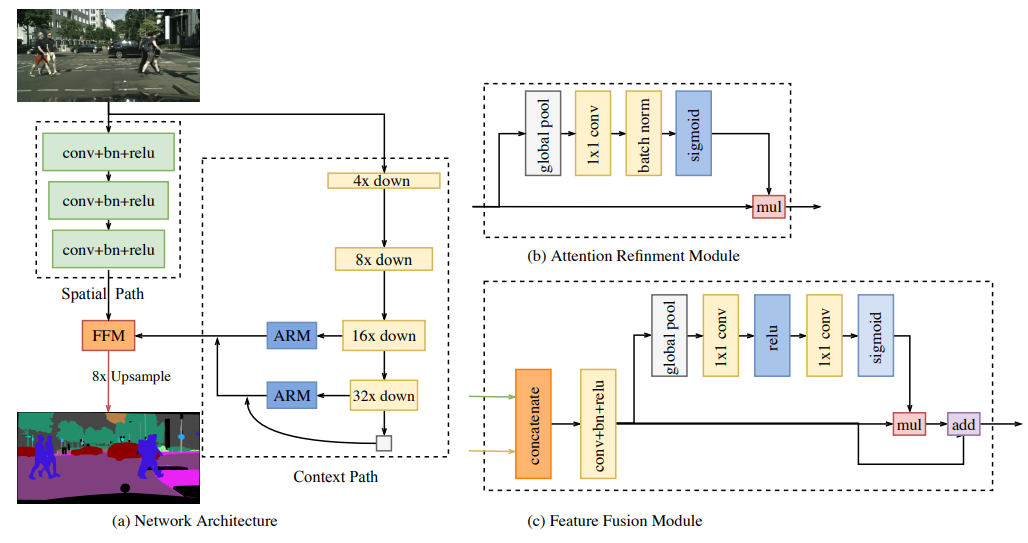
Semantic segmentation requires both rich spatial information and sizeable receptive field. However, modern approaches usually compromise spatial resolution to achieve real-time inference speed, which leads to poor performance. In this paper, we address this dilemma with a novel Bilateral Segmentation Network (BiSeNet). We first design a Spatial Path with a small stride to preserve the spatial information and generate high-resolution features. Meanwhile, a Context Path with a fast downsampling strategy is employed to obtain sufficient receptive field. On top of the two paths, we introduce a new Feature Fusion Module to combine features efficiently. The proposed architecture makes a right balance between the speed and segmentation performance on Cityscapes, CamVid, and COCO-Stuff datasets. Specifically, for a 2048x1024 input, we achieve 68.4% Mean IOU on the Cityscapes test dataset with speed of 105 FPS on one NVIDIA Titan XP card, which is significantly faster than the existing methods with comparable performance.
BiSeNetV1 (ECCV'2018)
@inproceedings{yu2018bisenet,
title={Bisenet: Bilateral segmentation network for real-time semantic segmentation},
author={Yu, Changqian and Wang, Jingbo and Peng, Chao and Gao, Changxin and Yu, Gang and Sang, Nong},
booktitle={Proceedings of the European conference on computer vision (ECCV)},
pages={325--341},
year={2018}
}| Method | Backbone | Crop Size | Lr schd | Mem (GB) | Inf time (fps) | mIoU | mIoU(ms+flip) | config | download |
|---|---|---|---|---|---|---|---|---|---|
| BiSeNetV1 (No Pretrain) | R-18-D32 | 1024x1024 | 160000 | 5.69 | 31.77 | 74.44 | 77.05 | config | model | log |
| BiSeNetV1 | R-18-D32 | 1024x1024 | 160000 | 5.69 | 31.77 | 74.37 | 76.91 | config | model | log |
| BiSeNetV1 (4x8) | R-18-D32 | 1024x1024 | 160000 | 11.17 | 31.77 | 75.16 | 77.24 | config | model | log |
| BiSeNetV1 (No Pretrain) | R-50-D32 | 1024x1024 | 160000 | 15.39 | 7.71 | 76.92 | 78.87 | config | model | log |
| BiSeNetV1 | R-50-D32 | 1024x1024 | 160000 | 15.39 | 7.71 | 77.68 | 79.57 | config | model | log |
| Method | Backbone | Crop Size | Lr schd | Mem (GB) | Inf time (fps) | mIoU | mIoU(ms+flip) | config | download |
|---|---|---|---|---|---|---|---|---|---|
| BiSeNetV1 (No Pretrain) | R-18-D32 | 512x512 | 160000 | - | - | 25.45 | 26.15 | config | model | log |
| BiSeNetV1 | R-18-D32 | 512x512 | 160000 | 6.33 | 74.24 | 28.55 | 29.26 | config | model | log |
| BiSeNetV1 (No Pretrain) | R-50-D32 | 512x512 | 160000 | - | - | 29.82 | 30.33 | config | model | log |
| BiSeNetV1 | R-50-D32 | 512x512 | 160000 | 9.28 | 32.60 | 34.88 | 35.37 | config | model | log |
| BiSeNetV1(No Pretrain) | R-101-D32 | 512x512 | 160000 | - | - | 31.14 | 31.76 | config | model | log |
| BiSeNetV1 | R-101-D32 | 512x512 | 160000 | 10.36 | 25.25 | 37.38 | 37.99 | config | model | log |
Note:
4x8: Using 4 GPUs with 8 samples per GPU in training.- For BiSeNetV1 on Cityscapes dataset, default setting is 4 GPUs with 4 samples per GPU in training.
No Pretrainmeans the model is trained from scratch.