В большинстве современных СУБД есть возможность использовать так называемые групповые функции (group functions), позволяющие анализировать сразу группы записей. Под группой записей понимается любой набор записей, имеющих что-то общее – например, записи, относящиеся к одному товару, одному отделу или одному временному интервалу. В операторе SELECT при помощи параметра GROUP BY можно определить состав групп, после чего при помощи групповых функций подсчитать количество записей, вошедших в группу, подсчитать итоговую сумму, а также минимальное, максимальное или среднее значение для каждой группы. Если параметр GROUP BY в запросе не указан, то группой записей считается все строки интересующей таблицы.
Функция возвращает количество записей в группе. Возможно три варианта использования функции COUNT:
COUNT(*) – подсчет количества записей в группе;
COUNT(поле) – подсчет количества отличных от NULL значений в указанном поле записей группы;
COUNT(DISTINCT поле) – подсчет количества уникальных отличных от NULL значений в указанном поле записей группы.
Примеры использования функции COUNT:
-- подсчет количества строк в таблице student
SELECT COUNT(*)
FROM student s;-- подсчет количества всех различных фамилий студентов
SELECT COUNT(DISTINCT L_name)
FROM student;Функция SUM возвращает суммарное значение для группы.
-- подсчет суммарного значения риска
SELECT SUM(risk)
FROM hobby;Функция MAX возвращает максимальное значение для группы.
-- подсчет максимальной даты рождения среди студентов, т. е. поиск самого молодого студента
SELECT MAX(date_birth)
FROM student;Функция MIN возвращает минимальное значение для группы.
поиск самого “старого” студента
SELECT MIN(date_birth)
FROM student;Функция AVG возвращает среднее значение для группы.
-- подсчет средней степени риска для хобби, названия которых заканчиваются на «ов»
SELECT AVG(risk)
FROM hobby
WHERE name LIKE '%ов';В предыдущих примерах в качестве группы рассматривался весь набор записей, полученный в результате выполнения запроса. При помощи параметра GROUP BY оператора SELECT можно указать способ разбиения полученного в результате выполнения запроса набора записей на группы. В параметре GROUP BY задается столбец (или столбцы), по значениям которого будет производиться группировка. При выполнении оператора SELECT, в котором присутствует параметр GROUP BY, СУБД проанализирует значение указанного столбца во всех строках, отобранных в результате выполнения запроса. Все строки, где значение указанного в параметре GROUP BY столбца одно и тоже, попадут в одну группу. После этого для каждой из групп будет вычислена указанная в параметре SELECT групповая функция. Например:
-- вывод номеров групп и количества студентов в каждой группе
SELECT n_group,
COUNT(n_group) AS stud_count
FROM student
GROUP BY n_group
ORDER BY n_group DESC;В данном запросе СУБД сначала выделит группы записей, относящиеся к разным группам (в зависимости от значения столбца n_group) и для каждой получившейся группы посчитает количество записей.
Будьте внимательны, по сути в GROUP BY должны быть записаны все атрибуты, которые присутствуют в SELECT. Наоборот - не обязательно. Тот же запрос, написанный выше может быть выполнен и таким образом:
SELECT COUNT(n_group) AS stud_count
FROM student
GROUP BY n_group;Он выполнится точно также, как и предыдущий, однако выдаст на экран только количества студентов, без номера группы.
Параметр HAVING оператора SELECT используется для исключения групп из результирующего набора записей на основе результатов выполнения групповых функций. После параметра HAVING также как и после параметра WHERE указывается условие фильтрации, но в отличие от параметра WHERE, условия которого используются для фильтрации отдельных строк, условия, указанные в параметре HAVING используются для фильтрации целых групп. Например:
-- отбор групп, в которых количество студентов более 12.
SELECT n_group,
COUNT(n_group) AS stud_count
FROM student
GROUP BY n_group
HAVING COUNT(n_group) > 12;Т.е. мы используем WHERE для создания условия на выбираемые из таблицы данные. А HAVING используем для отбора получаемых в результате выполнения функции агрегирования.
Аналогичный запрос сверху, с использованием HAVING можно переписать с использованием WHERE таким образом:
SELECT *
FROM
(SELECT n_group,
COUNT(n_group) AS stud_count
FROM student
GROUP BY n_group) t
WHERE stud_count > 12;Базы данных – это множество взаимосвязанных сущностей или отношений (таблиц) в терминологии реляционных СУБД. При проектировании стремятся создавать таблицы, в каждой из которых содержалась бы информация об одном типе сущностей. Это облегчает модификацию базы данных и поддержание ее целостности. Но такой подход тяжело усваивается начинающими проектировщиками и пользователями баз данных, которые пытаются привязать проект к будущим приложениям и так организовать таблицы, чтобы в каждой из них хранилось все необходимое для реализации возможных запросов.
Даже при отсутствии средств одновременного доступа ко многим таблицам нежелателен проект, в котором информация о многих типах сущностей перемешана в одной таблице. SQL же обладает великолепным механизмом для одновременной или последовательной обработки данных из нескольких взаимосвязанных таблиц. В нем реализованы возможности «соединять» или «объединять» несколько таблиц и так называемые «вложенные подзапросы».
- Декартово произведение таблиц
- Эквисоединение таблиц
- Естественное соединение таблиц
- Композиция таблиц
- Соединение таблиц с дополнительным условием
- Соединение таблицы со своей копией
- Внутреннее и внешнее объединение таблиц
Соединения – это подмножества декартова произведения. Так как декартово произведение N таблиц – это таблица, содержащая все возможные строки R, такие, что R является сцеплением какой-либо строки из первой таблицы, строки из второй таблицы, ... и строки из N-й таблицы, то осталось лишь выяснить, можно ли с помощью SELECT получить декартово произведение. Для получения декартова произведения нескольких таблиц надо указать в параметре FROM перечень перемножаемых таблиц, а во фразе SELECT – все их столбцы.
Так, для получения декартова произведения таблиц student и student_hobby, необходимо выполнить запрос:
SELECT student.*,
student_hobby.*
FROM student,
student_hobby;В зависимости от количества строк, содержащихся в обеих таблицах, результирующий набор записей будет содержать количество строк, равно N*M, где N – количество строк в таблице student, а M – количество строк в таблице student_hobby. При выполнении декартово произведения над большим количеством таблиц, количество получившихся строк еще более возрастет. Если взять любой из результатов, полученных после выполнения декартово произведения, то станет понятно, что актуальными записями являются лишь очень немногие. Поэтому операция декартово произведения является лишь промежуточным этапом.
Актуальные строки можно отобрать из декартового произведения путем ввода в запрос параметра WHERE, в котором устанавливается соответствие между полями, посредством которых каждая пара таблиц связана между собой.
Эквисоединение таблиц в предыдущем запросе выглядит следующим образом:
SELECT student.*,
student_hobby.*
FROM student,
student_hobby
WHERE student.id= student_hobby.student_id;Естественным соединением таблиц называется такое соединение, из которого исключены дубликаты столбцов, по которым проводилось эквисоединение (student.id и student_hobby.id). Для исключения дубликатов в операторе SELECT необходимо явно указать только один из столбцов этих пар, принадлежащего главной таблице:
SELECT student.id,
student.name,
student.surname,
student.date_birth,
student_hobby.name
FROM student,
student_hobby
WHERE student.id= student_hobby.student_id;Композицией таблиц называется соединение, из которого полностью исключены столбцы, по которым производилось соединение.
Наравне с уловными выражениями, предназначенными для указания способа соединения таблиц между собой, в параметре WHERE можно дополнительно указывать все описанные выше дополнительные условия фильтрации, объединенные с условными выражениями соединения при помощи оператора AND. Например:
-- получение информации о студентах из групп 2011,2012,3014 и их хобби
SELECT st.id,
st.name,
st.surname,
st.date_birth,
sh.id
FROM student st,
student_hobby sh
WHERE st.id = sh.student_id
AND st.n_group IN (2011,
2012,
3014);В ряде приложений возникает необходимость одновременной обработки данных какой-либо таблицы и одной или нескольких ее копий, создаваемых на время выполнения запроса.
Данная возможность часто используется для выявления объектов, имеющие общие значения атрибутов и находящиеся в одной таблице. В последнем случае в параметре WHERE устанавливают равенство значений всех одноименных столбцов этих таблиц, по значениям которых необходимо выявить совпадения, а для остальных установить неравенство значений (обычно достаточно установить неравенство значений полей, входящих в состав первичного ключа).
Временную копию таблицы можно сформировать, указав имя псевдонима за именем таблицы во фразе FROM.
Пример соединения таблиц со своей копией:
-- получение списка однофамильцев
SELECT s1.*
FROM student s1,
student s2
WHERE s1.surname=s2.surname
AND s1.id<>s2.id;Ранее были рассмотрены способы получения связанных между собой данных, находящихся в нескольких таблицах, при помощи комбинирования операций декартово произведения и горизонтальной фильтрации строк получившегося набора данных.
Кроме этого во многих СУБД существуют реализации операции внутреннего и внешнего условных соединений таблиц внутри одного запроса – INNER JOIN (внутреннее объединение), LEFT JOIN (полное левое объединение) и RIGHT JOIN (полное правое объединение).
Синтаксис применения операция объединения выглядит следующим образом:
SELECT _список_полей_
FROM _таблица1_ (INNER | LEFT | RIGHT | OUTER)
JOIN _таблица2_ ON _таблица1.связующее_поле = таблица2.связующее_поле_;В результате выполнения внутреннего объединения из кортежей двух объединяемых таблиц остаются только те, для которых выполняется указанное условие.
При полном (внешнем) левом объединении из кортежей двух объединяемых таблиц остаются все кортежи таблицы, указанной слева от условного выражения, и кортежи правой таблицы, для которых выполняется указанное условие.
При полном (внешнем) правом объединении из кортежей двух объединяемых таблиц остаются все кортежи таблицы, указанной справа от условного выражения, и кортежи левой таблицы, для которых выполняется указанное условие.
В СУБД ORACLE также для реализации левого внешнего объединения используется оператор (+) в предложении WHERE, который ставится справа от столбца, по которому осуществляется соединение, справа от знака =. Аналогично для правого объединения оператор (+) ставится справа от столбца слева от знака равенства.
Стоит остановиться более подробно на различных вариантах соединения 2-х таблиц.
Т.е.
-
Если таблицы не соединяются никак, то будут выведены все возможные варианты. Перемножено количество записей одной таблицы, на количество записей в другой. Такое практически никогда не бывает полезно.
-
INNER JOINили в Oracle есть вариант приравнять атрибуты вWHERE. В таком случае на экран будут выведены те данные, которые присутствуют в обоих таблицах.
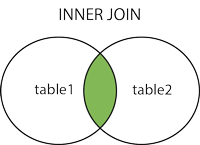
Select s.*
FROM student s
INNER JOIN student_hobby sh on s.id = sh.student_id;или
Select student.*
FROM student s, student_hobby sh
WHERE s.id = sh.student_id;LEFT JOINвыведет на экран все данные, которые есть на пересечении таблиц, а также все данные из таблицы, находящейся слева, которые не попали в пересечение.
Select s.*, sh.*
FROM student s
LEFT JOIN student_hobby sh on s.id = sh.student_id;или с использованием (+)
Select s.*, sh.*
FROM student s, student_hobby sh
where s.id = sh.student_id (+)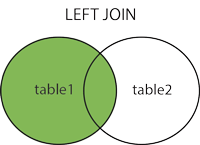
RIGHT JOINаналогичен левому. Только в результат попадут данные из таблицы справа
Select s.*, sh.*
FROM student s
RIGHT JOIN student_hobby sh on s.id = sh.student_id;или
Select s.*, sh.*
FROM student s, student_hobby sh
where s.id (+)= sh.student_id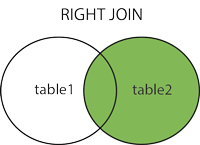
FULL OUTER JOINвыводит в результате всё, что было на пересечении двух таблиц, а также данные из левой и из правой, которые не попали в пересечение.
Select s.*, sh.*
FROM student s
FULL OUTER JOIN student_hobby sh on s.id = sh.student_id;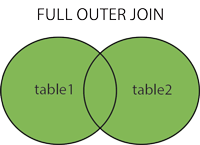
И ещё раз, саммари:

Вложенный подзапрос – это оператор SELECT, заключенный в круглые скобки и вложенный в команду языка DML, и использующийся в качестве источника данных для параметров SELECT, FROM, WHERE и HAVING. Каждый подзапрос в свою очередь может содержать в себе подзапрос и т.д. В каждой СУБД существуют ограничения на количество вложенных подзапросов, но обычно этих ограничений хватает, чтобы реализовать задачи любой известной сложности.
Вложенные подзапросы всегда применяются тогда, когда для выполнения основного запроса необходимо использовать данные, находящиеся в той же или других таблицах, которые невозможно получить при помощи соединения таблиц. Например, чтобы определить, какие хобби имеют степень риска, превышающую среднюю степень риска, необходимо предварительно вычислить эту среднюю степень риска.
Все подзапросы можно условно разделить на однострочные и многострочные, а также на простые и коррелированные.
Однострочные подзапросы возвращают в качестве результата всегда одну строку, не больше и не меньше, поэтому над результатами выполнения таких запросов можно использовать операции сравнения.
Многострочные запросы в общем случае могут вернуть любое количество строк, поэтому над результатами таких подзапросов нельзя использовать операции сравнения (если один из аргументов операции сравнения будет являться пустым множеством или множеством, состоящим более чем из одного элемента, то запрос завершиться с ошибкой). Для таких подзапросов применимы операторы IN и EXISTS.
Простыми, или независимыми, подзапросами называются вложенные подзапросы, выполнение которых не зависит от внешнего запроса. Простые вложенные подзапросы обрабатываются системой «снизу вверх». Первым обрабатывается вложенный подзапрос самого нижнего уровня. Множество значений, полученное в результате его выполнения, используется при реализации подзапроса более высокого уровня и т.д.
Запросы с коррелированными вложенными подзапросами обрабатываются системой в обратном порядке. Сначала выбирается первая строка рабочей таблицы, сформированной основным запросом, и из нее выбираются значения тех столбцов, которые используются во вложенном подзапросе (вложенных подзапросах). Если эти значения удовлетворяют условиям вложенного подзапроса, то выбранная строка включается в результат. Затем выбирается вторая строка и т.д., пока в результат не будут включены все строки, удовлетворяющие вложенному подзапросу (последовательности вложенных подзапросов).
Следует отметить, что SQL обладает большой избыточностью в том смысле, что он часто предоставляет несколько различных способов формулировки одного и того же запроса. Поэтому во многих примерах данной главы при помощи подзапросов будут решаться задачи, часть из которых успешнее реализуется с помощью соединений, но здесь все же будут приведены их варианты с использованием вложенных подзапросов. Это связано с необходимостью детального знакомства с созданием и принципом выполнения вложенных подзапросов, так как существует немало задач (особенно на удаление и изменение данных), которые не могут быть реализованы другим способом. Кроме того, разные формулировки одного и того же запроса требуют для своего выполнения различных ресурсов памяти и могут значительно отличаться по времени реализации в разных СУБД.
Однострочные вложенные подзапросы чаще всего применяются совместно с агрегатными функциями, результат вычисления которых и является единственным результатом подзапроса. Например:
-- получить название хобби, имеющего максимальную степень риска
SELECT name
FROM hobby
WHERE risk =
(SELECT max(risk)
FROM hobby)Примечание В данном случае вложенный подзапрос должен выполняться для каждой строки, обрабатываемой во внешнем запросе. Но очевидно, что результат вложенного запроса никоим образом не зависит от того, какая строка обрабатывается во внешнем запросе. В таких случаях, чтобы не выполнять один и тот же вложенный подзапрос, независящий от внешнего запроса, некоторые СУБД кэшируют (запоминают) результат, полученный в результате первого выполнения вложенного подзапроса, и подставляют для всех остальных строк таблиц, обрабатываемых во внешнем запросе.
Но sql такой язык, в котором один и тот же запрос можно выполнить множеством способов. Есть вариант лучше вывести максимальный
SELECT *
FROM hobby h
ORDER BY h.risk DESC
LIMIT 1SELECT *
FROM
(SELECT name
FROM hobby
ORDER BY risk DESC)
WHERE rownum <= 1При большом подзапросе этот вариант лучше. Однакомы с rownum мы не можем избавиться от вложенности. Если мы используем WHERE rownum <= 1 внутри подзапроса, то получится, что с начала мы возьмём нужное количество строк, а уже потом отсортируем их. Поэтому необходимо использовать вложенность.
Есть ещё, лучший вариант для написания подобных запросов
SELECT name
FROM hobby
ORDER BY risk DESC FETCH FIRST 1 ROWS ONLYМы избавляемся от вложенности, читаемость кода заметно выше. Этот вариант можно использовать для всех подобных задач во время курса. Однако надо быть внимательным при использовании других СУБД и не забывать другие варианты к написанию такого же запроса.
Многострочные вложенные подзапросы
Многострочные вложенные подзапросы используются для представления множества значений, исследование которых должно осуществляться в каком-либо предикате IN, что иллюстрируется в следующем примере:
-- определение номера зачеток студентов, которые не имеют ни одного хобби
SELECT id
FROM student
WHERE id NOT IN
(SELECT DISTINCT id
FROM student_hobby);Обратите внимание: использование вложенных запросов, когда его можно заменить на запрос с использование соединения таблиц - плохой подход. Используйте в первую очередь соединение таблиц. Во-первых, это быстрее - оптимизатор запросов в принципе может компенсировать разницу в скорости, но не всегда. Во-вторых, читаемость кода заметно ниже при использовании вложенности.
Пример запроса с использованием вложенности и с использование соединения:
-- определить номера зачеток студентов, которые имеют хотя бы одно хобби
SELECT id
FROM student
WHERE id IN
(SELECT DISTINCT id
FROM student_hobby);-- Эту задачу можно решить путем простого соединения таблиц
SELECT student.id
FROM student,
student_hobby
WHERE student.id= student_hobby.student_id;Коррелированные вложенные подзапросы
Коррелированные подзапросы характерны тем, что вложенный подзапрос не может быть обработан прежде, чем будет обрабатываться внешний подзапрос. Это связано с тем, что вложенный подзапрос зависит от значения внешнего запроса, а оно изменяется по мере того, как система проверяет различные строки таблицы, указанной во внешнем запросе. Например:
-- вывести фамилии студентов, названия тех их хобби, которыми каждый из них увлекается дольше всего
SELECT s.surname,
sh.id
FROM student s,
student_hobby sh
WHERE sh.student_id=s.id
AND sh.date_start=
(
SELECT MIN(date_start)
FROM student_hobby
WHERE id=s.id
);И ещё раз, этот запрос можно выполнить эффективнее Однострочные вложенные подзапросы
В sql вы можете применять CASE для создания различных условий:
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
WHEN conditionN THEN resultN
ELSE result
END;SELECT name,
surname,
n_group,
CASE
WHEN score > 4.5 THEN 'отличник'
WHEN score > 3.7
AND score <= 4.5 THEN 'хорошист'
WHEN score <= 3.7 THEN 'троешник'
ELSE 'что ты такое?'
END AS status
FROM studentРекурсивные запросы.
Применяются достаточно редко в первую очередь из-за сложности синтаксиса.
Но существует определённый набор задач, который решается при помощи рекурсивных запросов.
Данные, которые имеют иерархическую структуру очень плохо представляются в реляционной модели.
Создадим таблиц со следующими атрибутами:
CREATE table "REC_TABLE" (
"id" NUMBER(5,0),
"PID" NUMBER(5,0),
"NAME" VARCHAR2(200),
constraint "REC_TABLE_PK" primary key ("id")
)Добавим данные в неё:
Insert into rec_table values (1, null, 'Россия');
Insert into rec_table values (2, null, 'Испания');
Insert into rec_table values (3, null, 'Италия');
Insert into rec_table values (4, 1, 'Дубна');
Insert into rec_table values (5, 1, 'Москва');
Insert into rec_table values (6, 3, 'Милан');
Insert into rec_table values (7, 2, 'Барселона');
Insert into rec_table values (8, 3, 'Флоренция');
Insert into rec_table values (9, 2, 'Мадрид');
Insert into rec_table values (10, 3, 'Пиза');
Insert into rec_table values (11, 2, 'Севилья');
Insert into rec_table values (12, 4, 'Главный офис');
Insert into rec_table values (13, 4, 'Офис 1');
Insert into rec_table values (14, 7, 'Офис 2');
Insert into rec_table values (15, 10, 'Офис 3');
Insert into rec_table values (16, 6, 'Офис 4');
Insert into rec_table values (17, 13, 'Сервер 1');
Insert into rec_table values (18, 14, 'Сервер 2');
Insert into rec_table values (19, 15, 'Сервер 3');Для написания рекурсивного запроса в oracle применяется оператор CONNECT BY**.**
Также можно использовать START WITH**,** чтобы сказать СУБД с чего начинать цикл. Можно использовать любые условия.
CONNECT BY используется обязательно. В нём необходимо указать до какого момента мы продолжаем цикл. Внутри используется оператор PRIOR**.** С его помощью можно указать **PRIOR** id = pid**.** Т.е. мы указываем найти следующую запись от первой.
В итоге, СУБД находит первую запись, а потом ищет следующую через PRIOR.
Ещё в oracle есть псевдостолбец level, в котором содержится уровень записи по отношению к 1. Итоговый запрос будет выглядеть вот так:
SELECT LEVEL,
id,
pid,
name
FROM rec_table
START WITH pid IS NULL CONNECT BY
PRIOR id = pid;Если мы хотим отсортировать данные по названию, то order by name сломает всю сортировку.
Необходимо использовать order siblings by name**.**
Для наглядности можем добавить отступы. Сделать это можно так:
SELECT lpad('-', 5*(LEVEL-1), '-')||name AS Tree,
LEVEL
FROM rec_table
START WITH pid IS NULL CONNECT BY
PRIOR id = pid
ORDER SIBLINGS BY name;Можно получить путь по заданному id. Выглядеть это должно так:
/Россия/Дубна/Офис 1/Сервер 1
А реализовать это можно при помощи оператора SYS****CONNECT****BY
SELECT SYS_CONNECT_BY_PATH(name, '/') AS PATH
FROM rec_table
WHERE id=17
START WITH pid IS NULL CONNECT BY
PRIOR id = pid;Также в SELECT при помощи PRIOR name можно вывеси родительский элемент. А CONNECT_BY_ROOT – выведет на экран корневой элемент.
Пример:
SELECT LEVEL,
id,
pid,
name,
PRIOR name AS Parent,
CONNECT_BY_ROOT name AS Root
FROM rec_table
START WITH pid IS NULL CONNECT BY
PRIOR id = pid;Если в данных есть петля, то СУБД будет выдавать ошибку. Исправить это можно при помощи оператора NOCYCLE после CONNECT BY.