.html#lapply",
+ "href": "posts/17-loop-functions/index.html#lapply",
+ "title": "17 - Vectorization and loop functionals",
+ "section": "lapply()",
+ "text": "lapply()\nThe lapply() function does the following simple series of operations:\n\nit loops over a list, iterating over each element in that list\nit applies a function to each element of the list (a function that you specify)\nand returns a list (the l in lapply() is for “list”).\n\nThis function takes three arguments: (1) a list X; (2) a function (or the name of a function) FUN; (3) other arguments via its ... argument. If X is not a list, it will be coerced to a list using as.list().\nThe body of the lapply() function can be seen here.\n\nlapply\n\nfunction (X, FUN, ...) \n{\n FUN <- match.fun(FUN)\n if (!is.vector(X) || is.object(X)) \n X <- as.list(X)\n .Internal(lapply(X, FUN))\n}\n<bytecode: 0x12d9335d0>\n<environment: namespace:base>\n\n\n\n\n\n\n\n\nNote\n\n\n\nThe actual looping is done internally in C code for efficiency reasons.\n\n\nIt is important to remember that lapply() always returns a list, regardless of the class of the input.\n\n\n\n\n\n\nExample\n\n\n\nHere’s an example of applying the mean() function to all elements of a list. If the original list has names, the the names will be preserved in the output.\n\nx <- list(a = 1:5, b = rnorm(10))\nx\n\n$a\n[1] 1 2 3 4 5\n\n$b\n [1] -0.6113707 0.5950531 0.6319343 0.5595441 0.3188799 -0.4400711\n [7] 1.6687028 0.4501791 1.4356856 -0.3858270\n\nlapply(x, mean)\n\n$a\n[1] 3\n\n$b\n[1] 0.422271\n\n\nNotice that here we are passing the mean() function as an argument to the lapply() function.\n\n\nFunctions in R can be used this way and can be passed back and forth as arguments just like any other object inR.\nWhen you pass a function to another function, you do not need to include the open and closed parentheses () like you do when you are calling a function.\n\n\n\n\n\n\nExample\n\n\n\nHere is another example of using lapply().\n\nx <- list(a = 1:4, b = rnorm(10), c = rnorm(20, 1), d = rnorm(100, 5))\nlapply(x, mean)\n\n$a\n[1] 2.5\n\n$b\n[1] 0.1655327\n\n$c\n[1] 0.9767504\n\n$d\n[1] 4.951283\n\n\n\n\nYou can use lapply() to evaluate a function multiple times each with a different argument.\nNext is an example where I call the runif() function (to generate uniformly distributed random variables) four times, each time generating a different number of random numbers.\n\nx <- 1:4\nlapply(x, runif)\n\n[[1]]\n[1] 0.5924944\n\n[[2]]\n[1] 0.8660588 0.3277243\n\n[[3]]\n[1] 0.5009080 0.2951163 0.6264905\n\n[[4]]\n[1] 0.04282267 0.14951908 0.82034538 0.64614463\n\n\n\n\n\n\n\n\nWhat happened?\n\n\n\nWhen you pass a function to lapply(), lapply() takes elements of the list and passes them as the first argument of the function you are applying.\nIn the above example, the first argument of runif() is n, and so the elements of the sequence 1:4 all got passed to the n argument of runif().\n\n\nFunctions that you pass to lapply() may have other arguments. For example, the runif() function has a min and max argument too.\n\n\n\n\n\n\nQuestion\n\n\n\nIn the example above I used the default values for min and max.\n\nHow would you be able to specify different values for that in the context of lapply()?\n\n\n\nHere is where the ... argument to lapply() comes into play. Any arguments that you place in the ... argument will get passed down to the function being applied to the elements of the list.\nHere, the min = 0 and max = 10 arguments are passed down to runif() every time it gets called.\n\nx <- 1:4\nlapply(x, runif, min = 0, max = 10)\n\n[[1]]\n[1] 5.653385\n\n[[2]]\n[1] 8.325503 7.234466\n\n[[3]]\n[1] 5.968981 9.174316 7.920678\n\n[[4]]\n[1] 9.491500 3.023649 2.990945 8.757496\n\n\nSo now, instead of the random numbers being between 0 and 1 (the default), the are all between 0 and 10.\nThe lapply() function (and its friends) makes heavy use of anonymous functions. Anonymous functions are like members of Project Mayhem—they have no names. These functions are generated “on the fly” as you are using lapply(). Once the call to lapply() is finished, the function disappears and does not appear in the workspace.\n\n\n\n\n\n\nExample\n\n\n\nHere I am creating a list that contains two matrices.\n\nx <- list(a = matrix(1:4, 2, 2), b = matrix(1:6, 3, 2))\nx\n\n$a\n [,1] [,2]\n[1,] 1 3\n[2,] 2 4\n\n$b\n [,1] [,2]\n[1,] 1 4\n[2,] 2 5\n[3,] 3 6\n\n\nSuppose I wanted to extract the first column of each matrix in the list. I could write an anonymous function for extracting the first column of each matrix.\n\nlapply(x, function(elt) {\n elt[, 1]\n})\n\n$a\n[1] 1 2\n\n$b\n[1] 1 2 3\n\n\nNotice that I put the function() definition right in the call to lapply().\n\n\nThis is perfectly legal and acceptable. You can put an arbitrarily complicated function definition inside lapply(), but if it’s going to be more complicated, it’s probably a better idea to define the function separately.\nFor example, I could have done the following.\n\nf <- function(elt) {\n elt[, 1]\n}\nlapply(x, f)\n\n$a\n[1] 1 2\n\n$b\n[1] 1 2 3\n\n\n\n\n\n\n\n\nNote\n\n\n\nNow the function is no longer anonymous; its name is f.\n\n\nWhether you use an anonymous function or you define a function first depends on your context. If you think the function f is something you are going to need a lot in other parts of your code, you might want to define it separately. But if you are just going to use it for this call to lapply(), then it is probably simpler to use an anonymous function."
},
{
- "objectID": "posts/12-ggplot2-plotting-system-part-1/index.html#ggplot2-hello-world",
- "href": "posts/12-ggplot2-plotting-system-part-1/index.html#ggplot2-hello-world",
- "title": "12 - The ggplot2 plotting system: qplot()",
- "section": "ggplot2 “Hello, world!”",
- "text": "ggplot2 “Hello, world!”\nThis example dataset comes with the ggplot2 package and contains data on the fuel economy of 38 popular car models from 1999 to 2008.\n\nlibrary(tidyverse) # this loads the ggplot2 R package\n# library(ggplot2) # an alternative way to just load the ggplot2 R package\nglimpse(mpg)\n\nRows: 234\nColumns: 11\n$ manufacturer <chr> \"audi\", \"audi\", \"audi\", \"audi\", \"audi\", \"audi\", \"audi\", \"…\n$ model <chr> \"a4\", \"a4\", \"a4\", \"a4\", \"a4\", \"a4\", \"a4\", \"a4 quattro\", \"…\n$ displ <dbl> 1.8, 1.8, 2.0, 2.0, 2.8, 2.8, 3.1, 1.8, 1.8, 2.0, 2.0, 2.…\n$ year <int> 1999, 1999, 2008, 2008, 1999, 1999, 2008, 1999, 1999, 200…\n$ cyl <int> 4, 4, 4, 4, 6, 6, 6, 4, 4, 4, 4, 6, 6, 6, 6, 6, 6, 8, 8, …\n$ trans <chr> \"auto(l5)\", \"manual(m5)\", \"manual(m6)\", \"auto(av)\", \"auto…\n$ drv <chr> \"f\", \"f\", \"f\", \"f\", \"f\", \"f\", \"f\", \"4\", \"4\", \"4\", \"4\", \"4…\n$ cty <int> 18, 21, 20, 21, 16, 18, 18, 18, 16, 20, 19, 15, 17, 17, 1…\n$ hwy <int> 29, 29, 31, 30, 26, 26, 27, 26, 25, 28, 27, 25, 25, 25, 2…\n$ fl <chr> \"p\", \"p\", \"p\", \"p\", \"p\", \"p\", \"p\", \"p\", \"p\", \"p\", \"p\", \"p…\n$ class <chr> \"compact\", \"compact\", \"compact\", \"compact\", \"compact\", \"c…\n\n\nYou can see from the glimpse() (part of the dplyr package) output that all of the categorical variables (like “manufacturer” or “class”) are **appropriately coded with meaningful label*s**.\nThis will come in handy when qplot() has to label different aspects of a plot.\nAlso note that all of the columns/variables have meaningful names (if sometimes abbreviated), rather than names like “X1”, and “X2”, etc.\n\n\n\n\n\n\nExample\n\n\n\nWe can make a quick scatterplot using qplot() of the engine displacement (displ) and the highway miles per gallon (hwy).\n\nqplot(x = displ, y = hwy, data = mpg)\n\nWarning: `qplot()` was deprecated in ggplot2 3.4.0.\n\n\n\n\n\nPlot of engine displacement and highway mileage using the mtcars dataset\n\n\n\n\n\n\nIt has a very similar feeling to plot() in base R.\n\n\n\n\n\n\nNote\n\n\n\nIn the call to qplot() you must specify the data argument so that qplot() knows where to look up the variables.\nYou must also specify x and y, but hopefully that part is obvious."
+ "objectID": "posts/17-loop-functions/index.html#sapply",
+ "href": "posts/17-loop-functions/index.html#sapply",
+ "title": "17 - Vectorization and loop functionals",
+ "section": "sapply()",
+ "text": "sapply()\nThe sapply() function behaves similarly to lapply(); the only real difference is in the return value. sapply() will try to simplify the result of lapply() if possible. Essentially, sapply() calls lapply() on its input and then applies the following algorithm:\n\nIf the result is a list where every element is length 1, then a vector is returned\nIf the result is a list where every element is a vector of the same length (> 1), a matrix is returned.\nIf it can’t figure things out, a list is returned\n\nHere’s the result of calling lapply().\n\nx <- list(a = 1:4, b = rnorm(10), c = rnorm(20, 1), d = rnorm(100, 5))\nlapply(x, mean)\n\n$a\n[1] 2.5\n\n$b\n[1] -0.1478465\n\n$c\n[1] 0.819794\n\n$d\n[1] 4.954484\n\n\nNotice that lapply() returns a list (as usual), but that each element of the list has length 1.\nHere’s the result of calling sapply() on the same list.\n\nsapply(x, mean)\n\n a b c d \n 2.5000000 -0.1478465 0.8197940 4.9544836 \n\n\nBecause the result of lapply() was a list where each element had length 1, sapply() collapsed the output into a numeric vector, which is often more useful than a list."
},
{
- "objectID": "posts/12-ggplot2-plotting-system-part-1/index.html#modifying-aesthetics",
- "href": "posts/12-ggplot2-plotting-system-part-1/index.html#modifying-aesthetics",
- "title": "12 - The ggplot2 plotting system: qplot()",
- "section": "Modifying aesthetics",
- "text": "Modifying aesthetics\nWe can introduce a third variable into the plot by modifying the color of the points based on the value of that third variable.\nColor (or colour) is one type of aesthetic and using the ggplot2 language:\n\n“the color of each point can be mapped to a variable”\n\nThis sounds technical, but let’s give an example.\n\n\n\n\n\n\nExample\n\n\n\nWe map the color argument to the drv variable, which indicates whether a car is front wheel drive, rear wheel drive, or 4-wheel drive.\n\nqplot(displ, hwy, data = mpg, color = drv)\n\n\n\n\nEngine displacement and highway mileage by drive class\n\n\n\n\n\n\nNow we can see that the front wheel drive cars tend to have lower displacement relative to the 4-wheel or rear wheel drive cars.\nAlso, it’s clear that the 4-wheel drive cars have the lowest highway gas mileage.\n\n\n\n\n\n\nNote\n\n\n\nThe x argument and y argument are aesthetics too, and they got mapped to the displ and hwy variables, respectively.\n\n\n\n\n\n\n\n\nQuestion\n\n\n\nIn the above plot, I did not specify the x and y variable. What happens when you run these two code chunks. What’s the difference?\n\nqplot(displ, hwy, data = mpg, color = drv)\n\n\nqplot(x = displ, y = hwy, data = mpg, color = drv)\n\n\nqplot(hwy, displ, data = mpg, color = drv)\n\n\nqplot(y = hwy, x = displ, data = mpg, color = drv)\n\n\n\n\n\n\n\n\n\nExample\n\n\n\nLet’s try mapping colors in another dataset, namely the palmerpenguins dataset. These data contain observations for 344 penguins. There are 3 different species of penguins in this dataset, collected from 3 islands in the Palmer Archipelago, Antarctica.\n\n\n\n\n\nPalmer penguins\n\n\n\n\n[Source: Artwork by Allison Horst]\n\nlibrary(palmerpenguins)\n\n\nglimpse(penguins)\n\nRows: 344\nColumns: 8\n$ species <fct> Adelie, Adelie, Adelie, Adelie, Adelie, Adelie, Adel…\n$ island <fct> Torgersen, Torgersen, Torgersen, Torgersen, Torgerse…\n$ bill_length_mm <dbl> 39.1, 39.5, 40.3, NA, 36.7, 39.3, 38.9, 39.2, 34.1, …\n$ bill_depth_mm <dbl> 18.7, 17.4, 18.0, NA, 19.3, 20.6, 17.8, 19.6, 18.1, …\n$ flipper_length_mm <int> 181, 186, 195, NA, 193, 190, 181, 195, 193, 190, 186…\n$ body_mass_g <int> 3750, 3800, 3250, NA, 3450, 3650, 3625, 4675, 3475, …\n$ sex <fct> male, female, female, NA, female, male, female, male…\n$ year <int> 2007, 2007, 2007, 2007, 2007, 2007, 2007, 2007, 2007…\n\n\nIf we wanted to count the number of penguins for each of the three species, we can use the count() function in dplyr:\n\npenguins %>%\n count(species)\n\n# A tibble: 3 × 2\n species n\n <fct> <int>\n1 Adelie 152\n2 Chinstrap 68\n3 Gentoo 124\n\n\n\n\nFor example, we see there are a total of 152 Adelie penguins in the palmerpenguins dataset.\n\n\n\n\n\n\nQuestion\n\n\n\nIf we wanted to use qplot() to map flipper_length_mm and bill_length_mm to the x and y coordinates, what would we do?\n\n# try it yourself\n\nNow try mapping color to the species variable on top of the code you just wrote:\n\n# try it yourself"
+ "objectID": "posts/17-loop-functions/index.html#split",
+ "href": "posts/17-loop-functions/index.html#split",
+ "title": "17 - Vectorization and loop functionals",
+ "section": "split()",
+ "text": "split()\nThe split() function takes a vector or other objects and splits it into groups determined by a factor or list of factors.\nThe arguments to split() are\n\nstr(split)\n\nfunction (x, f, drop = FALSE, ...) \n\n\nwhere\n\nx is a vector (or list) or data frame\nf is a factor (or coerced to one) or a list of factors\ndrop indicates whether empty factors levels should be dropped\n\nThe combination of split() and a function like lapply() or sapply() is a common paradigm in R. The basic idea is that you can take a data structure, split it into subsets defined by another variable, and apply a function over those subsets. The results of applying that function over the subsets are then collated and returned as an object. This sequence of operations is sometimes referred to as “map-reduce” in other contexts.\nHere we simulate some data and split it according to a factor variable. Note that we use the gl() function to “generate levels” in a factor variable.\n\nx <- c(rnorm(10), runif(10), rnorm(10, 1))\nf <- gl(3, 10) # generate factor levels\nf\n\n [1] 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 3 3\nLevels: 1 2 3\n\n\n\nsplit(x, f)\n\n$`1`\n [1] 0.78541247 -0.06267966 -0.89713180 0.11796725 0.66689447 -0.02523006\n [7] -0.19081948 0.44974528 -0.51005146 -0.08103298\n\n$`2`\n [1] 0.29977033 0.31873253 0.53182993 0.85507540 0.21585775 0.89867742\n [7] 0.78109747 0.06887742 0.79661568 0.60022565\n\n$`3`\n [1] -0.38262045 0.06294368 0.41768485 1.57972821 1.17555228 1.47374130\n [7] 1.79199913 2.25569283 1.55226509 -1.51811384\n\n\nA common idiom is split followed by an lapply.\n\nlapply(split(x, f), mean)\n\n$`1`\n[1] 0.0253074\n\n$`2`\n[1] 0.536676\n\n$`3`\n[1] 0.8408873\n\n\n\nSplitting a Data Frame\n\nlibrary(datasets)\nhead(airquality)\n\n Ozone Solar.R Wind Temp Month Day\n1 41 190 7.4 67 5 1\n2 36 118 8.0 72 5 2\n3 12 149 12.6 74 5 3\n4 18 313 11.5 62 5 4\n5 NA NA 14.3 56 5 5\n6 28 NA 14.9 66 5 6\n\n\nWe can split the airquality data frame by the Month variable so that we have separate sub-data frames for each month.\n\ns <- split(airquality, airquality$Month)\nstr(s)\n\nList of 5\n $ 5:'data.frame': 31 obs. of 6 variables:\n ..$ Ozone : int [1:31] 41 36 12 18 NA 28 23 19 8 NA ...\n ..$ Solar.R: int [1:31] 190 118 149 313 NA NA 299 99 19 194 ...\n ..$ Wind : num [1:31] 7.4 8 12.6 11.5 14.3 14.9 8.6 13.8 20.1 8.6 ...\n ..$ Temp : int [1:31] 67 72 74 62 56 66 65 59 61 69 ...\n ..$ Month : int [1:31] 5 5 5 5 5 5 5 5 5 5 ...\n ..$ Day : int [1:31] 1 2 3 4 5 6 7 8 9 10 ...\n $ 6:'data.frame': 30 obs. of 6 variables:\n ..$ Ozone : int [1:30] NA NA NA NA NA NA 29 NA 71 39 ...\n ..$ Solar.R: int [1:30] 286 287 242 186 220 264 127 273 291 323 ...\n ..$ Wind : num [1:30] 8.6 9.7 16.1 9.2 8.6 14.3 9.7 6.9 13.8 11.5 ...\n ..$ Temp : int [1:30] 78 74 67 84 85 79 82 87 90 87 ...\n ..$ Month : int [1:30] 6 6 6 6 6 6 6 6 6 6 ...\n ..$ Day : int [1:30] 1 2 3 4 5 6 7 8 9 10 ...\n $ 7:'data.frame': 31 obs. of 6 variables:\n ..$ Ozone : int [1:31] 135 49 32 NA 64 40 77 97 97 85 ...\n ..$ Solar.R: int [1:31] 269 248 236 101 175 314 276 267 272 175 ...\n ..$ Wind : num [1:31] 4.1 9.2 9.2 10.9 4.6 10.9 5.1 6.3 5.7 7.4 ...\n ..$ Temp : int [1:31] 84 85 81 84 83 83 88 92 92 89 ...\n ..$ Month : int [1:31] 7 7 7 7 7 7 7 7 7 7 ...\n ..$ Day : int [1:31] 1 2 3 4 5 6 7 8 9 10 ...\n $ 8:'data.frame': 31 obs. of 6 variables:\n ..$ Ozone : int [1:31] 39 9 16 78 35 66 122 89 110 NA ...\n ..$ Solar.R: int [1:31] 83 24 77 NA NA NA 255 229 207 222 ...\n ..$ Wind : num [1:31] 6.9 13.8 7.4 6.9 7.4 4.6 4 10.3 8 8.6 ...\n ..$ Temp : int [1:31] 81 81 82 86 85 87 89 90 90 92 ...\n ..$ Month : int [1:31] 8 8 8 8 8 8 8 8 8 8 ...\n ..$ Day : int [1:31] 1 2 3 4 5 6 7 8 9 10 ...\n $ 9:'data.frame': 30 obs. of 6 variables:\n ..$ Ozone : int [1:30] 96 78 73 91 47 32 20 23 21 24 ...\n ..$ Solar.R: int [1:30] 167 197 183 189 95 92 252 220 230 259 ...\n ..$ Wind : num [1:30] 6.9 5.1 2.8 4.6 7.4 15.5 10.9 10.3 10.9 9.7 ...\n ..$ Temp : int [1:30] 91 92 93 93 87 84 80 78 75 73 ...\n ..$ Month : int [1:30] 9 9 9 9 9 9 9 9 9 9 ...\n ..$ Day : int [1:30] 1 2 3 4 5 6 7 8 9 10 ...\n\n\nThen we can take the column means for Ozone, Solar.R, and Wind for each sub-data frame.\n\nlapply(s, function(x) {\n colMeans(x[, c(\"Ozone\", \"Solar.R\", \"Wind\")])\n})\n\n$`5`\n Ozone Solar.R Wind \n NA NA 11.62258 \n\n$`6`\n Ozone Solar.R Wind \n NA 190.16667 10.26667 \n\n$`7`\n Ozone Solar.R Wind \n NA 216.483871 8.941935 \n\n$`8`\n Ozone Solar.R Wind \n NA NA 8.793548 \n\n$`9`\n Ozone Solar.R Wind \n NA 167.4333 10.1800 \n\n\nUsing sapply() might be better here for a more readable output.\n\nsapply(s, function(x) {\n colMeans(x[, c(\"Ozone\", \"Solar.R\", \"Wind\")])\n})\n\n 5 6 7 8 9\nOzone NA NA NA NA NA\nSolar.R NA 190.16667 216.483871 NA 167.4333\nWind 11.62258 10.26667 8.941935 8.793548 10.1800\n\n\nUnfortunately, there are NAs in the data so we cannot simply take the means of those variables. However, we can tell the colMeans function to remove the NAs before computing the mean.\n\nsapply(s, function(x) {\n colMeans(x[, c(\"Ozone\", \"Solar.R\", \"Wind\")],\n na.rm = TRUE\n )\n})\n\n 5 6 7 8 9\nOzone 23.61538 29.44444 59.115385 59.961538 31.44828\nSolar.R 181.29630 190.16667 216.483871 171.857143 167.43333\nWind 11.62258 10.26667 8.941935 8.793548 10.18000"
},
{
- "objectID": "posts/12-ggplot2-plotting-system-part-1/index.html#adding-a-geom",
- "href": "posts/12-ggplot2-plotting-system-part-1/index.html#adding-a-geom",
- "title": "12 - The ggplot2 plotting system: qplot()",
- "section": "Adding a geom",
- "text": "Adding a geom\nSometimes it is nice to add a smoother to a scatterplot to highlight any trends.\nTrends can be difficult to see if the data are very noisy or there are many data points obscuring the view.\nA smoother is a type of “geom” that you can add along with your data points.\n\n\n\n\n\n\nExample\n\n\n\n\nqplot(displ, hwy, data = mpg, geom = c(\"point\", \"smooth\"))\n\n`geom_smooth()` using method = 'loess' and formula = 'y ~ x'\n\n\n\n\n\nEngine displacement and highway mileage w/smoother\n\n\n\n\n\n\nHere it seems that engine displacement and highway mileage have a nonlinear U-shaped relationship, but from the previous plot we know that this is largely due to confounding by the drive class of the car.\n\n\n\n\n\n\nNote\n\n\n\nPreviously, we did not have to specify geom = \"point\" because that was done automatically.\nBut if you want the smoother overlaid with the points, then you need to specify both explicitly.\n\n\nLook at what happens if we do not include the point geom.\n\nqplot(displ, hwy, data = mpg, geom = c(\"smooth\"))\n\n`geom_smooth()` using method = 'loess' and formula = 'y ~ x'\n\n\n\n\n\nEngine displacement and highway mileage w/smoother\n\n\n\n\nSometimes that is the plot you want to show, but in this case it might make more sense to show the data along with the smoother.\n\n\n\n\n\n\nQuestion\n\n\n\nLet’s add a smoother to our palmerpenguins dataset example.\nUsing the code we previously wrote mapping variables to points and color, add a “point” and “smooth” geom:\n\n# try it yourself"
+ "objectID": "posts/17-loop-functions/index.html#tapply",
+ "href": "posts/17-loop-functions/index.html#tapply",
+ "title": "17 - Vectorization and loop functionals",
+ "section": "tapply",
+ "text": "tapply\ntapply() is used to apply a function over subsets of a vector. It can be thought of as a combination of split() and sapply() for vectors only. I’ve been told that the “t” in tapply() refers to “table”, but that is unconfirmed.\n\nstr(tapply)\n\nfunction (X, INDEX, FUN = NULL, ..., default = NA, simplify = TRUE) \n\n\nThe arguments to tapply() are as follows:\n\nX is a vector\nINDEX is a factor or a list of factors (or else they are coerced to factors)\nFUN is a function to be applied\n… contains other arguments to be passed FUN\nsimplify, should we simplify the result?\n\n\n\n\n\n\n\nExample\n\n\n\nGiven a vector of numbers, one simple operation is to take group means.\n\n## Simulate some data\nx <- c(rnorm(10), runif(10), rnorm(10, 1))\n## Define some groups with a factor variable\nf <- gl(3, 10)\nf\n\n [1] 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 3 3\nLevels: 1 2 3\n\ntapply(x, f, mean)\n\n 1 2 3 \n0.3554738 0.5195466 0.6764006 \n\n\n\n\nWe can also apply functions that return more than a single value. In this case, tapply() will not simplify the result and will return a list. Here’s an example of finding the range() (min and max) of each sub-group.\n\ntapply(x, f, range)\n\n$`1`\n[1] -1.431912 2.695089\n\n$`2`\n[1] 0.1263379 0.8959040\n\n$`3`\n[1] -1.207741 1.696309"
},
{
- "objectID": "posts/12-ggplot2-plotting-system-part-1/index.html#histograms-and-boxplots",
- "href": "posts/12-ggplot2-plotting-system-part-1/index.html#histograms-and-boxplots",
- "title": "12 - The ggplot2 plotting system: qplot()",
- "section": "Histograms and boxplots",
- "text": "Histograms and boxplots\nThe qplot() function can be used to be used to plot 1-dimensional data too.\nBy specifying a single variable, qplot() will by default make a histogram.\n\n\n\n\n\n\nExample\n\n\n\nWe can make a histogram of the highway mileage data and stratify on the drive class. So technically this is three histograms on top of each other.\n\nqplot(hwy, data = mpg, fill = drv, binwidth = 2)\n\n\n\n\nHistogram of highway mileage by drive class\n\n\n\n\n\n\n\n\n\n\n\n\nQuestion\n\n\n\nNotice, I used fill here to map color to the drv variable. Why is this? What happens when you use color instead?\n\n# try it yourself\n\n\n\nHaving the different colors for each drive class is nice, but the three histograms can be a bit difficult to separate out.\nSide-by-side boxplots are one solution to this problem.\n\nqplot(drv, hwy, data = mpg, geom = \"boxplot\")\n\n\n\n\nBoxplots of highway mileage by drive class\n\n\n\n\nAnother solution is to plot the histograms in separate panels using facets."
+ "objectID": "posts/17-loop-functions/index.html#apply",
+ "href": "posts/17-loop-functions/index.html#apply",
+ "title": "17 - Vectorization and loop functionals",
+ "section": "apply()",
+ "text": "apply()\nThe apply() function is used to a evaluate a function (often an anonymous one) over the margins of an array. It is most often used to apply a function to the rows or columns of a matrix (which is just a 2-dimensional array). However, it can be used with general arrays, for example, to take the average of an array of matrices. Using apply() is not really faster than writing a loop, but it works in one line and is highly compact.\n\nstr(apply)\n\nfunction (X, MARGIN, FUN, ..., simplify = TRUE) \n\n\nThe arguments to apply() are\n\nX is an array\nMARGIN is an integer vector indicating which margins should be “retained”.\nFUN is a function to be applied\n... is for other arguments to be passed to FUN\n\n\n\n\n\n\n\nExample\n\n\n\nHere I create a 20 by 10 matrix of Normal random numbers. I then compute the mean of each column.\n\nx <- matrix(rnorm(200), 20, 10)\nhead(x)\n\n [,1] [,2] [,3] [,4] [,5] [,6]\n[1,] 1.589728 0.7733454 -1.3311072 -0.77084025 -0.1947478 0.1748546\n[2,] 2.395088 0.3243910 -1.5133366 0.09199955 0.3850993 0.1851718\n[3,] 1.039643 -2.1721402 -0.9933217 -1.89261272 0.1748050 1.0563987\n[4,] -1.580978 -0.9884235 -1.4976744 -0.51011200 -2.7512079 0.5547477\n[5,] 1.264799 -2.0551874 0.4483417 -3.08561764 -0.1549359 -0.8384706\n[6,] 1.756973 0.9244522 0.2740854 -0.61441465 -1.0661350 1.4497808\n [,7] [,8] [,9] [,10]\n[1,] 0.7163086 -0.01817166 0.2193225 -0.3346788\n[2,] 0.7606851 0.42082416 0.1099027 0.2834439\n[3,] -1.1218204 -1.17000278 0.4302792 -0.5684986\n[4,] 0.6082452 0.46763465 -0.3481830 -0.1765517\n[5,] -0.7460224 -0.01123782 1.8116342 -0.1033175\n[6,] 1.0160202 -0.82361401 -0.1616471 -0.1628032\n\napply(x, 2, mean) ## Take the mean of each column\n\n [1] 0.083759441 -0.134507982 -0.246473461 -0.371270102 -0.078433882\n [6] -0.101665531 -0.007126106 -0.003193726 0.114767264 0.070612124\n\n\n\n\n\n\n\n\n\n\nExample\n\n\n\nI can also compute the sum of each row.\n\napply(x, 1, sum) ## Take the mean of each row\n\n [1] 0.82401382 3.44326903 -5.21727094 -6.22250299 -3.47001414 2.59269751\n [7] -1.76049948 -0.54534465 1.26993157 -0.05660623 1.89101638 2.60154094\n[13] -0.80804188 1.96321614 -2.68869045 0.56525640 0.44214056 -4.25890694\n[19] -3.02509115 -1.01075274\n\n\n\n\n\n\n\n\n\n\nNote\n\n\n\nIn both calls to apply(), the return value was a vector of numbers.\n\n\nYou’ve probably noticed that the second argument is either a 1 or a 2, depending on whether we want row statistics or column statistics. What exactly is the second argument to apply()?\nThe MARGIN argument essentially indicates to apply() which dimension of the array you want to preserve or retain.\nSo when taking the mean of each column, I specify\n\napply(x, 2, mean)\n\nbecause I want to collapse the first dimension (the rows) by taking the mean and I want to preserve the number of columns. Similarly, when I want the row sums, I run\n\napply(x, 1, mean)\n\nbecause I want to collapse the columns (the second dimension) and preserve the number of rows (the first dimension).\n\nCol/Row Sums and Means\n\n\n\n\n\n\nPro-tip\n\n\n\nFor the special case of column/row sums and column/row means of matrices, we have some useful shortcuts.\n\nrowSums = apply(x, 1, sum)\nrowMeans = apply(x, 1, mean)\ncolSums = apply(x, 2, sum)\ncolMeans = apply(x, 2, mean)\n\n\n\nThe shortcut functions are heavily optimized and hence are much faster, but you probably won’t notice unless you’re using a large matrix.\nAnother nice aspect of these functions is that they are a bit more descriptive. It’s arguably more clear to write colMeans(x) in your code than apply(x, 2, mean).\n\n\nOther Ways to Apply\nYou can do more than take sums and means with the apply() function.\n\n\n\n\n\n\nExample\n\n\n\nFor example, you can compute quantiles of the rows of a matrix using the quantile() function.\n\nx <- matrix(rnorm(200), 20, 10)\nhead(x)\n\n [,1] [,2] [,3] [,4] [,5] [,6]\n[1,] 0.58654399 -0.502546440 1.1493478 0.6257709 -0.02866237 1.490139530\n[2,] -0.14969248 0.327632870 0.0202589 0.2889600 -0.16552218 -0.829703298\n[3,] 1.12561766 0.707836011 0.6038607 -0.6722613 0.85092968 0.550785886\n[4,] -1.71719604 0.554424755 0.4229181 0.1484968 0.22134369 0.258853355\n[5,] 0.31827641 1.555568589 0.8971850 -0.7742244 0.45459793 -0.043814576\n[6,] -0.08429415 0.001737282 0.1906608 1.1145869 0.54156791 -0.004889302\n [,7] [,8] [,9] [,10]\n[1,] -0.7879713 1.02206400 -1.0420765 -1.2779945\n[2,] 1.7217146 0.06728039 0.6408182 -0.3551929\n[3,] -0.2439192 -0.71553120 -0.8273868 0.2559954\n[4,] -0.1085818 -0.28763268 1.9010457 1.7950971\n[5,] -1.4082747 -1.07621679 0.5428189 0.4538626\n[6,] -1.0644006 -0.04186614 -0.8150566 1.0490749\n\n## Get row quantiles\napply(x, 1, quantile, probs = c(0.25, 0.75))\n\n [,1] [,2] [,3] [,4] [,5] [,6]\n25% -0.7166151 -0.1615648 -0.5651758 -0.04431213 -0.5916219 -0.07368714\n75% 0.9229907 0.3179646 0.6818422 0.52154809 0.5207637 0.45384114\n [,7] [,8] [,9] [,10] [,11] [,12]\n25% -0.4355993 -0.1313015 -0.8149658 -0.9260982 0.02077709 -0.1343613\n75% 1.5985929 0.8889319 0.2213238 0.3661333 0.82424899 0.4156328\n [,13] [,14] [,15] [,16] [,17] [,18]\n25% -0.1281593 -0.6691927 -0.2824997 -0.6574923 0.06421797 -0.7905708\n75% 1.3073689 1.2450340 0.5072401 0.5023885 1.08294108 0.4653062\n [,19] [,20]\n25% -0.5826196 -0.6965163\n75% 0.1313324 0.6849689\n\n\nNotice that I had to pass the probs = c(0.25, 0.75) argument to quantile() via the ... argument to apply()."
},
{
- "objectID": "posts/12-ggplot2-plotting-system-part-1/index.html#facets",
- "href": "posts/12-ggplot2-plotting-system-part-1/index.html#facets",
- "title": "12 - The ggplot2 plotting system: qplot()",
- "section": "Facets",
- "text": "Facets\nFacets are a way to create multiple panels of plots based on the levels of categorical variable.\nHere, we want to see a histogram of the highway mileages and the categorical variable is the drive class variable. We can do that using the facets argument to qplot().\n\n\n\n\n\n\nNote\n\n\n\nThe facets argument expects a formula type of input, with a ~ separating the left hand side variable and the right hand side variable.\n\nThe left hand side variable indicates how the rows of the panels should be divided\nThe right hand side variable indicates how the columns of the panels should be divided\n\n\n\n\n\n\n\n\n\nExample\n\n\n\nHere, we just want three rows of histograms (and just one column), one for each drive class, so we specify drv on the left hand side and . on the right hand side indicating that there’s no variable there (it’s empty).\n\nqplot(hwy, data = mpg, facets = drv ~ ., binwidth = 2)\n\n\n\n\nHistogram of highway mileage by drive class\n\n\n\n\n\n\nWe could also look at more data using facets, so instead of histograms we could look at scatter plots of engine displacement and highway mileage by drive class.\nHere, we put the drv variable on the right hand side to indicate that we want a column for each drive class (as opposed to splitting by rows like we did above).\n\nqplot(displ, hwy, data = mpg, facets = . ~ drv)\n\n\n\n\nEngine displacement and highway mileage by drive class\n\n\n\n\nWhat if you wanted to add a smoother to each one of those panels? Simple, you literally just add the smoother as another geom.\n\nqplot(displ, hwy, data = mpg, facets = . ~ drv) +\n geom_smooth(method = \"lm\")\n\n\n\n\nEngine displacement and highway mileage by drive class w/smoother\n\n\n\n\n\n\n\n\n\n\nNote\n\n\n\nWe used a different type of smoother above.\nHere, we add a linear regression line (a type of smoother) to each group to see if there’s any difference.\n\n\n\n\n\n\n\n\nQuestion\n\n\n\nLet’s facet our palmerpenguins dataset example and explore different types of plots.\nBuilding off the code we previously wrote, perform the following tasks:\n\nFacet the plot based on species with the the three species along rows.\nAdd a linear regression line to each the types of species\n\n\n# try it yourself\n\nNext, make a histogram of the body_mass_g for each of the species colored by the three species.\n\n# try it yourself"
+ "objectID": "posts/17-loop-functions/index.html#vectorizing-a-function",
+ "href": "posts/17-loop-functions/index.html#vectorizing-a-function",
+ "title": "17 - Vectorization and loop functionals",
+ "section": "Vectorizing a Function",
+ "text": "Vectorizing a Function\nLet’s talk about how we can “vectorize” a function.\nWhat this means is that we can write function that typically only takes single arguments and create a new function that can take vector arguments.\nThis is often needed when you want to plot functions.\n\n\n\n\n\n\nExample\n\n\n\nHere’s an example of a function that computes the sum of squares given some data, a mean parameter and a standard deviation. The formula is \\(\\sum_{i=1}^n(x_i-\\mu)^2/\\sigma^2\\).\n\nsumsq <- function(mu, sigma, x) {\n sum(((x - mu) / sigma)^2)\n}\n\nThis function takes a mean mu, a standard deviation sigma, and some data in a vector x.\nIn many statistical applications, we want to minimize the sum of squares to find the optimal mu and sigma. Before we do that, we may want to evaluate or plot the function for many different values of mu or sigma.\n\nx <- rnorm(100) ## Generate some data\nsumsq(mu = 1, sigma = 1, x) ## This works (returns one value)\n\n[1] 248.8765\n\n\nHowever, passing a vector of mus or sigmas won’t work with this function because it’s not vectorized.\n\nsumsq(1:10, 1:10, x) ## This is not what we want\n\n[1] 119.3071\n\n\n\n\nThere’s even a function in R called Vectorize() that automatically can create a vectorized version of your function.\nSo we could create a vsumsq() function that is fully vectorized as follows.\n\nvsumsq <- Vectorize(sumsq, c(\"mu\", \"sigma\"))\nvsumsq(1:10, 1:10, x)\n\n [1] 248.8765 146.5055 124.7964 116.2695 111.8983 109.2945 107.5867 106.3890\n [9] 105.5067 104.8318\n\n\nPretty cool, right?"
},
{
- "objectID": "posts/12-ggplot2-plotting-system-part-1/index.html#summary",
- "href": "posts/12-ggplot2-plotting-system-part-1/index.html#summary",
- "title": "12 - The ggplot2 plotting system: qplot()",
- "section": "Summary",
- "text": "Summary\nThe qplot() function in ggplot2 is the analog of plot() in base graphics but with many built-in features that the traditionaly plot() does not provide. The syntax is somewhere in between the base and lattice graphics system. The qplot() function is useful for quickly putting data on the page/screen, but for ultimate customization, it may make more sense to use some of the lower level functions that we discuss later in the next lesson."
- },
- {
- "objectID": "posts/10-joining-data-in-r/index.html",
- "href": "posts/10-joining-data-in-r/index.html",
- "title": "10 - Joining data in R",
+ "objectID": "posts/25-python-for-r-users/index.html",
+ "href": "posts/25-python-for-r-users/index.html",
+ "title": "25 - Python for R Users",
"section": "",
"text": "This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history."
},
{
- "objectID": "posts/10-joining-data-in-r/index.html#keys",
- "href": "posts/10-joining-data-in-r/index.html#keys",
- "title": "10 - Joining data in R",
- "section": "Keys",
- "text": "Keys\nThe variables used to connect each pair of tables are called keys. A key is a variable (or set of variables) that uniquely identifies an observation. In simple cases, a single variable is sufficient to identify an observation.\n\n\n\n\n\n\nNote\n\n\n\nThere are two types of keys:\n\nA primary key uniquely identifies an observation in its own table.\nA foreign key uniquely identifies an observation in another table.\n\n\n\nLet’s consider an example to help us understand the difference between a primary key and foreign key."
+ "objectID": "posts/25-python-for-r-users/index.html#overview",
+ "href": "posts/25-python-for-r-users/index.html#overview",
+ "title": "25 - Python for R Users",
+ "section": "Overview",
+ "text": "Overview\nFor this lecture, we will be using the reticulate R package, which provides a set of tools for interoperability between Python and R. The package includes facilities for:\n\nCalling Python from R in a variety of ways including (i) R Markdown, (ii) sourcing Python scripts, (iii) importing Python modules, and (iv) using Python interactively within an R session.\nTranslation between R and Python objects (for example, between R and Pandas data frames, or between R matrices and NumPy arrays).\n\n\n[Source: Rstudio]\n\n\n\n\n\n\nPro-tip for installing python\n\n\n\nInstalling python: If you would like recommendations on installing python, I like these resources:\n\nPy Pkgs: https://py-pkgs.org/02-setup#installing-python\nmy fav: Using conda environments with mini-forge: https://github.com/conda-forge/miniforge\nfrom reticulate: https://rstudio.github.io/reticulate/articles/python_packages.html\n\nWhat’s happening under the hood?: reticulate embeds a Python session within your R session, enabling seamless, high-performance interoperability.\nIf you are an R developer that uses Python for some of your work or a member of data science team that uses both languages, reticulate can make your life better!"
},
{
- "objectID": "posts/10-joining-data-in-r/index.html#example-of-keys",
- "href": "posts/10-joining-data-in-r/index.html#example-of-keys",
- "title": "10 - Joining data in R",
- "section": "Example of keys",
- "text": "Example of keys\nImagine you are conduct a study and collecting data on subjects and a health outcome.\nOften, subjects will make multiple visits (a so-called longitudinal study) and so we will record the outcome for each visit. Similarly, we may record other information about them, such as the kind of housing they live in.\n\nThe first table\nThis code creates a simple table with some made up data about some hypothetical subjects’ outcomes.\n\nlibrary(tidyverse)\n\noutcomes <- tibble(\n id = rep(c(\"a\", \"b\", \"c\"), each = 3),\n visit = rep(0:2, 3),\n outcome = rnorm(3 * 3, 3)\n)\n\nprint(outcomes)\n\n# A tibble: 9 × 3\n id visit outcome\n <chr> <int> <dbl>\n1 a 0 3.07\n2 a 1 3.25\n3 a 2 3.93\n4 b 0 2.18\n5 b 1 2.91\n6 b 2 2.83\n7 c 0 1.49\n8 c 1 2.56\n9 c 2 1.46\n\n\nNote that subjects are labeled by a unique identifer in the id column.\n\n\nA second table\nHere is some code to create a second table (we will be joining the first and second tables shortly). This table contains some data about the hypothetical subjects’ housing situation by recording the type of house they live in.\n\nsubjects <- tibble(\n id = c(\"a\", \"b\", \"c\"),\n house = c(\"detached\", \"rowhouse\", \"rowhouse\")\n)\n\nprint(subjects)\n\n# A tibble: 3 × 2\n id house \n <chr> <chr> \n1 a detached\n2 b rowhouse\n3 c rowhouse\n\n\n\n\n\n\n\n\nQuestion\n\n\n\nWhat is the primary key and foreign key?\n\nThe outcomes$id is a primary key because it uniquely identifies each subject in the outcomes table.\nThe subjects$id is a foreign key because it appears in the subjects table where it matches each subject to a unique id."
+ "objectID": "posts/25-python-for-r-users/index.html#install-reticulate",
+ "href": "posts/25-python-for-r-users/index.html#install-reticulate",
+ "title": "25 - Python for R Users",
+ "section": "Install reticulate",
+ "text": "Install reticulate\nLet’s try it out. Before we get started, you will need to install the packages:\n\ninstall.package(\"reticulate\")\n\nWe will also load the here and tidyverse packages for our lesson:\n\nlibrary(here)\nlibrary(tidyverse)\nlibrary(reticulate)"
},
{
- "objectID": "posts/10-joining-data-in-r/index.html#left-join",
- "href": "posts/10-joining-data-in-r/index.html#left-join",
- "title": "10 - Joining data in R",
- "section": "Left Join",
- "text": "Left Join\nRecall the outcomes and subjects datasets above.\n\noutcomes\n\n# A tibble: 9 × 3\n id visit outcome\n <chr> <int> <dbl>\n1 a 0 3.07\n2 a 1 3.25\n3 a 2 3.93\n4 b 0 2.18\n5 b 1 2.91\n6 b 2 2.83\n7 c 0 1.49\n8 c 1 2.56\n9 c 2 1.46\n\nsubjects\n\n# A tibble: 3 × 2\n id house \n <chr> <chr> \n1 a detached\n2 b rowhouse\n3 c rowhouse\n\n\nSuppose we want to create a table that combines the information about houses (subjects) with the information about the outcomes (outcomes).\nWe can use the left_join() function to merge the outcomes and subjects tables and produce the output above.\n\nleft_join(x = outcomes, y = subjects, by = \"id\")\n\n# A tibble: 9 × 4\n id visit outcome house \n <chr> <int> <dbl> <chr> \n1 a 0 3.07 detached\n2 a 1 3.25 detached\n3 a 2 3.93 detached\n4 b 0 2.18 rowhouse\n5 b 1 2.91 rowhouse\n6 b 2 2.83 rowhouse\n7 c 0 1.49 rowhouse\n8 c 1 2.56 rowhouse\n9 c 2 1.46 rowhouse\n\n\n\n\n\n\n\n\nNote\n\n\n\nThe by argument indicates the column (or columns) that the two tables have in common.\n\n\n\nLeft Join with Incomplete Data\nIn the previous examples, the subjects table didn’t have a visit column. But suppose it did? Maybe people move around during the study. We could image a table like this one.\n\nsubjects <- tibble(\n id = c(\"a\", \"b\", \"c\"),\n visit = c(0, 1, 0),\n house = c(\"detached\", \"rowhouse\", \"rowhouse\"),\n)\n\nprint(subjects)\n\n# A tibble: 3 × 3\n id visit house \n <chr> <dbl> <chr> \n1 a 0 detached\n2 b 1 rowhouse\n3 c 0 rowhouse\n\n\nWhen we left joint the tables now we get:\n\nleft_join(outcomes, subjects, by = c(\"id\", \"visit\"))\n\n# A tibble: 9 × 4\n id visit outcome house \n <chr> <dbl> <dbl> <chr> \n1 a 0 3.07 detached\n2 a 1 3.25 <NA> \n3 a 2 3.93 <NA> \n4 b 0 2.18 <NA> \n5 b 1 2.91 rowhouse\n6 b 2 2.83 <NA> \n7 c 0 1.49 rowhouse\n8 c 1 2.56 <NA> \n9 c 2 1.46 <NA> \n\n\n\n\n\n\n\n\nNote\n\n\n\nTwo things to point out here:\n\nIf we do not have information about a subject’s housing in a given visit, the left_join() function automatically inserts an NA value to indicate that it is missing.\nWe can “join” on multiple variable (e.g. here we joined on the id and the visit columns).\n\n\n\nWe may even have a situation where we are missing housing data for a subject completely. The following table has no information about subject a.\n\nsubjects <- tibble(\n id = c(\"b\", \"c\"),\n visit = c(1, 0),\n house = c(\"rowhouse\", \"rowhouse\"),\n)\n\nsubjects\n\n# A tibble: 2 × 3\n id visit house \n <chr> <dbl> <chr> \n1 b 1 rowhouse\n2 c 0 rowhouse\n\n\nBut we can still join the tables together and the house values for subject a will all be NA.\n\nleft_join(x = outcomes, y = subjects, by = c(\"id\", \"visit\"))\n\n# A tibble: 9 × 4\n id visit outcome house \n <chr> <dbl> <dbl> <chr> \n1 a 0 3.07 <NA> \n2 a 1 3.25 <NA> \n3 a 2 3.93 <NA> \n4 b 0 2.18 <NA> \n5 b 1 2.91 rowhouse\n6 b 2 2.83 <NA> \n7 c 0 1.49 rowhouse\n8 c 1 2.56 <NA> \n9 c 2 1.46 <NA> \n\n\n\n\n\n\n\n\nImportant\n\n\n\nThe bottom line for left_join() is that it always retains the values in the “left” argument (in this case the outcomes table).\n\nIf there are no corresponding values in the “right” argument, NA values will be filled in."
+ "objectID": "posts/25-python-for-r-users/index.html#python-path",
+ "href": "posts/25-python-for-r-users/index.html#python-path",
+ "title": "25 - Python for R Users",
+ "section": "python path",
+ "text": "python path\nIf python is not installed on your computer, you can use the install_python() function from reticulate to install it.\n\nhttps://rstudio.github.io/reticulate/reference/install_python\n\nIf python is already installed, by default, reticulate uses the version of Python found on your PATH\n\nSys.which(\"python3\")\n\n python3 \n\"/usr/bin/python3\" \n\n\nThe use_python() function enables you to specify an alternate version, for example:\n\nuse_python(\"/usr/<new>/<path>/local/bin/python\")\n\nFor example, I can define the path explicitly:\n\nuse_python(\"/opt/homebrew/Caskroom/miniforge/base/bin/python\")\n\nYou can confirm that reticulate is using the correct version of python that you requested using the py_discover_config function:\n\npy_discover_config()\n\npython: /usr/bin/python3\nlibpython: /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.9/lib/python3.9/config-3.9-darwin/libpython3.9.dylib\npythonhome: /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.9:/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.9\nversion: 3.9.6 (default, May 7 2023, 23:32:44) [Clang 14.0.3 (clang-1403.0.22.14.1)]\nnumpy: /Users/leocollado/Library/Python/3.9/lib/python/site-packages/numpy\nnumpy_version: 1.25.2\n\nNOTE: Python version was forced by RETICULATE_PYTHON_FALLBACK"
},
{
- "objectID": "posts/10-joining-data-in-r/index.html#inner-join",
- "href": "posts/10-joining-data-in-r/index.html#inner-join",
- "title": "10 - Joining data in R",
- "section": "Inner Join",
- "text": "Inner Join\nThe inner_join() function only retains the rows of both tables that have corresponding values. Here we can see the difference.\n\ninner_join(x = outcomes, y = subjects, by = c(\"id\", \"visit\"))\n\n# A tibble: 2 × 4\n id visit outcome house \n <chr> <dbl> <dbl> <chr> \n1 b 1 2.91 rowhouse\n2 c 0 1.49 rowhouse"
+ "objectID": "posts/25-python-for-r-users/index.html#calling-python-in-r",
+ "href": "posts/25-python-for-r-users/index.html#calling-python-in-r",
+ "title": "25 - Python for R Users",
+ "section": "Calling Python in R",
+ "text": "Calling Python in R\nThere are a variety of ways to integrate Python code into your R projects:\n\nPython in R Markdown — A new Python language engine for R Markdown that supports bi-directional communication between R and Python (R chunks can access Python objects and vice-versa).\nImporting Python modules — The import() function enables you to import any Python module and call its functions directly from R.\nSourcing Python scripts — The source_python() function enables you to source a Python script the same way you would source() an R script (Python functions and objects defined within the script become directly available to the R session).\nPython REPL — The repl_python() function creates an interactive Python console within R. Objects you create within Python are available to your R session (and vice-versa).\n\nBelow I will focus on introducing the first and last one. However, before we do that, let’s introduce a bit about python basics."
},
{
- "objectID": "posts/10-joining-data-in-r/index.html#right-join",
- "href": "posts/10-joining-data-in-r/index.html#right-join",
- "title": "10 - Joining data in R",
- "section": "Right Join",
- "text": "Right Join\nThe right_join() function is like the left_join() function except that it gives priority to the “right” hand argument.\n\nright_join(x = outcomes, y = subjects, by = c(\"id\", \"visit\"))\n\n# A tibble: 2 × 4\n id visit outcome house \n <chr> <dbl> <dbl> <chr> \n1 b 1 2.91 rowhouse\n2 c 0 1.49 rowhouse"
+ "objectID": "posts/25-python-for-r-users/index.html#start-python",
+ "href": "posts/25-python-for-r-users/index.html#start-python",
+ "title": "25 - Python for R Users",
+ "section": "start python",
+ "text": "start python\nThere are two modes you can write Python code in: interactive mode or script mode. If you open up a UNIX command window and have a command-line interface, you can simply type python (or python3) in the shell:\n\npython3\n\nand the interactive mode will open up. You can write code in the interactive mode and Python will interpret the code using the python interpreter.\nAnother way to pass code to Python is to store code in a file ending in .py, and execute the file in the script mode using\n\npython3 myscript.py\n\nTo check what version of Python you are using, type the following in the shell:\n\npython3 --version"
},
{
- "objectID": "posts/14-r-nuts-and-bolts/index.html",
- "href": "posts/14-r-nuts-and-bolts/index.html",
- "title": "14 - R Nuts and Bolts",
- "section": "",
- "text": "This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history."
+ "objectID": "posts/25-python-for-r-users/index.html#r-or-python-via-terminal",
+ "href": "posts/25-python-for-r-users/index.html#r-or-python-via-terminal",
+ "title": "25 - Python for R Users",
+ "section": "R or python via terminal",
+ "text": "R or python via terminal\n(Demo in class)"
},
{
- "objectID": "posts/14-r-nuts-and-bolts/index.html#entering-input",
- "href": "posts/14-r-nuts-and-bolts/index.html#entering-input",
- "title": "14 - R Nuts and Bolts",
- "section": "Entering Input",
- "text": "Entering Input\nAt the R prompt we type expressions. The <- symbol is the assignment operator.\n\nx <- 1\nprint(x)\n\n[1] 1\n\nx\n\n[1] 1\n\nmsg <- \"hello\"\n\nThe grammar of the language determines whether an expression is complete or not.\n\nx <- ## Incomplete expression\n\nError: <text>:2:0: unexpected end of input\n1: x <- ## Incomplete expression\n ^\n\n\nThe # character indicates a comment.\nAnything to the right of the # (including the # itself) is ignored. This is the only comment character in R.\nUnlike some other languages, R does not support multi-line comments or comment blocks."
+ "objectID": "posts/25-python-for-r-users/index.html#objects-in-python",
+ "href": "posts/25-python-for-r-users/index.html#objects-in-python",
+ "title": "25 - Python for R Users",
+ "section": "objects in python",
+ "text": "objects in python\nEverything in Python is an object. Think of an object as a data structure that contains both data as well as functions. These objects can be variables, functions, and modules which are all objects. We can operate on this objects with what are called operators (e.g. addition, subtraction, concatenation or other operations), define/apply functions, test/apply for conditionals statements, (e.g. if, else statements) or iterate over the objects.\nNot all objects are required to have attributes and methods to operate on the objects in Python, but everything is an object (i.e. all objects can be assigned to a variable or passed as an argument to a function). A user can work with built-in defined classes of objects or can create new classes of objects. Using these objects, a user can perform operations on the objects by modifying / interacting with them."
},
{
- "objectID": "posts/14-r-nuts-and-bolts/index.html#evaluation",
- "href": "posts/14-r-nuts-and-bolts/index.html#evaluation",
- "title": "14 - R Nuts and Bolts",
- "section": "Evaluation",
- "text": "Evaluation\nWhen a complete expression is entered at the prompt, it is evaluated and the result of the evaluated expression is returned.\nThe result may be auto-printed.\n\nx <- 5 ## nothing printed\nx ## auto-printing occurs\n\n[1] 5\n\nprint(x) ## explicit printing\n\n[1] 5\n\n\nThe [1] shown in the output indicates that x is a vector and 5 is its first element.\nTypically with interactive work, we do not explicitly print objects with the print() function; it is much easier to just auto-print them by typing the name of the object and hitting return/enter.\nHowever, when writing scripts, functions, or longer programs, there is sometimes a need to explicitly print objects because auto-printing does not work in those settings.\nWhen an R vector is printed you will notice that an index for the vector is printed in square brackets [] on the side. For example, see this integer sequence of length 20.\n\nx <- 11:30\nx\n\n [1] 11 12 13 14 15 16 17 18 19 20 21 22\n[13] 23 24 25 26 27 28 29 30\n\n\nThe numbers in the square brackets are not part of the vector itself, they are merely part of the printed output.\n\n\n\n\n\n\nNote\n\n\n\nWith R, it’s important that one understand that there is a difference between the actual R object and the manner in which that R object is printed to the console.\nOften, the printed output may have additional bells and whistles to make the output more friendly to the users. However, these bells and whistles are not inherently part of the object.\n\n\n\n\n\n\n\n\nPro-tip\n\n\n\nThe : operator is used to create integer sequences.\n\n5:0\n\n[1] 5 4 3 2 1 0\n\n-15:15\n\n [1] -15 -14 -13 -12 -11 -10 -9 -8 -7 -6 -5 -4 -3 -2 -1 0 1 2 3\n[20] 4 5 6 7 8 9 10 11 12 13 14 15"
+ "objectID": "posts/25-python-for-r-users/index.html#variables",
+ "href": "posts/25-python-for-r-users/index.html#variables",
+ "title": "25 - Python for R Users",
+ "section": "variables",
+ "text": "variables\nVariable names are case sensitive, can contain numbers and letters, can contain underscores, cannot begin with a number, cannot contain illegal characters and cannot be one of the 31 keywords in Python:\n\n“and, as, assert, break, class, continue, def, del, elif, else, except, exec, finally, for, from, global, if, import, in, is, lambda, not, or, pass, print, raise, return, try, while, with, yield”"
},
{
- "objectID": "posts/14-r-nuts-and-bolts/index.html#r-objects",
- "href": "posts/14-r-nuts-and-bolts/index.html#r-objects",
- "title": "14 - R Nuts and Bolts",
- "section": "R Objects",
- "text": "R Objects\nThe most basic type of R object is a vector.\n\nVectors\nThere is really only one rule about vectors in R, which is that\n\nA vector can only contain objects of the same class\n\nTo understand what we mean here, we need to dig a little deeper. We will come back this in just a minute.\n\nTypes of vectors\nThere are two types of vectors in R:\n\nAtomic vectors:\n\nlogical: FALSE, TRUE, and NA\ninteger (and doubles): these are known collectively as numeric vectors (or real numbers)\ncomplex: complex numbers\ncharacter: the most complex type of atomic vector, because each element of a character vector is a string, and a string can contain an arbitrary amount of data\nraw: used to store fixed-length sequences of bytes. These are not commonly used directly in data analysis and I won’t cover them here.\n\nLists, which are sometimes called recursive vectors because lists can contain other lists.\n\n\n[Source: R 4 Data Science]\n\n\n\n\n\n\nNote\n\n\n\nThere’s one other related object: NULL.\n\nNULL is often used to represent the absence of a vector (as opposed to NA which is used to represent the absence of a value in a vector).\nNULL typically behaves like a vector of length 0.\n\n\n\n\n\nCreate an empty vector\nEmpty vectors can be created with the vector() function.\n\nvector(mode = \"numeric\", length = 4)\n\n[1] 0 0 0 0\n\nvector(mode = \"logical\", length = 4)\n\n[1] FALSE FALSE FALSE FALSE\n\nvector(mode = \"character\", length = 4)\n\n[1] \"\" \"\" \"\" \"\"\n\n\n\n\nCreating a non-empty vector\nThe c() function can be used to create vectors of objects by concatenating things together.\n\nx <- c(0.5, 0.6) ## numeric\nx <- c(TRUE, FALSE) ## logical\nx <- c(T, F) ## logical\nx <- c(\"a\", \"b\", \"c\") ## character\nx <- 9:29 ## integer\nx <- c(1+0i, 2+4i) ## complex\n\n\n\n\n\n\n\nNote\n\n\n\nIn the above example, T and F are short-hand ways to specify TRUE and FALSE.\nHowever, in general, one should try to use the explicit TRUE and FALSE values when indicating logical values.\nThe T and F values are primarily there for when you’re feeling lazy.\n\n\n\n\nLists\nSo, I know I said there is one rule about vectors:\n\nA vector can only contain objects of the same class\n\nBut of course, like any good rule, there is an exception, which is a list (which we will get to in greater details a bit later).\nFor now, just know a list is represented as a vector but can contain objects of different classes. Indeed, that’s usually why we use them.\n\n\n\n\n\n\nNote\n\n\n\nThe main difference between atomic vectors and lists is that atomic vectors are homogeneous, while lists can be heterogeneous.\n\n\n\n\n\nNumerics\nInteger and double vectors are known collectively as numeric vectors.\nIn R, numbers are doubles by default.\nTo make an integer, place an L after the number:\n\ntypeof(4)\n\n[1] \"double\"\n\ntypeof(4L)\n\n[1] \"integer\"\n\n\n\n\n\n\n\n\nNote\n\n\n\nThe distinction between integers and doubles is not usually important, but there are two important differences that you should be aware of:\n\nDoubles are approximations!\nDoubles represent floating point numbers that can not always be precisely represented with a fixed amount of memory. This means that you should consider all doubles to be approximations.\n\n\n\n\n\n\n\n\n\nQuestion\n\n\n\nLet’s explore this. What is square of the square root of two? i.e. \\((\\sqrt{2})^2\\)\n\nx <- sqrt(2) ^ 2\nx\n\n[1] 2\n\n\nTry subtracting 2 from x? What happened?\n\n## try it here\n\n\n\n\n\nNumbers\nNumbers in R are generally treated as numeric objects (i.e. double precision real numbers).\nThis means that even if you see a number like “1” or “2” in R, which you might think of as integers, they are likely represented behind the scenes as numeric objects (so something like “1.00” or “2.00”).\nThis isn’t important most of the time…except when it is!\nIf you explicitly want an integer, you need to specify the L suffix. So entering 1 in R gives you a numeric object; entering 1L explicitly gives you an integer object.\n\n\n\n\n\n\nNote\n\n\n\nThere is also a special number Inf which represents infinity. This allows us to represent entities like 1 / 0. This way, Inf can be used in ordinary calculations; e.g. 1 / Inf is 0.\nThe value NaN represents an undefined value (“not a number”); e.g. 0 / 0; NaN can also be thought of as a missing value (more on that later)\n\n\n\n\nAttributes\nR objects can have attributes, which are like metadata for the object.\nThese metadata can be very useful in that they help to describe the object.\nFor example, column names on a data frame help to tell us what data are contained in each of the columns. Some examples of R object attributes are\n\nnames, dimnames\ndimensions (e.g. matrices, arrays)\nclass (e.g. integer, numeric)\nlength\nother user-defined attributes/metadata\n\nAttributes of an object (if any) can be accessed using the attributes() function. Not all R objects contain attributes, in which case the attributes() function returns NULL.\nHowever, every vector has two key properties:\n\nIts type, which you can determine with typeof().\n\n\nletters\n\n [1] \"a\" \"b\" \"c\" \"d\" \"e\" \"f\" \"g\" \"h\" \"i\" \"j\" \"k\" \"l\" \"m\" \"n\" \"o\" \"p\" \"q\" \"r\" \"s\"\n[20] \"t\" \"u\" \"v\" \"w\" \"x\" \"y\" \"z\"\n\ntypeof(letters)\n\n[1] \"character\"\n\n1:10\n\n [1] 1 2 3 4 5 6 7 8 9 10\n\ntypeof(1:10)\n\n[1] \"integer\"\n\n\n\nIts length, which you can determine with length().\n\n\nx <- list(\"a\", \"b\", 1:10)\nx\n\n[[1]]\n[1] \"a\"\n\n[[2]]\n[1] \"b\"\n\n[[3]]\n [1] 1 2 3 4 5 6 7 8 9 10\n\nlength(x)\n\n[1] 3\n\ntypeof(x)\n\n[1] \"list\"\n\nattributes(x)\n\nNULL"
+ "objectID": "posts/25-python-for-r-users/index.html#operators",
+ "href": "posts/25-python-for-r-users/index.html#operators",
+ "title": "25 - Python for R Users",
+ "section": "operators",
+ "text": "operators\n\nNumeric operators are +, -, *, /, ** (exponent), % (modulus if applied to integers)\nString and list operators: + and * .\nAssignment operator: =\nThe augmented assignment operator += (or -=) can be used like n += x which is equal to n = n + x\nBoolean relational operators: == (equal), != (not equal), >, <, >= (greater than or equal to), <= (less than or equal to)\nBoolean expressions will produce True or False\nLogical operators: and, or, and not. e.g. x > 1 and x <= 5\n\n\n2 ** 3\n\n8\n\nx = 3 \nx > 1 and x <= 5\n\nTrue\n\n\nAnd in R, the execution changes from Python to R seamlessly\n\n2^3\n\n[1] 8\n\nx <- 3\nx > 1 & x <= 5\n\n[1] TRUE"
},
{
- "objectID": "posts/14-r-nuts-and-bolts/index.html#mixing-objects",
- "href": "posts/14-r-nuts-and-bolts/index.html#mixing-objects",
- "title": "14 - R Nuts and Bolts",
- "section": "Mixing Objects",
- "text": "Mixing Objects\nThere are occasions when different classes of R objects get mixed together.\nSometimes this happens by accident but it can also happen on purpose.\n\n\n\n\n\n\nQuestion\n\n\n\nLet’s use typeof() to ask what happens when we mix different classes of R objects together.\n\ny <- c(1.7, \"a\")\ny <- c(TRUE, 2)\ny <- c(\"a\", TRUE)\n\n\n## try it here\n\n\n\nWhy is this happening?\nIn each case above, we are mixing objects of two different classes in a vector.\nBut remember that the only rule about vectors says this is not allowed?\nWhen different objects are mixed in a vector, coercion occurs so that every element in the vector is of the same class.\nIn the example above, we see the effect of implicit coercion.\nWhat R tries to do is find a way to represent all of the objects in the vector in a reasonable fashion. Sometimes this does exactly what you want and…sometimes not.\nFor example, combining a numeric object with a character object will create a character vector, because numbers can usually be easily represented as strings."
+ "objectID": "posts/25-python-for-r-users/index.html#format-operators",
+ "href": "posts/25-python-for-r-users/index.html#format-operators",
+ "title": "25 - Python for R Users",
+ "section": "format operators",
+ "text": "format operators\nIf % is applied to strings, this operator is the format operator. It tells Python how to format a list of values in a string. For example,\n\n%d says to format the value as an integer\n%g says to format the value as an float\n%s says to format the value as an string\n\n\nprint('In %d days, I have eaten %g %s.' % (5, 3.5, 'cupcakes'))\n\nIn 5 days, I have eaten 3.5 cupcakes."
},
{
- "objectID": "posts/14-r-nuts-and-bolts/index.html#explicit-coercion",
- "href": "posts/14-r-nuts-and-bolts/index.html#explicit-coercion",
- "title": "14 - R Nuts and Bolts",
- "section": "Explicit Coercion",
- "text": "Explicit Coercion\nObjects can be explicitly coerced from one class to another using the as.*() functions, if available.\n\nx <- 0:6\nclass(x)\n\n[1] \"integer\"\n\nas.numeric(x)\n\n[1] 0 1 2 3 4 5 6\n\nas.logical(x)\n\n[1] FALSE TRUE TRUE TRUE TRUE TRUE TRUE\n\nas.character(x)\n\n[1] \"0\" \"1\" \"2\" \"3\" \"4\" \"5\" \"6\"\n\n\nSometimes, R can’t figure out how to coerce an object and this can result in NAs being produced.\n\nx <- c(\"a\", \"b\", \"c\")\nas.numeric(x)\n\nWarning: NAs introduced by coercion\n\n\n[1] NA NA NA\n\nas.logical(x)\n\n[1] NA NA NA\n\n\n\n\n\n\n\n\nQuestion\n\n\n\nLet’s try to convert the x vector above to integers.\n\n## try it here \n\n\n\nWhen nonsensical coercion takes place, you will usually get a warning from R."
+ "objectID": "posts/25-python-for-r-users/index.html#functions",
+ "href": "posts/25-python-for-r-users/index.html#functions",
+ "title": "25 - Python for R Users",
+ "section": "functions",
+ "text": "functions\nPython contains a small list of very useful built-in functions.\nAll other functions need defined by the user or need to be imported from modules.\n\n\n\n\n\n\nPro-tip\n\n\n\nFor a more detailed list on the built-in functions in Python, see Built-in Python Functions.\n\n\nThe first function we will discuss, type(), reports the type of any object, which is very useful when handling multiple data types (remember, everything in Python is an object). Here are some the mains types you will encounter:\n\ninteger (int)\nfloating-point (float)\nstring (str)\nlist (list)\ndictionary (dict)\ntuple (tuple)\nfunction (function)\nmodule (module)\nboolean (bool): e.g. True, False\nenumerate (enumerate)\n\nIf we asked for the type of a string “Let’s go Ravens!”\n\ntype(\"Let's go Ravens!\")\n\n<class 'str'>\n\n\nThis would return the str type.\nYou have also seen how to use the print() function. The function print will accept an argument and print the argument to the screen. Print can be used in two ways:\n\nprint(\"Let's go Ravens!\")\n\n[1] \"Let's go Ravens!\""
},
{
- "objectID": "posts/14-r-nuts-and-bolts/index.html#matrices",
- "href": "posts/14-r-nuts-and-bolts/index.html#matrices",
- "title": "14 - R Nuts and Bolts",
- "section": "Matrices",
- "text": "Matrices\nMatrices are vectors with a dimension attribute.\n\nThe dimension attribute is itself an integer vector of length 2 (number of rows, number of columns)\n\n\nm <- matrix(nrow = 2, ncol = 3) \nm\n\n [,1] [,2] [,3]\n[1,] NA NA NA\n[2,] NA NA NA\n\ndim(m)\n\n[1] 2 3\n\nattributes(m)\n\n$dim\n[1] 2 3\n\n\nMatrices are constructed column-wise, so entries can be thought of starting in the “upper left” corner and running down the columns.\n\nm <- matrix(1:6, nrow = 2, ncol = 3) \nm\n\n [,1] [,2] [,3]\n[1,] 1 3 5\n[2,] 2 4 6\n\n\n\n\n\n\n\n\nQuestion\n\n\n\nLet’s try to use attributes() function to look at the attributes of the m object\n\n## try it here \n\n\n\nMatrices can also be created directly from vectors by adding a dimension attribute.\n\nm <- 1:10 \nm\n\n [1] 1 2 3 4 5 6 7 8 9 10\n\ndim(m) <- c(2, 5)\nm\n\n [,1] [,2] [,3] [,4] [,5]\n[1,] 1 3 5 7 9\n[2,] 2 4 6 8 10\n\n\nMatrices can be created by column-binding or row-binding with the cbind() and rbind() functions.\n\nx <- 1:3\ny <- 10:12\ncbind(x, y)\n\n x y\n[1,] 1 10\n[2,] 2 11\n[3,] 3 12\n\n\n\n\n\n\n\n\nQuestion\n\n\n\nLet’s try to use rbind() to row bind x and y above.\n\n## try it here"
+ "objectID": "posts/25-python-for-r-users/index.html#new-functions",
+ "href": "posts/25-python-for-r-users/index.html#new-functions",
+ "title": "25 - Python for R Users",
+ "section": "new functions",
+ "text": "new functions\nNew functions can be defined using one of the 31 keywords in Python def.\n\ndef new_world(): \n return 'Hello world!'\n \nprint(new_world())\n\nHello world!\n\n\nThe first line of the function (the header) must start with def, the name of the function (which can contain underscores), parentheses (with any arguments inside of it) and a colon. The arguments can be specified in any order.\nThe rest of the function (the body) always has an indentation of four spaces. If you define a function in the interactive mode, the interpreter will print ellipses (…) to let you know the function is not complete. To complete the function, enter an empty line (not necessary in a script).\nTo return a value from a function, use return. The function will immediately terminate and not run any code written past this point.\n\ndef squared(x):\n \"\"\" Return the square of a \n value \"\"\"\n return x ** 2\n\nprint(squared(4))\n\n16\n\n\n\n\n\n\n\n\nNote\n\n\n\npython has its version of ... (also from docs.python.org)\n\ndef concat(*args, sep=\"/\"):\n return sep.join(args) \n\nconcat(\"a\", \"b\", \"c\")\n\n'a/b/c'"
},
{
- "objectID": "posts/14-r-nuts-and-bolts/index.html#lists-1",
- "href": "posts/14-r-nuts-and-bolts/index.html#lists-1",
- "title": "14 - R Nuts and Bolts",
- "section": "Lists",
- "text": "Lists\nLists are a special type of vector that can contain elements of different classes. Lists are a very important data type in R and you should get to know them well.\n\n\n\n\n\n\nPro-tip\n\n\n\nLists, in combination with the various “apply” functions discussed later, make for a powerful combination.\n\n\nLists can be explicitly created using the list() function, which takes an arbitrary number of arguments.\n\nx <- list(1, \"a\", TRUE, 1 + 4i) \nx\n\n[[1]]\n[1] 1\n\n[[2]]\n[1] \"a\"\n\n[[3]]\n[1] TRUE\n\n[[4]]\n[1] 1+4i\n\n\nWe can also create an empty list of a prespecified length with the vector() function\n\nx <- vector(\"list\", length = 5)\nx\n\n[[1]]\nNULL\n\n[[2]]\nNULL\n\n[[3]]\nNULL\n\n[[4]]\nNULL\n\n[[5]]\nNULL"
+ "objectID": "posts/25-python-for-r-users/index.html#iteration",
+ "href": "posts/25-python-for-r-users/index.html#iteration",
+ "title": "25 - Python for R Users",
+ "section": "iteration",
+ "text": "iteration\nIterative loops can be written with the for, while and break statements.\nDefining a for loop is similar to defining a new function.\n\nThe header ends with a colon and the body is indented.\nThe function range(n) takes in an integer n and creates a set of values from 0 to n - 1.\n\n\nfor i in range(3):\n print('Baby shark, doo doo doo doo doo doo!')\n\nBaby shark, doo doo doo doo doo doo!\nBaby shark, doo doo doo doo doo doo!\nBaby shark, doo doo doo doo doo doo!\n\nprint('Baby shark!')\n\nBaby shark!\n\n\nfor loops are not just for counters, but they can iterate through many types of objects such as strings, lists and dictionaries.\nThe function len() can be used to:\n\nCalculate the length of a string\nCalculate the number of elements in a list\nCalculate the number of items (key-value pairs) in a dictionary\nCalculate the number elements in the tuple\n\n\nx = 'Baby shark!'\nlen(x)\n\n11"
},
{
- "objectID": "posts/14-r-nuts-and-bolts/index.html#factors",
- "href": "posts/14-r-nuts-and-bolts/index.html#factors",
- "title": "14 - R Nuts and Bolts",
- "section": "Factors",
- "text": "Factors\nFactors are used to represent categorical data and can be unordered or ordered. One can think of a factor as an integer vector where each integer has a label.\n\n\n\n\n\n\nPro-tip\n\n\n\nFactors are important in statistical modeling and are treated specially by modelling functions like lm() and glm().\n\n\nUsing factors with labels is better than using integers because factors are self-describing.\n\n\n\n\n\n\nPro-tip\n\n\n\nHaving a variable that has values “Yes” and “No” or “Smoker” and “Non-Smoker” is better than a variable that has values 1 and 2.\n\n\nFactor objects can be created with the factor() function.\n\nx <- factor(c(\"yes\", \"yes\", \"no\", \"yes\", \"no\")) \nx\n\n[1] yes yes no yes no \nLevels: no yes\n\ntable(x) \n\nx\n no yes \n 2 3 \n\n## See the underlying representation of factor\nunclass(x) \n\n[1] 2 2 1 2 1\nattr(,\"levels\")\n[1] \"no\" \"yes\"\n\n\n\n\n\n\n\n\nQuestion\n\n\n\nLet’s try to use attributes() function to look at the attributes of the x object\n\n## try it here \n\n\n\nOften factors will be automatically created for you when you read in a dataset using a function like read.table().\n\nThose functions often default to creating factors when they encounter data that look like characters or strings.\n\nThe order of the levels of a factor can be set using the levels argument to factor(). This can be important in linear modeling because the first level is used as the baseline level.\n\nx <- factor(c(\"yes\", \"yes\", \"no\", \"yes\", \"no\"))\nx ## Levels are put in alphabetical order\n\n[1] yes yes no yes no \nLevels: no yes\n\nx <- factor(c(\"yes\", \"yes\", \"no\", \"yes\", \"no\"),\n levels = c(\"yes\", \"no\"))\nx\n\n[1] yes yes no yes no \nLevels: yes no"
+ "objectID": "posts/25-python-for-r-users/index.html#methods-for-each-type-of-object-dot-notation",
+ "href": "posts/25-python-for-r-users/index.html#methods-for-each-type-of-object-dot-notation",
+ "title": "25 - Python for R Users",
+ "section": "methods for each type of object (dot notation)",
+ "text": "methods for each type of object (dot notation)\nFor strings, lists and dictionaries, there are set of methods you can use to manipulate the objects. In general, the notation for methods is the dot notation.\nThe syntax is the name of the object followed by a dot (or period) followed by the name of the method.\n\nx = \"Hello Baltimore!\"\nx.split()\n\n['Hello', 'Baltimore!']"
},
{
- "objectID": "posts/14-r-nuts-and-bolts/index.html#missing-values",
- "href": "posts/14-r-nuts-and-bolts/index.html#missing-values",
- "title": "14 - R Nuts and Bolts",
- "section": "Missing Values",
- "text": "Missing Values\nMissing values are denoted by NA or NaN for undefined mathematical operations.\n\nis.na() is used to test objects if they are NA\nis.nan() is used to test for NaN\nNA values have a class also, so there are integer NA, character NA, etc.\nA NaN value is also NA but the converse is not true\n\n\n## Create a vector with NAs in it\nx <- c(1, 2, NA, 10, 3) \n## Return a logical vector indicating which elements are NA\nis.na(x) \n\n[1] FALSE FALSE TRUE FALSE FALSE\n\n## Return a logical vector indicating which elements are NaN\nis.nan(x) \n\n[1] FALSE FALSE FALSE FALSE FALSE\n\n\n\n## Now create a vector with both NA and NaN values\nx <- c(1, 2, NaN, NA, 4)\nis.na(x)\n\n[1] FALSE FALSE TRUE TRUE FALSE\n\nis.nan(x)\n\n[1] FALSE FALSE TRUE FALSE FALSE"
+ "objectID": "posts/25-python-for-r-users/index.html#data-structures",
+ "href": "posts/25-python-for-r-users/index.html#data-structures",
+ "title": "25 - Python for R Users",
+ "section": "Data structures",
+ "text": "Data structures\nWe have already seen lists. Python has other data structures built in.\n\nSets {\"a\", \"a\", \"a\", \"b\"} (unique elements)\nTuples (1, 2, 3) (a lot like lists but not mutable, i.e. need to create a new to modify)\nDictionaries\n\n\ndict = {\"a\" : 1, \"b\" : 2}\ndict['a']\n\n1\n\ndict['b']\n\n2\n\n\nMore about data structures can be founds at the python docs"
},
{
- "objectID": "posts/14-r-nuts-and-bolts/index.html#data-frames",
- "href": "posts/14-r-nuts-and-bolts/index.html#data-frames",
- "title": "14 - R Nuts and Bolts",
- "section": "Data Frames",
- "text": "Data Frames\nData frames are used to store tabular data in R. They are an important type of object in R and are used in a variety of statistical modeling applications. Hadley Wickham’s package dplyr has an optimized set of functions designed to work efficiently with data frames.\nData frames are represented as a special type of list where every element of the list has to have the same length.\n\nEach element of the list can be thought of as a column\nThe length of each element of the list is the number of rows\n\nUnlike matrices, data frames can store different classes of objects in each column. Matrices must have every element be the same class (e.g. all integers or all numeric).\nIn addition to column names, indicating the names of the variables or predictors, data frames have a special attribute called row.names which indicate information about each row of the data frame.\nData frames are usually created by reading in a dataset using the read.table() or read.csv(). However, data frames can also be created explicitly with the data.frame() function or they can be coerced from other types of objects like lists.\n\nx <- data.frame(foo = 1:4, bar = c(T, T, F, F)) \nx\n\n foo bar\n1 1 TRUE\n2 2 TRUE\n3 3 FALSE\n4 4 FALSE\n\nnrow(x)\n\n[1] 4\n\nncol(x)\n\n[1] 2\n\nattributes(x)\n\n$names\n[1] \"foo\" \"bar\"\n\n$class\n[1] \"data.frame\"\n\n$row.names\n[1] 1 2 3 4\n\n\nData frames can be converted to a matrix by calling data.matrix(). While it might seem that the as.matrix() function should be used to coerce a data frame to a matrix, almost always, what you want is the result of data.matrix().\n\ndata.matrix(x)\n\n foo bar\n[1,] 1 1\n[2,] 2 1\n[3,] 3 0\n[4,] 4 0\n\nattributes(data.matrix(x))\n\n$dim\n[1] 4 2\n\n$dimnames\n$dimnames[[1]]\nNULL\n\n$dimnames[[2]]\n[1] \"foo\" \"bar\"\n\n\n\nExample\n\n\n\n\n\n\nQuestion\n\n\n\nLet’s use the palmerpenguins dataset.\n\nWhat attributes does penguins have?\nWhat class is the penguins R object?\nWhat are the levels in the species column in the penguins dataset?\nCreate a logical vector for all the penguins measured from 2008.\nCreate a matrix with just the columns bill_length_mm, bill_depth_mm, flipper_length_mm, and body_mass_g\n\n\n# try it yourself\n\nlibrary(tidyverse)\nlibrary(palmerpenguins)\npenguins \n\n# A tibble: 344 × 8\n species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g\n <fct> <fct> <dbl> <dbl> <int> <int>\n 1 Adelie Torgersen 39.1 18.7 181 3750\n 2 Adelie Torgersen 39.5 17.4 186 3800\n 3 Adelie Torgersen 40.3 18 195 3250\n 4 Adelie Torgersen NA NA NA NA\n 5 Adelie Torgersen 36.7 19.3 193 3450\n 6 Adelie Torgersen 39.3 20.6 190 3650\n 7 Adelie Torgersen 38.9 17.8 181 3625\n 8 Adelie Torgersen 39.2 19.6 195 4675\n 9 Adelie Torgersen 34.1 18.1 193 3475\n10 Adelie Torgersen 42 20.2 190 4250\n# ℹ 334 more rows\n# ℹ 2 more variables: sex <fct>, year <int>"
+ "objectID": "posts/25-python-for-r-users/index.html#python-engine-within-r-markdown",
+ "href": "posts/25-python-for-r-users/index.html#python-engine-within-r-markdown",
+ "title": "25 - Python for R Users",
+ "section": "Python engine within R Markdown",
+ "text": "Python engine within R Markdown\nThe reticulate package includes a Python engine for R Markdown with the following features:\n\nRun Python chunks in a single Python session embedded within your R session (shared variables/state between Python chunks)\nPrinting of Python output, including graphical output from matplotlib.\nAccess to objects created within Python chunks from R using the py object (e.g. py$x would access an x variable created within Python from R).\nAccess to objects created within R chunks from Python using the r object (e.g. r.x would access to x variable created within R from Python)\n\n\n\n\n\n\n\nConversions\n\n\n\nBuilt in conversion for many Python object types is provided, including NumPy arrays and Pandas data frames."
},
{
- "objectID": "posts/14-r-nuts-and-bolts/index.html#names",
- "href": "posts/14-r-nuts-and-bolts/index.html#names",
- "title": "14 - R Nuts and Bolts",
- "section": "Names",
- "text": "Names\nR objects can have names, which is very useful for writing readable code and self-describing objects.\nHere is an example of assigning names to an integer vector.\n\nx <- 1:3\nnames(x)\n\nNULL\n\nnames(x) <- c(\"New York\", \"Seattle\", \"Los Angeles\") \nx\n\n New York Seattle Los Angeles \n 1 2 3 \n\nnames(x)\n\n[1] \"New York\" \"Seattle\" \"Los Angeles\"\n\nattributes(x)\n\n$names\n[1] \"New York\" \"Seattle\" \"Los Angeles\"\n\n\nLists can also have names, which is often very useful.\n\nx <- list(\"Los Angeles\" = 1, Boston = 2, London = 3) \nx\n\n$`Los Angeles`\n[1] 1\n\n$Boston\n[1] 2\n\n$London\n[1] 3\n\nnames(x)\n\n[1] \"Los Angeles\" \"Boston\" \"London\" \n\n\nMatrices can have both column and row names.\n\nm <- matrix(1:4, nrow = 2, ncol = 2)\ndimnames(m) <- list(c(\"a\", \"b\"), c(\"c\", \"d\")) \nm\n\n c d\na 1 3\nb 2 4\n\n\nColumn names and row names can be set separately using the colnames() and rownames() functions.\n\ncolnames(m) <- c(\"h\", \"f\")\nrownames(m) <- c(\"x\", \"z\")\nm\n\n h f\nx 1 3\nz 2 4\n\n\n\n\n\n\n\n\nNote\n\n\n\nFor data frames, there is a separate function for setting the row names, the row.names() function.\nAlso, data frames do not have column names, they just have names (like lists).\nSo to set the column names of a data frame just use the names() function. Yes, I know its confusing.\nHere’s a quick summary:\n\n\n\nObject\nSet column names\nSet row names\n\n\n\n\ndata frame\nnames()\nrow.names()\n\n\nmatrix\ncolnames()\nrownames()"
+ "objectID": "posts/25-python-for-r-users/index.html#from-python-to-r",
+ "href": "posts/25-python-for-r-users/index.html#from-python-to-r",
+ "title": "25 - Python for R Users",
+ "section": "From Python to R",
+ "text": "From Python to R\nAs an example, you can use Pandas to read and manipulate data then easily plot the Pandas data frame using ggplot2:\nLet’s first create a flights.csv dataset in R and save it using write_csv from readr:\n\n# checks to see if a folder called \"data\" exists; if not, it installs it\nif (!file.exists(here(\"data\"))) {\n dir.create(here(\"data\"))\n}\n\n# checks to see if a file called \"flights.csv\" exists; if not, it saves it to the data folder\nif (!file.exists(here(\"data\", \"flights.csv\"))) {\n readr::write_csv(nycflights13::flights,\n file = here(\"data\", \"flights.csv\")\n )\n}\n\nnycflights13::flights %>%\n head()\n\n# A tibble: 6 × 19\n year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time\n <int> <int> <int> <int> <int> <dbl> <int> <int>\n1 2013 1 1 517 515 2 830 819\n2 2013 1 1 533 529 4 850 830\n3 2013 1 1 542 540 2 923 850\n4 2013 1 1 544 545 -1 1004 1022\n5 2013 1 1 554 600 -6 812 837\n6 2013 1 1 554 558 -4 740 728\n# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,\n# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,\n# hour <dbl>, minute <dbl>, time_hour <dttm>\n\n\nNext, we use Python to read in the file and do some data wrangling\n\nimport pandas\nflights_path = \"/Users/leocollado/Dropbox/Code/jhustatcomputing2023/data/flights.csv\"\nflights = pandas.read_csv(flights_path)\nflights = flights[flights['dest'] == \"ORD\"]\nflights = flights[['carrier', 'dep_delay', 'arr_delay']]\nflights = flights.dropna()\nflights\n\n carrier dep_delay arr_delay\n5 UA -4.0 12.0\n9 AA -2.0 8.0\n25 MQ 8.0 32.0\n38 AA -1.0 14.0\n57 AA -4.0 4.0\n... ... ... ...\n336645 AA -12.0 -37.0\n336669 UA -7.0 -13.0\n336675 MQ -7.0 -11.0\n336696 B6 -5.0 -23.0\n336709 AA -13.0 -38.0\n\n[16566 rows x 3 columns]\n\n\n\nhead(py$flights)\n\n carrier dep_delay arr_delay\n5 UA -4 12\n9 AA -2 8\n25 MQ 8 32\n38 AA -1 14\n57 AA -4 4\n70 UA 9 20\n\npy$flights_path\n\n[1] \"/Users/leocollado/Dropbox/Code/jhustatcomputing2023/data/flights.csv\"\n\n\n\nclass(py$flights)\n\n[1] \"data.frame\"\n\nclass(py$flights_path)\n\n[1] \"character\"\n\n\nNext, we can use R to visualize the Pandas DataFrame.\nThe data frame is loaded in as an R object now stored in the variable py.\n\nggplot(py$flights, aes(x = carrier, y = arr_delay)) +\n geom_point() +\n geom_jitter()\n\n\n\n\n\n\n\n\n\n\nNote\n\n\n\nThe reticulate Python engine is enabled by default within R Markdown whenever reticulate is installed.\n\n\n\nFrom R to Python\nUse R to read and manipulate data\n\nlibrary(tidyverse)\nflights <- read_csv(here(\"data\", \"flights.csv\")) %>%\n filter(dest == \"ORD\") %>%\n select(carrier, dep_delay, arr_delay) %>%\n na.omit()\n\nRows: 336776 Columns: 19\n── Column specification ────────────────────────────────────────────────────────\nDelimiter: \",\"\nchr (4): carrier, tailnum, origin, dest\ndbl (14): year, month, day, dep_time, sched_dep_time, dep_delay, arr_time, ...\ndttm (1): time_hour\n\nℹ Use `spec()` to retrieve the full column specification for this data.\nℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.\n\nflights\n\n# A tibble: 16,566 × 3\n carrier dep_delay arr_delay\n <chr> <dbl> <dbl>\n 1 UA -4 12\n 2 AA -2 8\n 3 MQ 8 32\n 4 AA -1 14\n 5 AA -4 4\n 6 UA 9 20\n 7 UA 2 21\n 8 AA -6 -12\n 9 MQ 39 49\n10 B6 -2 15\n# ℹ 16,556 more rows\n\n\n\n\nUse Python to print R dataframe\nIf you recall, we can access objects created within R chunks from Python using the r object (e.g. r.x would access to x variable created within R from Python).\nWe can then ask for the first ten rows using the head() function in python.\n\nr.flights.head(10)\n\n carrier dep_delay arr_delay\n0 UA -4.0 12.0\n1 AA -2.0 8.0\n2 MQ 8.0 32.0\n3 AA -1.0 14.0\n4 AA -4.0 4.0\n5 UA 9.0 20.0\n6 UA 2.0 21.0\n7 AA -6.0 -12.0\n8 MQ 39.0 49.0\n9 B6 -2.0 15.0"
},
{
- "objectID": "posts/02-introduction-to-r-and-rstudio/index.html",
- "href": "posts/02-introduction-to-r-and-rstudio/index.html",
- "title": "02 - Introduction to R and RStudio!",
- "section": "",
- "text": "This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history.\n\nThere are only two kinds of languages: the ones people complain about and the ones nobody uses. —Bjarne Stroustrup\n\n\nPre-lecture materials\n\nRead ahead\n\n\n\n\n\n\nRead ahead\n\n\n\nBefore class, you can prepare by reading the following materials:\n\nAn overview and history of R from Roger Peng\nInstalling R and RStudio from Rafael Irizarry\nGetting Started in R and RStudio from Rafael Irizarry\n\n\n\n\n\nAcknowledgements\nMaterial for this lecture was borrowed and adopted from\n\nhttps://rdpeng.github.io/Biostat776/lecture-introduction-and-overview.html\nhttps://rafalab.github.io/dsbook\nhttps://rmd4sci.njtierney.com\nhttps://andreashandel.github.io/MADAcourse\n\n\n\n\nLearning objectives\n\n\n\n\n\n\nLearning objectives\n\n\n\nAt the end of this lesson you will:\n\nLearn about (some of) the history of R.\nIdentify some of the strengths and weaknesses of R.\nInstall R and Rstudio on your computer.\nKnow how to install and load R packages.\n\n\n\n\n\nOverview and history of R\nBelow is a very quick introduction to R, to get you set up and running. We’ll go deeper into R and coding later.\n\ntl;dr (R in a nutshell)\nLike every programming language, R has its advantages and disadvantages. If you search the internet, you will quickly discover lots of folks with opinions about R. Some of the features that are useful to know are:\n\nR is open-source, freely accessible, and cross-platform (multiple OS).\nR is a “high-level” programming language, relatively easy to learn.\n\nWhile “Low-level” programming languages (e.g. Fortran, C, etc) often have more efficient code, they can also be harder to learn because it is designed to be close to a machine language.\nIn contrast, high-level languages deal more with variables, objects, functions, loops, and other abstract CS concepts with a focus on usability over optimal program efficiency.\n\nR is great for statistics, data analysis, websites, web apps, data visualizations, and so much more!\nR integrates easily with document preparation systems like \\(\\LaTeX\\), but R files can also be used to create .docx, .pdf, .html, .ppt files with integrated R code output and graphics.\nThe R Community is very dynamic, helpful and welcoming.\n\nCheck out the #rstats or #rtistry on Twitter, TidyTuesday podcast and community activity in the R4DS Online Learning Community, and r/rstats subreddit.\nIf you are looking for more local resources, check out R-Ladies Baltimore.\n\nThrough R packages, it is easy to get lots of state-of-the-art algorithms.\nDocumentation and help files for R are generally good.\n\nWhile we use R in this course, it is not the only option to analyze data. Maybe the most similar to R, and widely used, is Python, which is also free. There is also commercial software that can be used to analyze data (e.g., Matlab, Mathematica, Tableau, SAS, SPSS). Other more general programming languages are suitable for certain types of analyses as well (e.g., C, Fortran, Perl, Java, Julia).\nDepending on your future needs or jobs, you might have to learn one or several of those additional languages. The good news is that even though those languages are all different, they all share general ways of thinking and structuring code. So once you understand a specific concept (e.g., variables, loops, branching statements or functions), it applies to all those languages. Thus, learning a new programming language is much easier once you already know one. And R is a good one to get started with.\nWith the skills gained in this course, hopefully you will find R a fun and useful programming language for your future projects.\n\n\n\nArtwork by Allison Horst on learning R\n\n\n[Source: Artwork by Allison Horst]\n\n\nBasic Features of R\nToday R runs on almost any standard computing platform and operating system. Its open source nature means that anyone is free to adapt the software to whatever platform they choose. Indeed, R has been reported to be running on modern tablets, phones, PDAs, and game consoles.\nOne nice feature that R shares with many popular open source projects is frequent releases. These days there is a major annual release, typically at the end of April, where major new features are incorporated and released to the public. Throughout the year, smaller-scale bugfix releases will be made as needed. The frequent releases and regular release cycle indicates active development of the software and ensures that bugs will be addressed in a timely manner. Of course, while the core developers control the primary source tree for R, many people around the world make contributions in the form of new feature, bug fixes, or both.\nAnother key advantage that R has over many other statistical packages (even today) is its sophisticated graphics capabilities. R’s ability to create “publication quality” graphics has existed since the very beginning and has generally been better than competing packages. Today, with many more visualization packages available than before, that trend continues. R’s base graphics system allows for very fine control over essentially every aspect of a plot or graph. Other newer graphics systems, like lattice (not as used nowadays) and ggplot2 (very widely used now) allow for complex and sophisticated visualizations of high-dimensional data.\nR has maintained the original S philosophy (see box below), which is that it provides a language that is both useful for interactive work, but contains a powerful programming language for developing new tools. This allows the user, who takes existing tools and applies them to data, to slowly but surely become a developer who is creating new tools.\n\n\n\n\n\n\nTip\n\n\n\nFor a great discussion on an overview and history of R and the S programming language, read through this chapter from Roger D. Peng.\n\n\nFinally, one of the joys of using R has nothing to do with the language itself, but rather with the active and vibrant user community. In many ways, a language is successful inasmuch as it creates a platform with which many people can create new things. R is that platform and thousands of people around the world have come together to make contributions to R, to develop packages, and help each other use R for all kinds of applications. The R-help and R-devel mailing lists have been highly active for over a decade now and there is considerable activity on web sites like GitHub, Posit (RStudio) Community, Bioconductor Support, Stack Overflow, Twitter #rstats, #rtistry, and Reddit.\n\n\nFree Software\nA major advantage that R has over many other statistical packages and is that it’s free in the sense of free software (it’s also free in the sense of free beer). The copyright for the primary source code for R is held by the R Foundation and is published under the GNU General Public License version 2.0.\nAccording to the Free Software Foundation, with free software, you are granted the following four freedoms\n\nThe freedom to run the program, for any purpose (freedom 0).\nThe freedom to study how the program works, and adapt it to your needs (freedom 1). Access to the source code is a precondition for this.\nThe freedom to redistribute copies so you can help your neighbor (freedom 2).\nThe freedom to improve the program, and release your improvements to the public, so that the whole community benefits (freedom 3). Access to the source code is a precondition for this.\n\n\n\n\n\n\n\nTip\n\n\n\nYou can visit the Free Software Foundation’s web site to learn a lot more about free software. The Free Software Foundation was founded by Richard Stallman in 1985 and Stallman’s personal web site is an interesting read if you happen to have some spare time.\n\n\n\n\nDesign of the R System\nThe primary R system is available from the Comprehensive R Archive Network, also known as CRAN. CRAN also hosts many add-on packages that can be used to extend the functionality of R.\nThe R system is divided into 2 conceptual parts:\n\nThe “base” R system that you download from CRAN:\n\n\nLinux\nWindows\nMac\n\n\nEverything else.\n\nR functionality is divided into a number of packages.\n\nThe “base” R system contains, among other things, the base package which is required to run R and contains the most fundamental functions.\nThe other packages contained in the “base” system include utils, stats, datasets, graphics, grDevices, grid, methods, tools, parallel, compiler, splines, tcltk, stats4.\nThere are also “Recommended” packages: boot, class, cluster, codetools, foreign, KernSmooth, lattice, mgcv, nlme, rpart, survival, MASS, spatial, nnet, Matrix.\n\nWhen you download a fresh installation of R from CRAN, you get all of the above, which represents a substantial amount of functionality. However, there are many other packages available:\n\nThere are over 10,000 packages on CRAN that have been developed by users and programmers around the world.\nThere are also over 2,000 packages associated with the Bioconductor project.\nPeople often make packages available on GitHub (very common) and their personal websites (not so common nowadays); there is no reliable way to keep track of how many packages are available in this fashion.\n\n\n\n\nSlide from 2012 by Roger D. Peng\n\n\n\n\n\n\n\n\nQuestions\n\n\n\n\nHow many R packages are on CRAN today?\nHow many R packages are on Bioconductor today?\nHow many R packages are on GitHub today?\n\n\n\nWant to learn more about Bioconductor? Check this video:\n\n\n\n\nLimitations of R\nNo programming language or statistical analysis system is perfect. R certainly has a number of drawbacks. For starters, R is essentially based on almost 50 year old technology, going back to the original S system developed at Bell Labs. There was originally little built in support for dynamic or 3-D graphics (but things have improved greatly since the “old days”).\nAnother commonly cited limitation of R is that objects must generally be stored in physical memory (though this is increasingly not true anymore). This is in part due to the scoping rules of the language, but R generally is more of a memory hog than other statistical packages. However, there have been a number of advancements to deal with this, both in the R core and also in a number of packages developed by contributors. Also, computing power and capacity has continued to grow over time and amount of physical memory that can be installed on even a consumer-level laptop is substantial. While we will likely never have enough physical memory on a computer to handle the increasingly large datasets that are being generated, the situation has gotten quite a bit easier over time.\nAt a higher level one “limitation” of R is that its functionality is based on consumer demand and (voluntary) user contributions. If no one feels like implementing your favorite method, then it’s your job to implement it (or you need to pay someone to do it). The capabilities of the R system generally reflect the interests of the R user community. As the community has ballooned in size over the past 10 years, the capabilities have similarly increased. When I first started using R, there was very little in the way of functionality for the physical sciences (physics, astronomy, etc.). However, now some of those communities have adopted R and we are seeing more code being written for those kinds of applications.\n\n\n\nUsing R and RStudio\n\nIf R is the engine and bare bones of your car, then RStudio is like the rest of the car. The engine is super critical part of your car. But in order to make things properly functional, you need to have a steering wheel, comfy seats, a radio, rear and side view mirrors, storage, and seatbelts. — Nicholas Tierney\n\n[Source]\nThe RStudio layout has the following features:\n\nOn the upper left, something called a Rmarkdown script\nOn the lower left, the R console\nOn the lower right, the view for files, plots, packages, help, and viewer.\nOn the upper right, the environment / history pane\n\n\n\n\nA screenshot of the RStudio integrated developer environment (IDE) – aka the working environment\n\n\nThe R console is the bit where you can run your code. This is where the R code in your Rmarkdown document gets sent to run (we’ll learn about these files later).\nThe file/plot/pkg viewer is a handy browser for your current files, like Finder, or File Explorer, plots are where your plots appear, you can view packages, see the help files. And the environment / history pane contains the list of things you have created, and the past commands that you have run.\n\nInstalling R and RStudio\n\nIf you have not already, install R first. If you already have R installed, make sure it is a fairly recent version, version 4.3.1 or newer. If yours is older that version 4.2.0, I suggest you update (install a new R version).\nOnce you have R installed, install the free version of RStudio Desktop. Again, make sure it’s a recent version.\n\n\n\n\n\n\n\nTip\n\n\n\nInstalling R and RStudio should be fairly straightforward. However, a great set of detailed instructions is in Rafael Irizarry’s dsbook\n\nhttps://rafalab.github.io/dsbook/installing-r-rstudio.html\n\n\n\nIf things don’t work, ask for help in the Courseplus discussion board.\nI have both a macOS and a winOS computer, and have used Linux (Ubuntu) in the past too, but I might be more limited in how much I can help you on Linux.\n\n\nRStudio default options\nTo first get set up, I highly recommend changing the following setting\nTools > Global Options (or Cmd + , on macOS)\nUnder the General tab:\n\nFor workspace\n\nUncheck restore .RData into workspace at startup\nSave workspace to .RData on exit : “Never”\n\nFor History\n\nUncheck “Always save history (even when not saving .RData)\nUncheck “Remove duplicate entries in history”\n\n\nThis means that you won’t save the objects and other things that you create in your R session and reload them. This is important for two reasons\n\nReproducibility: you don’t want to have objects from last week cluttering your session\nPrivacy: you don’t want to save private data or other things to your session. You only want to read these in.\n\nYour “history” is the commands that you have entered into R.\nAdditionally, not saving your history means that you won’t be relying on things that you typed in the last session, which is a good habit to get into!\n\n\nInstalling and loading R packages\nAs we discussed, most of the functionality and features in R come in the form of add-on packages. There are tens of thousands of packages available, some big, some small, some well documented, some not. We will be using many different packages in this course. Of course, you are free to install and use any package you come across for any of the assignments.\nThe “official” place for packages is the CRAN website. If you are interested in packages on a specific topic, the CRAN task views provide curated descriptions of packages sorted by topic.\nTo install an R package from CRAN, one can simply call the install.packages() function and pass the name of the package as an argument. For example, to install the ggplot2 package from CRAN: open RStudio,go to the R prompt (the > symbol) in the lower-left corner and type\n\ninstall.packages(\"ggplot2\")\n\n## Below is an example for installing more than one package at a time:\n\n## Install R packages for project 0\ninstall.packages(\n c(\"postcards\", \"usethis\", \"gitcreds\")\n)\n\nand the appropriate version of the package will be installed.\nOften, a package needs other packages to work (called dependencies), and they are installed automatically. It usually does not matter if you use a single or double quotation mark around the name of the package.\n\n\n\n\n\n\nQuestions\n\n\n\n\nAs you installed the ggplot2 package, what other packages were installed?\nWhat happens if you tried to install GGplot2?\n\n\n\nIt could be that you already have all packages required by ggplot2 installed. In that case, you will not see any other packages installed. To see which of the packages above ggplot2 needs (and thus installs if it is not present), type into the R console:\n\ntools::package_dependencies(\"ggplot2\")\n\nIn RStudio, you can also install (and update/remove) packages by clicking on the ‘Packages’ tab in the bottom right window.\nIt is very common these days for packages to be developed on GitHub. It is possible to install packages from GitHub directly. Those usually contain the latest version of the package, with features that might not be available yet on the CRAN website. Sometimes, in early development stages, a package is only on GitHub until the developer(s) feel it is good enough for CRAN submission. So installing from GitHub gives you the latest. The downside is that packages under development can often be buggy and not working right. To install packages from GitHub, you need to install the remotes package and then use the following function\n\nremotes::install_github()\n\nWe will not do that now, but it is quite likely that at one point later in this course we will.\nYou only need to install a package once, unless you upgrade/re-install R. Once installed, you still need to load the package before you can use it. That has to happen every time you start a new R session. You do that using the library() command. For instance to load the ggplot2 package, type\n\nlibrary(\"ggplot2\")\n\nYou may or may not see a short message on the screen. Some packages show messages when you load them, and others do not.\nThis was a quick overview of R packages. We will use a lot of them, so you will get used to them rather quickly.\n\n\nGetting started in RStudio\nWhile one can use R and do pretty much every task, including all the ones we cover in this class, without using RStudio, RStudio is very useful, has lots of features that make your R coding life easier and has become pretty much the default integrated development environment (IDE) for R. Since RStudio has lots of features, it takes time to learn them. A good resource to learn more about RStudio are the R Studio Essentials collection of videos.\n\n\n\n\n\n\nTip\n\n\n\nFor more information on setting up and getting started with R, RStudio, and R packages, read the Getting Started chapter in the dsbook:\n\nhttps://rafalab.github.io/dsbook/getting-started.html\n\nThis chapter gives some tips, shortcuts, and ideas that might be of interest even to those of you who already have R and/or RStudio experience.\n\n\n\n\n\nPost-lecture materials\n\nFinal Questions\nHere are some post-lecture questions to help you think about the material discussed.\n\n\n\n\n\n\nQuestions\n\n\n\n\nIf a software company asks you, as a requirement for using their software, to sign a license that restricts you from using their software to commit illegal activities, is this consistent with the “Four Freedoms” of Free Software?\nWhat is an R package and what is it used for?\nWhat function in R can be used to install packages from CRAN?\nWhat is a limitation of the current R system?\n\n\n\n\n\nAdditional Resources\n\n\n\n\n\n\nTip\n\n\n\n\nR for Data Science (2e) by Wickham & Grolemund (2017, 2e is from July 18th 2023). Covers most of the basics of using R for data analysis.\nAdvanced R by Wickham (2014). Covers a number of areas including object-oriented, programming, functional programming, profiling and other advanced topics.\nRStudio IDE cheatsheet\n\n\n\n\n\n\nR session information\n\noptions(width = 120)\nsessioninfo::session_info()\n\n─ Session info ───────────────────────────────────────────────────────────────────────────────────────────────────────\n setting value\n version R version 4.3.1 (2023-06-16)\n os macOS Ventura 13.5\n system aarch64, darwin20\n ui X11\n language (EN)\n collate en_US.UTF-8\n ctype en_US.UTF-8\n tz America/Mexico_City\n date 2023-08-28\n pandoc 3.1.5 @ /opt/homebrew/bin/ (via rmarkdown)\n\n─ Packages ───────────────────────────────────────────────────────────────────────────────────────────────────────────\n package * version date (UTC) lib source\n cli 3.6.1 2023-03-23 [1] CRAN (R 4.3.0)\n colorout 1.2-2 2023-05-06 [1] Github (jalvesaq/colorout@79931fd)\n digest 0.6.33 2023-07-07 [1] CRAN (R 4.3.0)\n evaluate 0.21 2023-05-05 [1] CRAN (R 4.3.0)\n fastmap 1.1.1 2023-02-24 [1] CRAN (R 4.3.0)\n htmltools 0.5.6 2023-08-10 [1] CRAN (R 4.3.0)\n htmlwidgets 1.6.2 2023-03-17 [1] CRAN (R 4.3.0)\n jsonlite 1.8.7 2023-06-29 [1] CRAN (R 4.3.0)\n knitr 1.43 2023-05-25 [1] CRAN (R 4.3.0)\n rlang 1.1.1 2023-04-28 [1] CRAN (R 4.3.0)\n rmarkdown 2.24 2023-08-14 [1] CRAN (R 4.3.1)\n rstudioapi 0.15.0 2023-07-07 [1] CRAN (R 4.3.0)\n sessioninfo 1.2.2 2021-12-06 [1] CRAN (R 4.3.0)\n xfun 0.40 2023-08-09 [1] CRAN (R 4.3.0)\n yaml 2.3.7 2023-01-23 [1] CRAN (R 4.3.0)\n\n [1] /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/library\n\n──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────"
+ "objectID": "posts/25-python-for-r-users/index.html#import-python-modules",
+ "href": "posts/25-python-for-r-users/index.html#import-python-modules",
+ "title": "25 - Python for R Users",
+ "section": "import python modules",
+ "text": "import python modules\nYou can use the import() function to import any Python module and call it from R. For example, this code imports the Python os module in python and calls the listdir() function:\n\nos <- import(\"os\")\nos$listdir(\".\")\n\n[1] \"index.qmd\" \"index_files\" \"index.rmarkdown\"\n\n\nFunctions and other data within Python modules and classes can be accessed via the $ operator (analogous to the way you would interact with an R list, environment, or reference class).\nImported Python modules support code completion and inline help:\n\n\n\n\n\nUsing reticulate tab completion\n\n\n\n\n[Source: Rstudio]\nSimilarly, we can import the pandas library:\n\npd <- import(\"pandas\")\ntest <- pd$read_csv(here(\"data\", \"flights.csv\"))\nhead(test)\n\n year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time\n1 2013 1 1 517 515 2 830 819\n2 2013 1 1 533 529 4 850 830\n3 2013 1 1 542 540 2 923 850\n4 2013 1 1 544 545 -1 1004 1022\n5 2013 1 1 554 600 -6 812 837\n6 2013 1 1 554 558 -4 740 728\n arr_delay carrier flight tailnum origin dest air_time distance hour minute\n1 11 UA 1545 N14228 EWR IAH 227 1400 5 15\n2 20 UA 1714 N24211 LGA IAH 227 1416 5 29\n3 33 AA 1141 N619AA JFK MIA 160 1089 5 40\n4 -18 B6 725 N804JB JFK BQN 183 1576 5 45\n5 -25 DL 461 N668DN LGA ATL 116 762 6 0\n6 12 UA 1696 N39463 EWR ORD 150 719 5 58\n time_hour\n1 2013-01-01T10:00:00Z\n2 2013-01-01T10:00:00Z\n3 2013-01-01T10:00:00Z\n4 2013-01-01T10:00:00Z\n5 2013-01-01T11:00:00Z\n6 2013-01-01T10:00:00Z\n\nclass(test)\n\n[1] \"data.frame\"\n\n\nor the scikit-learn python library:\n\nskl_lr <- import(\"sklearn.linear_model\")\nskl_lr\n\nModule(sklearn.linear_model)"
},
{
- "objectID": "posts/09-tidy-data-and-the-tidyverse/index.html",
- "href": "posts/09-tidy-data-and-the-tidyverse/index.html",
- "title": "09 - Tidy data and the Tidyverse",
- "section": "",
- "text": "This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history.\n\n\n“Happy families are all alike; every unhappy family is unhappy in its own way.” —- Leo Tolstoy\n\n\n“Tidy datasets are all alike, but every messy dataset is messy in its own way.” —- Hadley Wickham\n\n\nPre-lecture materials\n\nRead ahead\n\n\n\n\n\n\nRead ahead\n\n\n\nBefore class, you can prepare by reading the following materials:\n\nTidy Data paper published in the Journal of Statistical Software\nhttps://r4ds.had.co.nz/tidy-data\ntidyr cheat sheet from RStudio\n\n\n\n\n\nAcknowledgements\nMaterial for this lecture was borrowed and adopted from\n\nhttps://rdpeng.github.io/Biostat776/lecture-tidy-data-and-the-tidyverse\nhttps://r4ds.had.co.nz/tidy-data\n\n\n\n\nLearning objectives\n\n\n\n\n\n\nLearning objectives\n\n\n\nAt the end of this lesson you will:\n\nDefine tidy data\nBe able to transform non-tidy data into tidy data\nBe able to transform wide data into long data\nBe able to separate character columns into multiple columns\nBe able to unite multiple character columns into one column\n\n\n\n\n\nTidy data\nAs we learned in the last lesson, one unifying concept of the tidyverse is the notion of tidy data.\nAs defined by Hadley Wickham in his 2014 paper published in the Journal of Statistical Software, a tidy dataset has the following properties:\n\nEach variable forms a column.\nEach observation forms a row.\nEach type of observational unit forms a table.\n\n\n\n\nArtwork by Allison Horst on tidy data\n\n\n[Source: Artwork by Allison Horst]\nThe purpose of defining tidy data is to highlight the fact that most data do not start out life as tidy.\nIn fact, much of the work of data analysis may involve simply making the data tidy (at least this has been our experience).\n\nOnce a dataset is tidy, it can be used as input into a variety of other functions that may transform, model, or visualize the data.\n\n\n\n\n\n\n\nExample\n\n\n\nAs a quick example, consider the following data illustrating religion and income survey data with the number of respondents with income range in column name.\nThis is in a classic table format:\n\nlibrary(tidyr)\nrelig_income\n\n# A tibble: 18 × 11\n religion `<$10k` `$10-20k` `$20-30k` `$30-40k` `$40-50k` `$50-75k` `$75-100k`\n <chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>\n 1 Agnostic 27 34 60 81 76 137 122\n 2 Atheist 12 27 37 52 35 70 73\n 3 Buddhist 27 21 30 34 33 58 62\n 4 Catholic 418 617 732 670 638 1116 949\n 5 Don’t k… 15 14 15 11 10 35 21\n 6 Evangel… 575 869 1064 982 881 1486 949\n 7 Hindu 1 9 7 9 11 34 47\n 8 Histori… 228 244 236 238 197 223 131\n 9 Jehovah… 20 27 24 24 21 30 15\n10 Jewish 19 19 25 25 30 95 69\n11 Mainlin… 289 495 619 655 651 1107 939\n12 Mormon 29 40 48 51 56 112 85\n13 Muslim 6 7 9 10 9 23 16\n14 Orthodox 13 17 23 32 32 47 38\n15 Other C… 9 7 11 13 13 14 18\n16 Other F… 20 33 40 46 49 63 46\n17 Other W… 5 2 3 4 2 7 3\n18 Unaffil… 217 299 374 365 341 528 407\n# ℹ 3 more variables: `$100-150k` <dbl>, `>150k` <dbl>,\n# `Don't know/refused` <dbl>\n\n\n\n\nWhile this format is canonical and is useful for quickly observing the relationship between multiple variables, it is not tidy.\nThis format violates the tidy form because there are variables in the columns.\n\nIn this case the variables are religion, income bracket, and the number of respondents, which is the third variable, is presented inside the table.\n\nConverting this data to tidy format would give us\n\nlibrary(tidyverse)\n\nrelig_income %>%\n pivot_longer(-religion, names_to = \"income\", values_to = \"respondents\") %>%\n mutate(religion = factor(religion), income = factor(income))\n\n# A tibble: 180 × 3\n religion income respondents\n <fct> <fct> <dbl>\n 1 Agnostic <$10k 27\n 2 Agnostic $10-20k 34\n 3 Agnostic $20-30k 60\n 4 Agnostic $30-40k 81\n 5 Agnostic $40-50k 76\n 6 Agnostic $50-75k 137\n 7 Agnostic $75-100k 122\n 8 Agnostic $100-150k 109\n 9 Agnostic >150k 84\n10 Agnostic Don't know/refused 96\n# ℹ 170 more rows\n\n\nSome of these functions you have seen before, others might be new to you. Let’s talk about each one in the context of the tidyverse R packages.\n\n\nThe “Tidyverse”\nThere are a number of R packages that take advantage of the tidy data form and can be used to do interesting things with data. Many (but not all) of these packages are written by Hadley Wickham and the collection of packages is often referred to as the “tidyverse” because of their dependence on and presumption of tidy data.\n\n\n\n\n\n\nNote\n\n\n\nA subset of the “Tidyverse” packages include:\n\nggplot2: a plotting system based on the grammar of graphics\nmagrittr: defines the %>% operator for chaining functions together in a series of operations on data\ndplyr: a suite of (fast) functions for working with data frames\ntidyr: easily tidy data with pivot_wider() and pivot_longer() functions (also separate() and unite())\n\nA complete list can be found here (https://www.tidyverse.org/packages).\n\n\nWe will be using these packages quite a bit.\nThe “tidyverse” package can be used to install all of the packages in the tidyverse at once.\nFor example, instead of starting an R script with this:\n\nlibrary(dplyr)\nlibrary(tidyr)\nlibrary(readr)\nlibrary(ggplot2)\n\nYou can start with this:\n\nlibrary(tidyverse)\n\nIn the example above, let’s talk about what we did using the pivot_longer() function.\nWe will also talk about pivot_wider().\n\npivot_longer()\nThe tidyr package includes functions to transfer a data frame between long and wide.\n\nWide format data tends to have different attributes or variables describing an observation placed in separate columns.\nLong format data tends to have different attributes encoded as levels of a single variable, followed by another column that contains tha values of the observation at those different levels.\n\n\n\n\n\n\n\nExample\n\n\n\nIn the section above, we showed an example that used pivot_longer() to convert data into a tidy format.\nThe key problem with the tidyness of the data is that the income variables are not in their own columns, but rather are embedded in the structure of the columns.\nTo fix this, you can use the pivot_longer() function to gather values spread across several columns into a single column, here with the column names gathered into an income column.\nNote: when gathering, exclude any columns that you do not want “gathered” (religion in this case) by including the column names with a the minus sign in the pivot_longer() function.\nFor example:\n\n# Gather everything EXCEPT religion to tidy data\nrelig_income %>%\n pivot_longer(-religion, names_to = \"income\", values_to = \"respondents\")\n\n# A tibble: 180 × 3\n religion income respondents\n <chr> <chr> <dbl>\n 1 Agnostic <$10k 27\n 2 Agnostic $10-20k 34\n 3 Agnostic $20-30k 60\n 4 Agnostic $30-40k 81\n 5 Agnostic $40-50k 76\n 6 Agnostic $50-75k 137\n 7 Agnostic $75-100k 122\n 8 Agnostic $100-150k 109\n 9 Agnostic >150k 84\n10 Agnostic Don't know/refused 96\n# ℹ 170 more rows\n\n\n\n\nEven if your data is in a tidy format, pivot_longer() is occasionally useful for pulling data together to take advantage of faceting, or plotting separate plots based on a grouping variable. We will talk more about that in a future lecture.\n\n\npivot_wider()\nThe pivot_wider() function is less commonly needed to tidy data. It can, however, be useful for creating summary tables.\n\n\n\n\n\n\nExample\n\n\n\nYou use the summarize() function in dplyr to summarize the total number of respondents per income category.\n\nrelig_income %>%\n pivot_longer(-religion, names_to = \"income\", values_to = \"respondents\") %>%\n mutate(religion = factor(religion), income = factor(income)) %>%\n group_by(income) %>%\n summarize(total_respondents = sum(respondents)) %>%\n pivot_wider(\n names_from = \"income\",\n values_from = \"total_respondents\"\n ) %>%\n knitr::kable()\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n<$10k\n>150k\n$10-20k\n$100-150k\n$20-30k\n$30-40k\n$40-50k\n$50-75k\n$75-100k\nDon’t know/refused\n\n\n\n\n1930\n2608\n2781\n3197\n3357\n3302\n3085\n5185\n3990\n6121\n\n\n\n\n\n\n\nNotice in this example how pivot_wider() has been used at the very end of the code sequence to convert the summarized data into a shape that offers a better tabular presentation for a report.\n\n\n\n\n\n\nNote\n\n\n\nIn the pivot_wider() call, you first specify the name of the column to use for the new column names (income in this example) and then specify the column to use for the cell values (total_respondents here).\n\n\n\n\n\n\n\n\nExample of pivot_longer()\n\n\n\nLet’s try another dataset. This data contain an excerpt of the Gapminder data on life expectancy, GDP per capita, and population by country.\n\nlibrary(gapminder)\ngapminder\n\n# A tibble: 1,704 × 6\n country continent year lifeExp pop gdpPercap\n <fct> <fct> <int> <dbl> <int> <dbl>\n 1 Afghanistan Asia 1952 28.8 8425333 779.\n 2 Afghanistan Asia 1957 30.3 9240934 821.\n 3 Afghanistan Asia 1962 32.0 10267083 853.\n 4 Afghanistan Asia 1967 34.0 11537966 836.\n 5 Afghanistan Asia 1972 36.1 13079460 740.\n 6 Afghanistan Asia 1977 38.4 14880372 786.\n 7 Afghanistan Asia 1982 39.9 12881816 978.\n 8 Afghanistan Asia 1987 40.8 13867957 852.\n 9 Afghanistan Asia 1992 41.7 16317921 649.\n10 Afghanistan Asia 1997 41.8 22227415 635.\n# ℹ 1,694 more rows\n\n\nIf we wanted to make lifeExp, pop and gdpPercap (all measurements that we observe) go from a wide table into a long table, what would we do?\n\n# try it yourself\n\n\n\n\n\n\n\n\n\nExample\n\n\n\nOne more! Try using pivot_longer() to convert the the following data that contains made-up revenues for three companies by quarter for years 2006 to 2009.\nAfterward, use group_by() and summarize() to calculate the average revenue for each company across all years and all quarters.\nBonus: Calculate a mean revenue for each company AND each year (averaged across all 4 quarters).\n\ndf <- tibble(\n \"company\" = rep(1:3, each = 4),\n \"year\" = rep(2006:2009, 3),\n \"Q1\" = sample(x = 0:100, size = 12),\n \"Q2\" = sample(x = 0:100, size = 12),\n \"Q3\" = sample(x = 0:100, size = 12),\n \"Q4\" = sample(x = 0:100, size = 12),\n)\ndf\n\n# A tibble: 12 × 6\n company year Q1 Q2 Q3 Q4\n <int> <int> <int> <int> <int> <int>\n 1 1 2006 99 6 54 47\n 2 1 2007 28 79 90 9\n 3 1 2008 7 72 69 24\n 4 1 2009 16 56 6 100\n 5 2 2006 42 58 75 25\n 6 2 2007 64 1 100 6\n 7 2 2008 43 88 37 77\n 8 2 2009 95 74 17 44\n 9 3 2006 34 47 77 38\n10 3 2007 73 31 31 54\n11 3 2008 4 49 93 0\n12 3 2009 57 4 45 96\n\n\n\n# try it yourself\n\n\n\n\n\nseparate() and unite()\nThe same tidyr package also contains two useful functions:\n\nunite(): combine contents of two or more columns into a single column\nseparate(): separate contents of a column into two or more columns\n\nFirst, we combine the first three columns into one new column using unite().\n\ngapminder %>%\n unite(\n col = \"country_continent_year\",\n country:year,\n sep = \"_\"\n )\n\n# A tibble: 1,704 × 4\n country_continent_year lifeExp pop gdpPercap\n <chr> <dbl> <int> <dbl>\n 1 Afghanistan_Asia_1952 28.8 8425333 779.\n 2 Afghanistan_Asia_1957 30.3 9240934 821.\n 3 Afghanistan_Asia_1962 32.0 10267083 853.\n 4 Afghanistan_Asia_1967 34.0 11537966 836.\n 5 Afghanistan_Asia_1972 36.1 13079460 740.\n 6 Afghanistan_Asia_1977 38.4 14880372 786.\n 7 Afghanistan_Asia_1982 39.9 12881816 978.\n 8 Afghanistan_Asia_1987 40.8 13867957 852.\n 9 Afghanistan_Asia_1992 41.7 16317921 649.\n10 Afghanistan_Asia_1997 41.8 22227415 635.\n# ℹ 1,694 more rows\n\n\nNext, we show how to separate the columns into three separate columns using separate() using the col, into and sep arguments.\n\ngapminder %>%\n unite(\n col = \"country_continent_year\",\n country:year,\n sep = \"_\"\n ) %>%\n separate(\n col = \"country_continent_year\",\n into = c(\"country\", \"continent\", \"year\"),\n sep = \"_\"\n )\n\n# A tibble: 1,704 × 6\n country continent year lifeExp pop gdpPercap\n <chr> <chr> <chr> <dbl> <int> <dbl>\n 1 Afghanistan Asia 1952 28.8 8425333 779.\n 2 Afghanistan Asia 1957 30.3 9240934 821.\n 3 Afghanistan Asia 1962 32.0 10267083 853.\n 4 Afghanistan Asia 1967 34.0 11537966 836.\n 5 Afghanistan Asia 1972 36.1 13079460 740.\n 6 Afghanistan Asia 1977 38.4 14880372 786.\n 7 Afghanistan Asia 1982 39.9 12881816 978.\n 8 Afghanistan Asia 1987 40.8 13867957 852.\n 9 Afghanistan Asia 1992 41.7 16317921 649.\n10 Afghanistan Asia 1997 41.8 22227415 635.\n# ℹ 1,694 more rows\n\n\n\n\n\nPost-lecture materials\n\nFinal Questions\nHere are some post-lecture questions to help you think about the material discussed.\n\n\n\n\n\n\nQuestions\n\n\n\n\nUsing prose, describe how the variables and observations are organised in a tidy dataset versus an non-tidy dataset.\nWhat do the extra and fill arguments do in separate()? Experiment with the various options for the following two toy datasets.\n\n\ntibble(x = c(\"a,b,c\", \"d,e,f,g\", \"h,i,j\")) %>%\n separate(x, c(\"one\", \"two\", \"three\"))\n\ntibble(x = c(\"a,b,c\", \"d,e\", \"f,g,i\")) %>%\n separate(x, c(\"one\", \"two\", \"three\"))\n\n\nBoth unite() and separate() have a remove argument. What does it do? Why would you set it to FALSE?\nCompare and contrast separate() and extract(). Why are there three variations of separation (by position, by separator, and with groups), but only one unite()?\n\n\n\n\n\nAdditional Resources\n\n\n\n\n\n\nTip\n\n\n\n\nTidy Data paper published in the Journal of Statistical Software\nhttps://r4ds.had.co.nz/tidy-data.html\ntidyr cheat sheet from RStudio\n\n\n\n\n\n\nR session information\n\noptions(width = 120)\nsessioninfo::session_info()\n\n─ Session info ───────────────────────────────────────────────────────────────────────────────────────────────────────\n setting value\n version R version 4.3.1 (2023-06-16)\n os macOS Ventura 13.5\n system aarch64, darwin20\n ui X11\n language (EN)\n collate en_US.UTF-8\n ctype en_US.UTF-8\n tz America/New_York\n date 2023-08-17\n pandoc 3.1.5 @ /opt/homebrew/bin/ (via rmarkdown)\n\n─ Packages ───────────────────────────────────────────────────────────────────────────────────────────────────────────\n package * version date (UTC) lib source\n cli 3.6.1 2023-03-23 [1] CRAN (R 4.3.0)\n colorout 1.2-2 2023-05-06 [1] Github (jalvesaq/colorout@79931fd)\n colorspace 2.1-0 2023-01-23 [1] CRAN (R 4.3.0)\n digest 0.6.33 2023-07-07 [1] CRAN (R 4.3.0)\n dplyr * 1.1.2 2023-04-20 [1] CRAN (R 4.3.0)\n evaluate 0.21 2023-05-05 [1] CRAN (R 4.3.0)\n fansi 1.0.4 2023-01-22 [1] CRAN (R 4.3.0)\n fastmap 1.1.1 2023-02-24 [1] CRAN (R 4.3.0)\n forcats * 1.0.0 2023-01-29 [1] CRAN (R 4.3.0)\n gapminder * 1.0.0 2023-03-10 [1] CRAN (R 4.3.0)\n generics 0.1.3 2022-07-05 [1] CRAN (R 4.3.0)\n ggplot2 * 3.4.3 2023-08-14 [1] CRAN (R 4.3.1)\n glue 1.6.2 2022-02-24 [1] CRAN (R 4.3.0)\n gtable 0.3.3 2023-03-21 [1] CRAN (R 4.3.0)\n hms 1.1.3 2023-03-21 [1] CRAN (R 4.3.0)\n htmltools 0.5.6 2023-08-10 [1] CRAN (R 4.3.0)\n htmlwidgets 1.6.2 2023-03-17 [1] CRAN (R 4.3.0)\n jsonlite 1.8.7 2023-06-29 [1] CRAN (R 4.3.0)\n knitr 1.43 2023-05-25 [1] CRAN (R 4.3.0)\n lifecycle 1.0.3 2022-10-07 [1] CRAN (R 4.3.0)\n lubridate * 1.9.2 2023-02-10 [1] CRAN (R 4.3.0)\n magrittr 2.0.3 2022-03-30 [1] CRAN (R 4.3.0)\n munsell 0.5.0 2018-06-12 [1] CRAN (R 4.3.0)\n pillar 1.9.0 2023-03-22 [1] CRAN (R 4.3.0)\n pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.3.0)\n purrr * 1.0.2 2023-08-10 [1] CRAN (R 4.3.0)\n R6 2.5.1 2021-08-19 [1] CRAN (R 4.3.0)\n readr * 2.1.4 2023-02-10 [1] CRAN (R 4.3.0)\n rlang 1.1.1 2023-04-28 [1] CRAN (R 4.3.0)\n rmarkdown 2.24 2023-08-14 [1] CRAN (R 4.3.1)\n rstudioapi 0.15.0 2023-07-07 [1] CRAN (R 4.3.0)\n scales 1.2.1 2022-08-20 [1] CRAN (R 4.3.0)\n sessioninfo 1.2.2 2021-12-06 [1] CRAN (R 4.3.0)\n stringi 1.7.12 2023-01-11 [1] CRAN (R 4.3.0)\n stringr * 1.5.0 2022-12-02 [1] CRAN (R 4.3.0)\n tibble * 3.2.1 2023-03-20 [1] CRAN (R 4.3.0)\n tidyr * 1.3.0 2023-01-24 [1] CRAN (R 4.3.0)\n tidyselect 1.2.0 2022-10-10 [1] CRAN (R 4.3.0)\n tidyverse * 2.0.0 2023-02-22 [1] CRAN (R 4.3.0)\n timechange 0.2.0 2023-01-11 [1] CRAN (R 4.3.0)\n tzdb 0.4.0 2023-05-12 [1] CRAN (R 4.3.0)\n utf8 1.2.3 2023-01-31 [1] CRAN (R 4.3.0)\n vctrs 0.6.3 2023-06-14 [1] CRAN (R 4.3.0)\n withr 2.5.0 2022-03-03 [1] CRAN (R 4.3.0)\n xfun 0.40 2023-08-09 [1] CRAN (R 4.3.0)\n yaml 2.3.7 2023-01-23 [1] CRAN (R 4.3.0)\n\n [1] /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/library\n\n──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────"
+ "objectID": "posts/25-python-for-r-users/index.html#calling-python-scripts",
+ "href": "posts/25-python-for-r-users/index.html#calling-python-scripts",
+ "title": "25 - Python for R Users",
+ "section": "Calling python scripts",
+ "text": "Calling python scripts\n\nsource_python(\"secret_functions.py\")\nsubject_1 <- read_subject(\"secret_data.csv\")"
},
{
- "objectID": "posts/15-control-structures/index.html",
- "href": "posts/15-control-structures/index.html",
- "title": "15 - Control Structures",
+ "objectID": "posts/25-python-for-r-users/index.html#calling-the-python-repl",
+ "href": "posts/25-python-for-r-users/index.html#calling-the-python-repl",
+ "title": "25 - Python for R Users",
+ "section": "Calling the python repl",
+ "text": "Calling the python repl\nIf you want to work with Python interactively you can call the repl_python() function, which provides a Python REPL embedded within your R session.\n\nrepl_python()\n\nObjects created within the Python REPL can be accessed from R using the py object exported from reticulate. For example:\n\n\n\n\n\nUsing the repl_python() function\n\n\n\n\n[Source: Rstudio]\ni.e. objects do have permenancy in R after exiting the python repl.\nSo typing x = 4 in the repl will put py$x as 4 in R after you exit the repl.\nEnter exit within the Python REPL to return to the R prompt."
+ },
+ {
+ "objectID": "projects/project-0/index.html",
+ "href": "projects/project-0/index.html",
+ "title": "Project 0 (optional)",
"section": "",
- "text": "This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history."
+ "text": "This project, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history."
},
{
- "objectID": "posts/15-control-structures/index.html#if-else",
- "href": "posts/15-control-structures/index.html#if-else",
- "title": "15 - Control Structures",
- "section": "if-else",
- "text": "if-else\nThe if-else combination is probably the most commonly used control structure in R (or perhaps any language). This structure allows you to test a condition and act on it depending on whether it’s true or false.\nFor starters, you can just use the if statement.\nif(<condition>) {\n ## do something\n} \n## Continue with rest of code\nThe above code does nothing if the condition is false. If you have an action you want to execute when the condition is false, then you need an else clause.\nif(<condition>) {\n ## do something\n} \nelse {\n ## do something else\n}\nYou can have a series of tests by following the initial if with any number of else ifs.\nif(<condition1>) {\n ## do something\n} else if(<condition2>) {\n ## do something different\n} else {\n ## do something different\n}\nHere is an example of a valid if/else structure.\nLet’s use the runif(n, min=0, max=1) function which draws a random value between a min and max value with the default being between 0 and 1.\n\nx <- runif(n = 1, min = 0, max = 10)\nx\n\n[1] 3.521267\n\n\nThen, we can write and if-else statement that tests whethere x is greater than 3 or not.\n\nx > 3\n\n[1] TRUE\n\n\nIf x is greater than 3, then the first condition occurs. If x is not greater than 3, then the second condition occurs.\n\nif (x > 3) {\n y <- 10\n} else {\n y <- 0\n}\n\nFinally, we can auto print y to see what the value is.\n\ny\n\n[1] 10\n\n\nThis expression can also be written a different (but equivalent!) way in R.\n\ny <- if (x > 3) {\n 10\n} else {\n 0\n}\n\ny\n\n[1] 10\n\n\n\n\n\n\n\n\nNote\n\n\n\nNeither way of writing this expression is more correct than the other.\nWhich one you use will depend on your preference and perhaps those of the team you may be working with.\n\n\nOf course, the else clause is not necessary. You could have a series of if clauses that always get executed if their respective conditions are true.\nif(<condition1>) {\n\n}\n\nif(<condition2>) {\n\n}\n\n\n\n\n\n\nQuestion\n\n\n\nLet’s use the palmerpenguins dataset and write a if-else statement that\n\nRandomly samples a value from a standard normal distribution (Hint: check out the rnorm(n, mean = 0, sd = 1) function in base R).\nIf the value is larger than 0, use dplyr functions to keep only the Chinstrap penguins.\nOtherwise, keep only the Gentoo penguins.\nRe-run the code 10 times and look at output.\n\n\n# try it yourself\n\nlibrary(tidyverse)\nlibrary(palmerpenguins)\npenguins\n\n# A tibble: 344 × 8\n species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g\n <fct> <fct> <dbl> <dbl> <int> <int>\n 1 Adelie Torgersen 39.1 18.7 181 3750\n 2 Adelie Torgersen 39.5 17.4 186 3800\n 3 Adelie Torgersen 40.3 18 195 3250\n 4 Adelie Torgersen NA NA NA NA\n 5 Adelie Torgersen 36.7 19.3 193 3450\n 6 Adelie Torgersen 39.3 20.6 190 3650\n 7 Adelie Torgersen 38.9 17.8 181 3625\n 8 Adelie Torgersen 39.2 19.6 195 4675\n 9 Adelie Torgersen 34.1 18.1 193 3475\n10 Adelie Torgersen 42 20.2 190 4250\n# ℹ 334 more rows\n# ℹ 2 more variables: sex <fct>, year <int>"
+ "objectID": "projects/project-0/index.html#class-notes",
+ "href": "projects/project-0/index.html#class-notes",
+ "title": "Project 0 (optional)",
+ "section": "Class notes",
+ "text": "Class notes\nFirst, lets make one for our class notes where we will host data and R scripts. We won’t be hosting HTML files here, so we don’t need to use the gh-pages branch for hosting files on GitHub pages.\n\n## Create an Rstudio project\nusethis::create_project(\"~/Desktop/biostat776classnotes\")\n\n## Start version controlling it\nusethis::use_git()\n\n## Share it via GitHub with the world\nusethis::use_github()\n\nAbove I created the biostat766classnotes RStudio project + git / GitHub repository. I saved it on my ~/Desktop but you can save it wherever you want.\nOnce that’s created, create the R/ and data/ subdirectories. Inside R/, save your R scripts for every class. As for data/, copy the contents of https://github.com/lcolladotor/jhustatcomputing2023/tree/main/data into it. That way commands like here(\"data\", \"chocolate.RDS\") from the class lectures will work the same way.\nMy live example is available at https://github.com/lcolladotor/biostat776classnotes."
},
{
- "objectID": "posts/15-control-structures/index.html#for-loops",
- "href": "posts/15-control-structures/index.html#for-loops",
- "title": "15 - Control Structures",
- "section": "for Loops",
- "text": "for Loops\nFor loops are pretty much the only looping construct that you will need in R. While you may occasionally find a need for other types of loops, in my experience doing data analysis, I’ve found very few situations where a for loop was not sufficient.\nIn R, for loops take an iterator variable and assign it successive values from a sequence or vector.\nFor loops are most commonly used for iterating over the elements of an object (list, vector, etc.)\n\nfor (i in 1:10) {\n print(i)\n}\n\n[1] 1\n[1] 2\n[1] 3\n[1] 4\n[1] 5\n[1] 6\n[1] 7\n[1] 8\n[1] 9\n[1] 10\n\n\nThis loop takes the i variable and in each iteration of the loop gives it values 1, 2, 3, …, 10, then executes the code within the curly braces, and then the loop exits.\nThe following three loops all have the same behavior.\n\n## define the loop to iterate over\nx <- c(\"a\", \"b\", \"c\", \"d\")\n\n## create for loop\nfor (i in 1:4) {\n ## Print out each element of 'x'\n print(x[i])\n}\n\n[1] \"a\"\n[1] \"b\"\n[1] \"c\"\n[1] \"d\"\n\n\nWe can also print just the iteration value (i) itself\n\n## define the loop to iterate over\nx <- c(\"a\", \"b\", \"c\", \"d\")\n\n## create for loop\nfor (i in 1:4) {\n ## Print out just 'i'\n print(i)\n}\n\n[1] 1\n[1] 2\n[1] 3\n[1] 4\n\n\n\nseq_along()\nThe seq_along() function is commonly used in conjunction with for loops in order to generate an integer sequence based on the length of an object (or ncol() of an R object) (in this case, the object x).\n\nx\n\n[1] \"a\" \"b\" \"c\" \"d\"\n\nseq_along(x)\n\n[1] 1 2 3 4\n\n\nThe seq_along() function takes in a vector and then returns a sequence of integers that is the same length as the input vector. It doesn’t matter what class the vector is.\nLet’s put seq_along() and for loops together.\n\n## Generate a sequence based on length of 'x'\nfor (i in seq_along(x)) {\n print(x[i])\n}\n\n[1] \"a\"\n[1] \"b\"\n[1] \"c\"\n[1] \"d\"\n\n\nIt is not necessary to use an index-type variable (i.e. i).\n\nfor (babyshark in x) {\n print(babyshark)\n}\n\n[1] \"a\"\n[1] \"b\"\n[1] \"c\"\n[1] \"d\"\n\n\n\nfor (candyisgreat in x) {\n print(candyisgreat)\n}\n\n[1] \"a\"\n[1] \"b\"\n[1] \"c\"\n[1] \"d\"\n\n\n\nfor (RememberToVote in x) {\n print(RememberToVote)\n}\n\n[1] \"a\"\n[1] \"b\"\n[1] \"c\"\n[1] \"d\"\n\n\nYou can use any character index you want (but not with symbols or numbers).\n\nfor (1999 in x) {\n print(1999)\n}\n\nError: <text>:1:6: unexpected numeric constant\n1: for (1999\n ^\n\n\nFor one line loops, the curly braces are not strictly necessary.\n\nfor (i in 1:4) print(x[i])\n\n[1] \"a\"\n[1] \"b\"\n[1] \"c\"\n[1] \"d\"\n\n\nHowever, I like to use curly braces even for one-line loops, because that way if you decide to expand the loop to multiple lines, you won’t be burned because you forgot to add curly braces (and you will be burned by this).\n\n\n\n\n\n\nQuestion\n\n\n\nLet’s use the palmerpenguins dataset. Here are the tasks:\n\nStart a for loop\nIterate over the columns of penguins\nFor each column, extract the values of that column (Hint: check out the pull() function in dplyr).\nUsing a if-else statement, test whether or not the values in the column are numeric or not (Hint: remember the is.numeric() function to test if a value is numeric).\nIf they are numeric, compute the column mean. Otherwise, report a NA.\n\n\n# try it yourself\n\n\n\n\n\nNested for loops\nfor loops can be nested inside of each other.\n\nx <- matrix(1:6, nrow = 2, ncol = 3)\nx\n\n [,1] [,2] [,3]\n[1,] 1 3 5\n[2,] 2 4 6\n\n\n\nfor (i in seq_len(nrow(x))) {\n for (j in seq_len(ncol(x))) {\n print(x[i, j])\n }\n}\n\n[1] 1\n[1] 3\n[1] 5\n[1] 2\n[1] 4\n[1] 6\n\n\n\n\n\n\n\n\nNote\n\n\n\nThe j index goes across the columns. That’s why we values 1, 3, etc.\n\n\nNested loops are commonly needed for multidimensional or hierarchical data structures (e.g. matrices, lists). Be careful with nesting though.\nNesting beyond 2 to 3 levels often makes it difficult to read/understand the code.\nIf you find yourself in need of a large number of nested loops, you may want to break up the loops by using functions (discussed later)."
+ "objectID": "projects/project-0/index.html#for-each-project",
+ "href": "projects/project-0/index.html#for-each-project",
+ "title": "Project 0 (optional)",
+ "section": "For each project",
+ "text": "For each project\nWe can go ahead and\n\n## Create an Rstudio project\nusethis::create_project(\"~/Desktop/biostat776project1\")\n\n## Start version controlling it\nusethis::use_git()\n\n## Use the gh-pages branch in order for\n## GitHub pages https://pages.github.com/ to\n## host our website.\nusethis::git_default_branch_rename(to = \"gh-pages\")\n\n## Create a .nojekyll file\nwriteLines(\"\", here::here(\".nojekyll\"))\n\n## Share it via GitHub with the world\nusethis::use_github()\n\nOnce that’s done, create a index.Rmd (or index.qmd if you are using Quarto) file and make sure you version control the resulting index.html file (git add index.html) after you render your index.Rmd (or index.qmd) file.\nMy live example is available at https://github.com/lcolladotor/biostat776project1. The rendered website is available at https://lcolladotor.github.io/biostat776project1/."
},
{
- "objectID": "posts/15-control-structures/index.html#while-loops",
- "href": "posts/15-control-structures/index.html#while-loops",
- "title": "15 - Control Structures",
- "section": "while Loops",
- "text": "while Loops\nwhile loops begin by testing a condition.\nIf it is true, then they execute the loop body.\nOnce the loop body is executed, the condition is tested again, and so forth, until the condition is false, after which the loop exits.\n\ncount <- 0\nwhile (count < 10) {\n print(count)\n count <- count + 1\n}\n\n[1] 0\n[1] 1\n[1] 2\n[1] 3\n[1] 4\n[1] 5\n[1] 6\n[1] 7\n[1] 8\n[1] 9\n\n\nwhile loops can potentially result in infinite loops if not written properly. Use with care!\nSometimes there will be more than one condition in the test.\n\nz <- 5\nset.seed(1)\n\nwhile (z >= 3 && z <= 10) {\n coin <- rbinom(1, 1, 0.5)\n\n if (coin == 1) { ## random walk\n z <- z + 1\n } else {\n z <- z - 1\n }\n}\nprint(z)\n\n[1] 2\n\n\n\n\n\n\n\n\nPro-tip\n\n\n\nWhat’s the difference between using one & or two && ?\nIf you use only one &, these are vectorized operations, meaning they can return a vector, like this:\n\n-2:2\n\n[1] -2 -1 0 1 2\n\n((-2:2) >= 0) & ((-2:2) <= 0)\n\n[1] FALSE FALSE TRUE FALSE FALSE\n\n\nIf you use two && (as above), then these conditions are evaluated left to right. For example, in the above code, if z were less than 3, the second test would not have been evaluated.\n\n(2 >= 0) && (-2 <= 0)\n\n[1] TRUE\n\n(-2 >= 0) && (-2 <= 0)\n\n[1] FALSE"
+ "objectID": "projects/project-2/index.html",
+ "href": "projects/project-2/index.html",
+ "title": "Project 2",
+ "section": "",
+ "text": "This project, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history.\n\nBackground\nDue date: October 1st at 11:59pm\nThe goal of this assignment is to practice designing and writing functions along with practicing our tidyverse skills that we learned in our previous project. Writing functions involves thinking about how code should be divided up and what the interface/arguments should be. In addition, you need to think about what the function will return as output.\n\nTo submit your project\nPlease write up your project using R Markdown and processed with knitr. Compile your document as an HTML file and submit your HTML file to the dropbox on Courseplus. Please show all your code (i.e. make sure to set echo = TRUE) for each of the answers to each part.\n\n\nInstall packages\nBefore attempting this assignment, you should first install the following packages, if they are not already installed:\n\ninstall.packages(\"tidyverse\")\ninstall.packages(\"tidytuesdayR\")\n\n\n\n\nPart 1: Fun with functions\nIn this part, we are going to practice creating functions.\n\nPart 1A: Exponential transformation\nThe exponential of a number can be written as an infinite series expansion of the form \\[\n\\exp(x) = 1 + x + \\frac{x^2}{2!} + \\frac{x^3}{3!} + \\cdots\n\\] Of course, we cannot compute an infinite series by the end of this term and so we must truncate it at a certain point in the series. The truncated sum of terms represents an approximation to the true exponential, but the approximation may be usable.\nWrite a function that computes the exponential of a number using the truncated series expansion. The function should take two arguments:\n\nx: the number to be exponentiated\nk: the number of terms to be used in the series expansion beyond the constant 1. The value of k is always \\(\\geq 1\\).\n\nFor example, if \\(k = 1\\), then the Exp function should return the number \\(1 + x\\). If \\(k = 2\\), then you should return the number \\(1 + x + x^2/2!\\).\nInclude at least one example of output using your function.\n\n\n\n\n\n\nNote\n\n\n\n\nYou can assume that the input value x will always be a single number.\nYou can assume that the value k will always be an integer \\(\\geq 1\\).\nDo not use the exp() function in R.\nThe factorial() function can be used to compute factorials.\n\n\n\n\nExp <- function(x, k) {\n # Add your solution here\n}\n\n\n\nPart 1B: Sample mean and sample standard deviation\nNext, write two functions called sample_mean() and sample_sd() that takes as input a vector of data of length \\(N\\) and calculates the sample average and sample standard deviation for the set of \\(N\\) observations.\n\\[\n\\bar{x} = \\frac{1}{N} \\sum_{i=1}^n x_i\n\\] \\[\ns = \\sqrt{\\frac{1}{N-1} \\sum_{i=1}^N (x_i - \\overline{x})^2}\n\\] Include at least one example of output using your functions.\n\n\n\n\n\n\nNote\n\n\n\n\nYou can assume that the input value x will always be a vector of numbers of length N.\nDo not use the mean() and sd() functions in R.\n\n\n\n\nsample_mean <- function(x) {\n # Add your solution here\n}\n\nsample_sd <- function(x) {\n # Add your solution here\n}\n\n\n\nPart 1C: Confidence intervals\nNext, write a function called calculate_CI() that:\n\nThere should be two inputs to the calculate_CI(). First, it should take as input a vector of data of length \\(N\\). Second, the function should also have a conf (\\(=1-\\alpha\\)) argument that allows the confidence interval to be adapted for different \\(\\alpha\\).\nCalculates a confidence interval (CI) (e.g. a 95% CI) for the estimate of the mean in the population. If you are not familiar with confidence intervals, it is an interval that contains the population parameter with probability \\(1-\\alpha\\) taking on this form\n\n\\[\n\\bar{x} \\pm t_{\\alpha/2, N-1} s_{\\bar{x}}\n\\]\nwhere \\(t_{\\alpha/2, N-1}\\) is the value needed to generate an area of \\(\\alpha / 2\\) in each tail of the \\(t\\)-distribution with \\(N-1\\) degrees of freedom and \\(s_{\\bar{x}} = \\frac{s}{\\sqrt{N}}\\) is the standard error of the mean. For example, if we pick a 95% confidence interval and \\(N\\)=50, then you can calculate \\(t_{\\alpha/2, N-1}\\) as\n\nalpha <- 1 - 0.95\ndegrees_freedom <- 50 - 1\nt_score <- qt(p = alpha / 2, df = degrees_freedom, lower.tail = FALSE)\n\n\nReturns a named vector of length 2, where the first value is the lower_bound, the second value is the upper_bound.\n\n\ncalculate_CI <- function(x, conf = 0.95) {\n # Add your solution here\n}\n\nInclude example of output from your function showing the output when using two different levels of conf.\n\n\n\n\n\n\nNote\n\n\n\nIf you want to check if your function output matches an existing function in R, consider a vector \\(x\\) of length \\(N\\) and see if the following two code chunks match.\n\ncalculate_CI(x, conf = 0.95)\n\n\ndat <- data.frame(x = x)\nfit <- lm(x ~ 1, dat)\n\n# Calculate a 95% confidence interval\nconfint(fit, level = 0.95)\n\n\n\n\n\n\nPart 2: Wrangling data\nIn this part, we will practice our wrangling skills with the tidyverse that we learned about in module 1.\n\nData\nThe two datasets for this part of the assignment comes from TidyTuesday. Specifically, we will use the following data from January 2020, which I have provided for you below:\n\ntuesdata <- tidytuesdayR::tt_load(\"2020-01-07\")\nrainfall <- tuesdata$rainfall\ntemperature <- tuesdata$temperature\n\nHowever, to avoid re-downloading data, we will check to see if those files already exist using an if() statement:\n\nlibrary(here)\nif (!file.exists(here(\"data\", \"tuesdata_rainfall.RDS\"))) {\n tuesdata <- tidytuesdayR::tt_load(\"2020-01-07\")\n rainfall <- tuesdata$rainfall\n temperature <- tuesdata$temperature\n\n # save the files to RDS objects\n saveRDS(tuesdata$rainfall, file = here(\"data\", \"tuesdata_rainfall.RDS\"))\n saveRDS(tuesdata$temperature, file = here(\"data\", \"tuesdata_temperature.RDS\"))\n}\n\n\n\n\n\n\n\nNote\n\n\n\nThe above code will only run if it cannot find the path to the tuesdata_rainfall.RDS on your computer. Then, we can just read in these files every time we knit the R Markdown, instead of re-downloading them every time.\n\n\nLet’s load the datasets\n\nrainfall <- readRDS(here(\"data\", \"tuesdata_rainfall.RDS\"))\ntemperature <- readRDS(here(\"data\", \"tuesdata_temperature.RDS\"))\n\nNow we can look at the data with glimpse()\n\nlibrary(tidyverse)\n\nglimpse(rainfall)\n\nRows: 179,273\nColumns: 11\n$ station_code <chr> \"009151\", \"009151\", \"009151\", \"009151\", \"009151\", \"009151…\n$ city_name <chr> \"Perth\", \"Perth\", \"Perth\", \"Perth\", \"Perth\", \"Perth\", \"Pe…\n$ year <dbl> 1967, 1967, 1967, 1967, 1967, 1967, 1967, 1967, 1967, 196…\n$ month <chr> \"01\", \"01\", \"01\", \"01\", \"01\", \"01\", \"01\", \"01\", \"01\", \"01…\n$ day <chr> \"01\", \"02\", \"03\", \"04\", \"05\", \"06\", \"07\", \"08\", \"09\", \"10…\n$ rainfall <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…\n$ period <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…\n$ quality <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…\n$ lat <dbl> -31.96, -31.96, -31.96, -31.96, -31.96, -31.96, -31.96, -…\n$ long <dbl> 115.79, 115.79, 115.79, 115.79, 115.79, 115.79, 115.79, 1…\n$ station_name <chr> \"Subiaco Wastewater Treatment Plant\", \"Subiaco Wastewater…\n\nglimpse(temperature)\n\nRows: 528,278\nColumns: 5\n$ city_name <chr> \"PERTH\", \"PERTH\", \"PERTH\", \"PERTH\", \"PERTH\", \"PERTH\", \"PER…\n$ date <date> 1910-01-01, 1910-01-02, 1910-01-03, 1910-01-04, 1910-01-0…\n$ temperature <dbl> 26.7, 27.0, 27.5, 24.0, 24.8, 24.4, 25.3, 28.0, 32.6, 35.9…\n$ temp_type <chr> \"max\", \"max\", \"max\", \"max\", \"max\", \"max\", \"max\", \"max\", \"m…\n$ site_name <chr> \"PERTH AIRPORT\", \"PERTH AIRPORT\", \"PERTH AIRPORT\", \"PERTH …\n\n\nIf we look at the TidyTuesday github repo from 2020, we see this dataset contains temperature and rainfall data from Australia.\nHere is a data dictionary for what all the column names mean:\n\nhttps://github.com/rfordatascience/tidytuesday/blob/master/data/2020/2020-01-07/readme.md#data-dictionary\n\n\n\nTasks\nUsing the rainfall and temperature data, perform the following steps and create a new data frame called df:\n\nStart with rainfall dataset and drop any rows with NAs.\nCreate a new column titled date that combines the columns year, month, day into one column separated by “-”. (e.g. “2020-01-01”). This column should not be a character, but should be recognized as a date. (Hint: check out the ymd() function in lubridate R package). You will also want to add a column that just keeps the year.\nUsing the city_name column, convert the city names (character strings) to all upper case.\nJoin this wrangled rainfall dataset with the temperature dataset such that it includes only observations that are in both data frames. (Hint: there are two keys that you will need to join the two datasets together). (Hint: If all has gone well thus far, you should have a dataset with 83,964 rows and 13 columns).\n\n\n\n\n\n\n\nNote\n\n\n\n\nYou may need to use functions outside these packages to obtain this result, in particular you may find the functions drop_na() from tidyr and str_to_upper() function from stringr useful.\n\n\n\n\n# Add your solution here\n\n\n\n\nPart 3: Data visualization\nIn this part, we will practice our ggplot2 plotting skills within the tidyverse starting with our wrangled df data from Part 2. For full credit in this part (and for all plots that you make), your plots should include:\n\nAn overall title for the plot and a subtitle summarizing key trends that you found. Also include a caption in the figure.\nThere should be an informative x-axis and y-axis label.\n\nConsider playing around with the theme() function to make the figure shine, including playing with background colors, font, etc.\n\nPart 3A: Plotting temperature data over time\nUse the functions in ggplot2 package to make a line plot of the max and min temperature (y-axis) over time (x-axis) for each city in our wrangled data from Part 2. You should only consider years 2014 and onwards. For full credit, your plot should include:\n\nFor a given city, the min and max temperature should both appear on the plot, but they should be two different colors.\nUse a facet function to facet by city_name to show all cities in one figure.\n\n\n# Add your solution here\n\n\n\nPart 3B: Plotting rainfall over time\nHere we want to explore the distribution of rainfall (log scale) with histograms for a given city (indicated by the city_name column) for a given year (indicated by the year column) so we can make some exploratory plots of the data.\n\n\n\n\n\n\nNote\n\n\n\nYou are again using the wrangled data from Part 2.\n\n\nThe following code plots the data from one city (city_name == \"PERTH\") in a given year (year == 2000).\n\ndf %>%\n filter(city_name == \"PERTH\", year == 2000) %>%\n ggplot(aes(log(rainfall))) +\n geom_histogram()\n\nWhile this code is useful, it only provides us information on one city in one year. We could cut and paste this code to look at other cities/years, but that can be error prone and just plain messy.\nThe aim here is to design and implement a function that can be re-used to visualize all of the data in this dataset.\n\nThere are 2 aspects that may vary in the dataset: The city_name and the year. Note that not all combinations of city_name and year have measurements.\nYour function should take as input two arguments city_name and year.\nGiven the input from the user, your function should return a single histogram for that input. Furthermore, the data should be readable on that plot so that it is in fact useful. It should be possible visualize the entire dataset with your function (through repeated calls to your function).\nIf the user enters an input that does not exist in the dataset, your function should catch that and report an error (via the stop() function).\n\nFor this section,\n\nWrite a short description of how you chose to design your function and why.\nPresent the code for your function in the R markdown document.\nInclude at least one example of output from your function.\n\n\n# Add your solution here\n\n\n\n\nPart 4: Apply functions and plot\n\nPart 4A: Tasks\nIn this part, we will apply the functions we wrote in Part 1 to our rainfall data starting with our wrangled df data from Part 2.\n\nFirst, filter for only years including 2014 and onwards.\nFor a given city and for a given year, calculate the sample mean (using your function sample_mean()), the sample standard deviation (using your function sample_sd()), and a 95% confidence interval for the average rainfall (using your function calculate_CI()). Specifically, you should add two columns in this summarized dataset: a column titled lower_bound and a column titled upper_bound containing the lower and upper bounds for you CI that you calculated (using your function calculate_CI()).\nCall this summarized dataset rain_df.\n\n\n# Add your solution here\n\n\n\nPart 4B: Tasks\nUsing the rain_df, plots the estimates of mean rainfall and the 95% confidence intervals on the same plot. There should be a separate faceted plot for each city. Think about using ggplot() with both geom_point() (and geom_line() to connect the points) for the means and geom_errorbar() for the lower and upper bounds of the confidence interval.\n\n# Add your solution here\n\n\n\n\nR session information\n\noptions(width = 120)\nsessioninfo::session_info()\n\n─ Session info ───────────────────────────────────────────────────────────────────────────────────────────────────────\n setting value\n version R version 4.3.1 (2023-06-16)\n os macOS Ventura 13.5\n system aarch64, darwin20\n ui X11\n language (EN)\n collate en_US.UTF-8\n ctype en_US.UTF-8\n tz America/New_York\n date 2023-09-12\n pandoc 3.1.5 @ /opt/homebrew/bin/ (via rmarkdown)\n\n─ Packages ───────────────────────────────────────────────────────────────────────────────────────────────────────────\n package * version date (UTC) lib source\n cli 3.6.1 2023-03-23 [1] CRAN (R 4.3.0)\n colorout 1.2-2 2023-05-06 [1] Github (jalvesaq/colorout@79931fd)\n colorspace 2.1-0 2023-01-23 [1] CRAN (R 4.3.0)\n digest 0.6.33 2023-07-07 [1] CRAN (R 4.3.0)\n dplyr * 1.1.3 2023-09-03 [1] CRAN (R 4.3.0)\n evaluate 0.21 2023-05-05 [1] CRAN (R 4.3.0)\n fansi 1.0.4 2023-01-22 [1] CRAN (R 4.3.0)\n fastmap 1.1.1 2023-02-24 [1] CRAN (R 4.3.0)\n forcats * 1.0.0 2023-01-29 [1] CRAN (R 4.3.0)\n generics 0.1.3 2022-07-05 [1] CRAN (R 4.3.0)\n ggplot2 * 3.4.3 2023-08-14 [1] CRAN (R 4.3.0)\n glue 1.6.2 2022-02-24 [1] CRAN (R 4.3.0)\n gtable 0.3.4 2023-08-21 [1] CRAN (R 4.3.0)\n here * 1.0.1 2020-12-13 [1] CRAN (R 4.3.0)\n hms 1.1.3 2023-03-21 [1] CRAN (R 4.3.0)\n htmltools 0.5.6 2023-08-10 [1] CRAN (R 4.3.0)\n htmlwidgets 1.6.2 2023-03-17 [1] CRAN (R 4.3.0)\n jsonlite 1.8.7 2023-06-29 [1] CRAN (R 4.3.0)\n knitr 1.43 2023-05-25 [1] CRAN (R 4.3.0)\n lifecycle 1.0.3 2022-10-07 [1] CRAN (R 4.3.0)\n lubridate * 1.9.2 2023-02-10 [1] CRAN (R 4.3.0)\n magrittr 2.0.3 2022-03-30 [1] CRAN (R 4.3.0)\n munsell 0.5.0 2018-06-12 [1] CRAN (R 4.3.0)\n pillar 1.9.0 2023-03-22 [1] CRAN (R 4.3.0)\n pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.3.0)\n purrr * 1.0.2 2023-08-10 [1] CRAN (R 4.3.0)\n R6 2.5.1 2021-08-19 [1] CRAN (R 4.3.0)\n readr * 2.1.4 2023-02-10 [1] CRAN (R 4.3.0)\n rlang 1.1.1 2023-04-28 [1] CRAN (R 4.3.0)\n rmarkdown 2.24 2023-08-14 [1] CRAN (R 4.3.1)\n rprojroot 2.0.3 2022-04-02 [1] CRAN (R 4.3.0)\n rstudioapi 0.15.0 2023-07-07 [1] CRAN (R 4.3.0)\n scales 1.2.1 2022-08-20 [1] CRAN (R 4.3.0)\n sessioninfo 1.2.2 2021-12-06 [1] CRAN (R 4.3.0)\n stringi 1.7.12 2023-01-11 [1] CRAN (R 4.3.0)\n stringr * 1.5.0 2022-12-02 [1] CRAN (R 4.3.0)\n tibble * 3.2.1 2023-03-20 [1] CRAN (R 4.3.0)\n tidyr * 1.3.0 2023-01-24 [1] CRAN (R 4.3.0)\n tidyselect 1.2.0 2022-10-10 [1] CRAN (R 4.3.0)\n tidyverse * 2.0.0 2023-02-22 [1] CRAN (R 4.3.0)\n timechange 0.2.0 2023-01-11 [1] CRAN (R 4.3.0)\n tzdb 0.4.0 2023-05-12 [1] CRAN (R 4.3.0)\n utf8 1.2.3 2023-01-31 [1] CRAN (R 4.3.0)\n vctrs 0.6.3 2023-06-14 [1] CRAN (R 4.3.0)\n withr 2.5.0 2022-03-03 [1] CRAN (R 4.3.0)\n xfun 0.40 2023-08-09 [1] CRAN (R 4.3.0)\n yaml 2.3.7 2023-01-23 [1] CRAN (R 4.3.0)\n\n [1] /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/library\n\n──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────"
},
{
- "objectID": "posts/15-control-structures/index.html#repeat-loops",
- "href": "posts/15-control-structures/index.html#repeat-loops",
- "title": "15 - Control Structures",
- "section": "repeat Loops",
- "text": "repeat Loops\nrepeat initiates an infinite loop right from the start. These are not commonly used in statistical or data analysis applications, but they do have their uses.\n\n\n\n\n\n\nIMPORTANT (READ THIS AND DON’T FORGET… I’M SERIOUS… YOU WANT TO REMEMBER THIS.. FOR REALZ PLZ REMEMBER THIS)\n\n\n\nThe only way to exit a repeat loop is to call break.\n\n\nOne possible paradigm might be in an iterative algorithm where you may be searching for a solution and you do not want to stop until you are close enough to the solution.\nIn this kind of situation, you often don’t know in advance how many iterations it’s going to take to get “close enough” to the solution.\n\nx0 <- 1\ntol <- 1e-8\n\nrepeat {\n x1 <- computeEstimate()\n\n if (abs(x1 - x0) < tol) { ## Close enough?\n break\n } else {\n x0 <- x1\n }\n}\n\n\n\n\n\n\n\nNote\n\n\n\nThe above code will not run if the computeEstimate() function is not defined (I just made it up for the purposes of this demonstration).\n\n\n\n\n\n\n\n\nPro-tip\n\n\n\nThe loop above is a bit dangerous because there is no guarantee it will stop.\nYou could get in a situation where the values of x0 and x1 oscillate back and forth and never converge.\nBetter to set a hard limit on the number of iterations by using a for loop and then report whether convergence was achieved or not."
+ "objectID": "index.html",
+ "href": "index.html",
+ "title": "Welcome to Statistical Computing!",
+ "section": "",
+ "text": "Welcome to Statistical Computing at Johns Hopkins Bloomberg School of Public Health!"
},
{
- "objectID": "posts/15-control-structures/index.html#next-break",
- "href": "posts/15-control-structures/index.html#next-break",
- "title": "15 - Control Structures",
- "section": "next, break",
- "text": "next, break\nnext is used to skip an iteration of a loop.\n\nfor (i in 1:100) {\n if (i <= 20) {\n ## Skip the first 20 iterations\n next\n }\n ## Do something here\n}\n\nbreak is used to exit a loop immediately, regardless of what iteration the loop may be on.\n\nfor (i in 1:100) {\n print(i)\n\n if (i > 20) {\n ## Stop loop after 20 iterations\n break\n }\n}"
- },
- {
- "objectID": "posts/23-working-with-text-sentiment-analysis/index.html",
- "href": "posts/23-working-with-text-sentiment-analysis/index.html",
- "title": "23 - Tidytext and sentiment analysis",
- "section": "",
- "text": "This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history."
- },
- {
- "objectID": "posts/23-working-with-text-sentiment-analysis/index.html#the-sentiments-dataset",
- "href": "posts/23-working-with-text-sentiment-analysis/index.html#the-sentiments-dataset",
- "title": "23 - Tidytext and sentiment analysis",
- "section": "The sentiments dataset",
- "text": "The sentiments dataset\nInside the tidytext package are several sentiment lexicons. A few things to note:\n\nThe lexicons are based on unigrams (single words)\nThe lexicons contain many English words and the words are assigned scores for positive/negative sentiment, and also possibly emotions like joy, anger, sadness, and so forth\n\nYou can use the get_sentiments() function to extract a specific lexicon.\nThe nrc lexicon categorizes words into multiple categories of positive, negative, anger, anticipation, disgust, fear, joy, sadness, surprise, and trust\n\nget_sentiments(\"nrc\")\n\n# A tibble: 13,872 × 2\n word sentiment\n <chr> <chr> \n 1 abacus trust \n 2 abandon fear \n 3 abandon negative \n 4 abandon sadness \n 5 abandoned anger \n 6 abandoned fear \n 7 abandoned negative \n 8 abandoned sadness \n 9 abandonment anger \n10 abandonment fear \n# ℹ 13,862 more rows\n\n\nThe bing lexicon categorizes words in a binary fashion into positive and negative categories\n\nget_sentiments(\"bing\")\n\n# A tibble: 6,786 × 2\n word sentiment\n <chr> <chr> \n 1 2-faces negative \n 2 abnormal negative \n 3 abolish negative \n 4 abominable negative \n 5 abominably negative \n 6 abominate negative \n 7 abomination negative \n 8 abort negative \n 9 aborted negative \n10 aborts negative \n# ℹ 6,776 more rows\n\n\nThe AFINN lexicon assigns words with a score that runs between -5 and 5, with negative scores indicating negative sentiment and positive scores indicating positive sentiment\n\nget_sentiments(\"afinn\")\n\n# A tibble: 2,477 × 2\n word value\n <chr> <dbl>\n 1 abandon -2\n 2 abandoned -2\n 3 abandons -2\n 4 abducted -2\n 5 abduction -2\n 6 abductions -2\n 7 abhor -3\n 8 abhorred -3\n 9 abhorrent -3\n10 abhors -3\n# ℹ 2,467 more rows\n\n\nThe authors of the tidytext package note:\n\n“How were these sentiment lexicons put together and validated? They were constructed via either crowdsourcing (using, for example, Amazon Mechanical Turk) or by the labor of one of the authors, and were validated using some combination of crowdsourcing again, restaurant or movie reviews, or Twitter data. Given this information, we may hesitate to apply these sentiment lexicons to styles of text dramatically different from what they were validated on, such as narrative fiction from 200 years ago. While it is true that using these sentiment lexicons with, for example, Jane Austen’s novels may give us less accurate results than with tweets sent by a contemporary writer, we still can measure the sentiment content for words that are shared across the lexicon and the text.”\n\nTwo other caveats:\n\n“Not every English word is in the lexicons because many English words are pretty neutral. It is important to keep in mind that these methods do not take into account qualifiers before a word, such as in”no good” or “not true”; a lexicon-based method like this is based on unigrams only. For many kinds of text (like the narrative examples below), there are not sustained sections of sarcasm or negated text, so this is not an important effect.”\n\nand\n\n“One last caveat is that the size of the chunk of text that we use to add up unigram sentiment scores can have an effect on an analysis. A text the size of many paragraphs can often have positive and negative sentiment averaged out to about zero, while sentence-sized or paragraph-sized text often works better.”\n\n\nJoining together tidy text data with lexicons\nNow that we have our data in a tidy text format AND we have learned about different types of lexicons in application for sentiment analysis, we can join the words together using a join function.\n\n\n\n\n\n\nExample\n\n\n\nWhat are the most common joy words in the book Emma?\nHere, we use the nrc lexicon and join the tidy_books dataset with the nrc_joy lexicon using the inner_join() function in dplyr.\n\nnrc_joy <- get_sentiments(\"nrc\") %>%\n filter(sentiment == \"joy\")\n\ntidy_books %>%\n filter(book == \"Emma\") %>%\n inner_join(nrc_joy) %>%\n count(word, sort = TRUE)\n\nJoining with `by = join_by(word)`\n\n\n# A tibble: 297 × 2\n word n\n <chr> <int>\n 1 friend 166\n 2 hope 143\n 3 happy 125\n 4 love 117\n 5 deal 92\n 6 found 92\n 7 happiness 76\n 8 pretty 68\n 9 true 66\n10 comfort 65\n# ℹ 287 more rows\n\n\n\n\nWe can do things like investigate how the sentiment of the text changes throughout each of Jane’s novels.\nHere, we use the bing lexicon, find a sentiment score for each word, and then use inner_join().\n\ntidy_books %>%\n inner_join(get_sentiments(\"bing\"))\n\nJoining with `by = join_by(word)`\n\n\nWarning in inner_join(., get_sentiments(\"bing\")): Detected an unexpected many-to-many relationship between `x` and `y`.\nℹ Row 131015 of `x` matches multiple rows in `y`.\nℹ Row 5051 of `y` matches multiple rows in `x`.\nℹ If a many-to-many relationship is expected, set `relationship =\n \"many-to-many\"` to silence this warning.\n\n\n# A tibble: 44,171 × 5\n book linenumber chapter word sentiment\n <fct> <int> <int> <chr> <chr> \n 1 Sense & Sensibility 16 1 respectable positive \n 2 Sense & Sensibility 18 1 advanced positive \n 3 Sense & Sensibility 20 1 death negative \n 4 Sense & Sensibility 21 1 loss negative \n 5 Sense & Sensibility 25 1 comfortably positive \n 6 Sense & Sensibility 28 1 goodness positive \n 7 Sense & Sensibility 28 1 solid positive \n 8 Sense & Sensibility 29 1 comfort positive \n 9 Sense & Sensibility 30 1 relish positive \n10 Sense & Sensibility 33 1 steady positive \n# ℹ 44,161 more rows\n\n\nThen, we can count how many positive and negative words there are in each section of the books.\nWe create an index to help us keep track of where we are in the narrative, which uses integer division, and counts up sections of 80 lines of text.\n\ntidy_books %>%\n inner_join(get_sentiments(\"bing\")) %>%\n count(book,\n index = linenumber %/% 80,\n sentiment\n )\n\nJoining with `by = join_by(word)`\n\n\nWarning in inner_join(., get_sentiments(\"bing\")): Detected an unexpected many-to-many relationship between `x` and `y`.\nℹ Row 131015 of `x` matches multiple rows in `y`.\nℹ Row 5051 of `y` matches multiple rows in `x`.\nℹ If a many-to-many relationship is expected, set `relationship =\n \"many-to-many\"` to silence this warning.\n\n\n# A tibble: 1,840 × 4\n book index sentiment n\n <fct> <dbl> <chr> <int>\n 1 Sense & Sensibility 0 negative 16\n 2 Sense & Sensibility 0 positive 26\n 3 Sense & Sensibility 1 negative 19\n 4 Sense & Sensibility 1 positive 44\n 5 Sense & Sensibility 2 negative 12\n 6 Sense & Sensibility 2 positive 23\n 7 Sense & Sensibility 3 negative 15\n 8 Sense & Sensibility 3 positive 22\n 9 Sense & Sensibility 4 negative 16\n10 Sense & Sensibility 4 positive 29\n# ℹ 1,830 more rows\n\n\n\n\n\n\n\n\nNote\n\n\n\nThe %/% operator does integer division (x %/% y is equivalent to floor(x/y)) so the index keeps track of which 80-line section of text we are counting up negative and positive sentiment in.\n\n\nFinally, we use pivot_wider() to have positive and negative counts in different columns, and then use mutate() to calculate a net sentiment (positive - negative).\n\njane_austen_sentiment <-\n tidy_books %>%\n inner_join(get_sentiments(\"bing\")) %>%\n count(book,\n index = linenumber %/% 80,\n sentiment\n ) %>%\n pivot_wider(\n names_from = sentiment,\n values_from = n,\n values_fill = 0\n ) %>%\n mutate(sentiment = positive - negative)\n\nJoining with `by = join_by(word)`\n\n\nWarning in inner_join(., get_sentiments(\"bing\")): Detected an unexpected many-to-many relationship between `x` and `y`.\nℹ Row 131015 of `x` matches multiple rows in `y`.\nℹ Row 5051 of `y` matches multiple rows in `x`.\nℹ If a many-to-many relationship is expected, set `relationship =\n \"many-to-many\"` to silence this warning.\n\njane_austen_sentiment\n\n# A tibble: 920 × 5\n book index negative positive sentiment\n <fct> <dbl> <int> <int> <int>\n 1 Sense & Sensibility 0 16 26 10\n 2 Sense & Sensibility 1 19 44 25\n 3 Sense & Sensibility 2 12 23 11\n 4 Sense & Sensibility 3 15 22 7\n 5 Sense & Sensibility 4 16 29 13\n 6 Sense & Sensibility 5 16 39 23\n 7 Sense & Sensibility 6 24 37 13\n 8 Sense & Sensibility 7 22 39 17\n 9 Sense & Sensibility 8 30 35 5\n10 Sense & Sensibility 9 14 18 4\n# ℹ 910 more rows\n\n\nThen we can plot the sentiment scores across the sections of each novel:\n\njane_austen_sentiment %>%\n ggplot(aes(x = index, y = sentiment, fill = book)) +\n geom_col(show.legend = FALSE) +\n facet_wrap(. ~ book, ncol = 2, scales = \"free_x\")\n\n\n\n\nWe can see how the sentiment trajectory of the novel changes over time.\n\n\nWord clouds\nYou can also do things like create word clouds using the wordcloud package.\n\nlibrary(wordcloud)\n\nLoading required package: RColorBrewer\n\ntidy_books %>%\n anti_join(stop_words) %>%\n count(word) %>%\n with(wordcloud(word, n, max.words = 100))\n\nJoining with `by = join_by(word)`\n\n\nWarning in wordcloud(word, n, max.words = 100): miss could not be fit on page.\nIt will not be plotted."
- },
- {
- "objectID": "resources.html",
- "href": "resources.html",
- "title": "Resources",
- "section": "",
- "text": "Learning R\n\nR 101 LIBD rstats club blog post: https://research.libd.org/rstatsclub/2018/12/24/r_101/\nIntroductory videos from the LIBD rstats club such as this one:\n\n\n\n\n\n\nBig Book of R: https://www.bigbookofr.com\nList of resources to learn R (but also Python, SQL, Javascript): https://github.com/delabj/datacamp_alternatives/blob/master/index.md\nlearnr4free. Resources (books, videos, interactive websites, papers) to learn R. Some of the resources are beginner-friendly and start with the installation process: https://www.learnr4free.com/en\nData Science with R by Danielle Navarro: https://robust-tools.djnavarro.net"
- },
- {
- "objectID": "schedule.html",
- "href": "schedule.html",
- "title": "Schedule",
- "section": "",
- "text": "For Qmd files (markdown document with Quarto cross-language executable code), go to the course GitHub repository and navigate the directories, or best of all to git clone the repo and navigate within RStudio.\nCheck https://github.com/lcolladotor/biostat776classnotes for Leo’s live class notes.\n\n\n\n\n\n\n\n\n\n\n\nWeek\nLectures / due dates\nTopics\nProjects\n\n\n\n\n\nModule 1\n\nStatistical and computational tools for scientific and reproducible research\n\n\n\n\n\n\n\n\n\n\n\nWeek 1\nLecture 1 (Leo will be remote!)\n👋 Course introduction [html] [Qmd] [R]\n🌴 Project 0 [html] [Qmd] [R]\n\n\n\n\n\n👩💻 Introduction to R and RStudio [html] [Qmd] [R]\n\n\n\n\n\n\n🐙 Introduction to git/GitHub [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\n\nLecture 2 (Leo will be remote!)\n🔬 Reproducible Research [html] [Qmd] [R]\n\n\n\n\n\n\n👓 Literate programming [html] [Qmd] [R]\n\n\n\n\n\n\n🆒 Reference management [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\nModule 2\n\nData analysis in R\n\n\n\n\n\n\n\n\n\n\n\nWeek 2\nLecture 3\n👀 Reading and writing data [html] [Qmd] [R]\n🌴 Project 1 [html] [Qmd] [R]\n\n\n\n\n\n✂️ Managing data frames with Tidyverse [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\n\nLecture 4\n😻 Tidy data and the Tidyverse [html] [Qmd] [R]\n🍂 Project 0 due\n\n\n\n\n\n🤝 Joining data in R: Basics [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\nModule 3\n\nData visualizations R\n\n\n\n\n\n\n\n\n\n\n\nWeek 3\nLecture 5\n📊 Plotting systems in R [html] [Qmd] [R]\n\n\n\n\n\n\n📊 The ggplot2 plotting system: qplot() [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\n\nLecture 6\n📊 The ggplot2 plotting system: ggplot() [html] [Qmd] [R]\n🌴 Project 2 [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\nSept 17\n\n🍂 Project 1 due\n\n\n\n\n\n\n\n\n\n\nModule 4\n\nNuts and bolts of R\n\n\n\n\n\n\n\n\n\n\n\nWeek 4\nLecture 7\n🔩 R Nuts and Bolts [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\n\nLecture 8\n🔩 Control structures in R [html] [Qmd] [R]\n\n\n\n\n\n\n🔩 Functions in R [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\nWeek 5\nLecture 9\n🔩 Loop functions [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\n\nLecture 10\n🐛 Debugging code in R [html] [Qmd] [R]\n\n\n\n\n\n\n🐛 Error handling code in R [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\n\nOct 1\n\n🍂 Project 2 due\n\n\n\n\n\n\n\n\n\n\nModule 5\n\nSpecial data types in R\n\n\n\n\n\n\n\n\n\n\n\nWeek 6\nLecture 11\n📆 Working with dates and times [html] [Qmd] [R]\n🌴 Project 3 [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\nLecture 12\n✨ Regular expressions [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\nWeek 7\nLecture 13\n🐱 Working with factors [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\n\nLecture 14\n📆 Working with text data and sentiment analysis [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\nModule 6\n\nBest practices for working with data and other languages\n\n\n\n\n\n\n\n\n\n\n\nWeek 8\nLecture 15\n☁️ Best practices for data analysies [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\n\nLecture 16\n🐍 Leveraging Python within R [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\n\nOct 23\n\n🍂 Project 3 due"
- },
- {
- "objectID": "schedule.html#schedule-and-course-materials",
- "href": "schedule.html#schedule-and-course-materials",
- "title": "Schedule",
- "section": "",
- "text": "For Qmd files (markdown document with Quarto cross-language executable code), go to the course GitHub repository and navigate the directories, or best of all to git clone the repo and navigate within RStudio.\nCheck https://github.com/lcolladotor/biostat776classnotes for Leo’s live class notes.\n\n\n\n\n\n\n\n\n\n\n\nWeek\nLectures / due dates\nTopics\nProjects\n\n\n\n\n\nModule 1\n\nStatistical and computational tools for scientific and reproducible research\n\n\n\n\n\n\n\n\n\n\n\nWeek 1\nLecture 1 (Leo will be remote!)\n👋 Course introduction [html] [Qmd] [R]\n🌴 Project 0 [html] [Qmd] [R]\n\n\n\n\n\n👩💻 Introduction to R and RStudio [html] [Qmd] [R]\n\n\n\n\n\n\n🐙 Introduction to git/GitHub [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\n\nLecture 2 (Leo will be remote!)\n🔬 Reproducible Research [html] [Qmd] [R]\n\n\n\n\n\n\n👓 Literate programming [html] [Qmd] [R]\n\n\n\n\n\n\n🆒 Reference management [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\nModule 2\n\nData analysis in R\n\n\n\n\n\n\n\n\n\n\n\nWeek 2\nLecture 3\n👀 Reading and writing data [html] [Qmd] [R]\n🌴 Project 1 [html] [Qmd] [R]\n\n\n\n\n\n✂️ Managing data frames with Tidyverse [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\n\nLecture 4\n😻 Tidy data and the Tidyverse [html] [Qmd] [R]\n🍂 Project 0 due\n\n\n\n\n\n🤝 Joining data in R: Basics [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\nModule 3\n\nData visualizations R\n\n\n\n\n\n\n\n\n\n\n\nWeek 3\nLecture 5\n📊 Plotting systems in R [html] [Qmd] [R]\n\n\n\n\n\n\n📊 The ggplot2 plotting system: qplot() [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\n\nLecture 6\n📊 The ggplot2 plotting system: ggplot() [html] [Qmd] [R]\n🌴 Project 2 [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\nSept 17\n\n🍂 Project 1 due\n\n\n\n\n\n\n\n\n\n\nModule 4\n\nNuts and bolts of R\n\n\n\n\n\n\n\n\n\n\n\nWeek 4\nLecture 7\n🔩 R Nuts and Bolts [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\n\nLecture 8\n🔩 Control structures in R [html] [Qmd] [R]\n\n\n\n\n\n\n🔩 Functions in R [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\nWeek 5\nLecture 9\n🔩 Loop functions [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\n\nLecture 10\n🐛 Debugging code in R [html] [Qmd] [R]\n\n\n\n\n\n\n🐛 Error handling code in R [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\n\nOct 1\n\n🍂 Project 2 due\n\n\n\n\n\n\n\n\n\n\nModule 5\n\nSpecial data types in R\n\n\n\n\n\n\n\n\n\n\n\nWeek 6\nLecture 11\n📆 Working with dates and times [html] [Qmd] [R]\n🌴 Project 3 [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\nLecture 12\n✨ Regular expressions [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\nWeek 7\nLecture 13\n🐱 Working with factors [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\n\nLecture 14\n📆 Working with text data and sentiment analysis [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\nModule 6\n\nBest practices for working with data and other languages\n\n\n\n\n\n\n\n\n\n\n\nWeek 8\nLecture 15\n☁️ Best practices for data analysies [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\n\nLecture 16\n🐍 Leveraging Python within R [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\n\nOct 23\n\n🍂 Project 3 due"
- },
- {
- "objectID": "projects/project-2/index.html",
- "href": "projects/project-2/index.html",
- "title": "Project 2",
- "section": "",
- "text": "This project, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history.\n\nBackground\nDue date: October 1st at 11:59pm\nThe goal of this assignment is to practice designing and writing functions along with practicing our tidyverse skills that we learned in our previous project. Writing functions involves thinking about how code should be divided up and what the interface/arguments should be. In addition, you need to think about what the function will return as output.\n\nTo submit your project\nPlease write up your project using R Markdown and processed with knitr. Compile your document as an HTML file and submit your HTML file to the dropbox on Courseplus. Please show all your code (i.e. make sure to set echo = TRUE) for each of the answers to each part.\n\n\nInstall packages\nBefore attempting this assignment, you should first install the following packages, if they are not already installed:\n\ninstall.packages(\"tidyverse\")\ninstall.packages(\"tidytuesdayR\")\n\n\n\n\nPart 1: Fun with functions\nIn this part, we are going to practice creating functions.\n\nPart 1A: Exponential transformation\nThe exponential of a number can be written as an infinite series expansion of the form \\[\n\\exp(x) = 1 + x + \\frac{x^2}{2!} + \\frac{x^3}{3!} + \\cdots\n\\] Of course, we cannot compute an infinite series by the end of this term and so we must truncate it at a certain point in the series. The truncated sum of terms represents an approximation to the true exponential, but the approximation may be usable.\nWrite a function that computes the exponential of a number using the truncated series expansion. The function should take two arguments:\n\nx: the number to be exponentiated\nk: the number of terms to be used in the series expansion beyond the constant 1. The value of k is always \\(\\geq 1\\).\n\nFor example, if \\(k = 1\\), then the Exp function should return the number \\(1 + x\\). If \\(k = 2\\), then you should return the number \\(1 + x + x^2/2!\\).\nInclude at least one example of output using your function.\n\n\n\n\n\n\nNote\n\n\n\n\nYou can assume that the input value x will always be a single number.\nYou can assume that the value k will always be an integer \\(\\geq 1\\).\nDo not use the exp() function in R.\nThe factorial() function can be used to compute factorials.\n\n\n\n\nExp <- function(x, k) {\n # Add your solution here\n}\n\n\n\nPart 1B: Sample mean and sample standard deviation\nNext, write two functions called sample_mean() and sample_sd() that takes as input a vector of data of length \\(N\\) and calculates the sample average and sample standard deviation for the set of \\(N\\) observations.\n\\[\n\\bar{x} = \\frac{1}{N} \\sum_{i=1}^n x_i\n\\] \\[\ns = \\sqrt{\\frac{1}{N-1} \\sum_{i=1}^N (x_i - \\overline{x})^2}\n\\] Include at least one example of output using your functions.\n\n\n\n\n\n\nNote\n\n\n\n\nYou can assume that the input value x will always be a vector of numbers of length N.\nDo not use the mean() and sd() functions in R.\n\n\n\n\nsample_mean <- function(x) {\n # Add your solution here\n}\n\nsample_sd <- function(x) {\n # Add your solution here\n}\n\n\n\nPart 1C: Confidence intervals\nNext, write a function called calculate_CI() that:\n\nThere should be two inputs to the calculate_CI(). First, it should take as input a vector of data of length \\(N\\). Second, the function should also have a conf (\\(=1-\\alpha\\)) argument that allows the confidence interval to be adapted for different \\(\\alpha\\).\nCalculates a confidence interval (CI) (e.g. a 95% CI) for the estimate of the mean in the population. If you are not familiar with confidence intervals, it is an interval that contains the population parameter with probability \\(1-\\alpha\\) taking on this form\n\n\\[\n\\bar{x} \\pm t_{\\alpha/2, N-1} s_{\\bar{x}}\n\\]\nwhere \\(t_{\\alpha/2, N-1}\\) is the value needed to generate an area of \\(\\alpha / 2\\) in each tail of the \\(t\\)-distribution with \\(N-1\\) degrees of freedom and \\(s_{\\bar{x}} = \\frac{s}{\\sqrt{N}}\\) is the standard error of the mean. For example, if we pick a 95% confidence interval and \\(N\\)=50, then you can calculate \\(t_{\\alpha/2, N-1}\\) as\n\nalpha <- 1 - 0.95\ndegrees_freedom <- 50 - 1\nt_score <- qt(p = alpha / 2, df = degrees_freedom, lower.tail = FALSE)\n\n\nReturns a named vector of length 2, where the first value is the lower_bound, the second value is the upper_bound.\n\n\ncalculate_CI <- function(x, conf = 0.95) {\n # Add your solution here\n}\n\nInclude example of output from your function showing the output when using two different levels of conf.\n\n\n\n\n\n\nNote\n\n\n\nIf you want to check if your function output matches an existing function in R, consider a vector \\(x\\) of length \\(N\\) and see if the following two code chunks match.\n\ncalculate_CI(x, conf = 0.95)\n\n\ndat <- data.frame(x = x)\nfit <- lm(x ~ 1, dat)\n\n# Calculate a 95% confidence interval\nconfint(fit, level = 0.95)\n\n\n\n\n\n\nPart 2: Wrangling data\nIn this part, we will practice our wrangling skills with the tidyverse that we learned about in module 1.\n\nData\nThe two datasets for this part of the assignment comes from TidyTuesday. Specifically, we will use the following data from January 2020, which I have provided for you below:\n\ntuesdata <- tidytuesdayR::tt_load(\"2020-01-07\")\nrainfall <- tuesdata$rainfall\ntemperature <- tuesdata$temperature\n\nHowever, to avoid re-downloading data, we will check to see if those files already exist using an if() statement:\n\nlibrary(here)\nif (!file.exists(here(\"data\", \"tuesdata_rainfall.RDS\"))) {\n tuesdata <- tidytuesdayR::tt_load(\"2020-01-07\")\n rainfall <- tuesdata$rainfall\n temperature <- tuesdata$temperature\n\n # save the files to RDS objects\n saveRDS(tuesdata$rainfall, file = here(\"data\", \"tuesdata_rainfall.RDS\"))\n saveRDS(tuesdata$temperature, file = here(\"data\", \"tuesdata_temperature.RDS\"))\n}\n\n\n\n\n\n\n\nNote\n\n\n\nThe above code will only run if it cannot find the path to the tuesdata_rainfall.RDS on your computer. Then, we can just read in these files every time we knit the R Markdown, instead of re-downloading them every time.\n\n\nLet’s load the datasets\n\nrainfall <- readRDS(here(\"data\", \"tuesdata_rainfall.RDS\"))\ntemperature <- readRDS(here(\"data\", \"tuesdata_temperature.RDS\"))\n\nNow we can look at the data with glimpse()\n\nlibrary(tidyverse)\n\nglimpse(rainfall)\n\nRows: 179,273\nColumns: 11\n$ station_code <chr> \"009151\", \"009151\", \"009151\", \"009151\", \"009151\", \"009151…\n$ city_name <chr> \"Perth\", \"Perth\", \"Perth\", \"Perth\", \"Perth\", \"Perth\", \"Pe…\n$ year <dbl> 1967, 1967, 1967, 1967, 1967, 1967, 1967, 1967, 1967, 196…\n$ month <chr> \"01\", \"01\", \"01\", \"01\", \"01\", \"01\", \"01\", \"01\", \"01\", \"01…\n$ day <chr> \"01\", \"02\", \"03\", \"04\", \"05\", \"06\", \"07\", \"08\", \"09\", \"10…\n$ rainfall <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…\n$ period <dbl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…\n$ quality <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, N…\n$ lat <dbl> -31.96, -31.96, -31.96, -31.96, -31.96, -31.96, -31.96, -…\n$ long <dbl> 115.79, 115.79, 115.79, 115.79, 115.79, 115.79, 115.79, 1…\n$ station_name <chr> \"Subiaco Wastewater Treatment Plant\", \"Subiaco Wastewater…\n\nglimpse(temperature)\n\nRows: 528,278\nColumns: 5\n$ city_name <chr> \"PERTH\", \"PERTH\", \"PERTH\", \"PERTH\", \"PERTH\", \"PERTH\", \"PER…\n$ date <date> 1910-01-01, 1910-01-02, 1910-01-03, 1910-01-04, 1910-01-0…\n$ temperature <dbl> 26.7, 27.0, 27.5, 24.0, 24.8, 24.4, 25.3, 28.0, 32.6, 35.9…\n$ temp_type <chr> \"max\", \"max\", \"max\", \"max\", \"max\", \"max\", \"max\", \"max\", \"m…\n$ site_name <chr> \"PERTH AIRPORT\", \"PERTH AIRPORT\", \"PERTH AIRPORT\", \"PERTH …\n\n\nIf we look at the TidyTuesday github repo from 2020, we see this dataset contains temperature and rainfall data from Australia.\nHere is a data dictionary for what all the column names mean:\n\nhttps://github.com/rfordatascience/tidytuesday/blob/master/data/2020/2020-01-07/readme.md#data-dictionary\n\n\n\nTasks\nUsing the rainfall and temperature data, perform the following steps and create a new data frame called df:\n\nStart with rainfall dataset and drop any rows with NAs.\nCreate a new column titled date that combines the columns year, month, day into one column separated by “-”. (e.g. “2020-01-01”). This column should not be a character, but should be recognized as a date. (Hint: check out the ymd() function in lubridate R package). You will also want to add a column that just keeps the year.\nUsing the city_name column, convert the city names (character strings) to all upper case.\nJoin this wrangled rainfall dataset with the temperature dataset such that it includes only observations that are in both data frames. (Hint: there are two keys that you will need to join the two datasets together). (Hint: If all has gone well thus far, you should have a dataset with 83,964 rows and 13 columns).\n\n\n\n\n\n\n\nNote\n\n\n\n\nYou may need to use functions outside these packages to obtain this result, in particular you may find the functions drop_na() from tidyr and str_to_upper() function from stringr useful.\n\n\n\n\n# Add your solution here\n\n\n\n\nPart 3: Data visualization\nIn this part, we will practice our ggplot2 plotting skills within the tidyverse starting with our wrangled df data from Part 2. For full credit in this part (and for all plots that you make), your plots should include:\n\nAn overall title for the plot and a subtitle summarizing key trends that you found. Also include a caption in the figure.\nThere should be an informative x-axis and y-axis label.\n\nConsider playing around with the theme() function to make the figure shine, including playing with background colors, font, etc.\n\nPart 3A: Plotting temperature data over time\nUse the functions in ggplot2 package to make a line plot of the max and min temperature (y-axis) over time (x-axis) for each city in our wrangled data from Part 2. You should only consider years 2014 and onwards. For full credit, your plot should include:\n\nFor a given city, the min and max temperature should both appear on the plot, but they should be two different colors.\nUse a facet function to facet by city_name to show all cities in one figure.\n\n\n# Add your solution here\n\n\n\nPart 3B: Plotting rainfall over time\nHere we want to explore the distribution of rainfall (log scale) with histograms for a given city (indicated by the city_name column) for a given year (indicated by the year column) so we can make some exploratory plots of the data.\n\n\n\n\n\n\nNote\n\n\n\nYou are again using the wrangled data from Part 2.\n\n\nThe following code plots the data from one city (city_name == \"PERTH\") in a given year (year == 2000).\n\ndf %>%\n filter(city_name == \"PERTH\", year == 2000) %>%\n ggplot(aes(log(rainfall))) +\n geom_histogram()\n\nWhile this code is useful, it only provides us information on one city in one year. We could cut and paste this code to look at other cities/years, but that can be error prone and just plain messy.\nThe aim here is to design and implement a function that can be re-used to visualize all of the data in this dataset.\n\nThere are 2 aspects that may vary in the dataset: The city_name and the year. Note that not all combinations of city_name and year have measurements.\nYour function should take as input two arguments city_name and year.\nGiven the input from the user, your function should return a single histogram for that input. Furthermore, the data should be readable on that plot so that it is in fact useful. It should be possible visualize the entire dataset with your function (through repeated calls to your function).\nIf the user enters an input that does not exist in the dataset, your function should catch that and report an error (via the stop() function).\n\nFor this section,\n\nWrite a short description of how you chose to design your function and why.\nPresent the code for your function in the R markdown document.\nInclude at least one example of output from your function.\n\n\n# Add your solution here\n\n\n\n\nPart 4: Apply functions and plot\n\nPart 4A: Tasks\nIn this part, we will apply the functions we wrote in Part 1 to our rainfall data starting with our wrangled df data from Part 2.\n\nFirst, filter for only years including 2014 and onwards.\nFor a given city and for a given year, calculate the sample mean (using your function sample_mean()), the sample standard deviation (using your function sample_sd()), and a 95% confidence interval for the average rainfall (using your function calculate_CI()). Specifically, you should add two columns in this summarized dataset: a column titled lower_bound and a column titled upper_bound containing the lower and upper bounds for you CI that you calculated (using your function calculate_CI()).\nCall this summarized dataset rain_df.\n\n\n# Add your solution here\n\n\n\nPart 4B: Tasks\nUsing the rain_df, plots the estimates of mean rainfall and the 95% confidence intervals on the same plot. There should be a separate faceted plot for each city. Think about using ggplot() with both geom_point() (and geom_line() to connect the points) for the means and geom_errorbar() for the lower and upper bounds of the confidence interval.\n\n# Add your solution here\n\n\n\n\nR session information\n\noptions(width = 120)\nsessioninfo::session_info()\n\n─ Session info ───────────────────────────────────────────────────────────────────────────────────────────────────────\n setting value\n version R version 4.3.1 (2023-06-16)\n os macOS Ventura 13.5\n system aarch64, darwin20\n ui X11\n language (EN)\n collate en_US.UTF-8\n ctype en_US.UTF-8\n tz America/New_York\n date 2023-09-12\n pandoc 3.1.5 @ /opt/homebrew/bin/ (via rmarkdown)\n\n─ Packages ───────────────────────────────────────────────────────────────────────────────────────────────────────────\n package * version date (UTC) lib source\n cli 3.6.1 2023-03-23 [1] CRAN (R 4.3.0)\n colorout 1.2-2 2023-05-06 [1] Github (jalvesaq/colorout@79931fd)\n colorspace 2.1-0 2023-01-23 [1] CRAN (R 4.3.0)\n digest 0.6.33 2023-07-07 [1] CRAN (R 4.3.0)\n dplyr * 1.1.3 2023-09-03 [1] CRAN (R 4.3.0)\n evaluate 0.21 2023-05-05 [1] CRAN (R 4.3.0)\n fansi 1.0.4 2023-01-22 [1] CRAN (R 4.3.0)\n fastmap 1.1.1 2023-02-24 [1] CRAN (R 4.3.0)\n forcats * 1.0.0 2023-01-29 [1] CRAN (R 4.3.0)\n generics 0.1.3 2022-07-05 [1] CRAN (R 4.3.0)\n ggplot2 * 3.4.3 2023-08-14 [1] CRAN (R 4.3.0)\n glue 1.6.2 2022-02-24 [1] CRAN (R 4.3.0)\n gtable 0.3.4 2023-08-21 [1] CRAN (R 4.3.0)\n here * 1.0.1 2020-12-13 [1] CRAN (R 4.3.0)\n hms 1.1.3 2023-03-21 [1] CRAN (R 4.3.0)\n htmltools 0.5.6 2023-08-10 [1] CRAN (R 4.3.0)\n htmlwidgets 1.6.2 2023-03-17 [1] CRAN (R 4.3.0)\n jsonlite 1.8.7 2023-06-29 [1] CRAN (R 4.3.0)\n knitr 1.43 2023-05-25 [1] CRAN (R 4.3.0)\n lifecycle 1.0.3 2022-10-07 [1] CRAN (R 4.3.0)\n lubridate * 1.9.2 2023-02-10 [1] CRAN (R 4.3.0)\n magrittr 2.0.3 2022-03-30 [1] CRAN (R 4.3.0)\n munsell 0.5.0 2018-06-12 [1] CRAN (R 4.3.0)\n pillar 1.9.0 2023-03-22 [1] CRAN (R 4.3.0)\n pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.3.0)\n purrr * 1.0.2 2023-08-10 [1] CRAN (R 4.3.0)\n R6 2.5.1 2021-08-19 [1] CRAN (R 4.3.0)\n readr * 2.1.4 2023-02-10 [1] CRAN (R 4.3.0)\n rlang 1.1.1 2023-04-28 [1] CRAN (R 4.3.0)\n rmarkdown 2.24 2023-08-14 [1] CRAN (R 4.3.1)\n rprojroot 2.0.3 2022-04-02 [1] CRAN (R 4.3.0)\n rstudioapi 0.15.0 2023-07-07 [1] CRAN (R 4.3.0)\n scales 1.2.1 2022-08-20 [1] CRAN (R 4.3.0)\n sessioninfo 1.2.2 2021-12-06 [1] CRAN (R 4.3.0)\n stringi 1.7.12 2023-01-11 [1] CRAN (R 4.3.0)\n stringr * 1.5.0 2022-12-02 [1] CRAN (R 4.3.0)\n tibble * 3.2.1 2023-03-20 [1] CRAN (R 4.3.0)\n tidyr * 1.3.0 2023-01-24 [1] CRAN (R 4.3.0)\n tidyselect 1.2.0 2022-10-10 [1] CRAN (R 4.3.0)\n tidyverse * 2.0.0 2023-02-22 [1] CRAN (R 4.3.0)\n timechange 0.2.0 2023-01-11 [1] CRAN (R 4.3.0)\n tzdb 0.4.0 2023-05-12 [1] CRAN (R 4.3.0)\n utf8 1.2.3 2023-01-31 [1] CRAN (R 4.3.0)\n vctrs 0.6.3 2023-06-14 [1] CRAN (R 4.3.0)\n withr 2.5.0 2022-03-03 [1] CRAN (R 4.3.0)\n xfun 0.40 2023-08-09 [1] CRAN (R 4.3.0)\n yaml 2.3.7 2023-01-23 [1] CRAN (R 4.3.0)\n\n [1] /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/library\n\n──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────"
- },
- {
- "objectID": "projects/project-0/index.html",
- "href": "projects/project-0/index.html",
- "title": "Project 0 (optional)",
- "section": "",
- "text": "This project, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history."
- },
- {
- "objectID": "projects/project-0/index.html#class-notes",
- "href": "projects/project-0/index.html#class-notes",
- "title": "Project 0 (optional)",
- "section": "Class notes",
- "text": "Class notes\nFirst, lets make one for our class notes where we will host data and R scripts. We won’t be hosting HTML files here, so we don’t need to use the gh-pages branch for hosting files on GitHub pages.\n\n## Create an Rstudio project\nusethis::create_project(\"~/Desktop/biostat776classnotes\")\n\n## Start version controlling it\nusethis::use_git()\n\n## Share it via GitHub with the world\nusethis::use_github()\n\nAbove I created the biostat766classnotes RStudio project + git / GitHub repository. I saved it on my ~/Desktop but you can save it wherever you want.\nOnce that’s created, create the R/ and data/ subdirectories. Inside R/, save your R scripts for every class. As for data/, copy the contents of https://github.com/lcolladotor/jhustatcomputing2023/tree/main/data into it. That way commands like here(\"data\", \"chocolate.RDS\") from the class lectures will work the same way.\nMy live example is available at https://github.com/lcolladotor/biostat776classnotes."
- },
- {
- "objectID": "projects/project-0/index.html#for-each-project",
- "href": "projects/project-0/index.html#for-each-project",
- "title": "Project 0 (optional)",
- "section": "For each project",
- "text": "For each project\nWe can go ahead and\n\n## Create an Rstudio project\nusethis::create_project(\"~/Desktop/biostat776project1\")\n\n## Start version controlling it\nusethis::use_git()\n\n## Use the gh-pages branch in order for\n## GitHub pages https://pages.github.com/ to\n## host our website.\nusethis::git_default_branch_rename(to = \"gh-pages\")\n\n## Create a .nojekyll file\nwriteLines(\"\", here::here(\".nojekyll\"))\n\n## Share it via GitHub with the world\nusethis::use_github()\n\nOnce that’s done, create a index.Rmd (or index.qmd if you are using Quarto) file and make sure you version control the resulting index.html file (git add index.html) after you render your index.Rmd (or index.qmd) file.\nMy live example is available at https://github.com/lcolladotor/biostat776project1. The rendered website is available at https://lcolladotor.github.io/biostat776project1/."
- },
- {
- "objectID": "syllabus.html",
- "href": "syllabus.html",
- "title": "Syllabus",
- "section": "",
- "text": "Location: In person and Online for Fall 2023\nCourse time: Tuesdays and Thursdays from 9:00-10:20 a.m. (Eastern Daylight Time zone)\nCourse location: 140.776.01 is in person in W5030\nAssignments: Three projects\n\n\n\n\nTo add the course to your 1st term registration: You can sign up only for the in-person (140.776.01) course.\nAll lectures will be recorded and posted on CoursePlus. Classes will be recorded for flexibility purposes but this will not be a hybrid class.\nPlease course instructor if interested in auditing.\n\n\n\n\n\nLeonardo Collado Torres (http://lcolladotor.github.io/)\n\nOffice Location: 855 N. Wolfe, Office 385, Baltimore, MD 21205. Enter the Rangos building, register at the Security fron desk, ask the security guard to help you take the elevator to the third floor (it’s badge-controlled), register at the LIBD front desk, then they can point you to my office.\nEmail: lcollado@jhu.edu\n\n\nInstructor office hours are announced on CoursePlus. If there are conflicts and/or need to cancel office hours, announcements will be made on CoursePlus.\n\n\n\n\nEmily Norton (enorton7@jhmi.edu)\nJoe Sartini (jsartin1@jhu.edu)\nPhyllis Wei (ywei43@jhu.edu)\n\nTA office hours are announced on CoursePlus.\n\n\n\nIn order of preference, here is a preferred list of ways to get help:\n\nWe strongly encourage you to use CoursePlus to ask questions first, before joining office hours. The reason for this is so that other students in the class (who likely have similar questions) can also benefit from the questions and answers asked by your colleagues.\nYou are welcome to join office hours to get more group interactive feedback.\nIf you are not able to make the office hours, appointments can be made by email with the TAs."
- },
- {
- "objectID": "syllabus.html#course-information",
- "href": "syllabus.html#course-information",
- "title": "Syllabus",
- "section": "",
- "text": "Location: In person and Online for Fall 2023\nCourse time: Tuesdays and Thursdays from 9:00-10:20 a.m. (Eastern Daylight Time zone)\nCourse location: 140.776.01 is in person in W5030\nAssignments: Three projects\n\n\n\n\nTo add the course to your 1st term registration: You can sign up only for the in-person (140.776.01) course.\nAll lectures will be recorded and posted on CoursePlus. Classes will be recorded for flexibility purposes but this will not be a hybrid class.\nPlease course instructor if interested in auditing.\n\n\n\n\n\nLeonardo Collado Torres (http://lcolladotor.github.io/)\n\nOffice Location: 855 N. Wolfe, Office 385, Baltimore, MD 21205. Enter the Rangos building, register at the Security fron desk, ask the security guard to help you take the elevator to the third floor (it’s badge-controlled), register at the LIBD front desk, then they can point you to my office.\nEmail: lcollado@jhu.edu\n\n\nInstructor office hours are announced on CoursePlus. If there are conflicts and/or need to cancel office hours, announcements will be made on CoursePlus.\n\n\n\n\nEmily Norton (enorton7@jhmi.edu)\nJoe Sartini (jsartin1@jhu.edu)\nPhyllis Wei (ywei43@jhu.edu)\n\nTA office hours are announced on CoursePlus.\n\n\n\nIn order of preference, here is a preferred list of ways to get help:\n\nWe strongly encourage you to use CoursePlus to ask questions first, before joining office hours. The reason for this is so that other students in the class (who likely have similar questions) can also benefit from the questions and answers asked by your colleagues.\nYou are welcome to join office hours to get more group interactive feedback.\nIf you are not able to make the office hours, appointments can be made by email with the TAs."
- },
- {
- "objectID": "syllabus.html#important-links",
- "href": "syllabus.html#important-links",
- "title": "Syllabus",
- "section": "Important Links",
- "text": "Important Links\n\nCourse website: https://lcolladotor.github.io/jhustatcomputing2023/\nGitHub repository with all course material: https://github.com/lcolladotor/jhustatcomputing2023\nBug reports: https://github.com/lcolladotor/jhustatcomputing2023/issues"
- },
- {
- "objectID": "syllabus.html#learning-objectives",
- "href": "syllabus.html#learning-objectives",
- "title": "Syllabus",
- "section": "Learning Objectives:",
- "text": "Learning Objectives:\nUpon successfully completing this course, students will be able to:\n\nInstall and configure software necessary for a statistical programming environment\nDiscuss generic programming language concepts as they are implemented in a high-level statistical language\nWrite and debug code in base R and the tidyverse (and integrate code from Python modules)\nBuild basic data visualizations using R and the tidyverse\nDiscuss best practices for coding and reproducible research, basics of data ethics, basics of working with special data types, and basics of storing data"
- },
- {
- "objectID": "syllabus.html#lectures",
- "href": "syllabus.html#lectures",
- "title": "Syllabus",
- "section": "Lectures",
- "text": "Lectures\nIn Fall 2023, we will have in person lectures that will be recorded enabling students who missed a class for personal reasons to catch up as well as to review material discussed in class."
- },
- {
- "objectID": "syllabus.html#textbook-and-other-course-material",
- "href": "syllabus.html#textbook-and-other-course-material",
- "title": "Syllabus",
- "section": "Textbook and Other Course Material",
- "text": "Textbook and Other Course Material\nThere is no required textbook. We will make use of several freely available textbooks and other materials. All course materials will be provided. We will use the R software for data analysis, which is freely available for download."
- },
- {
- "objectID": "syllabus.html#software",
- "href": "syllabus.html#software",
- "title": "Syllabus",
- "section": "Software",
- "text": "Software\nWe will make heavy use of R in this course, so you should have R installed. You can obtain R from the Comprehensive R Archive Network. There are versions available for Mac, Windows, and Unix/Linux. This software is required for this course.\nIt is important that you have the latest version of R installed. For this course we will be using R version 4.3.1. You can determine what version of R you have by starting up R and typing into the console R.version.string and hitting the return/enter key. If you do not have the proper version of R installed, go to CRAN and download and install the latest version.\nWe will also make use of the RStudio interactive development environment (IDE). RStudio requires that R be installed, and so is an “add-on” to R. You can obtain the RStudio Desktop for free from the RStudio web site. In particular, we will make heavy use of it when developing R packages. It is also essential that you have the latest release of RStudio. You can determine the version of RStudio by looking at menu item Help > About RStudio. You should be using RStudio version RStudio 2023.06.1 or higher."
- },
- {
- "objectID": "syllabus.html#projects",
- "href": "syllabus.html#projects",
- "title": "Syllabus",
- "section": "Projects",
- "text": "Projects\nThere will be 4 assignments, due every 2–3 weeks. Projects will be submitted electronically via the Drop Box on the CoursePlus web site (unless otherwise specified).\nThe project assignments will be due on\n\nProject 0: September 10, 11:59pm (entirely optional and not graded but hopefully useful and fun)\nProject 1: September 17, 11:59pm\nProject 2: October 1, 11:59pm\nProject 3: October 23, 11:59pm\n\n\nProject collaboration\nPlease feel free to study together and talk to one another about project assignments. The mutual instruction that students give each other is among the most valuable that can be achieved.\nHowever, it is expected that project assignments will be implemented and written up independently unless otherwise specified. Specifically, please do not share analytic code or output. Please do not collaborate on write-up and interpretation. Please do not access or use solutions from any source before your project assignment is submitted for grading."
- },
- {
- "objectID": "syllabus.html#discussion-forum",
- "href": "syllabus.html#discussion-forum",
- "title": "Syllabus",
- "section": "Discussion Forum",
- "text": "Discussion Forum\nThe course will make use of the CoursePlus Discussion Forum in order to ask and answer questions regarding any of the course materials. The Instructor and the Teaching Assistants will monitor the discussion boards and answer questions when appropriate."
- },
- {
- "objectID": "syllabus.html#exams",
- "href": "syllabus.html#exams",
- "title": "Syllabus",
- "section": "Exams",
- "text": "Exams\nThere are no exams in this course."
- },
- {
- "objectID": "syllabus.html#grading",
- "href": "syllabus.html#grading",
- "title": "Syllabus",
- "section": "Grading",
- "text": "Grading\nGrades in the course will be based on Projects 0–3 with a percentage of the final grade being apportioned to each assignment. Each of Projects 1–3 counts approximately equally in the final grade. Grades for the projects and the final grade will be issued via the CoursePlus grade book."
- },
- {
- "objectID": "syllabus.html#policy-for-submitting-projects-late",
- "href": "syllabus.html#policy-for-submitting-projects-late",
- "title": "Syllabus",
- "section": "Policy for submitting projects late",
- "text": "Policy for submitting projects late\nThe instructor and TAs will not accept email late day policy requests.\n\nProjects 1, 2 and 3\n\nEach student will be given two free “late days” for the entire course.\nA late day extends the individual project deadline by 24 hours without penalty.\nThe late days can be applied to just one project (e.g. two late days for Project 2), or they can be split across the two projects (one late day for Project 2 and one late day for Project 3). This is entirely left up to the discretion of the student.\nLate days are intended to give you flexibility: you can use them for any reason no questions asked.\nYou do not get any bonus points for not using your late days.\n\nAlthough the each student is only given a total of two late days, we will be accepting homework from students that pass this limit.\n\nWe will be deducting 5% for each extra late day. For example, if you have already used all of your late days for the term, we will deduct 5% for the assignment that is <24 hours late, 10% points for the assignment that is 24-48 hours late, and 15% points for the assignment that is 48-72 hours late.\nWe will not grade assignments that are more than 3 days past the original due date.\n\n\n\nRegrading Policy\nIt is very important to us that all assignments are properly graded. If you believe there is an error in your assignment grading, please send an email to one of the instructors within 7 days of receiving the grade. No re-grade requests will be accepted orally, and no regrade requests will be accepted more than 7 days after you receive the grade for the assignment."
- },
- {
- "objectID": "syllabus.html#academic-ethics-and-student-conduct-code",
- "href": "syllabus.html#academic-ethics-and-student-conduct-code",
- "title": "Syllabus",
- "section": "Academic Ethics and Student Conduct Code",
- "text": "Academic Ethics and Student Conduct Code\nStudents enrolled in the Bloomberg School of Public Health of The Johns Hopkins University assume an obligation to conduct themselves in a manner appropriate to the University’s mission as an institution of higher education. A student is obligated to refrain from acts which he or she knows, or under the circumstances has reason to know, impair the academic integrity of the University. Violations of academic integrity include, but are not limited to: cheating; plagiarism; knowingly furnishing false information to any agent of the University for inclusion in the academic record; violation of the rights and welfare of animal or human subjects in research; and misconduct as a member of either School or University committees or recognized groups or organizations.\nStudents should be familiar with the policies and procedures specified under Policy and Procedure Manual Student-01 (Academic Ethics), available on the school’s portal.\nThe faculty, staff and students of the Bloomberg School of Public Health and the Johns Hopkins University have the shared responsibility to conduct themselves in a manner that upholds the law and respects the rights of others. Students enrolled in the School are subject to the Student Conduct Code (detailed in Policy and Procedure Manual Student-06) and assume an obligation to conduct themselves in a manner which upholds the law and respects the rights of others. They are responsible for maintaining the academic integrity of the institution and for preserving an environment conducive to the safe pursuit of the School’s educational, research, and professional practice missions."
- },
- {
- "objectID": "syllabus.html#disability-support-service",
- "href": "syllabus.html#disability-support-service",
- "title": "Syllabus",
- "section": "Disability Support Service",
- "text": "Disability Support Service\nStudents requiring accommodations for disabilities should register with Student Disability Service (SDS). It is the responsibility of the student to register for accommodations with SDS. Accommodations take effect upon approval and apply to the remainder of the time for which a student is registered and enrolled at the Bloomberg School of Public Health. Once you are f a student in your class has approved accommodations you will receive formal notification and the student will be encouraged to reach out. If you have questions about requesting accommodations, please contact BSPH.dss@jhu.edu."
- },
- {
- "objectID": "syllabus.html#prerequisites",
- "href": "syllabus.html#prerequisites",
- "title": "Syllabus",
- "section": "Prerequisites",
- "text": "Prerequisites\nThis is a quantitative course. We will not discuss the mathematical details of specific data analysis approaches, however some statistical background and being comfortable with quantitative thinking are useful. Previous experience with writing computer programs in general and R in particular is also helpful, but not necessary. If you have no programming experience, expect to spend extra time getting yourself familiar with R. As long as you are willing to invest the time to learn the programming and you do not mind thinking quantitatively, you should be able to take the course, independent of your background.\nFormal requirement for the course is Biostatistics 140.621. Knowledge of material from 140.621 is assumed. If you didn’t take this course, please contact me to get permission to enroll.\n\nGetting set up\nYou must install R and RStudio on your computer in order to complete this course. These are two different applications that must be installed separately before they can be used together:\n\nR is the core underlying programming language and computing engine that we will be learning in this course\nRStudio is an interface into R that makes many aspects of using and programming R simpler\n\nBoth R and RStudio are available for Windows, macOS, and most flavors of Unix and Linux. Please download the version that is suitable for your computing setup.\nThroughout the course, we will make use of numerous R add-on packages that must be installed over the Internet. Packages can be installed using the install.packages() function in R. For example, to install the tidyverse package, you can run\n\ninstall.packages(\"tidyverse\")\n\nin the R console.\n\nHow to Download R for Windows\nGo to https://cran.r-project.org and\n\nClick the link to “Download R for Windows”\nClick on “base”\nClick on “Download R 4.3.1 for Windows”\n\n\n\n\n\n\n\nWarning\n\n\n\nThe version in the video is not the latest version. Please download the latest version.\n\n\n\n\n\nVideo Demo for Downloading R for Windows\n\n\n\n\nHow to Download R for the Mac\nGoto https://cran.r-project.org and\n\nClick the link to “Download R for (Mac) OS X”.\nClick on “R-4.3.1.pkg”\n\n\n\n\n\n\n\nWarning\n\n\n\nThe version in the video is not the latest version. Please download the latest version.\n\n\n\n\n\nVideo Demo for Downloading R for the Mac\n\n\n\n\nHow to Download RStudio\nGoto https://rstudio.com and\n\nClick on “Products” in the top menu\nThen click on “RStudio” in the drop down menu\nClick on “RStudio Desktop”\nClick the button that says “DOWNLOAD RSTUDIO DESKTOP”\nClick the button under “RStudio Desktop” Free\nUnder the section “All Installers” choose the file that is appropriate for your operating system.\n\n\n\n\n\n\n\nWarning\n\n\n\nThe video shows how to download RStudio for the Mac but you should download RStudio for whatever computing setup you have\n\n\n\n\n\nVideo Demo for Downloading RStudio"
+ "objectID": "index.html#what-is-this-course",
+ "href": "index.html#what-is-this-course",
+ "title": "Welcome to Statistical Computing!",
+ "section": "What is this course?",
+ "text": "What is this course?\nThis course covers the basics of practical issues in programming and other computer skills required for the research and application of statistical methods. Includes programming in R and the tidyverse, data ethics, best practices for coding and reproducible research, introduction to data visualizations, best practices for working with special data types (dates/times, text data, etc), best practices for storing data, basics of debugging, organizing and commenting code, basics of leveraging Python from R. Topics in statistical data analysis provide working examples."
},
{
- "objectID": "syllabus.html#general-disclaimers",
- "href": "syllabus.html#general-disclaimers",
- "title": "Syllabus",
- "section": "General Disclaimers",
- "text": "General Disclaimers\n\nThis syllabus is a general plan, deviations announced to the class by the instructor may be necessary."
+ "objectID": "index.html#getting-started",
+ "href": "index.html#getting-started",
+ "title": "Welcome to Statistical Computing!",
+ "section": "Getting started",
+ "text": "Getting started\nI suggest that you start by looking over the Syllabus and Schedule under General Information. After that, start with the Lectures content in the given order."
},
{
- "objectID": "projects.html",
- "href": "projects.html",
- "title": "Projects",
- "section": "",
- "text": "Project 0 (optional)\n\n\n\n\n\n\n\nproject 0\n\n\nprojects\n\n\n\n\nInformation for Project 0 (entirely optional, but hopefully useful and fun!)\n\n\n\n\n\n\nLeonardo Collado Torres\n\n\n\n\n\n\n \n\n\n\n\nProject 1\n\n\n\n\n\n\n\nproject 1\n\n\nprojects\n\n\n\n\nFinding great chocolate bars!\n\n\n\n\n\n\nLeonardo Collado Torres\n\n\n\n\n\n\n \n\n\n\n\nProject 2\n\n\n\n\n\n\n\nproject 2\n\n\nprojects\n\n\n\n\nExploring temperature and rainfall in Australia\n\n\n\n\n\n\nLeonardo Collado Torres\n\n\n\n\n\n\n \n\n\n\n\nProject 3\n\n\n\n\n\n\n\nproject 3\n\n\nprojects\n\n\n\n\nExploring album sales and sentiment of lyrics from Beyoncé and Taylor Swift\n\n\n\n\n\n\nLeonardo Collado Torres\n\n\n\n\n\n\nNo matching items"
+ "objectID": "index.html#acknowledgements",
+ "href": "index.html#acknowledgements",
+ "title": "Welcome to Statistical Computing!",
+ "section": "Acknowledgements",
+ "text": "Acknowledgements\nThis course was developed in 2021 and 2022 by Stephanie Hicks and since 2023 it is being maintained by Leonardo Collado Torres.\nThe following individuals have contributed to improving the course or materials have been adapted from their courses: Roger D. Peng, Andreas Handel, Naim Rashid, Michael Love.\nThe course materials are licensed under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License. Linked and embedded materials are governed by their own licenses. I assume that all external materials used or embedded here are covered under the educational fair use policy. If this is not the case and any material displayed here violates copyright, please let me know and I will remove it."
},
{
"objectID": "projects/project-3/index.html",
@@ -804,41 +671,6 @@
"section": "",
"text": "This project, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history.\n\nBackground\nDue date: Sept 16 at 11:59pm\n\nTo submit your project\nPlease write up your project using R Markdown and knitr. Compile your document as an HTML file and submit your HTML file to the dropbox on Courseplus. Please show all your code for each of the answers to each part.\nTo get started, watch this video on setting up your R Markdown document.\n\n\nInstall tidyverse\nBefore attempting this assignment, you should first install the tidyverse package if you have not already. The tidyverse package is actually a collection of many packages that serves as a convenient way to install many packages without having to do them one by one. This can be done with the install.packages() function.\n\ninstall.packages(\"tidyverse\")\n\nRunning this function will install a host of other packages so it make take a minute or two depending on how fast your computer is. Once you have installed it, you will want to load the package.\n\nlibrary(tidyverse)\n\n\n\nData\nThat data for this part of the assignment comes from TidyTuesday, which is a weekly podcast and global community activity brought to you by the R4DS Online Learning Community. The goal of TidyTuesday is to help R learners learn in real-world contexts.\n\n[Source: TidyTuesday]\nIf we look at the TidyTuesday github repo from 2022, we see this dataset chocolate bar reviews.\nTo access the data, you need to install the tidytuesdayR R package and use the function tt_load() with the date of ‘2022-01-18’ to load the data.\n\ninstall.packages(\"tidytuesdayR\")\n\nThis is how you can download the data.\n\ntuesdata <- tidytuesdayR::tt_load(\"2022-01-18\")\nchocolate <- tuesdata$chocolate\n\nHowever, if you use this code, you will hit an API limit after trying to compile the document a few times. Instead, I suggest you use the following code below. Here, I provide the code below for you to avoid re-downloading data:\n\nlibrary(here)\nlibrary(tidyverse)\n\n# tests if a directory named \"data\" exists locally\nif (!dir.exists(here(\"data\"))) {\n dir.create(here(\"data\"))\n}\n\n# saves data only once (not each time you knit a R Markdown)\nif (!file.exists(here(\"data\", \"chocolate.RDS\"))) {\n url_csv <- \"https://raw.githubusercontent.com/rfordatascience/tidytuesday/master/data/2022/2022-01-18/chocolate.csv\"\n chocolate <- readr::read_csv(url_csv)\n\n # save the file to RDS objects\n saveRDS(chocolate, file = here(\"data\", \"chocolate.RDS\"))\n}\n\nHere we read in the .RDS dataset locally from our computing environment:\n\nchocolate <- readRDS(here(\"data\", \"chocolate.RDS\"))\nas_tibble(chocolate)\n\n# A tibble: 2,530 × 10\n ref company_manufacturer company_location review_date\n <dbl> <chr> <chr> <dbl>\n 1 2454 5150 U.S.A. 2019\n 2 2458 5150 U.S.A. 2019\n 3 2454 5150 U.S.A. 2019\n 4 2542 5150 U.S.A. 2021\n 5 2546 5150 U.S.A. 2021\n 6 2546 5150 U.S.A. 2021\n 7 2542 5150 U.S.A. 2021\n 8 797 A. Morin France 2012\n 9 797 A. Morin France 2012\n10 1011 A. Morin France 2013\n# ℹ 2,520 more rows\n# ℹ 6 more variables: country_of_bean_origin <chr>,\n# specific_bean_origin_or_bar_name <chr>, cocoa_percent <chr>,\n# ingredients <chr>, most_memorable_characteristics <chr>, rating <dbl>\n\n\nWe can take a glimpse at the data\n\nglimpse(chocolate)\n\nRows: 2,530\nColumns: 10\n$ ref <dbl> 2454, 2458, 2454, 2542, 2546, 2546, 2…\n$ company_manufacturer <chr> \"5150\", \"5150\", \"5150\", \"5150\", \"5150…\n$ company_location <chr> \"U.S.A.\", \"U.S.A.\", \"U.S.A.\", \"U.S.A.…\n$ review_date <dbl> 2019, 2019, 2019, 2021, 2021, 2021, 2…\n$ country_of_bean_origin <chr> \"Tanzania\", \"Dominican Republic\", \"Ma…\n$ specific_bean_origin_or_bar_name <chr> \"Kokoa Kamili, batch 1\", \"Zorzal, bat…\n$ cocoa_percent <chr> \"76%\", \"76%\", \"76%\", \"68%\", \"72%\", \"8…\n$ ingredients <chr> \"3- B,S,C\", \"3- B,S,C\", \"3- B,S,C\", \"…\n$ most_memorable_characteristics <chr> \"rich cocoa, fatty, bready\", \"cocoa, …\n$ rating <dbl> 3.25, 3.50, 3.75, 3.00, 3.00, 3.25, 3…\n\n\nHere is a data dictionary for what all the column names mean:\n\nhttps://github.com/rfordatascience/tidytuesday/blob/master/data/2022/2022-01-18/readme.md#data-dictionary\n\n\n\n\nPart 1: Explore data\nIn this part, use functions from dplyr and ggplot2 to answer the following questions.\n\nMake a histogram of the rating scores to visualize the overall distribution of scores. Change the number of bins from the default to 10, 15, 20, and 25. Pick on the one that you think looks the best. Explain what the difference is when you change the number of bins and explain why you picked the one you did.\n\n\n# Add your solution here and describe your answer afterwards\n\nThe ratings are discrete values making the histogram look strange. When you make the bin size smaller, it aggregates the ratings together in larger groups removing that effect. I picked 15, but there really is no wrong answer. Just looking for an answer here.\n\nConsider the countries where the beans originated from. How many reviews come from each country of bean origin?\n\n\n# Add your solution here\n\n\nWhat is average rating scores from reviews of chocolate bars that have Ecuador as country_of_bean_origin in this dataset? For this same set of reviews, also calculate (1) the total number of reviews and (2) the standard deviation of the rating scores. Your answer should be a new data frame with these three summary statistics in three columns. Label the name of these columns mean, sd, and total.\n\n\n# Add your solution here\n\n\nWhich company (name) makes the best chocolate (or has the highest ratings on average) with beans from Ecuador?\n\n\n# Add your solution here\n\n\nCalculate the average rating across all country of origins for beans. Which top 3 countries (for bean origin) have the highest ratings on average?\n\n\n# Add your solution here\n\n\nFollowing up on the previous problem, now remove any countries of bean origins that have less than 10 chocolate bar reviews. Now, which top 3 countries have the highest ratings on average?\n\n\n# Add your solution here\n\n\nFor this last part, let’s explore the relationship between percent chocolate and ratings.\n\nUse the functions in dplyr, tidyr, and lubridate to perform the following steps to the chocolate dataset:\n\nIdentify the countries of bean origin with at least 50 reviews. Remove reviews from countries are not in this list.\nUsing the variable describing the chocolate percentage for each review, create a new column that groups chocolate percentages into one of four groups: (i) <60%, (ii) >=60 to <70%, (iii) >=70 to <90%, and (iii) >=90% (Hint check out the substr() function in base R and the case_when() function from dplyr – see example below).\nUsing the new column described in #2, re-order the factor levels (if needed) to be starting with the smallest percentage group and increasing to the largest percentage group (Hint check out the fct_relevel() function from forcats).\nFor each country, make a set of four side-by-side boxplots plotting the groups on the x-axis and the ratings on the y-axis. These plots should be faceted by country.\n\nOn average, which category of chocolate percentage is most highly rated? Do these countries mostly agree or are there disagreements?\nHint: You may find the case_when() function useful in this part, which can be used to map values from one variable to different values in a new variable (when used in a mutate() call).\n\n## Generate some random numbers\ndat <- tibble(x = rnorm(100))\nslice(dat, 1:3)\n\n# A tibble: 3 × 1\n x\n <dbl>\n1 0.481\n2 1.06 \n3 0.529\n\n## Create a new column that indicates whether the value of 'x' is positive or negative\ndat %>%\n mutate(is_positive = case_when(\n x >= 0 ~ \"Yes\",\n x < 0 ~ \"No\"\n ))\n\n# A tibble: 100 × 2\n x is_positive\n <dbl> <chr> \n 1 0.481 Yes \n 2 1.06 Yes \n 3 0.529 Yes \n 4 -0.221 No \n 5 -0.906 No \n 6 2.96 Yes \n 7 -0.0564 No \n 8 -0.931 No \n 9 -0.0624 No \n10 0.240 Yes \n# ℹ 90 more rows\n\n\n\n# Add your solution here\n\n\n\nPart 2: Join two datasets together\nThe goal of this part of the assignment is to join two datasets together. gapminder is a R package that contains an excerpt from the Gapminder data.\n\nTasks\n\nUse this dataset it to create a new column called continent in our chocolate dataset that contains the continent name for each review where the country of bean origin is.\nOnly keep reviews that have reviews from countries of bean origin with at least 10 reviews.\nAlso, remove the country of bean origin named \"Blend\".\nMake a set of violin plots with ratings on the y-axis and continents on the x-axis.\n\nHint:\n\nCheck to see if there are any NAs in the new column. If there are any NAs, add the continent name for each row.\n\n\n# Add your solution here\n\n\n\n\nPart 3: Convert wide data into long data\nThe goal of this part of the assignment is to take a dataset that is either messy or simply not tidy and to make them tidy datasets. The objective is to gain some familiarity with the functions in the dplyr, tidyr packages. You may find it helpful to review the section on pivoting data from wide to long format and vice versa.\n\nTasks\nWe are going to create a set of features for us to plot over time. Use the functions in dplyr and tidyr to perform the following steps to the chocolate dataset:\n\nCreate a new set of columns titled beans, sugar, cocoa_butter, vanilla, letchin, and salt that contain a 1 or 0 representing whether or not that review for the chocolate bar contained that ingredient (1) or not (0).\nCreate a new set of columns titled char_cocoa, char_sweet, char_nutty, char_creamy, char_roasty, char_earthy that contain a 1 or 0 representing whether or not that the most memorable characteristic for the chocolate bar had that word (1) or not (0). For example, if the word “sweet” appears in the most_memorable_characteristics, then record a 1, otherwise a 0 for that review in the char_sweet column (Hint: check out str_detect() from the stringr package).\nFor each year (i.e. review_date), calculate the mean value in each new column you created across all reviews for that year. (Hint: If all has gone well thus far, you should have a dataset with 16 rows and 13 columns).\nConvert this wide dataset into a long dataset with a new feature and mean_score column.\n\nIt should look something like this:\nreview_date feature mean_score\n<dbl> <chr> <dbl>\n2006 beans 0.967741935 \n2006 sugar 0.967741935 \n2006 cocoa_butter 0.903225806 \n2006 vanilla 0.693548387 \n2006 letchin 0.693548387 \n2006 salt 0.000000000 \n2006 char_cocoa 0.209677419 \n2006 char_sweet 0.161290323 \n2006 char_nutty 0.032258065 \n2006 char_creamy 0.241935484 \n\n\nNotes\n\nYou may need to use functions outside these packages to obtain this result.\nDo not worry about the ordering of the rows or columns. Depending on whether you use gather() or pivot_longer(), the order of your output may differ from what is printed above. As long as the result is a tidy data set, that is sufficient.\n\n\n# Add your solution here\n\n\n\n\nPart 4: Data visualization\nIn this part of the project, we will continue to work with our now tidy song dataset from the previous part.\n\nTasks\nUse the functions in ggplot2 package to make a scatter plot of the mean_scores (y-axis) over time (x-axis). One plot for each mean_score. For full credit, your plot should include:\n\nAn overall title for the plot and a subtitle summarizing key trends that you found. Also include a caption in the figure with your name.\nBoth the observed points for the mean_score, but also a smoothed non-linear pattern of the trend\nAll plots should be shown in the one figure\nThere should be an informative x-axis and y-axis label\n\nConsider playing around with the theme() function to make the figure shine, including playing with background colors, font, etc.\n\n\nNotes\n\nYou may need to use functions outside these packages to obtain this result.\nDon’t worry about the ordering of the rows or columns. Depending on whether you use gather() or pivot_longer(), the order of your output may differ from what is printed above. As long as the result is a tidy data set, that is sufficient.\n\n\n# Add your solution here\n\n\n\n\nPart 5: Make the worst plot you can!\nThis sounds a bit crazy I know, but I want this to try and be FUN! Instead of trying to make a “good” plot, I want you to explore your creative side and make a really awful data visualization in every way. :)\n\nTasks\nUsing the chocolate dataset (or any of the modified versions you made throughout this assignment or anything else you wish you build upon it):\n\nMake the absolute worst plot that you can. You need to customize it in at least 7 ways to make it awful.\nIn your document, write 1 - 2 sentences about each different customization you added (using bullets – i.e. there should be at least 7 bullet points each with 1-2 sentences), and how it could be useful for you when you want to make an awesome data visualization.\n\n\n# Add your solution here\n\n\n\n\nPart 6: Make my plot a better plot!\nThe goal is to take my sad looking plot and make it better! If you’d like an example, here is a tweet I came across of someone who gave a talk about how to zhoosh up your ggplots.\n\nchocolate %>%\n ggplot(aes(\n x = as.factor(review_date),\n y = rating,\n fill = review_date\n )) +\n geom_violin()\n\n\n\n\n\nTasks\n\nYou need to customize it in at least 7 ways to make it better.\nIn your document, write 1 - 2 sentences about each different customization you added (using bullets – i.e. there should be at least 7 bullet points each with 1-2 sentences), describing how you improved it.\n\n\n# Add your solution here\n\n\n\n\nR session information\n\noptions(width = 120)\nsessioninfo::session_info()\n\n─ Session info ───────────────────────────────────────────────────────────────────────────────────────────────────────\n setting value\n version R version 4.3.1 (2023-06-16)\n os macOS Ventura 13.5\n system aarch64, darwin20\n ui X11\n language (EN)\n collate en_US.UTF-8\n ctype en_US.UTF-8\n tz America/New_York\n date 2023-09-13\n pandoc 3.1.5 @ /opt/homebrew/bin/ (via rmarkdown)\n\n─ Packages ───────────────────────────────────────────────────────────────────────────────────────────────────────────\n package * version date (UTC) lib source\n cli 3.6.1 2023-03-23 [1] CRAN (R 4.3.0)\n colorout 1.2-2 2023-05-06 [1] Github (jalvesaq/colorout@79931fd)\n colorspace 2.1-0 2023-01-23 [1] CRAN (R 4.3.0)\n digest 0.6.33 2023-07-07 [1] CRAN (R 4.3.0)\n dplyr * 1.1.3 2023-09-03 [1] CRAN (R 4.3.0)\n evaluate 0.21 2023-05-05 [1] CRAN (R 4.3.0)\n fansi 1.0.4 2023-01-22 [1] CRAN (R 4.3.0)\n farver 2.1.1 2022-07-06 [1] CRAN (R 4.3.0)\n fastmap 1.1.1 2023-02-24 [1] CRAN (R 4.3.0)\n forcats * 1.0.0 2023-01-29 [1] CRAN (R 4.3.0)\n generics 0.1.3 2022-07-05 [1] CRAN (R 4.3.0)\n ggplot2 * 3.4.3 2023-08-14 [1] CRAN (R 4.3.0)\n glue 1.6.2 2022-02-24 [1] CRAN (R 4.3.0)\n gtable 0.3.4 2023-08-21 [1] CRAN (R 4.3.0)\n here * 1.0.1 2020-12-13 [1] CRAN (R 4.3.0)\n hms 1.1.3 2023-03-21 [1] CRAN (R 4.3.0)\n htmltools 0.5.6 2023-08-10 [1] CRAN (R 4.3.0)\n htmlwidgets 1.6.2 2023-03-17 [1] CRAN (R 4.3.0)\n jsonlite 1.8.7 2023-06-29 [1] CRAN (R 4.3.0)\n knitr 1.43 2023-05-25 [1] CRAN (R 4.3.0)\n labeling 0.4.3 2023-08-29 [1] CRAN (R 4.3.0)\n lifecycle 1.0.3 2022-10-07 [1] CRAN (R 4.3.0)\n lubridate * 1.9.2 2023-02-10 [1] CRAN (R 4.3.0)\n magrittr 2.0.3 2022-03-30 [1] CRAN (R 4.3.0)\n munsell 0.5.0 2018-06-12 [1] CRAN (R 4.3.0)\n pillar 1.9.0 2023-03-22 [1] CRAN (R 4.3.0)\n pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.3.0)\n purrr * 1.0.2 2023-08-10 [1] CRAN (R 4.3.0)\n R6 2.5.1 2021-08-19 [1] CRAN (R 4.3.0)\n readr * 2.1.4 2023-02-10 [1] CRAN (R 4.3.0)\n rlang 1.1.1 2023-04-28 [1] CRAN (R 4.3.0)\n rmarkdown 2.24 2023-08-14 [1] CRAN (R 4.3.1)\n rprojroot 2.0.3 2022-04-02 [1] CRAN (R 4.3.0)\n rstudioapi 0.15.0 2023-07-07 [1] CRAN (R 4.3.0)\n scales 1.2.1 2022-08-20 [1] CRAN (R 4.3.0)\n sessioninfo 1.2.2 2021-12-06 [1] CRAN (R 4.3.0)\n stringi 1.7.12 2023-01-11 [1] CRAN (R 4.3.0)\n stringr * 1.5.0 2022-12-02 [1] CRAN (R 4.3.0)\n tibble * 3.2.1 2023-03-20 [1] CRAN (R 4.3.0)\n tidyr * 1.3.0 2023-01-24 [1] CRAN (R 4.3.0)\n tidyselect 1.2.0 2022-10-10 [1] CRAN (R 4.3.0)\n tidyverse * 2.0.0 2023-02-22 [1] CRAN (R 4.3.0)\n timechange 0.2.0 2023-01-11 [1] CRAN (R 4.3.0)\n tzdb 0.4.0 2023-05-12 [1] CRAN (R 4.3.0)\n utf8 1.2.3 2023-01-31 [1] CRAN (R 4.3.0)\n vctrs 0.6.3 2023-06-14 [1] CRAN (R 4.3.0)\n withr 2.5.0 2022-03-03 [1] CRAN (R 4.3.0)\n xfun 0.40 2023-08-09 [1] CRAN (R 4.3.0)\n yaml 2.3.7 2023-01-23 [1] CRAN (R 4.3.0)\n\n [1] /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/library\n\n──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────"
},
- {
- "objectID": "index.html",
- "href": "index.html",
- "title": "Welcome to Statistical Computing!",
- "section": "",
- "text": "Welcome to Statistical Computing at Johns Hopkins Bloomberg School of Public Health!"
- },
- {
- "objectID": "index.html#what-is-this-course",
- "href": "index.html#what-is-this-course",
- "title": "Welcome to Statistical Computing!",
- "section": "What is this course?",
- "text": "What is this course?\nThis course covers the basics of practical issues in programming and other computer skills required for the research and application of statistical methods. Includes programming in R and the tidyverse, data ethics, best practices for coding and reproducible research, introduction to data visualizations, best practices for working with special data types (dates/times, text data, etc), best practices for storing data, basics of debugging, organizing and commenting code, basics of leveraging Python from R. Topics in statistical data analysis provide working examples."
- },
- {
- "objectID": "index.html#getting-started",
- "href": "index.html#getting-started",
- "title": "Welcome to Statistical Computing!",
- "section": "Getting started",
- "text": "Getting started\nI suggest that you start by looking over the Syllabus and Schedule under General Information. After that, start with the Lectures content in the given order."
- },
- {
- "objectID": "index.html#acknowledgements",
- "href": "index.html#acknowledgements",
- "title": "Welcome to Statistical Computing!",
- "section": "Acknowledgements",
- "text": "Acknowledgements\nThis course was developed in 2021 and 2022 by Stephanie Hicks and since 2023 it is being maintained by Leonardo Collado Torres.\nThe following individuals have contributed to improving the course or materials have been adapted from their courses: Roger D. Peng, Andreas Handel, Naim Rashid, Michael Love.\nThe course materials are licensed under the Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License. Linked and embedded materials are governed by their own licenses. I assume that all external materials used or embedded here are covered under the educational fair use policy. If this is not the case and any material displayed here violates copyright, please let me know and I will remove it."
- },
- {
- "objectID": "posts/06-reference-management/index.html",
- "href": "posts/06-reference-management/index.html",
- "title": "06 - Reference management",
- "section": "",
- "text": "This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history.\n\n\nPre-lecture materials\n\nRead ahead\n\n\n\n\n\n\nRead ahead\n\n\n\nBefore class, you can prepare by reading the following materials:\n\nAuthoring in R Markdown from RStudio\nCitations from Reproducible Research in R from the Monash Data Fluency initiative\nBibliography from R Markdown Cookbook\n\n\n\n\n\nAcknowledgements\nMaterial for this lecture was borrowed and adopted from\n\nhttps://andreashandel.github.io/MADAcourse\nhttps://rmarkdown.rstudio.com/authoring_bibliographies_and_citations.html\nhttps://bookdown.org/yihui/rmarkdown-cookbook/bibliography.html\nhttps://monashdatafluency.github.io/r-rep-res/citations.html\n\n\n\n\nLearning objectives\n\n\n\n\n\n\nLearning objectives\n\n\n\nAt the end of this lesson you will:\n\nKnow what types of bibliography file formats can be used in a R Markdown file\nLearn how to add citations to a R Markdown file\nKnow how to change the citation style (e.g. APA, Chicago, etc)\n\n\n\n\n\nIntroduction\nFor almost any data analysis, especially if it is meant for publication in the academic literature, you will have to cite other people’s work and include the references (bibliographies or citations) in your work. In this class, you are likely to need to include references and cite other people’s work like in a regular research paper.\nR provides nice function citation() that helps us generating citation blob for R packages that we have used. Let’s try generating citation text for rmarkdown package by using the following command\n\ncitation(\"rmarkdown\")\n\nTo cite package 'rmarkdown' in publications use:\n\n Allaire J, Xie Y, Dervieux C, McPherson J, Luraschi J, Ushey K,\n Atkins A, Wickham H, Cheng J, Chang W, Iannone R (2023). _rmarkdown:\n Dynamic Documents for R_. R package version 2.24,\n <https://github.com/rstudio/rmarkdown>.\n\n Xie Y, Allaire J, Grolemund G (2018). _R Markdown: The Definitive\n Guide_. Chapman and Hall/CRC, Boca Raton, Florida. ISBN\n 9781138359338, <https://bookdown.org/yihui/rmarkdown>.\n\n Xie Y, Dervieux C, Riederer E (2020). _R Markdown Cookbook_. Chapman\n and Hall/CRC, Boca Raton, Florida. ISBN 9780367563837,\n <https://bookdown.org/yihui/rmarkdown-cookbook>.\n\nTo see these entries in BibTeX format, use 'print(<citation>,\nbibtex=TRUE)', 'toBibtex(.)', or set\n'options(citation.bibtex.max=999)'.\n\n\nI assume you are familiar with how citing references works, and hopefully, you are already using a reference manager. If not, let me know in the discussion boards.\nTo have something that plays well with R Markdown, you need file format that stores all the references. Click here to learn more other possible file formats available to you to use within a R Markdown file:\n\nhttps://rmarkdown.rstudio.com/authoring_bibliographies_and_citations.html\n\n\nCitation management software\nAs you can see, there are ton of file formats including .medline (MEDLINE), .bib (BibTeX), .ris (RIS), .enl (EndNote).\nI will not discuss underlying citational management software itself, but I will talk briefly how you might create one of these file formats.\nIf you recall the output from citation(\"rmarkdown\") above, we might consider manually copying and pasting the output into a citation management software, but instead we can use write_bib() function from knitr package to create a bibliography file ending in .bib.\nLet’s run the following code in order to generate a my-refs.bib file\n\nknitr::write_bib(\"rmarkdown\", file = \"my-refs.bib\")\n\nNow we can see we have the file saved locally.\n\nlist.files()\n\n[1] \"index.qmd\" \"index.rmarkdown\" \"my-refs.bib\" \n\n\nIf you open up the my-refs.bib file, you will see\n@Manual{R-rmarkdown,\n title = {rmarkdown: Dynamic Documents for R},\n author = {JJ Allaire and Yihui Xie and Jonathan McPherson and Javier Luraschi and Kevin Ushey and Aron Atkins and Hadley Wickham and Joe Cheng and Winston Chang and Richard Iannone},\n year = {2021},\n note = {R package version 2.8},\n url = {https://CRAN.R-project.org/package=rmarkdown},\n}\n\n@Book{rmarkdown2018,\n title = {R Markdown: The Definitive Guide},\n author = {Yihui Xie and J.J. Allaire and Garrett Grolemund},\n publisher = {Chapman and Hall/CRC},\n address = {Boca Raton, Florida},\n year = {2018},\n note = {ISBN 9781138359338},\n url = {https://bookdown.org/yihui/rmarkdown},\n}\n\n@Book{rmarkdown2020,\n title = {R Markdown Cookbook},\n author = {Yihui Xie and Christophe Dervieux and Emily Riederer},\n publisher = {Chapman and Hall/CRC},\n address = {Boca Raton, Florida},\n year = {2020},\n note = {ISBN 9780367563837},\n url = {https://bookdown.org/yihui/rmarkdown-cookbook},\n}\n\nNote there are three keys that we will use later on:\n\nR-rmarkdown\nrmarkdown2018\nrmarkdown2020\n\n\n\n\nLinking .bib file with .rmd (and .qmd) files\nIn order to use references within a R Markdown file, you will need to specify the name and a location of a bibliography file using the bibliography metadata field in a YAML metadata section. For example:\n---\ntitle: \"My top ten favorite R packages\"\noutput: html_document\nbibliography: my-refs.bib\n---\nYou can include multiple reference files using the following syntax, alternatively you can concatenate two bib files into one.\n---\nbibliography: [\"my-refs1.bib\", \"my-refs2.bib\"]\n---\n\n\nInline citation\nNow we can start using those bib keys that we have learned just before, using the following syntax\n\n[@key] for single citation\n[@key1; @key2] multiple citation can be separated by semi-colon\n[-@key] in order to suppress author name, and just display the year\n[see @key1 p 12; also this ref @key2] is also a valid syntax\n\nLet’s start by citing the rmarkdown package using the following code and press Knit button:\n\nI have been using the amazing Rmarkdown package (Allaire et al. 2023)! I should also go and read (Xie, Allaire, and Grolemund 2018; and Xie, Dervieux, and Riederer 2020) books.\n\nPretty cool, eh??\n\n\nCitation styles\nBy default, Pandoc will use a Chicago author-date format for citations and references.\nTo use another style, you will need to specify a CSL (Citation Style Language) file in the csl metadata field, e.g.,\n---\ntitle: \"My top ten favorite R packages\"\noutput: html_document\nbibliography: my-refs.bib\ncsl: biomed-central.csl\n---\n\nTo find your required formats, we recommend using the Zotero Style Repository, which makes it easy to search for and download your desired style.\n\nCSL files can be tweaked to meet custom formatting requirements. For example, we can change the number of authors required before “et al.” is used to abbreviate them. This can be simplified through the use of visual editors such as the one available at https://editor.citationstyles.org.\n\n\nOther cool features\n\nAdd an item to a bibliography without using it\nBy default, the bibliography will only display items that are directly referenced in the document. If you want to include items in the bibliography without actually citing them in the body text, you can define a dummy nocite metadata field and put the citations there.\n---\nnocite: |\n @item1, @item2\n---\n\n\nAdd all items to the bibliography\nIf we do not wish to explicitly state all of the items within the bibliography but would still like to show them in our references, we can use the following syntax:\n---\nnocite: '@*'\n---\nThis will force all items to be displayed in the bibliography.\n\nYou can also have an appendix appear after bibliography. For more on this, see:\n\nhttps://bookdown.org/yihui/rmarkdown-cookbook/bibliography.html\n\n\n\n\n\n\nOther useful tips\nWe have learned that inside your file that contains all your references (e.g. my-refs.bib), typically each reference gets a key, which is a shorthand that is generated by the reference manager or you can create yourself.\nFor instance, I use a format of lower-case first author last name followed by 4 digit year for each reference followed by a keyword (e.g name of a software package). Alternatively, you can omit the keyword. But note that if I cite a paper by the same first author that was published in the same year, then a lower case letter is added to the end. For instance, for a paper that I wrote as 1st author in 2010, my bibtex key might be hicks2022 or hicks2022a. You can decide what scheme to use, just pick one and use it forever.\nIn your R Markdown document, you can then cite the reference by adding the key, such as ...in the paper by Hicks et al. [@hicks2022]....\n\n\nSciWheel\nI use SciWheel for managing citations and writing papers on Google Docs as documented at https://lcolladotor.github.io/bioc_team_ds/writing-papers.html. I mention it here because you can import \\(BibTeX\\) files (.bib) on SciWheel, which can make your life easier if you want to import R package citations that way.\n\n\nPost-lecture materials\n\nPractice\nHere are some post-lecture tasks to practice some of the material discussed.\n\n\n\n\n\n\nQuestions\n\n\n\nTry out the following:\n\nWhat do you notice that’s different when you run citation(\"tidyverse\") (compared to citation(\"rmarkdown\"))?\nInstall the following packages:\n\n\ninstall.packages(c(\"bibtex\", \"RefManageR\"))\n\nWhat do they do? How might they be helpful to you in terms of reference management?\n\nInstead of using a .bib file, try using a different bibliography file format in an R Markdown document.\nPractice using a different CSL file to change the citation style.\n\n\n\n\n\n\nR session information\n\noptions(width = 120)\nsessioninfo::session_info()\n\n─ Session info ───────────────────────────────────────────────────────────────────────────────────────────────────────\n setting value\n version R version 4.3.1 (2023-06-16)\n os macOS Ventura 13.5\n system aarch64, darwin20\n ui X11\n language (EN)\n collate en_US.UTF-8\n ctype en_US.UTF-8\n tz America/Mexico_City\n date 2023-08-29\n pandoc 3.1.5 @ /opt/homebrew/bin/ (via rmarkdown)\n\n─ Packages ───────────────────────────────────────────────────────────────────────────────────────────────────────────\n package * version date (UTC) lib source\n cli 3.6.1 2023-03-23 [1] CRAN (R 4.3.0)\n colorout 1.2-2 2023-05-06 [1] Github (jalvesaq/colorout@79931fd)\n digest 0.6.33 2023-07-07 [1] CRAN (R 4.3.0)\n evaluate 0.21 2023-05-05 [1] CRAN (R 4.3.0)\n fastmap 1.1.1 2023-02-24 [1] CRAN (R 4.3.0)\n htmltools 0.5.6 2023-08-10 [1] CRAN (R 4.3.0)\n htmlwidgets 1.6.2 2023-03-17 [1] CRAN (R 4.3.0)\n jsonlite 1.8.7 2023-06-29 [1] CRAN (R 4.3.0)\n knitr 1.43 2023-05-25 [1] CRAN (R 4.3.0)\n rlang 1.1.1 2023-04-28 [1] CRAN (R 4.3.0)\n rmarkdown 2.24 2023-08-14 [1] CRAN (R 4.3.1)\n rstudioapi 0.15.0 2023-07-07 [1] CRAN (R 4.3.0)\n sessioninfo 1.2.2 2021-12-06 [1] CRAN (R 4.3.0)\n xfun 0.40 2023-08-09 [1] CRAN (R 4.3.0)\n yaml 2.3.7 2023-01-23 [1] CRAN (R 4.3.0)\n\n [1] /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/library\n\n──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────\n\n\n\n\n\n\n\nReferences\n\nAllaire, JJ, Yihui Xie, Christophe Dervieux, Jonathan McPherson, Javier Luraschi, Kevin Ushey, Aron Atkins, et al. 2023. Rmarkdown: Dynamic Documents for r. https://CRAN.R-project.org/package=rmarkdown.\n\n\nXie, Yihui, J. J. Allaire, and Garrett Grolemund. 2018. R Markdown: The Definitive Guide. Boca Raton, Florida: Chapman; Hall/CRC. https://bookdown.org/yihui/rmarkdown.\n\n\nXie, Yihui, Christophe Dervieux, and Emily Riederer. 2020. R Markdown Cookbook. Boca Raton, Florida: Chapman; Hall/CRC. https://bookdown.org/yihui/rmarkdown-cookbook."
- },
{
"objectID": "posts/18-debugging-r-code/index.html",
"href": "posts/18-debugging-r-code/index.html",
@@ -882,724 +714,892 @@
"text": "Using recover()\n\n\nClick here for how to use recover() with an interactive browser.\n\nThe recover() function can be used to modify the error behavior of R when an error occurs. Normally, when an error occurs in a function, R will print out an error message, exit out of the function, and return you to your workspace to await further commands.\nWith recover() you can tell R that when an error occurs, it should halt execution at the exact point at which the error occurred. That can give you the opportunity to poke around in the environment in which the error occurred. This can be useful to see if there are any R objects or data that have been corrupted or mistakenly modified.\n> options(error = recover) ## Change default R error behavior\n> read.csv(\"nosuchfile\") ## This code doesn't work\nError in file(file, \"rt\") : cannot open the connection\nIn addition: Warning message:\nIn file(file, \"rt\") :\n cannot open file ’nosuchfile’: No such file or directory\n \nEnter a frame number, or 0 to exit\n\n1: read.csv(\"nosuchfile\")\n2: read.table(file = file, header = header, sep = sep, quote = quote, dec =\n3: file(file, \"rt\")\n\nSelection:\nThe recover() function will first print out the function call stack when an error occurrs. Then, you can choose to jump around the call stack and investigate the problem. When you choose a frame number, you will be put in the browser (just like the interactive debugger triggered with debug()) and will have the ability to poke around."
},
{
- "objectID": "posts/08-managing-data-frames-with-tidyverse/index.html",
- "href": "posts/08-managing-data-frames-with-tidyverse/index.html",
- "title": "08 - Managing data frames with the Tidyverse",
+ "objectID": "posts/05-literate-programming/index.html",
+ "href": "posts/05-literate-programming/index.html",
+ "title": "05 - Literate Statistical Programming",
"section": "",
"text": "This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history."
},
{
- "objectID": "posts/08-managing-data-frames-with-tidyverse/index.html#tibbles",
- "href": "posts/08-managing-data-frames-with-tidyverse/index.html#tibbles",
- "title": "08 - Managing data frames with the Tidyverse",
- "section": "Tibbles",
- "text": "Tibbles\nAnother type of data structure that we need to discuss is called the tibble! It’s best to think of tibbles as an updated and stylish version of the data.frame.\nTibbles are what tidyverse packages work with most seamlessly. Now, that does not mean tidyverse packages require tibbles.\nIn fact, they still work with data.frames, but the more you work with tidyverse and tidyverse-adjacent packages, the more you will see the advantages of using tibbles.\nBefore we go any further, tibbles are data frames, but they have some new bells and whistles to make your life easier.\n\nHow tibbles differ from data.frame\nThere are a number of differences between tibbles and data.frames.\n\n\n\n\n\n\nNote\n\n\n\nTo see a full vignette about tibbles and how they differ from data.frame, you will want to execute vignette(\"tibble\") and read through that vignette.\n\n\nWe will summarize some of the most important points here:\n\nInput type remains unchanged - data.frame is notorious for treating strings as factors; this will not happen with tibbles\nVariable names remain unchanged - In base R, creating data.frames will remove spaces from names, converting them to periods or add “x” before numeric column names. Creating tibbles will not change variable (column) names.\nThere are no row.names() for a tibble - Tidy data requires that variables be stored in a consistent way, removing the need for row names.\nTibbles print first ten rows and columns that fit on one screen - Printing a tibble to screen will never print the entire huge data frame out. By default, it just shows what fits to your screen."
- },
- {
- "objectID": "posts/08-managing-data-frames-with-tidyverse/index.html#creating-a-tibble",
- "href": "posts/08-managing-data-frames-with-tidyverse/index.html#creating-a-tibble",
- "title": "08 - Managing data frames with the Tidyverse",
- "section": "Creating a tibble",
- "text": "Creating a tibble\nThe tibble package is part of the tidyverse and can thus be loaded in (once installed) using:\n\nlibrary(tidyverse)\n\n\nas_tibble()\nSince many packages use the historical data.frame from base R, you will often find yourself in the situation that you have a data.frame and want to convert that data.frame to a tibble.\nTo do so, the as_tibble() function is exactly what you are looking for.\nFor the example, here we use a dataset (chicago.rds) containing air pollution and temperature data for the city of Chicago in the U.S.\nThe dataset is available in the /data repository. You can load the data into R using the readRDS() function.\n\nlibrary(here)\n\nhere() starts at /Users/leocollado/Dropbox/Code/jhustatcomputing2023\n\nchicago <- readRDS(here(\"data\", \"chicago.rds\"))\n\nYou can see some basic characteristics of the dataset with the dim() and str() functions.\n\ndim(chicago)\n\n[1] 6940 8\n\nstr(chicago)\n\n'data.frame': 6940 obs. of 8 variables:\n $ city : chr \"chic\" \"chic\" \"chic\" \"chic\" ...\n $ tmpd : num 31.5 33 33 29 32 40 34.5 29 26.5 32.5 ...\n $ dptp : num 31.5 29.9 27.4 28.6 28.9 ...\n $ date : Date, format: \"1987-01-01\" \"1987-01-02\" ...\n $ pm25tmean2: num NA NA NA NA NA NA NA NA NA NA ...\n $ pm10tmean2: num 34 NA 34.2 47 NA ...\n $ o3tmean2 : num 4.25 3.3 3.33 4.38 4.75 ...\n $ no2tmean2 : num 20 23.2 23.8 30.4 30.3 ...\n\n\nWe see this data structure is a data.frame with 6940 observations and 8 variables.\nTo convert this data.frame to a tibble you would use the following:\n\nstr(as_tibble(chicago))\n\ntibble [6,940 × 8] (S3: tbl_df/tbl/data.frame)\n $ city : chr [1:6940] \"chic\" \"chic\" \"chic\" \"chic\" ...\n $ tmpd : num [1:6940] 31.5 33 33 29 32 40 34.5 29 26.5 32.5 ...\n $ dptp : num [1:6940] 31.5 29.9 27.4 28.6 28.9 ...\n $ date : Date[1:6940], format: \"1987-01-01\" \"1987-01-02\" ...\n $ pm25tmean2: num [1:6940] NA NA NA NA NA NA NA NA NA NA ...\n $ pm10tmean2: num [1:6940] 34 NA 34.2 47 NA ...\n $ o3tmean2 : num [1:6940] 4.25 3.3 3.33 4.38 4.75 ...\n $ no2tmean2 : num [1:6940] 20 23.2 23.8 30.4 30.3 ...\n\n\n\n\n\n\n\n\nNote\n\n\n\nTibbles, by default, only print the first ten rows to screen.\nIf you were to print the data.frame chicago to screen, all 6940 rows would be displayed. When working with large data.frames, this default behavior can be incredibly frustrating.\nUsing tibbles removes this frustration because of the default settings for tibble printing.\n\n\nAdditionally, you will note that the type of the variable is printed for each variable in the tibble. This helpful feature is another added bonus of tibbles relative to data.frame.\n\nWant to see more of the tibble?\nIf you do want to see more rows from the tibble, there are a few options!\n\nThe View() function in RStudio is incredibly helpful. The input to this function is the data.frame or tibble you would like to see.\n\nSpecifically, View(chicago) would provide you, the viewer, with a scrollable view (in a new tab) of the complete dataset.\n\nUse the fact that print() enables you to specify how many rows and columns you would like to display.\n\nHere, we again display the chicago data.frame as a tibble but specify that we would only like to see 5 rows. The width = Inf argument specifies that we would like to see all the possible columns. Here, there are only 8, but for larger datasets, this can be helpful to specify.\n\nas_tibble(chicago) %>%\n print(n = 5, width = Inf)\n\n# A tibble: 6,940 × 8\n city tmpd dptp date pm25tmean2 pm10tmean2 o3tmean2 no2tmean2\n <chr> <dbl> <dbl> <date> <dbl> <dbl> <dbl> <dbl>\n1 chic 31.5 31.5 1987-01-01 NA 34 4.25 20.0\n2 chic 33 29.9 1987-01-02 NA NA 3.30 23.2\n3 chic 33 27.4 1987-01-03 NA 34.2 3.33 23.8\n4 chic 29 28.6 1987-01-04 NA 47 4.38 30.4\n5 chic 32 28.9 1987-01-05 NA NA 4.75 30.3\n# ℹ 6,935 more rows\n\n\n\n\n\ntibble()\nAlternatively, you can create a tibble on the fly by using tibble() and specifying the information you would like stored in each column.\n\n\n\n\n\n\nNote\n\n\n\nIf you provide a single value, this value will be repeated across all rows of the tibble. This is referred to as “recycling inputs of length 1.”\nIn the example here, we see that the column c will contain the value ‘1’ across all rows.\n\ntibble(\n a = 1:5,\n b = 6:10,\n c = 1,\n z = (a + b)^2 + c\n)\n\n# A tibble: 5 × 4\n a b c z\n <int> <int> <dbl> <dbl>\n1 1 6 1 50\n2 2 7 1 82\n3 3 8 1 122\n4 4 9 1 170\n5 5 10 1 226\n\n\n\n\nThe tibble() function allows you to quickly generate tibbles and even allows you to reference columns within the tibble you are creating, as seen in column z of the example above.\n\n\n\n\n\n\nNote\n\n\n\nTibbles can have column names that are not allowed in data.frame.\nIn the example below, we see that to utilize a nontraditional variable name, you surround the column name with backticks.\nNote that to refer to such columns in other tidyverse packages, you willl continue to use backticks surrounding the variable name.\n\ntibble(\n `two words` = 1:5,\n `12` = \"numeric\",\n `:)` = \"smile\",\n)\n\n# A tibble: 5 × 3\n `two words` `12` `:)` \n <int> <chr> <chr>\n1 1 numeric smile\n2 2 numeric smile\n3 3 numeric smile\n4 4 numeric smile\n5 5 numeric smile"
+ "objectID": "posts/05-literate-programming/index.html#footnotes",
+ "href": "posts/05-literate-programming/index.html#footnotes",
+ "title": "05 - Literate Statistical Programming",
+ "section": "Footnotes",
+ "text": "Footnotes\n\n\nThis will become a hover-able footnote↩︎"
},
{
- "objectID": "posts/08-managing-data-frames-with-tidyverse/index.html#subsetting-tibbles",
- "href": "posts/08-managing-data-frames-with-tidyverse/index.html#subsetting-tibbles",
- "title": "08 - Managing data frames with the Tidyverse",
- "section": "Subsetting tibbles",
- "text": "Subsetting tibbles\nSubsetting tibbles also differs slightly from how subsetting occurs with data.frame.\nWhen it comes to tibbles,\n\n[[ can subset by name or position\n$ only subsets by name\n\nFor example:\n\ndf <- tibble(\n a = 1:5,\n b = 6:10,\n c = 1,\n z = (a + b)^2 + c\n)\n\n# Extract by name using $ or [[]]\ndf$z\n\n[1] 50 82 122 170 226\n\ndf[[\"z\"]]\n\n[1] 50 82 122 170 226\n\n# Extract by position requires [[]]\ndf[[4]]\n\n[1] 50 82 122 170 226\n\n\nHaving now discussed tibbles, which are the type of object most tidyverse and tidyverse-adjacent packages work best with, we now know the goal.\nIn many cases, tibbles are ultimately what we want to work with in R.\nHowever, data are stored in many different formats outside of R. We will spend the rest of this lesson discussing wrangling functions that work either a data.frame or tibble."
- },
- {
- "objectID": "posts/21-regular-expressions/index.html",
- "href": "posts/21-regular-expressions/index.html",
- "title": "21 - Regular expressions",
+ "objectID": "posts/23-working-with-text-sentiment-analysis/index.html",
+ "href": "posts/23-working-with-text-sentiment-analysis/index.html",
+ "title": "23 - Tidytext and sentiment analysis",
"section": "",
"text": "This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history."
},
{
- "objectID": "posts/21-regular-expressions/index.html#regex-basics",
- "href": "posts/21-regular-expressions/index.html#regex-basics",
- "title": "21 - Regular expressions",
- "section": "regex basics",
- "text": "regex basics\nA regular expression (also known as a “regex” or “regexp”) is a concise language for describing patterns in character strings.\nRegex could be patterns that could be contained within another string.\n\n\n\n\n\n\nExample\n\n\n\nFor example, if we wanted to search for the pattern “ai” in the character string “The rain in Spain”, we see it appears twice!\n“The rain in Spain”\n\n\nGenerally, a regular expression can be used for e.g.\n\nsearching for a pattern or string within another string (e.g searching for the string “a” in the string “Maryland”)\nreplacing one part of a string with another string (e.g replacing the string “t” with “p” in the string “hot” where you are changing the string “hot” to “hop”)\n\nIf you have never worked with regular expressions, it can seem like maybe a baby hit the keys on your keyboard (complete gibberish), but it will slowly make sense once you learn the syntax.\nSoon you will be able create incredibly powerful regular expressions in your day-to-day work."
+ "objectID": "posts/23-working-with-text-sentiment-analysis/index.html#the-sentiments-dataset",
+ "href": "posts/23-working-with-text-sentiment-analysis/index.html#the-sentiments-dataset",
+ "title": "23 - Tidytext and sentiment analysis",
+ "section": "The sentiments dataset",
+ "text": "The sentiments dataset\nInside the tidytext package are several sentiment lexicons. A few things to note:\n\nThe lexicons are based on unigrams (single words)\nThe lexicons contain many English words and the words are assigned scores for positive/negative sentiment, and also possibly emotions like joy, anger, sadness, and so forth\n\nYou can use the get_sentiments() function to extract a specific lexicon.\nThe nrc lexicon categorizes words into multiple categories of positive, negative, anger, anticipation, disgust, fear, joy, sadness, surprise, and trust\n\nget_sentiments(\"nrc\")\n\n# A tibble: 13,872 × 2\n word sentiment\n <chr> <chr> \n 1 abacus trust \n 2 abandon fear \n 3 abandon negative \n 4 abandon sadness \n 5 abandoned anger \n 6 abandoned fear \n 7 abandoned negative \n 8 abandoned sadness \n 9 abandonment anger \n10 abandonment fear \n# ℹ 13,862 more rows\n\n\nThe bing lexicon categorizes words in a binary fashion into positive and negative categories\n\nget_sentiments(\"bing\")\n\n# A tibble: 6,786 × 2\n word sentiment\n <chr> <chr> \n 1 2-faces negative \n 2 abnormal negative \n 3 abolish negative \n 4 abominable negative \n 5 abominably negative \n 6 abominate negative \n 7 abomination negative \n 8 abort negative \n 9 aborted negative \n10 aborts negative \n# ℹ 6,776 more rows\n\n\nThe AFINN lexicon assigns words with a score that runs between -5 and 5, with negative scores indicating negative sentiment and positive scores indicating positive sentiment\n\nget_sentiments(\"afinn\")\n\n# A tibble: 2,477 × 2\n word value\n <chr> <dbl>\n 1 abandon -2\n 2 abandoned -2\n 3 abandons -2\n 4 abducted -2\n 5 abduction -2\n 6 abductions -2\n 7 abhor -3\n 8 abhorred -3\n 9 abhorrent -3\n10 abhors -3\n# ℹ 2,467 more rows\n\n\nThe authors of the tidytext package note:\n\n“How were these sentiment lexicons put together and validated? They were constructed via either crowdsourcing (using, for example, Amazon Mechanical Turk) or by the labor of one of the authors, and were validated using some combination of crowdsourcing again, restaurant or movie reviews, or Twitter data. Given this information, we may hesitate to apply these sentiment lexicons to styles of text dramatically different from what they were validated on, such as narrative fiction from 200 years ago. While it is true that using these sentiment lexicons with, for example, Jane Austen’s novels may give us less accurate results than with tweets sent by a contemporary writer, we still can measure the sentiment content for words that are shared across the lexicon and the text.”\n\nTwo other caveats:\n\n“Not every English word is in the lexicons because many English words are pretty neutral. It is important to keep in mind that these methods do not take into account qualifiers before a word, such as in”no good” or “not true”; a lexicon-based method like this is based on unigrams only. For many kinds of text (like the narrative examples below), there are not sustained sections of sarcasm or negated text, so this is not an important effect.”\n\nand\n\n“One last caveat is that the size of the chunk of text that we use to add up unigram sentiment scores can have an effect on an analysis. A text the size of many paragraphs can often have positive and negative sentiment averaged out to about zero, while sentence-sized or paragraph-sized text often works better.”\n\n\nJoining together tidy text data with lexicons\nNow that we have our data in a tidy text format AND we have learned about different types of lexicons in application for sentiment analysis, we can join the words together using a join function.\n\n\n\n\n\n\nExample\n\n\n\nWhat are the most common joy words in the book Emma?\nHere, we use the nrc lexicon and join the tidy_books dataset with the nrc_joy lexicon using the inner_join() function in dplyr.\n\nnrc_joy <- get_sentiments(\"nrc\") %>%\n filter(sentiment == \"joy\")\n\ntidy_books %>%\n filter(book == \"Emma\") %>%\n inner_join(nrc_joy) %>%\n count(word, sort = TRUE)\n\nJoining with `by = join_by(word)`\n\n\n# A tibble: 297 × 2\n word n\n <chr> <int>\n 1 friend 166\n 2 hope 143\n 3 happy 125\n 4 love 117\n 5 deal 92\n 6 found 92\n 7 happiness 76\n 8 pretty 68\n 9 true 66\n10 comfort 65\n# ℹ 287 more rows\n\n\n\n\nWe can do things like investigate how the sentiment of the text changes throughout each of Jane’s novels.\nHere, we use the bing lexicon, find a sentiment score for each word, and then use inner_join().\n\ntidy_books %>%\n inner_join(get_sentiments(\"bing\"))\n\nJoining with `by = join_by(word)`\n\n\nWarning in inner_join(., get_sentiments(\"bing\")): Detected an unexpected many-to-many relationship between `x` and `y`.\nℹ Row 131015 of `x` matches multiple rows in `y`.\nℹ Row 5051 of `y` matches multiple rows in `x`.\nℹ If a many-to-many relationship is expected, set `relationship =\n \"many-to-many\"` to silence this warning.\n\n\n# A tibble: 44,171 × 5\n book linenumber chapter word sentiment\n <fct> <int> <int> <chr> <chr> \n 1 Sense & Sensibility 16 1 respectable positive \n 2 Sense & Sensibility 18 1 advanced positive \n 3 Sense & Sensibility 20 1 death negative \n 4 Sense & Sensibility 21 1 loss negative \n 5 Sense & Sensibility 25 1 comfortably positive \n 6 Sense & Sensibility 28 1 goodness positive \n 7 Sense & Sensibility 28 1 solid positive \n 8 Sense & Sensibility 29 1 comfort positive \n 9 Sense & Sensibility 30 1 relish positive \n10 Sense & Sensibility 33 1 steady positive \n# ℹ 44,161 more rows\n\n\nThen, we can count how many positive and negative words there are in each section of the books.\nWe create an index to help us keep track of where we are in the narrative, which uses integer division, and counts up sections of 80 lines of text.\n\ntidy_books %>%\n inner_join(get_sentiments(\"bing\")) %>%\n count(book,\n index = linenumber %/% 80,\n sentiment\n )\n\nJoining with `by = join_by(word)`\n\n\nWarning in inner_join(., get_sentiments(\"bing\")): Detected an unexpected many-to-many relationship between `x` and `y`.\nℹ Row 131015 of `x` matches multiple rows in `y`.\nℹ Row 5051 of `y` matches multiple rows in `x`.\nℹ If a many-to-many relationship is expected, set `relationship =\n \"many-to-many\"` to silence this warning.\n\n\n# A tibble: 1,840 × 4\n book index sentiment n\n <fct> <dbl> <chr> <int>\n 1 Sense & Sensibility 0 negative 16\n 2 Sense & Sensibility 0 positive 26\n 3 Sense & Sensibility 1 negative 19\n 4 Sense & Sensibility 1 positive 44\n 5 Sense & Sensibility 2 negative 12\n 6 Sense & Sensibility 2 positive 23\n 7 Sense & Sensibility 3 negative 15\n 8 Sense & Sensibility 3 positive 22\n 9 Sense & Sensibility 4 negative 16\n10 Sense & Sensibility 4 positive 29\n# ℹ 1,830 more rows\n\n\n\n\n\n\n\n\nNote\n\n\n\nThe %/% operator does integer division (x %/% y is equivalent to floor(x/y)) so the index keeps track of which 80-line section of text we are counting up negative and positive sentiment in.\n\n\nFinally, we use pivot_wider() to have positive and negative counts in different columns, and then use mutate() to calculate a net sentiment (positive - negative).\n\njane_austen_sentiment <-\n tidy_books %>%\n inner_join(get_sentiments(\"bing\")) %>%\n count(book,\n index = linenumber %/% 80,\n sentiment\n ) %>%\n pivot_wider(\n names_from = sentiment,\n values_from = n,\n values_fill = 0\n ) %>%\n mutate(sentiment = positive - negative)\n\nJoining with `by = join_by(word)`\n\n\nWarning in inner_join(., get_sentiments(\"bing\")): Detected an unexpected many-to-many relationship between `x` and `y`.\nℹ Row 131015 of `x` matches multiple rows in `y`.\nℹ Row 5051 of `y` matches multiple rows in `x`.\nℹ If a many-to-many relationship is expected, set `relationship =\n \"many-to-many\"` to silence this warning.\n\njane_austen_sentiment\n\n# A tibble: 920 × 5\n book index negative positive sentiment\n <fct> <dbl> <int> <int> <int>\n 1 Sense & Sensibility 0 16 26 10\n 2 Sense & Sensibility 1 19 44 25\n 3 Sense & Sensibility 2 12 23 11\n 4 Sense & Sensibility 3 15 22 7\n 5 Sense & Sensibility 4 16 29 13\n 6 Sense & Sensibility 5 16 39 23\n 7 Sense & Sensibility 6 24 37 13\n 8 Sense & Sensibility 7 22 39 17\n 9 Sense & Sensibility 8 30 35 5\n10 Sense & Sensibility 9 14 18 4\n# ℹ 910 more rows\n\n\nThen we can plot the sentiment scores across the sections of each novel:\n\njane_austen_sentiment %>%\n ggplot(aes(x = index, y = sentiment, fill = book)) +\n geom_col(show.legend = FALSE) +\n facet_wrap(. ~ book, ncol = 2, scales = \"free_x\")\n\n\n\n\nWe can see how the sentiment trajectory of the novel changes over time.\n\n\nWord clouds\nYou can also do things like create word clouds using the wordcloud package.\n\nlibrary(wordcloud)\n\nLoading required package: RColorBrewer\n\ntidy_books %>%\n anti_join(stop_words) %>%\n count(word) %>%\n with(wordcloud(word, n, max.words = 100))\n\nJoining with `by = join_by(word)`\n\n\nWarning in wordcloud(word, n, max.words = 100): miss could not be fit on page.\nIt will not be plotted."
},
{
- "objectID": "posts/21-regular-expressions/index.html#string-basics",
- "href": "posts/21-regular-expressions/index.html#string-basics",
- "title": "21 - Regular expressions",
- "section": "string basics",
- "text": "string basics\nIn R, you can create (character) strings with either single quotes ('hello!') or double quotes (\"hello!\") – no difference (not true for other languages!).\nI recommend using the double quotes, unless you want to create a string with multiple \".\n\nstring1 <- \"This is a string\"\nstring2 <- 'If I want to include a \"quote\" inside a string, I use single quotes'\n\n\n\n\n\n\n\nPro-tip\n\n\n\nStrings can be tricky when executing them. If you forget to close a quote, you’ll see +\n> \"This is a string without a closing quote\n+ \n+ \n+ HELP I'M STUCK\nIf this happen to you, take a deep breath, press Escape and try again.\n\n\nMultiple strings are often stored in a character vector, which you can create with c():\n\nc(\"one\", \"two\", \"three\")\n\n[1] \"one\" \"two\" \"three\""
+ "objectID": "posts/24-best-practices-data-analyses/index.html",
+ "href": "posts/24-best-practices-data-analyses/index.html",
+ "title": "24 - Best practices for data analyses",
+ "section": "",
+ "text": "This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history."
},
{
- "objectID": "posts/21-regular-expressions/index.html#metacharacters",
- "href": "posts/21-regular-expressions/index.html#metacharacters",
- "title": "21 - Regular expressions",
- "section": "metacharacters",
- "text": "metacharacters\nThe first metacharacter that we will discuss is \".\".\nThe metacharacter that only consists of a period represents any character other than a new line (we will discuss new lines soon).\n\n\n\n\n\n\nExample\n\n\n\nLet’s take a look at some examples using the period regex:\n\ngrepl(\".\", \"Maryland\")\n\n[1] TRUE\n\ngrepl(\".\", \"*&2[0+,%<@#~|}\")\n\n[1] TRUE\n\ngrepl(\".\", \"\")\n\n[1] FALSE\n\n\n\n\nAs you can see the period metacharacter is very liberal.\nThis metacharacter is most useful when you do not care about a set of characters in a regular expression.\n\n\n\n\n\n\nExample\n\n\n\nHere is another example\n\ngrepl(\"a.b\", c(\"aaa\", \"aab\", \"abb\", \"acadb\"))\n\n[1] FALSE TRUE TRUE TRUE\n\n\nIn the case above, grepl() returns TRUE for all strings that contain an a followed by any other character followed by a b."
+ "objectID": "posts/24-best-practices-data-analyses/index.html#defining-ethics",
+ "href": "posts/24-best-practices-data-analyses/index.html#defining-ethics",
+ "title": "24 - Best practices for data analyses",
+ "section": "Defining ethics",
+ "text": "Defining ethics\nWe start with a grounding in the definition of Ethics:\nEthics, also called moral philosophy, has three main branches:\n\nApplied ethics “is a branch of ethics devoted to the treatment of moral problems, practices, and policies in personal life, professions, technology, and government.”\nEthical theory “is concerned with the articulation and the justification of the fundamental principles that govern the issues of how we should live and what we morally ought to do. Its most general concerns are providing an account of moral evaluation and, possibly, articulating a decision procedure to guide moral action.”\nMetaethics “is the attempt to understand the metaphysical, epistemological, semantic, and psychological, presuppositions and commitments of moral thought, talk, and practice.”\n\nWhile, unfortunately, there are myriad examples of ethical data science problems (see, for example, blog posts bookclub and data feminism), here I aim to connect some of the broader data science ethics issues with the existing philosophical literature.\nNote, I am only scratching the surface and a deeper dive might involve education in related philosophical fields (epistemology, metaphysics, or philosophy of science), philosophical methodologies, and ethical schools of thought, but you can peruse all of these through, for example, a course or readings introducing the discipline of philosophy.\nBelow we provide some thoughts on how to approach a data science problem using a philosophical lens."
},
{
- "objectID": "posts/21-regular-expressions/index.html#repetition",
- "href": "posts/21-regular-expressions/index.html#repetition",
- "title": "21 - Regular expressions",
- "section": "repetition",
- "text": "repetition\nYou can specify a regular expression that contains a certain number of characters or metacharacters using the enumeration metacharacters (or sometimes called quantifiers).\n\n+: indicates that one or more of the preceding expression should be present (or matches at least 1 time)\n*: indicates that zero or more of the preceding expression is present (or matches at least 0 times)\n?: indicates that zero or 1 of the preceding expression is not present or present at most 1 time (or matches between 0 and 1 times)\n\n\n\n\n\n\n\nExample\n\n\n\nLet’s take a look at some examples using these metacharacters:\n\n# Does \"Maryland\" contain one or more of \"a\" ?\ngrepl(\"a+\", \"Maryland\")\n\n[1] TRUE\n\n# Does \"Maryland\" contain one or more of \"x\" ?\ngrepl(\"x+\", \"Maryland\")\n\n[1] FALSE\n\n# Does \"Maryland\" contain zero or more of \"x\" ?\ngrepl(\"x*\", \"Maryland\")\n\n[1] TRUE\n\n\n\n\nIf you want to do more than one character, you need to wrap it in ().\n\n# Does \"Maryland\" contain zero or more of \"x\" ?\ngrepl(\"(xx)*\", \"Maryland\")\n\n[1] TRUE\n\n\n\n\n\n\n\n\nQuestion\n\n\n\nLet’s practice a few out together. Make the following regular expressions for the character string “spookyhalloween”:\n\nDoes “zz” appear 1 or more times?\nDoes “ee” appear 1 or more times?\nDoes “oo” appear 0 or more times?\nDoes “ii” appear 0 or more times?\n\n\n## try it out\n\n\n\nYou can also specify exact numbers of expressions using curly brackets {}.\n\n{n}: exactly n\n{n,}: n or more\n{,m}: at most m\n{n,m}: between n and m\n\nFor example \"a{5}\" specifies “a exactly five times”, \"a{2,5}\" specifies “a between 2 and 5 times,” and \"a{2,}\" specifies “a at least 2 times.” Let’s take a look at some examples:\n\n# Does \"Mississippi\" contain exactly 2 adjacent \"s\" ?\ngrepl(\"s{2}\", \"Mississippi\")\n\n[1] TRUE\n\n# This is equivalent to the expression above:\ngrepl(\"ss\", \"Mississippi\")\n\n[1] TRUE\n\n# Does \"Mississippi\" contain between 1 and 3 adjacent \"s\" ?\ngrepl(\"s{1,3}\", \"Mississippi\")\n\n[1] TRUE\n\n# Does \"Mississippi\" contain between 2 and 3 adjacent \"i\" ?\ngrepl(\"i{2,3}\", \"Mississippi\")\n\n[1] FALSE\n\n# Does \"Mississippi\" contain between 2 adjacent \"iss\" ?\ngrepl(\"(iss){2}\", \"Mississippi\")\n\n[1] TRUE\n\n# Does \"Mississippi\" contain between 2 adjacent \"ss\" ?\ngrepl(\"(ss){2}\", \"Mississippi\")\n\n[1] FALSE\n\n# Does \"Mississippi\" contain the pattern of an \"i\" followed by\n# 2 of any character, with that pattern repeated three times adjacently?\ngrepl(\"(i.{2}){3}\", \"Mississippi\")\n\n[1] TRUE\n\n\n\n\n\n\n\n\nQuestion\n\n\n\nLet’s practice a few out together. Make the following regular expressions for the character string “spookyspookyhalloweenspookyspookyhalloween”:\n\nSearch for “spooky” exactly 2 times. What about 3 times?\nSearch for “spooky” exactly 2 times followed by any character of length 9 (i.e. “halloween”).\nSame search as above, but search for that twice in a row.\nSame search as above, but search for that three times in a row.\n\n\n## try it out"
+ "objectID": "posts/24-best-practices-data-analyses/index.html#case-study",
+ "href": "posts/24-best-practices-data-analyses/index.html#case-study",
+ "title": "24 - Best practices for data analyses",
+ "section": "Case Study",
+ "text": "Case Study\nWe begin by considering a case study around ethical data analyses.\nMany ethics case studies provided in a classroom setting describe algorithms built on data which are meant to predict outcomes.\n\n\n\n\n\n\nNote\n\n\n\nLarge scale algorithmic decision making presents particular ethical predicaments because of both the scale of impact and the “black-box” sense of how the algorithm is generating predictions.\n\n\nConsider the well-known issue of using facial recognition software in policing.\nThere are many questions surrounding the policing issue:\n\nWhat are the action options with respect to the outcome of the algorithm?\nWhat are the good and bad aspects of each action and how are these to be weighed against each other?\n\n\n[Source: CNN]\n\n\n\n\n\n\nImportant questions\n\n\n\nThe two main ethical concerns surrounding facial recognition software break down into\n\nHow the algorithms were developed?\nHow the algorithm is used?\n\n\n\nWhen thinking about the questions below, reflect on the good aspects and the bad aspects and how one might weight the good versus the bad.\n\nCreating the algorithm\n\nWhat data should be used to train the algorithm?\n\nIf the accuracy rates of the algorithm differ based on the demographics of the subgroups within the data, is more data and testing required?\n\nWho and what criteria should be used to tune the algorithm?\n\nWho should be involved in decisions on the tuning parameters of the algorithm?\nWhich optimization criteria should be used (e.g., accuracy? false positive rate? false negative rate?)\n\nIssues of access:\n\nWho should own or have control of the facial image data?\n\nDo individuals have a right to keep their facial image private from being in databases?\nDo individuals have a right to be notified that their facial image is in the data base? For example, if I ring someone’s doorbell and my face is captured in a database, do I need to be told? [While traditional human subjects and IRB requirements necessitate consent to be included in any research project, in most cases it is legal to photograph a person without their consent.]\n\nShould the data be accessible to researchers working to make the field more equitable? What if allowing accessibility thereby makes the data accessible to bad actors?\n\n\n\n\nUsing the algorithm\n\nIssues of personal impact:\n\nThe software might make it easier to accurately associate an individual with a crime, but it might also make it easier to mistakenly associate an individual with a crime. How should the pro vs con be weighed against each other?\nDo individuals have a right to know, correct, or delete personal information included in a database?\n\nIssues of societal impact:\n\nIs it permissible to use a facial recognition software which has been trained primarily on Caucasian faces, given that this results in false positive and false negative rates that are not equally dispersed across racial lines?\nWhile the software might make it easier to protect against criminal activity, it also makes it easier to undermine specific communities when their members are mistakenly identified with criminal activity. How should the pro vs con of different communities be weighed against each other?\n\nIssues of money:\n\nIs it permissible for a software company to profit from an algorithm while having no financial responsibility for its misuse or negative impacts?\nWho should pay the court fees and missed work hours of those who were mistakenly accused of crimes?\n\n\nTo settle the questions above, we need to study various ethical theories, and it turns out that the different theories may lead us to different conclusions. As non-philosophers, we recognize that the suggested readings and ideas may come across as overwhelming. If you are overwhelmed, we suggest that you choose one ethical theory, think carefully about how it informs decision making, and help your students to connect the ethical framework to a data science case study."
},
{
- "objectID": "posts/21-regular-expressions/index.html#capture-group",
- "href": "posts/21-regular-expressions/index.html#capture-group",
- "title": "21 - Regular expressions",
- "section": "capture group",
- "text": "capture group\nIn the examples above, I used parentheses () to create a capturing group. A capturing group allows you to use quantifiers on other regular expressions.\nIn the “Mississippi” example, I first created the regex \"i.{2}\" which matches i followed by any two characters (“iss” or “ipp”). Then, I used a capture group to wrap that regex, and to specify exactly three adjacent occurrences of that regex.\nYou can specify sets of characters (or character sets or character classes) with regular expressions, some of which come built in, but you can build your own character sets too.\nMore on character sets next."
+ "objectID": "posts/24-best-practices-data-analyses/index.html#final-thoughts",
+ "href": "posts/24-best-practices-data-analyses/index.html#final-thoughts",
+ "title": "24 - Best practices for data analyses",
+ "section": "Final thoughts",
+ "text": "Final thoughts\nThis is a challenging topic, but as you analyze data, ask yourself the following broad questions to help you with ethical considerations around the data analysis.\n\n\n\n\n\n\nQuestions to ask yourself when analyzing data?\n\n\n\n\nWhy are we producing this knowledge?\nFor whom are we producing this knowledge?\nWhat communities do they serve?\nWhich stakeholders need to be involved in making decisions in and around the data analysis?"
},
{
- "objectID": "posts/21-regular-expressions/index.html#character-sets",
- "href": "posts/21-regular-expressions/index.html#character-sets",
- "title": "21 - Regular expressions",
- "section": "character sets",
- "text": "character sets\nFirst, we will discuss the built in character sets:\n\nwords (\"\\\\w\") = Words specify any letter, digit, or a underscore\ndigits (\"\\\\d\") = Digits specify the digits 0 through 9\nwhitespace characters (\"\\\\s\") = Whitespace specifies line breaks, tabs, or spaces\n\nEach of these character sets have their own compliments:\n\nnot words (\"\\\\W\")\nnot digits (\"\\\\D\")\nnot whitespace characters (\"\\\\S\")\n\nEach specifies all of the characters not included in their corresponding character sets.\n\n\n\n\n\n\nInteresting fact\n\n\n\nTechnically, you are using the a character set \"\\d\" or \"\\s\" (with only one black slash), but because you are using this character set in a string, you need the second \\ to escape the string. So you will type \"\\\\d\" or \"\\\\s\".\n\n\"\\\\d\"\n\n[1] \"\\\\d\"\n\n\nSo for example, to include a literal single or double quote in a string you can use \\ to “escape” the string and being able to include a single or double quote:\n\ndouble_quote <- \"\\\"\"\ndouble_quote\n\n[1] \"\\\"\"\n\nsingle_quote <- \"'\"\nsingle_quote\n\n[1] \"'\"\n\n\nThat means if you want to include a literal backslash, you will need to double it up: \"\\\\\".\n\n\nIn fact, putting two backslashes before any punctuation mark that is also a metacharacter indicates that you are looking for the symbol and not the metacharacter meaning.\nFor example \"\\\\.\" indicates you are trying to match a period in a string. Let’s take a look at a few examples:\n\ngrepl(\"\\\\+\", \"tragedy + time = humor\")\n\n[1] TRUE\n\ngrepl(\"\\\\.\", \"https://publichealth.jhu.edu\")\n\n[1] TRUE\n\n\n\n\n\n\n\n\nBeware\n\n\n\nThe printed representation of a string is not the same as string itself, because the printed representation shows the escapes. To see the raw contents of the string, use writeLines():\n\nx <- c(\"\\'\", \"\\\"\", \"\\\\\")\nx\n\n[1] \"'\" \"\\\"\" \"\\\\\"\n\nwriteLines(x)\n\n'\n\"\n\\\n\n\n\n\nThere are a handful of other special characters. The most common are\n\n\"\\n\": newline\n\"\\t\": tab,\n\nbut you can see the complete list by requesting help (run the following in the console and a help file will appear:\n\n?\"'\"\n\nYou will also sometimes see strings like “0b5”, this is a way of writing non-English characters that works on all platforms:\n\nx <- c(\"\\\\t\", \"\\\\n\", \"\\u00b5\")\nx\n\n[1] \"\\\\t\" \"\\\\n\" \"µ\" \n\nwriteLines(x)\n\n\\t\n\\n\nµ\n\n\n\n\n\n\n\n\nExample\n\n\n\nLet’s take a look at a few examples of built in character sets: \"\\w\", \"\\d\", \"\\s\".\n\ngrepl(\"\\\\w\", \"abcdefghijklmnopqrstuvwxyz0123456789\")\n\n[1] TRUE\n\ngrepl(\"\\\\d\", \"0123456789\")\n\n[1] TRUE\n\n# \"\\n\" is the metacharacter for a new line\n# \"\\t\" is the metacharacter for a tab\ngrepl(\"\\\\s\", \"\\n\\t \")\n\n[1] TRUE\n\ngrepl(\"\\\\d\", \"abcdefghijklmnopqrstuvwxyz\")\n\n[1] FALSE\n\ngrepl(\"\\\\D\", \"abcdefghijklmnopqrstuvwxyz\")\n\n[1] TRUE\n\ngrepl(\"\\\\w\", \"\\n\\t \")\n\n[1] FALSE"
+ "objectID": "posts/24-best-practices-data-analyses/index.html#fair-principles",
+ "href": "posts/24-best-practices-data-analyses/index.html#fair-principles",
+ "title": "24 - Best practices for data analyses",
+ "section": "FAIR principles",
+ "text": "FAIR principles\nSharing data proves more useful when others can easily find and access, interpret, and reuse the data. To maximize the benefit of sharing your data, follow the findable, accessible, interoperable, and reusable (FAIR) guiding principles of data sharing, which optimize reuse of generated data.\n\n\n\n\n\n\nFAIR data sharing principles\n\n\n\n\nFindable. The first step in (re)using data is to find them. Metadata and data should be easy to find for both humans and computers. Machine-readable metadata are essential for automatic discovery of datasets and services, so this is an essential component of the FAIRification process.\nAccessible. Once the user finds the required data, she/he needs to know how can they be accessed, possibly including authentication and authorization.\nInteroperable. The data usually need to be integrated with other data. In addition, the data need to interoperate with applications or workflows for analysis, storage, and processing.\nReusable. The ultimate goal of FAIR is to optimize the reuse of data. To achieve this, metadata and data should be well-described so that they can be replicated and/or combined in different settings."
},
{
- "objectID": "posts/21-regular-expressions/index.html#brackets",
- "href": "posts/21-regular-expressions/index.html#brackets",
- "title": "21 - Regular expressions",
- "section": "brackets",
- "text": "brackets\nYou can also specify specific character sets using straight brackets [].\nFor example a character set of just the vowels would look like: \"[aeiou]\".\n\ngrepl(\"[aeiou]\", \"rhythms\")\n\n[1] FALSE\n\n\nYou can find the complement to a specific character by putting a carrot ^ after the first bracket. For example \"[^aeiou]\" matches all characters except the lowercase vowels.\n\ngrepl(\"[^aeiou]\", \"rhythms\")\n\n[1] TRUE"
+ "objectID": "posts/24-best-practices-data-analyses/index.html#why-share",
+ "href": "posts/24-best-practices-data-analyses/index.html#why-share",
+ "title": "24 - Best practices for data analyses",
+ "section": "Why share?",
+ "text": "Why share?\n\nBenefits of sharing data to science and society. Sharing data allows for transparency in scientific studies and allows one to fully understand what occurred in an analysis and reproduce the results. Without complete data, metadata, and information about resources used to generate the data, reproducing a study proves impossible.\nBenefits of sharing data to individual researchers. Sharing data increases the impact of a researcher’s work and reputation for sound science. Awards for those with an excellent record of data sharing or data reuse can exemplify this reputation.\n\n\nAddressing common concerns about data sharing\nDespite the clear benefits of sharing data, some researchers still have concerns about doing so.\n\nNovelty. Some worry that sharing data may decrease the novelty of their work and their chance to publish in prominent journals. You can address this concern by sharing your data only after publication. You can also choose to preprint your manuscript when you decide to share your data. Furthermore, you only need to share the data and metadata required to reproduce your published study.\nTime spent on sharing data. Some have concerns about the time it takes to organize and share data publicly. Many add ‘data available upon request’ to manuscripts instead of depositing the data in a public repository in hopes of getting the work out sooner. It does take time to organize data in preparation for sharing, but sharing data publicly may save you time. Sharing data in a public repository that guarantees archival persistence means that you will not have to worry about storing and backing up the data yourself.\nHuman subject data. Sharing of data on human subjects requires special ethical, legal, and privacy considerations. Existing recommendations largely aim to balance the privacy of human participants with the benefits of data sharing by de-identifying human participants and obtaining consent for sharing. Sharing human data poses a variety of challenges for analysis, transparency, reproducibility, interoperability, and access.\n\n\n\n\n\n\n\nHuman data\n\n\n\nSometimes you cannot publicly post all human data, even after de-identification. We suggest three strategies for making these data maximally accessible.\n\nDeposit raw data files in a controlled-access repository. Controlled-access repositories allow only qualified researchers who apply to access the data.\nEven if you cannot make individual-level raw data available, you can make as much processed data available as possible. This may take the form of summary statistics such as means and standard deviations, rather than individual-level data.\nYou may want to generate simulated data distinct from the original data but statistically similar to it. Simulated data would allow others to reproduce your analysis without disclosing the original data or requiring the security controls needed for controlled access."
},
{
- "objectID": "posts/21-regular-expressions/index.html#ranges",
- "href": "posts/21-regular-expressions/index.html#ranges",
- "title": "21 - Regular expressions",
- "section": "ranges",
- "text": "ranges\nYou can also specify ranges of characters using a hyphen - inside of the brackets.\nFor example:\n\n\"[a-m]\" matches all of the lowercase characters between a and m\n\"[5-8]\" matches any digit between 5 and 8 inclusive\n\n\n\n\n\n\n\nExample\n\n\n\nLet’s take a look at some examples using custom character sets:\n\ngrepl(\"[a-m]\", \"xyz\")\n\n[1] FALSE\n\ngrepl(\"[a-m]\", \"ABC\")\n\n[1] FALSE\n\ngrepl(\"[a-mA-M]\", \"ABC\")\n\n[1] TRUE"
+ "objectID": "posts/24-best-practices-data-analyses/index.html#what-data-to-share",
+ "href": "posts/24-best-practices-data-analyses/index.html#what-data-to-share",
+ "title": "24 - Best practices for data analyses",
+ "section": "What data to share?",
+ "text": "What data to share?\nDepending on the data type, you might be able to share the data itself, or a summarized version of it. Boradly thought, you want to share the following:\n\nThe data itself, or a summarized version, or a simulated data similar to the original.\nAny metadata to describe the primary data and the resources used to generate it. Most disciplines have specific metadata standards to follow (e.g. microarrays).\nData dictionary. These have crucial role in organizing your data, especially explaining the variables and their representation. Data dictionaries should provide short names for each variable, a longer text label for the variable, a definition for each variable, data type (such as floating-point number, integer, or string), measurement units, and expected minimum and maximum values. Data dictionaries can make explicit what future users would otherwise have to guess about the representation of data.\nSource code. Ideally, readers should have all materials needed to completely reproduce the study described in a publication, not just data. These materials include source code, preprocessing, and analysis scripts. Guidelines for organization of computational project can help you arrange your data and scripts in a way that will make it easier for you and other to access and reuse them.\nLicensing. Clear licensing information attached to your data avoids any questions of whether others may reuse it. Many data resources turn out not to be as reusable as the providers intended, due to lack of clarity in licensing or restrictive licensing choices.\n\n\n\n\n\n\n\nHow should you document your data?\n\n\n\nDocument your data in three ways:\n\nWith your manuscript.\nWith description fields in the metadata collected by repositories\nWith README files. README files provide abbreviated information about a collection of files (e.g. explain organization, file locations, observations and variables present in each file, details on the experimental design, etc)."
},
{
- "objectID": "posts/21-regular-expressions/index.html#beginning-and-end",
- "href": "posts/21-regular-expressions/index.html#beginning-and-end",
- "title": "21 - Regular expressions",
- "section": "beginning and end",
- "text": "beginning and end\nThere are also metacharacters for matching the beginning and the end of a string which are \"^\" and \"$\" respectively.\nLet’s take a look at a few examples:\n\ngrepl(\"^a\", c(\"bab\", \"aab\"))\n\n[1] FALSE TRUE\n\ngrepl(\"b$\", c(\"bab\", \"aab\"))\n\n[1] TRUE TRUE\n\ngrepl(\"^[ab]*$\", c(\"bab\", \"aab\", \"abc\"))\n\n[1] TRUE TRUE FALSE"
+ "objectID": "posts/24-best-practices-data-analyses/index.html#motiviation",
+ "href": "posts/24-best-practices-data-analyses/index.html#motiviation",
+ "title": "24 - Best practices for data analyses",
+ "section": "Motiviation",
+ "text": "Motiviation\n\n\n\n\n\n\nQuote from a hero of mine\n\n\n\n“The greatest value of a picture is when it forces us to notice what we never expected to see.” -John W. Tukey\n\n\n\n\n\n\n\n\n\n\n\nMistakes, biases, systematic errors and unexpected variability are commonly found in data regardless of applications. Failure to discover these problems often leads to flawed analyses and false discoveries.\nAs an example, consider that measurement devices sometimes fail and not all summarization procedures, such as the mean() function in R, are designed to detect these. Yet, these functions will still give you an answer.\nFurthermore, it may be hard or impossible to notice an error was made just from the reported summaries.\nData visualization is a powerful approach to detecting these problems. We refer to this particular task as exploratory data analysis (EDA), coined by John Tukey.\nOn a more positive note, data visualization can also lead to discoveries which would otherwise be missed if we simply subject the data to a battery of statistical summaries or procedures.\nWhen analyzing data, we often make use of exploratory plots to motivate the analyses we choose.\nIn this section, we will discuss some types of plots to avoid, better ways to visualize data, some principles to create good plots, and ways to use ggplot2 to create expository (intended to explain or describe something) graphs.\n\n\n\n\n\n\nExample\n\n\n\nThe following figure is from Lippmann et al. 2006:\n\n\n\nNickel concentration and PM10 health effects (Blue points represent average county-level concentrations from 2000–2005 for 72 U.S. counties representing 69 communities).\n\n\nThe following figure is from Dominici et al. 2007, in response to the work by Lippmann et al. above.\n\n\n\nNickel concentration and PM10 health effects (with and without New York).\n\n\nElevated levels of Ni and V PM2.5 chemical components in New York are likely attributed to oil-fired power plants and emissions from ships burning oil, as noted by Lippmann et al. (2006).\n\n\n\nGenerating data visualizations\nIn order to determine the effectiveness or quality of a visualization, we need to first understand three things:\n\n\n\n\n\n\nQuestions to ask yourself when building data visualizations\n\n\n\n\nWhat is the question we are trying to answer?\nWhy are we building this visualization?\nFor whom are we producing this data visualization for? Who is the intended audience to consume this visualization?\n\n\n\nNo plot (or any statistical tool, really) can be judged without knowing the answers to those questions. No plot or graphic exists in a vacuum. There is always context and other surrounding factors that play a role in determining a plot’s effectiveness.\nConversely, high-quality, well-made visualizations usually allow one to properly deduce what question is being asked and who the audience is meant to be. A good visualization tells a complete story in a single frame.\n\n\n\n\n\n\nBroad steps for creating data visualizations\n\n\n\nThe act of visualizing data typically proceeds in two broad steps:\n\nGiven the question and the audience, what type of plot should I make?\nGiven the plot I intend to make, how can I optimize it for clarity and effectiveness?"
},
{
- "objectID": "posts/21-regular-expressions/index.html#or-metacharacter",
- "href": "posts/21-regular-expressions/index.html#or-metacharacter",
- "title": "21 - Regular expressions",
- "section": "OR metacharacter",
- "text": "OR metacharacter\nThe last metacharacter we will discuss is the OR metacharacter (\"|\").\nThe OR metacharacter matches either the regex on the left or the regex on the right side of this character. A few examples:\n\ngrepl(\"a|b\", c(\"abc\", \"bcd\", \"cde\"))\n\n[1] TRUE TRUE FALSE\n\ngrepl(\"North|South\", c(\"South Dakota\", \"North Carolina\", \"West Virginia\"))\n\n[1] TRUE TRUE FALSE"
+ "objectID": "posts/24-best-practices-data-analyses/index.html#data-viz-principles",
+ "href": "posts/24-best-practices-data-analyses/index.html#data-viz-principles",
+ "title": "24 - Best practices for data analyses",
+ "section": "Data viz principles",
+ "text": "Data viz principles\n\nDeveloping plots\nInitially, one must decide what information should be presented. The following principles for developing analytic graphics come from Edward Tufte’s book Beautiful Evidence.\n\nShow comparisons\nShow causality, mechanism, explanation\nShow multivariate data\nIntegrate multiple modes of evidence\nDescribe and document the evidence\nContent is king - good plots start with good questions\n\n\n\nOptimizing plots\n\nMaximize the data/ink ratio – if “ink” can be removed without reducing the information being communicated, then it should be removed.\nMaximize the range of perceptual conditions – your audience’s perceptual abilities may not be fully known, so it’s best to allow for a wide range, to the extent possible (or knowable).\nShow variation in the data, not variation in the design.\n\nWhat’s sub-optimal about this plot?\n\nd <- airquality %>%\n mutate(Summer = ifelse(Month %in% c(7, 8, 9), 2, 3))\nwith(d, {\n plot(Temp, Ozone, col = unclass(Summer), pch = 19, frame.plot = FALSE)\n legend(\"topleft\",\n col = 2:3, pch = 19, bty = \"n\",\n legend = c(\"Summer\", \"Non-Summer\")\n )\n})\n\n\n\n\nWhat’s sub-optimal about this plot?\n\nairquality %>%\n mutate(Summer = ifelse(Month %in% c(7, 8, 9),\n \"Summer\", \"Non-Summer\"\n )) %>%\n ggplot(aes(Temp, Ozone)) +\n geom_point(aes(color = Summer), size = 2) +\n theme_minimal()\n\n\n\n\nSome of these principles are taken from Edward Tufte’s Visual Display of Quantitative Information:"
},
{
- "objectID": "posts/21-regular-expressions/index.html#state.name-example",
- "href": "posts/21-regular-expressions/index.html#state.name-example",
- "title": "21 - Regular expressions",
- "section": "state.name example",
- "text": "state.name example\n\n\n\n\n\n\nExample\n\n\n\nFinally, we have learned enough to create a regular expression that matches all state names that both begin and end with a vowel:\n\nWe match the beginning of a string.\nWe create a character set of just capitalized vowels.\nWe specify one instance of that set.\nThen any number of characters until:\nA character set of just lowercase vowels.\nWe specify one instance of that set.\nWe match the end of a string.\n\n\nstart_end_vowel <- \"^[AEIOU]{1}.+[aeiou]{1}$\"\nvowel_state_lgl <- grepl(start_end_vowel, state.name)\nhead(vowel_state_lgl)\n\n[1] TRUE TRUE TRUE FALSE FALSE FALSE\n\nstate.name[vowel_state_lgl]\n\n[1] \"Alabama\" \"Alaska\" \"Arizona\" \"Idaho\" \"Indiana\" \"Iowa\" \"Ohio\" \n[8] \"Oklahoma\"\n\n\n\n\nBelow is a table of several important metacharacters:\n\n\n\n\n\nMetacharacter\nMeaning\n\n\n\n\n.\nAny Character\n\n\n\\w\nA Word\n\n\n\\W\nNot a Word\n\n\n\\d\nA Digit\n\n\n\\D\nNot a Digit\n\n\n\\s\nWhitespace\n\n\n\\S\nNot Whitespace\n\n\n[xyz]\nA Set of Characters\n\n\n[^xyz]\nNegation of Set\n\n\n[a-z]\nA Range of Characters\n\n\n^\nBeginning of String\n\n\n$\nEnd of String\n\n\n\\n\nNewline\n\n\n+\nOne or More of Previous\n\n\n*\nZero or More of Previous\n\n\n?\nZero or One of Previous\n\n\n|\nEither the Previous or the Following\n\n\n{5}\nExactly 5 of Previous\n\n\n{2, 5}\nBetween 2 and 5 or Previous\n\n\n{2, }\nMore than 2 of Previous"
+ "objectID": "posts/24-best-practices-data-analyses/index.html#plots-to-avoid",
+ "href": "posts/24-best-practices-data-analyses/index.html#plots-to-avoid",
+ "title": "24 - Best practices for data analyses",
+ "section": "Plots to Avoid",
+ "text": "Plots to Avoid\nThis section is based on a talk by Karl W. Broman titled “How to Display Data Badly,” in which he described how the default plots offered by Microsoft Excel “obscure your data and annoy your readers” (here is a link to a collection of Karl Broman’s talks).\n\n\n\n\n\n\nFYI\n\n\n\nKarl’s lecture was inspired by the 1984 paper by H. Wainer: How to display data badly. American Statistician 38(2): 137–147.\nDr. Wainer was the first to elucidate the principles of the bad display of data.\nHowever, according to Karl Broman, “The now widespread use of Microsoft Excel has resulted in remarkable advances in the field.”\nHere we show examples of “bad plots” and how to improve them in R.\n\n\n\n\n\n\n\n\nSome general principles of bad plots\n\n\n\n\nDisplay as little information as possible.\nObscure what you do show (with chart junk).\nUse pseudo-3D and color gratuitously.\nMake a pie chart (preferably in color and 3D).\nUse a poorly chosen scale.\nIgnore significant figures."
},
{
- "objectID": "posts/21-regular-expressions/index.html#grep",
- "href": "posts/21-regular-expressions/index.html#grep",
- "title": "21 - Regular expressions",
- "section": "grep()",
- "text": "grep()\nThen, there is old fashioned grep(pattern, x), which returns the indices of the vector that match the regex:\n\ngrep(pattern = \"[Ii]\", x = c(\"Hawaii\", \"Illinois\", \"Kentucky\"))\n\n[1] 1 2"
+ "objectID": "posts/24-best-practices-data-analyses/index.html#examples",
+ "href": "posts/24-best-practices-data-analyses/index.html#examples",
+ "title": "24 - Best practices for data analyses",
+ "section": "Examples",
+ "text": "Examples\nHere are some examples of bad plots and suggestions on how to improve\n\nPie charts\nLet’s say we are interested in the most commonly used browsers. Wikipedia has a table with the “usage share of web browsers” or the proportion of visitors to a group of web sites that use a particular web browser from July 2017.\n\nbrowsers <- c(\n Chrome = 60, Safari = 14, UCBrowser = 7,\n Firefox = 5, Opera = 3, IE = 3, Noinfo = 8\n)\nbrowsers.df <- gather(\n data.frame(t(browsers)),\n \"browser\", \"proportion\"\n)\n\nLet’s say we want to report the results of the usage. The standard way of displaying these is with a pie chart:\n\npie(browsers, main = \"Browser Usage (July 2022)\")\n\n\n\n\nIf we look at the help file for pie():\n\n?pie\n\nIt states:\n\n“Pie charts are a very bad way of displaying information. The eye is good at judging linear measures and bad at judging relative areas. A bar chart or dot chart is a preferable way of displaying this type of data.”\n\nTo see this, look at the figure above and try to determine the percentages just from looking at the plot. Unless the percentages are close to 25%, 50% or 75%, this is not so easy. Simply showing the numbers is not only clear, but also saves on printing costs.\n\nInstead of pie charts, try bar plots\nIf you do want to plot them, then a barplot is appropriate. Here we use the geom_bar() function in ggplot2. Note, there are also horizontal lines at every multiple of 10, which helps the eye quickly make comparisons across:\n\np <- browsers.df %>%\n ggplot(aes(\n x = reorder(browser, -proportion),\n y = proportion\n )) +\n geom_bar(stat = \"identity\")\np\n\n\n\n\nNotice that we can now pretty easily determine the percentages by following a horizontal line to the x-axis.\n\n\nPolish your plots\nWhile this figure is already a big improvement over a pie chart, we can do even better. When you create figures, you want your figures to be self-sufficient, meaning someone looking at the plot can understand everything about it.\nSome possible critiques are:\n\nmake the axes bigger\nmake the labels bigger\nmake the labels be full names (e.g. “Browser” and “Proportion of users”, ideally with units when appropriate)\nadd a title\n\nLet’s explore how to do these things to make an even better figure.\nTo start, go to the help file for theme()\n\n?ggplot2::theme\n\nWe see there are arguments with text that control all the text sizes in the plot. If you scroll down, you see the text argument in the theme command requires class element_text. Let’s try it out.\nTo change the x-axis and y-axis labels to be full names, use xlab() and ylab()\n\np <- p + xlab(\"Browser\") +\n ylab(\"Proportion of Users\")\np\n\n\n\n\nMaybe a title\n\np + ggtitle(\"Browser Usage (July 2022)\")\n\n\n\n\nNext, we can also use the theme() function in ggplot2 to control the justifications and sizes of the axes, labels and titles.\nTo center the title\n\np + ggtitle(\"Browser Usage (July 2022)\") +\n theme(plot.title = element_text(hjust = 0.5))\n\n\n\n\nTo create bigger text/labels/titles:\n\np <- p + ggtitle(\"Browser Usage (July 2022)\") +\n theme(\n plot.title = element_text(hjust = 0.5),\n text = element_text(size = 15)\n )\np\n\n\n\n\n\n\n“I don’t like that theme”\n\np + theme_bw()\n\n\n\n\n\np + theme_dark()\n\n\n\n\n\np + theme_classic() # axis lines!\n\n\n\n\n\np + ggthemes::theme_base()\n\n\n\n\n\n\n\n3D barplots\nPlease, avoid a 3D version because it obfuscates the plot, making it more difficult to find the percentages by eye.\n\n\n\nDonut plots\nEven worse than pie charts are donut plots.\n\nThe reason is that by removing the center, we remove one of the visual cues for determining the different areas: the angles. There is no reason to ever use a donut plot to display data.\n\n\n\n\n\n\nQuestion\n\n\n\nWhy are pie/donut charts so common?\nhttps://blog.usejournal.com/why-humans-love-pie-charts-9cd346000bdc\n\n\n\n\nBarplots as data summaries\nWhile barplots are useful for showing percentages, they are incorrectly used to display data from two groups being compared. Specifically, barplots are created with height equal to the group means; an antenna is added at the top to represent standard errors. This plot is simply showing two numbers per group and the plot adds nothing:\n\n\nInstead of bar plots for summaries, try box plots\nIf the number of points is small enough, we might as well add them to the plot. When the number of points is too large for us to see them, just showing a boxplot is preferable.\nLet’s recreate these barplots as boxplots and overlay the points. We will simulate similar data to demonstrate one way to improve the graphic above.\n\nset.seed(1000)\ndat <- data.frame(\n \"Treatment\" = rnorm(10, 30, sd = 4),\n \"Control\" = rnorm(10, 36, sd = 4)\n)\ngather(dat, \"type\", \"response\") %>%\n ggplot(aes(type, response)) +\n geom_boxplot() +\n geom_point(position = \"jitter\") +\n ggtitle(\"Response to drug treatment\")\n\n\n\n\nNotice how much more we see here: the center, spread, range, and the points themselves. In the barplot, we only see the mean and the standard error (SE), and the SE has more to do with sample size than with the spread of the data.\nThis problem is magnified when our data has outliers or very large tails. For example, in the plot below, there appears to be very large and consistent differences between the two groups:\n\nHowever, a quick look at the data demonstrates that this difference is mostly driven by just two points.\n\nset.seed(1000)\ndat <- data.frame(\n \"Treatment\" = rgamma(10, 10, 1),\n \"Control\" = rgamma(10, 1, .01)\n)\ngather(dat, \"type\", \"response\") %>%\n ggplot(aes(type, response)) +\n geom_boxplot() +\n geom_point(position = \"jitter\")\n\n\n\n\n\n\nUse log scale if data includes outliers\nA version showing the data in the log-scale is much more informative.\n\ngather(dat, \"type\", \"response\") %>%\n ggplot(aes(type, response)) +\n geom_boxplot() +\n geom_point(position = \"jitter\") +\n scale_y_log10()\n\n\n\n\n\n\n\nBarplots for paired data\nA common task in data analysis is the comparison of two groups. When the dataset is small and data are paired, such as the outcomes before and after a treatment, two-color barplots are unfortunately often used to display the results.\n\n\nInstead of paired bar plots, try scatter plots\nThere are better ways of showing these data to illustrate that there is an increase after treatment. One is to simply make a scatter plot, which shows that most points are above the identity line. Another alternative is to plot the differences against the before values.\n\nset.seed(1000)\nbefore <- runif(6, 5, 8)\nafter <- rnorm(6, before * 1.15, 2)\nli <- range(c(before, after))\nymx <- max(abs(after - before))\n\npar(mfrow = c(1, 2))\nplot(before, after,\n xlab = \"Before\", ylab = \"After\",\n ylim = li, xlim = li\n)\nabline(0, 1, lty = 2, col = 1)\n\nplot(before, after - before,\n xlab = \"Before\", ylim = c(-ymx, ymx),\n ylab = \"Change (After - Before)\", lwd = 2\n)\nabline(h = 0, lty = 2, col = 1)\n\n\n\n\n\n\nor line plots\nLine plots are not a bad choice, although they can be harder to follow than the previous two. Boxplots show you the increase, but lose the paired information.\n\nz <- rep(c(0, 1), rep(6, 2))\npar(mfrow = c(1, 2))\nplot(z, c(before, after),\n xaxt = \"n\", ylab = \"Response\",\n xlab = \"\", xlim = c(-0.5, 1.5)\n)\naxis(side = 1, at = c(0, 1), c(\"Before\", \"After\"))\nsegments(rep(0, 6), before, rep(1, 6), after, col = 1)\n\nboxplot(before, after, names = c(\"Before\", \"After\"), ylab = \"Response\")\n\n\n\n\n\n\n\nGratuitous 3D\nThe figure below shows three curves. Pseudo 3D is used, but it is not clear why. Maybe to separate the three curves? Notice how difficult it is to determine the values of the curves at any given point:\n\nThis plot can be made better by simply using color to distinguish the three lines:\n\nx <- read_csv(\"https://github.com/kbroman/Talk_Graphs/raw/master/R/fig8dat.csv\") %>%\n as_tibble(.name_repair = make.names)\n\np <- x %>%\n gather(\"drug\", \"proportion\", -log.dose) %>%\n ggplot(aes(\n x = log.dose, y = proportion,\n color = drug\n )) +\n geom_line()\np\n\n\n\n\nThis plot demonstrates that using color is more than enough to distinguish the three lines.\nWe can make this plot better using the functions we learned above\n\np + ggtitle(\"Survival proportion\") +\n theme(\n plot.title = element_text(hjust = 0.5),\n text = element_text(size = 15)\n )\n\n\n\n\n\nLegends\nWe can also move the legend inside the plot\n\np + ggtitle(\"Survival proportion\") +\n theme(\n plot.title = element_text(hjust = 0.5),\n text = element_text(size = 15),\n legend.position = c(0.2, 0.3)\n )\n\n\n\n\nWe can also make the legend transparent\n\ntransparent_legend <- theme(\n legend.background = element_rect(fill = \"transparent\"),\n legend.key = element_rect(\n fill = \"transparent\",\n color = \"transparent\"\n )\n)\n\np + ggtitle(\"Survival proportion\") +\n theme(\n plot.title = element_text(hjust = 0.5),\n text = element_text(size = 15),\n legend.position = c(0.2, 0.3)\n ) +\n transparent_legend\n\n\n\n\n\n\n\nToo many significant digits\nBy default, statistical software like R returns many significant digits. This does not mean we should report them. Cutting and pasting directly from R is a bad idea since you might end up showing a table, such as the one below, comparing the heights of basketball players:\n\nheights <- cbind(\n rnorm(8, 73, 3), rnorm(8, 73, 3), rnorm(8, 80, 3),\n rnorm(8, 78, 3), rnorm(8, 78, 3)\n)\ncolnames(heights) <- c(\"SG\", \"PG\", \"C\", \"PF\", \"SF\")\nrownames(heights) <- paste(\"team\", 1:8)\nheights\n\n SG PG C PF SF\nteam 1 68.88065 73.07480 81.80948 76.60455 82.23521\nteam 2 70.05272 66.86024 74.64847 72.70140 78.55640\nteam 3 71.33653 73.63946 81.00483 78.56787 77.86893\nteam 4 73.36414 81.01021 81.68293 76.90146 77.35226\nteam 5 72.63738 69.31895 83.66281 81.17280 82.39133\nteam 6 68.99188 75.50274 79.36564 75.77514 78.68900\nteam 7 73.51017 74.59772 82.09829 73.95492 78.32287\nteam 8 73.46524 71.05953 77.88069 76.44808 73.86569\n\n\nWe are reporting precision up to 0.00001 inches. Do you know of a tape measure with that much precision? This can be easily remedied:\n\nround(heights, 1)\n\n SG PG C PF SF\nteam 1 68.9 73.1 81.8 76.6 82.2\nteam 2 70.1 66.9 74.6 72.7 78.6\nteam 3 71.3 73.6 81.0 78.6 77.9\nteam 4 73.4 81.0 81.7 76.9 77.4\nteam 5 72.6 69.3 83.7 81.2 82.4\nteam 6 69.0 75.5 79.4 75.8 78.7\nteam 7 73.5 74.6 82.1 74.0 78.3\nteam 8 73.5 71.1 77.9 76.4 73.9\n\n\n\n\nMinimal figure captions\nRecall the plot we had before:\n\ntransparent_legend <- theme(\n legend.background = element_rect(fill = \"transparent\"),\n legend.key = element_rect(\n fill = \"transparent\",\n color = \"transparent\"\n )\n)\n\np + ggtitle(\"Survival proportion\") +\n theme(\n plot.title = element_text(hjust = 0.5),\n text = element_text(size = 15),\n legend.position = c(0.2, 0.3)\n ) +\n xlab(\"dose (mg)\") +\n transparent_legend\n\n\n\n\nWhat type of caption would be good here?\nWhen creating figure captions, think about the following:\n\nBe specific\n\n\nA plot of the proportion of patients who survived after three drug treatments.\n\n\nLabel the caption\n\n\nFigure 1. A plot of the proportion of patients who survived after three drug treatments.\n\n\nTell a story\n\n\nFigure 1. Drug treatment survival. A plot of the proportion of patients who survived after three drug treatments.\n\n\nInclude units\n\n\nFigure 1. Drug treatment survival. A plot of the proportion of patients who survived after three drug treatments (milligram).\n\n\nExplain aesthetics\n\n\nFigure 1. Drug treatment survival. A plot of the proportion of patients who survived after three drug treatments (milligram). Three colors represent three drug treatments. Drug A results in largest survival proportion for the larger drug doses."
},
{
- "objectID": "posts/21-regular-expressions/index.html#sub",
- "href": "posts/21-regular-expressions/index.html#sub",
- "title": "21 - Regular expressions",
- "section": "sub()",
- "text": "sub()\nThe sub(pattern, replacement, x) function takes as arguments a regex, a “replacement,” and a vector of strings. This function will replace the first instance of that regex found in each string.\n\nsub(pattern = \"[Ii]\", replacement = \"1\", x = c(\"Hawaii\", \"Illinois\", \"Kentucky\"))\n\n[1] \"Hawa1i\" \"1llinois\" \"Kentucky\""
+ "objectID": "posts/24-best-practices-data-analyses/index.html#final-thoughts-data-viz",
+ "href": "posts/24-best-practices-data-analyses/index.html#final-thoughts-data-viz",
+ "title": "24 - Best practices for data analyses",
+ "section": "Final thoughts data viz",
+ "text": "Final thoughts data viz\nIn general, you should follow these principles:\n\nCreate expository graphs to tell a story (figure and caption should be self-sufficient; it’s the first thing people look at)\n\nBe accurate and clear\nLet the data speak\nMake axes, labels and titles big\nMake labels full names (ideally with units when appropriate)\nAdd informative legends; use space effectively\n\nShow as much information as possible, taking care not to obscure the message\nScience not sales: avoid unnecessary frills (especially gratuitous 3D)\nIn tables, every digit should be meaningful\n\n\nSome further reading\n\nN Cross (2011). Design Thinking: Understanding How Designers Think and Work. Bloomsbury Publishing.\nJ Tukey (1977). Exploratory Data Analysis.\nER Tufte (1983) The visual display of quantitative information. Graphics Press.\nER Tufte (1990) Envisioning information. Graphics Press.\nER Tufte (1997) Visual explanations. Graphics Press.\nER Tufte (2006) Beautiful Evidence. Graphics Press.\nWS Cleveland (1993) Visualizing data. Hobart Press.\nWS Cleveland (1994) The elements of graphing data. CRC Press.\nA Gelman, C Pasarica, R Dodhia (2002) Let’s practice what we preach: Turning tables into graphs. The American Statistician 56:121-130.\nNB Robbins (2004) Creating more effective graphs. Wiley.\nNature Methods columns"
},
{
- "objectID": "posts/21-regular-expressions/index.html#gsub",
- "href": "posts/21-regular-expressions/index.html#gsub",
- "title": "21 - Regular expressions",
- "section": "gsub()",
- "text": "gsub()\nThe gsub(pattern, replacement, x) function is nearly the same as sub() except it will replace every instance of the regex that is matched in each string.\n\ngsub(\"[Ii]\", \"1\", c(\"Hawaii\", \"Illinois\", \"Kentucky\"))\n\n[1] \"Hawa11\" \"1ll1no1s\" \"Kentucky\""
+ "objectID": "posts/08-managing-data-frames-with-tidyverse/index.html",
+ "href": "posts/08-managing-data-frames-with-tidyverse/index.html",
+ "title": "08 - Managing data frames with the Tidyverse",
+ "section": "",
+ "text": "This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history."
},
{
- "objectID": "posts/21-regular-expressions/index.html#strsplit",
- "href": "posts/21-regular-expressions/index.html#strsplit",
- "title": "21 - Regular expressions",
- "section": "strsplit()",
- "text": "strsplit()\nThe strsplit(x, split) function will split up strings (split) according to the provided regex (x) .\nIf strsplit() is provided with a vector of strings it will return a list of string vectors.\n\ntwo_s <- state.name[grep(\"ss\", state.name)]\ntwo_s\n\n[1] \"Massachusetts\" \"Mississippi\" \"Missouri\" \"Tennessee\" \n\nstrsplit(x = two_s, split = \"ss\")\n\n[[1]]\n[1] \"Ma\" \"achusetts\"\n\n[[2]]\n[1] \"Mi\" \"i\" \"ippi\"\n\n[[3]]\n[1] \"Mi\" \"ouri\"\n\n[[4]]\n[1] \"Tenne\" \"ee\""
+ "objectID": "posts/08-managing-data-frames-with-tidyverse/index.html#tibbles",
+ "href": "posts/08-managing-data-frames-with-tidyverse/index.html#tibbles",
+ "title": "08 - Managing data frames with the Tidyverse",
+ "section": "Tibbles",
+ "text": "Tibbles\nAnother type of data structure that we need to discuss is called the tibble! It’s best to think of tibbles as an updated and stylish version of the data.frame.\nTibbles are what tidyverse packages work with most seamlessly. Now, that does not mean tidyverse packages require tibbles.\nIn fact, they still work with data.frames, but the more you work with tidyverse and tidyverse-adjacent packages, the more you will see the advantages of using tibbles.\nBefore we go any further, tibbles are data frames, but they have some new bells and whistles to make your life easier.\n\nHow tibbles differ from data.frame\nThere are a number of differences between tibbles and data.frames.\n\n\n\n\n\n\nNote\n\n\n\nTo see a full vignette about tibbles and how they differ from data.frame, you will want to execute vignette(\"tibble\") and read through that vignette.\n\n\nWe will summarize some of the most important points here:\n\nInput type remains unchanged - data.frame is notorious for treating strings as factors; this will not happen with tibbles\nVariable names remain unchanged - In base R, creating data.frames will remove spaces from names, converting them to periods or add “x” before numeric column names. Creating tibbles will not change variable (column) names.\nThere are no row.names() for a tibble - Tidy data requires that variables be stored in a consistent way, removing the need for row names.\nTibbles print first ten rows and columns that fit on one screen - Printing a tibble to screen will never print the entire huge data frame out. By default, it just shows what fits to your screen."
},
{
- "objectID": "posts/21-regular-expressions/index.html#str_extract",
- "href": "posts/21-regular-expressions/index.html#str_extract",
- "title": "21 - Regular expressions",
- "section": "str_extract",
- "text": "str_extract\nThe str_extract(string, pattern) function returns the sub-string of a string (string) that matches the provided regular expression (pattern).\n\nlibrary(stringr)\nstate_tbl <- paste(state.name, state.area, state.abb)\nhead(state_tbl)\n\n[1] \"Alabama 51609 AL\" \"Alaska 589757 AK\" \"Arizona 113909 AZ\" \n[4] \"Arkansas 53104 AR\" \"California 158693 CA\" \"Colorado 104247 CO\" \n\nstr_extract(state_tbl, \"[0-9]+\")\n\n [1] \"51609\" \"589757\" \"113909\" \"53104\" \"158693\" \"104247\" \"5009\" \"2057\" \n [9] \"58560\" \"58876\" \"6450\" \"83557\" \"56400\" \"36291\" \"56290\" \"82264\" \n[17] \"40395\" \"48523\" \"33215\" \"10577\" \"8257\" \"58216\" \"84068\" \"47716\" \n[25] \"69686\" \"147138\" \"77227\" \"110540\" \"9304\" \"7836\" \"121666\" \"49576\" \n[33] \"52586\" \"70665\" \"41222\" \"69919\" \"96981\" \"45333\" \"1214\" \"31055\" \n[41] \"77047\" \"42244\" \"267339\" \"84916\" \"9609\" \"40815\" \"68192\" \"24181\" \n[49] \"56154\" \"97914\""
+ "objectID": "posts/08-managing-data-frames-with-tidyverse/index.html#creating-a-tibble",
+ "href": "posts/08-managing-data-frames-with-tidyverse/index.html#creating-a-tibble",
+ "title": "08 - Managing data frames with the Tidyverse",
+ "section": "Creating a tibble",
+ "text": "Creating a tibble\nThe tibble package is part of the tidyverse and can thus be loaded in (once installed) using:\n\nlibrary(tidyverse)\n\n\nas_tibble()\nSince many packages use the historical data.frame from base R, you will often find yourself in the situation that you have a data.frame and want to convert that data.frame to a tibble.\nTo do so, the as_tibble() function is exactly what you are looking for.\nFor the example, here we use a dataset (chicago.rds) containing air pollution and temperature data for the city of Chicago in the U.S.\nThe dataset is available in the /data repository. You can load the data into R using the readRDS() function.\n\nlibrary(here)\n\nhere() starts at /Users/leocollado/Dropbox/Code/jhustatcomputing2023\n\nchicago <- readRDS(here(\"data\", \"chicago.rds\"))\n\nYou can see some basic characteristics of the dataset with the dim() and str() functions.\n\ndim(chicago)\n\n[1] 6940 8\n\nstr(chicago)\n\n'data.frame': 6940 obs. of 8 variables:\n $ city : chr \"chic\" \"chic\" \"chic\" \"chic\" ...\n $ tmpd : num 31.5 33 33 29 32 40 34.5 29 26.5 32.5 ...\n $ dptp : num 31.5 29.9 27.4 28.6 28.9 ...\n $ date : Date, format: \"1987-01-01\" \"1987-01-02\" ...\n $ pm25tmean2: num NA NA NA NA NA NA NA NA NA NA ...\n $ pm10tmean2: num 34 NA 34.2 47 NA ...\n $ o3tmean2 : num 4.25 3.3 3.33 4.38 4.75 ...\n $ no2tmean2 : num 20 23.2 23.8 30.4 30.3 ...\n\n\nWe see this data structure is a data.frame with 6940 observations and 8 variables.\nTo convert this data.frame to a tibble you would use the following:\n\nstr(as_tibble(chicago))\n\ntibble [6,940 × 8] (S3: tbl_df/tbl/data.frame)\n $ city : chr [1:6940] \"chic\" \"chic\" \"chic\" \"chic\" ...\n $ tmpd : num [1:6940] 31.5 33 33 29 32 40 34.5 29 26.5 32.5 ...\n $ dptp : num [1:6940] 31.5 29.9 27.4 28.6 28.9 ...\n $ date : Date[1:6940], format: \"1987-01-01\" \"1987-01-02\" ...\n $ pm25tmean2: num [1:6940] NA NA NA NA NA NA NA NA NA NA ...\n $ pm10tmean2: num [1:6940] 34 NA 34.2 47 NA ...\n $ o3tmean2 : num [1:6940] 4.25 3.3 3.33 4.38 4.75 ...\n $ no2tmean2 : num [1:6940] 20 23.2 23.8 30.4 30.3 ...\n\n\n\n\n\n\n\n\nNote\n\n\n\nTibbles, by default, only print the first ten rows to screen.\nIf you were to print the data.frame chicago to screen, all 6940 rows would be displayed. When working with large data.frames, this default behavior can be incredibly frustrating.\nUsing tibbles removes this frustration because of the default settings for tibble printing.\n\n\nAdditionally, you will note that the type of the variable is printed for each variable in the tibble. This helpful feature is another added bonus of tibbles relative to data.frame.\n\nWant to see more of the tibble?\nIf you do want to see more rows from the tibble, there are a few options!\n\nThe View() function in RStudio is incredibly helpful. The input to this function is the data.frame or tibble you would like to see.\n\nSpecifically, View(chicago) would provide you, the viewer, with a scrollable view (in a new tab) of the complete dataset.\n\nUse the fact that print() enables you to specify how many rows and columns you would like to display.\n\nHere, we again display the chicago data.frame as a tibble but specify that we would only like to see 5 rows. The width = Inf argument specifies that we would like to see all the possible columns. Here, there are only 8, but for larger datasets, this can be helpful to specify.\n\nas_tibble(chicago) %>%\n print(n = 5, width = Inf)\n\n# A tibble: 6,940 × 8\n city tmpd dptp date pm25tmean2 pm10tmean2 o3tmean2 no2tmean2\n <chr> <dbl> <dbl> <date> <dbl> <dbl> <dbl> <dbl>\n1 chic 31.5 31.5 1987-01-01 NA 34 4.25 20.0\n2 chic 33 29.9 1987-01-02 NA NA 3.30 23.2\n3 chic 33 27.4 1987-01-03 NA 34.2 3.33 23.8\n4 chic 29 28.6 1987-01-04 NA 47 4.38 30.4\n5 chic 32 28.9 1987-01-05 NA NA 4.75 30.3\n# ℹ 6,935 more rows\n\n\n\n\n\ntibble()\nAlternatively, you can create a tibble on the fly by using tibble() and specifying the information you would like stored in each column.\n\n\n\n\n\n\nNote\n\n\n\nIf you provide a single value, this value will be repeated across all rows of the tibble. This is referred to as “recycling inputs of length 1.”\nIn the example here, we see that the column c will contain the value ‘1’ across all rows.\n\ntibble(\n a = 1:5,\n b = 6:10,\n c = 1,\n z = (a + b)^2 + c\n)\n\n# A tibble: 5 × 4\n a b c z\n <int> <int> <dbl> <dbl>\n1 1 6 1 50\n2 2 7 1 82\n3 3 8 1 122\n4 4 9 1 170\n5 5 10 1 226\n\n\n\n\nThe tibble() function allows you to quickly generate tibbles and even allows you to reference columns within the tibble you are creating, as seen in column z of the example above.\n\n\n\n\n\n\nNote\n\n\n\nTibbles can have column names that are not allowed in data.frame.\nIn the example below, we see that to utilize a nontraditional variable name, you surround the column name with backticks.\nNote that to refer to such columns in other tidyverse packages, you willl continue to use backticks surrounding the variable name.\n\ntibble(\n `two words` = 1:5,\n `12` = \"numeric\",\n `:)` = \"smile\",\n)\n\n# A tibble: 5 × 3\n `two words` `12` `:)` \n <int> <chr> <chr>\n1 1 numeric smile\n2 2 numeric smile\n3 3 numeric smile\n4 4 numeric smile\n5 5 numeric smile"
},
{
- "objectID": "posts/21-regular-expressions/index.html#str_detect",
- "href": "posts/21-regular-expressions/index.html#str_detect",
- "title": "21 - Regular expressions",
- "section": "str_detect",
- "text": "str_detect\nThe str_detect(string, pattern) is equivalent to grepl(pattern,x):\n\nstr_detect(state_tbl, \"[0-9]+\")\n\n [1] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE\n[16] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE\n[31] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE\n[46] TRUE TRUE TRUE TRUE TRUE\n\ngrepl(\"[0-9]+\", state_tbl)\n\n [1] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE\n[16] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE\n[31] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE\n[46] TRUE TRUE TRUE TRUE TRUE\n\n\nIt detects the presence or absence of a pattern in a string."
+ "objectID": "posts/08-managing-data-frames-with-tidyverse/index.html#subsetting-tibbles",
+ "href": "posts/08-managing-data-frames-with-tidyverse/index.html#subsetting-tibbles",
+ "title": "08 - Managing data frames with the Tidyverse",
+ "section": "Subsetting tibbles",
+ "text": "Subsetting tibbles\nSubsetting tibbles also differs slightly from how subsetting occurs with data.frame.\nWhen it comes to tibbles,\n\n[[ can subset by name or position\n$ only subsets by name\n\nFor example:\n\ndf <- tibble(\n a = 1:5,\n b = 6:10,\n c = 1,\n z = (a + b)^2 + c\n)\n\n# Extract by name using $ or [[]]\ndf$z\n\n[1] 50 82 122 170 226\n\ndf[[\"z\"]]\n\n[1] 50 82 122 170 226\n\n# Extract by position requires [[]]\ndf[[4]]\n\n[1] 50 82 122 170 226\n\n\nHaving now discussed tibbles, which are the type of object most tidyverse and tidyverse-adjacent packages work best with, we now know the goal.\nIn many cases, tibbles are ultimately what we want to work with in R.\nHowever, data are stored in many different formats outside of R. We will spend the rest of this lesson discussing wrangling functions that work either a data.frame or tibble."
},
{
- "objectID": "posts/21-regular-expressions/index.html#str_order",
- "href": "posts/21-regular-expressions/index.html#str_order",
- "title": "21 - Regular expressions",
- "section": "str_order",
- "text": "str_order\nThe str_order(x) function returns a numeric vector that corresponds to the alphabetical order of the strings in the provided vector (x).\n\nhead(state.name)\n\n[1] \"Alabama\" \"Alaska\" \"Arizona\" \"Arkansas\" \"California\"\n[6] \"Colorado\" \n\nstr_order(state.name)\n\n [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25\n[26] 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50\n\nhead(state.abb)\n\n[1] \"AL\" \"AK\" \"AZ\" \"AR\" \"CA\" \"CO\"\n\nstr_order(state.abb)\n\n [1] 2 1 4 3 5 6 7 8 9 10 11 15 12 13 14 16 17 18 21 20 19 22 23 25 24\n[26] 26 33 34 27 29 30 31 28 32 35 36 37 38 39 40 41 42 43 44 46 45 47 49 48 50"
+ "objectID": "posts/07-reading-and-writing-data/index.html",
+ "href": "posts/07-reading-and-writing-data/index.html",
+ "title": "07 - Reading and Writing data",
+ "section": "",
+ "text": "This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history.\n[Source]"
},
{
- "objectID": "posts/21-regular-expressions/index.html#str_replace",
- "href": "posts/21-regular-expressions/index.html#str_replace",
- "title": "21 - Regular expressions",
- "section": "str_replace",
- "text": "str_replace\nThe str_replace(string, pattern, replace) is equivalent to sub(pattern, replacement, x):\n\nstr_replace(string = state.name, pattern = \"[Aa]\", replace = \"B\")\n\n [1] \"Blabama\" \"Blaska\" \"Brizona\" \"Brkansas\" \n [5] \"CBlifornia\" \"ColorBdo\" \"Connecticut\" \"DelBware\" \n [9] \"FloridB\" \"GeorgiB\" \"HBwaii\" \"IdBho\" \n[13] \"Illinois\" \"IndiBna\" \"IowB\" \"KBnsas\" \n[17] \"Kentucky\" \"LouisiBna\" \"MBine\" \"MBryland\" \n[21] \"MBssachusetts\" \"MichigBn\" \"MinnesotB\" \"Mississippi\" \n[25] \"Missouri\" \"MontBna\" \"NebrBska\" \"NevBda\" \n[29] \"New HBmpshire\" \"New Jersey\" \"New Mexico\" \"New York\" \n[33] \"North CBrolina\" \"North DBkota\" \"Ohio\" \"OklBhoma\" \n[37] \"Oregon\" \"PennsylvBnia\" \"Rhode IslBnd\" \"South CBrolina\"\n[41] \"South DBkota\" \"Tennessee\" \"TexBs\" \"UtBh\" \n[45] \"Vermont\" \"VirginiB\" \"WBshington\" \"West VirginiB\" \n[49] \"Wisconsin\" \"Wyoming\" \n\nsub(pattern = \"[Aa]\", replacement = \"B\", x = state.name)\n\n [1] \"Blabama\" \"Blaska\" \"Brizona\" \"Brkansas\" \n [5] \"CBlifornia\" \"ColorBdo\" \"Connecticut\" \"DelBware\" \n [9] \"FloridB\" \"GeorgiB\" \"HBwaii\" \"IdBho\" \n[13] \"Illinois\" \"IndiBna\" \"IowB\" \"KBnsas\" \n[17] \"Kentucky\" \"LouisiBna\" \"MBine\" \"MBryland\" \n[21] \"MBssachusetts\" \"MichigBn\" \"MinnesotB\" \"Mississippi\" \n[25] \"Missouri\" \"MontBna\" \"NebrBska\" \"NevBda\" \n[29] \"New HBmpshire\" \"New Jersey\" \"New Mexico\" \"New York\" \n[33] \"North CBrolina\" \"North DBkota\" \"Ohio\" \"OklBhoma\" \n[37] \"Oregon\" \"PennsylvBnia\" \"Rhode IslBnd\" \"South CBrolina\"\n[41] \"South DBkota\" \"Tennessee\" \"TexBs\" \"UtBh\" \n[45] \"Vermont\" \"VirginiB\" \"WBshington\" \"West VirginiB\" \n[49] \"Wisconsin\" \"Wyoming\""
+ "objectID": "posts/07-reading-and-writing-data/index.html#txt-or-csv",
+ "href": "posts/07-reading-and-writing-data/index.html#txt-or-csv",
+ "title": "07 - Reading and Writing data",
+ "section": "txt or csv",
+ "text": "txt or csv\nThere are a few primary functions reading data from base R.\n\nread.table(), read.csv(): for reading tabular data\nreadLines(): for reading lines of a text file\n\nThere are analogous functions for writing data to files\n\nwrite.table(): for writing tabular data to text files (i.e. CSV) or connections\nwriteLines(): for writing character data line-by-line to a file or connection\n\nLet’s try reading some data into R with the read.csv() function.\n\ndf <- read.csv(here(\"data\", \"team_standings.csv\"))\ndf\n\n Standing Team\n1 1 Spain\n2 2 Netherlands\n3 3 Germany\n4 4 Uruguay\n5 5 Argentina\n6 6 Brazil\n7 7 Ghana\n8 8 Paraguay\n9 9 Japan\n10 10 Chile\n11 11 Portugal\n12 12 USA\n13 13 England\n14 14 Mexico\n15 15 South Korea\n16 16 Slovakia\n17 17 Ivory Coast\n18 18 Slovenia\n19 19 Switzerland\n20 20 South Africa\n21 21 Australia\n22 22 New Zealand\n23 23 Serbia\n24 24 Denmark\n25 25 Greece\n26 26 Italy\n27 27 Nigeria\n28 28 Algeria\n29 29 France\n30 30 Honduras\n31 31 Cameroon\n32 32 North Korea\n\n\nWe can use the $ symbol to pick out a specific column:\n\ndf$Team\n\n [1] \"Spain\" \"Netherlands\" \"Germany\" \"Uruguay\" \"Argentina\" \n [6] \"Brazil\" \"Ghana\" \"Paraguay\" \"Japan\" \"Chile\" \n[11] \"Portugal\" \"USA\" \"England\" \"Mexico\" \"South Korea\" \n[16] \"Slovakia\" \"Ivory Coast\" \"Slovenia\" \"Switzerland\" \"South Africa\"\n[21] \"Australia\" \"New Zealand\" \"Serbia\" \"Denmark\" \"Greece\" \n[26] \"Italy\" \"Nigeria\" \"Algeria\" \"France\" \"Honduras\" \n[31] \"Cameroon\" \"North Korea\" \n\n\nWe can also ask for the full paths for specific files\n\nhere(\"data\", \"team_standings.csv\")\n\n[1] \"/Users/leocollado/Dropbox/Code/jhustatcomputing2023/data/team_standings.csv\"\n\n\n\n\n\n\n\n\nQuestions\n\n\n\n\nWhat happens when you use readLines() function with the team_standings.csv data?\nHow would you only read in the first 5 lines?"
},
{
- "objectID": "posts/21-regular-expressions/index.html#str_pad",
- "href": "posts/21-regular-expressions/index.html#str_pad",
- "title": "21 - Regular expressions",
- "section": "str_pad",
- "text": "str_pad\nThe str_pad(string, width, side, pad) function pads strings (string) with other characters, which is often useful when the string is going to be eventually printed for a person to read.\n\nstr_pad(\"Thai\", width = 8, side = \"left\", pad = \"-\")\n\n[1] \"----Thai\"\n\nstr_pad(\"Thai\", width = 8, side = \"right\", pad = \"-\")\n\n[1] \"Thai----\"\n\nstr_pad(\"Thai\", width = 8, side = \"both\", pad = \"-\")\n\n[1] \"--Thai--\"\n\n\nThe str_to_title(string) function acts just like tolower() and toupper() except it puts strings into Title Case.\n\ncases <- c(\"CAPS\", \"low\", \"Title\")\nstr_to_title(cases)\n\n[1] \"Caps\" \"Low\" \"Title\""
+ "objectID": "posts/07-reading-and-writing-data/index.html#r-code",
+ "href": "posts/07-reading-and-writing-data/index.html#r-code",
+ "title": "07 - Reading and Writing data",
+ "section": "R code",
+ "text": "R code\nSometimes, someone will give you a file that ends in a .R.\nThis is what’s called an R script file. It may contain code someone has written (maybe even you!), for example, a function that you can use with your data. In this case, you want the function available for you to use.\nTo use the function, you have to first, read in the function from R script file into R.\nYou can check to see if the function already is loaded in R by looking at the Environment tab.\nThe function you want to use is\n\nsource(): for reading in R code files\n\nFor example, it might be something like this:\n\nsource(here::here(\"functions.R\"))"
},
{
- "objectID": "posts/21-regular-expressions/index.html#str_trim",
- "href": "posts/21-regular-expressions/index.html#str_trim",
- "title": "21 - Regular expressions",
- "section": "str_trim",
- "text": "str_trim\nThe str_trim(string) function deletes white space from both sides of a string.\n\nto_trim <- c(\" space\", \"the \", \" final frontier \")\nstr_trim(to_trim)\n\n[1] \"space\" \"the\" \"final frontier\""
+ "objectID": "posts/07-reading-and-writing-data/index.html#r-objects",
+ "href": "posts/07-reading-and-writing-data/index.html#r-objects",
+ "title": "07 - Reading and Writing data",
+ "section": "R objects",
+ "text": "R objects\nAlternatively, you might be interested in reading and writing R objects.\nWriting data in e.g. .txt, .csv or Excel file formats is good if you want to open these files with other analysis software, such as Excel. However, these formats do not preserve data structures, such as column data types (numeric, character or factor). In order to do that, the data should be written out in a R data format.\nThere are several types R data file formats to be aware of:\n\n.RData: Stores multiple R objects\n.Rda: This is short for .RData and is equivalent.\n.Rds: Stores a single R object\n\n\n\n\n\n\n\nQuestion\n\n\n\nWhy is saving data in as a R object useful?\nSaving data into R data formats can typically reduce considerably the size of large files by compression.\n\n\nNext, we will learn how to read and save\n\nA single R object\nMultiple R objects\nYour entire work space in a specified file\n\n\nReading in data from files\n\nload(): for reading in single or multiple R objects (opposite of save()) with a .Rda or .RData file format (objects must be same name)\nreadRDS(): for reading in a single object with a .Rds file format (can rename objects)\nunserialize(): for reading single R objects in binary form\n\n\n\nWriting data to files\n\nsave(): for saving an arbitrary number of R objects in binary format (possibly compressed) to a file.\nsaveRDS(): for saving a single object\nserialize(): for converting an R object into a binary format for outputting to a connection (or file).\nsave.image(): short for ‘save my current workspace’; while this sounds nice, it’s not terribly useful for reproducibility (hence not suggested); it’s also what happens when you try to quit R and it asks if you want to save your work space.\n\n\n\n\n\n\nSave data into R data file formats: RDS and RDATA\n\n\n\n\n[Source]\n\n\nExample\nLet’s try an example. Let’s save a vector of length 5 into the two file formats.\n\nx <- 1:5\nsave(x, file = here(\"data\", \"x.Rda\"))\nsaveRDS(x, file = here(\"data\", \"x.Rds\"))\nlist.files(path = here(\"data\"))\n\n [1] \"2016-07-19.csv.bz2\" \"b_lyrics.RDS\" \n [3] \"bmi_pm25_no2_sim.csv\" \"chicago.rds\" \n [5] \"chocolate.RDS\" \"flights.csv\" \n [7] \"maacs_sim.csv\" \"sales.RDS\" \n [9] \"storms_2004.csv.gz\" \"team_standings.csv\" \n[11] \"ts_lyrics.RDS\" \"tuesdata_rainfall.RDS\" \n[13] \"tuesdata_temperature.RDS\" \"x.Rda\" \n[15] \"x.Rds\" \n\n\nHere we assign the imported data to an object using readRDS()\n\nnew_x1 <- readRDS(here(\"data\", \"x.Rds\"))\nnew_x1\n\n[1] 1 2 3 4 5\n\n\nHere we assign the imported data to an object using load()\n\nnew_x2 <- load(here(\"data\", \"x.Rda\"))\nnew_x2\n\n[1] \"x\"\n\n\n\n\n\n\n\n\nNote\n\n\n\nload() simply returns the name of the objects loaded. Not the values.\n\n\nLet’s clean up our space.\n\nfile.remove(here(\"data\", \"x.Rda\"))\n\n[1] TRUE\n\nfile.remove(here(\"data\", \"x.Rds\"))\n\n[1] TRUE\n\nrm(x)\n\n\n\n\n\n\n\nQuestion\n\n\n\nWhat do you think this code will do?\nHint: change eval=TRUE to see result\n\nx <- 1:5\ny <- x^2\nsave(x, y, file = here(\"data\", \"x.Rda\"))\nnew_x2 <- load(here(\"data\", \"x.Rda\"))\n\nWhen you are done:\n\nfile.remove(here(\"data\", \"x.Rda\"))"
},
{
- "objectID": "posts/21-regular-expressions/index.html#str_wrap",
- "href": "posts/21-regular-expressions/index.html#str_wrap",
- "title": "21 - Regular expressions",
- "section": "str_wrap",
- "text": "str_wrap\nThe str_wrap(string) function inserts newlines in strings so that when the string is printed each line’s length is limited.\n\npasted_states <- paste(state.name[1:20], collapse = \" \")\n\ncat(str_wrap(pasted_states, width = 80))\n\nAlabama Alaska Arizona Arkansas California Colorado Connecticut Delaware Florida\nGeorgia Hawaii Idaho Illinois Indiana Iowa Kansas Kentucky Louisiana Maine\nMaryland\n\ncat(str_wrap(pasted_states, width = 30))\n\nAlabama Alaska Arizona\nArkansas California Colorado\nConnecticut Delaware Florida\nGeorgia Hawaii Idaho Illinois\nIndiana Iowa Kansas Kentucky\nLouisiana Maine Maryland"
+ "objectID": "posts/07-reading-and-writing-data/index.html#other-data-types",
+ "href": "posts/07-reading-and-writing-data/index.html#other-data-types",
+ "title": "07 - Reading and Writing data",
+ "section": "Other data types",
+ "text": "Other data types\nNow, there are of course, many R packages that have been developed to read in all kinds of other datasets, and you may need to resort to one of these packages if you are working in a specific area.\nFor example, check out\n\nDBI for relational databases\nhaven for SPSS, Stata, and SAS data\nhttr for web APIs\nreadxl for .xls and .xlsx sheets\ngooglesheets4 for Google Sheets\ngoogledrive for Google Drive files\nrvest for web scraping\njsonlite for JSON\nxml2 for XML."
},
{
- "objectID": "posts/21-regular-expressions/index.html#word",
- "href": "posts/21-regular-expressions/index.html#word",
- "title": "21 - Regular expressions",
- "section": "word",
- "text": "word\nThe word() function allows you to index each word in a string as if it were a vector.\n\na_tale <- \"It was the best of times it was the worst of times it was the age of wisdom it was the age of foolishness\"\n\nword(a_tale, 2)\n\n[1] \"was\"\n\nword(a_tale, end = 3) # end = last word to extract\n\n[1] \"It was the\"\n\nword(a_tale, start = 11, end = 15) # start = first word to extract\n\n[1] \"of times it was the\""
+ "objectID": "posts/07-reading-and-writing-data/index.html#reading-data-files-with-read.table",
+ "href": "posts/07-reading-and-writing-data/index.html#reading-data-files-with-read.table",
+ "title": "07 - Reading and Writing data",
+ "section": "Reading data files with read.table()",
+ "text": "Reading data files with read.table()\n\n\nFor details on reading data with read.table(), click here.\n\nThe read.table() function is one of the most commonly used functions for reading data. The help file for read.table() is worth reading in its entirety if only because the function gets used a lot (run ?read.table in R).\nI know, I know, everyone always says to read the help file, but this one is actually worth reading.\nThe read.table() function has a few important arguments:\n\nfile, the name of a file, or a connection\nheader, logical indicating if the file has a header line\nsep, a string indicating how the columns are separated\ncolClasses, a character vector indicating the class of each column in the dataset\nnrows, the number of rows in the dataset. By default read.table() reads an entire file.\ncomment.char, a character string indicating the comment character. This defaults to \"#\". If there are no commented lines in your file, it’s worth setting this to be the empty string \"\".\nskip, the number of lines to skip from the beginning\nstringsAsFactors, should character variables be coded as factors? This defaults to FALSE. However, back in the “old days”, it defaulted to TRUE. The reason for this was because, if you had data that were stored as strings, it was because those strings represented levels of a categorical variable. Now, we have lots of data that is text data and they do not always represent categorical variables. So you may want to set this to be FALSE in those cases. If you always want this to be FALSE, you can set a global option via options(stringsAsFactors = FALSE).\n\nI’ve never seen so much heat generated on discussion forums about an R function argument than the stringsAsFactors argument. Seriously.\nFor small to moderately sized datasets, you can usually call read.table() without specifying any other arguments\n\ndata <- read.table(\"foo.txt\")\n\n\n\n\n\n\n\nNote\n\n\n\nfoo.txt is not a real dataset here. It is only used as an example for how to use read.table()\n\n\nIn this case, R will automatically:\n\nskip lines that begin with a #\nfigure out how many rows there are (and how much memory needs to be allocated)\nfigure what type of variable is in each column of the table.\n\nTelling R all these things directly makes R run faster and more efficiently.\n\n\n\n\n\n\nNote\n\n\n\nThe read.csv() function is identical to read.table() except that some of the defaults are set differently (like the sep argument)."
},
{
- "objectID": "posts/17-loop-functions/index.html",
- "href": "posts/17-loop-functions/index.html",
- "title": "17 - Vectorization and loop functionals",
- "section": "",
- "text": "This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history."
+ "objectID": "posts/07-reading-and-writing-data/index.html#reading-in-larger-datasets-with-read.table",
+ "href": "posts/07-reading-and-writing-data/index.html#reading-in-larger-datasets-with-read.table",
+ "title": "07 - Reading and Writing data",
+ "section": "Reading in larger datasets with read.table()",
+ "text": "Reading in larger datasets with read.table()\n\n\nFor details on reading larger datasets with read.table(), click here.\n\nWith much larger datasets, there are a few things that you can do that will make your life easier and will prevent R from choking.\n\nRead the help page for read.table(), which contains many hints\nMake a rough calculation of the memory required to store your dataset (see the next section for an example of how to do this). If the dataset is larger than the amount of RAM on your computer, you can probably stop right here.\nSet comment.char = \"\" if there are no commented lines in your file.\nUse the colClasses argument. Specifying this option instead of using the default can make read.table() run MUCH faster, often twice as fast. In order to use this option, you have to know the class of each column in your data frame. If all of the columns are “numeric”, for example, then you can just set colClasses = \"numeric\". A quick an dirty way to figure out the classes of each column is the following:\n\n\ninitial <- read.table(\"datatable.txt\", nrows = 100)\nclasses <- sapply(initial, class)\ntabAll <- read.table(\"datatable.txt\", colClasses = classes)\n\nNote: datatable.txt is not a real dataset here. It is only used as an example for how to use read.table().\n\nSet nrows. This does not make R run faster but it helps with memory usage. A mild overestimate is okay. You can use the Unix tool wc to calculate the number of lines in a file.\n\nIn general, when using R with larger datasets, it’s also useful to know a few things about your system.\n\nHow much memory is available on your system?\nWhat other applications are in use? Can you close any of them?\nAre there other users logged into the same system?\nWhat operating system ar you using? Some operating systems can limit the amount of memory a single process can access"
},
{
- "objectID": "posts/17-loop-functions/index.html#vector-arithmetics",
- "href": "posts/17-loop-functions/index.html#vector-arithmetics",
- "title": "17 - Vectorization and loop functionals",
- "section": "Vector arithmetics",
- "text": "Vector arithmetics\n\nRescaling a vector\nIn R, arithmetic operations on vectors occur element-wise. For a quick example, suppose we have height in inches:\n\ninches <- c(69, 62, 66, 70, 70, 73, 67, 73, 67, 70)\n\nand want to convert to centimeters.\nNotice what happens when we multiply inches by 2.54:\n\ninches * 2.54\n\n [1] 175.26 157.48 167.64 177.80 177.80 185.42 170.18 185.42 170.18 177.80\n\n\nIn the line above, we multiplied each element by 2.54.\nSimilarly, if for each entry we want to compute how many inches taller or shorter than 69 inches (the average height for males), we can subtract it from every entry like this:\n\ninches - 69\n\n [1] 0 -7 -3 1 1 4 -2 4 -2 1\n\n\n\n\nTwo vectors\nIf we have two vectors of the same length, and we sum them in R, they will be added entry by entry as follows:\n\nx <- 1:10\ny <- 1:10\nx + y\n\n [1] 2 4 6 8 10 12 14 16 18 20\n\n\nThe same holds for other mathematical operations, such as -, * and /.\n\nx <- 1:10\nsqrt(x)\n\n [1] 1.000000 1.414214 1.732051 2.000000 2.236068 2.449490 2.645751 2.828427\n [9] 3.000000 3.162278\n\n\n\ny <- 1:10\nx * y\n\n [1] 1 4 9 16 25 36 49 64 81 100"
+ "objectID": "posts/07-reading-and-writing-data/index.html#advantages",
+ "href": "posts/07-reading-and-writing-data/index.html#advantages",
+ "title": "07 - Reading and Writing data",
+ "section": "Advantages",
+ "text": "Advantages\nThe advantage of the read_csv() function is perhaps better understood from an historical perspective.\n\nR’s built in read.csv() function similarly reads CSV files, but the read_csv() function in readr builds on that by removing some of the quirks and “gotchas” of read.csv() as well as dramatically optimizing the speed with which it can read data into R.\nThe read_csv() function also adds some nice user-oriented features like a progress meter and a compact method for specifying column types."
},
{
- "objectID": "posts/17-loop-functions/index.html#lapply",
- "href": "posts/17-loop-functions/index.html#lapply",
- "title": "17 - Vectorization and loop functionals",
- "section": "lapply()",
- "text": "lapply()\nThe lapply() function does the following simple series of operations:\n\nit loops over a list, iterating over each element in that list\nit applies a function to each element of the list (a function that you specify)\nand returns a list (the l in lapply() is for “list”).\n\nThis function takes three arguments: (1) a list X; (2) a function (or the name of a function) FUN; (3) other arguments via its ... argument. If X is not a list, it will be coerced to a list using as.list().\nThe body of the lapply() function can be seen here.\n\nlapply\n\nfunction (X, FUN, ...) \n{\n FUN <- match.fun(FUN)\n if (!is.vector(X) || is.object(X)) \n X <- as.list(X)\n .Internal(lapply(X, FUN))\n}\n<bytecode: 0x12d9335d0>\n<environment: namespace:base>\n\n\n\n\n\n\n\n\nNote\n\n\n\nThe actual looping is done internally in C code for efficiency reasons.\n\n\nIt is important to remember that lapply() always returns a list, regardless of the class of the input.\n\n\n\n\n\n\nExample\n\n\n\nHere’s an example of applying the mean() function to all elements of a list. If the original list has names, the the names will be preserved in the output.\n\nx <- list(a = 1:5, b = rnorm(10))\nx\n\n$a\n[1] 1 2 3 4 5\n\n$b\n [1] -0.6113707 0.5950531 0.6319343 0.5595441 0.3188799 -0.4400711\n [7] 1.6687028 0.4501791 1.4356856 -0.3858270\n\nlapply(x, mean)\n\n$a\n[1] 3\n\n$b\n[1] 0.422271\n\n\nNotice that here we are passing the mean() function as an argument to the lapply() function.\n\n\nFunctions in R can be used this way and can be passed back and forth as arguments just like any other object inR.\nWhen you pass a function to another function, you do not need to include the open and closed parentheses () like you do when you are calling a function.\n\n\n\n\n\n\nExample\n\n\n\nHere is another example of using lapply().\n\nx <- list(a = 1:4, b = rnorm(10), c = rnorm(20, 1), d = rnorm(100, 5))\nlapply(x, mean)\n\n$a\n[1] 2.5\n\n$b\n[1] 0.1655327\n\n$c\n[1] 0.9767504\n\n$d\n[1] 4.951283\n\n\n\n\nYou can use lapply() to evaluate a function multiple times each with a different argument.\nNext is an example where I call the runif() function (to generate uniformly distributed random variables) four times, each time generating a different number of random numbers.\n\nx <- 1:4\nlapply(x, runif)\n\n[[1]]\n[1] 0.5924944\n\n[[2]]\n[1] 0.8660588 0.3277243\n\n[[3]]\n[1] 0.5009080 0.2951163 0.6264905\n\n[[4]]\n[1] 0.04282267 0.14951908 0.82034538 0.64614463\n\n\n\n\n\n\n\n\nWhat happened?\n\n\n\nWhen you pass a function to lapply(), lapply() takes elements of the list and passes them as the first argument of the function you are applying.\nIn the above example, the first argument of runif() is n, and so the elements of the sequence 1:4 all got passed to the n argument of runif().\n\n\nFunctions that you pass to lapply() may have other arguments. For example, the runif() function has a min and max argument too.\n\n\n\n\n\n\nQuestion\n\n\n\nIn the example above I used the default values for min and max.\n\nHow would you be able to specify different values for that in the context of lapply()?\n\n\n\nHere is where the ... argument to lapply() comes into play. Any arguments that you place in the ... argument will get passed down to the function being applied to the elements of the list.\nHere, the min = 0 and max = 10 arguments are passed down to runif() every time it gets called.\n\nx <- 1:4\nlapply(x, runif, min = 0, max = 10)\n\n[[1]]\n[1] 5.653385\n\n[[2]]\n[1] 8.325503 7.234466\n\n[[3]]\n[1] 5.968981 9.174316 7.920678\n\n[[4]]\n[1] 9.491500 3.023649 2.990945 8.757496\n\n\nSo now, instead of the random numbers being between 0 and 1 (the default), the are all between 0 and 10.\nThe lapply() function (and its friends) makes heavy use of anonymous functions. Anonymous functions are like members of Project Mayhem—they have no names. These functions are generated “on the fly” as you are using lapply(). Once the call to lapply() is finished, the function disappears and does not appear in the workspace.\n\n\n\n\n\n\nExample\n\n\n\nHere I am creating a list that contains two matrices.\n\nx <- list(a = matrix(1:4, 2, 2), b = matrix(1:6, 3, 2))\nx\n\n$a\n [,1] [,2]\n[1,] 1 3\n[2,] 2 4\n\n$b\n [,1] [,2]\n[1,] 1 4\n[2,] 2 5\n[3,] 3 6\n\n\nSuppose I wanted to extract the first column of each matrix in the list. I could write an anonymous function for extracting the first column of each matrix.\n\nlapply(x, function(elt) {\n elt[, 1]\n})\n\n$a\n[1] 1 2\n\n$b\n[1] 1 2 3\n\n\nNotice that I put the function() definition right in the call to lapply().\n\n\nThis is perfectly legal and acceptable. You can put an arbitrarily complicated function definition inside lapply(), but if it’s going to be more complicated, it’s probably a better idea to define the function separately.\nFor example, I could have done the following.\n\nf <- function(elt) {\n elt[, 1]\n}\nlapply(x, f)\n\n$a\n[1] 1 2\n\n$b\n[1] 1 2 3\n\n\n\n\n\n\n\n\nNote\n\n\n\nNow the function is no longer anonymous; its name is f.\n\n\nWhether you use an anonymous function or you define a function first depends on your context. If you think the function f is something you are going to need a lot in other parts of your code, you might want to define it separately. But if you are just going to use it for this call to lapply(), then it is probably simpler to use an anonymous function."
+ "objectID": "posts/07-reading-and-writing-data/index.html#example-1",
+ "href": "posts/07-reading-and-writing-data/index.html#example-1",
+ "title": "07 - Reading and Writing data",
+ "section": "Example",
+ "text": "Example\nA typical call to read_csv() will look as follows.\n\nlibrary(readr)\nteams <- read_csv(here(\"data\", \"team_standings.csv\"))\n\nRows: 32 Columns: 2\n── Column specification ────────────────────────────────────────────────────────\nDelimiter: \",\"\nchr (1): Team\ndbl (1): Standing\n\nℹ Use `spec()` to retrieve the full column specification for this data.\nℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.\n\nteams\n\n# A tibble: 32 × 2\n Standing Team \n <dbl> <chr> \n 1 1 Spain \n 2 2 Netherlands\n 3 3 Germany \n 4 4 Uruguay \n 5 5 Argentina \n 6 6 Brazil \n 7 7 Ghana \n 8 8 Paraguay \n 9 9 Japan \n10 10 Chile \n# ℹ 22 more rows\n\n\nBy default, read_csv() will open a CSV file and read it in line-by-line. Similar to read.table(), you can tell the function to skip lines or which lines are comments:\n\nread_csv(\"The first line of metadata\n The second line of metadata\n x,y,z\n 1,2,3\",\n skip = 2\n)\n\nRows: 1 Columns: 3\n── Column specification ────────────────────────────────────────────────────────\nDelimiter: \",\"\ndbl (3): x, y, z\n\nℹ Use `spec()` to retrieve the full column specification for this data.\nℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.\n\n\n# A tibble: 1 × 3\n x y z\n <dbl> <dbl> <dbl>\n1 1 2 3\n\n\nAlternatively, you can use the comment argument:\n\nread_csv(\"# A comment I want to skip\n x,y,z\n 1,2,3\",\n comment = \"#\"\n)\n\nRows: 1 Columns: 3\n── Column specification ────────────────────────────────────────────────────────\nDelimiter: \",\"\ndbl (3): x, y, z\n\nℹ Use `spec()` to retrieve the full column specification for this data.\nℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.\n\n\n# A tibble: 1 × 3\n x y z\n <dbl> <dbl> <dbl>\n1 1 2 3\n\n\nIt will also (by default), read in the first few rows of the table in order to figure out the type of each column (i.e. integer, character, etc.). From the read_csv() help page:\n\nIf ‘NULL’, all column types will be imputed from the first 1000 rows on the input. This is convenient (and fast), but not robust. If the imputation fails, you’ll need to supply the correct types yourself.\n\nYou can specify the type of each column with the col_types argument.\n\n\n\n\n\n\nNote\n\n\n\nIn general, it is a good idea to specify the column types explicitly.\nThis rules out any possible guessing errors on the part of read_csv().\nAlso, specifying the column types explicitly provides a useful safety check in case anything about the dataset should change without you knowing about it.\n\n\nHere is an example of how to specify the column types explicitly:\n\nteams <- read_csv(here(\"data\", \"team_standings.csv\"),\n col_types = \"cc\"\n)\n\nNote that the col_types argument accepts a compact representation. Here \"cc\" indicates that the first column is character and the second column is character (there are only two columns). Using the col_types argument is useful because often it is not easy to automatically figure out the type of a column by looking at a few rows (especially if a column has many missing values).\n\n\n\n\n\n\nNote\n\n\n\nThe read_csv() function will also read compressed files automatically.\nThere is no need to decompress the file first or use the gzfile connection function.\n\n\nThe following call reads a gzip-compressed CSV file containing download logs from the RStudio CRAN mirror.\n\nlogs <- read_csv(here(\"data\", \"2016-07-19.csv.bz2\"),\n n_max = 10\n)\n\nRows: 10 Columns: 10\n── Column specification ────────────────────────────────────────────────────────\nDelimiter: \",\"\nchr (6): r_version, r_arch, r_os, package, version, country\ndbl (2): size, ip_id\ndate (1): date\ntime (1): time\n\nℹ Use `spec()` to retrieve the full column specification for this data.\nℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.\n\n\nNote that the warnings indicate that read_csv() may have had some difficulty identifying the type of each column. This can be solved by using the col_types argument.\n\nlogs <- read_csv(here(\"data\", \"2016-07-19.csv.bz2\"),\n col_types = \"ccicccccci\",\n n_max = 10\n)\nlogs\n\n# A tibble: 10 × 10\n date time size r_version r_arch r_os package version country ip_id\n <chr> <chr> <int> <chr> <chr> <chr> <chr> <chr> <chr> <int>\n 1 2016-07-19 22:00… 1.89e6 3.3.0 x86_64 ming… data.t… 1.9.6 US 1\n 2 2016-07-19 22:00… 4.54e4 3.3.1 x86_64 ming… assert… 0.1 US 2\n 3 2016-07-19 22:00… 1.43e7 3.3.1 x86_64 ming… stringi 1.1.1 DE 3\n 4 2016-07-19 22:00… 1.89e6 3.3.1 x86_64 ming… data.t… 1.9.6 US 4\n 5 2016-07-19 22:00… 3.90e5 3.3.1 x86_64 ming… foreach 1.4.3 US 4\n 6 2016-07-19 22:00… 4.88e4 3.3.1 x86_64 linu… tree 1.0-37 CO 5\n 7 2016-07-19 22:00… 5.25e2 3.3.1 x86_64 darw… surviv… 2.39-5 US 6\n 8 2016-07-19 22:00… 3.23e6 3.3.1 x86_64 ming… Rcpp 0.12.5 US 2\n 9 2016-07-19 22:00… 5.56e5 3.3.1 x86_64 ming… tibble 1.1 US 2\n10 2016-07-19 22:00… 1.52e5 3.3.1 x86_64 ming… magrit… 1.5 US 2\n\n\nYou can specify the column type in a more detailed fashion by using the various col_*() functions.\nFor example, in the log data above, the first column is actually a date, so it might make more sense to read it in as a Date object.\nIf we wanted to just read in that first column, we could do\n\nlogdates <- read_csv(here(\"data\", \"2016-07-19.csv.bz2\"),\n col_types = cols_only(date = col_date()),\n n_max = 10\n)\nlogdates\n\n# A tibble: 10 × 1\n date \n <date> \n 1 2016-07-19\n 2 2016-07-19\n 3 2016-07-19\n 4 2016-07-19\n 5 2016-07-19\n 6 2016-07-19\n 7 2016-07-19\n 8 2016-07-19\n 9 2016-07-19\n10 2016-07-19\n\n\nNow the date column is stored as a Date object which can be used for relevant date-related computations (for example, see the lubridate package).\n\n\n\n\n\n\nNote\n\n\n\nThe read_csv() function has a progress option that defaults to TRUE.\nThis options provides a nice progress meter while the CSV file is being read.\nHowever, if you are using read_csv() in a function, or perhaps embedding it in a loop, it is probably best to set progress = FALSE."
},
{
- "objectID": "posts/17-loop-functions/index.html#sapply",
- "href": "posts/17-loop-functions/index.html#sapply",
- "title": "17 - Vectorization and loop functionals",
- "section": "sapply()",
- "text": "sapply()\nThe sapply() function behaves similarly to lapply(); the only real difference is in the return value. sapply() will try to simplify the result of lapply() if possible. Essentially, sapply() calls lapply() on its input and then applies the following algorithm:\n\nIf the result is a list where every element is length 1, then a vector is returned\nIf the result is a list where every element is a vector of the same length (> 1), a matrix is returned.\nIf it can’t figure things out, a list is returned\n\nHere’s the result of calling lapply().\n\nx <- list(a = 1:4, b = rnorm(10), c = rnorm(20, 1), d = rnorm(100, 5))\nlapply(x, mean)\n\n$a\n[1] 2.5\n\n$b\n[1] -0.1478465\n\n$c\n[1] 0.819794\n\n$d\n[1] 4.954484\n\n\nNotice that lapply() returns a list (as usual), but that each element of the list has length 1.\nHere’s the result of calling sapply() on the same list.\n\nsapply(x, mean)\n\n a b c d \n 2.5000000 -0.1478465 0.8197940 4.9544836 \n\n\nBecause the result of lapply() was a list where each element had length 1, sapply() collapsed the output into a numeric vector, which is often more useful than a list."
+ "objectID": "posts/19-error-handling-and-generation/index.html",
+ "href": "posts/19-error-handling-and-generation/index.html",
+ "title": "19 - Error Handling and Generation",
+ "section": "",
+ "text": "This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history."
},
{
- "objectID": "posts/17-loop-functions/index.html#split",
- "href": "posts/17-loop-functions/index.html#split",
- "title": "17 - Vectorization and loop functionals",
- "section": "split()",
- "text": "split()\nThe split() function takes a vector or other objects and splits it into groups determined by a factor or list of factors.\nThe arguments to split() are\n\nstr(split)\n\nfunction (x, f, drop = FALSE, ...) \n\n\nwhere\n\nx is a vector (or list) or data frame\nf is a factor (or coerced to one) or a list of factors\ndrop indicates whether empty factors levels should be dropped\n\nThe combination of split() and a function like lapply() or sapply() is a common paradigm in R. The basic idea is that you can take a data structure, split it into subsets defined by another variable, and apply a function over those subsets. The results of applying that function over the subsets are then collated and returned as an object. This sequence of operations is sometimes referred to as “map-reduce” in other contexts.\nHere we simulate some data and split it according to a factor variable. Note that we use the gl() function to “generate levels” in a factor variable.\n\nx <- c(rnorm(10), runif(10), rnorm(10, 1))\nf <- gl(3, 10) # generate factor levels\nf\n\n [1] 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 3 3\nLevels: 1 2 3\n\n\n\nsplit(x, f)\n\n$`1`\n [1] 0.78541247 -0.06267966 -0.89713180 0.11796725 0.66689447 -0.02523006\n [7] -0.19081948 0.44974528 -0.51005146 -0.08103298\n\n$`2`\n [1] 0.29977033 0.31873253 0.53182993 0.85507540 0.21585775 0.89867742\n [7] 0.78109747 0.06887742 0.79661568 0.60022565\n\n$`3`\n [1] -0.38262045 0.06294368 0.41768485 1.57972821 1.17555228 1.47374130\n [7] 1.79199913 2.25569283 1.55226509 -1.51811384\n\n\nA common idiom is split followed by an lapply.\n\nlapply(split(x, f), mean)\n\n$`1`\n[1] 0.0253074\n\n$`2`\n[1] 0.536676\n\n$`3`\n[1] 0.8408873\n\n\n\nSplitting a Data Frame\n\nlibrary(datasets)\nhead(airquality)\n\n Ozone Solar.R Wind Temp Month Day\n1 41 190 7.4 67 5 1\n2 36 118 8.0 72 5 2\n3 12 149 12.6 74 5 3\n4 18 313 11.5 62 5 4\n5 NA NA 14.3 56 5 5\n6 28 NA 14.9 66 5 6\n\n\nWe can split the airquality data frame by the Month variable so that we have separate sub-data frames for each month.\n\ns <- split(airquality, airquality$Month)\nstr(s)\n\nList of 5\n $ 5:'data.frame': 31 obs. of 6 variables:\n ..$ Ozone : int [1:31] 41 36 12 18 NA 28 23 19 8 NA ...\n ..$ Solar.R: int [1:31] 190 118 149 313 NA NA 299 99 19 194 ...\n ..$ Wind : num [1:31] 7.4 8 12.6 11.5 14.3 14.9 8.6 13.8 20.1 8.6 ...\n ..$ Temp : int [1:31] 67 72 74 62 56 66 65 59 61 69 ...\n ..$ Month : int [1:31] 5 5 5 5 5 5 5 5 5 5 ...\n ..$ Day : int [1:31] 1 2 3 4 5 6 7 8 9 10 ...\n $ 6:'data.frame': 30 obs. of 6 variables:\n ..$ Ozone : int [1:30] NA NA NA NA NA NA 29 NA 71 39 ...\n ..$ Solar.R: int [1:30] 286 287 242 186 220 264 127 273 291 323 ...\n ..$ Wind : num [1:30] 8.6 9.7 16.1 9.2 8.6 14.3 9.7 6.9 13.8 11.5 ...\n ..$ Temp : int [1:30] 78 74 67 84 85 79 82 87 90 87 ...\n ..$ Month : int [1:30] 6 6 6 6 6 6 6 6 6 6 ...\n ..$ Day : int [1:30] 1 2 3 4 5 6 7 8 9 10 ...\n $ 7:'data.frame': 31 obs. of 6 variables:\n ..$ Ozone : int [1:31] 135 49 32 NA 64 40 77 97 97 85 ...\n ..$ Solar.R: int [1:31] 269 248 236 101 175 314 276 267 272 175 ...\n ..$ Wind : num [1:31] 4.1 9.2 9.2 10.9 4.6 10.9 5.1 6.3 5.7 7.4 ...\n ..$ Temp : int [1:31] 84 85 81 84 83 83 88 92 92 89 ...\n ..$ Month : int [1:31] 7 7 7 7 7 7 7 7 7 7 ...\n ..$ Day : int [1:31] 1 2 3 4 5 6 7 8 9 10 ...\n $ 8:'data.frame': 31 obs. of 6 variables:\n ..$ Ozone : int [1:31] 39 9 16 78 35 66 122 89 110 NA ...\n ..$ Solar.R: int [1:31] 83 24 77 NA NA NA 255 229 207 222 ...\n ..$ Wind : num [1:31] 6.9 13.8 7.4 6.9 7.4 4.6 4 10.3 8 8.6 ...\n ..$ Temp : int [1:31] 81 81 82 86 85 87 89 90 90 92 ...\n ..$ Month : int [1:31] 8 8 8 8 8 8 8 8 8 8 ...\n ..$ Day : int [1:31] 1 2 3 4 5 6 7 8 9 10 ...\n $ 9:'data.frame': 30 obs. of 6 variables:\n ..$ Ozone : int [1:30] 96 78 73 91 47 32 20 23 21 24 ...\n ..$ Solar.R: int [1:30] 167 197 183 189 95 92 252 220 230 259 ...\n ..$ Wind : num [1:30] 6.9 5.1 2.8 4.6 7.4 15.5 10.9 10.3 10.9 9.7 ...\n ..$ Temp : int [1:30] 91 92 93 93 87 84 80 78 75 73 ...\n ..$ Month : int [1:30] 9 9 9 9 9 9 9 9 9 9 ...\n ..$ Day : int [1:30] 1 2 3 4 5 6 7 8 9 10 ...\n\n\nThen we can take the column means for Ozone, Solar.R, and Wind for each sub-data frame.\n\nlapply(s, function(x) {\n colMeans(x[, c(\"Ozone\", \"Solar.R\", \"Wind\")])\n})\n\n$`5`\n Ozone Solar.R Wind \n NA NA 11.62258 \n\n$`6`\n Ozone Solar.R Wind \n NA 190.16667 10.26667 \n\n$`7`\n Ozone Solar.R Wind \n NA 216.483871 8.941935 \n\n$`8`\n Ozone Solar.R Wind \n NA NA 8.793548 \n\n$`9`\n Ozone Solar.R Wind \n NA 167.4333 10.1800 \n\n\nUsing sapply() might be better here for a more readable output.\n\nsapply(s, function(x) {\n colMeans(x[, c(\"Ozone\", \"Solar.R\", \"Wind\")])\n})\n\n 5 6 7 8 9\nOzone NA NA NA NA NA\nSolar.R NA 190.16667 216.483871 NA 167.4333\nWind 11.62258 10.26667 8.941935 8.793548 10.1800\n\n\nUnfortunately, there are NAs in the data so we cannot simply take the means of those variables. However, we can tell the colMeans function to remove the NAs before computing the mean.\n\nsapply(s, function(x) {\n colMeans(x[, c(\"Ozone\", \"Solar.R\", \"Wind\")],\n na.rm = TRUE\n )\n})\n\n 5 6 7 8 9\nOzone 23.61538 29.44444 59.115385 59.961538 31.44828\nSolar.R 181.29630 190.16667 216.483871 171.857143 167.43333\nWind 11.62258 10.26667 8.941935 8.793548 10.18000"
+ "objectID": "posts/19-error-handling-and-generation/index.html#what-is-an-error",
+ "href": "posts/19-error-handling-and-generation/index.html#what-is-an-error",
+ "title": "19 - Error Handling and Generation",
+ "section": "What is an error?",
+ "text": "What is an error?\nErrors most often occur when code is used in a way that it is not intended to be used.\n\n\n\n\n\n\nExample\n\n\n\nFor example adding two strings together produces the following error:\n\n\"hello\" + \"world\"\n\nError in \"hello\" + \"world\": non-numeric argument to binary operator\n\n\n\n\nThe + operator is essentially a function that takes two numbers as arguments and finds their sum.\nSince neither \"hello\" nor \"world\" are numbers, the R interpreter produces an error.\nErrors will stop the execution of your program, and they will (hopefully) print an error message to the R console.\nIn R there are two other constructs which are related to errors:\n\nWarnings\nMessages\n\nWarnings are meant to indicate that something seems to have gone wrong in your program that should be inspected.\n\n\n\n\n\n\nExample\n\n\n\nHere’s a simple example of a warning being generated:\n\nas.numeric(c(\"5\", \"6\", \"seven\"))\n\nWarning: NAs introduced by coercion\n\n\n[1] 5 6 NA\n\n\nThe as.numeric() function attempts to convert each string in c(\"5\", \"6\", \"seven\") into a number, however it is impossible to convert \"seven\", so a warning is generated.\nExecution of the code is not halted, and an NA is produced for \"seven\" instead of a number.\n\n\nMessages simply print to the R console, though they are generated by an underlying mechanism that is similar to how errors and warning are generated.\n\n\n\n\n\n\nExample\n\n\n\nHere’s a small function that will generate a message:\n\nf <- function() {\n message(\"This is a message.\")\n}\n\nf()\n\nThis is a message."
},
{
- "objectID": "posts/17-loop-functions/index.html#tapply",
- "href": "posts/17-loop-functions/index.html#tapply",
- "title": "17 - Vectorization and loop functionals",
- "section": "tapply",
- "text": "tapply\ntapply() is used to apply a function over subsets of a vector. It can be thought of as a combination of split() and sapply() for vectors only. I’ve been told that the “t” in tapply() refers to “table”, but that is unconfirmed.\n\nstr(tapply)\n\nfunction (X, INDEX, FUN = NULL, ..., default = NA, simplify = TRUE) \n\n\nThe arguments to tapply() are as follows:\n\nX is a vector\nINDEX is a factor or a list of factors (or else they are coerced to factors)\nFUN is a function to be applied\n… contains other arguments to be passed FUN\nsimplify, should we simplify the result?\n\n\n\n\n\n\n\nExample\n\n\n\nGiven a vector of numbers, one simple operation is to take group means.\n\n## Simulate some data\nx <- c(rnorm(10), runif(10), rnorm(10, 1))\n## Define some groups with a factor variable\nf <- gl(3, 10)\nf\n\n [1] 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 3 3 3 3 3 3 3 3 3 3\nLevels: 1 2 3\n\ntapply(x, f, mean)\n\n 1 2 3 \n0.3554738 0.5195466 0.6764006 \n\n\n\n\nWe can also apply functions that return more than a single value. In this case, tapply() will not simplify the result and will return a list. Here’s an example of finding the range() (min and max) of each sub-group.\n\ntapply(x, f, range)\n\n$`1`\n[1] -1.431912 2.695089\n\n$`2`\n[1] 0.1263379 0.8959040\n\n$`3`\n[1] -1.207741 1.696309"
+ "objectID": "posts/19-error-handling-and-generation/index.html#generating-errors",
+ "href": "posts/19-error-handling-and-generation/index.html#generating-errors",
+ "title": "19 - Error Handling and Generation",
+ "section": "Generating Errors",
+ "text": "Generating Errors\nThere are a few essential functions for generating errors, warnings, and messages in R.\nThe stop() function will generate an error.\n\n\n\n\n\n\nExample\n\n\n\nLet’s generate an error:\n\nstop(\"Something erroneous has occurred!\")\n\nError: Something erroneous has occurred!\n\n\nIf an error occurs inside of a function, then the name of that function will appear in the error message:\n\nname_of_function <- function() {\n stop(\"Something bad happened.\")\n}\n\nname_of_function()\n\nError in name_of_function(): Something bad happened.\n\n\nThe stopifnot() function takes a series of logical expressions as arguments and if any of them are false an error is generated specifying which expression is false.\n\n\n\n\n\n\nExample\n\n\n\nLet’s take a look at an example:\n\nerror_if_n_is_greater_than_zero <- function(n) {\n stopifnot(n <= 0)\n n\n}\n\nerror_if_n_is_greater_than_zero(5)\n\nError in error_if_n_is_greater_than_zero(5): n <= 0 is not TRUE\n\n\n\n\nThe warning() function creates a warning, and the function itself is very similar to the stop() function. Remember that a warning does not stop the execution of a program (unlike an error.)\n\n\n\n\n\n\nExample\n\n\n\n\nwarning(\"Consider yourself warned!\")\n\nWarning: Consider yourself warned!\n\n\n\n\nJust like errors, a warning generated inside of a function will include the name of the function in which it was generated:\n\nmake_NA <- function(x) {\n warning(\"Generating an NA.\")\n NA\n}\n\nmake_NA(\"Sodium\")\n\nWarning in make_NA(\"Sodium\"): Generating an NA.\n\n\n[1] NA\n\n\nMessages are simpler than errors or warnings; they just print strings to the R console.\nYou can issue a message with the message() function:\n\n\n\n\n\n\nExample\n\n\n\n\nmessage(\"In a bottle.\")\n\nIn a bottle."
},
{
- "objectID": "posts/17-loop-functions/index.html#apply",
- "href": "posts/17-loop-functions/index.html#apply",
- "title": "17 - Vectorization and loop functionals",
- "section": "apply()",
- "text": "apply()\nThe apply() function is used to a evaluate a function (often an anonymous one) over the margins of an array. It is most often used to apply a function to the rows or columns of a matrix (which is just a 2-dimensional array). However, it can be used with general arrays, for example, to take the average of an array of matrices. Using apply() is not really faster than writing a loop, but it works in one line and is highly compact.\n\nstr(apply)\n\nfunction (X, MARGIN, FUN, ..., simplify = TRUE) \n\n\nThe arguments to apply() are\n\nX is an array\nMARGIN is an integer vector indicating which margins should be “retained”.\nFUN is a function to be applied\n... is for other arguments to be passed to FUN\n\n\n\n\n\n\n\nExample\n\n\n\nHere I create a 20 by 10 matrix of Normal random numbers. I then compute the mean of each column.\n\nx <- matrix(rnorm(200), 20, 10)\nhead(x)\n\n [,1] [,2] [,3] [,4] [,5] [,6]\n[1,] 1.589728 0.7733454 -1.3311072 -0.77084025 -0.1947478 0.1748546\n[2,] 2.395088 0.3243910 -1.5133366 0.09199955 0.3850993 0.1851718\n[3,] 1.039643 -2.1721402 -0.9933217 -1.89261272 0.1748050 1.0563987\n[4,] -1.580978 -0.9884235 -1.4976744 -0.51011200 -2.7512079 0.5547477\n[5,] 1.264799 -2.0551874 0.4483417 -3.08561764 -0.1549359 -0.8384706\n[6,] 1.756973 0.9244522 0.2740854 -0.61441465 -1.0661350 1.4497808\n [,7] [,8] [,9] [,10]\n[1,] 0.7163086 -0.01817166 0.2193225 -0.3346788\n[2,] 0.7606851 0.42082416 0.1099027 0.2834439\n[3,] -1.1218204 -1.17000278 0.4302792 -0.5684986\n[4,] 0.6082452 0.46763465 -0.3481830 -0.1765517\n[5,] -0.7460224 -0.01123782 1.8116342 -0.1033175\n[6,] 1.0160202 -0.82361401 -0.1616471 -0.1628032\n\napply(x, 2, mean) ## Take the mean of each column\n\n [1] 0.083759441 -0.134507982 -0.246473461 -0.371270102 -0.078433882\n [6] -0.101665531 -0.007126106 -0.003193726 0.114767264 0.070612124\n\n\n\n\n\n\n\n\n\n\nExample\n\n\n\nI can also compute the sum of each row.\n\napply(x, 1, sum) ## Take the mean of each row\n\n [1] 0.82401382 3.44326903 -5.21727094 -6.22250299 -3.47001414 2.59269751\n [7] -1.76049948 -0.54534465 1.26993157 -0.05660623 1.89101638 2.60154094\n[13] -0.80804188 1.96321614 -2.68869045 0.56525640 0.44214056 -4.25890694\n[19] -3.02509115 -1.01075274\n\n\n\n\n\n\n\n\n\n\nNote\n\n\n\nIn both calls to apply(), the return value was a vector of numbers.\n\n\nYou’ve probably noticed that the second argument is either a 1 or a 2, depending on whether we want row statistics or column statistics. What exactly is the second argument to apply()?\nThe MARGIN argument essentially indicates to apply() which dimension of the array you want to preserve or retain.\nSo when taking the mean of each column, I specify\n\napply(x, 2, mean)\n\nbecause I want to collapse the first dimension (the rows) by taking the mean and I want to preserve the number of columns. Similarly, when I want the row sums, I run\n\napply(x, 1, mean)\n\nbecause I want to collapse the columns (the second dimension) and preserve the number of rows (the first dimension).\n\nCol/Row Sums and Means\n\n\n\n\n\n\nPro-tip\n\n\n\nFor the special case of column/row sums and column/row means of matrices, we have some useful shortcuts.\n\nrowSums = apply(x, 1, sum)\nrowMeans = apply(x, 1, mean)\ncolSums = apply(x, 2, sum)\ncolMeans = apply(x, 2, mean)\n\n\n\nThe shortcut functions are heavily optimized and hence are much faster, but you probably won’t notice unless you’re using a large matrix.\nAnother nice aspect of these functions is that they are a bit more descriptive. It’s arguably more clear to write colMeans(x) in your code than apply(x, 2, mean).\n\n\nOther Ways to Apply\nYou can do more than take sums and means with the apply() function.\n\n\n\n\n\n\nExample\n\n\n\nFor example, you can compute quantiles of the rows of a matrix using the quantile() function.\n\nx <- matrix(rnorm(200), 20, 10)\nhead(x)\n\n [,1] [,2] [,3] [,4] [,5] [,6]\n[1,] 0.58654399 -0.502546440 1.1493478 0.6257709 -0.02866237 1.490139530\n[2,] -0.14969248 0.327632870 0.0202589 0.2889600 -0.16552218 -0.829703298\n[3,] 1.12561766 0.707836011 0.6038607 -0.6722613 0.85092968 0.550785886\n[4,] -1.71719604 0.554424755 0.4229181 0.1484968 0.22134369 0.258853355\n[5,] 0.31827641 1.555568589 0.8971850 -0.7742244 0.45459793 -0.043814576\n[6,] -0.08429415 0.001737282 0.1906608 1.1145869 0.54156791 -0.004889302\n [,7] [,8] [,9] [,10]\n[1,] -0.7879713 1.02206400 -1.0420765 -1.2779945\n[2,] 1.7217146 0.06728039 0.6408182 -0.3551929\n[3,] -0.2439192 -0.71553120 -0.8273868 0.2559954\n[4,] -0.1085818 -0.28763268 1.9010457 1.7950971\n[5,] -1.4082747 -1.07621679 0.5428189 0.4538626\n[6,] -1.0644006 -0.04186614 -0.8150566 1.0490749\n\n## Get row quantiles\napply(x, 1, quantile, probs = c(0.25, 0.75))\n\n [,1] [,2] [,3] [,4] [,5] [,6]\n25% -0.7166151 -0.1615648 -0.5651758 -0.04431213 -0.5916219 -0.07368714\n75% 0.9229907 0.3179646 0.6818422 0.52154809 0.5207637 0.45384114\n [,7] [,8] [,9] [,10] [,11] [,12]\n25% -0.4355993 -0.1313015 -0.8149658 -0.9260982 0.02077709 -0.1343613\n75% 1.5985929 0.8889319 0.2213238 0.3661333 0.82424899 0.4156328\n [,13] [,14] [,15] [,16] [,17] [,18]\n25% -0.1281593 -0.6691927 -0.2824997 -0.6574923 0.06421797 -0.7905708\n75% 1.3073689 1.2450340 0.5072401 0.5023885 1.08294108 0.4653062\n [,19] [,20]\n25% -0.5826196 -0.6965163\n75% 0.1313324 0.6849689\n\n\nNotice that I had to pass the probs = c(0.25, 0.75) argument to quantile() via the ... argument to apply()."
+ "objectID": "posts/19-error-handling-and-generation/index.html#when-to-generate-errors-or-warnings",
+ "href": "posts/19-error-handling-and-generation/index.html#when-to-generate-errors-or-warnings",
+ "title": "19 - Error Handling and Generation",
+ "section": "When to generate errors or warnings",
+ "text": "When to generate errors or warnings\nStopping the execution of your program with stop() should only happen in the event of a catastrophe - meaning only if it is impossible for your program to continue.\n\nIf there are conditions that you can anticipate that would cause your program to create an error, then you should document those conditions so whoever uses your software is aware.\n\nAn example includes:\n\nProviding invalid arguments to a function. You could check this at the beginning of your program using stopifnot() so that the user can quickly realize something has gone wrong.\n\nYou can think of a function as kind of contract between you and the user:\n\nif the user provides specified arguments, your program will provide predictable results.\n\nOf course it’s impossible for you to anticipate all of the potential uses of your program.\nIt’s appropriate to create a warning when this contract between you and the user is violated.\nA perfect example of this situation is the result of\n\nas.numeric(c(\"5\", \"6\", \"seven\"))\n\nWarning: NAs introduced by coercion\n\n\n[1] 5 6 NA\n\n\nThe user expects a vector of numbers to be returned as the result of as.numeric() but \"seven\" is coerced into being NA, which is not completely intuitive.\nR has largely been developed according to the Unix Philosophy, which generally discourages printing text to the console unless something unexpected has occurred.\nLanguages that commonly run on Unix systems like C and C++ are rarely used interactively, meaning that they usually underpin computer infrastructure (computers “talking” to other computers).\nMessages printed to the console are therefore not very useful since nobody will ever read them and it’s not straightforward for other programs to capture and interpret them.\nIn contrast, R code is frequently executed by human beings in the R console, which serves as an interactive environment between the computer and person at the keyboard.\nIf you think your program should produce a message, make sure that the output of the message is primarily meant for a human to read.\nYou should avoid signaling a condition or the result of your program to another program by creating a message."
},
{
- "objectID": "posts/17-loop-functions/index.html#vectorizing-a-function",
- "href": "posts/17-loop-functions/index.html#vectorizing-a-function",
- "title": "17 - Vectorization and loop functionals",
- "section": "Vectorizing a Function",
- "text": "Vectorizing a Function\nLet’s talk about how we can “vectorize” a function.\nWhat this means is that we can write function that typically only takes single arguments and create a new function that can take vector arguments.\nThis is often needed when you want to plot functions.\n\n\n\n\n\n\nExample\n\n\n\nHere’s an example of a function that computes the sum of squares given some data, a mean parameter and a standard deviation. The formula is \\(\\sum_{i=1}^n(x_i-\\mu)^2/\\sigma^2\\).\n\nsumsq <- function(mu, sigma, x) {\n sum(((x - mu) / sigma)^2)\n}\n\nThis function takes a mean mu, a standard deviation sigma, and some data in a vector x.\nIn many statistical applications, we want to minimize the sum of squares to find the optimal mu and sigma. Before we do that, we may want to evaluate or plot the function for many different values of mu or sigma.\n\nx <- rnorm(100) ## Generate some data\nsumsq(mu = 1, sigma = 1, x) ## This works (returns one value)\n\n[1] 248.8765\n\n\nHowever, passing a vector of mus or sigmas won’t work with this function because it’s not vectorized.\n\nsumsq(1:10, 1:10, x) ## This is not what we want\n\n[1] 119.3071\n\n\n\n\nThere’s even a function in R called Vectorize() that automatically can create a vectorized version of your function.\nSo we could create a vsumsq() function that is fully vectorized as follows.\n\nvsumsq <- Vectorize(sumsq, c(\"mu\", \"sigma\"))\nvsumsq(1:10, 1:10, x)\n\n [1] 248.8765 146.5055 124.7964 116.2695 111.8983 109.2945 107.5867 106.3890\n [9] 105.5067 104.8318\n\n\nPretty cool, right?"
+ "objectID": "posts/19-error-handling-and-generation/index.html#how-should-errors-be-handled",
+ "href": "posts/19-error-handling-and-generation/index.html#how-should-errors-be-handled",
+ "title": "19 - Error Handling and Generation",
+ "section": "How should errors be handled?",
+ "text": "How should errors be handled?\nImagine writing a program that will take a long time to complete because of a complex calculation or because you’re handling a large amount of data. If an error occurs during this computation then you’re liable to lose all of the results that were calculated before the error, or your program may not finish a critical task that a program further down your pipeline is depending on. If you anticipate the possibility of errors occurring during the execution of your program, then you can design your program to handle them appropriately.\nThe tryCatch() function is the workhorse of handling errors and warnings in R. The first argument of this function is any R expression, followed by conditions which specify how to handle an error or a warning. The last argument, finally, specifies a function or expression that will be executed after the expression no matter what, even in the event of an error or a warning.\nLet’s construct a simple function I’m going to call beera that catches errors and warnings gracefully.\n\nbeera <- function(expr) {\n tryCatch(expr,\n error = function(e) {\n message(\"An error occurred:\\n\", e)\n },\n warning = function(w) {\n message(\"A warning occured:\\n\", w)\n },\n finally = {\n message(\"Finally done!\")\n }\n )\n}\n\nThis function takes an expression as an argument and tries to evaluate it. If the expression can be evaluated without any errors or warnings then the result of the expression is returned and the message Finally done! is printed to the R console. If an error or warning is generated, then the functions that are provided to the error or warning arguments are printed. Let’s try this function out with a few examples.\n\nbeera({\n 2 + 2\n})\n\nFinally done!\n\n\n[1] 4\n\nbeera({\n \"two\" + 2\n})\n\nAn error occurred:\nError in \"two\" + 2: non-numeric argument to binary operator\n\nFinally done!\n\nbeera({\n as.numeric(c(1, \"two\", 3))\n})\n\nA warning occured:\nsimpleWarning in doTryCatch(return(expr), name, parentenv, handler): NAs introduced by coercion\n\nFinally done!\n\n\nNotice that we’ve effectively transformed errors and warnings into messages.\nNow that you know the basics of generating and catching errors you’ll need to decide when your program should generate an error. My advice to you is to limit the number of errors your program generates as much as possible. Even if you design your program so that it’s able to catch and handle errors, the error handling process slows down your program by orders of magnitude. Imagine you wanted to write a simple function that checks if an argument is an even number. You might write the following:\n\nis_even <- function(n) {\n n %% 2 == 0\n}\n\nis_even(768)\n\n[1] TRUE\n\nis_even(\"two\")\n\nError in n%%2: non-numeric argument to binary operator\n\n\nYou can see that providing a string causes this function to raise an error. You could imagine though that you want to use this function across a list of different data types, and you only want to know which elements of that list are even numbers. You might think to write the following:\n\nis_even_error <- function(n) {\n tryCatch(n %% 2 == 0,\n error = function(e) {\n FALSE\n }\n )\n}\n\nis_even_error(714)\n\n[1] TRUE\n\nis_even_error(\"eight\")\n\n[1] FALSE\n\n\nThis appears to be working the way you intended, however when applied to more data this function will be seriously slow compared to alternatives. For example I could check that n is numeric before treating n like a number:\n\nis_even_check <- function(n) {\n is.numeric(n) && n %% 2 == 0\n}\n\nis_even_check(1876)\n\n[1] TRUE\n\nis_even_check(\"twelve\")\n\n[1] FALSE\n\n\n\nNotice that by using is.numeric() before the “AND” operator (&&), the expression n %% 2 == 0 is never evaluated. This is a programming language design feature called “short circuiting.” The expression can never evaluate to TRUE if the left hand side of && evaluates to FALSE, so the right hand side is ignored.\n\nTo demonstrate the difference in the speed of the code, we will use the microbenchmark package to measure how long it takes for each function to be applied to the same data.\n\nlibrary(microbenchmark)\nmicrobenchmark(sapply(letters, is_even_check))\n\nUnit: microseconds\n expr min lq mean median uq max neval\n sapply(letters, is_even_check) 46.224 47.7975 61.43616 48.6445 58.4755 167.091 100\n\nmicrobenchmark(sapply(letters, is_even_error))\n\nUnit: microseconds\n expr min lq mean median uq max neval\n sapply(letters, is_even_error) 640.067 678.0285 906.3037 784.4315 1044.501 2308.931 100\nThe error catching approach is nearly 15 times slower!\nProper error handling is an essential tool for any software developer so that you can design programs that are error tolerant. Creating clear and informative error messages is essential for building quality software.\n\n\n\n\n\n\nPro-tip\n\n\n\nOne closing tip I recommend is to put documentation for your software online, including the meaning of the errors that your software can potentially throw. Often a user’s first instinct when encountering an error is to search online for that error message, which should lead them to your documentation!"
},
{
- "objectID": "posts/13-ggplot2-plotting-system-part-2/index.html",
- "href": "posts/13-ggplot2-plotting-system-part-2/index.html",
- "title": "13 - The ggplot2 plotting system: ggplot()",
+ "objectID": "posts/12-ggplot2-plotting-system-part-1/index.html",
+ "href": "posts/12-ggplot2-plotting-system-part-1/index.html",
+ "title": "12 - The ggplot2 plotting system: qplot()",
"section": "",
"text": "This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history."
},
{
- "objectID": "posts/13-ggplot2-plotting-system-part-2/index.html#basic-components-of-a-ggplot2-plot",
- "href": "posts/13-ggplot2-plotting-system-part-2/index.html#basic-components-of-a-ggplot2-plot",
- "title": "13 - The ggplot2 plotting system: ggplot()",
- "section": "Basic components of a ggplot2 plot",
- "text": "Basic components of a ggplot2 plot\n\n\n\n\n\n\nKey components\n\n\n\nA ggplot2 plot consists of a number of key components.\n\nA data frame: stores all of the data that will be displayed on the plot\naesthetic mappings: describe how data are mapped to color, size, shape, location\ngeoms: geometric objects like points, lines, shapes\nfacets: describes how conditional/panel plots should be constructed\nstats: statistical transformations like binning, quantiles, smoothing\nscales: what scale an aesthetic map uses (example: left-handed = red, right-handed = blue)\ncoordinate system: describes the system in which the locations of the geoms will be drawn\n\n\n\nIt is essential to organize your data into a data frame before you start with ggplot2 (and all the appropriate metadata so that your data frame is self-describing and your plots will be self-documenting).\nWhen building plots in ggplot2 (rather than using qplot()), the “artist’s palette” model may be the closest analogy.\nEssentially, you start with some raw data, and then you gradually add bits and pieces to it to create a plot.\n\n\n\n\n\n\nNote\n\n\n\nPlots are built up in layers, with the typically ordering being\n\nPlot the data\nOverlay a summary\nAdd metadata and annotation\n\n\n\nFor quick exploratory plots you may not get past step 1."
- },
- {
- "objectID": "posts/13-ggplot2-plotting-system-part-2/index.html#example-bmi-pm2.5-asthma",
- "href": "posts/13-ggplot2-plotting-system-part-2/index.html#example-bmi-pm2.5-asthma",
- "title": "13 - The ggplot2 plotting system: ggplot()",
- "section": "Example: BMI, PM2.5, Asthma",
- "text": "Example: BMI, PM2.5, Asthma\nTo demonstrate the various pieces of ggplot2 we will use a running example from the Mouse Allergen and Asthma Cohort Study (MAACS). Here, the question we are interested in is\n\n“Are overweight individuals, as measured by body mass index (BMI), more susceptible than normal weight individuals to the harmful effects of PM2.5 on asthma symptoms?”\n\nThere is a suggestion that overweight individuals may be more susceptible to the negative effects of inhaling PM2.5.\nThis would suggest that increases in PM2.5 exposure in the home of an overweight child would be more deleterious to his/her asthma symptoms than they would be in the home of a normal weight child.\nWe want to see if we can see that difference in the data from MAACS.\n\n\n\n\n\n\nNote\n\n\n\nBecause the individual-level data for this study are protected by various U.S. privacy laws, we cannot make those data available.\nFor the purposes of this lesson, we have simulated data that share many of the same features of the original data, but do not contain any of the actual measurements or values contained in the original dataset.\n\n\n\n\n\n\n\n\nExample\n\n\n\nWe can look at the data quickly by reading it in as a tibble with read_csv() in the tidyverse package.\n\nlibrary(\"tidyverse\")\nlibrary(\"here\")\nmaacs <- read_csv(here(\"data\", \"bmi_pm25_no2_sim.csv\"),\n col_types = \"nnci\"\n)\nmaacs\n\n# A tibble: 517 × 4\n logpm25 logno2_new bmicat NocturnalSympt\n <dbl> <dbl> <chr> <int>\n 1 1.25 1.18 normal weight 1\n 2 1.12 1.55 overweight 0\n 3 1.93 1.43 normal weight 0\n 4 1.37 1.77 overweight 2\n 5 0.775 0.765 normal weight 0\n 6 1.49 1.11 normal weight 0\n 7 2.16 1.43 normal weight 0\n 8 1.65 1.40 normal weight 0\n 9 1.55 1.81 normal weight 0\n10 2.04 1.35 overweight 3\n# ℹ 507 more rows\n\n\n\n\nThe outcome we will look at here (NocturnalSymp) is the number of days in the past 2 weeks where the child experienced asthma symptoms (e.g. coughing, wheezing) while sleeping.\nThe other key variables are:\n\nlogpm25: average level of PM2.5 over the course of 7 days (micrograms per cubic meter) on the log scale\nlogno2_new: exhaled nitric oxide on the log scale\nbmicat: categorical variable with BMI status"
+ "objectID": "posts/12-ggplot2-plotting-system-part-1/index.html#the-basics-qplot",
+ "href": "posts/12-ggplot2-plotting-system-part-1/index.html#the-basics-qplot",
+ "title": "12 - The ggplot2 plotting system: qplot()",
+ "section": "The Basics: qplot()",
+ "text": "The Basics: qplot()\nThe qplot() function in ggplot2 is meant to get you going quickly.\nIt works much like the plot() function in base graphics system. It looks for variables to plot within a data frame, similar to lattice, or in the parent environment.\nIn general, it is good to get used to putting your data in a data frame and then passing it to qplot().\n\n\n\n\n\n\nPro tip\n\n\n\nThe qplot() function is somewhat discouraged in ggplot2 now and new users are encouraged to use the more general ggplot() function (more details in the next lesson).\nHowever, the qplot() function is still useful and may be easier to use if transitioning from the base plotting system or a different statistical package.\n\n\nPlots are made up of\n\naesthetics (e.g. size, shape, color)\ngeoms (e.g. points, lines)\n\nFactors play an important role for indicating subsets of the data (if they are to have different properties) so they should be labeled properly.\nThe qplot() hides much of what goes on underneath, which is okay for most operations, ggplot() is the core function and is very flexible for doing things qplot() cannot do."
},
{
- "objectID": "posts/13-ggplot2-plotting-system-part-2/index.html#first-plot-with-point-layer",
- "href": "posts/13-ggplot2-plotting-system-part-2/index.html#first-plot-with-point-layer",
- "title": "13 - The ggplot2 plotting system: ggplot()",
- "section": "First plot with point layer",
- "text": "First plot with point layer\nTo make a scatter plot, we need add at least one geom, such as points.\nHere, we add the geom_point() function to create a traditional scatter plot.\n\ng <- maacs %>%\n ggplot(aes(logpm25, NocturnalSympt))\ng + geom_point()\n\n\n\n\nScatterplot of PM2.5 and days with nocturnal symptoms\n\n\n\n\nHow does ggplot know what points to plot? In this case, it can grab them from the data frame maacs that served as the input into the ggplot() function."
+ "objectID": "posts/12-ggplot2-plotting-system-part-1/index.html#before-you-start-label-your-data",
+ "href": "posts/12-ggplot2-plotting-system-part-1/index.html#before-you-start-label-your-data",
+ "title": "12 - The ggplot2 plotting system: qplot()",
+ "section": "Before you start: label your data",
+ "text": "Before you start: label your data\nOne thing that is always true, but is particularly useful when using ggplot2, is that you should always use informative and descriptive labels on your data.\nMore generally, your data should have appropriate metadata so that you can quickly look at a dataset and know\n\nwhat are variables?\nwhat do the values of each variable mean?\n\n\n\n\n\n\n\nPro tip\n\n\n\n\nEach column of a data frame should have a meaningful (but concise) variable name that accurately reflects the data stored in that column\nNon-numeric or categorical variables should be coded as factor variables and have meaningful labels for each level of the factor.\n\nMight be common to code a binary variable as a “0” or a “1”, but the problem is that from quickly looking at the data, it’s impossible to know whether which level of that variable is represented by a “0” or a “1”.\nMuch better to simply label each observation as what they are.\nIf a variable represents temperature categories, it might be better to use “cold”, “mild”, and “hot” rather than “1”, “2”, and “3”.\n\n\n\n\nWhile it is sometimes a pain to make sure all of your data are properly labeled, this investment in time can pay dividends down the road when you’re trying to figure out what you were plotting.\nIn other words, including the proper metadata can make your exploratory plots essentially self-documenting."
},
{
- "objectID": "posts/13-ggplot2-plotting-system-part-2/index.html#adding-more-layers",
- "href": "posts/13-ggplot2-plotting-system-part-2/index.html#adding-more-layers",
- "title": "13 - The ggplot2 plotting system: ggplot()",
- "section": "Adding more layers",
- "text": "Adding more layers\n\nsmooth\nBecause the data appear rather noisy, it might be better if we added a smoother on top of the points to see if there is a trend in the data with PM2.5.\n\ng +\n geom_point() +\n geom_smooth()\n\n\n\n\nScatterplot with smoother\n\n\n\n\nThe default smoother is a loess smoother, which is flexible and nonparametric but might be too flexible for our purposes. Perhaps we’d prefer a simple linear regression line to highlight any first order trends. We can do this by specifying method = \"lm\" to geom_smooth().\n\ng +\n geom_point() +\n geom_smooth(method = \"lm\")\n\n\n\n\nScatterplot with linear regression line\n\n\n\n\nHere, we can see there appears to be a slight increasing trend, suggesting that higher levels of PM2.5 are associated with increased days with nocturnal symptoms.\n\n\n\n\n\n\nQuestion\n\n\n\nLet’s use the ggplot() function with our palmerpenguins dataset example and make a scatter plot with flipper_length_mm on the x-axis, bill_length_mm on the y-axis, colored by species, and a smoother by adding a linear regression.\n\n# try it yourself\n\nlibrary(\"palmerpenguins\")\npenguins\n\n# A tibble: 344 × 8\n species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g\n <fct> <fct> <dbl> <dbl> <int> <int>\n 1 Adelie Torgersen 39.1 18.7 181 3750\n 2 Adelie Torgersen 39.5 17.4 186 3800\n 3 Adelie Torgersen 40.3 18 195 3250\n 4 Adelie Torgersen NA NA NA NA\n 5 Adelie Torgersen 36.7 19.3 193 3450\n 6 Adelie Torgersen 39.3 20.6 190 3650\n 7 Adelie Torgersen 38.9 17.8 181 3625\n 8 Adelie Torgersen 39.2 19.6 195 4675\n 9 Adelie Torgersen 34.1 18.1 193 3475\n10 Adelie Torgersen 42 20.2 190 4250\n# ℹ 334 more rows\n# ℹ 2 more variables: sex <fct>, year <int>\n\n\n\n\n\n\nfacets\nBecause our primary question involves comparing overweight individuals to normal weight individuals, we can stratify the scatter plot of PM2.5 and nocturnal symptoms by the BMI category (bmicat) variable, which indicates whether an individual is overweight or not.\nTo visualize this we can add a facet_grid(), which takes a formula argument.\n\n\n\n\n\n\nExample\n\n\n\nWe want one row and two columns, one column for each weight category. So we specify bmicat on the right hand side of the forumla passed to facet_grid().\n\ng +\n geom_point() +\n geom_smooth(method = \"lm\") +\n facet_grid(. ~ bmicat)\n\n\n\n\nScatterplot of PM2.5 and nocturnal symptoms by BMI category\n\n\n\n\n\n\nNow it seems clear that the relationship between PM2.5 and nocturnal symptoms is relatively flat among normal weight individuals, while the relationship is increasing among overweight individuals.\nThis plot suggests that overweight individuals may be more susceptible to the effects of PM2.5."
+ "objectID": "posts/12-ggplot2-plotting-system-part-1/index.html#ggplot2-hello-world",
+ "href": "posts/12-ggplot2-plotting-system-part-1/index.html#ggplot2-hello-world",
+ "title": "12 - The ggplot2 plotting system: qplot()",
+ "section": "ggplot2 “Hello, world!”",
+ "text": "ggplot2 “Hello, world!”\nThis example dataset comes with the ggplot2 package and contains data on the fuel economy of 38 popular car models from 1999 to 2008.\n\nlibrary(tidyverse) # this loads the ggplot2 R package\n# library(ggplot2) # an alternative way to just load the ggplot2 R package\nglimpse(mpg)\n\nRows: 234\nColumns: 11\n$ manufacturer <chr> \"audi\", \"audi\", \"audi\", \"audi\", \"audi\", \"audi\", \"audi\", \"…\n$ model <chr> \"a4\", \"a4\", \"a4\", \"a4\", \"a4\", \"a4\", \"a4\", \"a4 quattro\", \"…\n$ displ <dbl> 1.8, 1.8, 2.0, 2.0, 2.8, 2.8, 3.1, 1.8, 1.8, 2.0, 2.0, 2.…\n$ year <int> 1999, 1999, 2008, 2008, 1999, 1999, 2008, 1999, 1999, 200…\n$ cyl <int> 4, 4, 4, 4, 6, 6, 6, 4, 4, 4, 4, 6, 6, 6, 6, 6, 6, 8, 8, …\n$ trans <chr> \"auto(l5)\", \"manual(m5)\", \"manual(m6)\", \"auto(av)\", \"auto…\n$ drv <chr> \"f\", \"f\", \"f\", \"f\", \"f\", \"f\", \"f\", \"4\", \"4\", \"4\", \"4\", \"4…\n$ cty <int> 18, 21, 20, 21, 16, 18, 18, 18, 16, 20, 19, 15, 17, 17, 1…\n$ hwy <int> 29, 29, 31, 30, 26, 26, 27, 26, 25, 28, 27, 25, 25, 25, 2…\n$ fl <chr> \"p\", \"p\", \"p\", \"p\", \"p\", \"p\", \"p\", \"p\", \"p\", \"p\", \"p\", \"p…\n$ class <chr> \"compact\", \"compact\", \"compact\", \"compact\", \"compact\", \"c…\n\n\nYou can see from the glimpse() (part of the dplyr package) output that all of the categorical variables (like “manufacturer” or “class”) are **appropriately coded with meaningful label*s**.\nThis will come in handy when qplot() has to label different aspects of a plot.\nAlso note that all of the columns/variables have meaningful names (if sometimes abbreviated), rather than names like “X1”, and “X2”, etc.\n\n\n\n\n\n\nExample\n\n\n\nWe can make a quick scatterplot using qplot() of the engine displacement (displ) and the highway miles per gallon (hwy).\n\nqplot(x = displ, y = hwy, data = mpg)\n\nWarning: `qplot()` was deprecated in ggplot2 3.4.0.\n\n\n\n\n\nPlot of engine displacement and highway mileage using the mtcars dataset\n\n\n\n\n\n\nIt has a very similar feeling to plot() in base R.\n\n\n\n\n\n\nNote\n\n\n\nIn the call to qplot() you must specify the data argument so that qplot() knows where to look up the variables.\nYou must also specify x and y, but hopefully that part is obvious."
},
{
- "objectID": "posts/13-ggplot2-plotting-system-part-2/index.html#customizing-the-smooth",
- "href": "posts/13-ggplot2-plotting-system-part-2/index.html#customizing-the-smooth",
- "title": "13 - The ggplot2 plotting system: ggplot()",
- "section": "Customizing the smooth",
- "text": "Customizing the smooth\nWe can also customize aspects of the geoms.\nFor example, we can customize the smoother that we overlay on the points with geom_smooth().\nHere we change the line type and increase the size from the default. We also remove the shaded standard error from the line.\n\ng +\n geom_point(aes(color = bmicat),\n size = 2,\n alpha = 1 / 2\n ) +\n geom_smooth(\n linewidth = 4,\n linetype = 3,\n method = \"lm\",\n se = FALSE\n )\n\n\n\n\nCustomizing a smoother"
+ "objectID": "posts/12-ggplot2-plotting-system-part-1/index.html#modifying-aesthetics",
+ "href": "posts/12-ggplot2-plotting-system-part-1/index.html#modifying-aesthetics",
+ "title": "12 - The ggplot2 plotting system: qplot()",
+ "section": "Modifying aesthetics",
+ "text": "Modifying aesthetics\nWe can introduce a third variable into the plot by modifying the color of the points based on the value of that third variable.\nColor (or colour) is one type of aesthetic and using the ggplot2 language:\n\n“the color of each point can be mapped to a variable”\n\nThis sounds technical, but let’s give an example.\n\n\n\n\n\n\nExample\n\n\n\nWe map the color argument to the drv variable, which indicates whether a car is front wheel drive, rear wheel drive, or 4-wheel drive.\n\nqplot(displ, hwy, data = mpg, color = drv)\n\n\n\n\nEngine displacement and highway mileage by drive class\n\n\n\n\n\n\nNow we can see that the front wheel drive cars tend to have lower displacement relative to the 4-wheel or rear wheel drive cars.\nAlso, it’s clear that the 4-wheel drive cars have the lowest highway gas mileage.\n\n\n\n\n\n\nNote\n\n\n\nThe x argument and y argument are aesthetics too, and they got mapped to the displ and hwy variables, respectively.\n\n\n\n\n\n\n\n\nQuestion\n\n\n\nIn the above plot, I did not specify the x and y variable. What happens when you run these two code chunks. What’s the difference?\n\nqplot(displ, hwy, data = mpg, color = drv)\n\n\nqplot(x = displ, y = hwy, data = mpg, color = drv)\n\n\nqplot(hwy, displ, data = mpg, color = drv)\n\n\nqplot(y = hwy, x = displ, data = mpg, color = drv)\n\n\n\n\n\n\n\n\n\nExample\n\n\n\nLet’s try mapping colors in another dataset, namely the palmerpenguins dataset. These data contain observations for 344 penguins. There are 3 different species of penguins in this dataset, collected from 3 islands in the Palmer Archipelago, Antarctica.\n\n\n\n\n\nPalmer penguins\n\n\n\n\n[Source: Artwork by Allison Horst]\n\nlibrary(palmerpenguins)\n\n\nglimpse(penguins)\n\nRows: 344\nColumns: 8\n$ species <fct> Adelie, Adelie, Adelie, Adelie, Adelie, Adelie, Adel…\n$ island <fct> Torgersen, Torgersen, Torgersen, Torgersen, Torgerse…\n$ bill_length_mm <dbl> 39.1, 39.5, 40.3, NA, 36.7, 39.3, 38.9, 39.2, 34.1, …\n$ bill_depth_mm <dbl> 18.7, 17.4, 18.0, NA, 19.3, 20.6, 17.8, 19.6, 18.1, …\n$ flipper_length_mm <int> 181, 186, 195, NA, 193, 190, 181, 195, 193, 190, 186…\n$ body_mass_g <int> 3750, 3800, 3250, NA, 3450, 3650, 3625, 4675, 3475, …\n$ sex <fct> male, female, female, NA, female, male, female, male…\n$ year <int> 2007, 2007, 2007, 2007, 2007, 2007, 2007, 2007, 2007…\n\n\nIf we wanted to count the number of penguins for each of the three species, we can use the count() function in dplyr:\n\npenguins %>%\n count(species)\n\n# A tibble: 3 × 2\n species n\n <fct> <int>\n1 Adelie 152\n2 Chinstrap 68\n3 Gentoo 124\n\n\n\n\nFor example, we see there are a total of 152 Adelie penguins in the palmerpenguins dataset.\n\n\n\n\n\n\nQuestion\n\n\n\nIf we wanted to use qplot() to map flipper_length_mm and bill_length_mm to the x and y coordinates, what would we do?\n\n# try it yourself\n\nNow try mapping color to the species variable on top of the code you just wrote:\n\n# try it yourself"
},
{
- "objectID": "posts/13-ggplot2-plotting-system-part-2/index.html#changing-the-theme",
- "href": "posts/13-ggplot2-plotting-system-part-2/index.html#changing-the-theme",
- "title": "13 - The ggplot2 plotting system: ggplot()",
- "section": "Changing the theme",
- "text": "Changing the theme\nThe default theme for ggplot2 uses the gray background with white grid lines.\nIf you don’t find this suitable, you can use the black and white theme by using the theme_bw() function.\nThe theme_bw() function also allows you to set the typeface for the plot, in case you don’t want the default Helvetica. Here we change the typeface to Times.\n\n\n\n\n\n\nNote\n\n\n\nFor things that only make sense globally, use theme(), i.e. theme(legend.position = \"none\"). Two standard appearance themes are included\n\ntheme_gray(): The default theme (gray background)\ntheme_bw(): More stark/plain\n\n\n\n\ng +\n geom_point(aes(color = bmicat)) +\n theme_bw(base_family = \"Times\")\n\n\n\n\nModifying the theme for a plot\n\n\n\n\n\n\n\n\n\n\nQuestion\n\n\n\nLet’s take our palmerpenguins scatterplot from above and change out the theme to use theme_dark().\n\n# try it yourself\n\nlibrary(\"palmerpenguins\")\npenguins\n\n# A tibble: 344 × 8\n species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g\n <fct> <fct> <dbl> <dbl> <int> <int>\n 1 Adelie Torgersen 39.1 18.7 181 3750\n 2 Adelie Torgersen 39.5 17.4 186 3800\n 3 Adelie Torgersen 40.3 18 195 3250\n 4 Adelie Torgersen NA NA NA NA\n 5 Adelie Torgersen 36.7 19.3 193 3450\n 6 Adelie Torgersen 39.3 20.6 190 3650\n 7 Adelie Torgersen 38.9 17.8 181 3625\n 8 Adelie Torgersen 39.2 19.6 195 4675\n 9 Adelie Torgersen 34.1 18.1 193 3475\n10 Adelie Torgersen 42 20.2 190 4250\n# ℹ 334 more rows\n# ℹ 2 more variables: sex <fct>, year <int>"
+ "objectID": "posts/12-ggplot2-plotting-system-part-1/index.html#adding-a-geom",
+ "href": "posts/12-ggplot2-plotting-system-part-1/index.html#adding-a-geom",
+ "title": "12 - The ggplot2 plotting system: qplot()",
+ "section": "Adding a geom",
+ "text": "Adding a geom\nSometimes it is nice to add a smoother to a scatterplot to highlight any trends.\nTrends can be difficult to see if the data are very noisy or there are many data points obscuring the view.\nA smoother is a type of “geom” that you can add along with your data points.\n\n\n\n\n\n\nExample\n\n\n\n\nqplot(displ, hwy, data = mpg, geom = c(\"point\", \"smooth\"))\n\n`geom_smooth()` using method = 'loess' and formula = 'y ~ x'\n\n\n\n\n\nEngine displacement and highway mileage w/smoother\n\n\n\n\n\n\nHere it seems that engine displacement and highway mileage have a nonlinear U-shaped relationship, but from the previous plot we know that this is largely due to confounding by the drive class of the car.\n\n\n\n\n\n\nNote\n\n\n\nPreviously, we did not have to specify geom = \"point\" because that was done automatically.\nBut if you want the smoother overlaid with the points, then you need to specify both explicitly.\n\n\nLook at what happens if we do not include the point geom.\n\nqplot(displ, hwy, data = mpg, geom = c(\"smooth\"))\n\n`geom_smooth()` using method = 'loess' and formula = 'y ~ x'\n\n\n\n\n\nEngine displacement and highway mileage w/smoother\n\n\n\n\nSometimes that is the plot you want to show, but in this case it might make more sense to show the data along with the smoother.\n\n\n\n\n\n\nQuestion\n\n\n\nLet’s add a smoother to our palmerpenguins dataset example.\nUsing the code we previously wrote mapping variables to points and color, add a “point” and “smooth” geom:\n\n# try it yourself"
},
{
- "objectID": "posts/13-ggplot2-plotting-system-part-2/index.html#modifying-labels",
- "href": "posts/13-ggplot2-plotting-system-part-2/index.html#modifying-labels",
- "title": "13 - The ggplot2 plotting system: ggplot()",
- "section": "Modifying labels",
- "text": "Modifying labels\n\n\n\n\n\n\nNote\n\n\n\nThere are a variety of annotations you can add to a plot, including different kinds of labels.\n\nxlab() for x-axis labels\nylab() for y-axis labels\nggtitle() for specifying plot titles\n\nlabs() function is generic and can be used to modify multiple types of labels at once\n\n\nHere is an example of modifying the title and the x and y labels to make the plot a bit more informative.\n\ng +\n geom_point(aes(color = bmicat)) +\n labs(title = \"MAACS Cohort\") +\n labs(\n x = expression(\"log \" * PM[2.5]),\n y = \"Nocturnal Symptoms\"\n )\n\n\n\n\nModifying plot labels"
+ "objectID": "posts/12-ggplot2-plotting-system-part-1/index.html#histograms-and-boxplots",
+ "href": "posts/12-ggplot2-plotting-system-part-1/index.html#histograms-and-boxplots",
+ "title": "12 - The ggplot2 plotting system: qplot()",
+ "section": "Histograms and boxplots",
+ "text": "Histograms and boxplots\nThe qplot() function can be used to be used to plot 1-dimensional data too.\nBy specifying a single variable, qplot() will by default make a histogram.\n\n\n\n\n\n\nExample\n\n\n\nWe can make a histogram of the highway mileage data and stratify on the drive class. So technically this is three histograms on top of each other.\n\nqplot(hwy, data = mpg, fill = drv, binwidth = 2)\n\n\n\n\nHistogram of highway mileage by drive class\n\n\n\n\n\n\n\n\n\n\n\n\nQuestion\n\n\n\nNotice, I used fill here to map color to the drv variable. Why is this? What happens when you use color instead?\n\n# try it yourself\n\n\n\nHaving the different colors for each drive class is nice, but the three histograms can be a bit difficult to separate out.\nSide-by-side boxplots are one solution to this problem.\n\nqplot(drv, hwy, data = mpg, geom = \"boxplot\")\n\n\n\n\nBoxplots of highway mileage by drive class\n\n\n\n\nAnother solution is to plot the histograms in separate panels using facets."
},
{
- "objectID": "posts/13-ggplot2-plotting-system-part-2/index.html#a-quick-aside-about-axis-limits",
- "href": "posts/13-ggplot2-plotting-system-part-2/index.html#a-quick-aside-about-axis-limits",
- "title": "13 - The ggplot2 plotting system: ggplot()",
- "section": "A quick aside about axis limits",
- "text": "A quick aside about axis limits\nOne quick quirk about ggplot2 that caught me up when I first started using the package can be displayed in the following example.\nIf you make a lot of time series plots, you often want to restrict the range of the y-axis while still plotting all the data.\nIn the base graphics system you can do that as follows.\n\ntestdat <- data.frame(\n x = 1:100,\n y = rnorm(100)\n)\ntestdat[50, 2] <- 100 ## Outlier!\nplot(testdat$x,\n testdat$y,\n type = \"l\",\n ylim = c(-3, 3)\n)\n\n\n\n\nTime series plot with base graphics\n\n\n\n\nHere, we have restricted the y-axis range to be between -3 and 3, even though there is a clear outlier in the data.\n\n\n\n\n\n\nExample\n\n\n\nWith ggplot2 the default settings will give you this.\n\ng <- ggplot(testdat, aes(x = x, y = y))\ng + geom_line()\n\n\n\n\nTime series plot with default settings\n\n\n\n\nOne might think that modifying the ylim() attribute would give you the same thing as the base plot, but it doesn’t (?????)\n\ng +\n geom_line() +\n ylim(-3, 3)\n\n\n\n\nTime series plot with modified ylim\n\n\n\n\n\n\nEffectively, what this does is subset the data so that only observations between -3 and 3 are included, then plot the data.\nTo plot the data without subsetting it first and still get the restricted range, you have to do the following.\n\ng +\n geom_line() +\n coord_cartesian(ylim = c(-3, 3))\n\n\n\n\nTime series plot with restricted y-axis range\n\n\n\n\nAnd now you know!"
+ "objectID": "posts/12-ggplot2-plotting-system-part-1/index.html#facets",
+ "href": "posts/12-ggplot2-plotting-system-part-1/index.html#facets",
+ "title": "12 - The ggplot2 plotting system: qplot()",
+ "section": "Facets",
+ "text": "Facets\nFacets are a way to create multiple panels of plots based on the levels of categorical variable.\nHere, we want to see a histogram of the highway mileages and the categorical variable is the drive class variable. We can do that using the facets argument to qplot().\n\n\n\n\n\n\nNote\n\n\n\nThe facets argument expects a formula type of input, with a ~ separating the left hand side variable and the right hand side variable.\n\nThe left hand side variable indicates how the rows of the panels should be divided\nThe right hand side variable indicates how the columns of the panels should be divided\n\n\n\n\n\n\n\n\n\nExample\n\n\n\nHere, we just want three rows of histograms (and just one column), one for each drive class, so we specify drv on the left hand side and . on the right hand side indicating that there’s no variable there (it’s empty).\n\nqplot(hwy, data = mpg, facets = drv ~ ., binwidth = 2)\n\n\n\n\nHistogram of highway mileage by drive class\n\n\n\n\n\n\nWe could also look at more data using facets, so instead of histograms we could look at scatter plots of engine displacement and highway mileage by drive class.\nHere, we put the drv variable on the right hand side to indicate that we want a column for each drive class (as opposed to splitting by rows like we did above).\n\nqplot(displ, hwy, data = mpg, facets = . ~ drv)\n\n\n\n\nEngine displacement and highway mileage by drive class\n\n\n\n\nWhat if you wanted to add a smoother to each one of those panels? Simple, you literally just add the smoother as another geom.\n\nqplot(displ, hwy, data = mpg, facets = . ~ drv) +\n geom_smooth(method = \"lm\")\n\n\n\n\nEngine displacement and highway mileage by drive class w/smoother\n\n\n\n\n\n\n\n\n\n\nNote\n\n\n\nWe used a different type of smoother above.\nHere, we add a linear regression line (a type of smoother) to each group to see if there’s any difference.\n\n\n\n\n\n\n\n\nQuestion\n\n\n\nLet’s facet our palmerpenguins dataset example and explore different types of plots.\nBuilding off the code we previously wrote, perform the following tasks:\n\nFacet the plot based on species with the the three species along rows.\nAdd a linear regression line to each the types of species\n\n\n# try it yourself\n\nNext, make a histogram of the body_mass_g for each of the species colored by the three species.\n\n# try it yourself"
},
{
- "objectID": "posts/03-introduction-to-gitgithub/index.html",
- "href": "posts/03-introduction-to-gitgithub/index.html",
- "title": "03 - Introduction to git/GitHub",
- "section": "",
- "text": "This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history.\n\n\nPre-lecture materials\n\nRead ahead\n\n\n\n\n\n\nRead ahead\n\n\n\nBefore class, you can prepare by reading the following materials:\n\nHappy Git with R from Jenny Bryan\nChapter on git and GitHub in dsbook from Rafael Irizarry\n\n\n\n\n\nAcknowledgements\nMaterial for this lecture was borrowed and adopted from\n\nhttps://andreashandel.github.io/MADAcourse\n\n\n\n\nLearning objectives\n\n\n\n\n\n\nLearning objectives\n\n\n\nAt the end of this lesson you will:\n\nKnow what Git and GitHub are.\nKnow why one might want to use them.\nHave created and set up a GitHub account.\n\n\n\n\n\nIntroduction to git/GitHub\nThis document gives a brief explanation of GitHub and how we will use it for this course.\n\ngit\nGit is what is called a version control system for file management. The main idea is that as you (and your collaborators) work on a project, the software tracks, and records any changes made by anyone.\n\nSimilar to the “track changes” features in Microsoft Word, but more rigorous, powerful, and scaled up to multiple files\nGreat for solo or collaborative work\n\n\n\nGitHub\nGitHub is a hosting service on internet for git-aware folders and projects\n\nSimilar to the DropBox or Google, but more structured, powerful, and programmatic\nGreat for solo or collaborative work!\nTechnically GitHub is distinct from Git. However, GitHub is in some sense the interface and Git the underlying engine (a bit like RStudio and R).\n\nSince we will only be using Git through GitHub, I tend to not distinguish between the two. In the following, I refer to all of it as just GitHub. Note that other interfaces to Git exist, e.g., Bitbucket, but GitHub is the most widely used one.\n\n\nWhy use git/GitHub?\nYou want to use GitHub to avoid this:\n\n\n\n\n\nHow not to use GitHub [image from PhD Comics]\n\n\n\n\n[Source: PhD Comics]\nGitHub gives you a clean way to track your projects. It is also very well suited to collaborative work. Historically, version control was used for software development. However, it has become broader and is now used for many types of projects, including data science projects.\nTo learn a bit more about Git/GitHub and why you might want to use it, read this article by Jenny Bryan.\nNote her explanation of what’s special with the README.md file on GitHub.\n\n\nWhat to (not) do\nGitHub is ideal if you have a project with a fair number of files, most of those files are text files (such as code, \\(LaTeX\\), (R)markdown, etc.) and different people work on different parts of the project.\nGitHub is less useful if you have a lot of non-text files (e.g. Word or Powerpoint) and different team members might want to edit the same document at the same time. In that instance, a solution like Google Docs, Word+Dropbox, Word+Onedrive, etc. might be better.\n\n\nHow to use Git/GitHub\nGit and GitHub is fundamentally based on commands you type into the command line. Lots of online resources show you how to use the command line. This is the most powerful, and the way I almost always interact with git/GitHub. However, many folks find this the most confusing way to use git/GitHub. Alternatively, there are graphical interfaces.\n\nGitHub itself provides a grapical interface with basic functionality.\nRStudio also has Git/GitHub integration. Of course this only works for R project GitHub integration.\nThere are also third party GitHub clients with many advanced features, most of which you won’t need initially, but might eventually.\n\nNote: As student, you can (and should) upgrade to the Pro version of GitHub for free (i.e. access to unlimited private repositories is one benefit), see the GitHub student developer pack on how to do this.\nWe will mostly be using Git commands through the RStudio Git panel. This panel will show up by default if RStudio recognizes that you have installed Git already.\n\n\n\nGetting Started\nOne of my favorite resources for getting started with git/GitHub is the Happy Git with R from Jenny Bryan:\n\nhttps://happygitwithr.com\n\n\n\n\n\n\nA screenshot of the Happy Git with R online book from Jenny Bryan\n\n\n\n\nIt truly is one of the best resources out there for getting started with git/GitHub, especially with the integration to RStudio. Therefore, at this point, I will encourage all of you to go read through the online book.\nSome of you may only need to skim it, others will need to spend some time reading through it. Either way, I will bet that you won’t regret the time investment.\nAlternatively, check the git to know git: an 8 minute introduction blog post by Amy Peterson.\n\n\nUsing git/GitHub in our course\nIn this course, you will use git/GitHub in the following ways:\n\nProject 0 (optional) - You will create a website introducing yourself to folks in the course and deploy it on GitHub.\nProjects 1-3 - You can practice using git locally (on your compute environment) to track your changes over time and, if you wish (but highly suggested), you can practice pushing your project solutions to a private GitHub repository on your GitHub account (i.e. git add, git commit, git push, git pull, etc) .\n\nLearning these skills will be useful down the road if you ever work collaboratively on a project (i.e. writing code as a group). In this scenario, you will use the skills you have been practicing in your projects to work together as a team in a single GitHub repository.\n\n\n“Help me help you”: reprex::reprex()\nInstall the reprex R package.\n\ninstall.packages(\"reprex\")\n\n\nWe’ll learn more about reproducible code soon. But in the meantime, you will definitely want to learn about reprex: Prepare Reproducible Example Code via the Clipboard.\nAs a quick exercise:\n\nInstall reprex\nLog in to your GitHub account and access https://github.com/lcolladotor/jhustatcomputing2023/issues/2\nCopy paste the following R code stop(\"This R error is weird\").\nType reprex::reprex() in your R console.\nPaste the output into https://github.com/lcolladotor/jhustatcomputing2023/issues/2 and click on the “comment” green button.\n\nHere is an actual example where I used reprex to ask a question: https://github.com/Bioconductor/BiocFileCache/issues/48.\nFor more details on reprex, check this video:\n\n\n\n\nPost-lecture materials\n\nFinal Questions\nHere are some post-lecture questions to help you think about the material discussed.\n\n\n\n\n\n\nQuestions\n\n\n\n\nWhat is version control?\nWhat is the difference between git and GitHub?\nWhat are other version controls software/tools that are available besides git?\n\n\n\n\n\nAdditional Resources\n\n\n\n\n\n\nTip\n\n\n\n\ngit and GitHub in the dsbook by Rafael Irizarry\n\n\n\n\n\n\nR session information\n\noptions(width = 120)\nsessioninfo::session_info()\n\n─ Session info ───────────────────────────────────────────────────────────────────────────────────────────────────────\n setting value\n version R version 4.3.1 (2023-06-16)\n os macOS Ventura 13.5\n system aarch64, darwin20\n ui X11\n language (EN)\n collate en_US.UTF-8\n ctype en_US.UTF-8\n tz America/Mexico_City\n date 2023-08-29\n pandoc 3.1.5 @ /opt/homebrew/bin/ (via rmarkdown)\n\n─ Packages ───────────────────────────────────────────────────────────────────────────────────────────────────────────\n package * version date (UTC) lib source\n cli 3.6.1 2023-03-23 [1] CRAN (R 4.3.0)\n colorout 1.2-2 2023-05-06 [1] Github (jalvesaq/colorout@79931fd)\n digest 0.6.33 2023-07-07 [1] CRAN (R 4.3.0)\n evaluate 0.21 2023-05-05 [1] CRAN (R 4.3.0)\n fastmap 1.1.1 2023-02-24 [1] CRAN (R 4.3.0)\n htmltools 0.5.6 2023-08-10 [1] CRAN (R 4.3.0)\n htmlwidgets 1.6.2 2023-03-17 [1] CRAN (R 4.3.0)\n jsonlite 1.8.7 2023-06-29 [1] CRAN (R 4.3.0)\n knitr 1.43 2023-05-25 [1] CRAN (R 4.3.0)\n rlang 1.1.1 2023-04-28 [1] CRAN (R 4.3.0)\n rmarkdown 2.24 2023-08-14 [1] CRAN (R 4.3.1)\n rstudioapi 0.15.0 2023-07-07 [1] CRAN (R 4.3.0)\n sessioninfo 1.2.2 2021-12-06 [1] CRAN (R 4.3.0)\n xfun 0.40 2023-08-09 [1] CRAN (R 4.3.0)\n yaml 2.3.7 2023-01-23 [1] CRAN (R 4.3.0)\n\n [1] /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/library\n\n──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────"
+ "objectID": "posts/12-ggplot2-plotting-system-part-1/index.html#summary",
+ "href": "posts/12-ggplot2-plotting-system-part-1/index.html#summary",
+ "title": "12 - The ggplot2 plotting system: qplot()",
+ "section": "Summary",
+ "text": "Summary\nThe qplot() function in ggplot2 is the analog of plot() in base graphics but with many built-in features that the traditionaly plot() does not provide. The syntax is somewhere in between the base and lattice graphics system. The qplot() function is useful for quickly putting data on the page/screen, but for ultimate customization, it may make more sense to use some of the lower level functions that we discuss later in the next lesson."
},
{
- "objectID": "posts/22-working-with-factors/index.html",
- "href": "posts/22-working-with-factors/index.html",
- "title": "22 - Factors",
+ "objectID": "posts/21-regular-expressions/index.html",
+ "href": "posts/21-regular-expressions/index.html",
+ "title": "21 - Regular expressions",
"section": "",
"text": "This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history."
},
{
- "objectID": "posts/22-working-with-factors/index.html#factor-basics",
- "href": "posts/22-working-with-factors/index.html#factor-basics",
- "title": "22 - Factors",
- "section": "Factor basics",
- "text": "Factor basics\nYou can fix both of these problems with a factor.\nTo create a factor you must start by creating a list of the valid levels:\n\nmonth_levels <- c(\n \"Jan\", \"Feb\", \"Mar\", \"Apr\", \"May\", \"Jun\",\n \"Jul\", \"Aug\", \"Sep\", \"Oct\", \"Nov\", \"Dec\"\n)\n\nNow we can create a factor with the factor() function defining the levels argument:\n\ny <- factor(x, levels = month_levels)\ny\n\n[1] Dec Apr Jan Mar\nLevels: Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec\n\n\nWe can see what happens if we try to sort the factor:\n\nsort(y)\n\n[1] Jan Mar Apr Dec\nLevels: Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec\n\n\nWe can also check the attributes of the factor:\n\nattributes(y)\n\n$levels\n [1] \"Jan\" \"Feb\" \"Mar\" \"Apr\" \"May\" \"Jun\" \"Jul\" \"Aug\" \"Sep\" \"Oct\" \"Nov\" \"Dec\"\n\n$class\n[1] \"factor\"\n\n\nIf you want to access the set of levels directly, you can do so with levels():\n\nlevels(y)\n\n [1] \"Jan\" \"Feb\" \"Mar\" \"Apr\" \"May\" \"Jun\" \"Jul\" \"Aug\" \"Sep\" \"Oct\" \"Nov\" \"Dec\"\n\n\n\n\n\n\n\n\nNote\n\n\n\nAny values not in the level will be silently converted to NA:\n\ny_typo <- factor(x_typo, levels = month_levels)\ny_typo\n\n[1] Dec Apr <NA> Mar \nLevels: Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec"
+ "objectID": "posts/21-regular-expressions/index.html#regex-basics",
+ "href": "posts/21-regular-expressions/index.html#regex-basics",
+ "title": "21 - Regular expressions",
+ "section": "regex basics",
+ "text": "regex basics\nA regular expression (also known as a “regex” or “regexp”) is a concise language for describing patterns in character strings.\nRegex could be patterns that could be contained within another string.\n\n\n\n\n\n\nExample\n\n\n\nFor example, if we wanted to search for the pattern “ai” in the character string “The rain in Spain”, we see it appears twice!\n“The rain in Spain”\n\n\nGenerally, a regular expression can be used for e.g.\n\nsearching for a pattern or string within another string (e.g searching for the string “a” in the string “Maryland”)\nreplacing one part of a string with another string (e.g replacing the string “t” with “p” in the string “hot” where you are changing the string “hot” to “hop”)\n\nIf you have never worked with regular expressions, it can seem like maybe a baby hit the keys on your keyboard (complete gibberish), but it will slowly make sense once you learn the syntax.\nSoon you will be able create incredibly powerful regular expressions in your day-to-day work."
},
{
- "objectID": "posts/22-working-with-factors/index.html#challenges-working-with-categorical-data",
- "href": "posts/22-working-with-factors/index.html#challenges-working-with-categorical-data",
- "title": "22 - Factors",
- "section": "Challenges working with categorical data",
- "text": "Challenges working with categorical data\nWorking with categorical data can really helpful in many situations, but it also be challenging.\nFor example,\n\nWhat if the original data source for where the categorical data is getting ingested changes?\n\nIf a domain expert is providing spreadsheet data at regular intervals, code that worked on the initial data may not generate an error message, but could silently produce incorrect results.\n\nWhat if a new level of a categorical data is added in an updated dataset?\nWhen categorical data are coded with numerical values, it can be easy to break the relationship between category numbers and category labels without realizing it, thus losing the information encoded in a variable.\n\nLet’s consider an example of this below.\n\n\n\n\n\n\n\n\nExample\n\n\n\nConsider a set of decades,\n\nlibrary(tidyverse)\n\nx1_original <- c(10, 10, 10, 50, 60, 20, 20, 40)\nx1_factor <- factor(x1_original)\nattributes(x1_factor)\n\n$levels\n[1] \"10\" \"20\" \"40\" \"50\" \"60\"\n\n$class\n[1] \"factor\"\n\ntibble(x1_original, x1_factor) %>%\n mutate(x1_numeric = as.numeric(x1_factor))\n\n# A tibble: 8 × 3\n x1_original x1_factor x1_numeric\n <dbl> <fct> <dbl>\n1 10 10 1\n2 10 10 1\n3 10 10 1\n4 50 50 4\n5 60 60 5\n6 20 20 2\n7 20 20 2\n8 40 40 3\n\n\nInstead of creating a new variable with a numeric version of the value of the factor variable x1_factor, the variable loses the original numerical categories and creates a factor number (i.e., 10 is mapped to 1, 20 is mapped to 2, and 40 is mapped to 3, etc).\n\n\nThis result is unexpected because base::as.numeric() is intended to recover numeric information by coercing a character variable.\n\n\n\n\n\n\nExample\n\n\n\nCompare the following:\n\nas.numeric(c(\"hello\"))\n\nWarning: NAs introduced by coercion\n\n\n[1] NA\n\nas.numeric(factor(c(\"hello\")))\n\n[1] 1\n\n\nIn the first example, R does not how to convert the character string to a numeric, so it returns a NA.\nIn the second example, it creates factor numbers and orders them according to an alphabetical order. Here is another example of this behavior:\n\nas.numeric(factor(c(\"hello\", \"goodbye\")))\n\n[1] 2 1\n\n\n\n\nThis behavior of the factor() function feels unexpected at best.\nAnother example of unexpected behavior is how the function will silently make a missing value because the values in the data and the levels do not match.\n\nfactor(\"a\", levels = \"c\")\n\n[1] <NA>\nLevels: c\n\n\nThe unfortunate behavior of factors in R has led to an online movement against the default behavior of many data import functions to make factors out of any variable composed as strings.\nThe tidyverse is part of this movement, with functions from the readr package defaulting to leaving strings as-is. (Others have chosen to add options(stringAsFactors=FALSE) into their start up commands.)"
+ "objectID": "posts/21-regular-expressions/index.html#string-basics",
+ "href": "posts/21-regular-expressions/index.html#string-basics",
+ "title": "21 - Regular expressions",
+ "section": "string basics",
+ "text": "string basics\nIn R, you can create (character) strings with either single quotes ('hello!') or double quotes (\"hello!\") – no difference (not true for other languages!).\nI recommend using the double quotes, unless you want to create a string with multiple \".\n\nstring1 <- \"This is a string\"\nstring2 <- 'If I want to include a \"quote\" inside a string, I use single quotes'\n\n\n\n\n\n\n\nPro-tip\n\n\n\nStrings can be tricky when executing them. If you forget to close a quote, you’ll see +\n> \"This is a string without a closing quote\n+ \n+ \n+ HELP I'M STUCK\nIf this happen to you, take a deep breath, press Escape and try again.\n\n\nMultiple strings are often stored in a character vector, which you can create with c():\n\nc(\"one\", \"two\", \"three\")\n\n[1] \"one\" \"two\" \"three\""
},
{
- "objectID": "posts/22-working-with-factors/index.html#factors-when-modeling-data",
- "href": "posts/22-working-with-factors/index.html#factors-when-modeling-data",
- "title": "22 - Factors",
- "section": "Factors when modeling data",
- "text": "Factors when modeling data\nSo if factors are so troublesome, what’s the point of them in the first place?\nFactors are still necessary for some data analytic tasks. The most salient case is in statistical modeling.\nWhen you pass a factor variable into lm() or glm(), R automatically creates indicator (or more colloquially ‘dummy’) variables for each of the levels and picks one as a reference group.\nFor simple cases, this behavior can also be achieved with a character vector.\nHowever, to choose which level to use as a reference level or to order classes, factors must be used.\n\n\n\n\n\n\nExample\n\n\n\nConsider a vector of character strings with three income levels:\n\nincome_level <- c(\n rep(\"low\", 10),\n rep(\"medium\", 10),\n rep(\"high\", 10)\n)\nincome_level\n\n [1] \"low\" \"low\" \"low\" \"low\" \"low\" \"low\" \"low\" \"low\" \n [9] \"low\" \"low\" \"medium\" \"medium\" \"medium\" \"medium\" \"medium\" \"medium\"\n[17] \"medium\" \"medium\" \"medium\" \"medium\" \"high\" \"high\" \"high\" \"high\" \n[25] \"high\" \"high\" \"high\" \"high\" \"high\" \"high\" \n\n\nHere, it might make sense to use the lowest income level (low) as the reference class so that all the other coefficients can be interpreted in comparison to it.\nHowever, R would use high as the reference by default because ‘h’ comes before ‘l’ in the alphabet.\n\nx <- factor(income_level)\nx\n\n [1] low low low low low low low low low low \n[11] medium medium medium medium medium medium medium medium medium medium\n[21] high high high high high high high high high high \nLevels: high low medium\n\ny <- rnorm(30) # generate some random obs from a normal dist\nlm(y ~ x)\n\n\nCall:\nlm(formula = y ~ x)\n\nCoefficients:\n(Intercept) xlow xmedium \n -0.5621 0.5728 0.4219"
+ "objectID": "posts/21-regular-expressions/index.html#metacharacters",
+ "href": "posts/21-regular-expressions/index.html#metacharacters",
+ "title": "21 - Regular expressions",
+ "section": "metacharacters",
+ "text": "metacharacters\nThe first metacharacter that we will discuss is \".\".\nThe metacharacter that only consists of a period represents any character other than a new line (we will discuss new lines soon).\n\n\n\n\n\n\nExample\n\n\n\nLet’s take a look at some examples using the period regex:\n\ngrepl(\".\", \"Maryland\")\n\n[1] TRUE\n\ngrepl(\".\", \"*&2[0+,%<@#~|}\")\n\n[1] TRUE\n\ngrepl(\".\", \"\")\n\n[1] FALSE\n\n\n\n\nAs you can see the period metacharacter is very liberal.\nThis metacharacter is most useful when you do not care about a set of characters in a regular expression.\n\n\n\n\n\n\nExample\n\n\n\nHere is another example\n\ngrepl(\"a.b\", c(\"aaa\", \"aab\", \"abb\", \"acadb\"))\n\n[1] FALSE TRUE TRUE TRUE\n\n\nIn the case above, grepl() returns TRUE for all strings that contain an a followed by any other character followed by a b."
},
{
- "objectID": "posts/22-working-with-factors/index.html#memory-req-for-factors-and-character-strings",
- "href": "posts/22-working-with-factors/index.html#memory-req-for-factors-and-character-strings",
- "title": "22 - Factors",
- "section": "Memory req for factors and character strings",
- "text": "Memory req for factors and character strings\nConsider a large character string such as income_level corresponding to a categorical variable.\n\nincome_level <- c(\n rep(\"low\", 10000),\n rep(\"medium\", 10000),\n rep(\"high\", 10000)\n)\n\nIn early versions of R, storing categorical data as a factor variable was considerably more efficient than storing the same data as strings, because factor variables only store the factor labels once.\nHowever, R now uses a global string pool, so each unique string is only stored once, which means storage is now less of an issue.\n\nformat(object.size(income_level), units = \"Kb\") # size of the character string\n\n[1] \"234.6 Kb\"\n\nformat(object.size(factor(income_level)), units = \"Kb\") # size of the factor\n\n[1] \"117.8 Kb\""
+ "objectID": "posts/21-regular-expressions/index.html#repetition",
+ "href": "posts/21-regular-expressions/index.html#repetition",
+ "title": "21 - Regular expressions",
+ "section": "repetition",
+ "text": "repetition\nYou can specify a regular expression that contains a certain number of characters or metacharacters using the enumeration metacharacters (or sometimes called quantifiers).\n\n+: indicates that one or more of the preceding expression should be present (or matches at least 1 time)\n*: indicates that zero or more of the preceding expression is present (or matches at least 0 times)\n?: indicates that zero or 1 of the preceding expression is not present or present at most 1 time (or matches between 0 and 1 times)\n\n\n\n\n\n\n\nExample\n\n\n\nLet’s take a look at some examples using these metacharacters:\n\n# Does \"Maryland\" contain one or more of \"a\" ?\ngrepl(\"a+\", \"Maryland\")\n\n[1] TRUE\n\n# Does \"Maryland\" contain one or more of \"x\" ?\ngrepl(\"x+\", \"Maryland\")\n\n[1] FALSE\n\n# Does \"Maryland\" contain zero or more of \"x\" ?\ngrepl(\"x*\", \"Maryland\")\n\n[1] TRUE\n\n\n\n\nIf you want to do more than one character, you need to wrap it in ().\n\n# Does \"Maryland\" contain zero or more of \"x\" ?\ngrepl(\"(xx)*\", \"Maryland\")\n\n[1] TRUE\n\n\n\n\n\n\n\n\nQuestion\n\n\n\nLet’s practice a few out together. Make the following regular expressions for the character string “spookyhalloween”:\n\nDoes “zz” appear 1 or more times?\nDoes “ee” appear 1 or more times?\nDoes “oo” appear 0 or more times?\nDoes “ii” appear 0 or more times?\n\n\n## try it out\n\n\n\nYou can also specify exact numbers of expressions using curly brackets {}.\n\n{n}: exactly n\n{n,}: n or more\n{,m}: at most m\n{n,m}: between n and m\n\nFor example \"a{5}\" specifies “a exactly five times”, \"a{2,5}\" specifies “a between 2 and 5 times,” and \"a{2,}\" specifies “a at least 2 times.” Let’s take a look at some examples:\n\n# Does \"Mississippi\" contain exactly 2 adjacent \"s\" ?\ngrepl(\"s{2}\", \"Mississippi\")\n\n[1] TRUE\n\n# This is equivalent to the expression above:\ngrepl(\"ss\", \"Mississippi\")\n\n[1] TRUE\n\n# Does \"Mississippi\" contain between 1 and 3 adjacent \"s\" ?\ngrepl(\"s{1,3}\", \"Mississippi\")\n\n[1] TRUE\n\n# Does \"Mississippi\" contain between 2 and 3 adjacent \"i\" ?\ngrepl(\"i{2,3}\", \"Mississippi\")\n\n[1] FALSE\n\n# Does \"Mississippi\" contain between 2 adjacent \"iss\" ?\ngrepl(\"(iss){2}\", \"Mississippi\")\n\n[1] TRUE\n\n# Does \"Mississippi\" contain between 2 adjacent \"ss\" ?\ngrepl(\"(ss){2}\", \"Mississippi\")\n\n[1] FALSE\n\n# Does \"Mississippi\" contain the pattern of an \"i\" followed by\n# 2 of any character, with that pattern repeated three times adjacently?\ngrepl(\"(i.{2}){3}\", \"Mississippi\")\n\n[1] TRUE\n\n\n\n\n\n\n\n\nQuestion\n\n\n\nLet’s practice a few out together. Make the following regular expressions for the character string “spookyspookyhalloweenspookyspookyhalloween”:\n\nSearch for “spooky” exactly 2 times. What about 3 times?\nSearch for “spooky” exactly 2 times followed by any character of length 9 (i.e. “halloween”).\nSame search as above, but search for that twice in a row.\nSame search as above, but search for that three times in a row.\n\n\n## try it out"
},
{
- "objectID": "posts/22-working-with-factors/index.html#summary",
- "href": "posts/22-working-with-factors/index.html#summary",
- "title": "22 - Factors",
- "section": "Summary",
- "text": "Summary\nFactors can be really useful in many data analytic tasks, but the base R functions to work with factors can lead to some unexpected behavior that can catch new R users.\nLet’s introduce a package to make wrangling factors easier."
+ "objectID": "posts/21-regular-expressions/index.html#capture-group",
+ "href": "posts/21-regular-expressions/index.html#capture-group",
+ "title": "21 - Regular expressions",
+ "section": "capture group",
+ "text": "capture group\nIn the examples above, I used parentheses () to create a capturing group. A capturing group allows you to use quantifiers on other regular expressions.\nIn the “Mississippi” example, I first created the regex \"i.{2}\" which matches i followed by any two characters (“iss” or “ipp”). Then, I used a capture group to wrap that regex, and to specify exactly three adjacent occurrences of that regex.\nYou can specify sets of characters (or character sets or character classes) with regular expressions, some of which come built in, but you can build your own character sets too.\nMore on character sets next."
},
{
- "objectID": "posts/22-working-with-factors/index.html#general-social-survey",
- "href": "posts/22-working-with-factors/index.html#general-social-survey",
- "title": "22 - Factors",
- "section": "General Social Survey",
- "text": "General Social Survey\nFor the rest of this lecture, we are going to use the gss_cat dataset that is installed when you load forcats.\nIt’s a sample of data from the General Social Survey, a long-running US survey conducted by the independent research organization NORC at the University of Chicago.\nThe survey has thousands of questions, so in gss_cat.\nI have selected a handful that will illustrate some common challenges you will encounter when working with factors.\n\ngss_cat\n\n# A tibble: 21,483 × 9\n year marital age race rincome partyid relig denom tvhours\n <int> <fct> <int> <fct> <fct> <fct> <fct> <fct> <int>\n 1 2000 Never married 26 White $8000 to 9999 Ind,near … Prot… Sout… 12\n 2 2000 Divorced 48 White $8000 to 9999 Not str r… Prot… Bapt… NA\n 3 2000 Widowed 67 White Not applicable Independe… Prot… No d… 2\n 4 2000 Never married 39 White Not applicable Ind,near … Orth… Not … 4\n 5 2000 Divorced 25 White Not applicable Not str d… None Not … 1\n 6 2000 Married 25 White $20000 - 24999 Strong de… Prot… Sout… NA\n 7 2000 Never married 36 White $25000 or more Not str r… Chri… Not … 3\n 8 2000 Divorced 44 White $7000 to 7999 Ind,near … Prot… Luth… NA\n 9 2000 Married 44 White $25000 or more Not str d… Prot… Other 0\n10 2000 Married 47 White $25000 or more Strong re… Prot… Sout… 3\n# ℹ 21,473 more rows\n\n\n\n\n\n\n\n\nPro-tip\n\n\n\nSince this dataset is provided by a package, you can get more information about the variables with ?gss_cat.\n\n\nWhen factors are stored in a tibble, you cannot see their levels so easily. One way to view them is with count():\n\ngss_cat %>%\n count(race)\n\n# A tibble: 3 × 2\n race n\n <fct> <int>\n1 Other 1959\n2 Black 3129\n3 White 16395\n\n\nOr with a bar chart using the geom_bar() geom:\n\ngss_cat %>%\n ggplot(aes(x = race)) +\n geom_bar()\n\n\n\n\n\n\n\n\n\n\nImportant\n\n\n\nWhen working with factors, the two most common operations are\n\nChanging the order of the levels\nChanging the values of the levels\n\n\n\nThose operations are described in the sections below."
+ "objectID": "posts/21-regular-expressions/index.html#character-sets",
+ "href": "posts/21-regular-expressions/index.html#character-sets",
+ "title": "21 - Regular expressions",
+ "section": "character sets",
+ "text": "character sets\nFirst, we will discuss the built in character sets:\n\nwords (\"\\\\w\") = Words specify any letter, digit, or a underscore\ndigits (\"\\\\d\") = Digits specify the digits 0 through 9\nwhitespace characters (\"\\\\s\") = Whitespace specifies line breaks, tabs, or spaces\n\nEach of these character sets have their own compliments:\n\nnot words (\"\\\\W\")\nnot digits (\"\\\\D\")\nnot whitespace characters (\"\\\\S\")\n\nEach specifies all of the characters not included in their corresponding character sets.\n\n\n\n\n\n\nInteresting fact\n\n\n\nTechnically, you are using the a character set \"\\d\" or \"\\s\" (with only one black slash), but because you are using this character set in a string, you need the second \\ to escape the string. So you will type \"\\\\d\" or \"\\\\s\".\n\n\"\\\\d\"\n\n[1] \"\\\\d\"\n\n\nSo for example, to include a literal single or double quote in a string you can use \\ to “escape” the string and being able to include a single or double quote:\n\ndouble_quote <- \"\\\"\"\ndouble_quote\n\n[1] \"\\\"\"\n\nsingle_quote <- \"'\"\nsingle_quote\n\n[1] \"'\"\n\n\nThat means if you want to include a literal backslash, you will need to double it up: \"\\\\\".\n\n\nIn fact, putting two backslashes before any punctuation mark that is also a metacharacter indicates that you are looking for the symbol and not the metacharacter meaning.\nFor example \"\\\\.\" indicates you are trying to match a period in a string. Let’s take a look at a few examples:\n\ngrepl(\"\\\\+\", \"tragedy + time = humor\")\n\n[1] TRUE\n\ngrepl(\"\\\\.\", \"https://publichealth.jhu.edu\")\n\n[1] TRUE\n\n\n\n\n\n\n\n\nBeware\n\n\n\nThe printed representation of a string is not the same as string itself, because the printed representation shows the escapes. To see the raw contents of the string, use writeLines():\n\nx <- c(\"\\'\", \"\\\"\", \"\\\\\")\nx\n\n[1] \"'\" \"\\\"\" \"\\\\\"\n\nwriteLines(x)\n\n'\n\"\n\\\n\n\n\n\nThere are a handful of other special characters. The most common are\n\n\"\\n\": newline\n\"\\t\": tab,\n\nbut you can see the complete list by requesting help (run the following in the console and a help file will appear:\n\n?\"'\"\n\nYou will also sometimes see strings like “0b5”, this is a way of writing non-English characters that works on all platforms:\n\nx <- c(\"\\\\t\", \"\\\\n\", \"\\u00b5\")\nx\n\n[1] \"\\\\t\" \"\\\\n\" \"µ\" \n\nwriteLines(x)\n\n\\t\n\\n\nµ\n\n\n\n\n\n\n\n\nExample\n\n\n\nLet’s take a look at a few examples of built in character sets: \"\\w\", \"\\d\", \"\\s\".\n\ngrepl(\"\\\\w\", \"abcdefghijklmnopqrstuvwxyz0123456789\")\n\n[1] TRUE\n\ngrepl(\"\\\\d\", \"0123456789\")\n\n[1] TRUE\n\n# \"\\n\" is the metacharacter for a new line\n# \"\\t\" is the metacharacter for a tab\ngrepl(\"\\\\s\", \"\\n\\t \")\n\n[1] TRUE\n\ngrepl(\"\\\\d\", \"abcdefghijklmnopqrstuvwxyz\")\n\n[1] FALSE\n\ngrepl(\"\\\\D\", \"abcdefghijklmnopqrstuvwxyz\")\n\n[1] TRUE\n\ngrepl(\"\\\\w\", \"\\n\\t \")\n\n[1] FALSE"
},
{
- "objectID": "posts/22-working-with-factors/index.html#modifying-factor-order",
- "href": "posts/22-working-with-factors/index.html#modifying-factor-order",
- "title": "22 - Factors",
- "section": "Modifying factor order",
- "text": "Modifying factor order\nIt’s often useful to change the order of the factor levels in a visualization.\nLet’s explore the relig (religion) factor:\n\ngss_cat %>%\n count(relig)\n\n# A tibble: 15 × 2\n relig n\n <fct> <int>\n 1 No answer 93\n 2 Don't know 15\n 3 Inter-nondenominational 109\n 4 Native american 23\n 5 Christian 689\n 6 Orthodox-christian 95\n 7 Moslem/islam 104\n 8 Other eastern 32\n 9 Hinduism 71\n10 Buddhism 147\n11 Other 224\n12 None 3523\n13 Jewish 388\n14 Catholic 5124\n15 Protestant 10846\n\n\nWe see there are 15 categories in the gss_cat dataset.\n\nattributes(gss_cat$relig)\n\n$levels\n [1] \"No answer\" \"Don't know\" \n [3] \"Inter-nondenominational\" \"Native american\" \n [5] \"Christian\" \"Orthodox-christian\" \n [7] \"Moslem/islam\" \"Other eastern\" \n [9] \"Hinduism\" \"Buddhism\" \n[11] \"Other\" \"None\" \n[13] \"Jewish\" \"Catholic\" \n[15] \"Protestant\" \"Not applicable\" \n\n$class\n[1] \"factor\"\n\n\nThe first level is “No answer” followed by “Don’t know”, and so on.\nImagine you want to explore the average number of hours spent watching TV (tvhours) per day across religions (relig):\n\nrelig_summary <- gss_cat %>%\n group_by(relig) %>%\n summarise(\n tvhours = mean(tvhours, na.rm = TRUE),\n n = n()\n )\n\nrelig_summary %>%\n ggplot(aes(x = tvhours, y = relig)) +\n geom_point()\n\n\n\n\nThe y-axis lists the levels of the relig factor in the order of the levels.\nHowever, it is hard to read this plot because there’s no overall pattern.\n\nfct_reorder\nWe can improve it by reordering the levels of relig using fct_reorder(). fct_reorder(.f, .x, .fun) takes three arguments:\n\n.f, the factor whose levels you want to modify.\n.x, a numeric vector that you want to use to reorder the levels.\nOptionally, .fun, a function that’s used if there are multiple values of x for each value of f. The default value is median.\n\n\nrelig_summary %>%\n ggplot(aes(\n x = tvhours,\n y = fct_reorder(.f = relig, .x = tvhours)\n )) +\n geom_point()\n\n\n\n\nReordering religion makes it much easier to see that people in the “Don’t know” category watch much more TV, and Hinduism & Other Eastern religions watch much less.\nAs you start making more complicated transformations, I recommend moving them out of aes() and into a separate mutate() step.\n\n\n\n\n\n\nExample\n\n\n\nYou could rewrite the plot above as:\n\nrelig_summary %>%\n mutate(relig = fct_reorder(relig, tvhours)) %>%\n ggplot(aes(x = tvhours, y = relig)) +\n geom_point()\n\n\n\n\n\n\n\n\n\n\n\n\nAnother example\n\n\n\nWhat if we create a similar plot looking at how average age varies across reported income level?\n\nrincome_summary <-\n gss_cat %>%\n group_by(rincome) %>%\n summarise(\n age = mean(age, na.rm = TRUE),\n n = n()\n )\n\nrincome_summary %>%\n ggplot(aes(x = age, y = fct_reorder(.f = rincome, .x = age))) +\n geom_point()\n\n\n\n\nHere, arbitrarily reordering the levels isn’t a good idea! That’s because rincome already has a principled order that we shouldn’t mess with.\n\n\n\n\n\n\n\n\nPro-tip\n\n\n\nReserve fct_reorder() for factors whose levels are arbitrarily ordered.\n\n\n\n\n\n\n\n\nQuestion\n\n\n\nLet’s practice fct_reorder(). Using the palmerpenguins dataset,\n\nCalculate the average bill_length_mm for each species\nCreate a scatter plot showing the average for each species.\n\nGo back and reorder the factor species based on the average bill length from largest to smallest.\nNow order it from smallest to largest\n\n\nlibrary(palmerpenguins)\npenguins\n\n# A tibble: 344 × 8\n species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g\n <fct> <fct> <dbl> <dbl> <int> <int>\n 1 Adelie Torgersen 39.1 18.7 181 3750\n 2 Adelie Torgersen 39.5 17.4 186 3800\n 3 Adelie Torgersen 40.3 18 195 3250\n 4 Adelie Torgersen NA NA NA NA\n 5 Adelie Torgersen 36.7 19.3 193 3450\n 6 Adelie Torgersen 39.3 20.6 190 3650\n 7 Adelie Torgersen 38.9 17.8 181 3625\n 8 Adelie Torgersen 39.2 19.6 195 4675\n 9 Adelie Torgersen 34.1 18.1 193 3475\n10 Adelie Torgersen 42 20.2 190 4250\n# ℹ 334 more rows\n# ℹ 2 more variables: sex <fct>, year <int>\n\n## Try it out\n\n\n\n\n\nfct_relevel\nHowever, it does make sense to pull “Not applicable” to the front with the other special levels.\nYou can use fct_relevel().\nIt takes a factor, f, and then any number of levels that you want to move to the front of the line.\n\nrincome_summary %>%\n ggplot(aes(age, fct_relevel(rincome, \"Not applicable\"))) +\n geom_point()\n\n\n\n\n\n\n\n\n\n\nNote\n\n\n\nAny levels not mentioned in fct_relevel will be left in their existing order.\n\n\nAnother type of reordering is useful when you are coloring the lines on a plot. fct_reorder2(f, x, y) reorders the factor f by the y values associated with the largest x values.\nThis makes the plot easier to read because the colors of the line at the far right of the plot will line up with the legend.\n\nby_age <-\n gss_cat %>%\n filter(!is.na(age)) %>%\n count(age, marital) %>%\n group_by(age) %>%\n mutate(prop = n / sum(n))\n\nby_age %>%\n ggplot(aes(age, prop, colour = marital)) +\n geom_line(na.rm = TRUE)\nby_age %>%\n ggplot(aes(age, prop, colour = fct_reorder2(marital, age, prop))) +\n geom_line() +\n labs(colour = \"marital\")\n\n\n\n\n\n\n\n\n\n\n\n\n\nfct_infreq\nFinally, for bar plots, you can use fct_infreq() to order levels in decreasing frequency: this is the simplest type of reordering because it doesn’t need any extra variables. Combine it with fct_rev() if you want them in increasing frequency so that in the bar plot largest values are on the right, not the left.\n\ngss_cat %>%\n mutate(marital = marital %>% fct_infreq() %>% fct_rev()) %>%\n ggplot(aes(marital)) +\n geom_bar()"
+ "objectID": "posts/21-regular-expressions/index.html#brackets",
+ "href": "posts/21-regular-expressions/index.html#brackets",
+ "title": "21 - Regular expressions",
+ "section": "brackets",
+ "text": "brackets\nYou can also specify specific character sets using straight brackets [].\nFor example a character set of just the vowels would look like: \"[aeiou]\".\n\ngrepl(\"[aeiou]\", \"rhythms\")\n\n[1] FALSE\n\n\nYou can find the complement to a specific character by putting a carrot ^ after the first bracket. For example \"[^aeiou]\" matches all characters except the lowercase vowels.\n\ngrepl(\"[^aeiou]\", \"rhythms\")\n\n[1] TRUE"
},
{
- "objectID": "posts/22-working-with-factors/index.html#modifying-factor-levels",
- "href": "posts/22-working-with-factors/index.html#modifying-factor-levels",
- "title": "22 - Factors",
- "section": "Modifying factor levels",
- "text": "Modifying factor levels\nMore powerful than changing the orders of the levels is changing their values. This allows you to clarify labels for publication, and collapse levels for high-level displays.\n\nfct_recode\nThe most general and powerful tool is fct_recode(). It allows you to recode, or change, the value of each level. For example, take the gss_cat$partyid:\n\ngss_cat %>%\n count(partyid)\n\n# A tibble: 10 × 2\n partyid n\n <fct> <int>\n 1 No answer 154\n 2 Don't know 1\n 3 Other party 393\n 4 Strong republican 2314\n 5 Not str republican 3032\n 6 Ind,near rep 1791\n 7 Independent 4119\n 8 Ind,near dem 2499\n 9 Not str democrat 3690\n10 Strong democrat 3490\n\n\nThe levels are terse and inconsistent.\nLet’s tweak them to be longer and use a parallel construction.\nLike most rename and recoding functions in the tidyverse:\n\nthe new values go on the left\nthe old values go on the right\n\n\ngss_cat %>%\n mutate(partyid = fct_recode(partyid,\n \"Republican, strong\" = \"Strong republican\",\n \"Republican, weak\" = \"Not str republican\",\n \"Independent, near rep\" = \"Ind,near rep\",\n \"Independent, near dem\" = \"Ind,near dem\",\n \"Democrat, weak\" = \"Not str democrat\",\n \"Democrat, strong\" = \"Strong democrat\"\n )) %>%\n count(partyid)\n\n# A tibble: 10 × 2\n partyid n\n <fct> <int>\n 1 No answer 154\n 2 Don't know 1\n 3 Other party 393\n 4 Republican, strong 2314\n 5 Republican, weak 3032\n 6 Independent, near rep 1791\n 7 Independent 4119\n 8 Independent, near dem 2499\n 9 Democrat, weak 3690\n10 Democrat, strong 3490\n\n\n\n\n\n\n\n\nNote\n\n\n\nfct_recode() will leave the levels that aren’t explicitly mentioned as is, and will warn you if you accidentally refer to a level that doesn’t exist.\n\n\nTo combine groups, you can assign multiple old levels to the same new level:\n\ngss_cat %>%\n mutate(partyid = fct_recode(partyid,\n \"Republican, strong\" = \"Strong republican\",\n \"Republican, weak\" = \"Not str republican\",\n \"Independent, near rep\" = \"Ind,near rep\",\n \"Independent, near dem\" = \"Ind,near dem\",\n \"Democrat, weak\" = \"Not str democrat\",\n \"Democrat, strong\" = \"Strong democrat\",\n \"Other\" = \"No answer\",\n \"Other\" = \"Don't know\",\n \"Other\" = \"Other party\"\n )) %>%\n count(partyid)\n\n# A tibble: 8 × 2\n partyid n\n <fct> <int>\n1 Other 548\n2 Republican, strong 2314\n3 Republican, weak 3032\n4 Independent, near rep 1791\n5 Independent 4119\n6 Independent, near dem 2499\n7 Democrat, weak 3690\n8 Democrat, strong 3490\n\n\nUse this technique with care: if you group together categories that are truly different you will end up with misleading results.\n\n\nfct_collapse\nIf you want to collapse a lot of levels, fct_collapse() is a useful variant of fct_recode().\nFor each new variable, you can provide a vector of old levels:\n\ngss_cat %>%\n mutate(partyid = fct_collapse(partyid,\n \"other\" = c(\"No answer\", \"Don't know\", \"Other party\"),\n \"rep\" = c(\"Strong republican\", \"Not str republican\"),\n \"ind\" = c(\"Ind,near rep\", \"Independent\", \"Ind,near dem\"),\n \"dem\" = c(\"Not str democrat\", \"Strong democrat\")\n )) %>%\n count(partyid)\n\n# A tibble: 4 × 2\n partyid n\n <fct> <int>\n1 other 548\n2 rep 5346\n3 ind 8409\n4 dem 7180\n\n\n\n\nfct_lump_*\nSometimes you just want to lump together the small groups to make a plot or table simpler.\nThat’s the job of the fct_lump_*() family of functions.\nfct_lump_lowfreq() is a simple starting point that progressively lumps the smallest groups categories into “Other”, always keeping “Other” as the smallest category.\n\ngss_cat %>%\n mutate(relig = fct_lump_lowfreq(relig)) %>%\n count(relig)\n\n# A tibble: 2 × 2\n relig n\n <fct> <int>\n1 Protestant 10846\n2 Other 10637\n\n\nIn this case it’s not very helpful: it is true that the majority of Americans in this survey are Protestant, but we’d probably like to see some more details!\nInstead, we can use the fct_lump_n() to specify that we want exactly 10 groups:\n\ngss_cat %>%\n mutate(relig = fct_lump_n(relig, n = 10)) %>%\n count(relig, sort = TRUE) %>%\n print(n = Inf)\n\n# A tibble: 10 × 2\n relig n\n <fct> <int>\n 1 Protestant 10846\n 2 Catholic 5124\n 3 None 3523\n 4 Christian 689\n 5 Other 458\n 6 Jewish 388\n 7 Buddhism 147\n 8 Inter-nondenominational 109\n 9 Moslem/islam 104\n10 Orthodox-christian 95\n\n\nRead the documentation to learn about fct_lump_min() and fct_lump_prop() which are useful in other cases."
+ "objectID": "posts/21-regular-expressions/index.html#ranges",
+ "href": "posts/21-regular-expressions/index.html#ranges",
+ "title": "21 - Regular expressions",
+ "section": "ranges",
+ "text": "ranges\nYou can also specify ranges of characters using a hyphen - inside of the brackets.\nFor example:\n\n\"[a-m]\" matches all of the lowercase characters between a and m\n\"[5-8]\" matches any digit between 5 and 8 inclusive\n\n\n\n\n\n\n\nExample\n\n\n\nLet’s take a look at some examples using custom character sets:\n\ngrepl(\"[a-m]\", \"xyz\")\n\n[1] FALSE\n\ngrepl(\"[a-m]\", \"ABC\")\n\n[1] FALSE\n\ngrepl(\"[a-mA-M]\", \"ABC\")\n\n[1] TRUE"
},
{
- "objectID": "posts/22-working-with-factors/index.html#ordered-factors",
- "href": "posts/22-working-with-factors/index.html#ordered-factors",
- "title": "22 - Factors",
- "section": "Ordered factors",
- "text": "Ordered factors\nThere’s a special type of factor that needs to be mentioned briefly: ordered factors.\nOrdered factors, created with ordered(), imply a strict ordering and equal distance between levels:\nThe first level is “less than” the second level by the same amount that the second level is “less than” the third level, and so on…\nYou can recognize them when printing because they use < between the factor levels:\n\nordered(c(\"a\", \"b\", \"c\"))\n\n[1] a b c\nLevels: a < b < c\n\n\nHowever, in practice, ordered() factors behave very similarly to regular factors."
+ "objectID": "posts/21-regular-expressions/index.html#beginning-and-end",
+ "href": "posts/21-regular-expressions/index.html#beginning-and-end",
+ "title": "21 - Regular expressions",
+ "section": "beginning and end",
+ "text": "beginning and end\nThere are also metacharacters for matching the beginning and the end of a string which are \"^\" and \"$\" respectively.\nLet’s take a look at a few examples:\n\ngrepl(\"^a\", c(\"bab\", \"aab\"))\n\n[1] FALSE TRUE\n\ngrepl(\"b$\", c(\"bab\", \"aab\"))\n\n[1] TRUE TRUE\n\ngrepl(\"^[ab]*$\", c(\"bab\", \"aab\", \"abc\"))\n\n[1] TRUE TRUE FALSE"
},
{
- "objectID": "posts/20-working-with-dates-and-times/index.html",
- "href": "posts/20-working-with-dates-and-times/index.html",
- "title": "20 - Working with dates and times",
- "section": "",
- "text": "This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history."
+ "objectID": "posts/21-regular-expressions/index.html#or-metacharacter",
+ "href": "posts/21-regular-expressions/index.html#or-metacharacter",
+ "title": "21 - Regular expressions",
+ "section": "OR metacharacter",
+ "text": "OR metacharacter\nThe last metacharacter we will discuss is the OR metacharacter (\"|\").\nThe OR metacharacter matches either the regex on the left or the regex on the right side of this character. A few examples:\n\ngrepl(\"a|b\", c(\"abc\", \"bcd\", \"cde\"))\n\n[1] TRUE TRUE FALSE\n\ngrepl(\"North|South\", c(\"South Dakota\", \"North Carolina\", \"West Virginia\"))\n\n[1] TRUE TRUE FALSE"
},
{
- "objectID": "posts/20-working-with-dates-and-times/index.html#the-lubridate-package",
- "href": "posts/20-working-with-dates-and-times/index.html#the-lubridate-package",
- "title": "20 - Working with dates and times",
- "section": "The lubridate package",
- "text": "The lubridate package\nHere, we will focus on the lubridate R package, which makes it easier to work with dates and times in R.\n\n\n\n\n\n\nPro-tip\n\n\n\nCheck out the lubridate cheat sheet at https://lubridate.tidyverse.org\n\n\nA few things to note about it:\n\nIt largely replaces the default date/time functions in base R\nIt contains methods for date/time arithmetic\nIt handles time zones, leap year, leap seconds, etc.\n\n [Source: Artwork by Allison Horst]\nlubridate is installed when you install tidyverse, but it is not loaded when you load tidyverse. Alternatively, you can install it separately.\n\ninstall.packages(\"lubridate\")\n\n\nlibrary(tidyverse)\nlibrary(lubridate)"
+ "objectID": "posts/21-regular-expressions/index.html#state.name-example",
+ "href": "posts/21-regular-expressions/index.html#state.name-example",
+ "title": "21 - Regular expressions",
+ "section": "state.name example",
+ "text": "state.name example\n\n\n\n\n\n\nExample\n\n\n\nFinally, we have learned enough to create a regular expression that matches all state names that both begin and end with a vowel:\n\nWe match the beginning of a string.\nWe create a character set of just capitalized vowels.\nWe specify one instance of that set.\nThen any number of characters until:\nA character set of just lowercase vowels.\nWe specify one instance of that set.\nWe match the end of a string.\n\n\nstart_end_vowel <- \"^[AEIOU]{1}.+[aeiou]{1}$\"\nvowel_state_lgl <- grepl(start_end_vowel, state.name)\nhead(vowel_state_lgl)\n\n[1] TRUE TRUE TRUE FALSE FALSE FALSE\n\nstate.name[vowel_state_lgl]\n\n[1] \"Alabama\" \"Alaska\" \"Arizona\" \"Idaho\" \"Indiana\" \"Iowa\" \"Ohio\" \n[8] \"Oklahoma\"\n\n\n\n\nBelow is a table of several important metacharacters:\n\n\n\n\n\nMetacharacter\nMeaning\n\n\n\n\n.\nAny Character\n\n\n\\w\nA Word\n\n\n\\W\nNot a Word\n\n\n\\d\nA Digit\n\n\n\\D\nNot a Digit\n\n\n\\s\nWhitespace\n\n\n\\S\nNot Whitespace\n\n\n[xyz]\nA Set of Characters\n\n\n[^xyz]\nNegation of Set\n\n\n[a-z]\nA Range of Characters\n\n\n^\nBeginning of String\n\n\n$\nEnd of String\n\n\n\\n\nNewline\n\n\n+\nOne or More of Previous\n\n\n*\nZero or More of Previous\n\n\n?\nZero or One of Previous\n\n\n|\nEither the Previous or the Following\n\n\n{5}\nExactly 5 of Previous\n\n\n{2, 5}\nBetween 2 and 5 or Previous\n\n\n{2, }\nMore than 2 of Previous"
},
{
- "objectID": "posts/20-working-with-dates-and-times/index.html#from-a-string",
- "href": "posts/20-working-with-dates-and-times/index.html#from-a-string",
- "title": "20 - Working with dates and times",
- "section": "1. From a string",
- "text": "1. From a string\nDates are of the Date class.\n\nx <- today()\nclass(x)\n\n[1] \"Date\"\n\n\nDates can be coerced from a character strings using some helper functions from lubridate. They automatically work out the format once you specify the order of the component.\nTo use the helper functions, identify the order in which year, month, and day appear in your dates, then arrange “y”, “m”, and “d” in the same order.\nThat gives you the name of the lubridate function that will parse your date. For example:\n\nymd(\"1970-01-01\")\n\n[1] \"1970-01-01\"\n\nymd(\"2017-01-31\")\n\n[1] \"2017-01-31\"\n\nmdy(\"January 31st, 2017\")\n\n[1] \"2017-01-31\"\n\ndmy(\"31-Jan-2017\")\n\n[1] \"2017-01-31\"\n\n\n\n\n\n\n\n\nPro-tip\n\n\n\n\nWhen reading in data with read_csv(), you may need to read in as character first and then convert to date/time\nDate objects have their own special print() methods that will always format as “YYYY-MM-DD”\nThese functions also take unquoted numbers.\n\n\nymd(20170131)\n\n[1] \"2017-01-31\"\n\n\n\n\n\nAlternate Formulations\nDifferent locales have different ways of formatting dates\n\nymd(\"2016-09-13\") ## International standard\n\n[1] \"2016-09-13\"\n\nymd(\"2016/09/13\") ## Just figure it out\n\n[1] \"2016-09-13\"\n\nmdy(\"09-13-2016\") ## Mostly U.S.\n\n[1] \"2016-09-13\"\n\ndmy(\"13-09-2016\") ## Europe\n\n[1] \"2016-09-13\"\n\n\nAll of the above are valid and lead to the exact same object.\nEven if the individual dates are formatted differently, ymd() can usually figure it out.\n\nx <- c(\n \"2016-04-05\",\n \"2016/05/06\",\n \"2016,10,4\"\n)\nymd(x)\n\n[1] \"2016-04-05\" \"2016-05-06\" \"2016-10-04\"\n\n\nCool right?"
+ "objectID": "posts/21-regular-expressions/index.html#grep",
+ "href": "posts/21-regular-expressions/index.html#grep",
+ "title": "21 - Regular expressions",
+ "section": "grep()",
+ "text": "grep()\nThen, there is old fashioned grep(pattern, x), which returns the indices of the vector that match the regex:\n\ngrep(pattern = \"[Ii]\", x = c(\"Hawaii\", \"Illinois\", \"Kentucky\"))\n\n[1] 1 2"
},
{
- "objectID": "posts/20-working-with-dates-and-times/index.html#from-individual-date-time-components",
- "href": "posts/20-working-with-dates-and-times/index.html#from-individual-date-time-components",
- "title": "20 - Working with dates and times",
- "section": "2. From individual date-time components",
- "text": "2. From individual date-time components\nSometimes the date components will come across multiple columns in a dataset.\n\nlibrary(nycflights13)\n\nflights %>%\n select(year, month, day)\n\n# A tibble: 336,776 × 3\n year month day\n <int> <int> <int>\n 1 2013 1 1\n 2 2013 1 1\n 3 2013 1 1\n 4 2013 1 1\n 5 2013 1 1\n 6 2013 1 1\n 7 2013 1 1\n 8 2013 1 1\n 9 2013 1 1\n10 2013 1 1\n# ℹ 336,766 more rows\n\n\nTo create a date/time from this sort of input, use\n\nmake_date(year,month,day) for dates, or\nmake_datetime(year,month,day,hour,min,sec,tz) for date-times\n\nWe combine these functions inside of mutate to add a new column to our dataset:\n\nflights %>%\n select(year, month, day) %>%\n mutate(departure = make_date(year, month, day))\n\n# A tibble: 336,776 × 4\n year month day departure \n <int> <int> <int> <date> \n 1 2013 1 1 2013-01-01\n 2 2013 1 1 2013-01-01\n 3 2013 1 1 2013-01-01\n 4 2013 1 1 2013-01-01\n 5 2013 1 1 2013-01-01\n 6 2013 1 1 2013-01-01\n 7 2013 1 1 2013-01-01\n 8 2013 1 1 2013-01-01\n 9 2013 1 1 2013-01-01\n10 2013 1 1 2013-01-01\n# ℹ 336,766 more rows\n\n\n\n\n\n\n\n\nQuestions\n\n\n\nThe flights also contains a hour and minute column.\n\nflights %>%\n select(year, month, day, hour, minute)\n\n# A tibble: 336,776 × 5\n year month day hour minute\n <int> <int> <int> <dbl> <dbl>\n 1 2013 1 1 5 15\n 2 2013 1 1 5 29\n 3 2013 1 1 5 40\n 4 2013 1 1 5 45\n 5 2013 1 1 6 0\n 6 2013 1 1 5 58\n 7 2013 1 1 6 0\n 8 2013 1 1 6 0\n 9 2013 1 1 6 0\n10 2013 1 1 6 0\n# ℹ 336,766 more rows\n\n\nLet’s use make_datetime() to create a date-time column called departure:\n\n# try it yourself"
+ "objectID": "posts/21-regular-expressions/index.html#sub",
+ "href": "posts/21-regular-expressions/index.html#sub",
+ "title": "21 - Regular expressions",
+ "section": "sub()",
+ "text": "sub()\nThe sub(pattern, replacement, x) function takes as arguments a regex, a “replacement,” and a vector of strings. This function will replace the first instance of that regex found in each string.\n\nsub(pattern = \"[Ii]\", replacement = \"1\", x = c(\"Hawaii\", \"Illinois\", \"Kentucky\"))\n\n[1] \"Hawa1i\" \"1llinois\" \"Kentucky\""
},
{
- "objectID": "posts/20-working-with-dates-and-times/index.html#from-other-types",
- "href": "posts/20-working-with-dates-and-times/index.html#from-other-types",
- "title": "20 - Working with dates and times",
- "section": "3. From other types",
- "text": "3. From other types\nYou may want to switch between a date-time and a date.\nThat is the job of as_datetime() and as_date():\n\ntoday()\n\n[1] \"2023-08-17\"\n\nas_datetime(today())\n\n[1] \"2023-08-17 UTC\"\n\nnow()\n\n[1] \"2023-08-17 21:47:52 EDT\"\n\nas_date(now())\n\n[1] \"2023-08-17\""
+ "objectID": "posts/21-regular-expressions/index.html#gsub",
+ "href": "posts/21-regular-expressions/index.html#gsub",
+ "title": "21 - Regular expressions",
+ "section": "gsub()",
+ "text": "gsub()\nThe gsub(pattern, replacement, x) function is nearly the same as sub() except it will replace every instance of the regex that is matched in each string.\n\ngsub(\"[Ii]\", \"1\", c(\"Hawaii\", \"Illinois\", \"Kentucky\"))\n\n[1] \"Hawa11\" \"1ll1no1s\" \"Kentucky\""
},
{
- "objectID": "posts/20-working-with-dates-and-times/index.html#from-a-string-1",
- "href": "posts/20-working-with-dates-and-times/index.html#from-a-string-1",
- "title": "20 - Working with dates and times",
- "section": "From a string",
- "text": "From a string\nymd() and friends create dates.\nTo create a date-time from a character string, add an underscore and one or more of “h”, “m”, and “s” to the name of the parsing function:\nTimes can be coerced from a character string with ymd_hms()\n\nymd_hms(\"2017-01-31 20:11:59\")\n\n[1] \"2017-01-31 20:11:59 UTC\"\n\nmdy_hm(\"01/31/2017 08:01\")\n\n[1] \"2017-01-31 08:01:00 UTC\"\n\n\nYou can also force the creation of a date-time from a date by supplying a timezone:\n\nymd_hms(\"2016-09-13 14:00:00\")\n\n[1] \"2016-09-13 14:00:00 UTC\"\n\nymd_hms(\"2016-09-13 14:00:00\", tz = \"America/New_York\")\n\n[1] \"2016-09-13 14:00:00 EDT\"\n\nymd_hms(\"2016-09-13 14:00:00\", tz = \"\")\n\n[1] \"2016-09-13 14:00:00 EDT\""
+ "objectID": "posts/21-regular-expressions/index.html#strsplit",
+ "href": "posts/21-regular-expressions/index.html#strsplit",
+ "title": "21 - Regular expressions",
+ "section": "strsplit()",
+ "text": "strsplit()\nThe strsplit(x, split) function will split up strings (split) according to the provided regex (x) .\nIf strsplit() is provided with a vector of strings it will return a list of string vectors.\n\ntwo_s <- state.name[grep(\"ss\", state.name)]\ntwo_s\n\n[1] \"Massachusetts\" \"Mississippi\" \"Missouri\" \"Tennessee\" \n\nstrsplit(x = two_s, split = \"ss\")\n\n[[1]]\n[1] \"Ma\" \"achusetts\"\n\n[[2]]\n[1] \"Mi\" \"i\" \"ippi\"\n\n[[3]]\n[1] \"Mi\" \"ouri\"\n\n[[4]]\n[1] \"Tenne\" \"ee\""
},
{
- "objectID": "posts/20-working-with-dates-and-times/index.html#posixct-or-the-posixlt-class",
- "href": "posts/20-working-with-dates-and-times/index.html#posixct-or-the-posixlt-class",
- "title": "20 - Working with dates and times",
- "section": "POSIXct or the POSIXlt class",
- "text": "POSIXct or the POSIXlt class\nLet’s get into some hairy details about date-times. Date-times are represented using the POSIXct or the POSIXlt class in R. What are these things?\n\nPOSIXct\nPOSIXct is just a very large integer under the hood. It is a useful class when you want to store times in something like a data frame.\nTechnically, the POSIXct class represents the number of seconds since 1 January 1970. (In case you were wondering, “POSIXct” stands for “Portable Operating System Interface”, calendar time.)\n\nx <- ymd_hm(\"1970-01-01 01:00\")\nclass(x)\n\n[1] \"POSIXct\" \"POSIXt\" \n\nunclass(x)\n\n[1] 3600\nattr(,\"tzone\")\n[1] \"UTC\"\n\ntypeof(x)\n\n[1] \"double\"\n\nattributes(x)\n\n$class\n[1] \"POSIXct\" \"POSIXt\" \n\n$tzone\n[1] \"UTC\"\n\n\n\n\nPOSIXlt\nPOSIXlt is a list underneath and it stores a bunch of other useful information like the day of the week, day of the year, month, day of the month\n\ny <- as.POSIXlt(x)\ny\n\n[1] \"1970-01-01 01:00:00 UTC\"\n\ntypeof(y)\n\n[1] \"list\"\n\nattributes(y)\n\n$names\n [1] \"sec\" \"min\" \"hour\" \"mday\" \"mon\" \"year\" \"wday\" \"yday\" \n [9] \"isdst\" \"zone\" \"gmtoff\"\n\n$class\n[1] \"POSIXlt\" \"POSIXt\" \n\n$tzone\n[1] \"UTC\"\n\n$balanced\n[1] TRUE\n\n\n\n\n\n\n\n\nPro-tip\n\n\n\nPOSIXlts are rare inside the tidyverse. They do crop up in base R, because they are needed to extract specific components of a date, like the year or month.\nSince lubridate provides helpers for you to do this instead, you do not really need them imho.\nPOSIXct’s are always easier to work with, so if you find you have a POSIXlt, you should always convert it to a regular data time lubridate::as_datetime()."
+ "objectID": "posts/21-regular-expressions/index.html#str_extract",
+ "href": "posts/21-regular-expressions/index.html#str_extract",
+ "title": "21 - Regular expressions",
+ "section": "str_extract",
+ "text": "str_extract\nThe str_extract(string, pattern) function returns the sub-string of a string (string) that matches the provided regular expression (pattern).\n\nlibrary(stringr)\nstate_tbl <- paste(state.name, state.area, state.abb)\nhead(state_tbl)\n\n[1] \"Alabama 51609 AL\" \"Alaska 589757 AK\" \"Arizona 113909 AZ\" \n[4] \"Arkansas 53104 AR\" \"California 158693 CA\" \"Colorado 104247 CO\" \n\nstr_extract(state_tbl, \"[0-9]+\")\n\n [1] \"51609\" \"589757\" \"113909\" \"53104\" \"158693\" \"104247\" \"5009\" \"2057\" \n [9] \"58560\" \"58876\" \"6450\" \"83557\" \"56400\" \"36291\" \"56290\" \"82264\" \n[17] \"40395\" \"48523\" \"33215\" \"10577\" \"8257\" \"58216\" \"84068\" \"47716\" \n[25] \"69686\" \"147138\" \"77227\" \"110540\" \"9304\" \"7836\" \"121666\" \"49576\" \n[33] \"52586\" \"70665\" \"41222\" \"69919\" \"96981\" \"45333\" \"1214\" \"31055\" \n[41] \"77047\" \"42244\" \"267339\" \"84916\" \"9609\" \"40815\" \"68192\" \"24181\" \n[49] \"56154\" \"97914\""
},
{
- "objectID": "posts/20-working-with-dates-and-times/index.html#arithmetic",
- "href": "posts/20-working-with-dates-and-times/index.html#arithmetic",
- "title": "20 - Working with dates and times",
- "section": "Arithmetic",
- "text": "Arithmetic\nYou can add and subtract dates and times.\n\nx <- ymd(\"2012-01-01\", tz = \"\") ## Midnight\ny <- dmy_hms(\"9 Jan 2011 11:34:21\", tz = \"\")\nx - y ## this works\n\nTime difference of 356.5178 days\n\n\nYou can do comparisons too (i.e. >, <, and ==)\n\nx < y ## this works\n\n[1] FALSE\n\nx > y ## this works\n\n[1] TRUE\n\nx == y ## this works\n\n[1] FALSE\n\nx + y ## what??? why does this not work?\n\nError in `+.POSIXt`(x, y): binary '+' is not defined for \"POSIXt\" objects\n\n\n\n\n\n\n\n\nNote\n\n\n\nThe class of x is POSIXct.\n\nclass(x)\n\n[1] \"POSIXct\" \"POSIXt\" \n\n\nPOSIXct objects are a measure of seconds from an origin, usually the UNIX epoch (1st Jan 1970).\nJust add the requisite number of seconds to the object:\n\nx + 3 * 60 * 60 # add 3 hours\n\n[1] \"2012-01-01 03:00:00 EST\"\n\n\n\n\nSame goes for days. For example, you can just keep the date portion using date():\n\ny <- date(y)\ny\n\n[1] \"2011-01-09\"\n\n\nAnd then add a number to the date (in this case 1 day)\n\ny + 1\n\n[1] \"2011-01-10\"\n\n\nCool eh?"
+ "objectID": "posts/21-regular-expressions/index.html#str_detect",
+ "href": "posts/21-regular-expressions/index.html#str_detect",
+ "title": "21 - Regular expressions",
+ "section": "str_detect",
+ "text": "str_detect\nThe str_detect(string, pattern) is equivalent to grepl(pattern,x):\n\nstr_detect(state_tbl, \"[0-9]+\")\n\n [1] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE\n[16] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE\n[31] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE\n[46] TRUE TRUE TRUE TRUE TRUE\n\ngrepl(\"[0-9]+\", state_tbl)\n\n [1] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE\n[16] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE\n[31] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE\n[46] TRUE TRUE TRUE TRUE TRUE\n\n\nIt detects the presence or absence of a pattern in a string."
},
{
- "objectID": "posts/20-working-with-dates-and-times/index.html#leaps-and-bounds",
- "href": "posts/20-working-with-dates-and-times/index.html#leaps-and-bounds",
- "title": "20 - Working with dates and times",
- "section": "Leaps and Bounds",
- "text": "Leaps and Bounds\nEven keeps track of leap years, leap seconds, daylight savings, and time zones.\nLeap years\n\nx <- ymd(\"2012-03-01\")\ny <- ymd(\"2012-02-28\")\nx - y\n\nTime difference of 2 days\n\n\nNot a leap year\n\nx <- ymd(\"2013-03-01\")\ny <- ymd(\"2013-02-28\")\nx - y\n\nTime difference of 1 days\n\n\nBUT beware of time zones!\n\nx <- ymd_hms(\"2012-10-25 01:00:00\", tz = \"\")\ny <- ymd_hms(\"2012-10-25 05:00:00\", tz = \"GMT\")\ny - x\n\nTime difference of 0 secs\n\n\nThere are also things called leap seconds.\n\n.leap.seconds\n\n [1] \"1972-07-01 GMT\" \"1973-01-01 GMT\" \"1974-01-01 GMT\" \"1975-01-01 GMT\"\n [5] \"1976-01-01 GMT\" \"1977-01-01 GMT\" \"1978-01-01 GMT\" \"1979-01-01 GMT\"\n [9] \"1980-01-01 GMT\" \"1981-07-01 GMT\" \"1982-07-01 GMT\" \"1983-07-01 GMT\"\n[13] \"1985-07-01 GMT\" \"1988-01-01 GMT\" \"1990-01-01 GMT\" \"1991-01-01 GMT\"\n[17] \"1992-07-01 GMT\" \"1993-07-01 GMT\" \"1994-07-01 GMT\" \"1996-01-01 GMT\"\n[21] \"1997-07-01 GMT\" \"1999-01-01 GMT\" \"2006-01-01 GMT\" \"2009-01-01 GMT\"\n[25] \"2012-07-01 GMT\" \"2015-07-01 GMT\" \"2017-01-01 GMT\""
+ "objectID": "posts/21-regular-expressions/index.html#str_order",
+ "href": "posts/21-regular-expressions/index.html#str_order",
+ "title": "21 - Regular expressions",
+ "section": "str_order",
+ "text": "str_order\nThe str_order(x) function returns a numeric vector that corresponds to the alphabetical order of the strings in the provided vector (x).\n\nhead(state.name)\n\n[1] \"Alabama\" \"Alaska\" \"Arizona\" \"Arkansas\" \"California\"\n[6] \"Colorado\" \n\nstr_order(state.name)\n\n [1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25\n[26] 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50\n\nhead(state.abb)\n\n[1] \"AL\" \"AK\" \"AZ\" \"AR\" \"CA\" \"CO\"\n\nstr_order(state.abb)\n\n [1] 2 1 4 3 5 6 7 8 9 10 11 15 12 13 14 16 17 18 21 20 19 22 23 25 24\n[26] 26 33 34 27 29 30 31 28 32 35 36 37 38 39 40 41 42 43 44 46 45 47 49 48 50"
},
{
- "objectID": "posts/20-working-with-dates-and-times/index.html#date-elements",
- "href": "posts/20-working-with-dates-and-times/index.html#date-elements",
- "title": "20 - Working with dates and times",
- "section": "Date Elements",
- "text": "Date Elements\n\nx <- ymd_hms(c(\n \"2012-10-25 01:13:46\",\n \"2015-04-23 15:11:23\"\n), tz = \"\")\nyear(x)\n\n[1] 2012 2015\n\nmonth(x)\n\n[1] 10 4\n\nday(x)\n\n[1] 25 23\n\nweekdays(x)\n\n[1] \"Thursday\" \"Thursday\""
+ "objectID": "posts/21-regular-expressions/index.html#str_replace",
+ "href": "posts/21-regular-expressions/index.html#str_replace",
+ "title": "21 - Regular expressions",
+ "section": "str_replace",
+ "text": "str_replace\nThe str_replace(string, pattern, replace) is equivalent to sub(pattern, replacement, x):\n\nstr_replace(string = state.name, pattern = \"[Aa]\", replace = \"B\")\n\n [1] \"Blabama\" \"Blaska\" \"Brizona\" \"Brkansas\" \n [5] \"CBlifornia\" \"ColorBdo\" \"Connecticut\" \"DelBware\" \n [9] \"FloridB\" \"GeorgiB\" \"HBwaii\" \"IdBho\" \n[13] \"Illinois\" \"IndiBna\" \"IowB\" \"KBnsas\" \n[17] \"Kentucky\" \"LouisiBna\" \"MBine\" \"MBryland\" \n[21] \"MBssachusetts\" \"MichigBn\" \"MinnesotB\" \"Mississippi\" \n[25] \"Missouri\" \"MontBna\" \"NebrBska\" \"NevBda\" \n[29] \"New HBmpshire\" \"New Jersey\" \"New Mexico\" \"New York\" \n[33] \"North CBrolina\" \"North DBkota\" \"Ohio\" \"OklBhoma\" \n[37] \"Oregon\" \"PennsylvBnia\" \"Rhode IslBnd\" \"South CBrolina\"\n[41] \"South DBkota\" \"Tennessee\" \"TexBs\" \"UtBh\" \n[45] \"Vermont\" \"VirginiB\" \"WBshington\" \"West VirginiB\" \n[49] \"Wisconsin\" \"Wyoming\" \n\nsub(pattern = \"[Aa]\", replacement = \"B\", x = state.name)\n\n [1] \"Blabama\" \"Blaska\" \"Brizona\" \"Brkansas\" \n [5] \"CBlifornia\" \"ColorBdo\" \"Connecticut\" \"DelBware\" \n [9] \"FloridB\" \"GeorgiB\" \"HBwaii\" \"IdBho\" \n[13] \"Illinois\" \"IndiBna\" \"IowB\" \"KBnsas\" \n[17] \"Kentucky\" \"LouisiBna\" \"MBine\" \"MBryland\" \n[21] \"MBssachusetts\" \"MichigBn\" \"MinnesotB\" \"Mississippi\" \n[25] \"Missouri\" \"MontBna\" \"NebrBska\" \"NevBda\" \n[29] \"New HBmpshire\" \"New Jersey\" \"New Mexico\" \"New York\" \n[33] \"North CBrolina\" \"North DBkota\" \"Ohio\" \"OklBhoma\" \n[37] \"Oregon\" \"PennsylvBnia\" \"Rhode IslBnd\" \"South CBrolina\"\n[41] \"South DBkota\" \"Tennessee\" \"TexBs\" \"UtBh\" \n[45] \"Vermont\" \"VirginiB\" \"WBshington\" \"West VirginiB\" \n[49] \"Wisconsin\" \"Wyoming\""
},
{
- "objectID": "posts/20-working-with-dates-and-times/index.html#time-elements",
- "href": "posts/20-working-with-dates-and-times/index.html#time-elements",
- "title": "20 - Working with dates and times",
- "section": "Time Elements",
- "text": "Time Elements\n\nx <- ymd_hms(c(\n \"2012-10-25 01:13:46\",\n \"2015-04-23 15:11:23\"\n), tz = \"\")\nminute(x)\n\n[1] 13 11\n\nsecond(x)\n\n[1] 46 23\n\nhour(x)\n\n[1] 1 15\n\nweek(x)\n\n[1] 43 17"
+ "objectID": "posts/21-regular-expressions/index.html#str_pad",
+ "href": "posts/21-regular-expressions/index.html#str_pad",
+ "title": "21 - Regular expressions",
+ "section": "str_pad",
+ "text": "str_pad\nThe str_pad(string, width, side, pad) function pads strings (string) with other characters, which is often useful when the string is going to be eventually printed for a person to read.\n\nstr_pad(\"Thai\", width = 8, side = \"left\", pad = \"-\")\n\n[1] \"----Thai\"\n\nstr_pad(\"Thai\", width = 8, side = \"right\", pad = \"-\")\n\n[1] \"Thai----\"\n\nstr_pad(\"Thai\", width = 8, side = \"both\", pad = \"-\")\n\n[1] \"--Thai--\"\n\n\nThe str_to_title(string) function acts just like tolower() and toupper() except it puts strings into Title Case.\n\ncases <- c(\"CAPS\", \"low\", \"Title\")\nstr_to_title(cases)\n\n[1] \"Caps\" \"Low\" \"Title\""
},
{
- "objectID": "posts/20-working-with-dates-and-times/index.html#reading-in-the-data",
- "href": "posts/20-working-with-dates-and-times/index.html#reading-in-the-data",
- "title": "20 - Working with dates and times",
- "section": "Reading in the Data",
- "text": "Reading in the Data\n\nlibrary(here)\nlibrary(readr)\nstorm <- read_csv(here(\"data\", \"storms_2004.csv.gz\"), progress = FALSE)\nstorm\n\n# A tibble: 52,409 × 51\n BEGIN_YEARMONTH BEGIN_DAY BEGIN_TIME END_YEARMONTH END_DAY END_TIME\n <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>\n 1 200412 29 1800 200412 30 1200\n 2 200412 29 1800 200412 30 1200\n 3 200412 8 1800 200412 8 1800\n 4 200412 19 1500 200412 19 1700\n 5 200412 14 600 200412 14 800\n 6 200412 21 400 200412 21 800\n 7 200412 21 400 200412 21 800\n 8 200412 26 1500 200412 27 800\n 9 200412 26 1500 200412 27 800\n10 200412 11 800 200412 11 1300\n# ℹ 52,399 more rows\n# ℹ 45 more variables: EPISODE_ID <dbl>, EVENT_ID <dbl>, STATE <chr>,\n# STATE_FIPS <dbl>, YEAR <dbl>, MONTH_NAME <chr>, EVENT_TYPE <chr>,\n# CZ_TYPE <chr>, CZ_FIPS <dbl>, CZ_NAME <chr>, WFO <chr>,\n# BEGIN_DATE_TIME <chr>, CZ_TIMEZONE <chr>, END_DATE_TIME <chr>,\n# INJURIES_DIRECT <dbl>, INJURIES_INDIRECT <dbl>, DEATHS_DIRECT <dbl>,\n# DEATHS_INDIRECT <dbl>, DAMAGE_PROPERTY <chr>, DAMAGE_CROPS <chr>, …\n\n\n\nnames(storm)\n\n [1] \"BEGIN_YEARMONTH\" \"BEGIN_DAY\" \"BEGIN_TIME\" \n [4] \"END_YEARMONTH\" \"END_DAY\" \"END_TIME\" \n [7] \"EPISODE_ID\" \"EVENT_ID\" \"STATE\" \n[10] \"STATE_FIPS\" \"YEAR\" \"MONTH_NAME\" \n[13] \"EVENT_TYPE\" \"CZ_TYPE\" \"CZ_FIPS\" \n[16] \"CZ_NAME\" \"WFO\" \"BEGIN_DATE_TIME\" \n[19] \"CZ_TIMEZONE\" \"END_DATE_TIME\" \"INJURIES_DIRECT\" \n[22] \"INJURIES_INDIRECT\" \"DEATHS_DIRECT\" \"DEATHS_INDIRECT\" \n[25] \"DAMAGE_PROPERTY\" \"DAMAGE_CROPS\" \"SOURCE\" \n[28] \"MAGNITUDE\" \"MAGNITUDE_TYPE\" \"FLOOD_CAUSE\" \n[31] \"CATEGORY\" \"TOR_F_SCALE\" \"TOR_LENGTH\" \n[34] \"TOR_WIDTH\" \"TOR_OTHER_WFO\" \"TOR_OTHER_CZ_STATE\"\n[37] \"TOR_OTHER_CZ_FIPS\" \"TOR_OTHER_CZ_NAME\" \"BEGIN_RANGE\" \n[40] \"BEGIN_AZIMUTH\" \"BEGIN_LOCATION\" \"END_RANGE\" \n[43] \"END_AZIMUTH\" \"END_LOCATION\" \"BEGIN_LAT\" \n[46] \"BEGIN_LON\" \"END_LAT\" \"END_LON\" \n[49] \"EPISODE_NARRATIVE\" \"EVENT_NARRATIVE\" \"DATA_SOURCE\" \n\n\n\n\n\n\n\n\nQuestions\n\n\n\nLet’s take a look at the BEGIN_DATE_TIME, EVENT_TYPE, and DEATHS_DIRECT variables from the storm dataset.\nTasks:\n\nCreate a subset of the storm dataset with only the four columns above.\nCreate a new column called begin that contains the BEGIN_DATE_TIME that has been converted to a date/time R object.\nRename the EVENT_TYPE column as type.\nRename the DEATHS_DIRECT column as deaths.\n\n\nlibrary(dplyr)\n\n# try it yourself\n\n\n\nNext, we do some wrangling to create a storm_sub data frame (code chunk set to echo=FALSE for the purposes of the lecture, but code is in the R Markdown).\n\nstorm_sub\n\n# A tibble: 52,409 × 3\n begin type deaths\n <dttm> <chr> <dbl>\n 1 2004-12-29 18:00:00 Heavy Snow 0\n 2 2004-12-29 18:00:00 Heavy Snow 0\n 3 2004-12-08 18:00:00 Winter Storm 0\n 4 2004-12-19 15:00:00 High Wind 0\n 5 2004-12-14 06:00:00 Winter Weather 0\n 6 2004-12-21 04:00:00 Winter Storm 0\n 7 2004-12-21 04:00:00 Winter Storm 0\n 8 2004-12-26 15:00:00 Winter Storm 0\n 9 2004-12-26 15:00:00 Winter Storm 0\n10 2004-12-11 08:00:00 Storm Surge/Tide 0\n# ℹ 52,399 more rows"
+ "objectID": "posts/21-regular-expressions/index.html#str_trim",
+ "href": "posts/21-regular-expressions/index.html#str_trim",
+ "title": "21 - Regular expressions",
+ "section": "str_trim",
+ "text": "str_trim\nThe str_trim(string) function deletes white space from both sides of a string.\n\nto_trim <- c(\" space\", \"the \", \" final frontier \")\nstr_trim(to_trim)\n\n[1] \"space\" \"the\" \"final frontier\""
},
{
- "objectID": "posts/20-working-with-dates-and-times/index.html#histograms-of-datestimes",
- "href": "posts/20-working-with-dates-and-times/index.html#histograms-of-datestimes",
- "title": "20 - Working with dates and times",
- "section": "Histograms of Dates/Times",
- "text": "Histograms of Dates/Times\nWe can make a histogram of the dates/times to get a sense of when storm events occur.\n\nlibrary(ggplot2)\nstorm_sub %>%\n ggplot(aes(x = begin)) +\n geom_histogram(bins = 20) +\n theme_bw()\n\n\n\n\nWe can group by event type too.\n\nlibrary(ggplot2)\nstorm_sub %>%\n ggplot(aes(x = begin)) +\n facet_wrap(~type) +\n geom_histogram(bins = 20) +\n theme_bw() +\n theme(axis.text.x.bottom = element_text(angle = 90))"
+ "objectID": "posts/21-regular-expressions/index.html#str_wrap",
+ "href": "posts/21-regular-expressions/index.html#str_wrap",
+ "title": "21 - Regular expressions",
+ "section": "str_wrap",
+ "text": "str_wrap\nThe str_wrap(string) function inserts newlines in strings so that when the string is printed each line’s length is limited.\n\npasted_states <- paste(state.name[1:20], collapse = \" \")\n\ncat(str_wrap(pasted_states, width = 80))\n\nAlabama Alaska Arizona Arkansas California Colorado Connecticut Delaware Florida\nGeorgia Hawaii Idaho Illinois Indiana Iowa Kansas Kentucky Louisiana Maine\nMaryland\n\ncat(str_wrap(pasted_states, width = 30))\n\nAlabama Alaska Arizona\nArkansas California Colorado\nConnecticut Delaware Florida\nGeorgia Hawaii Idaho Illinois\nIndiana Iowa Kansas Kentucky\nLouisiana Maine Maryland"
},
{
- "objectID": "posts/20-working-with-dates-and-times/index.html#scatterplots-of-datestimes",
- "href": "posts/20-working-with-dates-and-times/index.html#scatterplots-of-datestimes",
- "title": "20 - Working with dates and times",
- "section": "Scatterplots of Dates/Times",
- "text": "Scatterplots of Dates/Times\n\nstorm_sub %>%\n ggplot(aes(x = begin, y = deaths)) +\n geom_point()\n\n\n\n\nIf we focus on a single month, the x-axis adapts.\n\nstorm_sub %>%\n filter(month(begin) == 6) %>%\n ggplot(aes(begin, deaths)) +\n geom_point()\n\n\n\n\nSimilarly, we can focus on a single day.\n\nstorm_sub %>%\n filter(month(begin) == 6, day(begin) == 16) %>%\n ggplot(aes(begin, deaths)) +\n geom_point()"
+ "objectID": "posts/21-regular-expressions/index.html#word",
+ "href": "posts/21-regular-expressions/index.html#word",
+ "title": "21 - Regular expressions",
+ "section": "word",
+ "text": "word\nThe word() function allows you to index each word in a string as if it were a vector.\n\na_tale <- \"It was the best of times it was the worst of times it was the age of wisdom it was the age of foolishness\"\n\nword(a_tale, 2)\n\n[1] \"was\"\n\nword(a_tale, end = 3) # end = last word to extract\n\n[1] \"It was the\"\n\nword(a_tale, start = 11, end = 15) # start = first word to extract\n\n[1] \"of times it was the\""
},
{
- "objectID": "posts/25-python-for-r-users/index.html",
- "href": "posts/25-python-for-r-users/index.html",
- "title": "25 - Python for R Users",
+ "objectID": "posts/15-control-structures/index.html",
+ "href": "posts/15-control-structures/index.html",
+ "title": "15 - Control Structures",
"section": "",
"text": "This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history."
},
{
- "objectID": "posts/25-python-for-r-users/index.html#overview",
- "href": "posts/25-python-for-r-users/index.html#overview",
- "title": "25 - Python for R Users",
- "section": "Overview",
- "text": "Overview\nFor this lecture, we will be using the reticulate R package, which provides a set of tools for interoperability between Python and R. The package includes facilities for:\n\nCalling Python from R in a variety of ways including (i) R Markdown, (ii) sourcing Python scripts, (iii) importing Python modules, and (iv) using Python interactively within an R session.\nTranslation between R and Python objects (for example, between R and Pandas data frames, or between R matrices and NumPy arrays).\n\n\n[Source: Rstudio]\n\n\n\n\n\n\nPro-tip for installing python\n\n\n\nInstalling python: If you would like recommendations on installing python, I like these resources:\n\nPy Pkgs: https://py-pkgs.org/02-setup#installing-python\nmy fav: Using conda environments with mini-forge: https://github.com/conda-forge/miniforge\nfrom reticulate: https://rstudio.github.io/reticulate/articles/python_packages.html\n\nWhat’s happening under the hood?: reticulate embeds a Python session within your R session, enabling seamless, high-performance interoperability.\nIf you are an R developer that uses Python for some of your work or a member of data science team that uses both languages, reticulate can make your life better!"
+ "objectID": "posts/15-control-structures/index.html#if-else",
+ "href": "posts/15-control-structures/index.html#if-else",
+ "title": "15 - Control Structures",
+ "section": "if-else",
+ "text": "if-else\nThe if-else combination is probably the most commonly used control structure in R (or perhaps any language). This structure allows you to test a condition and act on it depending on whether it’s true or false.\nFor starters, you can just use the if statement.\nif(<condition>) {\n ## do something\n} \n## Continue with rest of code\nThe above code does nothing if the condition is false. If you have an action you want to execute when the condition is false, then you need an else clause.\nif(<condition>) {\n ## do something\n} \nelse {\n ## do something else\n}\nYou can have a series of tests by following the initial if with any number of else ifs.\nif(<condition1>) {\n ## do something\n} else if(<condition2>) {\n ## do something different\n} else {\n ## do something different\n}\nHere is an example of a valid if/else structure.\nLet’s use the runif(n, min=0, max=1) function which draws a random value between a min and max value with the default being between 0 and 1.\n\nx <- runif(n = 1, min = 0, max = 10)\nx\n\n[1] 3.521267\n\n\nThen, we can write and if-else statement that tests whethere x is greater than 3 or not.\n\nx > 3\n\n[1] TRUE\n\n\nIf x is greater than 3, then the first condition occurs. If x is not greater than 3, then the second condition occurs.\n\nif (x > 3) {\n y <- 10\n} else {\n y <- 0\n}\n\nFinally, we can auto print y to see what the value is.\n\ny\n\n[1] 10\n\n\nThis expression can also be written a different (but equivalent!) way in R.\n\ny <- if (x > 3) {\n 10\n} else {\n 0\n}\n\ny\n\n[1] 10\n\n\n\n\n\n\n\n\nNote\n\n\n\nNeither way of writing this expression is more correct than the other.\nWhich one you use will depend on your preference and perhaps those of the team you may be working with.\n\n\nOf course, the else clause is not necessary. You could have a series of if clauses that always get executed if their respective conditions are true.\nif(<condition1>) {\n\n}\n\nif(<condition2>) {\n\n}\n\n\n\n\n\n\nQuestion\n\n\n\nLet’s use the palmerpenguins dataset and write a if-else statement that\n\nRandomly samples a value from a standard normal distribution (Hint: check out the rnorm(n, mean = 0, sd = 1) function in base R).\nIf the value is larger than 0, use dplyr functions to keep only the Chinstrap penguins.\nOtherwise, keep only the Gentoo penguins.\nRe-run the code 10 times and look at output.\n\n\n# try it yourself\n\nlibrary(tidyverse)\nlibrary(palmerpenguins)\npenguins\n\n# A tibble: 344 × 8\n species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g\n <fct> <fct> <dbl> <dbl> <int> <int>\n 1 Adelie Torgersen 39.1 18.7 181 3750\n 2 Adelie Torgersen 39.5 17.4 186 3800\n 3 Adelie Torgersen 40.3 18 195 3250\n 4 Adelie Torgersen NA NA NA NA\n 5 Adelie Torgersen 36.7 19.3 193 3450\n 6 Adelie Torgersen 39.3 20.6 190 3650\n 7 Adelie Torgersen 38.9 17.8 181 3625\n 8 Adelie Torgersen 39.2 19.6 195 4675\n 9 Adelie Torgersen 34.1 18.1 193 3475\n10 Adelie Torgersen 42 20.2 190 4250\n# ℹ 334 more rows\n# ℹ 2 more variables: sex <fct>, year <int>"
},
{
- "objectID": "posts/25-python-for-r-users/index.html#install-reticulate",
- "href": "posts/25-python-for-r-users/index.html#install-reticulate",
- "title": "25 - Python for R Users",
- "section": "Install reticulate",
- "text": "Install reticulate\nLet’s try it out. Before we get started, you will need to install the packages:\n\ninstall.package(\"reticulate\")\n\nWe will also load the here and tidyverse packages for our lesson:\n\nlibrary(here)\nlibrary(tidyverse)\nlibrary(reticulate)"
+ "objectID": "posts/15-control-structures/index.html#for-loops",
+ "href": "posts/15-control-structures/index.html#for-loops",
+ "title": "15 - Control Structures",
+ "section": "for Loops",
+ "text": "for Loops\nFor loops are pretty much the only looping construct that you will need in R. While you may occasionally find a need for other types of loops, in my experience doing data analysis, I’ve found very few situations where a for loop was not sufficient.\nIn R, for loops take an iterator variable and assign it successive values from a sequence or vector.\nFor loops are most commonly used for iterating over the elements of an object (list, vector, etc.)\n\nfor (i in 1:10) {\n print(i)\n}\n\n[1] 1\n[1] 2\n[1] 3\n[1] 4\n[1] 5\n[1] 6\n[1] 7\n[1] 8\n[1] 9\n[1] 10\n\n\nThis loop takes the i variable and in each iteration of the loop gives it values 1, 2, 3, …, 10, then executes the code within the curly braces, and then the loop exits.\nThe following three loops all have the same behavior.\n\n## define the loop to iterate over\nx <- c(\"a\", \"b\", \"c\", \"d\")\n\n## create for loop\nfor (i in 1:4) {\n ## Print out each element of 'x'\n print(x[i])\n}\n\n[1] \"a\"\n[1] \"b\"\n[1] \"c\"\n[1] \"d\"\n\n\nWe can also print just the iteration value (i) itself\n\n## define the loop to iterate over\nx <- c(\"a\", \"b\", \"c\", \"d\")\n\n## create for loop\nfor (i in 1:4) {\n ## Print out just 'i'\n print(i)\n}\n\n[1] 1\n[1] 2\n[1] 3\n[1] 4\n\n\n\nseq_along()\nThe seq_along() function is commonly used in conjunction with for loops in order to generate an integer sequence based on the length of an object (or ncol() of an R object) (in this case, the object x).\n\nx\n\n[1] \"a\" \"b\" \"c\" \"d\"\n\nseq_along(x)\n\n[1] 1 2 3 4\n\n\nThe seq_along() function takes in a vector and then returns a sequence of integers that is the same length as the input vector. It doesn’t matter what class the vector is.\nLet’s put seq_along() and for loops together.\n\n## Generate a sequence based on length of 'x'\nfor (i in seq_along(x)) {\n print(x[i])\n}\n\n[1] \"a\"\n[1] \"b\"\n[1] \"c\"\n[1] \"d\"\n\n\nIt is not necessary to use an index-type variable (i.e. i).\n\nfor (babyshark in x) {\n print(babyshark)\n}\n\n[1] \"a\"\n[1] \"b\"\n[1] \"c\"\n[1] \"d\"\n\n\n\nfor (candyisgreat in x) {\n print(candyisgreat)\n}\n\n[1] \"a\"\n[1] \"b\"\n[1] \"c\"\n[1] \"d\"\n\n\n\nfor (RememberToVote in x) {\n print(RememberToVote)\n}\n\n[1] \"a\"\n[1] \"b\"\n[1] \"c\"\n[1] \"d\"\n\n\nYou can use any character index you want (but not with symbols or numbers).\n\nfor (1999 in x) {\n print(1999)\n}\n\nError: <text>:1:6: unexpected numeric constant\n1: for (1999\n ^\n\n\nFor one line loops, the curly braces are not strictly necessary.\n\nfor (i in 1:4) print(x[i])\n\n[1] \"a\"\n[1] \"b\"\n[1] \"c\"\n[1] \"d\"\n\n\nHowever, I like to use curly braces even for one-line loops, because that way if you decide to expand the loop to multiple lines, you won’t be burned because you forgot to add curly braces (and you will be burned by this).\n\n\n\n\n\n\nQuestion\n\n\n\nLet’s use the palmerpenguins dataset. Here are the tasks:\n\nStart a for loop\nIterate over the columns of penguins\nFor each column, extract the values of that column (Hint: check out the pull() function in dplyr).\nUsing a if-else statement, test whether or not the values in the column are numeric or not (Hint: remember the is.numeric() function to test if a value is numeric).\nIf they are numeric, compute the column mean. Otherwise, report a NA.\n\n\n# try it yourself\n\n\n\n\n\nNested for loops\nfor loops can be nested inside of each other.\n\nx <- matrix(1:6, nrow = 2, ncol = 3)\nx\n\n [,1] [,2] [,3]\n[1,] 1 3 5\n[2,] 2 4 6\n\n\n\nfor (i in seq_len(nrow(x))) {\n for (j in seq_len(ncol(x))) {\n print(x[i, j])\n }\n}\n\n[1] 1\n[1] 3\n[1] 5\n[1] 2\n[1] 4\n[1] 6\n\n\n\n\n\n\n\n\nNote\n\n\n\nThe j index goes across the columns. That’s why we values 1, 3, etc.\n\n\nNested loops are commonly needed for multidimensional or hierarchical data structures (e.g. matrices, lists). Be careful with nesting though.\nNesting beyond 2 to 3 levels often makes it difficult to read/understand the code.\nIf you find yourself in need of a large number of nested loops, you may want to break up the loops by using functions (discussed later)."
},
{
- "objectID": "posts/25-python-for-r-users/index.html#python-path",
- "href": "posts/25-python-for-r-users/index.html#python-path",
- "title": "25 - Python for R Users",
- "section": "python path",
- "text": "python path\nIf python is not installed on your computer, you can use the install_python() function from reticulate to install it.\n\nhttps://rstudio.github.io/reticulate/reference/install_python\n\nIf python is already installed, by default, reticulate uses the version of Python found on your PATH\n\nSys.which(\"python3\")\n\n python3 \n\"/usr/bin/python3\" \n\n\nThe use_python() function enables you to specify an alternate version, for example:\n\nuse_python(\"/usr/<new>/<path>/local/bin/python\")\n\nFor example, I can define the path explicitly:\n\nuse_python(\"/opt/homebrew/Caskroom/miniforge/base/bin/python\")\n\nYou can confirm that reticulate is using the correct version of python that you requested using the py_discover_config function:\n\npy_discover_config()\n\npython: /usr/bin/python3\nlibpython: /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.9/lib/python3.9/config-3.9-darwin/libpython3.9.dylib\npythonhome: /Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.9:/Library/Developer/CommandLineTools/Library/Frameworks/Python3.framework/Versions/3.9\nversion: 3.9.6 (default, May 7 2023, 23:32:44) [Clang 14.0.3 (clang-1403.0.22.14.1)]\nnumpy: /Users/leocollado/Library/Python/3.9/lib/python/site-packages/numpy\nnumpy_version: 1.25.2\n\nNOTE: Python version was forced by RETICULATE_PYTHON_FALLBACK"
+ "objectID": "posts/15-control-structures/index.html#while-loops",
+ "href": "posts/15-control-structures/index.html#while-loops",
+ "title": "15 - Control Structures",
+ "section": "while Loops",
+ "text": "while Loops\nwhile loops begin by testing a condition.\nIf it is true, then they execute the loop body.\nOnce the loop body is executed, the condition is tested again, and so forth, until the condition is false, after which the loop exits.\n\ncount <- 0\nwhile (count < 10) {\n print(count)\n count <- count + 1\n}\n\n[1] 0\n[1] 1\n[1] 2\n[1] 3\n[1] 4\n[1] 5\n[1] 6\n[1] 7\n[1] 8\n[1] 9\n\n\nwhile loops can potentially result in infinite loops if not written properly. Use with care!\nSometimes there will be more than one condition in the test.\n\nz <- 5\nset.seed(1)\n\nwhile (z >= 3 && z <= 10) {\n coin <- rbinom(1, 1, 0.5)\n\n if (coin == 1) { ## random walk\n z <- z + 1\n } else {\n z <- z - 1\n }\n}\nprint(z)\n\n[1] 2\n\n\n\n\n\n\n\n\nPro-tip\n\n\n\nWhat’s the difference between using one & or two && ?\nIf you use only one &, these are vectorized operations, meaning they can return a vector, like this:\n\n-2:2\n\n[1] -2 -1 0 1 2\n\n((-2:2) >= 0) & ((-2:2) <= 0)\n\n[1] FALSE FALSE TRUE FALSE FALSE\n\n\nIf you use two && (as above), then these conditions are evaluated left to right. For example, in the above code, if z were less than 3, the second test would not have been evaluated.\n\n(2 >= 0) && (-2 <= 0)\n\n[1] TRUE\n\n(-2 >= 0) && (-2 <= 0)\n\n[1] FALSE"
},
{
- "objectID": "posts/25-python-for-r-users/index.html#calling-python-in-r",
- "href": "posts/25-python-for-r-users/index.html#calling-python-in-r",
- "title": "25 - Python for R Users",
- "section": "Calling Python in R",
- "text": "Calling Python in R\nThere are a variety of ways to integrate Python code into your R projects:\n\nPython in R Markdown — A new Python language engine for R Markdown that supports bi-directional communication between R and Python (R chunks can access Python objects and vice-versa).\nImporting Python modules — The import() function enables you to import any Python module and call its functions directly from R.\nSourcing Python scripts — The source_python() function enables you to source a Python script the same way you would source() an R script (Python functions and objects defined within the script become directly available to the R session).\nPython REPL — The repl_python() function creates an interactive Python console within R. Objects you create within Python are available to your R session (and vice-versa).\n\nBelow I will focus on introducing the first and last one. However, before we do that, let’s introduce a bit about python basics."
+ "objectID": "posts/15-control-structures/index.html#repeat-loops",
+ "href": "posts/15-control-structures/index.html#repeat-loops",
+ "title": "15 - Control Structures",
+ "section": "repeat Loops",
+ "text": "repeat Loops\nrepeat initiates an infinite loop right from the start. These are not commonly used in statistical or data analysis applications, but they do have their uses.\n\n\n\n\n\n\nIMPORTANT (READ THIS AND DON’T FORGET… I’M SERIOUS… YOU WANT TO REMEMBER THIS.. FOR REALZ PLZ REMEMBER THIS)\n\n\n\nThe only way to exit a repeat loop is to call break.\n\n\nOne possible paradigm might be in an iterative algorithm where you may be searching for a solution and you do not want to stop until you are close enough to the solution.\nIn this kind of situation, you often don’t know in advance how many iterations it’s going to take to get “close enough” to the solution.\n\nx0 <- 1\ntol <- 1e-8\n\nrepeat {\n x1 <- computeEstimate()\n\n if (abs(x1 - x0) < tol) { ## Close enough?\n break\n } else {\n x0 <- x1\n }\n}\n\n\n\n\n\n\n\nNote\n\n\n\nThe above code will not run if the computeEstimate() function is not defined (I just made it up for the purposes of this demonstration).\n\n\n\n\n\n\n\n\nPro-tip\n\n\n\nThe loop above is a bit dangerous because there is no guarantee it will stop.\nYou could get in a situation where the values of x0 and x1 oscillate back and forth and never converge.\nBetter to set a hard limit on the number of iterations by using a for loop and then report whether convergence was achieved or not."
},
{
- "objectID": "posts/25-python-for-r-users/index.html#start-python",
- "href": "posts/25-python-for-r-users/index.html#start-python",
- "title": "25 - Python for R Users",
- "section": "start python",
- "text": "start python\nThere are two modes you can write Python code in: interactive mode or script mode. If you open up a UNIX command window and have a command-line interface, you can simply type python (or python3) in the shell:\n\npython3\n\nand the interactive mode will open up. You can write code in the interactive mode and Python will interpret the code using the python interpreter.\nAnother way to pass code to Python is to store code in a file ending in .py, and execute the file in the script mode using\n\npython3 myscript.py\n\nTo check what version of Python you are using, type the following in the shell:\n\npython3 --version"
+ "objectID": "posts/15-control-structures/index.html#next-break",
+ "href": "posts/15-control-structures/index.html#next-break",
+ "title": "15 - Control Structures",
+ "section": "next, break",
+ "text": "next, break\nnext is used to skip an iteration of a loop.\n\nfor (i in 1:100) {\n if (i <= 20) {\n ## Skip the first 20 iterations\n next\n }\n ## Do something here\n}\n\nbreak is used to exit a loop immediately, regardless of what iteration the loop may be on.\n\nfor (i in 1:100) {\n print(i)\n\n if (i > 20) {\n ## Stop loop after 20 iterations\n break\n }\n}"
},
{
- "objectID": "posts/25-python-for-r-users/index.html#r-or-python-via-terminal",
- "href": "posts/25-python-for-r-users/index.html#r-or-python-via-terminal",
- "title": "25 - Python for R Users",
- "section": "R or python via terminal",
- "text": "R or python via terminal\n(Demo in class)"
+ "objectID": "posts/14-r-nuts-and-bolts/index.html",
+ "href": "posts/14-r-nuts-and-bolts/index.html",
+ "title": "14 - R Nuts and Bolts",
+ "section": "",
+ "text": "This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history."
},
{
- "objectID": "posts/25-python-for-r-users/index.html#objects-in-python",
- "href": "posts/25-python-for-r-users/index.html#objects-in-python",
- "title": "25 - Python for R Users",
- "section": "objects in python",
- "text": "objects in python\nEverything in Python is an object. Think of an object as a data structure that contains both data as well as functions. These objects can be variables, functions, and modules which are all objects. We can operate on this objects with what are called operators (e.g. addition, subtraction, concatenation or other operations), define/apply functions, test/apply for conditionals statements, (e.g. if, else statements) or iterate over the objects.\nNot all objects are required to have attributes and methods to operate on the objects in Python, but everything is an object (i.e. all objects can be assigned to a variable or passed as an argument to a function). A user can work with built-in defined classes of objects or can create new classes of objects. Using these objects, a user can perform operations on the objects by modifying / interacting with them."
+ "objectID": "posts/14-r-nuts-and-bolts/index.html#entering-input",
+ "href": "posts/14-r-nuts-and-bolts/index.html#entering-input",
+ "title": "14 - R Nuts and Bolts",
+ "section": "Entering Input",
+ "text": "Entering Input\nAt the R prompt we type expressions. The <- symbol is the assignment operator.\n\nx <- 1\nprint(x)\n\n[1] 1\n\nx\n\n[1] 1\n\nmsg <- \"hello\"\n\nThe grammar of the language determines whether an expression is complete or not.\n\nx <- ## Incomplete expression\n\nError: <text>:2:0: unexpected end of input\n1: x <- ## Incomplete expression\n ^\n\n\nThe # character indicates a comment.\nAnything to the right of the # (including the # itself) is ignored. This is the only comment character in R.\nUnlike some other languages, R does not support multi-line comments or comment blocks."
},
{
- "objectID": "posts/25-python-for-r-users/index.html#variables",
- "href": "posts/25-python-for-r-users/index.html#variables",
- "title": "25 - Python for R Users",
- "section": "variables",
- "text": "variables\nVariable names are case sensitive, can contain numbers and letters, can contain underscores, cannot begin with a number, cannot contain illegal characters and cannot be one of the 31 keywords in Python:\n\n“and, as, assert, break, class, continue, def, del, elif, else, except, exec, finally, for, from, global, if, import, in, is, lambda, not, or, pass, print, raise, return, try, while, with, yield”"
+ "objectID": "posts/14-r-nuts-and-bolts/index.html#evaluation",
+ "href": "posts/14-r-nuts-and-bolts/index.html#evaluation",
+ "title": "14 - R Nuts and Bolts",
+ "section": "Evaluation",
+ "text": "Evaluation\nWhen a complete expression is entered at the prompt, it is evaluated and the result of the evaluated expression is returned.\nThe result may be auto-printed.\n\nx <- 5 ## nothing printed\nx ## auto-printing occurs\n\n[1] 5\n\nprint(x) ## explicit printing\n\n[1] 5\n\n\nThe [1] shown in the output indicates that x is a vector and 5 is its first element.\nTypically with interactive work, we do not explicitly print objects with the print() function; it is much easier to just auto-print them by typing the name of the object and hitting return/enter.\nHowever, when writing scripts, functions, or longer programs, there is sometimes a need to explicitly print objects because auto-printing does not work in those settings.\nWhen an R vector is printed you will notice that an index for the vector is printed in square brackets [] on the side. For example, see this integer sequence of length 20.\n\nx <- 11:30\nx\n\n [1] 11 12 13 14 15 16 17 18 19 20 21 22\n[13] 23 24 25 26 27 28 29 30\n\n\nThe numbers in the square brackets are not part of the vector itself, they are merely part of the printed output.\n\n\n\n\n\n\nNote\n\n\n\nWith R, it’s important that one understand that there is a difference between the actual R object and the manner in which that R object is printed to the console.\nOften, the printed output may have additional bells and whistles to make the output more friendly to the users. However, these bells and whistles are not inherently part of the object.\n\n\n\n\n\n\n\n\nPro-tip\n\n\n\nThe : operator is used to create integer sequences.\n\n5:0\n\n[1] 5 4 3 2 1 0\n\n-15:15\n\n [1] -15 -14 -13 -12 -11 -10 -9 -8 -7 -6 -5 -4 -3 -2 -1 0 1 2 3\n[20] 4 5 6 7 8 9 10 11 12 13 14 15"
},
{
- "objectID": "posts/25-python-for-r-users/index.html#operators",
- "href": "posts/25-python-for-r-users/index.html#operators",
- "title": "25 - Python for R Users",
- "section": "operators",
- "text": "operators\n\nNumeric operators are +, -, *, /, ** (exponent), % (modulus if applied to integers)\nString and list operators: + and * .\nAssignment operator: =\nThe augmented assignment operator += (or -=) can be used like n += x which is equal to n = n + x\nBoolean relational operators: == (equal), != (not equal), >, <, >= (greater than or equal to), <= (less than or equal to)\nBoolean expressions will produce True or False\nLogical operators: and, or, and not. e.g. x > 1 and x <= 5\n\n\n2 ** 3\n\n8\n\nx = 3 \nx > 1 and x <= 5\n\nTrue\n\n\nAnd in R, the execution changes from Python to R seamlessly\n\n2^3\n\n[1] 8\n\nx <- 3\nx > 1 & x <= 5\n\n[1] TRUE"
+ "objectID": "posts/14-r-nuts-and-bolts/index.html#r-objects",
+ "href": "posts/14-r-nuts-and-bolts/index.html#r-objects",
+ "title": "14 - R Nuts and Bolts",
+ "section": "R Objects",
+ "text": "R Objects\nThe most basic type of R object is a vector.\n\nVectors\nThere is really only one rule about vectors in R, which is that\n\nA vector can only contain objects of the same class\n\nTo understand what we mean here, we need to dig a little deeper. We will come back this in just a minute.\n\nTypes of vectors\nThere are two types of vectors in R:\n\nAtomic vectors:\n\nlogical: FALSE, TRUE, and NA\ninteger (and doubles): these are known collectively as numeric vectors (or real numbers)\ncomplex: complex numbers\ncharacter: the most complex type of atomic vector, because each element of a character vector is a string, and a string can contain an arbitrary amount of data\nraw: used to store fixed-length sequences of bytes. These are not commonly used directly in data analysis and I won’t cover them here.\n\nLists, which are sometimes called recursive vectors because lists can contain other lists.\n\n\n[Source: R 4 Data Science]\n\n\n\n\n\n\nNote\n\n\n\nThere’s one other related object: NULL.\n\nNULL is often used to represent the absence of a vector (as opposed to NA which is used to represent the absence of a value in a vector).\nNULL typically behaves like a vector of length 0.\n\n\n\n\n\nCreate an empty vector\nEmpty vectors can be created with the vector() function.\n\nvector(mode = \"numeric\", length = 4)\n\n[1] 0 0 0 0\n\nvector(mode = \"logical\", length = 4)\n\n[1] FALSE FALSE FALSE FALSE\n\nvector(mode = \"character\", length = 4)\n\n[1] \"\" \"\" \"\" \"\"\n\n\n\n\nCreating a non-empty vector\nThe c() function can be used to create vectors of objects by concatenating things together.\n\nx <- c(0.5, 0.6) ## numeric\nx <- c(TRUE, FALSE) ## logical\nx <- c(T, F) ## logical\nx <- c(\"a\", \"b\", \"c\") ## character\nx <- 9:29 ## integer\nx <- c(1+0i, 2+4i) ## complex\n\n\n\n\n\n\n\nNote\n\n\n\nIn the above example, T and F are short-hand ways to specify TRUE and FALSE.\nHowever, in general, one should try to use the explicit TRUE and FALSE values when indicating logical values.\nThe T and F values are primarily there for when you’re feeling lazy.\n\n\n\n\nLists\nSo, I know I said there is one rule about vectors:\n\nA vector can only contain objects of the same class\n\nBut of course, like any good rule, there is an exception, which is a list (which we will get to in greater details a bit later).\nFor now, just know a list is represented as a vector but can contain objects of different classes. Indeed, that’s usually why we use them.\n\n\n\n\n\n\nNote\n\n\n\nThe main difference between atomic vectors and lists is that atomic vectors are homogeneous, while lists can be heterogeneous.\n\n\n\n\n\nNumerics\nInteger and double vectors are known collectively as numeric vectors.\nIn R, numbers are doubles by default.\nTo make an integer, place an L after the number:\n\ntypeof(4)\n\n[1] \"double\"\n\ntypeof(4L)\n\n[1] \"integer\"\n\n\n\n\n\n\n\n\nNote\n\n\n\nThe distinction between integers and doubles is not usually important, but there are two important differences that you should be aware of:\n\nDoubles are approximations!\nDoubles represent floating point numbers that can not always be precisely represented with a fixed amount of memory. This means that you should consider all doubles to be approximations.\n\n\n\n\n\n\n\n\n\nQuestion\n\n\n\nLet’s explore this. What is square of the square root of two? i.e. \\((\\sqrt{2})^2\\)\n\nx <- sqrt(2) ^ 2\nx\n\n[1] 2\n\n\nTry subtracting 2 from x? What happened?\n\n## try it here\n\n\n\n\n\nNumbers\nNumbers in R are generally treated as numeric objects (i.e. double precision real numbers).\nThis means that even if you see a number like “1” or “2” in R, which you might think of as integers, they are likely represented behind the scenes as numeric objects (so something like “1.00” or “2.00”).\nThis isn’t important most of the time…except when it is!\nIf you explicitly want an integer, you need to specify the L suffix. So entering 1 in R gives you a numeric object; entering 1L explicitly gives you an integer object.\n\n\n\n\n\n\nNote\n\n\n\nThere is also a special number Inf which represents infinity. This allows us to represent entities like 1 / 0. This way, Inf can be used in ordinary calculations; e.g. 1 / Inf is 0.\nThe value NaN represents an undefined value (“not a number”); e.g. 0 / 0; NaN can also be thought of as a missing value (more on that later)\n\n\n\n\nAttributes\nR objects can have attributes, which are like metadata for the object.\nThese metadata can be very useful in that they help to describe the object.\nFor example, column names on a data frame help to tell us what data are contained in each of the columns. Some examples of R object attributes are\n\nnames, dimnames\ndimensions (e.g. matrices, arrays)\nclass (e.g. integer, numeric)\nlength\nother user-defined attributes/metadata\n\nAttributes of an object (if any) can be accessed using the attributes() function. Not all R objects contain attributes, in which case the attributes() function returns NULL.\nHowever, every vector has two key properties:\n\nIts type, which you can determine with typeof().\n\n\nletters\n\n [1] \"a\" \"b\" \"c\" \"d\" \"e\" \"f\" \"g\" \"h\" \"i\" \"j\" \"k\" \"l\" \"m\" \"n\" \"o\" \"p\" \"q\" \"r\" \"s\"\n[20] \"t\" \"u\" \"v\" \"w\" \"x\" \"y\" \"z\"\n\ntypeof(letters)\n\n[1] \"character\"\n\n1:10\n\n [1] 1 2 3 4 5 6 7 8 9 10\n\ntypeof(1:10)\n\n[1] \"integer\"\n\n\n\nIts length, which you can determine with length().\n\n\nx <- list(\"a\", \"b\", 1:10)\nx\n\n[[1]]\n[1] \"a\"\n\n[[2]]\n[1] \"b\"\n\n[[3]]\n [1] 1 2 3 4 5 6 7 8 9 10\n\nlength(x)\n\n[1] 3\n\ntypeof(x)\n\n[1] \"list\"\n\nattributes(x)\n\nNULL"
},
{
- "objectID": "posts/25-python-for-r-users/index.html#format-operators",
- "href": "posts/25-python-for-r-users/index.html#format-operators",
- "title": "25 - Python for R Users",
- "section": "format operators",
- "text": "format operators\nIf % is applied to strings, this operator is the format operator. It tells Python how to format a list of values in a string. For example,\n\n%d says to format the value as an integer\n%g says to format the value as an float\n%s says to format the value as an string\n\n\nprint('In %d days, I have eaten %g %s.' % (5, 3.5, 'cupcakes'))\n\nIn 5 days, I have eaten 3.5 cupcakes."
+ "objectID": "posts/14-r-nuts-and-bolts/index.html#mixing-objects",
+ "href": "posts/14-r-nuts-and-bolts/index.html#mixing-objects",
+ "title": "14 - R Nuts and Bolts",
+ "section": "Mixing Objects",
+ "text": "Mixing Objects\nThere are occasions when different classes of R objects get mixed together.\nSometimes this happens by accident but it can also happen on purpose.\n\n\n\n\n\n\nQuestion\n\n\n\nLet’s use typeof() to ask what happens when we mix different classes of R objects together.\n\ny <- c(1.7, \"a\")\ny <- c(TRUE, 2)\ny <- c(\"a\", TRUE)\n\n\n## try it here\n\n\n\nWhy is this happening?\nIn each case above, we are mixing objects of two different classes in a vector.\nBut remember that the only rule about vectors says this is not allowed?\nWhen different objects are mixed in a vector, coercion occurs so that every element in the vector is of the same class.\nIn the example above, we see the effect of implicit coercion.\nWhat R tries to do is find a way to represent all of the objects in the vector in a reasonable fashion. Sometimes this does exactly what you want and…sometimes not.\nFor example, combining a numeric object with a character object will create a character vector, because numbers can usually be easily represented as strings."
},
{
- "objectID": "posts/25-python-for-r-users/index.html#functions",
- "href": "posts/25-python-for-r-users/index.html#functions",
- "title": "25 - Python for R Users",
- "section": "functions",
- "text": "functions\nPython contains a small list of very useful built-in functions.\nAll other functions need defined by the user or need to be imported from modules.\n\n\n\n\n\n\nPro-tip\n\n\n\nFor a more detailed list on the built-in functions in Python, see Built-in Python Functions.\n\n\nThe first function we will discuss, type(), reports the type of any object, which is very useful when handling multiple data types (remember, everything in Python is an object). Here are some the mains types you will encounter:\n\ninteger (int)\nfloating-point (float)\nstring (str)\nlist (list)\ndictionary (dict)\ntuple (tuple)\nfunction (function)\nmodule (module)\nboolean (bool): e.g. True, False\nenumerate (enumerate)\n\nIf we asked for the type of a string “Let’s go Ravens!”\n\ntype(\"Let's go Ravens!\")\n\n<class 'str'>\n\n\nThis would return the str type.\nYou have also seen how to use the print() function. The function print will accept an argument and print the argument to the screen. Print can be used in two ways:\n\nprint(\"Let's go Ravens!\")\n\n[1] \"Let's go Ravens!\""
+ "objectID": "posts/14-r-nuts-and-bolts/index.html#explicit-coercion",
+ "href": "posts/14-r-nuts-and-bolts/index.html#explicit-coercion",
+ "title": "14 - R Nuts and Bolts",
+ "section": "Explicit Coercion",
+ "text": "Explicit Coercion\nObjects can be explicitly coerced from one class to another using the as.*() functions, if available.\n\nx <- 0:6\nclass(x)\n\n[1] \"integer\"\n\nas.numeric(x)\n\n[1] 0 1 2 3 4 5 6\n\nas.logical(x)\n\n[1] FALSE TRUE TRUE TRUE TRUE TRUE TRUE\n\nas.character(x)\n\n[1] \"0\" \"1\" \"2\" \"3\" \"4\" \"5\" \"6\"\n\n\nSometimes, R can’t figure out how to coerce an object and this can result in NAs being produced.\n\nx <- c(\"a\", \"b\", \"c\")\nas.numeric(x)\n\nWarning: NAs introduced by coercion\n\n\n[1] NA NA NA\n\nas.logical(x)\n\n[1] NA NA NA\n\n\n\n\n\n\n\n\nQuestion\n\n\n\nLet’s try to convert the x vector above to integers.\n\n## try it here \n\n\n\nWhen nonsensical coercion takes place, you will usually get a warning from R."
},
{
- "objectID": "posts/25-python-for-r-users/index.html#new-functions",
- "href": "posts/25-python-for-r-users/index.html#new-functions",
- "title": "25 - Python for R Users",
- "section": "new functions",
- "text": "new functions\nNew functions can be defined using one of the 31 keywords in Python def.\n\ndef new_world(): \n return 'Hello world!'\n \nprint(new_world())\n\nHello world!\n\n\nThe first line of the function (the header) must start with def, the name of the function (which can contain underscores), parentheses (with any arguments inside of it) and a colon. The arguments can be specified in any order.\nThe rest of the function (the body) always has an indentation of four spaces. If you define a function in the interactive mode, the interpreter will print ellipses (…) to let you know the function is not complete. To complete the function, enter an empty line (not necessary in a script).\nTo return a value from a function, use return. The function will immediately terminate and not run any code written past this point.\n\ndef squared(x):\n \"\"\" Return the square of a \n value \"\"\"\n return x ** 2\n\nprint(squared(4))\n\n16\n\n\n\n\n\n\n\n\nNote\n\n\n\npython has its version of ... (also from docs.python.org)\n\ndef concat(*args, sep=\"/\"):\n return sep.join(args) \n\nconcat(\"a\", \"b\", \"c\")\n\n'a/b/c'"
+ "objectID": "posts/14-r-nuts-and-bolts/index.html#matrices",
+ "href": "posts/14-r-nuts-and-bolts/index.html#matrices",
+ "title": "14 - R Nuts and Bolts",
+ "section": "Matrices",
+ "text": "Matrices\nMatrices are vectors with a dimension attribute.\n\nThe dimension attribute is itself an integer vector of length 2 (number of rows, number of columns)\n\n\nm <- matrix(nrow = 2, ncol = 3) \nm\n\n [,1] [,2] [,3]\n[1,] NA NA NA\n[2,] NA NA NA\n\ndim(m)\n\n[1] 2 3\n\nattributes(m)\n\n$dim\n[1] 2 3\n\n\nMatrices are constructed column-wise, so entries can be thought of starting in the “upper left” corner and running down the columns.\n\nm <- matrix(1:6, nrow = 2, ncol = 3) \nm\n\n [,1] [,2] [,3]\n[1,] 1 3 5\n[2,] 2 4 6\n\n\n\n\n\n\n\n\nQuestion\n\n\n\nLet’s try to use attributes() function to look at the attributes of the m object\n\n## try it here \n\n\n\nMatrices can also be created directly from vectors by adding a dimension attribute.\n\nm <- 1:10 \nm\n\n [1] 1 2 3 4 5 6 7 8 9 10\n\ndim(m) <- c(2, 5)\nm\n\n [,1] [,2] [,3] [,4] [,5]\n[1,] 1 3 5 7 9\n[2,] 2 4 6 8 10\n\n\nMatrices can be created by column-binding or row-binding with the cbind() and rbind() functions.\n\nx <- 1:3\ny <- 10:12\ncbind(x, y)\n\n x y\n[1,] 1 10\n[2,] 2 11\n[3,] 3 12\n\n\n\n\n\n\n\n\nQuestion\n\n\n\nLet’s try to use rbind() to row bind x and y above.\n\n## try it here"
},
{
- "objectID": "posts/25-python-for-r-users/index.html#iteration",
- "href": "posts/25-python-for-r-users/index.html#iteration",
- "title": "25 - Python for R Users",
- "section": "iteration",
- "text": "iteration\nIterative loops can be written with the for, while and break statements.\nDefining a for loop is similar to defining a new function.\n\nThe header ends with a colon and the body is indented.\nThe function range(n) takes in an integer n and creates a set of values from 0 to n - 1.\n\n\nfor i in range(3):\n print('Baby shark, doo doo doo doo doo doo!')\n\nBaby shark, doo doo doo doo doo doo!\nBaby shark, doo doo doo doo doo doo!\nBaby shark, doo doo doo doo doo doo!\n\nprint('Baby shark!')\n\nBaby shark!\n\n\nfor loops are not just for counters, but they can iterate through many types of objects such as strings, lists and dictionaries.\nThe function len() can be used to:\n\nCalculate the length of a string\nCalculate the number of elements in a list\nCalculate the number of items (key-value pairs) in a dictionary\nCalculate the number elements in the tuple\n\n\nx = 'Baby shark!'\nlen(x)\n\n11"
+ "objectID": "posts/14-r-nuts-and-bolts/index.html#lists-1",
+ "href": "posts/14-r-nuts-and-bolts/index.html#lists-1",
+ "title": "14 - R Nuts and Bolts",
+ "section": "Lists",
+ "text": "Lists\nLists are a special type of vector that can contain elements of different classes. Lists are a very important data type in R and you should get to know them well.\n\n\n\n\n\n\nPro-tip\n\n\n\nLists, in combination with the various “apply” functions discussed later, make for a powerful combination.\n\n\nLists can be explicitly created using the list() function, which takes an arbitrary number of arguments.\n\nx <- list(1, \"a\", TRUE, 1 + 4i) \nx\n\n[[1]]\n[1] 1\n\n[[2]]\n[1] \"a\"\n\n[[3]]\n[1] TRUE\n\n[[4]]\n[1] 1+4i\n\n\nWe can also create an empty list of a prespecified length with the vector() function\n\nx <- vector(\"list\", length = 5)\nx\n\n[[1]]\nNULL\n\n[[2]]\nNULL\n\n[[3]]\nNULL\n\n[[4]]\nNULL\n\n[[5]]\nNULL"
},
{
- "objectID": "posts/25-python-for-r-users/index.html#methods-for-each-type-of-object-dot-notation",
- "href": "posts/25-python-for-r-users/index.html#methods-for-each-type-of-object-dot-notation",
- "title": "25 - Python for R Users",
- "section": "methods for each type of object (dot notation)",
- "text": "methods for each type of object (dot notation)\nFor strings, lists and dictionaries, there are set of methods you can use to manipulate the objects. In general, the notation for methods is the dot notation.\nThe syntax is the name of the object followed by a dot (or period) followed by the name of the method.\n\nx = \"Hello Baltimore!\"\nx.split()\n\n['Hello', 'Baltimore!']"
+ "objectID": "posts/14-r-nuts-and-bolts/index.html#factors",
+ "href": "posts/14-r-nuts-and-bolts/index.html#factors",
+ "title": "14 - R Nuts and Bolts",
+ "section": "Factors",
+ "text": "Factors\nFactors are used to represent categorical data and can be unordered or ordered. One can think of a factor as an integer vector where each integer has a label.\n\n\n\n\n\n\nPro-tip\n\n\n\nFactors are important in statistical modeling and are treated specially by modelling functions like lm() and glm().\n\n\nUsing factors with labels is better than using integers because factors are self-describing.\n\n\n\n\n\n\nPro-tip\n\n\n\nHaving a variable that has values “Yes” and “No” or “Smoker” and “Non-Smoker” is better than a variable that has values 1 and 2.\n\n\nFactor objects can be created with the factor() function.\n\nx <- factor(c(\"yes\", \"yes\", \"no\", \"yes\", \"no\")) \nx\n\n[1] yes yes no yes no \nLevels: no yes\n\ntable(x) \n\nx\n no yes \n 2 3 \n\n## See the underlying representation of factor\nunclass(x) \n\n[1] 2 2 1 2 1\nattr(,\"levels\")\n[1] \"no\" \"yes\"\n\n\n\n\n\n\n\n\nQuestion\n\n\n\nLet’s try to use attributes() function to look at the attributes of the x object\n\n## try it here \n\n\n\nOften factors will be automatically created for you when you read in a dataset using a function like read.table().\n\nThose functions often default to creating factors when they encounter data that look like characters or strings.\n\nThe order of the levels of a factor can be set using the levels argument to factor(). This can be important in linear modeling because the first level is used as the baseline level.\n\nx <- factor(c(\"yes\", \"yes\", \"no\", \"yes\", \"no\"))\nx ## Levels are put in alphabetical order\n\n[1] yes yes no yes no \nLevels: no yes\n\nx <- factor(c(\"yes\", \"yes\", \"no\", \"yes\", \"no\"),\n levels = c(\"yes\", \"no\"))\nx\n\n[1] yes yes no yes no \nLevels: yes no"
},
{
- "objectID": "posts/25-python-for-r-users/index.html#data-structures",
- "href": "posts/25-python-for-r-users/index.html#data-structures",
- "title": "25 - Python for R Users",
- "section": "Data structures",
- "text": "Data structures\nWe have already seen lists. Python has other data structures built in.\n\nSets {\"a\", \"a\", \"a\", \"b\"} (unique elements)\nTuples (1, 2, 3) (a lot like lists but not mutable, i.e. need to create a new to modify)\nDictionaries\n\n\ndict = {\"a\" : 1, \"b\" : 2}\ndict['a']\n\n1\n\ndict['b']\n\n2\n\n\nMore about data structures can be founds at the python docs"
+ "objectID": "posts/14-r-nuts-and-bolts/index.html#missing-values",
+ "href": "posts/14-r-nuts-and-bolts/index.html#missing-values",
+ "title": "14 - R Nuts and Bolts",
+ "section": "Missing Values",
+ "text": "Missing Values\nMissing values are denoted by NA or NaN for undefined mathematical operations.\n\nis.na() is used to test objects if they are NA\nis.nan() is used to test for NaN\nNA values have a class also, so there are integer NA, character NA, etc.\nA NaN value is also NA but the converse is not true\n\n\n## Create a vector with NAs in it\nx <- c(1, 2, NA, 10, 3) \n## Return a logical vector indicating which elements are NA\nis.na(x) \n\n[1] FALSE FALSE TRUE FALSE FALSE\n\n## Return a logical vector indicating which elements are NaN\nis.nan(x) \n\n[1] FALSE FALSE FALSE FALSE FALSE\n\n\n\n## Now create a vector with both NA and NaN values\nx <- c(1, 2, NaN, NA, 4)\nis.na(x)\n\n[1] FALSE FALSE TRUE TRUE FALSE\n\nis.nan(x)\n\n[1] FALSE FALSE TRUE FALSE FALSE"
},
{
- "objectID": "posts/25-python-for-r-users/index.html#python-engine-within-r-markdown",
- "href": "posts/25-python-for-r-users/index.html#python-engine-within-r-markdown",
- "title": "25 - Python for R Users",
- "section": "Python engine within R Markdown",
- "text": "Python engine within R Markdown\nThe reticulate package includes a Python engine for R Markdown with the following features:\n\nRun Python chunks in a single Python session embedded within your R session (shared variables/state between Python chunks)\nPrinting of Python output, including graphical output from matplotlib.\nAccess to objects created within Python chunks from R using the py object (e.g. py$x would access an x variable created within Python from R).\nAccess to objects created within R chunks from Python using the r object (e.g. r.x would access to x variable created within R from Python)\n\n\n\n\n\n\n\nConversions\n\n\n\nBuilt in conversion for many Python object types is provided, including NumPy arrays and Pandas data frames."
+ "objectID": "posts/14-r-nuts-and-bolts/index.html#data-frames",
+ "href": "posts/14-r-nuts-and-bolts/index.html#data-frames",
+ "title": "14 - R Nuts and Bolts",
+ "section": "Data Frames",
+ "text": "Data Frames\nData frames are used to store tabular data in R. They are an important type of object in R and are used in a variety of statistical modeling applications. Hadley Wickham’s package dplyr has an optimized set of functions designed to work efficiently with data frames.\nData frames are represented as a special type of list where every element of the list has to have the same length.\n\nEach element of the list can be thought of as a column\nThe length of each element of the list is the number of rows\n\nUnlike matrices, data frames can store different classes of objects in each column. Matrices must have every element be the same class (e.g. all integers or all numeric).\nIn addition to column names, indicating the names of the variables or predictors, data frames have a special attribute called row.names which indicate information about each row of the data frame.\nData frames are usually created by reading in a dataset using the read.table() or read.csv(). However, data frames can also be created explicitly with the data.frame() function or they can be coerced from other types of objects like lists.\n\nx <- data.frame(foo = 1:4, bar = c(T, T, F, F)) \nx\n\n foo bar\n1 1 TRUE\n2 2 TRUE\n3 3 FALSE\n4 4 FALSE\n\nnrow(x)\n\n[1] 4\n\nncol(x)\n\n[1] 2\n\nattributes(x)\n\n$names\n[1] \"foo\" \"bar\"\n\n$class\n[1] \"data.frame\"\n\n$row.names\n[1] 1 2 3 4\n\n\nData frames can be converted to a matrix by calling data.matrix(). While it might seem that the as.matrix() function should be used to coerce a data frame to a matrix, almost always, what you want is the result of data.matrix().\n\ndata.matrix(x)\n\n foo bar\n[1,] 1 1\n[2,] 2 1\n[3,] 3 0\n[4,] 4 0\n\nattributes(data.matrix(x))\n\n$dim\n[1] 4 2\n\n$dimnames\n$dimnames[[1]]\nNULL\n\n$dimnames[[2]]\n[1] \"foo\" \"bar\"\n\n\n\nExample\n\n\n\n\n\n\nQuestion\n\n\n\nLet’s use the palmerpenguins dataset.\n\nWhat attributes does penguins have?\nWhat class is the penguins R object?\nWhat are the levels in the species column in the penguins dataset?\nCreate a logical vector for all the penguins measured from 2008.\nCreate a matrix with just the columns bill_length_mm, bill_depth_mm, flipper_length_mm, and body_mass_g\n\n\n# try it yourself\n\nlibrary(tidyverse)\nlibrary(palmerpenguins)\npenguins \n\n# A tibble: 344 × 8\n species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g\n <fct> <fct> <dbl> <dbl> <int> <int>\n 1 Adelie Torgersen 39.1 18.7 181 3750\n 2 Adelie Torgersen 39.5 17.4 186 3800\n 3 Adelie Torgersen 40.3 18 195 3250\n 4 Adelie Torgersen NA NA NA NA\n 5 Adelie Torgersen 36.7 19.3 193 3450\n 6 Adelie Torgersen 39.3 20.6 190 3650\n 7 Adelie Torgersen 38.9 17.8 181 3625\n 8 Adelie Torgersen 39.2 19.6 195 4675\n 9 Adelie Torgersen 34.1 18.1 193 3475\n10 Adelie Torgersen 42 20.2 190 4250\n# ℹ 334 more rows\n# ℹ 2 more variables: sex <fct>, year <int>"
},
{
- "objectID": "posts/25-python-for-r-users/index.html#from-python-to-r",
- "href": "posts/25-python-for-r-users/index.html#from-python-to-r",
- "title": "25 - Python for R Users",
- "section": "From Python to R",
- "text": "From Python to R\nAs an example, you can use Pandas to read and manipulate data then easily plot the Pandas data frame using ggplot2:\nLet’s first create a flights.csv dataset in R and save it using write_csv from readr:\n\n# checks to see if a folder called \"data\" exists; if not, it installs it\nif (!file.exists(here(\"data\"))) {\n dir.create(here(\"data\"))\n}\n\n# checks to see if a file called \"flights.csv\" exists; if not, it saves it to the data folder\nif (!file.exists(here(\"data\", \"flights.csv\"))) {\n readr::write_csv(nycflights13::flights,\n file = here(\"data\", \"flights.csv\")\n )\n}\n\nnycflights13::flights %>%\n head()\n\n# A tibble: 6 × 19\n year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time\n <int> <int> <int> <int> <int> <dbl> <int> <int>\n1 2013 1 1 517 515 2 830 819\n2 2013 1 1 533 529 4 850 830\n3 2013 1 1 542 540 2 923 850\n4 2013 1 1 544 545 -1 1004 1022\n5 2013 1 1 554 600 -6 812 837\n6 2013 1 1 554 558 -4 740 728\n# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,\n# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,\n# hour <dbl>, minute <dbl>, time_hour <dttm>\n\n\nNext, we use Python to read in the file and do some data wrangling\n\nimport pandas\nflights_path = \"/Users/leocollado/Dropbox/Code/jhustatcomputing2023/data/flights.csv\"\nflights = pandas.read_csv(flights_path)\nflights = flights[flights['dest'] == \"ORD\"]\nflights = flights[['carrier', 'dep_delay', 'arr_delay']]\nflights = flights.dropna()\nflights\n\n carrier dep_delay arr_delay\n5 UA -4.0 12.0\n9 AA -2.0 8.0\n25 MQ 8.0 32.0\n38 AA -1.0 14.0\n57 AA -4.0 4.0\n... ... ... ...\n336645 AA -12.0 -37.0\n336669 UA -7.0 -13.0\n336675 MQ -7.0 -11.0\n336696 B6 -5.0 -23.0\n336709 AA -13.0 -38.0\n\n[16566 rows x 3 columns]\n\n\n\nhead(py$flights)\n\n carrier dep_delay arr_delay\n5 UA -4 12\n9 AA -2 8\n25 MQ 8 32\n38 AA -1 14\n57 AA -4 4\n70 UA 9 20\n\npy$flights_path\n\n[1] \"/Users/leocollado/Dropbox/Code/jhustatcomputing2023/data/flights.csv\"\n\n\n\nclass(py$flights)\n\n[1] \"data.frame\"\n\nclass(py$flights_path)\n\n[1] \"character\"\n\n\nNext, we can use R to visualize the Pandas DataFrame.\nThe data frame is loaded in as an R object now stored in the variable py.\n\nggplot(py$flights, aes(x = carrier, y = arr_delay)) +\n geom_point() +\n geom_jitter()\n\n\n\n\n\n\n\n\n\n\nNote\n\n\n\nThe reticulate Python engine is enabled by default within R Markdown whenever reticulate is installed.\n\n\n\nFrom R to Python\nUse R to read and manipulate data\n\nlibrary(tidyverse)\nflights <- read_csv(here(\"data\", \"flights.csv\")) %>%\n filter(dest == \"ORD\") %>%\n select(carrier, dep_delay, arr_delay) %>%\n na.omit()\n\nRows: 336776 Columns: 19\n── Column specification ────────────────────────────────────────────────────────\nDelimiter: \",\"\nchr (4): carrier, tailnum, origin, dest\ndbl (14): year, month, day, dep_time, sched_dep_time, dep_delay, arr_time, ...\ndttm (1): time_hour\n\nℹ Use `spec()` to retrieve the full column specification for this data.\nℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.\n\nflights\n\n# A tibble: 16,566 × 3\n carrier dep_delay arr_delay\n <chr> <dbl> <dbl>\n 1 UA -4 12\n 2 AA -2 8\n 3 MQ 8 32\n 4 AA -1 14\n 5 AA -4 4\n 6 UA 9 20\n 7 UA 2 21\n 8 AA -6 -12\n 9 MQ 39 49\n10 B6 -2 15\n# ℹ 16,556 more rows\n\n\n\n\nUse Python to print R dataframe\nIf you recall, we can access objects created within R chunks from Python using the r object (e.g. r.x would access to x variable created within R from Python).\nWe can then ask for the first ten rows using the head() function in python.\n\nr.flights.head(10)\n\n carrier dep_delay arr_delay\n0 UA -4.0 12.0\n1 AA -2.0 8.0\n2 MQ 8.0 32.0\n3 AA -1.0 14.0\n4 AA -4.0 4.0\n5 UA 9.0 20.0\n6 UA 2.0 21.0\n7 AA -6.0 -12.0\n8 MQ 39.0 49.0\n9 B6 -2.0 15.0"
+ "objectID": "posts/14-r-nuts-and-bolts/index.html#names",
+ "href": "posts/14-r-nuts-and-bolts/index.html#names",
+ "title": "14 - R Nuts and Bolts",
+ "section": "Names",
+ "text": "Names\nR objects can have names, which is very useful for writing readable code and self-describing objects.\nHere is an example of assigning names to an integer vector.\n\nx <- 1:3\nnames(x)\n\nNULL\n\nnames(x) <- c(\"New York\", \"Seattle\", \"Los Angeles\") \nx\n\n New York Seattle Los Angeles \n 1 2 3 \n\nnames(x)\n\n[1] \"New York\" \"Seattle\" \"Los Angeles\"\n\nattributes(x)\n\n$names\n[1] \"New York\" \"Seattle\" \"Los Angeles\"\n\n\nLists can also have names, which is often very useful.\n\nx <- list(\"Los Angeles\" = 1, Boston = 2, London = 3) \nx\n\n$`Los Angeles`\n[1] 1\n\n$Boston\n[1] 2\n\n$London\n[1] 3\n\nnames(x)\n\n[1] \"Los Angeles\" \"Boston\" \"London\" \n\n\nMatrices can have both column and row names.\n\nm <- matrix(1:4, nrow = 2, ncol = 2)\ndimnames(m) <- list(c(\"a\", \"b\"), c(\"c\", \"d\")) \nm\n\n c d\na 1 3\nb 2 4\n\n\nColumn names and row names can be set separately using the colnames() and rownames() functions.\n\ncolnames(m) <- c(\"h\", \"f\")\nrownames(m) <- c(\"x\", \"z\")\nm\n\n h f\nx 1 3\nz 2 4\n\n\n\n\n\n\n\n\nNote\n\n\n\nFor data frames, there is a separate function for setting the row names, the row.names() function.\nAlso, data frames do not have column names, they just have names (like lists).\nSo to set the column names of a data frame just use the names() function. Yes, I know its confusing.\nHere’s a quick summary:\n\n\n\nObject\nSet column names\nSet row names\n\n\n\n\ndata frame\nnames()\nrow.names()\n\n\nmatrix\ncolnames()\nrownames()"
},
{
- "objectID": "posts/25-python-for-r-users/index.html#import-python-modules",
- "href": "posts/25-python-for-r-users/index.html#import-python-modules",
- "title": "25 - Python for R Users",
- "section": "import python modules",
- "text": "import python modules\nYou can use the import() function to import any Python module and call it from R. For example, this code imports the Python os module in python and calls the listdir() function:\n\nos <- import(\"os\")\nos$listdir(\".\")\n\n[1] \"index.qmd\" \"index_files\" \"index.rmarkdown\"\n\n\nFunctions and other data within Python modules and classes can be accessed via the $ operator (analogous to the way you would interact with an R list, environment, or reference class).\nImported Python modules support code completion and inline help:\n\n\n\n\n\nUsing reticulate tab completion\n\n\n\n\n[Source: Rstudio]\nSimilarly, we can import the pandas library:\n\npd <- import(\"pandas\")\ntest <- pd$read_csv(here(\"data\", \"flights.csv\"))\nhead(test)\n\n year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time\n1 2013 1 1 517 515 2 830 819\n2 2013 1 1 533 529 4 850 830\n3 2013 1 1 542 540 2 923 850\n4 2013 1 1 544 545 -1 1004 1022\n5 2013 1 1 554 600 -6 812 837\n6 2013 1 1 554 558 -4 740 728\n arr_delay carrier flight tailnum origin dest air_time distance hour minute\n1 11 UA 1545 N14228 EWR IAH 227 1400 5 15\n2 20 UA 1714 N24211 LGA IAH 227 1416 5 29\n3 33 AA 1141 N619AA JFK MIA 160 1089 5 40\n4 -18 B6 725 N804JB JFK BQN 183 1576 5 45\n5 -25 DL 461 N668DN LGA ATL 116 762 6 0\n6 12 UA 1696 N39463 EWR ORD 150 719 5 58\n time_hour\n1 2013-01-01T10:00:00Z\n2 2013-01-01T10:00:00Z\n3 2013-01-01T10:00:00Z\n4 2013-01-01T10:00:00Z\n5 2013-01-01T11:00:00Z\n6 2013-01-01T10:00:00Z\n\nclass(test)\n\n[1] \"data.frame\"\n\n\nor the scikit-learn python library:\n\nskl_lr <- import(\"sklearn.linear_model\")\nskl_lr\n\nModule(sklearn.linear_model)"
+ "objectID": "posts/22-working-with-factors/index.html",
+ "href": "posts/22-working-with-factors/index.html",
+ "title": "22 - Factors",
+ "section": "",
+ "text": "This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history."
},
{
- "objectID": "posts/25-python-for-r-users/index.html#calling-python-scripts",
- "href": "posts/25-python-for-r-users/index.html#calling-python-scripts",
- "title": "25 - Python for R Users",
- "section": "Calling python scripts",
- "text": "Calling python scripts\n\nsource_python(\"secret_functions.py\")\nsubject_1 <- read_subject(\"secret_data.csv\")"
+ "objectID": "posts/22-working-with-factors/index.html#factor-basics",
+ "href": "posts/22-working-with-factors/index.html#factor-basics",
+ "title": "22 - Factors",
+ "section": "Factor basics",
+ "text": "Factor basics\nYou can fix both of these problems with a factor.\nTo create a factor you must start by creating a list of the valid levels:\n\nmonth_levels <- c(\n \"Jan\", \"Feb\", \"Mar\", \"Apr\", \"May\", \"Jun\",\n \"Jul\", \"Aug\", \"Sep\", \"Oct\", \"Nov\", \"Dec\"\n)\n\nNow we can create a factor with the factor() function defining the levels argument:\n\ny <- factor(x, levels = month_levels)\ny\n\n[1] Dec Apr Jan Mar\nLevels: Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec\n\n\nWe can see what happens if we try to sort the factor:\n\nsort(y)\n\n[1] Jan Mar Apr Dec\nLevels: Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec\n\n\nWe can also check the attributes of the factor:\n\nattributes(y)\n\n$levels\n [1] \"Jan\" \"Feb\" \"Mar\" \"Apr\" \"May\" \"Jun\" \"Jul\" \"Aug\" \"Sep\" \"Oct\" \"Nov\" \"Dec\"\n\n$class\n[1] \"factor\"\n\n\nIf you want to access the set of levels directly, you can do so with levels():\n\nlevels(y)\n\n [1] \"Jan\" \"Feb\" \"Mar\" \"Apr\" \"May\" \"Jun\" \"Jul\" \"Aug\" \"Sep\" \"Oct\" \"Nov\" \"Dec\"\n\n\n\n\n\n\n\n\nNote\n\n\n\nAny values not in the level will be silently converted to NA:\n\ny_typo <- factor(x_typo, levels = month_levels)\ny_typo\n\n[1] Dec Apr <NA> Mar \nLevels: Jan Feb Mar Apr May Jun Jul Aug Sep Oct Nov Dec"
},
{
- "objectID": "posts/25-python-for-r-users/index.html#calling-the-python-repl",
- "href": "posts/25-python-for-r-users/index.html#calling-the-python-repl",
- "title": "25 - Python for R Users",
- "section": "Calling the python repl",
- "text": "Calling the python repl\nIf you want to work with Python interactively you can call the repl_python() function, which provides a Python REPL embedded within your R session.\n\nrepl_python()\n\nObjects created within the Python REPL can be accessed from R using the py object exported from reticulate. For example:\n\n\n\n\n\nUsing the repl_python() function\n\n\n\n\n[Source: Rstudio]\ni.e. objects do have permenancy in R after exiting the python repl.\nSo typing x = 4 in the repl will put py$x as 4 in R after you exit the repl.\nEnter exit within the Python REPL to return to the R prompt."
+ "objectID": "posts/22-working-with-factors/index.html#challenges-working-with-categorical-data",
+ "href": "posts/22-working-with-factors/index.html#challenges-working-with-categorical-data",
+ "title": "22 - Factors",
+ "section": "Challenges working with categorical data",
+ "text": "Challenges working with categorical data\nWorking with categorical data can really helpful in many situations, but it also be challenging.\nFor example,\n\nWhat if the original data source for where the categorical data is getting ingested changes?\n\nIf a domain expert is providing spreadsheet data at regular intervals, code that worked on the initial data may not generate an error message, but could silently produce incorrect results.\n\nWhat if a new level of a categorical data is added in an updated dataset?\nWhen categorical data are coded with numerical values, it can be easy to break the relationship between category numbers and category labels without realizing it, thus losing the information encoded in a variable.\n\nLet’s consider an example of this below.\n\n\n\n\n\n\n\n\nExample\n\n\n\nConsider a set of decades,\n\nlibrary(tidyverse)\n\nx1_original <- c(10, 10, 10, 50, 60, 20, 20, 40)\nx1_factor <- factor(x1_original)\nattributes(x1_factor)\n\n$levels\n[1] \"10\" \"20\" \"40\" \"50\" \"60\"\n\n$class\n[1] \"factor\"\n\ntibble(x1_original, x1_factor) %>%\n mutate(x1_numeric = as.numeric(x1_factor))\n\n# A tibble: 8 × 3\n x1_original x1_factor x1_numeric\n <dbl> <fct> <dbl>\n1 10 10 1\n2 10 10 1\n3 10 10 1\n4 50 50 4\n5 60 60 5\n6 20 20 2\n7 20 20 2\n8 40 40 3\n\n\nInstead of creating a new variable with a numeric version of the value of the factor variable x1_factor, the variable loses the original numerical categories and creates a factor number (i.e., 10 is mapped to 1, 20 is mapped to 2, and 40 is mapped to 3, etc).\n\n\nThis result is unexpected because base::as.numeric() is intended to recover numeric information by coercing a character variable.\n\n\n\n\n\n\nExample\n\n\n\nCompare the following:\n\nas.numeric(c(\"hello\"))\n\nWarning: NAs introduced by coercion\n\n\n[1] NA\n\nas.numeric(factor(c(\"hello\")))\n\n[1] 1\n\n\nIn the first example, R does not how to convert the character string to a numeric, so it returns a NA.\nIn the second example, it creates factor numbers and orders them according to an alphabetical order. Here is another example of this behavior:\n\nas.numeric(factor(c(\"hello\", \"goodbye\")))\n\n[1] 2 1\n\n\n\n\nThis behavior of the factor() function feels unexpected at best.\nAnother example of unexpected behavior is how the function will silently make a missing value because the values in the data and the levels do not match.\n\nfactor(\"a\", levels = \"c\")\n\n[1] <NA>\nLevels: c\n\n\nThe unfortunate behavior of factors in R has led to an online movement against the default behavior of many data import functions to make factors out of any variable composed as strings.\nThe tidyverse is part of this movement, with functions from the readr package defaulting to leaving strings as-is. (Others have chosen to add options(stringAsFactors=FALSE) into their start up commands.)"
},
{
- "objectID": "posts/19-error-handling-and-generation/index.html",
- "href": "posts/19-error-handling-and-generation/index.html",
- "title": "19 - Error Handling and Generation",
+ "objectID": "posts/22-working-with-factors/index.html#factors-when-modeling-data",
+ "href": "posts/22-working-with-factors/index.html#factors-when-modeling-data",
+ "title": "22 - Factors",
+ "section": "Factors when modeling data",
+ "text": "Factors when modeling data\nSo if factors are so troublesome, what’s the point of them in the first place?\nFactors are still necessary for some data analytic tasks. The most salient case is in statistical modeling.\nWhen you pass a factor variable into lm() or glm(), R automatically creates indicator (or more colloquially ‘dummy’) variables for each of the levels and picks one as a reference group.\nFor simple cases, this behavior can also be achieved with a character vector.\nHowever, to choose which level to use as a reference level or to order classes, factors must be used.\n\n\n\n\n\n\nExample\n\n\n\nConsider a vector of character strings with three income levels:\n\nincome_level <- c(\n rep(\"low\", 10),\n rep(\"medium\", 10),\n rep(\"high\", 10)\n)\nincome_level\n\n [1] \"low\" \"low\" \"low\" \"low\" \"low\" \"low\" \"low\" \"low\" \n [9] \"low\" \"low\" \"medium\" \"medium\" \"medium\" \"medium\" \"medium\" \"medium\"\n[17] \"medium\" \"medium\" \"medium\" \"medium\" \"high\" \"high\" \"high\" \"high\" \n[25] \"high\" \"high\" \"high\" \"high\" \"high\" \"high\" \n\n\nHere, it might make sense to use the lowest income level (low) as the reference class so that all the other coefficients can be interpreted in comparison to it.\nHowever, R would use high as the reference by default because ‘h’ comes before ‘l’ in the alphabet.\n\nx <- factor(income_level)\nx\n\n [1] low low low low low low low low low low \n[11] medium medium medium medium medium medium medium medium medium medium\n[21] high high high high high high high high high high \nLevels: high low medium\n\ny <- rnorm(30) # generate some random obs from a normal dist\nlm(y ~ x)\n\n\nCall:\nlm(formula = y ~ x)\n\nCoefficients:\n(Intercept) xlow xmedium \n -0.5621 0.5728 0.4219"
+ },
+ {
+ "objectID": "posts/22-working-with-factors/index.html#memory-req-for-factors-and-character-strings",
+ "href": "posts/22-working-with-factors/index.html#memory-req-for-factors-and-character-strings",
+ "title": "22 - Factors",
+ "section": "Memory req for factors and character strings",
+ "text": "Memory req for factors and character strings\nConsider a large character string such as income_level corresponding to a categorical variable.\n\nincome_level <- c(\n rep(\"low\", 10000),\n rep(\"medium\", 10000),\n rep(\"high\", 10000)\n)\n\nIn early versions of R, storing categorical data as a factor variable was considerably more efficient than storing the same data as strings, because factor variables only store the factor labels once.\nHowever, R now uses a global string pool, so each unique string is only stored once, which means storage is now less of an issue.\n\nformat(object.size(income_level), units = \"Kb\") # size of the character string\n\n[1] \"234.6 Kb\"\n\nformat(object.size(factor(income_level)), units = \"Kb\") # size of the factor\n\n[1] \"117.8 Kb\""
+ },
+ {
+ "objectID": "posts/22-working-with-factors/index.html#summary",
+ "href": "posts/22-working-with-factors/index.html#summary",
+ "title": "22 - Factors",
+ "section": "Summary",
+ "text": "Summary\nFactors can be really useful in many data analytic tasks, but the base R functions to work with factors can lead to some unexpected behavior that can catch new R users.\nLet’s introduce a package to make wrangling factors easier."
+ },
+ {
+ "objectID": "posts/22-working-with-factors/index.html#general-social-survey",
+ "href": "posts/22-working-with-factors/index.html#general-social-survey",
+ "title": "22 - Factors",
+ "section": "General Social Survey",
+ "text": "General Social Survey\nFor the rest of this lecture, we are going to use the gss_cat dataset that is installed when you load forcats.\nIt’s a sample of data from the General Social Survey, a long-running US survey conducted by the independent research organization NORC at the University of Chicago.\nThe survey has thousands of questions, so in gss_cat.\nI have selected a handful that will illustrate some common challenges you will encounter when working with factors.\n\ngss_cat\n\n# A tibble: 21,483 × 9\n year marital age race rincome partyid relig denom tvhours\n <int> <fct> <int> <fct> <fct> <fct> <fct> <fct> <int>\n 1 2000 Never married 26 White $8000 to 9999 Ind,near … Prot… Sout… 12\n 2 2000 Divorced 48 White $8000 to 9999 Not str r… Prot… Bapt… NA\n 3 2000 Widowed 67 White Not applicable Independe… Prot… No d… 2\n 4 2000 Never married 39 White Not applicable Ind,near … Orth… Not … 4\n 5 2000 Divorced 25 White Not applicable Not str d… None Not … 1\n 6 2000 Married 25 White $20000 - 24999 Strong de… Prot… Sout… NA\n 7 2000 Never married 36 White $25000 or more Not str r… Chri… Not … 3\n 8 2000 Divorced 44 White $7000 to 7999 Ind,near … Prot… Luth… NA\n 9 2000 Married 44 White $25000 or more Not str d… Prot… Other 0\n10 2000 Married 47 White $25000 or more Strong re… Prot… Sout… 3\n# ℹ 21,473 more rows\n\n\n\n\n\n\n\n\nPro-tip\n\n\n\nSince this dataset is provided by a package, you can get more information about the variables with ?gss_cat.\n\n\nWhen factors are stored in a tibble, you cannot see their levels so easily. One way to view them is with count():\n\ngss_cat %>%\n count(race)\n\n# A tibble: 3 × 2\n race n\n <fct> <int>\n1 Other 1959\n2 Black 3129\n3 White 16395\n\n\nOr with a bar chart using the geom_bar() geom:\n\ngss_cat %>%\n ggplot(aes(x = race)) +\n geom_bar()\n\n\n\n\n\n\n\n\n\n\nImportant\n\n\n\nWhen working with factors, the two most common operations are\n\nChanging the order of the levels\nChanging the values of the levels\n\n\n\nThose operations are described in the sections below."
+ },
+ {
+ "objectID": "posts/22-working-with-factors/index.html#modifying-factor-order",
+ "href": "posts/22-working-with-factors/index.html#modifying-factor-order",
+ "title": "22 - Factors",
+ "section": "Modifying factor order",
+ "text": "Modifying factor order\nIt’s often useful to change the order of the factor levels in a visualization.\nLet’s explore the relig (religion) factor:\n\ngss_cat %>%\n count(relig)\n\n# A tibble: 15 × 2\n relig n\n <fct> <int>\n 1 No answer 93\n 2 Don't know 15\n 3 Inter-nondenominational 109\n 4 Native american 23\n 5 Christian 689\n 6 Orthodox-christian 95\n 7 Moslem/islam 104\n 8 Other eastern 32\n 9 Hinduism 71\n10 Buddhism 147\n11 Other 224\n12 None 3523\n13 Jewish 388\n14 Catholic 5124\n15 Protestant 10846\n\n\nWe see there are 15 categories in the gss_cat dataset.\n\nattributes(gss_cat$relig)\n\n$levels\n [1] \"No answer\" \"Don't know\" \n [3] \"Inter-nondenominational\" \"Native american\" \n [5] \"Christian\" \"Orthodox-christian\" \n [7] \"Moslem/islam\" \"Other eastern\" \n [9] \"Hinduism\" \"Buddhism\" \n[11] \"Other\" \"None\" \n[13] \"Jewish\" \"Catholic\" \n[15] \"Protestant\" \"Not applicable\" \n\n$class\n[1] \"factor\"\n\n\nThe first level is “No answer” followed by “Don’t know”, and so on.\nImagine you want to explore the average number of hours spent watching TV (tvhours) per day across religions (relig):\n\nrelig_summary <- gss_cat %>%\n group_by(relig) %>%\n summarise(\n tvhours = mean(tvhours, na.rm = TRUE),\n n = n()\n )\n\nrelig_summary %>%\n ggplot(aes(x = tvhours, y = relig)) +\n geom_point()\n\n\n\n\nThe y-axis lists the levels of the relig factor in the order of the levels.\nHowever, it is hard to read this plot because there’s no overall pattern.\n\nfct_reorder\nWe can improve it by reordering the levels of relig using fct_reorder(). fct_reorder(.f, .x, .fun) takes three arguments:\n\n.f, the factor whose levels you want to modify.\n.x, a numeric vector that you want to use to reorder the levels.\nOptionally, .fun, a function that’s used if there are multiple values of x for each value of f. The default value is median.\n\n\nrelig_summary %>%\n ggplot(aes(\n x = tvhours,\n y = fct_reorder(.f = relig, .x = tvhours)\n )) +\n geom_point()\n\n\n\n\nReordering religion makes it much easier to see that people in the “Don’t know” category watch much more TV, and Hinduism & Other Eastern religions watch much less.\nAs you start making more complicated transformations, I recommend moving them out of aes() and into a separate mutate() step.\n\n\n\n\n\n\nExample\n\n\n\nYou could rewrite the plot above as:\n\nrelig_summary %>%\n mutate(relig = fct_reorder(relig, tvhours)) %>%\n ggplot(aes(x = tvhours, y = relig)) +\n geom_point()\n\n\n\n\n\n\n\n\n\n\n\n\nAnother example\n\n\n\nWhat if we create a similar plot looking at how average age varies across reported income level?\n\nrincome_summary <-\n gss_cat %>%\n group_by(rincome) %>%\n summarise(\n age = mean(age, na.rm = TRUE),\n n = n()\n )\n\nrincome_summary %>%\n ggplot(aes(x = age, y = fct_reorder(.f = rincome, .x = age))) +\n geom_point()\n\n\n\n\nHere, arbitrarily reordering the levels isn’t a good idea! That’s because rincome already has a principled order that we shouldn’t mess with.\n\n\n\n\n\n\n\n\nPro-tip\n\n\n\nReserve fct_reorder() for factors whose levels are arbitrarily ordered.\n\n\n\n\n\n\n\n\nQuestion\n\n\n\nLet’s practice fct_reorder(). Using the palmerpenguins dataset,\n\nCalculate the average bill_length_mm for each species\nCreate a scatter plot showing the average for each species.\n\nGo back and reorder the factor species based on the average bill length from largest to smallest.\nNow order it from smallest to largest\n\n\nlibrary(palmerpenguins)\npenguins\n\n# A tibble: 344 × 8\n species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g\n <fct> <fct> <dbl> <dbl> <int> <int>\n 1 Adelie Torgersen 39.1 18.7 181 3750\n 2 Adelie Torgersen 39.5 17.4 186 3800\n 3 Adelie Torgersen 40.3 18 195 3250\n 4 Adelie Torgersen NA NA NA NA\n 5 Adelie Torgersen 36.7 19.3 193 3450\n 6 Adelie Torgersen 39.3 20.6 190 3650\n 7 Adelie Torgersen 38.9 17.8 181 3625\n 8 Adelie Torgersen 39.2 19.6 195 4675\n 9 Adelie Torgersen 34.1 18.1 193 3475\n10 Adelie Torgersen 42 20.2 190 4250\n# ℹ 334 more rows\n# ℹ 2 more variables: sex <fct>, year <int>\n\n## Try it out\n\n\n\n\n\nfct_relevel\nHowever, it does make sense to pull “Not applicable” to the front with the other special levels.\nYou can use fct_relevel().\nIt takes a factor, f, and then any number of levels that you want to move to the front of the line.\n\nrincome_summary %>%\n ggplot(aes(age, fct_relevel(rincome, \"Not applicable\"))) +\n geom_point()\n\n\n\n\n\n\n\n\n\n\nNote\n\n\n\nAny levels not mentioned in fct_relevel will be left in their existing order.\n\n\nAnother type of reordering is useful when you are coloring the lines on a plot. fct_reorder2(f, x, y) reorders the factor f by the y values associated with the largest x values.\nThis makes the plot easier to read because the colors of the line at the far right of the plot will line up with the legend.\n\nby_age <-\n gss_cat %>%\n filter(!is.na(age)) %>%\n count(age, marital) %>%\n group_by(age) %>%\n mutate(prop = n / sum(n))\n\nby_age %>%\n ggplot(aes(age, prop, colour = marital)) +\n geom_line(na.rm = TRUE)\nby_age %>%\n ggplot(aes(age, prop, colour = fct_reorder2(marital, age, prop))) +\n geom_line() +\n labs(colour = \"marital\")\n\n\n\n\n\n\n\n\n\n\n\n\n\nfct_infreq\nFinally, for bar plots, you can use fct_infreq() to order levels in decreasing frequency: this is the simplest type of reordering because it doesn’t need any extra variables. Combine it with fct_rev() if you want them in increasing frequency so that in the bar plot largest values are on the right, not the left.\n\ngss_cat %>%\n mutate(marital = marital %>% fct_infreq() %>% fct_rev()) %>%\n ggplot(aes(marital)) +\n geom_bar()"
+ },
+ {
+ "objectID": "posts/22-working-with-factors/index.html#modifying-factor-levels",
+ "href": "posts/22-working-with-factors/index.html#modifying-factor-levels",
+ "title": "22 - Factors",
+ "section": "Modifying factor levels",
+ "text": "Modifying factor levels\nMore powerful than changing the orders of the levels is changing their values. This allows you to clarify labels for publication, and collapse levels for high-level displays.\n\nfct_recode\nThe most general and powerful tool is fct_recode(). It allows you to recode, or change, the value of each level. For example, take the gss_cat$partyid:\n\ngss_cat %>%\n count(partyid)\n\n# A tibble: 10 × 2\n partyid n\n <fct> <int>\n 1 No answer 154\n 2 Don't know 1\n 3 Other party 393\n 4 Strong republican 2314\n 5 Not str republican 3032\n 6 Ind,near rep 1791\n 7 Independent 4119\n 8 Ind,near dem 2499\n 9 Not str democrat 3690\n10 Strong democrat 3490\n\n\nThe levels are terse and inconsistent.\nLet’s tweak them to be longer and use a parallel construction.\nLike most rename and recoding functions in the tidyverse:\n\nthe new values go on the left\nthe old values go on the right\n\n\ngss_cat %>%\n mutate(partyid = fct_recode(partyid,\n \"Republican, strong\" = \"Strong republican\",\n \"Republican, weak\" = \"Not str republican\",\n \"Independent, near rep\" = \"Ind,near rep\",\n \"Independent, near dem\" = \"Ind,near dem\",\n \"Democrat, weak\" = \"Not str democrat\",\n \"Democrat, strong\" = \"Strong democrat\"\n )) %>%\n count(partyid)\n\n# A tibble: 10 × 2\n partyid n\n <fct> <int>\n 1 No answer 154\n 2 Don't know 1\n 3 Other party 393\n 4 Republican, strong 2314\n 5 Republican, weak 3032\n 6 Independent, near rep 1791\n 7 Independent 4119\n 8 Independent, near dem 2499\n 9 Democrat, weak 3690\n10 Democrat, strong 3490\n\n\n\n\n\n\n\n\nNote\n\n\n\nfct_recode() will leave the levels that aren’t explicitly mentioned as is, and will warn you if you accidentally refer to a level that doesn’t exist.\n\n\nTo combine groups, you can assign multiple old levels to the same new level:\n\ngss_cat %>%\n mutate(partyid = fct_recode(partyid,\n \"Republican, strong\" = \"Strong republican\",\n \"Republican, weak\" = \"Not str republican\",\n \"Independent, near rep\" = \"Ind,near rep\",\n \"Independent, near dem\" = \"Ind,near dem\",\n \"Democrat, weak\" = \"Not str democrat\",\n \"Democrat, strong\" = \"Strong democrat\",\n \"Other\" = \"No answer\",\n \"Other\" = \"Don't know\",\n \"Other\" = \"Other party\"\n )) %>%\n count(partyid)\n\n# A tibble: 8 × 2\n partyid n\n <fct> <int>\n1 Other 548\n2 Republican, strong 2314\n3 Republican, weak 3032\n4 Independent, near rep 1791\n5 Independent 4119\n6 Independent, near dem 2499\n7 Democrat, weak 3690\n8 Democrat, strong 3490\n\n\nUse this technique with care: if you group together categories that are truly different you will end up with misleading results.\n\n\nfct_collapse\nIf you want to collapse a lot of levels, fct_collapse() is a useful variant of fct_recode().\nFor each new variable, you can provide a vector of old levels:\n\ngss_cat %>%\n mutate(partyid = fct_collapse(partyid,\n \"other\" = c(\"No answer\", \"Don't know\", \"Other party\"),\n \"rep\" = c(\"Strong republican\", \"Not str republican\"),\n \"ind\" = c(\"Ind,near rep\", \"Independent\", \"Ind,near dem\"),\n \"dem\" = c(\"Not str democrat\", \"Strong democrat\")\n )) %>%\n count(partyid)\n\n# A tibble: 4 × 2\n partyid n\n <fct> <int>\n1 other 548\n2 rep 5346\n3 ind 8409\n4 dem 7180\n\n\n\n\nfct_lump_*\nSometimes you just want to lump together the small groups to make a plot or table simpler.\nThat’s the job of the fct_lump_*() family of functions.\nfct_lump_lowfreq() is a simple starting point that progressively lumps the smallest groups categories into “Other”, always keeping “Other” as the smallest category.\n\ngss_cat %>%\n mutate(relig = fct_lump_lowfreq(relig)) %>%\n count(relig)\n\n# A tibble: 2 × 2\n relig n\n <fct> <int>\n1 Protestant 10846\n2 Other 10637\n\n\nIn this case it’s not very helpful: it is true that the majority of Americans in this survey are Protestant, but we’d probably like to see some more details!\nInstead, we can use the fct_lump_n() to specify that we want exactly 10 groups:\n\ngss_cat %>%\n mutate(relig = fct_lump_n(relig, n = 10)) %>%\n count(relig, sort = TRUE) %>%\n print(n = Inf)\n\n# A tibble: 10 × 2\n relig n\n <fct> <int>\n 1 Protestant 10846\n 2 Catholic 5124\n 3 None 3523\n 4 Christian 689\n 5 Other 458\n 6 Jewish 388\n 7 Buddhism 147\n 8 Inter-nondenominational 109\n 9 Moslem/islam 104\n10 Orthodox-christian 95\n\n\nRead the documentation to learn about fct_lump_min() and fct_lump_prop() which are useful in other cases."
+ },
+ {
+ "objectID": "posts/22-working-with-factors/index.html#ordered-factors",
+ "href": "posts/22-working-with-factors/index.html#ordered-factors",
+ "title": "22 - Factors",
+ "section": "Ordered factors",
+ "text": "Ordered factors\nThere’s a special type of factor that needs to be mentioned briefly: ordered factors.\nOrdered factors, created with ordered(), imply a strict ordering and equal distance between levels:\nThe first level is “less than” the second level by the same amount that the second level is “less than” the third level, and so on…\nYou can recognize them when printing because they use < between the factor levels:\n\nordered(c(\"a\", \"b\", \"c\"))\n\n[1] a b c\nLevels: a < b < c\n\n\nHowever, in practice, ordered() factors behave very similarly to regular factors."
+ },
+ {
+ "objectID": "posts/16-functions/index.html",
+ "href": "posts/16-functions/index.html",
+ "title": "16 - Functions",
"section": "",
"text": "This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history."
},
{
- "objectID": "posts/19-error-handling-and-generation/index.html#what-is-an-error",
- "href": "posts/19-error-handling-and-generation/index.html#what-is-an-error",
- "title": "19 - Error Handling and Generation",
- "section": "What is an error?",
- "text": "What is an error?\nErrors most often occur when code is used in a way that it is not intended to be used.\n\n\n\n\n\n\nExample\n\n\n\nFor example adding two strings together produces the following error:\n\n\"hello\" + \"world\"\n\nError in \"hello\" + \"world\": non-numeric argument to binary operator\n\n\n\n\nThe + operator is essentially a function that takes two numbers as arguments and finds their sum.\nSince neither \"hello\" nor \"world\" are numbers, the R interpreter produces an error.\nErrors will stop the execution of your program, and they will (hopefully) print an error message to the R console.\nIn R there are two other constructs which are related to errors:\n\nWarnings\nMessages\n\nWarnings are meant to indicate that something seems to have gone wrong in your program that should be inspected.\n\n\n\n\n\n\nExample\n\n\n\nHere’s a simple example of a warning being generated:\n\nas.numeric(c(\"5\", \"6\", \"seven\"))\n\nWarning: NAs introduced by coercion\n\n\n[1] 5 6 NA\n\n\nThe as.numeric() function attempts to convert each string in c(\"5\", \"6\", \"seven\") into a number, however it is impossible to convert \"seven\", so a warning is generated.\nExecution of the code is not halted, and an NA is produced for \"seven\" instead of a number.\n\n\nMessages simply print to the R console, though they are generated by an underlying mechanism that is similar to how errors and warning are generated.\n\n\n\n\n\n\nExample\n\n\n\nHere’s a small function that will generate a message:\n\nf <- function() {\n message(\"This is a message.\")\n}\n\nf()\n\nThis is a message."
+ "objectID": "posts/16-functions/index.html#functions-in-r",
+ "href": "posts/16-functions/index.html#functions-in-r",
+ "title": "16 - Functions",
+ "section": "Functions in R",
+ "text": "Functions in R\nFunctions in R are “first class objects”, which means that they can be treated much like any other R object.\n\n\n\n\n\n\nImportant facts about R functions\n\n\n\n\nFunctions can be passed as arguments to other functions.\n\nThis is very handy for the various apply functions, like lapply() and sapply().\n\nFunctions can be nested, so that you can define a function inside of another function.\n\n\n\nIf you are familiar with common language like C, these features might appear a bit strange. However, they are really important in R and can be useful for data analysis."
},
{
- "objectID": "posts/19-error-handling-and-generation/index.html#generating-errors",
- "href": "posts/19-error-handling-and-generation/index.html#generating-errors",
- "title": "19 - Error Handling and Generation",
- "section": "Generating Errors",
- "text": "Generating Errors\nThere are a few essential functions for generating errors, warnings, and messages in R.\nThe stop() function will generate an error.\n\n\n\n\n\n\nExample\n\n\n\nLet’s generate an error:\n\nstop(\"Something erroneous has occurred!\")\n\nError: Something erroneous has occurred!\n\n\nIf an error occurs inside of a function, then the name of that function will appear in the error message:\n\nname_of_function <- function() {\n stop(\"Something bad happened.\")\n}\n\nname_of_function()\n\nError in name_of_function(): Something bad happened.\n\n\nThe stopifnot() function takes a series of logical expressions as arguments and if any of them are false an error is generated specifying which expression is false.\n\n\n\n\n\n\nExample\n\n\n\nLet’s take a look at an example:\n\nerror_if_n_is_greater_than_zero <- function(n) {\n stopifnot(n <= 0)\n n\n}\n\nerror_if_n_is_greater_than_zero(5)\n\nError in error_if_n_is_greater_than_zero(5): n <= 0 is not TRUE\n\n\n\n\nThe warning() function creates a warning, and the function itself is very similar to the stop() function. Remember that a warning does not stop the execution of a program (unlike an error.)\n\n\n\n\n\n\nExample\n\n\n\n\nwarning(\"Consider yourself warned!\")\n\nWarning: Consider yourself warned!\n\n\n\n\nJust like errors, a warning generated inside of a function will include the name of the function in which it was generated:\n\nmake_NA <- function(x) {\n warning(\"Generating an NA.\")\n NA\n}\n\nmake_NA(\"Sodium\")\n\nWarning in make_NA(\"Sodium\"): Generating an NA.\n\n\n[1] NA\n\n\nMessages are simpler than errors or warnings; they just print strings to the R console.\nYou can issue a message with the message() function:\n\n\n\n\n\n\nExample\n\n\n\n\nmessage(\"In a bottle.\")\n\nIn a bottle."
+ "objectID": "posts/16-functions/index.html#your-first-function",
+ "href": "posts/16-functions/index.html#your-first-function",
+ "title": "16 - Functions",
+ "section": "Your First Function",
+ "text": "Your First Function\nFunctions are defined using the function() directive and are stored as R objects just like anything else.\n\n\n\n\n\n\nImportant\n\n\n\nIn particular, functions are R objects of class function.\nHere’s a simple function that takes no arguments and does nothing.\n\nf <- function() {\n ## This is an empty function\n}\n## Functions have their own class\nclass(f)\n\n[1] \"function\"\n\n## Execute this function\nf()\n\nNULL\n\n\n\n\nNot very interesting, but it is a start!\nThe next thing we can do is create a function that actually has a non-trivial function body.\n\nf <- function() {\n # this is the function body\n hello <- \"Hello, world!\\n\"\n cat(hello)\n}\nf()\n\nHello, world!\n\n\n\n\n\n\n\n\nPro-tip\n\n\n\ncat() is useful and preferable to print() in several settings. One reason is that it doesn’t output new lines (i.e. \\n).\n\nhello <- \"Hello, world!\\n\"\n\nprint(hello)\n\n[1] \"Hello, world!\\n\"\n\ncat(hello)\n\nHello, world!\n\n\n\n\nThe last aspect of a basic function is the function arguments.\nThese are the options that you can specify to the user that the user may explicitly set.\nFor this basic function, we can add an argument that determines how many times “Hello, world!” is printed to the console.\n\nf <- function(num) {\n for (i in seq_len(num)) {\n hello <- \"Hello, world!\\n\"\n cat(hello)\n }\n}\nf(3)\n\nHello, world!\nHello, world!\nHello, world!\n\n\nObviously, we could have just cut-and-pasted the cat(\"Hello, world!\\n\") code three times to achieve the same effect, but then we wouldn’t be programming, would we?\nAlso, it would be un-neighborly of you to give your code to someone else and force them to cut-and-paste the code however many times the need to see “Hello, world!”.\n\n\n\n\n\n\nPro-tip\n\n\n\nIf you find yourself doing a lot of cutting and pasting, that’s usually a good sign that you might need to write a function.\n\n\nFinally, the function above doesn’t return anything.\nIt just prints “Hello, world!” to the console num number of times and then exits.\nBut often it is useful if a function returns something that perhaps can be fed into another section of code.\nThis next function returns the total number of characters printed to the console.\n\nf <- function(num) {\n hello <- \"Hello, world!\\n\"\n for (i in seq_len(num)) {\n cat(hello)\n }\n chars <- nchar(hello) * num\n chars\n}\nmeaningoflife <- f(3)\n\nHello, world!\nHello, world!\nHello, world!\n\nprint(meaningoflife)\n\n[1] 42\n\n\nIn the above function, we did not have to indicate anything special in order for the function to return the number of characters.\nIn R, the return value of a function is always the very last expression that is evaluated.\nBecause the chars variable is the last expression that is evaluated in this function, that becomes the return value of the function.\n\n\n\n\n\n\nNote\n\n\n\nThere is a return() function that can be used to return an explicitly value from a function, but it is rarely used in R (we will discuss it a bit later in this lesson).\n\n\nFinally, in the above function, the user must specify the value of the argument num. If it is not specified by the user, R will throw an error.\n\nf()\n\nError in f(): argument \"num\" is missing, with no default\n\n\nWe can modify this behavior by setting a default value for the argument num.\nAny function argument can have a default value, if you wish to specify it.\nSometimes, argument values are rarely modified (except in special cases) and it makes sense to set a default value for that argument. This relieves the user from having to specify the value of that argument every single time the function is called.\nHere, for example, we could set the default value for num to be 1, so that if the function is called without the num argument being explicitly specified, then it will print “Hello, world!” to the console once.\n\nf <- function(num = 1) {\n hello <- \"Hello, world!\\n\"\n for (i in seq_len(num)) {\n cat(hello)\n }\n chars <- nchar(hello) * num\n chars\n}\n\n\nf() ## Use default value for 'num'\n\nHello, world!\n\n\n[1] 14\n\nf(2) ## Use user-specified value\n\nHello, world!\nHello, world!\n\n\n[1] 28\n\n\nRemember that the function still returns the number of characters printed to the console.\n\n\n\n\n\n\nPro-tip\n\n\n\nThe formals() function returns a list of all the formal arguments of a function\n\nformals(f)\n\n$num\n[1] 1"
},
{
- "objectID": "posts/19-error-handling-and-generation/index.html#when-to-generate-errors-or-warnings",
- "href": "posts/19-error-handling-and-generation/index.html#when-to-generate-errors-or-warnings",
- "title": "19 - Error Handling and Generation",
- "section": "When to generate errors or warnings",
- "text": "When to generate errors or warnings\nStopping the execution of your program with stop() should only happen in the event of a catastrophe - meaning only if it is impossible for your program to continue.\n\nIf there are conditions that you can anticipate that would cause your program to create an error, then you should document those conditions so whoever uses your software is aware.\n\nAn example includes:\n\nProviding invalid arguments to a function. You could check this at the beginning of your program using stopifnot() so that the user can quickly realize something has gone wrong.\n\nYou can think of a function as kind of contract between you and the user:\n\nif the user provides specified arguments, your program will provide predictable results.\n\nOf course it’s impossible for you to anticipate all of the potential uses of your program.\nIt’s appropriate to create a warning when this contract between you and the user is violated.\nA perfect example of this situation is the result of\n\nas.numeric(c(\"5\", \"6\", \"seven\"))\n\nWarning: NAs introduced by coercion\n\n\n[1] 5 6 NA\n\n\nThe user expects a vector of numbers to be returned as the result of as.numeric() but \"seven\" is coerced into being NA, which is not completely intuitive.\nR has largely been developed according to the Unix Philosophy, which generally discourages printing text to the console unless something unexpected has occurred.\nLanguages that commonly run on Unix systems like C and C++ are rarely used interactively, meaning that they usually underpin computer infrastructure (computers “talking” to other computers).\nMessages printed to the console are therefore not very useful since nobody will ever read them and it’s not straightforward for other programs to capture and interpret them.\nIn contrast, R code is frequently executed by human beings in the R console, which serves as an interactive environment between the computer and person at the keyboard.\nIf you think your program should produce a message, make sure that the output of the message is primarily meant for a human to read.\nYou should avoid signaling a condition or the result of your program to another program by creating a message."
+ "objectID": "posts/16-functions/index.html#summary",
+ "href": "posts/16-functions/index.html#summary",
+ "title": "16 - Functions",
+ "section": "Summary",
+ "text": "Summary\nWe have written a function that\n\nhas one formal argument named num with a default value of 1. The formal arguments are the arguments included in the function definition.\nprints the message “Hello, world!” to the console a number of times indicated by the argument num\nreturns the number of characters printed to the console"
},
{
- "objectID": "posts/19-error-handling-and-generation/index.html#how-should-errors-be-handled",
- "href": "posts/19-error-handling-and-generation/index.html#how-should-errors-be-handled",
- "title": "19 - Error Handling and Generation",
- "section": "How should errors be handled?",
- "text": "How should errors be handled?\nImagine writing a program that will take a long time to complete because of a complex calculation or because you’re handling a large amount of data. If an error occurs during this computation then you’re liable to lose all of the results that were calculated before the error, or your program may not finish a critical task that a program further down your pipeline is depending on. If you anticipate the possibility of errors occurring during the execution of your program, then you can design your program to handle them appropriately.\nThe tryCatch() function is the workhorse of handling errors and warnings in R. The first argument of this function is any R expression, followed by conditions which specify how to handle an error or a warning. The last argument, finally, specifies a function or expression that will be executed after the expression no matter what, even in the event of an error or a warning.\nLet’s construct a simple function I’m going to call beera that catches errors and warnings gracefully.\n\nbeera <- function(expr) {\n tryCatch(expr,\n error = function(e) {\n message(\"An error occurred:\\n\", e)\n },\n warning = function(w) {\n message(\"A warning occured:\\n\", w)\n },\n finally = {\n message(\"Finally done!\")\n }\n )\n}\n\nThis function takes an expression as an argument and tries to evaluate it. If the expression can be evaluated without any errors or warnings then the result of the expression is returned and the message Finally done! is printed to the R console. If an error or warning is generated, then the functions that are provided to the error or warning arguments are printed. Let’s try this function out with a few examples.\n\nbeera({\n 2 + 2\n})\n\nFinally done!\n\n\n[1] 4\n\nbeera({\n \"two\" + 2\n})\n\nAn error occurred:\nError in \"two\" + 2: non-numeric argument to binary operator\n\nFinally done!\n\nbeera({\n as.numeric(c(1, \"two\", 3))\n})\n\nA warning occured:\nsimpleWarning in doTryCatch(return(expr), name, parentenv, handler): NAs introduced by coercion\n\nFinally done!\n\n\nNotice that we’ve effectively transformed errors and warnings into messages.\nNow that you know the basics of generating and catching errors you’ll need to decide when your program should generate an error. My advice to you is to limit the number of errors your program generates as much as possible. Even if you design your program so that it’s able to catch and handle errors, the error handling process slows down your program by orders of magnitude. Imagine you wanted to write a simple function that checks if an argument is an even number. You might write the following:\n\nis_even <- function(n) {\n n %% 2 == 0\n}\n\nis_even(768)\n\n[1] TRUE\n\nis_even(\"two\")\n\nError in n%%2: non-numeric argument to binary operator\n\n\nYou can see that providing a string causes this function to raise an error. You could imagine though that you want to use this function across a list of different data types, and you only want to know which elements of that list are even numbers. You might think to write the following:\n\nis_even_error <- function(n) {\n tryCatch(n %% 2 == 0,\n error = function(e) {\n FALSE\n }\n )\n}\n\nis_even_error(714)\n\n[1] TRUE\n\nis_even_error(\"eight\")\n\n[1] FALSE\n\n\nThis appears to be working the way you intended, however when applied to more data this function will be seriously slow compared to alternatives. For example I could check that n is numeric before treating n like a number:\n\nis_even_check <- function(n) {\n is.numeric(n) && n %% 2 == 0\n}\n\nis_even_check(1876)\n\n[1] TRUE\n\nis_even_check(\"twelve\")\n\n[1] FALSE\n\n\n\nNotice that by using is.numeric() before the “AND” operator (&&), the expression n %% 2 == 0 is never evaluated. This is a programming language design feature called “short circuiting.” The expression can never evaluate to TRUE if the left hand side of && evaluates to FALSE, so the right hand side is ignored.\n\nTo demonstrate the difference in the speed of the code, we will use the microbenchmark package to measure how long it takes for each function to be applied to the same data.\n\nlibrary(microbenchmark)\nmicrobenchmark(sapply(letters, is_even_check))\n\nUnit: microseconds\n expr min lq mean median uq max neval\n sapply(letters, is_even_check) 46.224 47.7975 61.43616 48.6445 58.4755 167.091 100\n\nmicrobenchmark(sapply(letters, is_even_error))\n\nUnit: microseconds\n expr min lq mean median uq max neval\n sapply(letters, is_even_error) 640.067 678.0285 906.3037 784.4315 1044.501 2308.931 100\nThe error catching approach is nearly 15 times slower!\nProper error handling is an essential tool for any software developer so that you can design programs that are error tolerant. Creating clear and informative error messages is essential for building quality software.\n\n\n\n\n\n\nPro-tip\n\n\n\nOne closing tip I recommend is to put documentation for your software online, including the meaning of the errors that your software can potentially throw. Often a user’s first instinct when encountering an error is to search online for that error message, which should lead them to your documentation!"
+ "objectID": "posts/16-functions/index.html#named-arguments",
+ "href": "posts/16-functions/index.html#named-arguments",
+ "title": "16 - Functions",
+ "section": "Named arguments",
+ "text": "Named arguments\nAbove, we have learned that functions have named arguments, which can optionally have default values.\nBecause all function arguments have names, they can be specified using their name.\n\nf(num = 2)\n\nHello, world!\nHello, world!\n\n\n[1] 28\n\n\nSpecifying an argument by its name is sometimes useful if a function has many arguments and it may not always be clear which argument is being specified.\nHere, our function only has one argument so there’s no confusion."
},
{
- "objectID": "posts/01-welcome/index.html",
- "href": "posts/01-welcome/index.html",
- "title": "01 - Welcome!",
- "section": "",
- "text": "This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history.\nWelcome! I am very excited to have you in our one-term (i.e. half a semester) course on Statistical Computing course number (140.776) offered by the Department of Biostatistics at the Johns Hopkins Bloomberg School of Public Health. This will be my first time as the lead instructor of a JHBSPH course! 🙌🏽\nThis course is designed for ScM and PhD students at Johns Hopkins Bloomberg School of Public Health. I am pretty flexible about permitting outside students, but I want everyone to be aware of the goals and assumptions so no one feels like they are surprised by how the class works.\nThis class is not designed to teach the theoretical aspects of statistical or computational methods, but rather the goal is to help with the practical issues related to setting up a statistical computing environment for data analyses, developing high-quality R packages, conducting reproducible data analyses, best practices for data visualization and writing code, and creating websites for personal or project use."
+ "objectID": "posts/16-functions/index.html#argument-matching",
+ "href": "posts/16-functions/index.html#argument-matching",
+ "title": "16 - Functions",
+ "section": "Argument matching",
+ "text": "Argument matching\nCalling an R function with multiple arguments can be done in a variety of ways.\nThis may be confusing at first, but it’s really handy when doing interactive work at the command line. R functions arguments can be matched positionally or by name.\n\nPositional matching just means that R assigns the first value to the first argument, the second value to second argument, etc.\n\nSo, in the following call to rnorm()\n\nstr(rnorm)\n\nfunction (n, mean = 0, sd = 1) \n\nmydata <- rnorm(100, 2, 1) ## Generate some data\n\n100 is assigned to the n argument, 2 is assigned to the mean argument, and 1 is assigned to the sd argument, all by positional matching.\nThe following calls to the sd() function (which computes the empirical standard deviation of a vector of numbers) are all equivalent.\n\n\n\n\n\n\nNote\n\n\n\nsd(x, na.rm = FALSE) has two arguments:\n\nx indicates the vector of numbers\nna.rm is a logical indicating whether missing values should be removed or not (default is FALSE)\n\n\n## Positional match first argument, default for 'na.rm'\nsd(mydata)\n\n[1] 1.014286\n\n## Specify 'x' argument by name, default for 'na.rm'\nsd(x = mydata)\n\n[1] 1.014286\n\n## Specify both arguments by name\nsd(x = mydata, na.rm = FALSE)\n\n[1] 1.014286\n\n\n\n\nWhen specifying the function arguments by name, it doesn’t matter in what order you specify them.\nIn the example below, we specify the na.rm argument first, followed by x, even though x is the first argument defined in the function definition.\n\n## Specify both arguments by name\nsd(na.rm = FALSE, x = mydata)\n\n[1] 1.014286\n\n\nYou can mix positional matching with matching by name.\nWhen an argument is matched by name, it is “taken out” of the argument list and the remaining unnamed arguments are matched in the order that they are listed in the function definition.\n\nsd(na.rm = FALSE, mydata)\n\n[1] 1.014286\n\n\nHere, the mydata object is assigned to the x argument, because it’s the only argument not yet specified.\n\n\n\n\n\n\nPro-tip\n\n\n\nThe args() function displays the argument names and corresponding default values of a function\n\nargs(f)\n\nfunction (num = 1) \nNULL\n\n\n\n\nBelow is the argument list for the lm() function, which fits linear models to a dataset.\n\nargs(lm)\n\nfunction (formula, data, subset, weights, na.action, method = \"qr\", \n model = TRUE, x = FALSE, y = FALSE, qr = TRUE, singular.ok = TRUE, \n contrasts = NULL, offset, ...) \nNULL\n\n\nThe following two calls are equivalent.\nlm(data = mydata, y ~ x, model = FALSE, 1:100)\nlm(y ~ x, mydata, 1:100, model = FALSE)\n\n\n\n\n\n\nPro-tip\n\n\n\nEven though it’s legal, I don’t recommend messing around with the order of the arguments too much, since it can lead to some confusion.\n\n\nMost of the time, named arguments are helpful:\n\nOn the command line when you have a long argument list and you want to use the defaults for everything except for an argument near the end of the list\nIf you can remember the name of the argument and not its position on the argument list\n\nFor example, plotting functions often have a lot of options to allow for customization, but this makes it difficult to remember exactly the position of every argument on the argument list.\nFunction arguments can also be partially matched, which is useful for interactive work.\n\n\n\n\n\n\nPro-tip\n\n\n\nThe order of operations when given an argument is\n\nCheck for exact match for a named argument\nCheck for a partial match\nCheck for a positional match\n\n\n\nPartial matching should be avoided when writing longer code or programs, because it may lead to confusion if someone is reading the code. However, partial matching is very useful when calling functions interactively that have very long argument names."
},
{
- "objectID": "posts/01-welcome/index.html#disability-support-service",
- "href": "posts/01-welcome/index.html#disability-support-service",
- "title": "01 - Welcome!",
- "section": "Disability Support Service",
- "text": "Disability Support Service\nStudents requiring accommodations for disabilities should register with Student Disability Service (SDS). It is the responsibility of the student to register for accommodations with SDS. Accommodations take effect upon approval and apply to the remainder of the time for which a student is registered and enrolled at the Bloomberg School of Public Health. Once you are f a student in your class has approved accommodations you will receive formal notification and the student will be encouraged to reach out. If you have questions about requesting accommodations, please contact BSPH.dss@jhu.edu."
+ "objectID": "posts/16-functions/index.html#lazy-evaluation",
+ "href": "posts/16-functions/index.html#lazy-evaluation",
+ "title": "16 - Functions",
+ "section": "Lazy Evaluation",
+ "text": "Lazy Evaluation\nArguments to functions are evaluated lazily, so they are evaluated only as needed in the body of the function.\nIn this example, the function f() has two arguments: a and b.\n\nf <- function(a, b) {\n a^2\n}\nf(2)\n\n[1] 4\n\n\nThis function never actually uses the argument b, so calling f(2) will not produce an error because the 2 gets positionally matched to a.\nThis behavior can be good or bad. It’s common to write a function that doesn’t use an argument and not notice it simply because R never throws an error.\nThis example also shows lazy evaluation at work, but does eventually result in an error.\n\nf <- function(a, b) {\n print(a)\n print(b)\n}\nf(45)\n\n[1] 45\n\n\nError in f(45): argument \"b\" is missing, with no default\n\n\nNotice that “45” got printed first before the error was triggered! This is because b did not have to be evaluated until after print(a).\nOnce the function tried to evaluate print(b) the function had to throw an error."
},
{
- "objectID": "posts/01-welcome/index.html#previous-versions-of-the-class",
- "href": "posts/01-welcome/index.html#previous-versions-of-the-class",
- "title": "01 - Welcome!",
- "section": "Previous versions of the class",
- "text": "Previous versions of the class\n\nhttps://www.stephaniehicks.com/jhustatcomputing2022\nhttps://www.stephaniehicks.com/jhustatcomputing2021\nhttps://rdpeng.github.io/Biostat776"
+ "objectID": "posts/16-functions/index.html#the-...-argument",
+ "href": "posts/16-functions/index.html#the-...-argument",
+ "title": "16 - Functions",
+ "section": "The ... Argument",
+ "text": "The ... Argument\nThere is a special argument in R known as the ... argument, which indicates a variable number of arguments that are usually passed on to other functions.\nThe ... argument is often used when extending another function and you do not want to copy the entire argument list of the original function\nFor example, a custom plotting function may want to make use of the default plot() function along with its entire argument list. The function below changes the default for the type argument to the value type = \"l\" (the original default was type = \"p\").\nmyplot <- function(x, y, type = \"l\", ...) {\n plot(x, y, type = type, ...) ## Pass '...' to 'plot' function\n}\nGeneric functions use ... so that extra arguments can be passed to methods.\n\nmean\n\nfunction (x, ...) \nUseMethod(\"mean\")\n<bytecode: 0x1075ea1e8>\n<environment: namespace:base>\n\n\nThe ... argument is necessary when the number of arguments passed to the function cannot be known in advance. This is clear in functions like paste() and cat().\n\npaste(\"one\", \"two\", \"three\")\n\n[1] \"one two three\"\n\npaste(\"one\", \"two\", \"three\", \"four\", \"five\", sep = \"_\")\n\n[1] \"one_two_three_four_five\"\n\n\n\nargs(paste)\n\nfunction (..., sep = \" \", collapse = NULL, recycle0 = FALSE) \nNULL\n\n\nBecause paste() prints out text to the console by combining multiple character vectors together, it is impossible for this function to know in advance how many character vectors will be passed to the function by the user.\nSo the first argument in the function is ...."
},
{
- "objectID": "posts/01-welcome/index.html#typos-and-corrections",
- "href": "posts/01-welcome/index.html#typos-and-corrections",
- "title": "01 - Welcome!",
- "section": "Typos and corrections",
- "text": "Typos and corrections\nFeel free to submit typos/errors/etc via the GitHub repository associated with the class: https://github.com/lcolladotor/jhustatcomputing2023/issues. You will have the thanks of your grateful instructor!"
+ "objectID": "posts/16-functions/index.html#arguments-coming-after-the-...-argument",
+ "href": "posts/16-functions/index.html#arguments-coming-after-the-...-argument",
+ "title": "16 - Functions",
+ "section": "Arguments Coming After the ... Argument",
+ "text": "Arguments Coming After the ... Argument\nOne catch with ... is that any arguments that appear after ... on the argument list must be named explicitly and cannot be partially matched or matched positionally.\nTake a look at the arguments to the paste() function.\n\nargs(paste)\n\nfunction (..., sep = \" \", collapse = NULL, recycle0 = FALSE) \nNULL\n\n\nWith the paste() function, the arguments sep and collapse must be named explicitly and in full if the default values are not going to be used.\nHere, I specify that I want “a” and “b” to be pasted together and separated by a colon.\n\npaste(\"a\", \"b\", sep = \":\")\n\n[1] \"a:b\"\n\n\nIf I don’t specify the sep argument in full and attempt to rely on partial matching, I don’t get the expected result.\n\npaste(\"a\", \"b\", se = \":\")\n\n[1] \"a b :\""
},
{
- "objectID": "posts/04-reproducible-research/index.html",
- "href": "posts/04-reproducible-research/index.html",
- "title": "04 - Reproducible Research",
+ "objectID": "posts/16-functions/index.html#the-name-of-a-function-is-important",
+ "href": "posts/16-functions/index.html#the-name-of-a-function-is-important",
+ "title": "16 - Functions",
+ "section": "The name of a function is important",
+ "text": "The name of a function is important\nIn an ideal world, you want the name of your function to be short but clearly describe what the function does. This is not always easy, but here are some tips.\nThe function names should be verbs, and arguments should be nouns.\nThere are some exceptions:\n\nnouns are ok if the function computes a very well known noun (i.e. mean() is better than compute_mean()).\nA good sign that a noun might be a better choice is if you are using a very broad verb like “get”, “compute”, “calculate”, or “determine”. Use your best judgement and do not be afraid to rename a function if you figure out a better name later.\n\n\n# Too short\nf()\n\n# Not a verb, or descriptive\nmy_awesome_function()\n\n# Long, but clear\nimpute_missing()\ncollapse_years()"
+ },
+ {
+ "objectID": "posts/16-functions/index.html#snake_case-vs-camelcase",
+ "href": "posts/16-functions/index.html#snake_case-vs-camelcase",
+ "title": "16 - Functions",
+ "section": "snake_case vs camelCase",
+ "text": "snake_case vs camelCase\nIf your function name is composed of multiple words, use “snake_case”, where each lowercase word is separated by an underscore.\n“camelCase” is a popular alternative. It does not really matter which one you pick, the important thing is to be consistent: pick one or the other and stick with it.\nR itself is not very consistent, but there is nothing you can do about that. Make sure you do not fall into the same trap by making your code as consistent as possible.\n\n# Never do this!\ncol_mins <- function(x, y) {}\nrowMaxes <- function(x, y) {}"
+ },
+ {
+ "objectID": "posts/16-functions/index.html#use-a-common-prefix",
+ "href": "posts/16-functions/index.html#use-a-common-prefix",
+ "title": "16 - Functions",
+ "section": "Use a common prefix",
+ "text": "Use a common prefix\nIf you have a family of functions that do similar things, make sure they have consistent names and arguments.\nIt’s a good idea to indicate that they are connected. That is better than a common suffix because autocomplete allows you to type the prefix and see all the members of the family.\n\n# Good\ninput_select()\ninput_checkbox()\ninput_text()\n\n# Not so good\nselect_input()\ncheckbox_input()\ntext_input()"
+ },
+ {
+ "objectID": "posts/16-functions/index.html#avoid-overriding-exisiting-functions",
+ "href": "posts/16-functions/index.html#avoid-overriding-exisiting-functions",
+ "title": "16 - Functions",
+ "section": "Avoid overriding exisiting functions",
+ "text": "Avoid overriding exisiting functions\nWhere possible, avoid overriding existing functions and variables.\nIt is impossible to do in general because so many good names are already taken by other packages, but avoiding the most common names from base R will avoid confusion.\n\n# Don't do this!\nT <- FALSE\nc <- 10\nmean <- function(x) sum(x)"
+ },
+ {
+ "objectID": "posts/16-functions/index.html#use-comments",
+ "href": "posts/16-functions/index.html#use-comments",
+ "title": "16 - Functions",
+ "section": "Use comments",
+ "text": "Use comments\nUse comments are lines starting with #. They can explain the “why” of your code.\nYou generally should avoid comments that explain the “what” or the “how”. If you can’t understand what the code does from reading it, you should think about how to rewrite it to be more clear.\n\nDo you need to add some intermediate variables with useful names?\nDo you need to break out a subcomponent of a large function so you can name it?\n\nHowever, your code can never capture the reasoning behind your decisions:\n\nWhy did you choose this approach instead of an alternative?\nWhat else did you try that didn’t work?\n\nIt’s a great idea to capture that sort of thinking in a comment."
+ },
+ {
+ "objectID": "schedule.html",
+ "href": "schedule.html",
+ "title": "Schedule",
"section": "",
- "text": "This lecture, as the rest of the course, is adapted from the version Stephanie C. Hicks designed and maintained in 2021 and 2022. Check the recent changes to this file through the GitHub history.\n[Link to Claerbout and Karrenbach (1992) article]"
+ "text": "For Qmd files (markdown document with Quarto cross-language executable code), go to the course GitHub repository and navigate the directories, or best of all to git clone the repo and navigate within RStudio.\nCheck https://github.com/lcolladotor/biostat776classnotes for Leo’s live class notes.\n\n\n\n\n\n\n\n\n\n\n\nWeek\nLectures / due dates\nTopics\nProjects\n\n\n\n\n\nModule 1\n\nStatistical and computational tools for scientific and reproducible research\n\n\n\n\n\n\n\n\n\n\n\nWeek 1\nLecture 1 (Leo will be remote!)\n👋 Course introduction [html] [Qmd] [R]\n🌴 Project 0 [html] [Qmd] [R]\n\n\n\n\n\n👩💻 Introduction to R and RStudio [html] [Qmd] [R]\n\n\n\n\n\n\n🐙 Introduction to git/GitHub [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\n\nLecture 2 (Leo will be remote!)\n🔬 Reproducible Research [html] [Qmd] [R]\n\n\n\n\n\n\n👓 Literate programming [html] [Qmd] [R]\n\n\n\n\n\n\n🆒 Reference management [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\nModule 2\n\nData analysis in R\n\n\n\n\n\n\n\n\n\n\n\nWeek 2\nLecture 3\n👀 Reading and writing data [html] [Qmd] [R]\n🌴 Project 1 [html] [Qmd] [R]\n\n\n\n\n\n✂️ Managing data frames with Tidyverse [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\n\nLecture 4\n😻 Tidy data and the Tidyverse [html] [Qmd] [R]\n🍂 Project 0 due\n\n\n\n\n\n🤝 Joining data in R: Basics [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\nModule 3\n\nData visualizations R\n\n\n\n\n\n\n\n\n\n\n\nWeek 3\nLecture 5\n📊 Plotting systems in R [html] [Qmd] [R]\n\n\n\n\n\n\n📊 The ggplot2 plotting system: qplot() [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\n\nLecture 6\n📊 The ggplot2 plotting system: ggplot() [html] [Qmd] [R]\n🌴 Project 2 [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\nSept 17\n\n🍂 Project 1 due\n\n\n\n\n\n\n\n\n\n\nModule 4\n\nNuts and bolts of R\n\n\n\n\n\n\n\n\n\n\n\nWeek 4\nLecture 7\n🔩 R Nuts and Bolts [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\n\nLecture 8\n🔩 Control structures in R [html] [Qmd] [R]\n\n\n\n\n\n\n🔩 Functions in R [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\nWeek 5\nLecture 9\n🔩 Loop functions [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\n\nLecture 10\n🐛 Debugging code in R [html] [Qmd] [R]\n\n\n\n\n\n\n🐛 Error handling code in R [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\n\nOct 1\n\n🍂 Project 2 due\n\n\n\n\n\n\n\n\n\n\nModule 5\n\nSpecial data types in R\n\n\n\n\n\n\n\n\n\n\n\nWeek 6\nLecture 11\n📆 Working with dates and times [html] [Qmd] [R]\n🌴 Project 3 [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\nLecture 12\n✨ Regular expressions [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\nWeek 7\nLecture 13\n🐱 Working with factors [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\n\nLecture 14\n📆 Working with text data and sentiment analysis [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\nModule 6\n\nBest practices for working with data and other languages\n\n\n\n\n\n\n\n\n\n\n\nWeek 8\nLecture 15\n☁️ Best practices for data analysies [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\n\nLecture 16\n🐍 Leveraging Python within R [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\n\nOct 23\n\n🍂 Project 3 due"
},
{
- "objectID": "posts/04-reproducible-research/index.html#here",
- "href": "posts/04-reproducible-research/index.html#here",
- "title": "04 - Reproducible Research",
- "section": "here",
- "text": "here\nhere makes it easy to write code that you can share by avoiding full file paths and making it easier to use relative file paths. The file paths are made relative to your project home, which is automatically detected based on a few files. These can be:\n\nThe directory where you have a .git directory. That is, the beginning of your git repository.\nThe directory where you have an RStudio project file (*.Rproj). For RStudio projects with a git repository, this is typically the same directory.\nThe directory where you have a .here file (very uncommon scenario).\n\n\n## This is my relative directory\nhere::here()\n\n[1] \"/Users/leocollado/Dropbox/Code/jhustatcomputing2023\"\n\n## I can now easily share code to access files from this project\n## such as access to the flight.csv file saved under the data\n## directory.\nhere::here(\"data\", \"flights.csv\")\n\n[1] \"/Users/leocollado/Dropbox/Code/jhustatcomputing2023/data/flights.csv\"\n\n## This would not be easily shareable as you don't have\n## \"/Users/leocollado/Dropbox/Code\" on your computer\nfull_path <- \"/Users/leocollado/Dropbox/Code/jhustatcomputing2023/data/flights.csv\""
+ "objectID": "schedule.html#schedule-and-course-materials",
+ "href": "schedule.html#schedule-and-course-materials",
+ "title": "Schedule",
+ "section": "",
+ "text": "For Qmd files (markdown document with Quarto cross-language executable code), go to the course GitHub repository and navigate the directories, or best of all to git clone the repo and navigate within RStudio.\nCheck https://github.com/lcolladotor/biostat776classnotes for Leo’s live class notes.\n\n\n\n\n\n\n\n\n\n\n\nWeek\nLectures / due dates\nTopics\nProjects\n\n\n\n\n\nModule 1\n\nStatistical and computational tools for scientific and reproducible research\n\n\n\n\n\n\n\n\n\n\n\nWeek 1\nLecture 1 (Leo will be remote!)\n👋 Course introduction [html] [Qmd] [R]\n🌴 Project 0 [html] [Qmd] [R]\n\n\n\n\n\n👩💻 Introduction to R and RStudio [html] [Qmd] [R]\n\n\n\n\n\n\n🐙 Introduction to git/GitHub [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\n\nLecture 2 (Leo will be remote!)\n🔬 Reproducible Research [html] [Qmd] [R]\n\n\n\n\n\n\n👓 Literate programming [html] [Qmd] [R]\n\n\n\n\n\n\n🆒 Reference management [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\nModule 2\n\nData analysis in R\n\n\n\n\n\n\n\n\n\n\n\nWeek 2\nLecture 3\n👀 Reading and writing data [html] [Qmd] [R]\n🌴 Project 1 [html] [Qmd] [R]\n\n\n\n\n\n✂️ Managing data frames with Tidyverse [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\n\nLecture 4\n😻 Tidy data and the Tidyverse [html] [Qmd] [R]\n🍂 Project 0 due\n\n\n\n\n\n🤝 Joining data in R: Basics [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\nModule 3\n\nData visualizations R\n\n\n\n\n\n\n\n\n\n\n\nWeek 3\nLecture 5\n📊 Plotting systems in R [html] [Qmd] [R]\n\n\n\n\n\n\n📊 The ggplot2 plotting system: qplot() [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\n\nLecture 6\n📊 The ggplot2 plotting system: ggplot() [html] [Qmd] [R]\n🌴 Project 2 [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\nSept 17\n\n🍂 Project 1 due\n\n\n\n\n\n\n\n\n\n\nModule 4\n\nNuts and bolts of R\n\n\n\n\n\n\n\n\n\n\n\nWeek 4\nLecture 7\n🔩 R Nuts and Bolts [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\n\nLecture 8\n🔩 Control structures in R [html] [Qmd] [R]\n\n\n\n\n\n\n🔩 Functions in R [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\nWeek 5\nLecture 9\n🔩 Loop functions [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\n\nLecture 10\n🐛 Debugging code in R [html] [Qmd] [R]\n\n\n\n\n\n\n🐛 Error handling code in R [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\n\nOct 1\n\n🍂 Project 2 due\n\n\n\n\n\n\n\n\n\n\nModule 5\n\nSpecial data types in R\n\n\n\n\n\n\n\n\n\n\n\nWeek 6\nLecture 11\n📆 Working with dates and times [html] [Qmd] [R]\n🌴 Project 3 [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\nLecture 12\n✨ Regular expressions [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\nWeek 7\nLecture 13\n🐱 Working with factors [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\n\nLecture 14\n📆 Working with text data and sentiment analysis [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\nModule 6\n\nBest practices for working with data and other languages\n\n\n\n\n\n\n\n\n\n\n\nWeek 8\nLecture 15\n☁️ Best practices for data analysies [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\n\nLecture 16\n🐍 Leveraging Python within R [html] [Qmd] [R]\n\n\n\n\n\n\n\n\n\n\n\n\nOct 23\n\n🍂 Project 3 due"
},
{
- "objectID": "posts/04-reproducible-research/index.html#sessioninfo",
- "href": "posts/04-reproducible-research/index.html#sessioninfo",
- "title": "04 - Reproducible Research",
- "section": "sessioninfo",
- "text": "sessioninfo\nThis R package is excellent for sharing all details about the R packages you are using for a particular script. I typically include these lines at the end of my scripts as you can see at https://github.com/LieberInstitute/template_project/blob/3987e7f307611b2bcf657d1aa6930e76c4cc2b9a/code/01_read_data_to_r/01_read_data_to_r.R#L32-L39:\n\n## Reproducibility information\nprint(\"Reproducibility information:\")\nSys.time()\nproc.time()\noptions(width = 120)\nsessioninfo::session_info()\n\nNote that I made a GitHub permalink (permanent link) above, which is another way we can communicate precisely with others. It’s very useful to include GitHub permalinks when asking questions about code you or others have made public on GitHub. See https://docs.github.com/en/get-started/writing-on-github/working-with-advanced-formatting/creating-a-permanent-link-to-a-code-snippet for more details about how to create GitHub permalinks.\nHere is the actual output of those commands:\n\n## Reproducibility information\nprint(\"Reproducibility information:\")\n\n[1] \"Reproducibility information:\"\n\nSys.time()\n\n[1] \"2023-08-29 09:18:40 CST\"\n\nproc.time()\n\n user system elapsed \n 0.574 0.086 0.696 \n\noptions(width = 120)\nsessioninfo::session_info()\n\n─ Session info ───────────────────────────────────────────────────────────────────────────────────────────────────────\n setting value\n version R version 4.3.1 (2023-06-16)\n os macOS Ventura 13.5\n system aarch64, darwin20\n ui X11\n language (EN)\n collate en_US.UTF-8\n ctype en_US.UTF-8\n tz America/Mexico_City\n date 2023-08-29\n pandoc 3.1.5 @ /opt/homebrew/bin/ (via rmarkdown)\n\n─ Packages ───────────────────────────────────────────────────────────────────────────────────────────────────────────\n package * version date (UTC) lib source\n cli 3.6.1 2023-03-23 [1] CRAN (R 4.3.0)\n colorout 1.2-2 2023-05-06 [1] Github (jalvesaq/colorout@79931fd)\n colorspace 2.1-0 2023-01-23 [1] CRAN (R 4.3.0)\n digest 0.6.33 2023-07-07 [1] CRAN (R 4.3.0)\n dplyr 1.1.2 2023-04-20 [1] CRAN (R 4.3.0)\n emojifont 0.5.5 2021-04-20 [1] CRAN (R 4.3.0)\n evaluate 0.21 2023-05-05 [1] CRAN (R 4.3.0)\n fansi 1.0.4 2023-01-22 [1] CRAN (R 4.3.0)\n fastmap 1.1.1 2023-02-24 [1] CRAN (R 4.3.0)\n generics 0.1.3 2022-07-05 [1] CRAN (R 4.3.0)\n ggplot2 3.4.3 2023-08-14 [1] CRAN (R 4.3.0)\n glue 1.6.2 2022-02-24 [1] CRAN (R 4.3.0)\n gtable 0.3.3 2023-03-21 [1] CRAN (R 4.3.0)\n here * 1.0.1 2020-12-13 [1] CRAN (R 4.3.0)\n htmltools 0.5.6 2023-08-10 [1] CRAN (R 4.3.0)\n htmlwidgets 1.6.2 2023-03-17 [1] CRAN (R 4.3.0)\n jsonlite 1.8.7 2023-06-29 [1] CRAN (R 4.3.0)\n knitr 1.43 2023-05-25 [1] CRAN (R 4.3.0)\n lifecycle 1.0.3 2022-10-07 [1] CRAN (R 4.3.0)\n magrittr 2.0.3 2022-03-30 [1] CRAN (R 4.3.0)\n munsell 0.5.0 2018-06-12 [1] CRAN (R 4.3.0)\n pillar 1.9.0 2023-03-22 [1] CRAN (R 4.3.0)\n pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.3.0)\n proto 1.0.0 2016-10-29 [1] CRAN (R 4.3.0)\n R6 2.5.1 2021-08-19 [1] CRAN (R 4.3.0)\n rlang 1.1.1 2023-04-28 [1] CRAN (R 4.3.0)\n rmarkdown 2.24 2023-08-14 [1] CRAN (R 4.3.1)\n rprojroot 2.0.3 2022-04-02 [1] CRAN (R 4.3.0)\n rstudioapi 0.15.0 2023-07-07 [1] CRAN (R 4.3.0)\n scales 1.2.1 2022-08-20 [1] CRAN (R 4.3.0)\n sessioninfo 1.2.2 2021-12-06 [1] CRAN (R 4.3.0)\n showtext 0.9-6 2023-05-03 [1] CRAN (R 4.3.0)\n showtextdb 3.0 2020-06-04 [1] CRAN (R 4.3.0)\n sysfonts 0.8.8 2022-03-13 [1] CRAN (R 4.3.0)\n tibble 3.2.1 2023-03-20 [1] CRAN (R 4.3.0)\n tidyselect 1.2.0 2022-10-10 [1] CRAN (R 4.3.0)\n utf8 1.2.3 2023-01-31 [1] CRAN (R 4.3.0)\n vctrs 0.6.3 2023-06-14 [1] CRAN (R 4.3.0)\n xfun 0.40 2023-08-09 [1] CRAN (R 4.3.0)\n yaml 2.3.7 2023-01-23 [1] CRAN (R 4.3.0)\n\n [1] /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/library\n\n──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────\n\n\nsessioninfo::session_info() has a first section that includes information about my R installation and other computer environment variables (like my operating system). The second section includes information about the R packages that I used, their version numbers, and where I installed them from.\n\nlibrary(\"colorout\") ## Load a package I installed from GitHub\nsessioninfo::session_info()\n\n─ Session info ───────────────────────────────────────────────────────────────────────────────────────────────────────\n setting value\n version R version 4.3.1 (2023-06-16)\n os macOS Ventura 13.5\n system aarch64, darwin20\n ui X11\n language (EN)\n collate en_US.UTF-8\n ctype en_US.UTF-8\n tz America/Mexico_City\n date 2023-08-29\n pandoc 3.1.5 @ /opt/homebrew/bin/ (via rmarkdown)\n\n─ Packages ───────────────────────────────────────────────────────────────────────────────────────────────────────────\n package * version date (UTC) lib source\n cli 3.6.1 2023-03-23 [1] CRAN (R 4.3.0)\n colorout * 1.2-2 2023-05-06 [1] Github (jalvesaq/colorout@79931fd)\n colorspace 2.1-0 2023-01-23 [1] CRAN (R 4.3.0)\n digest 0.6.33 2023-07-07 [1] CRAN (R 4.3.0)\n dplyr 1.1.2 2023-04-20 [1] CRAN (R 4.3.0)\n emojifont 0.5.5 2021-04-20 [1] CRAN (R 4.3.0)\n evaluate 0.21 2023-05-05 [1] CRAN (R 4.3.0)\n fansi 1.0.4 2023-01-22 [1] CRAN (R 4.3.0)\n fastmap 1.1.1 2023-02-24 [1] CRAN (R 4.3.0)\n generics 0.1.3 2022-07-05 [1] CRAN (R 4.3.0)\n ggplot2 3.4.3 2023-08-14 [1] CRAN (R 4.3.0)\n glue 1.6.2 2022-02-24 [1] CRAN (R 4.3.0)\n gtable 0.3.3 2023-03-21 [1] CRAN (R 4.3.0)\n here * 1.0.1 2020-12-13 [1] CRAN (R 4.3.0)\n htmltools 0.5.6 2023-08-10 [1] CRAN (R 4.3.0)\n htmlwidgets 1.6.2 2023-03-17 [1] CRAN (R 4.3.0)\n jsonlite 1.8.7 2023-06-29 [1] CRAN (R 4.3.0)\n knitr 1.43 2023-05-25 [1] CRAN (R 4.3.0)\n lifecycle 1.0.3 2022-10-07 [1] CRAN (R 4.3.0)\n magrittr 2.0.3 2022-03-30 [1] CRAN (R 4.3.0)\n munsell 0.5.0 2018-06-12 [1] CRAN (R 4.3.0)\n pillar 1.9.0 2023-03-22 [1] CRAN (R 4.3.0)\n pkgconfig 2.0.3 2019-09-22 [1] CRAN (R 4.3.0)\n proto 1.0.0 2016-10-29 [1] CRAN (R 4.3.0)\n R6 2.5.1 2021-08-19 [1] CRAN (R 4.3.0)\n rlang 1.1.1 2023-04-28 [1] CRAN (R 4.3.0)\n rmarkdown 2.24 2023-08-14 [1] CRAN (R 4.3.1)\n rprojroot 2.0.3 2022-04-02 [1] CRAN (R 4.3.0)\n rstudioapi 0.15.0 2023-07-07 [1] CRAN (R 4.3.0)\n scales 1.2.1 2022-08-20 [1] CRAN (R 4.3.0)\n sessioninfo 1.2.2 2021-12-06 [1] CRAN (R 4.3.0)\n showtext 0.9-6 2023-05-03 [1] CRAN (R 4.3.0)\n showtextdb 3.0 2020-06-04 [1] CRAN (R 4.3.0)\n sysfonts 0.8.8 2022-03-13 [1] CRAN (R 4.3.0)\n tibble 3.2.1 2023-03-20 [1] CRAN (R 4.3.0)\n tidyselect 1.2.0 2022-10-10 [1] CRAN (R 4.3.0)\n utf8 1.2.3 2023-01-31 [1] CRAN (R 4.3.0)\n vctrs 0.6.3 2023-06-14 [1] CRAN (R 4.3.0)\n xfun 0.40 2023-08-09 [1] CRAN (R 4.3.0)\n yaml 2.3.7 2023-01-23 [1] CRAN (R 4.3.0)\n\n [1] /Library/Frameworks/R.framework/Versions/4.3-arm64/Resources/library\n\n──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────\n\n\nFor packages that we installed from GitHub, it includes the specific git commit ID for the version we installed. This is super precise information that is very useful to have.\nCheck https://github.com/LieberInstitute/template_project/blob/main/code/01_read_data_to_r/01_read_data_to_r.R for a full script example part of https://github.com/LieberInstitute/template_project.\nCheck https://github.com/Bioconductor/BiocFileCache/issues/48 for an example on how the output from sessioninfo::session_info() provided useful hints that allowed me and others to resolve a problem.\nIn this video I talked about both here and sessioninfo as well as R and RStudio:\n\n\nhere and sessioninfo are so useful that people have made a Python versions of these R packages."
+ "objectID": "syllabus.html",
+ "href": "syllabus.html",
+ "title": "Syllabus",
+ "section": "",
+ "text": "Location: In person and Online for Fall 2023\nCourse time: Tuesdays and Thursdays from 9:00-10:20 a.m. (Eastern Daylight Time zone)\nCourse location: 140.776.01 is in person in W5030\nAssignments: Three projects\n\n\n\n\nTo add the course to your 1st term registration: You can sign up only for the in-person (140.776.01) course.\nAll lectures will be recorded and posted on CoursePlus. Classes will be recorded for flexibility purposes but this will not be a hybrid class.\nPlease course instructor if interested in auditing.\n\n\n\n\n\nLeonardo Collado Torres (http://lcolladotor.github.io/)\n\nOffice Location: 855 N. Wolfe, Office 385, Baltimore, MD 21205. Enter the Rangos building, register at the Security fron desk, ask the security guard to help you take the elevator to the third floor (it’s badge-controlled), register at the LIBD front desk, then they can point you to my office.\nEmail: lcollado@jhu.edu\n\n\nInstructor office hours are announced on CoursePlus. If there are conflicts and/or need to cancel office hours, announcements will be made on CoursePlus.\n\n\n\n\nEmily Norton (enorton7@jhmi.edu)\nJoe Sartini (jsartin1@jhu.edu)\nPhyllis Wei (ywei43@jhu.edu)\n\nTA office hours are announced on CoursePlus.\n\n\n\nIn order of preference, here is a preferred list of ways to get help:\n\nWe strongly encourage you to use CoursePlus to ask questions first, before joining office hours. The reason for this is so that other students in the class (who likely have similar questions) can also benefit from the questions and answers asked by your colleagues.\nYou are welcome to join office hours to get more group interactive feedback.\nIf you are not able to make the office hours, appointments can be made by email with the TAs."
+ },
+ {
+ "objectID": "syllabus.html#course-information",
+ "href": "syllabus.html#course-information",
+ "title": "Syllabus",
+ "section": "",
+ "text": "Location: In person and Online for Fall 2023\nCourse time: Tuesdays and Thursdays from 9:00-10:20 a.m. (Eastern Daylight Time zone)\nCourse location: 140.776.01 is in person in W5030\nAssignments: Three projects\n\n\n\n\nTo add the course to your 1st term registration: You can sign up only for the in-person (140.776.01) course.\nAll lectures will be recorded and posted on CoursePlus. Classes will be recorded for flexibility purposes but this will not be a hybrid class.\nPlease course instructor if interested in auditing.\n\n\n\n\n\nLeonardo Collado Torres (http://lcolladotor.github.io/)\n\nOffice Location: 855 N. Wolfe, Office 385, Baltimore, MD 21205. Enter the Rangos building, register at the Security fron desk, ask the security guard to help you take the elevator to the third floor (it’s badge-controlled), register at the LIBD front desk, then they can point you to my office.\nEmail: lcollado@jhu.edu\n\n\nInstructor office hours are announced on CoursePlus. If there are conflicts and/or need to cancel office hours, announcements will be made on CoursePlus.\n\n\n\n\nEmily Norton (enorton7@jhmi.edu)\nJoe Sartini (jsartin1@jhu.edu)\nPhyllis Wei (ywei43@jhu.edu)\n\nTA office hours are announced on CoursePlus.\n\n\n\nIn order of preference, here is a preferred list of ways to get help:\n\nWe strongly encourage you to use CoursePlus to ask questions first, before joining office hours. The reason for this is so that other students in the class (who likely have similar questions) can also benefit from the questions and answers asked by your colleagues.\nYou are welcome to join office hours to get more group interactive feedback.\nIf you are not able to make the office hours, appointments can be made by email with the TAs."
+ },
+ {
+ "objectID": "syllabus.html#important-links",
+ "href": "syllabus.html#important-links",
+ "title": "Syllabus",
+ "section": "Important Links",
+ "text": "Important Links\n\nCourse website: https://lcolladotor.github.io/jhustatcomputing2023/\nGitHub repository with all course material: https://github.com/lcolladotor/jhustatcomputing2023\nBug reports: https://github.com/lcolladotor/jhustatcomputing2023/issues"
+ },
+ {
+ "objectID": "syllabus.html#learning-objectives",
+ "href": "syllabus.html#learning-objectives",
+ "title": "Syllabus",
+ "section": "Learning Objectives:",
+ "text": "Learning Objectives:\nUpon successfully completing this course, students will be able to:\n\nInstall and configure software necessary for a statistical programming environment\nDiscuss generic programming language concepts as they are implemented in a high-level statistical language\nWrite and debug code in base R and the tidyverse (and integrate code from Python modules)\nBuild basic data visualizations using R and the tidyverse\nDiscuss best practices for coding and reproducible research, basics of data ethics, basics of working with special data types, and basics of storing data"
+ },
+ {
+ "objectID": "syllabus.html#lectures",
+ "href": "syllabus.html#lectures",
+ "title": "Syllabus",
+ "section": "Lectures",
+ "text": "Lectures\nIn Fall 2023, we will have in person lectures that will be recorded enabling students who missed a class for personal reasons to catch up as well as to review material discussed in class."
+ },
+ {
+ "objectID": "syllabus.html#textbook-and-other-course-material",
+ "href": "syllabus.html#textbook-and-other-course-material",
+ "title": "Syllabus",
+ "section": "Textbook and Other Course Material",
+ "text": "Textbook and Other Course Material\nThere is no required textbook. We will make use of several freely available textbooks and other materials. All course materials will be provided. We will use the R software for data analysis, which is freely available for download."
+ },
+ {
+ "objectID": "syllabus.html#software",
+ "href": "syllabus.html#software",
+ "title": "Syllabus",
+ "section": "Software",
+ "text": "Software\nWe will make heavy use of R in this course, so you should have R installed. You can obtain R from the Comprehensive R Archive Network. There are versions available for Mac, Windows, and Unix/Linux. This software is required for this course.\nIt is important that you have the latest version of R installed. For this course we will be using R version 4.3.1. You can determine what version of R you have by starting up R and typing into the console R.version.string and hitting the return/enter key. If you do not have the proper version of R installed, go to CRAN and download and install the latest version.\nWe will also make use of the RStudio interactive development environment (IDE). RStudio requires that R be installed, and so is an “add-on” to R. You can obtain the RStudio Desktop for free from the RStudio web site. In particular, we will make heavy use of it when developing R packages. It is also essential that you have the latest release of RStudio. You can determine the version of RStudio by looking at menu item Help > About RStudio. You should be using RStudio version RStudio 2023.06.1 or higher."
+ },
+ {
+ "objectID": "syllabus.html#projects",
+ "href": "syllabus.html#projects",
+ "title": "Syllabus",
+ "section": "Projects",
+ "text": "Projects\nThere will be 4 assignments, due every 2–3 weeks. Projects will be submitted electronically via the Drop Box on the CoursePlus web site (unless otherwise specified).\nThe project assignments will be due on\n\nProject 0: September 10, 11:59pm (entirely optional and not graded but hopefully useful and fun)\nProject 1: September 17, 11:59pm\nProject 2: October 1, 11:59pm\nProject 3: October 23, 11:59pm\n\n\nProject collaboration\nPlease feel free to study together and talk to one another about project assignments. The mutual instruction that students give each other is among the most valuable that can be achieved.\nHowever, it is expected that project assignments will be implemented and written up independently unless otherwise specified. Specifically, please do not share analytic code or output. Please do not collaborate on write-up and interpretation. Please do not access or use solutions from any source before your project assignment is submitted for grading."
+ },
+ {
+ "objectID": "syllabus.html#discussion-forum",
+ "href": "syllabus.html#discussion-forum",
+ "title": "Syllabus",
+ "section": "Discussion Forum",
+ "text": "Discussion Forum\nThe course will make use of the CoursePlus Discussion Forum in order to ask and answer questions regarding any of the course materials. The Instructor and the Teaching Assistants will monitor the discussion boards and answer questions when appropriate."
+ },
+ {
+ "objectID": "syllabus.html#exams",
+ "href": "syllabus.html#exams",
+ "title": "Syllabus",
+ "section": "Exams",
+ "text": "Exams\nThere are no exams in this course."
+ },
+ {
+ "objectID": "syllabus.html#grading",
+ "href": "syllabus.html#grading",
+ "title": "Syllabus",
+ "section": "Grading",
+ "text": "Grading\nGrades in the course will be based on Projects 0–3 with a percentage of the final grade being apportioned to each assignment. Each of Projects 1–3 counts approximately equally in the final grade. Grades for the projects and the final grade will be issued via the CoursePlus grade book."
+ },
+ {
+ "objectID": "syllabus.html#policy-for-submitting-projects-late",
+ "href": "syllabus.html#policy-for-submitting-projects-late",
+ "title": "Syllabus",
+ "section": "Policy for submitting projects late",
+ "text": "Policy for submitting projects late\nThe instructor and TAs will not accept email late day policy requests.\n\nProjects 1, 2 and 3\n\nEach student will be given two free “late days” for the entire course.\nA late day extends the individual project deadline by 24 hours without penalty.\nThe late days can be applied to just one project (e.g. two late days for Project 2), or they can be split across the two projects (one late day for Project 2 and one late day for Project 3). This is entirely left up to the discretion of the student.\nLate days are intended to give you flexibility: you can use them for any reason no questions asked.\nYou do not get any bonus points for not using your late days.\n\nAlthough the each student is only given a total of two late days, we will be accepting homework from students that pass this limit.\n\nWe will be deducting 5% for each extra late day. For example, if you have already used all of your late days for the term, we will deduct 5% for the assignment that is <24 hours late, 10% points for the assignment that is 24-48 hours late, and 15% points for the assignment that is 48-72 hours late.\nWe will not grade assignments that are more than 3 days past the original due date.\n\n\n\nRegrading Policy\nIt is very important to us that all assignments are properly graded. If you believe there is an error in your assignment grading, please send an email to one of the instructors within 7 days of receiving the grade. No re-grade requests will be accepted orally, and no regrade requests will be accepted more than 7 days after you receive the grade for the assignment."
+ },
+ {
+ "objectID": "syllabus.html#academic-ethics-and-student-conduct-code",
+ "href": "syllabus.html#academic-ethics-and-student-conduct-code",
+ "title": "Syllabus",
+ "section": "Academic Ethics and Student Conduct Code",
+ "text": "Academic Ethics and Student Conduct Code\nStudents enrolled in the Bloomberg School of Public Health of The Johns Hopkins University assume an obligation to conduct themselves in a manner appropriate to the University’s mission as an institution of higher education. A student is obligated to refrain from acts which he or she knows, or under the circumstances has reason to know, impair the academic integrity of the University. Violations of academic integrity include, but are not limited to: cheating; plagiarism; knowingly furnishing false information to any agent of the University for inclusion in the academic record; violation of the rights and welfare of animal or human subjects in research; and misconduct as a member of either School or University committees or recognized groups or organizations.\nStudents should be familiar with the policies and procedures specified under Policy and Procedure Manual Student-01 (Academic Ethics), available on the school’s portal.\nThe faculty, staff and students of the Bloomberg School of Public Health and the Johns Hopkins University have the shared responsibility to conduct themselves in a manner that upholds the law and respects the rights of others. Students enrolled in the School are subject to the Student Conduct Code (detailed in Policy and Procedure Manual Student-06) and assume an obligation to conduct themselves in a manner which upholds the law and respects the rights of others. They are responsible for maintaining the academic integrity of the institution and for preserving an environment conducive to the safe pursuit of the School’s educational, research, and professional practice missions."
+ },
+ {
+ "objectID": "syllabus.html#disability-support-service",
+ "href": "syllabus.html#disability-support-service",
+ "title": "Syllabus",
+ "section": "Disability Support Service",
+ "text": "Disability Support Service\nStudents requiring accommodations for disabilities should register with Student Disability Service (SDS). It is the responsibility of the student to register for accommodations with SDS. Accommodations take effect upon approval and apply to the remainder of the time for which a student is registered and enrolled at the Bloomberg School of Public Health. Once you are f a student in your class has approved accommodations you will receive formal notification and the student will be encouraged to reach out. If you have questions about requesting accommodations, please contact BSPH.dss@jhu.edu."
+ },
+ {
+ "objectID": "syllabus.html#prerequisites",
+ "href": "syllabus.html#prerequisites",
+ "title": "Syllabus",
+ "section": "Prerequisites",
+ "text": "Prerequisites\nThis is a quantitative course. We will not discuss the mathematical details of specific data analysis approaches, however some statistical background and being comfortable with quantitative thinking are useful. Previous experience with writing computer programs in general and R in particular is also helpful, but not necessary. If you have no programming experience, expect to spend extra time getting yourself familiar with R. As long as you are willing to invest the time to learn the programming and you do not mind thinking quantitatively, you should be able to take the course, independent of your background.\nFormal requirement for the course is Biostatistics 140.621. Knowledge of material from 140.621 is assumed. If you didn’t take this course, please contact me to get permission to enroll.\n\nGetting set up\nYou must install R and RStudio on your computer in order to complete this course. These are two different applications that must be installed separately before they can be used together:\n\nR is the core underlying programming language and computing engine that we will be learning in this course\nRStudio is an interface into R that makes many aspects of using and programming R simpler\n\nBoth R and RStudio are available for Windows, macOS, and most flavors of Unix and Linux. Please download the version that is suitable for your computing setup.\nThroughout the course, we will make use of numerous R add-on packages that must be installed over the Internet. Packages can be installed using the install.packages() function in R. For example, to install the tidyverse package, you can run\n\ninstall.packages(\"tidyverse\")\n\nin the R console.\n\nHow to Download R for Windows\nGo to https://cran.r-project.org and\n\nClick the link to “Download R for Windows”\nClick on “base”\nClick on “Download R 4.3.1 for Windows”\n\n\n\n\n\n\n\nWarning\n\n\n\nThe version in the video is not the latest version. Please download the latest version.\n\n\n\n\n\nVideo Demo for Downloading R for Windows\n\n\n\n\nHow to Download R for the Mac\nGoto https://cran.r-project.org and\n\nClick the link to “Download R for (Mac) OS X”.\nClick on “R-4.3.1.pkg”\n\n\n\n\n\n\n\nWarning\n\n\n\nThe version in the video is not the latest version. Please download the latest version.\n\n\n\n\n\nVideo Demo for Downloading R for the Mac\n\n\n\n\nHow to Download RStudio\nGoto https://rstudio.com and\n\nClick on “Products” in the top menu\nThen click on “RStudio” in the drop down menu\nClick on “RStudio Desktop”\nClick the button that says “DOWNLOAD RSTUDIO DESKTOP”\nClick the button under “RStudio Desktop” Free\nUnder the section “All Installers” choose the file that is appropriate for your operating system.\n\n\n\n\n\n\n\nWarning\n\n\n\nThe video shows how to download RStudio for the Mac but you should download RStudio for whatever computing setup you have\n\n\n\n\n\nVideo Demo for Downloading RStudio"
+ },
+ {
+ "objectID": "syllabus.html#general-disclaimers",
+ "href": "syllabus.html#general-disclaimers",
+ "title": "Syllabus",
+ "section": "General Disclaimers",
+ "text": "General Disclaimers\n\nThis syllabus is a general plan, deviations announced to the class by the instructor may be necessary."
}
]
\ No newline at end of file
diff --git a/sitemap.xml b/sitemap.xml
index 7222bd8..abebf99 100644
--- a/sitemap.xml
+++ b/sitemap.xml
@@ -1,143 +1,143 @@
- https://lcolladotor.github.io/jhustatcomputing2023/lectures.html
- 2023-09-14T02:33:34.896Z
+ https://lcolladotor.github.io/jhustatcomputing2023/projects.html
+ 2023-09-14T15:19:57.780Z
- https://lcolladotor.github.io/jhustatcomputing2023/posts/11-plotting-systems/index.html
- 2023-09-14T02:33:30.652Z
+ https://lcolladotor.github.io/jhustatcomputing2023/lectures.html
+ 2023-09-14T15:19:56.184Z
- https://lcolladotor.github.io/jhustatcomputing2023/posts/05-literate-programming/index.html
- 2023-09-14T02:33:28.188Z
+ https://lcolladotor.github.io/jhustatcomputing2023/resources.html
+ 2023-09-14T15:19:52.664Z
- https://lcolladotor.github.io/jhustatcomputing2023/posts/07-reading-and-writing-data/index.html
- 2023-09-14T02:33:25.388Z
+ https://lcolladotor.github.io/jhustatcomputing2023/posts/13-ggplot2-plotting-system-part-2/index.html
+ 2023-09-14T15:19:50.760Z
- https://lcolladotor.github.io/jhustatcomputing2023/posts/24-best-practices-data-analyses/index.html
- 2023-09-14T02:33:21.868Z
+ https://lcolladotor.github.io/jhustatcomputing2023/posts/10-joining-data-in-r/index.html
+ 2023-09-14T15:19:46.612Z
- https://lcolladotor.github.io/jhustatcomputing2023/posts/16-functions/index.html
- 2023-09-14T02:33:17.924Z
+ https://lcolladotor.github.io/jhustatcomputing2023/posts/20-working-with-dates-and-times/index.html
+ 2023-09-14T15:19:43.748Z
- https://lcolladotor.github.io/jhustatcomputing2023/posts/12-ggplot2-plotting-system-part-1/index.html
- 2023-09-14T02:33:14.564Z
+ https://lcolladotor.github.io/jhustatcomputing2023/posts/11-plotting-systems/index.html
+ 2023-09-14T15:19:40.844Z
- https://lcolladotor.github.io/jhustatcomputing2023/posts/10-joining-data-in-r/index.html
- 2023-09-14T02:33:11.828Z
+ https://lcolladotor.github.io/jhustatcomputing2023/posts/01-welcome/index.html
+ 2023-09-14T15:19:37.948Z
- https://lcolladotor.github.io/jhustatcomputing2023/posts/14-r-nuts-and-bolts/index.html
- 2023-09-14T02:33:08.232Z
+ https://lcolladotor.github.io/jhustatcomputing2023/posts/03-introduction-to-gitgithub/index.html
+ 2023-09-14T15:19:34.648Z
https://lcolladotor.github.io/jhustatcomputing2023/posts/02-introduction-to-r-and-rstudio/index.html
- 2023-09-14T02:33:04.848Z
-
-
- https://lcolladotor.github.io/jhustatcomputing2023/posts/09-tidy-data-and-the-tidyverse/index.html
- 2023-09-14T02:33:01.444Z
+ 2023-09-14T15:19:32.604Z
- https://lcolladotor.github.io/jhustatcomputing2023/posts/15-control-structures/index.html
- 2023-09-14T02:32:58.292Z
+ https://lcolladotor.github.io/jhustatcomputing2023/posts/06-reference-management/index.html
+ 2023-09-14T15:19:29.268Z
- https://lcolladotor.github.io/jhustatcomputing2023/posts/23-working-with-text-sentiment-analysis/index.html
- 2023-09-14T02:32:55.588Z
+ https://lcolladotor.github.io/jhustatcomputing2023/posts/09-tidy-data-and-the-tidyverse/index.html
+ 2023-09-14T15:19:26.308Z
- https://lcolladotor.github.io/jhustatcomputing2023/resources.html
- 2023-09-14T02:32:52.804Z
+ https://lcolladotor.github.io/jhustatcomputing2023/posts/04-reproducible-research/index.html
+ 2023-09-14T15:19:23.044Z
- https://lcolladotor.github.io/jhustatcomputing2023/schedule.html
- 2023-09-14T02:32:52.128Z
+ https://lcolladotor.github.io/jhustatcomputing2023/posts/17-loop-functions/index.html
+ 2023-09-14T15:19:19.792Z
- https://lcolladotor.github.io/jhustatcomputing2023/projects/project-2/index.html
- 2023-09-14T02:32:50.324Z
+ https://lcolladotor.github.io/jhustatcomputing2023/posts/25-python-for-r-users/index.html
+ 2023-09-14T15:19:16.628Z
https://lcolladotor.github.io/jhustatcomputing2023/projects/project-0/index.html
- 2023-09-14T02:32:48.264Z
+ 2023-09-14T15:19:13.800Z
- https://lcolladotor.github.io/jhustatcomputing2023/syllabus.html
- 2023-09-14T02:32:46.156Z
+ https://lcolladotor.github.io/jhustatcomputing2023/projects/project-2/index.html
+ 2023-09-14T15:19:11.564Z
- https://lcolladotor.github.io/jhustatcomputing2023/projects.html
- 2023-09-14T02:32:47.128Z
+ https://lcolladotor.github.io/jhustatcomputing2023/index.html
+ 2023-09-14T15:19:09.144Z
https://lcolladotor.github.io/jhustatcomputing2023/projects/project-3/index.html
- 2023-09-14T02:32:49.240Z
+ 2023-09-14T15:19:10.452Z
https://lcolladotor.github.io/jhustatcomputing2023/projects/project-1/index.html
- 2023-09-14T02:32:51.408Z
+ 2023-09-14T15:19:12.656Z
- https://lcolladotor.github.io/jhustatcomputing2023/index.html
- 2023-09-14T02:32:52.480Z
+ https://lcolladotor.github.io/jhustatcomputing2023/posts/18-debugging-r-code/index.html
+ 2023-09-14T15:19:15.212Z
- https://lcolladotor.github.io/jhustatcomputing2023/posts/06-reference-management/index.html
- 2023-09-14T02:32:53.728Z
+ https://lcolladotor.github.io/jhustatcomputing2023/posts/05-literate-programming/index.html
+ 2023-09-14T15:19:18.204Z
- https://lcolladotor.github.io/jhustatcomputing2023/posts/18-debugging-r-code/index.html
- 2023-09-14T02:32:57.032Z
+ https://lcolladotor.github.io/jhustatcomputing2023/posts/23-working-with-text-sentiment-analysis/index.html
+ 2023-09-14T15:19:21.648Z
+
+
+ https://lcolladotor.github.io/jhustatcomputing2023/posts/24-best-practices-data-analyses/index.html
+ 2023-09-14T15:19:25.196Z
https://lcolladotor.github.io/jhustatcomputing2023/posts/08-managing-data-frames-with-tidyverse/index.html
- 2023-09-14T02:33:00.316Z
+ 2023-09-14T15:19:28.276Z
- https://lcolladotor.github.io/jhustatcomputing2023/posts/21-regular-expressions/index.html
- 2023-09-14T02:33:03.364Z
+ https://lcolladotor.github.io/jhustatcomputing2023/posts/07-reading-and-writing-data/index.html
+ 2023-09-14T15:19:31.132Z
- https://lcolladotor.github.io/jhustatcomputing2023/posts/17-loop-functions/index.html
- 2023-09-14T02:33:06.428Z
+ https://lcolladotor.github.io/jhustatcomputing2023/posts/19-error-handling-and-generation/index.html
+ 2023-09-14T15:19:33.752Z
- https://lcolladotor.github.io/jhustatcomputing2023/posts/13-ggplot2-plotting-system-part-2/index.html
- 2023-09-14T02:33:10.712Z
+ https://lcolladotor.github.io/jhustatcomputing2023/posts/12-ggplot2-plotting-system-part-1/index.html
+ 2023-09-14T15:19:36.496Z
- https://lcolladotor.github.io/jhustatcomputing2023/posts/03-introduction-to-gitgithub/index.html
- 2023-09-14T02:33:12.696Z
+ https://lcolladotor.github.io/jhustatcomputing2023/posts/21-regular-expressions/index.html
+ 2023-09-14T15:19:39.840Z
- https://lcolladotor.github.io/jhustatcomputing2023/posts/22-working-with-factors/index.html
- 2023-09-14T02:33:16.172Z
+ https://lcolladotor.github.io/jhustatcomputing2023/posts/15-control-structures/index.html
+ 2023-09-14T15:19:42.112Z
- https://lcolladotor.github.io/jhustatcomputing2023/posts/20-working-with-dates-and-times/index.html
- 2023-09-14T02:33:19.596Z
+ https://lcolladotor.github.io/jhustatcomputing2023/posts/14-r-nuts-and-bolts/index.html
+ 2023-09-14T15:19:45.528Z
- https://lcolladotor.github.io/jhustatcomputing2023/posts/25-python-for-r-users/index.html
- 2023-09-14T02:33:23.424Z
+ https://lcolladotor.github.io/jhustatcomputing2023/posts/22-working-with-factors/index.html
+ 2023-09-14T15:19:48.184Z
- https://lcolladotor.github.io/jhustatcomputing2023/posts/19-error-handling-and-generation/index.html
- 2023-09-14T02:33:26.552Z
+ https://lcolladotor.github.io/jhustatcomputing2023/posts/16-functions/index.html
+ 2023-09-14T15:19:52.344Z
- https://lcolladotor.github.io/jhustatcomputing2023/posts/01-welcome/index.html
- 2023-09-14T02:33:29.632Z
+ https://lcolladotor.github.io/jhustatcomputing2023/schedule.html
+ 2023-09-14T15:19:53.340Z
- https://lcolladotor.github.io/jhustatcomputing2023/posts/04-reproducible-research/index.html
- 2023-09-14T02:33:32.068Z
+ https://lcolladotor.github.io/jhustatcomputing2023/syllabus.html
+ 2023-09-14T15:19:57.204Z