diff --git a/README.md b/README.md
index edb05a8a8..cfbe55dd8 100644
--- a/README.md
+++ b/README.md
@@ -48,15 +48,25 @@ The purpose is to build infrastructure in the field of large models, through the
### AI-Native Data App
---
-- 🔥🔥🔥 [Released V0.5.0 | Develop native data applications through workflows and agents](https://docs.dbgpt.site/docs/changelog/Released_V0.5.0)
+- 🔥🔥🔥 [Released V0.6.0 | A set of significant upgrades](https://docs.dbgpt.cn/docs/changelog/Released_V0.6.0)
+ - [The AWEL upgrade to 2.0]()
+ - [GraphRAG]()
+ - [AI Native Data App construction and management]()
+ - [The GPT-Vis upgrade, supporting a variety of visualization charts]()
+ - [Support Text2NLU and Text2GQL fine-tuning]()
+ - [Support Intent recognition, slot filling, and Prompt management]()
+
+
+- [Released V0.5.0 | Develop native data applications through workflows and agents](http://docs.dbgpt.cn/docs/changelog/Released_V0.5.0)
---
-
+
-
+
-
+
+
## Contents
- [Introduction](#introduction)
@@ -197,8 +207,6 @@ At present, we have introduced several key features to showcase our current capa
- Support Datasources
- [Datasources](http://docs.dbgpt.site/docs/modules/connections)
-
-
## Image
🌐 [AutoDL Image](https://www.codewithgpu.com/i/eosphoros-ai/DB-GPT/dbgpt)
@@ -216,7 +224,6 @@ At present, we have introduced several key features to showcase our current capa
-
## Licence
The MIT License (MIT)
diff --git a/README.zh.md b/README.zh.md
index b75879a26..02c7bae28 100644
--- a/README.zh.md
+++ b/README.zh.md
@@ -48,16 +48,27 @@
### AI原生数据智能应用
---
-- 🔥🔥🔥 [V0.5.0发布——通过工作流与智能体开发原生数据应用](https://www.yuque.com/eosphoros/dbgpt-docs/owcrh9423f9rqkg2)
+- [V0.6.0发布——一系列重大功能更新](https://www.yuque.com/eosphoros/dbgpt-docs/fho86kk4e9y4rkpd)
+ - AWEL协议升级2.0,支持更复杂的编排,同时优化了前端可视化与交互能力。
+ - 支持数据应用的创建与生命周期管理,提供多种应用构建模式。1. 多智能体自动规划模式、2. 任务流编排模式、3. 单一智能体模式、4. 原生应用模式
+ - GraphRAG支持图社区摘要与混合检索,性能与检索效果有显著优势,同时支持丰富的前端可视化。
+ - 支持意图识别、槽位填充与Prompt管理。
+ - GPT-Vis前端可视化升级,支持更丰富的可视化图表。
+ - 支持Text2NLU与Text2GQL微调, 即新增意图分类与从自然语言到图语言的微调。
+
+- [V0.5.0发布——通过工作流与智能体开发原生数据应用](https://www.yuque.com/eosphoros/dbgpt-docs/owcrh9423f9rqkg2)
---
### Data Agents
-
+
-
+
+
+
+
+
-
## 目录
- [架构方案](#架构方案)
diff --git a/docs/blog/2024-09-04-dbgpt-v0.6.0-Defining new standards for AI-native data applications.md b/docs/blog/2024-09-04-dbgpt-v0.6.0-Defining new standards for AI-native data applications.md
new file mode 100644
index 000000000..f59cc67d7
--- /dev/null
+++ b/docs/blog/2024-09-04-dbgpt-v0.6.0-Defining new standards for AI-native data applications.md
@@ -0,0 +1 @@
+# DB-GPT V0.6.0, Defining new standards for AI-native data applications.
\ No newline at end of file
diff --git a/docs/docs/application/app_usage.md b/docs/docs/application/app_usage.md
deleted file mode 100644
index 7dfe1c7d9..000000000
--- a/docs/docs/application/app_usage.md
+++ /dev/null
@@ -1,59 +0,0 @@
-# Data App Usage
-
-Starting with version 0.5.0, the DB-GPT project has natively integrated the management and distribution of data-centric applications. The application management repository is also part of the open-source [dbgpts](https://github.com/eosphoros-ai/dbgpts) project. The [dbgpts](https://github.com/eosphoros-ai/dbgpts) project manages and shares resources categorized into the following:
-
-- [apps](https://github.com/eosphoros-ai/dbgpts/tree/main/apps): These are native intelligent data applications developed using the DB-GPT framework.
-- [workflow](https://github.com/eosphoros-ai/dbgpts/tree/main/workflow): Workflows constructed using the AWEL (Agentic Workflow Expression Language).
-- [agents](https://github.com/eosphoros-ai/dbgpts/tree/main/agents): Intelligent agents that can perform various tasks.
-- [operators](https://github.com/eosphoros-ai/dbgpts/tree/main/operators): Basic operational operators (or symbols) that can be used within workflows.
-
-:::info NOTE
-
-Please note that this tutorial primarily focuses on the installation and use of intelligent agent workflows. For the development of applications, you should refer to the `Development Guide`.
-
-Support for these capabilities is provided from version V0.5.0 onwards. For developers and teams looking to build and distribute their applications through DB-GPT, this structured approach provides both a framework and ecosystem for creating, sharing, and managing data applications effectively.
-:::
-
-Here we introduce the creation of a data intelligence analysis assistant application. This tutorial utilizes the auto-planning capability of Multi-Agents.
-
-The effect is as follows:
-
-
-  -
-
-
-In the application panel, click on `Create Application` and fill in the parameters as shown in the image. It is important to note that the work mode selected here is `auto_plan`. This involves the collaboration of two dependent Agents: 1. DataScientist and 2. Reporter. Both of these agents depend on the resource `database`, and for testing, you can use the default database and data provided in the official tutorial.
-
-Special Note: Currently, in auto-plan mode, the building of applications is conducted through multiple Agents. This project has a number of built-in Agents, which currently include:
-- [CodeEngineer](https://github.com/eosphoros-ai/DB-GPT/blob/main/dbgpt/agent/agents/expand/code_assistant_agent.py)
-- [Reporter](https://github.com/eosphoros-ai/DB-GPT/blob/main/dbgpt/agent/agents/expand/dashboard_assistant_agent.py)
-- [DataScientist](https://github.com/eosphoros-ai/DB-GPT/blob/main/dbgpt/agent/agents/expand/data_scientist_agent.py)
-- [ToolExpert](https://github.com/eosphoros-ai/DB-GPT/blob/main/dbgpt/agent/agents/expand/plugin_assistant_agent.py)
-- [RetrieveSummarizer](https://github.com/eosphoros-ai/DB-GPT/blob/main/dbgpt/agent/agents/expand/retrieve_summary_assistant_agent.py)
-- [Summarizer](https://github.com/eosphoros-ai/DB-GPT/blob/main/dbgpt/agent/agents/expand/summary_assistant_agent.py)
-
-If you wish to expand and implement customized Agents, you can refer to the `Agents Development Guide`.
-
-
-  -
-
-
-
-  -
-
-
-After adding the necessary information, choose to submit to complete the creation of the application. In the application panel, click the dialogue button to enter the dialogue interface.
-
-
-  -
-
-
-
-  -
-
-
-
-# Summary
-This tutorial is just a simple introduction to application construction. If you are interested in more complex applications, you can achieve more intricate scenarios by orchestrating AWEL workflows and customizing the expansion of Agents.
-
-
diff --git a/docs/docs/application/apps/app_chat.md b/docs/docs/application/apps/app_chat.md
new file mode 100644
index 000000000..fcb1c6f6a
--- /dev/null
+++ b/docs/docs/application/apps/app_chat.md
@@ -0,0 +1,15 @@
+# App Chat
+
+The online Chat interface provides the main conversation capabilities, showing the historical conversation records and the application currently in conversation. As shown in the figure below, clicking any smart application will also jump to this interface.
+
+
+  +
+
+
+In the dialogue interface, a series of operations such as refreshing and pausing the dialogue are supported. The specific operation buttons are in the edit box at the bottom right. At the same time, the dialog box also provides a variety of parameter selections, such as model selection, temperature parameter adjustment, file upload, etc.
+
+
+  +
+
+
+If you find new problems or have good ideas during use, you can also directly post them on Github [issue](https://github.com/eosphoros-ai/DB-GPT/issues) feedback.
diff --git a/docs/docs/application/apps/app_explore.md b/docs/docs/application/apps/app_explore.md
new file mode 100644
index 000000000..0a84fb2b1
--- /dev/null
+++ b/docs/docs/application/apps/app_explore.md
@@ -0,0 +1,17 @@
+# App Explore
+
+In the new version of DB-GPT V0.6.0, the application management has been comprehensively upgraded. The search square module is mainly used to discover various interesting, fun and useful data applications.KeywordsIn addition to searching for apps, it also provides popular recommendations, comprehensive apps, my favorites, etc.
+
+After the default installation, the previous six application scenarios are retained.
+
+- [Chat Excel](chat_excel.md)
+- Chat Normal
+- [Chat DB](chat_db.md)
+- [Chat DashBoard](chat_dashboard.md)
+- [Chat Data](chat_data.md)
+- [Chat Knowledge Base](chat_knowledge.md)
+
+
+
+  +
+
\ No newline at end of file
diff --git a/docs/docs/application/apps/app_manage.md b/docs/docs/application/apps/app_manage.md
new file mode 100644
index 000000000..02fda4e82
--- /dev/null
+++ b/docs/docs/application/apps/app_manage.md
@@ -0,0 +1,55 @@
+# App Manage
+
+The application management panel provides many capabilities. Here we mainly introduce the management of the data intelligence application life cycle, including application creation, editing, deletion, and use.
+
+
+  +
+
+
+As shown in the figure, the application management interface. First, let's take a look at the creation of an application. In DB-GPT, four application creation modes are provided.
+
+- Multi-agent automatic planning mode
+- Task flow orchestration mode
+- Single Agent Mode
+- Native application mode
+
+
+  +
+
+
+Next, we will explain the creation of applications in each mode respectively. Native application mode In the early versions of DB-GPT, six types of native application scenarios were provided, such as `Chat DB`, `Chat Data`, `Chat Dashboard`, `Chat Knowledge Base`, `Chat Normal`, `Chat Excel`, etc.
+
+By creating a data intelligence application in the native application mode, you can quickly build a similar application based on your own database, knowledge base and other parameters. Click the upper right cornerCreate an applicationbutton, select **Native application mode**, enter the application name and description, click **Sure**
+
+
+  +
+
+
+After confirmation, enter the parameter selection panel. As shown in the figure below, we can see selection boxes such as application type, model, temperature, and recommended questions.
+
+
+  +
+
+
+Here, we select **Chat Data** Application, fill in the parameters in order according to the requirements. Note that in the data dialogue application, the parameter column needs to fill in the data source. If you do not have a data source, you need to follow [Data Source Tutorial](../datasources.md) to add it.
+
+
+After completing the parameters, click **Save** to view related applications in the application panel.
+
+
+  +
+
+
+Please note that after creating an application, there is a **Publish Application** button. Only after the application is published can it be discovered and used by other users.
+
+
+  +
+
+
+Finally, click the **Start a conversation** button to start a conversation with the application you just created.
+
+
+  +
+
+
+In addition, you can also edit and delete applications. Just operate on the corresponding interface.
diff --git a/docs/docs/application/started_tutorial/chat_dashboard.md b/docs/docs/application/apps/chat_dashboard.md
similarity index 71%
rename from docs/docs/application/started_tutorial/chat_dashboard.md
rename to docs/docs/application/apps/chat_dashboard.md
index f167d1643..fd5d71ba9 100644
--- a/docs/docs/application/started_tutorial/chat_dashboard.md
+++ b/docs/docs/application/apps/chat_dashboard.md
@@ -6,7 +6,7 @@ Report analysis corresponds to the `Chat Dashboard` scenario in DB-GPT, and inte
The following are the steps for using report analysis:
- 1.Data preparation
- 2.Add data source
-- 3.Select Chat Dashboard
+- 3.Select Chat Dashboard App
- 4.Start chat
@@ -27,38 +27,25 @@ python docker/examples/dashboard/test_case_mysql_data.py
The steps to add a data source are the same as [Chat Data](./chat_data.md). Select the corresponding database type in the data source management tab, then create it. Fill in the necessary information to complete the creation.
-
-  -
-
-
-
### Select Chat Dashboard
After the data source is added, select `Chat Dashboard` on the home scene page to perform report analysis.
-
-  +
+
+ 
-
### Start chat
Enter specific questions in the dialog box on the right to start a data conversation.
-
-  -
-
-
-
:::info note
-⚠️ Data dialogue has relatively high requirements on model capabilities, and `ChatGPT/GPT-4` has a high success rate. Other open source models you can try `Vicuna-13B`
+⚠️ Data dialogue has relatively high requirements on model capabilities, and `ChatGPT/GPT-4` has a high success rate. Other open source models you can try `qwen2`
:::
-Of course, in addition to `preview mode`, `editor mode` is also provided. In editor mode, SQL can be edited and modified. You can see the changes in the chart synchronously.
-
-
-  -
-
+
+  +
+
\ No newline at end of file
diff --git a/docs/docs/application/apps/chat_data.md b/docs/docs/application/apps/chat_data.md
new file mode 100644
index 000000000..2a7285d9a
--- /dev/null
+++ b/docs/docs/application/apps/chat_data.md
@@ -0,0 +1,36 @@
+# Chat Data
+
+Chat data capability is to dialogue with data through natural language. Currently, it is mainly dialogue between structured and semi-structured data, which can assist in data analysis and insight.
+
+:::info note
+
+Before starting the data conversation, we first need to add the data source
+:::
+
+## steps
+
+To start a data conversation, you need to go through the following steps:
+- 1.Add data source
+- 2.Select ChatData
+- 3.Select the corresponding database
+- 4.Start a conversation
+
+### Add data source
+
+First, select the [data source](../datasources.md) on the left to add and add a database. Currently, DB-GPT supports multiple database types. Just select the corresponding database type to add. Here we choose MySQL as a demonstration. For the test data of the demonstration, see the [test sample](https://github.com/eosphoros-ai/DB-GPT/tree/main/docker/examples/sqls).
+
+
+### Choose ChatData App
+
+
+  +
+
+
+### Start a conversation
+
+
+  +
+
+
+
+
diff --git a/docs/docs/application/started_tutorial/chat_db.md b/docs/docs/application/apps/chat_db.md
similarity index 100%
rename from docs/docs/application/started_tutorial/chat_db.md
rename to docs/docs/application/apps/chat_db.md
diff --git a/docs/docs/application/started_tutorial/chat_excel.md b/docs/docs/application/apps/chat_excel.md
similarity index 59%
rename from docs/docs/application/started_tutorial/chat_excel.md
rename to docs/docs/application/apps/chat_excel.md
index cb1a2ccaf..fdbc7aaf6 100644
--- a/docs/docs/application/started_tutorial/chat_excel.md
+++ b/docs/docs/application/apps/chat_excel.md
@@ -11,46 +11,35 @@ Chat Excel means that you can interpret and analyze Excel data through natural l
## Steps
The steps to use Chat Excel are relatively simple and are mainly divided into the following steps:
-- 1.Select Chat Excel dialogue scene
+- 1.Select Chat Excel dialogue app
- 2.Upload Excel document
- 3.Start chat
### Select `Chat Excel`
-
-
-  +
+
+ 
### Upload Excel document
+
+  +
+
+
:::info note
⚠️ the Excel file format is converted to `.csv` format
:::
-
-  -
-
After the upload is successful, the content will be summarized by default and some questioning strategies will be recommended.
-
-  -
-
-
### Start chat
You can then start a conversation based on the uploaded file.
-
-  -
-
-
-
-Use open source models
-
-
-  -
-
+
+  +
+
\ No newline at end of file
diff --git a/docs/docs/application/started_tutorial/chat_financial_report.md b/docs/docs/application/apps/chat_financial_report.md
similarity index 100%
rename from docs/docs/application/started_tutorial/chat_financial_report.md
rename to docs/docs/application/apps/chat_financial_report.md
diff --git a/docs/docs/application/started_tutorial/chat_knowledge.md b/docs/docs/application/apps/chat_knowledge.md
similarity index 83%
rename from docs/docs/application/started_tutorial/chat_knowledge.md
rename to docs/docs/application/apps/chat_knowledge.md
index 4d4c57652..33ff26b5b 100644
--- a/docs/docs/application/started_tutorial/chat_knowledge.md
+++ b/docs/docs/application/apps/chat_knowledge.md
@@ -1,11 +1,10 @@
-# Chat Knowledge
+# Chat Knowledge Base
-`Chat knowledge` provides the ability to question and answer questions based on private domain knowledge, and can build intelligent question and answer systems, reading assistants and other products based on the `knowledge base`. `RAG` technology is also used in DB-GPT to enhance knowledge retrieval.
+`Chat knowledge Base` provides the ability to question and answer questions based on private domain knowledge, and can build intelligent question and answer systems, reading assistants and other products based on the `knowledge base`. `RAG` technology is also used in DB-GPT to enhance knowledge retrieval.
## Noun explanation
-
:::info note
`Knowledge Space`: is a document space that manages a type of knowledge. Document knowledge of the same type can be uploaded to a knowledge space.
@@ -17,17 +16,23 @@ The knowledge base operation process is relatively simple and is mainly divided
- 1.Create knowledge space
- 2.Upload documents
- 3.Wait for document vectorization
-- 4.Knowledge base chat
+- 4.Select Knowledge Base App
+- 5.Chat With App
### Create knowledge space
-Select the knowledge base, click the `Create` button, and fill in the necessary information to complete the creation of the knowledge space.
+At first open the `Construct App` and select the `Knowledge` on the top.
+
+
+  +
+
+Select the knowledge base, click the `Create` button, and fill in the necessary information to complete the creation of the knowledge space.
-
-  +
+
+ 
### Upload documents
diff --git a/docs/docs/application/awel.md b/docs/docs/application/awel.md
new file mode 100644
index 000000000..d5e78461b
--- /dev/null
+++ b/docs/docs/application/awel.md
@@ -0,0 +1,7 @@
+# Use Data App With AWEL
+
+
+## Reference
+- [AWEL](../awel/awel.md)
+- [AWEL CookBook](../awel/cookbook/)
+- [AWEL Tutorial](../awel/awel_tutorial/)
diff --git a/docs/docs/application/awel_flow_usage.md b/docs/docs/application/awel_flow_usage.md
deleted file mode 100644
index 282fb52ef..000000000
--- a/docs/docs/application/awel_flow_usage.md
+++ /dev/null
@@ -1,75 +0,0 @@
-# AWEL Flow Usage
-
-:::info NOTE
-
-⚠️ Please note that this tutorial mainly introduces the installation and use of agent workflows. For the development of workflows, please refer to the `Development Guide`.
-This capability is supported after version V0.5.0.
-:::
-
-
-  -
-
-
-As shown in the picture, this is the management and editing interface for DB-GPT workflows. Intelligent agents can be orchestrated into definitive workflows using the Agentic Workflow Expression Language (AWEL). These workflows can be used for subsequent application creation.
-
-
-  -
-
-
-## Workflow Installation
-
-As part of this introductory tutorial, we will cover the installation and use of workflows.
-
-Before you can start using workflows, you need to complete the installation and deployment of DB-GPT. For detailed deployment instructions, you can refer to the quick start guide. Once the project is deployed, you can begin installing and using AWEL workflows. The DB-GPT official provides an application repository that can be used for installation. Here, we will use the command line for operation. Execute `dbgpt --help` in the terminal to check if the command line is installed correctly.
-
-
-  -
-
-
-As illustrated, the dbgpt command supports various operations, including model-related tasks, knowledge base interactions, Trace logs, and more. Here, we will focus on the operations related to apps.
-
-
-  -
-
-
-By using the `dbgpt app list-remote` command, we can see that there are three available AWEL workflows in the current repository. Here, we will install the `awel-flow-web-info-search` workflow. To do this, execute the command dbgpt app install `awel-flow-web-info-search`.
-
-Let's also install the other official workflows provided:
-
-```
-dbgpt app install awel-flow-web-info-search
-dbgpt app install awel-flow-example-chat
-dbgpt app install awel-flow-simple-streaming-chat
-```
-By executing these commands, you will install the respective workflows onto your system.
-
-
-  -
-
-
-After successful installation, restart the DB-GPT service (dynamic hot loading is on the way 😊). Refresh the page, and you will be able to see the corresponding workflows on the AWEL workflow page.
-
-## Creating Applications Based on Workflows
-
-Earlier, we introduced the construction and installation of AWEL workflows. Next, let's discuss how to create data applications based on large models.
-
-Here, we will create a search dialogue application based on the `awel-flow-web-info-search` workflow.
-
-The core capability of the search dialogue application is to search for relevant knowledge using a search engine (such as Baidu or Google) and then provide a summarized answer. The effect is as follows:
-
-
-  -
-
-
-Creating the aforementioned application is very simple. In the application creation panel, click `Create`, enter the following parameters, and the creation process will be complete. There are a few parameters that require attention:
-
-- Work Mode
-- Flows
-The work mode we are using here is `awel_layout`. The AWEL workflow selected is `awel-flow-web-info-search`, which is the workflow that was installed previously.
-
-
-  -
-
-
-The above is the basic introduction to using the intelligent agent workflow. We look forward to more of your suggestions on how to play around with it. For instructions on how to develop workflows, you can refer to the development tutorial that follows.
-
diff --git a/docs/docs/application/datasources.md b/docs/docs/application/datasources.md
new file mode 100644
index 000000000..76ac33c2d
--- /dev/null
+++ b/docs/docs/application/datasources.md
@@ -0,0 +1,14 @@
+# Datasources
+
+The DB-GPT data source module is designed to manage the structured and semi-structured data assets of an enterprise, connect databases, data warehouses, data lakes, etc. to the DB-GPT framework, and quickly build data-based intelligent applications and large models. Currently, DB-GPT supports some common data sources and also supports custom extensions.
+
+
+  +
+
+
+
+You can add data sources through the upper right corner **Add a data source** button to add. In the pop-up dialog box, select the corresponding database type and fill in the required parameters to complete the addition.
+
+
+  +
+
diff --git a/docs/docs/application/graph_rag.md b/docs/docs/application/graph_rag.md
new file mode 100644
index 000000000..3b81a7bec
--- /dev/null
+++ b/docs/docs/application/graph_rag.md
@@ -0,0 +1 @@
+# GraphRAG
\ No newline at end of file
diff --git a/docs/docs/application/llms.md b/docs/docs/application/llms.md
new file mode 100644
index 000000000..9f223494d
--- /dev/null
+++ b/docs/docs/application/llms.md
@@ -0,0 +1,15 @@
+# LLMs
+
+In the new version, the location of model management has moved to **Application Management** Under the panel, other functional modules remain unchanged
+
+
+
+  +
+
+
+
+For the use of multi-model management, please refer to the following documents.
+
+- [Multi-Model Management](../application/advanced_tutorial/smmf.md)
+- [Model Service deployment](../installation/model_service/)
+- [Introduction to the principles of multi-model management](../modules/smmf.md)
diff --git a/docs/docs/application/prompts.md b/docs/docs/application/prompts.md
new file mode 100644
index 000000000..256220462
--- /dev/null
+++ b/docs/docs/application/prompts.md
@@ -0,0 +1,61 @@
+# Prompts
+
+In the actual application development process, Prompt needs to be customized in different scenarios, Agent, RAG and other modules. In order to make the editing and adjustment of Prompt more flexible, an independent Prompt module is created.
+
+## Browse
+
+As shown in the figure below, click **Application Management** ->**Prompt** You can enter the corresponding management interface. The interface displays a custom prompt list by default, and you can manage all prompts.
+
+
+  +
+
+
+## Added
+Next, let's see how to create a new prompt. Click the **Add Prompt** button and the prompt edit box will pop up.
+
+
+  +
+
+
+We define four types of prompts:
+- AGENT: Agent Prompt
+- SCENE: Scene Prompt
+- NORMAL: Normal prompt word
+- EVALUATE: Evaluation Mode Prompt
+
+When the AGENT type is selected, all registered agents can be seen in the drop-down list menu, and you can select an agent to set the prompt.
+
+
+  +
+
+
+After setting the prompt, a unique UID will be generated. You can bind the corresponding prompt according to the ID when using it.
+
+
+  +
+
+
+
+## Usage
+
+Enter the AWEL editing interface, as shown below, click **Application Management** -> **Create Workflow**
+
+
+
+  +
+
+
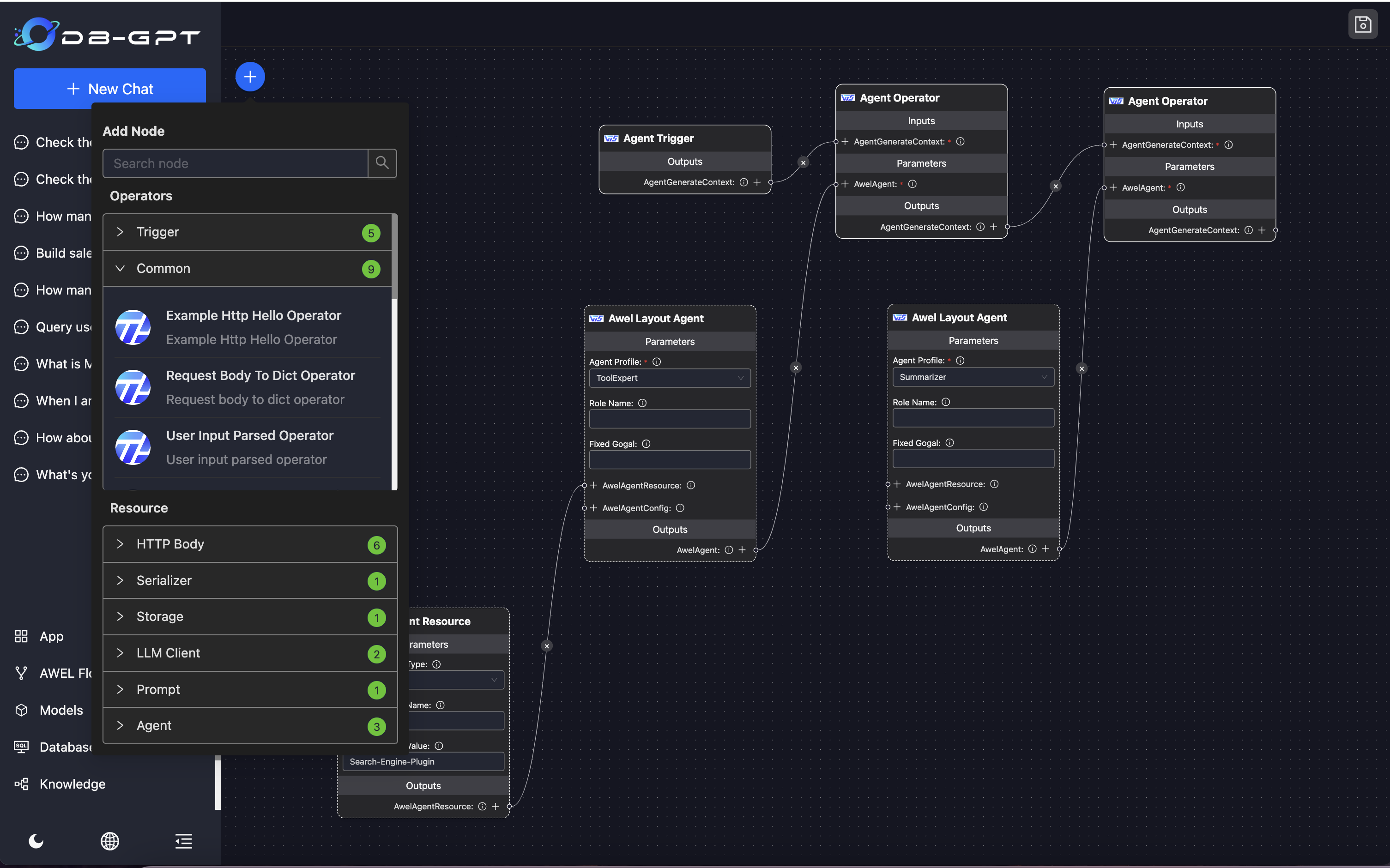
+Find the Agent resource and select the AWEL Layout Agent operator. We can see that each Agent contains the following information:
+
+- Profile
+- Role
+- Goal
+- Resource (AWELResource): The resource that Agent depends on
+- AgentConfig(AWELAgentConfig) Agent Config
+- AgentPrompt: Prompt
+
+
+  +
+
+
+Click the [+] next to **AgentPrompt**, select the Prompt operator that pops up, and select the corresponding Prompt name or UID in the parameter panel to bind our newly created Prompt to the Agent, and debug the Agent's behavior in turn.
diff --git a/docs/docs/application/started_tutorial/agents/crawl_data_analysis_agents.md b/docs/docs/application/started_tutorial/agents/crawl_data_analysis_agents.md
deleted file mode 100644
index 26e18c63d..000000000
--- a/docs/docs/application/started_tutorial/agents/crawl_data_analysis_agents.md
+++ /dev/null
@@ -1,71 +0,0 @@
-# Crawl data analysis agents
-
-In this case, the usage of an agent that automatcally writes programs to scrape internet data and perform analysis is demonstrated. One can observe through natural language interaction how the agent step by step completes the code writing process, and accomplishes the task handling. Unlike data analysis agents, the agent handles everything from code writing to data scraping and analysis autonomously, supporting direct data crawling from the internet for analysis.
-
-## How to use?
-Below are the steps for using the data scraping and analysis agent:
-
-- **Write the agent**: in this case, we have already prepared the code writing assistant CodeAssistantAgent, with the source code located at dbgpt/agent/agents/expand/code_assistant_agent.py
-- **Insert Metadata**
-- **Select Dialogue Scenario**
-- **Start Dialogue**
-
-### Write the agent
-In this case, the agent has already been programmed in the code, and the detailed code path is `dbgpt/agent/agents/expand/code_assistant_agent.py`. The specifics of the code are as follows.
-
-:::info note
-
-At the same time, under the `dbgpt/agent/agents/expand` path, several other Agents have been implemented. Interested students can expand on their own.
-:::
-
-
-  -
-
-
-### Insert Metadata
-
-The purpose of inserting metadata is to enable us to interact with the agent through the interactive interface.
-
-```sql
-INSERT INTO dbgpt.gpts_instance
-(gpts_name, gpts_describe, resource_db, resource_internet, resource_knowledge, gpts_agents, gpts_models, `language`, user_code, sys_code, created_at, updated_at, team_mode, is_sustainable)
-VALUES (
- '互联网数据分析助手',
- '互联网数据分析助手',
- '',
- '{"type": "\\u4e92\\u8054\\u7f51\\u6570\\u636e", "name": "\\u6240\\u6709\\u6765\\u6e90\\u4e92\\u8054\\u7f51\\u7684\\u6570\\u636e", "introduce": "string"}',
- '{"type": "\\u6587\\u6863\\u7a7a\\u95f4", "name": "TY", "introduce": " MYSQL\\u6570\\u636e\\u5e93\\u7684\\u5b98\\u65b9\\u64cd\\u4f5c\\u624b\\u518c"}',
- '[ "CodeEngineer"]',
- '{"DataScientist": ["vicuna-13b-v1.5", "tongyi_proxyllm", "chatgpt_proxyllm"], "CodeEngineer": ["chatgpt_proxyllm", "tongyi_proxyllm", "vicuna-13b-v1.5"], "default": ["chatgpt_proxyllm", "tongyi_proxyllm", "vicuna-13b-v1.5"]}',
- 'en',
- '',
- '',
- '2023-12-19 01:52:30',
- '2023-12-19 01:52:30',
- 'auto_plan',
- 0
- );
-```
-
-### Select Dialogue Scenario
-
-We choose `Agent Chat` scene.
-
-
-  -
-
-
-After entering the scene, select the `Internet Data Analysis Assistant Agent` that we have just prepared, and then you can fulfill the requirements through a dialogue.
-
-
-  -
-
-
-
-### Start Dialogue
-
-> To obtain and analyze the issue data for the 'eosphoros-ai/DB-GPT' repository over the past week and create a Markdown table grouped by day and status.
-
-
-  -
-
diff --git a/docs/docs/application/started_tutorial/agents/db_data_analysis_agents.md b/docs/docs/application/started_tutorial/agents/db_data_analysis_agents.md
deleted file mode 100644
index 71717fe37..000000000
--- a/docs/docs/application/started_tutorial/agents/db_data_analysis_agents.md
+++ /dev/null
@@ -1,50 +0,0 @@
-# Local Data Analysis Agents
-
-In this case, we will show you how to use a data analysis agents, serving as a typical `GBI(Generative Business Intelligence)` application scenario. One can observe how Agents step by step analyze and solve problems through natural language interaction.
-
-## How to use?
-- **Data Preparation**
-- **Add Data Source**
-- **Insert Metadata**
-- **Select Dialogue Scenario**
-- **Select Agent**
-- **Start Dialogue**
-
-
-### Data Preparation
-For data preparation, we can reuse the test data from the introductory tutorial; for detailed preparation steps, please refer to: [Data Preparation](/docs/application/started_tutorial/chat_dashboard#data-preparation).
-
-### Add Data Source
-Similarly, you may refer to the introductory tutorial on [how to add a data source](/docs/application/started_tutorial/chat_dashboard#add-data-source).
-
-
-### Insert Metadata
-Execute the following SQL statement to insert metadata.
-```SQL
-INSERT INTO dbgpt.gpts_instance
-( gpts_name, gpts_describe, resource_db, resource_internet, resource_knowledge, gpts_agents, gpts_models, `language`, user_code, sys_code, created_at, updated_at, team_mode, is_sustainable)
-VALUES('数据分析AI助手', '数据分析AI助手', '{"type": "\\u672c\\u5730\\u6570\\u636e\\u5e93", "name": "dbgpt_test", "introduce": ""}', '{"type": "\\u672c\\u5730\\u6570\\u636e\\u5e93", "name": "dbgpt_test", "introduce": ""}', '{"type": "\\u6587\\u6863\\u7a7a\\u95f4", "name": "TY", "introduce": " MYSQL\\u6570\\u636e\\u5e93\\u7684\\u5b98\\u65b9\\u64cd\\u4f5c\\u624b\\u518c"}', '["DataScientist", "Reporter"]', '{"DataScientist": ["vicuna-13b-v1.5", "tongyi_proxyllm", "chatgpt_proxyllm"], "Reporter": ["chatgpt_proxyllm", "tongyi_proxyllm","vicuna-13b-v1.5"], "default": ["chatgpt_proxyllm", "tongyi_proxyllm", "vicuna-13b-v1.5"]}', 'en', '', '', '2023-12-15 06:58:29', '2023-12-15 06:58:29', 'auto_plan', 0);
-```
-
-### Select Dialogue Scenario
-
-
-
-
-
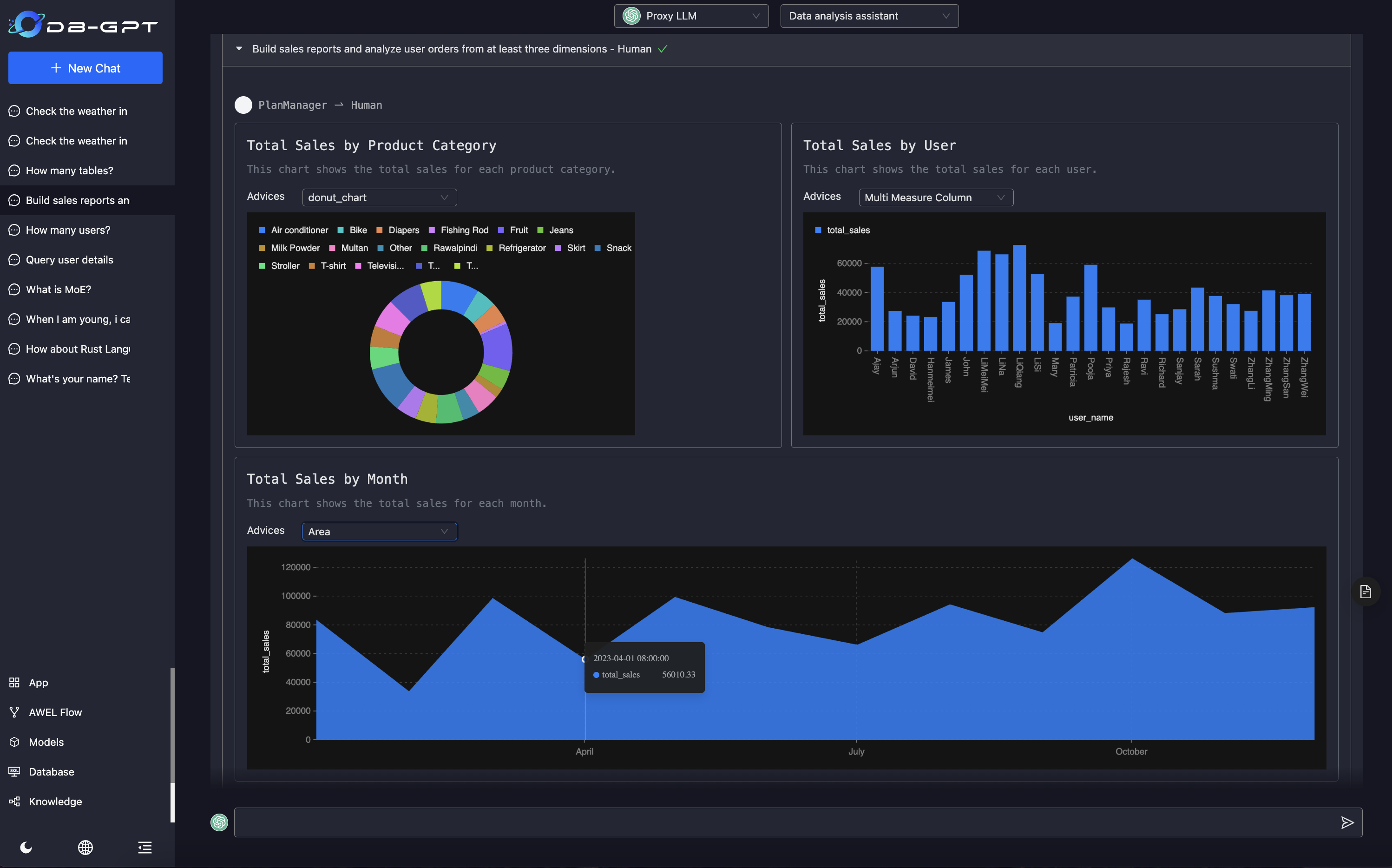
-### Select Agent
-
-
-  -
-
-
-### Start conversation
-> 构建销售报表,分析用户的订单,从至少三个维度分析
-
-
-  -
-
-
-
-  -
-
diff --git a/docs/docs/application/started_tutorial/agents/plugin.md b/docs/docs/application/started_tutorial/agents/plugin.md
deleted file mode 100644
index 173617e6d..000000000
--- a/docs/docs/application/started_tutorial/agents/plugin.md
+++ /dev/null
@@ -1,62 +0,0 @@
-# Data Agent
-
-Regarding the use of plugin(data agent), the current project supports basic plugin warehouses and plugin expansion capabilities. The project currently has a built-in search plugin. Let's experience the basic usage of the plugin.
-
-## Steps
-The use of the default plugin mainly includes the following steps. For more advanced features, you can follow the subsequent advanced tutorials.
-- 1.Enter the plugin market
-- 2.View the list of plugins in the GitHub repository
-- 3.Download the plugin
-- 4.Select Data Agent
-- 5.Start chat
-
-### View plugin list
-First, you can click the `Update GitHub plugin` button, and the plugin list in the [GitHub plugin repository](https://github.com/eosphoros-ai/DB-GPT-Plugins) will automatically be displayed here.
-
-
-
-  -
-
-
-### Download plugin
-
-Click the `download` button to download the plugin locally
-
-
-  -
-
-
-After the download is successful, you can see the plugin list in the my plugin interface. Of course, it also supports uploading models through local upload.
-
-
-  -
-
-
-
-### Select `Data Agent`
-Select the plugin dialog to enable plugin use.
-
-
-  -
-
-
-
-### Configure cookies
-
-Before starting to use the default search plugin, you need to configure cookies. For detailed configuration tutorials, see the [plugin description](https://github.com/eosphoros-ai/DB-GPT-Plugins/tree/main/src/dbgpt_plugins/search_engine).
-
-Specify the corresponding cookie configuration items in the `.env` file to complete the configuration.
-
-
-### Start chat
-After configuring cookies, we can start using the plugin.
-
-
-  -
-
-
-
-:::info note
-
-For more plugin expansion and advanced gameplay, welcome to [communicate](https://github.com/eosphoros-ai/DB-GPT/issues) with us.
-:::
diff --git a/docs/docs/application/started_tutorial/chat_data.md b/docs/docs/application/started_tutorial/chat_data.md
deleted file mode 100644
index a283b2048..000000000
--- a/docs/docs/application/started_tutorial/chat_data.md
+++ /dev/null
@@ -1,64 +0,0 @@
-# Chat Data
-Chat data capability is to dialogue with data through natural language. Currently, it is mainly dialogue between structured and semi-structured data, which can assist in data analysis and insight.
-
-:::info note
-
-Before starting the data conversation, we first need to add the data source
-:::
-
-## steps
-
-To start a data conversation, you need to go through the following steps:
-- 1.Add data source
-- 2.Select ChatData
-- 3.Select the corresponding database
-- 4.Start a conversation
-
-
-### Add data source
-
-First, select the `data source` on the left to add and add a database. Currently, DB-GPT supports multiple database types. Just select the corresponding database type to add. Here we choose MySQL as a demonstration. For the test data of the demonstration, see the [test sample](https://github.com/eosphoros-ai/DB-GPT/tree/main/docker/examples/sqls).
-
-
-
-  -
-
-
-
-
-### Choose ChatData
-
-
-  -
-
-
-### Start a conversation
-
-
-:::info note
-
-⚠️ Pay attention to selecting the corresponding model and database during the dialogue. At the same time, DB-GPT also provides preview mode and editing mode.
-:::
-
-
-:::tip
-
-preview mode
-:::
-
-
-
-  -
-
-
-
-
-:::tip
-
-editing mode
-:::
-
-
-  -
-
-
diff --git a/docs/docs/changelog/Released_V0.6.0.md b/docs/docs/changelog/Released_V0.6.0.md
new file mode 100644
index 000000000..f59cc67d7
--- /dev/null
+++ b/docs/docs/changelog/Released_V0.6.0.md
@@ -0,0 +1 @@
+# DB-GPT V0.6.0, Defining new standards for AI-native data applications.
\ No newline at end of file
diff --git a/docs/docs/upgrade/v0.6.0.md b/docs/docs/upgrade/v0.6.0.md
new file mode 100644
index 000000000..ac1a930b8
--- /dev/null
+++ b/docs/docs/upgrade/v0.6.0.md
@@ -0,0 +1,184 @@
+# Upgrade To v0.6.0
+
+## Overview
+
+This guide is for upgrading from v0.5.10 to v0.6.0. If you use SQLite, you not need to upgrade the database. If you use MySQL, you need to upgrade the database.
+
+
+## Prepare
+
+### Backup Your Database
+
+To prevent data loss, it is recommended to back up your database before upgrading. The backup way according to your database type.
+
+## Upgrade
+
+### Stop DB-GPT Service
+
+Stop the DB-GPT service according to your start way.
+
+### Upgrade database
+Execute the following SQL to upgrade the database.
+
+:::tip
+The asset files required for the version upgrade are placed [here](https://github.com/eosphoros-ai/DB-GPT/tree/main/assets/schema/upgrade).
+:::
+
+```sql
+USE dbgpt;
+-- chat_history
+ALTER TABLE chat_history ADD COLUMN `app_code` varchar(255) DEFAULT NULL COMMENT 'App unique code' after `message_ids`;
+
+-- gpts_app
+ALTER TABLE gpts_app ADD COLUMN `published` varchar(64) DEFAULT 'false' COMMENT 'Has it been published?';
+ALTER TABLE gpts_app ADD COLUMN `param_need` text DEFAULT NULL COMMENT 'Parameter information supported by the application';
+ALTER TABLE gpts_app ADD COLUMN `admins` text DEFAULT NULL COMMENT 'administrator';
+
+
+-- connect_config
+ALTER TABLE connect_config ADD COLUMN `user_name` varchar(255) DEFAULT NULL COMMENT 'user name';
+ALTER TABLE connect_config ADD COLUMN `user_id` varchar(255) DEFAULT NULL COMMENT 'user id';
+
+-- document_chunk
+ALTER TABLE document_chunk ADD COLUMN `questions` text DEFAULT NULL COMMENT 'chunk related questions';
+
+-- knowledge_document
+ALTER TABLE knowledge_document ADD COLUMN `doc_token` varchar(100) DEFAULT NULL COMMENT 'doc token';
+ALTER TABLE knowledge_document ADD COLUMN `questions` text DEFAULT NULL COMMENT 'document related questions';
+
+-- gpts_messages
+ALTER TABLE gpts_messages ADD COLUMN `is_success` int(4) NULL DEFAULT 0 COMMENT 'agent message is success';
+ALTER TABLE gpts_messages ADD COLUMN `app_code` varchar(255) NOT NULL COMMENT 'Current AI assistant code';
+ALTER TABLE gpts_messages ADD COLUMN `app_name` varchar(255) NOT NULL COMMENT 'Current AI assistant name';
+ALTER TABLE gpts_messages ADD COLUMN `resource_info` text DEFAULT NULL COMMENT 'Current conversation resource info';
+
+-- prompt_manage
+ALTER TABLE prompt_manage ADD COLUMN `prompt_code` varchar(255) NULL COMMENT 'Prompt code';
+ALTER TABLE prompt_manage ADD COLUMN `response_schema` text NULL COMMENT 'Prompt response schema';
+ALTER TABLE prompt_manage ADD COLUMN `user_code` varchar(128) NULL COMMENT 'User code';
+
+-- chat_feed_back
+ALTER TABLE chat_feed_back ADD COLUMN `message_id` varchar(255) NULL COMMENT 'Message id';
+ALTER TABLE chat_feed_back ADD COLUMN `feedback_type` varchar(50) NULL COMMENT 'Feedback type like or unlike';
+ALTER TABLE chat_feed_back ADD COLUMN `reason_types` varchar(255) NULL COMMENT 'Feedback reason categories';
+ALTER TABLE chat_feed_back ADD COLUMN `user_code` varchar(128) NULL COMMENT 'User code';
+ALTER TABLE chat_feed_back ADD COLUMN `remark` text NULL COMMENT 'Feedback remark';
+
+-- dbgpt_serve_flow
+ALTER TABLE dbgpt_serve_flow ADD COLUMN `variables` text DEFAULT NULL COMMENT 'Flow variables, JSON format';
+
+-- dbgpt.recommend_question definition
+CREATE TABLE `recommend_question` (
+ `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'autoincrement id',
+ `gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT 'create time',
+ `gmt_modified` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT 'last update time',
+ `app_code` varchar(255) DEFAULT NULL COMMENT 'Current AI assistant code',
+ `question` text DEFAULT NULL COMMENT 'question',
+ `user_code` int(11) DEFAULT NULL COMMENT 'user code',
+ `sys_code` varchar(255) DEFAULT NULL COMMENT 'system app code',
+ `valid` varchar(10) DEFAULT 'true' COMMENT 'is it effective,true/false',
+ `chat_mode` varchar(255) DEFAULT NULL COMMENT 'Conversation scene mode,chat_knowledge...',
+ `params` text DEFAULT NULL COMMENT 'question param',
+ `is_hot_question` varchar(10) DEFAULT 'false' COMMENT 'Is it a popular recommendation question?',
+ PRIMARY KEY (`id`),
+ KEY `idx_rec_q_app_code` (`app_code`)
+) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT="AI application related recommendation issues";
+
+-- dbgpt.user_recent_apps definition
+CREATE TABLE `user_recent_apps` (
+ `id` bigint(20) unsigned NOT NULL AUTO_INCREMENT COMMENT 'autoincrement id',
+ `gmt_create` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT 'create time',
+ `gmt_modified` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT 'last update time',
+ `app_code` varchar(255) DEFAULT NULL COMMENT 'AI assistant code',
+ `last_accessed` timestamp NULL DEFAULT NULL COMMENT 'User recent usage time',
+ `user_code` varchar(255) DEFAULT NULL COMMENT 'user code',
+ `sys_code` varchar(255) DEFAULT NULL COMMENT 'system app code',
+ PRIMARY KEY (`id`),
+ KEY `idx_user_r_app_code` (`app_code`),
+ KEY `idx_last_accessed` (`last_accessed`),
+ KEY `idx_user_code` (`user_code`)
+) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci COMMENT='User recently used apps';
+
+-- dbgpt.dbgpt_serve_file definition
+CREATE TABLE `dbgpt_serve_file` (
+ `id` int NOT NULL AUTO_INCREMENT COMMENT 'Auto increment id',
+ `bucket` varchar(255) NOT NULL COMMENT 'Bucket name',
+ `file_id` varchar(255) NOT NULL COMMENT 'File id',
+ `file_name` varchar(256) NOT NULL COMMENT 'File name',
+ `file_size` int DEFAULT NULL COMMENT 'File size',
+ `storage_type` varchar(32) NOT NULL COMMENT 'Storage type',
+ `storage_path` varchar(512) NOT NULL COMMENT 'Storage path',
+ `uri` varchar(512) NOT NULL COMMENT 'File URI',
+ `custom_metadata` text DEFAULT NULL COMMENT 'Custom metadata, JSON format',
+ `file_hash` varchar(128) DEFAULT NULL COMMENT 'File hash',
+ `user_name` varchar(128) DEFAULT NULL COMMENT 'User name',
+ `sys_code` varchar(128) DEFAULT NULL COMMENT 'System code',
+ `gmt_created` datetime DEFAULT CURRENT_TIMESTAMP COMMENT 'Record creation time',
+ `gmt_modified` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT 'Record update time',
+ PRIMARY KEY (`id`),
+ UNIQUE KEY `uk_bucket_file_id` (`bucket`, `file_id`)
+) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
+
+-- dbgpt.dbgpt_serve_variables definition
+CREATE TABLE `dbgpt_serve_variables` (
+ `id` int NOT NULL AUTO_INCREMENT COMMENT 'Auto increment id',
+ `key` varchar(128) NOT NULL COMMENT 'Variable key',
+ `name` varchar(128) DEFAULT NULL COMMENT 'Variable name',
+ `label` varchar(128) DEFAULT NULL COMMENT 'Variable label',
+ `value` text DEFAULT NULL COMMENT 'Variable value, JSON format',
+ `value_type` varchar(32) DEFAULT NULL COMMENT 'Variable value type(string, int, float, bool)',
+ `category` varchar(32) DEFAULT 'common' COMMENT 'Variable category(common or secret)',
+ `encryption_method` varchar(32) DEFAULT NULL COMMENT 'Variable encryption method(fernet, simple, rsa, aes)',
+ `salt` varchar(128) DEFAULT NULL COMMENT 'Variable salt',
+ `scope` varchar(32) DEFAULT 'global' COMMENT 'Variable scope(global,flow,app,agent,datasource,flow_priv,agent_priv, ""etc)',
+ `scope_key` varchar(256) DEFAULT NULL COMMENT 'Variable scope key, default is empty, for scope is "flow_priv", the scope_key is dag id of flow',
+ `enabled` int DEFAULT 1 COMMENT 'Variable enabled, 0: disabled, 1: enabled',
+ `description` text DEFAULT NULL COMMENT 'Variable description',
+ `user_name` varchar(128) DEFAULT NULL COMMENT 'User name',
+ `sys_code` varchar(128) DEFAULT NULL COMMENT 'System code',
+ `gmt_created` datetime DEFAULT CURRENT_TIMESTAMP COMMENT 'Record creation time',
+ `gmt_modified` datetime DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT 'Record update time',
+ PRIMARY KEY (`id`),
+ KEY `ix_your_table_name_key` (`key`),
+ KEY `ix_your_table_name_name` (`name`)
+) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
+
+-- dbgpt.dbgpt_serve_dbgpts_my definition
+CREATE TABLE `dbgpt_serve_dbgpts_my` (
+ `id` int NOT NULL AUTO_INCREMENT COMMENT 'autoincrement id',
+ `name` varchar(255) NOT NULL COMMENT 'plugin name',
+ `user_name` varchar(255) DEFAULT NULL COMMENT 'user name',
+ `file_name` varchar(255) NOT NULL COMMENT 'plugin package file name',
+ `type` varchar(255) DEFAULT NULL COMMENT 'plugin type',
+ `version` varchar(255) DEFAULT NULL COMMENT 'plugin version',
+ `use_count` int DEFAULT NULL COMMENT 'plugin total use count',
+ `succ_count` int DEFAULT NULL COMMENT 'plugin total success count',
+ `sys_code` varchar(128) DEFAULT NULL COMMENT 'System code',
+ `gmt_created` TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT 'plugin install time',
+ `gmt_modified` TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT 'update time',
+ PRIMARY KEY (`id`),
+ UNIQUE KEY `name` (`name`, `user_name`),
+ KEY `ix_my_plugin_sys_code` (`sys_code`)
+) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
+
+-- dbgpt.dbgpt_serve_dbgpts_hub definition
+CREATE TABLE `dbgpt_serve_dbgpts_hub` (
+ `id` int NOT NULL AUTO_INCREMENT COMMENT 'autoincrement id',
+ `name` varchar(255) NOT NULL COMMENT 'plugin name',
+ `description` varchar(255) NULL COMMENT 'plugin description',
+ `author` varchar(255) DEFAULT NULL COMMENT 'plugin author',
+ `email` varchar(255) DEFAULT NULL COMMENT 'plugin author email',
+ `type` varchar(255) DEFAULT NULL COMMENT 'plugin type',
+ `version` varchar(255) DEFAULT NULL COMMENT 'plugin version',
+ `storage_channel` varchar(255) DEFAULT NULL COMMENT 'plugin storage channel',
+ `storage_url` varchar(255) DEFAULT NULL COMMENT 'plugin download url',
+ `download_param` varchar(255) DEFAULT NULL COMMENT 'plugin download param',
+ `gmt_created` TIMESTAMP DEFAULT CURRENT_TIMESTAMP COMMENT 'plugin upload time',
+ `gmt_modified` TIMESTAMP DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT 'update time',
+ `installed` int DEFAULT NULL COMMENT 'plugin already installed count',
+ PRIMARY KEY (`id`),
+ UNIQUE KEY `name` (`name`)
+) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
+
+```
+
diff --git a/docs/docusaurus.config.js b/docs/docusaurus.config.js
index ab8585bca..a874884aa 100755
--- a/docs/docusaurus.config.js
+++ b/docs/docusaurus.config.js
@@ -43,7 +43,7 @@ const config = {
favicon: 'img/eosphoros.jpeg',
// Set the production url of your site here
- url: 'http://docs.dbgpt.site',
+ url: 'http://docs.dbgpt.cn',
// Set the // pathname under which your site is served
// For GitHub pages deployment, it is often '//'
baseUrl: '/',
diff --git a/docs/sidebars.js b/docs/sidebars.js
index dabf974be..75751fbd7 100755
--- a/docs/sidebars.js
+++ b/docs/sidebars.js
@@ -269,65 +269,79 @@ const sidebars = {
collapsed: false,
collapsible: false,
items: [
- {
- type: 'doc',
- id: 'application/app_usage'
- },
- {
- type: 'doc',
- id: 'application/awel_flow_usage'
- },
{
type: 'category',
label: 'Getting Started Tutorial',
items: [
{
type: 'doc',
- id: 'application/started_tutorial/chat_knowledge',
+ id: 'application/apps/app_explore',
+ label: "App Explore"
},
{
type: 'doc',
- id: 'application/started_tutorial/chat_data',
+ id: 'application/apps/app_chat',
+ label: "App Chat"
+ },
+ {
+ type: 'doc',
+ id: 'application/apps/app_manage',
+ label: "App Manage"
+ },
+ {
+ type: 'doc',
+ id: 'application/apps/chat_data',
+ label: "Chat Data"
},
{
type: 'doc',
- id: 'application/started_tutorial/chat_excel',
+ id: 'application/apps/chat_excel',
+ label: "Chat Excel"
},
{
type: 'doc',
- id: 'application/started_tutorial/chat_db',
+ id: 'application/apps/chat_db',
+ label: "chat DB"
},
{
type: 'doc',
- id: 'application/started_tutorial/chat_dashboard',
+ id: 'application/apps/chat_knowledge',
+ label: "Chat Knowledge Base"
+ },
+ {
+ type: 'doc',
+ id: 'application/apps/chat_dashboard',
+ label: "Chat Dashboard"
},{
type: 'doc',
- id: 'application/started_tutorial/chat_financial_report',
+ id: 'application/apps/chat_financial_report',
},
- {
- type: "category",
- label: "Agents",
- items: [
- {
- type: 'doc',
- id: 'application/started_tutorial/agents/plugin',
- },
- {
- type: "doc",
- id: "application/started_tutorial/agents/db_data_analysis_agents",
- },
- {
- type: "doc",
- id: "application/started_tutorial/agents/crawl_data_analysis_agents",
- }
- ],
- link: {
- type: 'generated-index',
- slug: "agents",
- },
- }
],
},
+ {
+ type: 'doc',
+ id: 'application/prompts',
+ label: "Prompt"
+ },
+ {
+ type: 'doc',
+ id: 'application/llms',
+ label: "LLMs"
+ },
+ {
+ type: 'doc',
+ id: 'application/datasources',
+ label: "Datasources"
+ },
+ {
+ type: 'doc',
+ id: 'application/graph_rag',
+ label: "GraphRAG"
+ },
+ {
+ type: 'doc',
+ id: 'application/awel',
+ },
{
type: 'category',
label: 'Advanced Tutorial',
@@ -489,16 +503,6 @@ const sidebars = {
type: 'doc',
id: "agents/introduction/custom_agents"
},
- // {
- // type: "category",
- // label: "Cookbook",
- // items: [
- // {
- // type: "doc",
- // id: "agents/cookbook/calculator_with_agents"
- // },
- // ],
- // },
{
type: "category",
label: "Modules",
@@ -667,6 +671,10 @@ const sidebars = {
type: 'doc',
id: 'changelog/doc',
},
+ {
+ type: 'doc',
+ id: 'changelog/Released_V0.6.0',
+ },
{
type: 'doc',
id: 'changelog/Released_V0.5.0',
@@ -682,10 +690,15 @@ const sidebars = {
{
type: 'doc',
id: 'upgrade/v0.5.0',
- }, {
+ },
+ {
type: 'doc',
id: 'upgrade/v0.5.1',
},
+ {
+ type: 'doc',
+ id: 'upgrade/v0.6.0',
+ }
],
},
diff --git a/docs/static/img/app/agent_prompt_awel_v0.6.jpg b/docs/static/img/app/agent_prompt_awel_v0.6.jpg
new file mode 100644
index 000000000..0b7d08d31
Binary files /dev/null and b/docs/static/img/app/agent_prompt_awel_v0.6.jpg differ
diff --git a/docs/static/img/app/agent_prompt_code_v0.6.jpg b/docs/static/img/app/agent_prompt_code_v0.6.jpg
new file mode 100644
index 000000000..7a492227f
Binary files /dev/null and b/docs/static/img/app/agent_prompt_code_v0.6.jpg differ
diff --git a/docs/static/img/app/agent_prompt_v0.6.jpg b/docs/static/img/app/agent_prompt_v0.6.jpg
new file mode 100644
index 000000000..8606aca59
Binary files /dev/null and b/docs/static/img/app/agent_prompt_v0.6.jpg differ
diff --git a/docs/static/img/app/app_chat_op_v0.6.jpg b/docs/static/img/app/app_chat_op_v0.6.jpg
new file mode 100644
index 000000000..48a882219
Binary files /dev/null and b/docs/static/img/app/app_chat_op_v0.6.jpg differ
diff --git a/docs/static/img/app/app_chat_v0.6.jpg b/docs/static/img/app/app_chat_v0.6.jpg
new file mode 100644
index 000000000..a68fea29e
Binary files /dev/null and b/docs/static/img/app/app_chat_v0.6.jpg differ
diff --git a/docs/static/img/app/app_explore_v0.6.jpg b/docs/static/img/app/app_explore_v0.6.jpg
new file mode 100644
index 000000000..44478ca42
Binary files /dev/null and b/docs/static/img/app/app_explore_v0.6.jpg differ
diff --git a/docs/static/img/app/app_manage_app_publish_v0.6.jpg b/docs/static/img/app/app_manage_app_publish_v0.6.jpg
new file mode 100644
index 000000000..a5d498c68
Binary files /dev/null and b/docs/static/img/app/app_manage_app_publish_v0.6.jpg differ
diff --git a/docs/static/img/app/app_manage_app_v0.6.jpg b/docs/static/img/app/app_manage_app_v0.6.jpg
new file mode 100644
index 000000000..ec4407565
Binary files /dev/null and b/docs/static/img/app/app_manage_app_v0.6.jpg differ
diff --git a/docs/static/img/app/app_manage_chat_data_editor_v0.6.jpg b/docs/static/img/app/app_manage_chat_data_editor_v0.6.jpg
new file mode 100644
index 000000000..d5eee7174
Binary files /dev/null and b/docs/static/img/app/app_manage_chat_data_editor_v0.6.jpg differ
diff --git a/docs/static/img/app/app_manage_chat_data_v0.6.jpg b/docs/static/img/app/app_manage_chat_data_v0.6.jpg
new file mode 100644
index 000000000..61183bcfa
Binary files /dev/null and b/docs/static/img/app/app_manage_chat_data_v0.6.jpg differ
diff --git a/docs/static/img/app/app_manage_chat_v0.6.jpg b/docs/static/img/app/app_manage_chat_v0.6.jpg
new file mode 100644
index 000000000..677c68199
Binary files /dev/null and b/docs/static/img/app/app_manage_chat_v0.6.jpg differ
diff --git a/docs/static/img/app/app_manage_mode_v0.6.jpg b/docs/static/img/app/app_manage_mode_v0.6.jpg
new file mode 100644
index 000000000..3ddcb7a93
Binary files /dev/null and b/docs/static/img/app/app_manage_mode_v0.6.jpg differ
diff --git a/docs/static/img/app/app_manage_v0.6.jpg b/docs/static/img/app/app_manage_v0.6.jpg
new file mode 100644
index 000000000..de90ef728
Binary files /dev/null and b/docs/static/img/app/app_manage_v0.6.jpg differ
diff --git a/docs/static/img/app/awel_create.jpg b/docs/static/img/app/awel_create.jpg
new file mode 100644
index 000000000..ccb82ea73
Binary files /dev/null and b/docs/static/img/app/awel_create.jpg differ
diff --git a/docs/static/img/app/chat_dashboard_display_v0.6.jpg b/docs/static/img/app/chat_dashboard_display_v0.6.jpg
new file mode 100644
index 000000000..4ded132fa
Binary files /dev/null and b/docs/static/img/app/chat_dashboard_display_v0.6.jpg differ
diff --git a/docs/static/img/app/chat_dashboard_v0.6.jpg b/docs/static/img/app/chat_dashboard_v0.6.jpg
new file mode 100644
index 000000000..9c4436c61
Binary files /dev/null and b/docs/static/img/app/chat_dashboard_v0.6.jpg differ
diff --git a/docs/static/img/app/chat_data_display_v0.6.jpg b/docs/static/img/app/chat_data_display_v0.6.jpg
new file mode 100644
index 000000000..c0b5f40ab
Binary files /dev/null and b/docs/static/img/app/chat_data_display_v0.6.jpg differ
diff --git a/docs/static/img/app/chat_data_v0.6.jpg b/docs/static/img/app/chat_data_v0.6.jpg
new file mode 100644
index 000000000..367e31f4b
Binary files /dev/null and b/docs/static/img/app/chat_data_v0.6.jpg differ
diff --git a/docs/static/img/app/chat_excel_upload_succ_v0.6.jpg b/docs/static/img/app/chat_excel_upload_succ_v0.6.jpg
new file mode 100644
index 000000000..d6c63991f
Binary files /dev/null and b/docs/static/img/app/chat_excel_upload_succ_v0.6.jpg differ
diff --git a/docs/static/img/app/chat_excel_upload_v0.6.jpg b/docs/static/img/app/chat_excel_upload_v0.6.jpg
new file mode 100644
index 000000000..db473168b
Binary files /dev/null and b/docs/static/img/app/chat_excel_upload_v0.6.jpg differ
diff --git a/docs/static/img/app/chat_excel_v0.6.jpg b/docs/static/img/app/chat_excel_v0.6.jpg
new file mode 100644
index 000000000..c49b02486
Binary files /dev/null and b/docs/static/img/app/chat_excel_v0.6.jpg differ
diff --git a/docs/static/img/app/datasource.jpg b/docs/static/img/app/datasource.jpg
new file mode 100644
index 000000000..633aa0628
Binary files /dev/null and b/docs/static/img/app/datasource.jpg differ
diff --git a/docs/static/img/app/datasource_add.jpg b/docs/static/img/app/datasource_add.jpg
new file mode 100644
index 000000000..b7fc6cb33
Binary files /dev/null and b/docs/static/img/app/datasource_add.jpg differ
diff --git a/docs/static/img/app/knowledge_build_v0.6.jpg b/docs/static/img/app/knowledge_build_v0.6.jpg
new file mode 100644
index 000000000..d1a07e8fd
Binary files /dev/null and b/docs/static/img/app/knowledge_build_v0.6.jpg differ
diff --git a/docs/static/img/app/knowledge_chunks_v0.6.jpg b/docs/static/img/app/knowledge_chunks_v0.6.jpg
new file mode 100644
index 000000000..7a058f22e
Binary files /dev/null and b/docs/static/img/app/knowledge_chunks_v0.6.jpg differ
diff --git a/docs/static/img/app/knowledge_space_v0.6.jpg b/docs/static/img/app/knowledge_space_v0.6.jpg
new file mode 100644
index 000000000..0af8f1ade
Binary files /dev/null and b/docs/static/img/app/knowledge_space_v0.6.jpg differ
diff --git a/docs/static/img/app/llms_v0.6.jpg b/docs/static/img/app/llms_v0.6.jpg
new file mode 100644
index 000000000..13e157928
Binary files /dev/null and b/docs/static/img/app/llms_v0.6.jpg differ
diff --git a/docs/static/img/app/prompt_add_v0.6.jpg b/docs/static/img/app/prompt_add_v0.6.jpg
new file mode 100644
index 000000000..3489ba4d2
Binary files /dev/null and b/docs/static/img/app/prompt_add_v0.6.jpg differ
diff --git a/docs/static/img/app/prompt_v0.6.jpg b/docs/static/img/app/prompt_v0.6.jpg
new file mode 100644
index 000000000..e52b4fa0b
Binary files /dev/null and b/docs/static/img/app/prompt_v0.6.jpg differ
diff --git a/docs/yarn.lock b/docs/yarn.lock
index c80ab37b7..cfe9b97bb 100644
--- a/docs/yarn.lock
+++ b/docs/yarn.lock
@@ -1832,15 +1832,10 @@
dependencies:
"@types/mdx" "^2.0.0"
-"@node-rs/jieba-linux-x64-gnu@1.10.3":
+"@node-rs/jieba-darwin-arm64@1.10.3":
version "1.10.3"
- resolved "https://registry.npmmirror.com/@node-rs/jieba-linux-x64-gnu/-/jieba-linux-x64-gnu-1.10.3.tgz"
- integrity sha512-GF5cfvu/0wXO2fVX/XV3WYH/xEGWzMBvfqLhGiA1OA1xHIufnA1T7uU3ZXkyoNi5Bzf6dmxnwtE4CJL0nvhwjQ==
-
-"@node-rs/jieba-linux-x64-musl@1.10.3":
- version "1.10.3"
- resolved "https://registry.npmmirror.com/@node-rs/jieba-linux-x64-musl/-/jieba-linux-x64-musl-1.10.3.tgz"
- integrity sha512-h45HMVU/hgzQ0saXNsK9fKlGdah1i1cXZULpB5vQRlRL2ZIaGp+ULtWTogS7vkoo2K8s2l4tqakWMg9eUjIJ2A==
+ resolved "https://registry.npmmirror.com/@node-rs/jieba-darwin-arm64/-/jieba-darwin-arm64-1.10.3.tgz"
+ integrity sha512-dwPhkav1tEARskwPz91UUXL2NXy4h0lJYTuJzpGgwXxm552zBM2JJ41kjah1364j+EOq5At3NQvf5r5rH89phQ==
"@node-rs/jieba@^1.6.0":
version "1.10.3"
@@ -4692,6 +4687,11 @@ fs.realpath@^1.0.0:
resolved "https://registry.npmjs.org/fs.realpath/-/fs.realpath-1.0.0.tgz"
integrity sha512-OO0pH2lK6a0hZnAdau5ItzHPI6pUlvI7jMVnxUQRtw4owF2wk8lOSabtGDCTP4Ggrg2MbGnWO9X8K1t4+fGMDw==
+fsevents@~2.3.2:
+ version "2.3.3"
+ resolved "https://registry.npmjs.org/fsevents/-/fsevents-2.3.3.tgz"
+ integrity sha512-5xoDfX+fL7faATnagmWPpbFtwh/R77WmMMqqHGS65C3vvB0YHrgF+B1YmZ3441tMj5n63k0212XNoJwzlhffQw==
+
function-bind@^1.1.1:
version "1.1.1"
resolved "https://registry.npmjs.org/function-bind/-/function-bind-1.1.1.tgz"