Data conversion is a multi-step process that involves retrieving data from a source, transforming it into a format that is compatible with a Vector Store, and ultimately uploading it into a Weaviate Vector Database. The source can be a structured or unstructured data source. The only requirement is that the data be in a format that can be transformed into natural language. Here is a depiction of one way the conversion process can be implemented with a Knowledge Graph as the source:
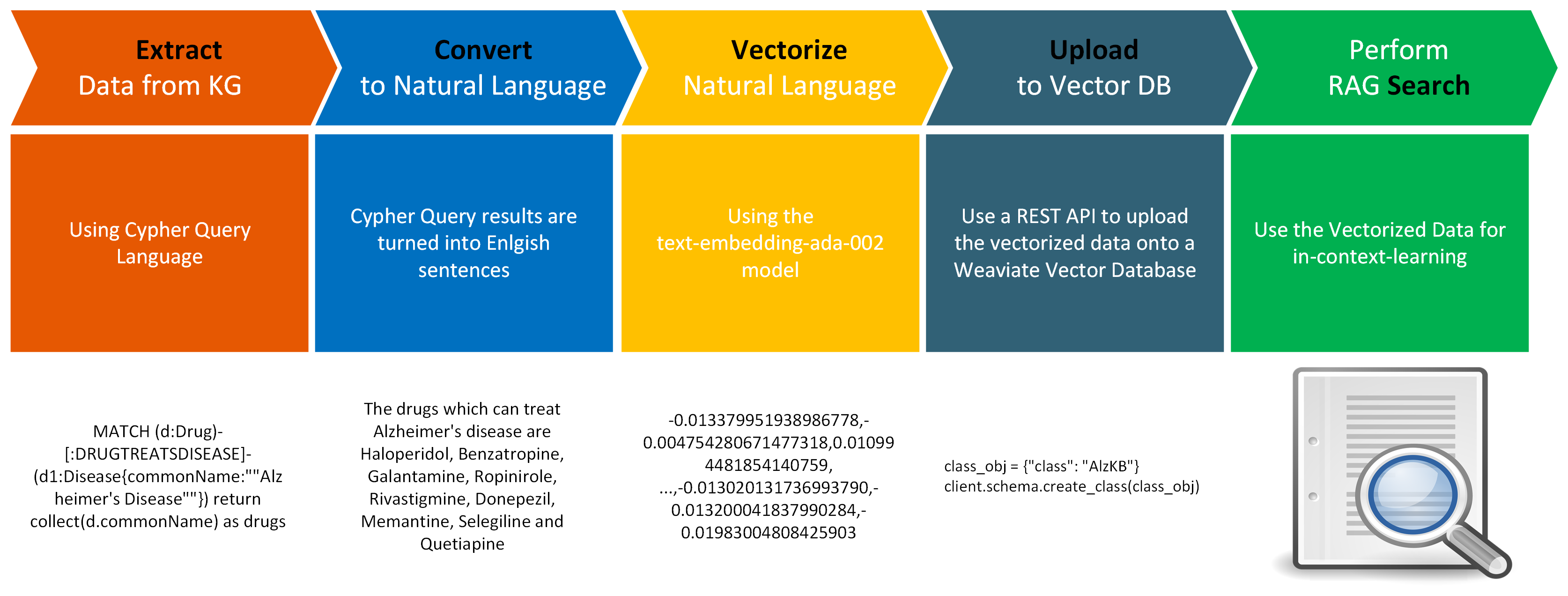
The data extraction is done using a query language that is specific to the Knowledge Graph (e.g. Cypher for Neo4j). Once the data is extracted, KRAGEN will handle the transformation of the data to make it compatible with a Weaviate Vector Database. See the Installation Instructions for more infomation on how to run this process.
For a description of the Alzheimer's Knowledgebase, please see our AlzKB GitHub repository.
The conversion process consisted of the following steps:
- Relationships were extracted using Cypher Query Language and output as a CSV file. source
- The CSV file was then parsed and converted into English sentences using language that is specific to the existing structure and relationships in the Alzheimer's Knowledgebase. source
- This natural language was then vectorized using the
text-embedding-ada-002model via OpenAI's API. source - The vectorized data was then uploaded into a Weaviate Vector Database. source