Golang中与时间有关的操作,主要涉及到 time 包,核心数据结构是 time.Time,如下:
type Time struct {
wall uint64
ext int64
loc *Location
}// 返回当前时间,注意此时返回的是 time.Time 类型
now := time.Now()
fmt.Println(now)
// 当前时间戳
fmt.Println(now.Unix())
// 纳秒级时间戳
fmt.Println(now.UnixNano())
// 时间戳小数部分 单位:纳秒
fmt.Println(now.Nanosecond())输出:
2021-01-10 14:56:15.930562 +0800 CST m=+0.000124449
1610261775
1610261775930562000
930562000now := time.Now()
// 返回日期
year, month, day := now.Date()
fmt.Printf("year:%d, month:%d, day:%d\n", year, month, day)
// 年
fmt.Println(now.Year())
// 月
fmt.Println(now.Month())
// 日
fmt.Println(now.Day())
// 时分秒
hour, minute, second := now.Clock()
fmt.Printf("hour:%d, minute:%d, second:%d\n", hour, minute, second)
// 时
fmt.Println(now.Hour())
// 分
fmt.Println(now.Minute())
// 秒
fmt.Println(now.Second())
// 返回星期
fmt.Println(now.Weekday())
//返回一年中对应的第几天
fmt.Println(now.YearDay())
//返回时区
fmt.Println(now.Location())
// 返回一年中第几天
fmt.Println(now.YearDay())Go 语言提供了时间类型格式化函数 Format(),需要注意的是 Go 语言格式化时间模板不是常见的 Y-m-d H:i:s,而是 2006-01-02 15:04:05,也很好记忆(2006 1 2 3 4 5)。
now := time.Now()
fmt.Println(now.Format("2006-01-02 15:04:05"))
fmt.Println(now.Format("2006-01-02"))
fmt.Println(now.Format("15:04:05"))
fmt.Println(now.Format("2006/01/02 15:04"))
fmt.Println(now.Format("15:04 2006/01/02"))时间戳转成日期格式,需要先转成将时间戳转成 time.Time 类型再格式化成日期格式。
now := time.Now()
layout := "2006-01-02 15:04:05"
t := time.Unix(now.Unix(),0) // 参数分别是:秒数,纳秒数
fmt.Println(t.Format(layout))now := time.Now()
layout := "2006-01-02 15:04:05"
//根据指定时间返回 time.Time 类型
//分别指定年,月,日,时,分,秒,纳秒,时区
t := time.Date(2011, time.Month(3), 12, 15, 30, 20, 0, now.Location())
fmt.Println(t.Format(layout))t, _ := time.ParseInLocation("2006-01-02 15:04:05", time.Now().Format("2006-01-02 15:04:05"), time.Local)
fmt.Println(t)
// 输出 2021-01-10 17:28:50 +0800 CST
// time.Local 指定本地时间解析的时候需要特别注意时区的问题:
fmt.Println(time.Now())
fmt.Println(time.Now().Location())
t, _ := time.Parse("2006-01-02 15:04:05", "2021-01-10 15:01:02")
fmt.Println(t)输出:
2021-01-10 17:22:10.951904 +0800 CST m=+0.000094166
Local
2021-01-10 15:01:02 +0000 UTC
可以看到,time.Now() 使用的 CST(中国标准时间),而 time.Parse() 默认的是 UTC(零时区),它们相差 8 小时。所以解析时常用 time.ParseInLocation(),可以指定时区。

讲到日期的计算就不得不提 time 包提供的一种新的类型 Duration,源码是这样定义的:
type Duration int64底层类型是 int64,表示一段时间间隔,单位是 纳秒。
now := time.Now()
fmt.Println(now)
// 1小时1分1s之后
t1, _ := time.ParseDuration("1h1m1s")
fmt.Println(t1)
m1 := now.Add(t1)
fmt.Println(m1)
// 1小时1分1s之前
t2, _ := time.ParseDuration("-1h1m1s")
m2 := now.Add(t2)
fmt.Println(m2)
// 3小时之前
t3, _ := time.ParseDuration("-1h")
m3 := now.Add(t3 * 3)
fmt.Println(m3)
// 10 分钟之后
t4, _ := time.ParseDuration("10m")
m4 := now.Add(t4)
fmt.Println(m4)
// Sub 计算两个时间差
sub1 := now.Sub(m3)
fmt.Println(sub1.Hours()) // 相差小时数
fmt.Println(sub1.Minutes()) // 相差分钟数额外再介绍两个函数 time.Since()、time.Until():
// 返回当前时间与 t 的时间差,返回值是 Duration
time.Since(t Time) Duration
// 返回 t 与当前时间的时间差,返回值是 Duration
time.Until(t Time) Duration
now := time.Now()
fmt.Println(now)
t1, _ := time.ParseDuration("-1h")
m1 := now.Add(t1)
fmt.Println(m1)
fmt.Println(time.Since(m1))
fmt.Println(time.Until(m1))输出:
2021-01-10 20:41:48.668232 +0800 CST m=+0.000095594
2021-01-10 19:41:48.668232 +0800 CST m=-3599.999904406
1h0m0.000199007s
-1h0m0.000203035s
涉及到一天以外的时间计算,就需要用到 time.AddDate(),函数原型:
func (t Time) AddDate(years int, months int, days int) Time比如想知道 一年一个月零一天 之后的时间,就可以这样:
now := time.Now()
fmt.Println(now)
m1 := now.AddDate(1,1,1)
fmt.Println(m1)再比如,想获得 2 天之前时间:
now := time.Now()
fmt.Println(now)
m1 := now.AddDate(0,0,-2)
fmt.Println(m1)日期的比较总共有三种:之前、之后和相等。
// 如果 t 代表的时间点在 u 之前,返回真;否则返回假。
func (t Time) Before(u Time) bool
// 如果 t 代表的时间点在 u 之后,返回真;否则返回假。
func (t Time) After(u Time) bool
// 比较时间是否相等,相等返回真;否则返回假。
func (t Time) Equal(u Time) bool
now := time.Now()
fmt.Println(now)
// 1小时之后
t1, _ := time.ParseDuration("1h")
m1 := now.Add(t1)
fmt.Println(m1)
fmt.Println(m1.After(now))
fmt.Println(now.Before(m1))
fmt.Println(now.Equal(m1))输出:
2021-01-10 21:00:44.409785 +0800 CST m=+0.000186800
2021-01-10 22:00:44.409785 +0800 CST m=+3600.000186800
true
true
false
下面列举一些常见的例子和函数封装。
func TimeStr2Time(fmtStr,valueStr, locStr string) int64 {
loc := time.Local
if locStr != "" {
loc, _ = time.LoadLocation(locStr) // 设置时区
}
if fmtStr == "" {
fmtStr = "2006-01-02 15:04:05"
}
t, _ := time.ParseInLocation(fmtStr, valueStr, loc)
return t.Unix()
}func GetCurrentFormatStr(fmtStr string) string {
if fmtStr == "" {
fmtStr = "2006-01-02 15:04:05"
}
return time.Now().Format(fmtStr)
}func Sec2TimeStr(sec int64, fmtStr string) string {
if fmtStr == "" {
fmtStr = "2006-01-02 15:04:05"
}
return time.Unix(sec, 0).Format(fmtStr)
}package main
import (
"fmt"
"regexp"
)
const text = "My email is [email protected]"
func main() {
compile := regexp.MustCompile(`[a-zA-Z0-9]+@[a-zA-Z0-9]+\.[a-zA-Z0-9]+`)
match := compile.FindString(text)
fmt.Println(match)
}
计算的体系架构,CPU,内存,网络,IO。那么 IO 是什么呢?一般理解成 Input、Output 的缩写,通俗话就是输入输出的意思。
IO 分为网络和存储 IO 两种类型(其实网络 IO 和磁盘 IO 在 Go 里面有着根本性区别)。网络 IO 对应的是网络数据传输过程,网络是分布式系统的基石,通过网络把离散的物理节点连接起来,形成一个有机的系统。
存储 IO 对应的就是数据存储到物理介质的过程,通常物理介质对应的是磁盘,磁盘上一般会分个区,然后在上面格式化个文件系统出来,所以普通程序员最常看见的是文件 IO 的形式。
在 Golang 里可以归类出两种读写文件的方式:
- 标准库封装:操作对象
File; - 系统调用 :操作对象
fd;
文件的读写最核心的要素是什么?
通俗来讲:读文件,就是把磁盘上的文件的特定位置的数据读到内存的 buffer 。写文件,就是把内存 buffer 的数据写到磁盘的文件的特定位置。
这里注意到两个关键词:
- 特定位置;
- 内存 buffer;
特定位置怎么理解?怎么指定所谓的特定位置?
很简单,用 [ offset, length ] 这两个参数就能标识一段位置。
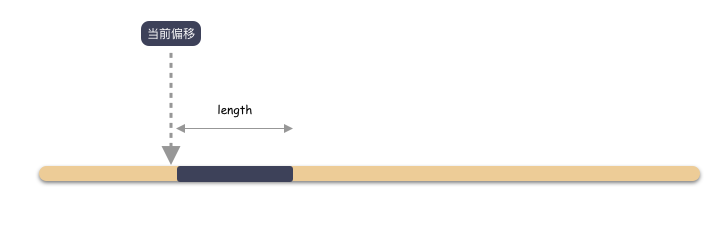
也就是 IO 偏移和长度,Offset 和 Length。
内存 buffer 怎么理解?
归根结底,文件的数据和谁直接打交道?内存,写的时候是从内存写到磁盘文件的,读的时候是从磁盘文件读到内存的。
本质上,下面的 IO 函数都离不开 Offset,Length,buffer 这三个要素。
Go 对文件进行读写非常简单,因为 Go 已经封装了一个非常便捷的使用接口,位于标准库 os 中。Go 标准库对文件 IO 的封装也就是 Go 推荐对文件进行 IO 时使用的操作方式。
func OpenFile(name string, flag int, perm FileMode) (*File, error)Open 文件之后,获取到一个句柄,也就是 File 结构,之后对文件的读写都是基于 File 结构之上进行的。
type File struct {
*file // os specific
}文件读写只需要针对这个句柄结构体做操作即可。
另外有一点隐藏起来的知识点必须要提一下:偏移。也就是最开始强调的读写 3 要素之一的 Offset 。打开(Open)文件的时候,文件当前偏移量默认设置为 0,也就是说 IO 的起始位置就是文件的最开头。举个例子,如果这个时候,写 4K 的数据到文件,那么就是写 [0, 4K] 这个位置的数据,如果之前这上面已经有数据了,那么就会是覆盖写。
除非 Open 文件的时候指定 O_APPEND 选项,偏移量会设置为文件末尾,那么 IO 都是从文件末尾开始。
文件 File 句柄对象有两个写方法:
第一种:写一个 buffer 到文件 ,使用文件当前偏移
func (f *File) Write(b []byte) (n int, err error)注意:该写操作会导致文件偏移量的增加。
第二种:从指定文件偏移,写入 buffer 到文件
func (f *File) WriteAt(b []byte, off int64) (n int, err error)注意:该写操作不会更新文件偏移量
和写对应,文件 File 句柄对象有两个读方法:
第一种:从文件当前偏移读一个 buffer 的数据上来
func (f *File) Read(b []byte) (n int, err error)注意:该读操作会导致文件偏移量的增加。
第二种:从指定文件偏移,读一个 buffer 大小的数据上来
func (f *File) ReadAt(b []byte, off int64) (n int, err error)注意:该读操作不会更新文件偏移量
func (f *File) Seek(offset int64, whence int) (ret int64, err error)这个句柄方法允许用户指定文件的偏移位置。这个很容易理解,举个例子,文件刚开始是 0 字节,写 1M 的数据下去,大小变成 1M,Offset 往后挪 1M ,默认就是往后挪。
现在 Seek 方法允许把写的偏移定位到任意位置,可以就可以从任意地方覆盖写入数据。
所以在 Go 里面,文件 IO 非常简单,先 Open 一个文件,拿到 File 句柄,然后就可以使用这个句柄 Write ,Read,Seek 就能进行 IO 了。
Go 的标准库 os 提供了极其方便的封装,深入最原始的本质可以发现最核心的东西:系统调用。
Go 标准库的文件存储 IO 就是基于系统调用之上的。可以稍微跟一下 os.OpenFile 的调用:
os 库的 OpenFile 函数:
func OpenFile(name string, flag int, perm FileMode) (*File, error) {
f, err := openFileNolog(name, flag, perm)
if err != nil {
return nil, err
}
f.appendMode = flag&O_APPEND != 0
return f, nil
}稍微看下 openFileNolog 函数:
func openFileNolog(name string, flag int, perm FileMode) (*File, error) {
var r int
for {
var e error
r, e = syscall.Open(name, flag|syscall.O_CLOEXEC, syscallMode(perm))
if e == nil {
break
}
if runtime.GOOS == "darwin" && e == syscall.EINTR {
continue
}
return nil, &PathError{"open", name, e}
}
return newFile(uintptr(r), name, kindOpenFile), nil
}可以看到 syscall.Open ,这个函数获取到一个整数,也就是在 c 语言里最常见的 fd 句柄,而 File 结构体则仅仅是基于这个的一层封装而已。
思考下,为什么会有标准库封装这一层存在?
划重点:为了屏蔽操作系统的区别,使用这个标准库的所有操作都是跨平台的。换句话说,如果是特殊操作系统才有的特性,那么在 os 库里就找不到对应封装的 IO 操作。
那么怎么使用系统调用?
直接使用 syscall 库,也就是系统调用。从名字也能看出来,系统调用是和操作系统强相关的,因为是操作系统提供的调用接口,所以系统调用会因为操作系统不同而导致不同的特性,不同的接口。
所以,如果直接使用 syscall 库来使用系统调用,那么需要自己来承受系统带来的兼容性问题。
系统调用在 syscall 里有一层最基础的封装:
func Open(path string, mode int, perm uint32) (fd int, err error) func Read(fd int, p []byte) (n int, err error) func Pread(fd int, p []byte, offset int64) (n int, err error) 文件读有两个接口,一个 Read 是从当前默认偏移读一个 buffer 数据,Pread 接口则是从指定位置读数据的接口。
思考一个问题:Pread 从效果上来讲等于 Seek 和 Read 组合起来使用,那么是否可以认为 Pread 就可以被 Seek + Read 替代呢?
不行!根本原因在于 Seek + Read 是在用户层就是两步操作,而 Pread 虽然是 Seek + Read 的效果,但是操作系统给到用户的语义是:Pread 是一个原子操作。还有一个重要区别,Pread 不会改变当前文件的偏移量(普通的 Read 调用会更新偏移量)。
所以,总结下,**Pread** 和顺序调用 **Seek** 后调用 **Read** 有两点重要区别:
Pread对用户提供的语义是原子操作,在调用Pread时,无法中断Seek和Read操作;Pread调用不会更新当前文件偏移量;
func Write(fd int, p []byte) (n int, err error) func Pwrite(fd int, p []byte, offset int64) (n int, err error) 文件写对应也是有两种接口,Wrtie 和 Pwrite 分别是对应 Read 和 Pread 。同样的,Pwrite 作用上也是相当于先调用 Seek 再调用 Write ,但是同样的也有两点不同:
Pwrite完成Seek和Write对外是原子操作的语义;Pwrite调用不会更新当前文件偏移量;
func Seek(fd int, offset int64, whence int) (off int64, err error) 这个函数调用允许用户指定偏移(这个会影响到 Read 和 Write 读写的位置)。一般来说,每个打开文件都有一个相关联的“当前文件偏移量”( current file offset )。读(Read)、写(Write)操作都是从当前文件偏移量处开始,并且 Read 和 Write 会导致偏移量增加,增加量就是所读写的字节数。
小结一下:Go核心的 Open,Read,Write,Seek 几个系统调用,可以发现一个明显不同与标准 IO 库的区别:系统调用操作对象是一个整数句柄。Open 文件得到一个整数 fd,之后的所有 IO 都是针对这个 fd 来操作的。这个明显和标准库不同,os 标准库 OpenFile 得到的是一个 File 结构体,所有的 IO 也是针对这个结构体的。
那么究竟封装的层次一般是什么样的呢, Unix 编程里面开篇就有一张如下图:
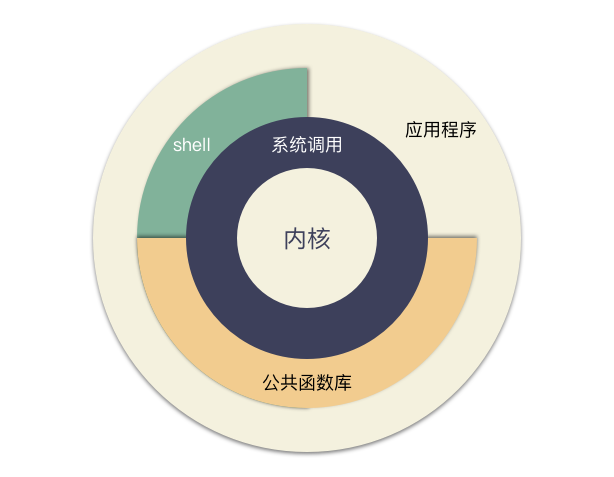
这张图就非常形象的讲明白了整个 Unix 体系结构。
-
内核是最核心的实现,包括了和 IO 设备,硬件交互等功能。与内核紧密的一层是内核提供给外部调用的系统调用,系统调用提供了用户态到内核态调用的一个通道;
-
对于系统调用,各个语言的标准库会有一些封装,比如 C 语言的 libc 库,Go 语言的 os ,syscall 库都是类似的地位,这个就是所谓的公共库。这层封装的作用最主要是简化普通程序员使用效率,并且屏蔽系统细节,为跨平台提供基础(同样的,为了跨平台的特性,可能会阉割很多不兼容的功能,所以才会有直接调用系统掉调用的需求);
-
当然,右上角还看到一个缺口,应用程序除了可以使用公共函数库,其实是可以直接调用系统调用的,但是由此带来的复杂性又应用自己承担。这种需求也是很常见的,标准库封装了通用的东西,同样割舍了很多系统调用的功能,这种情况下,只能通过系统调用来获取;
-
IO 大类分为网络 IO 和磁盘 IO,IO 对文件来说就是读写操作,写的时候数据从内存到磁盘,读的时候数据从磁盘到内存;
-
Go 文件 IO 最常用的是 os 库,使用 Go 封装的标准库,
os.OpenFile打开,File.Write,File.Read进行读写,操作对象都是File结构体; -
Go 标准库对 IO 的封装是为了屏蔽复杂的系统调用,提供跨平台的使用姿势。然后单独提供
syscall库,让程序员自我决策使用要使用更丰富的系统调用功能,当然后果自负; -
Go 标准库 IO 操作对象是
File,系统调用 IO 操作对象是 fd(非负整数)。 -
Open文件默认当前偏移量是 0 (文件最开始),加上O_APPEND参数之后偏移量会是文件末尾。通过 Seek 调用可以任意指定文件偏移,从而影响文件 IO 的位置; -
Read,Write函数只有 buffer (buffer 有长度),偏移则使用当前文件偏移量; -
Pread,Pwrite的系统调用效果等同于Seek偏移量然后Read,Write,但是又大有不同。对外语义是原子操作,并且不更新当前文件偏移量;
package main
import (
"bufio"
"fmt"
"io"
"os"
)
/*在已存在文件清空原有内容进行追加*/
func main() {
filePath := "D:\\fcofficework\\DNS\\1.txt"
file, err := os.OpenFile(filePath, os.O_RDWR|os.O_APPEND, 0666)
if err != nil {
fmt.Printf("open file err = %v\n", err)
return
}
/*关闭文件流*/
defer file.Close()
/*读取*/
reader := bufio.NewReader(file)
for {
str, err := reader.ReadString('\n')
if err == io.EOF {
break
}
fmt.Print(str)
}
/*写入文件*/
str := "hello FCC您好!!!\r\n"
writer := bufio.NewWriter(file)
for i := 0; i < 5; i++ {
writer.WriteString(str)
}
/*因为writer是带缓存的,需要通过flush到磁盘*/
writer.Flush()
}package main
import (
"fmt"
"io/ioutil"
)
/*将文件1的内容拷贝到文件2*/
func main() {
file1Path := "D:\\fcofficework\\DNS\\1.txt"
file2Path := "D:\\fcofficework\\DNS\\2.txt"
data, err := ioutil.ReadFile(file1Path)
if err != nil {
fmt.Printf("read file err=%v", err)
return
}
err = ioutil.WriteFile(file2Path, data, 0666)
if err != nil {
fmt.Printf("write file err=%v\n", err)
}
}package main
import (
"fmt"
"os"
)
/*判断文件以及目录是否存在*/
func PathExists(path string) (bool, error) {
_, err := os.Stat(path)
if err == nil {
fmt.Println("当前文件存在!")
return true, nil
}
if os.IsNotExist(err) {
fmt.Println("当前文件不存在!")
return false, nil
}
return false, nil
}
func main() {
path := "D:\\fcofficework\\2.txt"
PathExists(path)
}package main
import (
"bufio"
"fmt"
"io"
"os"
)
/*文件的拷贝*/
func CopyFile(dstFileName string, srcFileName string) (written int64, err error) {
srcFile, err := os.Open(srcFileName)
if err != nil {
fmt.Printf("open file err=%v\n", err)
}
reader := bufio.NewReader(srcFile)
dstFile, err := os.OpenFile(dstFileName, os.O_WRONLY|os.O_CREATE, 0666)
if err != nil {
fmt.Printf("open file err=%v\n", err)
return
}
writer := bufio.NewWriter(dstFile)
defer dstFile.Close()
return io.Copy(writer, reader)
}
func main() {
srcFile := "D:\\Photos\\Datapicture\\mmexport1530688562488.jpg"
dstFile := "D:\\Photos\\1.jpg"
_, err := CopyFile(dstFile, srcFile)
if err == nil {
fmt.Println("拷贝完成!")
} else {
fmt.Println("拷贝失败,err=", err)
}
}package main
import (
"bufio"
"fmt"
"io"
"os"
)
/*统计文件的字符个数*/
type CharCount struct {
/*英文的个数*/
ChCount int
/*数字的个数*/
NumCount int
/*空格的个数*/
SpaceCount int
/*其他字符的个数*/
OtherCount int
}
func main() {
fileName := "D:\\fcofficework\\DNS\\1.txt"
file, err := os.Open(fileName)
if err != nil {
fmt.Printf("open file err=%v\n", err)
return
}
defer file.Close()
var count CharCount
reader := bufio.NewReader(file)
for {
str, err := reader.ReadString('\n')
if err == io.EOF {
break
}
for _, v := range str {
switch {
case v >= 'a' && v <= 'z':
fallthrough
case v >= 'A' && v <= 'Z':
count.ChCount++
case v == ' ' || v == '\t':
count.SpaceCount++
case v >= '0' && v <= '9':
count.NumCount++
default:
count.OtherCount++
}
}
}
fmt.Printf("字符的个数为:%v 数字的个数为:%v 空格的个数为:%v 其他字符的个数为:%v",
count.ChCount, count.NumCount, count.SpaceCount, count.OtherCount)
}package main
import (
"fmt"
"os"
)
func main() {
file, err := os.Open("d:\\Photos\\Screenshots\\暗物质\\IMG_20180927_194619.jpg")
if err != nil {
fmt.Println("open file err", err)
}
fmt.Printf("file=%v", file)
err1 := file.Close()
if err1 != nil {
fmt.Println("close file err = ", err1)
}
}package main
import (
"bufio"
"fmt"
"io"
"os"
)
/*缓冲式读取文件*/
func main() {
file, err := os.Open("d:\\Photos\\Screenshots\\暗物质\\IMG_20180927_194619.jpg")
if err != nil {
fmt.Println("open file err", err)
}
defer file.Close()
reader := bufio.NewReader(file)
for {
str, err := reader.ReadString('\n')
if err == io.EOF {
break
}
fmt.Print(str)
}
fmt.Println("文件读取结束!")
}package main
import (
"fmt"
"io/ioutil"
)
func main() {
file := "D:\\fcofficework\\DNS\\authorized_keys"
content, err := ioutil.ReadFile(file)
if err != nil {
fmt.Printf("read file err=%v", err)
}
fmt.Printf("%v", string(content))
}package main
import (
"bufio"
"fmt"
"os"
)
/*在文件写入内容,没有文件则重新创建*/
func main() {
filePath := "D:\\fcofficework\\DNS\\1.txt"
file, err := os.OpenFile(filePath, os.O_WRONLY|os.O_CREATE, 0666)
if err != nil {
fmt.Printf("open file err = %v\n", err)
return
}
defer file.Close()
str := "hello world\r\n"
writer := bufio.NewWriter(file)
for i := 0; i < 5; i++ {
writer.WriteString(str)
}
/*因为writer是带缓存的,需要通过flush到磁盘*/
writer.Flush()
}package main
import (
"bufio"
"fmt"
"os"
)
/*在已存在文件清空原有内容重新写入*/
func main() {
filePath := "D:\\fcofficework\\DNS\\1.txt"
file, err := os.OpenFile(filePath, os.O_WRONLY|os.O_TRUNC, 0666)
if err != nil {
fmt.Printf("open file err = %v\n", err)
return
}
defer file.Close()
str := "hello FCC\r\n"
writer := bufio.NewWriter(file)
for i := 0; i < 5; i++ {
writer.WriteString(str)
}
/*因为writer是带缓存的,需要通过flush到磁盘*/
writer.Flush()
}package main
import (
"bufio"
"fmt"
"os"
)
/*在已存在文件清空原有内容进行追加*/
func main() {
filePath := "D:\\fcofficework\\DNS\\1.txt"
file, err := os.OpenFile(filePath, os.O_WRONLY|os.O_APPEND, 0666)
if err != nil {
fmt.Printf("open file err = %v\n", err)
return
}
defer file.Close()
str := "hello FCC您好!!!\r\n"
writer := bufio.NewWriter(file)
for i := 0; i < 5; i++ {
writer.WriteString(str)
}
/*因为writer是带缓存的,需要通过flush到磁盘*/
writer.Flush()
}package main
import (
"fmt"
"os"
)
/*解析命令行参数*/
func main() {
fmt.Println("命令行参数有:", len(os.Args))
for i, v := range os.Args {
fmt.Printf("args[%v]=%v\n", i, v)
}
}
package main
import (
"flag"
"fmt"
)
/*解析命令行参数*/
func main() {
var user string
var pwd string
var host string
var port int
flag.StringVar(&user, "u", "", "用户名,默认为空")
flag.StringVar(&pwd, "pwd", "", "密码,默认为空")
flag.StringVar(&host, "h", "localhost", "主机名,默认为空")
flag.IntVar(&port, "port", 3306, "端口号,默认为空")
/*转换*/
flag.Parse()
fmt.Printf("user=%v pwd=%v host=%v port=%v", user, pwd, host, port)
}package main
import (
"encoding/json"
"fmt"
)
type Monster struct {
Name string `json:"name"`
Age int `json:"age"`
Birthday string `json:"birthday"`
Sal float64 `json:"sal"`
Skill string `json:"skill"`
}
/*结构体序列化*/
func NewMinsterStruct() {
monster := Monster{
Name: "孙悟空",
Age: 500,
Birthday: "2011-11-11",
Sal: 8000.0,
Skill: "如意七十二变",
}
data, err := json.Marshal(&monster)
if err != nil {
fmt.Printf("序列化错误err:%v\n", err)
}
fmt.Printf("Map序列化后=%v\n", string(data))
}
/*Map序列化*/
func MapSerlizer() {
var a map[string]interface{}
a = make(map[string]interface{})
a["name"] = "牛魔王"
a["age"] = 10
a["address"] = "火云洞"
data, err := json.Marshal(a)
if err != nil {
fmt.Printf("序列化错误err:%v\n", err)
}
fmt.Printf("monster序列化后=%v\n", string(data))
}
/*切片序列化*/
func SliceSerlizer() {
var slice []map[string]interface{}
var m1 map[string]interface{}
m1 = make(map[string]interface{})
m1["name"] = "TGH"
m1["age"] = "19"
m1["address"] = "北京"
slice = append(slice, m1)
var m2 map[string]interface{}
m2 = make(map[string]interface{})
m2["name"] = "FCC"
m2["age"] = "18"
m2["address"] = [2]string{"华府", "影视帝国"}
slice = append(slice, m2)
data, err := json.Marshal(slice)
if err != nil {
fmt.Printf("序列化错误err:%v\n", err)
}
fmt.Printf("切片序列化后=%v\n", string(data))
}
/*基本数据类型序列化*/
func FloatSerlize() {
var num1 float64 = 245.56
data, err := json.Marshal(num1)
if err != nil {
fmt.Printf("序列化错误err:%v\n", err)
}
fmt.Printf("基本数据类型序列化后=%v\n", string(data))
}
func main() {
NewMinsterStruct()
MapSerlizer()
SliceSerlizer()
FloatSerlize()
}
Map序列化后={"name":"孙悟空","age":500,"birthday":"2011-11-11","sal":8000,"skill":"如意七十二变"}
monster序列化后={"address":"火云洞","age":10,"name":"牛魔王"}
切片序列化后=[{"address":"北京","age":"19","name":"TGH"},{"address":["华府","影视帝国"],"age":"18","name":"FCC"}]
基本数据类型序列化后=245.56package main
import (
"encoding/json"
"fmt"
)
type Monster struct {
Name string `json:"name"`
Age int `json:"age"`
Birthday string `json:"birthday"`
Sal float64 `json:"sal"`
Skill string `json:"skill"`
}
func unmarshalStruct() {
str := "{\"name\":\"孙悟空\",\"age\":500,\"birthday\":\"2011-11-11\",\"sal\":8000,\"skill\":\"如意七十二变\"}"
var monster Monster
err := json.Unmarshal([]byte(str), &monster)
if err != nil {
fmt.Printf("反序列化失败err:%v\n", err)
}
fmt.Printf("反序列化后monster:%v\n", monster)
}
func unmarshallMap() {
str := "{\"address\":\"火云洞\",\"age\":10,\"name\":\"牛魔王\"}"
var a map[string]interface{}
err := json.Unmarshal([]byte(str), &a)
if err != nil {
fmt.Printf("反序列化失败err:%v\n", err)
}
fmt.Printf("反序列化Map后:%v\n", a)
}
func unmarshalSlice() {
str := "[{\"address\":\"北京\",\"age\":\"19\",\"name\":\"TGH\"}," +
"{\"address\":[\"华府\",\"影视帝国\"],\"age\":\"18\",\"name\":\"FCC\"}]"
var slice []map[string]interface{}
err := json.Unmarshal([]byte(str), &slice)
if err != nil {
fmt.Printf("反序列化失败err:%v\n", err)
}
fmt.Printf("反序列化Slice后:%v\n", slice)
}
func main() {
unmarshalStruct()
unmarshallMap()
unmarshalSlice()
}输出结果:
反序列化后monster:{孙悟空 500 2011-11-11 8000 如意七十二变}
反序列化Map后:map[address:火云洞 age:10 name:牛魔王]
反序列化Slice后:[map[address:北京 age:19 name:TGH] map[address:[华府 影视帝国] age:18 name:FCC]]Web是基于http协议的一个服务,Go语言里面提供了一个完善的net/http包,通过http包可以很方便的搭建起来一个可以运行的Web服务。同时使用这个包能很简单地对Web的路由,静态文件,模版,cookie等数据进行设置和操作。
package main
import (
"fmt"
"net/http"
"strings"
"log"
)
func sayhelloName(w http.ResponseWriter, r *http.Request) {
r.ParseForm() //解析参数,默认是不会解析的
fmt.Println(r.Form) //这些信息是输出到服务器端的打印信息
fmt.Println("path", r.URL.Path)
fmt.Println("scheme", r.URL.Scheme)
fmt.Println(r.Form["url_long"])
for k, v := range r.Form {
fmt.Println("key:", k)
fmt.Println("val:", strings.Join(v, ""))
}
fmt.Fprintf(w, "Hello golang!") //这个写入到w的是输出到客户端的
}
func main() {
http.HandleFunc("/", sayhelloName) //设置访问的路由
err := http.ListenAndServe(":8080", nil) //设置监听的端口
if err != nil {
log.Fatal("ListenAndServe: ", err)
}
}上面这个代码,build之后,然后执行web.exe,这个时候其实已经在8080端口监听http链接请求了。
在浏览器输入http://localhost:8080
可以看到浏览器页面输出了Hello golang!
浏览器输入地址:
http://localhost:8080/?url_long=var1&url_long=var2
可以看看浏览器输出的是什么
看到上面的代码,要编写一个Web服务器很简单,只要调用http包的两个函数就可以了。
package main
import (
"fmt"
"net/http"
"net/http/httputil"
)
func main() {
request, err := http.NewRequest(http.MethodGet, "http://www.imooc.com", nil)
if err != nil {
panic(err)
}
request.Header.Add("User-Agent",
"Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1")
client := http.Client{
CheckRedirect: func(req *http.Request, via []*http.Request) error {
fmt.Println("Redirect:", req)
return nil
},
}
resp, err := client.Do(request)
//resp, err := http.DefaultClient.Do(request)
//resp, err := http.Get("http://www.imooc.com")
if err != nil {
panic(err)
}
defer resp.Body.Close()
s, err := httputil.DumpResponse(resp, true)
if err != nil {
panic(err)
}
fmt.Println(string(s))
}程序运行打印出HTML内容
来看一段日常代码。
package main
import (
"bytes"
"encoding/json"
"fmt"
"io/ioutil"
"net"
"net/http"
"time"
)
var tr *http.Transport
func init() {
tr = &http.Transport{
MaxIdleConns: 100,
Dial: func(netw, addr string) (net.Conn, error) {
conn, err := net.DialTimeout(netw, addr, time.Second*2) //设置建立连接超时
if err != nil {
return nil, err
}
err = conn.SetDeadline(time.Now().Add(time.Second * 3)) //设置发送接受数据超时
if err != nil {
return nil, err
}
return conn, nil
},
}
}
func main() {
for {
_, err := Get("http://www.baidu.com/")
if err != nil {
fmt.Println(err)
break
}
}
}
func Get(url string) ([]byte, error) {
m := make(map[string]interface{})
data, err := json.Marshal(m)
if err != nil {
return nil, err
}
body := bytes.NewReader(data)
req, _ := http.NewRequest("Get", url, body)
req.Header.Add("content-type", "application/json")
client := &http.Client{
Transport: tr,
}
res, err := client.Do(req)
if res != nil {
defer res.Body.Close()
}
if err != nil {
return nil, err
}
resBody, err := ioutil.ReadAll(res.Body)
if err != nil {
return nil, err
}
return resBody, nil
}做的事情,比较简单,就是循环去请求http://www.baidu.com/, 然后等待响应。
看上去貌似没啥问题吧。
代码跑起来,也确实能正常收发消息。
但是这段代码跑一段时间,就会出现i/o timeout的报错。
这其实是最近排查了的一个问题,发现这个坑可能比较容易踩上,这边对代码做了简化。
实际生产中发生的现象是,golang服务在发起http调用时,虽然http.Transport设置了3s超时,会偶发出现i/o timeout的报错。
但是查看下游服务的时候,发现下游服务其实100ms就已经返回了。
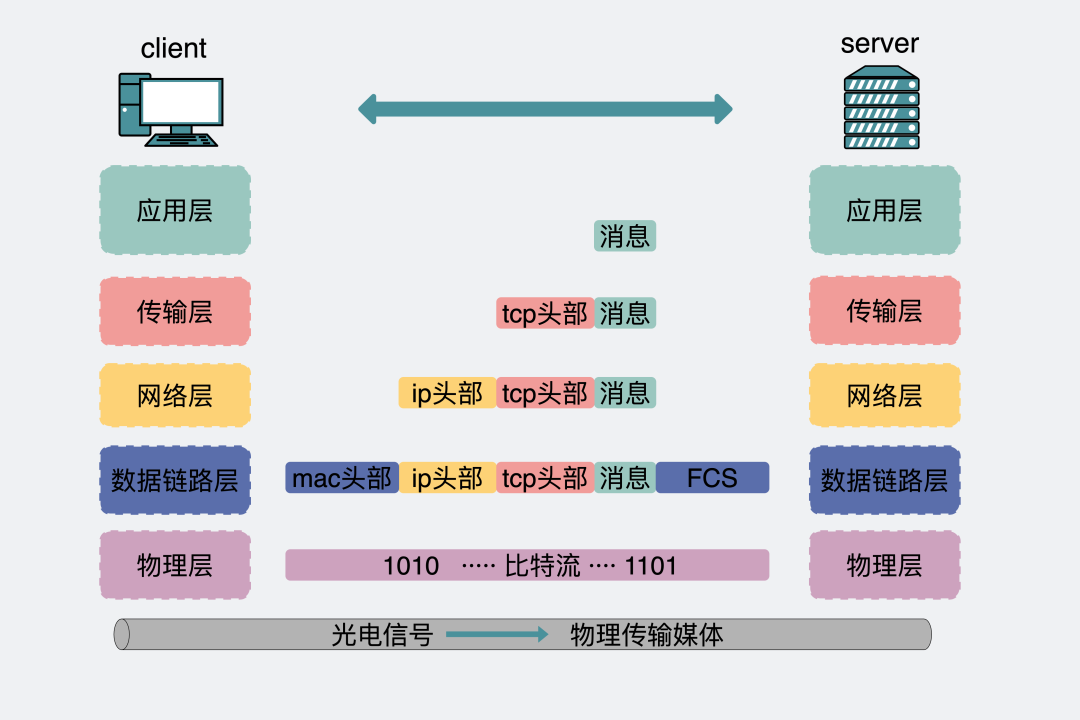
五层网络协议对应的消息体变化分析
就很奇怪了,明明服务端显示处理耗时才100ms,且客户端超时设的是3s, 怎么就出现超时报错i/o timeout呢?
这里推测有两个可能。
- 因为服务端打印的日志其实只是服务端应用层打印的日志。但客户端应用层发出数据后,中间还经过客户端的传输层,网络层,数据链路层和物理层,再经过服务端的物理层,数据链路层,网络层,传输层到服务端的应用层。服务端应用层处耗时100ms,再原路返回。那剩下的3s-100ms可能是耗在了整个流程里的各个层上。比如网络不好的情况下,传输层TCP使劲丢包重传之类的原因。
- 网络没问题,客户端到服务端链路整个收发流程大概耗时就是100ms左右。客户端处理逻辑问题导致超时。
一般遇到问题,大部分情况下都不会是底层网络的问题,大胆怀疑是自己的问题就对了,不死心就抓个包看下。
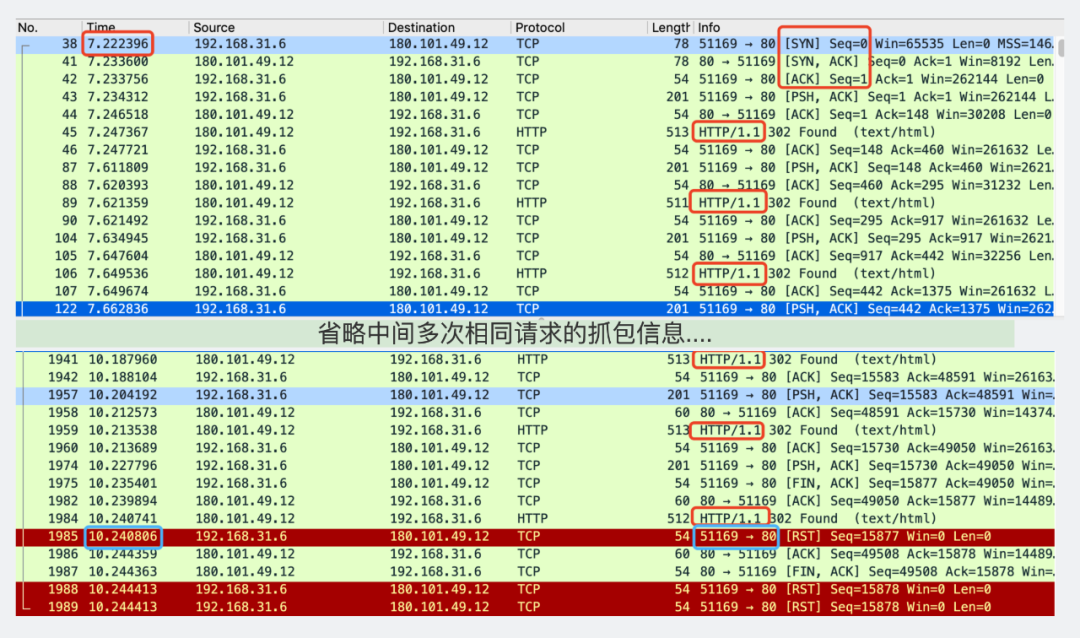
抓包结果
分析下,从刚开始三次握手(画了红框的地方)。
到最后出现超时报错i/o timeout(画了蓝框的地方)。
从time那一列从7到10,确实间隔3s。而且看右下角的蓝框,是51169端口发到80端口的一次Reset连接。
80端口是服务端的端口。换句话说就是客户端3s超时主动断开链接的。
但是再仔细看下第一行三次握手到最后客户端超时主动断开连接的中间,其实有非常多次HTTP请求。
回去看代码设置超时的方式。
tr = &http.Transport{
MaxIdleConns: 100,
Dial: func(netw, addr string) (net.Conn, error) {
conn, err := net.DialTimeout(netw, addr, time.Second*2) //设置建立连接超时
if err != nil {
return nil, err
}
err = conn.SetDeadline(time.Now().Add(time.Second * 3)) //设置发送接受数据超时
if err != nil {
return nil, err
}
return conn, nil
},
}也就是说,这里的3s超时,其实是在建立连接之后开始算的,而不是单次调用开始算的超时。
看注释里写的是
SetDeadline sets the read and write deadlines associated with theconnection.
大家知道HTTP是应用层协议,传输层用的是TCP协议。
HTTP协议从1.0以前,默认用的是短连接,每次发起请求都会建立TCP连接。收发数据。然后断开连接。
TCP连接每次都是三次握手。每次断开都要四次挥手。
其实没必要每次都建立新连接,建立的连接不断开就好了,每次发送数据都复用就好了。
于是乎,HTTP协议从1.1之后就默认使用长连接。具体相关信息可以看之前的这篇文章。
那么golang标准库里也兼容这种实现。
通过建立一个连接池,针对每个域名建立一个TCP长连接,比如http://baidu.com和http://golang.com就是两个不同的域名。
第一次访问http://baidu.com域名的时候会建立一个连接,用完之后放到空闲连接池里,下次再要访问http://baidu.com的时候会重新从连接池里把这个连接捞出来复用。
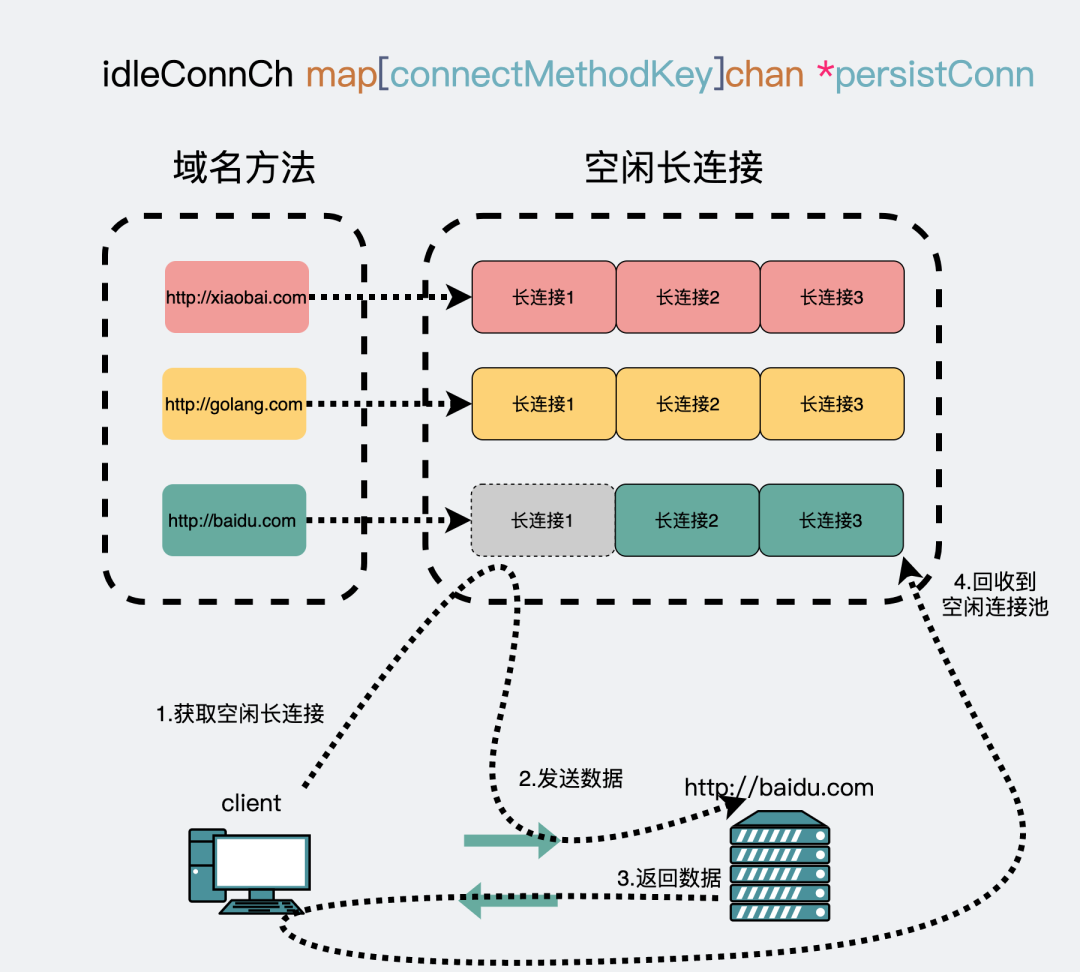
复用长连接
为什么要强调是同一个域名:一个域名会建立一个连接,一个连接对应一个读goroutine和一个写goroutine。正因为是同一个域名,所以最后才会泄漏3个goroutine,如果不同域名的话,那就会泄漏1+2*N个协程,N就是域名数。
假设第一次请求要100ms,每次请求完http://baidu.com后都放入连接池中,下次继续复用,重复29次,耗时2900ms。
第30次请求的时候,连接从建立开始到服务返回前就已经用了3000ms,刚好到设置的3s超时阈值,那么此时客户端就会报超时i/o timeout。
虽然这时候服务端其实才花了100ms,但耐不住前面29次加起来的耗时已经很长。
也就是说只要通过http.Transport设置了err = conn.SetDeadline(time.Now().Add(time.Second * 3)),并且用了长连接,哪怕服务端处理再快,客户端设置的超时再长,总有一刻,程序会报超时错误。
原本预期是给每次调用设置一个超时,而不是给整个连接设置超时。
另外,上面出现问题的原因是给长连接设置了超时,且长连接会复用。
基于这两点,改一下代码。
package main
import (
"bytes"
"encoding/json"
"fmt"
"io/ioutil"
"net/http"
"time"
)
var tr *http.Transport
func init() {
tr = &http.Transport{
MaxIdleConns: 100,
// 下面的代码被干掉了
//Dial: func(netw, addr string) (net.Conn, error) {
// conn, err := net.DialTimeout(netw, addr, time.Second*2) //设置建立连接超时
// if err != nil {
// return nil, err
// }
// err = conn.SetDeadline(time.Now().Add(time.Second * 3)) //设置发送接受数据超时
// if err != nil {
// return nil, err
// }
// return conn, nil
//},
}
}
func Get(url string) ([]byte, error) {
m := make(map[string]interface{})
data, err := json.Marshal(m)
if err != nil {
return nil, err
}
body := bytes.NewReader(data)
req, _ := http.NewRequest("Get", url, body)
req.Header.Add("content-type", "application/json")
client := &http.Client{
Transport: tr,
Timeout: 3*time.Second, // 超时加在这里,是每次调用的超时
}
res, err := client.Do(req)
if res != nil {
defer res.Body.Close()
}
if err != nil {
return nil, err
}
resBody, err := ioutil.ReadAll(res.Body)
if err != nil {
return nil, err
}
return resBody, nil
}
func main() {
for {
_, err := Get("http://www.baidu.com/")
if err != nil {
fmt.Println(err)
break
}
}
}看注释会发现,改动的点有两个
http.Transport里的建立连接时的一些超时设置干掉了。- 在发起http请求的时候会场景
http.Client,此时加入超时设置,这里的超时就可以理解为单次请求的超时了。同样可以看下注释
Timeout specifies a time limit forrequestsmade by this Client.
到这里,代码就改好了,实际生产中问题也就解决了。
实例代码里,如果拿去跑的话,其实还会下面的错
Get http://www.baidu.com/: EOF
这个是因为调用得太猛了,http://www.baidu.com那边主动断开的连接,可以理解为一个限流措施,目的是为了保护服务器,毕竟每个人都像这么搞,服务器是会炸的。。。
解决方案很简单,每次HTTP调用中间加个sleep间隔时间就好。
到这里,其实问题已经解决了,下面会在源码层面分析出现问题的原因。
用的go版本是1.12.7。
从发起一个网络请求开始跟。
res, err := client.Do(req)
func (c *Client) Do(req *Request) (*Response, error) {
return c.do(req)
}
func (c *Client) do(req *Request) {
// ...
if resp, didTimeout, err = c.send(req, deadline); err != nil {
// ...
}
// ...
}
func send(ireq *Request, rt RoundTripper, deadline time.Time) {
// ...
resp, err = rt.RoundTrip(req)
// ...
}
// 从这里进入 RoundTrip 逻辑
/src/net/http/roundtrip.go: 16
func (t *Transport) RoundTrip(req *Request) (*Response, error) {
return t.roundTrip(req)
}
func (t *Transport) roundTrip(req *Request) (*Response, error) {
// 尝试去获取一个空闲连接,用于发起 http 连接
pconn, err := t.getConn(treq, cm)
// ...
}
// 重点关注这个函数,返回是一个长连接
func (t *Transport) getConn(treq *transportRequest, cm connectMethod) (*persistConn, error) {
// 省略了大量逻辑,只关注下面两点
// 有空闲连接就返回
pc := <-t.getIdleConnCh(cm)
// 没有创建连接
pc, err := t.dialConn(ctx, cm)
}这里上面很多代码,其实只是为了展示这部分代码是怎么跟踪下来的,方便大家去看源码的时候去跟一下。
最后一个上面的代码里有个getConn方法。在发起网络请求的时候,会先取一个网络连接,取连接有两个来源。
- 如果有空闲连接,就拿空闲连接
// /src/net/http/tansport.go:810
func (t *Transport) getIdleConnCh(cm connectMethod) chan *persistConn {
// 返回放空闲连接的chan
ch, ok := t.idleConnCh[key]
// ...
return ch
}- 没有空闲连接,就创建长连接。
// /src/net/http/tansport.go:1357
func (t *Transport) dialConn() {
//...
conn, err := t.dial(ctx, "tcp", cm.addr())
// ...
go pconn.readLoop()
go pconn.writeLoop()
// ...
}当第一次发起一个http请求时,这时候肯定没有空闲连接,会建立一个新连接。同时会创建一个读goroutine和一个写goroutine。
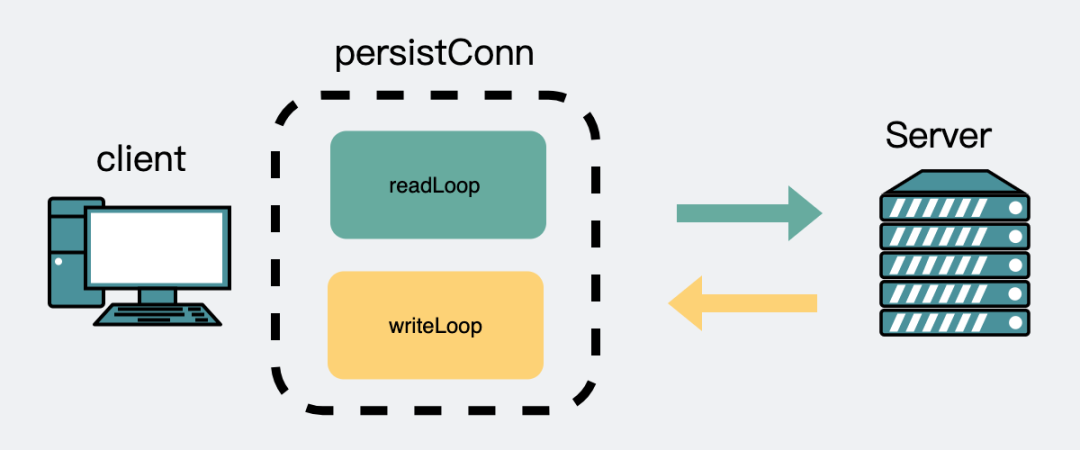
读写协程
注意上面代码里的t.dial(ctx, "tcp", cm.addr()),如果像文章开头那样设置了http.Transport的
Dial: func(netw, addr string) (net.Conn, error) {
conn, err := net.DialTimeout(netw, addr, time.Second*2) //设置建立连接超时
if err != nil {
return nil, err
}
err = conn.SetDeadline(time.Now().Add(time.Second * 3)) //设置发送接受数据超时
if err != nil {
return nil, err
}
return conn, nil
},那么这里就会在下面的dial里被执行到
func (t *Transport) dial(ctx context.Context, network, addr string) (net.Conn, error) {
// ...
c, err := t.Dial(network, addr)
// ...
}这里面调用的设置超时,会执行到
// /src/net/net.go
func (c *conn) SetDeadline(t time.Time) error {
//...
c.fd.SetDeadline(t)
//...
}
//...
func setDeadlineImpl(fd *FD, t time.Time, mode int) error {
// ...
runtime_pollSetDeadline(fd.pd.runtimeCtx, d, mode)
return nil
}
//go:linkname poll_runtime_pollSetDeadline internal/poll.runtime_pollSetDeadline
func poll_runtime_pollSetDeadline(pd *pollDesc, d int64, mode int) {
// ...
// 设置一个定时器事件
rtf = netpollDeadline
// 并将事件注册到定时器里
modtimer(&pd.rt, pd.rd, 0, rtf, pd, pd.rseq)
} 上面的源码,简单来说就是,当第一次调用请求的,会建立个连接,这时候还会注册一个定时器事件,假设时间设了3s,那么这个事件会在3s后发生,然后执行注册事件的逻辑。而这个注册事件就是netpollDeadline。注意这个netpollDeadline,待会会提到。
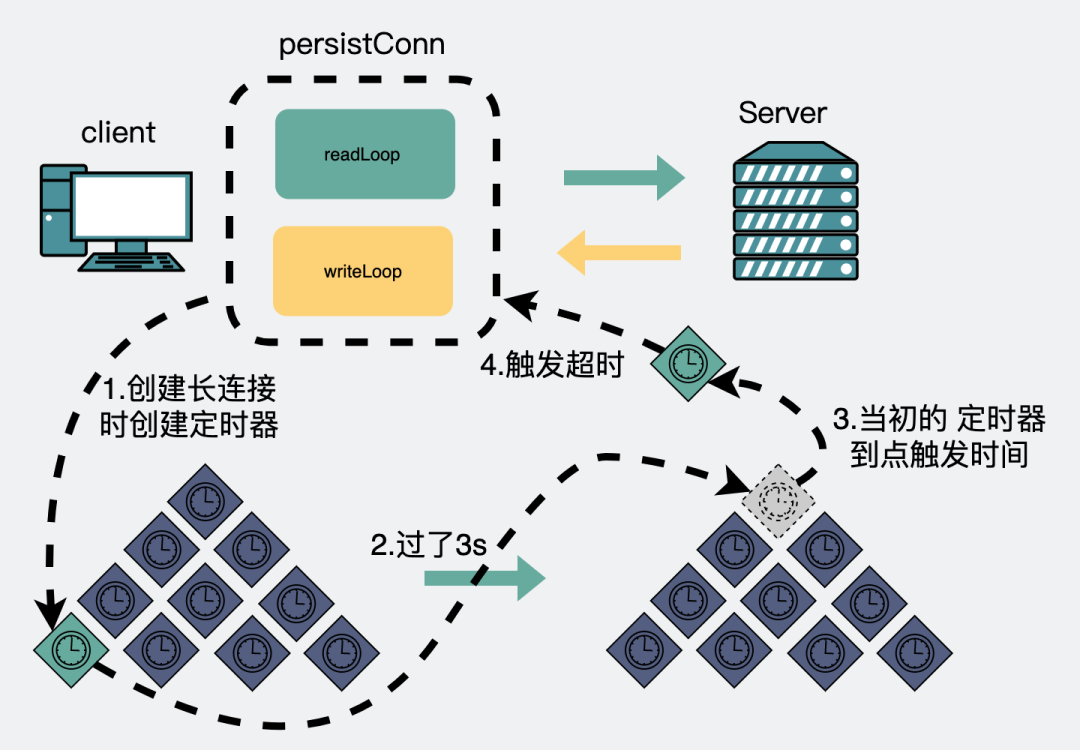
读写协程定时器事件
设置了超时事件,且超时事件是3s后之后,发生。再次期间正常收发数据。一切如常。
直到3s过后,这时候看读goroutine,会等待网络数据返回。
// /src/net/http/tansport.go:1642
func (pc *persistConn) readLoop() {
//...
for alive {
_, err := pc.br.Peek(1) // 阻塞读取服务端返回的数据
//...
}然后就是一直跟代码。
src/bufio/bufio.go: 129
func (b *Reader) Peek(n int) ([]byte, error) {
// ...
b.fill()
// ...
}
func (b *Reader) fill() {
// ...
n, err := b.rd.Read(b.buf[b.w:])
// ...
}
/src/net/http/transport.go: 1517
func (pc *persistConn) Read(p []byte) (n int, err error) {
// ...
n, err = pc.conn.Read(p)
// ...
}
// /src/net/net.go: 173
func (c *conn) Read(b []byte) (int, error) {
// ...
n, err := c.fd.Read(b)
// ...
}
func (fd *netFD) Read(p []byte) (n int, err error) {
n, err = fd.pfd.Read(p)
// ...
}
/src/internal/poll/fd_unix.go:
func (fd *FD) Read(p []byte) (int, error) {
//...
if err = fd.pd.waitRead(fd.isFile); err == nil {
continue
}
// ...
}
func (pd *pollDesc) waitRead(isFile bool) error {
return pd.wait('r', isFile)
}
func (pd *pollDesc) wait(mode int, isFile bool) error {
// ...
res := runtime_pollWait(pd.runtimeCtx, mode)
return convertErr(res, isFile)
}直到跟到runtime_pollWait,这个可以简单认为是等待服务端数据返回。
//go:linkname poll_runtime_pollWait internal/poll.runtime_pollWait
func poll_runtime_pollWait(pd *pollDesc, mode int) int {
// 1.如果网络正常返回数据就跳出
for !netpollblock(pd, int32(mode), false) {
// 2.如果有出错情况也跳出
err = netpollcheckerr(pd, int32(mode))
if err != 0 {
return err
}
}
return 0
}整条链路跟下来,就是会一直等待数据,等待的结果只有两个
- 有可以读的数据
- 出现报错
这里面的报错,又有那么两种
- 连接关闭
- 超时
func netpollcheckerr(pd *pollDesc, mode int32) int {
if pd.closing {
return 1 // errClosing
}
if (mode == 'r' && pd.rd < 0) || (mode == 'w' && pd.wd < 0) {
return 2 // errTimeout
}
return 0
}其中提到的超时,就是指这里面返回的数字2,会通过下面的函数,转化为ErrTimeout, 而ErrTimeout.Error()其实就是i/o timeout。
func convertErr(res int, isFile bool) error {
switch res {
case 0:
return nil
case 1:
return errClosing(isFile)
case 2:
return ErrTimeout // ErrTimeout.Error() 就是 "i/o timeout"
}
println("unreachable: ", res)
panic("unreachable")
}那么问题来了。上面返回的超时错误,也就是返回2的时候的条件是怎么满足的?
if (mode == 'r' && pd.rd < 0) || (mode == 'w' && pd.wd < 0) {
return 2 // errTimeout
}还记得刚刚提到的netpollDeadline吗?
这里面放了定时器3s到点时执行的逻辑。
func timerproc(tb *timersBucket) {
// 计时器到设定时间点了,触发之前注册函数
f(arg, seq) // 之前注册的是 netpollDeadline
}
func netpollDeadline(arg interface{}, seq uintptr) {
netpolldeadlineimpl(arg.(*pollDesc), seq, true, true)
}
/src/runtime/netpoll.go: 428
func netpolldeadlineimpl(pd *pollDesc, seq uintptr, read, write bool) {
//...
if read {
pd.rd = -1
rg = netpollunblock(pd, 'r', false)
}
//...
}这里会设置pd.rd=-1,是指poller descriptor.read deadline,含义网络轮询器文件描述符的读超时时间, 在linux里万物皆文件,这里的文件其实是指这次网络通讯中使用到的socket。
这时候再回去看发生超时的条件就是if (mode == 'r' && pd.rd < 0)。
至此。代码里就收到了io timeout的报错。
- 不要在
http.Transport中设置超时,那是连接的超时,不是请求的超时。否则可能会出现莫名io timeout报错。 - 请求的超时在创建
client里设置。
Go 语言让复杂的编码问题变得简单很多,极大的减轻了程序员的心智负担。为了方便对 unicode 字符串进行处理,Go 语言标准库提供三个包:unicode、unicode/utf8 和 unicode/utf16。
这里简单介绍下三个包的功能:
-
unicode:unicode 提供数据和函数来测试 Unicode 代码点(Code Point,用 rune 存储)的某些属性。
-
unicode/utf8:用于处理 UTF-8 编码的文本,提供一些常量和函数,包括在 rune(码点) 和 UTF-8 字节序列之间的转换。
-
unicode/utf16:函数比较少,主要是 UTF-16 序列的编码和解码。
Go 中字符串的写法。
在 Go 语言中,字符串字面值有 4 种写法,比如「徐新华」可以这么写:
s1 := "徐新华"
s2 := "\u5F90\u65B0\u534E"
s3 := "\U00005F90\U000065B0\U0000534E"
s4 := "\xe5\xbe\x90\xe6\x96\xb0\xe5\x8d\x8e"简单来生活就是 \u 紧跟四个十六进制数,\U 紧跟八个十六进制数。其中 \u 或 \U 代表后面是 Unicode 码点。而 \x 紧跟两个十六进制数,这些十六进制不是 Unicode 码点,而是 UTF-8 编码。
下面的代码有利于理解:
package main
import (
"fmt"
"unicode/utf8"
)
func main() {
s := `徐新华`
var (
buf = make([]byte, 4)
n int
)
fmt.Println("字符\tUnicode码点\tUTF-8编码十六进制\tUTF-8编码二进制")
for _, r := range s {
n = utf8.EncodeRune(buf, r)
fmt.Printf("%q\t%U\t\t%X\t\t%b\n", r, r, buf[:n], buf[:n])
}
s2 := "\u5F90\u65B0\u534E"
s3 := "\U00005F90\U000065B0\U0000534E"
s4 := "\xe5\xbe\x90\xe6\x96\xb0\xe5\x8d\x8e"
fmt.Println(s2)
fmt.Println(s3)
fmt.Println(s4)
}运行结果:
字符 Unicode码点 UTF-8编码十六进制 UTF-8编码二进制
'徐' U+5F90 E5BE90 [11100101 10111110 10010000]
'新' U+65B0 E696B0 [11100110 10010110 10110000]
'华' U+534E E58D8E [11100101 10001101 10001110]
徐新华
徐新华
徐新华此外,关于字符串其他方面的处理,比如编码转换等,可以到 https://pkg.go.dev/golang.org/x/text 里找。
一个字符使用多字节存储时,涉及到哪个在前哪个在后。以汉字「徐」为例,Unicode 码点是 5F90,需要用两个字节存储,一个字节是5F,另一个字节是90。存储的时候,5F在前,90 在后,这就是 Big endian 方式;90在前,5F在后,这是 Little endian 方式。
这两个古怪的名称来自英国作家斯威夫特的《格列佛游记》。在该书中,小人国里爆发了内战,战争起因是人们争论,吃鸡蛋时究竟是从大头(Big-endian)敲开还是从小头(Little-endian)敲开。为了这件事情,前后爆发了六次战争,一个皇帝送了命,另一个皇帝丢了王位。
第一个字节在前,就是"大端方式"(Big endian),第二个字节在前就是"小端方式"(Little endian)。
那么很自然的,就会出现一个问题:计算机怎么知道某一个文件到底采用哪一种方式编码?
Unicode 规范定义,每一个文件的最前面分别加入一个表示编码顺序的字符,这个字符的名字叫做"零宽度非换行空格"(zero width no-break space),用 FEFF 表示。这正好是两个字节,而且 FF 比 FE 大1。
如果一个文本文件的头两个字节是 FE FF,就表示该文件采用大端方式;如果头两个字节是 FF FE,就表示该文件采用小端方式。
但从上面关于 UTF-8 编码的说明可以看出,虽然 UTF-8 存在多字节表示一个字符的情况,但顺序是固定的,没有字节序的问题。Unix 系统下,UTF-8 没有任何前置字符,但 Windows 下记事本保存的 UTF-8 文件会带上 BOM(Byte Order Mark),即 EF BB BF 这三个字节。关于这一点,Unicode 之父 Rob Pike 明确说 UTF-8 不需要 BOM,所以一开始 Go 源文件是不允许有 BOM 的,否则编译不通过,不过现在已经可以有了。但建议还是别带 BOM。
UTF-8 带 BOM 说不是为了区分字节序,而是为了更方便的知晓这是一个 UTF-8 文件。
unsafe包下定义了一个ArbitratyType类型,代表了任意的Go表达式。
type ArbitraryType intPointer定义:
type Pointer *ArbitraryTypePointer代表了一个指向任意类型的指针,有四种只适用对Pointer而不适用于其他类型的操作。
-
任意类型的指针值可以被转换为一个
Pointer -
一个
Pointer可以被转换为任意类型的指针值 -
一个
uintptr可以被转换为一个Pointer -
一个
Pointer也可以被转换为一个uintptr
因此,Pointer可以跳过类型系统而直接指向任意类型。所以需要十分小心的使用。
关于使用Pointer的规则,不使用这些规则的代码是不可用的,或者在未来是不可用的。
前提是T2的大小不超过T1,而且两者的内存分布相同。
func Float64bits(f float64) uint64 { return *(*uint64)(unsafe.Pointer(&f))}把Pointer转换为uintptr将产生一个指向类型值的int变量。常用来打印一个uintptr。
将uintptr转换为Pointer是不可用的。
因为uintptr是一个整数值,而不是引用。就是说uintptr和指针没有任何关系。可以说是将Pointer指向的地址的值返回给uintptr,即使uintptr中的值对应的地址的对象更新了或者删除了,uintptr也不会改变。
如果Pointer指向一个分配的对象,那么如下转换可以把Pointer指针向后移动。
p = unsafe.Pointer(uintptr(p) + offset)最常用的是指向结构体中不同字段或者数组中的元素
// equivalent to f := unsafe.Pointer(&s.f)
f := unsafe.Pointer(uintptr(unsafe.Pointer(&s)) + unsafe.Offsetof(s.f))
// equivalent to e := unsafe.Pointer(&x[i])
e := unsafe.Pointer(uintptr(unsafe.Pointer(&x[0])) + i*unsafe.Sizeof(x[0]))这可以用来向前或向后移动指针,通过加或者减offset。指针移动之后,也应该指向该内存范围中。
将Pointer移动超过其对象的原始内存分配范围是不可用的,如:
// INVALID: end points outside allocated space.
var s thing
end = unsafe.Pointer(uintptr(unsafe.Pointer(&s)) + unsafe.Sizeof(s))
// INVALID: end points outside allocated space.
b := make([]byte, n)
end = unsafe.Pointer(uintptr(unsafe.Pointer(&b[0])) + uintptr(n))当然如下代码也是错误的,因为uintptr不可以储存在变量中:
// INVALID: uintptr cannot be stored in variable
// before conversion back to Pointer.
u := uintptr(p)
p = unsafe.Pointer(u + offset)
Pointer`必须指向一个已经分配好的对象,而不能是`nil
// INVALID: conversion of nil pointer
u := unsafe.Pointer(nil)
p := unsafe.Pointer(uintptr(u) + offset)syscall包下的Syscall函数把uintptr参数传递给操作系统,然后根据调用的相关信息,把相应的uintptr再转换为指针。
如果一个指针参数必须被转换为uintptr作为参数的话,这个转换只能在调用函数中的参数表达式完成,因为uintptr是不能储存在变量中的。
syscall.Syscall(SYS_READ, uintptr(fd), uintptr(unsafe.Pointer(p)), uintptr(n))编译器处理函数调用中的指针时,该指针所指向的对象会被保留到函数调用结束,即使该对象在函数调用时并不使用。
如下是错误的代码,因为uintptr不能保存在变量中
// INVALID: uintptr cannot be stored in variable
// before implicit conversion back to Pointer during system call.
u := uintptr(unsafe.Pointer(p))
syscall.Syscall(SYS_READ, uintptr(fd), u, uintptr(n))包reflect下Value的Pointer方法和UnsafeAddr方法返回的是uintptr而不是Pointer类型,以便于调用者不使用usafe包就可以转换为任意类型。这也意味着,这两个方法的返回值必须使用Pointer进行转换才可以使用:
p := (*int)(unsafe.Pointer(reflect.ValueOf(new(int)).Pointer()))因为这两个函数调用的返回值是uintptr,所以也是不可以变量储存的。
前面说过,返回uintptr是为了调用者可以直接进行不同类型的转换,而不用导入unsafe包。这意味着,只有当指针解析为切片或者字符串时SliceHeader和StringHeader才可以被使用。
var s string
hdr := (*reflect.StringHeader)(unsafe.Pointer(&s)) // case 1
hdr.Data = uintptr(unsafe.Pointer(p)) // case 6 (this case)
hdr.Len = n通常情况下,SliceHeader和StringHeader只能作为*SliceHeader和*StringHeader使用,而不可以使用其结构体形式。
// INVALID: a directly-declared header will not hold Data as a reference.
var hdr reflect.StringHeader
hdr.Data = uintptr(unsafe.Pointer(p))
hdr.Len = n
s := *(*string)(unsafe.Pointer(&hdr)) // p possibly already lost定义:
func Sizeof(x ArbitraryType) uintptr直接复制标准文档中的内容,下同。
Sizeof返回类型v本身数据所占用的字节数。返回值是“顶层”的数据占有的字节数。例如,若v是一个切片,它会返回该切片描述符的大小,而非该切片底层引用的内存的大小。
定义:
func Alignof(v ArbitraryType) uintptrAlignof返回类型v的对齐方式(即类型v在内存中占用的字节数);若是结构体类型的字段的形式,它会返回字段f在该结构体中的对齐方式。
定义:
func Offsetof(v ArbitraryType) uintptrOffsetof返回类型v所代表的结构体字段在结构体中的偏移量,它必须为结构体类型的字段的形式。换句话说,它返回该结构起始处与该字段起始处之间的字节数。
1.2中的Pointer和uintptr的区别:
假设在内存中有一个变量a := 1
那么p := Pointer(&a)中,p包含的就是a的实际地址,假设为1000,当a在内存中移动时,p中的地址值也会实时更新。
而uintprt(p)只是1000,就是a的地址值,但是当a在内存中移动时,原来获取的uintptr值并不会发生变化,一直都是1000。
也是因为这个原因,syscall.Syscall传入的uintptr如果代表一个对象的指针,那么该对象在内存中是一直被保留的,而且不能移动,否则的话uintptr指向的就不是原来的对象了,容易内存泄漏。
还有一个就是uintptr不能保存在变量中,只能使用Pointer进行转换然后才能保存。
HTTP 协议基于文本传输,字符编码将文本变为二进制,二进制编码将二进制变为文本。TCP 协议基于二进制传输,数据读取时需要处理字节序。本文将介绍常见的字符编码、二进制编码及字节序,并一探 Golang 中的实现。
引言:如何把“Hello world”变成字节?
-
Step1:得到要表示的全量字符(字符表)
-
Step2:为每个字符指定一个整数编号(编码字符集)
-
Step3:将编号映射成有限长度比特值(字符编码表)
字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。全世界共使用 5651 种语言,其中使用人数超过 5000 万的语言有 13 种,每种语言有自己的字符。汉语中,一个汉字就是一个字符。英语中,一个字母就是一个字符。甚至看不见的也可以是字符(如控制字符)。字符的集合即为字符表,如英文字母表,阿拉伯数字表。ASCII 码表中一共有 128 个字符。
为字符表中的每个字符指定一个编号(码点,Code Point),即得到编码字符集。常见有 ASCII 字符集、Unicode 字符集、GB2312 字符集、BIG5 字符集、 GB18030 字符集等。ASCII 字符集中一共有 128 个字符,包括了 94 个可打印字符(英文大小写字母 52 个、阿拉伯数字 10 个、西文符号 32 个)和 34 个控制符或通信专用字符,码点值范围为[0, 128),如下图所示。Unicode 字符集是一个很大的集合,现有容量将近 2^21 个字符,码点值范围为[0, 2^20+2^16)。
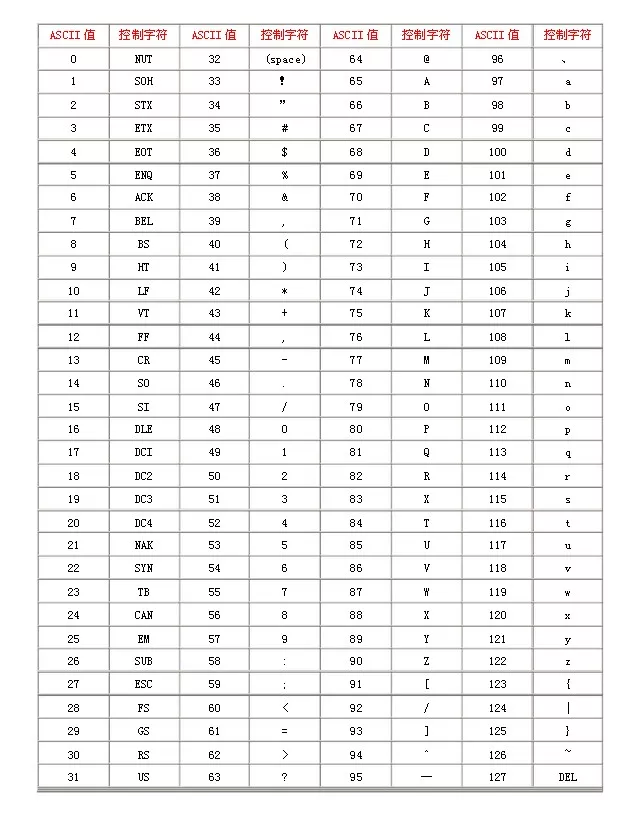
ASCII字符编码表
编码字符集只定义了字符与码点的映射,并没有规定码点的字节表示方式。由于 1 个字节可以表示 256 个编号,足以容纳 ASCII 字符集,因此ASCII 编码的规则很简单:直接将码点值用 uint8 表示即可。对于 Unicode 字符集,容纳 2^21 至少需要 3 字节。可以采用类似 ASCII 的编码规则:直接将编码点值用 uint32 表示即可,这正是 UTF-32 编码。
这种一刀切的定长编码方式虽然简单粗暴,弊端也很明显:对于纯英文文本,UTF-32 编码空间占用将是 ACSII 编码的 4 倍,造成极大的空间浪费,几乎没什么人用。有没有更优雅的解决方案?当然,这就是 UTF-8 和 UTF-16,两种当前比较流行的 Unicode 编码方式。
历史的经验,成功的设计往往具有包容性。UTF-8 是一个典型,漂亮的实现了对 ASCII 码的向后兼容,以保证可以被大众接受。UTF-8 是目前互联网上使用最广泛的一种 Unicode 编码方式,它的最大特点就是可变长,随码点变换长度(从 1 字节到 4 字节)。text
大道至简,优雅的设计一定是简单的,UTF-8 的编码规则也诠释了这一点。编码规则如下:
- <=127(U+7F)的码点采用单字节编码,与 ASCII 保持一致;
- >127(U+7F)的码点采用 N 字节(N 属于 2,3,4)编码,首字节的前 N 位为 1,第 N+1 位为 0,剩余 N-1 个字节的前两位都为 10,剩下的二进制位使用字符的码点来填充。
其中(U+7F)表示 Unicode 的十六进制码点值,即 127。如果觉得编码规则抽象,结合下表更加清晰:
| Unicode 码点范围 | 码点数量 | UTF-8 编码格式 |
|---|---|---|
| 0000 0000 ~ 0000 007F | 2^7 | 0xxxxxxx |
| 0000 0080 ~ 0000 07FF | 2^11 - 2^7 | 110xxxxx 10xxxxxx |
| 0000 0800 ~ 0000 FFFF | 2^16 - 2^11 | 1110xxxx 10xxxxxx 10xxxxxx |
| 0001 0000 ~ 0010 FFFF | 2^20 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
举个例子,如“汉”的 Unicode 码点是 U+6C49(110 1100 0100 1001),根据上表可得需要 3 字节编码,填充码点值后得到 0xE6 0xB7 0x89(11100110 10110001 10001001)。
根据编码规则,解码也很简单,关键是如何判断连续的字节数:首字节连续 1 的个数即为字节数。
需要一提的是,在 MySQL 中,utf8 是“虚假的 utf8”,最大只支持 3 个字节,如果建表时选择 CHARSET=utf8,会导致很多特殊字符和 emoji 表情都无法插入。utf8mb4 才是“真正的 utf8”,mb4 即most bytes 4。为什么 MySQL 中 utf8 最大只支持 3 字节?历史原因,在 MySQL 刚开发那会儿,Unicode 空间只有 2^16,Unicode 委员会还在做 “65535 个字符足够全世界用了”的美梦呢。
在 C/C++ 中遇到的wchar_t类型或 Java 中的char类型,这些类型占内存两个字节,因为 Unicode 中常用的字符都处于[U+0, U+FFFF](基本平面)的范围之内,因此两个字节几乎可以覆盖大部分的常用字符,这正是 UTF-16 编码的一个前提。
相比 UTF-32 与 UTF-8,UTF-16 编码是一个折中:小于(U+FFFF)2^16 的码点(基本平面)使用 2 字节编码,大于(U+FFFF)2^16 的码点(辅助码点)使用 4 字节编码。由于基础平面空间会占用 2 字节的所有比特位,无法像 UTF-8 那样留有“10”前缀。那么问题来了:当遇到两个节时,如何判断是 2 字节编码还是 4 字节编码?
UTF-16 的编码的另一个前提:在基本平面内,****[U+D800, U+DFFF]****是一个空段(空间大小为 2^11),这些码点不对应任何字符。因此,这个空段可以用来映射辅助平面的字符。
辅助平面容量为 2^20,至少需要 20 个二进制位,UTF-16 将这 20 个二进制位分成两半,前 10 位映射在 U+D800 到 U+DBFF(空间大小 2^10),称为高位(H),后 10 位映射在 U+DC00 到 U+DFFF(空间大小 2^10),称为低位(L)。
映射方式采用线性映射。Unicode3.0 中给出了辅助平面字符的转换公式:
H = Math.floor((c-0x10000) / 0x400) + 0xD800
L = (c - 0x10000) % 0x400 + 0xDC00
也就是说,一个辅助平面的码点,被拆成两个基本平面的空段码点表示。如果双字节的值在[U+D800, U+DBFF]中,则要和后续相邻的双字节一同解码。具体编码规则为:
- <= (U+FFFF)的码点采用双字节编码,直接将码点使用 uint16 表示;
- > (U+FFFF)的码点采用 4 字节编码,作差计算码点溢出值,将溢出值用 uint20 表示后,前 10 位映射到[U+D800, U+DBFF],后 10 位映射到[U+DC00, U+DFFF];
小结: 定长编码的优点是转换规则简单直观,查找效率高,缺点是空间浪费,以及不可扩展。如果 Unicode 字符集进一步扩充,UTF-16 和 UTF-32 都将不可用,而 UTF-8 具有更强的可扩展性。
不像 C++、Java 等语言支持五花八门的字符编码,Golang 遵从“大道至简”的原则:全用 UTF-8。所以 go 程序员再也不用担心乱码问题,甚至可以用汉字和表情包写代码,string 与字节数组转换也是直接转换。
func TestTemp(t *testing.T) {
来自打工人的问候()
}
func 来自打工人的问候() {
问候语 := "早安,打工人😁"
fmt.Println(问候语)
bytes := []byte(问候语)
fmt.Println(hex.EncodeToString(bytes))
}// 执行结果-->
早安,打工人😁
e697a9e5ae89efbc8ce68993e5b7a5e4babaf09f9881
值得一提的是,Golang 中 string 的底层模型就是字节数组,所以类型转换过程中无需编解码。也因此,Golang 中 string 的底层模型是字节数组,其长度并非字符数,而是对应字节数。如果要取字符数,需要先将字符串转换为字符数组。字符类型(rune)实际上是 int32 的别名,即用 UTF-32 编码表示字符。
func TestTemp(t *testing.T) {
fmt.Println(len("早")) // 3
fmt.Println(len([]byte("早"))) // 3
fmt.Println(len([]rune("早")) // 1
}
// rune is an alias for int32 and is equivalent to int32 in all ways. It is
// used, by convention, to distinguish character values from integer values.
type rune = int32再看一下 go 中 utf-8 编码的具体实现。首先获取字符的码点值,然后根据范围判断字节数,根据对应格式生成编码值。如果是无效的码点值,或码点值位于空段,则返回U+FFFD(即 �)。解码过程不再赘述。
// EncodeRune writes into p (which must be large enough) the UTF-8 encoding of the rune.
// It returns the number of bytes written.
func EncodeRune(p []byte, r rune) int {
// Negative values are erroneous. Making it unsigned addresses the problem.
switch i := uint32(r); {
case i <= rune1Max:
p[0] = byte(r)
return 1
case i <= rune2Max:
_ = p[1] // eliminate bounds checks
p[0] = t2 | byte(r>>6)
p[1] = tx | byte(r)&maskx
return 2
case i > MaxRune, surrogateMin <= i && i <= surrogateMax:
r = RuneError
fallthrough
case i <= rune3Max:
_ = p[2] // eliminate bounds checks
p[0] = t3 | byte(r>>12)
p[1] = tx | byte(r>>6)&maskx
p[2] = tx | byte(r)&maskx
return 3
default:
_ = p[3] // eliminate bounds checks
p[0] = t4 | byte(r>>18)
p[1] = tx | byte(r>>12)&maskx
p[2] = tx | byte(r>>6)&maskx
p[3] = tx | byte(r)&maskx
return 4
}
}
const(
t1 = 0b00000000
tx = 0b10000000
t2 = 0b11000000
t3 = 0b11100000
t4 = 0b11110000
t5 = 0b11111000
maskx = 0b00111111
mask2 = 0b00011111
mask3 = 0b00001111
mask4 = 0b00000111
rune1Max = 1<<7 - 1
rune2Max = 1<<11 - 1
rune3Max = 1<<16 - 1
RuneError = '\uFFFD' // the "error" Rune or "Unicode replacement character"
)
// Code points in the surrogate range are not valid for UTF-8.
const (
surrogateMin = 0xD800
surrogateMax = 0xDFFF
)引言:HTTP 是怎么传输二进制数据的?
-
Step1:定义字符集;
-
Step2:将二进制数据分组;
-
Step3:将每组映射为字符;
字符编码是「文本」变为「二进制」的过程,那如何将任意「二进制」变为「文本」?答案是进行二进制编码,常见有 Hex 编码与 Base64 编码。
显然不能按字符编码直接解码,因为字符编码的结果二进制是满足编码规律的,而非「任意」的,非法格式进行字符解码会出现乱码(比如对0b11xxxxxx进行 UTF-8 解码)。
Hex 编码是最直观的二进制编码方式,所见即所得。上文中的十六进制表示就是用的 Hex 编码。规则如下:
-
Hex 字符集为0123456789abcdef;
-
每 4bit 为 1 组(2^4=16);
-
每组映射为一个 Hex 字符;
计算机中二进制数据都是以字节为单位存储的,1 个字节 8bit,不会出现无法被 4 整除的情况。
每个字节编码为 2 个 Hex 字符,即编码后的字符数是原始数据字节数的 2 倍。在 ASCII 或 UTF-8 编码下,存储 Hex 结果字符串需要的空间是原始数据的 2 倍,存储效率为 50%。
Base64 编码,顾名思义,是基于 64 个字符进行编码。规则如下:
- Base64 字符集(以标准 Base64 为例, 26 大写, 26 小写, 10 数字, 以及+、/)为ABC...YZabc...yz012...89+/;
- 每 6bit 为一组(2^6=64),即每 3 个字节为 4 组;
- 每组映射为一个 Base64 字符;
如果要编码的二进制数据不是 3 的倍数,最后会剩下 1 个或 2 个字节怎么办?**标准编码(StdEncoding)**会先在末尾用 0x00 补齐再分组,并将最后 2 个或 1 个 6bit 分组(全为 0 填充)映射为'=',表示补齐的 0 字节数量。
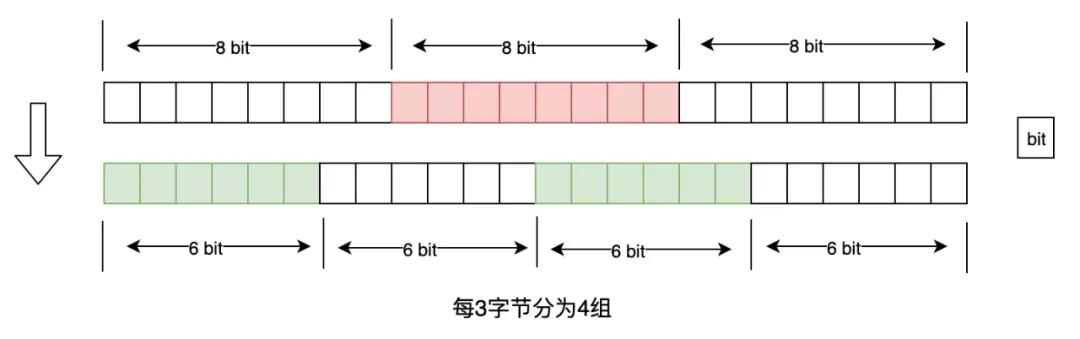
举个例子,以0x12 34 ab cd编码为标准 base64 为例:
- 不足 3 的倍数,先用两个 0 字节补齐 -->0x12 34 ab cd 00 00
- 0x12 34 ab编码为EjSr
- 0xcd 00 00二进制为0b1100 1101 0000 0000 0000 0000,分为 4 组后为110011 010000 000000 000000,编码结果为zQ==
- 最终编码结果为EjSrzQ==
解码过程注意末尾字节的处理即可,此处不再赘述。
- EjSrzQ==-->0x12 34 ab cd 00 00-->0x12 34 ab cd
标准编码中编码结果字符长度一定是 4 的倍数,且是原始数据字节数的 4/3 倍,因为会将字节数据补齐至 3 的倍数,每 3 个字节编码为 4 个字符。在 ASCII 或 UTF-8 编码下,存储结果字符串需要的空间是原始数据的 4/3 倍,存储效率为 75%。
根据字符集的不同,Base64 编码有几个变种,除了标准编码(StdEncoding),常见的还有 URL 编码(URLEncoding)、原始标准编码(RawStdEncoding)以及原始 URL 编码(RawUrlEncoded)。
简单来说,Raw 指的是无 Padding,URL 指的是用-和_取代编码结果中包含的 url 关键字+和/。不妨参考 Golang 中encoding/base64包中的描述:
// StdEncoding is the standard base64 encoding, as defined in
// RFC 4648.
var StdEncoding = NewEncoding(*encodeStd*)
// URLEncoding is the alternate base64 encoding defined in RFC 4648.
// It is typically used in URLs and file names.
var URLEncoding = NewEncoding(*encodeURL*)
// RawStdEncoding is the standard raw, unpadded base64 encoding,
// as defined in RFC 4648 section 3.2.
// This is the same as StdEncoding but omits padding characters.
var RawStdEncoding = StdEncoding.WithPadding(*NoPadding*)
// RawURLEncoding is the unpadded alternate base64 encoding defined in RFC 4648.
// It is typically used in URLs and file names.
// This is the same as URLEncoding but omits padding characters.
var RawURLEncoding = URLEncoding.WithPadding(*NoPadding*)与标准编码不同的是,原始编码中,字节数不足 3 的倍数时不会补齐字节数,采用如下方案:
- 如果剩余 1 字节,则左移 4bit 后转换为 2 字符;
- 如果剩余 2 字节,则左移 2bit 后转化为 3 字符;
即原始编码方案中,结果字符串长度可以不是 4 的倍数。
Hex 编码可以看成“Base16 编码”。随着字符数量的增加,存储效率也随之增加。如果有“Base256”编码,存储效率岂不就 100%了?很遗憾,主流字符编码中,单字节能表示的可打印字符只有 92 个。通过扩充多字节字符,或用组合字符实现 base256 意义不大。
看一下 Golang 中 Base64 编码的实现。首先通过EncodedLen方法确定结果长度,生成输出buf,然后通过Encode方法将编码结果填充到buf并返回结果字符串。
// EncodeToString returns the base64 encoding of src.
func (enc *Encoding) EncodeToString(src []byte) string {
buf := make([]byte, enc.EncodedLen(len(src)))
enc.Encode(buf, src)
return string(buf)
}如前述,标准编码和原始编码(无 Padding)的结果长度不同:如果需要 Padding,直接根据字节数计算即可,反之则需要根据 bit 数计算。
// EncodedLen returns the length in bytes of the base64 encoding
// of an input buffer of length n.
func (enc *Encoding) EncodedLen(n int) int {
if enc.padChar == *NoPadding* {
return (n*8 + 5) / 6 // minimum # chars at 6 bits per char
}
return (n + 2) / 3 * 4 // minimum # 4-char quanta, 3 bytes each
}Encode方法实现了编码细节。首先遍历字节数组,将每 3 个字节编码为 4 个字符。最后处理剩余的 1 或 2 个字节(如有):首先使用移位运算进行 0bit 填充,然后进行字符转换。如前述,无 Padding 时,剩下 1 字节对应 2 字符,剩下 2 字节对应 3 字符,即至少会有 2 字符。最后在switch代码段中,根据剩余字节数填充第 3 个字符和 Padding 字符(如有)即可。
func (enc *Encoding) Encode(dst, src []byte) {
if len(src) == 0 {
return
}
// enc is a pointer receiver, so the use of enc.encode within the hot
// loop below means a nil check at every operation. Lift that nil check
// outside of the loop to speed up the encoder.
_ = enc.encode
di, si := 0, 0
n := (len(src) / 3) * 3
for si < n {
// Convert 3x 8bit source bytes into 4 bytes
val := uint(src[si+0])<<16 | uint(src[si+1])<<8 | uint(src[si+2])
dst[di+0] = enc.encode[val>>18&0x3F]
dst[di+1] = enc.encode[val>>12&0x3F]
dst[di+2] = enc.encode[val>>6&0x3F]
dst[di+3] = enc.encode[val&0x3F]
si += 3
di += 4
}
remain := len(src) - si
if remain == 0 {
return
}
// Add the remaining small block
val := uint(src[si+0]) << 16
if remain == 2 {
val |= uint(src[si+1]) << 8
}
dst[di+0] = enc.encode[val>>18&0x3F]
dst[di+1] = enc.encode[val>>12&0x3F]
switch remain {
case 2:
dst[di+2] = enc.encode[val>>6&0x3F]
if enc.padChar != *NoPadding* {
dst[di+3] = byte(enc.padChar)
}
case 1:
if enc.padChar != *NoPadding* {
dst[di+2] = byte(enc.padChar)
dst[di+3] = byte(enc.padChar)
}
}
}引言:拿到两个字节,如何解析为整形?
- Step1:明确字节高低位顺序
- Step2:按高低位权重计算结果
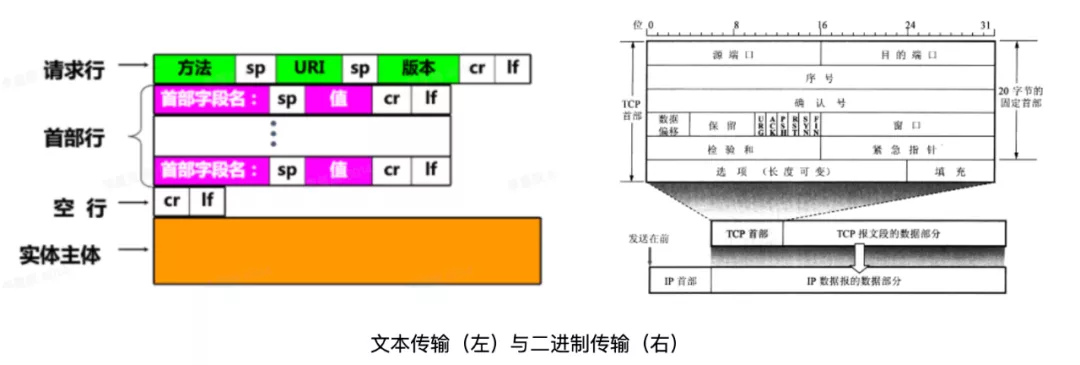
上述二进制编码主要用于文本传输,能不能不进行编码,直接传输二进制?当然可以,基于二进制传输协议,如 TCP 协议。那么什么是文本传输,什么是二进制传输?简单来说,文本传输,内容为文本,自带描述信息(参数名),如 HTTP 中的字段都以 KV 形式存在。二进制传输,内容为二进制,以预先定义好的格式拼在一起,如 TCP 协议报文格式。
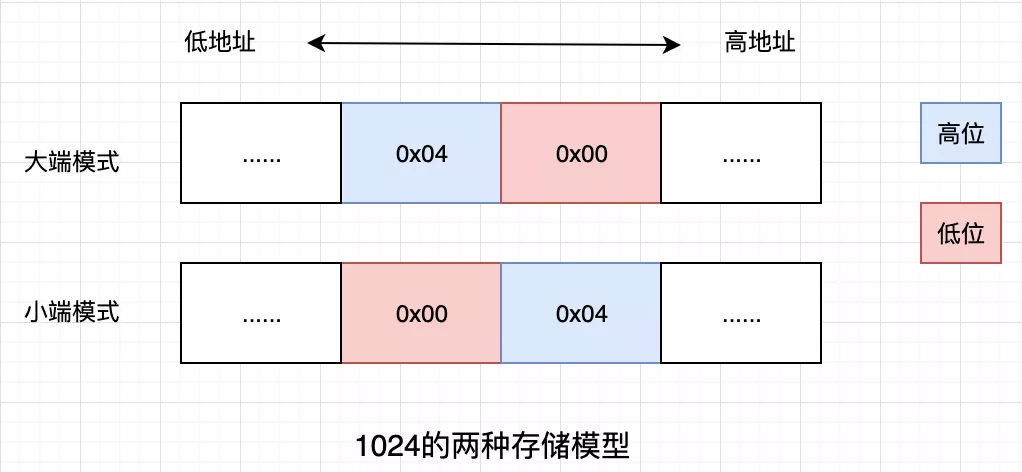
聊到二进制传输,一个避不开的话题是字节序。什么是字节序?假设读取到一个两字节的 uint16 0x04 0x00,如果从左往右(从高位往低位)解码,得到的是 1024,反过来(从低位往高位)解码则是 4,这就是字节序。符合人类阅读习惯的(从高位往低位)是大端(BigEndian),反之为小端(LittleEndian)。
另一种大小端的定义:LittleEndian 将低序字节存储在低地址,BigEndian 将高序字节存储在低地址。理解起来有些抽象,本质上是一致的。
为什么会有小端字节序,统一都用大端不好么?
计算机不这么想,因为计算机中计算都是从低位开始的,电路先处理低位字节效率比较高。但是,人类还是习惯读写大端字节序。所以,除了计算机的内部处理,其他的场合几乎都是大端字节序,比如网络传输和文件储存。
那什么时候程序员需要进行字节序处理呢?当多字节整形(uint16,uint32,uint64)需要和字节数组互相转换时。字节数组是无字节序的,客户端写入啥,服务端就读取啥,不会出现逆序,写入和读取无需考虑字节序,这点大可放心。只有当多字节整形和字节数组互转时必须指明字节序。
以 uint16 与字节数组互转为例,看一下 Golang 中 encoding/binary 包中的字节序处理与实现。可见实现并不复杂,注意字节顺序即可。
func TestEndian(t *testing.T) {
bytes := make([]byte, 2)
binary.LittleEndian.PutUint16(bytes, 1024) // 小端写 --> 0x0004
binary.BigEndian.PutUint16(bytes, 1024) // 大端写 --> 0x0400
binary.LittleEndian.Uint16(bytes) // 小端读 --> 4
binary.BigEndian.Uint16(bytes) // 大端读 --> 1024
}
func (littleEndian) PutUint16(b []byte, v uint16) {
_ = b[1] // early bounds check to guarantee safety of writes below
b[0] = byte(v)
b[1] = byte(v >> 8)
}
func (bigEndian) PutUint16(b []byte, v uint16) {
_ = b[1] // early bounds check to guarantee safety of writes below
b[0] = byte(v >> 8)
b[1] = byte(v)
}
func (littleEndian) Uint16(b []byte) uint16 {
_ = b[1] // bounds check hint to compiler; see golang.org/issue/14808
return uint16(b[0]) | uint16(b[1])<<8
}
func (bigEndian) Uint16(b []byte) uint16 {
_ = b[1] // bounds check hint to compiler; see golang.org/issue/14808
return uint16(b[1]) | uint16(b[0])<<8
}在加解密场景中,通常会对明文加密得到密文,对密文解密得到明文。比如对密码"123456"(明文)进行对称加密(如 SM4)得到"G7EeTPnuvSU41T68qsuc_g"(密文)。明文和密文都是由可打印字符构成的文本,通常明文人类可直接阅读其含义(不考虑二次加密),密文需要解密后才能理解含义。
那么上述明文变成密文,期间经历了哪些编码过程呢?以加密为例:
- 将明文"123456"进行字符解码(如 UTF-8),得到明文字节序列0x31 32 33 34 35 36;
- 将明文字节序列输入 SM4 加密算法,输出密文字节序列0x1b b1 1e 4c f9 ee bd 25 38 d5 3e bc aa cb 9c fe;
- 将密文字节序列进行二进制编码(如 RawURLBase64),得到密文"G7EeTPnuvSU41T68qsuc_g";
同理,将"G7EeTPnuvSU41T68qsuc_g"解密成"123456"过程中,应与加密过程的编码方式对应:先进行 RawRULBase64 解码,再解密,最后再进行 UTF-8 编码。
加解密算法的输入输出都是字节序列,所以要将明文、密文与字节序列进行转换。有两点需要注意:
- 明文解码为明文字节序列,解码方式因场景而定。对于多次加密场景(如对“G7EeTPnuvSU41T68qsuc_g”再次加密),明文是 Base64 编码得到的,建议采用一致的方式解码。虽然也可以直接进行 UTF-8 解码,但会使加解密流程设计变得复杂。
- 密文字节序列编码为密文,必须用二进制编码,不能用字符编码。使用字符编码会产生乱码(意味着数据丢失,无法逆向解码出原始数据)。上述密文序列密文序列进行 UTF-8 编码的结果是 �L���%8�>��˜�。
合规要求,加解密场景中应使用硬件加密机。通常硬件加密机提供基于 TCP 的字节流通信方式,比如约定每次通信数据中的前 2 字节为数据长度,后面的为真实数据。发送时,需要将真实数据长度转为 2 字节拼在前面,接收时,需要先读取前两字节得到真实数据长度 N,再读取 N 字节得到真实数据。其中长度与字节序列的转换需要关注字节序:发送方和接收方的字节序处理保持一致即可,比如全用大端。下面给出了数据发送的示例代码:
func (m *EncryptMachine) sendData(conn net.Conn, data []byte) error {
// add length
newData := m.addLength(data)
// send new data
return util.SocketWriteData(conn, newData)
}
func (m *EncryptMachine) addLength(data []byte) []byte {
lengthBytes := make([]byte, 2)
binary.BigEndian.PutUint16(lengthBytes, uint16(len(data)))
return append(lengthBytes, data...)
}编码虽然基础,但却容易出错,切莫眼高手低。希望本文能帮助大家进一步了解字符编码、二进制编码与字节序,避免踩坑。
未完,待续