这些是我在阅读官方文档时觉得比较重要的资料, 当然一些比如设置环境Get Started之类的文档略过
-
Developing LLVM passes out of source
- 示例的LLVM Pass的结构目录如下
<project dir>/ | CMakeLists.txt <pass name>/ | CMakeLists.txt Pass.cpp ...
- /CMakeLists.txt 内容
find_package(LLVM REQUIRED CONFIG) add_definitions(${LLVM_DEFINITIONS}) include_directories(${LLVM_INCLUDE_DIRS}) add_subdirectory(<pass name>)
- //CMakeLists.txt:
add_library(LLVMPassname MODULE Pass.cpp) - 如果想更好地整合进LLVM源码里(通过add_llvm_library), 可以使用以下方式:
- 将以下内容添加到/CMakeLists.txt文件里去(在find_package(LLVM ...)后)
list(APPEND CMAKE_MODULE_PATH "${LLVM_CMAKE_DIR}") include(AddLLVM) - 修改//CMakeLists.txt为以下:
add_llvm_library(LLVMPassname MODULE Pass.cpp )
- 集合进LLVM源码:
- 拷贝文件夹到/lib/Transform
- 添加add_subdirectory()到/lib/Transform/CMakeLists.txt
- 示例的LLVM Pass的结构目录如下
-
LLVM’s Analysis and Transform Passes: 对各个pass的用途进行了介绍, 也有很多分析的实现, 可以作为样例去学习
-
- formatv用于格式化字符串输出
- 使用assert进行断言:
assert(isPhysReg(R) && "All virt regs should have been allocated already."); - 使用llvm_unreachable函数指定控制流不会到达的分支
混合模糊测试在CGC中被证明有效, 但同时现有的混合执行存在性能瓶颈, 且难以运用于复杂大型软件, QSYM应运而生.
QSYM通过动态二进制翻译技术, 将本地执行和符号执行紧密结合在一起. 此外QSYM放宽了传统混合执行引擎的健壮性要求以提高性能, 但利用更高效的Fuzzer进行验证, 在一些方面比如约束求解和修剪无用基本块提高了性能.
传统模糊测试能快速探索输入空间, 但无法很好地进入深层空间, 而混合执行则擅长深层空间的状态但难以解决复杂的约束. 混合模糊测试则是将两者结合在一起, 而作者认为混合执行引擎的性能瓶颈时制约混合模糊测试的主要因素, 而论文的解决性能瓶颈的方法就是将符号执行的部分通过动态二进制翻译(DBT)的方案转变成本地执行, 同时相对现有的混合执行引擎而言, 也能实现更细粒度的指令级别执行. 此外也降低了健壮性的一些要求使其性能更高, 能应用于大规模测试.
论文探讨了符号执行低效的原因: 首先符号执行对IR的依赖降低了性能, 其次针对IR的优化器没有充分地进行优化(限制了优化空间), 特别是将程序翻译成基本块级别IR这部分. 最后是没法跳过不涉及符号执行的那部分指令.
IR能够降低原型实现的复杂度, 但同时也带来了额外的开销. 比如amd64架构指令是CISC, 而IR是RISC, 在转换过程中一条机器指令就会被转化成多条IR, 从实验结果来看, Angr使用的VEX IR则平均膨胀了4.69倍.
IR优化器有自己的一些优化策略, 比如不涉及符号变量的基本块就不进行符号执行, 这确实能提高性能但不充分, 因为对于含有符号变量的基本块, 从真实软件测试来看, 只有约30%的指令需要符号执行. 也就意味着指令级别的符号执行能减少不必要的符号执行开销. 但现有的混合执行引擎因为IR缓存策略, 常常以基本块为单位转换成IR以降低缓存的成本, 因此没有从基本块级别上做优化.
论文则是以此出发, 移除了IR转换, 增加实现复杂性, 和尽可能最小化符号执行的使用.
传统混合执行引擎使用快照来减少重新执行目标程序的开销, 但对于一些混合执行引擎来说快照机制是必要的, 例如Driller. 传统符号执行需要快照来保存分支的探索状态, 而对于混合模糊测试中的混合符号执行引擎, 则是从从Fuzzer处拿测试样例, 而这些样例的路径很可能是不同的, 因此也就没有必要使用快照来保存分支状态.
同时快照机制需要频繁地与外部环境比如文件系统和内存管理系统交互, 但当进程通过fork族的系统调用创建子进程时, 内核不再维护其状态, 因此混合执行引擎需要自行维护状态.
快照机制还会有其他的问题, 论文中则对重复的混合执行进行优化, 移除了快照机制, 取而代之使用具体执行.
混合执行会试图收集完整的约束来保证健壮性, 确保满足约束的输入能引导到预期路径. 然而计算完整约束的代价可能非常昂贵. 比如一些密码学或解压的函数, 强求完整约束会使得其没法探索其他有趣的代码. 此外过度约束也会带来计算开销.
论文里则是收集不完整的部分约束, 并针对过度约束情况仅求解其部分约束.
QSYM的设计架构如下图所示:
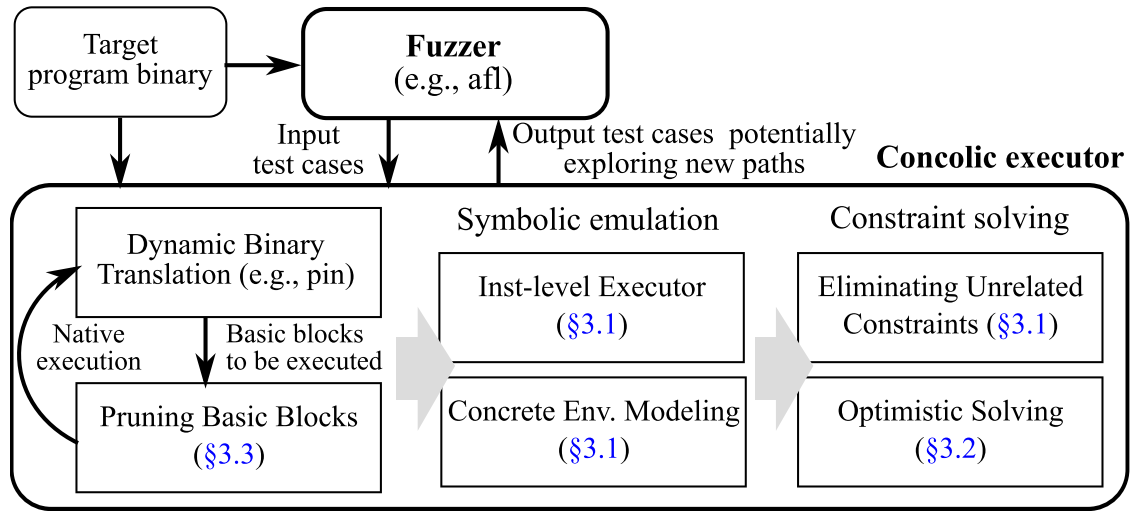
使用了四种技术来对混合执行引擎进行优化.
- 指令级别的符号执行: 使用DBT在单个进程允许本地和符号执行, 使得其模式的切换开销非常小
- 只求解相关约束: 只求解跟目标分支相关的约束并产生新的测试样例. 传统符号执行引擎例如S2E和Driller会逐步求解约束, 并关注于通过前段执行解决当前执行中约束的最新部分, 而这对于没有初始输入可供探索的符号执行器而言是非常有效的. 但并不适用于混合执行. QSYM相比Driller在输出测试样例能够仅修改跟分支相关的约束. 但这里对QSYM的输出没有很好的解释.
- 更多使用重新执行而非快照: 重新执行程序到达特定路径状态的开销可能比快照恢复要高的多, 但当QSYM的混合执行引擎变快, 快照恢复的开销会高于重新执行.
- 具体的外部环境: 不再对外部环境进行建模而是与具体的外部环境进行交互, 将外部环境视为黑盒给予具体值运行, 这是处理那些无法模拟的函数的常用手段, 但很难适用于给予fork的符号执行, 因为这会打破进程边界. QSYM做了折衷的方案, 损失一定的健壮性, 通过Fuzzer来快速检查及丢弃测试用例来停止进一步的分析.
混合执行容易遇到过度求解的问题. QSYM通过求解最后一条路径约束来达到提速的目的, 这样有两点考虑, 一是乐观地认为最后一条约束通常具有比较简单的形式, 能很高效地进行约束求解(作者也有考虑过求unsat_core的补集, 但其也是计算高昂), 二是求解最后一条约束, 能保证后续的约束求解结果也一定满足这最后一条到底该分支的约束.
重复代码生成的约束对于实际测试中查找新的代码覆盖率没有帮助, 并且有的时候会因为复杂的基本块带来的约束限制了进一步的探索.
QSYM会在运行时测量每一个基本块执行的频率, 并选择重复的基本块进行修剪. 如果基本块执行的过于频繁, 则会放弃从该基本块生成进一步的约束. 当然除开那些不引入任何新符号表达式的常量指令组成的基本块, 例如x86的mov指令以及使用常量对指令进行移位/屏蔽.
QSYM利用2的指数来计算基本块的频率, 这可以快速地制止过于频繁的基本块, 但同时也带来了过度修剪的问题, QSYM采用了两种方式来解决过度修剪: 基本块组合和上下文敏感性.
基本块组合是将多个基本块视为一个组合, 比如8个基本块视为一个组合, 那么当这个组合执行了8次之后, 其频率才加一, 也就是一种缓和的策略.
上下文敏感则是为了对在不同上下文运行的同一基本块做区分. 比如两个strcmp(), 其上下文是不同的, 故这两次调用需要视为不同的基本块进行频率计数. QSYM会维护当前执行的调用堆栈, 并计算其哈希来区分不同的上下文.
在混合执行有了较大进展的背景下, 针对于漏洞检测场景混合执行的效果并不乐观, 而作者主要认为有两个原因: 首先盲目选择种子用于混合执行以及不加重点地关注所有的代码, 其次就是混合模糊测试注重于让测试过程继续下去而非去检查内部的漏洞缺陷. 于是作者提出了SAVIOR, 它会优先考虑种子的混合执行并验证执行路径上所有易受攻击的程序位置.
说白了, SAVIOR想解决混合模糊测试里乱选种子的行为, 并且希望以Bug为导向去选择种子. 那么具体的策略就是, 在测试前, SAVIOR会静态分析源代码并标记潜在的易受攻击位置. 此外, SAVIOR会计算每个分支可达的基本块集合, 在动态测试期间, SAVIOR优先考虑可以访问更重要分支的种子进行混合执行.
除开上述说的能加快漏洞检测速度, SAVIOR还会验证混合执行引擎遍历过路径上标记的漏洞. 具体就是, SAVIOR综合了各个漏洞路径上的约束, 如果该约束在当前路径条件下可以满足, 那么SAVIOR就会求解该约束以构造输入进行测试. 否则SAVIOR会证明该漏洞在此路径上不可行.
Bug驱动的关键是找到一个方法去评估某个种子在混合执行时能暴露出的漏洞数量, 这个评估取决于两个先决条件:
- R1 - 种子执行完后评估可访问代码区域的方法
- R2 - 量化代码块中漏洞数量的指标
针对R1, SAVIOR结合动静态分析去评估种子的可探索代码区域. 在编译期间, SAVIOR会从每个分支静态地计算可达的基本块集合, 在运行期间, SAVIOR则会在种子的执行路径上标记未探索的分支, 以及计算这些分支可访问的基本块集合.
针对R2, SAVIOR则是利用UBSan来标注待测程序里的三种潜在的错误类型. 然后将每个代码区域中的标签计算为R2的定量指标. 同时SAVIOR也采用了一些过滤方法来删除UBSan的无用标签.
该技术可以确保在到达了漏洞函数路径上能进行可靠的漏洞检测. 从模糊测试处给定种子, SAVIOR会将其执行起来并沿执行路径提取各个漏洞标签. 之后SAVIOR会检查当前路径条件下的可满足性, 满足即漏洞有效.
SAVIOR由多个部分组成: 构建在Clang+LLVM之上的工具链, 基于AFL的Fuzzer, KLEE移植过来的混合执行引擎和负责编排的协调器.
SAVIOR的编译工具链可用于漏洞标记, 控制流的可达性分析以及不同组件的构建.
漏洞标记则是基于UBSan, 当然UBSan有一些不如意的地方, SAVIOR对其进行了一些调整.
可达性分析用于计算CFG中每个基本快可到达的漏洞标签的数量. 它分为两个阶段, 第一步是类似SVF方法去构建过程间CFG, 其首先会为每个函数构建过程内CFG再通过调用关系建立过程间的关系. 为了解决间接调用, 算法会反复执行Andersen的指针分析, 以防止SAVIOR丢失间接调用的函数别名信息, 也使得优先级划分不会漏算漏洞标签数量. 此外通过检查CFG, SAVIOR还提取了基本块和子对象之间的边, 以便后续在协调器的进一步使用. 第二步则是计算过程间CFG中每个基本块可到达的代码区域, 并计算这些区域中UBSan标记的数量, 以此作为该基本块的优先级指标.
组件构建则是去编译三个binary: 一个用于fuzzer的binary, 一个用于协调器的SAVIOR-binary, 一个则是用于混合执行引擎的LLVM bitcode.
协调器则是用于挑选优先级高的种子, 以及一些后续处理. 混合执行引擎则采取了一些策略去解决约束问题.