From 6d9c27a26e6ad7775f14d4eaf7b5b914dc8783bf Mon Sep 17 00:00:00 2001
From: nawnie <106923464+nawnie@users.noreply.github.com>
Date: Fri, 23 Dec 2022 11:35:58 -0600
Subject: [PATCH 01/15] change steps to epoch
removed the 200 min step requirement since i am now using epochs
---
train_dreambooth.py | 852 ++++++++++++++++++++++++++++++++++++++++++++
1 file changed, 852 insertions(+)
create mode 100644 train_dreambooth.py
diff --git a/train_dreambooth.py b/train_dreambooth.py
new file mode 100644
index 00000000..65878b6a
--- /dev/null
+++ b/train_dreambooth.py
@@ -0,0 +1,852 @@
+import argparse
+import itertools
+import math
+import os
+from pathlib import Path
+from typing import Optional
+import subprocess
+import sys
+
+import torch
+import torch.nn.functional as F
+import torch.utils.checkpoint
+from torch.utils.data import Dataset
+
+from accelerate import Accelerator
+from accelerate.logging import get_logger
+from accelerate.utils import set_seed
+from diffusers import AutoencoderKL, DDPMScheduler, StableDiffusionPipeline, UNet2DConditionModel
+from diffusers.optimization import get_scheduler
+from huggingface_hub import HfFolder, Repository, whoami
+from PIL import Image
+from torchvision import transforms
+from tqdm.auto import tqdm
+from transformers import CLIPTextModel, CLIPTokenizer
+
+
+logger = get_logger(__name__)
+
+
+def parse_args():
+ parser = argparse.ArgumentParser(description="Simple example of a training script.")
+ parser.add_argument(
+ "--pretrained_model_name_or_path",
+ type=str,
+ default=None,
+ required=True,
+ help="Path to pretrained model or model identifier from huggingface.co/models.",
+ )
+ parser.add_argument(
+ "--tokenizer_name",
+ type=str,
+ default=None,
+ help="Pretrained tokenizer name or path if not the same as model_name",
+ )
+ parser.add_argument(
+ "--instance_data_dir",
+ type=str,
+ default=None,
+ required=True,
+ help="A folder containing the training data of instance images.",
+ )
+ parser.add_argument(
+ "--class_data_dir",
+ type=str,
+ default=None,
+ required=False,
+ help="A folder containing the training data of class images.",
+ )
+ parser.add_argument(
+ "--instance_prompt",
+ type=str,
+ default=None,
+ help="The prompt with identifier specifying the instance",
+ )
+ parser.add_argument(
+ "--class_prompt",
+ type=str,
+ default="",
+ help="The prompt to specify images in the same class as provided instance images.",
+ )
+ parser.add_argument(
+ "--with_prior_preservation",
+ default=False,
+ action="store_true",
+ help="Flag to add prior preservation loss.",
+ )
+ parser.add_argument("--prior_loss_weight", type=float, default=1.0, help="The weight of prior preservation loss.")
+ parser.add_argument(
+ "--num_class_images",
+ type=int,
+ default=100,
+ help=(
+ "Minimal class images for prior preservation loss. If not have enough images, additional images will be"
+ " sampled with class_prompt."
+ ),
+ )
+ parser.add_argument(
+ "--output_dir",
+ type=str,
+ default="",
+ help="The output directory where the model predictions and checkpoints will be written.",
+ )
+ parser.add_argument("--seed", type=int, default=None, help="A seed for reproducible training.")
+ parser.add_argument(
+ "--resolution",
+ type=int,
+ default=512,
+ help=(
+ "The resolution for input images, all the images in the train/validation dataset will be resized to this"
+ " resolution"
+ ),
+ )
+ parser.add_argument(
+ "--center_crop", action="store_true", help="Whether to center crop images before resizing to resolution"
+ )
+ parser.add_argument("--train_text_encoder", action="store_true", help="Whether to train the text encoder")
+ parser.add_argument(
+ "--train_batch_size", type=int, default=4, help="Batch size (per device) for the training dataloader."
+ )
+ parser.add_argument(
+ "--sample_batch_size", type=int, default=4, help="Batch size (per device) for sampling images."
+ )
+ parser.add_argument("--num_train_epochs", type=int, default=1)
+ parser.add_argument(
+ "--max_train_steps",
+ type=int,
+ default=None,
+ help="Total number of training steps to perform. If provided, overrides num_train_epochs.",
+ )
+ parser.add_argument(
+ "--gradient_accumulation_steps",
+ type=int,
+ default=1,
+ help="Number of updates steps to accumulate before performing a backward/update pass.",
+ )
+ parser.add_argument(
+ "--gradient_checkpointing",
+ action="store_true",
+ help="Whether or not to use gradient checkpointing to save memory at the expense of slower backward pass.",
+ )
+ parser.add_argument(
+ "--learning_rate",
+ type=float,
+ default=5e-6,
+ help="Initial learning rate (after the potential warmup period) to use.",
+ )
+ parser.add_argument(
+ "--scale_lr",
+ action="store_true",
+ default=False,
+ help="Scale the learning rate by the number of GPUs, gradient accumulation steps, and batch size.",
+ )
+ parser.add_argument(
+ "--lr_scheduler",
+ type=str,
+ default="constant",
+ help=(
+ 'The scheduler type to use. Choose between ["linear", "cosine", "cosine_with_restarts", "polynomial",'
+ ' "constant", "constant_with_warmup"]'
+ ),
+ )
+ parser.add_argument(
+ "--lr_warmup_steps", type=int, default=500, help="Number of steps for the warmup in the lr scheduler."
+ )
+ parser.add_argument(
+ "--use_8bit_adam", action="store_true", help="Whether or not to use 8-bit Adam from bitsandbytes."
+ )
+ parser.add_argument("--adam_beta1", type=float, default=0.9, help="The beta1 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_beta2", type=float, default=0.999, help="The beta2 parameter for the Adam optimizer.")
+ parser.add_argument("--adam_weight_decay", type=float, default=1e-2, help="Weight decay to use.")
+ parser.add_argument("--adam_epsilon", type=float, default=1e-08, help="Epsilon value for the Adam optimizer")
+ parser.add_argument("--max_grad_norm", default=1.0, type=float, help="Max gradient norm.")
+ parser.add_argument("--push_to_hub", action="store_true", help="Whether or not to push the model to the Hub.")
+ parser.add_argument("--hub_token", type=str, default=None, help="The token to use to push to the Model Hub.")
+ parser.add_argument(
+ "--hub_model_id",
+ type=str,
+ default=None,
+ help="The name of the repository to keep in sync with the local `output_dir`.",
+ )
+ parser.add_argument(
+ "--logging_dir",
+ type=str,
+ default="logs",
+ help=(
+ "[TensorBoard](https://www.tensorflow.org/tensorboard) log directory. Will default to"
+ " *output_dir/runs/**CURRENT_DATETIME_HOSTNAME***."
+ ),
+ )
+ parser.add_argument(
+ "--mixed_precision",
+ type=str,
+ default="no",
+ choices=["no", "fp16", "bf16"],
+ help=(
+ "Whether to use mixed precision. Choose"
+ "between fp16 and bf16 (bfloat16). Bf16 requires PyTorch >= 1.10."
+ "and an Nvidia Ampere GPU."
+ ),
+ )
+
+ parser.add_argument(
+ "--save_n_steps",
+ type=int,
+ default=1,
+ help=("Save the model every n global_steps"),
+ )
+
+
+ parser.add_argument(
+ "--save_starting_step",
+ type=int,
+ default=1,
+ help=("The step from which it starts saving intermediary checkpoints"),
+ )
+
+ parser.add_argument(
+ "--stop_text_encoder_training",
+ type=int,
+ default=1000000,
+ help=("The step at which the text_encoder is no longer trained"),
+ )
+
+
+ parser.add_argument(
+ "--image_captions_filename",
+ action="store_true",
+ help="Get captions from filename",
+ )
+
+
+ parser.add_argument(
+ "--dump_only_text_encoder",
+ action="store_true",
+ default=False,
+ help="Dump only text-encoder",
+ )
+
+ parser.add_argument(
+ "--train_only_unet",
+ action="store_true",
+ default=False,
+ help="Train only the unet",
+ )
+
+ parser.add_argument(
+ "--train_only_text_encoder",
+ action="store_true",
+ default=False,
+ help="Train only the text-encoder",
+ )
+
+ parser.add_argument(
+ "--Style",
+ action="store_true",
+ default=False,
+ help="Further reduce overfitting",
+ )
+
+ parser.add_argument(
+ "--Session_dir",
+ type=str,
+ default="",
+ help="Current session directory",
+ )
+
+ parser.add_argument(
+ "--external_captions",
+ action="store_true",
+ default=False,
+ help="Use captions stored in a txt file",
+ )
+
+ parser.add_argument(
+ "--captions_dir",
+ type=str,
+ default="",
+ help="The folder where captions files are stored",
+ )
+
+
+ parser.add_argument("--local_rank", type=int, default=-1, help="For distributed training: local_rank")
+
+ args = parser.parse_args()
+ env_local_rank = int(os.environ.get("LOCAL_RANK", -1))
+ if env_local_rank != -1 and env_local_rank != args.local_rank:
+ args.local_rank = env_local_rank
+
+ if args.instance_data_dir is None:
+ raise ValueError("You must specify a train data directory.")
+
+ if args.with_prior_preservation:
+ if args.class_data_dir is None:
+ raise ValueError("You must specify a data directory for class images.")
+ if args.class_prompt is None:
+ raise ValueError("You must specify prompt for class images.")
+
+ return args
+
+
+class DreamBoothDataset(Dataset):
+ """
+ A dataset to prepare the instance and class images with the prompts for fine-tuning the model.
+ It pre-processes the images and the tokenizes prompts.
+ """
+
+ def __init__(
+ self,
+ instance_data_root,
+ instance_prompt,
+ tokenizer,
+ args,
+ class_data_root=None,
+ class_prompt=None,
+ size=512,
+ center_crop=False,
+ ):
+ self.size = size
+ self.center_crop = center_crop
+ self.tokenizer = tokenizer
+ self.image_captions_filename = None
+
+ self.instance_data_root = Path(instance_data_root)
+ if not self.instance_data_root.exists():
+ raise ValueError("Instance images root doesn't exists.")
+
+ self.instance_images_path = list(Path(instance_data_root).iterdir())
+ self.num_instance_images = len(self.instance_images_path)
+ self.instance_prompt = instance_prompt
+ self._length = self.num_instance_images
+
+ if args.image_captions_filename:
+ self.image_captions_filename = True
+
+ if class_data_root is not None:
+ self.class_data_root = Path(class_data_root)
+ self.class_data_root.mkdir(parents=True, exist_ok=True)
+ self.class_images_path = list(self.class_data_root.iterdir())
+ self.num_class_images = len(self.class_images_path)
+ self._length = max(self.num_class_images, self.num_instance_images)
+ self.class_prompt = class_prompt
+ else:
+ self.class_data_root = None
+
+ self.image_transforms = transforms.Compose(
+ [
+ transforms.Resize(size, interpolation=transforms.InterpolationMode.BILINEAR),
+ transforms.CenterCrop(size) if center_crop else transforms.RandomCrop(size),
+ transforms.ToTensor(),
+ transforms.Normalize([0.5], [0.5]),
+ ]
+ )
+
+ def __len__(self):
+ return self._length
+
+ def __getitem__(self, index, args=parse_args()):
+ example = {}
+ path = self.instance_images_path[index % self.num_instance_images]
+ instance_image = Image.open(path)
+ if not instance_image.mode == "RGB":
+ instance_image = instance_image.convert("RGB")
+
+ instance_prompt = self.instance_prompt
+
+ if self.image_captions_filename:
+ filename = Path(path).stem
+
+ pt=''.join([i for i in filename if not i.isdigit()])
+ pt=pt.replace("_"," ")
+ pt=pt.replace("(","")
+ pt=pt.replace(")","")
+ pt=pt.replace("-","")
+ pt=pt.replace("conceptimagedb","")
+
+ if args.external_captions:
+ cptpth=os.path.join(args.captions_dir, filename+'.txt')
+ if os.path.exists(cptpth):
+ with open(cptpth, "r") as f:
+ instance_prompt=pt+' '+f.read()
+ else:
+ instance_prompt=pt
+ else:
+ if args.Style:
+ instance_prompt = ""
+ else:
+ instance_prompt = pt
+ sys.stdout.write(" �[0;32m" +instance_prompt[:45]+" �[0m")
+ sys.stdout.flush()
+
+
+ example["instance_images"] = self.image_transforms(instance_image)
+ example["instance_prompt_ids"] = self.tokenizer(
+ instance_prompt,
+ padding="do_not_pad",
+ truncation=True,
+ max_length=self.tokenizer.model_max_length,
+ ).input_ids
+
+ if self.class_data_root:
+ class_image = Image.open(self.class_images_path[index % self.num_class_images])
+ if not class_image.mode == "RGB":
+ class_image = class_image.convert("RGB")
+ example["class_images"] = self.image_transforms(class_image)
+ example["class_prompt_ids"] = self.tokenizer(
+ self.class_prompt,
+ padding="do_not_pad",
+ truncation=True,
+ max_length=self.tokenizer.model_max_length,
+ ).input_ids
+
+ return example
+
+
+
+class PromptDataset(Dataset):
+ "A simple dataset to prepare the prompts to generate class images on multiple GPUs."
+
+ def __init__(self, prompt, num_samples):
+ self.prompt = prompt
+ self.num_samples = num_samples
+
+ def __len__(self):
+ return self.num_samples
+
+ def __getitem__(self, index):
+ example = {}
+ example["prompt"] = self.prompt
+ example["index"] = index
+ return example
+
+
+def get_full_repo_name(model_id: str, organization: Optional[str] = None, token: Optional[str] = None):
+ if token is None:
+ token = HfFolder.get_token()
+ if organization is None:
+ username = whoami(token)["name"]
+ return f"{username}/{model_id}"
+ else:
+ return f"{organization}/{model_id}"
+
+
+def main():
+ args = parse_args()
+ logging_dir = Path(args.output_dir, args.logging_dir)
+ i=args.save_starting_step
+ accelerator = Accelerator(
+ gradient_accumulation_steps=args.gradient_accumulation_steps,
+ mixed_precision=args.mixed_precision,
+ log_with="tensorboard",
+ logging_dir=logging_dir,
+ )
+
+ # Currently, it's not possible to do gradient accumulation when training two models with accelerate.accumulate
+ # This will be enabled soon in accelerate. For now, we don't allow gradient accumulation when training two models.
+ # TODO (patil-suraj): Remove this check when gradient accumulation with two models is enabled in accelerate.
+ if args.train_text_encoder and args.gradient_accumulation_steps > 1 and accelerator.num_processes > 1:
+ raise ValueError(
+ "Gradient accumulation is not supported when training the text encoder in distributed training. "
+ "Please set gradient_accumulation_steps to 1. This feature will be supported in the future."
+ )
+
+ if args.seed is not None:
+ set_seed(args.seed)
+
+ if args.with_prior_preservation:
+ class_images_dir = Path(args.class_data_dir)
+ if not class_images_dir.exists():
+ class_images_dir.mkdir(parents=True)
+ cur_class_images = len(list(class_images_dir.iterdir()))
+
+ if cur_class_images < args.num_class_images:
+ torch_dtype = torch.float16 if accelerator.device.type == "cuda" else torch.float32
+ pipeline = StableDiffusionPipeline.from_pretrained(
+ args.pretrained_model_name_or_path, torch_dtype=torch_dtype
+ )
+ pipeline.set_progress_bar_config(disable=True)
+
+ num_new_images = args.num_class_images - cur_class_images
+ logger.info(f"Number of class images to sample: {num_new_images}.")
+
+ sample_dataset = PromptDataset(args.class_prompt, num_new_images)
+ sample_dataloader = torch.utils.data.DataLoader(sample_dataset, batch_size=args.sample_batch_size)
+
+ sample_dataloader = accelerator.prepare(sample_dataloader)
+ pipeline.to(accelerator.device)
+
+ for example in tqdm(
+ sample_dataloader, desc="Generating class images", disable=not accelerator.is_local_main_process
+ ):
+ with torch.autocast("cuda"):
+ images = pipeline(example["prompt"]).images
+
+ for i, image in enumerate(images):
+ image.save(class_images_dir / f"{example['index'][i] + cur_class_images}.jpg")
+
+ del pipeline
+ if torch.cuda.is_available():
+ torch.cuda.empty_cache()
+
+ # Handle the repository creation
+ if accelerator.is_main_process:
+ if args.push_to_hub:
+ if args.hub_model_id is None:
+ repo_name = get_full_repo_name(Path(args.output_dir).name, token=args.hub_token)
+ else:
+ repo_name = args.hub_model_id
+ repo = Repository(args.output_dir, clone_from=repo_name)
+
+ with open(os.path.join(args.output_dir, ".gitignore"), "w+") as gitignore:
+ if "step_*" not in gitignore:
+ gitignore.write("step_*\n")
+ if "epoch_*" not in gitignore:
+ gitignore.write("epoch_*\n")
+ elif args.output_dir is not None:
+ os.makedirs(args.output_dir, exist_ok=True)
+
+ # Load the tokenizer
+ if args.tokenizer_name:
+ tokenizer = CLIPTokenizer.from_pretrained(args.tokenizer_name)
+ elif args.pretrained_model_name_or_path:
+ tokenizer = CLIPTokenizer.from_pretrained(args.pretrained_model_name_or_path, subfolder="tokenizer")
+
+ # Load models and create wrapper for stable diffusion
+ if args.train_only_unet or args.dump_only_text_encoder:
+ if os.path.exists(str(args.output_dir+"/text_encoder_trained")):
+ text_encoder = CLIPTextModel.from_pretrained(args.output_dir, subfolder="text_encoder_trained")
+ else:
+ text_encoder = CLIPTextModel.from_pretrained(args.pretrained_model_name_or_path, subfolder="text_encoder")
+ else:
+ text_encoder = CLIPTextModel.from_pretrained(args.pretrained_model_name_or_path, subfolder="text_encoder")
+ vae = AutoencoderKL.from_pretrained(args.pretrained_model_name_or_path, subfolder="vae")
+ unet = UNet2DConditionModel.from_pretrained(args.pretrained_model_name_or_path, subfolder="unet")
+
+ vae.requires_grad_(False)
+ if not args.train_text_encoder:
+ text_encoder.requires_grad_(False)
+
+ if args.gradient_checkpointing:
+ unet.enable_gradient_checkpointing()
+ if args.train_text_encoder:
+ text_encoder.gradient_checkpointing_enable()
+
+ if args.scale_lr:
+ args.learning_rate = (
+ args.learning_rate * args.gradient_accumulation_steps * args.train_batch_size * accelerator.num_processes
+ )
+
+ # Use 8-bit Adam for lower memory usage or to fine-tune the model in 16GB GPUs
+ if args.use_8bit_adam:
+ try:
+ import bitsandbytes as bnb
+ except ImportError:
+ raise ImportError(
+ "To use 8-bit Adam, please install the bitsandbytes library: `pip install bitsandbytes`."
+ )
+
+ optimizer_class = bnb.optim.AdamW8bit
+ else:
+ optimizer_class = torch.optim.AdamW
+
+ params_to_optimize = (
+ itertools.chain(unet.parameters(), text_encoder.parameters()) if args.train_text_encoder else unet.parameters()
+ )
+ optimizer = optimizer_class(
+ params_to_optimize,
+ lr=args.learning_rate,
+ betas=(args.adam_beta1, args.adam_beta2),
+ weight_decay=args.adam_weight_decay,
+ eps=args.adam_epsilon,
+ )
+
+ noise_scheduler = DDPMScheduler.from_config(args.pretrained_model_name_or_path, subfolder="scheduler")
+
+ train_dataset = DreamBoothDataset(
+ instance_data_root=args.instance_data_dir,
+ instance_prompt=args.instance_prompt,
+ class_data_root=args.class_data_dir if args.with_prior_preservation else None,
+ class_prompt=args.class_prompt,
+ tokenizer=tokenizer,
+ size=args.resolution,
+ center_crop=args.center_crop,
+ args=args,
+ )
+
+ def collate_fn(examples):
+ input_ids = [example["instance_prompt_ids"] for example in examples]
+ pixel_values = [example["instance_images"] for example in examples]
+
+ # Concat class and instance examples for prior preservation.
+ # We do this to avoid doing two forward passes.
+ if args.with_prior_preservation:
+ input_ids += [example["class_prompt_ids"] for example in examples]
+ pixel_values += [example["class_images"] for example in examples]
+
+ pixel_values = torch.stack(pixel_values)
+ pixel_values = pixel_values.to(memory_format=torch.contiguous_format).float()
+
+ input_ids = tokenizer.pad({"input_ids": input_ids}, padding=True, return_tensors="pt").input_ids
+
+ batch = {
+ "input_ids": input_ids,
+ "pixel_values": pixel_values,
+ }
+ return batch
+
+ train_dataloader = torch.utils.data.DataLoader(
+ train_dataset, batch_size=args.train_batch_size, shuffle=True, collate_fn=collate_fn
+ )
+
+ # Scheduler and math around the number of training steps.
+ overrode_max_train_steps = False
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if args.max_train_steps is None:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ overrode_max_train_steps = True
+
+ lr_scheduler = get_scheduler(
+ args.lr_scheduler,
+ optimizer=optimizer,
+ num_warmup_steps=args.lr_warmup_steps * args.gradient_accumulation_steps,
+ num_training_steps=args.max_train_steps * args.gradient_accumulation_steps,
+ )
+
+ if args.train_text_encoder:
+ unet, text_encoder, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
+ unet, text_encoder, optimizer, train_dataloader, lr_scheduler
+ )
+ else:
+ unet, optimizer, train_dataloader, lr_scheduler = accelerator.prepare(
+ unet, optimizer, train_dataloader, lr_scheduler
+ )
+
+ weight_dtype = torch.float32
+ if args.mixed_precision == "fp16":
+ weight_dtype = torch.float16
+ elif args.mixed_precision == "bf16":
+ weight_dtype = torch.bfloat16
+
+ # Move text_encode and vae to gpu.
+ # For mixed precision training we cast the text_encoder and vae weights to half-precision
+ # as these models are only used for inference, keeping weights in full precision is not required.
+ vae.to(accelerator.device, dtype=weight_dtype)
+ if not args.train_text_encoder:
+ text_encoder.to(accelerator.device, dtype=weight_dtype)
+
+ # We need to recalculate our total training steps as the size of the training dataloader may have changed.
+ num_update_steps_per_epoch = math.ceil(len(train_dataloader) / args.gradient_accumulation_steps)
+ if overrode_max_train_steps:
+ args.max_train_steps = args.num_train_epochs * num_update_steps_per_epoch
+ # Afterwards we recalculate our number of training epochs
+ args.num_train_epochs = math.ceil(args.max_train_steps / num_update_steps_per_epoch)
+
+ # We need to initialize the trackers we use, and also store our configuration.
+ # The trackers initializes automatically on the main process.
+ if accelerator.is_main_process:
+ accelerator.init_trackers("dreambooth", config=vars(args))
+
+ def bar(prg):
+ br='|'+'█' * prg + ' ' * (25-prg)+'|'
+ return br
+
+ # Train!
+ total_batch_size = args.train_batch_size * accelerator.num_processes * args.gradient_accumulation_steps
+
+ logger.info("***** Running training *****")
+ logger.info(f" Num examples = {len(train_dataset)}")
+ logger.info(f" Num batches each epoch = {len(train_dataloader)}")
+ logger.info(f" Num Epochs = {args.num_train_epochs}")
+ logger.info(f" Instantaneous batch size per device = {args.train_batch_size}")
+ logger.info(f" Total train batch size (w. parallel, distributed & accumulation) = {total_batch_size}")
+ logger.info(f" Gradient Accumulation steps = {args.gradient_accumulation_steps}")
+ logger.info(f" Total optimization steps = {args.max_train_steps}")
+ # Only show the progress bar once on each machine.
+ progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
+ global_step = 0
+
+ for epoch in range(args.num_train_epochs):
+ unet.train()
+ if args.train_text_encoder:
+ text_encoder.train()
+ for step, batch in enumerate(train_dataloader):
+ with accelerator.accumulate(unet):
+ # Convert images to latent space
+ latents = vae.encode(batch["pixel_values"].to(dtype=weight_dtype)).latent_dist.sample()
+ latents = latents * 0.18215
+
+ # Sample noise that we'll add to the latents
+ noise = torch.randn_like(latents)
+ bsz = latents.shape[0]
+ # Sample a random timestep for each image
+ timesteps = torch.randint(0, noise_scheduler.config.num_train_timesteps, (bsz,), device=latents.device)
+ timesteps = timesteps.long()
+
+ # Add noise to the latents according to the noise magnitude at each timestep
+ # (this is the forward diffusion process)
+ noisy_latents = noise_scheduler.add_noise(latents, noise, timesteps)
+
+ # Get the text embedding for conditioning
+ encoder_hidden_states = text_encoder(batch["input_ids"])[0]
+
+ # Predict the noise residual
+ model_pred = unet(noisy_latents, timesteps, encoder_hidden_states).sample
+
+ # Get the target for loss depending on the prediction type
+ if noise_scheduler.config.prediction_type == "epsilon":
+ target = noise
+ elif noise_scheduler.config.prediction_type == "v_prediction":
+ target = noise_scheduler.get_velocity(latents, noise, timesteps)
+ else:
+ raise ValueError(f"Unknown prediction type {noise_scheduler.config.prediction_type}")
+
+ if args.with_prior_preservation:
+ # Chunk the noise and model_pred into two parts and compute the loss on each part separately.
+ model_pred, model_pred_prior = torch.chunk(model_pred, 2, dim=0)
+ target, target_prior = torch.chunk(target, 2, dim=0)
+
+ # Compute instance loss
+ loss = F.mse_loss(model_pred.float(), target.float(), reduction="none").mean([1, 2, 3]).mean()
+
+ # Compute prior loss
+ prior_loss = F.mse_loss(model_pred_prior.float(), target_prior.float(), reduction="mean")
+
+ # Add the prior loss to the instance loss.
+ loss = loss + args.prior_loss_weight * prior_loss
+ else:
+ loss = F.mse_loss(model_pred.float(), target.float(), reduction="mean")
+
+ accelerator.backward(loss)
+ if accelerator.sync_gradients:
+ params_to_clip = (
+ itertools.chain(unet.parameters(), text_encoder.parameters())
+ if args.train_text_encoder
+ else unet.parameters()
+ )
+ accelerator.clip_grad_norm_(params_to_clip, args.max_grad_norm)
+ optimizer.step()
+ lr_scheduler.step()
+ optimizer.zero_grad()
+
+ # Checks if the accelerator has performed an optimization step behind the scenes
+ if accelerator.sync_gradients:
+ progress_bar.update(1)
+ global_step += 1
+
+ fll=round((global_step*100)/args.max_train_steps)
+ fll=round(fll/4)
+ pr=bar(fll)
+
+ logs = {"loss": loss.detach().item(), "lr": lr_scheduler.get_last_lr()[0]}
+ progress_bar.set_postfix(**logs)
+ progress_bar.set_description_str("Progress:"+pr)
+ accelerator.log(logs, step=global_step)
+
+ if global_step >= args.max_train_steps:
+ break
+
+ if args.train_text_encoder and global_step == args.stop_text_encoder_training and global_step >= 5:
+ if accelerator.is_main_process:
+ print(" �[0;32m" +" Freezing the text_encoder ..."+" �[0m")
+ frz_dir=args.output_dir + "/text_encoder_frozen"
+ if os.path.exists(frz_dir):
+ subprocess.call('rm -r '+ frz_dir, shell=True)
+ os.mkdir(frz_dir)
+ pipeline = StableDiffusionPipeline.from_pretrained(
+ args.pretrained_model_name_or_path,
+ unet=accelerator.unwrap_model(unet),
+ text_encoder=accelerator.unwrap_model(text_encoder),
+ )
+ pipeline.text_encoder.save_pretrained(frz_dir)
+
+ if args.save_n_steps >= 1:
+ if global_step < args.max_train_steps and global_step+1==i:
+ ckpt_name = "_step_" + str(global_step+1)
+ save_dir = Path(args.output_dir+ckpt_name)
+ save_dir=str(save_dir)
+ save_dir=save_dir.replace(" ", "_")
+ if not os.path.exists(save_dir):
+ os.mkdir(save_dir)
+ inst=save_dir[16:]
+ inst=inst.replace(" ", "_")
+ print(" �[1;32mSAVING CHECKPOINT...")
+ # Create the pipeline using the trained modules and save it.
+ if accelerator.is_main_process:
+ pipeline = StableDiffusionPipeline.from_pretrained(
+ args.pretrained_model_name_or_path,
+ unet=accelerator.unwrap_model(unet),
+ text_encoder=accelerator.unwrap_model(text_encoder),
+ )
+ pipeline.save_pretrained(save_dir)
+ frz_dir=args.output_dir + "/text_encoder_frozen"
+ if args.train_text_encoder and os.path.exists(frz_dir):
+ subprocess.call('rm -r '+save_dir+'/text_encoder/*.*', shell=True)
+ subprocess.call('cp -f '+frz_dir +'/*.* '+ save_dir+'/text_encoder', shell=True)
+ chkpth=args.Session_dir+"/"+inst+".ckpt"
+ if args.mixed_precision=="fp16":
+ subprocess.call('python /content/diffusers/scripts/convertosdv2.py ' + save_dir + ' ' + chkpth + ' --fp16', shell=True)
+ else:
+ subprocess.call('python /content/diffusers/scripts/convertosdv2.py ' + save_dir + ' ' + chkpth, shell=True)
+ print("Done, resuming training ...�[0m")
+ subprocess.call('rm -r '+ save_dir, shell=True)
+ i=i+args.save_n_steps
+
+ if args.external_captions and global_step == args.stop_text_encoder_training and global_step >= 5:
+ subprocess.call('mv '+args.captions_dir+' '+args.captions_dir+'off', shell=True)
+
+ accelerator.wait_for_everyone()
+
+ # Create the pipeline using using the trained modules and save it.
+ if accelerator.is_main_process:
+ if args.dump_only_text_encoder:
+ txt_dir=args.output_dir + "/text_encoder_trained"
+ if args.train_only_text_encoder:
+ pipeline = StableDiffusionPipeline.from_pretrained(
+ args.pretrained_model_name_or_path,
+ text_encoder=accelerator.unwrap_model(text_encoder),
+ )
+ pipeline.save_pretrained(args.output_dir)
+ else:
+ if not os.path.exists(txt_dir):
+ os.mkdir(txt_dir)
+ pipeline = StableDiffusionPipeline.from_pretrained(
+ args.pretrained_model_name_or_path,
+ unet=accelerator.unwrap_model(unet),
+ text_encoder=accelerator.unwrap_model(text_encoder),
+ )
+ pipeline.text_encoder.save_pretrained(txt_dir)
+
+ elif args.train_only_unet:
+ pipeline = StableDiffusionPipeline.from_pretrained(
+ args.pretrained_model_name_or_path,
+ unet=accelerator.unwrap_model(unet),
+ text_encoder=accelerator.unwrap_model(text_encoder),
+ )
+ pipeline.save_pretrained(args.output_dir)
+ txt_dir=args.output_dir + "/text_encoder_trained"
+ if os.path.exists(txt_dir):
+ subprocess.call('rm -r '+txt_dir, shell=True)
+
+ else:
+ pipeline = StableDiffusionPipeline.from_pretrained(
+ args.pretrained_model_name_or_path,
+ unet=accelerator.unwrap_model(unet),
+ text_encoder=accelerator.unwrap_model(text_encoder),
+ )
+ frz_dir=args.output_dir + "/text_encoder_frozen"
+ pipeline.save_pretrained(args.output_dir)
+ if args.train_text_encoder and os.path.exists(frz_dir):
+ subprocess.call('mv -f '+frz_dir +'/*.* '+ args.output_dir+'/text_encoder', shell=True)
+ subprocess.call('rm -r '+ frz_dir, shell=True)
+
+ if args.push_to_hub:
+ repo.push_to_hub(commit_message="End of training", blocking=False, auto_lfs_prune=True)
+
+ if os.path.exists(args.captions_dir+'off'):
+ subprocess.call('mv '+args.captions_dir+'off '+args.captions_dir, shell=True)
+
+
+ accelerator.end_training()
+
+if __name__ == "__main__":
+ main()
From a789676f920afadef4d8254510ee0ad985a7bef3 Mon Sep 17 00:00:00 2001
From: nawnie <106923464+nawnie@users.noreply.github.com>
Date: Fri, 23 Dec 2022 11:58:03 -0600
Subject: [PATCH 02/15] Created using Colaboratory
---
fast-DreamBooth.ipynb | 293 ++++++++++++++++++++++++++----------------
1 file changed, 180 insertions(+), 113 deletions(-)
diff --git a/fast-DreamBooth.ipynb b/fast-DreamBooth.ipynb
index 4f471b5f..af70af93 100644
--- a/fast-DreamBooth.ipynb
+++ b/fast-DreamBooth.ipynb
@@ -1,5 +1,15 @@
{
"cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "view-in-github",
+ "colab_type": "text"
+ },
+ "source": [
+ "<a href=\"https://colab.research.google.com/github/nawnie/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>"
+ ]
+ },
{
"cell_type": "markdown",
"metadata": {
@@ -12,31 +22,55 @@
},
{
"cell_type": "code",
- "execution_count": null,
+ "execution_count": 1,
"metadata": {
- "id": "A4Bae3VP6UsE"
+ "id": "A4Bae3VP6UsE",
+ "cellView": "form",
+ "outputId": "e9f640fd-175a-48dc-b098-91fde351bd28",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ }
},
- "outputs": [],
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "Mounted at /content/gdrive\n"
+ ]
+ }
+ ],
"source": [
+ "#@markdown # Mount Gdrive\n",
"from google.colab import drive\n",
"drive.mount('/content/gdrive')"
]
},
{
"cell_type": "code",
- "execution_count": null,
+ "execution_count": 2,
"metadata": {
- "cellView": "form",
- "id": "QyvcqeiL65Tj"
+ "id": "QyvcqeiL65Tj",
+ "outputId": "d9b8adf1-8858-4ff8-f06d-c518b6859770",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ }
},
- "outputs": [],
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "\u001b[1;32mDONE !\n"
+ ]
+ }
+ ],
"source": [
"#@markdown # Dependencies\n",
"\n",
"from IPython.utils import capture\n",
"import time\n",
"\n",
- "print('\u001b[1;32mInstalling dependencies...')\n",
"with capture.capture_output() as cap:\n",
" %cd /content/\n",
" !pip install -q accelerate==0.12.0\n",
@@ -50,9 +84,11 @@
" for i in range(1,6):\n",
" !rm \"Dependencies.7z.00{i}\"\n",
" !pip uninstall -y diffusers\n",
- " !git clone --branch updt https://github.com/TheLastBen/diffusers\n",
+ " !git clone https://github.com/nawnie/diffusers\n",
" !pip install -q /content/diffusers\n",
- "print('\u001b[1;32mDone, proceed') "
+ " !pip install onnxruntime\n",
+ " \n",
+ "print('\u001b[1;32mDONE !') "
]
},
{
@@ -108,7 +144,7 @@
"\n",
"#@markdown Or\n",
"\n",
- "CKPT_Path = \"\" #@param {type:\"string\"}\n",
+ "CKPT_Path = \"/content/gdrive/MyDrive/sd_v1-5_vae.ckpt\" #@param {type:\"string\"}\n",
"\n",
"#@markdown Or\n",
"\n",
@@ -164,7 +200,7 @@
" !git lfs install --system --skip-repo\n",
" !git remote add -f origin \"https://USER:{token}@huggingface.co/stabilityai/stable-diffusion-2-1\"\n",
" !git config core.sparsecheckout true\n",
- " !echo -e \"scheduler\\ntext_encoder\\ntokenizer\\nunet\\nvae\\nfeature_extractor\\nmodel_index.json\" > .git/info/sparse-checkout\n",
+ " !echo -e \"scheduler\\ntext_encoder\\ntokenizer\\nunet\\nvae\\nmodel_index.json\" > .git/info/sparse-checkout\n",
" !git pull origin main\n",
" clear_output()\n",
" print('\u001b[1;32mDONE !')\n",
@@ -180,7 +216,7 @@
" !git lfs install --system --skip-repo\n",
" !git remote add -f origin \"https://USER:{token}@huggingface.co/stabilityai/stable-diffusion-2-1-base\"\n",
" !git config core.sparsecheckout true\n",
- " !echo -e \"scheduler\\ntext_encoder\\ntokenizer\\nunet\\nvae\\nfeature_extractor\\nmodel_index.json\" > .git/info/sparse-checkout\n",
+ " !echo -e \"scheduler\\ntext_encoder\\ntokenizer\\nunet\\nvae\\nmodel_index.json\" > .git/info/sparse-checkout\n",
" !git pull origin main\n",
" clear_output()\n",
" print('\u001b[1;32mDONE !')\n",
@@ -199,7 +235,7 @@
" !git lfs install --system --skip-repo\n",
" !git remote add -f origin \"https://USER:{token}@huggingface.co/{Path_to_HuggingFace}\"\n",
" !git config core.sparsecheckout true\n",
- " !echo -e \"scheduler\\ntext_encoder\\ntokenizer\\nunet\\nvae\\nfeature_extractor\\nmodel_index.json\" > .git/info/sparse-checkout\n",
+ " !echo -e \"scheduler\\ntext_encoder\\ntokenizer\\nunet\\nvae\\nmodel_index.json\" > .git/info/sparse-checkout\n",
" !git pull origin main\n",
" if os.path.exists('/content/stable-diffusion-custom/unet/diffusion_pytorch_model.bin'):\n",
" !rm -r /content/stable-diffusion-custom/.git\n",
@@ -379,7 +415,7 @@
" \n",
"PT=\"\"\n",
"\n",
- "Session_Name = \"\" #@param{type: 'string'}\n",
+ "Session_Name = \"retry3\" #@param{type: 'string'}\n",
"while Session_Name==\"\":\n",
" print('\u001b[1;31mInput the Session Name:') \n",
" Session_Name=input('')\n",
@@ -507,8 +543,8 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "cellView": "form",
- "id": "LC4ukG60fgMy"
+ "id": "LC4ukG60fgMy",
+ "cellView": "form"
},
"outputs": [],
"source": [
@@ -523,7 +559,7 @@
"#@markdown\n",
"#@markdown - Run the cell to upload the instance pictures.\n",
"\n",
- "Remove_existing_instance_images= True #@param{type: 'boolean'}\n",
+ "Remove_existing_instance_images= False #@param{type: 'boolean'}\n",
"#@markdown - Uncheck the box to keep the existing instance images.\n",
"\n",
"\n",
@@ -534,11 +570,11 @@
"if not os.path.exists(str(INSTANCE_DIR)):\n",
" %mkdir -p \"$INSTANCE_DIR\"\n",
"\n",
- "IMAGES_FOLDER_OPTIONAL=\"\" #@param{type: 'string'}\n",
+ "IMAGES_FOLDER_OPTIONAL=\"/content/gdrive/MyDrive/Fast-Dreambooth/Sessions/retry3/instance_images2\" #@param{type: 'string'}\n",
"\n",
"#@markdown - If you prefer to specify directly the folder of the pictures instead of uploading, this will add the pictures to the existing (if any) instance images. Leave EMPTY to upload.\n",
"\n",
- "Crop_images= True #@param{type: 'boolean'}\n",
+ "Crop_images= False #@param{type: 'boolean'}\n",
"Crop_size = \"512\" #@param [\"512\", \"576\", \"640\", \"704\", \"768\", \"832\", \"896\", \"960\", \"1024\"]\n",
"Crop_size=int(Crop_size)\n",
"\n",
@@ -551,7 +587,7 @@
"if IMAGES_FOLDER_OPTIONAL!=\"\":\n",
" if Crop_images:\n",
" for filename in tqdm(os.listdir(IMAGES_FOLDER_OPTIONAL), bar_format=' |{bar:15}| {n_fmt}/{total_fmt} Uploaded'):\n",
- " extension = filename.split(\".\")[-1]\n",
+ " extension = filename.split(\".\")[1]\n",
" identifier=filename.split(\".\")[0]\n",
" new_path_with_file = os.path.join(INSTANCE_DIR, filename)\n",
" file = Image.open(IMAGES_FOLDER_OPTIONAL+\"/\"+filename)\n",
@@ -575,7 +611,7 @@
" for filename in tqdm(os.listdir(IMAGES_FOLDER_OPTIONAL), bar_format=' |{bar:15}| {n_fmt}/{total_fmt} Uploaded'):\n",
" %cp -r \"$IMAGES_FOLDER_OPTIONAL/$filename\" \"$INSTANCE_DIR\"\n",
" \n",
- " print('\\n\u001b[1;32mDone, proceed to the next cell')\n",
+ " print('\\n\u001b[1;32mDone, proceed to the training cell')\n",
"\n",
"\n",
"elif IMAGES_FOLDER_OPTIONAL ==\"\":\n",
@@ -583,7 +619,7 @@
" if Crop_images:\n",
" for filename in tqdm(uploaded.keys(), bar_format=' |{bar:15}| {n_fmt}/{total_fmt} Uploaded'):\n",
" shutil.move(filename, INSTANCE_DIR)\n",
- " extension = filename.split(\".\")[-1]\n",
+ " extension = filename.split(\".\")[1]\n",
" identifier=filename.split(\".\")[0]\n",
" new_path_with_file = os.path.join(INSTANCE_DIR, filename)\n",
" file = Image.open(new_path_with_file)\n",
@@ -606,7 +642,7 @@
" shutil.move(filename, INSTANCE_DIR)\n",
" clear_output()\n",
"\n",
- " print('\\n\u001b[1;32mDone, proceed to the next cell')\n",
+ " print('\\n\u001b[1;32mDone, proceed to the training cell')\n",
"\n",
"with capture.capture_output() as cap:\n",
" %cd \"$INSTANCE_DIR\"\n",
@@ -622,8 +658,8 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "cellView": "form",
- "id": "LxEv3u8mQos3"
+ "id": "LxEv3u8mQos3",
+ "cellView": "form"
},
"outputs": [],
"source": [
@@ -650,7 +686,7 @@
"if not os.path.exists(str(CONCEPT_DIR)):\n",
" %mkdir -p \"$CONCEPT_DIR\"\n",
"\n",
- "IMAGES_FOLDER_OPTIONAL=\"\" #@param{type: 'string'}\n",
+ "IMAGES_FOLDER_OPTIONAL=\"/content/gdrive/MyDrive/SFW_Data_sets/Futurama_extras\" #@param{type: 'string'}\n",
"\n",
"#@markdown - If you prefer to specify directly the folder of the pictures instead of uploading, this will add the pictures to the existing (if any) concept images. Leave EMPTY to upload.\n",
"\n",
@@ -665,7 +701,7 @@
"if IMAGES_FOLDER_OPTIONAL!=\"\":\n",
" if Crop_images:\n",
" for filename in tqdm(os.listdir(IMAGES_FOLDER_OPTIONAL), bar_format=' |{bar:15}| {n_fmt}/{total_fmt} Uploaded'):\n",
- " extension = filename.split(\".\")[-1]\n",
+ " extension = filename.split(\".\")[1]\n",
" identifier=filename.split(\".\")[0]\n",
" new_path_with_file = os.path.join(CONCEPT_DIR, filename)\n",
" file = Image.open(IMAGES_FOLDER_OPTIONAL+\"/\"+filename)\n",
@@ -689,12 +725,15 @@
" for filename in tqdm(os.listdir(IMAGES_FOLDER_OPTIONAL), bar_format=' |{bar:15}| {n_fmt}/{total_fmt} Uploaded'):\n",
" %cp -r \"$IMAGES_FOLDER_OPTIONAL/$filename\" \"$CONCEPT_DIR\"\n",
" \n",
+ " print('\\n\u001b[1;32mDone, proceed to the training cell')\n",
+ "\n",
+ "\n",
"elif IMAGES_FOLDER_OPTIONAL ==\"\":\n",
" uploaded = files.upload()\n",
" if Crop_images:\n",
" for filename in tqdm(uploaded.keys(), bar_format=' |{bar:15}| {n_fmt}/{total_fmt} Uploaded'):\n",
" shutil.move(filename, CONCEPT_DIR)\n",
- " extension = filename.split(\".\")[-1]\n",
+ " extension = filename.split(\".\")[1]\n",
" identifier=filename.split(\".\")[0]\n",
" new_path_with_file = os.path.join(CONCEPT_DIR, filename)\n",
" file = Image.open(new_path_with_file)\n",
@@ -717,12 +756,12 @@
" shutil.move(filename, CONCEPT_DIR)\n",
" clear_output()\n",
"\n",
- " \n",
- "print('\\n\u001b[1;32mAlmost done...')\n",
- "with capture.capture_output() as cap: \n",
+ " print('\\n\u001b[1;32mDone, proceed to the training cell')\n",
+ "\n",
+ "with capture.capture_output() as cap: \n",
" i=0\n",
" for filename in os.listdir(CONCEPT_DIR):\n",
- " extension = filename.split(\".\")[-1]\n",
+ " extension = filename.split(\".\")[1]\n",
" identifier=filename.split(\".\")[0]\n",
" new_path_with_file = os.path.join(CONCEPT_DIR, \"conceptimagedb\"+str(i)+\".\"+extension)\n",
" filepath=os.path.join(CONCEPT_DIR,filename)\n",
@@ -732,9 +771,7 @@
" %cd $SESSION_DIR\n",
" !rm concept_images.zip\n",
" !zip -r concept_images concept_images\n",
- " %cd /content\n",
- "\n",
- "print('\\n\u001b[1;32mDone, proceed to the training cell')"
+ " %cd /content"
]
},
{
@@ -750,7 +787,6 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "cellView": "form",
"id": "1-9QbkfAVYYU"
},
"outputs": [],
@@ -764,14 +800,29 @@
"from google.colab import runtime\n",
"import time\n",
"import random\n",
+ " # note to any user reading this, this is not an attempt to steal from ben but give users more options to change without looking at intimidaiting code\n",
+ " # any request by ben to remove or if he adds these functions i will remove my fork - Make some pretty pictures ya'll\n",
"\n",
"if os.path.exists(INSTANCE_DIR+\"/.ipynb_checkpoints\"):\n",
" %rm -r $INSTANCE_DIR\"/.ipynb_checkpoints\"\n",
"\n",
+ "\n",
"if os.path.exists(CONCEPT_DIR+\"/.ipynb_checkpoints\"):\n",
" %rm -r $CONCEPT_DIR\"/.ipynb_checkpoints\" \n",
"\n",
- "Resume_Training = False #@param {type:\"boolean\"}\n",
+ "Resume_Training = True #@param {type:\"boolean\"}\n",
+ "\n",
+ "#@markdown - If you're not satisfied with the result, check this box, run again the cell and it will continue training the current model.\n",
+ "\n",
+ "Warm_up= True #@param {type:\"boolean\"}\n",
+ "\n",
+ "#@markdown - use a warm up phase\n",
+ "\n",
+ "Disconnect_after_training=False #@param {type:\"boolean\"}\n",
+ "\n",
+ "#@markdown - Auto-disconnect from google colab after the training to avoid wasting compute units.\n",
+ "\n",
+ "\n",
"\n",
"try:\n",
" resume\n",
@@ -794,28 +845,65 @@
" print('\u001b[1;31mNo model found, use the \"Model Download\" cell to download a model.')\n",
" time.sleep(5)\n",
"\n",
- "#@markdown - If you're not satisfied with the result, check this box, run again the cell and it will continue training the current model.\n",
+ "\n",
+ "\n",
+ "dir_path =INSTANCE_DIR\n",
+ "image_count = (len([entry for entry in os.listdir(dir_path) if os.path.isfile(os.path.join(dir_path, entry))]))\n",
+ "\n",
"\n",
"MODELT_NAME=MODEL_NAME\n",
+ "#number_images = 137 #@param {type:\"integer\"}\n",
"\n",
- "UNet_Training_Steps=3000 #@param{type: 'number'}\n",
- "UNet_Learning_Rate = 2e-6 #@param [\"1e-6\",\"2e-6\",\"3e-6\",\"4e-6\",\"5e-6\"] {type:\"raw\"}\n",
- "untlr=UNet_Learning_Rate\n",
"\n",
- "#@markdown - Start with 3000 or lower, test the model, higher leaning rate = faster learning but higher risk of overfitting, if not enough, resume training for 1000 steps, keep testing until you get the desired output, `set it to 0 to train only the text_encoder`. \n",
+ "#@markdown ---------------------------\n",
+ "#@markdown An $ epoch $ is a $repeat$ of the entire set of instance images\n",
+ "#@markdown ---------------------------\n",
"\n",
- "Text_Encoder_Training_Steps=350 #@param{type: 'number'}\n",
+ "#@markdown ---------------------------\n",
"\n",
- "#@markdown - 350-600 steps is enough for a small dataset, keep this number small to avoid overfitting, set to 0 to disable, `set it to 0 before resuming training if it is already trained`.\n",
"\n",
- "Text_Encoder_Concept_Training_Steps=0 #@param{type: 'number'}\n",
"\n",
- "#@markdown - Suitable for training a style/concept as it acts as heavy regularization, set it to 1500 steps for 200 concept images (you can go higher), set to 0 to disable, set both the settings above to 0 to fintune only the text_encoder on the concept, `set it to 0 before resuming training if it is already trained`.\n",
+ "epoch = 1 #@param {type:\"number\"}\n",
+ "#@markdown most models will require < 200 epochs\n",
+ "batch_size = 1 #@param {type:\"number\"}\n",
+ "#@markdown how many images to scan per iteration on 1.5 the free colab can do 4\n",
+ "steps_per_iteration = 1 #@param {type:\"number\"}\n",
+ "#@markdown how many sets of batches to make before writting to the model *more then 2 not adivsed\n",
+ "Rate_of_Learning=\"2e-6\" #@param {type:\"string\"}\n",
+ "#@markdown rate to train images\n",
+ "Rate_of_Encoder=\"9e-7\" #@param {type:\"string\"}\n",
+ "#@markdown rate to train the encoder\n",
+ "Learning_schedule = \"polynomial\" #@param [\"consine\", \"constant\", \"linear\", \"polynomial\"] {allow-input: true}\n",
+ "#@markdown formula to slow learning rate slows down \n",
+ "\n",
+ "bs=batch_size\n",
+ "gs=steps_per_iteration\n",
+ "lr=Rate_of_Learning \n",
+ "lr2=Rate_of_Encoder\n",
+ "sched=Learning_schedule \n",
+ "Seed='' #@param{type: 'string'}\n",
+ "UNet_Training_Steps=0\n",
"\n",
- "Text_Encoder_Learning_Rate = 1e-6 #@param [\"1e-6\",\"8e-7\",\"6e-7\",\"5e-7\",\"4e-7\"] {type:\"raw\"}\n",
- "txlr=Text_Encoder_Learning_Rate\n",
"\n",
- "#@markdown - Learning rate for both text_encoder and concept_text_encoder, keep it low to avoid overfitting (1e-6 is higher than 4e-7)\n",
+ "MODELT_NAME=MODEL_NAME\n",
+ "# Training_Steps\n",
+ "UNet_Training_Steps=int((image_count*epoch)/(bs*gs))\n",
+ "\n",
+ "if Warm_up:\n",
+ " wu=int((UNet_Training_Steps/20))\n",
+ " UNet_Training_Steps=UNet_Training_Steps+wu # adds warm up to total steps\n",
+ "else:\n",
+ " wu=0\n",
+ "Text_Encoder_Training_Steps=0 #@param{type: 'number'}\n",
+ "\n",
+ "# adds warm up to total steps\n",
+ "UNet_Training_Steps=UNet_Training_Steps+wu\n",
+ "\n",
+ "#@markdown - 350-600 steps is enough for a small dataset, keep this number small to avoid overfitting, set to 0 to disable, `set it to 0 before resuming training if it is already trained`.\n",
+ "\n",
+ "Text_Encoder_Concept_Training_Steps=0 #@param{type: 'number'}\n",
+ "\n",
+ "#@markdown - helps prevent over fitting\n",
"\n",
"trnonltxt=\"\"\n",
"if UNet_Training_Steps==0:\n",
@@ -825,7 +913,7 @@
"\n",
"Style_Training = False #@param {type:\"boolean\"}\n",
"\n",
- "#@markdown - Further reduce overfitting, suitable when training a style or a general theme, don't check the box at the beginning, check it after training for at least 2000 steps.\n",
+ "#@markdown - Further reduce overfitting, aka Unconditional drop out best kept at 2 epochs\n",
"\n",
"Style=\"\"\n",
"if Style_Training:\n",
@@ -843,8 +931,6 @@
"else:\n",
" Seed=int(Seed)\n",
"\n",
- "GC=\"--gradient_checkpointing\"\n",
- "\n",
"if fp16:\n",
" prec=\"fp16\"\n",
"else:\n",
@@ -852,9 +938,9 @@
"\n",
"s = getoutput('nvidia-smi')\n",
"if 'A100' in s:\n",
- " GC=\"\"\n",
- "\n",
- "precision=prec\n",
+ " precision=\"no\"\n",
+ "else:\n",
+ " precision=prec\n",
"\n",
"resuming=\"\"\n",
"if Resume_Training and os.path.exists(OUTPUT_DIR+'/unet/diffusion_pytorch_model.bin'):\n",
@@ -892,8 +978,8 @@
" Textenc=\"\"\n",
"\n",
"#@markdown ---------------------------\n",
- "Save_Checkpoint_Every_n_Steps = False #@param {type:\"boolean\"}\n",
- "Save_Checkpoint_Every=500 #@param{type: 'number'}\n",
+ "Save_Checkpoint_Every_n_Steps = True #@param {type:\"boolean\"}\n",
+ "Save_Checkpoint_Every=1000 #@param{type: 'number'}\n",
"if Save_Checkpoint_Every==None:\n",
" Save_Checkpoint_Every=1\n",
"#@markdown - Minimum 200 steps between each save.\n",
@@ -908,10 +994,6 @@
" stp=Save_Checkpoint_Every\n",
"#@markdown - Start saving intermediary checkpoints from this step.\n",
"\n",
- "Disconnect_after_training=False #@param {type:\"boolean\"}\n",
- "\n",
- "#@markdown - Auto-disconnect from google colab after the training to avoid wasting compute units.\n",
- "\n",
"def dump_only_textenc(trnonltxt, MODELT_NAME, INSTANCE_DIR, OUTPUT_DIR, PT, Seed, precision, Training_Steps):\n",
" \n",
" !accelerate launch /content/diffusers/examples/dreambooth/train_dreambooth.py \\\n",
@@ -927,10 +1009,10 @@
" --resolution=512 \\\n",
" --mixed_precision=$precision \\\n",
" --train_batch_size=1 \\\n",
- " --gradient_accumulation_steps=1 $GC \\\n",
+ " --gradient_accumulation_steps=1 --gradient_checkpointing \\\n",
" --use_8bit_adam \\\n",
- " --learning_rate=$txlr \\\n",
- " --lr_scheduler=\"polynomial\" \\\n",
+ " --learning_rate=9e-7 \\\n",
+ " --lr_scheduler=\"constant\" \\\n",
" --lr_warmup_steps=0 \\\n",
" --max_train_steps=$Training_Steps\n",
"\n",
@@ -953,12 +1035,12 @@
" --seed=$Seed \\\n",
" --resolution=$Res \\\n",
" --mixed_precision=$precision \\\n",
- " --train_batch_size=1 \\\n",
- " --gradient_accumulation_steps=1 $GC \\\n",
+ " --train_batch_size=$bs \\\n",
+ " --gradient_accumulation_steps=$gs --gradient_checkpointing \\\n",
" --use_8bit_adam \\\n",
- " --learning_rate=$untlr \\\n",
- " --lr_scheduler=\"polynomial\" \\\n",
- " --lr_warmup_steps=0 \\\n",
+ " --learning_rate=$lr \\\n",
+ " --lr_scheduler=\"$sched\" \\\n",
+ " --lr_warmup_steps=$wu \\\n",
" --max_train_steps=$Training_Steps\n",
"\n",
"\n",
@@ -968,13 +1050,13 @@
" %rm -r $OUTPUT_DIR\"/text_encoder_trained\"\n",
" dump_only_textenc(trnonltxt, MODELT_NAME, INSTANCE_DIR, OUTPUT_DIR, PT, Seed, precision, Training_Steps=stptxt)\n",
"if Enable_Text_Encoder_Concept_Training and os.listdir(CONCEPT_DIR)!=[]:\n",
- " clear_output()\n",
+ " #clear_output()\n",
" if resuming==\"Yes\":\n",
" print('\u001b[1;32mResuming Training...\u001b[0m') \n",
" print('\u001b[1;33mTraining the text encoder on the concept...\u001b[0m')\n",
" dump_only_textenc(trnonltxt, MODELT_NAME, CONCEPT_DIR, OUTPUT_DIR, PT, Seed, precision, Training_Steps=stptxtc)\n",
"elif Enable_Text_Encoder_Concept_Training and os.listdir(CONCEPT_DIR)==[]:\n",
- " print('\u001b[1;31mNo concept images found, skipping concept training...')\n",
+ " print('\u001b[1;31mNo Concept Images found, skipping concept training...')\n",
" time.sleep(8)\n",
"if UNet_Training_Steps!=0:\n",
" train_only_unet(stpsv, stp, SESSION_DIR, MODELT_NAME, INSTANCE_DIR, OUTPUT_DIR, PT, Seed, Res, precision, Training_Steps=UNet_Training_Steps)\n",
@@ -984,25 +1066,25 @@
" prc=\"--fp16\" if precision==\"fp16\" else \"\"\n",
" if V2:\n",
" !python /content/diffusers/scripts/convertosdv2.py $prc $OUTPUT_DIR $SESSION_DIR/$Session_Name\".ckpt\"\n",
- " clear_output()\n",
+ " #clear_output()\n",
" if os.path.exists(SESSION_DIR+\"/\"+INSTANCE_NAME+'.ckpt'):\n",
- " clear_output()\n",
+ " #clear_output()\n",
" print(\"\u001b[1;32mDONE, the CKPT model is in your Gdrive in the sessions folder\")\n",
+ " time.sleep(2)\n",
" if Disconnect_after_training :\n",
- " time.sleep(20) \n",
" runtime.unassign() \n",
" else:\n",
" print(\"\u001b[1;31mSomething went wrong\") \n",
" else: \n",
" !wget -O /content/convertosd.py https://github.com/TheLastBen/fast-stable-diffusion/raw/main/Dreambooth/convertosd.py\n",
- " clear_output()\n",
+ " #clear_output()\n",
" if precision==\"no\":\n",
" !sed -i '226s@.*@@' /content/convertosd.py\n",
" !sed -i '201s@.*@ model_path = \"{OUTPUT_DIR}\"@' /content/convertosd.py\n",
" !sed -i '202s@.*@ checkpoint_path= \"{SESSION_DIR}/{Session_Name}.ckpt\"@' /content/convertosd.py\n",
" !python /content/convertosd.py\n",
" !rm /content/convertosd.py\n",
- " clear_output()\n",
+ " #clear_output()\n",
" if os.path.exists(SESSION_DIR+\"/\"+INSTANCE_NAME+'.ckpt'): \n",
" print(\"\u001b[1;32mDONE, the CKPT model is in your Gdrive in the sessions folder\")\n",
" if Disconnect_after_training :\n",
@@ -1028,8 +1110,8 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "cellView": "form",
- "id": "iAZGngFcI8hq"
+ "id": "iAZGngFcI8hq",
+ "cellView": "form"
},
"outputs": [],
"source": [
@@ -1045,7 +1127,7 @@
"Model_Version = \"1.5\" #@param [\"1.5\", \"V2.1-512\", \"V2.1-768\"]\n",
"#@markdown - Important! Choose the correct version and resolution of the model\n",
"\n",
- "Update_repo = True\n",
+ "Update_repo = True #@param {type:\"boolean\"}\n",
"\n",
"Session__Name=\"\" #@param{type: 'string'}\n",
"\n",
@@ -1097,16 +1179,15 @@
" %cd /content/\n",
" !ln -s /content/gdrive/MyDrive/sd/stable-diffusion-webui/cache/huggingface ../root/.cache/\n",
" !ln -s /content/gdrive/MyDrive/sd/stable-diffusion-webui/cache/torch ../root/.cache/\n",
- " !wget -O /content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/shared.py https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/modules/shared.py\n",
"\n",
"if Update_repo:\n",
- " with capture.capture_output() as cap: \n",
- " !rm /content/gdrive/MyDrive/sd/stable-diffusion-webui/webui.sh \n",
- " !rm /content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/paths.py\n",
- " !rm /content/gdrive/MyDrive/sd/stable-diffusion-webui/webui.py \n",
- " !rm /content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/ui.py\n",
- " !rm /content/gdrive/MyDrive/sd/stable-diffusion-webui/style.css\n",
- " %cd /content/gdrive/MyDrive/sd/stable-diffusion-webui/\n",
+ " !rm /content/gdrive/MyDrive/sd/stable-diffusion-webui/webui.sh \n",
+ " !rm /content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/paths.py\n",
+ " !rm /content/gdrive/MyDrive/sd/stable-diffusion-webui/webui.py \n",
+ " !rm /content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/ui.py\n",
+ " !rm /content/gdrive/MyDrive/sd/stable-diffusion-webui/style.css\n",
+ " %cd /content/gdrive/MyDrive/sd/stable-diffusion-webui/\n",
+ " clear_output()\n",
" print('\u001b[1;32m')\n",
" !git pull\n",
"\n",
@@ -1139,29 +1220,20 @@
" %cd /content/gdrive/MyDrive/sd/stable-diffusion-webui/\n",
" time.sleep(1)\n",
" !wget -O webui.py https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/webui.py\n",
- " !sed -i 's@ui.create_ui().*@ui.create_ui();shared.demo.queue(concurrency_count=999999,status_update_rate=0.1)@' /content/gdrive/MyDrive/sd/stable-diffusion-webui/webui.py\n",
+ " !sed -i 's@ui.create_ui().*@ui.create_ui();shared.demo.queue(concurrency_count=10)@' /content/gdrive/MyDrive/sd/stable-diffusion-webui/webui.py\n",
" %cd /content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/\n",
" !wget -O ui.py https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/modules/ui.py\n",
" !sed -i 's@css = \"\".*@with open(os.path.join(script_path, \"style.css\"), \"r\", encoding=\"utf8\") as file:\\n css = file.read()@' /content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/ui.py \n",
" %cd /content/gdrive/MyDrive/sd/stable-diffusion-webui\n",
" !wget -O style.css https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/style.css\n",
" !sed -i 's@min-height: 4.*@min-height: 5.5em;@g' /content/gdrive/MyDrive/sd/stable-diffusion-webui/style.css\n",
- " !sed -i 's@\"multiple_tqdm\": true,@\\\"multiple_tqdm\": false,@' /content/gdrive/MyDrive/sd/stable-diffusion-webui/config.json\n",
- " !sed -i '902s@.*@ self.logvar = self.logvar.to(self.device)@' /content/gdrive/MyDrive/sd/stablediffusion/ldm/models/diffusion/ddpm.py\n",
+ " !sed -i 's@\"multiple_tqdm\": true,@\\\"multiple_tqdm\": false,@' /content/gdrive/MyDrive/sd/stable-diffusion-webui/config.json \n",
" %cd /content\n",
"\n",
"\n",
- "Use_Gradio_Server = True #@param {type:\"boolean\"}\n",
+ "Use_Gradio_Server = False #@param {type:\"boolean\"}\n",
"#@markdown - Only if you have trouble connecting to the local server.\n",
"\n",
- "Large_Model= False #@param {type:\"boolean\"}\n",
- "#@markdown - Check if you have trouble loading a model 7GB+\n",
- "\n",
- "if Large_Model:\n",
- " !sed -i 's@cmd_opts.lowram else \\\"cpu\\\"@cmd_opts.lowram else \\\"cuda\\\"@' /content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/shared.py\n",
- "else:\n",
- " !sed -i 's@cmd_opts.lowram else \\\"cuda\\\"@cmd_opts.lowram else \\\"cpu\\\"@' /content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/shared.py\n",
- "\n",
"\n",
"share=''\n",
"if Use_Gradio_Server:\n",
@@ -1224,9 +1296,9 @@
" xformers=\"\"\n",
"\n",
"if os.path.isfile(path_to_trained_model):\n",
- " !python /content/gdrive/MyDrive/sd/stable-diffusion-webui/webui.py $share --disable-safe-unpickle --no-half-vae --enable-insecure-extension-access --ckpt \"$path_to_trained_model\" $configf $xformers\n",
+ " !python /content/gdrive/MyDrive/sd/stable-diffusion-webui/webui.py $share --disable-safe-unpickle --no-half-vae --ckpt \"$path_to_trained_model\" $configf $xformers\n",
"else:\n",
- " !python /content/gdrive/MyDrive/sd/stable-diffusion-webui/webui.py $share --disable-safe-unpickle --no-half-vae --enable-insecure-extension-access --ckpt-dir \"$path_to_trained_model\" $configf $xformers"
+ " !python /content/gdrive/MyDrive/sd/stable-diffusion-webui/webui.py $share --disable-safe-unpickle --no-half-vae --ckpt-dir \"/content/gdrive/MyDrive/Fast-Dreambooth/Sessions/futurama4\" $configf $xformers"
]
},
{
@@ -1293,10 +1365,6 @@
"\n",
"print(\"\u001b[1;32mLoading...\")\n",
"\n",
- "NM=\"False\"\n",
- "if os.path.getsize(OUTPUT_DIR+\"/text_encoder/pytorch_model.bin\") > 670901463:\n",
- " NM=\"True\"\n",
- "\n",
"\n",
"if NM==\"False\":\n",
" with capture.capture_output() as cap:\n",
@@ -1529,11 +1597,9 @@
"metadata": {
"accelerator": "GPU",
"colab": {
- "collapsed_sections": [
- "bbKbx185zqlz",
- "AaLtXBbPleBr"
- ],
- "provenance": []
+ "provenance": [],
+ "machine_shape": "hm",
+ "include_colab_link": true
},
"kernelspec": {
"display_name": "Python 3",
@@ -1541,8 +1607,9 @@
},
"language_info": {
"name": "python"
- }
+ },
+ "gpuClass": "standard"
},
"nbformat": 4,
"nbformat_minor": 0
-}
+}
\ No newline at end of file
From f1d58cf7340a953b3870d3c0cd9e05f40adbf94b Mon Sep 17 00:00:00 2001
From: nawnie <106923464+nawnie@users.noreply.github.com>
Date: Fri, 23 Dec 2022 18:23:03 -0600
Subject: [PATCH 03/15] Created using Colaboratory
---
fast-DreamBooth.ipynb | 97 ++++++++++++++++++++-----------------------
1 file changed, 45 insertions(+), 52 deletions(-)
diff --git a/fast-DreamBooth.ipynb b/fast-DreamBooth.ipynb
index af70af93..58ff3d6c 100644
--- a/fast-DreamBooth.ipynb
+++ b/fast-DreamBooth.ipynb
@@ -22,24 +22,12 @@
},
{
"cell_type": "code",
- "execution_count": 1,
+ "execution_count": null,
"metadata": {
"id": "A4Bae3VP6UsE",
- "cellView": "form",
- "outputId": "e9f640fd-175a-48dc-b098-91fde351bd28",
- "colab": {
- "base_uri": "https://localhost:8080/"
- }
+ "cellView": "form"
},
- "outputs": [
- {
- "output_type": "stream",
- "name": "stdout",
- "text": [
- "Mounted at /content/gdrive\n"
- ]
- }
- ],
+ "outputs": [],
"source": [
"#@markdown # Mount Gdrive\n",
"from google.colab import drive\n",
@@ -48,23 +36,23 @@
},
{
"cell_type": "code",
- "execution_count": 2,
+ "source": [
+ "!rm -r /content/diffusers"
+ ],
+ "metadata": {
+ "id": "6tOq8y7hNYCB"
+ },
+ "execution_count": null,
+ "outputs": []
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
"metadata": {
"id": "QyvcqeiL65Tj",
- "outputId": "d9b8adf1-8858-4ff8-f06d-c518b6859770",
- "colab": {
- "base_uri": "https://localhost:8080/"
- }
+ "cellView": "form"
},
- "outputs": [
- {
- "output_type": "stream",
- "name": "stdout",
- "text": [
- "\u001b[1;32mDONE !\n"
- ]
- }
- ],
+ "outputs": [],
"source": [
"#@markdown # Dependencies\n",
"\n",
@@ -84,9 +72,10 @@
" for i in range(1,6):\n",
" !rm \"Dependencies.7z.00{i}\"\n",
" !pip uninstall -y diffusers\n",
- " !git clone https://github.com/nawnie/diffusers\n",
+ " !git clone --branch updt https://github.com/TheLastBen/diffusers\n",
" !pip install -q /content/diffusers\n",
" !pip install onnxruntime\n",
+ " !git clone https://github.com/nawnie/diffused\n",
" \n",
"print('\u001b[1;32mDONE !') "
]
@@ -144,7 +133,7 @@
"\n",
"#@markdown Or\n",
"\n",
- "CKPT_Path = \"/content/gdrive/MyDrive/sd_v1-5_vae.ckpt\" #@param {type:\"string\"}\n",
+ "CKPT_Path = \"\" #@param {type:\"string\"}\n",
"\n",
"#@markdown Or\n",
"\n",
@@ -415,7 +404,7 @@
" \n",
"PT=\"\"\n",
"\n",
- "Session_Name = \"retry3\" #@param{type: 'string'}\n",
+ "Session_Name = \"fg44\" #@param{type: 'string'}\n",
"while Session_Name==\"\":\n",
" print('\u001b[1;31mInput the Session Name:') \n",
" Session_Name=input('')\n",
@@ -570,7 +559,7 @@
"if not os.path.exists(str(INSTANCE_DIR)):\n",
" %mkdir -p \"$INSTANCE_DIR\"\n",
"\n",
- "IMAGES_FOLDER_OPTIONAL=\"/content/gdrive/MyDrive/Fast-Dreambooth/Sessions/retry3/instance_images2\" #@param{type: 'string'}\n",
+ "IMAGES_FOLDER_OPTIONAL=\"\" #@param{type: 'string'}\n",
"\n",
"#@markdown - If you prefer to specify directly the folder of the pictures instead of uploading, this will add the pictures to the existing (if any) instance images. Leave EMPTY to upload.\n",
"\n",
@@ -686,7 +675,7 @@
"if not os.path.exists(str(CONCEPT_DIR)):\n",
" %mkdir -p \"$CONCEPT_DIR\"\n",
"\n",
- "IMAGES_FOLDER_OPTIONAL=\"/content/gdrive/MyDrive/SFW_Data_sets/Futurama_extras\" #@param{type: 'string'}\n",
+ "IMAGES_FOLDER_OPTIONAL=\"\" #@param{type: 'string'}\n",
"\n",
"#@markdown - If you prefer to specify directly the folder of the pictures instead of uploading, this will add the pictures to the existing (if any) concept images. Leave EMPTY to upload.\n",
"\n",
@@ -787,7 +776,8 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "id": "1-9QbkfAVYYU"
+ "id": "1-9QbkfAVYYU",
+ "cellView": "form"
},
"outputs": [],
"source": [
@@ -863,13 +853,13 @@
"\n",
"\n",
"\n",
- "epoch = 1 #@param {type:\"number\"}\n",
+ "epoch = 20 #@param {type:\"number\"}\n",
"#@markdown most models will require < 200 epochs\n",
- "batch_size = 1 #@param {type:\"number\"}\n",
+ "batch_size = 4 #@param {type:\"number\"}\n",
"#@markdown how many images to scan per iteration on 1.5 the free colab can do 4\n",
- "steps_per_iteration = 1 #@param {type:\"number\"}\n",
+ "steps_per_iteration = 2 #@param {type:\"number\"}\n",
"#@markdown how many sets of batches to make before writting to the model *more then 2 not adivsed\n",
- "Rate_of_Learning=\"2e-6\" #@param {type:\"string\"}\n",
+ "Rate_of_Learning=\"9e-7\" #@param {type:\"string\"}\n",
"#@markdown rate to train images\n",
"Rate_of_Encoder=\"9e-7\" #@param {type:\"string\"}\n",
"#@markdown rate to train the encoder\n",
@@ -894,7 +884,7 @@
" UNet_Training_Steps=UNet_Training_Steps+wu # adds warm up to total steps\n",
"else:\n",
" wu=0\n",
- "Text_Encoder_Training_Steps=0 #@param{type: 'number'}\n",
+ "Text_Encoder_Training_Steps=60 #@param{type: 'number'}\n",
"\n",
"# adds warm up to total steps\n",
"UNet_Training_Steps=UNet_Training_Steps+wu\n",
@@ -978,25 +968,28 @@
" Textenc=\"\"\n",
"\n",
"#@markdown ---------------------------\n",
- "Save_Checkpoint_Every_n_Steps = True #@param {type:\"boolean\"}\n",
- "Save_Checkpoint_Every=1000 #@param{type: 'number'}\n",
+ "Save_Checkpoint_Every_n_Epoch = True #@param {type:\"boolean\"}\n",
+ "Save_Checkpoint_Every=2 #@param{type: 'number'}\n",
"if Save_Checkpoint_Every==None:\n",
- " Save_Checkpoint_Every=1\n",
- "#@markdown - Minimum 200 steps between each save.\n",
+ " Save_Checkpoint_Every=10\n",
+ " \n",
"stp=0\n",
- "Start_saving_from_the_step=500 #@param{type: 'number'}\n",
+ "Start_saving_from_the_step=1 #@param{type: 'number'}\n",
"if Start_saving_from_the_step==None:\n",
- " Start_saving_from_the_step=0\n",
+ " Start_saving_from_the_step=1\n",
"if (Start_saving_from_the_step < 200):\n",
" Start_saving_from_the_step=Save_Checkpoint_Every\n",
"stpsv=Start_saving_from_the_step\n",
- "if Save_Checkpoint_Every_n_Steps:\n",
+ "if Save_Checkpoint_Every_n_Epoch:\n",
" stp=Save_Checkpoint_Every\n",
- "#@markdown - Start saving intermediary checkpoints from this step.\n",
+ "\n",
+ "epochs2save=stp*(image_count/(bs*gs))\n",
+ "stp=int(epochs2save)\n",
+ "#@markdown - Start saving intermediary checkpoints from this Epoch.\n",
"\n",
"def dump_only_textenc(trnonltxt, MODELT_NAME, INSTANCE_DIR, OUTPUT_DIR, PT, Seed, precision, Training_Steps):\n",
" \n",
- " !accelerate launch /content/diffusers/examples/dreambooth/train_dreambooth.py \\\n",
+ " !accelerate launch /content/diffused/trainer.py \\\n",
" $trnonltxt \\\n",
" --image_captions_filename \\\n",
" --train_text_encoder \\\n",
@@ -1021,7 +1014,7 @@
" if resuming==\"Yes\":\n",
" print('\u001b[1;32mResuming Training...\u001b[0m') \n",
" print('\u001b[1;33mTraining the UNet...\u001b[0m')\n",
- " !accelerate launch /content/diffusers/examples/dreambooth/train_dreambooth.py \\\n",
+ " !accelerate launch /content/diffused/trainer.py \\\n",
" $Style \\\n",
" --image_captions_filename \\\n",
" --train_only_unet \\\n",
@@ -1129,7 +1122,7 @@
"\n",
"Update_repo = True #@param {type:\"boolean\"}\n",
"\n",
- "Session__Name=\"\" #@param{type: 'string'}\n",
+ "Session__Name=\"fg44\" #@param{type: 'string'}\n",
"\n",
"#@markdown - Leave empty if you want to use the current trained model.\n",
"\n",
@@ -1298,7 +1291,7 @@
"if os.path.isfile(path_to_trained_model):\n",
" !python /content/gdrive/MyDrive/sd/stable-diffusion-webui/webui.py $share --disable-safe-unpickle --no-half-vae --ckpt \"$path_to_trained_model\" $configf $xformers\n",
"else:\n",
- " !python /content/gdrive/MyDrive/sd/stable-diffusion-webui/webui.py $share --disable-safe-unpickle --no-half-vae --ckpt-dir \"/content/gdrive/MyDrive/Fast-Dreambooth/Sessions/futurama4\" $configf $xformers"
+ " !python /content/gdrive/MyDrive/sd/stable-diffusion-webui/webui.py $share --disable-safe-unpickle --no-half-vae --ckpt-dir \"$path_to_trained_model\" $configf $xformers"
]
},
{
From a769c7ee67b142434e34941807c6cc0b4b228b77 Mon Sep 17 00:00:00 2001
From: nawnie <106923464+nawnie@users.noreply.github.com>
Date: Sun, 25 Dec 2022 01:02:14 -0600
Subject: [PATCH 04/15] Sample Pictures with training
---
fast-DreamBooth.ipynb | 25 ++++++++++++++++++-------
1 file changed, 18 insertions(+), 7 deletions(-)
diff --git a/fast-DreamBooth.ipynb b/fast-DreamBooth.ipynb
index 58ff3d6c..8c68b32d 100644
--- a/fast-DreamBooth.ipynb
+++ b/fast-DreamBooth.ipynb
@@ -853,13 +853,13 @@
"\n",
"\n",
"\n",
- "epoch = 20 #@param {type:\"number\"}\n",
+ "epoch = 200 #@param {type:\"number\"}\n",
"#@markdown most models will require < 200 epochs\n",
- "batch_size = 4 #@param {type:\"number\"}\n",
+ "batch_size = 1 #@param {type:\"number\"}\n",
"#@markdown how many images to scan per iteration on 1.5 the free colab can do 4\n",
- "steps_per_iteration = 2 #@param {type:\"number\"}\n",
+ "steps_per_iteration = 1 #@param {type:\"number\"}\n",
"#@markdown how many sets of batches to make before writting to the model *more then 2 not adivsed\n",
- "Rate_of_Learning=\"9e-7\" #@param {type:\"string\"}\n",
+ "Rate_of_Learning=\"2e-6\" #@param {type:\"string\"}\n",
"#@markdown rate to train images\n",
"Rate_of_Encoder=\"9e-7\" #@param {type:\"string\"}\n",
"#@markdown rate to train the encoder\n",
@@ -884,7 +884,7 @@
" UNet_Training_Steps=UNet_Training_Steps+wu # adds warm up to total steps\n",
"else:\n",
" wu=0\n",
- "Text_Encoder_Training_Steps=60 #@param{type: 'number'}\n",
+ "Text_Encoder_Training_Steps=0 #@param{type: 'number'}\n",
"\n",
"# adds warm up to total steps\n",
"UNet_Training_Steps=UNet_Training_Steps+wu\n",
@@ -914,6 +914,15 @@
"\n",
"#@markdown - Higher resolution = Higher quality, make sure the instance images are cropped to this selected size (or larger).\n",
"\n",
+ "\n",
+ "#@markdown - generate Sample Images \n",
+ "samples=True #@param{type:boolean}\n",
+ "Sample_Prommpt=\"\" #@param{type:\"string\"}\n",
+ "if samples:\n",
+ " prompt=Sample_Prompt\n",
+ "prompt-\"\"\n",
+ "\n",
+ "Sample_Prommpt\n",
"fp16 = True\n",
"\n",
"if Seed =='' or Seed=='0':\n",
@@ -969,7 +978,7 @@
"\n",
"#@markdown ---------------------------\n",
"Save_Checkpoint_Every_n_Epoch = True #@param {type:\"boolean\"}\n",
- "Save_Checkpoint_Every=2 #@param{type: 'number'}\n",
+ "Save_Checkpoint_Every=1 #@param{type: 'number'}\n",
"if Save_Checkpoint_Every==None:\n",
" Save_Checkpoint_Every=10\n",
" \n",
@@ -1034,6 +1043,8 @@
" --learning_rate=$lr \\\n",
" --lr_scheduler=\"$sched\" \\\n",
" --lr_warmup_steps=$wu \\\n",
+ " --save_sample_prompt=\"$prompt\" \\\n",
+ " --n_save_sample=2 \\\n",
" --max_train_steps=$Training_Steps\n",
"\n",
"\n",
@@ -1122,7 +1133,7 @@
"\n",
"Update_repo = True #@param {type:\"boolean\"}\n",
"\n",
- "Session__Name=\"fg44\" #@param{type: 'string'}\n",
+ "Session__Name=\"\" #@param{type: 'string'}\n",
"\n",
"#@markdown - Leave empty if you want to use the current trained model.\n",
"\n",
From 85ff2ac67957b7bed079019b2ec72809d76ff9ae Mon Sep 17 00:00:00 2001
From: nawnie <106923464+nawnie@users.noreply.github.com>
Date: Fri, 30 Dec 2022 00:46:03 -0600
Subject: [PATCH 05/15] Update README.md
---
README.md | 24 +++++++++++-------------
1 file changed, 11 insertions(+), 13 deletions(-)
diff --git a/README.md b/README.md
index 2b96b07a..64dd2321 100644
--- a/README.md
+++ b/README.md
@@ -1,16 +1,14 @@
-# fast-stable-diffusion Colab Notebooks, AUTOMATIC1111 + DreamBooth
-Colab adaptations AUTOMATIC1111 Webui and Dreambooth, train your model using this easy simple and fast colab, all you have to do is enter you huggingface token once, and it will cache all the files in GDrive, including the trained model and you will be able to use it directly from the colab, make sure you use high quality reference pictures for the training, enjoy !!
-
-
-<center><b> AUTOMATIC1111 DreamBooth
-
-<br>
-<a href="https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb">
-<img src='https://github.com/TheLastBen/fast-stable-diffusion/raw/main/Dreambooth/1.jpg'></a>
-<a href="https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb"><img src='https://github.com/TheLastBen/fast-stable-diffusion/raw/main/Dreambooth/4.jpg'></a>
+Code taken from:Huggingface, ShivamShrirao, XavieroXiao, and of course TheLastBen, whom this is forked and based off of https://github.com/ShivamShrirao/diffusers https://github.com/XavierXiao/Dreambooth-Stable-Diffusion https://github.com/TheLastBen/fast-stable-diffusion
-[Step by Step guide](https://github.com/Excalibro1/fast-stable-diffusionwik/wiki/fast-stable-diffusion-wiki) by Excalibro1
+ImageGeneration during Training qul Ui update
-Dreambooth paper : https://dreambooth.github.io/
+Planned Emphasis on 1.5 training i do not plan to remove 2.x but i may end up having ddefault settings that do not play well with 2.x, options will always be made available to change these, the Goal of this colab is to be simple but give the User a wide Variety of options that are not currently easily accessible.
-SD implementation by @XavierXiao : https://github.com/XavierXiao/Dreambooth-Stable-Diffusion
+save logs to gdrive combine unet and text encoder training if wanted
+
+[gold animation](https://user-images.githubusercontent.com/106923464/210042127-f07fb7da-5632-4b53-9932-e27cda5f6f6e.png)
+
+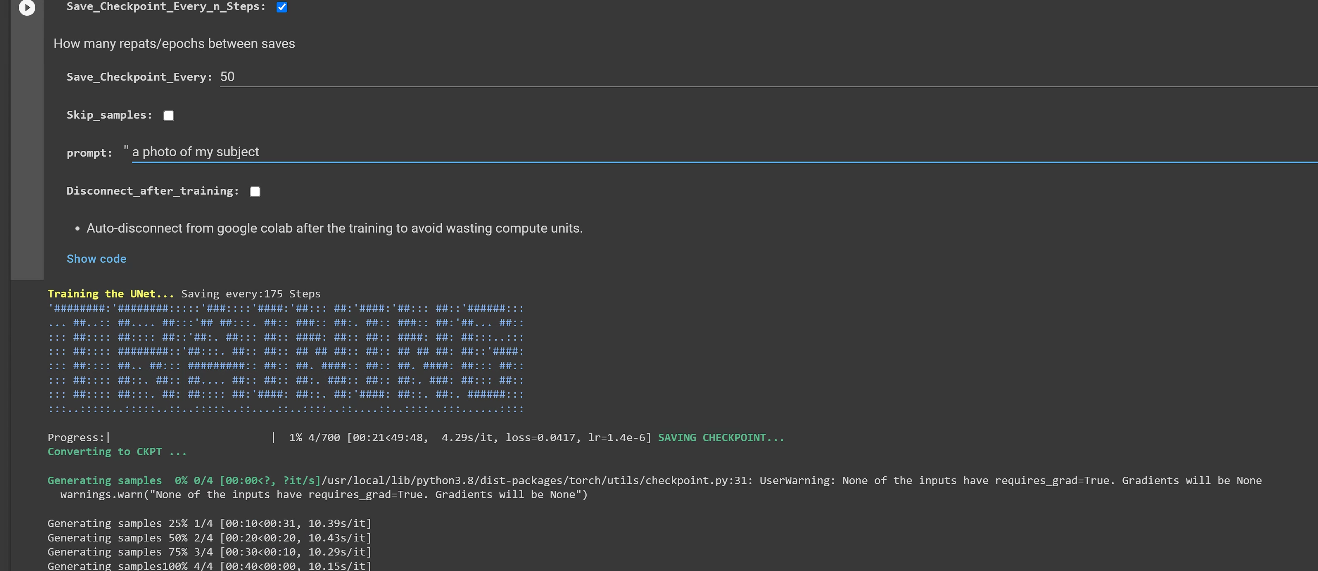
+
+
+Last bit of credit im going to give is to victorchall and his every EveryDream-Trainer Project he has been extremly helpful in learining about how these programs work EveryDream is not dreambooth, but i do recomend giving it a try for HUGE data sets or professional projects!
From 170af7b961589373b9bb72f6cb9d1a08249ec545 Mon Sep 17 00:00:00 2001
From: nawnie <106923464+nawnie@users.noreply.github.com>
Date: Fri, 30 Dec 2022 00:48:20 -0600
Subject: [PATCH 06/15] Created using Colaboratory
---
fast-DreamBooth.ipynb | 382 +++++++++++++++++++++---------------------
1 file changed, 193 insertions(+), 189 deletions(-)
diff --git a/fast-DreamBooth.ipynb b/fast-DreamBooth.ipynb
index 8c68b32d..bd20f454 100644
--- a/fast-DreamBooth.ipynb
+++ b/fast-DreamBooth.ipynb
@@ -16,7 +16,7 @@
"id": "qEsNHTtVlbkV"
},
"source": [
- "# **fast-DreamBooth colab From https://github.com/TheLastBen/fast-stable-diffusion, if you face any issues, feel free to discuss them.** \n",
+ "# A Remaster of **fast-DreamBooth colab From https://github.com/TheLastBen/fast-stable-diffusion, if you face any issues, feel free to discuss them.** \n",
"Keep your notebook updated for best experience. [Support](https://ko-fi.com/thelastben)\n"
]
},
@@ -29,22 +29,12 @@
},
"outputs": [],
"source": [
- "#@markdown # Mount Gdrive\n",
+ "#@title Mount Gdrive\n",
+ "\n",
"from google.colab import drive\n",
"drive.mount('/content/gdrive')"
]
},
- {
- "cell_type": "code",
- "source": [
- "!rm -r /content/diffusers"
- ],
- "metadata": {
- "id": "6tOq8y7hNYCB"
- },
- "execution_count": null,
- "outputs": []
- },
{
"cell_type": "code",
"execution_count": null,
@@ -59,6 +49,7 @@
"from IPython.utils import capture\n",
"import time\n",
"\n",
+ "print('\u001b[1;32mInstalling dependencies...')\n",
"with capture.capture_output() as cap:\n",
" %cd /content/\n",
" !pip install -q accelerate==0.12.0\n",
@@ -67,17 +58,18 @@
" !mv \"Dependencies.{i}\" \"Dependencies.7z.00{i}\"\n",
" !7z x -y Dependencies.7z.001\n",
" time.sleep(2)\n",
+ " %cd /content/usr/local/lib/python3.8/dist-packages\n",
+ " !rm -r PIL Pillow.libs Pillow-9.3.0.dist-info\n",
" !cp -r /content/usr/local/lib/python3.8/dist-packages /usr/local/lib/python3.8/\n",
" !rm -r /content/usr\n",
+ " %cd /content\n",
" for i in range(1,6):\n",
" !rm \"Dependencies.7z.00{i}\"\n",
" !pip uninstall -y diffusers\n",
" !git clone --branch updt https://github.com/TheLastBen/diffusers\n",
" !pip install -q /content/diffusers\n",
- " !pip install onnxruntime\n",
- " !git clone https://github.com/nawnie/diffused\n",
- " \n",
- "print('\u001b[1;32mDONE !') "
+ " !git clone https://github.com/nawnie/dreamboothtrainers.git\n",
+ "print('\u001b[1;32mDone, proceed')"
]
},
{
@@ -103,7 +95,7 @@
"from IPython.display import clear_output\n",
"import wget\n",
"\n",
- "#@markdown - Skip this cell if you are loading a previous session\n",
+ "#@markdown - Skip this cell if you are loading a previous session that contains a trained model.\n",
"\n",
"#@markdown ---\n",
"\n",
@@ -111,8 +103,6 @@
"\n",
"#@markdown - Choose which version to finetune.\n",
"\n",
- "#@markdown ---\n",
- "\n",
"with capture.capture_output() as cap: \n",
" %cd /content/\n",
"\n",
@@ -133,14 +123,14 @@
"\n",
"#@markdown Or\n",
"\n",
- "CKPT_Path = \"\" #@param {type:\"string\"}\n",
+ "CKPT_Path = \"/content/gdrive/MyDrive/A_Yaml_folder/sd_v1-5_vae.ckpt\" #@param {type:\"string\"}\n",
"\n",
"#@markdown Or\n",
"\n",
"CKPT_Link = \"\" #@param {type:\"string\"}\n",
"\n",
"#@markdown - A CKPT direct link, huggingface CKPT link or a shared CKPT from gdrive.\n",
- "#@markdown ---\n",
+ "\n",
"\n",
"def downloadmodel():\n",
" token=Huggingface_Token\n",
@@ -189,8 +179,9 @@
" !git lfs install --system --skip-repo\n",
" !git remote add -f origin \"https://USER:{token}@huggingface.co/stabilityai/stable-diffusion-2-1\"\n",
" !git config core.sparsecheckout true\n",
- " !echo -e \"scheduler\\ntext_encoder\\ntokenizer\\nunet\\nvae\\nmodel_index.json\" > .git/info/sparse-checkout\n",
+ " !echo -e \"scheduler\\ntext_encoder\\ntokenizer\\nunet\\nvae\\nfeature_extractor\\nmodel_index.json\" > .git/info/sparse-checkout\n",
" !git pull origin main\n",
+ " !rm -r /content/stable-diffusion-v2-768/.git\n",
" clear_output()\n",
" print('\u001b[1;32mDONE !')\n",
"\n",
@@ -205,8 +196,9 @@
" !git lfs install --system --skip-repo\n",
" !git remote add -f origin \"https://USER:{token}@huggingface.co/stabilityai/stable-diffusion-2-1-base\"\n",
" !git config core.sparsecheckout true\n",
- " !echo -e \"scheduler\\ntext_encoder\\ntokenizer\\nunet\\nvae\\nmodel_index.json\" > .git/info/sparse-checkout\n",
+ " !echo -e \"scheduler\\ntext_encoder\\ntokenizer\\nunet\\nvae\\nfeature_extractor\\nmodel_index.json\" > .git/info/sparse-checkout\n",
" !git pull origin main\n",
+ " !rm -r /content/stable-diffusion-v2-512/.git\n",
" clear_output()\n",
" print('\u001b[1;32mDONE !')\n",
" \n",
@@ -224,7 +216,7 @@
" !git lfs install --system --skip-repo\n",
" !git remote add -f origin \"https://USER:{token}@huggingface.co/{Path_to_HuggingFace}\"\n",
" !git config core.sparsecheckout true\n",
- " !echo -e \"scheduler\\ntext_encoder\\ntokenizer\\nunet\\nvae\\nmodel_index.json\" > .git/info/sparse-checkout\n",
+ " !echo -e \"scheduler\\ntext_encoder\\ntokenizer\\nunet\\nvae\\nfeature_extractor\\nmodel_index.json\" > .git/info/sparse-checkout\n",
" !git pull origin main\n",
" if os.path.exists('/content/stable-diffusion-custom/unet/diffusion_pytorch_model.bin'):\n",
" !rm -r /content/stable-diffusion-custom/.git\n",
@@ -258,7 +250,7 @@
" !rm model_index.json\n",
" time.sleep(1)\n",
" wget.download('https://raw.githubusercontent.com/TheLastBen/fast-stable-diffusion/main/Dreambooth/model_index.json')\n",
- " !sed -i 's@\"clip_sample\": false@@g' /content/stable-diffusion-custom/scheduler/scheduler_config.json\n",
+ " !sed -i 's@\"clip_sample\": false,@@g' /content/stable-diffusion-custom/scheduler/scheduler_config.json\n",
" !sed -i 's@\"trained_betas\": null,@\"trained_betas\": null@g' /content/stable-diffusion-custom/scheduler/scheduler_config.json\n",
" !sed -i 's@\"sample_size\": 256,@\"sample_size\": 512,@g' /content/stable-diffusion-custom/vae/config.json \n",
" %cd /content/ \n",
@@ -381,8 +373,8 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "cellView": "form",
- "id": "A1B299g-_VJo"
+ "id": "A1B299g-_VJo",
+ "cellView": "form"
},
"outputs": [],
"source": [
@@ -404,7 +396,7 @@
" \n",
"PT=\"\"\n",
"\n",
- "Session_Name = \"fg44\" #@param{type: 'string'}\n",
+ "Session_Name = \"\" #@param{type: 'string'}\n",
"while Session_Name==\"\":\n",
" print('\u001b[1;31mInput the Session Name:') \n",
" Session_Name=input('')\n",
@@ -559,11 +551,11 @@
"if not os.path.exists(str(INSTANCE_DIR)):\n",
" %mkdir -p \"$INSTANCE_DIR\"\n",
"\n",
- "IMAGES_FOLDER_OPTIONAL=\"\" #@param{type: 'string'}\n",
+ "IMAGES_FOLDER_OPTIONAL=\"/content/gdrive/MyDrive/Data_Sets/Nsfw_data_sets/Kim Possible \" #@param{type: 'string'}\n",
"\n",
"#@markdown - If you prefer to specify directly the folder of the pictures instead of uploading, this will add the pictures to the existing (if any) instance images. Leave EMPTY to upload.\n",
"\n",
- "Crop_images= False #@param{type: 'boolean'}\n",
+ "Crop_images= True #@param{type: 'boolean'}\n",
"Crop_size = \"512\" #@param [\"512\", \"576\", \"640\", \"704\", \"768\", \"832\", \"896\", \"960\", \"1024\"]\n",
"Crop_size=int(Crop_size)\n",
"\n",
@@ -576,7 +568,7 @@
"if IMAGES_FOLDER_OPTIONAL!=\"\":\n",
" if Crop_images:\n",
" for filename in tqdm(os.listdir(IMAGES_FOLDER_OPTIONAL), bar_format=' |{bar:15}| {n_fmt}/{total_fmt} Uploaded'):\n",
- " extension = filename.split(\".\")[1]\n",
+ " extension = filename.split(\".\")[-1]\n",
" identifier=filename.split(\".\")[0]\n",
" new_path_with_file = os.path.join(INSTANCE_DIR, filename)\n",
" file = Image.open(IMAGES_FOLDER_OPTIONAL+\"/\"+filename)\n",
@@ -597,10 +589,10 @@
" !cp \"$IMAGES_FOLDER_OPTIONAL/$filename\" \"$INSTANCE_DIR\"\n",
"\n",
" else:\n",
- " for filename in tqdm(os.listdir(IMAGES_FOLDER_OPTIONAL), bar_format=' |{bar:15}| {n_fmt}/{total_fmt} Uploaded'):\n",
+ " for filename in tqdm(os.listdir(IMAGES_FOLDER_OPTIONAL), bar_format=' |{bar:15}| {n_fmt}/{total_fmt} Uploaded'): \n",
" %cp -r \"$IMAGES_FOLDER_OPTIONAL/$filename\" \"$INSTANCE_DIR\"\n",
" \n",
- " print('\\n\u001b[1;32mDone, proceed to the training cell')\n",
+ " print('\\n\u001b[1;32mDone, proceed to the next cell')\n",
"\n",
"\n",
"elif IMAGES_FOLDER_OPTIONAL ==\"\":\n",
@@ -608,7 +600,7 @@
" if Crop_images:\n",
" for filename in tqdm(uploaded.keys(), bar_format=' |{bar:15}| {n_fmt}/{total_fmt} Uploaded'):\n",
" shutil.move(filename, INSTANCE_DIR)\n",
- " extension = filename.split(\".\")[1]\n",
+ " extension = filename.split(\".\")[-1]\n",
" identifier=filename.split(\".\")[0]\n",
" new_path_with_file = os.path.join(INSTANCE_DIR, filename)\n",
" file = Image.open(new_path_with_file)\n",
@@ -631,12 +623,11 @@
" shutil.move(filename, INSTANCE_DIR)\n",
" clear_output()\n",
"\n",
- " print('\\n\u001b[1;32mDone, proceed to the training cell')\n",
+ " print('\\n\u001b[1;32mDone, proceed to the next cell')\n",
"\n",
"with capture.capture_output() as cap:\n",
" %cd \"$INSTANCE_DIR\"\n",
- " !find . -name \"* *\" -type f | rename 's/ /-/g' \n",
- "\n",
+ " !find . -name \"* *\" -type f | rename 's/ /_/g' \n",
" %cd $SESSION_DIR\n",
" !rm instance_images.zip\n",
" !zip -r instance_images instance_images\n",
@@ -647,8 +638,8 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "id": "LxEv3u8mQos3",
- "cellView": "form"
+ "cellView": "form",
+ "id": "LxEv3u8mQos3"
},
"outputs": [],
"source": [
@@ -657,12 +648,12 @@
"from PIL import Image\n",
"from tqdm import tqdm\n",
"\n",
- "#@markdown #Concept Images\n",
+ "#@markdown #Concept Images (Regularization)\n",
"#@markdown ----\n",
"\n",
"#@markdown\n",
"#@markdown - Run this `optional` cell to upload concept pictures. If you're traning on a specific face, skip this cell.\n",
- "#@markdown - Training a model on a restricted number of instance images tends to indoctrinate it and limit its imagination, so concept images help re-opening its \"mind\" to diversity and greatly widen the range of possibilities of the output, concept images should contain anything related to the instance pictures, including objects, ideas, scenes, phenomenons, concepts (obviously), don't be afraid to slightly diverge from the trained style. The resolution of the pictures doesn't matter.\n",
+ "#@markdown - Training a model on a restricted number of instance images tends to indoctrinate it and limit its imagination, so concept images help re-opening its \"mind\" to diversity and greatly widen the range of possibilities of the output, concept images should contain anything related to the instance pictures, including objects, ideas, scenes, phenomenons, concepts (obviously), don't be afraid to slightly diverge from the trained style.\n",
"\n",
"Remove_existing_concept_images= True #@param{type: 'boolean'}\n",
"#@markdown - Uncheck the box to keep the existing concept images.\n",
@@ -690,7 +681,7 @@
"if IMAGES_FOLDER_OPTIONAL!=\"\":\n",
" if Crop_images:\n",
" for filename in tqdm(os.listdir(IMAGES_FOLDER_OPTIONAL), bar_format=' |{bar:15}| {n_fmt}/{total_fmt} Uploaded'):\n",
- " extension = filename.split(\".\")[1]\n",
+ " extension = filename.split(\".\")[-1]\n",
" identifier=filename.split(\".\")[0]\n",
" new_path_with_file = os.path.join(CONCEPT_DIR, filename)\n",
" file = Image.open(IMAGES_FOLDER_OPTIONAL+\"/\"+filename)\n",
@@ -714,15 +705,12 @@
" for filename in tqdm(os.listdir(IMAGES_FOLDER_OPTIONAL), bar_format=' |{bar:15}| {n_fmt}/{total_fmt} Uploaded'):\n",
" %cp -r \"$IMAGES_FOLDER_OPTIONAL/$filename\" \"$CONCEPT_DIR\"\n",
" \n",
- " print('\\n\u001b[1;32mDone, proceed to the training cell')\n",
- "\n",
- "\n",
"elif IMAGES_FOLDER_OPTIONAL ==\"\":\n",
" uploaded = files.upload()\n",
" if Crop_images:\n",
" for filename in tqdm(uploaded.keys(), bar_format=' |{bar:15}| {n_fmt}/{total_fmt} Uploaded'):\n",
" shutil.move(filename, CONCEPT_DIR)\n",
- " extension = filename.split(\".\")[1]\n",
+ " extension = filename.split(\".\")[-1]\n",
" identifier=filename.split(\".\")[0]\n",
" new_path_with_file = os.path.join(CONCEPT_DIR, filename)\n",
" file = Image.open(new_path_with_file)\n",
@@ -745,12 +733,12 @@
" shutil.move(filename, CONCEPT_DIR)\n",
" clear_output()\n",
"\n",
- " print('\\n\u001b[1;32mDone, proceed to the training cell')\n",
- "\n",
- "with capture.capture_output() as cap: \n",
+ " \n",
+ "print('\\n\u001b[1;32mAlmost done...')\n",
+ "with capture.capture_output() as cap: \n",
" i=0\n",
" for filename in os.listdir(CONCEPT_DIR):\n",
- " extension = filename.split(\".\")[1]\n",
+ " extension = filename.split(\".\")[-1]\n",
" identifier=filename.split(\".\")[0]\n",
" new_path_with_file = os.path.join(CONCEPT_DIR, \"conceptimagedb\"+str(i)+\".\"+extension)\n",
" filepath=os.path.join(CONCEPT_DIR,filename)\n",
@@ -760,7 +748,9 @@
" %cd $SESSION_DIR\n",
" !rm concept_images.zip\n",
" !zip -r concept_images concept_images\n",
- " %cd /content"
+ " %cd /content\n",
+ "\n",
+ "print('\\n\u001b[1;32mDone, proceed to the training cell')"
]
},
{
@@ -790,30 +780,18 @@
"from google.colab import runtime\n",
"import time\n",
"import random\n",
- " # note to any user reading this, this is not an attempt to steal from ben but give users more options to change without looking at intimidaiting code\n",
- " # any request by ben to remove or if he adds these functions i will remove my fork - Make some pretty pictures ya'll\n",
+ "\n",
+ "\n",
+ "Img_Count = (len([entry for entry in os.listdir(INSTANCE_DIR) if os.path.isfile(os.path.join(INSTANCE_DIR, entry))]))\n",
"\n",
"if os.path.exists(INSTANCE_DIR+\"/.ipynb_checkpoints\"):\n",
" %rm -r $INSTANCE_DIR\"/.ipynb_checkpoints\"\n",
"\n",
- "\n",
"if os.path.exists(CONCEPT_DIR+\"/.ipynb_checkpoints\"):\n",
" %rm -r $CONCEPT_DIR\"/.ipynb_checkpoints\" \n",
"\n",
"Resume_Training = True #@param {type:\"boolean\"}\n",
"\n",
- "#@markdown - If you're not satisfied with the result, check this box, run again the cell and it will continue training the current model.\n",
- "\n",
- "Warm_up= True #@param {type:\"boolean\"}\n",
- "\n",
- "#@markdown - use a warm up phase\n",
- "\n",
- "Disconnect_after_training=False #@param {type:\"boolean\"}\n",
- "\n",
- "#@markdown - Auto-disconnect from google colab after the training to avoid wasting compute units.\n",
- "\n",
- "\n",
- "\n",
"try:\n",
" resume\n",
" if resume and not Resume_Training:\n",
@@ -835,94 +813,85 @@
" print('\u001b[1;31mNo model found, use the \"Model Download\" cell to download a model.')\n",
" time.sleep(5)\n",
"\n",
+ "#@markdown - If you're not satisfied with the result, check this box, run again the cell and it will continue training the current model.\n",
"\n",
"\n",
- "dir_path =INSTANCE_DIR\n",
- "image_count = (len([entry for entry in os.listdir(dir_path) if os.path.isfile(os.path.join(dir_path, entry))]))\n",
"\n",
"\n",
"MODELT_NAME=MODEL_NAME\n",
- "#number_images = 137 #@param {type:\"integer\"}\n",
- "\n",
- "\n",
- "#@markdown ---------------------------\n",
- "#@markdown An $ epoch $ is a $repeat$ of the entire set of instance images\n",
- "#@markdown ---------------------------\n",
- "\n",
- "#@markdown ---------------------------\n",
- "\n",
+ "Repeats=200 #@param{type:\"number\"}\n",
+ "warmup_steps=0 #@param{type:\"number\"}\n",
+ "wu=warmup_steps\n",
+ "batch_size=4 #@param{type:\"number\"}\n",
+ "bs=batch_size\n",
+ "gradient_steps=2 #@param{type:\"number\"}\n",
+ "gs=gradient_steps\n",
+ "UNet_Training_Steps=((Repeats*Img_Count)/(gs*bs))\n",
+ "UNet_Learning_Rate = 4e-6 #@param [\"2e-6\", \"1e-6\", \"1e-5\", \"1e-4\", \"5e-7\"] {type:\"raw\", allow-input: true}\n",
"\n",
+ "#@markdown * 1e-7 is lowest, 1e-4 is the highest, 2e-7 is twice as fast as 1e-7 experiment and adjust the repeats to accomidate diffrent learning rates \n",
"\n",
- "epoch = 200 #@param {type:\"number\"}\n",
- "#@markdown most models will require < 200 epochs\n",
- "batch_size = 1 #@param {type:\"number\"}\n",
- "#@markdown how many images to scan per iteration on 1.5 the free colab can do 4\n",
- "steps_per_iteration = 1 #@param {type:\"number\"}\n",
- "#@markdown how many sets of batches to make before writting to the model *more then 2 not adivsed\n",
- "Rate_of_Learning=\"2e-6\" #@param {type:\"string\"}\n",
- "#@markdown rate to train images\n",
- "Rate_of_Encoder=\"9e-7\" #@param {type:\"string\"}\n",
- "#@markdown rate to train the encoder\n",
- "Learning_schedule = \"polynomial\" #@param [\"consine\", \"constant\", \"linear\", \"polynomial\"] {allow-input: true}\n",
- "#@markdown formula to slow learning rate slows down \n",
+ "lr_schedule = \"polynomial\" #@param [\"polynomial\", \"constant\"] {allow-input: true}\n",
+ "untlr=UNet_Learning_Rate\n",
+ "UNet_Training_Steps=int(UNet_Training_Steps+wu)\n",
"\n",
- "bs=batch_size\n",
- "gs=steps_per_iteration\n",
- "lr=Rate_of_Learning \n",
- "lr2=Rate_of_Encoder\n",
- "sched=Learning_schedule \n",
- "Seed='' #@param{type: 'string'}\n",
- "UNet_Training_Steps=0\n",
+ "#@markdown - These default settings are for a dataset of 10 pictures which is enough for training a face, start with 650 or lower, test the model, if not enough, resume training for 150 steps, keep testing until you get the desired output, `set it to 0 to train only the text_encoder`. \n",
"\n",
+ "Text_Encoder_Training_Steps=125 #@param{type: 'number'}\n",
"\n",
- "MODELT_NAME=MODEL_NAME\n",
- "# Training_Steps\n",
- "UNet_Training_Steps=int((image_count*epoch)/(bs*gs))\n",
+ "#@markdown - 200-450 steps is enough for a small dataset, keep this number small to avoid overfitting, set to 0 to disable, `set it to 0 before resuming training if it is already trained`.\n",
"\n",
- "if Warm_up:\n",
- " wu=int((UNet_Training_Steps/20))\n",
- " UNet_Training_Steps=UNet_Training_Steps+wu # adds warm up to total steps\n",
- "else:\n",
- " wu=0\n",
- "Text_Encoder_Training_Steps=0 #@param{type: 'number'}\n",
+ "Text_Batch_Size = 2 #@param {type:\"integer\"}\n",
+ "tbs=Text_Batch_Size\n",
"\n",
- "# adds warm up to total steps\n",
- "UNet_Training_Steps=UNet_Training_Steps+wu\n",
+ "Text_Encoder_Concept_Training_Steps=0 #@param{type: 'number'}\n",
"\n",
- "#@markdown - 350-600 steps is enough for a small dataset, keep this number small to avoid overfitting, set to 0 to disable, `set it to 0 before resuming training if it is already trained`.\n",
+ "#@markdown - Suitable for training a style/concept as it acts as heavy regularization, set it to 1500 steps for 200 concept images (you can go higher), set to 0 to disable, set both the settings above to 0 to fintune only the text_encoder on the concept, `set it to 0 before resuming training if it is already trained`.\n",
"\n",
- "Text_Encoder_Concept_Training_Steps=0 #@param{type: 'number'}\n",
+ "Text_Encoder_Learning_Rate = 2e-6 #@param [\"2e-6\", \"8e-7\", \"6e-7\", \"5e-7\", \"4e-7\"] {type:\"raw\", allow-input: true}\n",
+ "txlr=Text_Encoder_Learning_Rate\n",
"\n",
- "#@markdown - helps prevent over fitting\n",
+ "#@markdown - Learning rate for both text_encoder and concept_text_encoder, keep it low to avoid overfitting (1e-7 is lowest, 1e-4 is the highest, 2e-7 is twice as fast as 1e-7 experiment and adjust the repeats to accomidate diffrent learning rates )\n",
"\n",
"trnonltxt=\"\"\n",
"if UNet_Training_Steps==0:\n",
" trnonltxt=\"--train_only_text_encoder\"\n",
"\n",
- "Seed='' \n",
+ "Seed='69' \n",
"\n",
"Style_Training = False #@param {type:\"boolean\"}\n",
"\n",
- "#@markdown - Further reduce overfitting, aka Unconditional drop out best kept at 2 epochs\n",
+ "#@markdown -Forced Drop out, Drops caption from images, helps fine tuning a style without over-fitting simpsons model could of benefitted from this\n",
"\n",
"Style=\"\"\n",
"if Style_Training:\n",
- " Style=\"--Style\"\n",
+ " Style = \"--Style\"\n",
+ "\n",
+ "Flip_Images = True #@param {type:\"boolean\"}\n",
+ "Percent_to_flip = 20 #@param{type:\"raw\"}\n",
+ "flip_rate = (Percent_to_flip/100)\n",
+ "\n",
+ "#@markdown Flip a random 10% of images, helps add veriety to smaller data-sets\n",
+ "\n",
+ "flip=\"\"\n",
+ "if Flip_Images:\n",
+ " flip=\"--hflip\"\n",
+ "\n",
+ "Conditional_dropout = 10 #@param {type:\"raw\"}\n",
+ "\n",
+ "#@markdown drop a random X% of images, helps avoid over fitting, very similar to style training\n",
+ "\n",
+ "drop='0'\n",
+ "drop= (Conditional_dropout/100)\n",
+ "\n",
+ "\n",
+ "\n",
"\n",
"Resolution = \"512\" #@param [\"512\", \"576\", \"640\", \"704\", \"768\", \"832\", \"896\", \"960\", \"1024\"]\n",
"Res=int(Resolution)\n",
"\n",
"#@markdown - Higher resolution = Higher quality, make sure the instance images are cropped to this selected size (or larger).\n",
"\n",
- "\n",
- "#@markdown - generate Sample Images \n",
- "samples=True #@param{type:boolean}\n",
- "Sample_Prommpt=\"\" #@param{type:\"string\"}\n",
- "if samples:\n",
- " prompt=Sample_Prompt\n",
- "prompt-\"\"\n",
- "\n",
- "Sample_Prommpt\n",
"fp16 = True\n",
"\n",
"if Seed =='' or Seed=='0':\n",
@@ -930,6 +899,8 @@
"else:\n",
" Seed=int(Seed)\n",
"\n",
+ "GC=\"--gradient_checkpointing\"\n",
+ "\n",
"if fp16:\n",
" prec=\"fp16\"\n",
"else:\n",
@@ -937,9 +908,9 @@
"\n",
"s = getoutput('nvidia-smi')\n",
"if 'A100' in s:\n",
- " precision=\"no\"\n",
- "else:\n",
- " precision=prec\n",
+ " GC=\"\"\n",
+ "\n",
+ "precision=prec\n",
"\n",
"resuming=\"\"\n",
"if Resume_Training and os.path.exists(OUTPUT_DIR+'/unet/diffusion_pytorch_model.bin'):\n",
@@ -977,28 +948,29 @@
" Textenc=\"\"\n",
"\n",
"#@markdown ---------------------------\n",
- "Save_Checkpoint_Every_n_Epoch = True #@param {type:\"boolean\"}\n",
- "Save_Checkpoint_Every=1 #@param{type: 'number'}\n",
- "if Save_Checkpoint_Every==None:\n",
- " Save_Checkpoint_Every=10\n",
- " \n",
+ "Save_Checkpoint_Every_n_Steps = True #@param {type:\"boolean\"}\n",
+ "#@markdown How many repats/epochs between saves\n",
+ "Save_Checkpoint_Every=50 #@param{type: 'number'}\n",
"stp=0\n",
- "Start_saving_from_the_step=1 #@param{type: 'number'}\n",
- "if Start_saving_from_the_step==None:\n",
- " Start_saving_from_the_step=1\n",
- "if (Start_saving_from_the_step < 200):\n",
- " Start_saving_from_the_step=Save_Checkpoint_Every\n",
- "stpsv=Start_saving_from_the_step\n",
- "if Save_Checkpoint_Every_n_Epoch:\n",
- " stp=Save_Checkpoint_Every\n",
- "\n",
- "epochs2save=stp*(image_count/(bs*gs))\n",
- "stp=int(epochs2save)\n",
- "#@markdown - Start saving intermediary checkpoints from this Epoch.\n",
+ "stpsv=5\n",
+ "if Save_Checkpoint_Every_n_Steps:\n",
+ " stp=((Save_Checkpoint_Every*Img_Count)/(gs*bs))\n",
+ "stp=int(stp)\n",
+ "\n",
+ "Skip_samples = False #@param {type:\"boolean\"}\n",
+ "prompt= \"\" #@param{type:\"string\"}\n",
+ "if Skip_samples:\n",
+ " prompt=\"None\"\n",
+ "\n",
+ "\n",
+ "\n",
+ "Disconnect_after_training=False #@param {type:\"boolean\"}\n",
+ "\n",
+ "#@markdown - Auto-disconnect from google colab after the training to avoid wasting compute units.\n",
"\n",
"def dump_only_textenc(trnonltxt, MODELT_NAME, INSTANCE_DIR, OUTPUT_DIR, PT, Seed, precision, Training_Steps):\n",
" \n",
- " !accelerate launch /content/diffused/trainer.py \\\n",
+ " !accelerate launch /content/diffusers/examples/dreambooth/train_dreambooth.py \\\n",
" $trnonltxt \\\n",
" --image_captions_filename \\\n",
" --train_text_encoder \\\n",
@@ -1010,21 +982,22 @@
" --seed=$Seed \\\n",
" --resolution=512 \\\n",
" --mixed_precision=$precision \\\n",
- " --train_batch_size=1 \\\n",
- " --gradient_accumulation_steps=1 --gradient_checkpointing \\\n",
+ " --train_batch_size=$tbs \\\n",
+ " --gradient_accumulation_steps=1 $GC \\\n",
" --use_8bit_adam \\\n",
- " --learning_rate=9e-7 \\\n",
- " --lr_scheduler=\"constant\" \\\n",
- " --lr_warmup_steps=0 \\\n",
+ " --learning_rate=$txlr \\\n",
+ " --lr_scheduler=\"polynomial\" \\\n",
+ " --lr_warmup_steps=10 \\\n",
" --max_train_steps=$Training_Steps\n",
"\n",
"def train_only_unet(stpsv, stp, SESSION_DIR, MODELT_NAME, INSTANCE_DIR, OUTPUT_DIR, PT, Seed, Res, precision, Training_Steps):\n",
" clear_output()\n",
" if resuming==\"Yes\":\n",
" print('\u001b[1;32mResuming Training...\u001b[0m') \n",
- " print('\u001b[1;33mTraining the UNet...\u001b[0m')\n",
- " !accelerate launch /content/diffused/trainer.py \\\n",
+ " print('\u001b[1;33mTraining the UNet...\u001b[0m Saving every:'+str(stp)+' Steps')\n",
+ " !accelerate launch /content/dreamboothtrainers/Trainer.py \\\n",
" $Style \\\n",
+ " $flip \\\n",
" --image_captions_filename \\\n",
" --train_only_unet \\\n",
" --save_starting_step=$stpsv \\\n",
@@ -1034,17 +1007,18 @@
" --instance_data_dir=\"$INSTANCE_DIR\" \\\n",
" --output_dir=\"$OUTPUT_DIR\" \\\n",
" --instance_prompt=\"$PT\" \\\n",
+ " --save_sample_prompt=\"$prompt\" \\\n",
" --seed=$Seed \\\n",
" --resolution=$Res \\\n",
" --mixed_precision=$precision \\\n",
" --train_batch_size=$bs \\\n",
- " --gradient_accumulation_steps=$gs --gradient_checkpointing \\\n",
+ " --gradient_accumulation_steps=$gs $GC \\\n",
" --use_8bit_adam \\\n",
- " --learning_rate=$lr \\\n",
- " --lr_scheduler=\"$sched\" \\\n",
- " --lr_warmup_steps=$wu \\\n",
- " --save_sample_prompt=\"$prompt\" \\\n",
- " --n_save_sample=2 \\\n",
+ " --learning_rate=$untlr \\\n",
+ " --lr_scheduler=\"$lr_schedule\" \\\n",
+ " --Drop_out=$drop \\\n",
+ " --flip_rate=$flip_rate \\\n",
+ " --lr_warmup_steps=10 \\\n",
" --max_train_steps=$Training_Steps\n",
"\n",
"\n",
@@ -1053,15 +1027,28 @@
" if os.path.exists(OUTPUT_DIR+'/'+'text_encoder_trained'):\n",
" %rm -r $OUTPUT_DIR\"/text_encoder_trained\"\n",
" dump_only_textenc(trnonltxt, MODELT_NAME, INSTANCE_DIR, OUTPUT_DIR, PT, Seed, precision, Training_Steps=stptxt)\n",
- "if Enable_Text_Encoder_Concept_Training and os.listdir(CONCEPT_DIR)!=[]:\n",
- " #clear_output()\n",
- " if resuming==\"Yes\":\n",
- " print('\u001b[1;32mResuming Training...\u001b[0m') \n",
- " print('\u001b[1;33mTraining the text encoder on the concept...\u001b[0m')\n",
- " dump_only_textenc(trnonltxt, MODELT_NAME, CONCEPT_DIR, OUTPUT_DIR, PT, Seed, precision, Training_Steps=stptxtc)\n",
- "elif Enable_Text_Encoder_Concept_Training and os.listdir(CONCEPT_DIR)==[]:\n",
- " print('\u001b[1;31mNo Concept Images found, skipping concept training...')\n",
- " time.sleep(8)\n",
+ "\n",
+ "if Enable_Text_Encoder_Concept_Training:\n",
+ " if os.path.exists(CONCEPT_DIR):\n",
+ " if os.listdir(CONCEPT_DIR)!=[]:\n",
+ " # clear_output()\n",
+ " if resuming==\"Yes\":\n",
+ " print('\u001b[1;32mResuming Training...\u001b[0m') \n",
+ " print('\u001b[1;33mTraining the text encoder on the concept...\u001b[0m')\n",
+ " dump_only_textenc(trnonltxt, MODELT_NAME, CONCEPT_DIR, OUTPUT_DIR, PT, Seed, precision, Training_Steps=stptxtc)\n",
+ " else:\n",
+ " # clear_output()\n",
+ " if resuming==\"Yes\":\n",
+ " print('\u001b[1;32mResuming Training...\u001b[0m') \n",
+ " print('\u001b[1;31mNo concept images found, skipping concept training...')\n",
+ " time.sleep(8)\n",
+ " else:\n",
+ " #clear_output()\n",
+ " if resuming==\"Yes\":\n",
+ " print('\u001b[1;32mResuming Training...\u001b[0m')\n",
+ " print('\u001b[1;31mNo concept images found, skipping concept training...')\n",
+ " time.sleep(8)\n",
+ " \n",
"if UNet_Training_Steps!=0:\n",
" train_only_unet(stpsv, stp, SESSION_DIR, MODELT_NAME, INSTANCE_DIR, OUTPUT_DIR, PT, Seed, Res, precision, Training_Steps=UNet_Training_Steps)\n",
" \n",
@@ -1074,8 +1061,8 @@
" if os.path.exists(SESSION_DIR+\"/\"+INSTANCE_NAME+'.ckpt'):\n",
" #clear_output()\n",
" print(\"\u001b[1;32mDONE, the CKPT model is in your Gdrive in the sessions folder\")\n",
- " time.sleep(2)\n",
" if Disconnect_after_training :\n",
+ " time.sleep(20) \n",
" runtime.unassign() \n",
" else:\n",
" print(\"\u001b[1;31mSomething went wrong\") \n",
@@ -1087,7 +1074,7 @@
" !sed -i '201s@.*@ model_path = \"{OUTPUT_DIR}\"@' /content/convertosd.py\n",
" !sed -i '202s@.*@ checkpoint_path= \"{SESSION_DIR}/{Session_Name}.ckpt\"@' /content/convertosd.py\n",
" !python /content/convertosd.py\n",
- " !rm /content/convertosd.py\n",
+ "\n",
" #clear_output()\n",
" if os.path.exists(SESSION_DIR+\"/\"+INSTANCE_NAME+'.ckpt'): \n",
" print(\"\u001b[1;32mDONE, the CKPT model is in your Gdrive in the sessions folder\")\n",
@@ -1114,8 +1101,8 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "id": "iAZGngFcI8hq",
- "cellView": "form"
+ "cellView": "form",
+ "id": "iAZGngFcI8hq"
},
"outputs": [],
"source": [
@@ -1131,7 +1118,7 @@
"Model_Version = \"1.5\" #@param [\"1.5\", \"V2.1-512\", \"V2.1-768\"]\n",
"#@markdown - Important! Choose the correct version and resolution of the model\n",
"\n",
- "Update_repo = True #@param {type:\"boolean\"}\n",
+ "Update_repo = True\n",
"\n",
"Session__Name=\"\" #@param{type: 'string'}\n",
"\n",
@@ -1185,13 +1172,14 @@
" !ln -s /content/gdrive/MyDrive/sd/stable-diffusion-webui/cache/torch ../root/.cache/\n",
"\n",
"if Update_repo:\n",
- " !rm /content/gdrive/MyDrive/sd/stable-diffusion-webui/webui.sh \n",
- " !rm /content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/paths.py\n",
- " !rm /content/gdrive/MyDrive/sd/stable-diffusion-webui/webui.py \n",
- " !rm /content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/ui.py\n",
- " !rm /content/gdrive/MyDrive/sd/stable-diffusion-webui/style.css\n",
- " %cd /content/gdrive/MyDrive/sd/stable-diffusion-webui/\n",
- " clear_output()\n",
+ " with capture.capture_output() as cap:\n",
+ " !rm /content/gdrive/MyDrive/sd/stable-diffusion-webui/webui.sh\n",
+ " !rm /content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/paths.py\n",
+ " !rm /content/gdrive/MyDrive/sd/stable-diffusion-webui/webui.py\n",
+ " !rm /content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/ui.py\n",
+ " !rm /content/gdrive/MyDrive/sd/stable-diffusion-webui/style.css\n",
+ " !rm /content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/shared.py\n",
+ " %cd /content/gdrive/MyDrive/sd/stable-diffusion-webui/\n",
" print('\u001b[1;32m')\n",
" !git pull\n",
"\n",
@@ -1207,9 +1195,9 @@
" !git clone https://github.com/sczhou/CodeFormer\n",
" !git clone https://github.com/crowsonkb/k-diffusion\n",
" !mv /content/gdrive/MyDrive/sd/stablediffusion/src/CLIP /content/gdrive/MyDrive/sd/stablediffusion/src/clip\n",
- " !mv /content/gdrive/MyDrive/sd/stablediffusion/src/BLIP /content/gdrive/MyDrive/sd/stablediffusion/src/blip \n",
- " !mv /content/gdrive/MyDrive/sd/stablediffusion/src/CodeFormer /content/gdrive/MyDrive/sd/stablediffusion/src/codeformer \n",
- " !cp -r /content/gdrive/MyDrive/sd/stablediffusion/src/k-diffusion/k_diffusion /content/gdrive/MyDrive/sd/stable-diffusion-webui/ \n",
+ " !mv /content/gdrive/MyDrive/sd/stablediffusion/src/BLIP /content/gdrive/MyDrive/sd/stablediffusion/src/blip\n",
+ " !mv /content/gdrive/MyDrive/sd/stablediffusion/src/CodeFormer /content/gdrive/MyDrive/sd/stablediffusion/src/codeformer\n",
+ " !cp -r /content/gdrive/MyDrive/sd/stablediffusion/src/k-diffusion/k_diffusion /content/gdrive/MyDrive/sd/stable-diffusion-webui/\n",
"\n",
"\n",
"with capture.capture_output() as cap: \n",
@@ -1220,24 +1208,33 @@
" if not os.path.exists('/tools/node/bin/lt'):\n",
" !npm install -g localtunnel\n",
"\n",
- "with capture.capture_output() as cap: \n",
+ "with capture.capture_output() as cap:\n",
" %cd /content/gdrive/MyDrive/sd/stable-diffusion-webui/\n",
- " time.sleep(1)\n",
" !wget -O webui.py https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/webui.py\n",
- " !sed -i 's@ui.create_ui().*@ui.create_ui();shared.demo.queue(concurrency_count=10)@' /content/gdrive/MyDrive/sd/stable-diffusion-webui/webui.py\n",
+ " !sed -i 's@ui.create_ui().*@ui.create_ui();shared.demo.queue(concurrency_count=999999,status_update_rate=0.1)@' /content/gdrive/MyDrive/sd/stable-diffusion-webui/webui.py\n",
" %cd /content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/\n",
+ " !wget -O shared.py https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/modules/shared.py\n",
" !wget -O ui.py https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/modules/ui.py\n",
- " !sed -i 's@css = \"\".*@with open(os.path.join(script_path, \"style.css\"), \"r\", encoding=\"utf8\") as file:\\n css = file.read()@' /content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/ui.py \n",
+ " !sed -i 's@css = \"\".*@with open(os.path.join(script_path, \"style.css\"), \"r\", encoding=\"utf8\") as file:\\n css = file.read()@' /content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/ui.py\n",
" %cd /content/gdrive/MyDrive/sd/stable-diffusion-webui\n",
" !wget -O style.css https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/style.css\n",
" !sed -i 's@min-height: 4.*@min-height: 5.5em;@g' /content/gdrive/MyDrive/sd/stable-diffusion-webui/style.css\n",
- " !sed -i 's@\"multiple_tqdm\": true,@\\\"multiple_tqdm\": false,@' /content/gdrive/MyDrive/sd/stable-diffusion-webui/config.json \n",
+ " !sed -i 's@\"multiple_tqdm\": true,@\\\"multiple_tqdm\": false,@' /content/gdrive/MyDrive/sd/stable-diffusion-webui/config.json\n",
+ " !sed -i '902s@.*@ self.logvar = self.logvar.to(self.device)@' /content/gdrive/MyDrive/sd/stablediffusion/ldm/models/diffusion/ddpm.py\n",
" %cd /content\n",
"\n",
"\n",
"Use_Gradio_Server = False #@param {type:\"boolean\"}\n",
"#@markdown - Only if you have trouble connecting to the local server.\n",
"\n",
+ "Large_Model= False #@param {type:\"boolean\"}\n",
+ "#@markdown - Check if you have trouble loading a model 7GB+\n",
+ "\n",
+ "if Large_Model:\n",
+ " !sed -i 's@cmd_opts.lowram else \\\"cpu\\\"@cmd_opts.lowram else \\\"cuda\\\"@' /content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/shared.py\n",
+ "else:\n",
+ " !sed -i 's@cmd_opts.lowram else \\\"cuda\\\"@cmd_opts.lowram else \\\"cpu\\\"@' /content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/shared.py\n",
+ "\n",
"\n",
"share=''\n",
"if Use_Gradio_Server:\n",
@@ -1300,9 +1297,9 @@
" xformers=\"\"\n",
"\n",
"if os.path.isfile(path_to_trained_model):\n",
- " !python /content/gdrive/MyDrive/sd/stable-diffusion-webui/webui.py $share --disable-safe-unpickle --no-half-vae --ckpt \"$path_to_trained_model\" $configf $xformers\n",
+ " !python /content/gdrive/MyDrive/sd/stable-diffusion-webui/webui.py $share --disable-safe-unpickle --no-half-vae --enable-insecure-extension-access --ckpt \"$path_to_trained_model\" $configf $xformers\n",
"else:\n",
- " !python /content/gdrive/MyDrive/sd/stable-diffusion-webui/webui.py $share --disable-safe-unpickle --no-half-vae --ckpt-dir \"$path_to_trained_model\" $configf $xformers"
+ " !python /content/gdrive/MyDrive/sd/stable-diffusion-webui/webui.py $share --disable-safe-unpickle --no-half-vae --enable-insecure-extension-access --ckpt-dir \"$path_to_trained_model\" $configf $xformers"
]
},
{
@@ -1369,6 +1366,10 @@
"\n",
"print(\"\u001b[1;32mLoading...\")\n",
"\n",
+ "NM=\"False\"\n",
+ "if os.path.getsize(OUTPUT_DIR+\"/text_encoder/pytorch_model.bin\") > 670901463:\n",
+ " NM=\"True\"\n",
+ "\n",
"\n",
"if NM==\"False\":\n",
" with capture.capture_output() as cap:\n",
@@ -1601,8 +1602,11 @@
"metadata": {
"accelerator": "GPU",
"colab": {
+ "collapsed_sections": [
+ "bbKbx185zqlz",
+ "AaLtXBbPleBr"
+ ],
"provenance": [],
- "machine_shape": "hm",
"include_colab_link": true
},
"kernelspec": {
From f2e15f01ddb91999655882d4b5b1b2665bc247c9 Mon Sep 17 00:00:00 2001
From: nawnie <106923464+nawnie@users.noreply.github.com>
Date: Fri, 30 Dec 2022 01:02:29 -0600
Subject: [PATCH 07/15] Created using Colaboratory
---
fast-DreamBooth.ipynb | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
diff --git a/fast-DreamBooth.ipynb b/fast-DreamBooth.ipynb
index bd20f454..5f79a42f 100644
--- a/fast-DreamBooth.ipynb
+++ b/fast-DreamBooth.ipynb
@@ -857,7 +857,7 @@
"if UNet_Training_Steps==0:\n",
" trnonltxt=\"--train_only_text_encoder\"\n",
"\n",
- "Seed='69' \n",
+ "Seed='' \n",
"\n",
"Style_Training = False #@param {type:\"boolean\"}\n",
"\n",
From bd6d1a4814e1bae104591a19c07c961bff994b78 Mon Sep 17 00:00:00 2001
From: nawnie <106923464+nawnie@users.noreply.github.com>
Date: Mon, 2 Jan 2023 00:26:30 -0600
Subject: [PATCH 08/15] updating from legacy prime
alot
---
fast-DreamBooth.ipynb | 43 +++++++++++++++++++------------------------
1 file changed, 19 insertions(+), 24 deletions(-)
diff --git a/fast-DreamBooth.ipynb b/fast-DreamBooth.ipynb
index 5f79a42f..1475bd45 100644
--- a/fast-DreamBooth.ipynb
+++ b/fast-DreamBooth.ipynb
@@ -7,7 +7,7 @@
"colab_type": "text"
},
"source": [
- "<a href=\"https://colab.research.google.com/github/nawnie/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>"
+ "<a href=\"https://colab.research.google.com/github/nawnie/fast-stable-diffusion/blob/Legacy-Prime/fast-DreamBooth.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>"
]
},
{
@@ -16,7 +16,7 @@
"id": "qEsNHTtVlbkV"
},
"source": [
- "# A Remaster of **fast-DreamBooth colab From https://github.com/TheLastBen/fast-stable-diffusion, if you face any issues, feel free to discuss them.** \n",
+ "# **fast-DreamBooth colab From https://github.com/TheLastBen/fast-stable-diffusion, if you face any issues, feel free to discuss them.** \n",
"Keep your notebook updated for best experience. [Support](https://ko-fi.com/thelastben)\n"
]
},
@@ -123,7 +123,7 @@
"\n",
"#@markdown Or\n",
"\n",
- "CKPT_Path = \"/content/gdrive/MyDrive/A_Yaml_folder/sd_v1-5_vae.ckpt\" #@param {type:\"string\"}\n",
+ "CKPT_Path = \"\" #@param {type:\"string\"}\n",
"\n",
"#@markdown Or\n",
"\n",
@@ -373,8 +373,8 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "id": "A1B299g-_VJo",
- "cellView": "form"
+ "cellView": "form",
+ "id": "A1B299g-_VJo"
},
"outputs": [],
"source": [
@@ -551,7 +551,7 @@
"if not os.path.exists(str(INSTANCE_DIR)):\n",
" %mkdir -p \"$INSTANCE_DIR\"\n",
"\n",
- "IMAGES_FOLDER_OPTIONAL=\"/content/gdrive/MyDrive/Data_Sets/Nsfw_data_sets/Kim Possible \" #@param{type: 'string'}\n",
+ "IMAGES_FOLDER_OPTIONAL=\"/content/gdrive/MyDrive/Data_Sets/People_Data-sets/Retry_fin_SUBJECT AS FILE NAME/Kennedy\" #@param{type: 'string'}\n",
"\n",
"#@markdown - If you prefer to specify directly the folder of the pictures instead of uploading, this will add the pictures to the existing (if any) instance images. Leave EMPTY to upload.\n",
"\n",
@@ -589,7 +589,7 @@
" !cp \"$IMAGES_FOLDER_OPTIONAL/$filename\" \"$INSTANCE_DIR\"\n",
"\n",
" else:\n",
- " for filename in tqdm(os.listdir(IMAGES_FOLDER_OPTIONAL), bar_format=' |{bar:15}| {n_fmt}/{total_fmt} Uploaded'): \n",
+ " for filename in tqdm(os.listdir(IMAGES_FOLDER_OPTIONAL), bar_format=' |{bar:15}| {n_fmt}/{total_fmt} Uploaded'):\n",
" %cp -r \"$IMAGES_FOLDER_OPTIONAL/$filename\" \"$INSTANCE_DIR\"\n",
" \n",
" print('\\n\u001b[1;32mDone, proceed to the next cell')\n",
@@ -628,6 +628,7 @@
"with capture.capture_output() as cap:\n",
" %cd \"$INSTANCE_DIR\"\n",
" !find . -name \"* *\" -type f | rename 's/ /_/g' \n",
+ "\n",
" %cd $SESSION_DIR\n",
" !rm instance_images.zip\n",
" !zip -r instance_images instance_images\n",
@@ -790,7 +791,7 @@
"if os.path.exists(CONCEPT_DIR+\"/.ipynb_checkpoints\"):\n",
" %rm -r $CONCEPT_DIR\"/.ipynb_checkpoints\" \n",
"\n",
- "Resume_Training = True #@param {type:\"boolean\"}\n",
+ "Resume_Training = False #@param {type:\"boolean\"}\n",
"\n",
"try:\n",
" resume\n",
@@ -820,14 +821,14 @@
"\n",
"MODELT_NAME=MODEL_NAME\n",
"Repeats=200 #@param{type:\"number\"}\n",
- "warmup_steps=0 #@param{type:\"number\"}\n",
+ "warmup_steps=1 #@param{type:\"number\"}\n",
"wu=warmup_steps\n",
"batch_size=4 #@param{type:\"number\"}\n",
"bs=batch_size\n",
"gradient_steps=2 #@param{type:\"number\"}\n",
"gs=gradient_steps\n",
"UNet_Training_Steps=((Repeats*Img_Count)/(gs*bs))\n",
- "UNet_Learning_Rate = 4e-6 #@param [\"2e-6\", \"1e-6\", \"1e-5\", \"1e-4\", \"5e-7\"] {type:\"raw\", allow-input: true}\n",
+ "UNet_Learning_Rate = 2e-6 #@param [\"2e-6\", \"1e-6\", \"1e-5\", \"1e-4\", \"5e-7\"] {type:\"raw\", allow-input: true}\n",
"\n",
"#@markdown * 1e-7 is lowest, 1e-4 is the highest, 2e-7 is twice as fast as 1e-7 experiment and adjust the repeats to accomidate diffrent learning rates \n",
"\n",
@@ -837,11 +838,11 @@
"\n",
"#@markdown - These default settings are for a dataset of 10 pictures which is enough for training a face, start with 650 or lower, test the model, if not enough, resume training for 150 steps, keep testing until you get the desired output, `set it to 0 to train only the text_encoder`. \n",
"\n",
- "Text_Encoder_Training_Steps=125 #@param{type: 'number'}\n",
+ "Text_Encoder_Training_Steps=300 #@param{type: 'number'}\n",
"\n",
"#@markdown - 200-450 steps is enough for a small dataset, keep this number small to avoid overfitting, set to 0 to disable, `set it to 0 before resuming training if it is already trained`.\n",
"\n",
- "Text_Batch_Size = 2 #@param {type:\"integer\"}\n",
+ "Text_Batch_Size = 1 #@param {type:\"integer\"}\n",
"tbs=Text_Batch_Size\n",
"\n",
"Text_Encoder_Concept_Training_Steps=0 #@param{type: 'number'}\n",
@@ -857,7 +858,7 @@
"if UNet_Training_Steps==0:\n",
" trnonltxt=\"--train_only_text_encoder\"\n",
"\n",
- "Seed='' \n",
+ "Seed='69' \n",
"\n",
"Style_Training = False #@param {type:\"boolean\"}\n",
"\n",
@@ -868,7 +869,7 @@
" Style = \"--Style\"\n",
"\n",
"Flip_Images = True #@param {type:\"boolean\"}\n",
- "Percent_to_flip = 20 #@param{type:\"raw\"}\n",
+ "Percent_to_flip = 10 #@param{type:\"raw\"}\n",
"flip_rate = (Percent_to_flip/100)\n",
"\n",
"#@markdown Flip a random 10% of images, helps add veriety to smaller data-sets\n",
@@ -877,7 +878,7 @@
"if Flip_Images:\n",
" flip=\"--hflip\"\n",
"\n",
- "Conditional_dropout = 10 #@param {type:\"raw\"}\n",
+ "Conditional_dropout = 5 #@param {type:\"raw\"}\n",
"\n",
"#@markdown drop a random X% of images, helps avoid over fitting, very similar to style training\n",
"\n",
@@ -950,20 +951,14 @@
"#@markdown ---------------------------\n",
"Save_Checkpoint_Every_n_Steps = True #@param {type:\"boolean\"}\n",
"#@markdown How many repats/epochs between saves\n",
- "Save_Checkpoint_Every=50 #@param{type: 'number'}\n",
+ "Save_Checkpoint_Every=20 #@param{type: 'number'}\n",
"stp=0\n",
- "stpsv=5\n",
+ "stpsv=1\n",
"if Save_Checkpoint_Every_n_Steps:\n",
" stp=((Save_Checkpoint_Every*Img_Count)/(gs*bs))\n",
"stp=int(stp)\n",
"\n",
- "Skip_samples = False #@param {type:\"boolean\"}\n",
"prompt= \"\" #@param{type:\"string\"}\n",
- "if Skip_samples:\n",
- " prompt=\"None\"\n",
- "\n",
- "\n",
- "\n",
"Disconnect_after_training=False #@param {type:\"boolean\"}\n",
"\n",
"#@markdown - Auto-disconnect from google colab after the training to avoid wasting compute units.\n",
@@ -1620,4 +1615,4 @@
},
"nbformat": 4,
"nbformat_minor": 0
-}
\ No newline at end of file
+}
From 13446a2f9aa3e1c3c4a4d8bd722f77ccf1df69bd Mon Sep 17 00:00:00 2001
From: nawnie <106923464+nawnie@users.noreply.github.com>
Date: Wed, 4 Jan 2023 09:26:17 -0600
Subject: [PATCH 09/15] Created using Colaboratory
---
fast-DreamBooth.ipynb | 69 ++++++++++++++++++++++++++-----------------
1 file changed, 42 insertions(+), 27 deletions(-)
diff --git a/fast-DreamBooth.ipynb b/fast-DreamBooth.ipynb
index 1475bd45..141e063b 100644
--- a/fast-DreamBooth.ipynb
+++ b/fast-DreamBooth.ipynb
@@ -7,7 +7,7 @@
"colab_type": "text"
},
"source": [
- "<a href=\"https://colab.research.google.com/github/nawnie/fast-stable-diffusion/blob/Legacy-Prime/fast-DreamBooth.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>"
+ "<a href=\"https://colab.research.google.com/github/nawnie/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>"
]
},
{
@@ -373,8 +373,8 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "cellView": "form",
- "id": "A1B299g-_VJo"
+ "id": "A1B299g-_VJo",
+ "cellView": "form"
},
"outputs": [],
"source": [
@@ -540,7 +540,7 @@
"#@markdown\n",
"#@markdown - Run the cell to upload the instance pictures.\n",
"\n",
- "Remove_existing_instance_images= False #@param{type: 'boolean'}\n",
+ "Remove_existing_instance_images= True #@param{type: 'boolean'}\n",
"#@markdown - Uncheck the box to keep the existing instance images.\n",
"\n",
"\n",
@@ -551,12 +551,17 @@
"if not os.path.exists(str(INSTANCE_DIR)):\n",
" %mkdir -p \"$INSTANCE_DIR\"\n",
"\n",
- "IMAGES_FOLDER_OPTIONAL=\"/content/gdrive/MyDrive/Data_Sets/People_Data-sets/Retry_fin_SUBJECT AS FILE NAME/Kennedy\" #@param{type: 'string'}\n",
+ "IMAGES_FOLDER_OPTIONAL=\"\" #@param{type: 'string'}\n",
+ "\n",
+ "if os.path.exists(IMAGES_FOLDER_OPTIONAL+\"/.ipynb_checkpoints\"):\n",
+ " %rm -r $IMAGES_FOLDER_OPTIONAL\"/.ipynb_checkpoints\"\n",
+ "if os.path.exists(IMAGES_FOLDER_OPTIONAL+\"/Desktop.ini\"):\n",
+ " %rm -r $IMAGES_FOLDER_OPTIONAL\"/Desktop.ini\"\n",
"\n",
"#@markdown - If you prefer to specify directly the folder of the pictures instead of uploading, this will add the pictures to the existing (if any) instance images. Leave EMPTY to upload.\n",
"\n",
"Crop_images= True #@param{type: 'boolean'}\n",
- "Crop_size = \"512\" #@param [\"512\", \"576\", \"640\", \"704\", \"768\", \"832\", \"896\", \"960\", \"1024\"]\n",
+ "Crop_size = \"768\" #@param [\"512\", \"576\", \"640\", \"704\", \"768\", \"832\", \"896\", \"960\", \"1024\"]\n",
"Crop_size=int(Crop_size)\n",
"\n",
"#@markdown - Unless you want to crop them manually in a precise way, you don't need to crop your instance images externally.\n",
@@ -639,8 +644,8 @@
"cell_type": "code",
"execution_count": null,
"metadata": {
- "cellView": "form",
- "id": "LxEv3u8mQos3"
+ "id": "LxEv3u8mQos3",
+ "cellView": "form"
},
"outputs": [],
"source": [
@@ -664,11 +669,15 @@
" if os.path.exists(str(CONCEPT_DIR)):\n",
" !rm -r \"$CONCEPT_DIR\"\n",
"\n",
+ "\n",
"if not os.path.exists(str(CONCEPT_DIR)):\n",
" %mkdir -p \"$CONCEPT_DIR\"\n",
"\n",
"IMAGES_FOLDER_OPTIONAL=\"\" #@param{type: 'string'}\n",
- "\n",
+ "if os.path.exists(IMAGES_FOLDER_OPTIONAL+\"/.ipynb_checkpoints\"):\n",
+ " %rm -r $IMAGES_FOLDER_OPTIONAL\"/.ipynb_checkpoints\"\n",
+ "if os.path.exists(IMAGES_FOLDER_OPTIONAL+\"/Desktop.ini\"):\n",
+ " %rm -r $IMAGES_FOLDER_OPTIONAL\"/Desktop.ini\"\n",
"#@markdown - If you prefer to specify directly the folder of the pictures instead of uploading, this will add the pictures to the existing (if any) concept images. Leave EMPTY to upload.\n",
"\n",
"Crop_images= True \n",
@@ -782,7 +791,7 @@
"import time\n",
"import random\n",
"\n",
- "\n",
+ "# Determine number of images in the Instance folder\n",
"Img_Count = (len([entry for entry in os.listdir(INSTANCE_DIR) if os.path.isfile(os.path.join(INSTANCE_DIR, entry))]))\n",
"\n",
"if os.path.exists(INSTANCE_DIR+\"/.ipynb_checkpoints\"):\n",
@@ -791,8 +800,9 @@
"if os.path.exists(CONCEPT_DIR+\"/.ipynb_checkpoints\"):\n",
" %rm -r $CONCEPT_DIR\"/.ipynb_checkpoints\" \n",
"\n",
- "Resume_Training = False #@param {type:\"boolean\"}\n",
- "\n",
+ "Resume_Training = True #@param {type:\"boolean\"}\n",
+ "# user input request if a prior training has been started\n",
+ "# but resume is not selected\n",
"try:\n",
" resume\n",
" if resume and not Resume_Training:\n",
@@ -818,17 +828,18 @@
"\n",
"\n",
"\n",
+ "# declare Unet training Vaiables\n",
"\n",
"MODELT_NAME=MODEL_NAME\n",
"Repeats=200 #@param{type:\"number\"}\n",
- "warmup_steps=1 #@param{type:\"number\"}\n",
+ "warmup_steps=2 #@param{type:\"number\"}\n",
"wu=warmup_steps\n",
"batch_size=4 #@param{type:\"number\"}\n",
"bs=batch_size\n",
"gradient_steps=2 #@param{type:\"number\"}\n",
"gs=gradient_steps\n",
"UNet_Training_Steps=((Repeats*Img_Count)/(gs*bs))\n",
- "UNet_Learning_Rate = 2e-6 #@param [\"2e-6\", \"1e-6\", \"1e-5\", \"1e-4\", \"5e-7\"] {type:\"raw\", allow-input: true}\n",
+ "UNet_Learning_Rate = 5e-5 #@param [\"2e-6\", \"1e-6\", \"1e-5\", \"1e-4\", \"5e-7\"] {type:\"raw\", allow-input: true}\n",
"\n",
"#@markdown * 1e-7 is lowest, 1e-4 is the highest, 2e-7 is twice as fast as 1e-7 experiment and adjust the repeats to accomidate diffrent learning rates \n",
"\n",
@@ -838,18 +849,22 @@
"\n",
"#@markdown - These default settings are for a dataset of 10 pictures which is enough for training a face, start with 650 or lower, test the model, if not enough, resume training for 150 steps, keep testing until you get the desired output, `set it to 0 to train only the text_encoder`. \n",
"\n",
- "Text_Encoder_Training_Steps=300 #@param{type: 'number'}\n",
- "\n",
+ "Text_Encoder_Training_steps=25 #@param{type: 'number'}\n",
"#@markdown - 200-450 steps is enough for a small dataset, keep this number small to avoid overfitting, set to 0 to disable, `set it to 0 before resuming training if it is already trained`.\n",
"\n",
- "Text_Batch_Size = 1 #@param {type:\"integer\"}\n",
+ "# declare text batch size\n",
+ "Text_Batch_Size = 8 #@param {type:\"integer\"}\n",
"tbs=Text_Batch_Size\n",
"\n",
- "Text_Encoder_Concept_Training_Steps=0 #@param{type: 'number'}\n",
- "\n",
+ "Text_Encoder_Concept_Training_steps=400 #@param{type: 'number'}\n",
+ "# adjust text steps for batch size\n",
+ "Text_Encoder_Concept_Training_Steps=(Text_Encoder_Concept_Training_steps/tbs)\n",
+ "Text_Encoder_Training_Steps=(Text_Encoder_Training_steps/tbs)\n",
+ "Text_Encoder_Concept_Training_Steps=int(Text_Encoder_Concept_Training_Steps)\n",
+ "Text_Encoder_Training_Steps=int(Text_Encoder_Training_Steps)\n",
"#@markdown - Suitable for training a style/concept as it acts as heavy regularization, set it to 1500 steps for 200 concept images (you can go higher), set to 0 to disable, set both the settings above to 0 to fintune only the text_encoder on the concept, `set it to 0 before resuming training if it is already trained`.\n",
"\n",
- "Text_Encoder_Learning_Rate = 2e-6 #@param [\"2e-6\", \"8e-7\", \"6e-7\", \"5e-7\", \"4e-7\"] {type:\"raw\", allow-input: true}\n",
+ "Text_Encoder_Learning_Rate = 1e-6 #@param [\"2e-6\", \"8e-7\", \"6e-7\", \"5e-7\", \"4e-7\"] {type:\"raw\", allow-input: true}\n",
"txlr=Text_Encoder_Learning_Rate\n",
"\n",
"#@markdown - Learning rate for both text_encoder and concept_text_encoder, keep it low to avoid overfitting (1e-7 is lowest, 1e-4 is the highest, 2e-7 is twice as fast as 1e-7 experiment and adjust the repeats to accomidate diffrent learning rates )\n",
@@ -858,7 +873,7 @@
"if UNet_Training_Steps==0:\n",
" trnonltxt=\"--train_only_text_encoder\"\n",
"\n",
- "Seed='69' \n",
+ "Seed = None #@param {type:\"integer\"}\n",
"\n",
"Style_Training = False #@param {type:\"boolean\"}\n",
"\n",
@@ -869,7 +884,7 @@
" Style = \"--Style\"\n",
"\n",
"Flip_Images = True #@param {type:\"boolean\"}\n",
- "Percent_to_flip = 10 #@param{type:\"raw\"}\n",
+ "Percent_to_flip = 35 #@param{type:\"raw\"}\n",
"flip_rate = (Percent_to_flip/100)\n",
"\n",
"#@markdown Flip a random 10% of images, helps add veriety to smaller data-sets\n",
@@ -878,7 +893,7 @@
"if Flip_Images:\n",
" flip=\"--hflip\"\n",
"\n",
- "Conditional_dropout = 5 #@param {type:\"raw\"}\n",
+ "Conditional_dropout = 35 #@param {type:\"raw\"}\n",
"\n",
"#@markdown drop a random X% of images, helps avoid over fitting, very similar to style training\n",
"\n",
@@ -951,9 +966,9 @@
"#@markdown ---------------------------\n",
"Save_Checkpoint_Every_n_Steps = True #@param {type:\"boolean\"}\n",
"#@markdown How many repats/epochs between saves\n",
- "Save_Checkpoint_Every=20 #@param{type: 'number'}\n",
+ "Save_Checkpoint_Every=25 #@param{type: 'number'}\n",
"stp=0\n",
- "stpsv=1\n",
+ "stpsv=10\n",
"if Save_Checkpoint_Every_n_Steps:\n",
" stp=((Save_Checkpoint_Every*Img_Count)/(gs*bs))\n",
"stp=int(stp)\n",
@@ -981,7 +996,7 @@
" --gradient_accumulation_steps=1 $GC \\\n",
" --use_8bit_adam \\\n",
" --learning_rate=$txlr \\\n",
- " --lr_scheduler=\"polynomial\" \\\n",
+ " --lr_scheduler=\"constant\" \\\n",
" --lr_warmup_steps=10 \\\n",
" --max_train_steps=$Training_Steps\n",
"\n",
@@ -1615,4 +1630,4 @@
},
"nbformat": 4,
"nbformat_minor": 0
-}
+}
\ No newline at end of file
From d070145919f617eef36eb85b90c08e0b603032d8 Mon Sep 17 00:00:00 2001
From: nawnie <106923464+nawnie@users.noreply.github.com>
Date: Wed, 11 Jan 2023 14:14:57 -0600
Subject: [PATCH 10/15] Created using Colaboratory
---
fast-DreamBooth.ipynb | 202 +++++++++++++++++++++++++++++++++---------
1 file changed, 159 insertions(+), 43 deletions(-)
diff --git a/fast-DreamBooth.ipynb b/fast-DreamBooth.ipynb
index 141e063b..878392d9 100644
--- a/fast-DreamBooth.ipynb
+++ b/fast-DreamBooth.ipynb
@@ -22,12 +22,24 @@
},
{
"cell_type": "code",
- "execution_count": null,
+ "execution_count": 1,
"metadata": {
"id": "A4Bae3VP6UsE",
- "cellView": "form"
+ "cellView": "form",
+ "outputId": "b1455ef8-9099-4608-bb77-fdacb11b0556",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ }
},
- "outputs": [],
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "Mounted at /content/gdrive\n"
+ ]
+ }
+ ],
"source": [
"#@title Mount Gdrive\n",
"\n",
@@ -37,12 +49,24 @@
},
{
"cell_type": "code",
- "execution_count": null,
+ "execution_count": 2,
"metadata": {
"id": "QyvcqeiL65Tj",
- "cellView": "form"
+ "outputId": "fcc22f05-8582-4bc6-9521-afbaf978646d",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ }
},
- "outputs": [],
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "\u001b[1;32mInstalling dependencies...\n",
+ "\u001b[1;32mDone, proceed\n"
+ ]
+ }
+ ],
"source": [
"#@markdown # Dependencies\n",
"\n",
@@ -83,12 +107,23 @@
},
{
"cell_type": "code",
- "execution_count": null,
+ "execution_count": 9,
"metadata": {
- "cellView": "form",
- "id": "O3KHGKqyeJp9"
+ "id": "O3KHGKqyeJp9",
+ "outputId": "5c38d86f-ef33-4290-f6fd-efb71cf287e3",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ }
},
- "outputs": [],
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "\u001b[1;32mDONE !\n"
+ ]
+ }
+ ],
"source": [
"import os\n",
"import time\n",
@@ -123,7 +158,7 @@
"\n",
"#@markdown Or\n",
"\n",
- "CKPT_Path = \"\" #@param {type:\"string\"}\n",
+ "CKPT_Path = \"/content/gdrive/MyDrive/A_Training_folder/models/Realistic_proto.ckpt\" #@param {type:\"string\"}\n",
"\n",
"#@markdown Or\n",
"\n",
@@ -374,9 +409,21 @@
"execution_count": null,
"metadata": {
"id": "A1B299g-_VJo",
- "cellView": "form"
+ "outputId": "127c8398-c153-4f3f-e3d7-33096151d8e9",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ }
},
- "outputs": [],
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "\u001b[1;32mSession found, loading the trained model ...\n",
+ "\u001b[1;32mConverting to Diffusers ...\n"
+ ]
+ }
+ ],
"source": [
"import os\n",
"from IPython.display import clear_output\n",
@@ -396,7 +443,7 @@
" \n",
"PT=\"\"\n",
"\n",
- "Session_Name = \"\" #@param{type: 'string'}\n",
+ "Session_Name = \"MatPat\" #@param{type: 'string'}\n",
"while Session_Name==\"\":\n",
" print('\u001b[1;31mInput the Session Name:') \n",
" Session_Name=input('')\n",
@@ -522,12 +569,31 @@
},
{
"cell_type": "code",
- "execution_count": null,
+ "execution_count": 5,
"metadata": {
"id": "LC4ukG60fgMy",
- "cellView": "form"
+ "outputId": "257aa11d-cf10-44bf-d1c0-04285878bb21",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ }
},
- "outputs": [],
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stderr",
+ "text": [
+ " |███████████████| 9/9 Uploaded\n"
+ ]
+ },
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "\n",
+ "\u001b[1;32mDone, proceed to the next cell\n"
+ ]
+ }
+ ],
"source": [
"import shutil\n",
"from google.colab import files\n",
@@ -551,7 +617,7 @@
"if not os.path.exists(str(INSTANCE_DIR)):\n",
" %mkdir -p \"$INSTANCE_DIR\"\n",
"\n",
- "IMAGES_FOLDER_OPTIONAL=\"\" #@param{type: 'string'}\n",
+ "IMAGES_FOLDER_OPTIONAL=\"/content/gdrive/MyDrive/A_Training_folder/Cali\" #@param{type: 'string'}\n",
"\n",
"if os.path.exists(IMAGES_FOLDER_OPTIONAL+\"/.ipynb_checkpoints\"):\n",
" %rm -r $IMAGES_FOLDER_OPTIONAL\"/.ipynb_checkpoints\"\n",
@@ -560,8 +626,8 @@
"\n",
"#@markdown - If you prefer to specify directly the folder of the pictures instead of uploading, this will add the pictures to the existing (if any) instance images. Leave EMPTY to upload.\n",
"\n",
- "Crop_images= True #@param{type: 'boolean'}\n",
- "Crop_size = \"768\" #@param [\"512\", \"576\", \"640\", \"704\", \"768\", \"832\", \"896\", \"960\", \"1024\"]\n",
+ "Crop_images= False #@param{type: 'boolean'}\n",
+ "Crop_size = \"576\" #@param [\"512\", \"576\", \"640\", \"704\", \"768\", \"832\", \"896\", \"960\", \"1024\"]\n",
"Crop_size=int(Crop_size)\n",
"\n",
"#@markdown - Unless you want to crop them manually in a precise way, you don't need to crop your instance images externally.\n",
@@ -642,12 +708,35 @@
},
{
"cell_type": "code",
- "execution_count": null,
+ "execution_count": 28,
"metadata": {
"id": "LxEv3u8mQos3",
- "cellView": "form"
+ "cellView": "form",
+ "outputId": "25b51b7a-e0c3-489a-8c3b-bcafbd9d81f2",
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 1000
+ }
},
- "outputs": [],
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stderr",
+ "text": [
+ " |███████████████| 98/98 Uploaded\n"
+ ]
+ },
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "\n",
+ "\u001b[1;32mAlmost done...\n",
+ "\n",
+ "\u001b[1;32mDone, proceed to the training cell\n"
+ ]
+ }
+ ],
"source": [
"import shutil\n",
"from google.colab import files\n",
@@ -661,7 +750,7 @@
"#@markdown - Run this `optional` cell to upload concept pictures. If you're traning on a specific face, skip this cell.\n",
"#@markdown - Training a model on a restricted number of instance images tends to indoctrinate it and limit its imagination, so concept images help re-opening its \"mind\" to diversity and greatly widen the range of possibilities of the output, concept images should contain anything related to the instance pictures, including objects, ideas, scenes, phenomenons, concepts (obviously), don't be afraid to slightly diverge from the trained style.\n",
"\n",
- "Remove_existing_concept_images= True #@param{type: 'boolean'}\n",
+ "Remove_existing_concept_images= False #@param{type: 'boolean'}\n",
"#@markdown - Uncheck the box to keep the existing concept images.\n",
"\n",
"\n",
@@ -673,7 +762,7 @@
"if not os.path.exists(str(CONCEPT_DIR)):\n",
" %mkdir -p \"$CONCEPT_DIR\"\n",
"\n",
- "IMAGES_FOLDER_OPTIONAL=\"\" #@param{type: 'string'}\n",
+ "IMAGES_FOLDER_OPTIONAL=\"/content/gdrive/MyDrive/A_Training_folder/woman2\" #@param{type: 'string'}\n",
"if os.path.exists(IMAGES_FOLDER_OPTIONAL+\"/.ipynb_checkpoints\"):\n",
" %rm -r $IMAGES_FOLDER_OPTIONAL\"/.ipynb_checkpoints\"\n",
"if os.path.exists(IMAGES_FOLDER_OPTIONAL+\"/Desktop.ini\"):\n",
@@ -800,7 +889,7 @@
"if os.path.exists(CONCEPT_DIR+\"/.ipynb_checkpoints\"):\n",
" %rm -r $CONCEPT_DIR\"/.ipynb_checkpoints\" \n",
"\n",
- "Resume_Training = True #@param {type:\"boolean\"}\n",
+ "Resume_Training = False #@param {type:\"boolean\"}\n",
"# user input request if a prior training has been started\n",
"# but resume is not selected\n",
"try:\n",
@@ -831,15 +920,15 @@
"# declare Unet training Vaiables\n",
"\n",
"MODELT_NAME=MODEL_NAME\n",
- "Repeats=200 #@param{type:\"number\"}\n",
- "warmup_steps=2 #@param{type:\"number\"}\n",
+ "Repeats=50 #@param{type:\"number\"}\n",
+ "warmup_steps=0 #@param{type:\"number\"}\n",
"wu=warmup_steps\n",
"batch_size=4 #@param{type:\"number\"}\n",
"bs=batch_size\n",
"gradient_steps=2 #@param{type:\"number\"}\n",
"gs=gradient_steps\n",
"UNet_Training_Steps=((Repeats*Img_Count)/(gs*bs))\n",
- "UNet_Learning_Rate = 5e-5 #@param [\"2e-6\", \"1e-6\", \"1e-5\", \"1e-4\", \"5e-7\"] {type:\"raw\", allow-input: true}\n",
+ "UNet_Learning_Rate = 2e-6 #@param [\"2e-6\", \"1e-6\", \"1e-5\", \"1e-4\", \"5e-7\"] {type:\"raw\", allow-input: true}\n",
"\n",
"#@markdown * 1e-7 is lowest, 1e-4 is the highest, 2e-7 is twice as fast as 1e-7 experiment and adjust the repeats to accomidate diffrent learning rates \n",
"\n",
@@ -849,14 +938,14 @@
"\n",
"#@markdown - These default settings are for a dataset of 10 pictures which is enough for training a face, start with 650 or lower, test the model, if not enough, resume training for 150 steps, keep testing until you get the desired output, `set it to 0 to train only the text_encoder`. \n",
"\n",
- "Text_Encoder_Training_steps=25 #@param{type: 'number'}\n",
+ "Text_Encoder_Training_steps=0 #@param{type: 'number'}\n",
"#@markdown - 200-450 steps is enough for a small dataset, keep this number small to avoid overfitting, set to 0 to disable, `set it to 0 before resuming training if it is already trained`.\n",
"\n",
"# declare text batch size\n",
- "Text_Batch_Size = 8 #@param {type:\"integer\"}\n",
+ "Text_Batch_Size = 7 #@param {type:\"integer\"}\n",
"tbs=Text_Batch_Size\n",
"\n",
- "Text_Encoder_Concept_Training_steps=400 #@param{type: 'number'}\n",
+ "Text_Encoder_Concept_Training_steps=0 #@param{type: 'number'}\n",
"# adjust text steps for batch size\n",
"Text_Encoder_Concept_Training_Steps=(Text_Encoder_Concept_Training_steps/tbs)\n",
"Text_Encoder_Training_Steps=(Text_Encoder_Training_steps/tbs)\n",
@@ -864,7 +953,7 @@
"Text_Encoder_Training_Steps=int(Text_Encoder_Training_Steps)\n",
"#@markdown - Suitable for training a style/concept as it acts as heavy regularization, set it to 1500 steps for 200 concept images (you can go higher), set to 0 to disable, set both the settings above to 0 to fintune only the text_encoder on the concept, `set it to 0 before resuming training if it is already trained`.\n",
"\n",
- "Text_Encoder_Learning_Rate = 1e-6 #@param [\"2e-6\", \"8e-7\", \"6e-7\", \"5e-7\", \"4e-7\"] {type:\"raw\", allow-input: true}\n",
+ "Text_Encoder_Learning_Rate = 2e-6 #@param [\"2e-6\", \"8e-7\", \"6e-7\", \"5e-7\", \"4e-7\"] {type:\"raw\", allow-input: true}\n",
"txlr=Text_Encoder_Learning_Rate\n",
"\n",
"#@markdown - Learning rate for both text_encoder and concept_text_encoder, keep it low to avoid overfitting (1e-7 is lowest, 1e-4 is the highest, 2e-7 is twice as fast as 1e-7 experiment and adjust the repeats to accomidate diffrent learning rates )\n",
@@ -873,7 +962,7 @@
"if UNet_Training_Steps==0:\n",
" trnonltxt=\"--train_only_text_encoder\"\n",
"\n",
- "Seed = None #@param {type:\"integer\"}\n",
+ "Seed = 42825032 #@param {type:\"integer\"}\n",
"\n",
"Style_Training = False #@param {type:\"boolean\"}\n",
"\n",
@@ -884,7 +973,7 @@
" Style = \"--Style\"\n",
"\n",
"Flip_Images = True #@param {type:\"boolean\"}\n",
- "Percent_to_flip = 35 #@param{type:\"raw\"}\n",
+ "Percent_to_flip = 10 #@param{type:\"raw\"}\n",
"flip_rate = (Percent_to_flip/100)\n",
"\n",
"#@markdown Flip a random 10% of images, helps add veriety to smaller data-sets\n",
@@ -893,7 +982,7 @@
"if Flip_Images:\n",
" flip=\"--hflip\"\n",
"\n",
- "Conditional_dropout = 35 #@param {type:\"raw\"}\n",
+ "Conditional_dropout = 3 #@param {type:\"raw\"}\n",
"\n",
"#@markdown drop a random X% of images, helps avoid over fitting, very similar to style training\n",
"\n",
@@ -903,7 +992,7 @@
"\n",
"\n",
"\n",
- "Resolution = \"512\" #@param [\"512\", \"576\", \"640\", \"704\", \"768\", \"832\", \"896\", \"960\", \"1024\"]\n",
+ "Resolution = \"576\" #@param [\"512\", \"576\", \"640\", \"704\", \"768\", \"832\", \"896\", \"960\", \"1024\"]\n",
"Res=int(Resolution)\n",
"\n",
"#@markdown - Higher resolution = Higher quality, make sure the instance images are cropped to this selected size (or larger).\n",
@@ -966,14 +1055,16 @@
"#@markdown ---------------------------\n",
"Save_Checkpoint_Every_n_Steps = True #@param {type:\"boolean\"}\n",
"#@markdown How many repats/epochs between saves\n",
- "Save_Checkpoint_Every=25 #@param{type: 'number'}\n",
+ "Save_Checkpoint_Every=10 #@param{type: 'number'}\n",
"stp=0\n",
"stpsv=10\n",
"if Save_Checkpoint_Every_n_Steps:\n",
" stp=((Save_Checkpoint_Every*Img_Count)/(gs*bs))\n",
"stp=int(stp)\n",
+ "Number_Of_Samples = 8 #@param {type:\"integer\"}\n",
+ "NoS=Number_Of_Samples\n",
"\n",
- "prompt= \"\" #@param{type:\"string\"}\n",
+ "prompt= \"a photo of matpat\" #@param{type:\"string\"}\n",
"Disconnect_after_training=False #@param {type:\"boolean\"}\n",
"\n",
"#@markdown - Auto-disconnect from google colab after the training to avoid wasting compute units.\n",
@@ -1017,6 +1108,7 @@
" --instance_data_dir=\"$INSTANCE_DIR\" \\\n",
" --output_dir=\"$OUTPUT_DIR\" \\\n",
" --instance_prompt=\"$PT\" \\\n",
+ " --n_save_sample=$NoS \\\n",
" --save_sample_prompt=\"$prompt\" \\\n",
" --seed=$Seed \\\n",
" --resolution=$Res \\\n",
@@ -1109,12 +1201,36 @@
},
{
"cell_type": "code",
- "execution_count": null,
+ "execution_count": 19,
"metadata": {
"cellView": "form",
- "id": "iAZGngFcI8hq"
+ "id": "iAZGngFcI8hq",
+ "outputId": "102db37b-945c-43c5-807d-3b70903ecd78",
+ "colab": {
+ "base_uri": "https://localhost:8080/",
+ "height": 397
+ }
},
- "outputs": [],
+ "outputs": [
+ {
+ "output_type": "error",
+ "ename": "KeyboardInterrupt",
+ "evalue": "ignored",
+ "traceback": [
+ "\u001b[0;31m---------------------------------------------------------------------------\u001b[0m",
+ "\u001b[0;31mKeyboardInterrupt\u001b[0m Traceback (most recent call last)",
+ "\u001b[0;32m/usr/local/lib/python3.8/dist-packages/IPython/core/async_helpers.py\u001b[0m in \u001b[0;36m_pseudo_sync_runner\u001b[0;34m(coro)\u001b[0m\n\u001b[1;32m 66\u001b[0m \"\"\"\n\u001b[1;32m 67\u001b[0m \u001b[0;32mtry\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m---> 68\u001b[0;31m \u001b[0mcoro\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0msend\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0;32mNone\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[1;32m 69\u001b[0m \u001b[0;32mexcept\u001b[0m \u001b[0mStopIteration\u001b[0m \u001b[0;32mas\u001b[0m \u001b[0mexc\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 70\u001b[0m \u001b[0;32mreturn\u001b[0m \u001b[0mexc\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mvalue\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n",
+ "\u001b[0;32m/usr/local/lib/python3.8/dist-packages/IPython/core/interactiveshell.py\u001b[0m in \u001b[0;36mrun_cell_async\u001b[0;34m(self, raw_cell, store_history, silent, shell_futures)\u001b[0m\n\u001b[1;32m 2971\u001b[0m \u001b[0;31m# it in the history.\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 2972\u001b[0m \u001b[0;32mtry\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m-> 2973\u001b[0;31m \u001b[0mcell\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mself\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mtransform_cell\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mraw_cell\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[1;32m 2974\u001b[0m \u001b[0;32mexcept\u001b[0m \u001b[0mException\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 2975\u001b[0m \u001b[0mpreprocessing_exc_tuple\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0msys\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mexc_info\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n",
+ "\u001b[0;32m/usr/local/lib/python3.8/dist-packages/IPython/core/interactiveshell.py\u001b[0m in \u001b[0;36mtransform_cell\u001b[0;34m(self, raw_cell)\u001b[0m\n\u001b[1;32m 3088\u001b[0m \"\"\"\n\u001b[1;32m 3089\u001b[0m \u001b[0;31m# Static input transformations\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m-> 3090\u001b[0;31m \u001b[0mcell\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mself\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0minput_transformer_manager\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mtransform_cell\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mraw_cell\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[1;32m 3091\u001b[0m \u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 3092\u001b[0m \u001b[0;32mif\u001b[0m \u001b[0mlen\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mcell\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0msplitlines\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m)\u001b[0m \u001b[0;34m==\u001b[0m \u001b[0;36m1\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n",
+ "\u001b[0;32m/usr/local/lib/python3.8/dist-packages/IPython/core/inputtransformer2.py\u001b[0m in \u001b[0;36mtransform_cell\u001b[0;34m(self, cell)\u001b[0m\n\u001b[1;32m 588\u001b[0m \u001b[0mlines\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mtransform\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mlines\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 589\u001b[0m \u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m--> 590\u001b[0;31m \u001b[0mlines\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mself\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mdo_token_transforms\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mlines\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[1;32m 591\u001b[0m \u001b[0;32mreturn\u001b[0m \u001b[0;34m''\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mjoin\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mlines\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 592\u001b[0m \u001b[0;34m\u001b[0m\u001b[0m\n",
+ "\u001b[0;32m/usr/local/lib/python3.8/dist-packages/IPython/core/inputtransformer2.py\u001b[0m in \u001b[0;36mdo_token_transforms\u001b[0;34m(self, lines)\u001b[0m\n\u001b[1;32m 573\u001b[0m \u001b[0;32mdef\u001b[0m \u001b[0mdo_token_transforms\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mself\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mlines\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 574\u001b[0m \u001b[0;32mfor\u001b[0m \u001b[0m_\u001b[0m \u001b[0;32min\u001b[0m \u001b[0mrange\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mTRANSFORM_LOOP_LIMIT\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m--> 575\u001b[0;31m \u001b[0mchanged\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mlines\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mself\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mdo_one_token_transform\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mlines\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[1;32m 576\u001b[0m \u001b[0;32mif\u001b[0m \u001b[0;32mnot\u001b[0m \u001b[0mchanged\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 577\u001b[0m \u001b[0;32mreturn\u001b[0m \u001b[0mlines\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n",
+ "\u001b[0;32m/usr/local/lib/python3.8/dist-packages/IPython/core/inputtransformer2.py\u001b[0m in \u001b[0;36mdo_one_token_transform\u001b[0;34m(self, lines)\u001b[0m\n\u001b[1;32m 553\u001b[0m \u001b[0ma\u001b[0m \u001b[0mperformance\u001b[0m \u001b[0missue\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 554\u001b[0m \"\"\"\n\u001b[0;32m--> 555\u001b[0;31m \u001b[0mtokens_by_line\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mmake_tokens_by_line\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mlines\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[1;32m 556\u001b[0m \u001b[0mcandidates\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;34m[\u001b[0m\u001b[0;34m]\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 557\u001b[0m \u001b[0;32mfor\u001b[0m \u001b[0mtransformer_cls\u001b[0m \u001b[0;32min\u001b[0m \u001b[0mself\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mtoken_transformers\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n",
+ "\u001b[0;32m/usr/local/lib/python3.8/dist-packages/IPython/core/inputtransformer2.py\u001b[0m in \u001b[0;36mmake_tokens_by_line\u001b[0;34m(lines)\u001b[0m\n\u001b[1;32m 482\u001b[0m \u001b[0mparenlev\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;36m0\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 483\u001b[0m \u001b[0;32mtry\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m--> 484\u001b[0;31m \u001b[0;32mfor\u001b[0m \u001b[0mtoken\u001b[0m \u001b[0;32min\u001b[0m \u001b[0mtokenize\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mgenerate_tokens\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0miter\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mlines\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0m__next__\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[1;32m 485\u001b[0m \u001b[0mtokens_by_line\u001b[0m\u001b[0;34m[\u001b[0m\u001b[0;34m-\u001b[0m\u001b[0;36m1\u001b[0m\u001b[0;34m]\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mappend\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mtoken\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 486\u001b[0m \u001b[0;32mif\u001b[0m \u001b[0;34m(\u001b[0m\u001b[0mtoken\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mtype\u001b[0m \u001b[0;34m==\u001b[0m \u001b[0mNEWLINE\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;31m \u001b[0m\u001b[0;31m\\\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n",
+ "\u001b[0;32m/usr/lib/python3.8/tokenize.py\u001b[0m in \u001b[0;36m_tokenize\u001b[0;34m(readline, encoding)\u001b[0m\n\u001b[1;32m 544\u001b[0m \u001b[0;32myield\u001b[0m \u001b[0mTokenInfo\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mCOMMENT\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mtoken\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mspos\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mepos\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mline\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 545\u001b[0m \u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m--> 546\u001b[0;31m \u001b[0;32melif\u001b[0m \u001b[0mtoken\u001b[0m \u001b[0;32min\u001b[0m \u001b[0mtriple_quoted\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[1;32m 547\u001b[0m \u001b[0mendprog\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0m_compile\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mendpats\u001b[0m\u001b[0;34m[\u001b[0m\u001b[0mtoken\u001b[0m\u001b[0;34m]\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 548\u001b[0m \u001b[0mendmatch\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mendprog\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mmatch\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mline\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mpos\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n",
+ "\u001b[0;31mKeyboardInterrupt\u001b[0m: "
+ ]
+ }
+ ],
"source": [
"import os\n",
"import time\n",
@@ -1134,7 +1250,7 @@
"\n",
"#@markdown - Leave empty if you want to use the current trained model.\n",
"\n",
- "Use_Custom_Path = False #@param {type:\"boolean\"}\n",
+ "Use_Custom_Path = True #@param {type:\"boolean\"}\n",
"\n",
"try:\n",
" INSTANCE_NAME\n",
From ccf2225c766ff1d987237783e80c0e275258a1a3 Mon Sep 17 00:00:00 2001
From: nawnie <106923464+nawnie@users.noreply.github.com>
Date: Fri, 13 Jan 2023 19:04:29 -0600
Subject: [PATCH 11/15] Created using Colaboratory
---
fast-DreamBooth.ipynb | 53 ++++++++++++++++++++++++++++++++++++-------
1 file changed, 45 insertions(+), 8 deletions(-)
diff --git a/fast-DreamBooth.ipynb b/fast-DreamBooth.ipynb
index 878392d9..5d65012d 100644
--- a/fast-DreamBooth.ipynb
+++ b/fast-DreamBooth.ipynb
@@ -22,7 +22,7 @@
},
{
"cell_type": "code",
- "execution_count": 1,
+ "execution_count": null,
"metadata": {
"id": "A4Bae3VP6UsE",
"cellView": "form",
@@ -49,7 +49,7 @@
},
{
"cell_type": "code",
- "execution_count": 2,
+ "execution_count": null,
"metadata": {
"id": "QyvcqeiL65Tj",
"outputId": "fcc22f05-8582-4bc6-9521-afbaf978646d",
@@ -107,7 +107,7 @@
},
{
"cell_type": "code",
- "execution_count": 9,
+ "execution_count": null,
"metadata": {
"id": "O3KHGKqyeJp9",
"outputId": "5c38d86f-ef33-4290-f6fd-efb71cf287e3",
@@ -569,7 +569,7 @@
},
{
"cell_type": "code",
- "execution_count": 5,
+ "execution_count": null,
"metadata": {
"id": "LC4ukG60fgMy",
"outputId": "257aa11d-cf10-44bf-d1c0-04285878bb21",
@@ -708,7 +708,7 @@
},
{
"cell_type": "code",
- "execution_count": 28,
+ "execution_count": null,
"metadata": {
"id": "LxEv3u8mQos3",
"cellView": "form",
@@ -866,9 +866,46 @@
"execution_count": null,
"metadata": {
"id": "1-9QbkfAVYYU",
- "cellView": "form"
+ "cellView": "form",
+ "colab": {
+ "base_uri": "https://localhost:8080/"
+ },
+ "outputId": "ca25a328-cf62-4d94-8534-306c1ce63d61"
},
- "outputs": [],
+ "outputs": [
+ {
+ "output_type": "stream",
+ "name": "stdout",
+ "text": [
+ "\u001b[1;32mResuming Training...\u001b[0m\n",
+ "\u001b[1;33mTraining the UNet...\u001b[0m Saving every:110 Steps\n",
+ "\u001b[34m'########:'########:::::'###::::'####:'##::: ##:'####:'##::: ##::'######:::\n",
+ "... ##..:: ##.... ##:::'## ##:::. ##:: ###:: ##:. ##:: ###:: ##:'##... ##::\n",
+ "::: ##:::: ##:::: ##::'##:. ##::: ##:: ####: ##:: ##:: ####: ##: ##:::..:::\n",
+ "::: ##:::: ########::'##:::. ##:: ##:: ## ## ##:: ##:: ## ## ##: ##::'####:\n",
+ "::: ##:::: ##.. ##::: #########:: ##:: ##. ####:: ##:: ##. ####: ##::: ##::\n",
+ "::: ##:::: ##::. ##:: ##.... ##:: ##:: ##:. ###:: ##:: ##:. ###: ##::: ##::\n",
+ "::: ##:::: ##:::. ##: ##:::: ##:'####: ##::. ##:'####: ##::. ##:. ######:::\n",
+ ":::..:::::..:::::..::..:::::..::....::..::::..::....::..::::..:::......::::\n",
+ "\u001b[0m\n",
+ "Progress:| | 0% 9/22000 [00:16<6:20:23, 1.04s/it, loss=0.21, lr=1.8e-6] \u001b[1;32mSAVING CHECKPOINT...\n",
+ "\u001b[1;32mConverting to CKPT ...\n",
+ "\n",
+ "Generating samples 0% 0/6 [00:00<?, ?it/s]\u001b[A/usr/local/lib/python3.8/dist-packages/torch/utils/checkpoint.py:31: UserWarning: None of the inputs have requires_grad=True. Gradients will be None\n",
+ " warnings.warn(\"None of the inputs have requires_grad=True. Gradients will be None\")\n",
+ "\n",
+ "Generating samples 17% 1/6 [00:09<00:45, 9.17s/it]\u001b[A\n",
+ "Generating samples 33% 2/6 [00:17<00:34, 8.71s/it]\u001b[A\n",
+ "Generating samples 50% 3/6 [00:26<00:25, 8.59s/it]\u001b[A\n",
+ "Generating samples 67% 4/6 [00:34<00:17, 8.54s/it]\u001b[A\n",
+ "Generating samples 83% 5/6 [00:42<00:08, 8.52s/it]\u001b[A\n",
+ "Generating samples100% 6/6 [00:51<00:00, 8.60s/it]\n",
+ "[*] samples saved at /content/gdrive/MyDrive/Fast-Dreambooth/Sessions/Sam/Sam_step_10/samples\n",
+ "Done, resuming training ...\u001b[0m\n",
+ "Progress:| | 0% 65/22000 [03:13<5:59:23, 1.02it/s, loss=0.0565, lr=2e-6] \u001b[0;32mSamantha \u001b[0m"
+ ]
+ }
+ ],
"source": [
"#@markdown ---\n",
"#@markdown #Start DreamBooth\n",
@@ -1201,7 +1238,7 @@
},
{
"cell_type": "code",
- "execution_count": 19,
+ "execution_count": null,
"metadata": {
"cellView": "form",
"id": "iAZGngFcI8hq",
From da58acab5ec2206b830b93adac6efd63432b962a Mon Sep 17 00:00:00 2001
From: nawnie <106923464+nawnie@users.noreply.github.com>
Date: Tue, 17 Jan 2023 17:57:03 -0600
Subject: [PATCH 12/15] Delete fast-DreamBooth.ipynb
---
fast-DreamBooth.ipynb | 1786 -----------------------------------------
1 file changed, 1786 deletions(-)
delete mode 100644 fast-DreamBooth.ipynb
diff --git a/fast-DreamBooth.ipynb b/fast-DreamBooth.ipynb
deleted file mode 100644
index 5d65012d..00000000
--- a/fast-DreamBooth.ipynb
+++ /dev/null
@@ -1,1786 +0,0 @@
-{
- "cells": [
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "view-in-github",
- "colab_type": "text"
- },
- "source": [
- "<a href=\"https://colab.research.google.com/github/nawnie/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "qEsNHTtVlbkV"
- },
- "source": [
- "# **fast-DreamBooth colab From https://github.com/TheLastBen/fast-stable-diffusion, if you face any issues, feel free to discuss them.** \n",
- "Keep your notebook updated for best experience. [Support](https://ko-fi.com/thelastben)\n"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "A4Bae3VP6UsE",
- "cellView": "form",
- "outputId": "b1455ef8-9099-4608-bb77-fdacb11b0556",
- "colab": {
- "base_uri": "https://localhost:8080/"
- }
- },
- "outputs": [
- {
- "output_type": "stream",
- "name": "stdout",
- "text": [
- "Mounted at /content/gdrive\n"
- ]
- }
- ],
- "source": [
- "#@title Mount Gdrive\n",
- "\n",
- "from google.colab import drive\n",
- "drive.mount('/content/gdrive')"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "QyvcqeiL65Tj",
- "outputId": "fcc22f05-8582-4bc6-9521-afbaf978646d",
- "colab": {
- "base_uri": "https://localhost:8080/"
- }
- },
- "outputs": [
- {
- "output_type": "stream",
- "name": "stdout",
- "text": [
- "\u001b[1;32mInstalling dependencies...\n",
- "\u001b[1;32mDone, proceed\n"
- ]
- }
- ],
- "source": [
- "#@markdown # Dependencies\n",
- "\n",
- "from IPython.utils import capture\n",
- "import time\n",
- "\n",
- "print('\u001b[1;32mInstalling dependencies...')\n",
- "with capture.capture_output() as cap:\n",
- " %cd /content/\n",
- " !pip install -q accelerate==0.12.0\n",
- " for i in range(1,6):\n",
- " !wget -q \"https://github.com/TheLastBen/fast-stable-diffusion/raw/main/Dependencies/Dependencies.{i}\"\n",
- " !mv \"Dependencies.{i}\" \"Dependencies.7z.00{i}\"\n",
- " !7z x -y Dependencies.7z.001\n",
- " time.sleep(2)\n",
- " %cd /content/usr/local/lib/python3.8/dist-packages\n",
- " !rm -r PIL Pillow.libs Pillow-9.3.0.dist-info\n",
- " !cp -r /content/usr/local/lib/python3.8/dist-packages /usr/local/lib/python3.8/\n",
- " !rm -r /content/usr\n",
- " %cd /content\n",
- " for i in range(1,6):\n",
- " !rm \"Dependencies.7z.00{i}\"\n",
- " !pip uninstall -y diffusers\n",
- " !git clone --branch updt https://github.com/TheLastBen/diffusers\n",
- " !pip install -q /content/diffusers\n",
- " !git clone https://github.com/nawnie/dreamboothtrainers.git\n",
- "print('\u001b[1;32mDone, proceed')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "R3SsbIlxw66N"
- },
- "source": [
- "# Model Download"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "O3KHGKqyeJp9",
- "outputId": "5c38d86f-ef33-4290-f6fd-efb71cf287e3",
- "colab": {
- "base_uri": "https://localhost:8080/"
- }
- },
- "outputs": [
- {
- "output_type": "stream",
- "name": "stdout",
- "text": [
- "\u001b[1;32mDONE !\n"
- ]
- }
- ],
- "source": [
- "import os\n",
- "import time\n",
- "from IPython.display import clear_output\n",
- "import wget\n",
- "\n",
- "#@markdown - Skip this cell if you are loading a previous session that contains a trained model.\n",
- "\n",
- "#@markdown ---\n",
- "\n",
- "Model_Version = \"1.5\" #@param [ \"1.5\", \"V2.1-512px\", \"V2.1-768px\"]\n",
- "\n",
- "#@markdown - Choose which version to finetune.\n",
- "\n",
- "with capture.capture_output() as cap: \n",
- " %cd /content/\n",
- "\n",
- "Huggingface_Token = \"\" #@param {type:\"string\"}\n",
- "token=Huggingface_Token\n",
- "\n",
- "#@markdown - Leave EMPTY if you're using the v2 model.\n",
- "#@markdown - Make sure you've accepted the terms in https://huggingface.co/runwayml/stable-diffusion-v1-5\n",
- "\n",
- "#@markdown ---\n",
- "Custom_Model_Version=\"1.5\" #@param [ \"1.5\", \"V2.1-512px\", \"V2.1-768px\"]\n",
- "#@markdown - Choose wisely!\n",
- "\n",
- "Path_to_HuggingFace= \"\" #@param {type:\"string\"}\n",
- "\n",
- "\n",
- "#@markdown - Load and finetune a model from Hugging Face, must specify if v2, use the format \"profile/model\" like : runwayml/stable-diffusion-v1-5\n",
- "\n",
- "#@markdown Or\n",
- "\n",
- "CKPT_Path = \"/content/gdrive/MyDrive/A_Training_folder/models/Realistic_proto.ckpt\" #@param {type:\"string\"}\n",
- "\n",
- "#@markdown Or\n",
- "\n",
- "CKPT_Link = \"\" #@param {type:\"string\"}\n",
- "\n",
- "#@markdown - A CKPT direct link, huggingface CKPT link or a shared CKPT from gdrive.\n",
- "\n",
- "\n",
- "def downloadmodel():\n",
- " token=Huggingface_Token\n",
- " if token==\"\":\n",
- " token=input(\"Insert your huggingface token :\")\n",
- " if os.path.exists('/content/stable-diffusion-v1-5'):\n",
- " !rm -r /content/stable-diffusion-v1-5\n",
- " clear_output()\n",
- "\n",
- " %cd /content/\n",
- " clear_output()\n",
- " !mkdir /content/stable-diffusion-v1-5\n",
- " %cd /content/stable-diffusion-v1-5\n",
- " !git init\n",
- " !git lfs install --system --skip-repo\n",
- " !git remote add -f origin \"https://USER:{token}@huggingface.co/runwayml/stable-diffusion-v1-5\"\n",
- " !git config core.sparsecheckout true\n",
- " !echo -e \"scheduler\\ntext_encoder\\ntokenizer\\nunet\\nmodel_index.json\" > .git/info/sparse-checkout\n",
- " !git pull origin main\n",
- " if os.path.exists('/content/stable-diffusion-v1-5/unet/diffusion_pytorch_model.bin'):\n",
- " !git clone \"https://USER:{token}@huggingface.co/stabilityai/sd-vae-ft-mse\"\n",
- " !mv /content/stable-diffusion-v1-5/sd-vae-ft-mse /content/stable-diffusion-v1-5/vae\n",
- " !rm -r /content/stable-diffusion-v1-5/.git\n",
- " %cd /content/stable-diffusion-v1-5\n",
- " !rm model_index.json\n",
- " time.sleep(1) \n",
- " wget.download('https://raw.githubusercontent.com/TheLastBen/fast-stable-diffusion/main/Dreambooth/model_index.json')\n",
- " !sed -i 's@\"clip_sample\": false@@g' /content/stable-diffusion-v1-5/scheduler/scheduler_config.json\n",
- " !sed -i 's@\"trained_betas\": null,@\"trained_betas\": null@g' /content/stable-diffusion-v1-5/scheduler/scheduler_config.json\n",
- " !sed -i 's@\"sample_size\": 256,@\"sample_size\": 512,@g' /content/stable-diffusion-v1-5/vae/config.json \n",
- " %cd /content/ \n",
- " clear_output()\n",
- " print('\u001b[1;32mDONE !')\n",
- " else:\n",
- " while not os.path.exists('/content/stable-diffusion-v1-5/unet/diffusion_pytorch_model.bin'):\n",
- " print('\u001b[1;31mMake sure you accepted the terms in https://huggingface.co/runwayml/stable-diffusion-v1-5')\n",
- " time.sleep(5)\n",
- "\n",
- "def newdownloadmodel():\n",
- "\n",
- " %cd /content/\n",
- " clear_output()\n",
- " !mkdir /content/stable-diffusion-v2-768\n",
- " %cd /content/stable-diffusion-v2-768\n",
- " !git init\n",
- " !git lfs install --system --skip-repo\n",
- " !git remote add -f origin \"https://USER:{token}@huggingface.co/stabilityai/stable-diffusion-2-1\"\n",
- " !git config core.sparsecheckout true\n",
- " !echo -e \"scheduler\\ntext_encoder\\ntokenizer\\nunet\\nvae\\nfeature_extractor\\nmodel_index.json\" > .git/info/sparse-checkout\n",
- " !git pull origin main\n",
- " !rm -r /content/stable-diffusion-v2-768/.git\n",
- " clear_output()\n",
- " print('\u001b[1;32mDONE !')\n",
- "\n",
- "\n",
- "def newdownloadmodelb():\n",
- "\n",
- " %cd /content/\n",
- " clear_output()\n",
- " !mkdir /content/stable-diffusion-v2-512\n",
- " %cd /content/stable-diffusion-v2-512\n",
- " !git init\n",
- " !git lfs install --system --skip-repo\n",
- " !git remote add -f origin \"https://USER:{token}@huggingface.co/stabilityai/stable-diffusion-2-1-base\"\n",
- " !git config core.sparsecheckout true\n",
- " !echo -e \"scheduler\\ntext_encoder\\ntokenizer\\nunet\\nvae\\nfeature_extractor\\nmodel_index.json\" > .git/info/sparse-checkout\n",
- " !git pull origin main\n",
- " !rm -r /content/stable-diffusion-v2-512/.git\n",
- " clear_output()\n",
- " print('\u001b[1;32mDONE !')\n",
- " \n",
- "\n",
- "if Path_to_HuggingFace != \"\":\n",
- " if Custom_Model_Version=='V2.1-512px' or Custom_Model_Version=='V2.1-768px':\n",
- " if os.path.exists('/content/stable-diffusion-custom'):\n",
- " !rm -r /content/stable-diffusion-custom\n",
- " clear_output()\n",
- " %cd /content/\n",
- " clear_output()\n",
- " !mkdir /content/stable-diffusion-custom\n",
- " %cd /content/stable-diffusion-custom\n",
- " !git init\n",
- " !git lfs install --system --skip-repo\n",
- " !git remote add -f origin \"https://USER:{token}@huggingface.co/{Path_to_HuggingFace}\"\n",
- " !git config core.sparsecheckout true\n",
- " !echo -e \"scheduler\\ntext_encoder\\ntokenizer\\nunet\\nvae\\nfeature_extractor\\nmodel_index.json\" > .git/info/sparse-checkout\n",
- " !git pull origin main\n",
- " if os.path.exists('/content/stable-diffusion-custom/unet/diffusion_pytorch_model.bin'):\n",
- " !rm -r /content/stable-diffusion-custom/.git\n",
- " %cd /content/ \n",
- " MODEL_NAME=\"/content/stable-diffusion-custom\" \n",
- " clear_output()\n",
- " print('\u001b[1;32mDONE !')\n",
- " else:\n",
- " while not os.path.exists('/content/stable-diffusion-custom/unet/diffusion_pytorch_model.bin'):\n",
- " print('\u001b[1;31mCheck the link you provided')\n",
- " time.sleep(5)\n",
- " else:\n",
- " if os.path.exists('/content/stable-diffusion-custom'):\n",
- " !rm -r /content/stable-diffusion-custom\n",
- " clear_output()\n",
- " %cd /content/\n",
- " clear_output()\n",
- " !mkdir /content/stable-diffusion-custom\n",
- " %cd /content/stable-diffusion-custom\n",
- " !git init\n",
- " !git lfs install --system --skip-repo\n",
- " !git remote add -f origin \"https://USER:{token}@huggingface.co/{Path_to_HuggingFace}\"\n",
- " !git config core.sparsecheckout true\n",
- " !echo -e \"scheduler\\ntext_encoder\\ntokenizer\\nunet\\nmodel_index.json\" > .git/info/sparse-checkout\n",
- " !git pull origin main\n",
- " if os.path.exists('/content/stable-diffusion-custom/unet/diffusion_pytorch_model.bin'):\n",
- " !git clone \"https://USER:{token}@huggingface.co/stabilityai/sd-vae-ft-mse\"\n",
- " !mv /content/stable-diffusion-custom/sd-vae-ft-mse /content/stable-diffusion-custom/vae\n",
- " !rm -r /content/stable-diffusion-custom/.git\n",
- " %cd /content/stable-diffusion-custom\n",
- " !rm model_index.json\n",
- " time.sleep(1)\n",
- " wget.download('https://raw.githubusercontent.com/TheLastBen/fast-stable-diffusion/main/Dreambooth/model_index.json')\n",
- " !sed -i 's@\"clip_sample\": false,@@g' /content/stable-diffusion-custom/scheduler/scheduler_config.json\n",
- " !sed -i 's@\"trained_betas\": null,@\"trained_betas\": null@g' /content/stable-diffusion-custom/scheduler/scheduler_config.json\n",
- " !sed -i 's@\"sample_size\": 256,@\"sample_size\": 512,@g' /content/stable-diffusion-custom/vae/config.json \n",
- " %cd /content/ \n",
- " MODEL_NAME=\"/content/stable-diffusion-custom\" \n",
- " clear_output()\n",
- " print('\u001b[1;32mDONE !')\n",
- " else:\n",
- " while not os.path.exists('/content/stable-diffusion-custom/unet/diffusion_pytorch_model.bin'):\n",
- " print('\u001b[1;31mCheck the link you provided')\n",
- " time.sleep(5) \n",
- "\n",
- "elif CKPT_Path !=\"\":\n",
- " %cd /content\n",
- " clear_output() \n",
- " if os.path.exists(str(CKPT_Path)):\n",
- " if Custom_Model_Version=='1.5':\n",
- " !wget -O refmdlz https://github.com/TheLastBen/fast-stable-diffusion/raw/main/Dreambooth/refmdlz\n",
- " !unzip -o -q refmdlz\n",
- " !rm -f refmdlz \n",
- " !wget -O convertodiff.py https://raw.githubusercontent.com/TheLastBen/fast-stable-diffusion/main/Dreambooth/convertodiffv1.py\n",
- " clear_output()\n",
- " !python /content/convertodiff.py \"$CKPT_Path\" /content/stable-diffusion-custom --v1\n",
- " !rm -r /content/refmdl\n",
- " elif Custom_Model_Version=='V2.1-512px':\n",
- " !wget -O convertodiff.py https://raw.githubusercontent.com/TheLastBen/fast-stable-diffusion/main/Dreambooth/convertodiffv2.py\n",
- " clear_output()\n",
- " !python /content/convertodiff.py \"$CKPT_Path\" /content/stable-diffusion-custom --v2 --reference_model stabilityai/stable-diffusion-2-1-base\n",
- " elif Custom_Model_Version=='V2.1-768px':\n",
- " !wget -O convertodiff.py https://raw.githubusercontent.com/TheLastBen/fast-stable-diffusion/main/Dreambooth/convertodiffv2.py\n",
- " clear_output()\n",
- " !python /content/convertodiff.py \"$CKPT_Path\" /content/stable-diffusion-custom --v2 --reference_model stabilityai/stable-diffusion-2-1\n",
- " !rm /content/convertodiff.py\n",
- " if os.path.exists('/content/stable-diffusion-custom/unet/diffusion_pytorch_model.bin'):\n",
- " clear_output()\n",
- " MODEL_NAME=\"/content/stable-diffusion-custom\"\n",
- " print('\u001b[1;32mDONE !')\n",
- " else:\n",
- " !rm -r /content/stable-diffusion-custom\n",
- " while not os.path.exists('/content/stable-diffusion-custom/unet/diffusion_pytorch_model.bin'):\n",
- " print('\u001b[1;31mConversion error')\n",
- " time.sleep(5)\n",
- " else:\n",
- " while not os.path.exists(str(CKPT_Path)):\n",
- " print('\u001b[1;31mWrong path, use the colab file explorer to copy the path')\n",
- " time.sleep(5) \n",
- "\n",
- "elif CKPT_Link !=\"\": \n",
- " %cd /content\n",
- " clear_output() \n",
- " !gdown --fuzzy -O model.ckpt $CKPT_Link\n",
- " clear_output() \n",
- " if os.path.exists('/content/model.ckpt'):\n",
- " if os.path.getsize(\"/content/model.ckpt\") > 1810671599:\n",
- " if Custom_Model_Version=='1.5':\n",
- " !wget -O refmdlz https://github.com/TheLastBen/fast-stable-diffusion/raw/main/Dreambooth/refmdlz\n",
- " !unzip -o -q refmdlz\n",
- " !rm -f refmdlz \n",
- " !wget -O convertodiff.py https://raw.githubusercontent.com/TheLastBen/fast-stable-diffusion/main/Dreambooth/convertodiffv1.py\n",
- " clear_output()\n",
- " !python /content/convertodiff.py /content/model.ckpt /content/stable-diffusion-custom --v1\n",
- " !rm -r /content/refmdl\n",
- " elif Custom_Model_Version=='V2.1-512px':\n",
- " !wget -O convertodiff.py https://raw.githubusercontent.com/TheLastBen/fast-stable-diffusion/main/Dreambooth/convertodiffv2.py\n",
- " clear_output()\n",
- " !python /content/convertodiff.py /content/model.ckpt /content/stable-diffusion-custom --v2 --reference_model stabilityai/stable-diffusion-2-1-base\n",
- " elif Custom_Model_Version=='V2.1-768px':\n",
- " !wget -O convertodiff.py https://raw.githubusercontent.com/TheLastBen/fast-stable-diffusion/main/Dreambooth/convertodiffv2.py\n",
- " clear_output()\n",
- " !python /content/convertodiff.py /content/model.ckpt /content/stable-diffusion-custom --v2 --reference_model stabilityai/stable-diffusion-2-1\n",
- " !rm /content/convertodiff.py\n",
- " if os.path.exists('/content/stable-diffusion-custom/unet/diffusion_pytorch_model.bin'):\n",
- " clear_output()\n",
- " MODEL_NAME=\"/content/stable-diffusion-custom\"\n",
- " print('\u001b[1;32mDONE !')\n",
- " else:\n",
- " !rm -r /content/stable-diffusion-custom\n",
- " !rm /content/model.ckpt\n",
- " while not os.path.exists('/content/stable-diffusion-custom/unet/diffusion_pytorch_model.bin'):\n",
- " print('\u001b[1;31mConversion error')\n",
- " time.sleep(5)\n",
- " else:\n",
- " while os.path.getsize('/content/model.ckpt') < 1810671599:\n",
- " print('\u001b[1;31mWrong link, check that the link is valid')\n",
- " time.sleep(5)\n",
- " \n",
- "else:\n",
- " if Model_Version==\"1.5\":\n",
- " if not os.path.exists('/content/stable-diffusion-v1-5'):\n",
- " downloadmodel()\n",
- " MODEL_NAME=\"/content/stable-diffusion-v1-5\"\n",
- " else:\n",
- " MODEL_NAME=\"/content/stable-diffusion-v1-5\"\n",
- " print(\"\u001b[1;32mThe v1.5 model already exists, using this model.\")\n",
- " elif Model_Version==\"V2.1-512px\":\n",
- " if not os.path.exists('/content/stable-diffusion-v2-512'):\n",
- " newdownloadmodelb()\n",
- " MODEL_NAME=\"/content/stable-diffusion-v2-512\"\n",
- " else:\n",
- " MODEL_NAME=\"/content/stable-diffusion-v2-512\"\n",
- " print(\"\u001b[1;32mThe v2-512px model already exists, using this model.\") \n",
- " elif Model_Version==\"V2.1-768px\":\n",
- " if not os.path.exists('/content/stable-diffusion-v2-768'): \n",
- " newdownloadmodel()\n",
- " MODEL_NAME=\"/content/stable-diffusion-v2-768\"\n",
- " else:\n",
- " MODEL_NAME=\"/content/stable-diffusion-v2-768\"\n",
- " print(\"\u001b[1;32mThe v2-768px model already exists, using this model.\") "
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "0tN76Cj5P3RL"
- },
- "source": [
- "# Dreambooth"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "A1B299g-_VJo",
- "outputId": "127c8398-c153-4f3f-e3d7-33096151d8e9",
- "colab": {
- "base_uri": "https://localhost:8080/"
- }
- },
- "outputs": [
- {
- "output_type": "stream",
- "name": "stdout",
- "text": [
- "\u001b[1;32mSession found, loading the trained model ...\n",
- "\u001b[1;32mConverting to Diffusers ...\n"
- ]
- }
- ],
- "source": [
- "import os\n",
- "from IPython.display import clear_output\n",
- "from IPython.utils import capture\n",
- "from os import listdir\n",
- "from os.path import isfile\n",
- "import wget\n",
- "import time\n",
- "\n",
- "#@markdown #Create/Load a Session\n",
- "\n",
- "try:\n",
- " MODEL_NAME\n",
- " pass\n",
- "except:\n",
- " MODEL_NAME=\"\"\n",
- " \n",
- "PT=\"\"\n",
- "\n",
- "Session_Name = \"MatPat\" #@param{type: 'string'}\n",
- "while Session_Name==\"\":\n",
- " print('\u001b[1;31mInput the Session Name:') \n",
- " Session_Name=input('')\n",
- "Session_Name=Session_Name.replace(\" \",\"_\")\n",
- "\n",
- "#@markdown - Enter the session name, it if it exists, it will load it, otherwise it'll create an new session.\n",
- "\n",
- "Session_Link_optional = \"\" #@param{type: 'string'}\n",
- "\n",
- "#@markdown - Import a session from another gdrive, the shared gdrive link must point to the specific session's folder that contains the trained CKPT, remove any intermediary CKPT if any.\n",
- "\n",
- "WORKSPACE='/content/gdrive/MyDrive/Fast-Dreambooth'\n",
- "\n",
- "if Session_Link_optional !=\"\":\n",
- " print('\u001b[1;32mDownloading session...')\n",
- "with capture.capture_output() as cap:\n",
- " %cd /content\n",
- " if Session_Link_optional != \"\":\n",
- " if not os.path.exists(str(WORKSPACE+'/Sessions')):\n",
- " %mkdir -p $WORKSPACE'/Sessions'\n",
- " time.sleep(1)\n",
- " %cd $WORKSPACE'/Sessions'\n",
- " !gdown --folder --remaining-ok -O $Session_Name $Session_Link_optional\n",
- " %cd $Session_Name\n",
- " !rm -r instance_images\n",
- " !unzip instance_images.zip\n",
- " !rm -r concept_images\n",
- " !unzip concept_images.zip \n",
- " %cd /content\n",
- "\n",
- "\n",
- "INSTANCE_NAME=Session_Name\n",
- "OUTPUT_DIR=\"/content/models/\"+Session_Name\n",
- "SESSION_DIR=WORKSPACE+'/Sessions/'+Session_Name\n",
- "INSTANCE_DIR=SESSION_DIR+'/instance_images'\n",
- "CONCEPT_DIR=SESSION_DIR+'/concept_images'\n",
- "MDLPTH=str(SESSION_DIR+\"/\"+Session_Name+'.ckpt')\n",
- "\n",
- "Model_Version = \"1.5\" #@param [ \"1.5\", \"V2.1-512px\", \"V2.1-768px\"]\n",
- "#@markdown - Ignore this if you're not loading a previous session that contains a trained model\n",
- "\n",
- "\n",
- "if os.path.exists(str(SESSION_DIR)):\n",
- " mdls=[ckpt for ckpt in listdir(SESSION_DIR) if ckpt.split(\".\")[-1]==\"ckpt\"]\n",
- " if not os.path.exists(MDLPTH) and '.ckpt' in str(mdls): \n",
- " \n",
- " def f(n): \n",
- " k=0\n",
- " for i in mdls: \n",
- " if k==n: \n",
- " !mv \"$SESSION_DIR/$i\" $MDLPTH\n",
- " k=k+1\n",
- "\n",
- " k=0\n",
- " print('\u001b[1;33mNo final checkpoint model found, select which intermediary checkpoint to use, enter only the number, (000 to skip):\\n\u001b[1;34m')\n",
- "\n",
- " for i in mdls: \n",
- " print(str(k)+'- '+i)\n",
- " k=k+1\n",
- " n=input()\n",
- " while int(n)>k-1:\n",
- " n=input() \n",
- " if n!=\"000\":\n",
- " f(int(n))\n",
- " print('\u001b[1;32mUsing the model '+ mdls[int(n)]+\" ...\")\n",
- " time.sleep(2)\n",
- " else:\n",
- " print('\u001b[1;32mSkipping the intermediary checkpoints.')\n",
- " del n\n",
- "\n",
- " \n",
- "if os.path.exists(str(SESSION_DIR)) and not os.path.exists(MDLPTH):\n",
- " print('\u001b[1;32mLoading session with no previous model, using the original model or the custom downloaded model')\n",
- " if MODEL_NAME==\"\":\n",
- " print('\u001b[1;31mNo model found, use the \"Model Download\" cell to download a model.')\n",
- " else:\n",
- " print('\u001b[1;32mSession Loaded, proceed to uploading instance images')\n",
- "\n",
- "elif os.path.exists(MDLPTH):\n",
- " print('\u001b[1;32mSession found, loading the trained model ...')\n",
- " if Model_Version=='1.5':\n",
- " !wget -O refmdlz https://github.com/TheLastBen/fast-stable-diffusion/raw/main/Dreambooth/refmdlz\n",
- " !unzip -o -q refmdlz\n",
- " !rm -f refmdlz \n",
- " !wget -O convertodiff.py https://raw.githubusercontent.com/TheLastBen/fast-stable-diffusion/main/Dreambooth/convertodiffv1.py\n",
- " clear_output()\n",
- " print('\u001b[1;32mSession found, loading the trained model ...')\n",
- " !python /content/convertodiff.py \"$MDLPTH\" \"$OUTPUT_DIR\" --v1\n",
- " !rm -r /content/refmdl\n",
- " elif Model_Version=='V2.1-512px':\n",
- " !wget -O convertodiff.py https://raw.githubusercontent.com/TheLastBen/fast-stable-diffusion/main/Dreambooth/convertodiffv2.py\n",
- " clear_output()\n",
- " print('\u001b[1;32mSession found, loading the trained model ...')\n",
- " !python /content/convertodiff.py \"$MDLPTH\" \"$OUTPUT_DIR\" --v2 --reference_model stabilityai/stable-diffusion-2-1-base\n",
- " elif Model_Version=='V2.1-768px':\n",
- " !wget -O convertodiff.py https://raw.githubusercontent.com/TheLastBen/fast-stable-diffusion/main/Dreambooth/convertodiffv2.py\n",
- " clear_output()\n",
- " print('\u001b[1;32mSession found, loading the trained model ...')\n",
- " !python /content/convertodiff.py \"$MDLPTH\" \"$OUTPUT_DIR\" --v2 --reference_model stabilityai/stable-diffusion-2-1\n",
- " !rm /content/convertodiff.py \n",
- " if os.path.exists(OUTPUT_DIR+'/unet/diffusion_pytorch_model.bin'):\n",
- " resume=True \n",
- " clear_output()\n",
- " print('\u001b[1;32mSession loaded.')\n",
- " else: \n",
- " if not os.path.exists(OUTPUT_DIR+'/unet/diffusion_pytorch_model.bin'):\n",
- " print('\u001b[1;31mConversion error, if the error persists, remove the CKPT file from the current session folder')\n",
- "\n",
- "elif not os.path.exists(str(SESSION_DIR)):\n",
- " %mkdir -p \"$INSTANCE_DIR\"\n",
- " print('\u001b[1;32mCreating session...')\n",
- " if MODEL_NAME==\"\":\n",
- " print('\u001b[1;31mNo model found, use the \"Model Download\" cell to download a model.')\n",
- " else:\n",
- " print('\u001b[1;32mSession created, proceed to uploading instance images')\n",
- "\n",
- " #@markdown \n",
- "\n",
- " #@markdown # The most importent step is to rename the instance pictures of each subject to a unique unknown identifier, example :\n",
- " #@markdown - If you have 30 pictures of yourself, simply select them all and rename only one to the chosen identifier for example : phtmejhn, the files would be : phtmejhn (1).jpg, phtmejhn (2).png ....etc then upload them, do the same for other people or objects with a different identifier, and that's it.\n",
- " #@markdown - Check out this example : https://i.imgur.com/d2lD3rz.jpeg"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "LC4ukG60fgMy",
- "outputId": "257aa11d-cf10-44bf-d1c0-04285878bb21",
- "colab": {
- "base_uri": "https://localhost:8080/"
- }
- },
- "outputs": [
- {
- "output_type": "stream",
- "name": "stderr",
- "text": [
- " |███████████████| 9/9 Uploaded\n"
- ]
- },
- {
- "output_type": "stream",
- "name": "stdout",
- "text": [
- "\n",
- "\u001b[1;32mDone, proceed to the next cell\n"
- ]
- }
- ],
- "source": [
- "import shutil\n",
- "from google.colab import files\n",
- "from PIL import Image\n",
- "from tqdm import tqdm\n",
- "\n",
- "#@markdown #Instance Images\n",
- "#@markdown ----\n",
- "\n",
- "#@markdown\n",
- "#@markdown - Run the cell to upload the instance pictures.\n",
- "\n",
- "Remove_existing_instance_images= True #@param{type: 'boolean'}\n",
- "#@markdown - Uncheck the box to keep the existing instance images.\n",
- "\n",
- "\n",
- "if Remove_existing_instance_images:\n",
- " if os.path.exists(str(INSTANCE_DIR)):\n",
- " !rm -r \"$INSTANCE_DIR\"\n",
- "\n",
- "if not os.path.exists(str(INSTANCE_DIR)):\n",
- " %mkdir -p \"$INSTANCE_DIR\"\n",
- "\n",
- "IMAGES_FOLDER_OPTIONAL=\"/content/gdrive/MyDrive/A_Training_folder/Cali\" #@param{type: 'string'}\n",
- "\n",
- "if os.path.exists(IMAGES_FOLDER_OPTIONAL+\"/.ipynb_checkpoints\"):\n",
- " %rm -r $IMAGES_FOLDER_OPTIONAL\"/.ipynb_checkpoints\"\n",
- "if os.path.exists(IMAGES_FOLDER_OPTIONAL+\"/Desktop.ini\"):\n",
- " %rm -r $IMAGES_FOLDER_OPTIONAL\"/Desktop.ini\"\n",
- "\n",
- "#@markdown - If you prefer to specify directly the folder of the pictures instead of uploading, this will add the pictures to the existing (if any) instance images. Leave EMPTY to upload.\n",
- "\n",
- "Crop_images= False #@param{type: 'boolean'}\n",
- "Crop_size = \"576\" #@param [\"512\", \"576\", \"640\", \"704\", \"768\", \"832\", \"896\", \"960\", \"1024\"]\n",
- "Crop_size=int(Crop_size)\n",
- "\n",
- "#@markdown - Unless you want to crop them manually in a precise way, you don't need to crop your instance images externally.\n",
- "\n",
- "while IMAGES_FOLDER_OPTIONAL !=\"\" and not os.path.exists(str(IMAGES_FOLDER_OPTIONAL)):\n",
- " print('\u001b[1;31mThe image folder specified does not exist, use the colab file explorer to copy the path :')\n",
- " IMAGES_FOLDER_OPTIONAL=input('')\n",
- "\n",
- "if IMAGES_FOLDER_OPTIONAL!=\"\":\n",
- " if Crop_images:\n",
- " for filename in tqdm(os.listdir(IMAGES_FOLDER_OPTIONAL), bar_format=' |{bar:15}| {n_fmt}/{total_fmt} Uploaded'):\n",
- " extension = filename.split(\".\")[-1]\n",
- " identifier=filename.split(\".\")[0]\n",
- " new_path_with_file = os.path.join(INSTANCE_DIR, filename)\n",
- " file = Image.open(IMAGES_FOLDER_OPTIONAL+\"/\"+filename)\n",
- " width, height = file.size\n",
- " if file.size !=(Crop_size, Crop_size): \n",
- " side_length = min(width, height)\n",
- " left = (width - side_length)/2\n",
- " top = (height - side_length)/2\n",
- " right = (width + side_length)/2\n",
- " bottom = (height + side_length)/2\n",
- " image = file.crop((left, top, right, bottom))\n",
- " image = image.resize((Crop_size, Crop_size))\n",
- " if (extension.upper() == \"JPG\"):\n",
- " image.save(new_path_with_file, format=\"JPEG\", quality = 100)\n",
- " else:\n",
- " image.save(new_path_with_file, format=extension.upper())\n",
- " else:\n",
- " !cp \"$IMAGES_FOLDER_OPTIONAL/$filename\" \"$INSTANCE_DIR\"\n",
- "\n",
- " else:\n",
- " for filename in tqdm(os.listdir(IMAGES_FOLDER_OPTIONAL), bar_format=' |{bar:15}| {n_fmt}/{total_fmt} Uploaded'):\n",
- " %cp -r \"$IMAGES_FOLDER_OPTIONAL/$filename\" \"$INSTANCE_DIR\"\n",
- " \n",
- " print('\\n\u001b[1;32mDone, proceed to the next cell')\n",
- "\n",
- "\n",
- "elif IMAGES_FOLDER_OPTIONAL ==\"\":\n",
- " uploaded = files.upload()\n",
- " if Crop_images:\n",
- " for filename in tqdm(uploaded.keys(), bar_format=' |{bar:15}| {n_fmt}/{total_fmt} Uploaded'):\n",
- " shutil.move(filename, INSTANCE_DIR)\n",
- " extension = filename.split(\".\")[-1]\n",
- " identifier=filename.split(\".\")[0]\n",
- " new_path_with_file = os.path.join(INSTANCE_DIR, filename)\n",
- " file = Image.open(new_path_with_file)\n",
- " width, height = file.size\n",
- " if file.size !=(Crop_size, Crop_size): \n",
- " side_length = min(width, height)\n",
- " left = (width - side_length)/2\n",
- " top = (height - side_length)/2\n",
- " right = (width + side_length)/2\n",
- " bottom = (height + side_length)/2\n",
- " image = file.crop((left, top, right, bottom))\n",
- " image = image.resize((Crop_size, Crop_size))\n",
- " if (extension.upper() == \"JPG\"):\n",
- " image.save(new_path_with_file, format=\"JPEG\", quality = 100)\n",
- " else:\n",
- " image.save(new_path_with_file, format=extension.upper())\n",
- " clear_output()\n",
- " else:\n",
- " for filename in tqdm(uploaded.keys(), bar_format=' |{bar:15}| {n_fmt}/{total_fmt} Uploaded'):\n",
- " shutil.move(filename, INSTANCE_DIR)\n",
- " clear_output()\n",
- "\n",
- " print('\\n\u001b[1;32mDone, proceed to the next cell')\n",
- "\n",
- "with capture.capture_output() as cap:\n",
- " %cd \"$INSTANCE_DIR\"\n",
- " !find . -name \"* *\" -type f | rename 's/ /_/g' \n",
- "\n",
- " %cd $SESSION_DIR\n",
- " !rm instance_images.zip\n",
- " !zip -r instance_images instance_images\n",
- " %cd /content"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "LxEv3u8mQos3",
- "cellView": "form",
- "outputId": "25b51b7a-e0c3-489a-8c3b-bcafbd9d81f2",
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 1000
- }
- },
- "outputs": [
- {
- "output_type": "stream",
- "name": "stderr",
- "text": [
- " |███████████████| 98/98 Uploaded\n"
- ]
- },
- {
- "output_type": "stream",
- "name": "stdout",
- "text": [
- "\n",
- "\u001b[1;32mAlmost done...\n",
- "\n",
- "\u001b[1;32mDone, proceed to the training cell\n"
- ]
- }
- ],
- "source": [
- "import shutil\n",
- "from google.colab import files\n",
- "from PIL import Image\n",
- "from tqdm import tqdm\n",
- "\n",
- "#@markdown #Concept Images (Regularization)\n",
- "#@markdown ----\n",
- "\n",
- "#@markdown\n",
- "#@markdown - Run this `optional` cell to upload concept pictures. If you're traning on a specific face, skip this cell.\n",
- "#@markdown - Training a model on a restricted number of instance images tends to indoctrinate it and limit its imagination, so concept images help re-opening its \"mind\" to diversity and greatly widen the range of possibilities of the output, concept images should contain anything related to the instance pictures, including objects, ideas, scenes, phenomenons, concepts (obviously), don't be afraid to slightly diverge from the trained style.\n",
- "\n",
- "Remove_existing_concept_images= False #@param{type: 'boolean'}\n",
- "#@markdown - Uncheck the box to keep the existing concept images.\n",
- "\n",
- "\n",
- "if Remove_existing_concept_images:\n",
- " if os.path.exists(str(CONCEPT_DIR)):\n",
- " !rm -r \"$CONCEPT_DIR\"\n",
- "\n",
- "\n",
- "if not os.path.exists(str(CONCEPT_DIR)):\n",
- " %mkdir -p \"$CONCEPT_DIR\"\n",
- "\n",
- "IMAGES_FOLDER_OPTIONAL=\"/content/gdrive/MyDrive/A_Training_folder/woman2\" #@param{type: 'string'}\n",
- "if os.path.exists(IMAGES_FOLDER_OPTIONAL+\"/.ipynb_checkpoints\"):\n",
- " %rm -r $IMAGES_FOLDER_OPTIONAL\"/.ipynb_checkpoints\"\n",
- "if os.path.exists(IMAGES_FOLDER_OPTIONAL+\"/Desktop.ini\"):\n",
- " %rm -r $IMAGES_FOLDER_OPTIONAL\"/Desktop.ini\"\n",
- "#@markdown - If you prefer to specify directly the folder of the pictures instead of uploading, this will add the pictures to the existing (if any) concept images. Leave EMPTY to upload.\n",
- "\n",
- "Crop_images= True \n",
- "Crop_size = \"512\"\n",
- "Crop_size=int(Crop_size)\n",
- "\n",
- "while IMAGES_FOLDER_OPTIONAL !=\"\" and not os.path.exists(str(IMAGES_FOLDER_OPTIONAL)):\n",
- " print('\u001b[1;31mThe image folder specified does not exist, use the colab file explorer to copy the path :')\n",
- " IMAGES_FOLDER_OPTIONAL=input('')\n",
- "\n",
- "if IMAGES_FOLDER_OPTIONAL!=\"\":\n",
- " if Crop_images:\n",
- " for filename in tqdm(os.listdir(IMAGES_FOLDER_OPTIONAL), bar_format=' |{bar:15}| {n_fmt}/{total_fmt} Uploaded'):\n",
- " extension = filename.split(\".\")[-1]\n",
- " identifier=filename.split(\".\")[0]\n",
- " new_path_with_file = os.path.join(CONCEPT_DIR, filename)\n",
- " file = Image.open(IMAGES_FOLDER_OPTIONAL+\"/\"+filename)\n",
- " width, height = file.size\n",
- " if file.size !=(Crop_size, Crop_size): \n",
- " side_length = min(width, height)\n",
- " left = (width - side_length)/2\n",
- " top = (height - side_length)/2\n",
- " right = (width + side_length)/2\n",
- " bottom = (height + side_length)/2\n",
- " image = file.crop((left, top, right, bottom))\n",
- " image = image.resize((Crop_size, Crop_size))\n",
- " if (extension.upper() == \"JPG\"):\n",
- " image.save(new_path_with_file, format=\"JPEG\", quality = 100)\n",
- " else:\n",
- " image.save(new_path_with_file, format=extension.upper())\n",
- " else:\n",
- " !cp \"$IMAGES_FOLDER_OPTIONAL/$filename\" \"$CONCEPT_DIR\"\n",
- "\n",
- " else:\n",
- " for filename in tqdm(os.listdir(IMAGES_FOLDER_OPTIONAL), bar_format=' |{bar:15}| {n_fmt}/{total_fmt} Uploaded'):\n",
- " %cp -r \"$IMAGES_FOLDER_OPTIONAL/$filename\" \"$CONCEPT_DIR\"\n",
- " \n",
- "elif IMAGES_FOLDER_OPTIONAL ==\"\":\n",
- " uploaded = files.upload()\n",
- " if Crop_images:\n",
- " for filename in tqdm(uploaded.keys(), bar_format=' |{bar:15}| {n_fmt}/{total_fmt} Uploaded'):\n",
- " shutil.move(filename, CONCEPT_DIR)\n",
- " extension = filename.split(\".\")[-1]\n",
- " identifier=filename.split(\".\")[0]\n",
- " new_path_with_file = os.path.join(CONCEPT_DIR, filename)\n",
- " file = Image.open(new_path_with_file)\n",
- " width, height = file.size\n",
- " if file.size !=(Crop_size, Crop_size): \n",
- " side_length = min(width, height)\n",
- " left = (width - side_length)/2\n",
- " top = (height - side_length)/2\n",
- " right = (width + side_length)/2\n",
- " bottom = (height + side_length)/2\n",
- " image = file.crop((left, top, right, bottom))\n",
- " image = image.resize((Crop_size, Crop_size))\n",
- " if (extension.upper() == \"JPG\"):\n",
- " image.save(new_path_with_file, format=\"JPEG\", quality = 100)\n",
- " else:\n",
- " image.save(new_path_with_file, format=extension.upper())\n",
- " clear_output()\n",
- " else:\n",
- " for filename in tqdm(uploaded.keys(), bar_format=' |{bar:15}| {n_fmt}/{total_fmt} Uploaded'):\n",
- " shutil.move(filename, CONCEPT_DIR)\n",
- " clear_output()\n",
- "\n",
- " \n",
- "print('\\n\u001b[1;32mAlmost done...')\n",
- "with capture.capture_output() as cap: \n",
- " i=0\n",
- " for filename in os.listdir(CONCEPT_DIR):\n",
- " extension = filename.split(\".\")[-1]\n",
- " identifier=filename.split(\".\")[0]\n",
- " new_path_with_file = os.path.join(CONCEPT_DIR, \"conceptimagedb\"+str(i)+\".\"+extension)\n",
- " filepath=os.path.join(CONCEPT_DIR,filename)\n",
- " !mv \"$filepath\" $new_path_with_file\n",
- " i=i+1\n",
- "\n",
- " %cd $SESSION_DIR\n",
- " !rm concept_images.zip\n",
- " !zip -r concept_images concept_images\n",
- " %cd /content\n",
- "\n",
- "print('\\n\u001b[1;32mDone, proceed to the training cell')"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "ZnmQYfZilzY6"
- },
- "source": [
- "# Training"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "id": "1-9QbkfAVYYU",
- "cellView": "form",
- "colab": {
- "base_uri": "https://localhost:8080/"
- },
- "outputId": "ca25a328-cf62-4d94-8534-306c1ce63d61"
- },
- "outputs": [
- {
- "output_type": "stream",
- "name": "stdout",
- "text": [
- "\u001b[1;32mResuming Training...\u001b[0m\n",
- "\u001b[1;33mTraining the UNet...\u001b[0m Saving every:110 Steps\n",
- "\u001b[34m'########:'########:::::'###::::'####:'##::: ##:'####:'##::: ##::'######:::\n",
- "... ##..:: ##.... ##:::'## ##:::. ##:: ###:: ##:. ##:: ###:: ##:'##... ##::\n",
- "::: ##:::: ##:::: ##::'##:. ##::: ##:: ####: ##:: ##:: ####: ##: ##:::..:::\n",
- "::: ##:::: ########::'##:::. ##:: ##:: ## ## ##:: ##:: ## ## ##: ##::'####:\n",
- "::: ##:::: ##.. ##::: #########:: ##:: ##. ####:: ##:: ##. ####: ##::: ##::\n",
- "::: ##:::: ##::. ##:: ##.... ##:: ##:: ##:. ###:: ##:: ##:. ###: ##::: ##::\n",
- "::: ##:::: ##:::. ##: ##:::: ##:'####: ##::. ##:'####: ##::. ##:. ######:::\n",
- ":::..:::::..:::::..::..:::::..::....::..::::..::....::..::::..:::......::::\n",
- "\u001b[0m\n",
- "Progress:| | 0% 9/22000 [00:16<6:20:23, 1.04s/it, loss=0.21, lr=1.8e-6] \u001b[1;32mSAVING CHECKPOINT...\n",
- "\u001b[1;32mConverting to CKPT ...\n",
- "\n",
- "Generating samples 0% 0/6 [00:00<?, ?it/s]\u001b[A/usr/local/lib/python3.8/dist-packages/torch/utils/checkpoint.py:31: UserWarning: None of the inputs have requires_grad=True. Gradients will be None\n",
- " warnings.warn(\"None of the inputs have requires_grad=True. Gradients will be None\")\n",
- "\n",
- "Generating samples 17% 1/6 [00:09<00:45, 9.17s/it]\u001b[A\n",
- "Generating samples 33% 2/6 [00:17<00:34, 8.71s/it]\u001b[A\n",
- "Generating samples 50% 3/6 [00:26<00:25, 8.59s/it]\u001b[A\n",
- "Generating samples 67% 4/6 [00:34<00:17, 8.54s/it]\u001b[A\n",
- "Generating samples 83% 5/6 [00:42<00:08, 8.52s/it]\u001b[A\n",
- "Generating samples100% 6/6 [00:51<00:00, 8.60s/it]\n",
- "[*] samples saved at /content/gdrive/MyDrive/Fast-Dreambooth/Sessions/Sam/Sam_step_10/samples\n",
- "Done, resuming training ...\u001b[0m\n",
- "Progress:| | 0% 65/22000 [03:13<5:59:23, 1.02it/s, loss=0.0565, lr=2e-6] \u001b[0;32mSamantha \u001b[0m"
- ]
- }
- ],
- "source": [
- "#@markdown ---\n",
- "#@markdown #Start DreamBooth\n",
- "#@markdown ---\n",
- "import os\n",
- "from subprocess import getoutput\n",
- "from IPython.display import clear_output\n",
- "from google.colab import runtime\n",
- "import time\n",
- "import random\n",
- "\n",
- "# Determine number of images in the Instance folder\n",
- "Img_Count = (len([entry for entry in os.listdir(INSTANCE_DIR) if os.path.isfile(os.path.join(INSTANCE_DIR, entry))]))\n",
- "\n",
- "if os.path.exists(INSTANCE_DIR+\"/.ipynb_checkpoints\"):\n",
- " %rm -r $INSTANCE_DIR\"/.ipynb_checkpoints\"\n",
- "\n",
- "if os.path.exists(CONCEPT_DIR+\"/.ipynb_checkpoints\"):\n",
- " %rm -r $CONCEPT_DIR\"/.ipynb_checkpoints\" \n",
- "\n",
- "Resume_Training = False #@param {type:\"boolean\"}\n",
- "# user input request if a prior training has been started\n",
- "# but resume is not selected\n",
- "try:\n",
- " resume\n",
- " if resume and not Resume_Training:\n",
- " print('\u001b[1;31mOverwrite your previously trained model ?, answering \"yes\" will train a new model, answering \"no\" will resume the training of the previous model? yes or no ?\u001b[0m')\n",
- " while True:\n",
- " ansres=input('')\n",
- " if ansres=='no':\n",
- " Resume_Training = True\n",
- " del ansres\n",
- " break\n",
- " elif ansres=='yes':\n",
- " Resume_Training = False\n",
- " resume= False\n",
- " break\n",
- "except:\n",
- " pass\n",
- "\n",
- "while not Resume_Training and MODEL_NAME==\"\":\n",
- " print('\u001b[1;31mNo model found, use the \"Model Download\" cell to download a model.')\n",
- " time.sleep(5)\n",
- "\n",
- "#@markdown - If you're not satisfied with the result, check this box, run again the cell and it will continue training the current model.\n",
- "\n",
- "\n",
- "\n",
- "# declare Unet training Vaiables\n",
- "\n",
- "MODELT_NAME=MODEL_NAME\n",
- "Repeats=50 #@param{type:\"number\"}\n",
- "warmup_steps=0 #@param{type:\"number\"}\n",
- "wu=warmup_steps\n",
- "batch_size=4 #@param{type:\"number\"}\n",
- "bs=batch_size\n",
- "gradient_steps=2 #@param{type:\"number\"}\n",
- "gs=gradient_steps\n",
- "UNet_Training_Steps=((Repeats*Img_Count)/(gs*bs))\n",
- "UNet_Learning_Rate = 2e-6 #@param [\"2e-6\", \"1e-6\", \"1e-5\", \"1e-4\", \"5e-7\"] {type:\"raw\", allow-input: true}\n",
- "\n",
- "#@markdown * 1e-7 is lowest, 1e-4 is the highest, 2e-7 is twice as fast as 1e-7 experiment and adjust the repeats to accomidate diffrent learning rates \n",
- "\n",
- "lr_schedule = \"polynomial\" #@param [\"polynomial\", \"constant\"] {allow-input: true}\n",
- "untlr=UNet_Learning_Rate\n",
- "UNet_Training_Steps=int(UNet_Training_Steps+wu)\n",
- "\n",
- "#@markdown - These default settings are for a dataset of 10 pictures which is enough for training a face, start with 650 or lower, test the model, if not enough, resume training for 150 steps, keep testing until you get the desired output, `set it to 0 to train only the text_encoder`. \n",
- "\n",
- "Text_Encoder_Training_steps=0 #@param{type: 'number'}\n",
- "#@markdown - 200-450 steps is enough for a small dataset, keep this number small to avoid overfitting, set to 0 to disable, `set it to 0 before resuming training if it is already trained`.\n",
- "\n",
- "# declare text batch size\n",
- "Text_Batch_Size = 7 #@param {type:\"integer\"}\n",
- "tbs=Text_Batch_Size\n",
- "\n",
- "Text_Encoder_Concept_Training_steps=0 #@param{type: 'number'}\n",
- "# adjust text steps for batch size\n",
- "Text_Encoder_Concept_Training_Steps=(Text_Encoder_Concept_Training_steps/tbs)\n",
- "Text_Encoder_Training_Steps=(Text_Encoder_Training_steps/tbs)\n",
- "Text_Encoder_Concept_Training_Steps=int(Text_Encoder_Concept_Training_Steps)\n",
- "Text_Encoder_Training_Steps=int(Text_Encoder_Training_Steps)\n",
- "#@markdown - Suitable for training a style/concept as it acts as heavy regularization, set it to 1500 steps for 200 concept images (you can go higher), set to 0 to disable, set both the settings above to 0 to fintune only the text_encoder on the concept, `set it to 0 before resuming training if it is already trained`.\n",
- "\n",
- "Text_Encoder_Learning_Rate = 2e-6 #@param [\"2e-6\", \"8e-7\", \"6e-7\", \"5e-7\", \"4e-7\"] {type:\"raw\", allow-input: true}\n",
- "txlr=Text_Encoder_Learning_Rate\n",
- "\n",
- "#@markdown - Learning rate for both text_encoder and concept_text_encoder, keep it low to avoid overfitting (1e-7 is lowest, 1e-4 is the highest, 2e-7 is twice as fast as 1e-7 experiment and adjust the repeats to accomidate diffrent learning rates )\n",
- "\n",
- "trnonltxt=\"\"\n",
- "if UNet_Training_Steps==0:\n",
- " trnonltxt=\"--train_only_text_encoder\"\n",
- "\n",
- "Seed = 42825032 #@param {type:\"integer\"}\n",
- "\n",
- "Style_Training = False #@param {type:\"boolean\"}\n",
- "\n",
- "#@markdown -Forced Drop out, Drops caption from images, helps fine tuning a style without over-fitting simpsons model could of benefitted from this\n",
- "\n",
- "Style=\"\"\n",
- "if Style_Training:\n",
- " Style = \"--Style\"\n",
- "\n",
- "Flip_Images = True #@param {type:\"boolean\"}\n",
- "Percent_to_flip = 10 #@param{type:\"raw\"}\n",
- "flip_rate = (Percent_to_flip/100)\n",
- "\n",
- "#@markdown Flip a random 10% of images, helps add veriety to smaller data-sets\n",
- "\n",
- "flip=\"\"\n",
- "if Flip_Images:\n",
- " flip=\"--hflip\"\n",
- "\n",
- "Conditional_dropout = 3 #@param {type:\"raw\"}\n",
- "\n",
- "#@markdown drop a random X% of images, helps avoid over fitting, very similar to style training\n",
- "\n",
- "drop='0'\n",
- "drop= (Conditional_dropout/100)\n",
- "\n",
- "\n",
- "\n",
- "\n",
- "Resolution = \"576\" #@param [\"512\", \"576\", \"640\", \"704\", \"768\", \"832\", \"896\", \"960\", \"1024\"]\n",
- "Res=int(Resolution)\n",
- "\n",
- "#@markdown - Higher resolution = Higher quality, make sure the instance images are cropped to this selected size (or larger).\n",
- "\n",
- "fp16 = True\n",
- "\n",
- "if Seed =='' or Seed=='0':\n",
- " Seed=random.randint(1, 999999)\n",
- "else:\n",
- " Seed=int(Seed)\n",
- "\n",
- "GC=\"--gradient_checkpointing\"\n",
- "\n",
- "if fp16:\n",
- " prec=\"fp16\"\n",
- "else:\n",
- " prec=\"no\"\n",
- "\n",
- "s = getoutput('nvidia-smi')\n",
- "if 'A100' in s:\n",
- " GC=\"\"\n",
- "\n",
- "precision=prec\n",
- "\n",
- "resuming=\"\"\n",
- "if Resume_Training and os.path.exists(OUTPUT_DIR+'/unet/diffusion_pytorch_model.bin'):\n",
- " MODELT_NAME=OUTPUT_DIR\n",
- " print('\u001b[1;32mResuming Training...\u001b[0m')\n",
- " resuming=\"Yes\"\n",
- "elif Resume_Training and not os.path.exists(OUTPUT_DIR+'/unet/diffusion_pytorch_model.bin'):\n",
- " print('\u001b[1;31mPrevious model not found, training a new model...\u001b[0m')\n",
- " MODELT_NAME=MODEL_NAME\n",
- " while MODEL_NAME==\"\":\n",
- " print('\u001b[1;31mNo model found, use the \"Model Download\" cell to download a model.')\n",
- " time.sleep(5)\n",
- "\n",
- "V2=False\n",
- "if os.path.getsize(MODELT_NAME+\"/text_encoder/pytorch_model.bin\") > 670901463:\n",
- " V2=True\n",
- "\n",
- "Enable_text_encoder_training= True \n",
- "Enable_Text_Encoder_Concept_Training= True\n",
- "\n",
- "if Text_Encoder_Training_Steps==0:\n",
- " Enable_text_encoder_training= False\n",
- "else:\n",
- " stptxt=Text_Encoder_Training_Steps\n",
- "\n",
- "if Text_Encoder_Concept_Training_Steps==0:\n",
- " Enable_Text_Encoder_Concept_Training= False\n",
- "else:\n",
- " stptxtc=Text_Encoder_Concept_Training_Steps\n",
- "\n",
- "\n",
- "if Enable_text_encoder_training:\n",
- " Textenc=\"--train_text_encoder\"\n",
- "else:\n",
- " Textenc=\"\"\n",
- "\n",
- "#@markdown ---------------------------\n",
- "Save_Checkpoint_Every_n_Steps = True #@param {type:\"boolean\"}\n",
- "#@markdown How many repats/epochs between saves\n",
- "Save_Checkpoint_Every=10 #@param{type: 'number'}\n",
- "stp=0\n",
- "stpsv=10\n",
- "if Save_Checkpoint_Every_n_Steps:\n",
- " stp=((Save_Checkpoint_Every*Img_Count)/(gs*bs))\n",
- "stp=int(stp)\n",
- "Number_Of_Samples = 8 #@param {type:\"integer\"}\n",
- "NoS=Number_Of_Samples\n",
- "\n",
- "prompt= \"a photo of matpat\" #@param{type:\"string\"}\n",
- "Disconnect_after_training=False #@param {type:\"boolean\"}\n",
- "\n",
- "#@markdown - Auto-disconnect from google colab after the training to avoid wasting compute units.\n",
- "\n",
- "def dump_only_textenc(trnonltxt, MODELT_NAME, INSTANCE_DIR, OUTPUT_DIR, PT, Seed, precision, Training_Steps):\n",
- " \n",
- " !accelerate launch /content/diffusers/examples/dreambooth/train_dreambooth.py \\\n",
- " $trnonltxt \\\n",
- " --image_captions_filename \\\n",
- " --train_text_encoder \\\n",
- " --dump_only_text_encoder \\\n",
- " --pretrained_model_name_or_path=\"$MODELT_NAME\" \\\n",
- " --instance_data_dir=\"$INSTANCE_DIR\" \\\n",
- " --output_dir=\"$OUTPUT_DIR\" \\\n",
- " --instance_prompt=\"$PT\" \\\n",
- " --seed=$Seed \\\n",
- " --resolution=512 \\\n",
- " --mixed_precision=$precision \\\n",
- " --train_batch_size=$tbs \\\n",
- " --gradient_accumulation_steps=1 $GC \\\n",
- " --use_8bit_adam \\\n",
- " --learning_rate=$txlr \\\n",
- " --lr_scheduler=\"constant\" \\\n",
- " --lr_warmup_steps=10 \\\n",
- " --max_train_steps=$Training_Steps\n",
- "\n",
- "def train_only_unet(stpsv, stp, SESSION_DIR, MODELT_NAME, INSTANCE_DIR, OUTPUT_DIR, PT, Seed, Res, precision, Training_Steps):\n",
- " clear_output()\n",
- " if resuming==\"Yes\":\n",
- " print('\u001b[1;32mResuming Training...\u001b[0m') \n",
- " print('\u001b[1;33mTraining the UNet...\u001b[0m Saving every:'+str(stp)+' Steps')\n",
- " !accelerate launch /content/dreamboothtrainers/Trainer.py \\\n",
- " $Style \\\n",
- " $flip \\\n",
- " --image_captions_filename \\\n",
- " --train_only_unet \\\n",
- " --save_starting_step=$stpsv \\\n",
- " --save_n_steps=$stp \\\n",
- " --Session_dir=$SESSION_DIR \\\n",
- " --pretrained_model_name_or_path=\"$MODELT_NAME\" \\\n",
- " --instance_data_dir=\"$INSTANCE_DIR\" \\\n",
- " --output_dir=\"$OUTPUT_DIR\" \\\n",
- " --instance_prompt=\"$PT\" \\\n",
- " --n_save_sample=$NoS \\\n",
- " --save_sample_prompt=\"$prompt\" \\\n",
- " --seed=$Seed \\\n",
- " --resolution=$Res \\\n",
- " --mixed_precision=$precision \\\n",
- " --train_batch_size=$bs \\\n",
- " --gradient_accumulation_steps=$gs $GC \\\n",
- " --use_8bit_adam \\\n",
- " --learning_rate=$untlr \\\n",
- " --lr_scheduler=\"$lr_schedule\" \\\n",
- " --Drop_out=$drop \\\n",
- " --flip_rate=$flip_rate \\\n",
- " --lr_warmup_steps=10 \\\n",
- " --max_train_steps=$Training_Steps\n",
- "\n",
- "\n",
- "if Enable_text_encoder_training :\n",
- " print('\u001b[1;33mTraining the text encoder...\u001b[0m')\n",
- " if os.path.exists(OUTPUT_DIR+'/'+'text_encoder_trained'):\n",
- " %rm -r $OUTPUT_DIR\"/text_encoder_trained\"\n",
- " dump_only_textenc(trnonltxt, MODELT_NAME, INSTANCE_DIR, OUTPUT_DIR, PT, Seed, precision, Training_Steps=stptxt)\n",
- "\n",
- "if Enable_Text_Encoder_Concept_Training:\n",
- " if os.path.exists(CONCEPT_DIR):\n",
- " if os.listdir(CONCEPT_DIR)!=[]:\n",
- " # clear_output()\n",
- " if resuming==\"Yes\":\n",
- " print('\u001b[1;32mResuming Training...\u001b[0m') \n",
- " print('\u001b[1;33mTraining the text encoder on the concept...\u001b[0m')\n",
- " dump_only_textenc(trnonltxt, MODELT_NAME, CONCEPT_DIR, OUTPUT_DIR, PT, Seed, precision, Training_Steps=stptxtc)\n",
- " else:\n",
- " # clear_output()\n",
- " if resuming==\"Yes\":\n",
- " print('\u001b[1;32mResuming Training...\u001b[0m') \n",
- " print('\u001b[1;31mNo concept images found, skipping concept training...')\n",
- " time.sleep(8)\n",
- " else:\n",
- " #clear_output()\n",
- " if resuming==\"Yes\":\n",
- " print('\u001b[1;32mResuming Training...\u001b[0m')\n",
- " print('\u001b[1;31mNo concept images found, skipping concept training...')\n",
- " time.sleep(8)\n",
- " \n",
- "if UNet_Training_Steps!=0:\n",
- " train_only_unet(stpsv, stp, SESSION_DIR, MODELT_NAME, INSTANCE_DIR, OUTPUT_DIR, PT, Seed, Res, precision, Training_Steps=UNet_Training_Steps)\n",
- " \n",
- "\n",
- "if os.path.exists('/content/models/'+INSTANCE_NAME+'/unet/diffusion_pytorch_model.bin'):\n",
- " prc=\"--fp16\" if precision==\"fp16\" else \"\"\n",
- " if V2:\n",
- " !python /content/diffusers/scripts/convertosdv2.py $prc $OUTPUT_DIR $SESSION_DIR/$Session_Name\".ckpt\"\n",
- " #clear_output()\n",
- " if os.path.exists(SESSION_DIR+\"/\"+INSTANCE_NAME+'.ckpt'):\n",
- " #clear_output()\n",
- " print(\"\u001b[1;32mDONE, the CKPT model is in your Gdrive in the sessions folder\")\n",
- " if Disconnect_after_training :\n",
- " time.sleep(20) \n",
- " runtime.unassign() \n",
- " else:\n",
- " print(\"\u001b[1;31mSomething went wrong\") \n",
- " else: \n",
- " !wget -O /content/convertosd.py https://github.com/TheLastBen/fast-stable-diffusion/raw/main/Dreambooth/convertosd.py\n",
- " #clear_output()\n",
- " if precision==\"no\":\n",
- " !sed -i '226s@.*@@' /content/convertosd.py\n",
- " !sed -i '201s@.*@ model_path = \"{OUTPUT_DIR}\"@' /content/convertosd.py\n",
- " !sed -i '202s@.*@ checkpoint_path= \"{SESSION_DIR}/{Session_Name}.ckpt\"@' /content/convertosd.py\n",
- " !python /content/convertosd.py\n",
- "\n",
- " #clear_output()\n",
- " if os.path.exists(SESSION_DIR+\"/\"+INSTANCE_NAME+'.ckpt'): \n",
- " print(\"\u001b[1;32mDONE, the CKPT model is in your Gdrive in the sessions folder\")\n",
- " if Disconnect_after_training :\n",
- " time.sleep(20)\n",
- " runtime.unassign()\n",
- " else:\n",
- " print(\"\u001b[1;31mSomething went wrong\")\n",
- " \n",
- "else:\n",
- " print(\"\u001b[1;31mSomething went wrong\")"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "ehi1KKs-l-ZS"
- },
- "source": [
- "# Test The Trained Model"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "id": "iAZGngFcI8hq",
- "outputId": "102db37b-945c-43c5-807d-3b70903ecd78",
- "colab": {
- "base_uri": "https://localhost:8080/",
- "height": 397
- }
- },
- "outputs": [
- {
- "output_type": "error",
- "ename": "KeyboardInterrupt",
- "evalue": "ignored",
- "traceback": [
- "\u001b[0;31m---------------------------------------------------------------------------\u001b[0m",
- "\u001b[0;31mKeyboardInterrupt\u001b[0m Traceback (most recent call last)",
- "\u001b[0;32m/usr/local/lib/python3.8/dist-packages/IPython/core/async_helpers.py\u001b[0m in \u001b[0;36m_pseudo_sync_runner\u001b[0;34m(coro)\u001b[0m\n\u001b[1;32m 66\u001b[0m \"\"\"\n\u001b[1;32m 67\u001b[0m \u001b[0;32mtry\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m---> 68\u001b[0;31m \u001b[0mcoro\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0msend\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0;32mNone\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[1;32m 69\u001b[0m \u001b[0;32mexcept\u001b[0m \u001b[0mStopIteration\u001b[0m \u001b[0;32mas\u001b[0m \u001b[0mexc\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 70\u001b[0m \u001b[0;32mreturn\u001b[0m \u001b[0mexc\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mvalue\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n",
- "\u001b[0;32m/usr/local/lib/python3.8/dist-packages/IPython/core/interactiveshell.py\u001b[0m in \u001b[0;36mrun_cell_async\u001b[0;34m(self, raw_cell, store_history, silent, shell_futures)\u001b[0m\n\u001b[1;32m 2971\u001b[0m \u001b[0;31m# it in the history.\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 2972\u001b[0m \u001b[0;32mtry\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m-> 2973\u001b[0;31m \u001b[0mcell\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mself\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mtransform_cell\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mraw_cell\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[1;32m 2974\u001b[0m \u001b[0;32mexcept\u001b[0m \u001b[0mException\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 2975\u001b[0m \u001b[0mpreprocessing_exc_tuple\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0msys\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mexc_info\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n",
- "\u001b[0;32m/usr/local/lib/python3.8/dist-packages/IPython/core/interactiveshell.py\u001b[0m in \u001b[0;36mtransform_cell\u001b[0;34m(self, raw_cell)\u001b[0m\n\u001b[1;32m 3088\u001b[0m \"\"\"\n\u001b[1;32m 3089\u001b[0m \u001b[0;31m# Static input transformations\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m-> 3090\u001b[0;31m \u001b[0mcell\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mself\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0minput_transformer_manager\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mtransform_cell\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mraw_cell\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[1;32m 3091\u001b[0m \u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 3092\u001b[0m \u001b[0;32mif\u001b[0m \u001b[0mlen\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mcell\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0msplitlines\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m)\u001b[0m \u001b[0;34m==\u001b[0m \u001b[0;36m1\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n",
- "\u001b[0;32m/usr/local/lib/python3.8/dist-packages/IPython/core/inputtransformer2.py\u001b[0m in \u001b[0;36mtransform_cell\u001b[0;34m(self, cell)\u001b[0m\n\u001b[1;32m 588\u001b[0m \u001b[0mlines\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mtransform\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mlines\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 589\u001b[0m \u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m--> 590\u001b[0;31m \u001b[0mlines\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mself\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mdo_token_transforms\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mlines\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[1;32m 591\u001b[0m \u001b[0;32mreturn\u001b[0m \u001b[0;34m''\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mjoin\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mlines\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 592\u001b[0m \u001b[0;34m\u001b[0m\u001b[0m\n",
- "\u001b[0;32m/usr/local/lib/python3.8/dist-packages/IPython/core/inputtransformer2.py\u001b[0m in \u001b[0;36mdo_token_transforms\u001b[0;34m(self, lines)\u001b[0m\n\u001b[1;32m 573\u001b[0m \u001b[0;32mdef\u001b[0m \u001b[0mdo_token_transforms\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mself\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mlines\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 574\u001b[0m \u001b[0;32mfor\u001b[0m \u001b[0m_\u001b[0m \u001b[0;32min\u001b[0m \u001b[0mrange\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mTRANSFORM_LOOP_LIMIT\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m--> 575\u001b[0;31m \u001b[0mchanged\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mlines\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mself\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mdo_one_token_transform\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mlines\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[1;32m 576\u001b[0m \u001b[0;32mif\u001b[0m \u001b[0;32mnot\u001b[0m \u001b[0mchanged\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 577\u001b[0m \u001b[0;32mreturn\u001b[0m \u001b[0mlines\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n",
- "\u001b[0;32m/usr/local/lib/python3.8/dist-packages/IPython/core/inputtransformer2.py\u001b[0m in \u001b[0;36mdo_one_token_transform\u001b[0;34m(self, lines)\u001b[0m\n\u001b[1;32m 553\u001b[0m \u001b[0ma\u001b[0m \u001b[0mperformance\u001b[0m \u001b[0missue\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 554\u001b[0m \"\"\"\n\u001b[0;32m--> 555\u001b[0;31m \u001b[0mtokens_by_line\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mmake_tokens_by_line\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mlines\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[1;32m 556\u001b[0m \u001b[0mcandidates\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;34m[\u001b[0m\u001b[0;34m]\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 557\u001b[0m \u001b[0;32mfor\u001b[0m \u001b[0mtransformer_cls\u001b[0m \u001b[0;32min\u001b[0m \u001b[0mself\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mtoken_transformers\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n",
- "\u001b[0;32m/usr/local/lib/python3.8/dist-packages/IPython/core/inputtransformer2.py\u001b[0m in \u001b[0;36mmake_tokens_by_line\u001b[0;34m(lines)\u001b[0m\n\u001b[1;32m 482\u001b[0m \u001b[0mparenlev\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0;36m0\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 483\u001b[0m \u001b[0;32mtry\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m--> 484\u001b[0;31m \u001b[0;32mfor\u001b[0m \u001b[0mtoken\u001b[0m \u001b[0;32min\u001b[0m \u001b[0mtokenize\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mgenerate_tokens\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0miter\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mlines\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0m__next__\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[1;32m 485\u001b[0m \u001b[0mtokens_by_line\u001b[0m\u001b[0;34m[\u001b[0m\u001b[0;34m-\u001b[0m\u001b[0;36m1\u001b[0m\u001b[0;34m]\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mappend\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mtoken\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 486\u001b[0m \u001b[0;32mif\u001b[0m \u001b[0;34m(\u001b[0m\u001b[0mtoken\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mtype\u001b[0m \u001b[0;34m==\u001b[0m \u001b[0mNEWLINE\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;31m \u001b[0m\u001b[0;31m\\\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n",
- "\u001b[0;32m/usr/lib/python3.8/tokenize.py\u001b[0m in \u001b[0;36m_tokenize\u001b[0;34m(readline, encoding)\u001b[0m\n\u001b[1;32m 544\u001b[0m \u001b[0;32myield\u001b[0m \u001b[0mTokenInfo\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mCOMMENT\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mtoken\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mspos\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mepos\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mline\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 545\u001b[0m \u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0;32m--> 546\u001b[0;31m \u001b[0;32melif\u001b[0m \u001b[0mtoken\u001b[0m \u001b[0;32min\u001b[0m \u001b[0mtriple_quoted\u001b[0m\u001b[0;34m:\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[0m\u001b[1;32m 547\u001b[0m \u001b[0mendprog\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0m_compile\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mendpats\u001b[0m\u001b[0;34m[\u001b[0m\u001b[0mtoken\u001b[0m\u001b[0;34m]\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n\u001b[1;32m 548\u001b[0m \u001b[0mendmatch\u001b[0m \u001b[0;34m=\u001b[0m \u001b[0mendprog\u001b[0m\u001b[0;34m.\u001b[0m\u001b[0mmatch\u001b[0m\u001b[0;34m(\u001b[0m\u001b[0mline\u001b[0m\u001b[0;34m,\u001b[0m \u001b[0mpos\u001b[0m\u001b[0;34m)\u001b[0m\u001b[0;34m\u001b[0m\u001b[0;34m\u001b[0m\u001b[0m\n",
- "\u001b[0;31mKeyboardInterrupt\u001b[0m: "
- ]
- }
- ],
- "source": [
- "import os\n",
- "import time\n",
- "import sys\n",
- "import fileinput\n",
- "from IPython.display import clear_output\n",
- "from subprocess import getoutput\n",
- "from IPython.utils import capture\n",
- "\n",
- "\n",
- "Model_Version = \"1.5\" #@param [\"1.5\", \"V2.1-512\", \"V2.1-768\"]\n",
- "#@markdown - Important! Choose the correct version and resolution of the model\n",
- "\n",
- "Update_repo = True\n",
- "\n",
- "Session__Name=\"\" #@param{type: 'string'}\n",
- "\n",
- "#@markdown - Leave empty if you want to use the current trained model.\n",
- "\n",
- "Use_Custom_Path = True #@param {type:\"boolean\"}\n",
- "\n",
- "try:\n",
- " INSTANCE_NAME\n",
- " INSTANCET=INSTANCE_NAME \n",
- "except:\n",
- " pass\n",
- "#@markdown - if checked, an input box will ask the full path to a desired model.\n",
- "\n",
- "if Session__Name!=\"\":\n",
- " INSTANCET=Session__Name\n",
- " INSTANCET=INSTANCET.replace(\" \",\"_\")\n",
- "\n",
- "if Use_Custom_Path:\n",
- " try:\n",
- " INSTANCET\n",
- " del INSTANCET\n",
- " except:\n",
- " pass\n",
- "\n",
- "try:\n",
- " INSTANCET\n",
- " if Session__Name!=\"\":\n",
- " path_to_trained_model='/content/gdrive/MyDrive/Fast-Dreambooth/Sessions/'+Session__Name+\"/\"+Session__Name+'.ckpt'\n",
- " else:\n",
- " path_to_trained_model=SESSION_DIR+\"/\"+INSTANCET+'.ckpt'\n",
- "except:\n",
- " print('\u001b[1;31mIt seems that you did not perform training during this session \u001b[1;32mor you chose to use a custom path,\\nprovide the full path to the model (including the name of the model):\\n')\n",
- " path_to_trained_model=input()\n",
- " \n",
- "while not os.path.exists(path_to_trained_model):\n",
- " print(\"\u001b[1;31mThe model doesn't exist on you Gdrive, use the file explorer to get the path : \")\n",
- " path_to_trained_model=input()\n",
- "\n",
- " \n",
- "with capture.capture_output() as cap:\n",
- " %cd /content/gdrive/MyDrive/\n",
- " %mkdir sd\n",
- " %cd sd\n",
- " !git clone https://github.com/Stability-AI/stablediffusion\n",
- " !git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui\n",
- " %cd /content/gdrive/MyDrive/sd/stable-diffusion-webui/\n",
- " !mkdir -p cache/{huggingface,torch}\n",
- " %cd /content/\n",
- " !ln -s /content/gdrive/MyDrive/sd/stable-diffusion-webui/cache/huggingface ../root/.cache/\n",
- " !ln -s /content/gdrive/MyDrive/sd/stable-diffusion-webui/cache/torch ../root/.cache/\n",
- "\n",
- "if Update_repo:\n",
- " with capture.capture_output() as cap:\n",
- " !rm /content/gdrive/MyDrive/sd/stable-diffusion-webui/webui.sh\n",
- " !rm /content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/paths.py\n",
- " !rm /content/gdrive/MyDrive/sd/stable-diffusion-webui/webui.py\n",
- " !rm /content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/ui.py\n",
- " !rm /content/gdrive/MyDrive/sd/stable-diffusion-webui/style.css\n",
- " !rm /content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/shared.py\n",
- " %cd /content/gdrive/MyDrive/sd/stable-diffusion-webui/\n",
- " print('\u001b[1;32m')\n",
- " !git pull\n",
- "\n",
- "\n",
- "with capture.capture_output() as cap:\n",
- " \n",
- " if not os.path.exists('/content/gdrive/MyDrive/sd/stablediffusion/src/k-diffusion/k_diffusion'):\n",
- " !mkdir /content/gdrive/MyDrive/sd/stablediffusion/src\n",
- " %cd /content/gdrive/MyDrive/sd/stablediffusion/src\n",
- " !git clone https://github.com/CompVis/taming-transformers\n",
- " !git clone https://github.com/openai/CLIP\n",
- " !git clone https://github.com/salesforce/BLIP\n",
- " !git clone https://github.com/sczhou/CodeFormer\n",
- " !git clone https://github.com/crowsonkb/k-diffusion\n",
- " !mv /content/gdrive/MyDrive/sd/stablediffusion/src/CLIP /content/gdrive/MyDrive/sd/stablediffusion/src/clip\n",
- " !mv /content/gdrive/MyDrive/sd/stablediffusion/src/BLIP /content/gdrive/MyDrive/sd/stablediffusion/src/blip\n",
- " !mv /content/gdrive/MyDrive/sd/stablediffusion/src/CodeFormer /content/gdrive/MyDrive/sd/stablediffusion/src/codeformer\n",
- " !cp -r /content/gdrive/MyDrive/sd/stablediffusion/src/k-diffusion/k_diffusion /content/gdrive/MyDrive/sd/stable-diffusion-webui/\n",
- "\n",
- "\n",
- "with capture.capture_output() as cap: \n",
- " %cd /content/gdrive/MyDrive/sd/stable-diffusion-webui/modules\n",
- " !wget -O paths.py https://raw.githubusercontent.com/TheLastBen/fast-stable-diffusion/main/AUTOMATIC1111_files/paths.py\n",
- "\n",
- "with capture.capture_output() as cap:\n",
- " if not os.path.exists('/tools/node/bin/lt'):\n",
- " !npm install -g localtunnel\n",
- "\n",
- "with capture.capture_output() as cap:\n",
- " %cd /content/gdrive/MyDrive/sd/stable-diffusion-webui/\n",
- " !wget -O webui.py https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/webui.py\n",
- " !sed -i 's@ui.create_ui().*@ui.create_ui();shared.demo.queue(concurrency_count=999999,status_update_rate=0.1)@' /content/gdrive/MyDrive/sd/stable-diffusion-webui/webui.py\n",
- " %cd /content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/\n",
- " !wget -O shared.py https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/modules/shared.py\n",
- " !wget -O ui.py https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/modules/ui.py\n",
- " !sed -i 's@css = \"\".*@with open(os.path.join(script_path, \"style.css\"), \"r\", encoding=\"utf8\") as file:\\n css = file.read()@' /content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/ui.py\n",
- " %cd /content/gdrive/MyDrive/sd/stable-diffusion-webui\n",
- " !wget -O style.css https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/style.css\n",
- " !sed -i 's@min-height: 4.*@min-height: 5.5em;@g' /content/gdrive/MyDrive/sd/stable-diffusion-webui/style.css\n",
- " !sed -i 's@\"multiple_tqdm\": true,@\\\"multiple_tqdm\": false,@' /content/gdrive/MyDrive/sd/stable-diffusion-webui/config.json\n",
- " !sed -i '902s@.*@ self.logvar = self.logvar.to(self.device)@' /content/gdrive/MyDrive/sd/stablediffusion/ldm/models/diffusion/ddpm.py\n",
- " %cd /content\n",
- "\n",
- "\n",
- "Use_Gradio_Server = False #@param {type:\"boolean\"}\n",
- "#@markdown - Only if you have trouble connecting to the local server.\n",
- "\n",
- "Large_Model= False #@param {type:\"boolean\"}\n",
- "#@markdown - Check if you have trouble loading a model 7GB+\n",
- "\n",
- "if Large_Model:\n",
- " !sed -i 's@cmd_opts.lowram else \\\"cpu\\\"@cmd_opts.lowram else \\\"cuda\\\"@' /content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/shared.py\n",
- "else:\n",
- " !sed -i 's@cmd_opts.lowram else \\\"cuda\\\"@cmd_opts.lowram else \\\"cpu\\\"@' /content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/shared.py\n",
- "\n",
- "\n",
- "share=''\n",
- "if Use_Gradio_Server:\n",
- " share='--share'\n",
- " for line in fileinput.input('/usr/local/lib/python3.8/dist-packages/gradio/blocks.py', inplace=True):\n",
- " if line.strip().startswith('self.server_name ='):\n",
- " line = ' self.server_name = server_name\\n'\n",
- " if line.strip().startswith('self.server_port ='):\n",
- " line = ' self.server_port = server_port\\n'\n",
- " sys.stdout.write(line)\n",
- " clear_output()\n",
- " \n",
- "else:\n",
- " share=''\n",
- " !nohup lt --port 7860 > srv.txt 2>&1 &\n",
- " time.sleep(2)\n",
- " !grep -o 'https[^ ]*' /content/srv.txt >srvr.txt\n",
- " time.sleep(2)\n",
- " srv= getoutput('cat /content/srvr.txt')\n",
- "\n",
- " for line in fileinput.input('/usr/local/lib/python3.8/dist-packages/gradio/blocks.py', inplace=True):\n",
- " if line.strip().startswith('self.server_name ='):\n",
- " line = f' self.server_name = \"{srv[8:]}\"\\n'\n",
- " if line.strip().startswith('self.server_port ='):\n",
- " line = ' self.server_port = 443\\n'\n",
- " if line.strip().startswith('self.protocol = \"https\"'):\n",
- " line = ' self.protocol = \"https\"\\n'\n",
- " if line.strip().startswith('if self.local_url.startswith(\"https\") or self.is_colab'):\n",
- " line = '' \n",
- " if line.strip().startswith('else \"http\"'):\n",
- " line = '' \n",
- " sys.stdout.write(line)\n",
- " \n",
- "\n",
- " !sed -i '13s@.*@ \"PUBLIC_SHARE_TRUE\": \"\u001b[32mConnected\",@' /usr/local/lib/python3.8/dist-packages/gradio/strings.py\n",
- " \n",
- " !rm /content/srv.txt\n",
- " !rm /content/srvr.txt\n",
- " clear_output()\n",
- "\n",
- "with capture.capture_output() as cap:\n",
- " %cd /content/gdrive/MyDrive/sd/stablediffusion/\n",
- "\n",
- "if Model_Version == \"V2.1-768\":\n",
- " configf=\"--config /content/gdrive/MyDrive/sd/stablediffusion/configs/stable-diffusion/v2-inference-v.yaml\"\n",
- " !sed -i 's@def load_state_dict(checkpoint_path: str, map_location.*@def load_state_dict(checkpoint_path: str, map_location=\"cuda\"):@' /usr/local/lib/python3.8/dist-packages/open_clip/factory.py\n",
- " NM=\"True\"\n",
- "elif Model_Version == \"V2.1-512\":\n",
- " configf=\"--config /content/gdrive/MyDrive/sd/stablediffusion/configs/stable-diffusion/v2-inference.yaml\"\n",
- " !sed -i 's@def load_state_dict(checkpoint_path: str, map_location.*@def load_state_dict(checkpoint_path: str, map_location=\"cuda\"):@' /usr/local/lib/python3.8/dist-packages/open_clip/factory.py\n",
- " NM=\"True\"\n",
- "else:\n",
- " configf=\"\"\n",
- " !sed -i 's@def load_state_dict(checkpoint_path: str, map_location.*@def load_state_dict(checkpoint_path: str, map_location=\"cpu\"):@' /usr/local/lib/python3.8/dist-packages/open_clip/factory.py\n",
- " NM=\"False\"\n",
- "\n",
- "if os.path.exists('/usr/local/lib/python3.8/dist-packages/xformers'):\n",
- " xformers=\"--xformers\" \n",
- "else:\n",
- " xformers=\"\"\n",
- "\n",
- "if os.path.isfile(path_to_trained_model):\n",
- " !python /content/gdrive/MyDrive/sd/stable-diffusion-webui/webui.py $share --disable-safe-unpickle --no-half-vae --enable-insecure-extension-access --ckpt \"$path_to_trained_model\" $configf $xformers\n",
- "else:\n",
- " !python /content/gdrive/MyDrive/sd/stable-diffusion-webui/webui.py $share --disable-safe-unpickle --no-half-vae --enable-insecure-extension-access --ckpt-dir \"$path_to_trained_model\" $configf $xformers"
- ]
- },
- {
- "cell_type": "markdown",
- "metadata": {
- "id": "d_mQ23XsOc5R"
- },
- "source": [
- "# Upload The Trained Model to Hugging Face "
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "id": "NTqUIuhROdH4"
- },
- "outputs": [],
- "source": [
- "from slugify import slugify\n",
- "from huggingface_hub import HfApi, HfFolder, CommitOperationAdd\n",
- "from huggingface_hub import create_repo\n",
- "from IPython.display import display_markdown\n",
- "from IPython.display import clear_output\n",
- "from IPython.utils import capture\n",
- "from google.colab import files\n",
- "import shutil\n",
- "import time\n",
- "import os\n",
- "\n",
- "Upload_sample_images = False #@param {type:\"boolean\"}\n",
- "#@markdown - Upload showcase images of your trained model\n",
- "\n",
- "Name_of_your_concept = \"\" #@param {type:\"string\"}\n",
- "if(Name_of_your_concept == \"\"):\n",
- " Name_of_your_concept = Session_Name\n",
- "Name_of_your_concept=Name_of_your_concept.replace(\" \",\"-\") \n",
- " \n",
- "Save_concept_to = \"My_Profile\" #@param [\"Public_Library\", \"My_Profile\"]\n",
- "\n",
- "#@markdown - [Create a write access token](https://huggingface.co/settings/tokens) , go to \"New token\" -> Role : Write. A regular read token won't work here.\n",
- "hf_token_write = \"\" #@param {type:\"string\"}\n",
- "if hf_token_write ==\"\":\n",
- " print('\u001b[1;32mYour Hugging Face write access token : ')\n",
- " hf_token_write=input()\n",
- "\n",
- "hf_token = hf_token_write\n",
- "\n",
- "api = HfApi()\n",
- "your_username = api.whoami(token=hf_token)[\"name\"]\n",
- "\n",
- "if(Save_concept_to == \"Public_Library\"):\n",
- " repo_id = f\"sd-dreambooth-library/{slugify(Name_of_your_concept)}\"\n",
- " #Join the Concepts Library organization if you aren't part of it already\n",
- " !curl -X POST -H 'Authorization: Bearer '$hf_token -H 'Content-Type: application/json' https://huggingface.co/organizations/sd-dreambooth-library/share/SSeOwppVCscfTEzFGQaqpfcjukVeNrKNHX\n",
- "else:\n",
- " repo_id = f\"{your_username}/{slugify(Name_of_your_concept)}\"\n",
- "output_dir = f'/content/models/'+INSTANCE_NAME\n",
- "\n",
- "def bar(prg):\n",
- " br=\"\u001b[1;33mUploading to HuggingFace : \" '\u001b[0m|'+'█' * prg + ' ' * (25-prg)+'| ' +str(prg*4)+ \"%\"\n",
- " return br\n",
- "\n",
- "print(\"\u001b[1;32mLoading...\")\n",
- "\n",
- "NM=\"False\"\n",
- "if os.path.getsize(OUTPUT_DIR+\"/text_encoder/pytorch_model.bin\") > 670901463:\n",
- " NM=\"True\"\n",
- "\n",
- "\n",
- "if NM==\"False\":\n",
- " with capture.capture_output() as cap:\n",
- " %cd $OUTPUT_DIR\n",
- " !rm -r safety_checker feature_extractor .git\n",
- " !rm model_index.json\n",
- " !git init\n",
- " !git lfs install --system --skip-repo\n",
- " !git remote add -f origin \"https://USER:{hf_token}@huggingface.co/runwayml/stable-diffusion-v1-5\"\n",
- " !git config core.sparsecheckout true\n",
- " !echo -e \"feature_extractor\\nsafety_checker\\nmodel_index.json\" > .git/info/sparse-checkout\n",
- " !git pull origin main\n",
- " !rm -r .git\n",
- " %cd /content\n",
- "\n",
- "image_string = \"\"\n",
- "\n",
- "if os.path.exists('/content/sample_images'):\n",
- " !rm -r /content/sample_images\n",
- "Samples=\"/content/sample_images\"\n",
- "!mkdir $Samples\n",
- "clear_output()\n",
- "\n",
- "if Upload_sample_images:\n",
- "\n",
- " print(\"\u001b[1;32mUpload Sample images of the model\")\n",
- " uploaded = files.upload()\n",
- " for filename in uploaded.keys():\n",
- " shutil.move(filename, Samples)\n",
- " %cd $Samples\n",
- " !find . -name \"* *\" -type f | rename 's/ /_/g'\n",
- " %cd /content\n",
- " clear_output()\n",
- "\n",
- " print(bar(1))\n",
- "\n",
- " images_upload = os.listdir(Samples)\n",
- " instance_prompt_list = []\n",
- " for i, image in enumerate(images_upload):\n",
- " image_string = f'''\n",
- " {image_string}\n",
- " '''\n",
- " \n",
- "readme_text = f'''---\n",
- "license: creativeml-openrail-m\n",
- "tags:\n",
- "- text-to-image\n",
- "- stable-diffusion\n",
- "---\n",
- "### {Name_of_your_concept} Dreambooth model trained by {api.whoami(token=hf_token)[\"name\"]} with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook\n",
- "\n",
- "\n",
- "Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)\n",
- "Or you can run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb)\n",
- "\n",
- "Sample pictures of this concept:\n",
- "{image_string}\n",
- "'''\n",
- "#Save the readme to a file\n",
- "readme_file = open(\"README.md\", \"w\")\n",
- "readme_file.write(readme_text)\n",
- "readme_file.close()\n",
- "\n",
- "operations = [\n",
- " CommitOperationAdd(path_in_repo=\"README.md\", path_or_fileobj=\"README.md\"),\n",
- " CommitOperationAdd(path_in_repo=f\"{Session_Name}.ckpt\",path_or_fileobj=MDLPTH)\n",
- "\n",
- "]\n",
- "create_repo(repo_id,private=True, token=hf_token)\n",
- "\n",
- "api.create_commit(\n",
- " repo_id=repo_id,\n",
- " operations=operations,\n",
- " commit_message=f\"Upload the concept {Name_of_your_concept} embeds and token\",\n",
- " token=hf_token\n",
- ")\n",
- "\n",
- "if NM==\"False\":\n",
- " api.upload_folder(\n",
- " folder_path=OUTPUT_DIR+\"/feature_extractor\",\n",
- " path_in_repo=\"feature_extractor\",\n",
- " repo_id=repo_id,\n",
- " token=hf_token\n",
- " )\n",
- "\n",
- "clear_output()\n",
- "print(bar(4))\n",
- "\n",
- "if NM==\"False\":\n",
- " api.upload_folder(\n",
- " folder_path=OUTPUT_DIR+\"/safety_checker\",\n",
- " path_in_repo=\"safety_checker\",\n",
- " repo_id=repo_id,\n",
- " token=hf_token\n",
- " )\n",
- "\n",
- "clear_output()\n",
- "print(bar(8))\n",
- "\n",
- "\n",
- "api.upload_folder(\n",
- " folder_path=OUTPUT_DIR+\"/scheduler\",\n",
- " path_in_repo=\"scheduler\",\n",
- " repo_id=repo_id,\n",
- " token=hf_token\n",
- ")\n",
- "\n",
- "clear_output()\n",
- "print(bar(9))\n",
- "\n",
- "api.upload_folder(\n",
- " folder_path=OUTPUT_DIR+\"/text_encoder\",\n",
- " path_in_repo=\"text_encoder\",\n",
- " repo_id=repo_id,\n",
- " token=hf_token\n",
- ")\n",
- "\n",
- "clear_output()\n",
- "print(bar(12))\n",
- "\n",
- "api.upload_folder(\n",
- " folder_path=OUTPUT_DIR+\"/tokenizer\",\n",
- " path_in_repo=\"tokenizer\",\n",
- " repo_id=repo_id,\n",
- " token=hf_token\n",
- ")\n",
- "\n",
- "clear_output()\n",
- "print(bar(13))\n",
- "\n",
- "api.upload_folder(\n",
- " folder_path=OUTPUT_DIR+\"/unet\",\n",
- " path_in_repo=\"unet\",\n",
- " repo_id=repo_id,\n",
- " token=hf_token\n",
- ")\n",
- "\n",
- "clear_output()\n",
- "print(bar(21))\n",
- "\n",
- "api.upload_folder(\n",
- " folder_path=OUTPUT_DIR+\"/vae\",\n",
- " path_in_repo=\"vae\",\n",
- " repo_id=repo_id,\n",
- " token=hf_token\n",
- ")\n",
- "\n",
- "clear_output()\n",
- "print(bar(23))\n",
- "\n",
- "api.upload_file(\n",
- " path_or_fileobj=OUTPUT_DIR+\"/model_index.json\",\n",
- " path_in_repo=\"model_index.json\",\n",
- " repo_id=repo_id,\n",
- " token=hf_token\n",
- ")\n",
- "\n",
- "clear_output()\n",
- "print(bar(24))\n",
- "\n",
- "api.upload_folder(\n",
- " folder_path=Samples,\n",
- " path_in_repo=\"sample_images\",\n",
- " repo_id=repo_id,\n",
- " token=hf_token\n",
- ")\n",
- "\n",
- "clear_output()\n",
- "print(bar(25))\n",
- "\n",
- "display_markdown(f'''## Your concept was saved successfully. [Click here to access it](https://huggingface.co/{repo_id})\n",
- "''', raw=True)"
- ]
- },
- {
- "cell_type": "code",
- "execution_count": null,
- "metadata": {
- "cellView": "form",
- "id": "iVqNi8IDzA1Z"
- },
- "outputs": [],
- "source": [
- "#@markdown #Free Gdrive Space\n",
- "\n",
- "#@markdown Display the list of sessions from your gdrive and choose which ones to remove.\n",
- "\n",
- "import ipywidgets as widgets\n",
- "\n",
- "Sessions=os.listdir(\"/content/gdrive/MyDrive/Fast-Dreambooth/Sessions\")\n",
- "\n",
- "s = widgets.Select(\n",
- " options=Sessions,\n",
- " rows=5,\n",
- " description='',\n",
- " disabled=False\n",
- ")\n",
- "\n",
- "out=widgets.Output()\n",
- "\n",
- "d = widgets.Button(\n",
- " description='Remove',\n",
- " disabled=False,\n",
- " button_style='warning',\n",
- " tooltip='Removet the selected session',\n",
- " icon='warning'\n",
- ")\n",
- "\n",
- "def rem(d):\n",
- " with out:\n",
- " if s.value is not None:\n",
- " clear_output()\n",
- " print(\"\u001b[1;33mTHE SESSION \u001b[1;31m\"+s.value+\" \u001b[1;33mHAS BEEN REMOVED FROM YOUR GDRIVE\")\n",
- " !rm -r '/content/gdrive/MyDrive/Fast-Dreambooth/Sessions/{s.value}'\n",
- " s.options=os.listdir(\"/content/gdrive/MyDrive/Fast-Dreambooth/Sessions\") \n",
- " else:\n",
- " d.close()\n",
- " s.close()\n",
- " clear_output()\n",
- " print(\"\u001b[1;32mNOTHING TO REMOVE\")\n",
- "\n",
- "d.on_click(rem)\n",
- "if s.value is not None:\n",
- " display(s,d,out)\n",
- "else:\n",
- " print(\"\u001b[1;32mNOTHING TO REMOVE\")"
- ]
- }
- ],
- "metadata": {
- "accelerator": "GPU",
- "colab": {
- "collapsed_sections": [
- "bbKbx185zqlz",
- "AaLtXBbPleBr"
- ],
- "provenance": [],
- "include_colab_link": true
- },
- "kernelspec": {
- "display_name": "Python 3",
- "name": "python3"
- },
- "language_info": {
- "name": "python"
- },
- "gpuClass": "standard"
- },
- "nbformat": 4,
- "nbformat_minor": 0
-}
\ No newline at end of file
From 49418280565388518fa2d504bc0d5098b5d3f9db Mon Sep 17 00:00:00 2001
From: nawnie <106923464+nawnie@users.noreply.github.com>
Date: Tue, 17 Jan 2023 17:58:40 -0600
Subject: [PATCH 13/15] Created using Colaboratory
---
Copy_of_fast_DreamBooth.ipynb | 1633 +++++++++++++++++++++++++++++++++
1 file changed, 1633 insertions(+)
create mode 100644 Copy_of_fast_DreamBooth.ipynb
diff --git a/Copy_of_fast_DreamBooth.ipynb b/Copy_of_fast_DreamBooth.ipynb
new file mode 100644
index 00000000..46ddaf54
--- /dev/null
+++ b/Copy_of_fast_DreamBooth.ipynb
@@ -0,0 +1,1633 @@
+{
+ "cells": [
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "view-in-github",
+ "colab_type": "text"
+ },
+ "source": [
+ "<a href=\"https://colab.research.google.com/github/nawnie/fast-stable-diffusion/blob/main/Copy_of_fast_DreamBooth.ipynb\" target=\"_parent\"><img src=\"https://colab.research.google.com/assets/colab-badge.svg\" alt=\"Open In Colab\"/></a>"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "qEsNHTtVlbkV"
+ },
+ "source": [
+ "# **fast-DreamBooth colab From https://github.com/TheLastBen/fast-stable-diffusion, if you face any issues, feel free to discuss them.** \n",
+ "Keep your notebook updated for best experience. [Support](https://ko-fi.com/thelastben)\n"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "A4Bae3VP6UsE",
+ "cellView": "form"
+ },
+ "outputs": [],
+ "source": [
+ "#@title Mount Gdrive\n",
+ "\n",
+ "from google.colab import drive\n",
+ "drive.mount('/content/gdrive')"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "QyvcqeiL65Tj",
+ "cellView": "form"
+ },
+ "outputs": [],
+ "source": [
+ "#@markdown # Dependencies\n",
+ "\n",
+ "from IPython.utils import capture\n",
+ "from subprocess import getoutput\n",
+ "import time\n",
+ "\n",
+ "print('[1;32mInstalling dependencies...')\n",
+ "with capture.capture_output() as cap:\n",
+ " %cd /content/\n",
+ " !pip install -q --no-deps accelerate==0.12.0\n",
+ " !wget -q -i \"https://github.com/TheLastBen/fast-stable-diffusion/raw/main/Dependencies/dbdeps.txt\"\n",
+ " for i in range(1,8):\n",
+ " !mv \"deps.{i}\" \"deps.7z.00{i}\"\n",
+ " !7z x -y -o/ deps.7z.001\n",
+ " !rm *.00* *.txt\n",
+ " !git clone --depth 1 --branch updt https://github.com/TheLastBen/diffusers\n",
+ " s = getoutput('nvidia-smi')\n",
+ " if \"A100\" in s:\n",
+ " !wget -q https://github.com/TheLastBen/fast-stable-diffusion/raw/main/precompiled/A100/A100\n",
+ " !rm -r /usr/local/lib/python3.8/dist-packages/xformers\n",
+ " !7z x -y -o/usr/local/lib/python3.8/dist-packages/ /content/A100\n",
+ " !rm /content/A100\n",
+ "!git clone https://github.com/nawnie/dreamboothtrainers.git\n",
+ "print('\u001b[1;32mDone, proceed')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "R3SsbIlxw66N"
+ },
+ "source": [
+ "# Model Download"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "O3KHGKqyeJp9",
+ "cellView": "form"
+ },
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "import time\n",
+ "from IPython.display import clear_output\n",
+ "import wget\n",
+ "\n",
+ "#@markdown - Skip this cell if you are loading a previous session that contains a trained model.\n",
+ "\n",
+ "#@markdown ---\n",
+ "\n",
+ "Model_Version = \"1.5\" #@param [ \"1.5\", \"V2.1-512px\", \"V2.1-768px\"]\n",
+ "\n",
+ "#@markdown - Choose which version to finetune.\n",
+ "\n",
+ "with capture.capture_output() as cap: \n",
+ " %cd /content/\n",
+ "\n",
+ "Huggingface_Token = \"\" #@param {type:\"string\"}\n",
+ "token=Huggingface_Token\n",
+ "\n",
+ "#@markdown - Leave EMPTY if you're using the v2 model.\n",
+ "#@markdown - Make sure you've accepted the terms in https://huggingface.co/runwayml/stable-diffusion-v1-5\n",
+ "\n",
+ "#@markdown ---\n",
+ "Custom_Model_Version=\"1.5\" #@param [ \"1.5\", \"V2.1-512px\", \"V2.1-768px\"]\n",
+ "#@markdown - Choose wisely!\n",
+ "\n",
+ "Path_to_HuggingFace= \"\" #@param {type:\"string\"}\n",
+ "\n",
+ "\n",
+ "#@markdown - Load and finetune a model from Hugging Face, must specify if v2, use the format \"profile/model\" like : runwayml/stable-diffusion-v1-5\n",
+ "\n",
+ "#@markdown Or\n",
+ "\n",
+ "CKPT_Path = \"/content/gdrive/MyDrive/A_Training_folder/models/Realistic_proto.ckpt\" #@param {type:\"string\"}\n",
+ "\n",
+ "#@markdown Or\n",
+ "\n",
+ "CKPT_Link = \"\" #@param {type:\"string\"}\n",
+ "\n",
+ "#@markdown - A CKPT direct link, huggingface CKPT link or a shared CKPT from gdrive.\n",
+ "\n",
+ "\n",
+ "def downloadmodel():\n",
+ " token=Huggingface_Token\n",
+ " if token==\"\":\n",
+ " token=input(\"Insert your huggingface token :\")\n",
+ " if os.path.exists('/content/stable-diffusion-v1-5'):\n",
+ " !rm -r /content/stable-diffusion-v1-5\n",
+ " clear_output()\n",
+ "\n",
+ " %cd /content/\n",
+ " clear_output()\n",
+ " !mkdir /content/stable-diffusion-v1-5\n",
+ " %cd /content/stable-diffusion-v1-5\n",
+ " !git init\n",
+ " !git lfs install --system --skip-repo\n",
+ " !git remote add -f origin \"https://USER:{token}@huggingface.co/runwayml/stable-diffusion-v1-5\"\n",
+ " !git config core.sparsecheckout true\n",
+ " !echo -e \"scheduler\\ntext_encoder\\ntokenizer\\nunet\\nmodel_index.json\" > .git/info/sparse-checkout\n",
+ " !git pull origin main\n",
+ " if os.path.exists('/content/stable-diffusion-v1-5/unet/diffusion_pytorch_model.bin'):\n",
+ " !git clone \"https://USER:{token}@huggingface.co/stabilityai/sd-vae-ft-mse\"\n",
+ " !mv /content/stable-diffusion-v1-5/sd-vae-ft-mse /content/stable-diffusion-v1-5/vae\n",
+ " !rm -r /content/stable-diffusion-v1-5/.git\n",
+ " %cd /content/stable-diffusion-v1-5\n",
+ " !rm model_index.json\n",
+ " time.sleep(1) \n",
+ " wget.download('https://raw.githubusercontent.com/TheLastBen/fast-stable-diffusion/main/Dreambooth/model_index.json')\n",
+ " !sed -i 's@\"clip_sample\": false@@g' /content/stable-diffusion-v1-5/scheduler/scheduler_config.json\n",
+ " !sed -i 's@\"trained_betas\": null,@\"trained_betas\": null@g' /content/stable-diffusion-v1-5/scheduler/scheduler_config.json\n",
+ " !sed -i 's@\"sample_size\": 256,@\"sample_size\": 512,@g' /content/stable-diffusion-v1-5/vae/config.json \n",
+ " %cd /content/ \n",
+ " clear_output()\n",
+ " print('\u001b[1;32mDONE !')\n",
+ " else:\n",
+ " while not os.path.exists('/content/stable-diffusion-v1-5/unet/diffusion_pytorch_model.bin'):\n",
+ " print('\u001b[1;31mMake sure you accepted the terms in https://huggingface.co/runwayml/stable-diffusion-v1-5')\n",
+ " time.sleep(5)\n",
+ "\n",
+ "def newdownloadmodel():\n",
+ "\n",
+ " %cd /content/\n",
+ " clear_output()\n",
+ " !mkdir /content/stable-diffusion-v2-768\n",
+ " %cd /content/stable-diffusion-v2-768\n",
+ " !git init\n",
+ " !git lfs install --system --skip-repo\n",
+ " !git remote add -f origin \"https://USER:{token}@huggingface.co/stabilityai/stable-diffusion-2-1\"\n",
+ " !git config core.sparsecheckout true\n",
+ " !echo -e \"scheduler\\ntext_encoder\\ntokenizer\\nunet\\nvae\\nfeature_extractor\\nmodel_index.json\" > .git/info/sparse-checkout\n",
+ " !git pull origin main\n",
+ " !rm -r /content/stable-diffusion-v2-768/.git\n",
+ " clear_output()\n",
+ " print('\u001b[1;32mDONE !')\n",
+ "\n",
+ "\n",
+ "def newdownloadmodelb():\n",
+ "\n",
+ " %cd /content/\n",
+ " clear_output()\n",
+ " !mkdir /content/stable-diffusion-v2-512\n",
+ " %cd /content/stable-diffusion-v2-512\n",
+ " !git init\n",
+ " !git lfs install --system --skip-repo\n",
+ " !git remote add -f origin \"https://USER:{token}@huggingface.co/stabilityai/stable-diffusion-2-1-base\"\n",
+ " !git config core.sparsecheckout true\n",
+ " !echo -e \"scheduler\\ntext_encoder\\ntokenizer\\nunet\\nvae\\nfeature_extractor\\nmodel_index.json\" > .git/info/sparse-checkout\n",
+ " !git pull origin main\n",
+ " !rm -r /content/stable-diffusion-v2-512/.git\n",
+ " clear_output()\n",
+ " print('\u001b[1;32mDONE !')\n",
+ " \n",
+ "\n",
+ "if Path_to_HuggingFace != \"\":\n",
+ " if Custom_Model_Version=='V2.1-512px' or Custom_Model_Version=='V2.1-768px':\n",
+ " if os.path.exists('/content/stable-diffusion-custom'):\n",
+ " !rm -r /content/stable-diffusion-custom\n",
+ " clear_output()\n",
+ " %cd /content/\n",
+ " clear_output()\n",
+ " !mkdir /content/stable-diffusion-custom\n",
+ " %cd /content/stable-diffusion-custom\n",
+ " !git init\n",
+ " !git lfs install --system --skip-repo\n",
+ " !git remote add -f origin \"https://USER:{token}@huggingface.co/{Path_to_HuggingFace}\"\n",
+ " !git config core.sparsecheckout true\n",
+ " !echo -e \"scheduler\\ntext_encoder\\ntokenizer\\nunet\\nvae\\nfeature_extractor\\nmodel_index.json\" > .git/info/sparse-checkout\n",
+ " !git pull origin main\n",
+ " if os.path.exists('/content/stable-diffusion-custom/unet/diffusion_pytorch_model.bin'):\n",
+ " !rm -r /content/stable-diffusion-custom/.git\n",
+ " %cd /content/ \n",
+ " MODEL_NAME=\"/content/stable-diffusion-custom\" \n",
+ " clear_output()\n",
+ " print('\u001b[1;32mDONE !')\n",
+ " else:\n",
+ " while not os.path.exists('/content/stable-diffusion-custom/unet/diffusion_pytorch_model.bin'):\n",
+ " print('\u001b[1;31mCheck the link you provided')\n",
+ " time.sleep(5)\n",
+ " else:\n",
+ " if os.path.exists('/content/stable-diffusion-custom'):\n",
+ " !rm -r /content/stable-diffusion-custom\n",
+ " clear_output()\n",
+ " %cd /content/\n",
+ " clear_output()\n",
+ " !mkdir /content/stable-diffusion-custom\n",
+ " %cd /content/stable-diffusion-custom\n",
+ " !git init\n",
+ " !git lfs install --system --skip-repo\n",
+ " !git remote add -f origin \"https://USER:{token}@huggingface.co/{Path_to_HuggingFace}\"\n",
+ " !git config core.sparsecheckout true\n",
+ " !echo -e \"scheduler\\ntext_encoder\\ntokenizer\\nunet\\nmodel_index.json\" > .git/info/sparse-checkout\n",
+ " !git pull origin main\n",
+ " if os.path.exists('/content/stable-diffusion-custom/unet/diffusion_pytorch_model.bin'):\n",
+ " !git clone \"https://USER:{token}@huggingface.co/stabilityai/sd-vae-ft-mse\"\n",
+ " !mv /content/stable-diffusion-custom/sd-vae-ft-mse /content/stable-diffusion-custom/vae\n",
+ " !rm -r /content/stable-diffusion-custom/.git\n",
+ " %cd /content/stable-diffusion-custom\n",
+ " !rm model_index.json\n",
+ " time.sleep(1)\n",
+ " wget.download('https://raw.githubusercontent.com/TheLastBen/fast-stable-diffusion/main/Dreambooth/model_index.json')\n",
+ " !sed -i 's@\"clip_sample\": false,@@g' /content/stable-diffusion-custom/scheduler/scheduler_config.json\n",
+ " !sed -i 's@\"trained_betas\": null,@\"trained_betas\": null@g' /content/stable-diffusion-custom/scheduler/scheduler_config.json\n",
+ " !sed -i 's@\"sample_size\": 256,@\"sample_size\": 512,@g' /content/stable-diffusion-custom/vae/config.json \n",
+ " %cd /content/ \n",
+ " MODEL_NAME=\"/content/stable-diffusion-custom\" \n",
+ " clear_output()\n",
+ " print('\u001b[1;32mDONE !')\n",
+ " else:\n",
+ " while not os.path.exists('/content/stable-diffusion-custom/unet/diffusion_pytorch_model.bin'):\n",
+ " print('\u001b[1;31mCheck the link you provided')\n",
+ " time.sleep(5) \n",
+ "\n",
+ "elif CKPT_Path !=\"\":\n",
+ " %cd /content\n",
+ " clear_output() \n",
+ " if os.path.exists(str(CKPT_Path)):\n",
+ " if Custom_Model_Version=='1.5':\n",
+ " !wget -O refmdlz https://github.com/TheLastBen/fast-stable-diffusion/raw/main/Dreambooth/refmdlz\n",
+ " !unzip -o -q refmdlz\n",
+ " !rm -f refmdlz \n",
+ " !wget -O convertodiff.py https://raw.githubusercontent.com/TheLastBen/fast-stable-diffusion/main/Dreambooth/convertodiffv1.py\n",
+ " clear_output()\n",
+ " !python /content/convertodiff.py \"$CKPT_Path\" /content/stable-diffusion-custom --v1\n",
+ " !rm -r /content/refmdl\n",
+ " elif Custom_Model_Version=='V2.1-512px':\n",
+ " !wget -O convertodiff.py https://raw.githubusercontent.com/TheLastBen/fast-stable-diffusion/main/Dreambooth/convertodiffv2.py\n",
+ " clear_output()\n",
+ " !python /content/convertodiff.py \"$CKPT_Path\" /content/stable-diffusion-custom --v2 --reference_model stabilityai/stable-diffusion-2-1-base\n",
+ " elif Custom_Model_Version=='V2.1-768px':\n",
+ " !wget -O convertodiff.py https://raw.githubusercontent.com/TheLastBen/fast-stable-diffusion/main/Dreambooth/convertodiffv2.py\n",
+ " clear_output()\n",
+ " !python /content/convertodiff.py \"$CKPT_Path\" /content/stable-diffusion-custom --v2 --reference_model stabilityai/stable-diffusion-2-1\n",
+ " !rm /content/convertodiff.py\n",
+ " if os.path.exists('/content/stable-diffusion-custom/unet/diffusion_pytorch_model.bin'):\n",
+ " clear_output()\n",
+ " MODEL_NAME=\"/content/stable-diffusion-custom\"\n",
+ " print('\u001b[1;32mDONE !')\n",
+ " else:\n",
+ " !rm -r /content/stable-diffusion-custom\n",
+ " while not os.path.exists('/content/stable-diffusion-custom/unet/diffusion_pytorch_model.bin'):\n",
+ " print('\u001b[1;31mConversion error')\n",
+ " time.sleep(5)\n",
+ " else:\n",
+ " while not os.path.exists(str(CKPT_Path)):\n",
+ " print('\u001b[1;31mWrong path, use the colab file explorer to copy the path')\n",
+ " time.sleep(5) \n",
+ "\n",
+ "elif CKPT_Link !=\"\": \n",
+ " %cd /content\n",
+ " clear_output() \n",
+ " !gdown --fuzzy -O model.ckpt $CKPT_Link\n",
+ " clear_output() \n",
+ " if os.path.exists('/content/model.ckpt'):\n",
+ " if os.path.getsize(\"/content/model.ckpt\") > 1810671599:\n",
+ " if Custom_Model_Version=='1.5':\n",
+ " !wget -O refmdlz https://github.com/TheLastBen/fast-stable-diffusion/raw/main/Dreambooth/refmdlz\n",
+ " !unzip -o -q refmdlz\n",
+ " !rm -f refmdlz \n",
+ " !wget -O convertodiff.py https://raw.githubusercontent.com/TheLastBen/fast-stable-diffusion/main/Dreambooth/convertodiffv1.py\n",
+ " clear_output()\n",
+ " !python /content/convertodiff.py /content/model.ckpt /content/stable-diffusion-custom --v1\n",
+ " !rm -r /content/refmdl\n",
+ " elif Custom_Model_Version=='V2.1-512px':\n",
+ " !wget -O convertodiff.py https://raw.githubusercontent.com/TheLastBen/fast-stable-diffusion/main/Dreambooth/convertodiffv2.py\n",
+ " clear_output()\n",
+ " !python /content/convertodiff.py /content/model.ckpt /content/stable-diffusion-custom --v2 --reference_model stabilityai/stable-diffusion-2-1-base\n",
+ " elif Custom_Model_Version=='V2.1-768px':\n",
+ " !wget -O convertodiff.py https://raw.githubusercontent.com/TheLastBen/fast-stable-diffusion/main/Dreambooth/convertodiffv2.py\n",
+ " clear_output()\n",
+ " !python /content/convertodiff.py /content/model.ckpt /content/stable-diffusion-custom --v2 --reference_model stabilityai/stable-diffusion-2-1\n",
+ " !rm /content/convertodiff.py\n",
+ " if os.path.exists('/content/stable-diffusion-custom/unet/diffusion_pytorch_model.bin'):\n",
+ " clear_output()\n",
+ " MODEL_NAME=\"/content/stable-diffusion-custom\"\n",
+ " print('\u001b[1;32mDONE !')\n",
+ " else:\n",
+ " !rm -r /content/stable-diffusion-custom\n",
+ " !rm /content/model.ckpt\n",
+ " while not os.path.exists('/content/stable-diffusion-custom/unet/diffusion_pytorch_model.bin'):\n",
+ " print('\u001b[1;31mConversion error')\n",
+ " time.sleep(5)\n",
+ " else:\n",
+ " while os.path.getsize('/content/model.ckpt') < 1810671599:\n",
+ " print('\u001b[1;31mWrong link, check that the link is valid')\n",
+ " time.sleep(5)\n",
+ " \n",
+ "else:\n",
+ " if Model_Version==\"1.5\":\n",
+ " if not os.path.exists('/content/stable-diffusion-v1-5'):\n",
+ " downloadmodel()\n",
+ " MODEL_NAME=\"/content/stable-diffusion-v1-5\"\n",
+ " else:\n",
+ " MODEL_NAME=\"/content/stable-diffusion-v1-5\"\n",
+ " print(\"\u001b[1;32mThe v1.5 model already exists, using this model.\")\n",
+ " elif Model_Version==\"V2.1-512px\":\n",
+ " if not os.path.exists('/content/stable-diffusion-v2-512'):\n",
+ " newdownloadmodelb()\n",
+ " MODEL_NAME=\"/content/stable-diffusion-v2-512\"\n",
+ " else:\n",
+ " MODEL_NAME=\"/content/stable-diffusion-v2-512\"\n",
+ " print(\"\u001b[1;32mThe v2-512px model already exists, using this model.\") \n",
+ " elif Model_Version==\"V2.1-768px\":\n",
+ " if not os.path.exists('/content/stable-diffusion-v2-768'): \n",
+ " newdownloadmodel()\n",
+ " MODEL_NAME=\"/content/stable-diffusion-v2-768\"\n",
+ " else:\n",
+ " MODEL_NAME=\"/content/stable-diffusion-v2-768\"\n",
+ " print(\"\u001b[1;32mThe v2-768px model already exists, using this model.\") "
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "0tN76Cj5P3RL"
+ },
+ "source": [
+ "# Dreambooth"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "A1B299g-_VJo",
+ "cellView": "form"
+ },
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "from IPython.display import clear_output\n",
+ "from IPython.utils import capture\n",
+ "from os import listdir\n",
+ "from os.path import isfile\n",
+ "import wget\n",
+ "import time\n",
+ "\n",
+ "#@markdown #Create/Load a Session\n",
+ "\n",
+ "try:\n",
+ " MODEL_NAME\n",
+ " pass\n",
+ "except:\n",
+ " MODEL_NAME=\"\"\n",
+ " \n",
+ "PT=\"\"\n",
+ "\n",
+ "Session_Name = \"\" #@param{type: 'string'}\n",
+ "while Session_Name==\"\":\n",
+ " print('\u001b[1;31mInput the Session Name:') \n",
+ " Session_Name=input('')\n",
+ "Session_Name=Session_Name.replace(\" \",\"_\")\n",
+ "\n",
+ "#@markdown - Enter the session name, it if it exists, it will load it, otherwise it'll create an new session.\n",
+ "\n",
+ "Session_Link_optional = \"\" #@param{type: 'string'}\n",
+ "\n",
+ "#@markdown - Import a session from another gdrive, the shared gdrive link must point to the specific session's folder that contains the trained CKPT, remove any intermediary CKPT if any.\n",
+ "\n",
+ "WORKSPACE='/content/gdrive/MyDrive/Fast-Dreambooth'\n",
+ "\n",
+ "if Session_Link_optional !=\"\":\n",
+ " print('\u001b[1;32mDownloading session...')\n",
+ "with capture.capture_output() as cap:\n",
+ " %cd /content\n",
+ " if Session_Link_optional != \"\":\n",
+ " if not os.path.exists(str(WORKSPACE+'/Sessions')):\n",
+ " %mkdir -p $WORKSPACE'/Sessions'\n",
+ " time.sleep(1)\n",
+ " %cd $WORKSPACE'/Sessions'\n",
+ " !gdown --folder --remaining-ok -O $Session_Name $Session_Link_optional\n",
+ " %cd $Session_Name\n",
+ " !rm -r instance_images\n",
+ " !unzip instance_images.zip\n",
+ " !rm -r concept_images\n",
+ " !unzip concept_images.zip \n",
+ " %cd /content\n",
+ "\n",
+ "\n",
+ "INSTANCE_NAME=Session_Name\n",
+ "OUTPUT_DIR=\"/content/models/\"+Session_Name\n",
+ "SESSION_DIR=WORKSPACE+'/Sessions/'+Session_Name\n",
+ "INSTANCE_DIR=SESSION_DIR+'/instance_images'\n",
+ "CONCEPT_DIR=SESSION_DIR+'/concept_images'\n",
+ "MDLPTH=str(SESSION_DIR+\"/\"+Session_Name+'.ckpt')\n",
+ "\n",
+ "Model_Version = \"1.5\" #@param [ \"1.5\", \"V2.1-512px\", \"V2.1-768px\"]\n",
+ "#@markdown - Ignore this if you're not loading a previous session that contains a trained model\n",
+ "\n",
+ "\n",
+ "if os.path.exists(str(SESSION_DIR)):\n",
+ " mdls=[ckpt for ckpt in listdir(SESSION_DIR) if ckpt.split(\".\")[-1]==\"ckpt\"]\n",
+ " if not os.path.exists(MDLPTH) and '.ckpt' in str(mdls): \n",
+ " \n",
+ " def f(n): \n",
+ " k=0\n",
+ " for i in mdls: \n",
+ " if k==n: \n",
+ " !mv \"$SESSION_DIR/$i\" $MDLPTH\n",
+ " k=k+1\n",
+ "\n",
+ " k=0\n",
+ " print('\u001b[1;33mNo final checkpoint model found, select which intermediary checkpoint to use, enter only the number, (000 to skip):\\n\u001b[1;34m')\n",
+ "\n",
+ " for i in mdls: \n",
+ " print(str(k)+'- '+i)\n",
+ " k=k+1\n",
+ " n=input()\n",
+ " while int(n)>k-1:\n",
+ " n=input() \n",
+ " if n!=\"000\":\n",
+ " f(int(n))\n",
+ " print('\u001b[1;32mUsing the model '+ mdls[int(n)]+\" ...\")\n",
+ " time.sleep(2)\n",
+ " else:\n",
+ " print('\u001b[1;32mSkipping the intermediary checkpoints.')\n",
+ " del n\n",
+ "\n",
+ " \n",
+ "if os.path.exists(str(SESSION_DIR)) and not os.path.exists(MDLPTH):\n",
+ " print('\u001b[1;32mLoading session with no previous model, using the original model or the custom downloaded model')\n",
+ " if MODEL_NAME==\"\":\n",
+ " print('\u001b[1;31mNo model found, use the \"Model Download\" cell to download a model.')\n",
+ " else:\n",
+ " print('\u001b[1;32mSession Loaded, proceed to uploading instance images')\n",
+ "\n",
+ "elif os.path.exists(MDLPTH):\n",
+ " print('\u001b[1;32mSession found, loading the trained model ...')\n",
+ " if Model_Version=='1.5':\n",
+ " !wget -O refmdlz https://github.com/TheLastBen/fast-stable-diffusion/raw/main/Dreambooth/refmdlz\n",
+ " !unzip -o -q refmdlz\n",
+ " !rm -f refmdlz \n",
+ " !wget -O convertodiff.py https://raw.githubusercontent.com/TheLastBen/fast-stable-diffusion/main/Dreambooth/convertodiffv1.py\n",
+ " clear_output()\n",
+ " print('\u001b[1;32mSession found, loading the trained model ...')\n",
+ " !python /content/convertodiff.py \"$MDLPTH\" \"$OUTPUT_DIR\" --v1\n",
+ " !rm -r /content/refmdl\n",
+ " elif Model_Version=='V2.1-512px':\n",
+ " !wget -O convertodiff.py https://raw.githubusercontent.com/TheLastBen/fast-stable-diffusion/main/Dreambooth/convertodiffv2.py\n",
+ " clear_output()\n",
+ " print('\u001b[1;32mSession found, loading the trained model ...')\n",
+ " !python /content/convertodiff.py \"$MDLPTH\" \"$OUTPUT_DIR\" --v2 --reference_model stabilityai/stable-diffusion-2-1-base\n",
+ " elif Model_Version=='V2.1-768px':\n",
+ " !wget -O convertodiff.py https://raw.githubusercontent.com/TheLastBen/fast-stable-diffusion/main/Dreambooth/convertodiffv2.py\n",
+ " clear_output()\n",
+ " print('\u001b[1;32mSession found, loading the trained model ...')\n",
+ " !python /content/convertodiff.py \"$MDLPTH\" \"$OUTPUT_DIR\" --v2 --reference_model stabilityai/stable-diffusion-2-1\n",
+ " !rm /content/convertodiff.py \n",
+ " if os.path.exists(OUTPUT_DIR+'/unet/diffusion_pytorch_model.bin'):\n",
+ " resume=True \n",
+ " clear_output()\n",
+ " print('\u001b[1;32mSession loaded.')\n",
+ " else: \n",
+ " if not os.path.exists(OUTPUT_DIR+'/unet/diffusion_pytorch_model.bin'):\n",
+ " print('\u001b[1;31mConversion error, if the error persists, remove the CKPT file from the current session folder')\n",
+ "\n",
+ "elif not os.path.exists(str(SESSION_DIR)):\n",
+ " %mkdir -p \"$INSTANCE_DIR\"\n",
+ " print('\u001b[1;32mCreating session...')\n",
+ " if MODEL_NAME==\"\":\n",
+ " print('\u001b[1;31mNo model found, use the \"Model Download\" cell to download a model.')\n",
+ " else:\n",
+ " print('\u001b[1;32mSession created, proceed to uploading instance images')\n",
+ "\n",
+ " #@markdown \n",
+ "\n",
+ " #@markdown # The most importent step is to rename the instance pictures of each subject to a unique unknown identifier, example :\n",
+ " #@markdown - If you have 30 pictures of yourself, simply select them all and rename only one to the chosen identifier for example : phtmejhn, the files would be : phtmejhn (1).jpg, phtmejhn (2).png ....etc then upload them, do the same for other people or objects with a different identifier, and that's it.\n",
+ " #@markdown - Check out this example : https://i.imgur.com/d2lD3rz.jpeg"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "LC4ukG60fgMy",
+ "cellView": "form"
+ },
+ "outputs": [],
+ "source": [
+ "import shutil\n",
+ "from google.colab import files\n",
+ "from PIL import Image\n",
+ "from tqdm import tqdm\n",
+ "\n",
+ "#@markdown #Instance Images\n",
+ "#@markdown ----\n",
+ "\n",
+ "#@markdown\n",
+ "#@markdown - Run the cell to upload the instance pictures.\n",
+ "\n",
+ "Remove_existing_instance_images= True #@param{type: 'boolean'}\n",
+ "#@markdown - Uncheck the box to keep the existing instance images.\n",
+ "\n",
+ "\n",
+ "if Remove_existing_instance_images:\n",
+ " if os.path.exists(str(INSTANCE_DIR)):\n",
+ " !rm -r \"$INSTANCE_DIR\"\n",
+ "\n",
+ "if not os.path.exists(str(INSTANCE_DIR)):\n",
+ " %mkdir -p \"$INSTANCE_DIR\"\n",
+ "\n",
+ "IMAGES_FOLDER_OPTIONAL=\"/content/gdrive/MyDrive/A_Training_folder/Cali\" #@param{type: 'string'}\n",
+ "\n",
+ "if os.path.exists(IMAGES_FOLDER_OPTIONAL+\"/.ipynb_checkpoints\"):\n",
+ " %rm -r $IMAGES_FOLDER_OPTIONAL\"/.ipynb_checkpoints\"\n",
+ "if os.path.exists(IMAGES_FOLDER_OPTIONAL+\"/Desktop.ini\"):\n",
+ " %rm -r $IMAGES_FOLDER_OPTIONAL\"/Desktop.ini\"\n",
+ "\n",
+ "#@markdown - If you prefer to specify directly the folder of the pictures instead of uploading, this will add the pictures to the existing (if any) instance images. Leave EMPTY to upload.\n",
+ "\n",
+ "Crop_images= False #@param{type: 'boolean'}\n",
+ "Crop_size = \"576\" #@param [\"512\", \"576\", \"640\", \"704\", \"768\", \"832\", \"896\", \"960\", \"1024\"]\n",
+ "Crop_size=int(Crop_size)\n",
+ "\n",
+ "#@markdown - Unless you want to crop them manually in a precise way, you don't need to crop your instance images externally.\n",
+ "\n",
+ "while IMAGES_FOLDER_OPTIONAL !=\"\" and not os.path.exists(str(IMAGES_FOLDER_OPTIONAL)):\n",
+ " print('\u001b[1;31mThe image folder specified does not exist, use the colab file explorer to copy the path :')\n",
+ " IMAGES_FOLDER_OPTIONAL=input('')\n",
+ "\n",
+ "if IMAGES_FOLDER_OPTIONAL!=\"\":\n",
+ " if Crop_images:\n",
+ " for filename in tqdm(os.listdir(IMAGES_FOLDER_OPTIONAL), bar_format=' |{bar:15}| {n_fmt}/{total_fmt} Uploaded'):\n",
+ " extension = filename.split(\".\")[-1]\n",
+ " identifier=filename.split(\".\")[0]\n",
+ " new_path_with_file = os.path.join(INSTANCE_DIR, filename)\n",
+ " file = Image.open(IMAGES_FOLDER_OPTIONAL+\"/\"+filename)\n",
+ " width, height = file.size\n",
+ " if file.size !=(Crop_size, Crop_size): \n",
+ " side_length = min(width, height)\n",
+ " left = (width - side_length)/2\n",
+ " top = (height - side_length)/2\n",
+ " right = (width + side_length)/2\n",
+ " bottom = (height + side_length)/2\n",
+ " image = file.crop((left, top, right, bottom))\n",
+ " image = image.resize((Crop_size, Crop_size))\n",
+ " if (extension.upper() == \"JPG\"):\n",
+ " image.save(new_path_with_file, format=\"JPEG\", quality = 100)\n",
+ " else:\n",
+ " image.save(new_path_with_file, format=extension.upper())\n",
+ " else:\n",
+ " !cp \"$IMAGES_FOLDER_OPTIONAL/$filename\" \"$INSTANCE_DIR\"\n",
+ "\n",
+ " else:\n",
+ " for filename in tqdm(os.listdir(IMAGES_FOLDER_OPTIONAL), bar_format=' |{bar:15}| {n_fmt}/{total_fmt} Uploaded'):\n",
+ " %cp -r \"$IMAGES_FOLDER_OPTIONAL/$filename\" \"$INSTANCE_DIR\"\n",
+ " \n",
+ " print('\\n\u001b[1;32mDone, proceed to the next cell')\n",
+ "\n",
+ "\n",
+ "elif IMAGES_FOLDER_OPTIONAL ==\"\":\n",
+ " uploaded = files.upload()\n",
+ " if Crop_images:\n",
+ " for filename in tqdm(uploaded.keys(), bar_format=' |{bar:15}| {n_fmt}/{total_fmt} Uploaded'):\n",
+ " shutil.move(filename, INSTANCE_DIR)\n",
+ " extension = filename.split(\".\")[-1]\n",
+ " identifier=filename.split(\".\")[0]\n",
+ " new_path_with_file = os.path.join(INSTANCE_DIR, filename)\n",
+ " file = Image.open(new_path_with_file)\n",
+ " width, height = file.size\n",
+ " if file.size !=(Crop_size, Crop_size): \n",
+ " side_length = min(width, height)\n",
+ " left = (width - side_length)/2\n",
+ " top = (height - side_length)/2\n",
+ " right = (width + side_length)/2\n",
+ " bottom = (height + side_length)/2\n",
+ " image = file.crop((left, top, right, bottom))\n",
+ " image = image.resize((Crop_size, Crop_size))\n",
+ " if (extension.upper() == \"JPG\"):\n",
+ " image.save(new_path_with_file, format=\"JPEG\", quality = 100)\n",
+ " else:\n",
+ " image.save(new_path_with_file, format=extension.upper())\n",
+ " clear_output()\n",
+ " else:\n",
+ " for filename in tqdm(uploaded.keys(), bar_format=' |{bar:15}| {n_fmt}/{total_fmt} Uploaded'):\n",
+ " shutil.move(filename, INSTANCE_DIR)\n",
+ " clear_output()\n",
+ "\n",
+ " print('\\n\u001b[1;32mDone, proceed to the next cell')\n",
+ "\n",
+ "with capture.capture_output() as cap:\n",
+ " %cd \"$INSTANCE_DIR\"\n",
+ " !find . -name \"* *\" -type f | rename 's/ /_/g' \n",
+ "\n",
+ " %cd $SESSION_DIR\n",
+ " !rm instance_images.zip\n",
+ " !zip -r instance_images instance_images\n",
+ " %cd /content"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "LxEv3u8mQos3",
+ "cellView": "form"
+ },
+ "outputs": [],
+ "source": [
+ "import shutil\n",
+ "from google.colab import files\n",
+ "from PIL import Image\n",
+ "from tqdm import tqdm\n",
+ "\n",
+ "#@markdown #Concept Images (Regularization)\n",
+ "#@markdown ----\n",
+ "\n",
+ "#@markdown\n",
+ "#@markdown - Run this `optional` cell to upload concept pictures. If you're traning on a specific face, skip this cell.\n",
+ "#@markdown - Training a model on a restricted number of instance images tends to indoctrinate it and limit its imagination, so concept images help re-opening its \"mind\" to diversity and greatly widen the range of possibilities of the output, concept images should contain anything related to the instance pictures, including objects, ideas, scenes, phenomenons, concepts (obviously), don't be afraid to slightly diverge from the trained style.\n",
+ "\n",
+ "Remove_existing_concept_images= False #@param{type: 'boolean'}\n",
+ "#@markdown - Uncheck the box to keep the existing concept images.\n",
+ "\n",
+ "\n",
+ "if Remove_existing_concept_images:\n",
+ " if os.path.exists(str(CONCEPT_DIR)):\n",
+ " !rm -r \"$CONCEPT_DIR\"\n",
+ "\n",
+ "\n",
+ "if not os.path.exists(str(CONCEPT_DIR)):\n",
+ " %mkdir -p \"$CONCEPT_DIR\"\n",
+ "\n",
+ "IMAGES_FOLDER_OPTIONAL=\"/content/gdrive/MyDrive/A_Training_folder/woman2\" #@param{type: 'string'}\n",
+ "if os.path.exists(IMAGES_FOLDER_OPTIONAL+\"/.ipynb_checkpoints\"):\n",
+ " %rm -r $IMAGES_FOLDER_OPTIONAL\"/.ipynb_checkpoints\"\n",
+ "if os.path.exists(IMAGES_FOLDER_OPTIONAL+\"/Desktop.ini\"):\n",
+ " %rm -r $IMAGES_FOLDER_OPTIONAL\"/Desktop.ini\"\n",
+ "#@markdown - If you prefer to specify directly the folder of the pictures instead of uploading, this will add the pictures to the existing (if any) concept images. Leave EMPTY to upload.\n",
+ "\n",
+ "Crop_images= True \n",
+ "Crop_size = \"512\"\n",
+ "Crop_size=int(Crop_size)\n",
+ "\n",
+ "while IMAGES_FOLDER_OPTIONAL !=\"\" and not os.path.exists(str(IMAGES_FOLDER_OPTIONAL)):\n",
+ " print('\u001b[1;31mThe image folder specified does not exist, use the colab file explorer to copy the path :')\n",
+ " IMAGES_FOLDER_OPTIONAL=input('')\n",
+ "\n",
+ "if IMAGES_FOLDER_OPTIONAL!=\"\":\n",
+ " if Crop_images:\n",
+ " for filename in tqdm(os.listdir(IMAGES_FOLDER_OPTIONAL), bar_format=' |{bar:15}| {n_fmt}/{total_fmt} Uploaded'):\n",
+ " extension = filename.split(\".\")[-1]\n",
+ " identifier=filename.split(\".\")[0]\n",
+ " new_path_with_file = os.path.join(CONCEPT_DIR, filename)\n",
+ " file = Image.open(IMAGES_FOLDER_OPTIONAL+\"/\"+filename)\n",
+ " width, height = file.size\n",
+ " if file.size !=(Crop_size, Crop_size): \n",
+ " side_length = min(width, height)\n",
+ " left = (width - side_length)/2\n",
+ " top = (height - side_length)/2\n",
+ " right = (width + side_length)/2\n",
+ " bottom = (height + side_length)/2\n",
+ " image = file.crop((left, top, right, bottom))\n",
+ " image = image.resize((Crop_size, Crop_size))\n",
+ " if (extension.upper() == \"JPG\"):\n",
+ " image.save(new_path_with_file, format=\"JPEG\", quality = 100)\n",
+ " else:\n",
+ " image.save(new_path_with_file, format=extension.upper())\n",
+ " else:\n",
+ " !cp \"$IMAGES_FOLDER_OPTIONAL/$filename\" \"$CONCEPT_DIR\"\n",
+ "\n",
+ " else:\n",
+ " for filename in tqdm(os.listdir(IMAGES_FOLDER_OPTIONAL), bar_format=' |{bar:15}| {n_fmt}/{total_fmt} Uploaded'):\n",
+ " %cp -r \"$IMAGES_FOLDER_OPTIONAL/$filename\" \"$CONCEPT_DIR\"\n",
+ " \n",
+ "elif IMAGES_FOLDER_OPTIONAL ==\"\":\n",
+ " uploaded = files.upload()\n",
+ " if Crop_images:\n",
+ " for filename in tqdm(uploaded.keys(), bar_format=' |{bar:15}| {n_fmt}/{total_fmt} Uploaded'):\n",
+ " shutil.move(filename, CONCEPT_DIR)\n",
+ " extension = filename.split(\".\")[-1]\n",
+ " identifier=filename.split(\".\")[0]\n",
+ " new_path_with_file = os.path.join(CONCEPT_DIR, filename)\n",
+ " file = Image.open(new_path_with_file)\n",
+ " width, height = file.size\n",
+ " if file.size !=(Crop_size, Crop_size): \n",
+ " side_length = min(width, height)\n",
+ " left = (width - side_length)/2\n",
+ " top = (height - side_length)/2\n",
+ " right = (width + side_length)/2\n",
+ " bottom = (height + side_length)/2\n",
+ " image = file.crop((left, top, right, bottom))\n",
+ " image = image.resize((Crop_size, Crop_size))\n",
+ " if (extension.upper() == \"JPG\"):\n",
+ " image.save(new_path_with_file, format=\"JPEG\", quality = 100)\n",
+ " else:\n",
+ " image.save(new_path_with_file, format=extension.upper())\n",
+ " clear_output()\n",
+ " else:\n",
+ " for filename in tqdm(uploaded.keys(), bar_format=' |{bar:15}| {n_fmt}/{total_fmt} Uploaded'):\n",
+ " shutil.move(filename, CONCEPT_DIR)\n",
+ " clear_output()\n",
+ "\n",
+ " \n",
+ "print('\\n\u001b[1;32mAlmost done...')\n",
+ "with capture.capture_output() as cap: \n",
+ " i=0\n",
+ " for filename in os.listdir(CONCEPT_DIR):\n",
+ " extension = filename.split(\".\")[-1]\n",
+ " identifier=filename.split(\".\")[0]\n",
+ " new_path_with_file = os.path.join(CONCEPT_DIR, \"conceptimagedb\"+str(i)+\".\"+extension)\n",
+ " filepath=os.path.join(CONCEPT_DIR,filename)\n",
+ " !mv \"$filepath\" $new_path_with_file\n",
+ " i=i+1\n",
+ "\n",
+ " %cd $SESSION_DIR\n",
+ " !rm concept_images.zip\n",
+ " !zip -r concept_images concept_images\n",
+ " %cd /content\n",
+ "\n",
+ "print('\\n\u001b[1;32mDone, proceed to the training cell')"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ZnmQYfZilzY6"
+ },
+ "source": [
+ "# Training"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "id": "1-9QbkfAVYYU"
+ },
+ "outputs": [],
+ "source": [
+ "#@markdown ---\n",
+ "#@markdown #Start DreamBooth\n",
+ "#@markdown ---\n",
+ "import os\n",
+ "from subprocess import getoutput\n",
+ "from IPython.display import clear_output\n",
+ "from google.colab import runtime\n",
+ "import time\n",
+ "import random\n",
+ "\n",
+ "# Determine number of images in the Instance folder\n",
+ "Img_Count = (len([entry for entry in os.listdir(INSTANCE_DIR) if os.path.isfile(os.path.join(INSTANCE_DIR, entry))]))\n",
+ "\n",
+ "if os.path.exists(INSTANCE_DIR+\"/.ipynb_checkpoints\"):\n",
+ " %rm -r $INSTANCE_DIR\"/.ipynb_checkpoints\"\n",
+ "\n",
+ "if os.path.exists(CONCEPT_DIR+\"/.ipynb_checkpoints\"):\n",
+ " %rm -r $CONCEPT_DIR\"/.ipynb_checkpoints\" \n",
+ "\n",
+ "Resume_Training = False #@param {type:\"boolean\"}\n",
+ "# user input request if a prior training has been started\n",
+ "# but resume is not selected\n",
+ "try:\n",
+ " resume\n",
+ " if resume and not Resume_Training:\n",
+ " print('\u001b[1;31mOverwrite your previously trained model ?, answering \"yes\" will train a new model, answering \"no\" will resume the training of the previous model? yes or no ?\u001b[0m')\n",
+ " while True:\n",
+ " ansres=input('')\n",
+ " if ansres=='no':\n",
+ " Resume_Training = True\n",
+ " del ansres\n",
+ " break\n",
+ " elif ansres=='yes':\n",
+ " Resume_Training = False\n",
+ " resume= False\n",
+ " break\n",
+ "except:\n",
+ " pass\n",
+ "\n",
+ "while not Resume_Training and MODEL_NAME==\"\":\n",
+ " print('\u001b[1;31mNo model found, use the \"Model Download\" cell to download a model.')\n",
+ " time.sleep(5)\n",
+ "\n",
+ "#@markdown - If you're not satisfied with the result, check this box, run again the cell and it will continue training the current model.\n",
+ "\n",
+ "\n",
+ "\n",
+ "# declare Unet training Vaiables\n",
+ "\n",
+ "MODELT_NAME=MODEL_NAME\n",
+ "Repeats=50 #@param{type:\"number\"}\n",
+ "warmup_steps=0 #@param{type:\"number\"}\n",
+ "wu=warmup_steps\n",
+ "batch_size=4 #@param{type:\"number\"}\n",
+ "bs=batch_size\n",
+ "gradient_steps=2 #@param{type:\"number\"}\n",
+ "gs=gradient_steps\n",
+ "UNet_Training_Steps=((Repeats*Img_Count)/(gs*bs))\n",
+ "UNet_Learning_Rate = 2e-6 #@param [\"2e-6\", \"1e-6\", \"1e-5\", \"1e-4\", \"5e-7\"] {type:\"raw\", allow-input: true}\n",
+ "\n",
+ "#@markdown * 1e-7 is lowest, 1e-4 is the highest, 2e-7 is twice as fast as 1e-7 experiment and adjust the repeats to accomidate diffrent learning rates \n",
+ "\n",
+ "lr_schedule = \"polynomial\" #@param [\"polynomial\", \"constant\"] {allow-input: true}\n",
+ "untlr=UNet_Learning_Rate\n",
+ "UNet_Training_Steps=int(UNet_Training_Steps+wu)\n",
+ "\n",
+ "#@markdown - These default settings are for a dataset of 10 pictures which is enough for training a face, start with 650 or lower, test the model, if not enough, resume training for 150 steps, keep testing until you get the desired output, `set it to 0 to train only the text_encoder`. \n",
+ "\n",
+ "Text_Encoder_Training_steps=0 #@param{type: 'number'}\n",
+ "#@markdown - 200-450 steps is enough for a small dataset, keep this number small to avoid overfitting, set to 0 to disable, `set it to 0 before resuming training if it is already trained`.\n",
+ "\n",
+ "# declare text batch size\n",
+ "Text_Batch_Size = 7 #@param {type:\"integer\"}\n",
+ "tbs=Text_Batch_Size\n",
+ "\n",
+ "Text_Encoder_Concept_Training_steps=0 #@param{type: 'number'}\n",
+ "# adjust text steps for batch size\n",
+ "Text_Encoder_Concept_Training_Steps=(Text_Encoder_Concept_Training_steps/tbs)\n",
+ "Text_Encoder_Training_Steps=(Text_Encoder_Training_steps/tbs)\n",
+ "Text_Encoder_Concept_Training_Steps=int(Text_Encoder_Concept_Training_Steps)\n",
+ "Text_Encoder_Training_Steps=int(Text_Encoder_Training_Steps)\n",
+ "#@markdown - Suitable for training a style/concept as it acts as heavy regularization, set it to 1500 steps for 200 concept images (you can go higher), set to 0 to disable, set both the settings above to 0 to fintune only the text_encoder on the concept, `set it to 0 before resuming training if it is already trained`.\n",
+ "\n",
+ "Text_Encoder_Learning_Rate = 2e-6 #@param [\"2e-6\", \"8e-7\", \"6e-7\", \"5e-7\", \"4e-7\"] {type:\"raw\", allow-input: true}\n",
+ "txlr=Text_Encoder_Learning_Rate\n",
+ "\n",
+ "#@markdown - Learning rate for both text_encoder and concept_text_encoder, keep it low to avoid overfitting (1e-7 is lowest, 1e-4 is the highest, 2e-7 is twice as fast as 1e-7 experiment and adjust the repeats to accomidate diffrent learning rates )\n",
+ "\n",
+ "trnonltxt=\"\"\n",
+ "if UNet_Training_Steps==0:\n",
+ " trnonltxt=\"--train_only_text_encoder\"\n",
+ "\n",
+ "Seed = 42825032 #@param {type:\"integer\"}\n",
+ "\n",
+ "Style_Training = False #@param {type:\"boolean\"}\n",
+ "\n",
+ "#@markdown -Forced Drop out, Drops caption from images, helps fine tuning a style without over-fitting simpsons model could of benefitted from this\n",
+ "\n",
+ "Style=\"\"\n",
+ "if Style_Training:\n",
+ " Style = \"--Style\"\n",
+ "\n",
+ "Flip_Images = True #@param {type:\"boolean\"}\n",
+ "Percent_to_flip = 10 #@param{type:\"raw\"}\n",
+ "flip_rate = (Percent_to_flip/100)\n",
+ "\n",
+ "#@markdown Flip a random 10% of images, helps add veriety to smaller data-sets\n",
+ "\n",
+ "flip=\"\"\n",
+ "if Flip_Images:\n",
+ " flip=\"--hflip\"\n",
+ "\n",
+ "Conditional_dropout = 10 #@param {type:\"raw\"}\n",
+ "\n",
+ "#@markdown drop a random X% of images, helps avoid over fitting, very similar to style training\n",
+ "\n",
+ "drop='0'\n",
+ "drop= (Conditional_dropout/100)\n",
+ "\n",
+ "\n",
+ "\n",
+ "\n",
+ "Resolution = \"512\" #@param [\"512\", \"576\", \"640\", \"704\", \"768\", \"832\", \"896\", \"960\", \"1024\"]\n",
+ "Res=int(Resolution)\n",
+ "\n",
+ "#@markdown - Higher resolution = Higher quality, make sure the instance images are cropped to this selected size (or larger).\n",
+ "\n",
+ "fp16 = True\n",
+ "\n",
+ "if Seed =='' or Seed=='0':\n",
+ " Seed=random.randint(1, 999999)\n",
+ "else:\n",
+ " Seed=int(Seed)\n",
+ "\n",
+ "GC=\"--gradient_checkpointing\"\n",
+ "\n",
+ "if fp16:\n",
+ " prec=\"fp16\"\n",
+ "else:\n",
+ " prec=\"no\"\n",
+ "\n",
+ "s = getoutput('nvidia-smi')\n",
+ "if 'A100' in s:\n",
+ " GC=\"\"\n",
+ "\n",
+ "precision=prec\n",
+ "\n",
+ "resuming=\"\"\n",
+ "if Resume_Training and os.path.exists(OUTPUT_DIR+'/unet/diffusion_pytorch_model.bin'):\n",
+ " MODELT_NAME=OUTPUT_DIR\n",
+ " print('\u001b[1;32mResuming Training...\u001b[0m')\n",
+ " resuming=\"Yes\"\n",
+ "elif Resume_Training and not os.path.exists(OUTPUT_DIR+'/unet/diffusion_pytorch_model.bin'):\n",
+ " print('\u001b[1;31mPrevious model not found, training a new model...\u001b[0m')\n",
+ " MODELT_NAME=MODEL_NAME\n",
+ " while MODEL_NAME==\"\":\n",
+ " print('\u001b[1;31mNo model found, use the \"Model Download\" cell to download a model.')\n",
+ " time.sleep(5)\n",
+ "\n",
+ "V2=False\n",
+ "if os.path.getsize(MODELT_NAME+\"/text_encoder/pytorch_model.bin\") > 670901463:\n",
+ " V2=True\n",
+ "\n",
+ "Enable_text_encoder_training= True \n",
+ "Enable_Text_Encoder_Concept_Training= True\n",
+ "\n",
+ "if Text_Encoder_Training_Steps==0:\n",
+ " Enable_text_encoder_training= False\n",
+ "else:\n",
+ " stptxt=Text_Encoder_Training_Steps\n",
+ "\n",
+ "if Text_Encoder_Concept_Training_Steps==0:\n",
+ " Enable_Text_Encoder_Concept_Training= False\n",
+ "else:\n",
+ " stptxtc=Text_Encoder_Concept_Training_Steps\n",
+ "\n",
+ "\n",
+ "if Enable_text_encoder_training:\n",
+ " Textenc=\"--train_text_encoder\"\n",
+ "else:\n",
+ " Textenc=\"\"\n",
+ "\n",
+ "#@markdown ---------------------------\n",
+ "Save_Checkpoint_Every_n_Steps = True #@param {type:\"boolean\"}\n",
+ "#@markdown How many repats/epochs between saves\n",
+ "Save_Checkpoint_Every=25 #@param{type: 'number'}\n",
+ "stp=0\n",
+ "stpsv=10\n",
+ "if Save_Checkpoint_Every_n_Steps:\n",
+ " stp=((Save_Checkpoint_Every*Img_Count)/(gs*bs))\n",
+ "stp=int(stp)\n",
+ "Number_Of_Samples = 4 #@param {type:\"integer\"}\n",
+ "NoS=Number_Of_Samples\n",
+ "\n",
+ "prompt= \"\" #@param{type:\"string\"}\n",
+ "Disconnect_after_training=False #@param {type:\"boolean\"}\n",
+ "\n",
+ "#@markdown - Auto-disconnect from google colab after the training to avoid wasting compute units.\n",
+ "\n",
+ "def dump_only_textenc(trnonltxt, MODELT_NAME, INSTANCE_DIR, OUTPUT_DIR, PT, Seed, precision, Training_Steps):\n",
+ " \n",
+ " !accelerate launch /content/diffusers/examples/dreambooth/train_dreambooth.py \\\n",
+ " $trnonltxt \\\n",
+ " --image_captions_filename \\\n",
+ " --train_text_encoder \\\n",
+ " --dump_only_text_encoder \\\n",
+ " --pretrained_model_name_or_path=\"$MODELT_NAME\" \\\n",
+ " --instance_data_dir=\"$INSTANCE_DIR\" \\\n",
+ " --output_dir=\"$OUTPUT_DIR\" \\\n",
+ " --instance_prompt=\"$PT\" \\\n",
+ " --seed=$Seed \\\n",
+ " --resolution=512 \\\n",
+ " --mixed_precision=$precision \\\n",
+ " --train_batch_size=$tbs \\\n",
+ " --gradient_accumulation_steps=1 $GC \\\n",
+ " --use_8bit_adam \\\n",
+ " --learning_rate=$txlr \\\n",
+ " --lr_scheduler=\"polynomial\" \\\n",
+ " --lr_warmup_steps=10 \\\n",
+ " --max_train_steps=$Training_Steps\n",
+ "\n",
+ "def train_only_unet(stpsv, stp, SESSION_DIR, MODELT_NAME, INSTANCE_DIR, OUTPUT_DIR, PT, Seed, Res, precision, Training_Steps):\n",
+ " clear_output()\n",
+ " if resuming==\"Yes\":\n",
+ " print('\u001b[1;32mResuming Training...\u001b[0m') \n",
+ " print('\u001b[1;33mTraining the UNet...\u001b[0m Saving every:'+str(stp)+' Steps')\n",
+ " !accelerate launch /content/dreamboothtrainers/Trainer.py \\\n",
+ " $Style \\\n",
+ " $flip \\\n",
+ " --image_captions_filename \\\n",
+ " --train_only_unet \\\n",
+ " --save_starting_step=$stpsv \\\n",
+ " --save_n_steps=$stp \\\n",
+ " --Session_dir=$SESSION_DIR \\\n",
+ " --pretrained_model_name_or_path=\"$MODELT_NAME\" \\\n",
+ " --instance_data_dir=\"$INSTANCE_DIR\" \\\n",
+ " --output_dir=\"$OUTPUT_DIR\" \\\n",
+ " --instance_prompt=\"$PT\" \\\n",
+ " --n_save_sample=$NoS \\\n",
+ " --save_sample_prompt=\"$prompt\" \\\n",
+ " --seed=$Seed \\\n",
+ " --resolution=$Res \\\n",
+ " --mixed_precision=$precision \\\n",
+ " --train_batch_size=$bs \\\n",
+ " --gradient_accumulation_steps=$gs $GC \\\n",
+ " --use_8bit_adam \\\n",
+ " --learning_rate=$untlr \\\n",
+ " --lr_scheduler=\"$lr_schedule\" \\\n",
+ " --Drop_out=$drop \\\n",
+ " --flip_rate=$flip_rate \\\n",
+ " --lr_warmup_steps=$wu \\\n",
+ " --max_train_steps=$Training_Steps\n",
+ "\n",
+ "\n",
+ "if Enable_text_encoder_training :\n",
+ " print('\u001b[1;33mTraining the text encoder...\u001b[0m')\n",
+ " if os.path.exists(OUTPUT_DIR+'/'+'text_encoder_trained'):\n",
+ " %rm -r $OUTPUT_DIR\"/text_encoder_trained\"\n",
+ " dump_only_textenc(trnonltxt, MODELT_NAME, INSTANCE_DIR, OUTPUT_DIR, PT, Seed, precision, Training_Steps=stptxt)\n",
+ "\n",
+ "if Enable_Text_Encoder_Concept_Training:\n",
+ " if os.path.exists(CONCEPT_DIR):\n",
+ " if os.listdir(CONCEPT_DIR)!=[]:\n",
+ " # clear_output()\n",
+ " if resuming==\"Yes\":\n",
+ " print('\u001b[1;32mResuming Training...\u001b[0m') \n",
+ " print('\u001b[1;33mTraining the text encoder on the concept...\u001b[0m')\n",
+ " dump_only_textenc(trnonltxt, MODELT_NAME, CONCEPT_DIR, OUTPUT_DIR, PT, Seed, precision, Training_Steps=stptxtc)\n",
+ " else:\n",
+ " # clear_output()\n",
+ " if resuming==\"Yes\":\n",
+ " print('\u001b[1;32mResuming Training...\u001b[0m') \n",
+ " print('\u001b[1;31mNo concept images found, skipping concept training...')\n",
+ " time.sleep(8)\n",
+ " else:\n",
+ " #clear_output()\n",
+ " if resuming==\"Yes\":\n",
+ " print('\u001b[1;32mResuming Training...\u001b[0m')\n",
+ " print('\u001b[1;31mNo concept images found, skipping concept training...')\n",
+ " time.sleep(8)\n",
+ " \n",
+ "if UNet_Training_Steps!=0:\n",
+ " train_only_unet(stpsv, stp, SESSION_DIR, MODELT_NAME, INSTANCE_DIR, OUTPUT_DIR, PT, Seed, Res, precision, Training_Steps=UNet_Training_Steps)\n",
+ " \n",
+ "\n",
+ "if os.path.exists('/content/models/'+INSTANCE_NAME+'/unet/diffusion_pytorch_model.bin'):\n",
+ " prc=\"--fp16\" if precision==\"fp16\" else \"\"\n",
+ " if V2:\n",
+ " !python /content/diffusers/scripts/convertosdv2.py $prc $OUTPUT_DIR $SESSION_DIR/$Session_Name\".ckpt\"\n",
+ " #clear_output()\n",
+ " if os.path.exists(SESSION_DIR+\"/\"+INSTANCE_NAME+'.ckpt'):\n",
+ " #clear_output()\n",
+ " print(\"\u001b[1;32mDONE, the CKPT model is in your Gdrive in the sessions folder\")\n",
+ " if Disconnect_after_training :\n",
+ " time.sleep(20) \n",
+ " runtime.unassign() \n",
+ " else:\n",
+ " print(\"\u001b[1;31mSomething went wrong\") \n",
+ " else: \n",
+ " !wget -O /content/convertosd.py https://github.com/TheLastBen/fast-stable-diffusion/raw/main/Dreambooth/convertosd.py\n",
+ " #clear_output()\n",
+ " if precision==\"no\":\n",
+ " !sed -i '226s@.*@@' /content/convertosd.py\n",
+ " !sed -i '201s@.*@ model_path = \"{OUTPUT_DIR}\"@' /content/convertosd.py\n",
+ " !sed -i '202s@.*@ checkpoint_path= \"{SESSION_DIR}/{Session_Name}.ckpt\"@' /content/convertosd.py\n",
+ " !python /content/convertosd.py\n",
+ "\n",
+ " #clear_output()\n",
+ " if os.path.exists(SESSION_DIR+\"/\"+INSTANCE_NAME+'.ckpt'): \n",
+ " print(\"\u001b[1;32mDONE, the CKPT model is in your Gdrive in the sessions folder\")\n",
+ " if Disconnect_after_training :\n",
+ " time.sleep(20)\n",
+ " runtime.unassign()\n",
+ " else:\n",
+ " print(\"\u001b[1;31mSomething went wrong\")\n",
+ " \n",
+ "else:\n",
+ " print(\"\u001b[1;31mSomething went wrong\")"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "ehi1KKs-l-ZS"
+ },
+ "source": [
+ "# Test The Trained Model"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "id": "iAZGngFcI8hq"
+ },
+ "outputs": [],
+ "source": [
+ "import os\n",
+ "import time\n",
+ "import sys\n",
+ "import fileinput\n",
+ "from IPython.display import clear_output\n",
+ "from subprocess import getoutput\n",
+ "from IPython.utils import capture\n",
+ "\n",
+ "\n",
+ "Model_Version = \"1.5\" #@param [\"1.5\", \"V2.1-512\", \"V2.1-768\"]\n",
+ "#@markdown - Important! Choose the correct version and resolution of the model\n",
+ "\n",
+ "Update_repo = True\n",
+ "\n",
+ "Session__Name=\"\" #@param{type: 'string'}\n",
+ "\n",
+ "#@markdown - Leave empty if you want to use the current trained model.\n",
+ "\n",
+ "Use_Custom_Path = True #@param {type:\"boolean\"}\n",
+ "\n",
+ "try:\n",
+ " INSTANCE_NAME\n",
+ " INSTANCET=INSTANCE_NAME \n",
+ "except:\n",
+ " pass\n",
+ "#@markdown - if checked, an input box will ask the full path to a desired model.\n",
+ "\n",
+ "if Session__Name!=\"\":\n",
+ " INSTANCET=Session__Name\n",
+ " INSTANCET=INSTANCET.replace(\" \",\"_\")\n",
+ "\n",
+ "if Use_Custom_Path:\n",
+ " try:\n",
+ " INSTANCET\n",
+ " del INSTANCET\n",
+ " except:\n",
+ " pass\n",
+ "\n",
+ "try:\n",
+ " INSTANCET\n",
+ " if Session__Name!=\"\":\n",
+ " path_to_trained_model='/content/gdrive/MyDrive/Fast-Dreambooth/Sessions/'+Session__Name+\"/\"+Session__Name+'.ckpt'\n",
+ " else:\n",
+ " path_to_trained_model=SESSION_DIR+\"/\"+INSTANCET+'.ckpt'\n",
+ "except:\n",
+ " print('\u001b[1;31mIt seems that you did not perform training during this session \u001b[1;32mor you chose to use a custom path,\\nprovide the full path to the model (including the name of the model):\\n')\n",
+ " path_to_trained_model=input()\n",
+ " \n",
+ "while not os.path.exists(path_to_trained_model):\n",
+ " print(\"\u001b[1;31mThe model doesn't exist on you Gdrive, use the file explorer to get the path : \")\n",
+ " path_to_trained_model=input()\n",
+ "\n",
+ " \n",
+ "with capture.capture_output() as cap:\n",
+ " %cd /content/gdrive/MyDrive/\n",
+ " %mkdir sd\n",
+ " %cd sd\n",
+ " !git clone https://github.com/Stability-AI/stablediffusion\n",
+ " !git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui\n",
+ " %cd /content/gdrive/MyDrive/sd/stable-diffusion-webui/\n",
+ " !mkdir -p cache/{huggingface,torch}\n",
+ " %cd /content/\n",
+ " !ln -s /content/gdrive/MyDrive/sd/stable-diffusion-webui/cache/huggingface ../root/.cache/\n",
+ " !ln -s /content/gdrive/MyDrive/sd/stable-diffusion-webui/cache/torch ../root/.cache/\n",
+ "\n",
+ "if Update_repo:\n",
+ " with capture.capture_output() as cap:\n",
+ " !rm /content/gdrive/MyDrive/sd/stable-diffusion-webui/webui.sh\n",
+ " !rm /content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/paths.py\n",
+ " !rm /content/gdrive/MyDrive/sd/stable-diffusion-webui/webui.py\n",
+ " !rm /content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/ui.py\n",
+ " !rm /content/gdrive/MyDrive/sd/stable-diffusion-webui/style.css\n",
+ " !rm /content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/shared.py\n",
+ " %cd /content/gdrive/MyDrive/sd/stable-diffusion-webui/\n",
+ " print('\u001b[1;32m')\n",
+ " !git pull\n",
+ "\n",
+ "\n",
+ "with capture.capture_output() as cap:\n",
+ " \n",
+ " if not os.path.exists('/content/gdrive/MyDrive/sd/stablediffusion/src/k-diffusion/k_diffusion'):\n",
+ " !mkdir /content/gdrive/MyDrive/sd/stablediffusion/src\n",
+ " %cd /content/gdrive/MyDrive/sd/stablediffusion/src\n",
+ " !git clone https://github.com/CompVis/taming-transformers\n",
+ " !git clone https://github.com/openai/CLIP\n",
+ " !git clone https://github.com/salesforce/BLIP\n",
+ " !git clone https://github.com/sczhou/CodeFormer\n",
+ " !git clone https://github.com/crowsonkb/k-diffusion\n",
+ " !mv /content/gdrive/MyDrive/sd/stablediffusion/src/CLIP /content/gdrive/MyDrive/sd/stablediffusion/src/clip\n",
+ " !mv /content/gdrive/MyDrive/sd/stablediffusion/src/BLIP /content/gdrive/MyDrive/sd/stablediffusion/src/blip\n",
+ " !mv /content/gdrive/MyDrive/sd/stablediffusion/src/CodeFormer /content/gdrive/MyDrive/sd/stablediffusion/src/codeformer\n",
+ " !cp -r /content/gdrive/MyDrive/sd/stablediffusion/src/k-diffusion/k_diffusion /content/gdrive/MyDrive/sd/stable-diffusion-webui/\n",
+ "\n",
+ "\n",
+ "with capture.capture_output() as cap: \n",
+ " %cd /content/gdrive/MyDrive/sd/stable-diffusion-webui/modules\n",
+ " !wget -O paths.py https://raw.githubusercontent.com/TheLastBen/fast-stable-diffusion/main/AUTOMATIC1111_files/paths.py\n",
+ "\n",
+ "with capture.capture_output() as cap:\n",
+ " if not os.path.exists('/tools/node/bin/lt'):\n",
+ " !npm install -g localtunnel\n",
+ "\n",
+ "with capture.capture_output() as cap:\n",
+ " %cd /content/gdrive/MyDrive/sd/stable-diffusion-webui/\n",
+ " !wget -O webui.py https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/webui.py\n",
+ " !sed -i 's@ui.create_ui().*@ui.create_ui();shared.demo.queue(concurrency_count=999999,status_update_rate=0.1)@' /content/gdrive/MyDrive/sd/stable-diffusion-webui/webui.py\n",
+ " %cd /content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/\n",
+ " !wget -O shared.py https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/modules/shared.py\n",
+ " !wget -O ui.py https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/modules/ui.py\n",
+ " !sed -i 's@css = \"\".*@with open(os.path.join(script_path, \"style.css\"), \"r\", encoding=\"utf8\") as file:\\n css = file.read()@' /content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/ui.py\n",
+ " %cd /content/gdrive/MyDrive/sd/stable-diffusion-webui\n",
+ " !wget -O style.css https://raw.githubusercontent.com/AUTOMATIC1111/stable-diffusion-webui/master/style.css\n",
+ " !sed -i 's@min-height: 4.*@min-height: 5.5em;@g' /content/gdrive/MyDrive/sd/stable-diffusion-webui/style.css\n",
+ " !sed -i 's@\"multiple_tqdm\": true,@\\\"multiple_tqdm\": false,@' /content/gdrive/MyDrive/sd/stable-diffusion-webui/config.json\n",
+ " !sed -i '902s@.*@ self.logvar = self.logvar.to(self.device)@' /content/gdrive/MyDrive/sd/stablediffusion/ldm/models/diffusion/ddpm.py\n",
+ " %cd /content\n",
+ "\n",
+ "\n",
+ "Use_Gradio_Server = False #@param {type:\"boolean\"}\n",
+ "#@markdown - Only if you have trouble connecting to the local server.\n",
+ "\n",
+ "Large_Model= False #@param {type:\"boolean\"}\n",
+ "#@markdown - Check if you have trouble loading a model 7GB+\n",
+ "\n",
+ "if Large_Model:\n",
+ " !sed -i 's@cmd_opts.lowram else \\\"cpu\\\"@cmd_opts.lowram else \\\"cuda\\\"@' /content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/shared.py\n",
+ "else:\n",
+ " !sed -i 's@cmd_opts.lowram else \\\"cuda\\\"@cmd_opts.lowram else \\\"cpu\\\"@' /content/gdrive/MyDrive/sd/stable-diffusion-webui/modules/shared.py\n",
+ "\n",
+ "\n",
+ "share=''\n",
+ "if Use_Gradio_Server:\n",
+ " share='--share'\n",
+ " for line in fileinput.input('/usr/local/lib/python3.8/dist-packages/gradio/blocks.py', inplace=True):\n",
+ " if line.strip().startswith('self.server_name ='):\n",
+ " line = ' self.server_name = server_name\\n'\n",
+ " if line.strip().startswith('self.server_port ='):\n",
+ " line = ' self.server_port = server_port\\n'\n",
+ " sys.stdout.write(line)\n",
+ " clear_output()\n",
+ " \n",
+ "else:\n",
+ " share=''\n",
+ " !nohup lt --port 7860 > srv.txt 2>&1 &\n",
+ " time.sleep(2)\n",
+ " !grep -o 'https[^ ]*' /content/srv.txt >srvr.txt\n",
+ " time.sleep(2)\n",
+ " srv= getoutput('cat /content/srvr.txt')\n",
+ "\n",
+ " for line in fileinput.input('/usr/local/lib/python3.8/dist-packages/gradio/blocks.py', inplace=True):\n",
+ " if line.strip().startswith('self.server_name ='):\n",
+ " line = f' self.server_name = \"{srv[8:]}\"\\n'\n",
+ " if line.strip().startswith('self.server_port ='):\n",
+ " line = ' self.server_port = 443\\n'\n",
+ " if line.strip().startswith('self.protocol = \"https\"'):\n",
+ " line = ' self.protocol = \"https\"\\n'\n",
+ " if line.strip().startswith('if self.local_url.startswith(\"https\") or self.is_colab'):\n",
+ " line = '' \n",
+ " if line.strip().startswith('else \"http\"'):\n",
+ " line = '' \n",
+ " sys.stdout.write(line)\n",
+ " \n",
+ "\n",
+ " !sed -i '13s@.*@ \"PUBLIC_SHARE_TRUE\": \"\u001b[32mConnected\",@' /usr/local/lib/python3.8/dist-packages/gradio/strings.py\n",
+ " \n",
+ " !rm /content/srv.txt\n",
+ " !rm /content/srvr.txt\n",
+ " clear_output()\n",
+ "\n",
+ "with capture.capture_output() as cap:\n",
+ " %cd /content/gdrive/MyDrive/sd/stablediffusion/\n",
+ "\n",
+ "if Model_Version == \"V2.1-768\":\n",
+ " configf=\"--config /content/gdrive/MyDrive/sd/stablediffusion/configs/stable-diffusion/v2-inference-v.yaml\"\n",
+ " !sed -i 's@def load_state_dict(checkpoint_path: str, map_location.*@def load_state_dict(checkpoint_path: str, map_location=\"cuda\"):@' /usr/local/lib/python3.8/dist-packages/open_clip/factory.py\n",
+ " NM=\"True\"\n",
+ "elif Model_Version == \"V2.1-512\":\n",
+ " configf=\"--config /content/gdrive/MyDrive/sd/stablediffusion/configs/stable-diffusion/v2-inference.yaml\"\n",
+ " !sed -i 's@def load_state_dict(checkpoint_path: str, map_location.*@def load_state_dict(checkpoint_path: str, map_location=\"cuda\"):@' /usr/local/lib/python3.8/dist-packages/open_clip/factory.py\n",
+ " NM=\"True\"\n",
+ "else:\n",
+ " configf=\"\"\n",
+ " !sed -i 's@def load_state_dict(checkpoint_path: str, map_location.*@def load_state_dict(checkpoint_path: str, map_location=\"cpu\"):@' /usr/local/lib/python3.8/dist-packages/open_clip/factory.py\n",
+ " NM=\"False\"\n",
+ "\n",
+ "if os.path.exists('/usr/local/lib/python3.8/dist-packages/xformers'):\n",
+ " xformers=\"--xformers\" \n",
+ "else:\n",
+ " xformers=\"\"\n",
+ "\n",
+ "if os.path.isfile(path_to_trained_model):\n",
+ " !python /content/gdrive/MyDrive/sd/stable-diffusion-webui/webui.py $share --disable-safe-unpickle --no-half-vae --enable-insecure-extension-access --ckpt \"$path_to_trained_model\" $configf $xformers\n",
+ "else:\n",
+ " !python /content/gdrive/MyDrive/sd/stable-diffusion-webui/webui.py $share --disable-safe-unpickle --no-half-vae --enable-insecure-extension-access --ckpt-dir \"$path_to_trained_model\" $configf $xformers"
+ ]
+ },
+ {
+ "cell_type": "markdown",
+ "metadata": {
+ "id": "d_mQ23XsOc5R"
+ },
+ "source": [
+ "# Upload The Trained Model to Hugging Face "
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "id": "NTqUIuhROdH4"
+ },
+ "outputs": [],
+ "source": [
+ "from slugify import slugify\n",
+ "from huggingface_hub import HfApi, HfFolder, CommitOperationAdd\n",
+ "from huggingface_hub import create_repo\n",
+ "from IPython.display import display_markdown\n",
+ "from IPython.display import clear_output\n",
+ "from IPython.utils import capture\n",
+ "from google.colab import files\n",
+ "import shutil\n",
+ "import time\n",
+ "import os\n",
+ "\n",
+ "Upload_sample_images = False #@param {type:\"boolean\"}\n",
+ "#@markdown - Upload showcase images of your trained model\n",
+ "\n",
+ "Name_of_your_concept = \"\" #@param {type:\"string\"}\n",
+ "if(Name_of_your_concept == \"\"):\n",
+ " Name_of_your_concept = Session_Name\n",
+ "Name_of_your_concept=Name_of_your_concept.replace(\" \",\"-\") \n",
+ " \n",
+ "Save_concept_to = \"My_Profile\" #@param [\"Public_Library\", \"My_Profile\"]\n",
+ "\n",
+ "#@markdown - [Create a write access token](https://huggingface.co/settings/tokens) , go to \"New token\" -> Role : Write. A regular read token won't work here.\n",
+ "hf_token_write = \"\" #@param {type:\"string\"}\n",
+ "if hf_token_write ==\"\":\n",
+ " print('\u001b[1;32mYour Hugging Face write access token : ')\n",
+ " hf_token_write=input()\n",
+ "\n",
+ "hf_token = hf_token_write\n",
+ "\n",
+ "api = HfApi()\n",
+ "your_username = api.whoami(token=hf_token)[\"name\"]\n",
+ "\n",
+ "if(Save_concept_to == \"Public_Library\"):\n",
+ " repo_id = f\"sd-dreambooth-library/{slugify(Name_of_your_concept)}\"\n",
+ " #Join the Concepts Library organization if you aren't part of it already\n",
+ " !curl -X POST -H 'Authorization: Bearer '$hf_token -H 'Content-Type: application/json' https://huggingface.co/organizations/sd-dreambooth-library/share/SSeOwppVCscfTEzFGQaqpfcjukVeNrKNHX\n",
+ "else:\n",
+ " repo_id = f\"{your_username}/{slugify(Name_of_your_concept)}\"\n",
+ "output_dir = f'/content/models/'+INSTANCE_NAME\n",
+ "\n",
+ "def bar(prg):\n",
+ " br=\"\u001b[1;33mUploading to HuggingFace : \" '\u001b[0m|'+'█' * prg + ' ' * (25-prg)+'| ' +str(prg*4)+ \"%\"\n",
+ " return br\n",
+ "\n",
+ "print(\"\u001b[1;32mLoading...\")\n",
+ "\n",
+ "NM=\"False\"\n",
+ "if os.path.getsize(OUTPUT_DIR+\"/text_encoder/pytorch_model.bin\") > 670901463:\n",
+ " NM=\"True\"\n",
+ "\n",
+ "\n",
+ "if NM==\"False\":\n",
+ " with capture.capture_output() as cap:\n",
+ " %cd $OUTPUT_DIR\n",
+ " !rm -r safety_checker feature_extractor .git\n",
+ " !rm model_index.json\n",
+ " !git init\n",
+ " !git lfs install --system --skip-repo\n",
+ " !git remote add -f origin \"https://USER:{hf_token}@huggingface.co/runwayml/stable-diffusion-v1-5\"\n",
+ " !git config core.sparsecheckout true\n",
+ " !echo -e \"feature_extractor\\nsafety_checker\\nmodel_index.json\" > .git/info/sparse-checkout\n",
+ " !git pull origin main\n",
+ " !rm -r .git\n",
+ " %cd /content\n",
+ "\n",
+ "image_string = \"\"\n",
+ "\n",
+ "if os.path.exists('/content/sample_images'):\n",
+ " !rm -r /content/sample_images\n",
+ "Samples=\"/content/sample_images\"\n",
+ "!mkdir $Samples\n",
+ "clear_output()\n",
+ "\n",
+ "if Upload_sample_images:\n",
+ "\n",
+ " print(\"\u001b[1;32mUpload Sample images of the model\")\n",
+ " uploaded = files.upload()\n",
+ " for filename in uploaded.keys():\n",
+ " shutil.move(filename, Samples)\n",
+ " %cd $Samples\n",
+ " !find . -name \"* *\" -type f | rename 's/ /_/g'\n",
+ " %cd /content\n",
+ " clear_output()\n",
+ "\n",
+ " print(bar(1))\n",
+ "\n",
+ " images_upload = os.listdir(Samples)\n",
+ " instance_prompt_list = []\n",
+ " for i, image in enumerate(images_upload):\n",
+ " image_string = f'''\n",
+ " {image_string}\n",
+ " '''\n",
+ " \n",
+ "readme_text = f'''---\n",
+ "license: creativeml-openrail-m\n",
+ "tags:\n",
+ "- text-to-image\n",
+ "- stable-diffusion\n",
+ "---\n",
+ "### {Name_of_your_concept} Dreambooth model trained by {api.whoami(token=hf_token)[\"name\"]} with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook\n",
+ "\n",
+ "\n",
+ "Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)\n",
+ "Or you can run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb)\n",
+ "\n",
+ "Sample pictures of this concept:\n",
+ "{image_string}\n",
+ "'''\n",
+ "#Save the readme to a file\n",
+ "readme_file = open(\"README.md\", \"w\")\n",
+ "readme_file.write(readme_text)\n",
+ "readme_file.close()\n",
+ "\n",
+ "operations = [\n",
+ " CommitOperationAdd(path_in_repo=\"README.md\", path_or_fileobj=\"README.md\"),\n",
+ " CommitOperationAdd(path_in_repo=f\"{Session_Name}.ckpt\",path_or_fileobj=MDLPTH)\n",
+ "\n",
+ "]\n",
+ "create_repo(repo_id,private=True, token=hf_token)\n",
+ "\n",
+ "api.create_commit(\n",
+ " repo_id=repo_id,\n",
+ " operations=operations,\n",
+ " commit_message=f\"Upload the concept {Name_of_your_concept} embeds and token\",\n",
+ " token=hf_token\n",
+ ")\n",
+ "\n",
+ "if NM==\"False\":\n",
+ " api.upload_folder(\n",
+ " folder_path=OUTPUT_DIR+\"/feature_extractor\",\n",
+ " path_in_repo=\"feature_extractor\",\n",
+ " repo_id=repo_id,\n",
+ " token=hf_token\n",
+ " )\n",
+ "\n",
+ "clear_output()\n",
+ "print(bar(4))\n",
+ "\n",
+ "if NM==\"False\":\n",
+ " api.upload_folder(\n",
+ " folder_path=OUTPUT_DIR+\"/safety_checker\",\n",
+ " path_in_repo=\"safety_checker\",\n",
+ " repo_id=repo_id,\n",
+ " token=hf_token\n",
+ " )\n",
+ "\n",
+ "clear_output()\n",
+ "print(bar(8))\n",
+ "\n",
+ "\n",
+ "api.upload_folder(\n",
+ " folder_path=OUTPUT_DIR+\"/scheduler\",\n",
+ " path_in_repo=\"scheduler\",\n",
+ " repo_id=repo_id,\n",
+ " token=hf_token\n",
+ ")\n",
+ "\n",
+ "clear_output()\n",
+ "print(bar(9))\n",
+ "\n",
+ "api.upload_folder(\n",
+ " folder_path=OUTPUT_DIR+\"/text_encoder\",\n",
+ " path_in_repo=\"text_encoder\",\n",
+ " repo_id=repo_id,\n",
+ " token=hf_token\n",
+ ")\n",
+ "\n",
+ "clear_output()\n",
+ "print(bar(12))\n",
+ "\n",
+ "api.upload_folder(\n",
+ " folder_path=OUTPUT_DIR+\"/tokenizer\",\n",
+ " path_in_repo=\"tokenizer\",\n",
+ " repo_id=repo_id,\n",
+ " token=hf_token\n",
+ ")\n",
+ "\n",
+ "clear_output()\n",
+ "print(bar(13))\n",
+ "\n",
+ "api.upload_folder(\n",
+ " folder_path=OUTPUT_DIR+\"/unet\",\n",
+ " path_in_repo=\"unet\",\n",
+ " repo_id=repo_id,\n",
+ " token=hf_token\n",
+ ")\n",
+ "\n",
+ "clear_output()\n",
+ "print(bar(21))\n",
+ "\n",
+ "api.upload_folder(\n",
+ " folder_path=OUTPUT_DIR+\"/vae\",\n",
+ " path_in_repo=\"vae\",\n",
+ " repo_id=repo_id,\n",
+ " token=hf_token\n",
+ ")\n",
+ "\n",
+ "clear_output()\n",
+ "print(bar(23))\n",
+ "\n",
+ "api.upload_file(\n",
+ " path_or_fileobj=OUTPUT_DIR+\"/model_index.json\",\n",
+ " path_in_repo=\"model_index.json\",\n",
+ " repo_id=repo_id,\n",
+ " token=hf_token\n",
+ ")\n",
+ "\n",
+ "clear_output()\n",
+ "print(bar(24))\n",
+ "\n",
+ "api.upload_folder(\n",
+ " folder_path=Samples,\n",
+ " path_in_repo=\"sample_images\",\n",
+ " repo_id=repo_id,\n",
+ " token=hf_token\n",
+ ")\n",
+ "\n",
+ "clear_output()\n",
+ "print(bar(25))\n",
+ "\n",
+ "display_markdown(f'''## Your concept was saved successfully. [Click here to access it](https://huggingface.co/{repo_id})\n",
+ "''', raw=True)"
+ ]
+ },
+ {
+ "cell_type": "code",
+ "execution_count": null,
+ "metadata": {
+ "cellView": "form",
+ "id": "iVqNi8IDzA1Z"
+ },
+ "outputs": [],
+ "source": [
+ "#@markdown #Free Gdrive Space\n",
+ "\n",
+ "#@markdown Display the list of sessions from your gdrive and choose which ones to remove.\n",
+ "\n",
+ "import ipywidgets as widgets\n",
+ "\n",
+ "Sessions=os.listdir(\"/content/gdrive/MyDrive/Fast-Dreambooth/Sessions\")\n",
+ "\n",
+ "s = widgets.Select(\n",
+ " options=Sessions,\n",
+ " rows=5,\n",
+ " description='',\n",
+ " disabled=False\n",
+ ")\n",
+ "\n",
+ "out=widgets.Output()\n",
+ "\n",
+ "d = widgets.Button(\n",
+ " description='Remove',\n",
+ " disabled=False,\n",
+ " button_style='warning',\n",
+ " tooltip='Removet the selected session',\n",
+ " icon='warning'\n",
+ ")\n",
+ "\n",
+ "def rem(d):\n",
+ " with out:\n",
+ " if s.value is not None:\n",
+ " clear_output()\n",
+ " print(\"\u001b[1;33mTHE SESSION \u001b[1;31m\"+s.value+\" \u001b[1;33mHAS BEEN REMOVED FROM YOUR GDRIVE\")\n",
+ " !rm -r '/content/gdrive/MyDrive/Fast-Dreambooth/Sessions/{s.value}'\n",
+ " s.options=os.listdir(\"/content/gdrive/MyDrive/Fast-Dreambooth/Sessions\") \n",
+ " else:\n",
+ " d.close()\n",
+ " s.close()\n",
+ " clear_output()\n",
+ " print(\"\u001b[1;32mNOTHING TO REMOVE\")\n",
+ "\n",
+ "d.on_click(rem)\n",
+ "if s.value is not None:\n",
+ " display(s,d,out)\n",
+ "else:\n",
+ " print(\"\u001b[1;32mNOTHING TO REMOVE\")"
+ ]
+ }
+ ],
+ "metadata": {
+ "accelerator": "GPU",
+ "colab": {
+ "collapsed_sections": [
+ "bbKbx185zqlz",
+ "AaLtXBbPleBr"
+ ],
+ "provenance": [],
+ "include_colab_link": true
+ },
+ "kernelspec": {
+ "display_name": "Python 3",
+ "name": "python3"
+ },
+ "language_info": {
+ "name": "python"
+ },
+ "gpuClass": "standard"
+ },
+ "nbformat": 4,
+ "nbformat_minor": 0
+}
\ No newline at end of file
From 76255bc4da51d3dc133912ae943b1a82cdd9c455 Mon Sep 17 00:00:00 2001
From: nawnie <106923464+nawnie@users.noreply.github.com>
Date: Tue, 17 Jan 2023 17:59:57 -0600
Subject: [PATCH 14/15] Rename Copy_of_fast_DreamBooth.ipynb to
Fast-DreamBooth_Redeux.ipynb
---
Copy_of_fast_DreamBooth.ipynb => Fast-DreamBooth_Redeux.ipynb | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
rename Copy_of_fast_DreamBooth.ipynb => Fast-DreamBooth_Redeux.ipynb (99%)
diff --git a/Copy_of_fast_DreamBooth.ipynb b/Fast-DreamBooth_Redeux.ipynb
similarity index 99%
rename from Copy_of_fast_DreamBooth.ipynb
rename to Fast-DreamBooth_Redeux.ipynb
index 46ddaf54..3aee1fa6 100644
--- a/Copy_of_fast_DreamBooth.ipynb
+++ b/Fast-DreamBooth_Redeux.ipynb
@@ -1630,4 +1630,4 @@
},
"nbformat": 4,
"nbformat_minor": 0
-}
\ No newline at end of file
+}
From c598955eb4c564c6d3d29cff83a766a246c0f489 Mon Sep 17 00:00:00 2001
From: nawnie <106923464+nawnie@users.noreply.github.com>
Date: Tue, 17 Jan 2023 18:10:34 -0600
Subject: [PATCH 15/15] Rename Fast-DreamBooth_Redeux.ipynb to
Copy_of_fast_DreamBooth.ipynb
---
Fast-DreamBooth_Redeux.ipynb => Copy_of_fast_DreamBooth.ipynb | 0
1 file changed, 0 insertions(+), 0 deletions(-)
rename Fast-DreamBooth_Redeux.ipynb => Copy_of_fast_DreamBooth.ipynb (100%)
diff --git a/Fast-DreamBooth_Redeux.ipynb b/Copy_of_fast_DreamBooth.ipynb
similarity index 100%
rename from Fast-DreamBooth_Redeux.ipynb
rename to Copy_of_fast_DreamBooth.ipynb