欢迎大家参与本项目,贡献其他语言版本的代码,拥抱开源,让更多学习算法的小伙伴们收益!
20张树形结构图、14道精选回溯题目,21篇回溯法精讲文章,由浅入深,一气呵成,这是全网最强回溯算法总结!
转眼间「代码随想录」里已经分享连续讲解了21天的回溯算法,是时候做一个大总结了,本篇高能,需要花费很大的精力来看!
关于回溯算法理论基础,我录了一期B站视频带你学透回溯算法(理论篇)如果对回溯算法还不了解的话,可以看一下。
在关于回溯算法,你该了解这些!中我们详细的介绍了回溯算法的理论知识,不同于教科书般的讲解,这里介绍的回溯法的效率,解决的问题以及模板都是在刷题的过程中非常实用!
回溯是递归的副产品,只要有递归就会有回溯,所以回溯法也经常和二叉树遍历,深度优先搜索混在一起,因为这两种方式都是用了递归。
回溯法就是暴力搜索,并不是什么高效的算法,最多再剪枝一下。
回溯算法能解决如下问题:
- 组合问题:N个数里面按一定规则找出k个数的集合
- 排列问题:N个数按一定规则全排列,有几种排列方式
- 切割问题:一个字符串按一定规则有几种切割方式
- 子集问题:一个N个数的集合里有多少符合条件的子集
- 棋盘问题:N皇后,解数独等等
我在回溯算法系列讲解中就按照这个顺序给大家讲解,可以说深入浅出,步步到位。
回溯法确实不好理解,所以需要把回溯法抽象为一个图形来理解就容易多了,在后面的每一道回溯法的题目我都将遍历过程抽象为树形结构方便大家的理解。
在关于回溯算法,你该了解这些!还用了回溯三部曲来分析回溯算法,并给出了回溯法的模板:
void backtracking(参数) {
if (终止条件) {
存放结果;
return;
}
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
处理节点;
backtracking(路径,选择列表); // 递归
回溯,撤销处理结果
}
}
事实证明这个模板会伴随整个回溯法系列!
在回溯算法:求组合问题!中,我们开始用回溯法解决第一道题目:组合问题。
我在文中开始的时候给大家列举k层for循环例子,进而得出都是同样是暴利解法,为什么要用回溯法!
此时大家应该深有体会回溯法的魅力,用递归控制for循环嵌套的数量!
本题我把回溯问题抽象为树形结构,如题:
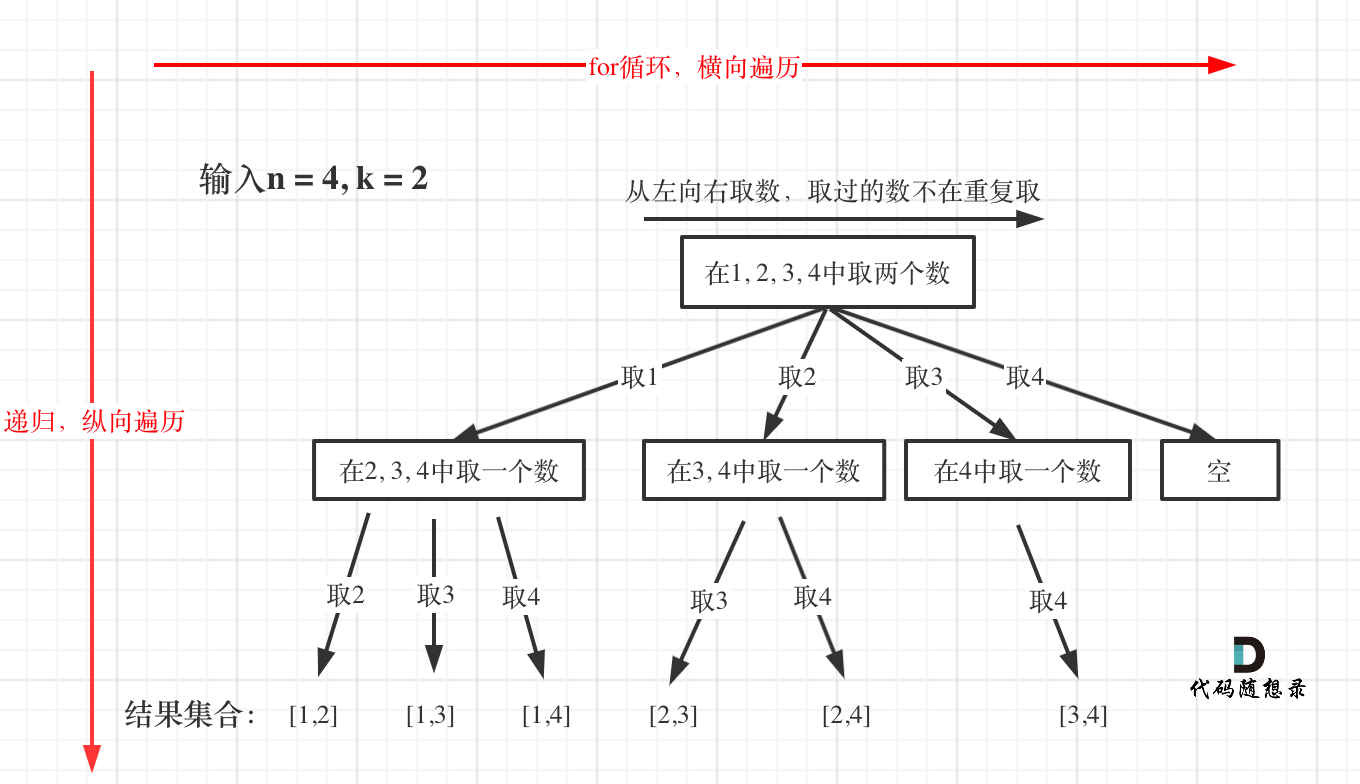
可以直观的看出其搜索的过程:for循环横向遍历,递归纵向遍历,回溯不断调整结果集,这个理念贯穿整个回溯法系列,也是我做了很多回溯的题目,不断摸索其规律才总结出来的。
对于回溯法的整体框架,网上搜的文章这块都说不清楚,按照天上掉下来的代码对着讲解,不知道究竟是怎么来的,也不知道为什么要这么写。
所以,录友们刚开始学回溯法,起跑姿势就很标准了!
优化回溯算法只有剪枝一种方法,在回溯算法:组合问题再剪剪枝中把回溯法代码做了剪枝优化,树形结构如图:
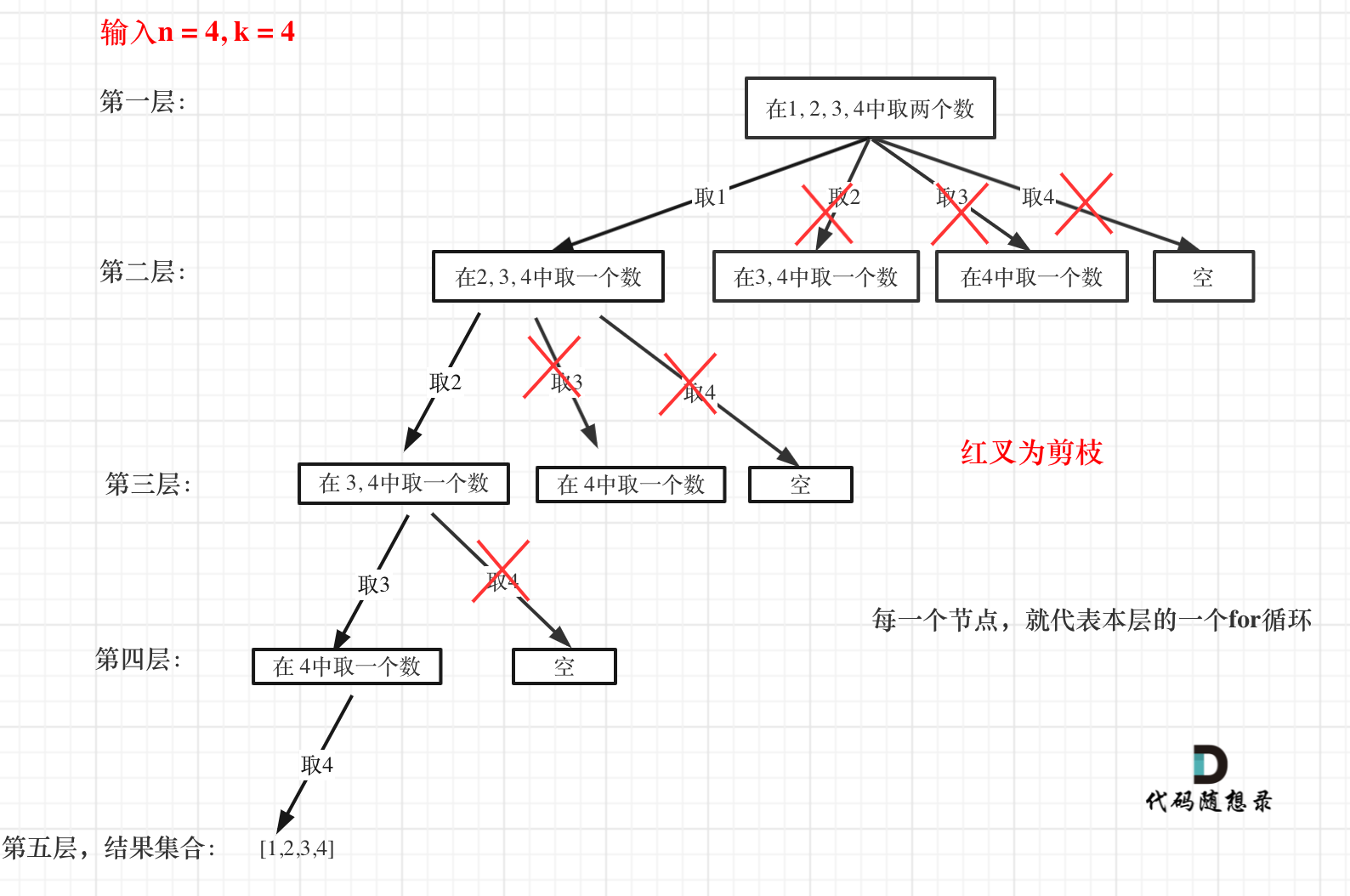
大家可以一目了然剪的究竟是哪里。
回溯算法:求组合问题!剪枝精髓是:for循环在寻找起点的时候要有一个范围,如果这个起点到集合终止之间的元素已经不够题目要求的k个元素了,就没有必要搜索了。
在for循环上做剪枝操作是回溯法剪枝的常见套路! 后面的题目还会经常用到。
在回溯算法:求组合总和!中,相当于 回溯算法:求组合问题!加了一个元素总和的限制。
树形结构如图:
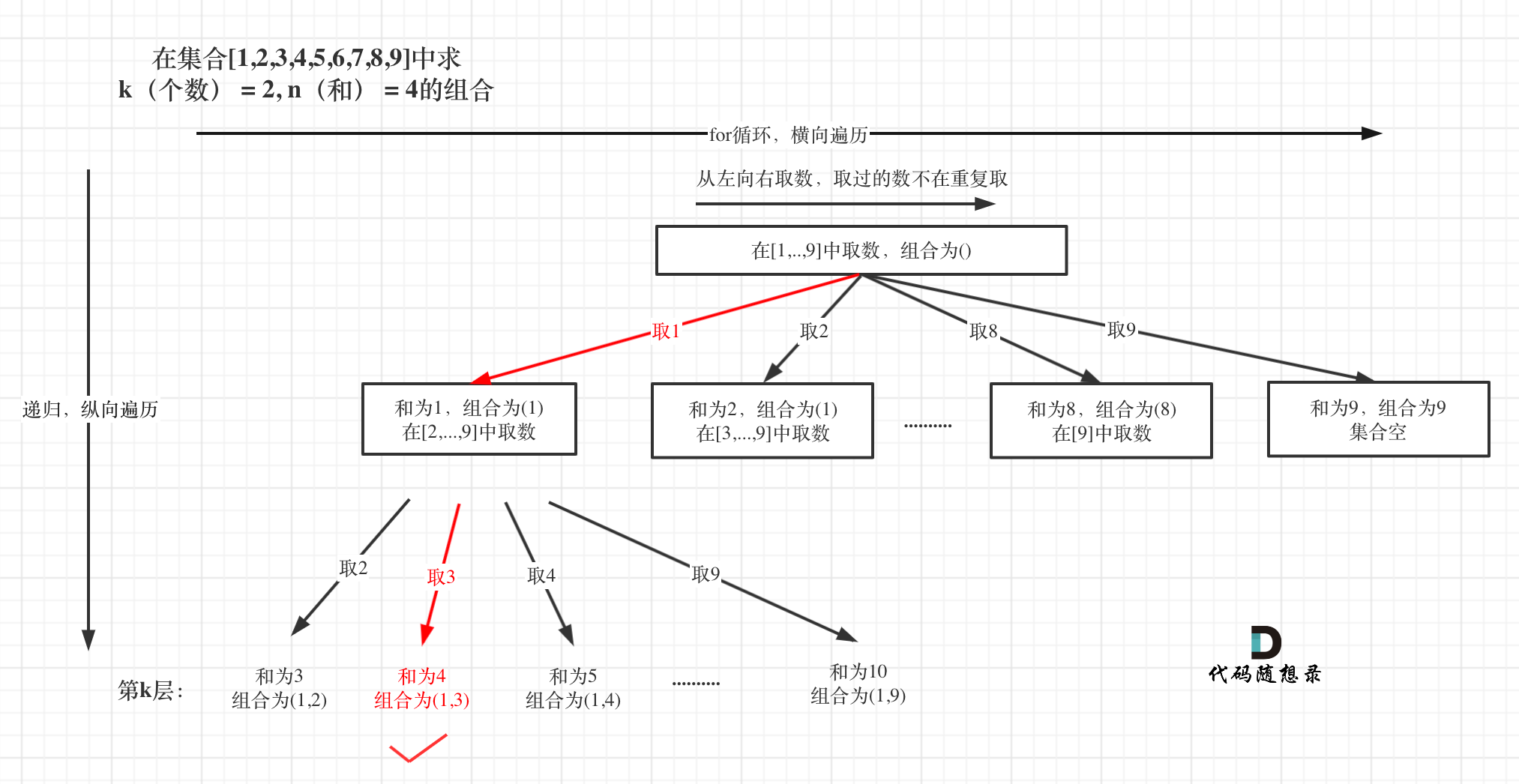
整体思路还是一样的,本题的剪枝会好想一些,即:已选元素总和如果已经大于n(题中要求的和)了,那么往后遍历就没有意义了,直接剪掉,如图:
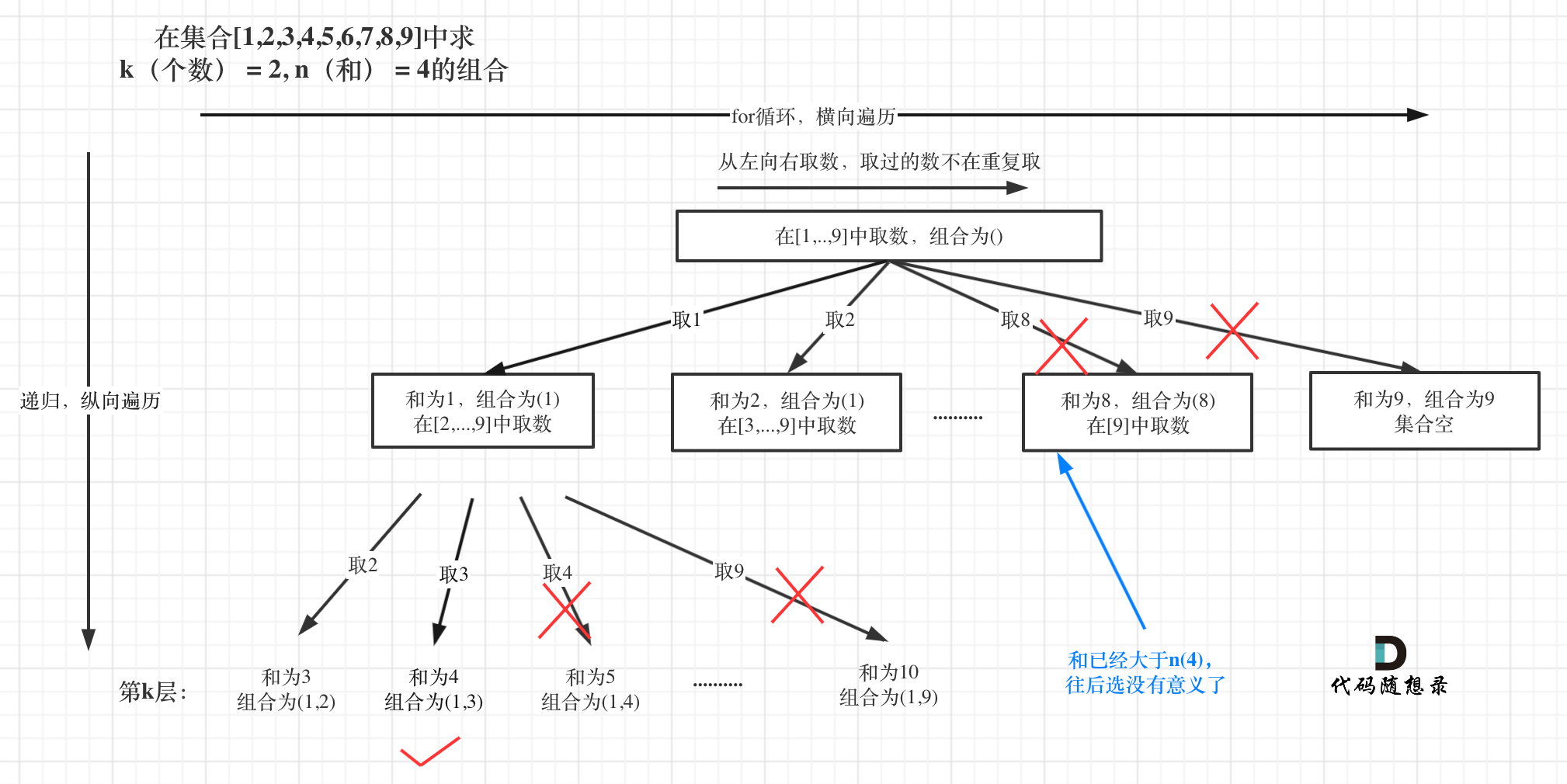
在本题中,依然还可以有一个剪枝,就是回溯算法:组合问题再剪剪枝中提到的,对for循环选择的起始范围的剪枝。
所以剪枝的代码可以在for循环加上 i <= 9 - (k - path.size()) + 1 的限制!
在回溯算法:求组合总和(二)中讲解的组合总和问题,和回溯算法:求组合问题!,回溯算法:求组合总和!和区别是:本题没有数量要求,可以无限重复,但是有总和的限制,所以间接的也是有个数的限制。
不少同学都是看到可以重复选择,就义无反顾的把startIndex去掉了。
本题还需要startIndex来控制for循环的起始位置,对于组合问题,什么时候需要startIndex呢?
我举过例子,如果是一个集合来求组合的话,就需要startIndex,例如:回溯算法:求组合问题!,回溯算法:求组合总和!。
如果是多个集合取组合,各个集合之间相互不影响,那么就不用startIndex,例如:回溯算法:电话号码的字母组合
注意以上我只是说求组合的情况,如果是排列问题,又是另一套分析的套路。
树形结构如下:
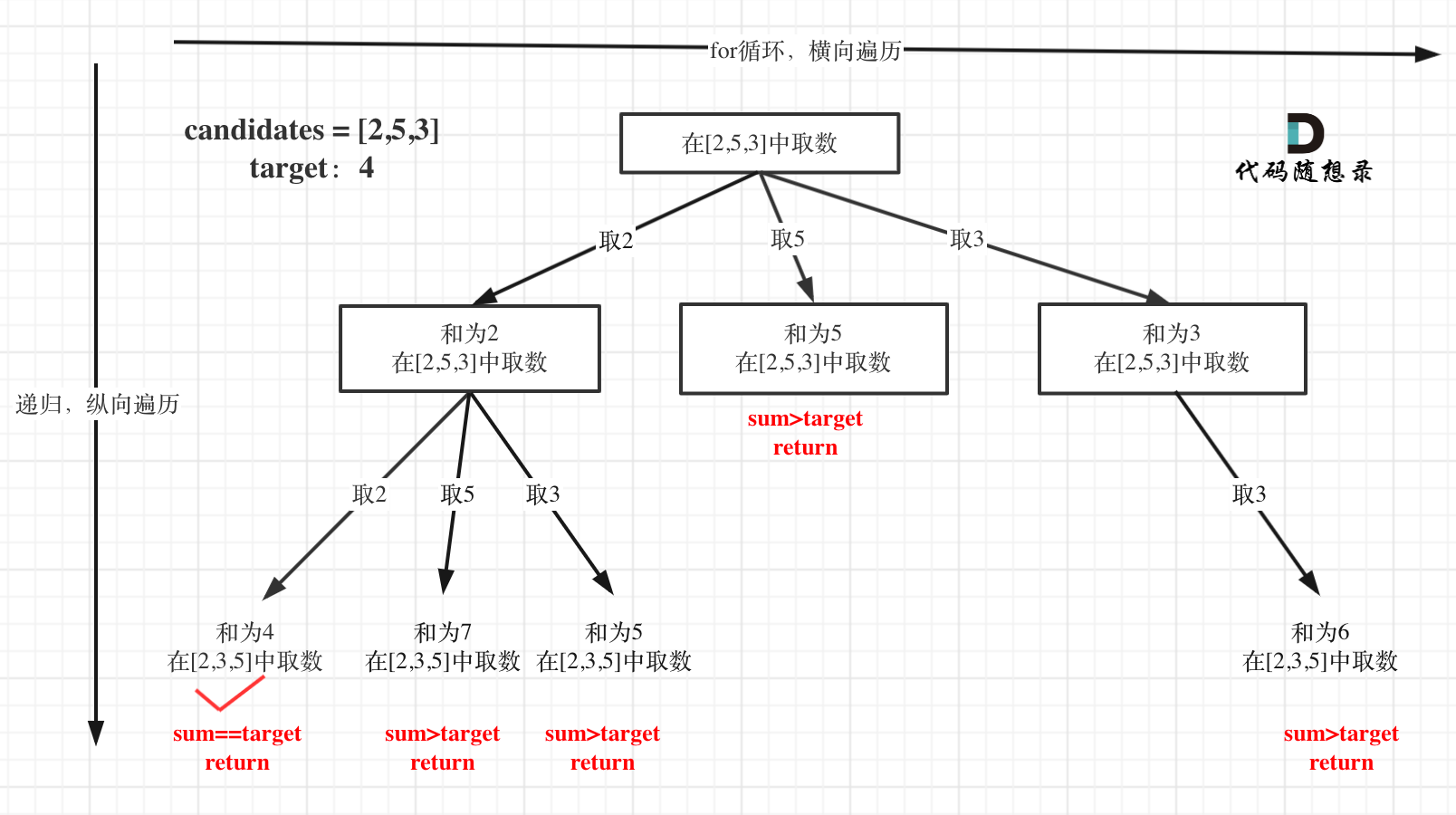
最后还给出了本题的剪枝优化,如下:
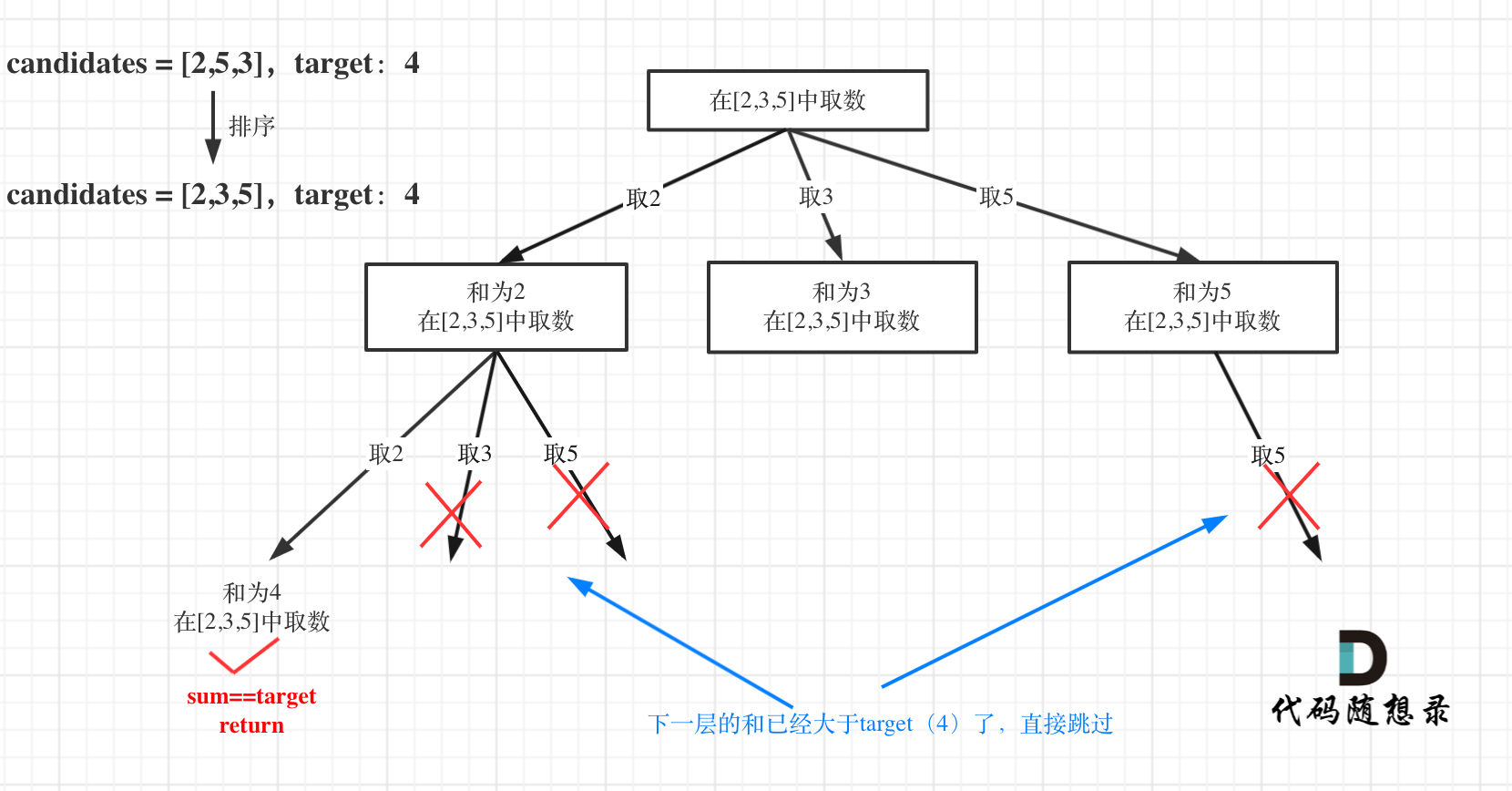
for (int i = startIndex; i < candidates.size() && sum + candidates[i] <= target; i++)
优化后树形结构如下:
在回溯算法:求组合总和(三)中集合元素会有重复,但要求解集不能包含重复的组合。
所以难就难在去重问题上了。
这个去重问题,相信做过的录友都知道有多么的晦涩难懂。网上的题解一般就说“去掉重复”,但说不清怎么个去重,代码一甩就完事了。
为了讲解这个去重问题,Carl自创了两个词汇,“树枝去重”和“树层去重”。
都知道组合问题可以抽象为树形结构,那么“使用过”在这个树形结构上是有两个维度的,一个维度是同一树枝上“使用过”,一个维度是同一树层上“使用过”。没有理解这两个层面上的“使用过” 是造成大家没有彻底理解去重的根本原因。
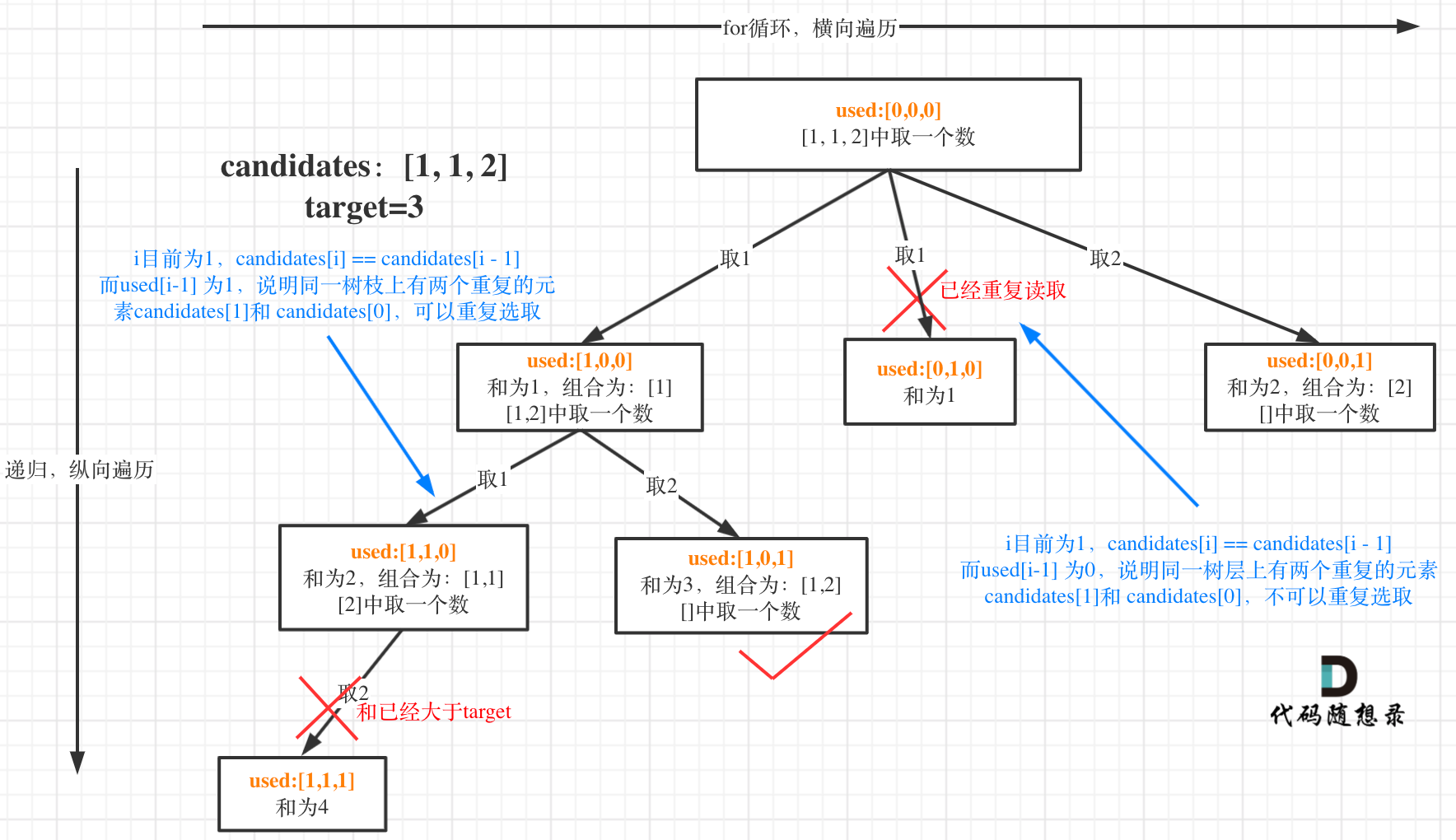
我在图中将used的变化用橘黄色标注上,可以看出在candidates[i] == candidates[i - 1]相同的情况下:
- used[i - 1] == true,说明同一树支candidates[i - 1]使用过
- used[i - 1] == false,说明同一树层candidates[i - 1]使用过
这块去重的逻辑很抽象,网上搜的题解基本没有能讲清楚的,如果大家之前思考过这个问题或者刷过这道题目,看到这里一定会感觉通透了很多!
对于去重,其实排列和子集问题也是一样的道理。
在回溯算法:电话号码的字母组合中,开始用多个集合来求组合,还是熟悉的模板题目,但是有一些细节。
例如这里for循环,可不像是在 回溯算法:求组合问题!和回溯算法:求组合总和!中从startIndex开始遍历的。
因为本题每一个数字代表的是不同集合,也就是求不同集合之间的组合,而回溯算法:求组合问题!和回溯算法:求组合总和!都是是求同一个集合中的组合!
树形结构如下:
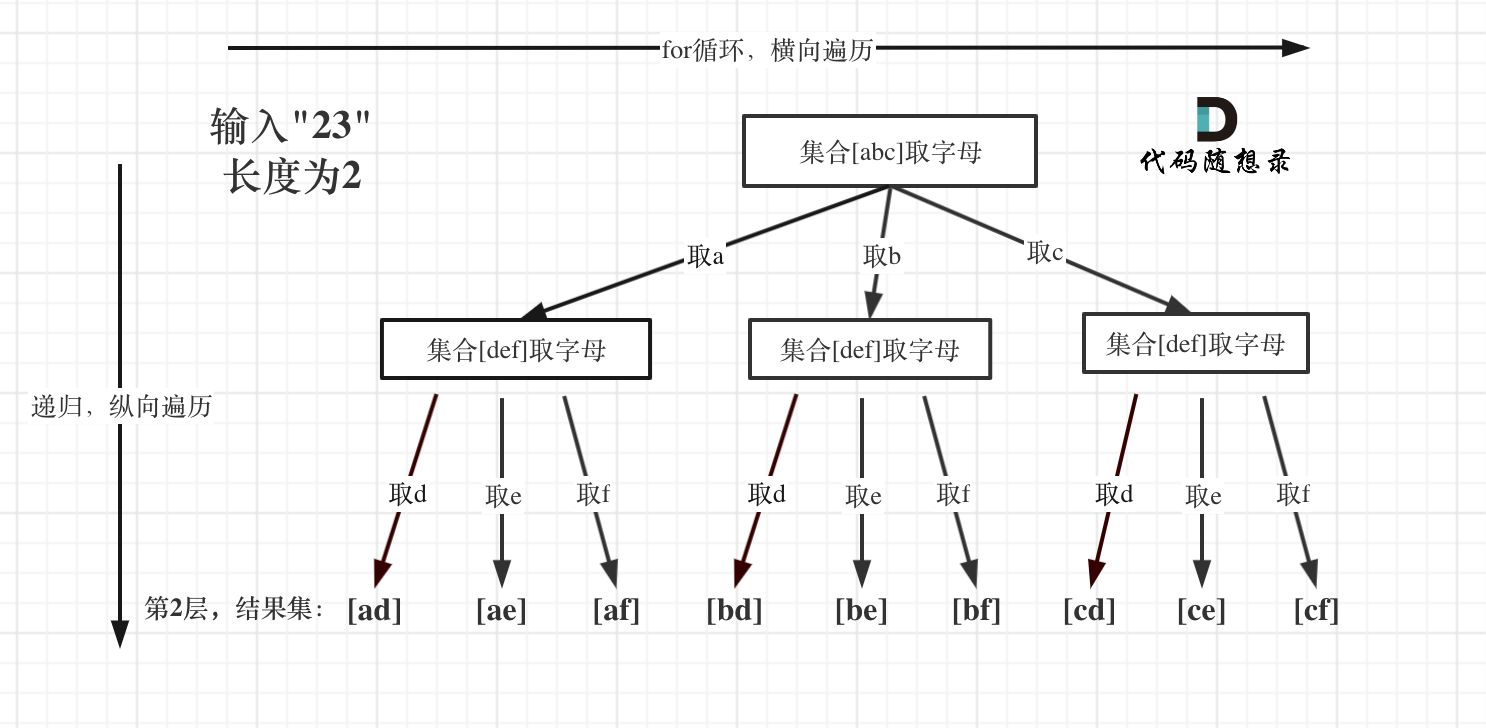
如果大家在现场面试的时候,一定要注意各种输入异常的情况,例如本题输入1 * #按键。
其实本题不算难,但也处处是细节,还是要反复琢磨。
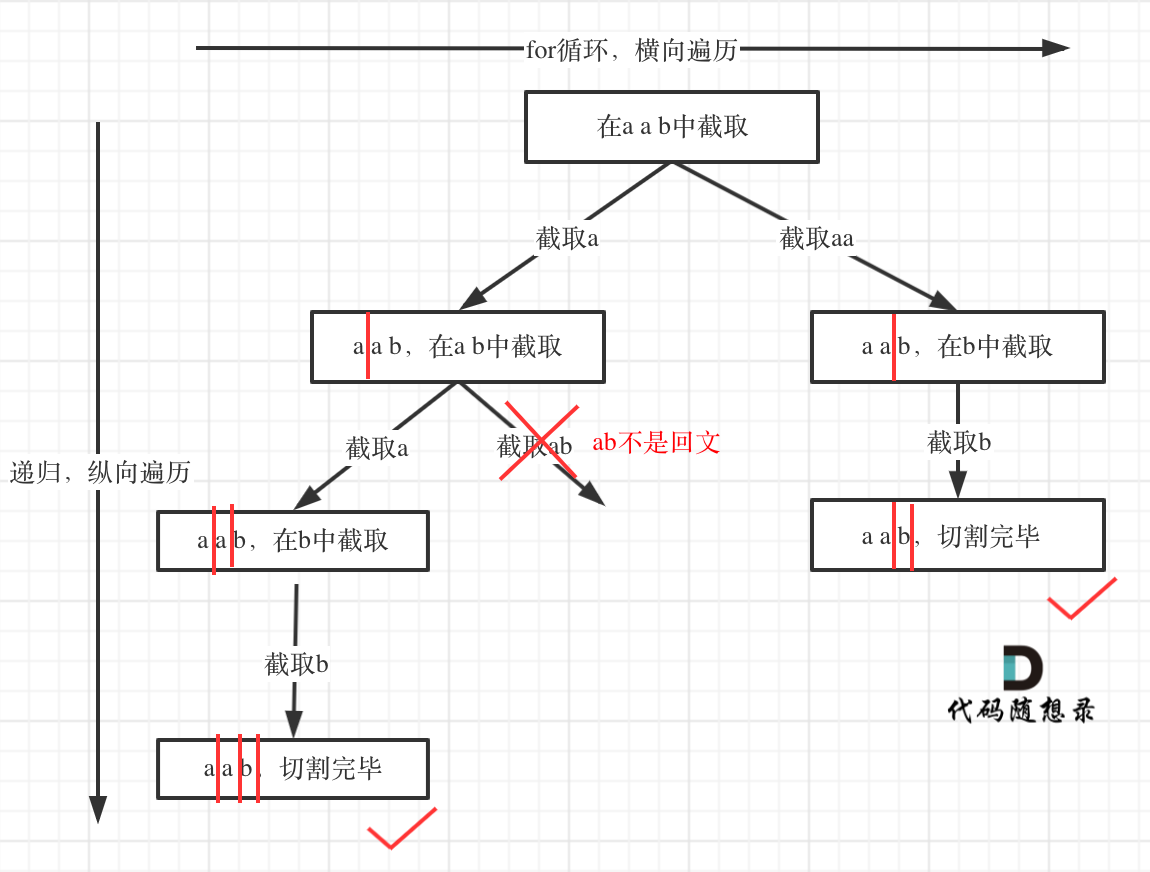
在回溯算法:分割回文串中,我们开始讲解切割问题,虽然最后代码看起来好像是一道模板题,但是从分析到学会套用这个模板,是比较难的。
我列出如下几个难点:
- 切割问题其实类似组合问题
- 如何模拟那些切割线
- 切割问题中递归如何终止
- 在递归循环中如何截取子串
- 如何判断回文
如果想到了用求解组合问题的思路来解决 切割问题本题就成功一大半了,接下来就可以对着模板照葫芦画瓢。
但后序如何模拟切割线,如何终止,如何截取子串,其实都不好想,最后判断回文算是最简单的了。
所以本题应该是一个道hard题目了。
除了这些难点,本题还有细节,例如:切割过的地方不能重复切割所以递归函数需要传入i + 1。
树形结构如下:
在回溯算法:求子集问题!中讲解了子集问题,在树形结构中子集问题是要收集所有节点的结果,而组合问题是收集叶子节点的结果。
如图:
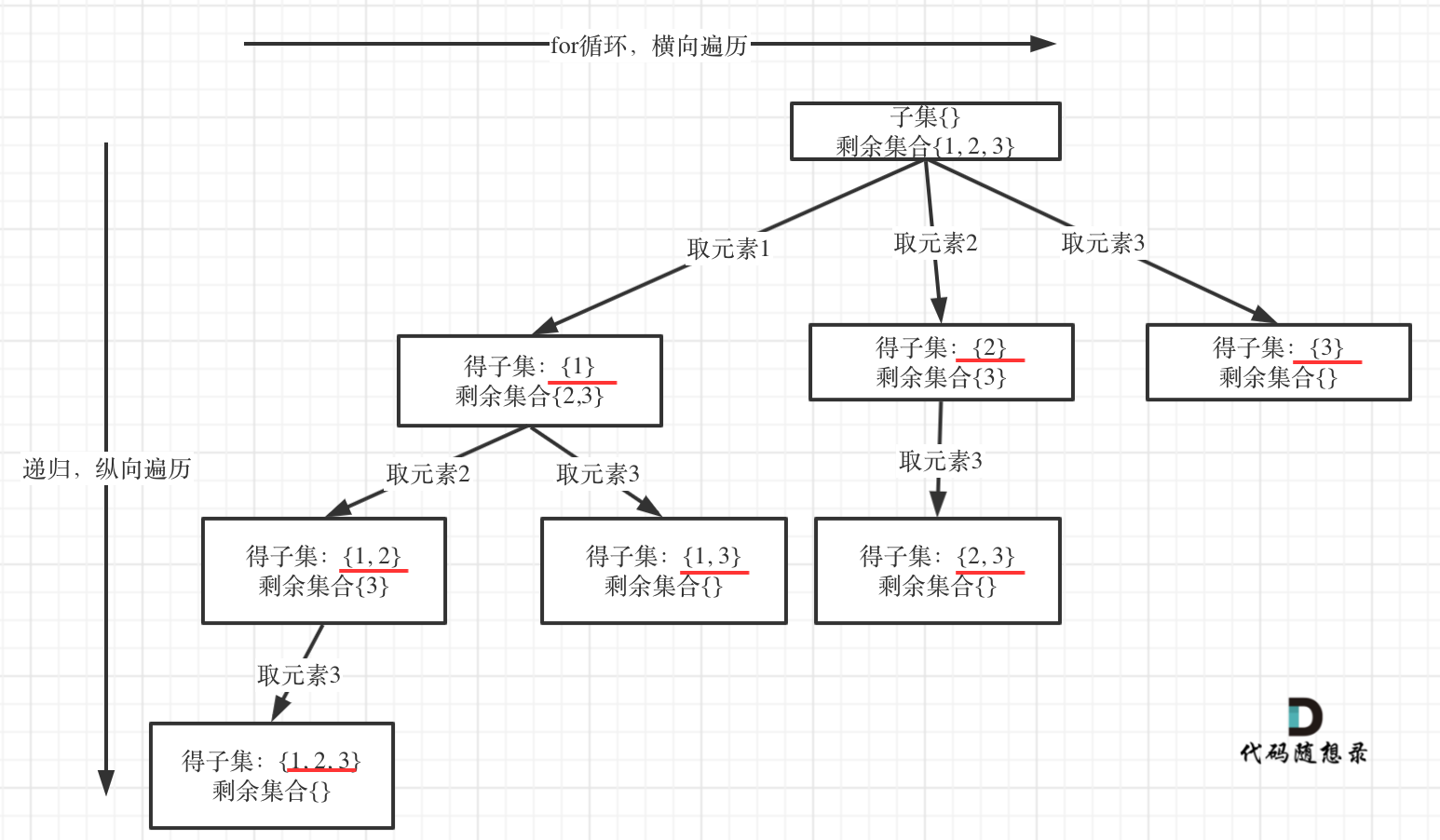
认清这个本质之后,今天的题目就是一道模板题了。
本题其实可以不需要加终止条件,因为startIndex >= nums.size(),本层for循环本来也结束了,本来我们就要遍历整颗树。
有的同学可能担心不写终止条件会不会无限递归?
并不会,因为每次递归的下一层就是从i+1开始的。
如果要写终止条件,注意:result.push_back(path);要放在终止条件的上面,如下:
result.push_back(path); // 收集子集,要放在终止添加的上面,否则会漏掉结果
if (startIndex >= nums.size()) { // 终止条件可以不加
return;
}
在回溯算法:求子集问题(二)中,开始针对子集问题进行去重。
本题就是回溯算法:求子集问题!的基础上加上了去重,去重我们在回溯算法:求组合总和(三)也讲过了,一样的套路。
树形结构如下:
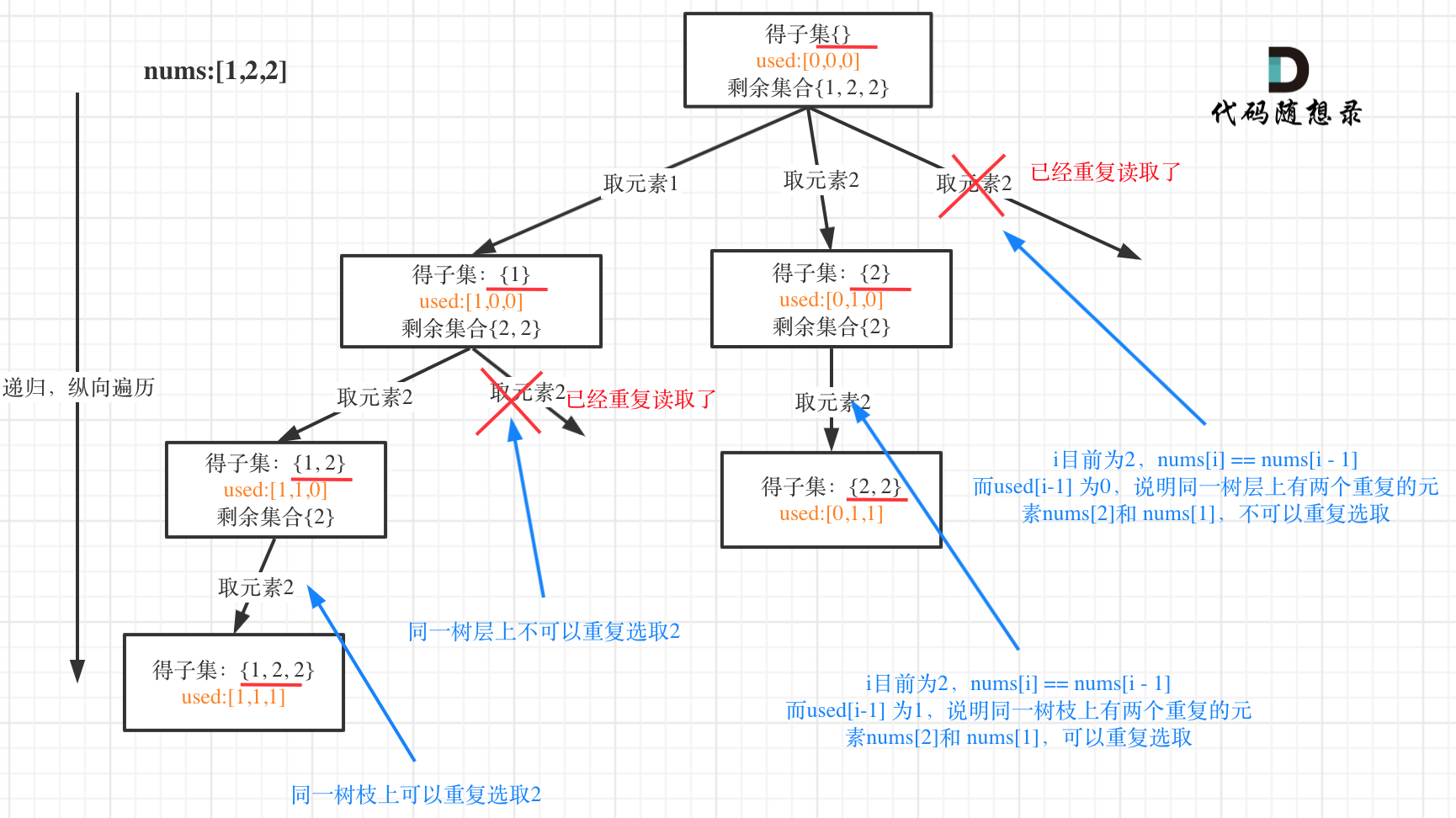
在回溯算法:递增子序列中,处处都能看到子集的身影,但处处是陷阱,值得好好琢磨琢磨!
树形结构如下:
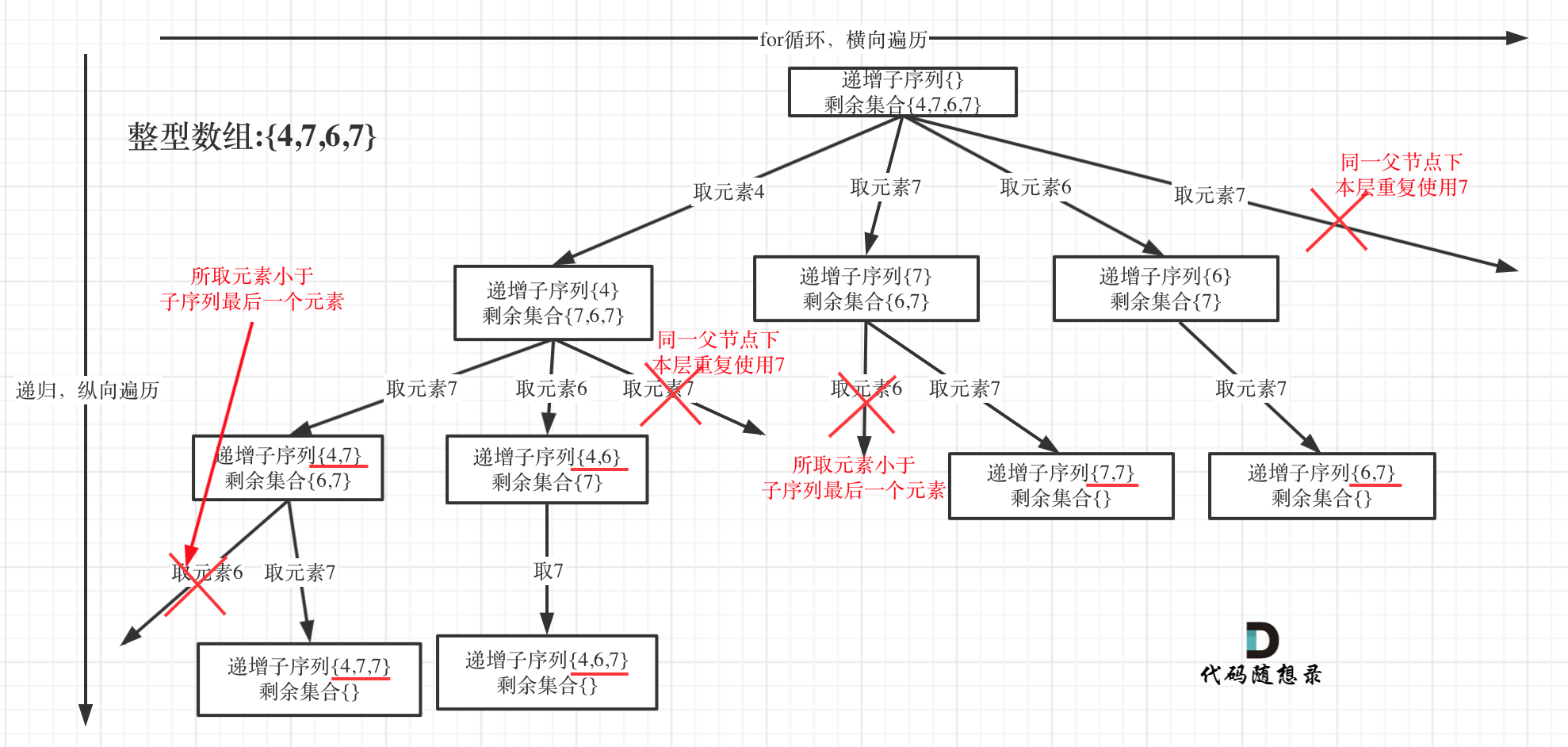
很多同学都会把这道题目和回溯算法:求子集问题(二)混在一起。
回溯算法:求子集问题(二)也可以使用set针对同一父节点本层去重,但子集问题一定要排序,为什么呢?
我用没有排序的集合{2,1,2,2}来举个例子画一个图,如下:
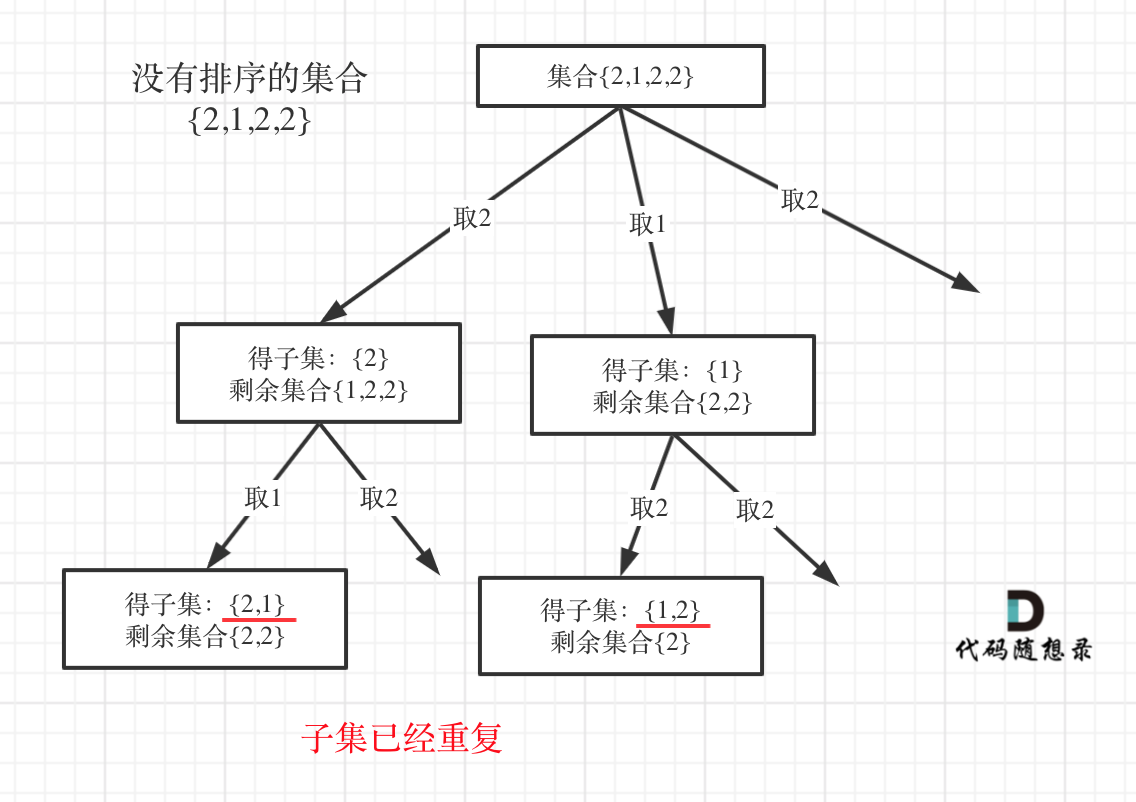
相信这个图胜过千言万语的解释了。
回溯算法:排列问题! 又不一样了。
排列是有序的,也就是说[1,2] 和[2,1] 是两个集合,这和之前分析的子集以及组合所不同的地方。
可以看出元素1在[1,2]中已经使用过了,但是在[2,1]中还要在使用一次1,所以处理排列问题就不用使用startIndex了。
如图:
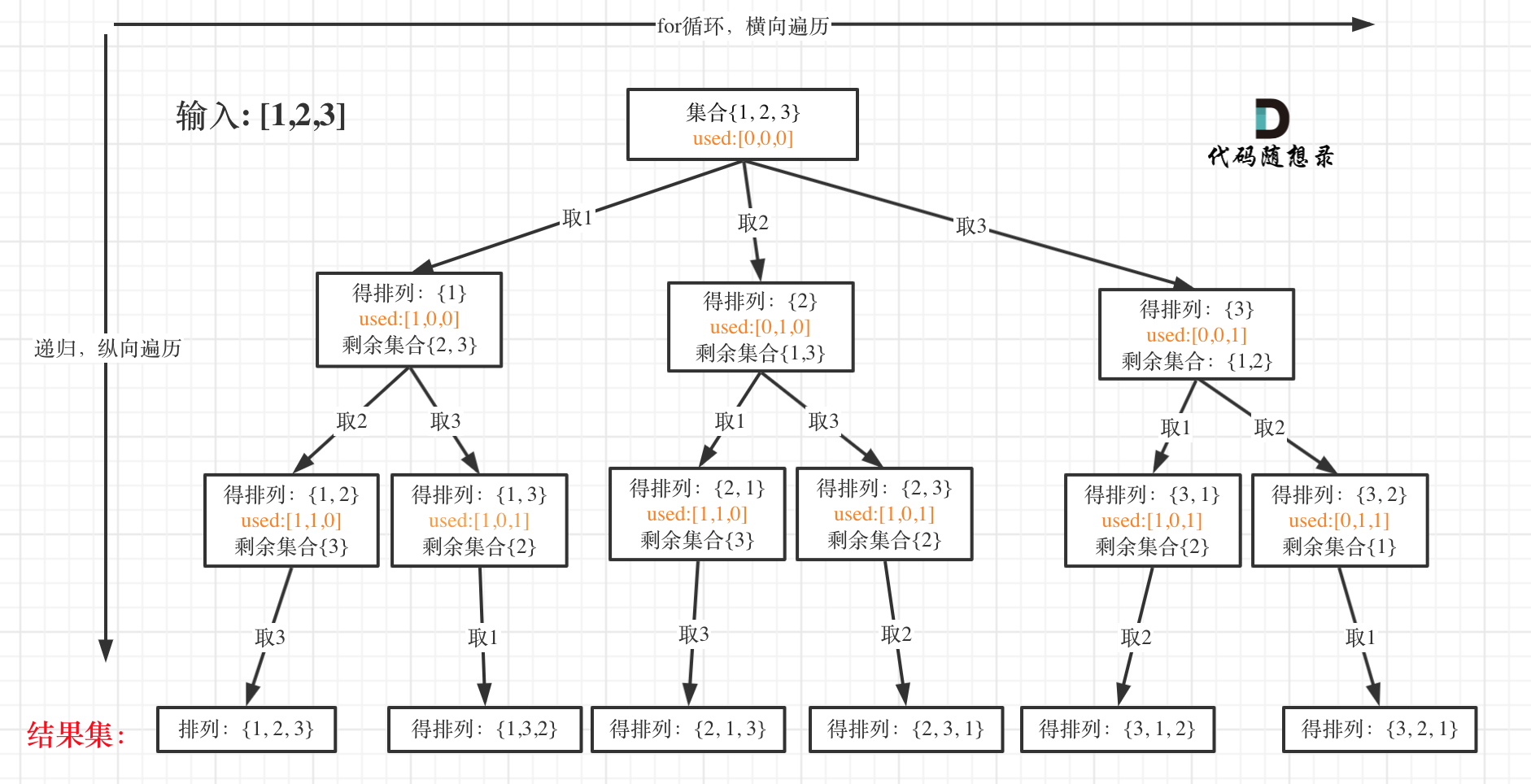
大家此时可以感受出排列问题的不同:
- 每层都是从0开始搜索而不是startIndex
- 需要used数组记录path里都放了哪些元素了
排列问题也要去重了,在回溯算法:排列问题(二)中又一次强调了“树层去重”和“树枝去重”。
树形结构如下:
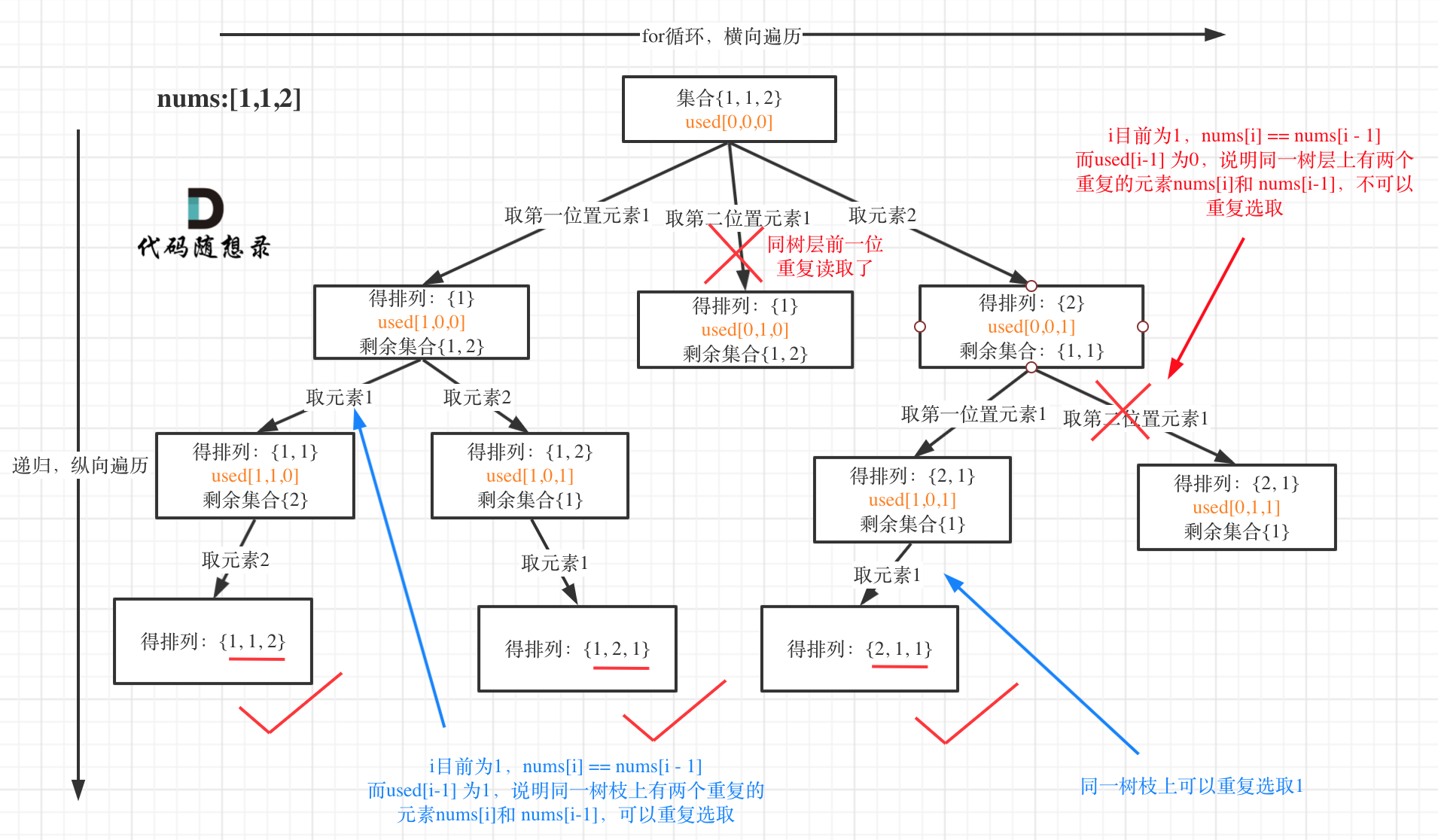
这道题目神奇的地方就是used[i - 1] == false也可以,used[i - 1] == true也可以!
我就用输入: [1,1,1] 来举一个例子。
树层上去重(used[i - 1] == false),的树形结构如下:
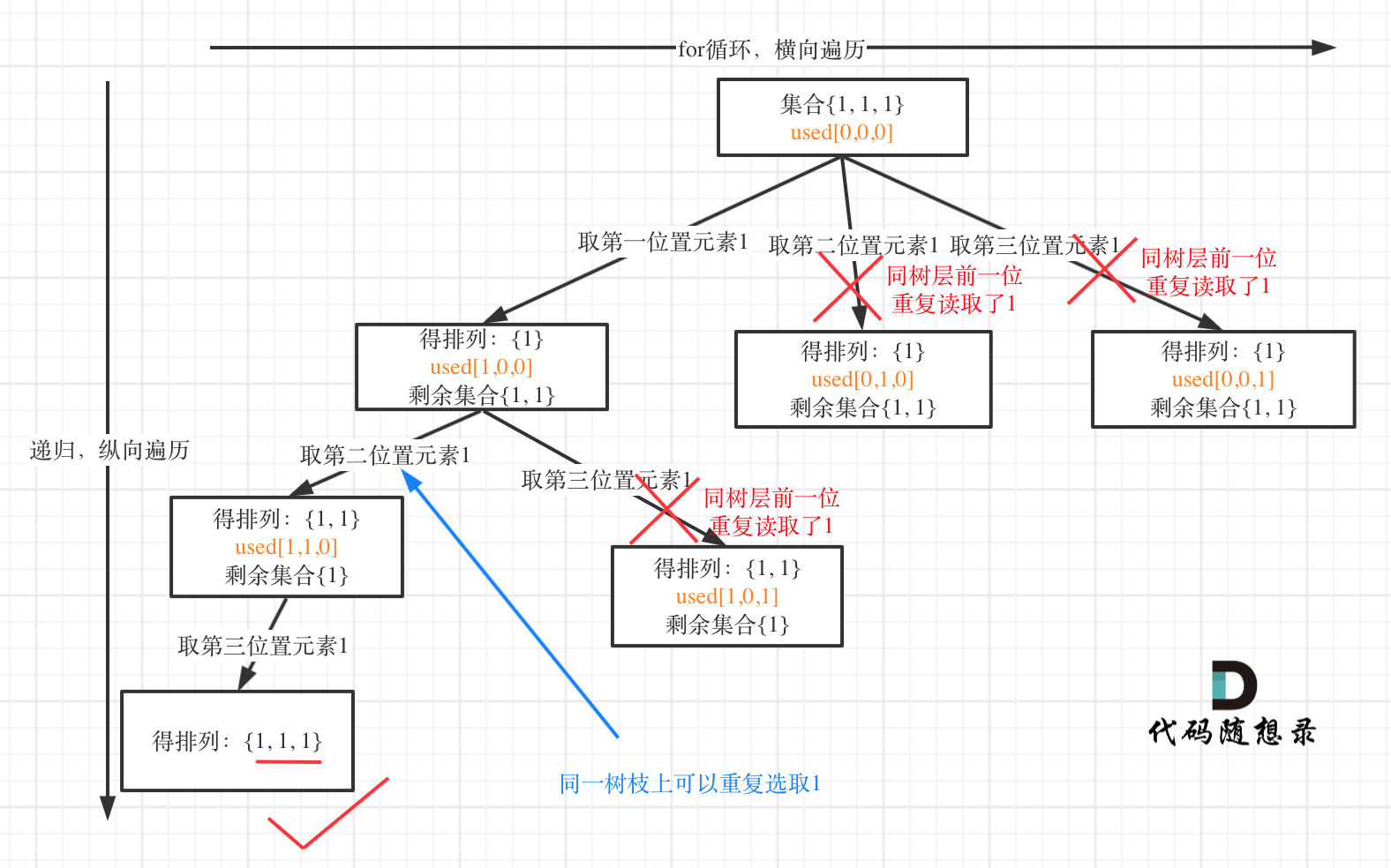
树枝上去重(used[i - 1] == true)的树型结构如下:
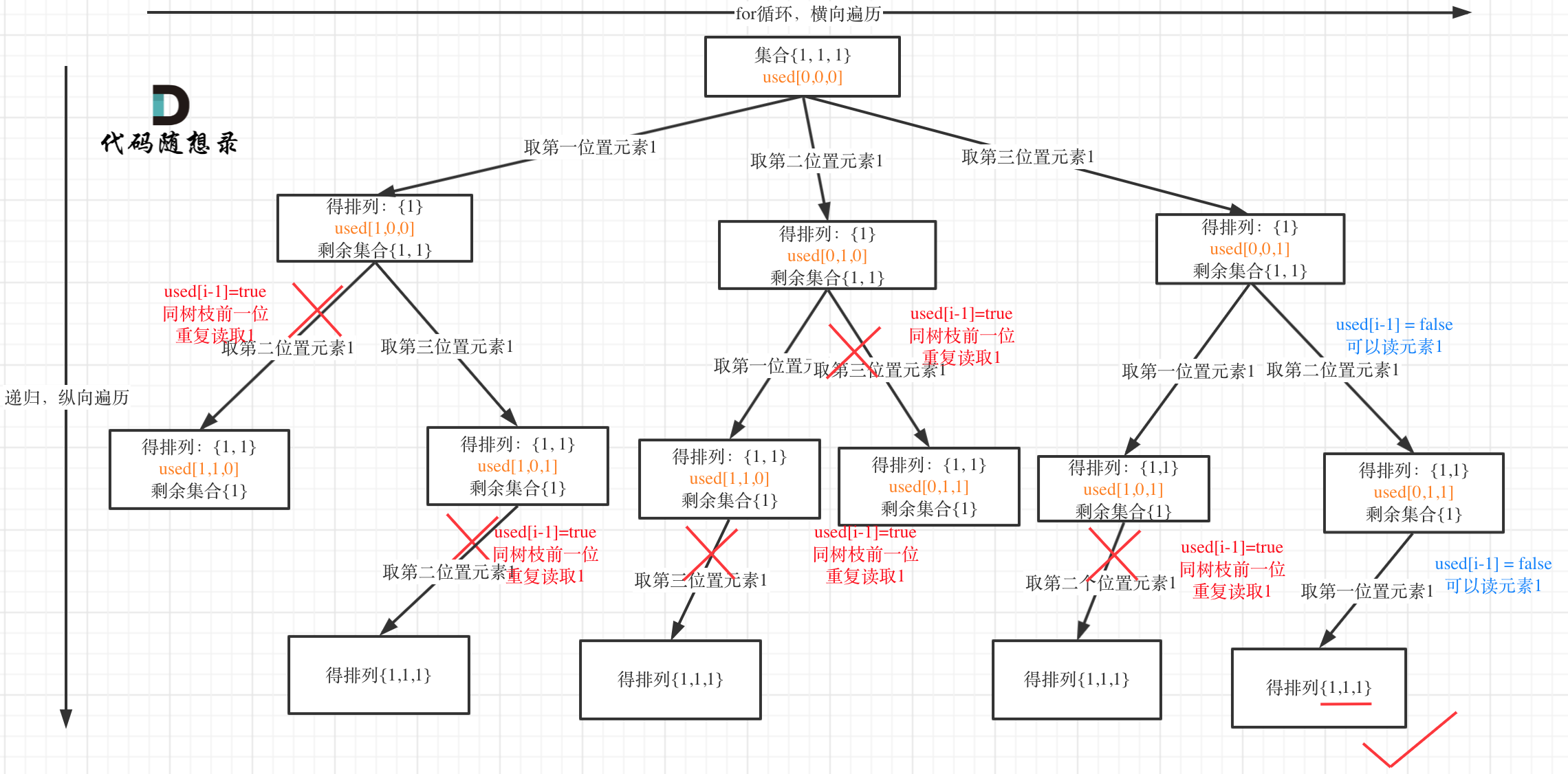
可以清晰的看到使用(used[i - 1] == false),即树层去重,效率更高!
本题used数组即是记录path里都放了哪些元素,同时也用来去重,一举两得。
以上我都是统一使用used数组来去重的,其实使用set也可以用来去重!
在本周小结!(回溯算法系列三)续集中给出了子集、组合、排列问题使用set来去重的解法以及具体代码,并纠正一些同学的常见错误写法。
同时详细分析了 使用used数组去重 和 使用set去重 两种写法的性能差异:
使用set去重的版本相对于used数组的版本效率都要低很多,大家在leetcode上提交,能明显发现。
原因在回溯算法:递增子序列中也分析过,主要是因为程序运行的时候对unordered_set 频繁的insert,unordered_set需要做哈希映射(也就是把key通过hash function映射为唯一的哈希值)相对费时间,而且insert的时候其底层的符号表也要做相应的扩充,也是费时的。
而使用used数组在时间复杂度上几乎没有额外负担!
使用set去重,不仅时间复杂度高了,空间复杂度也高了,在本周小结!(回溯算法系列三)中分析过,组合,子集,排列问题的空间复杂度都是O(n),但如果使用set去重,空间复杂度就变成了O(n^2),因为每一层递归都有一个set集合,系统栈空间是n,每一个空间都有set集合。
那有同学可能疑惑 用used数组也是占用O(n)的空间啊?
used数组可是全局变量,每层与每层之间公用一个used数组,所以空间复杂度是O(n + n),最终空间复杂度还是O(n)。
之前说过,有递归的地方就有回溯,深度优先搜索也是用递归来实现的,所以往往伴随着回溯。
在回溯算法:重新安排行程其实也算是图论里深搜的题目,但是我用回溯法的套路来讲解这道题目,算是给大家拓展一下思路,原来回溯法还可以这么玩!
以输入:[["JFK", "KUL"], ["JFK", "NRT"], ["NRT", "JFK"]为例,抽象为树形结构如下:
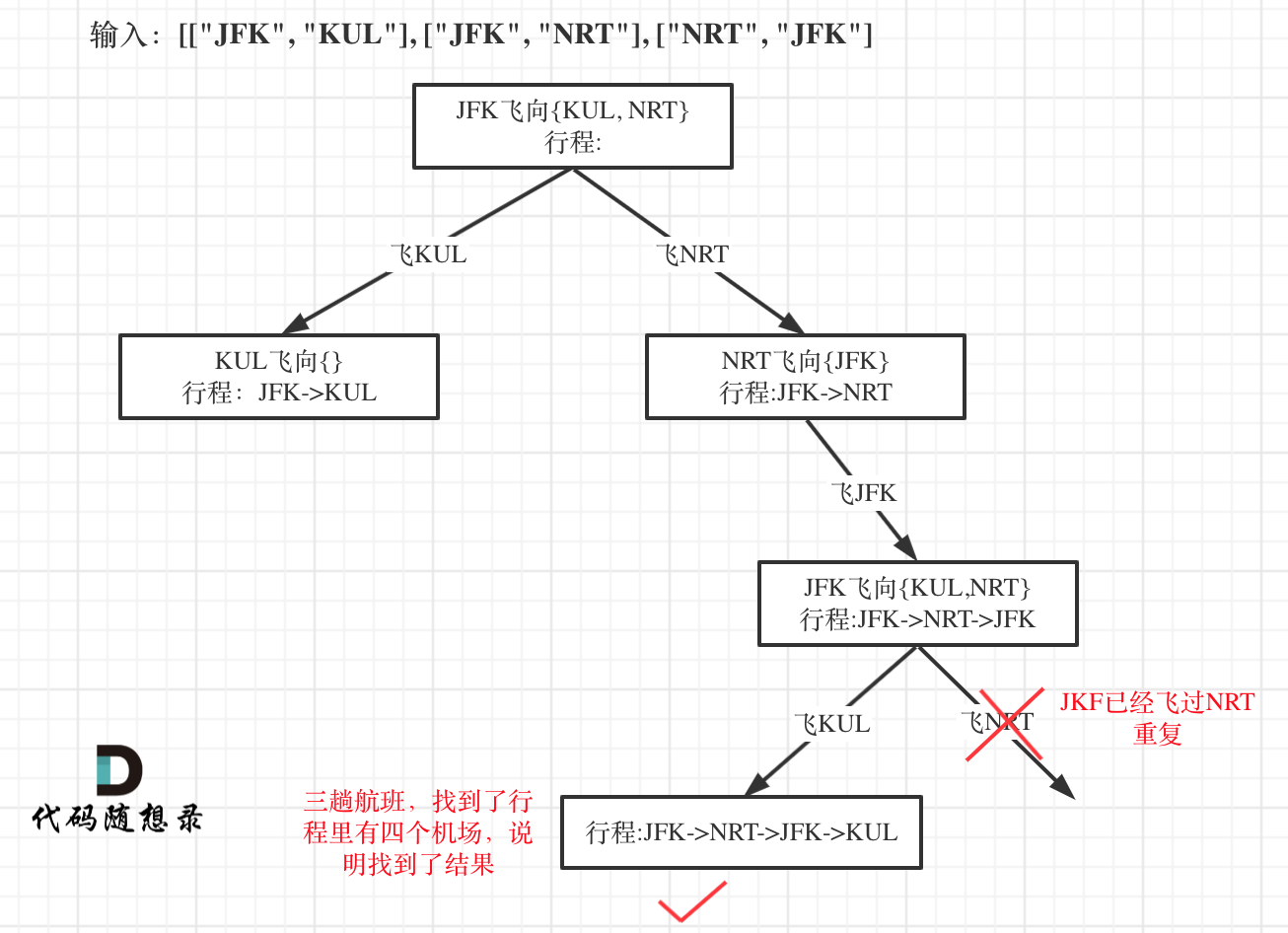
本题可以算是一道hard的题目了,关于本题的难点我在文中已经详细列出。
如果单纯的回溯搜索(深搜)并不难,难还难在容器的选择和使用上!
本题其实是一道深度优先搜索的题目,但是我完全使用回溯法的思路来讲解这道题题目,算是给大家拓展一下思维方式,其实深搜和回溯也是分不开的,毕竟最终都是用递归。
在回溯算法:N皇后问题中终于迎来了传说中的N皇后。
下面我用一个3 * 3 的棋牌,将搜索过程抽象为一颗树,如图:
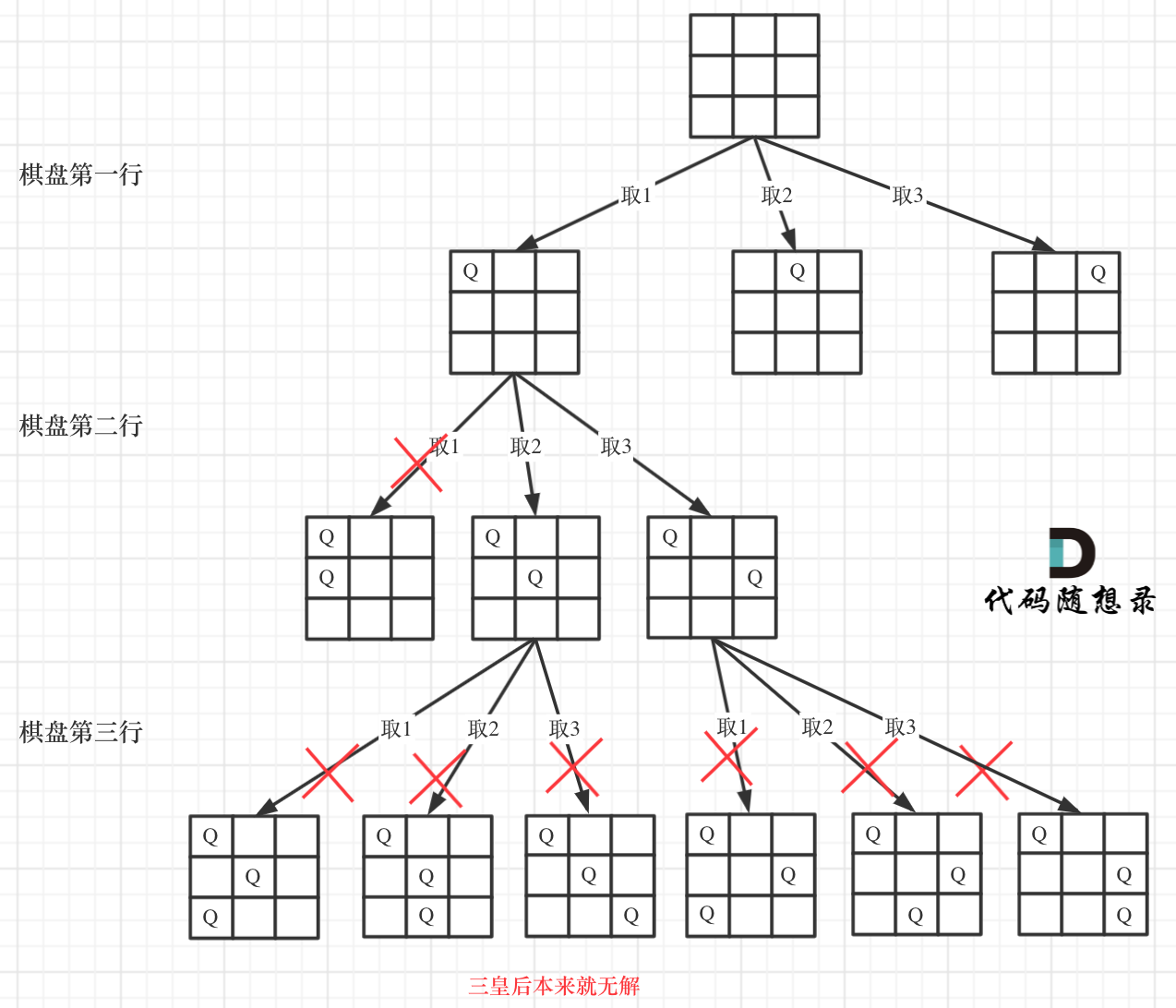
从图中,可以看出,二维矩阵中矩阵的高就是这颗树的高度,矩阵的宽就是树形结构中每一个节点的宽度。
那么我们用皇后们的约束条件,来回溯搜索这颗树,只要搜索到了树的叶子节点,说明就找到了皇后们的合理位置了。
如果从来没有接触过N皇后问题的同学看着这样的题会感觉无从下手,可能知道要用回溯法,但也不知道该怎么去搜。
这里我明确给出了棋盘的宽度就是for循环的长度,递归的深度就是棋盘的高度,这样就可以套进回溯法的模板里了。
相信看完本篇回溯算法:N皇后问题也没那么难了,传说已经不是传说了,哈哈。
在回溯算法:解数独中要征服回溯法的最后一道山峰。
解数独应该是棋盘很难的题目了,比N皇后还要复杂一些,但只要理解 “二维递归”这个过程,其实发现就没那么难了。
大家已经跟着「代码随想录」刷过了如下回溯法题目,例如:77.组合(组合问题),131.分割回文串(分割问题),78.子集(子集问题),46.全排列(排列问题),以及51.N皇后(N皇后问题),其实这些题目都是一维递归。
其中N皇后问题是因为每一行每一列只放一个皇后,只需要一层for循环遍历一行,递归来遍历列,然后一行一列确定皇后的唯一位置。
本题就不一样了,本题中棋盘的每一个位置都要放一个数字,并检查数字是否合法,解数独的树形结构要比N皇后更宽更深。
因为这个树形结构太大了,我抽取一部分,如图所示:
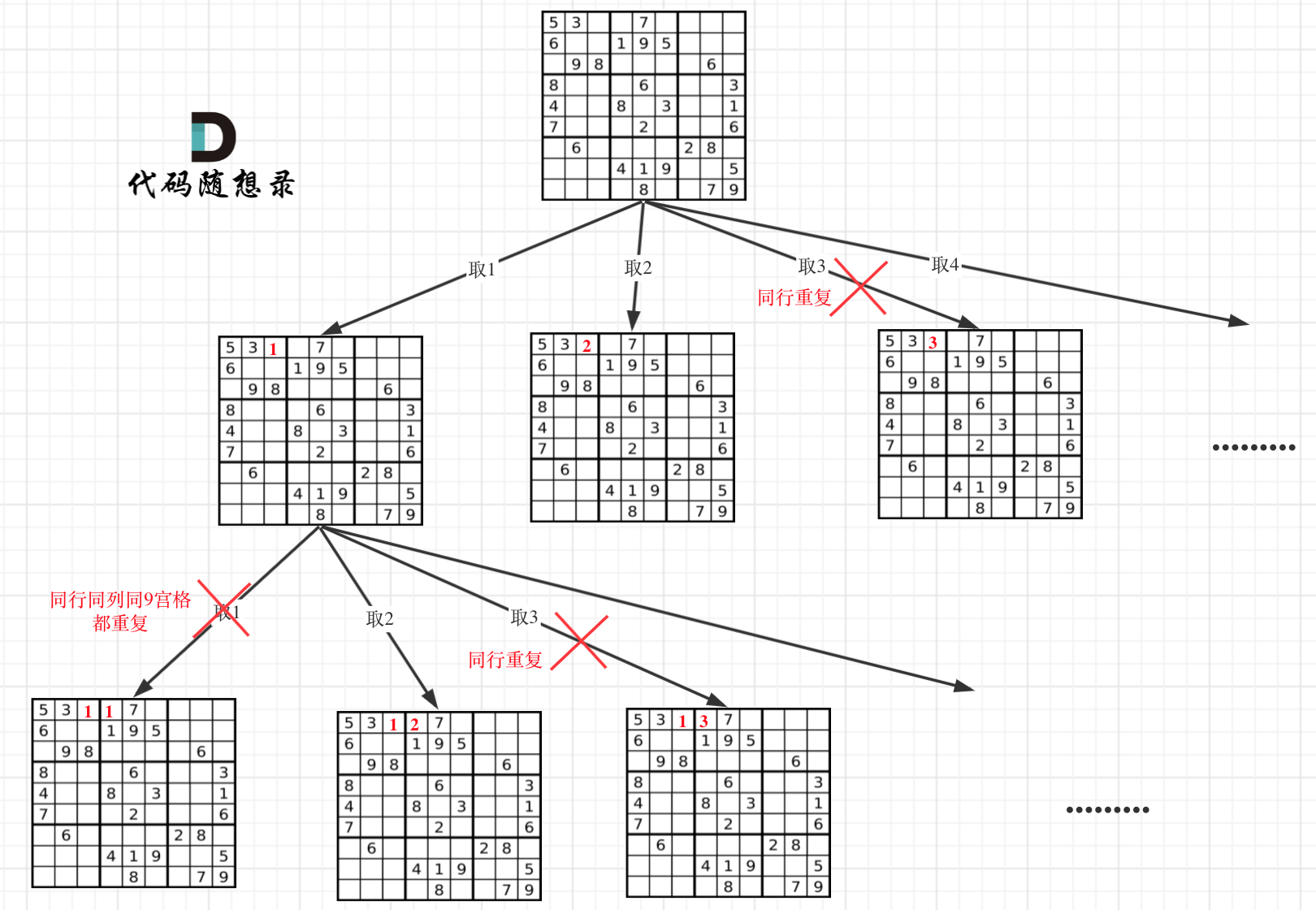
{kind=link}
解数独可以说是非常难的题目了,如果还一直停留在一维递归的逻辑中,这道题目可以让大家瞬间崩溃。
所以我在回溯算法:解数独中开篇就提到了二维递归,这也是我自创词汇,希望可以帮助大家理解解数独的搜索过程。
一波分析之后,在看代码会发现其实也不难,唯一难点就是理解二维递归的思维逻辑。
这样,解数独这么难的问题也被我们攻克了。
关于回溯算法的复杂度分析在网上的资料鱼龙混杂,一些所谓的经典面试书籍不讲回溯算法,算法书籍对这块也避而不谈,感觉就像是算法里模糊的边界。
所以这块就说一说我个人理解,对内容持开放态度,集思广益,欢迎大家来讨论!
以下在计算空间复杂度的时候我都把系统栈(不是数据结构里的栈)所占空间算进去。
子集问题分析:
- 时间复杂度:O(n * 2^n),因为每一个元素的状态无外乎取与不取,所以时间复杂度为O(2^n),构造每一组子集都需要填进数组,又有需要O(n),最终时间复杂度:O(n * 2^n)
- 空间复杂度:O(n),递归深度为n,所以系统栈所用空间为O(n),每一层递归所用的空间都是常数级别,注意代码里的result和path都是全局变量,就算是放在参数里,传的也是引用,并不会新申请内存空间,最终空间复杂度为O(n)
排列问题分析:
- 时间复杂度:O(n!),这个可以从排列的树形图中很明显发现,每一层节点为n,第二层每一个分支都延伸了n-1个分支,再往下又是n-2个分支,所以一直到叶子节点一共就是 n * n-1 * n-2 * ..... 1 = n!。
- 空间复杂度:O(n),和子集问题同理。
组合问题分析:
- 时间复杂度:O(n * 2^n),组合问题其实就是一种子集的问题,所以组合问题最坏的情况,也不会超过子集问题的时间复杂度。
- 空间复杂度:O(n),和子集问题同理。
N皇后问题分析:
- 时间复杂度:O(n!) ,其实如果看树形图的话,直觉上是O(n^n),但皇后之间不能见面所以在搜索的过程中是有剪枝的,最差也就是O(n!),n!表示n * (n-1) * .... * 1。
- 空间复杂度:O(n),和子集问题同理。
解数独问题分析:
- 时间复杂度:O(9^m) , m是'.'的数目。
- 空间复杂度:O(n^2),递归的深度是n^2
一般说道回溯算法的复杂度,都说是指数级别的时间复杂度,这也算是一个概括吧!
「代码随想录」历时21天,14道经典题目分析,20张树形图,21篇回溯法精讲文章,从组合到切割,从子集到排列,从棋盘问题到最后的复杂度分析,至此收尾了。
这里的每一种问题,讲解的时候我都会和其他问题作对比,做分析,确保每一个问题都讲的通透。
可以说方方面面都详细介绍到了。
例如:
- 如何理解回溯法的搜索过程?
- 什么时候用startIndex,什么时候不用?
- 如何去重?如何理解“树枝去重”与“树层去重”?
- 去重的几种方法?
- 如何理解二维递归?
这里的每一个问题,网上几乎找不到能讲清楚的文章,这也是直击回溯算法本质的问题。
相信一路坚持下来的录友们,对回溯算法已经都深刻的认识。
此时回溯算法系列就要正式告一段落了。
录友们可以回顾一下这21天,每天的打卡,每天在交流群里和大家探讨代码,最终换来的都是不知不觉的成长。
同样也感谢录友们的坚持,这也是我持续写作的动力,正是因为大家的积极参与,我才知道这件事件是非常有意义的。
最后希望大家可以转发这篇文章给身边的朋友们,因为还有很多学习算法的小伙伴依然在浩如烟海的信息中迷茫,而我相信「代码随想录」会让大家少走弯路!
回溯算法系列正式结束,新的系列终将开始,录友们准备开启新的征程!
Java:
Python:
Go:
